
11
Exploring TDD with Quality Assurance
Previous chapters have covered the technical practices needed to design and test well-engineered code. The approach presented has been primarily for developers to gain rapid feedback on software design. Testing has been almost a byproduct of these efforts.
The combination of TDD, continuous integration, and pipelines provides us with a high level of confidence in our code. But they are not the whole picture when it comes to software Quality Assurance (QA). Creating the highest-quality software needs additional processes, featuring the human touch. In this chapter, we will highlight the importance of manual exploratory testing, code reviews, user experience, and security testing, together with approaches to adding a human decision point to a software release.
In this chapter, we’re going to cover the following main topics:
- TDD – its place in the bigger quality picture
- Manual exploratory testing – discovering the unexpected
- Code review and ensemble programming
- User interface and user experience testing
- Security testing and operations monitoring
- Incorporating manual elements into CI/CD workflows
TDD – its place in the bigger quality picture
In this section, we will take a critical look at what TDD has brought to the testing table, and what remains human activities. While TDD undoubtedly has advantages as part of a test strategy, it can never be the entire strategy for a successful software system.
Understanding the limits of TDD
TDD is a relatively recent discipline as far as mainstream development goes. The modern genesis of TDD lies with Kent Beck in the Chrysler Comprehensive Compensation System (see the Further reading section, where the idea of test-first unit testing came from). The project began in 1993 and Kent Beck’s involvement commenced in 1996.
The Chrysler Comprehensive Compensation project was characterized by extensive use of unit tests driving small iterations and frequent releases of code. Hopefully, we recognize those ideas from the preceding chapters in this book. Much has changed since then – the deployment options are different, the number of users has increased, and agile approaches are more common – but the goals of testing remain the same. Those goals are to drive out correct, well-engineered code and ultimately satisfy users.
The alternative to test automation is to run tests without automation – in other words, run them manually. A better term might be human-driven. Before test automation became commonplace, an important part of any development plan was a test strategy document. These lengthy documents defined when testing would be done, how it would be done, and who would be doing that testing.
This strategy document existed alongside detailed test plans. These would also be written documents, describing each test to be performed – how it would be set up, what steps exactly were to be tested, and what the expected results should be. The traditional waterfall-style project would spend a lot of time defining these documents. In some ways, these documents were similar to our TDD test code, only written on paper, rather than source code.
Executing these manual test plans was a large effort. Running a test needs us to set up test data by hand, run the application, then click through user interfaces. Results must be documented. Defects found must be recorded in defect reports. These must be fed back up the waterfall, triggering redesigns and recoding. This must happen with every single release. Human-driven testing is repeatable, but only at the great cost of preparing, updating, and following test documents. All of this took time – and a lot of time at that.
Against this background, Beck’s TDD ideas seemed remarkable. Test documents became executable code and could be run as often as desired, for a fraction of the cost of human testing. This was a compelling vision. The responsibility of testing code was part of the developer’s world now. The tests were part of the source code itself. These tests were automated, capable of being run in full on every build, and kept up to date as the code changed.
No more need for manual testing?
It’s tempting to think that using TDD as described in this book might eliminate manual testing. It does eliminate some manual processes, but certainly not all. The main manual steps we replace with automation are feature testing during development and regression testing before release.
As we develop a new feature with TDD, we start by writing automated tests for that feature. Every automated test we write is a test that does not need to be run by hand. We save all that test setup time, together with the often lengthy process to click through a user interface to trigger the behavior we’re testing. The main difference TDD brings is replacing test plans written in a word processor with test code written in an IDE. Development feature manual testing is replaced by automation.
TDD also provides us with automated regression testing, for free:

Figure 11.1 – Regression testing
Using TDD, we add one or more tests as we build out each feature. Significantly, we retain all those tests. We naturally build up a large suite of automated tests, captured in source control and executed on every build automatically. This is known as a regression test suite. Regression testing means that we re-check all the tests run to date on every build. This ensures that as we make changes to the system, we don’t break anything. Moving fast and not breaking things might be how we describe this approach.
Regression tests also include tests for previously reported defects. These regression tests confirm that they have not been re-introduced. It bears repeating that the regression suite saves on all the manual effort required by non-automated tests each and every time the suite gets executed. This adds up over the full software life cycle to a huge reduction.
Test automation is good, but an automated test is a software machine. It cannot think for itself. It cannot visually inspect code. It cannot assess the appearance of a user interface. It cannot tell whether the user experience is good or bad. It cannot determine whether the overall system is fit for purpose.
This is where human-driven manual testing comes in. The following sections will look at areas where we need human-led testing, starting with an obvious one: finding bugs that our tests missed.
Manual exploratory – discovering the unexpected
In this section, we will appreciate the role of manual exploratory testing as an important line of defense against defects where TDD is used.
The biggest threat to our success with TDD lies in our ability to think about all the conditions our software needs to handle. Any reasonably complex piece of software has a huge range of possible input combinations, edge cases, and configuration options.
Consider using TDD to write code to restrict the sales of a product to buyers who are 18 years old and above. We must first write a happy-path test to check whether the sale is allowed, make it pass, then write a negative test, confirming that the sale can be blocked based on age. This test has the following form:
public class RestrictedSalesTest {
@Test
void saleRestrictedTo17yearOld() {
// ... test code omitted
}
@Test
void salePermittedTo19yearOld() {
// ... test code omitted
}
}The error is obvious when we’re looking for it: what happens at the boundary between the ages of 17 and 18? Can an 18-year-old buy this product or not? We don’t know, because there is no test for that. We tested for 17 and 19 years old. For that matter, what should happen on that boundary? In general, that’s a stakeholder decision.
Automated tests cannot do two things:
- Ask a stakeholder what they want the software to do
- Spot a missing test
This is where manual exploratory testing comes in. This is an approach to testing that makes the most of human creativity. It uses our instincts and intelligence to work out what tests we might be missing. It then uses scientific experimentation to discover whether our predictions of a missing test were correct. If proven true, we can provide feedback on these findings and repair the defect. This can be done either as an informal discussion or using a formal defect tracking tool. In due course, we can write new automated tests to capture our discoveries and provide regression tests for the future.
This kind of exploratory testing is a highly technical job, based on knowledge of what kinds of boundaries exist in software systems. It also requires extensive knowledge of local deployment and setup of software systems, together with knowing how software is built, and where defects are likely to appear. To an extent, it relies on knowing how developers think and predicting the kinds of things they may overlook.
Some key differences between automated testing and exploratory testing can be summarized as follows:
|
Automated Testing |
Manual Exploratory Testing |
|
Repeatable |
Creative |
|
Tests for known outcomes |
Finds unknown outcomes |
|
Possible by machine |
Requires human creativity |
|
Behavior verification |
Behavior investigation |
|
Planned |
Opportunistic |
|
Code is in control of the testing |
Human minds control the testing |
Table 11.1 – Automated versus manual exploratory testing
Manual exploratory testing will always be needed. Even the best developers get pressed for time, distracted, or have yet another meeting that should have been an email. Once concentration is lost, it’s all too easy for mistakes to creep in. Some missing tests relate to edge cases that we cannot see alone. Another human perspective often brings a fresh insight we would simply never have unaided. Manual exploratory testing provides an important extra layer of defense in depth against defects going unnoticed.
Once exploratory testing identifies some unexpected behavior, we can feed this back into development. At that point, we can use TDD to write a test for the correct behavior, confirm the presence of the defect, then develop the fix. We now have a fix and a regression test to ensure the bug remains fixed. We can think of manual exploratory testing as the fastest possible feedback loop for a defect we missed. An excellent guide to exploratory testing is listed in the Further reading section.
Seen in this light, automation testing and TDD do not make manual efforts less important. Instead, their value is amplified. The two approaches work together to build quality into the code base.
Manual testing for things we missed isn’t the only development time activity of value that cannot be automated. We also have the task of checking the quality of our source code, which is the subject of the next section.
Code review and ensemble programming
This section reviews another area surprisingly resistant to automation: checking code quality.
As we’ve seen throughout this book, TDD is primarily concerned with the design of our code. As we build up a unit test, we define how our code will be used by its consumers. The implementation of that design is of no concern to our test, but it does concern us as software engineers. We want that implementation to perform well and to be easy for the next reader to understand. Code is read many more times than it is written over its life cycle.
Some automated tools exist to help with checking code quality. These are known as static code analysis tools. The name comes from the fact that they do not run code; instead, they perform an automated review of the source code. One popular tool for Java is Sonarqube (at https://www.sonarqube.org/), which runs a set of rules across a code base.
Out of the box, tools like this give warnings about the following:
- Variable name conventions not being followed
- Uninitialized variables leading to possible NullPointerException problems
- Security vulnerabilities
- Poor or risky use of programming constructs
- Violations of community-accepted practices and standards
These rules can be modified and added to, allowing customization to be made to the local project house style and rules.
Of course, such automated assessments have limitations. As with manual exploratory testing, there are simply some things only a human can do (at least at the time of writing). In terms of code analysis, this mainly involves bringing context to the decisions. One simple example here is preferring longer, more descriptive variable names to a primitive such as int, compared to a more detailed type such as WordRepository. Static tools lack that understanding of the different contexts.
Automated code analysis has its benefits and limitations, as summarized here:
|
Automated Analysis |
Human Review |
|
Rigid rules (for example, variable name length) |
Relaxes rules based on context |
|
Applies a fixed set of assessment criteria |
Applies experiential learning |
|
Reports pass/fail outcomes |
Suggests alternative improvements |
Table 11.2 – Automated analysis versus human review
Google has a very interesting system called Google Tricorder. This is a set of program analysis tools that combines the creativity of Google engineers in devising rules for good code with the automation to apply them. For more information, see https://research.google/pubs/pub43322/.
Manually reviewing code can be done in various ways, with some common approaches:
- Code review on pull requests:
A pull request, also known as a merge request, is made by a developer when they wish to integrate their latest code changes into the main code base. This provides an opportunity for another developer to review that work and suggest improvements. They may even visually spot defects. Once the original developer makes agreed changes, the request is approved and the code is merged.
- Pair programming:
Pair programming is a way of working where two developers work on the same task at the same time. There is a continuous discussion about how to write the code in the best way. It is a continuous review process. As soon as either developer spots a problem, or has a suggested improvement, a discussion happens and a decision is made. The code is continuously corrected and refined as it is developed.
- Ensemble (mob) programming:
Like pair programming, only the whole team takes part in writing the code for one task. The ultimate in collaboration, which continuously brings the expertise and opinions of an entire team to bear on every piece of code written.
The dramatic difference here is that a code review happens after the code is written, but pair programming and mobbing happen while the code is being written. Code reviews performed after the code is written frequently happen too late to allow meaningful changes to be made. Pairing and mobbing avoid this by reviewing and refining code continuously. Changes are made the instant they are identified. This can result in higher quality output delivered sooner compared to the code-then-review workflow.
Different development situations will adopt different practices. In every case, adding a second pair of human eyes (or more) provides an opportunity for a design-level improvement, not a syntax-level one.
With that, we’ve seen how developers can benefit from adding manual exploratory testing and code review to their TDD work. Manual techniques benefit our users as well, as we will cover in the next section.
User interface and user experience testing
In this section, we will consider how we evaluate the impact of our user interface on users. This is another area where automation brings benefits but cannot complete the job without humans being involved.
Testing the user interface
User interfaces are the only part of our software system that matters to the most important people of all: our users. They are – quite literally – their windows into our world. Whether we have a command-line interface, a mobile web application, or a desktop GUI, our users will be helped or hindered in their tasks by our user interface.
The success of a user interface rests on two things being done well:
- It provides all the functionality a user needs (and wants)
- It allows a user to accomplish their end goals in an effective and efficient manner
The first of these, providing functionality, is the more programmatic of the two. In the same way that we use TDD to drive a good design for our server-side code, we can use it in our frontend code as well. If our Java application generates HTML – called server-side rendering – TDD is trivial to use. We test the HTML generation adapter and we’re done. If we are using a JavaScript/Typescript framework running in the browser, we can use TDD there, with a test framework such as Jest (https://jestjs.io/).
Having tested we’re providing the right functions to the user, automation then becomes less useful. With TDD, we can verify that all the right sorts of graphical elements are present in our user interface. But we can’t tell whether they are meeting the needs of the user.
Consider this fictional user interface for buying merchandise relating to our Wordz application:
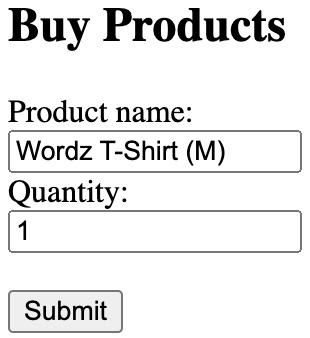
Figure 11.2 – Example user interface
We can use TDD to test that all those interface elements – the boxes and buttons – are present and working. But will our users care? Here are the questions we need to ask:
- Does it look and feel good?
- Does it align with corporate branding and house style guides?
- For the task of buying a T-shirt, is it easy to use?
- Does it present a logical flow to the user, guiding them through their task?
Quite deliberately for this example, the answer is no to all these questions. This is, quite frankly, a terrible user interface layout. It has no style, no feeling, and no brand identity. You have to type in the product name in the text field. There is no product image, no description, and no price! This user interface is truly the worst imaginable for an e-commerce product sales page. Yet it would pass all our automated functionality tests.
Designing effective user interfaces is a very human skill. It involves a little psychology in knowing how humans behave when presented with a task, mixed with an artistic eye, backed by creativity. These qualities of a user interface are best assessed by humans, adding another manual step to our development process.
Evaluating the user experience
Closely related to user interface design is user experience design.
User experience goes beyond any individual element or view on a user interface. It is the entire experience our users have, end to end. When we want to order the latest Wordz T-shirt from our e-commerce store, we want the entire process to be easy. We want the workflow across every screen to be obvious, uncluttered, and easier to get right than to get wrong. Going further, service design is about optimizing the experience from wanting a T-shirt to wearing it.
Ensuring users have a great experience is the job of a user experience designer. It is a human activity that combines empathy, psychology, and experimentation. Automation is limited in how it can help here. Some mechanical parts of this can be automated. Obvious candidates are applications such as Invision (https://www.invisionapp.com/), which allows us to produce a screen mockup that can be interacted with, and Google Forms, which allows us to collect feedback over the web, with no code to set that up.
After creating a candidate user experience, we can craft experiments where potential users are given a task to complete, then asked to provide feedback on how they found the experience.
A simple, manual form is more than adequate to capture this feedback:
|
Experience |
Rating of 1 (Poor) – 5 (Good) |
Comments |
|
My task was easy to complete |
4 |
I completed the task ok after being prompted by your researcher. |
|
I felt confident completing my task without instructions |
2 |
The text entry field about T-shirt size confused me. Could it be a dropdown of available options instead? |
|
The interface guided me through the task |
3 |
It was ok in the end – but that text field was an annoyance, so I scored this task lower. |
Table 11.3 – User experience feedback form
User experience design is primarily a human activity. So is the evaluation of test results. These tools only go as far as allowing us to create a mockup of our visions and collect experimental results. We must run sessions with real users, solicit their opinions on how their experience was, then feed back the results in an improved design.
While user experience is important, the next section deals with a mission-critical aspect of our code: security and operations.
Security testing and operations monitoring
This section reflects on the critical aspects of security and operations concerns.
So far, we have created an application that is well-engineered and has very low defects. Our user experience feedback has been positive – it is easy to use. But all that potential can be lost in an instant if we cannot keep the application running. If hackers target our site and harm users, the situation becomes even worse.
An application that is not running does not exist. The discipline of operations – often called DevOps these days – aims to keep applications running in good health and alert us if that health starts to fail.
Security testing – also called penetration testing (pentesting) – is a special case of manual exploratory testing. By its nature, we are looking for new exploits and unknown vulnerabilities in our application. Such work is not best served by automation. Automation repeats what is already known; to discover the unknown requires human ingenuity.
Penetration testing is the discipline that takes a piece of software and attempts to circumvent its security. Security breaches can be expensive, embarrassing, or business-ending for a company. The exploits used to create the breach are often very simple.
Security risks can be summarized roughly as follows:
- Things we shouldn’t see
- Things we shouldn’t change
- Things we shouldn’t use as often
- Things we should not be able to lie about
This is an oversimplification, of course. But the fact remains that our application may be vulnerable to these damaging activities – and we need to know whether that is the case or not. This requires testing. This kind of testing must be adaptive, creative, devious, and continually updated. An automated approach is none of those things, meaning security testing must take its place as a manual step in our development process.
A great starting point is to review the latest OWASP Top 10 Web Application Security Risks (https://owasp.org/www-project-top-ten/) and begin some manual exploratory testing based on the risks listed. Further information on threat models such as Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege (STRIDE) can be found at https://www.eccouncil.org/threat-modeling/. OWASP also has some excellent resources on useful tools at https://owasp.org/www-community/Fuzzing. Fuzzing is an automated way of discovering defects, although it requires a human to interpret the results of a failed test.
As with other manual exploratory tests, these ad hoc experiments may lead to some future test automation. But the real value lies in the creativity applied to investigating the unknown.
The preceding sections have made a case for the importance of manual interventions to complement our test automation efforts. But how does that fit in with a continuous integration/continuous delivery (CI/CD) approach? That’s the focus of the next section.
Incorporating manual elements into CI/CD workflows
We’ve seen that not only are manual processes important in our overall workflow but for some things, they are irreplaceable. But how do manual steps fit into heavily automated workflows? That’s the challenge we will cover in this section.
Integrating manual processes into an automated CI/CD pipeline can be difficult. The two approaches are not natural partners in terms of a linear, repeatable sequence of activities. The approach we take depends on our ultimate goal. Do we want a fully automated continuous deployment system, or are we happy with some manual interruptions?
The simplest approach to incorporating a manual process is to simply stop the automation at a suitable point, begin the manual process, then resume automaton once the manual process completes. We can think of this as a blocking workflow, as all further automated steps in the pipeline must stop until the manual work is completed. This is illustrated in the following diagram:

Figure 11.3 – Blocking workflow
By organizing our development process as a series of stages, some being automated and some being manual, we create a simple blocking workflow. Blocking here means that the flow of value is blocked by each stage. The automation stages typically run more quickly than the manual stages.
This workflow has some advantages in that it’s simple to understand and operate. Each iteration of software we deliver will have all automated tests run as well as all the current manual processes. In one sense, this release is of the highest quality we know how to make at that time. The disadvantage is that each iteration must wait for all manual processes to complete:
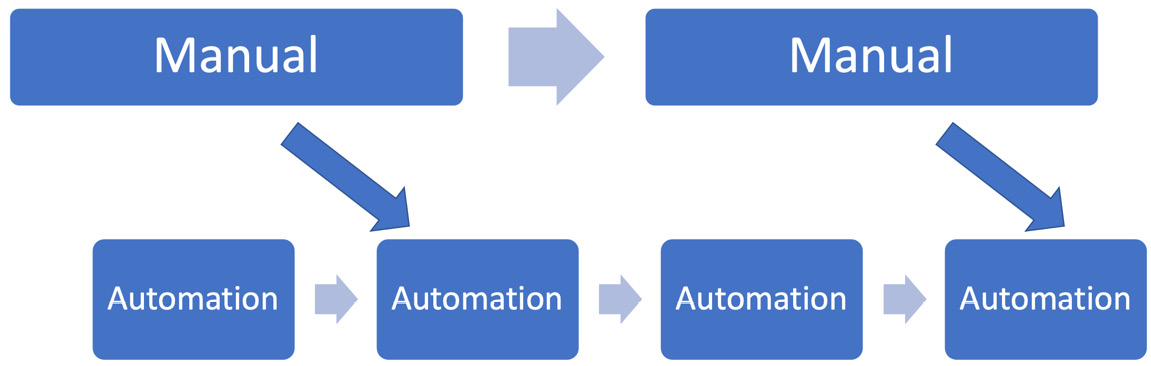
Figure 11.4 – Dual track workflow
One enabler for very smooth dual-track workflows is to use a single main trunk for the whole code base. All developers commit to this main trunk. There are no other branches. Any features in active development are isolated by feature flags. These are Boolean values that can be set to true or false at runtime. The code inspects these flags and decides whether to run a feature or not. Manual testing can then happen without having to pause deployments. During testing, the features in progress are enabled via the relevant feature flags. For the general end users, features in progress are disabled.
We can select the approach that fits our delivery goals the best. The blocking workflow trades off less rework for an extended delivery cycle. The dual-track approach allows for more frequent feature delivery, with a risk of having defects in production before they are discovered by a manual process and, subsequently, repaired.
Selecting the right process to use involves a trade-off between feature release cadence and tolerating defects. Whatever we choose, the goal is to focus the expertise of the whole team on creating software with a low defect rate.
Balancing automated workflows with manual, human workflows isn’t easy, but it does result in getting the most human intuition and experience into the product. That’s good for our development teams and it is good for our users. They benefit from improved ease of use and robustness in their applications. Hopefully, this chapter has shown you how we can combine these two worlds and cross that traditional developer-tester divide. We can make one great team, aiming at one excellent outcome.
Summary
This chapter discussed the importance of various manual processes during development.
Despite its advantages, we’ve seen how TDD cannot prevent all kinds of defects in software. First, we covered the benefits of applying human creativity to manual exploratory testing, where we can uncover defects that we missed during TDD. Then, we highlighted the quality improvements that code reviews and analysis bring. We also covered the very manual nature of creating and verifying excellent user interfaces with satisfying user experiences. Next, we emphasized the importance of security testing and operations monitoring in keeping a live system working well. Finally, we reviewed approaches to integrating manual steps into automation workflows, and the trade-offs we need to make.
In the next chapter, we’ll review some ways of working related to when and where we develop tests, before moving on to Part 3 of this book, where we will finish building our Wordz application.
Questions and answers
The following are some questions and answers regarding this chapter’s content:
- Have TDD and CI/CD pipelines eliminated the need for manual testing?
No. They have changed where the value lies. Some manual processes have become irrelevant, whereas others have increased in importance. Traditionally, manual steps, such as following test documents for feature testing and regression testing, are no longer required. Running feature and regression tests has changed from writing test plans in a word processor to writing test code in an IDE. But for many human-centric tasks, having a human mind in the loop remains vital to success.
- Will artificial intelligence (AI) automate away the remaining tasks?
This is unknown. Advances in AI at this time (the early 2020s) can probably improve visual identification and static code analysis. It is conceivable that AI image analysis may one day be able to provide a good/bad analysis of usability – but that is pure speculation, based on AI’s abilities to generate artworks today. Such a thing may remain impossible. In terms of practical advice now, assume that the recommended manual processes in this chapter will remain manual for some time.
Further reading
To learn more about the topics that were covered in this chapter, take a look at the following resources:
An overview of the modern genesis of TDD by Kent Beck. While the ideas certainly predate this project, this is the central reference of modern TDD practice. This paper contains many important insights into software development and teams – including the quote make it run, make it right, make it fast, and the need to not feel like we are working all the time. Well worth reading.
- Explore It, Elizabeth Hendrickson, ISBN 978-1937785024.
- https://trunkbaseddevelopment.com/.
- https://martinfowler.com/articles/feature-toggles.html.
- Inspired: How to create tech products customers love, Marty Cagan, ISBN 978-1119387503:
An interesting book that talks about product management. While this may seem strange in a developer book on TDD, a lot of the ideas in this chapter came from developer experience in a dual-track agile project, following this book. Dual agile means that fast feedback loops on feature discovery feed into fast feedback agile/TDD delivery. Essentially, manual TDD is done at the product requirements level. This book is an interesting read regarding modern product management, which has adopted the principles of TDD for rapid validation of assumptions about user features. Many ideas in this chapter aim to improve the software at the product level.