
Specifying Synthetic Instruments
When an ATE designer is first faced with an ATE problem that they want to fit to some synthetic instrument-based solution, the first step is to capture the requirements for solution. These requirements should specify the synthetic instrumentation from a high level, giving the properties and elements for the synthetic solution.
There are many ways to do this. Engineers have attempted to specify synthetic instruments all sorts of ways, and I personally have seen this process attacked from many different directions. However, so far as I am aware at the date of this writing, there is no standard way to do this. I do know that there are many bad ways.
One quite common bad approach is the following: measurement system specifications are written in the vaguest of terms and delivered to the designer. Habitually, this consists of a list of stimuli to be provided and responses to be recorded, and maybe there is some accuracies specified for the recorded values, often based on marketing brochures from legacy products.
At that point, the first mistake is made. The designer begins to specify hardware modules that accomplish the measurement tasks. Already they have left the path to a synthetic solution. The designer goes down the list of stimuli and picks modules that make each stimulus. Maybe, if they’re lucky, they can find a module that does two of the stimuli, but in general the idea is to make a distinct mapping between required stimuli, and required stimulus modules. Specifications on accuracy of a stimulus are applied directly onto the associated module.
Following that, a similar misguided process results in a list of required response modules corresponding to the required responses to be recorded. Specifications on accuracy of a response measurement are reiteratively levied directly onto the associated module.
This results in a modular system design with easy to understand requirements traceability. Block diagrams are drawn. Specification compliance matrices are compiled. There’s only one small problem. The system isn’t synthetic! Instead, specific hardware is assigned to specific measurement tasks. It’s our old rack-em-stack-em friend in disguise in modular clothing. Sort of a “bookshelf” system, where each book represents a specific measurement.

At this point, the designer can try to “back door” a synthetic solution by looking at some of the modules that have been specified. Maybe they can design them with a synthetic approach and in that way call the whole design synthetic. So the designer writes some vague requirements and attempts a synthetic design of the modules themselves. Here the process repeats and the same mistakes are made again.
Synthetic Instrument Definition and XML
A significant observation about the wrong-headed approach described in the previous section is that the system software that makes these modules do the job (a job as yet not clearly defined) is held implicit during the requirements capture and analysis stage. Later on, once the hardware is defined, ATE programmers may be invited to generate software requirements based on the original measurement specifications using this modular hardware. The software requirements that results will inevitably lead to a procedural test program. Maybe in a few spots some synthetic concepts can briefly appear, but the overall focus is on procedural test executive functionality.
How do we fix this? How do we avoid being led down the garden path to ingrained ATE design methods? The answer is that we need to set off in a consistent and beneficial direction toward synthetic design if we want to end up specifying synthetic instruments. We must take a formally rigorous approach that focuses on the measurement and fits the problem to a concrete synthetic solution. Only then will we find that our system design is fully synthetic. Only then will we end up realizing all the efficiencies and benefits of a synthetic design.
To provide the consistent and beneficial direction toward synthetic design during the capture of requirements, I have developed an XML-based method of specifying synthetic instruments. I submit that it is a right way to specify synthetic instruments. I believe this XML-based method can lead us more consistently toward a true synthetic design. For that reason, if this approach is eventually adopted by the community as the right way or not, for the purposes of this book it will serve my purposes of illustrating a “right thinking” method for specifying synthetic instruments that propels the designer closer to the goal.
Why XML?
Any popular new software technology has a gee-wizz factor that draws designers to it like so many moths to a flame. Designers are attracted regardless if the new technology is appropriate to the task at hand, often resulting in their demise. So long as a technology is new and interesting, with lots of cryptic acronyms, designers will use it appropriate or not. XML is certainly popular today and has tons of related acronyms, but at first glance XML’s roots as a text document markup language may seem inappropriate for specifying ATE. Why then, exactly, should we use it?
You should use XML because XML has several compelling features that make it ideal to use in the context of synthetic instruments. These compelling features make XML appropriate as a mechanism for describing both synthetic instrument hardware and software and the two working together as a system.
XML has the following distinct advantages in the context of synthetic instrumentation:
Hierarchical
XML provides a convenient way to describe hierarchical things. In fact, an XML document must be strictly tree structured. If you use XML to describe a synthetic instrument, the description will inevitably be tree structured. This is a good thing. Synthetic instruments must be designed in this way. Using a tool like XML with a strict hierarchical structure keeps you on the right road when you design your measurement system.
Extensible
XML is an eXtensible Markup Language. That means it can be extended with a new schema of tags that serve the needs of new contexts. You are free to define an <Abscissa> tag and give it semantic meaning specific to your synthetic instrument application. Extensibility in XML is a formalized and expected part of the way XML works. In XML, you define a document type description (DTD) or an XML schema that sets down the syntactic rules for your document.
Abstract
An XML description of a measurement is a pure and abstract description that exists outside of any particular hardware context. Often, synthetic instruments developed as replacements for legacy instruments make the mistake of using the legacy instrument specifications as a specification for the new synthetic instrument. This mistake can be largely avoided by abstracting the pure measurement capabilities of the old instrument away from its original hardware context.
Standards-Based
XML is a growing open standard derived from SGML (ISO 8879). Because XML is a standard, that means there are many open source and commercial tools available for authoring, manipulating, parsing, and rendering XML[B6]. The standardization of XML allow these tools to interoperate well. Because of its wide applicability, it’s easy to find training to get up to speed. The bookstores are filled with introductory XML books, classes are offered in colleges, and even training videos are available. Note, too, that SGML is a popular standard within the U.S. government, and the U.S. government is the largest market today for synthetic instruments.
Programming Neutral
XML is not a programming language. It is a markup language. It’s goal is to describe the logical structure of something, not to directly define algorithms in detail. XML does not replace the use of full-featured programming languages in describing detailed procedures or data structures. This is important since no one wants to give up what has already been achieved with traditional programming. Nobody will be re-coding FFTs in XML. Instead, XML will assist in the generation of program code by encapsulating the hierarchical structure of a synthetic measurement system in a way that can guide and control and even automate the programming.
Portable
XML is not tied to any one computing platform, operating system, or commercial vendor. It flourishes across the spectrum of computing environments. Moreover, there are standards such as the document object model (DOM) and simple API for XML (SAX) that give a platform-neutral way for programs to interact with XML. The portability of XML is advantageous. No bias or restriction is placed on the hardware and software options based on the description methodology chosen.
I’ve decided to define a system that uses XML to describe and specify synthetic instrumentation. XML is somewhat of a blank slate with regards to test and measurement, and therefore it will be mostly paradigm-neutral when applied. I think this is a great advantage. It will help focus the discussion toward what I am trying to explain about defining synthetic instruments and away from widely addressed questions surrounding traditional instruments.
ATML
Automated test markup language (ATML) is a cooperative effort by members of the ATE industry to define define a collection of XML schemas that allows ATE and test information to be exchanged in a common format adhering to the XML standard. The work in this book is independent of that effort.
Based on the work I have seen on ATML to date, the XML techniques described in this book are more complimentary to ATML than they are redundant or conflicting. Because of the measurement focus required by synthetic instrumentation descriptions, I address a narrower scope of issues with XML technology than the ATML group is addressing.
I’ll go out on a limb and predict that like many other ATE-related software tools and techniques, ATML will experience gravitation toward the routine, procedural, instrument oriented measurement paradigm. To counterbalance this inevitable gravitation, I would encourage everyone involved with ATML to attempt as much as possible to use the blank slate of XML as an opportunity to do something truly new and better, rather than to simply translate the same old methods into a new syntax.
Why Not SCPI, ATLAS, …?
Before I get into the use of XML, I need to address an objection that I know will be raised by some people. Some folks might think that it would be reasonable to use something else for describing synthetic measurements.
One possibility I’ve heard suggested is SCPI. After all, The Standard Commands for Programmable Instrumentation (SCPI) defines a standard set of commands to control programmable test and measurement devices in instrumentation systems. That seems, at first glance, an appropriate standard. Automated instrumentation developers already know SCPI. In fact, the whole purpose of SCPI was to provide a standardized lingua franca for programmable instrumentation, particularly over the IEEE-488 bus, but over other interfaces (for example, VXI) as well.

No doubt, SCPI can be used quite readily within a synthetic instrumentation system as a way to talk to the individual physical instruments. SCPI has a tree-oriented structure, not unlike XML. It’s also true that SCPI has a related data interchange format (DIF) for recording output data. It’s also certain that it definitely can be used to talk to synthetic instrument systems as a whole and to define interfaces to new synthetic instruments.
Unfortunately, SCPI has certain aspects that make it somewhat problematic for use in describing synthetic instruments, both here in this book, and possibly in a wider context.
First, SCPI provides a standard for an instrument communication interface, not a controllably extensible method for describing synthetic measurements. As such, SCPI really doesn’t exactly fit the bill for the purpose I intend.
Second, listing the set of functions an instrument performs based on the commands it responds to does, to some degree, tell us what measurements can be made. I still could use SCPI to describe measurements, at least SCPI syntax, which is tree oriented, exactly like XML. In this way, I make SCPI do double duty with its role as an interfacing language. However, I believe this would inevitably lead us to a mixed-model, leading us away from an synthetic approach in the design. In its effort to allow for all the diverse functionality of the wide range of automated instrumentation, SCPI provides a rich facility that can be used to describe the interface to virtually any instrument, existing or imagined. That’s not to say it has no limitations. Any practical system must have limitations. Rather, I’m saying that SCPI provides too much flexibility, and thereby allows the designer the ability to design measurements and talk to instruments with any paradigm, synthetic or not.
Problems with Other Legacy Software Approaches
There really is no point in belaboring the issue by listing all possible legacy software choices available and explaining why they can’t be used or aren’t appropriate to synthetic instruments. To do so leads us into religious war. I indulged in one crusade, my prediction regarding ATML and argument against SCPI, and that should be enough.
Notwithstanding the advantages already stated that argue for the use of XML, in point of fact, there is no fundamental reason why one can’t define and manipulate synthetic instruments and synthetic measurement systems using any system or combination thereof that strikes one’s fancy: SCPI, ATLAS, FORTH, BASIC, Java, SQL, FORTRAN, C, or any other reasonable programming tool or environment. They’re just not as cool as XML.
Introduction to XML
As I alluded to earlier, one might think of XML only as a markup language for documents, where documents are text-processing things that get displayed on web pages or printed in books. In fact, as I write this book, I’m writing the text with XML markup. XML is in some sense a subset of SGML, the Standard Generalized Markup Language defined by ISO 8879.
But a document is really any data containing structured information. Myriad applications are currently being developed that make use of XML documents in contexts that are far removed from text processing. There are already an amazing number of XML Document Type Descriptions. Any kind of structured information is amenable to description by an XML-based format.
Since XML can describe structured information, it can be used to describe synthetic instruments. However, just because something is possible doesn’t mean it’s necessarily a good idea. Why is the application of XML to the structured description of synthetic instrumentation a good idea?
Automatic Descriptions
XML can be applied practically as a description language in a fully automated context. That is to say it would be practical to start with an XML description of a synthetic instrumentation system, and turn it into a real, high speed instrument using nothing but automated tools.
XML is easy to use with modern compiler tools. Part of this facility stems from the fact that it is possible to express the syntax of XML in Extended Backus-Naur Form (EBNF). If you’ve never heard of EBNF before, don’t be frightened. EBNF is merely a system for describing the valid syntax of a grammar like XML. It’s a way to describe what can and can’t be said in a purely mechanical way.
EBNF comprises a set of rules, called productions. Every production rule describes a specific fragment of syntax. A complete, syntactically valid program or document can be reduced to a single, specific rule, with nothing left over, by repeated application of the production rules. It is possible to express the syntax of XML in Extended Backus-Naur Form, and therefore it is possible to use modern compiler tools that can take EBNF and turn it into compilable high-speed computer codes. Any modern compiler book[B0] will explain how this works.
Actually, there’s really no need to work at the level of EBNF if you don’t want to. XML has associated with it a large collection of parsers, formatters, and other tools that allow designers to easily attach semantic functionality to XML documents. In most cases, these XML-specific tools are better at doing this than generic compiler tools.
Notwithstanding attempts by some companies to patent encumber various XML applications, thus far XML remains a relatively free and open technology. XML parsing libraries are freely available across many operating systems, and will be found integrated into many development tools. Similarly, there are a wide collection of tools that can be used to write XML. Constructing a GUI, for example, that generates well formed XML is a simple task given all the help available.
Note the statement that XML can be turned into compilable computer code, as compared with interpreted code. Either is possible. The difference between the two is this: Should an XML measurement description be compiled, that implies that all the work of parsing the description and recasting it into a form that can be executed at high speed is accomplished once, up front, before the measurement is ever run. Interpreted code, in contrast, is not processed beforehand. It is processed while the measurement is being run.
Because the processing of interpreted code occurs at measurement time, it has the potential of slowing down the measurement. It’s my opinion that interpreted scripting should be avoided for this reason. Measurement descriptions must be compiled into high-speed, isometrologically optimized state machine descriptions of a canonical map before they are run.
Admittedly, given the ever-increasing speed of computers, this distinction seems less of an issue. Given a fast enough CPU, you can interpret and optimize your measurement every time it runs with no real penalty. Still, I feel that faster CPUs should not be an excuse for slower software or skipping the optimization step. There will always be situations where the maximum possible speed is needed, and you shouldn’t give that capability away for no reason.
Not a Script
The use of XML in automated test applications is nothing new. I have already mentioned the ATML effort. Another application of XML to ATE appears in Johnson and Roselli[C2], where XML is used as a flexible, portable test script language. Although clever and useful in certain circumstances, I believe “scripting” is an inappropriate use of XML in ATE. XML syntax is clunky for detailed procedural programming; a clunky script language is not what you want from XML in the context of synthetic instrumentation.
Scripting implies sequential execution of a procedural design. Even if object-oriented (OO) techniques are used, and even if the script is compiled, the result is still not as map-oriented and OO as you want; it works at much too low a level; it can’t get optimized effectively. Scripting results in too much freedom, and thereby doesn’t constrain the design approach sufficiently to allow for the best performance.
There are better things to use for scripting than XML. This point is true notwithstanding some of the advantages to the use of XML for scripting that are pointed out by Johnson and Roselli. In scripting, some hierarchical structure is definitely used (subroutines, loop blocks, if-else) but the basic flow is top-down event oriented. For the most part, therefore, XML just dirties up the syntax of what could be a clear procedural script if rendered with a clearer procedural syntax, like one finds in C, Perl, Java, or Forth.
XML is better used as a descriptive language. It shines in its ability to mark things up in a hierarchical or tree structured manner. When you mark up something, like a text document, the markup adds attributes to the text content at the lowest level. It also allows higher level logical structure (paragraphs, tables, sections, chapters, and so on) to be built up with hierarchical layers of markup.
Some applications of XML have what is called mixed content with the hierarchical XML markup intertwined with raw text data at every level. In other cases, there is no content other than structural elements that nest downward at lower levels, possibly with raw data at the very bottom of the hierarchy. In this latter situation, tags and attributes are applied to lower level tags and attributes, down and down till you reach the atoms of content that represent fundamental things that do not apply to anything lower.
XML Basics
Let’s dive right in and look at an example XML document.
Study Example 9-1 and see if you can discern the structure of XML syntax. If you are familiar with HTML, this should look very understandable to you. This is a great advantage of XML, by the way. It’s human readable and leverages the understanding of HTML already possessed by millions of people.
If you aren’t familiar with tagged markup, like HTML, here’s a brief tutorial.
First of all, you need to know that the angle brackets ”<>“are special characters that enclose something called a tag. XML consists of these tags that themselves enclose elements. A start tag begins the enclosed area of text, known as an element, according to the tag name. The element defined by the tag ends with the end tag. An end tag starts with a slash.
One difference between XML and HTML is that in XML, a start tag like <foo> must be followed by an end tag </foo>. The end tag is not optional. However, in XML something called an empty tag is allowed. These have a slash before the closing angle.
Here is an example of a start and end tag enclosing an item:
Empty tags don’t enclose anything, so they have no associated item. But that doesn’t mean empty tags are, well, “empty.” End tags, like items with no embedded tags, represent a kind of “leaf” of an XML syntax tree.
As with HTML, XML tags may include a list of attributes consisting of an attribute name and an attribute value separated by an equals sign. An example would be <foo bar=“asdf”>, where “bar” is the attribute name, and “asdf” is the attribute value.
For the moment, that’s it. (That wasn’t hard, now was it?) As you can see, XML has extremely simple syntax. In a sense, XML is a way of writing fancy parenthesis to enclose and nest things in a tree structure with handy places to assign attributes at each branching of the tree. There are more things to talk about with regard to XML. I refer you to the many fine books on the subject that are now available[B6].
Synthetic Measurement Systems and XML
There are many different ways XML fits into the description of a synthetic instrument, but they can basically be divided into these interrelated duties:
The first of these duties is to provide an abstract description of the measurement to be performed. Since synthetic instruments do their work on generic hardware, this first duty is most important. There needs to be a way to describe measurements in a way separate from hardware. XML is exactly that way.
Even though it’s most important, capturing the measurements to be performed is still only part of the picture. The available hardware must be defined so that these hardware resources can be allocated to the measurement tasks at hand. The description of the hardware suite is best done relative to some anticipated fixed yet abstract model so as to structure the description in a way that allows it to be most effectively used. XML can provide exactly this framework.
When the measurement is brought together with the hardware description, the synthetic instrument is generated, loaded into the hardware, and run. The result of the run is a set of measurement data. This resulting data needs to be captured, stored, analyzed, visualized, and possibly augmented or reduced by post processing. Again, XML can serve quite nicely as a data language, encapsulating hierarchical data in a way that can be easily manipulated both by a human and by a computer.
Describing the Measurement with XML
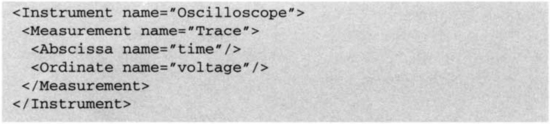
Let’s begin with a simple example in order to show how XML is applied to the task of describing a measurement. Consider a synthetic oscilloscope instrument that measures voltage as a function of time. Here is a simple XML description of the single measurement done by this instrument.
Let’s take a different view of Example 9-2. Figure 9-3 is a diagram of its tree structure.


At the highest level, I have defined an “Instrument” called an Oscilloscope. Enclosed in that instrument is one “Measurement” which I named a “Trace”. The measurement consists of the “time” abscissa and “voltage” ordinate. In Example 9-2, I chose to use empty tags for abscissa and ordinate, with a simple attribute “name=” to give them an identifying title.
I think Example 9-2 is simple enough that you probably understand what I have described using XML, and how I went about it. Admittedly, this a very superficial description. It is also true that I could have used XML in quite different ways to make the same description. I could have structured the description in XML this way instead:
As you can see, what were once attributes have been replaced by a deeper nesting of tags. Is there a reason to prefer one approach over the other? Should a tag attribute be used for “name” rather than a child tag?
In many cases, the answer to this XML style question is unclear. It could be done either way without much difference in this case. One approach would be to use attributes for things that are clearly and tightly associated with the specific tag itself, and no other, rather than something, possibly reusable, that the tag describes or otherwise comprises. In Example 9-3, you should see how the tag <Name> is reused at different levels. Any reusable entity that might apply to different things is probably best a tag rather than an attribute. On the other hand, extremely generic attributes like “name=” are so common that an argument for syntactic simplicity could be made, suggesting that these common things should be attributes, saving us typing, at the sacrifice of complicating reuse somewhat.

There is one situation where there is no decision, where you must use a deeper tag nesting rather than an attribute. Multiple occurrences of an attribute are not permitted. Specifically, it would not be acceptable to make “Abscissa” an attribute of “Measurement” since a measurement could have multiple abscissas. For example, the map description of a image scanner might look like this:

Horizontal and vertical position are the two abscissas, and RGB ordinates describe the color image data. It would not be acceptable to list both abscissas and three ordinates as attributes of the measurement. They must be listed as nested, child tags.
Defining an Instrument
Let’s do another example, a little more worked out to illustrate some further points. This example describes a synthetic instrument that can do two measurements. One called Reflection and the other Transmission. RF Engineers will recognize these as the main measurements of a vector network analyzer, like the Agilent 8510.


The tree structure here is again evident and I have introduced some new nesting elements: Stimulus, Response, and Port.

The <Stimulus> and <Response> elements tells us if the enclosed elements are associated with stimulating the DUT, or measuring some response. Abscissas or ordinates may be defined as canonical only as a a stimulus or only as a response. Thus the stimulus and response nesting will decide what axes in the measurement map must be inverted prior to data acquisition.
The <Port> element is a deceptively simple way to say what physical DUT ports are associated with what parameters of the enclosed elements. Abscissas and ordinate port parameters within are assumed to refer to the listed ports. In Example 9-5, all the abscissas, and the Reflection ordinate refer to the port named input. That name serves to uniquely identify a particular port. It would be assigned in the measurement system description, or possibly as a measurement parameter.
In contrast, the “Gain” ordinate does refer to a particular port; it refers to a <PortGroup>, which are a group of ports referred to collectively. In this case, the port group comprises the ports named input and output. Gain is measured once for this port group. A port group is different than a list of ports, where the ordinate would be measured once for each port in the list. Gain requires two ports to be specified in order to make a single measurement. If you wanted several gain measurements, you would need to give a list of PortGroups.
Ports are, deep down, really just another abscissa. <Port> is defined as an element that contains abscissas and ordinates so as to clarify the parameter passing and grouping issues, but otherwise <Port> will act like any other abscissa. You must set their value explicitly.
You also must say explicitly what the other abscissa values should be for the measurement. Remember, an abscissa is an independent variable, so it needs to be set independently. A Port or an abscissa can be set to a constant value, or it can vary. The “Frequency” abscissa values are an example of an abscissa that varies. It is given as an enumerated list in the first measurement, and by using a <UniformSteps> tag in the second case. Both result in the same actual abscissa points.
The <Unit> element allows us to say what the name of the units are for abscissa and ordinate, as well as giving them an attribute. This allows for automatic unit conversions and tracking.
The ordinates specified in Example 9-5 would probably both be compound ordinates in a real instruments. This concept is described in the section titled “Canonical Maps.” It means that there is a calibration strategy specified that will give a schema to rewrite the map into canonical form, with only atomic ordinates specified. Let’s look at what that simple calibration strategy definition might look like for “Gain”.
Calibration Strategy Example
Measurement systems can’t measure gain directly. It’s a relative measurement. Gain can be defined as the ratio of output power to input power of some signal passing through a DUT. The units of gain are customarily expressed in dimensionless decibels (dB), which is 10 log of the power ratio. Unlike gain, power is something that measurement system can often measure directly—it can be a canonical ordinate. If it can measure power canonically, it can break up the compound ordinate “Gain” into two copies of the canonical ordinate “Power”, one measured at the input port and the other measured at the output port of the DUT.
Since input and output power are measured at different ports, I will expand the map with a port abscissa, then specify post processing to collapse the map back down along the port axis.
Study Example 9-6 carefully. There are several interesting elements that deserve some comment. First of all, at the highest level in the tree, I have just an ordinate named “Gain” with units specified just like it was in the network analyzer example. Instead of ending there as it did before, now the ordinate also contains a map for a new (unnamed) internal measurement. The new measurement has no stimulus section, only response. The abscissa of this new measurement is actually the <Port> element (remember I said that ports were really abscissas in disguise). This is a canonical abscissa that specifies how to interact with the DUT. Within the port abscissa, you see that I give an enumerated list of response ports where the system will measure the ordinate, “Power”. This isn’t a port group, it’s a list of ports.

The response port named “input” is really a loopback measurement of stimulus power. I assume that the measurement system hardware allows a loopback measurement of the stimulus at the DUT input. If it doesn’t, then the response port is not canonical over this part of the abscissa domain, and would need to be broken down further, possibly in terms of a stimulus power abscissa. Alternatively, I could define gain itself directly in terms of a stimulus power abscissa, instead of loopback response measured at the DUT input. This alternative approach would not work well on systems that did not have loopback capability. In general, it’s best to say what you really want at the highest level, and break things down till you have what the system can actually do (or at least what some standard set of interface maps can do). Don’t try to make it easy on the system by precanonicalizing based on what hardware you know you have. If you try to do this, you will sacrifice portability.
The <Collapse> element is new. This tells us that the “Port” abscissa is to be collapsed by means of the algebraic equation given. Since there is only one ordinate and it’s a scalar, and the abscissa is an enumerated list, I can use a simple, scalar algebraic equation to perform the collapse. The syntax for the algebraic is given as the simplistic “Power [out]/Power [in]”, which is expresses the calculation of Gain as a ration of two Powers. The “Power” manifold is herein treated as an array indexed by the previously named values “in” and “out” along the axis (named “port”) that I have specified for collapsing.
I call the algebraic syntax simplistic, not because it doesn’t work for this case, and many others, but because one may want to use something more complex here in general. For example, MATLAB syntax could be used, or J, or Perl, or C if you must. You could even link to external code here. Calibration strategy axes collapses need to be able to express all sorts of multidimensional array manipulations, so it would be good to pick something that worked well with that sort of thing.
Here’s an example of a more sophisticated axis collapse one may need. I have assumed power measurement was canonical, but what if it isn’t? If the hardware does not have some fundamental power measuring system like a wattmeter, power would need to be measured by doing a mean square integral of voltage, current, or some other calculation (for example, FFT) based on a block of data. The canonical ordinate in that case might be an array of voltage samples. The map collapse that case would be summing the squares of the data array, perhaps with a primitive as an algebraic expression, perhaps with a full blown script within a <script> element.
Note how units are specified for the result collapse. The units are empty, and therefore dimensionless linear by default, with the conversion to dB left implicit by the fact that the enclosing compound “Gain” ordinate is specified as “dB”. Scale and unit conversions should be performed automagically based on what unit is specified for each axis. This is facilitated by using standard string identifiers for unit names and scales and a separate unit conversion schema that can also be nicely specified in XML.
Another point to notice is the way I introduced identifier references. This is the first time I have used the idea of reference and it represents a watershed in this XML method of describing measurement maps. I have named an axis and some of its elements to facilitate wiring them to the algebraic function. Identifiers and references lead us to the idea of Measurement Map parameters.
Functional Decomposition and Scope
When I defined a compound ordinate like Gain in terms of atomic ordinates, this is really quite similar to the classic functional decomposition that is used with programming languages like C. You start with a complex function, and then partially factor it with several, subroutines. Some of these subfunctions are factored again, and those again, and so on down till you have functions that don’t call any subroutines.1 Each function in such a decomposition represents a node in a tree much in the same way as the <Measurement> elements represent nodes in the XML tree I have presented for describing measurement maps.
In a classic functional decomposition, each function can have parameters, and optionally return values. This allows us to pass information downward and upward in the functional tree. In the measurement map and calibration strategy schema I have outlined, information flow is implicit between the atoms and the compounds, relying on the fact that their interfaces fit. While it would be nice to believe that this fitting would happen spontaneously on its own, realistically I need a way to specify an interface.
I have used “name=” identifiers to label things within the measurement. Let’s add an explicit <ParameterList> element to say what internal parameters are passed into the measurement from outside. The names associated with these parameters become placeholders for the value passed in. Here’s the calibration strategy map for “Gain” restated with an explicit parameter list.


In addition to their use as parameter labels, I have used element “name=” identifiers as local variables within the measurement, allowing us to refer to specific abscissa values from the <Collapse> block. It would be reasonable to expect that the implied scope of a local identifier is delimited at the <Measurement>, just like the scope of functional parameters.
Measurement Parameters—A Hazard
The <ParameterList> element allows measurements to have parameters. The reason I introduced this capability was because compounds have dependencies on abscissas for calibration strategy. I needed a way to connect this together in an unambiguous way. Using named parameters seems unavoidable here.
Now that they are introduced, measurement parameters have more possible uses that just the atom-compound interface. You may want a way for the test to interface with the measurement, passing down test parameters into a fixed map with variables, rather than rewriting the map with new constants. You can use the <ParameterList> interface for this if you wish.
But do you want to do that? At this point, I start to wonder: When I introduced parameters and variables, aren’t I in danger of turning the XML description of measurements into a real programming language? Isn’t that a bad thing?
Yes, indeed, this is a very dangerous point. Introducing reference in the form of functional parameters and local variables was a watershed for the XML stimulus response measurement map method. It potentially opens Pandora’s box, setting free all the demons that plague anything that threatens to become “real” programming. Until now, everything was pretty and perfect in a context-free way, but parameters and variables seem to threaten that austere beauty, introducing ugly semantic context.
Don’t get me wrong. I’m as much a fan of gnarly-old variable naming and scoping as anyone, but you must remember the goal here is to provide a system that focuses on the measurement with a minimum of computer science arcana. I am dangerously close to introducing a whole bunch of issues that are well understood by programmers, but may alienate nonprogrammers (assuming any are even still reading at this point).
Admittedly I am in danger, but XML itself comes to the rescue. Things are not as bad as they may seem. A Turing-strength programming language has virtually infinite freedom. From this freedom springs most of the problems people have with programming. But XML is different. XML allows freedom, but only in strictly regulated ways permitted by the schema and DTD. The clever folks that invented XML have already seen this hazard and have paved many ways around it.
Therefore, the trick to avoiding these dangers, I believe, has two important aspects:
1. Design the XML DTD and schema to enforce strictly unambiguous reference of measurement parameters. For example, if an ordinate requires a PortGroup parameter, make sure it gets one.
2. With the assumption of unambiguity guaranteed by the schema, allow measurement parameters and functional data flow to remain implicit as much as possible; only introduce them when absolutely necessary, or when they would make sense to a test engineer.
This trick is easier than it might seem. After all, look at what I have achieved so far with only very limited use of naming and reference. Furthermore, as I have already noted, test engineers are smart people. They will know, intuitively that some measurement parameter is missing and be happy to provide it if asked at the right time. Just don’t turn them into namespace accountants (i.e., programmers). If you do, they will rebel.
Describing the Measurement System with XML
By now you should have a pretty good idea how to describe a measurement with XML, but what about the measurement system itself? At some point, we need all this XML stuff to interact with real hardware. How does that happen?
A good part of the answer to these questions lies within the map manipulation process I have already described. Within calibration strategy, map canonicalization proceeds until it reaches a map expressed entirely in terms of the set of atomic abscissas and ordinates. That set represents the real hardware, at least from the point of view of the map stance. Therefore, a necessary step in describing the measurement system with XML is to identify the atomic ordinates and abscissas that the system can implement natively. Calibration strategy is then given this list; test engineers can write any measurement map they want; as long as the calibration strategy can find a way to canonicalize their map, real hardware can be told how to measure it.
Another part of the answer is given by defining the ports and modes available from the hardware. As I have described in the section titled “Ports and Modes,” ports and modes specify the state of the hardware during measurement. Ports tend to indicate what DUT interfaces the system is stimulating or is measuring from. Modes tend to indicate the internal settings of the measurement system itself. Both ports and modes can be canonical or atomic. Once again, specifying the complete list of atomic ports and modes is necessary to specify the hardware from the point of view of the map stance. The map then “knows” what the hardware can do. All that remains is telling the hardware to do it.
The “telling the hardware” part of an atomic ordinate, abscissa, port, or mode is a hardware-implementation specific thing. It may be as simple as reading or writing a register, or as complex as you please. There are many established approaches to this problem. There are “plug and play” driver interface standards, and there are proprietary “site file” formats for describing the details needed for hardware interaction.
Any abstract system for describing hardware interactions (setting atomic ports, modes, abscissas, or reading atomic ordinates) that I present here in this book risks being irrelevant. Hardware vendors tend to like to keep ownership of the set of hardware driver standards they support, picking ones to support that they think will sell the most of their product. They jealously guard the low level details of interfacing with their products, preventing any other drivers from being developed, preventing any sales to people using other standards, and thus “proving” they chose the right standard to support in the first place. Therefore, I won’t bother to introduce yet another standard to be shunned. I will, however, risk giving a very simple example of how an interface description could be accomplished in XML with no intention to propose it as a generalization.
All that said, I fearlessly consider how an atomic port might be specified with enough detail to effect hardware interaction.
Starting with the trivial case, if the measurement system has just one stimulus port, and one response port, and this connects to a DUT with just one gozinta and one gozouta (a.k.a. input and output) there really isn’t any work to do. I can always assume that the port in the Stimulus element of the measurement map is the one stimulus port, and the port in the Response element is the one response port. Done.

Suppose now that I have a DUT with multiple inputs and multiple output, but I still have the single stimulus, single response SMS. Commonly the way people solve this is to use a switch matrix between the DUT and the measurement system. This allows an instrument with a small number of interfaces (in the one-to-many case, only one stimulus and one response interface) to be able to make measurements at numerous DUT ports. In the on-to-many case, the matrix is really just a TDM commutator with a different name. (Multiplexing options were discussed in the section titled “Simultaneous Channels and Multiplexing.”)
When a commutator style switch matrix is used for DUT interfacing, all I need to do to specify a port in the measurement map is to somehow set the position of the commutator switch. The proper incantation I must perform to set this switch position depends on the details of the hardware interfacing, but more often than not this involves little more than writing something to a register someplace, or calling an “official” driver function, which secretly writes something to a register someplace.
Under the above set of assumptions about the hardware model, a suitable XML schema to capture the relevant details might be something as trivially simple as this:

Something as simple as that, either maintained separately, or placed within the scope of the Instrument element in the XML measurement map schema I have thus far defined, could bind the logical port named “output” to an explicit action for interacting with hardware.
To extend this schema to the purpose of setting modes and abscissas would require a more structure and get us involved in the concept of parameter reference that I discussed in the section titled “Functional Decomposition and Scope.” Still, despite the additional semantic structure, it’s likely that I need do little more, hardware wise, than map referenced parameters to specific values the system writes to certain addresses. For ordinates, I will need to specify that the system should read values from certain addresses, but the concept is otherwise the same.
Of course, the above discussion is rather simplistic. Some modes and abscissas require a complex algorithm to set. Consider the case of a frequency converter in a signal conditioner. There might be several tunable frequencies that need setting, amplifier and filter band-switches that need controlling, and so on, in order to get the conditioner tuned to the desired frequency abscissa. Similarly, with the response system, reading the digitizer may require a complex algorithm, timing consideration, and other details. Clearly, a lot more could be accomplished here. However, for reasons stated above, I’ll leave the rest of the XML schema for hardware interfacing as an exercise for the interested reader, or hardware vendor.
Describing Measurement Results with XML
As discussed in the section titled “Abscissas and Ordinates,” measurements are mappings (i.e., vector valued functions) over separable and nonseparable domain grids. The typical data types for abscissas and ordinate elements are manifolds over the set of integers, real numbers, complex numbers, or even numeric arrays. Therefore, the basic requirement for a measurement results data structure is the ability to efficiently accumulate collections of tables of numeric data of the above types.
Obviously, if you define the measurement in XML, and you define the measurement system in XML, it might seem natural to record the data in an XML format. This is certainly reasonable. It’s even a good idea. Listing the actual data values measured for an ordinate right in the XML map description is a great way to create a self-documenting data structure that can be manipulated with the same set of software tools you used for manipulating the measurement prior to the acquisition of data.
The problem with jumping to the obvious conclusion that one should use XML as a data recording format is the existence of a plethora of possibilities for data structures and data file formats (for example: Microsoft Excel, MATLAB, DIF, SQL, Flat TDF or CSV, and so on) that can accumulate measurement data. Interoperating with these to various degrees, there is a second plethora of report generation and data visualization tools. People like these tools and understand the formats they rely on. Thus, it’s not possible to ignore this dual-legacy of prior art and go with XML for data storage, regardless of the advantages XML might have.2
Because the options are so diverse, I won’t bother surveying the topic beyond some observations regarding the basic data structure requirements of a synthetic instrument. To this end, I will explore only two different basic data structures for the storage of measurement data.
Column and Array Data
Column data is the most general data format. It is equivalent to a typical PC spreadsheet data structure. Consider the following example:

Column data tables can represent any number of scalar ordinates and abscissas, including data taken over abscissas that are not separable. If efficiency was not an issue, a column data structure could serve for all measurement map data. That means you can use Excel, or any other spreadsheet format to store map data.
Column data is inefficient in the case of separable abscissa domains. If the abscissa is separable, it is far more efficient, space wise, to store only the factored individual scales for the abscissas rather than the outer product. The ordinate data is stored in ordinary array format. Spreadsheets can store arrays too, but tools that specialize in arrays (J, MATLAB, Mathematica) show their power here. Here’s an example for two abscissas and one ordinate:

The array data format can easily be converted to the column data format, although the reverse is not true, in general.
Self-Documenting Features
Data should always be self-documenting. A flat file of numbers has no meaning once it is separated from the context in which it was acquired. The requirement to self-document derives from good lab practice in general. All abscissa and ordinates must be traceable to type, title, and units. Calibration offsets and other meta-data may also be of importance, so provision should be made for attaching general attribute data to each abscissa or ordinate axis. This should include the capability for “attribute=value” style attributes or the equivalent.

One of the great advantages of object orientation is that if facilitates self-documentation. If the measurement object comprises both the stimulus response measurement map description and the SRMM data, together, and all subsequent report generation and visualization draws from this unified object, you will accumulate a completely self-descriptive entity that paints a complete picture of your measurement. The SRMM object is to the measurement what the TPS is to the test.
Arrays as Elements
Some ordinates are not scalars. For example, the spectra ordinate is a set of spectral power measurements over some domain of frequencies. There fore, column data and outer product array data structures must include the capability of handling arrays as elements. In fact, the most general case allows a data element to be a column data or outer product array. With such a hierarchical format, all possible measurement data can be efficiently and naturally represented.
One way to avoid allowing arrays as elements, but still to permit the same hierarchical freedom, is to allow relations to be defined between data sets. For example, instead of storing a list or array at one location in a table, it could be stored in a totally different table with the two tables linked by a common code number or key. Those of you familiar with relational databases will know that most fields with array contents (other than strings) are stored in separate tables and linked by relations.
SQL Database Concepts and Data Objects
I have been talking about stimulus response measurement map measurement using mathematical terminology from calculus and linear algebra (arrays, vectors, manifolds, functions, mappings). There is, however, an alternative way to conceive SRMM measurements. You can think in database terms (tables, records, fields). The collection of ordinates for a given set of abscissas can be considered a record with the individual abscissas and ordinates representing fields.
Not only can you think about data structures in database terms, you could actually use a SQL database to store measurement maps. This would allow us to conveniently sort and select portions of a larger dataset using standard SQL commands, and the ability to relate other kinds of contextual data for the measurement: date and time, configuration state of the equipment, identifying information from the DUT, and so forth. The idea of using a real database to store measurements has many positive aspects.
The database viewpoint is particularly relevant when arrays are elements. Although linked structures can be built many ways in order to accommodate this kind of element, the methodology of relational database design can help us immensely here.
On the other hand, the creation of a hashed database can be somewhat wasteful for SRMM measurement data because random access to individual records is not a typical requirement. More often, the data is rotated, subdivided, or abstracted in a sequential process for the purpose of visualizing the data with graphs, charts, or plots. Moreover, the raw data itself tends to be very large, making storage efficiency the paramount requirement over efficiency of random access queries and over sorting and searching. Therefore, although the structure of data will readily translate into typical database structures, a simpler, direct indexed data format for acquisition storage can often be a better choice.
HDF
I will sing the praises of XML a lot, but one alternative data format that meets most of the requirements for recording map data is hierarchical data format (HDF). HDF is a multiobject file format standardized and maintained by the National Center for Supercomputing Applications (NCSA) that facilitates the transfer of various types of scientific data between machines and operating systems. Machines currently supported include the HP, Sun, IBM, Macintosh, and ordinary PC computers running most any operating system, even Microsoft Windows. HDF allows self-documenting of data content and easy extensibility for future enhancements or compatibility with other standard formats. HDF includes JAVA and C calling interfaces, and utilities to prepare raw image of data files or for use with other software. The HDF library contains interfaces for storing and retrieving compressed or uncompressed 8-bit and 24-bit raster images with palettes, n-Dimensional scientific data sets and binary tables. An interface is also included that allows arbitrary grouping of other HDF objects.
Any object in an HDF file can have annotations associated with it. There are a number of types of annotations: Labels are assumed to be short strings giving the name of a data object. Descriptions are longer text segments that are useful for giving more in depth information about a data object file annotations are assumed to apply to all of the objects in a single file.
The scientific data set (SDS) is the HDF concept for storing n-dimensional gridded data. The actual data in the dataset can be any of the standard number types: 8-, 16- and 32-bit signed and unsigned integers and 32- and 64-bit floating-point values. In addition, a certain amount of meta-data can be stored with an SDS including:
![]() The coordinate system to use when interpreting or displaying the data
The coordinate system to use when interpreting or displaying the data
![]() Scales to be used for each dimension
Scales to be used for each dimension
![]() Labels for each dimension and the dataset as a whole
Labels for each dimension and the dataset as a whole
![]() Units for each dimension of the data
Units for each dimension of the data
![]() The valid maximum and minimum values for the data
The valid maximum and minimum values for the data
A more general framework for meta-data within the SDS data model (allowing ‘name = value’ style meta-data) is also possible. There is also allowance for an unlimited dimension in the SDS data-model, making it possible to append planes to an array along one dimension.
HDF is an open, public domain standard. It is matute and well established. It represents a good alternative to XML or SQL databases for the storage and manipulation of synthetic instrument data. The HDF web page is located at http://hdf.ncsa.uiuc.edu/.
1Assuming, of course, that you do not recurse.
2On the other hand, as of the date of this writing, numerous vendors of data acquisition, storage, analysis and visualization tools have either begun implementing support for open XML data formats in their legacy tools, or announced plans to transition their proprietary data files to XML format. Most prominent of these is Microsoft Corporation.