
This chapter focuses on variations of producer-consumer synchronization using mutex locks, semaphores, condition variables and signals. Implementations for different types of stopping conditions are developed with careful attention to error handling and shutdown. The chapter describes two projects, a parallel file copy and a print server. The parallel file copy uses bounded buffers; the print server uses unbounded buffers.
Producer-consumer problems involve three types of participants—producers, consumers and temporary holding areas called buffer slots. A buffer is a collection of buffer slots. Producers create items and place them in buffer slots. Consumers remove items from buffer slots and use the items in some specified way so that they are no longer available.
Producer-consumer synchronization is required because producers and consumers do not operate at exactly the same speed, hence the holding areas are needed. For example, many fast food restaurants precook food and place it under lights in a warming area to get ahead of the mealtime rush. The cooks are the producers, and the customers are the consumers. The buffer is the area that holds the cooked food before it is given to the customer. Similarly, airplanes line up on a holding runway before being authorized to take off. Here the control tower or the airline terminals (depending on your view) produce airplanes. The take-off runways consume them.
Producer-consumer problems are ubiquitous in computer systems because of the asynchronous nature of most interactions. Network routers, printer queues and disk controllers follow the producer-consumer pattern. Because buffers in computer systems have finite capacity, producer-consumer problems are sometimes called bounded buffer problems, but producer-consumer problems also occur with unbounded buffers.
Chapter 13 introduced reader-writer synchronization. Both reader-writer and producer-consumer synchronization involve two distinguished parties. In reader-writer synchronization, a writer may create new resources or modify existing ones. A reader, however, does not change a resource by accessing it. In producer-consumer synchronization, a producer creates a resource. In contrast to readers, consumers remove or destroy the resource by accessing it. Shared data structures that do not act as buffers generally should use reader-writer synchronization or simple mutex locks rather than producer-consumer synchronization.
Figure 16.1 shows a schematic of the producer-consumer problem. Producer and consumer threads share a buffer and must synchronize when inserting or removing items. Implementations must avoid the following synchronization errors.

A consumer removes an item that a producer is in the process of inserting in the buffer.
A consumer removes an item that is not there at all.
A consumer removes an item that has already been removed.
A producer inserts an item in the buffer when there is no free slot (bounded buffer only).
A producer overwrites an item that has not been removed.
Two distinct time scales occur in synchronization problems—the short, bounded duration holding of resources, and the unbounded duration waiting until some event occurs. Producers should acquire a lock on the buffer only when a buffer slot is available and they have an item to insert. They should hold the lock only during the insertion period. Similarly, consumers should lock the buffer only while removing an item and release the lock before processing the removed item. Both of these locking actions are of short, bounded duration (in virtual time), and mutex locks are ideal for these.
When the buffer is empty (no buffer slots are filled), consumer threads should wait until there are items to remove. In addition, if the buffer has fixed size (an upper bound for the number of slots), producers should wait for room to become available before producing more data. These actions are not of bounded duration, and you must take care that your producers and consumers do not hold locks when waiting for such events. Semaphores or condition variables can be used for waiting of this type.
More complicated producer-consumer flow control might include high-water and low-water marks. When a buffer reaches a certain size (the high-water mark), producers block until the buffer empties to the low-water mark. Condition variables and semaphores can be used to control these aspects of the producer-consumer problem.
This chapter explores different aspects of the producer-consumer problem, using a simple mathematical calculation. We begin by demonstrating that mutex locks are not sufficient for an efficient implementation, motivating the need for condition variables (Section 13.4) and semaphores (Section 14.3). The chapter then specifies two projects that have a producer-consumer structure. A parallel file copier project based on the program of Section 12.3.5 uses the bounded buffers developed in this chapter. A threaded print server project uses unbounded buffers.
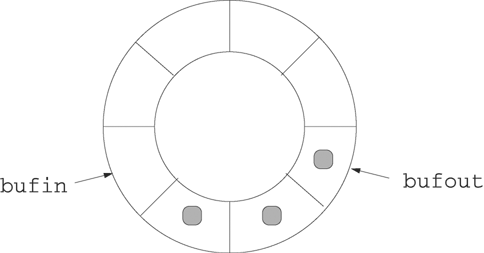
Figure 16.2 shows a diagram of a circular buffer with eight slots that might be used as a holding area between producers and consumers. The buffer has three data items, and the remaining five slots are free. The bufout variable has the slot number of the next data item to be removed, and the bufin variable has the number of the next slot to be filled.
Program 16.1 is an initial version of a circular buffer implemented as a shared object. The data structures for the buffer have internal linkage because the static qualifier limits their scope. (See Appendix A.5 for a discussion of the two meanings of the static qualifier in C.) The code is in a separate file so that the program can access the buffer only through getitem and putitem. The header file, buffer.h, contains the definitions of BUFSIZE and buffer_t. The functions of Program 16.1 follow the preferred POSIX error-handling semantics and return 0 if successful or a nonzero error code if unsuccessful.
Example 16.1. bufferbad.c
A flawed circular buffer protected by mutex locks.
#include <pthread.h>
#include "buffer.h"
static buffer_t buffer[BUFSIZE];
static pthread_mutex_t bufferlock = PTHREAD_MUTEX_INITIALIZER;
static int bufin = 0;
static int bufout = 0;
int getitem(buffer_t *itemp) { /* remove item from buffer and put in *itemp */
int error;
if (error = pthread_mutex_lock(&bufferlock)) /* no mutex, give up */
return error;
*itemp = buffer[bufout];
bufout = (bufout + 1) % BUFSIZE;
return pthread_mutex_unlock(&bufferlock);
}
int putitem(buffer_t item) { /* insert item in the buffer */
int error;
if (error = pthread_mutex_lock(&bufferlock)) /* no mutex, give up */
return error;
buffer[bufin] = item;
bufin = (bufin + 1) % BUFSIZE;
return pthread_mutex_unlock(&bufferlock);
}
Example 16.1.
The following code segment uses the circular buffer defined in Program 16.1. What happens when it executes?
int myitem;
if (getitem(&myitem) == 0)
printf("retrieved %d from the buffer
", myitem);
Answer:
The result cannot be predicted. The getitem returns an error only when the locking fails, but it does not keep track of the number of items in the buffer. If a consumer executes this code before a producer calls putitem, the value retrieved for myitem will not be meaningful.
Example 16.2.
The following code segment uses the circular buffer defined in Program 16.1. What happens when it executes?
int i;
for (i = 0; i < 10; i++)
if (putitem(i))
break;
Answer:
The buffer has only 8 slots, but this code segment calls putitem 10 times. The putitem does not keep track of how many empty slots are available, so it does not report an error if full slots are overwritten. If a consumer does not call getitem, the code overwrites the first items in the buffer.
Program 16.1 is flawed because the code does not protect the buffer from overflows or underflows. Program 16.2 is a revised implementation that keeps track of the number of items actually in the buffer. If successful, getitem and putitem return 0. If unsuccessful, these functions return a nonzero error code. In particular, getitem returns EAGAIN if the buffer is empty, and putitem returns EAGAIN if the buffer is full.
Example 16.3.
The following code segment attempts to retrieve at most 10 items from the buffer of Program 16.2.
int error;
int i;
int item;
for (i = 0; i < 10; i++) {
while((error = getitem(&item)) && (error == EAGAIN)) ;
if (error) /* real error occurred */
break;
printf("Retrieved item %d: %d
", i, item);
}
Example 16.2. buffer.c
A circular buffer implementation that does not allow overwriting of full slots or retrieval of empty slots.
#include <errno.h>
#include <pthread.h>
#include "buffer.h"
static buffer_t buffer[BUFSIZE];
static pthread_mutex_t bufferlock = PTHREAD_MUTEX_INITIALIZER;
static int bufin = 0;
static int bufout = 0;
static int totalitems = 0;
int getitem(buffer_t *itemp) { /* remove item from buffer and put in *itemp */
int error;
int erroritem = 0;
if (error = pthread_mutex_lock(&bufferlock)) /* no mutex, give up */
return error;
if (totalitems > 0) { /* buffer has something to remove */
*itemp = buffer[bufout];
bufout = (bufout + 1) % BUFSIZE;
totalitems--;
} else
erroritem = EAGAIN;
if (error = pthread_mutex_unlock(&bufferlock))
return error; /* unlock error more serious than no item */
return erroritem;
}
int putitem(buffer_t item) { /* insert item in the buffer */
int error;
int erroritem = 0;
if (error = pthread_mutex_lock(&bufferlock)) /* no mutex, give up */
return error;
if (totalitems < BUFSIZE) { /* buffer has room for another item */
buffer[bufin] = item;
bufin = (bufin + 1) % BUFSIZE;
totalitems++;
} else
erroritem = EAGAIN;
if (error = pthread_mutex_unlock(&bufferlock))
return error; /* unlock error more serious than no slot */
return erroritem;
}
The while loop of Example 16.3 uses busy waiting. The implementation is worse than you might imagine. Not only does busy waiting waste CPU time, but consumers executing this code segment block the producers, resulting in even more delay. Depending on the thread-scheduling algorithm, a busy-waiting consumer could prevent a producer from ever obtaining the CPU.
A more efficient implementation uses POSIX:SEM semaphores (introduced in Section 14.3). Recall that POSIX:SEM semaphores are not part of the POSIX:THR Extension but can be used with threads. Semaphores differ in several operational respects from the POSIX thread functions. If unsuccessful, the semaphore functions return –1 and set errno. In contrast, the POSIX:THR thread functions return a nonzero error code. The blocking semaphore functions can be interrupted by a signal and are cancellation points for thread cancellation, so you must be careful to handle the effects of signals and cancellation when using semaphores.
The traditional semaphore solution to the producer-consumer problem uses two counting semaphores to represent the number of items in the buffer and the number of free slots, respectively. When a thread needs a resource of a particular type, it decrements the corresponding semaphore by calling sem_wait. Similarly when the thread releases a resource, it increments the appropriate semaphore by calling sem_post. Since the semaphore variable never falls below zero, threads cannot use resources that are not there. Always initialize a counting semaphore to the number of resources initially available.
Program 16.3 shows a bounded buffer that synchronizes its access with semaphores. The semslots semaphore, which is initialized to BUFSIZE, represents the number of free slots available. This semaphore is decremented by producers and incremented by consumers through the sem_wait and sem_post calls, respectively. Similarly, the semitems semaphore, which is initialized to 0, represents the number of items in the buffer. This semaphore is decremented by consumers and incremented by producers through the sem_wait and sem_post calls, respectively.
POSIX:SEM semaphores do not have a static initializer and must be explicitly initialized before they are referenced. The implementation assumes that the bufferinit function will be called exactly once before any threads access the buffer. Program 16.4 and Program 16.5 give alternative implementations of bufferinit that do not make these assumptions.
Program 16.3 illustrates several differences between semaphores and mutex locks. The sem_wait function is a cancellation point, so a thread that is blocked on a semaphore can be terminated. The getitem and putitem functions have no other cancellation points, so the threads cannot be interrupted while the buffer data structure is being modified. Since the mutex is not held very long, a canceled thread quickly hits another cancellation point. The semaphore operations, unlike the mutex operations, can also be interrupted by a signal. If we want to use Program 16.3 with a program that catches signals, we need to restart the functions that can return an error with errno set to EINTR. Because semaphore functions return –1 and set errno rather than returning the error directly, the error handling must be modified.
Example 16.3. bufferseminit.c
A bounded buffer synchronized by semaphores. Threads using these functions may be canceled with deferred cancellation without corrupting the buffer.
#include <errno.h>
#include <pthread.h>
#include <semaphore.h>
#include "buffer.h"
static buffer_t buffer[BUFSIZE];
static pthread_mutex_t bufferlock = PTHREAD_MUTEX_INITIALIZER;
static int bufin = 0;
static int bufout = 0;
static sem_t semitems;
static sem_t semslots;
int bufferinit(void) { /* call this exactly once BEFORE getitem and putitem */
int error;
if (sem_init(&semitems, 0, 0))
return errno;
if (sem_init(&semslots, 0, BUFSIZE)) {
error = errno;
sem_destroy(&semitems); /* free the other semaphore */
return error;
}
return 0;
}
int getitem(buffer_t *itemp) { /* remove item from buffer and put in *itemp */
int error;
while (((error = sem_wait(&semitems)) == -1) && (errno == EINTR)) ;
if (error)
return errno;
if (error = pthread_mutex_lock(&bufferlock))
return error;
*itemp = buffer[bufout];
bufout = (bufout + 1) % BUFSIZE;
if (error = pthread_mutex_unlock(&bufferlock))
return error;
if (sem_post(&semslots) == -1)
return errno;
return 0;
}
int putitem(buffer_t item) { /* insert item in the buffer */
int error;
while (((error = sem_wait(&semslots)) == -1) && (errno == EINTR)) ;
if (error)
return errno;
if (error = pthread_mutex_lock(&bufferlock))
return error;
buffer[bufin] = item;
bufin = (bufin + 1) % BUFSIZE;
if (error = pthread_mutex_unlock(&bufferlock))
return error;
if (sem_post(&semitems) == -1)
return errno;
return 0;
}
Program 16.3 assumes that programs call bufferinit exactly once before referencing the buffer. Program 16.4 shows an alternative implementation that does not make these assumptions. The code assumes that programs call bufferinitmutex at least once before any thread accesses the buffer. The bufferinitmutex function can be called by each thread when the thread starts execution. The static initializer for the mutex ensures that smutex is initialized before any call. The bufferinitmutex can be called any number of times but initializes the semaphores only once.
Example 16.4. bufferinitmutex.c
An initialization function for bufferseminit.c that can be called more than once.
#include <pthread.h>
static int seminit = 0;
static pthread_mutex_t smutex = PTHREAD_MUTEX_INITIALIZER;
int bufferinit(void);
int bufferinitmutex(void) { /* initialize buffer at most once */
int error = 0;
int errorinit = 0;
if (error = pthread_mutex_lock(&smutex))
return error;
if (!seminit && !(errorinit = bufferinit()))
seminit = 1;
error = pthread_mutex_unlock(&smutex);
if (errorinit) /* buffer initialization error occurred first */
return errorinit;
return error;
}
Example 16.4.
How can we make the initialization of the semaphores completely transparent to the calling program?
Answer:
Make bufferinitmutex have internal linkage by adding the static qualifier. Now getitem and putitem should call bufferinitmutex before calling sem_wait. The initialization is now transparent, but we pay a price in efficiency.
Program 16.5 shows an alternative to bufferinitmutex for providing at-most-once initialization of the buffer in Program 16.3. The implementation uses pthread_once. Notice that initerror isn’t protected by a mutex lock, because it will only be changed once and that modification occurs before any call to bufferinitonce returns. Call the bufferinitonce function from each thread when it is created, or just from the main thread before it creates the producer and consumer threads. You can make initialization transparent by calling bufferinitonce at the start of getitem and putitem.
Example 16.5. bufferinitonce.c
An initialization function for bufferseminit.c that uses pthread_once to ensure that initialization is performed only once.
#include <pthread.h>
static int initerror = 0;
static pthread_once_t initonce = PTHREAD_ONCE_INIT;
int bufferinit(void);
static void initialization(void) {
initerror = bufferinit();
return;
}
int bufferinitonce(void) { /* initialize buffer at most once */
int error;
if (error = pthread_once(&initonce, initialization))
return error;
return initerror;
}
Program 16.6 shows an alternative way of making the buffer initialization transparent without the overhead of calling the initialization routine from each putitem and getitem. The initdone variable is declared to be of type volatile sig_atomic_t. The volatile qualifier indicates that the value may change asynchronously to the running thread. The sig_atomic_t type is one that can be accessed atomically.
Example 16.6. buffersem.c
A semaphore buffer implementation that does not require explicit initialization and has low initialization overhead.
#include <errno.h>
#include <pthread.h>
#include <semaphore.h>
#include <signal.h>
#include "buffer.h"
static buffer_t buffer[BUFSIZE];
static pthread_mutex_t bufferlock = PTHREAD_MUTEX_INITIALIZER;
static int bufin = 0;
static int bufout = 0;
static volatile sig_atomic_t initdone = 0;
static int initerror = 0;
static pthread_once_t initonce = PTHREAD_ONCE_INIT;
static sem_t semitems;
static sem_t semslots;
static int bufferinit(void) { /* called exactly once by getitem and putitem */
int error;
if (sem_init(&semitems, 0, 0))
return errno;
if (sem_init(&semslots, 0, BUFSIZE)) {
error = errno;
sem_destroy(&semitems); /* free the other semaphore */
return error;
}
return 0;
}
static void initialization(void) {
initerror = bufferinit();
if (!initerror)
initdone = 1;
}
static int bufferinitonce(void) { /* initialize buffer at most once */
int error;
if (error = pthread_once(&initonce, initialization))
return error;
return initerror;
}
int getitem(buffer_t *itemp) { /* remove item from buffer and put in *itemp */
int error;
if (!initdone)
bufferinitonce();
while (((error = sem_wait(&semitems)) == -1) && (errno == EINTR)) ;
if (error)
return errno;
if (error = pthread_mutex_lock(&bufferlock))
return error;
*itemp = buffer[bufout];
bufout = (bufout + 1) % BUFSIZE;
if (error = pthread_mutex_unlock(&bufferlock))
return error;
if (sem_post(&semslots) == -1)
return errno;
return 0;
}
int putitem(buffer_t item) { /* insert item in the buffer */
int error;
if (!initdone)
bufferinitonce();
while (((error = sem_wait(&semslots)) == -1) && (errno == EINTR)) ;
if (error)
return errno;
if (error = pthread_mutex_lock(&bufferlock))
return error;
buffer[bufin] = item;
bufin = (bufin + 1) % BUFSIZE;
if (error = pthread_mutex_unlock(&bufferlock))
return error;
if (sem_post(&semitems) == -1)
return errno;
return 0;
}
The initdone variable is statically initialized to 0. Its value changes only when the initialization has completed and the value is changed to 1. If the value of initdone is nonzero, we may assume that the initialization has completed successfully. If the value is 0, the initialization may have been done, so we use the bufferinitonce as in Program 16.5. Using initdone lowers the overhead of checking for the initialization once the initialization has completed. It does not require additional function calls once the initialization is complete.
The bounded buffer implementation of this section has no mechanism for termination. It assumes that producers and consumers that access the buffer run forever. The semaphores are not deleted unless an initialization error occurs.
This section introduces a simple producer-consumer problem to test the buffer implementations; the problem is based on Programs 13.6 and 13.7 in Section 13.2.3. The programs approximate the average value of sin(x) on the interval from 0 to 1, using a probabilistic algorithm. The producers calculate random numbers between 0 and 1 and put them in a buffer. Each consumer removes a value x from the buffer and adds the value of sin(x) to a running sum, keeping track of the number of entries summed. At any time, the sum divided by the count gives an estimate of the average value. Simple calculus shows that the exact average value is 1 – cos(1) or about 0.4597. Using bounded buffers is not a particularly efficient way of solving this problem, but it illustrates many of the relevant ideas needed to solve more interesting problems.
Program 16.7 shows a threaded producer object that uses the bounded buffer defined by Program 16.6. Each producer of Program 16.7 generates random double values and places them in the buffer. The implementation uses the globalerror object of Program 13.4 on page 455 to keep the number of the first error that occurs and uses the thread-safe randsafe of Program 13.2 on page 454 to generate random numbers. The initproducer function, which creates a producer thread, can be called multiple times if multiple producers are needed.
Program 16.8 shows an implementation of a consumer object. The publicly accessible initconsumer function allows an application to create as many consumer threads as desired. In case of an error, the offending thread sets the global error and returns. The other threads continue unless they also detect that an error occurred.
Program 16.9 is a main program that can be used with the producer (Program 16.7) and consumer (Program 16.8) threads as well as the buffersem buffer implementation (Program 16.6). The implementation assumes that no explicit buffer initialization is required. Program 16.9 takes three command-line arguments; a sleeptime in seconds, the number of producer threads and the number of consumer threads. The main program starts the threads, sleeps for the indicated time, and displays the results so far. After sleeping again, the main program displays the results and returns, terminating all the threads. This application illustrates the producer-consumer problem when the threads run forever or until main terminates.
The main program of Program 16.9 can display errors by using strerror rather than strerror_r because it is the only thread making this call. Program 16.9 calls the showresults function of Program 13.8 on page 459 to display the statistics.
Example 16.7. randproducer.c
An implementation of a producer that generates random numbers and places them in a synchronized buffer, such as the one shown in Program 16.6.
#include <pthread.h>
#include "buffer.h"
#include "globalerror.h"
#include "randsafe.h"
/* ARGSUSED */
static void *producer(void *arg1) { /* generate pseudorandom numbers */
int error;
buffer_t item;
for ( ; ; ) {
if (error = randsafe(&item))
break;
if (error = putitem(item))
break;
}
seterror(error);
return NULL;
}
/* --------------- Public functions ---------------------------------------- */
int initproducer(pthread_t *tproducer) { /* initialize */
int error;
error = pthread_create(tproducer, NULL, producer, NULL);
return (seterror(error));
}
Example 16.5.
What happens to the semaphores when Program 16.9 terminates?
Answer:
Since we are using POSIX:SEM unnamed semaphores with pshared equal to 0, the resources of the semaphores are released when the process terminates. If we had been using named semaphores or POSIX:XSI semaphores, they would still exist after the process terminated.
Example 16.8. randconsumer.c
An implementation of a consumer that calculates the sine of double values removed from a shared buffer and adds them to a running sum.
#include <math.h>
#include <pthread.h>
#include "buffer.h"
#include "globalerror.h"
#include "sharedsum.h"
/* ARGSUSED */
static void *consumer(void *arg) { /* compute partial sums */
int error;
buffer_t nextitem;
double value;
for ( ; ; ) {
if (error = getitem(&nextitem)) /* retrieve the next item */
break;
value = sin(nextitem);
if (error = add(value))
break;
}
seterror(error);
return NULL;
}
/* --------------- Public functions ---------------------------------------- */
int initconsumer(pthread_t *tconsumer) { /* initialize */
int error;
error = pthread_create(tconsumer, NULL, consumer, NULL);
return (seterror(error));
}
Example 16.6.
Suppose Program 16.9 runs on a machine with a single processor under preemptive priority scheduling. In what order are the items processed if BUFSIZE is 8 and one of the producers starts first?
Answer:
For preemptive priority scheduling, a thread with greater priority than the currently running thread preempts it. If the producer and consumers have the same priority, as in Program 16.9, a producer deposits eight items in the buffer and then blocks. The first consumer then retrieves the first eight items. One of the producers then produces the next 8 items, and so on. This alternation of blocks occurs because the producers and consumers are of equal priority. On the other hand, if the consumers have a higher priority, a consumer preempts the producer after the producer deposits a single item, so the producer and the consumers alternately process individual items. If the producer has higher priority, it fills the buffer with 8 items and then preempts the consumers after each slot becomes available.
Example 16.9. randpcforever.c
A main program that creates any number of producer and consumer threads.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "buffer.h"
#include "globalerror.h"
#include "sharedsum.h"
int initconsumer(pthread_t *tid);
int initproducer(pthread_t *tid);
int showresults(void);
int main(int argc, char *argv[]) {
int error;
int i;
int numberconsumers;
int numberproducers;
int sleeptime;
pthread_t tid;
if (argc != 4) {
fprintf(stderr, "Usage: %s sleeptime producers consumers
", argv[0]);
return 1;
}
sleeptime = atoi(argv[1]);
numberproducers = atoi(argv[2]);
numberconsumers = atoi(argv[3]);
for (i = 0; i < numberconsumers; i++) /* initialize consumers */
if (error = initconsumer(&tid)) {
fprintf(stderr, "Failed to create consumer %d:%s
",
i, strerror(error));
return 1;
}
for (i = 0; i < numberproducers; i++) /* initialize producers */
if (error = initproducer(&tid)) {
fprintf(stderr, "Failed to create producer %d:%s
",
i, strerror(error));
return 1;
}
sleep(sleeptime); /* wait to get the partial sum */
if (showresults())
return 1;
sleep(sleeptime); /* wait again before terminating */
if (showresults())
return 1;
return 0;
}
Program 16.10 gives a condition variable implementation of a bounded buffer that is similar to the semaphore implementation of Program 16.6.
Example 16.10. buffercond.c
Condition variable implementation of a bounded buffer.
#include <pthread.h>
#include "buffer.h"
static buffer_t buffer[BUFSIZE];
static pthread_mutex_t bufferlock = PTHREAD_MUTEX_INITIALIZER;
static int bufin = 0;
static int bufout = 0;
static pthread_cond_t items = PTHREAD_COND_INITIALIZER;
static pthread_cond_t slots = PTHREAD_COND_INITIALIZER;
static int totalitems = 0;
int getitem(buffer_t *itemp) { /* remove an item from buffer and put in itemp */
int error;
if (error = pthread_mutex_lock(&bufferlock))
return error;
while ((totalitems <= 0) && !error)
error = pthread_cond_wait (&items, &bufferlock);
if (error) {
pthread_mutex_unlock(&bufferlock);
return error;
}
*itemp = buffer[bufout];
bufout = (bufout + 1) % BUFSIZE;
totalitems--;
if (error = pthread_cond_signal(&slots)) {
pthread_mutex_unlock(&bufferlock);
return error;
}
return pthread_mutex_unlock(&bufferlock);
}
int putitem(buffer_t item) { /* insert an item in the buffer */
int error;
if (error = pthread_mutex_lock(&bufferlock))
return error;
while ((totalitems >= BUFSIZE) && !error)
error = pthread_cond_wait (&slots, &bufferlock);
if (error) {
pthread_mutex_unlock(&bufferlock);
return error;
}
buffer[bufin] = item;
bufin = (bufin + 1) % BUFSIZE;
totalitems++;
if (error = pthread_cond_signal(&items)) {
pthread_mutex_unlock(&bufferlock);
return error;
}
return pthread_mutex_unlock(&bufferlock);
}
Program 16.10 is simpler than the semaphore implementation because condition variables have static initializers. Test Program 16.10 on a producer-consumer problem by linking it with Programs 16.7, 16.8 and 16.9. It also needs Program 13.4 (globalerror), Program 13.2 (randsafe) and Program 13.5 (sharedsum).
The bounded buffer implementations of Section 16.3 and Section 16.5 do not have any mechanism for indicating that no more items will be deposited in the buffer. Unending producer-consumer problems occur frequently at the system level. For example, every network router has a buffer between incoming and outgoing packets. The producers are the processes that handle the incoming lines, and the consumers are the processes handling the outgoing lines. A web server is another example of an unending producer-consumer. The web server clients (browsers) are producers of requests. The web server acts as a consumer in handling these requests.
Things are not so simple when the producers or consumers are controlled by more complicated exit conditions. In a producer-driven variation on the producer-consumer problem, there is one producer and an arbitrary number of consumers. The producer puts an unspecified number of items in the buffer and then exits. The consumers continue until all items have been consumed and the producer has exited.
A possible approach is for the producer to set a flag signifying that it has completed its operation. However, this approach is not straightforward, as illustrated by the next exercise.
Example 16.7.
Consider the following proposed solution to a producer-driven problem. The producer thread produces only numitem values, calls setdone of Program 13.3 on page 454, and exits. The consumer calls getdone on each iteration of the loop to discover whether the producer has completed. What can go wrong?
Answer:
If the producer calls setdone while consumer is blocked on getitem with an empty buffer, the consumer never receives notification and it deadlocks, waiting for an item to be produced. Also, when consumer detects that producer has called setdone, it has no way of determining whether there are items left in the buffer to be processed without blocking.
Both the semaphore implementation of the bounded buffer in Program 16.6 and the condition variable implementation of the bounded buffer in Program 16.10 have no way of unblocking getitem after setdone is called. Program 16.11 shows an implementation that moves the doneflag into the buffer object. The setdone function not only sets the doneflag but also wakes up all threads that are waiting on condition variables. If getitem is called with an empty buffer after the producer has finished, getitem returns the error ECANCELED. The consumer then terminates when it tries to retrieve the next item.
Example 16.11. bufferconddone.c
A buffer that uses condition variables to detect completion.
#include <errno.h>
#include <pthread.h>
#include "buffer.h"
static buffer_t buffer[BUFSIZE];
static pthread_mutex_t bufferlock = PTHREAD_MUTEX_INITIALIZER;
static int bufin = 0;
static int bufout = 0;
static int doneflag = 0;
static pthread_cond_t items = PTHREAD_COND_INITIALIZER;
static pthread_cond_t slots = PTHREAD_COND_INITIALIZER;
static int totalitems = 0;
int getitem(buffer_t *itemp) {/* remove an item from buffer and put in itemp */
int error;
if (error = pthread_mutex_lock(&bufferlock))
return error;
while ((totalitems <= 0) && !error && !doneflag)
error = pthread_cond_wait (&items, &bufferlock);
if (error) {
pthread_mutex_unlock(&bufferlock);
return error;
}
if (doneflag && (totalitems <= 0)) {
pthread_mutex_unlock(&bufferlock);
return ECANCELED;
}
*itemp = buffer[bufout];
bufout = (bufout + 1) % BUFSIZE;
totalitems--;
if (error = pthread_cond_signal(&slots)) {
pthread_mutex_unlock(&bufferlock);
return error;
}
return pthread_mutex_unlock(&bufferlock);
}
int putitem(buffer_t item) { /* insert an item in the buffer */
int error;
if (error = pthread_mutex_lock(&bufferlock))
return error;
while ((totalitems >= BUFSIZE) && !error && !doneflag)
error = pthread_cond_wait (&slots, &bufferlock);
if (error) {
pthread_mutex_unlock(&bufferlock);
return error;
}
if (doneflag) { /* consumers may be gone, don't put item in */
pthread_mutex_unlock(&bufferlock);
return ECANCELED;
}
buffer[bufin] = item;
bufin = (bufin + 1) % BUFSIZE;
totalitems++;
if (error = pthread_cond_signal(&items)) {
pthread_mutex_unlock(&bufferlock);
return error;
}
return pthread_mutex_unlock(&bufferlock);
}
int getdone(int *flag) { /* get the flag */
int error;
if (error = pthread_mutex_lock(&bufferlock))
return error;
*flag = doneflag;
return pthread_mutex_unlock(&bufferlock);
}
int setdone(void) { /* set the doneflag and inform all waiting threads */
int error1;
int error2;
int error3;
if (error1 = pthread_mutex_lock(&bufferlock))
return error1;
doneflag = 1;
error1 = pthread_cond_broadcast(&items); /* wake up everyone */
error2 = pthread_cond_broadcast(&slots);
error3 = pthread_mutex_unlock(&bufferlock);
if (error1)
return error1;
if (error2)
return error2;
if (error3)
return error3;
return 0;
}
Example 16.8.
Why did we use the same mutex to protect doneflag in getdone and setdone as we used to protect the buffer in getitem and putitem?
Answer:
The getitem function needs to access doneflag at a time when it owns the bufferlock mutex. Using the same mutex simplifies the program.
Example 16.9.
Can the mutex calls in getdone and setdone be eliminated?
Answer:
The lock around doneflag in getdone could be eliminated if we knew that access to an int was atomic. We can guarantee that accesses to doneflag are atomic by declaring it to have type sig_atomic_t. In setdone, it is best to do the condition variable broadcasts while owning the lock, and we need to make sure that the threads see that doneflag has been set to 1 when they wake up.
Program 16.12 and Program 16.13 show modifications of producer of Program 16.7 and consumer of Program 16.8 to account for termination. They are linked with Program 16.11, which provides setdone. They handle the error ECANCELED by terminating without calling seterror.
Example 16.12. randproducerdone.c
A producer that detects whether processing should end.
#include <errno.h>
#include <pthread.h>
#include "buffer.h"
#include "globalerror.h"
#include "randsafe.h"
int getdone(int *flag);
/* ARGSUSED */
static void *producer(void *arg1) { /* generate pseudorandom numbers */
int error;
buffer_t item;
int localdone = 0;
while (!localdone) {
if (error = randsafe(&item))
break;
if (error = putitem(item))
break;
if (error = getdone(&localdone))
break;
}
if (error != ECANCELED)
seterror(error);
return NULL;
}
/* --------------- Public functions ---------------------------------------- */
int initproducer(pthread_t *tproducer) { /* initialize */
int error;
error = pthread_create(tproducer, NULL, producer, NULL);
return (seterror(error));
}
Example 16.13. randconsumerdone.c
A consumer that detects whether the buffer has finished.
#include <errno.h>
#include <math.h>
#include <pthread.h>
#include "buffer.h"
#include "globalerror.h"
#include "sharedsum.h"
/* ARGSUSED */
static void *consumer(void *arg) { /* compute partial sums */
int error;
buffer_t nextitem;
double value;
for ( ; ; ) {
if (error = getitem(&nextitem)) /* retrieve the next item */
break;
value = sin(nextitem);
if (error = add(value))
break;
}
if (error != ECANCELED)
seterror(error);
return NULL;
}
/* --------------- Public functions ---------------------------------------- */
int initconsumer(pthread_t *tconsumer) { /* initialize */
int error;
error = pthread_create(tconsumer, NULL, consumer, NULL);
return (seterror(error));
}
Program 16.14 shows a main program that creates a specified number of the producer threads (Program 16.12) and consumer threads (Program 16.13). After creating the threads, main sleeps for a specified amount of time and then calls the setdone function of Program 16.11. The program joins with all the threads to make sure that they have finished their computations before calling showresults of Program 13.8 on page 459 to display the results.
Example 16.10.
What would happen if randconsumerdone of Program 16.13 called seterror when getitem returned ECANCELED?
Answer:
The results of the calculation would not be displayed. The showresults function only prints an error message if geterror returns a nonzero value.
Example 16.14. randpcdone.c
A main program that creates producer threads of Program 16.12 and consumer threads of Program 16.13. After sleeping, it calls setdone. The program should use the buffer of Program 16.11.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "buffer.h"
#include "doneflag.h"
#include "globalerror.h"
int initconsumer(pthread_t *tid);
int initproducer(pthread_t *tid);
int showresults(void);
int main(int argc, char *argv[]) {
int error;
int i;
int numberconsumers;
int numberproducers;
int sleeptime;
pthread_t *tidc;
pthread_t *tidp;
if (argc != 4) {
fprintf(stderr, "Usage: %s sleeptime producers consumers
", argv[0]);
return 1;
}
sleeptime = atoi(argv[1]);
numberproducers = atoi(argv[2]);
numberconsumers = atoi(argv[3]);
tidp = (pthread_t *)calloc(numberproducers, sizeof(pthread_t));
if (tidp == NULL) {
perror("Failed to allocate space for producer IDs");
return 1;
}
tidc = (pthread_t *)calloc(numberconsumers, sizeof(pthread_t));
if (tidc == NULL) {
perror("Failed to allocate space for consumer IDs");
return 1;
}
for (i = 0; i < numberconsumers; i++) /* initialize consumers */
if (error = initconsumer(tidc+i)) {
fprintf(stderr, "Failed to create consumer %d:%s
",
i, strerror(error));
return 1;
}
for (i = 0; i < numberproducers; i++) /* initialize producers */
if (error = initproducer(tidp+i)) {
fprintf(stderr, "Failed to create producer %d:%s
",
i, strerror(error));
return 1;
}
sleep(sleeptime); /* wait a while to get the partial sum */
if (error = setdone()) {
fprintf(stderr, "Failed to set done indicator:%s
", strerror(error));
return 1;
}
for (i = 0; i < numberproducers; i++) /* wait for producers */
if (error = pthread_join(tidp[i], NULL)) {
fprintf(stderr, "Failed producer %d join:%s
", i, strerror(error));
return 1;
}
for (i = 0; i < numberconsumers; i++) /* wait for consumers */
if (error = pthread_join(tidc[i], NULL)) {
fprintf(stderr, "Failed consumer %d join:%s
", i, strerror(error));
return 1;
}
if (showresults())
return 1;
return 0;
}
Program 16.15 shows a second version of main that creates a signal thread of Program 13.14 on page 476 to wait on SIGUSR1. Program 13.14 should be linked to bufferconddone.c rather than doneflag.c so that it calls the correct setdone. As before, main creates a specified number of the producer and consumer threads of Program 16.12 and Program 16.13. After creating the threads, main waits for the threads to complete by executing pthread_join before displaying the results. The threads continue to compute until the user sends a SIGUSR1 signal from the command line. At this point, the signalthread calls setdone, causing the producers and consumers to terminate.
Example 16.15. randpcsig.c
A main program that creates producer threads of Program 16.12 and consumer threads of Program 16.13. The threads detect done when the user enters SIGUSR1.
#include <pthread.h>
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "buffer.h"
#include "globalerror.h"
#include "sharedsum.h"
#include "signalthread.h"
int initconsumer(pthread_t *tid);
int initproducer(pthread_t *tid);
int showresults(void);
int main(int argc, char *argv[]) {
int error;
int i;
int numberconsumers;
int numberproducers;
pthread_t *tidc;
pthread_t *tidp;
if (argc != 3) {
fprintf(stderr, "Usage: %s producers consumers
", argv[0]);
return 1;
}
numberproducers = atoi(argv[1]);
numberconsumers = atoi(argv[2]);
if (error = signalthreadinit(SIGUSR1)) {
perror("Failed to start signalthread");
return 1;
}
fprintf(stderr,"Process %ld will run until SIGUSR1 (%d) signal.
",
(long)getpid(), SIGUSR1);
tidp = (pthread_t *)calloc(numberproducers, sizeof(pthread_t));
if (tidp == NULL) {
perror("malloc producer IDs");
return 1;
}
tidc = (pthread_t *)calloc(numberconsumers, sizeof(pthread_t));
if (tidc == NULL) {
perror("malloc consumer IDs");
return 1;
}
for (i = 0; i < numberconsumers; i++) /* initialize consumers */
if (error = initconsumer(tidc + i)) {
fprintf(stderr, "Failed to create consumer %d:%s
",
i, strerror(error));
return 1;
}
for (i = 0; i < numberproducers; i++) /* initialize producers */
if (error = initproducer(tidp + i)) {
fprintf(stderr, "Failed to create producer %d:%s
",
i, strerror(error));
return 1;
}
for (i = 0; i < numberproducers; i++) /* wait for producers */
if (error = pthread_join(tidp[i], NULL)) {
fprintf(stderr, "Failed producer %d join:%s
", i, strerror(error));
return 1;
}
for (i = 0; i < numberconsumers; i++) /* wait for consumers */
if (error = pthread_join(tidc[i], NULL)) {
fprintf(stderr, "Failed consumer %d join:%s
", i, strerror(error));
return 1;
}
if (showresults())
return 1;
return 0;
}
This section revisits the parallel file copy of Program 12.8 on page 427. The straightforward implementation of the parallel file copy creates a new thread to copy each file and each directory. When called with a large directory tree, this implementation quickly exceeds system resources. This section outlines a worker pool implementation that regulates how many threads are active at any time. In a worker pool implementation, a fixed number of threads are available to handle the load. The workers block on a synchronization point (in this case, an empty buffer) and one worker unblocks when a request comes in (an item is put in the buffer). Chapter 22 compares the performance of worker pools to other server threading strategies.
Begin by creating a producer thread function that takes as a parameter an array of size 2 containing the pathnames of two directories. For each regular file in the first directory, the producer opens the file for reading and opens a file of the same name in the second directory for writing. If a file already exists in the destination directory with the same name, that file should be opened and truncated. If an error occurs in opening either file, both files are closed and an informative message is sent to standard output. The two open file descriptors and the name of the file are put into the buffer. Use the bufferconddone implementation so that the threads can be terminated gracefully. The buffer.h file contains the definition of buffer_t, the type of a buffer entry. Use the following definition for this project.
typedef struct {
int infd;
int outfd;
char filename[PATH_MAX];
} buffer_t;
Only ordinary files will be copied for this version of the program. The filename member should contain the name of the file only, without a path specification. Use the opendir and readdir functions described in Section 5.2 on page 152 to access the source directory. These functions are not thread-safe, but there will be only one producer thread and only this thread will call these functions. Use the lstat function described in Section 5.2.1 on page 155 to determine if the file is a regular file. The file is a regular file if the S_ISREG macro returns true when applied to the st_mode field of the stat structure. Program 16.16 shows a function that returns true if filename represents a regular file and false otherwise.
This is a producer-driven bounded buffer problem. When the producer is finished filling the buffer with filenames from the given directory, it calls setdone in Program 16.11 and exits.
Each consumer thread reads an item from the buffer, copies the file from the source file descriptor to the destination file descriptor, closes the files, and writes a message to standard output giving the file name and the completion status of the copy.
Note that the producer and multiple consumers are writing to standard output and that this is a critical section that must be protected. Devise a method for writing these messages atomically.
The consumers should terminate when they detect that a done flag has been set and no more entries remain in the buffer, as in Program 16.13.
The main program should take the number of consumers and the source and destination directories as command-line arguments. The application always has exactly one producer thread.
The main program should start the threads and use pthread_join to wait for the threads to complete, as in Program 16.15. Use gettimeofday to get the time before the first thread is created and after the last join. Display the total time to copy the files in the directory.
Experiment with different buffer sizes and different numbers of consumer threads. Which combinations produce the best results? Be careful not to exceed the per-process limit on the number of open file descriptors. The number of open file descriptors is determined by the size of the buffer and the number of consumers. Make sure that the consumers close the file descriptors after copying a file and before removing another item from the buffer.
After the programs described above are working correctly, add the following enhancements.
Copy subdirectories as well as ordinary files, but do not (at this time) copy the contents of the subdirectories. (Just create a subdirectory in the destination directory for each subdirectory in the source directory.) You can either have the producer do this (and not put a new entry into the buffer) or add a field in
buffer_tgiving the type of file to be copied. Read item 3 below before deciding which method to use.Copy FIFOs. For each FIFO in the source directory, make a FIFO with the same name in the destination directory. You can handle this as in item 1.
Recursively copy subdirectories. This part should just require modifying the producer if the producer creates the subdirectory. If the consumers create the subdirectories, you need to figure out how to avoid having the producer try to open a destination file before its directory has been created. Store the path of the file relative to the source directory in the buffer slots so that the consumers can print relevant messages.
Keep statistics about the number and types of files copied. Keep track of the total number of bytes copied. Keep track of the shortest and longest copy times.
Add a signal thread that outputs the statistics accumulated so far when the process receives a
SIGUSR1signal. Make sure that the handler output is atomic with respect to the output generated by the producer and the consumers.
This section develops a project based on producer-consumer synchronization that uses an unbounded buffer rather than a buffer of fixed size.
The lp command on most systems does not send a file directly to the specified printer. Instead, lp sends the request to a process called a print server or a printer daemon. The print server places the request in a queue and makes an identification number available to the user in case the user decides to cancel the print job. When a printer becomes free, the print server begins copying the file to the printer device. The file to be printed may not be copied to a temporary spool device unless the user explicitly specifies that it should be. Many implementations of lp try to create a hard link to the file while it is waiting to be printed, to prevent the file from being removed completely. It is not always possible for the lp command to link to the file, and the man page warns the user not to change the file until after it is printed.
Example 16.11.
The following UNIX lp command outputs the file myfile.ps to the printer designated as nps.
lp -d nps myfile.ps
The lp command might respond with a request number similar to the following.
Request nps-358 queued
Use the nps-358 in a cancel command to delete the print job.
Printers are slow devices relative to process execution times, and one print server process can handle many printers. Like the problem of handling input from multiple descriptors, the problems of print serving are natural for multithreading. Figure 16.3 shows a schematic organization of a threaded print server. The server uses a dedicated thread to read user requests from an input source. The request thread allocates space for the request and adds it to the request buffer.

The print server of Figure 16.3 has dedicated threads for handling its printers. Each printer thread removes a request from the request buffer and copies the file specified in the request to the printer. When the copying is complete, the printer thread frees the request and handles another request.
The threads within the print server require producer-consumer synchronization with a single producer (the request thread) and multiple consumers (the printer threads). The buffer itself must be protected so that items are removed and added in a consistent manner. The consumers must synchronize on the requests available in the buffer so that they do not attempt to remove nonexistent requests. The request buffer is not bounded because the request thread dynamically allocates space for requests as they come in. The request thread could also use a high-water mark to limit the number of requests that it buffers before blocking. In this more complicated situation, the request thread synchronizes on a predicate involving the size of the buffer.
Several aspects of the print server are simplified for this exercise. A real server may accept input from a network port or by remote procedure call. There is no requirement for printers to be identical, and realistic print requests allow a variety of options for users to specify how the printing is to be done. The system administrator can install default filters that act on files of particular types. The print server can analyze request types and direct requests to the best printer for the job. Printer requests may have priorities or other characteristics that affect the way in which they are printed. The individual printer threads should respond to error conditions and status reports from the printer device drivers.
This exercise describes the print server represented schematically in Figure 16.3. Keep pending requests in a request buffer. Synchronize the number of pending requests with a condition variable, called items, in a manner similar to the standard producer-consumer problem. This exercise does not require a condition variable for slots, since the request buffer can grow arbitrarily large. Represent print requests by a string consisting of an integer followed by a blank and a string specifying the full pathname of the file to be printed.
Represent the request buffer by a linked list of nodes of type prcmd_t. The following is a sample definition.
typedef struct pr_struct {
int owner;
char filename[PATH_MAX];
struct pr_struct *nextprcmd;
} prcmd_t;
static prcmd_t *prhead = NULL;
static prcmd_t *prtail = NULL;
static int pending = 0;
static pthread_mutex_t prmutex = PTHREAD_MUTEX_INITIALIZER;
Put the request buffer data structure in a separate file and access it only through the following functions.
int add(prcmd_t *node);
adds a node to the request buffer. The
addfunction incrementspendingand insertsnodeat the end of the request buffer. If successful,addreturns 0. If unsuccessful,addreturns –1 and setserrno.
int remove(prcmd_t **node);
removes a node from the request buffer. The
removefunction blocks if the buffer is empty. If the buffer is not empty, theremovefunction decrementspendingand removes the first node from the request buffer. It sets*nodeto point to the removed node. Ifremovesuccessfully removes a node, it returns 0. If unsuccessful,removereturns –1 and setserrno.
int getnumber(void);
returns the size of the request buffer, which is the value of
pending.
Use the synchronization strategy of Program 16.11, but eliminate the conditions for controlling the number of slots.
The producer thread, getrequests, inserts input requests in the buffer.
void *getrequests(void *arg);
The parameter arg points to an open file descriptor specifying the location where the requests are read. The getrequests function reads the user ID and the pathname of the file to be printed, creates a prcmd_t node to hold the information, and calls add to add the request to the printer request list. If getrequests fails to allocate space for prcmd_t or if it detects end-of-file, it returns after setting a global error flag. Otherwise, it continues to monitor the open file descriptor for the next request.
Write a main program to test getrequests. The main program creates the getrequests thread with STDIN_FILENO as the input file. It then goes into a loop in which it waits for pending to become nonzero. The main thread removes the next request from the buffer and writes the user ID and the filename to standard output. Run the program with input requests typed from the keyboard. Test the program with standard input redirected from a file.
Each consumer thread, printer, removes a request from the printer request buffer and “prints” it. The prototype for printer is the following.
void *printer(void *arg);
The parameter arg points to an open file descriptor to which printer outputs the file to be printed. The printer function waits for the counter pending to become nonzero in a manner similar to consumer in Program 16.13. When a request is available, remove the request from the buffer, open the file specified by the filename member for reading, and copy the contents of the file to the output file. Then close the input file, free the space occupied by the request node, and resume waiting for more requests. If a consumer thread encounters an error when reading the input file, write an appropriate error message, close the input file, and resume waiting for more requests. Since the output file plays the role of the printer in this exercise, an output file error corresponds to a printer failure. If printer encounters an error on output, close the output file, write an appropriate error message, set a global error flag, and return.
Write a new main program to implement the print server. The server supports a maximum of MAX_PRINT printers. (Five should suffice for testing.) The main program takes two command-line arguments: the output file basename and the number of printers. The input requests are taken from standard input, which may be redirected to take requests from a file. The output for each printer goes to a separate file whose filename starts with the output file basename. For example, if the basename is printer.out, the output files are printer.out.1, printer.out.2, and so on. The main program creates a thread to run get_requests and a printer thread for each printer to be supported. It then waits for all the threads to exit before exiting itself. The main program should not exit just because an error occurred in one of the printer threads. Thoroughly test the print server.
Add facilities so that each printer thread keeps track of statistics such as total number of files printed and total number of bytes printed. When the server receives a SIGUSR1 signal, it writes the statistics for all the printers to standard error.
Add facilities so that the input now includes a command as well as a user ID and filename. The commands are as follows.
| Add the request to the buffer and echo a request ID to standard output. |
| Remove the request from the buffer if it is there. |
| Write to standard output a summary of all pending requests and requests currently being printed on each printer. |
Modify the synchronization mechanism of the buffer to use highmark and lowmark to control the size of the request buffer. Once the number of requests reaches the highmark value, getrequests blocks until the size of the request buffer is less than lowmark.
Most classical books on operating systems discuss some variation of the producer-consumer problem. See, for example, [107, 122]. Unfortunately, in most classic treatments, producers and consumers loop forever, uninterrupted by signals or other complications that arise from a finite universe. “Experimentation with bounded buffer synchronization,” by S. Robbins [96] introduces some simple models for estimating how long it takes for an error to show in an incorrectly synchronized bounded buffer program. An online simulator is available for experimentation.