
4
Segmentals
DAVID DETERDING
Introduction
The development of an alphabetic system of writing is one of the major milestones in the evolution of Western civilization, allowing a huge range of words to be shown using a small set of symbols. However, the 26 letters in the Roman alphabet are not sufficient to represent all the sounds of English in a straightforward manner, particularly as there are only five vowel letters while there are many more vowel sounds in all varieties of English. As a result, additional symbols have been developed to represent the segmental sounds accurately, not just for English but for all human languages, using the International Phonetic Alphabet (IPA).
However, it is unclear how many consonants and vowels there actually are in English and also how they should best be represented. Some of this uncertainty arises because of the existence of different accents, so that, for example, some people differentiate which from witch, so these speakers may have one more consonant than those for whom these two words are homophones, and the vowel in words such as hot and calm is different in many varieties of British English but the same for most speakers in the United States, which means that there is an extra monophthong vowel in British English. In addition, while use of IPA symbols for the consonants and vowels is certainly a convenient way of showing how words are pronounced, it is not clear whether these symbols in fact accurately reflect the true nature of English sounds, or whether some other kind of representation might be more appropriate, maybe using distinctive features such as [+voice] and [–nasal] or else by showing components of the sounds such as voicing and nasality on separate tiers. Discussion of the inventory of English segments, the symbols that are used to represent them, and also the nature of the phonological representation of consonants and vowels can provide valuable insights into the sound system of English.
In this chapter, after describing the emergence of a standard for the pronunciation of English, I will provide an overview of the symbols that are adopted to represent the vowels and consonants of English, including a comparison between the symbols that are typically used in Britain and in North America, and also the lists of sounds that are generally considered to constitute the inventory of phonemes in each variety. I will then briefly consider alternative nonsegmental models of pronunciation, such as the use of distinctive features and also autosegmental phonology, before discussing nonprescriptive ways of representing the segmental phonemes of English in order to derive a system that is not linked to any one standard that is promoted as the norm. There are many ways of pronouncing English, and some speakers around the world prefer no longer to be constrained by the symbols that are more appropriate for representing a standard accent that comes from Britain or North America, so it is valuable to consider how we can show the sounds of English without linking the representation to one accent.
The emergence of standard pronunciation
In the time of Shakespeare at the end of the sixteenth century, there was no established norm for the pronunciation of English, and it was only in the following centuries that a standard gradually emerged, largely based on the pronunciation of educated people in London and the south-east of England (Mugglestone 2003). Selection of one particular accent as the standard for pronunciation resulted in that accent having a privileged status while other styles of speaking were often disparaged, even though linguistically there is nothing inherently superior in one variety over another.
In 1755, one and a half centuries after the time of Shakespeare, when Dr. Samuel Johnson was compiling his dictionary, he still concluded that sounds were highly volatile and any attempt to fix them was futile; yet within a few decades, people such as John Walker and Thomas Sheridan were making substantial careers out of writing books and presenting well-attended lectures about elegant and correct pronunciation. Indeed, in his Critical Pronouncing Dictionary published in 1791, John Walker asserted that deviations from the elegant patterns of speech of genteel people were “ridiculous and embarrassing” (Mugglestone 2003: 23).
Of course, attempts to fix the pronunciation of English have proved somewhat elusive, just as Dr. Johnson predicted, and it is instructive to note that many features that are firmly established as standard in RP British English today, including the use of /ɑː/ in words such as fast and bath as well as the loss of postvocalic /r/ in words such as morn and sort, were condemned as “vulgar” or even “atrocities” by many people in the nineteenth century. Indeed, in a review written in 1818, the poet John Keats was condemned as uneducated and lacking in imagination partly because he rhymed thoughts with sorts, but rhyming these two words would nowadays be regarded as perfectly standard in British English (Mugglestone 2003: 78, 88).
In fact, two alternative standards for the pronunciation of English have emerged, one derived from the educated speech of the south-east of England and the other based on that of North America. These alternative standards give rise to a number of issues about how many consonants and vowels there are in English and also how they should be represented, as I will outline in the following sections.
In the modern world, there are many valuable reference works showing the pronunciation of English words, especially the two principle pronouncing dictionaries, Wells (2008) and Jones et al. (2003). However, modern lexicographers usually see their role as descriptive rather than prescriptive, documenting a range of possible pronunciations for many words and sometimes offering substantial evidence for the patterns of pronunciation they report. Indeed, throughout his dictionary, John Wells provides data from a series of detailed surveys about pronunciation preferences. For example, forehead used to be pronounced with no /h/ in the middle, but Wells (2008: 317) reports that 65% of British respondents and 88% of Americans now prefer a pronunciation with a medial /h/. Furthermore, the percentage is highest among younger respondents, suggesting it is becoming established as the norm. We can say that the pronunciation of this word has changed because of the influence of its spelling (Algeo 2010: 46). Similarly, 27% of British respondents and 22% of Americans now state that they prefer often with a medial /t/, another trend that seems to be growing among younger people, though the fact that only a minority currently have a /t/ in this word suggests that this pronunciation is less advanced in becoming the norm (Wells 2008: 560). This work in conducting preference surveys to provide in-depth snapshots into changing patterns of speech represents a welcome effort to reflect pronunciation as it actually is rather than trying to impose some preconceived notion of what it should be. The fact that the pronunciation of words such as forehead and often seems to be shifting also illustrates that, even though standards nowadays exist for the pronunciation of English, the details are always undergoing change.
The International Phonetic Association (IPA)
The International Phonetic Association was established in 1886 with the aim of developing a set of symbols that could be used for representing all the sounds of the languages of the world (IPA 1999: 3). As far as possible, the letters from the Roman alphabet were adopted to represent their familiar sounds, so [b] is the IPA symbol for the voiced plosive produced at the lips and [s] is the symbol for the voiceless fricative produced by the tip of the tongue against the alveolar ridge. This is consistent with the way these letters are generally used in the writing systems of most European languages. Some of the extra symbols needed for other sounds were taken from the Greek alphabet, with, for example, [θ] representing a voiceless dental fricative, and other symbols were created by altering the shape of an existing letter, so, for instance, [ŋ] represents the nasal sound produced at the velum. Inevitably, with only five vowel letters in the Roman alphabet, additional symbols were needed to represent the full range of vowel sounds that occur in the languages of the world, so, for example, [ɒ] is the symbol that was created to represent an open back rounded vowel.
The IPA chart now shows 58 basic consonants, 10 nonpulmonic consonants (for clicks, implosives, and ejectives), 10 other consonant symbols such as [w] and its voiceless counterpart [ʍ], which both involve two places of articulation (labial and velar), and 28 vowels, as well as a range of symbols for tones, other suprasegmentals, and diacritics. The IPA symbols are periodically updated, such as at the Kiel Convention in 1989, to reflect enhanced knowledge about languages around the world. Nevertheless, few fundamental changes were made at the Kiel Convention (Esling 2010: 681), as the IPA is now well established and allows phoneticians to describe and compare a wide range of different languages quite effectively.
One issue that might be questioned concerning the IPA symbols is the use of [a] to represent a front vowel while [ɑ] is a back vowel. This seems to be the only case where a variant of a common Roman letter represents something different – it might be noted, for example, that selection between [g] and [ɡ] does not indicate a different sound – and the occurrence of both [a] and [ɑ] can give rise to confusion. Indeed, some writers use [a] not for a front vowel but to represent an unspecified open vowel, or sometimes even a back vowel. Because of this, Roca and Johnson (1999: 128) decided to take “the bold step of departing from IPA doctrine” in using [æ] instead of [a] to represent a fully open front unrounded vowel. However, for the representation of vowel quality in a range of languages, other writers do not seem to have followed their lead in this matter, apart from in the description of English for which the open front vowel in a word such as man is indeed represented as /æ/. I will now discuss the symbols used to show the sounds of English.
Phonemes and allophones
In the discussion of the IPA in the previous section, the symbols were enclosed in phonetic square brackets: [ ]. This is because the discussion was dealing with language-independent sounds such as [b] and [s] rather than the sounds of any one language. However, when considering the inventory of sounds in English, the consonant and vowel phonemes are shown in phonemic slashes: //. First, however, let us consider what is meant by a phoneme.
A phoneme is a contrastive sound in a language, which means that changing from one phoneme to another can create a new word (Laver 1994: 38). For example, the sound at the start of the word pat is represented as /p/, but if this /p/ is replaced with /b/, we get a different word, bat. We call pat and bat a minimal pair, and the existence of a minimal pair such as this confirms that /p/ and /b/ are different phonemes of English. Similarly, save and safe constitute a minimal pair, the existence of which demonstrates that /v/ and /f/ are different phonemes of English.
Another entity that should be introduced is the allophone. Allophones are variants of phonemes. For example, the /k/ at the start of kit is similar but not quite the same as the /k/ in cat, because the former is pronounced a little further forward in the mouth as a result of the influence of the following vowel (Ladefoged and Johnson 2011: 77). We show allophones in phonetic square brackets and we use diacritics to indicate the fine details of the pronunciation, so the sound at the start of kit can be shown as [k̟] to indicate that it is produced further forward in the mouth than the [k̠] in cat. Allophones cannot create a new word because their occurrence can be predicted from where they are in a word and what occurs before them and after them (Gussenhoven and Jacobs 2011: 62).
I will now consider the inventory of phonemes in English, starting with consonants and then dealing with vowels.
Representing the consonants of English
Consonants can be described in terms of three basic parameters: whether they are voiced or voiceless; where in the vocal tract they are pronounced; and how they are pronounced. We can therefore say, for example, that the /p/ sound at the start of pit is a voiceless bilabial plosive. In other words, the vocal folds are not vibrating when it is produced (so it is voiceless); it is produced with both lips (it is bilabial); and it is articulated by means of a sudden release of the closure (it is a plosive).
It is generally agreed that there are 24 consonant phonemes in English, as shown in Table 4.1. The columns in Table 4.1 represent the place of articulation, so /p/ is presented in the column for bilabial sounds; the rows indicate the manner of articulation, so /p/ is in the row for plosives. Symbols on the left of any cell are voiceless, while those on the right of a cell are voiced, so /p/ is on the left of its cell to show it is voiceless, while its voiced equivalent, /b/, is on the right of the same cell. Many cells only have a single symbol. For example, /m/ appears on the right of the cell for bilabial nasal, but there is no voiceless equivalent as voiceless nasals do not occur in English.
Table 4.1 The 24 consonant phonemes of English, classified according to place and manner of articulation.
| Place of articulation | |||||||||
| Bilabial | Labiodental | Dental | Alveolar | Postalveolar | Palatal | Velar | Glottal | ||
| Manner of articulation | Plosive | p b | t d | k ɡ | |||||
| Fricative | f v | θ ð | s z | ʃ ʒ | h | ||||
| Affricate | tʃ dʒ | ||||||||
| Nasal | m | n | ŋ | ||||||
| Lateral | l | ||||||||
| Approximant | w | r | j | ||||||
One issue with the consonants as shown in Table 4.1 concerns /w/, which actually has two places of articulation, bilabial and velar, though it is only shown in the bilabial column. In fact, as mentioned above, in the IPA chart [w] is listed under “other symbols” rather than in the main table of consonants (IPA 1999: ix), because of this anomaly in its having dual articulation.
One might note that the use of /r/ to represent the postalveolar approximant is not quite accurate according to the IPA chart, in which [r] represents a trill, not an approximant. Strictly speaking, the postalveolar approximant should be shown as /ɹ/ rather than /r/. However, the more familiar symbol /r/ is adopted here, following the usual practice of scholars such as Cruttenden (2008: 157) and Roach (2009: 52).
I will discuss three issues regarding the inventory of 24 English consonants that are shown in Table 4.1: why /tʃ/ and /dʒ/ are considered as phonemes; whether /ŋ/ is really a phoneme in English; and whether /ʍ/, the voiceless counterpart of /w/, might be included.
The phonemes /tʃ/ and /dʒ/ consist of two consecutive sounds, a plosive followed by a fricative. So why do we classify them as single phonemes rather than two separate consonants? After all, tax /tæks/ is considered to have two consonants at the end, /k/ followed by /s/, so why do we regard catch /kætʃ/ as having just one consonant at the end, /tʃ/, rather than /t/ followed by /ʃ/? Also, why is /tʃ/ shown in Table 4.1 while /ks/ is not? One factor here is that /tʃ/ and /dʒ/ are the only affricates that can occur at the start of a syllable, in words like chip /tʃɪp/ and jug /dʒʌɡ/, so in this respect they behave differently from other sequences of a plosive and fricative in English. For example, */ksɪp/ and */pfet/ are not well-formed words in English. (Here I am using the ‘*’ symbol to indicate that a sequence of sounds is not well formed.) In addition, /tʃ/ and /dʒ/ are generally felt by users of English to be single consonants (Wells 1982: 48).
Now let us consider /ŋ/. Before /k/ and /ɡ/, /ŋ/ occurs and we never find /n/. As mentioned above, if a sound can be predicted from the surrounding sounds, then it should be regarded as an allophone rather than a phoneme. Therefore it seems that if /ŋ/ might actually be regarded as an allophone of /n/, then it should be shown as [ŋ] (an allophone) rather than as the phoneme /ŋ/ (Roach 2009: 51). However, in some words, such as sung, /ŋ/ occurs without a following /k/ or /ɡ/, and indeed there are minimal pairs such as sung /sʌŋ/ and sun /sʌn/ in which /ŋ/ contrasts with /n/. One possibility here is to suggest that sung actually has a /ɡ/ after the nasal consonant, but this /ɡ/ is silent as it is deleted when it occurs following a nasal consonant at the end of a word. However, suggesting the existence of silent underlying sounds is a level of abstraction that is generally avoided in representing the sounds of English, and this is why most writers prefer to regard /ŋ/ as a phoneme.
Finally, let us consider whether /ʍ/, the voiceless counterpart of /w/, should be included in Table 4.1. For some speakers, which and witch constitute a minimal pair: the first starts with /ʍ/ while the second starts with /w/. Therefore, should /ʍ/ be included in the inventory of English consonants? It is not included because only a minority of speakers nowadays have this sound. Wells (2008: 898) reports that only 23% of British speakers have /ʍ/ at the start of white, and for younger speakers the number is less than 10%, though the number is probably rather higher in North America (Wells 1982: 229).
Variation in the consonant symbols
Representation of the consonants of English using the IPA symbols listed in Table 4.1 is fairly standard, though there remain some differences between British and American usage. In particular, many writers in America (e.g., Fromkin and Rodman 1993; Finnegan 1994) use the ‘hacek’ symbols /š, ž, č, ǰ/ instead of the respective IPA symbols /ʃ, ʒ, tʃ, dʒ/. One advantage of using the hacek symbols is that /č/ and /ǰ/ clearly represent the affricates as single phonemes, which (as mentioned above) reflects the intuition of most speakers. In addition, some writers prefer the symbol /y/ instead of /j/ for the palatal approximant that occurs at the beginning of words such as yes and yam. Notice that the use of /y/ for the palatal approximant mirrors the English spelling, which is an advantage for people who are primarily interested in representing the sounds of English and are not too concerned with the pronunciation of other languages. However, for cross-linguistic comparisons, it is best to use /j/ for the English approximant, as the IPA symbol [y] actually indicates a front rounded vowel such as that found in the French word tu (‘you’).
Representing the monophthong vowels of English
The quality of a vowel is usually described in terms of three basic variables: open/close; front/back; and rounded/unrounded. The first two depend on the position of the highest point of the tongue when producing the vowel. If the tongue is high in the mouth, we describe the vowel as close, while if it is low in the mouth, we say that the vowel is open; if the tongue is towards the front of the mouth, we describe the vowel as front, while if it is bunched at the back of the mouth, we say that it is a back vowel. The third variable depends on whether the lips are rounded or not. For example, the vowel in food (represented by the symbol /uː/ by most people in Britain, though many in North America prefer to show it as /u/) can be described as close back rounded, as the tongue is close to the roof and at the back of the mouth and the lips are rounded, while /æ/, the vowel in man, is open front unrounded, as the jaw is nearly fully open, the tongue is at the front of the mouth, and the lips are not rounded. Many scholars (e.g., Harrington 2010: 84) have suggested that these variables, particularly open/close and front/back, are in fact related more closely to the acoustics of the vowel rather than its articulation, as there is considerable variation in the ways that different speakers produce the same vowel. Nevertheless, the traditional labels provide an effective way of describing the quality of vowels even if they do not in fact reflect their actual articulation very closely.
The quality of the vowels can be shown on a vowel quadrilateral such as that in Figure 4.1, in which the front vowels are towards the left while the back vowels are on the right and close vowels are at the top while open vowels are near the bottom. This two-dimensional figure does not show rounding, but in English /uː/, /ʊ/, /ɔː/, and /ɒ/ are all rounded. The eleven monophthong vowels of British English that occur in stressed syllables are included in this figure. The position of the symbols, and also the shape of the vowel quadrilateral, are as shown in Roach (2009: 13 and 16).

Figure 4.1 The monophthong vowels of British English.
One vowel of English that is omitted from Figure 4.1 is the schwa /ə/, because it can never occur in stressed syllables. If it were included, it would occupy the same position as /ɜː/, and this raises the issue of whether a separate symbol should be used for /ɜː/ and /ə/ or if the former should instead be shown as /əː/, i.e., as a long version of /ə/. The rationale for adopting a different symbol is that the other long/short vowel pairs, such as /iː/ and /ɪ/, are represented by means of distinct symbols as well as the length diacritic, so it would be an anomaly if /ɜː/ and /ə/ were an exception.
These symbols are fairly well established, though some people use /ɛ/ instead of /e/ for the vowel in a word such as pet because this vowel is usually nearly open-mid. Indeed, Schmitt (2007) makes a strong case that /ɛ/ is preferable.
One other issue regarding the use of symbols is whether the length diacritic should be used with /iː, ɑː, ɔː, uː, ɜː/. Some people omit this diacritic on the basis that these vowels are tense rather than long, and the tense vowels may actually be shorter in duration in many situations than the lax vowels, depending on the phonological environment and speaking rate. For example, the tense vowel /iː/ in beat may in fact be shorter than the lax vowel /ɪ/ in bid, because the final voiceless consonant in beat shortens the duration of the preceding vowel (Roach 2009: 28).
One might also note that /ɒ/ is absent from many varieties of American English (Wells 1982: 273), because the majority of people in the United States pronounce words such as hot and shop with /ɑː/ rather than /ɒ/ (though most speakers in Canada have /ɒ/ in these words). One other difference is that the mid central vowel in North America generally has r-coloring so it is sometimes shown as /ɝː/ (Wells 2008).
The location of some of the vowels in Figure 4.1 might be discussed further, in particular the exact positioning of /uː/. Acoustic measurements have suggested that /uː/ in modern RP Britain English is actually often more fronted than suggested by Figure 4.1 (Deterding 2006) and it seems that this is becoming increasingly true for younger speakers (Hawkins and Midgley 2005). However, like Roach (2009: 16), Wells (2008: xxiii) shows it as a back vowel and so does Cruttenden (2008: 127), who observes that a fronted variant mostly only occurs after the approximant /j/ in words such as youth and cute.
Diphthongs
The quality of monophthongs does not change very much during the course of the vowel. In contrast, diphthongs have a shifting quality. RP British English generally has eight diphthongs: five closing diphthongs /eɪ, aɪ, ɔɪ, əʊ, aʊ/, in which the quality of the vowel moves from a relatively open vowel towards a more close one, and three centring diphthongs /ɪə, eə, ʊə/, in which the endpoint of the vowel is at the centre of the vowel quadrilateral.
The major differences for North American Englishes are that /əʊ/ is usually represented as /oʊ/ (suggesting a less front starting point) and, as the pronunciation of most speakers is rhotic, there are no centring diphthongs, because the vowels /ɪə, eə, ʊə/ in words such as peer, pair, and poor are a sequence of a monophthong followed by /r/ so the rhyme of these words is /ɪr/, /er/, and /ʊr/ respectively. In a few words, such as idea, which have /ɪə/ in RP British English, there is no potential final /r/, so in most North American Englishes this word has three syllables /aɪ diː ə/ while it just has two syllables /aɪ dɪə/ in British English (Wells 2008: 398).
One other issue in the inventory of diphthongs is that Ladefoged and Johnson (2011: 93) regard /ju/, the vowel in a word such as cue, as a phoneme of English. However, as they note, this makes it distinct from all the other diphthongs of English, as it is the only one in which the most prominent part is at the end, which is one reason why most people consider it as a sequence of the approximant /j/ and the monophthong /uː/ rather than a diphthong of English.
Two of the centring diphthongs in British English might be discussed further: / ʊə/ and /eə/. Many speakers in Britain nowadays have /ɔː/ rather than /ʊə/ in words such as poor, sure, and tour, so for 74% of people poor and pour are homophones (Wells 2008: 627). However, most speakers have /ʊə/ after /j/ in words such as cure and pure, so it seems that the /ʊə/ diphthong still exists for the majority of people in Britain.
For /eə/, many speakers have little diphthongal movement in this vowel, and Cruttenden (2008: 151) describes its realization as a long monophthong [ɛː] as “a completely acceptable alternative in General RP”. One might therefore suggest that the vowel in a word such as hair could be represented as /ɛː/. Nevertheless, most writers continue to use the symbol /eə/ for this vowel because it is well established and we should be hesitant about abandoning a convention that is adopted in textbooks throughout the world whenever there are small shifts in actual pronunciation.
We might further ask whether there is actually a need to list any diphthongs in English, and indeed some writers prefer to show the vowel /aʊ/ in a word like how as /aw/ (i.e., a monophthong followed by an approximant). We might note that say is similar to yes spoken backwards and also that my is rather like yum said backwards, and if yes and yum are transcribed with an initial approximant, then it might seem to make sense similarly to represent say and my with a final approximant, as /sej/ and /maj/ respectively, though Wells (1982: 49) notes that it is uncertain if the vowel in my should be /maj/ or /mʌj/ or something else. Similarly, words such as low and cow might be shown as /low/ and /kaw/ respectively. If we show these words with /j/ and /w/ at the end, then there is no need to list closing diphthongs in the inventory of English vowels, as we only have monophthongs optionally followed by an approximant. However, this solution works better for a rhotic accent such as most varieties of North American English than a non-rhotic accent such as RP British English, because RP has the additional centring diphthongs /ɪə, eə, ʊə/ in words such as peer, pair, and poor. So it seems that diphthongs are needed for representing RP, and if diphthongs are needed for the centring diphthongs, then we might as well show say and my with diphthongs as well.
We can further consider which sounds are classified as diphthongs. The vowels in words such as day and go are actually monophthongs in many varieties of English, including those of most speakers from Wales (Wells 1982: 382), Scotland (Wells 1982: 407), Singapore (Deterding 2007: 25) and many other places (Mesthrie and Bhatt 2008: 123–124). It is therefore not clear if it is appropriate that these two sounds should be classified as diphthongs just because RP speakers from Britain and many speakers in North America pronounce them that way. At the end of this paper, I will discuss nonprescriptive ways of referring to these vowels, using the keywords face and goat and thereby avoiding symbols such as /eɪ/ and /əʊ/, which make the assumption that they are diphthongs.
Feature-based representations of sounds
One issue with representing the sounds of English (or any other language) in terms of phonetic symbols is that it fails to reflect some regularities. For example, /p, t, k/ form a natural class of consonants, namely the voiceless plosives, while /m, s, j/ do not form a natural class, but this is not reflected by showing them as a list of symbols. It is not easy to write a rule to represent some phonological process unless there is some formal way of identifying natural classes of sounds. For instance, when the voiceless plosives occur at the start of a stressed syllable (e.g., pan, tough, kill), they are usually aspirated, which means that a little puff of air occurs after they are released. However, when they occur after initial /s/ (e.g., span, stuff, skill), they are not aspirated, and we cannot easily write a rule to show this using IPA symbols. Similarly, if we want to list the consonants that can occur after /k/ at the start of a syllable in English, we find only /r, w, j, l/ are permissible sounds in this position. However, this is not a random list of symbols, and it would be best to have a formal way of representing them.
One possible solution to this is to use distinctive features. For example, [+obstruent] represents a sound that is produced with a complete or partial blockage of the airflow, [+continuant] means that the blockage is not complete, [+delayed release] is used to represent the affricates, and [+voice] means that the sound is voiced, and we can then represent the voiceless plosives in terms of four distinctive features: [+obstruent −continuant –delayed release −voice]. Similarly, the approximants /r, w, j, l/ can be represented as [–obstruent +continuant] (Carr 1993: 65). Under this model, a phoneme such as /p/ does not really exist and is just the shorthand for a bundle of features. This was the approach proposed in the highly influential work The Sound Pattern of English (Chomsky and Halle 1968).
An essential goal of the work of Chomsky and Halle was to capture all the regularities that are found in English. However, this involved adopting highly abstract representations, such as a silent final /ɡ/ in a word like sung that I mentioned above. Moreover, some of the rules could become exceptionally complex. For example, Chomsky and Halle (1968: 52) proposed a rule that converts the /eɪ/ vowel in sane to the short vowel /æ/ in the first syllable of sanity, on the basis that this process occurs in a range of other words, including vane/vanity and profane/profanity, but in the attempts to capture this regularity, the representation of words ended up being substantially different from their surface realization. For this reason, the full rule-based framework proposed by Chomsky and Halle is not widely adopted by phonologists today in representing the phonology of English.
However, distinctive features are still often used to represent classes of sounds and to describe some of the phonological processes they undergo in speech. One issue that concerns these features is whether they are all binary, as with [±voice], or whether some of them might be unary, such as [labial] (Gussenhoven and Jacobs 2011: 74), but the details of this issue are beyond the scope of this brief overview of the segments of English.
Autosegmental representations
The use of distinctive features discussed in the previous section assumes that segment-sized phonemes may not be the fundamental phonological units of speech, and there is something smaller, namely the distinctive feature. One could alternatively propose that the segment is actually too small a unit for representing many aspects of phonology, and we should make use of features that extend over more than one segment. For example, in English, we do not find voiced consonants following voiceless ones at the end of a syllable, so /fɪst/ is fine but */fɪsd/ is not, as it involves voiced /d/ following voiceless /s/ in the coda of the syllable. In situations like this, it is redundant to show the voicing of both /s/ and /t/ independently, and maybe the [–voice] feature should be represented as extending over two successive segments. If voicing is separated from the rest of the segments and then shown in its own tier, we get something like this:
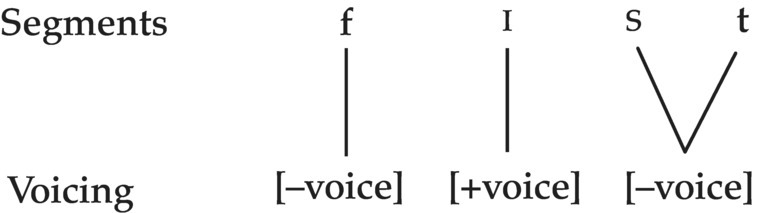
This representation accurately reflects the fact that the voicing feature can only change twice in an English syllable, from [–voice] to [+voice] and back to [–voice], so even in a syllable with seven segments such as strengths [streŋθs], the representation of voicing is still [–voice] [+voice] [–voice].
This kind of proposal, with separate tiers for different components of the pronunciation, was suggested by Goldsmith (1976) (though his work was mostly concerned with the representation of tones), and is termed autosegmental phonology.
Another feature that might be considered to belong on its own tier is nasality, and we might note that nasality does not always coincide with segment boundaries. For example, in a word such as pan, the vowel before a final nasal consonant becomes nasalized, but in fact only the end of the vowel gets nasalized. If nasality is represented in its own separate tier, as below, we can use a dotted line to show that the nasality of the final consonant extends over the previous sound while it does not prevent the first part of the vowel continuing to be non-nasal:

This representation of the word pan accurately reflects the fact that, for this word, both nasality and voicing only change once, even though there are three segments in it.
Nonprescriptive representations
Traditionally, a language such as English has been regarded as belonging to its native speakers, and IPA symbols for the standard pronunciation that native speakers use are assumed to be appropriate for representing the segments of the language. However, in the globalized modern world this assumption that native speakers own the English language has become problematic for many reasons. Firstly, it is hard to be sure what we mean exactly by a native speaker of English (McKay 2002: 28). If someone grows up speaking two languages equally well, are they a native speaker of both? And if someone only starts to speak English from the age of five but then develops perfect competency, are they a native speaker? Secondly, when English as a lingua franca (ELF) has become so widely used in the world and there are now far more non-native than native speakers using the language on a daily basis (Crystal 2003), can we continue to assume that ownership resides solely with its native speakers from places such as Britain and the United States?
In the past, some writers have suggested that native speakers are irrelevant for the description of ELF (Jenkins 2000). Others argue that native speakers may have a role in ELF corpora and thereby contribute to the analysis of patterns of usage that are discovered from those corpora (Seidlhofer 2011); indeed, more recently, when discussing the composition of ELF corpora, Jennifer Jenkins has acknowledged that native speakers do not need to be excluded from such corpora when they are talking to non-native speakers (Jenkins, Cogo, and Dewey 2011: 283). One way or another, whatever the status of native speakers in the description of ELF, there is nowadays a widely held view that non-native speakers should also have a prominent voice in the evolution of standards for worldwide English, particularly proficient users in what Kachru (2005) has termed the outer-circle countries such as India, Nigeria, and Singapore, which were once colonies and where English continues to function widely as an official language.
This raises a question. How should we talk about the sounds of English without assuming that one style of pronunciation is “correct” or “better” than another? If proficient speakers of English around the world pronounce the sound at the start of a word such as think as [θ], [t], [s], or [f], how do we refer to this sound without assuming that one of these realizations (such as the dental fricative /θ/) is somehow better than the others? And if the vowel in a word such as say is a diphthong in some varieties of English but a monophthong in others, does it make any sense to represent it using the symbol /eɪ/ or, indeed, to list it as a diphthong as was done above in presenting the inventory of vowels of English?
The solution proposed by Wells (1982) is to use upper-case letters for many of the consonants and keywords written in small caps for the vowels. Using this system, we can talk about how the voiceless TH sound is realized in different accents, we can refer to processes such as T-glottaling and L-vocalization that affect consonants, and we can consider how vowels such as face and goat are pronounced around the world. Indeed, Wells introduced a set of 24 keywords for representing the vowels of English, and this system allows us to talk about differences between varieties of English in a nonprescriptive way. For example, we can say that trap is usually pronounced as [æ] and palm is generally [ɑː], but the vowel in words such as staff, brass, ask, and dance that belong in the bath lexical set may be pronounced as [ɑː] in the UK or as [æ] in the USA (Wells 1982: xviii). Note that this way of representing the pronunciation avoids giving a privileged status to either of the two accents.
This system is now quite widely adopted, though there are still some problems. For example, it would usually be assumed that the vowel in bed is dress and so in most varieties of English it is pronounced as [e] (usually written as [ɛ] for American English). However, in Singapore English the word bed actually rhymes with made and not with fed (Deterding 2005), which suggests that it may belong with face rather than dress. To some extent, therefore, we need to extend or modify the keywords. Deterding (2007: 12) introduced the keyword poor to represent the vowel in words such as poor, tour, and sure, which in Singapore English are all pronounced as [ʊə]. The problem here is that the keyword for /ʊə/ is cure, but in Singapore the word cure is usually pronounced as [kjɔː], and it seems unfortunate if the word cure does not have the cure vowel. In fact, it is likely that further extensions and adaptations to the keywords may be needed to offer a comprehensive description of Englishes around the world.
Conclusion
Over the past two centuries, a standard pronunciation of English has emerged, originally based on the accent of educated people in London but later with an alternative standard based on the pronunciation of people in North America. At the same time, the IPA symbols have been developed as a means of accurately representing all the sounds of human languages, and following from this, a fairly well-established set of symbols has emerged to represent the segmental sounds of English, even though there remain some differences between a few of the symbols that are used, particularly because of differences in the standard pronunciations of Britain and the United States. The adoption of an established set of symbols for indicating pronunciation is useful because there are substantial advantages in maintaining agreed conventions for the range of textbooks and reference materials that are produced today.
The use of the IPA segmental symbols may not accurately reflect some aspects of the structure and some of the processes that characterize English syllables, such as alternations in voicing in English syllables and the predictive assimilation of nasality for a vowel before a nasal consonant. However, there seems little chance that alternative representations, such as those based on distinctive features or tier-based autosegmental phonology, will displace the convenient, widely understood, and highly flexible IPA symbols to represent the sounds of English.
Perhaps the greatest challenge to the use of these well-established IPA symbols is the burgeoning spread of ELF and the corresponding need for nonprescriptive ways of referring to the sounds. Only time will tell how extensively writers will adopt the upper-case letters for consonants and small-caps keywords for vowels suggested by Wells (1982), whether the problems that remain in using these symbols will be ironed out, or if some alternative representation of the consonants and vowels of English will eventually emerge.
REFERENCES
- Algeo, J. 2010. The Origins and Development of the English Language, 6th edition, Boston, MA: Wadsworth Cengage Learning.
- Carr, P. 1993. Phonology, London: Macmillan.
- Chomsky, N. and Halle, M. 1968. The Sound Pattern of English, Cambridge, MA: MIT Press.
- Cruttenden, A. 2008. Gimson’s Pronunciation of English, 7th edition, London: Hodder Education.
- Crystal, D. 2003. English as a Global Language, Cambridge: Cambridge University Press.
- Deterding, D. 2005. Emergent patterns in the vowels of Singapore English. English World-Wide 26: 179–197.
- Deterding, D. 2006. The North Wind versus a Wolf: short texts for the description and measurement of English pronunciation. Journal of the International Phonetic Association 36: 187–196.
- Deterding, D. 2007. Singapore English, Edinburgh: Edinburgh University Press.
- Esling, J. 2010. Phonetic notation. In: The Handbook of Phonetic Sciences, 2nd edition, W.J. Hardcastle, J. Laver, and F. Gibbon (eds.), 678–702, Malden, MA: Wiley-Blackwell.
- Finnegan, E. 1994. Language: Its Structure and Use, 2nd edition, Fort Worth, TX: Harcourt Brace.
- Fromkin, V. and Rodman, R. 1993. An Introduction to Language, 5th edition, Fort Worth, TX: Harcourt Brace Jovanovich.
- Goldsmith, J.A. 1976. An overview of autosegmental phonology. Linguistic Analysis 2(1): 23–68. Reprinted in Phonological Theory: The Essential Readings, J.A. Goldsmith (ed.), 137–161, Malden, MA: Blackwell.
- Gussenhoven, C. and Jacobs, H. 2011. Understanding Phonology, 3rd edition, London: Hodder Education.
- Harrington, J. 2010. Acoustic phonetics. In: The Handbook of Phonetic Sciences, 2nd edition, W.J. Hardcastle, J. Laver, and F. Gibbon (eds.), 81–129, Malden, MA: Wiley-Blackwell.
- Hawkins, S. and Midgley, J. 2005. Formant frequencies of RP monophthongs in four age groups of speakers. Journal of the International Phonetic Association 35: 183–200.
- IPA. 1999. Handbook of the International Phonetic Association, Cambridge: Cambridge University Press.
- Jenkins, J. 2000. The Phonology of English as an International Language, Oxford: Oxford University Press.
- Jenkins, J., Cogo, A., and Dewey, M. 2011. Review of developments in research into English as a lingua franca. Language Teaching 44(3): 281–315.
- Jones, D., Roach, P., Hartman, J., and Setter. J. 2003. Cambridge English Pronouncing Dictionary, 16th edition, Cambridge: Cambridge University Press.
- Kachru, B.B. 2005. Asian Englishes: Beyond the Canon, Hong Kong: Hong Kong University Press.
- Ladefoged, P. and Johnson, K. 2011. A Course in Phonetics, 6th edition, Boston, MA: Wadsworth/Cengage Learning.
- Laver, J. 1994. Principles of Phonetics, Cambridge: Cambridge University Press.
- McKay, S.L. 2002. Teaching English as an International Language, Oxford: Oxford University Press.
- Mesthrie, R. and Bhatt, R.M. 2008. World Englishes: The Study of New Linguistic Varieties, Cambridge: Cambridge University Press.
- Mugglestone, L. 2003. Talking Proper: The Rise of Accent as a Social Symbol, 2nd edition, Oxford: Oxford University Press.
- Roach, P. 2009. English Phonetics and Phonology: A Practical Course, 4th edition, Cambridge: Cambridge University Press.
- Roca, I. and Johnson, W. 1999. A Course in Phonology, Oxford: Blackwell.
- Schmitt, H. 2007. The case for the epsilon symbol (ε) in RP dress. Journal of the International Phonetic Association 37: 321–328.
- Seidlhofer, B. 2011. Understanding English as a Lingua Franca, Oxford: Oxford University Press.
- Wells, J.C. 1982. Accents of English, Cambridge: Cambridge University Press.
- Wells, J.C. 2008. Longman Pronunciation Dictionary, 3rd edition, Harlow: Pearson Longman.