
8 Palatable scalability
- Scalability vs. performance
- Progressive scalability
- Breaking database rules
- Smoother parallelization
- The truth in monolith
“It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness.”
—Charles Dickens on scalability
I’ve had my share of experience with scalability because of the technical decisions I made for Ekşi Sözlük back in 1999. The whole database for the website was a single text file at first. The writes held locks on the text file, causing everything to freeze for all visitors. The reads weren’t very efficient, either—retrieving a single record would be in O(N) time, which required scanning the whole database. It was the worst of the worst possible technical designs.
It wasn’t because the server’s hardware was so slow that the code froze. The data structures and the parallelization decisions all contributed to the sluggishness. That’s the gist of scalability itself. Performance alone can’t make a system scalable. You need all aspects of your design to cater to an increasing number of users.
More importantly, that terrible design wasn’t more important than how quickly I released the website, which took place in mere hours. Initial technical decisions didn’t matter in the long run because I was able to pay most of the technical debt along the way. I changed the database technology as soon as it started causing too many problems. I wrote the code from scratch when the technology I used didn’t work out anymore. A Turkish proverb states, “A caravan is prepared on the road,” which means, “Make it up as you go.”
I have also recommended measuring twice and cutting once at several places in this book, which seemingly is in conflict with the “Que será, será”1 motto. That’s because there’s no single prescription for all our problems. We need to keep all these methods in our tool belts and apply the right one for the problem at hand.
From a systems perspective, scalability means the ability to make a system faster by throwing more hardware at it. From a programming perspective, a scalable code can keep its responsiveness constant in the face of increasing demand. There is obviously an upper limit of how some code can keep up with the load, and the goal of writing scalable code is to push that upper limit as far as possible.
Like refactoring, scalability is best addressed progressively in tangible, smaller steps toward a bigger goal. It’s possible to design a system to be fully scalable from scratch, but the amount of effort and time required to achieve that and the returns you get are overshadowed by the importance of getting a product released as soon as possible.
Some things don’t scale at all. As Fred Brooks eloquently said in his marvelous book The Mythical Man Month, “The bearing of a child takes nine months, no matter how many women are assigned.” Brooks was talking about how assigning more people to an already delayed project might only add to the delays, but it’s also applicable to certain factors of scalability. For example, you can’t make a CPU core run more instructions in a second than its clock frequency. Yes, I’ve said that we can surpass it slightly by appealing to SIMD, branch prediction, and so forth, but there is still an upper limit to the performance you can achieve on a single CPU core.
The first step to achieving scalable code is to remove the bad code that prevents it from scaling. Such code can create bottlenecks, causing the code to remain slow even after you’ve added more hardware resources. Removing some of such code may even seem counterintuitive to you. Let’s go over these potential bottlenecks and how we can remove them.
8.1 Don’t use locks
In programming, locking is a feature that lets you write thread-safe code. Thread-safe means that a piece of code can work consistently even when it’s called by two or more threads simultaneously. Consider a class that’s responsible for generating unique identifiers for entities created in your application, and let’s assume that it needs to generate sequential numeric identifiers. That’s usually not a good idea, as I discussed in chapter 6, because incremental identifiers can leak information about your application. You may not want to expose how many orders you receive in a day, how many users you have, and so forth. Let’s assume that there’s a legitimate business reason for having consecutive identifiers, say, to ensure there are no missing items. A simple implementation would look like this:
class UniqueIdGenerator {
private int value;
public int GetNextValue() => ++value;
}When you have multiple threads using the same instance of this class, it’s possible for two threads to receive the same value, or values that are out of order. That’s because the expression ++value translates to multiple operations on the CPU: one that reads value, one that increments it, one that stores the incremented value back in the field, and finally one that returns the result, as can be seen clearly in the x86 assembly output of the JIT compiler:2
UniqueIdGenerator.GetNextValue()
mov eax, [rcx+8] ❶
inc eax ❷
mov [rcx+8], eax ❸
ret ❹❶ Move the field’s value in memory into the EAX register (read).
❷ Increment the value of the EAX register (increment).
❸ Move the incremented value back into the field (store).
❹ Return the result in the EAX register (return)
Every line is an instruction that a CPU runs, one after the other. When you try to visualize multiple CPU cores running the same instructions at the same time, it’s easier to see how that can cause conflicts in the class, as figure 8.1 shows. There you can see that three threads return the same value, 1, even though the function was called three times.

Figure 8.1 Multiple threads running simultaneously, causing state to break
The previous code that uses the EAX register isn’t thread-safe. The way all threads try to manipulate the data themselves without respecting other threads is called a race condition. CPUs, programming languages, and operating systems provide a variety of features that can help you deal with that problem. They usually all come down to blocking other CPU cores from reading from or writing to the same memory region at the same time, and that, folks, is called locking.
In the next example, the most optimized way is to use an atomic increment operation that increments the value in the memory location directly and prevents other CPU cores from accessing the same memory region while doing that, so no thread reads the same value or incorrectly skips values. It would look like this:
using System.Threading;
class UniqueIdGeneratorAtomic {
private int value;
public int GetNextValue() => Interlocked.Increment(ref value);
}In this case, the locking is implemented by the CPU itself, and it would behave as is shown in figure 8.2 when it’s executed. The CPU’s lock instruction only holds the execution on parallel cores at that location during the lifetime of the instruction that immediately follows it, so the lock automatically gets released when each atomic in-memory add operation is executed. Notice that the return instructions don’t return the field’s current value, but the result of a memory add operation instead. The field’s value stays sequential regardless.

Figure 8.2 CPU cores wait for each other when atomic increment is used.
There will be many cases when a simple atomic increment operation isn’t enough to make your code thread-safe. For example, what if you needed to update two different counters in sync? In cases when you can’t ensure consistency with atomic operations, you can use C#’s lock statement, as shown in listing 8.1. For simplicity, we stick to our original counter example, but locks can be used to serialize any state change on the same process. We allocate a new dummy object to use as a lock because .NET uses an object’s header to keep lock information.
Listing 8.1 A thread-safe counter with C#’s lock statement
class UniqueIdGeneratorLock {
private int value;
private object valueLock = new object(); ❶
public int GetNextValue() {
lock (valueLock) { ❷
return ++value; ❸
}
}
}❶ Our lock object, specific for our purpose
❷ Other threads wait until we’re done.
❸ Exiting the scope automatically releases the lock.
Why do we allocate a new object? Couldn’t we just use this so our own instance would also act like a lock? That would save us some typing. The problem is that your instance can also be locked by some code outside of your control. That can cause unnecessary delays or even deadlocks because your code might be waiting on that other code.

Our own implemented locking code would behave like that in figure 8.3. As you can see, it’s not as efficient as an atomic increment operation, but it’s still perfectly thread-safe.

Figure 8.3 Using C#’s lock statement to avoid race conditions
As you can see, locks can make other threads stop and wait for a certain condition. While providing consistency, this can be one of the greatest challenges against scalability. There’s nothing worse than wasting valuable CPU time waiting. You should strive to wait as little as possible. How do you achieve that?
First, make sure that you really need locks. I’ve seen code written by smart programmers that can be fine without acquiring any locks at all, but that unnecessarily waits for a certain condition to be met. If an object instance won’t be manipulated by other threads, that means you may not need locks at all. I don’t say you won’t because it’s hard to assess the side effects of code. Even a locally scoped object can use shared objects and therefore might require locks. You need to be clear about your intent and the side effects of your code. Don’t use locks because they magically make the code they surround thread-safe. Understand how locks work, and be explicit about what you’re doing.
Second, find out if the shared data structure you use has a lock-free alternative. Lock-free data structures can be directly accessed by multiple threads without requiring any locks. That said, the implementation of lock-free structures can be complicated. They can even be slower than their locked counterparts, but they can be more scalable. A common scenario in which a lock-free structure can be beneficial is shared dictionaries, or, as they’re called in some platforms, maps. You might need a dictionary of something shared by all threads, like certain keys and values, and the usual way to handle that is to use locks.
Consider an example in which you need to keep API tokens in memory so you don’t have to query the database for their validity every time they’re accessed. A correct data structure for this purpose would be a cache, and cache data structures can have lock-free implementations too, but developers tend to use the tool that’s closest when they try to solve a problem, in this case, a dictionary:
public Dictionary<string, Token> Tokens { get; } = new();Notice the cool new() syntax in C# 9.0? Finally, the dark days of writing the same type twice when declaring class members are over. The compiler can now assume its type based on its declaration.
Anyway, we know that dictionaries aren’t thread-safe, but thread-safety is only a concern when there will be multiple threads modifying a given data structure. That’s an important point: if you have a data structure that you initialize at the start of your application and you never change it, you don’t need it to be locked or thread-safe by other means because all read-only structures without side effects are thread-safe.
Because we need to manipulate the data structure in the example, we need to have a wrapper interface to provide locking, as shown in listing 8.2. You can see in the get method that if the token can’t be found in the dictionary, it’s rebuilt by reading related data from the database. Reading from the database can be time consuming, and that means all requests would be put on hold until that read operation finished.
Listing 8.2 Lock-based thread-safe dictionary
class ApiTokens {
private Dictionary<string, Token> tokens { get; } = new(); ❶
public void Set(string key, Token value) {
lock (tokens) {
tokens[key] = value; ❷
}
}
public Token Get(string key) {
lock (tokens) {
if (!tokens.TryGetValue(key, out Token value)) {
value = getTokenFromDb(key); ❸
tokens[key] = value;
return tokens[key];
}
return value;
}
}
private Token getTokenFromDb(string key) {
. . . a time-consuming task . . .
}
}❶ This is the shared instance of the dictionary.
❷ A lock is still needed here because it’s a multistep operation.
❸ This call can take a long time, thereby blocking all other callers.
That’s not scalable at all, and a lock-free alternative would be great here. .NET provides two different sets of thread-safe data structures. The names of one start with Concurrent*, in which short-lived locks are used. They’re not all lock-free. They still use locks, but they’re optimized to hold them for brief periods of time, making them quite fast and possibly simpler than a true lock-free alternative. The other set of alternatives is Immutable*, in which the original data is never changed, but every modify operation creates a new copy of the data with the modifications. It’s as slow as it sounds, but there are cases when they might be preferable to Concurrent flavors.
If we use a ConcurrentDictionary instead, our code suddenly becomes way more scalable, as shown in the following listing. You can now see that lock statements aren’t needed anymore, so the time-consuming query can run better in parallel with other requests and will block as little as possible.
Listing 8.3 Lock-free thread-safe dictionary
class ApiTokensLockFree {
private ConcurrentDictionary<string, Token> tokens { get; } = new();
public void Set(string key, Token value) {
tokens[key] = value;
}
public Token Get(string key) {
if (!tokens.TryGetValue(key, out Token value)) {
value = getTokenFromDb(key); ❶
tokens[key] = value;
return tokens[key];
}
return value;
}
private Token getTokenFromDb(string key) {
. . . a time-consuming task . . .
}
}❶ This will run in parallel now!
A minor downside of this change is that multiple requests can run an expensive operation such as getTokenFromDb for the same token in parallel because no locks are preventing that from happening anymore. In the worst case, you’d be running the same time-consuming operation in parallel for the same token unnecessarily, but even so, you wouldn’t be blocking any other requests, so it’s likely to beat the alternate scenario. Not using locks might be worth it.
8.1.1 Double-checked locking
Another simple technique lets you avoid using locks for certain scenarios. For example, ensuring that only a single instance of an object is created when multiple threads are requesting it can be hard. What if two threads make the same request at once? For example, let’s say we have a cache object. If we accidentally provide two different instances, different parts of the code would have a different cache, causing inconsistencies or waste. To avoid this, you protect your initialization code inside a lock to make sure, as shown in the following listing. The static Instance property would hold a lock before creating an object, so it makes sure that no other instances will create the same instance twice.
Listing 8.4 Ensuring only one instance is created
class Cache {
private static object instanceLock = new object(); ❶
private static Cache instance; ❷
public static Cache Instance {
get {
lock(instanceLock) { ❸
if (instance is null) {
instance = new Cache(); ❹
}
return instance;
}
}
}
}❸ All other callers wait here if there is another thread running in this block.
❹ The object gets created, and only once, too!
The code works okay, but every access to the Instance property will cause a lock to be held. That can create unnecessary waits. Our goal is to reduce locking. You can add a secondary check for the value of an instance: return its value before acquiring the lock if it’s already initialized, and acquire the lock only if it hasn’t been, as shown in listing 8.5. It’s a simple addition, but it eliminates 99.9% of lock contentions in your code, making it more scalable. We still need the secondary check inside the lock statement because there’s a small possibility that another thread may have already initialized the value and released the lock just before we acquired it.
Listing 8.5 Double-checked locking
public static Cache Instance {
get {
if (instance is not null) { ❶
return instance; ❷
}
lock (instanceLock) {
if (instance is null) {
instance = new Cache();
}
return instance;
}
}
}❶ Notice the pattern-matching-based “not null” check in C# 9.0.
❷ Return the instance without locking anything.
Double-checked locking may not be possible with all data structures. For example, you can’t do it for members of a dictionary because it’s impossible to read from a dictionary in a thread-safe manner outside of a lock while it’s being manipulated.
C# has come a long way and made safe singleton initializations much easier with helper classes like LazyInitializer. You can write the same property code in a simpler way. It already performs double-checked locking behind the scenes, saving you extra work.
Listing 8.6 Safe initialization with LazyInitializer
public static Cache Instance {
get {
return LazyInitializer.EnsureInitialized(ref instance);
}
}There are other cases in which double-checked locking might be beneficial. For example, if you want to make sure a list only contains a certain number of items at most, you can safely check its Count property because you’re not accessing any of the list items during the check. Count is usually just a simple field access and is mostly thread-safe unless you use the number you read for iterating through the items. An example would look like the following listing, and it would be fully thread-safe.
Listing 8.7 Alternative double-checked locking scenarios
class LimitedList<T> {
private List<T> items = new();
public LimitedList(int limit) {
Limit = limit;
}
public bool Add(T item) {
if (items.Count >= Limit) { ❶
return false;
}
lock (items) {
if (items.Count >= Limit) { ❷
return false;
}
items.Add(item);
return true;
}
}
public bool Remove(T item) {
lock (items) {
return items.Remove(item);
}
}
public int Count => items.Count;
public int Limit { get; }
}❶ First check outside the lock
❷ Second check inside the lock
You might have noticed that the code in listing 8.7 doesn’t contain an indexer property to access list items with their index. That’s because it’s impossible to provide thread-safe enumeration on direct index access without fully locking the list before enumerating. Our class is only useful for counting items, not accessing them. But accessing the counter property itself is quite safe, so we can employ it in our double-checked locking to get better scalability.
8.2 Embrace inconsistency
Databases provide a vast number of features to avoid inconsistencies: locks, transactions, atomic counters, transaction logs, page checksums, snapshots, and so forth. That’s because they’re designed for systems in which you can’t afford to retrieve the wrong data, like banks, nuclear reactors, and matchmaking apps.
Reliability isn’t a black-and-white concept. There are levels of unreliability that you can survive with significant gains in performance and scalability. NoSQL is a philosophy that foregoes certain consistency affordances of traditional relational database systems, like foreign keys and transactions, while gaining performance, scalability, and obscurity in return.
You don’t need to go full NoSQL to get the benefits of such an approach. You can achieve similar gains on a traditional database like MySQL or SQL Server.
8.2.1 The dreaded NOLOCK
As a query hint, NOLOCK dictates that the SQL engine that reads it can be inconsistent and can contain data from not-yet-committed transactions. That might sound scary, but is it really? Think about it. Let’s consider Blabber, the microblogging platform we discussed in chapter 4. When you post every time, another table that contains post counts would be updated, too. If a post isn’t posted, the counter shouldn’t get incremented, either. Sample code would look like that in the following listing. You can see in the code that we wrap everything in a transaction, so if the operation fails at any point, we don’t get inconsistent numbers in post counts.
Listing 8.8 A tale of two tables
public void AddPost(PostContent content) {
using (var transaction = db.BeginTransaction()) { ❶
db.InsertPost(content); ❷
int postCount = db.GetPostCount(userId); ❸
postCount++;
db.UpdatePostCount(userId, postCount); ❹
}
}❶ Encapsulate everything in a transaction.
❷ Insert the post into its own table
❹ Update the incremented post count.
The code might remind you of our unique ID generator example in the previous section; remember how threads worked in parallel with steps like read, increment, and store, and we had to use a lock to ensure that we kept consistent values? The same thing’s happening here. Because of that, we sacrifice scalability. But do we need this kind of consistency? Can I entertain you with the idea of eventual consistency?
Eventual consistency means you ensure certain consistency guarantees, but only after a delay. In this example, you can update the incorrect post counts at certain time intervals. The best thing about that is that such an operation doesn’t need to hold any locks. Users will rarely see their post counts not reflecting the actual post count until it gets fixed by the system. You gain scalability because the fewer locks you hold, the more parallel requests can be run on the database.
A periodic query that updates a table would still hold locks on that table, but they would be more granular locks, probably on a certain row, or in the worst case, on a single page on the disk. You can alleviate that problem with double-checked locking: you can first run a read-only query that just queries which rows need to be updated, and you can run just your update query thereafter. That would make sure that the database doesn’t get nervous about locking stuff because you simply executed an update statement on the database. A similar query would look like that in listing 8.9. First, we execute a SELECT query to identify mismatched counts, which doesn’t hold locks. We then update post counts based on our mismatched records. We can also batch these updates, but running them individually would hold more granular locks, possibly at the row level, so it would allow more queries to be run on the same table without holding a lock any longer than necessary. The drawback is that updating every individual row will take longer, but it will end eventually.
Listing 8.9 Code running periodically to achieve eventual consistency
public void UpdateAllPostCounts() {
var inconsistentCounts = db.GetMismatchedPostCounts(); ❶
foreach (var entry in inconsistentCounts) {
db.UpdatePostCount(entry.UserId, entry.ActualCount); ❷
}
}❶ No locks are held while running this query.
❷ A lock is held only for a single row when running this.
A SELECT query in SQL doesn’t hold locks on the table, but it can still be delayed by another transaction. That’s where NOLOCK as a query hint comes into the picture. A NOLOCK query hint lets a query read dirty data, but in return, it doesn’t need to respect locks held by other queries or transactions. It’s easy for you, too. For example, in SQL Server, instead of SELECT * FROM customers, you use SELECT * FROM customers (NOLOCK), which applies NOLOCK to the customers table.
What is dirty data? If a transaction starts to write some records to the database but isn’t finished yet, those records are regarded as dirty at that moment. That means a query with a NOLOCK hint can return rows that may not exist on the database yet or that will never exist. In many scenarios, that can be a level of inconsistency your app can live with. For example, don’t use NOLOCK when authenticating a user because that might be a security issue, but there shouldn’t be a problem with using it on, say, showing posts. At worst, you’ll see a post that seemingly exists only a brief period, and it will go away in the next refresh anyway. You might have experienced this already with the social platforms you’re using. Users delete their content, but those posts keep showing up in your feed, although you usually get an error if you try to interact with them. That’s because the platform is okay with some level of inconsistency for the sake of scalability.
You can apply NOLOCK to everything in an SQL connection by running an SQL statement first that sounds unnecessarily profound: SET TRANSACTION ISOLATION LEVEL READ_UNCOMMITTED. I think Pink Floyd released a song with a similar title. Anyway, the statement makes more sense and conveys your intent better, too.
Don’t be afraid of inconsistencies if you’re aware of the consequences. If you can see the impact of the tradeoff clearly, you can prefer intentional inconsistency to allow space for more scalability.
8.3 Don’t cache database connections
It’s a rather common malpractice to open a single connection to a database and share it in the code. The idea is sane on paper: it avoids the overhead of connection and authentication for every query, so they become faster. It’s also a bit cumbersome to write open and close commands everywhere. But the truth is, when you only have a single connection to a database, you can’t run parallel queries against the database. You can effectively only run one query at a time. That’s a huge scalability blocker, as can be seen in figure 8.4.
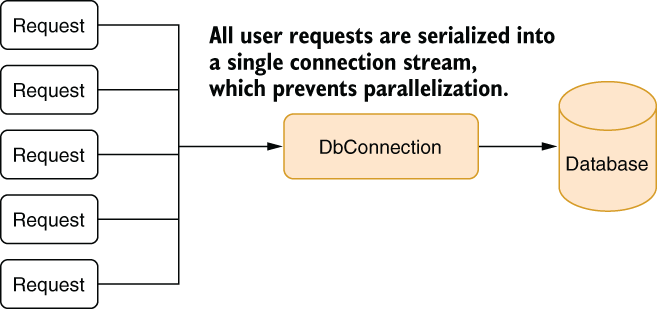
Figure 8.4 A bottleneck created by sharing a single connection in the application
Having a single connection isn’t a good idea for other reasons, too. Queries might require different transaction scopes when they’re running, and they may conflict when you try to reuse a single connection for multiple queries at once.
I must agree that part of the problem comes from naming these things connections when, in fact, they’re not. You see, most client-side database connectivity libraries don’t really open a connection when you create a connection object. They instead maintain a certain number of already open connections and just retrieve one for you. When you think you’re opening a connection, you’re in fact retrieving an already open connection from what’s famously called the connection pool. When you close the connection, the actual connection isn’t closed, either. It’s put back into the pool, and its state gets reset, so any leftover work from a previously running query wouldn’t affect the new queries.
I can hear you saying, “I know what to do! I’ll just keep a connection for every request and close the connection when the request ends!” That would allow parallel requests to run without blocking each other, as shown in figure 8.5. You can see that every request gets a separate connection, and thanks to that, they can run in parallel.

Figure 8.5 Keeping a single connection per HTTP request
The problem with that approach is that when there are more than five requests, the connection pool must make the client wait until it can serve an available connection to them. Those requests wait in the queue, killing the ability to scale more requests, even though the request may not be in use at the time, because the connection pool has no way of knowing if the connection requested is in use unless it’s closed explicitly. This situation is depicted in figure 8.6.

Figure 8.6 Per-request connection objects blocking additional requests
What if I told you that there is an even better approach that’s completely counterintuitive but that will make the code as scalable as possible? The secret solution is to maintain connections only for the lifetime of the queries. This would return a connection to the pool as soon as possible, allowing other requests to grab the available connection and leading to maximum scalability. Figure 8.7 shows how it works. You can see how the connection pool serves no more than three queries at once, leaving room for another request or two.

Figure 8.7 Per-query connections to the database
The reason that works is because a request is never just about running a query. Some processing is usually going on besides the queries themselves. That means that the time you hold a connection object while something irrelevant is running is wasted. By keeping connections open as briefly as possible, you leave a maximum number of connections available for other requests.
The problem is that it’s more work. Consider an example in which you need to update the preferences of a customer based on their name. Normally, a query execution is pretty much like that in the following listing. You run the queries right away, without considering connection lifetime.
Listing 8.10 A typical query execution with a shared connection instance
public void UpdateCustomerPreferences(string name, string prefs) {
int? result = MySqlHelper.ExecuteScalar(customerConnection, ❶
"SELECT id FROM customers WHERE name=@name",
new MySqlParameter("name", name)) as int?;
if (result.HasValue) {
MySqlHelper.ExecuteNonQuery(customerConnection, ❶
"UPDATE customer_prefs SET pref=@prefs",
new MySqlParameter("prefs", prefs));
}
}That’s because you have an open connection that you can reuse. Had you added the connection open-and-close code, it would have become a little bit more involved, like that in listing 8.11. You might think we should close and open the connection between two queries so the connection can be returned to the connection pool for other requests, but that’s completely unnecessary for such a brief period. You’d even be adding more overhead. Also note that we don’t explicitly close the connection at the end of the function. The reason is that the using statement at the beginning ensures that all resources regarding the connection object are freed immediately upon exiting the function, forcing the connection to be closed in turn.
Listing 8.11 Opening connections for each query
public void UpdateCustomerPreferences(string name, string prefs) {
using var connection = new MySqlConnection(connectionString); ❶
connection.Open(); ❶
int? result = MySqlHelper.ExecuteScalar(customerConnection,
"SELECT id FROM customers WHERE name=@name",
new MySqlParameter("name", name)) as int?;
//connection.Close(); ❷
//connection.Open(); ❷
if (result.HasValue) {
MySqlHelper.ExecuteNonQuery(customerConnection,
"UPDATE customer_prefs SET pref=@prefs",
new MySqlParameter("prefs", prefs));
}
}❶ The ceremony to open a connection to database
You can wrap the connection-open ceremony in a helper function and avoid writing it everywhere like this:
using var connection = ConnectionHelper.Open();
That saves you some keystrokes, but it’s prone to mistakes. You might forget to put the using statement before the call, and the compiler might forget to remind you about it. You can forget closing connections this way.
8.3.1 In the form of an ORM
Luckily, modern object relational mapping (ORM) tools are libraries that hide the intricacies of a database by providing an entirely different set of intricate abstractions, like Entity Framework, that do this automatically for you, so you don’t need to care about when the connection would be opened or closed. It opens the connection when necessary and closes it when it’s done with it. You can use a single, shared instance of a DbContext with Entity Framework throughout the lifetime of a request. You may not want to use a single instance of it for the whole app, though, because DbContext isn’t thread-safe.
A query similar to listing 8.11 can be written like that in listing 8.12 with Entity Framework. You can write the same queries using LINQ’s syntax, but I find this functional syntax easier to read and more composable.
Listing 8.12 Multiple queries with Entity Framework
public void UpdateCustomerPreferences(string name, string prefs) {
int? result = context.Customers
.Where(c => c.Name == name)
.Select(c => c.Id)
.Cast<int?>()
.SingleOrDefault(); ❶
if (result.HasValue) {
var pref = context.CustomerPrefs
.Where(p => p.CustomerId == result)
.Single(); ❶
pref.Prefs = prefs;
context.SaveChanges(); ❶
}
}❶ The connection will be opened before and closed automatically after each of these lines.
You can have more space to scale your application over when you are aware of the lifetime semantics of the Connection classes, connection pools, and actual network connections established to the database.
8.4 Don’t use threads
Scalability isn’t only about more parallelization—it’s also about conserving resources. You can’t scale beyond a full memory, nor can you scale beyond 100% of CPU usage. ASP.NET Core uses a thread pool structure to keep a certain number of threads to serve web requests in parallel. The idea is quite similar to a connection pool: having a set of already initialized threads lets you avoid the overhead of creating them every time. Thread pools usually have more threads than the number of CPU cores on the system because threads frequently wait for something to complete, mostly I/O. This way, other threads can be scheduled on the same CPU core while certain threads are waiting for I/O to complete. You can see how more threads than the number of CPU cores can help utilize CPU cores better in figure 8.8. The CPU can use the time a thread is waiting for something to complete to run another thread on the same core by serving more threads than the number of available CPU cores.

Figure 8.8 Optimizing CPU usage by having more threads than the number of CPU cores
This is better than having the same number of threads as CPU cores, but it’s not precise enough to make the best use of your precious CPU time. The operating system gives threads a short amount of time to execute and then relinquishes the CPU core to other threads to make sure every thread gets a chance to run in a reasonable time. That technique is called preemption, and it’s how multitasking used to work with single-core CPUs. The operating system juggled all the threads on the same core, creating the illusion of multitasking. Luckily, since most threads wait for I/O, users wouldn’t notice that threads took turns to run on the single CPU they have unless they ran a CPU-intensive application. Then they’d feel its effects.
Because of how operating systems schedule threads, having a greater number of threads in the thread pool than the number of CPU cores is just a ballpark way of getting more utilization, but as a matter of fact, it can even harm scalability. If you have too many threads, they all start to get a smaller slice of CPU time, so they take longer to run, bringing your website or API to a crawl.
A more precise way to leverage time spent waiting for I/O is to use asynchronous I/O, as I discussed in chapter 7. Asynchronous I/O is explicit: wherever you have an await keyword, that means the thread will wait for a result of a callback, so the same thread can be used by other requests while the hardware is working on the I/O request itself. You can serve multiple requests on the same thread in parallel this way, as you can see in figure 8.9.
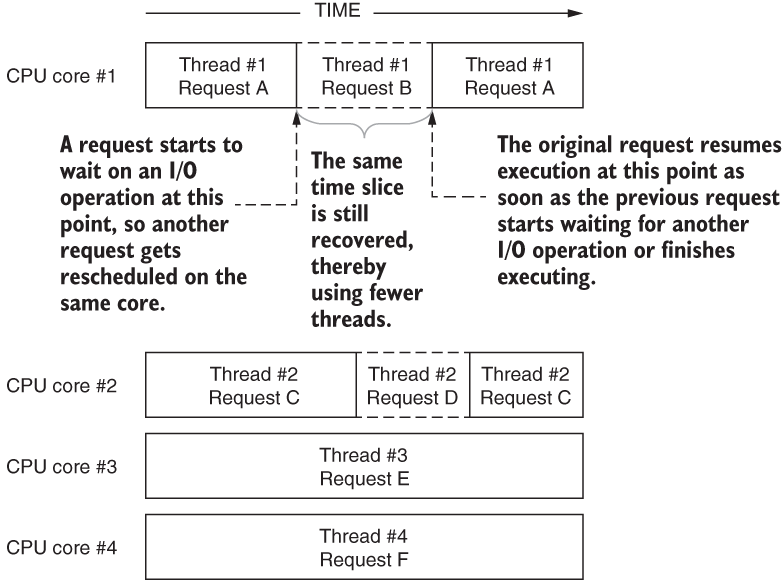
Figure 8.9 Achieving better concurrency with fewer threads and async I/O
Asynchronous I/O is very promising. Upgrading an existing code to asynchronous I/O is straightforward, too, as long as you have a framework that supports async calls at the root. For example, on ASP.NET Core, controller actions or Razor Page handlers can be written either as regular methods or as asynchronous methods because the framework builds the necessary scaffolding around them. All you need to do is to rewrite the function using asynchronous calls and mark the method as async. Yes, you still need to make sure that your code works properly and passes your tests, but it’s still a straightforward process.
Let’s revise the example in listing 8.6 and convert it to async in listing 8.13. You don’t need to go back and see the original code because the differences are highlighted in the listing in bold. Take a look at the differences, and I’ll break them down afterward.
Listing 8.13 Converting blocking code to async code
public async Task UpdateCustomerPreferencesAsync(string name, string prefs) { int? result = await MySqlHelper.ExecuteScalarAsync( customerConnection, "SELECT id FROM customers WHERE name=@name", new MySqlParameter("name", name)) as int?; if (result.HasValue) { await MySqlHelper.ExecuteNonQueryAsync(customerConnection, "UPDATE customer_prefs SET pref=@prefs", new MySqlParameter("prefs", prefs)); } }
It’s important that you know what all these are for, so you can use them consciously and correctly.
-
Async functions don’t actually need to be named with the suffix
Async, but the convention helps you see that it’s something you need to await. You might think, “But theasynckeyword is right there!” but the keyword only affects the implementation and isn’t part of the function signature. You must navigate the source code to find out if an async function is really async. If you don’t await an async function, it returns immediately while you may incorrectly assume it has finished running. Try to stick to convention unless you can’t afford it when you need specific names for your functions, such as the names of controller actions because they can designate the URL routes as well. It also helps if you want to have two overloads of the same function with the same name because return types aren’t considered a differentiator for overloads. That’s why almost all async methods are named with anAsyncsuffix in .NET. -
The
asynckeyword at the beginning of the function declaration just means you can useawaitin the function. Behind the scenes, the compiler takes thoseasyncstatements, generates the necessary handling code, and converts them into a series of callbacks. -
All async functions must return a
TaskorTask<T>. An async function without a return value could also have avoidreturn type, but that’s known to cause problems. For example, exception-handling semantics change, and you lose composability. Composability in async functions lets you define an action that will happen when a function finishes in a programmatical way usingTaskmethods likeContinueWith. Because of all that, async functions that don’t have a return value should always useTaskinstead. When you decorate a function with theasynckeyword, values afterreturnstatements are automatically wrapped with aTask<T>, so you don’t need to deal with creating aTask<T>yourself. -
The
awaitkeyword ensures that the next line will only be executed after the expression that precedes it has finished running. If you don’t putawaitin front of multiple async calls, they will start running in parallel, and that can be desirable at times, but you need to make sure that you wait for them to finish because, otherwise, the tasks may be interrupted. On the other hand, parallel operations are prone to bugs; for example, you can’t run multiple queries in parallel by using the sameDbContextin Entity Framework Core becauseDbContextitself isn’t thread-safe. However, you can parallelize other I/O this way, like reading a file. Think of an example in which you want to make two web requests at once. You may not want them to wait for each other. You can make two web requests concurrently and wait for both of them to finish, as is shown in listing 8.14. We define a function that receives a list of URLs and starts a download task for each URL without waiting for the previous one to complete so that the downloads run in parallel on a single thread. We can use a single instance of theHttpClientobject because it’s thread-safe. The function waits for all tasks to complete and builds a final response out of the results of all tasks.
Listing 8.14 Downloading multiple web pages in parallel on a single thread
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net.Http;
using System.Threading.Tasks;
namespace Connections {
public static class ParallelWeb {
public static async Task<Dictionary<Uri, string>> ❶
DownloadAll(IEnumerable<Uri> uris) {
var runningTasks = new Dictionary<Uri, Task<string>>(); ❷
var client = new HttpClient(); ❸
foreach (var uri in uris) {
var task = client.GetStringAsync(uri); ❹
runningTasks.Add(uri, task); ❺
}
await Task.WhenAll(runningTasks.Values); ❻
return runningTasks.ToDictionary(kp => kp.Key,
kp => kp.Value.Result); ❼
}
}
}❷ Temporary storage to keep track of running tasks
❸ A single instance is enough.
❹ Start the task, but don’t await it.
❻ Wait until all tasks are complete.
❼ Build a new result Dictionary out of the results of the completed Tasks.
8.4.1 The gotchas of async code
You need to keep certain things in mind when you’re converting your code to async. It’s easy to think “Make everything async!” and make everything worse in the process. Let’s go over some of those pitfalls.
If a function doesn’t call an async function, it doesn’t need to be async. Asynchronous programming only helps with scalability when you use it with I/O-bound operations. Using async on a CPU-bound operation won’t help scalability because those operations will need separate threads to run on, unlike I/O operations, which can run in parallel on a single thread. The compiler might also warn you when you try to use an async keyword on a function that doesn’t run other async operations. If you choose to ignore those warnings, you’ll just get unnecessarily bloated and perhaps slower code due to the async-related scaffolding added to the function. Here’s an example of unnecessary use of an async keyword:
public async Task<int> Sum(int a, int b) {
return a + b;
}I know this happens because I’ve seen it in the wild, where people just decorated their functions as async for no good reason. Always be explicit and clear about why you want to make a function async.
It’s extremely hard to call an async function in a synchronous context safely. People will say, “Hey, just call Task.Wait(), or call Task.Result, and you’ll be fine.” No, you won’t. That code will haunt your dreams, it will cause problems at the most unexpected times, and eventually, you’ll wish you could get some sleep instead of having nightmares.
The greatest problem with waiting for async functions in synchronous code is that it can cause a deadlock due to other functions in the async function that depend on the caller code to complete. Exception handling can also be counterintuitive because it would be wrapped inside a separate AggregateException.
Try not to mix asynchronous code inside a synchronous context. It’s a complicated setup, which is why only frameworks do it, usually. C# 7.1 added support for async Main functions, which means you can start running async code right away, but you can’t call an async function from your synchronous web action. The opposite is fine, though. You can, and you will, have synchronous code in your async functions because not every function is suitable for async.
8.4.2 Multithreading with async
Asynchronous I/O provides better scalability characteristics than multithreading on I/O heavy code because it consumes less resources. But multithreading and async are not mutually exclusive. You can have both. You can even use asynchronous programming constructs to write multithreaded code. For example, you can handle long-running CPU work in an async fashion like this:
await Task.Run(() => computeMeaningOfLifeUniverseAndEverything());
It will still run the code in a separate thread, but the await mechanism simplifies the synchronization of work completion. If you wrote the same code using traditional threads, it would look a little bit more involved. You need to have a synchronization primitive such as an event:
ManualResetEvent completionEvent = new(initialState: false);
The event object you declare also needs to be accessible from the point of synchronization, which creates additional complexity. The actual code becomes more involved too:
ThreadPool.QueueUserWorkItem(state => {
computeMeaningOfLifeUniverseAndEverything();
completionEvent.Set();
});Thus, async programming can make some multithreaded work easier to write, but it’s neither a complete replacement for multithreading nor does it help scalability. Multithreaded code written in async syntax is still regular multithreaded code; it doesn’t conserve resources like async code
8.5 Respect the monolith
There should be a note stuck to your monitor that you’ll only remove when you become rich from your vested startup stocks. It should say, “No microservices.”
The idea behind microservices is simple: if we split our code into separate self-hosted projects, it will be easier in the future to deploy those projects to separate servers, so, free scaling! The problem here, like many of the issues in software development I’ve discussed, is added complexity. Do you split all the shared code? Do the projects really not share anything? What about their dependencies? How many projects will you need to update when you just change the database? How do you share context, like authentication and authorization? How do you ensure security? There’ll be added round trip delays caused by the millisecond-level delays between servers. How do you preserve compatibility? What if you deploy one first, and another one breaks because of the new change? Do you have the capacity to handle this level of complexity?
I use the term monolith as the opposite of microservices, where the components of your software reside in a single project, or at least in tightly coupled multiple projects deployed together to the same server. Because the components are interdependent, how do you move some of them to another server to make your app scale?
In this chapter, we’ve seen how we can achieve better scalability even on a single CPU core, let alone on a single server. A monolith can scale. It can work fine for a long time until you find yourself in a situation where you must split your app. At that point, the startup you’re working for is already rich enough to hire more developers to do the work. Don’t complicate a new project with microservices when authentication, coordination, and synchronization can become troublesome at such an early stage in the lifetime of the product. Ekşi Sözlük, more than 20 years later, is still serving 40 million users every month on a monolithic architecture. A monolith is the natural next step to switch to from your local prototype, too. Go with the flow and consider adopting a microservice architecture only when its benefits outweigh its drawbacks.
Summary
-
Approach scalability as a multistep diet program. Small improvements can eventually lead you to a better, scalable system.
-
One of the greatest blocks of scalability is locks. You can’t live with them, and you can’t live without them. Understand that they’re sometimes dispensable.
-
Prefer lock-free or concurrent data structures over acquiring locks yourself manually to make your code more scalable.
-
Learn to live with inconsistencies for better scalability. Choose which types of inconsistencies your business would be okay with, and use the opportunity to create more scalable code.
-
ORMs, while usually seen as a chore, can also help you create more scalable apps by employing optimizations that you may not think of.
-
Use asynchronous I/O in all the I/O-bound code that needs to be highly scalable to conserve available threads and optimize CPU usage.
-
Use multithreading for parallelizing CPU-bound work, but don’t expect the scalability benefits of asynchronous I/O, even when you use multithreading with async programming constructs.
-
A monolith architecture will complete a full tour around the world before the design discussion over a microservice architecture is finished.
1. A popular song from the 1950s by Doris Day, my father’s favorite singer, “Que Será, Será” means “Whatever will be, will be” in Italian. It’s the official mantra for code deploys on Fridays, usually followed by the 4 Non Blondes hit “What’s Up?” on Saturday, which ends with Aimee Mann’s “Calling It Quits” on Monday.
2. A JIT (just in time) compiler converts either source code or the intermediate code (called bytecode, IL, IR, etc.) to the native instruction set of the CPU architecture it’s running on to make it faster.