
Chapter 2 - TASM
“Regret for wasted time is more wasted time.”
Three Levels of Workload Management
| Viewpoint Workload Designer – Creates workload definitions in order to classify users, accounts and queries into workload definitions. It is here that we can classify groups in order to setup rules when queries are active. | |
| Priority Scheduler – Based on the user, objects the user are accessing, or the type of SQL that is being run we can assign certain CPU priorities to determine if the query should run at a Low, Med, High, or Rush priority. | |
| DBQL – The Database Query Log allow examination and analysis of the queries that have been run on the system. |
The three levels of workload management begin with Viewpoint Workload Designer in order to create workloads for pre-execution rules. The second level is Priority Scheduler which then has instructions for CPU usage based on the user or workload. The third level is the Database Query Log (DBQL) which allows analysis on which queries were run.
Pre-execution, Query Execution, and Post-execution
| Pre-execution | Viewpoint Workload Designer – Control what and how much is allowed to begin execution. | |
| Query executes | Priority Scheduler – The query executes and is given a CPU weight and priority in order to run at a certain speed. | |
| Post-execution | DBQL – The Database Query Log allow examination and analysis of the queries that have been run on the system. |
Use Viewpoint Workload Designer to classify queries into workloads. When a query is run, the system determines which workload it belongs to, and assigns the appropriate CPU allocation to control the speed. DBQL is the audit trail of what queries have been run on the system. The combination of all three levels allows a Teradata customer to plan, execute and re-examine their environment to optimize their system.
What is TASM?
Teradata Active System Management
| Teradata Workload Designer and Viewpoint - TASM automates the allocation of CPU resources to workloads in order to control who can ‘execute’ queries, ‘what’ type of queries they can run, and ‘Where’ (which objects they can run queries against). | |
| Teradata Workload Analyzer – Uses the Database Query Log (DBQL) to analyze what queries have been running on the system in the past in order to prepare for the future. |
Teradata Active System Management (TASM) is made up of two major products/tools that help the DBA in defining the rules that control the allocation of CPU resources to workloads running on a system. These rules include filters, throttles, and “workload definitions”.
Query Management compared to Workload Management
| Query Management is a set of “rules” to determine whether logon and query requests will be accepted by Teradata, and then determines whether to run the query immediately or to delay the query. | |
| Workload Management is all about controlling workload distribution by assigning CPU resources to queries determined to be of the same workload. For example, tactical queries that utilize a single AMP via a Primary Index might be in one workload. Long Decision Support known queries in another workload, and Ad Hoc requests might be in another workload. Workload Management establishes “rules” to follow for a certain workload, such as delaying long Decision Support know queries if more than 10 are already running. |
The purpose of “delaying” queries is to limit the number of CPU resources that are tied up in running low priority or long running DSS queries. This is also to establish Service Level Agreements (SLA's) for tactical queries that must run in sub-second time. Even though a query is delayed, it is still part of the user's session. Workload management takes “like” queries grouped in a named workload and establishes rules for how and when to process them.
What is the Secret Sauce for Query Management?
Query Management is a set of “rules” to determine whether logon and query requests will be accepted by Teradata, and then determines whether to run the query immediately or to delay the query.
| There are two Secret Sauce ingredients for Query Management. | |
| Filters - object access and query resource rules used to reject queries. An example might be to reject all “Unconstrained Product Joins”. Another example might be to reject access to the Order_Table during the hours of 5:00 PM to Midnight. | |
| Throttles - object and load utility rules used to delay or reject queries. An example might be to delay a Full Table Scan if more than 100,000 records are projected to be returned. |
The purpose of “delaying” queries is to limit the number of CPU resources that are tied up in running low priority or long running DSS queries. This is also to establish Service Level Agreements (SLA's) for tactical queries that must run in sub-second time. The DBA can now control what queries run on the system at a specific point in time.
The life of a Query
Nexus Query Chameleon
SQL Assistant
BTEQ
JDBC Application
| A User enters their login (with an Account ID) and submits a query from any application such as Nexus, SQL Assistant, BTEQ, JDBC, or a load utility. | |
| A User or Account can have a set of rules that must be followed. | |
| The Parsing Engine (PE) checks the rules before executing the query. | |
| Filters are checked first, and queries that don't pass are automatically rejected. | |
| Throttles are then checked to see if the query should be executed, delayed, or rejected based on if the system is deemed to busy. |
The brilliant piece of Teradata system management is that it doesn't matter what application submitted the query, but Teradata can still follow the rules that have been set up to execute, delay or reject the query.
What is a Workload?
| A workload represents queries (grouped in a workload) that are running on a system. A Workload Definition (WD) defines the queries in the group and then the DBA can create operating rules used to manage these queries. | |
| The purpose of grouping these queries into workloads is that requests that belong to the same workload will share the same Priority Scheduler resource priority and exception conditions. | |
| Teradata determines which queries belong to the workload based on query characteristics which are analyzed prior to a query executing on the Teradata system. |
Classification Criteria Examples
WHO
User Account Name Profile
WHAT
Insert/Update/Delete All-AMP operation? What type of Load?
WHERE
Table, macro, Stored Procedure being accessed
Queries grouped into a workload can establish rules to manage the workload queries.
Workload Examples

There are Four Types of Query Rules
There are three sets of workload management rules that are available. Each set can be enabled or disabled.
- System-wide query management filters
- System-wide query management throttles
- Workload Definitions
| Object Access Filters - Access to and from specific Teradata Database objects and object combinations by a particular user, some users, or every user. | |
| Query Resource Filters - Which Teradata Database requirements are necessary to execute specific queries? This might include the type of join, limiting row counts, or a maximum processing time. | |
| Object Throttles - How many queries can be running against a Teradata table, view, macro, or Stored Procedure? How many sessions are accessing an object? | |
| Load Utility - How many FastLoad, MutliLoad, or FastExport utilities can run individually or simultaneously. |
Common Sense Examples of Filters and Throttles
| Object Access Filters |
| Limit Access to certain Databases | |
| Limit Access to certain Tables |
| Query Resource Filters |
| Limit Cartesian and Product Joins |
Day and Time are important considerations. Based on a specific day or time, the rules can be set to be enforced. These are called Performance Periods.
| Object Throttles |
| Limit # of Sessions | |
| Limit # of Queries |
| Load Utility |
| Limit # of FastLoad Jobs |
Performance Period Examples
| Object Access Filters |
On Saturday, MRKT Users cannot log on to the Teradata Database.
On Weekdays between 10:00 am and 4:00 pm, Order_Table cannot be accessed.
| Query Resource Filters |
On Fridays between 8:00 am and 4:00 pm, Sales_Table cannot be involved in a Product Join.
On Tuesdays between 12:30 pm and 4:00 pm, queries estimated to take longer than 30 minutes cannot run.
| Object Throttles |
On Weekdays between 8:00 am and 5:00 pm, ALL Product_Table DDL statements will automatically be rejected.
Object Access filters, Query Resource filters, and Object throttles can specify the types of SQL requests to which the rule applies. For example, you can specify ALL, DDL, DML, or SELECT in your rules.
The Scoop on Object Throttles
| Defining Object Throttles allow you to limit the number of logon sessions and/or queries active on particular Database objects. | |
| SQL requests evaluated under this category must include an ALL-AMP step to be considered against throttle values. Single AMP operations (for example, primary index) are always allowed to run and are not counted against throttle limits on context objects. | |
| You cannot associate Object Combinations with Object Throttles. | |
| You can set up this type of rule to reject or to delay any query that cannot be immediately processed. | |
| You can associate Macros and Stored Procedures with Object Throttles, but Teradata recognizes them by name and not their object type. | |
| Context objects relate to the conditions in an issued request. Context objects relate to “who” issued the request, and you will hear them referred to as “who” objects. The types of context objects you can associate with rules fall into four categories: Users, Accounts, Performance Groups, and Profiles. |
Load Utility Throttles
| Defining Load Utility throttles lets you control how many load utilities are simultaneously running on a Teradata Database at any given point in time. | |
| Using this throttle type lets you override the MaxLoadTasks value set using the DBS Control Utility. A Load Utility Throttle will always override the MaxLoadTasks value without having to change it using the DBS Control Utility. | |
| You can specify limits for all load utilities as a group, and/or specify limits for each individual load utility. These apply only to FastLoad, MultiLoad, and FastExport which are block level utilities. | |
| Because Load Utility throttles apply only to the kind and number of load utilities running on the Teradata Database, you cannot associate Teradata Database objects with them, such as the Sales_Table can't have a MultiLoad. |
On Weekdays between 9:00 and 16:00, the maximum number of simultaneous FastLoad and/or MultiLoad and/or FastExport jobs is 7.
Above is some more detailed information about Load Utility throttles.
Creating Workloads
There are two sources for analyzing data for creating Workloads:
| Priority Scheduler settings captured in PD (Priority Definition) sets. | |
| The DBQL log (Database Query Log) data that represents all captured queries for a period of time (e.g., two months) that represent the typical workload. |
There are two ways to create Workloads:
| By hand using the DBQL log. Start with the ‘Who’ and later add the ‘What’ or ‘Where’ if necessary. | |
| Use the Viewpoint Workload Analyzer to analyze both the Priority Scheduler (Priority Definition) PD sets, and the DBQL log. |
When creating workload definitions, the Database Query Log will show what queries have been run over the past couple of months, and the Priority Scheduler will have captured settings in their Priority Definition sets. Then you can use Workload Analyzer to analyze these two sources. You can also decide to create workloads by hand after analyzing the DBQL log.
When Creating Workloads the “WHO” is your Foundation
Classification Criteria Examples
WHO
User
Account Name
Profile
Application
WHAT
Insert/Update/Delete All-AMP operation? What type of Load?
WHERE
Table, View, Macro or Stored Procedure being accessed
When creating a Workload, start with the “Who”, and later add the “What” or “Where” if necessary. The “Who” can be classified in many ways:
User – e.g., DBC, Tcoffing, HiteshPatel (These are user login names)
Account – the user's unexpanded account string (e.g., $M1$MRKT)
Profile – the user's Teradata profile name (e.g., MRKTUser, SalesProfile)
Application – the application name on the network client (e.g., Nexus)
Client Address – the IP address of the network client (e.g., 231.216.18.42)
Client ID – the logon name on the network client (e.g., Microstategy1)
By creating workloads with the “Who”, you can easily create workloads of common interest, which makes adding “What” and “Where” later less complicated.
After the “WHO” comes the “WHERE”
Classification Criteria Examples

The “WHERE” criteria will come after you create the workload definitions based on the foundation of “WHO”. Why? “WHO” criteria has lower overhead than “WHERE” and “WHAT” because “WHO” is determined once per session logon, whereas, “WHERE” and “WHAT” are determined once per query.
After the “WHO” and the “WHERE” comes the “WHAT”
Classification Criteria Examples
WHO
User Account Name Profile
WHAT
Insert/Update/Delete All-AMP operation? What type of Load?
WHERE
Table, macro, Stored Procedure being accessed
When creating a Workload, start with the “Who”, and later add the “What” or “Where” if necessary. The “What” is based on the PE's estimates:
AMP Limits – is this an all-AMP request or is it not?
Load Utility Type – FASTLOAD, MULTILOAD, FASTEXPORT
Statement Type – the statement type (e.g., SELECT, DDL, DML)
Row Count – minimum/maximum rows at each step for spool files and result set
Final Row Count – minimum/maximum rows for result set only
CPU Time – minimum and/or maximum estimated processing time.
By creating workloads with the “Who”, you can easily create workloads of common interest which makes adding “What” and “Where” later less complicated.
Exception Actions
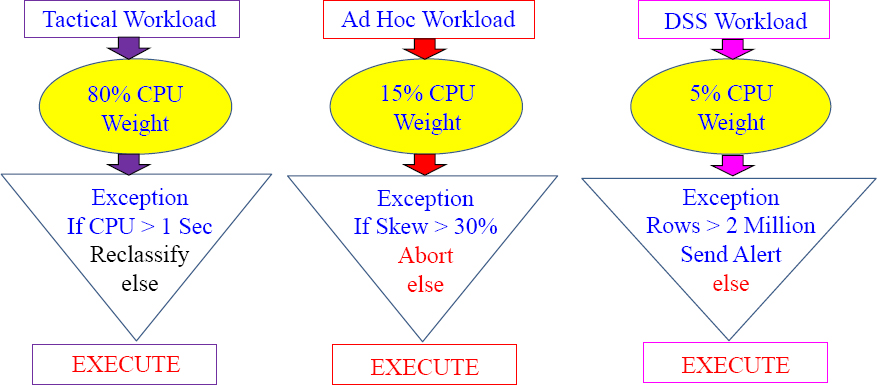
Exception Actions specify what to do when an Exception condition is met:
- No exception monitoring – exceptions turned off and are NOT logged.
- Abort – query is aborted.
- Change Workload – reclassify and move the query into a different workload.
- Raise Alert - no change to query; send a Teradata Manager Alert
- Run Program - no change to query; have Teradata Manager execute a program.
When and How Teradata checks for Exceptions
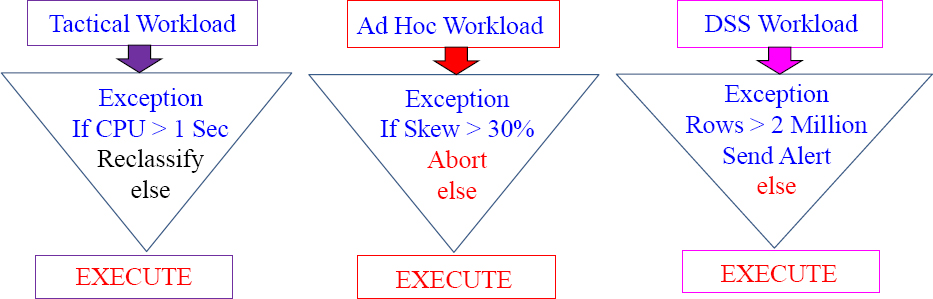
Teradata checks for exception conditions at the following times.
- Synchronously – at the end of each individual AMP step.
- Asynchronously – at the configurable time interval (1-3600 seconds).
Any query exception is automatically logged in the DBC.TDWMExceptionLog.
Skew is NOT calculated synchronously at the end of query steps, but instead Skew is checked Asynchronously at the configurable time interval.
DBC.TDWMExceptionLog
SELECT *
FROM DBC.TDWMExceptionLog;
| Query request was rejected because of an Object Access Filter rule. |
| TWM Limit for this utility type was exceeded for load utilities. |
| Logon request was rejected because of an Object Throttle rule. |
| Logon request was rejected due to an Object Access Filter rule. |
| Query request was rejected because of an Object Throttle rule. |
| Query request was rejected because of an Object Access Filter rule. |
| Query request was rejected due to a Query Resource Filter rule. |
| Query request was rejected because of an Object Access Filter rule. |
The exception log is where exceptions are logged. The user is also given an error for their query if the query aborts so the user knows why the query was aborted.
Teradata Workload Analyzer
Workload Analyzer uses two sources for analysis when creating workloads:
| Priority Scheduler settings captured in PD (Priority Definition) sets. | |
| The DBQL log (Database Query Log) data that represents all captured queries for a period of time (e.g., two months) that represent the typical workload. |
Teradata Workload Analyzer Identifies classes of queries and recommends workload definitions (WD) and operating rules:
- Recommends workload to allocation group mappings and Priority Scheduler weights.
- Provides recommendations for workload Service Level Goals (SLG).
- Can migrate existing Priority Scheduler Definitions into new workloads.
Workload Analyzer provides the conversion of existing Priority Scheduler Definitions (PD Sets) into brand new workloads. This collection of data includes the resource partition, allocation group, period type, and other definitions that control how Priority Scheduler will manage and schedule execution.
Teradata Workload Analyzer

Teradata checks for exception conditions at the following times.
- Synchronously – at the end of each individual AMP step.
- Asynchronously – at the configurable time interval (1-3600 seconds).
Any query exception is automatically logged in the DBC.TDWMExceptionLog.
Skew is NOT calculated synchronously at the end of query steps but, instead Skew is checked asynchronously at the configurable time interval.
Pre-execution, Query Execution, and Post-execution
| Pre-execution | Viewpoint Workload Designer – Control what and how much is allowed to begin execution. | |
| Query executes | Priority Scheduler – The query executes and is given a CPU weight and priority in order to run at a certain speed. | |
| Post-execution | DBQL – The Database Query Log allow examination and analysis of the queries that have been run on the system. |
Priority Scheduler comes into play when the query executes. Each query is given a CPU weight which controls how many CPU resources are dedicated to the query. This will allow queries designed to be fast to get the resources they need, without worrying about long-running DSS queries effecting important queries designed to run in sub-seconds. Priority Scheduler is designed to bring a sense of control on Teradata systems with a lot of users and a wide mix of queries.
Why use Priority Scheduler?
| Assign very high priority users to a very high priority level to support Active Data Warehousing. | |
| In conjunction with Active Data Warehousing, Priority Scheduler can help control the impact of TPump load utility jobs on queries that are running on the loaded table at the same time the user might need to query it. | |
| Large data warehouses can be somewhat unpredictable, so Priority Scheduler helps to ensure your most important queries get executed in a timely manner. | |
| It allows you to divide your Teradata resources among different applications, users, and departments so that expectations are met (Service Level Agreements). | |
| The brilliance is that Priority Scheduler allows changes in CPU priority based on the day, time of day, or after a specific ceiling has been reached. |
Priority Scheduler will break the Teradata system in Resource Partitions and then within Resource Partitions further define Performance Groups, which will be assigned CPU weights that control the amount of CPU processing power. It is like hitting the gas on a car to go fast and the brake to slow down depending on the need for speed.
The Concept of a Resource Partition
A Large Teradata Enterprise Data Warehouse System
| Resource Partition 1 Financial | Resource Partition 2 Insurance |
| 50% of the systems power goes to Financial | 50% of the systems power goes to Insurance |
Resource Partitioning is like two people sharing one big meal with each getting to eat and equal amount of the food.
Imagine you have two different major organizations that make up your company. For example, you have a company that is made up of the Insurance Division and the Financial Division. Both divisions decide to bring in a Teradata data warehouse, but decide they want to have both parts of the company separated logically. A Resource Partition could logically and physically provide resources 50/50 to both divisions.
Resource Partitions
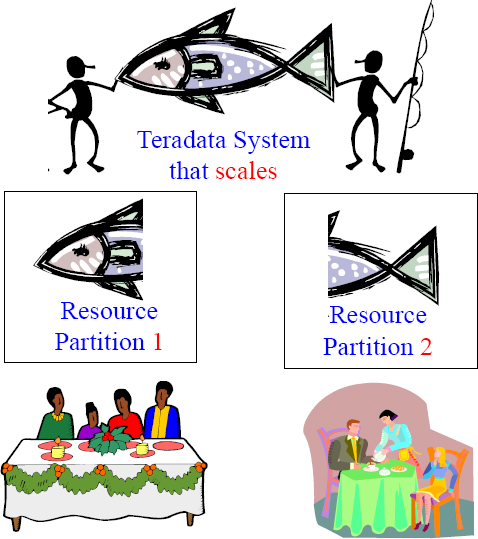
Imagine two friends catching a giant fish. They each get 50% of the fish. Now each person takes their portion of the catch to their own family for dinner. The baby only needs a little but mom and dad need more.
The Clever Idea behind Resource Partitioning
A Large Teradata Enterprise Data Warehouse System
| Resource Partition 1 Financial | Resource Partition 2 Insurance |
| 100% of the systems power goes to Financial | No Users running queries In the Insurance Division |
 |
Imagine two people sharing a meal. One of them is not hungry and the other is starving. Let's have the starving person eat the entire meal.
One of the clever ideas behind the Resource Partition is that if no users in one of the Resource Partitions are logged on, the other Resource Partition (with users) will get all of the CPU power. Nothing goes to waste.
The Brilliant Idea behind Resource Partitioning

Resource Partitions (RP) can divide their power into Partition Groups (PG).
Imagine two friends catch a giant fish. They each get 50% of the fish. Now, each person takes their portion of the catch to their own family for dinner. The baby only needs a little, but mom and dad need more.
Financial has 50% power and Insurance has 50% power in their Resource Partitions. The 50% can further be divided with into Performance Groups. In this example, Financial gives 25% of their power to sales and 25% to their call center department.
The Concept of Resource Partitions and Weights?
Resource Partition 0 (comes automatically with Teradata)

Then we CREATE users and assign their Account to a Performance Group Name
CREATE USER TeraTom AS PERM=0, SPOOL=300e6, PASSWORD=teacher, ACCOUNT=('$L_Training'),
CREATE USER BillyBob AS PERM=0, SPOOL=300e6, PASSWORD=braintrust, ACCOUNT=('$M_Mrkt'),
CREATE USER HiteshP AS PERM=0, SPOOL=300e6, PASSWORD=Callcenter, ACCOUNT=('$H_CallCenter'),
TeraTom queries run twice as slow as BillyBob queries. HiteshP queries will run twice as fast as BillyBob queries and four times as fast as TeraTom queries.
The Concept of a Workload in a Resource Partition

When a User provides their logon and password their queries will automatically run inside their Resource Partition at the proper speed!
Based on a User's Account ID (and some have multiple Account IDs), their queries run in one of the four partitions. The $R partition will guarantee the fastest speeds.
Calculating your CPU Percentage 1
| Performance Group | Default Weight | Explanation and General Guidelines |
| $L | 5 | Batch Jobs are often used with $L (Low Priority) |
| $M | 10 | Complex Queries and Ad Hoc requests are often $M |
| $H | 20 | Tactical Queries needing fast response times are $H |
| $R | 40 | Consider $R for your fastest Primary Index queries |

Can you figure out the Relative Weight Calculation and the CPU Percent Allocated?
Answers to Calculating your CPU Percentage 1
| Performance Group | Default Weight | Explanation and General Guidelines |
| $L | 5 | Batch Jobs are often used with $L (Low Priority) |
| $M | 10 | Complex Queries and Ad Hoc requests are often $M |
| $H | 20 | Tactical Queries needing fast response times are $H |
| $R | 40 | Consider $R for your fastest Primary Index queries |

Calculating your CPU Percentage 2

Can you figure out the Relative Weight Calculation and the CPU Percent Allocated?
Answers to Calculating your CPU Percentage 2

Above are your answers. When Performance Groups are not active, they don't count against your CPU percentage. The $M group is the only group active so they get it all!
Calculating your CPU Percentage 3
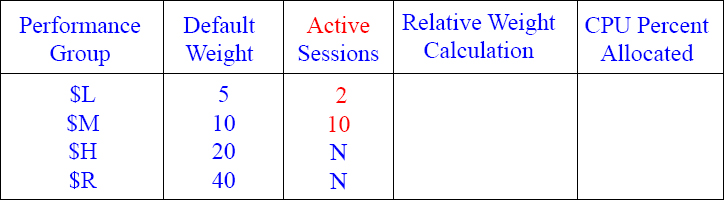
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated?
Answers to Calculating your CPU Percentage 3
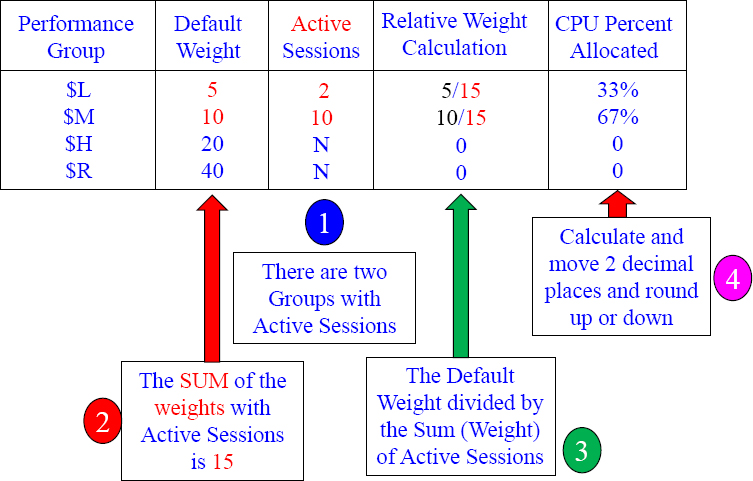
Above are your answers. When Performance Groups are not active they don't count against your CPU percentage. The $L and $M group combined get their share of it all!
Calculating your CPU Percentage 4

Can you figure out the Relative Weight Calculation and the CPU Percent Allocated?
Answers to Calculating your CPU Percentage 4

Above are your answers. When Performance Groups are not active they don't count against your CPU percentage. The $L, $M, and $H groups get the CPU only!
Calculating your CPU Percentage 5

Can you figure out the Relative Weight Calculation and the CPU Percent Allocated?
Answers to Calculating your CPU Percentage 5

Above are your answers.
Calculating your CPU Percentage 6
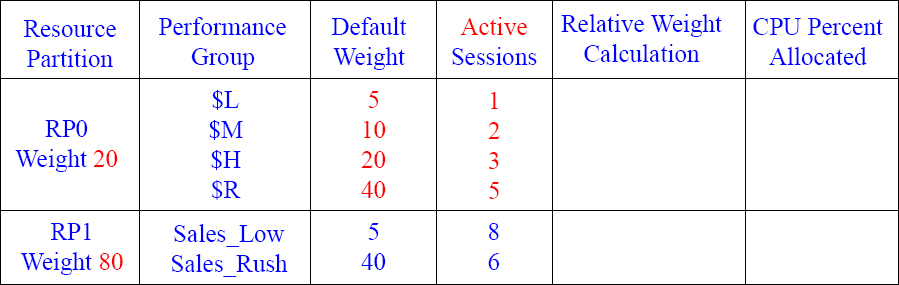
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are two Resource Partitions?
Answers to Calculating your CPU Percentage 6
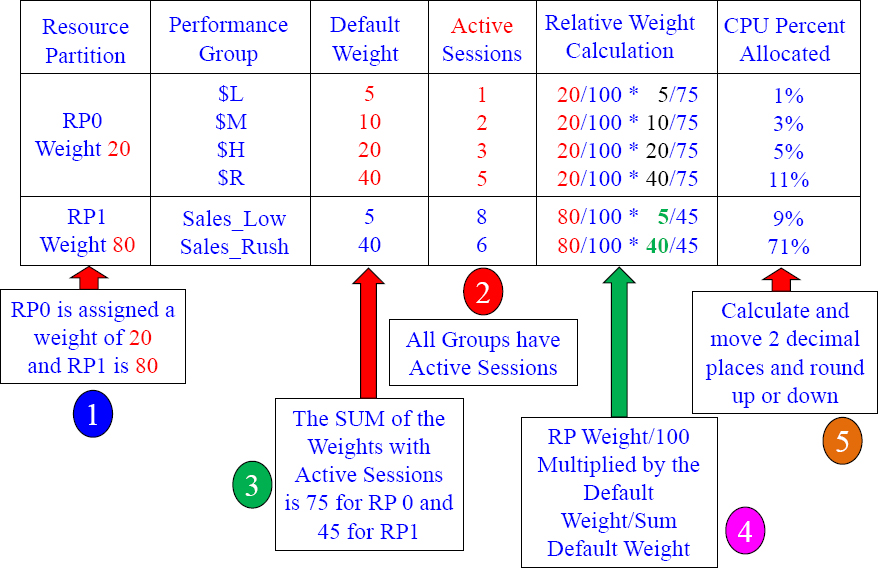
Calculating your CPU Percentage 7
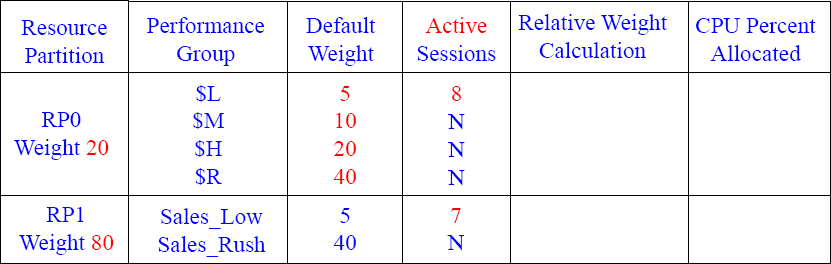
Each RP has only 1 PG with active sessions
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are two Resource Partitions with only 1 active session in each Performance Group (PG)?
Answers to Calculating your CPU Percentage 7

Calculating your CPU Percentage 8

RP 0 has only 1 active session and RP 1 has no active sessions
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are two Resource Partitions with only 1 active session in Performance Group 0 (PG) ?
Answers to Calculating your CPU Percentage 8

Calculating your CPU Percentage 9

RP 0 has only 2 active sessions and RP 1 has no active sessions
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are two Resource Partitions with 2 active sessions in Performance Group 0 (PG) and no active sessions in Resource Partition 1?
Answers to Calculating your CPU Percentage 9

Calculating your CPU Percentage 10
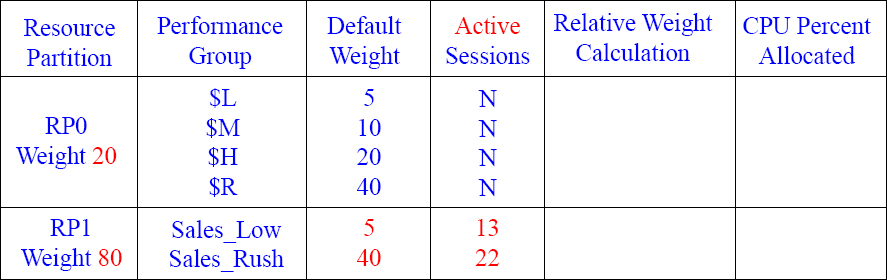
RP 0 has no active sessions and RP 1 has two active sessions
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are two Resource Partitions with 2 active sessions in Performance Group 1 (PG) and no active sessions in Resource Partition 0?
Answers to Calculating your CPU Percentage 10
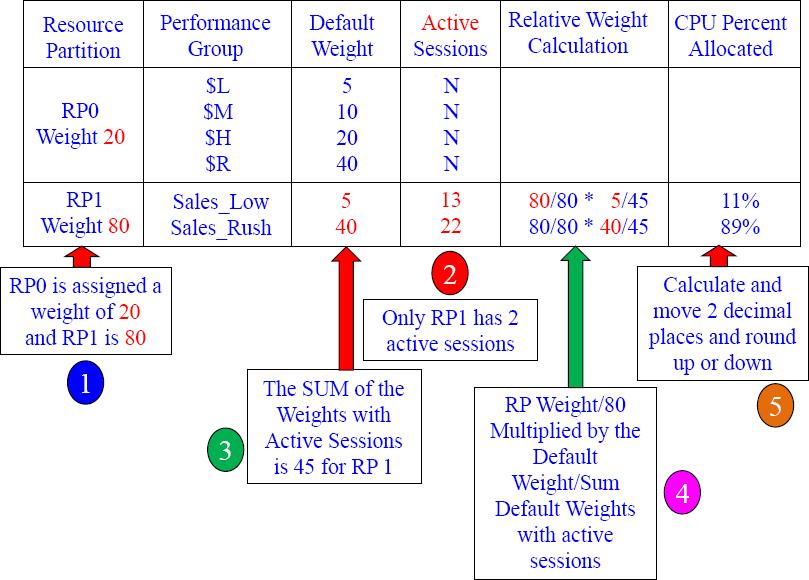
Calculating your CPU Percentage 11
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are three Resource Partitions with active sessions in in each Performance Group?
Answers to Calculating your CPU Percentage 11

Since all Resource Partitions are active, and each Performance Group has sessions, you first divide the RP weight by 100 (since 100% of the Resource Partitions are active). Next, SUM (add up) the default weight in each Performance Group (in that Resource Partition) and divide by the actual weight. Then, move over 2 decimal places and round up or down.
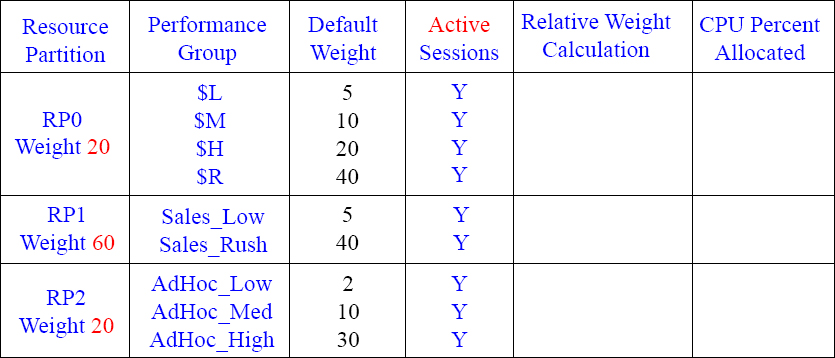
Calculating your CPU Percentage 12
Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are three Resource Partitions? Notice that Resource Partition one (RP1) has no active sessions. Good luck.
Answers to Calculating your CPU Percentage 12

Since Resource Partition (RP1) has no sessions that are active, you now first divide the RP weight by 40 (RP 0 Weight + RP2 weight = 40). Next, SUM (add up) the default weight in each Performance Group (in that Resource Partition) and divide by the actual weight. Then, move over 2 decimal places and round up or down.
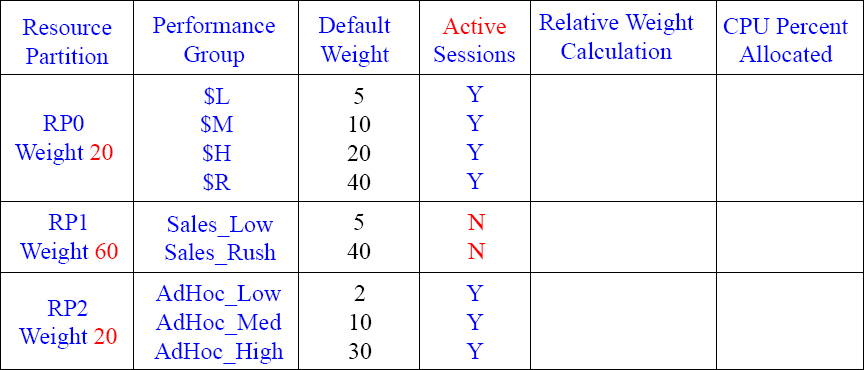
Calculating your CPU Percentage 13

Can you figure out the Relative Weight Calculation and the CPU Percent Allocated now that there are three Resource Partitions? Notice that each Resource Partition (RP) has active sessions, but not all Performance Groups (PG) within the RP have active sessions.
Answers to Calculating your CPU Percentage 13

Since all Resource Partitions have active sessions, you now first divide the RP weight by 100 (RP 0 Weight + RP1 Weight + RP2 weight = 100). Next, SUM (add up) the default weights (with active sessions) in each Performance Group (in that Resource Partition) and divide by the actual weight. Then, move over 2 decimal places and round up or down.