
8
Durable Functions
Azure Functions is a great service for developing a variety of different applications but lacks one key feature when building more complicated workloads – state management. To leverage things such as orchestrations, replays, and external events, you will need to use an advanced framework called Durable Functions. It is specifically designed to cover all those scenarios where Azure Functions may not be the best choice and excels in bringing stateful services into the Function-as-a-Service model. In this chapter, you will learn about the following things:
- What is Durable Functions?
- Working with orchestrations
- Timers, external events, and error handling
- Eternal and singleton orchestrations, stateful entities, and task hubs
- Advanced features – instance management, versioning, and high availability
Technical requirements
To perform the exercises in this chapter, you will need the following:
- Access to an Azure subscription
- Visual Studio Code installed (available at https://code.visualstudio.com/) with the Azure Functions extension
- The Azure CLI (https://docs.microsoft.com/en-us/cli/azure/)
What is Durable Functions?
In most cases, the best idea for working with Azure Functions is to keep them stateless. This makes things much easier as you do not have to worry about sharing resources and storing state. However, there are cases where you would like to access it and distribute it between different instances of your functions. In such scenarios (such as orchestrating a workflow or scheduling a task to be done), a better option to start with would be to leverage the capabilities of Durable Functions, an extension to the main runtime, which changes the way you work somewhat.
The Durable Functions framework changes the way Azure Functions works as it lets you resume from where the execution was paused or stopped and introduces the possibility to take the output of one function and pass it as input. To get started, you don't need any extra extensions—the only thing you will need is the very same extension in Visual Studio Code that you used for standard Azure Functions.
Note
Durable Functions is IDE-agnostic. This means that you can use them in any software environment, which supports running Azure Functions. However, as they present a different behavior and are a separate feature of the Azure Functions service, the overall experience in different IDEs besides Visual Studio and Visual Studio Code may be a little bit lacking.
In Visual Studio Code, a Durable Functions template can be selected when creating a new project or when adding a new function to an already existing project.

Figure 8.1 – Durable Functions template in Visual Studio Code
However, before acquiring some hands-on experience, let's briefly describe Durable Functions and its main elements.
Orchestrations and activities
The main elements of Durable Functions are orchestrations and activities. There are some significant differences between them:
- Orchestrations: These are designed to orchestrate different activities. They should be single-threaded and idempotent, and they can use only a very limited set of asynchronous methods. They are scaled based on the number of internal queues. What's more? They can also control the flow of one or more activities.
- Activities: These should contain most of the logic of your application. They work as typical functions (without the limits of orchestrations). They are scaled to multiple VMs.
Here, you can find the code for both types of functions:
[FunctionName("Orchestration")]
public static async Task Orchestration_Start([OrchestrationTrigger] DurableOrchestrationContext context)
{
var payload = context.GetInput<string>();
await context.CallActivityAsync(nameof(Activity), payload);
}
[FunctionName("Activity")]
public static string Activity([ActivityTrigger] DurableActivityContext context)
{
var payload = context.GetInput<string>();
return $"Current payload is {payload}!";
}As you can see, they are both decorated with the [FunctionName] attribute as a typical function—the difference comes from the trigger that's used.
Orchestration client
To get started with an orchestration, you need a host. In Durable Functions, that host is the orchestration client, which enables you to perform the following actions on an orchestration:
- Start it
- Terminate it
- Get its status
- Raise an event and pass it to an orchestration
The basic code for a client is shown as follows:
[FunctionName("Orchestration_Client")]
public static async Task<string> Orchestration_Client(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "start")] HttpRequestMessage input,
[OrchestrationClient] DurableOrchestrationClient starter)
{
return await starter.StartNewAsync("Orchestration", await input.Content.ReadAsStringAsync());
}As you can see from the preceding code, we started an orchestration by providing its name and passing some payload, which will be deserialized and decoded. Here, you can find an example of a client that has been hosted to terminate an instance by passing its identifier:
[FunctionName("Terminate")]
public static async Task Terminate(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "terminate/{id}")] HttpRequestMessage input,
string id,
[OrchestrationClient] DurableOrchestrationClient client) {
var reason = "Manual termination";
await client.TerminateAsync(id, reason);
}To terminate an instance, you just need its ID and a reason (which, of course, can be empty). Once the function is executed, your orchestration will shut down.
Orchestration history
The way Durable Functions works ensures that there is no duplicated work. In other words, if any activity is replayed, its result will not be evaluated again (hence, orchestrations must be idempotent). Here, you can find a diagram that shows how the framework works in detail:
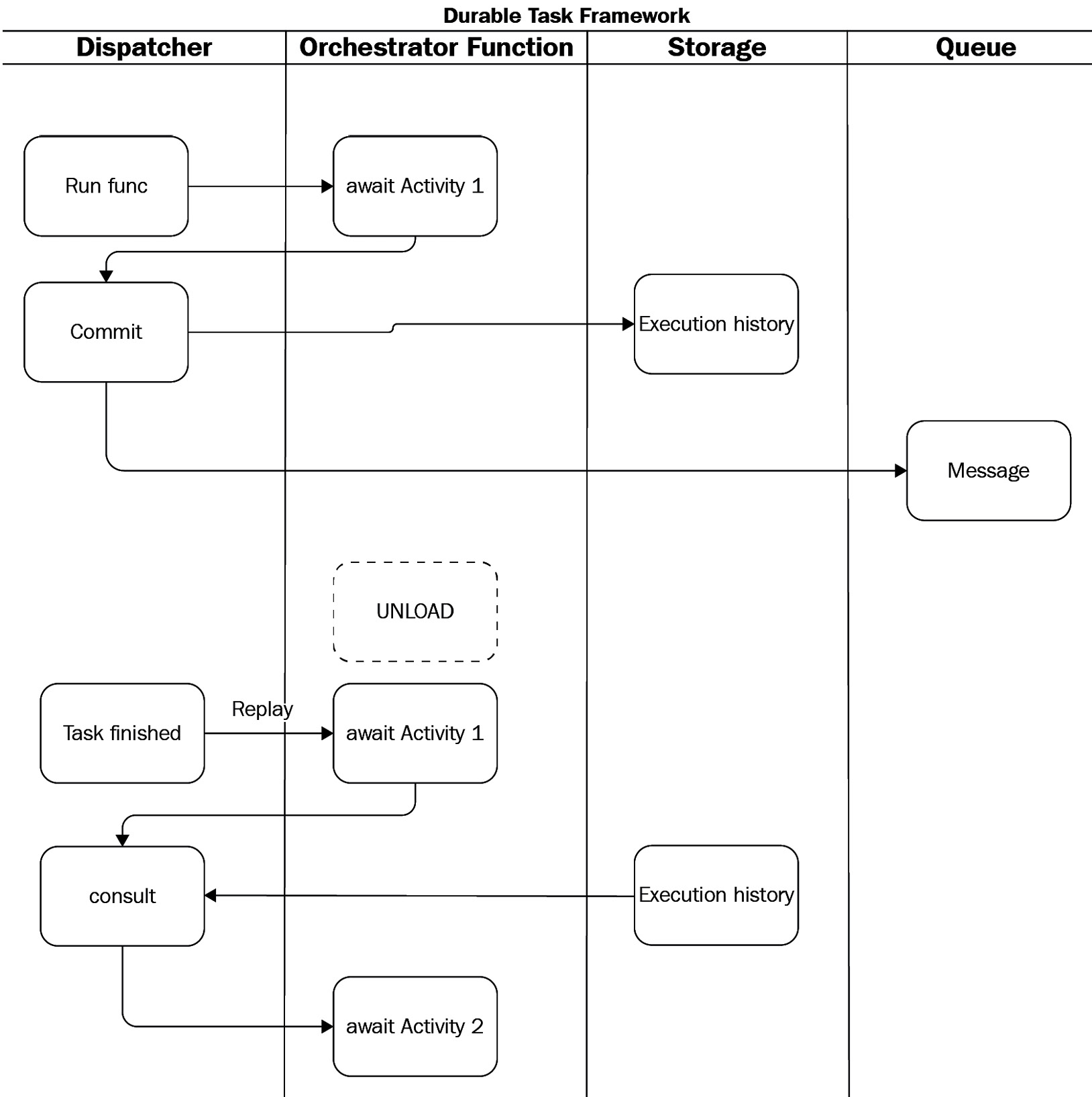
Figure 8.2 – Durable Task Framework under the hood
To cut a long story short, I have divided the process into four parts:
- Dispatcher: This is the internal part of the framework, which is responsible for calling orchestrations, performing replays, and saving the state.
- Orchestrator function: This is an orchestration that calls activities.
- Storage: This is the place where the orchestration history is stored.
- Queue: This is an internal queue (implemented using Azure Storage Queues), which is used to control the flow of execution of an orchestration.
The way Durable Functions works is explained as follows:
- Dispatchers run an orchestration, which calls Activity1 and awaits its result.
- The control is returned to a dispatcher, which commits the state in the orchestration history and pushes a message to a queue.
- In the meantime, orchestration is deallocated, saving memory and processor space.
- After fetching a message from a queue and finishing a task, the dispatcher recreates an orchestration and replays all activities.
- If it finds that this activity has been finished, it retrieves the result and proceeds to another activity.
The preceding process lasts until all the activities are processed. Information about execution history can be found in a table called DurableFunctionsHubHistory, which you can find inside the Azure Table storage used by your function app.
Let's now learn how we can work with orchestrations and how they can be used for more advanced scenarios.
Working with orchestrations
As described before, orchestrations are the main components of each workflow built with Durable Functions. It is important to remember that orchestrations are responsible for running the process and routing all the requests to appropriate places. In other words, when you implement your orchestration, it becomes the boundary of your process – Durable Functions takes care of creating checkpoints each time you await asynchronous methods.
What is more, remember that you may have several instances of the same orchestration running – in reality, it is only a matter of how long an orchestration takes to complete and how frequently it is run. For example, if your orchestration takes 8 hours to complete but is started every 4 hours, you will always have at least 2 instances of your orchestrations active. The reason I am stating this right now is simple – each orchestration has its own identity. You can treat it as an ID that is assigned to an instance of orchestration so that it can be identified.
Tip
Orchestration's identity can be either autogenerated or user-generated. There are pros and cons of both methods, but in most cases, you should go for autogenerated identities because they are easier to maintain and grant sufficient functionality for the majority of scenarios. If your process involves mapping between external processes and orchestrations in Durable Functions, you may find user-generated identities helpful.
It is important to understand the limits of orchestrations as currently described by the framework:
- Orchestrations cannot perform I/O operations (filesystem read, networking) – instead, you should delegate such operations to activities.
- Dates should be fetched via the Durable Functions API (such as accessing the CurrentUtcDateStamp property in your orchestration context) because standard libraries are nondeterministic.
- Random values and numbers should be generated by activities so that they are the same with each replay.
- Asynchronous operations are forbidden unless performed via the IDurableOrchestrationContext API.
- Environment variables shouldn't be used.
- Avoid infinite loops so that you will not run out of memory.
As you can see, these are strict requirements for running an orchestration. Personally, I believe that they can be simplified to a single rule – activities should perform all the work, while orchestrations should be used only for their control. To avoid performance or data integrity problems, avoid doing any custom logic in orchestration. Instead, delegate all the operations to activities, especially if you are unsure where that logic belongs.
Sub-orchestrations
When your process keeps getting bigger and bigger, it is difficult to manage it using a single orchestration. Fortunately, Durable Functions offers a feature called sub-orchestration, which looks exactly like this:
public static async Task ProcessReportOrchestration(
[OrchestrationTrigger] IDurableOrchestrationContext context)
{
var date = context.GetInput<string>();
Uri blobUrl = await context.CallActivityAsync<Uri>("SubmitPollingRequest", date);
await context.CallActivityAsync("DownloadReport", blobUrl));
}As you can see, it is just a normal orchestration. What is different in sub-orchestration is how they are called. To use the preceding orchestration as part of a bigger process, simply call it using the CallSubOrchestratorAsync function:
[FunctionName("ProcessCostReport")]
public static async Task ProvisionNewDevices(
[OrchestrationTrigger] ProcessCostReport context)
{
string[] dates = await context.CallActivityAsync<string[]>("Dates");
var reportingTasks = new List<Task>();
foreach (string date in dates)
{
Task reportingTask = context.CallSubOrchestratorAsync("ProcessReportOrchestration", date);
reportingTasks.Add(reportingTask);
}
await Task.WhenAll(reportingTasks);
}Without sub-orchestration, you would need to perform all the steps in sequence. When using that feature of Durable Functions, remember that sub-orchestrations must be defined in the same function app. Unfortunately, cross-function calls are not supported and for that kind of functionality, you would need to implement your own consumer pooling pattern (refer to the Further reading section for details).
Let's now learn about the additional features of Durable Functions that allow the implementation of timers, handling errors, and events.
Timers, external events, and error handling
As we have already mentioned, Durable Functions are implemented in a way that implies some specific patterns. In this section, we will discuss some proper ways of implementing common scenarios, starting with timers.
Timers
Sometimes, you might want to schedule work following a specific delay. While using traditional functions, you must create a custom solution that will somehow trigger a workflow at a specific time. In Durable Functions, it is as easy as writing one line of code. Consider the following example:
[FunctionName("Orchestration_Client")]
public static async Task<string> Orchestration_Client(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "start")] HttpRequestMessage input,
[OrchestrationClient] DurableOrchestrationClient starter)
{
return await starter.StartNewAsync("Orchestration", null);
}
[FunctionName("Orchestration")]
public static async Task Orchestration_Start([OrchestrationTrigger] DurableOrchestrationContext context, TraceWriter log)
{
log.Info($"Scheduled at {context.CurrentUtcDateTime}");
await context.CreateTimer(context.CurrentUtcDateTime.AddHours(1), CancellationToken.None);
await context.CallActivityAsync(nameof(Activity), context.CurrentUtcDateTime);
}
[FunctionName("Activity")]
public static void Activity([ActivityTrigger] DurableActivityContext context, TraceWriter log)
{
var date = context.GetInput<DateTime>();
log.Info($"Executed at {date}");
}In the preceding example, I used the context.CreateTimer() method, which allows for the creation of a delay in function execution. If the previous orchestration is executed, it will return control to the dispatcher after awaiting a timer. Thanks to this, you will not be charged for this function execution as it will be deallocated and recreated later, after waiting for a specific interval.
External events
In Durable Functions, it is possible to wait for an external event before proceeding with a workflow. This is especially helpful if you want to create an interactive flow, where you initiate a process in one place and have to wait for someone's decision (could be a process or a person) indefinitely. To raise an event, you can use the following function:
[FunctionName("Orchestration_Raise")]
public static async Task Orchestration_Raise(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "start_raise/{id}/{event}")] HttpRequestMessage input,
string id,
string @event,
[OrchestrationClient] DurableOrchestrationClient starter) {
await starter.RaiseEventAsync(id, @event, await input.Content.ReadAsStringAsync());
}
Here, you can find an example of waiting for an event:
[FunctionName("Orchestration")]
public static async Task<string> Orchestration_Start([OrchestrationTrigger] DurableOrchestrationContext context)
{
var @event = await context.WaitForExternalEvent<int>("Approved");
if (@event == 1)
{
var result = await context.CallActivityAsync<string>(nameof(Activity), @event);
return result;
}
return "Not Approved";
}The way this works can be described as follows: the first function allows you to raise a custom event by passing the appropriate parameters. The second function is paused while waiting for the context.WaitForExternalEvent() function. If you send an event with the Approved type, a function will be resumed and will continue. Additionally, you can pass a payload of an event, which will be passed as a result of WaitForExternalEvent(). This method works in the same way as timers and other Durable Functions, which are available in DurableOrchestrationType—while waiting, control is returned to the dispatcher and the function itself is deallocated.
Error handling
In Durable Functions, error handling is a straightforward feature, yet the whole behavior can be a little misleading initially. In general, remember, that each error that happens inside an activity function will be thrown as a FunctionFailedException error and should be handled inside an orchestration function. Consider the following example:
[FunctionName("MoneyTransfer")]
public static async Task Run([OrchestrationTrigger] IDurableOrchestrationContext context)
{
await context.CallActivityAsync("Subtract",
new
{
Account = "John Doe",
Amount = 1000
});
try
{
await context.CallActivityAsync("Add",
new
{
Account = "Jane Doe",
Amount = 1000
});
}
catch (Exception)
{
await context.CallActivityAsync("Add",
new
{
Account = "John Doe",
Amount = 1000
});
}
}This simple example presents you with the following logic:
- Subtract a value of 1000 from the first account.
- Add a value of 1000 to the second account.
- If something goes wrong, add a value of 1000 back to the first account.
The presents pattern can be called "compensation" – you are basically creating a special logic inside your code to reset the system's state in case anything goes wrong. In Durable Functions, the only thing worth remembering is handling such cases inside orchestrations – this allows us to use the basic framework components and ensure that the whole history is properly saved.
Note
You may be wondering – what if the activity inside the catch block also throws an exception. Well, if you believe this is feasible, you will need to implement a more sophisticated logic. Maybe multiple try/catch blocks? Maybe you should leverage a thing called a poison queue and let a human operator fix those errors case by case? It will depend on the characteristics of your system – the more complex the tasks you are performing, the more safeguards should be inside your code base.
An interesting feature of Durable Functions is the ability to call an activity with a retry using a native API function:
[FunctionName("TimerOrchestratorWithRetry")]
public static async Task Run([OrchestrationTrigger] IDurableOrchestrationContext context)
{
var retryOptions = new RetryOptions(
firstRetryInterval: TimeSpan.FromSeconds(5),
maxNumberOfAttempts: 10);
await context.CallActivityWithRetryAsync("ActivityWhichCanBeRetried", retryOptions, null);
}As you can see, you need to use the CallActivityWithRetryAsync function and then pass the RetryOptions object containing your retry logic. It is especially helpful in cloud environments, where many services can face transient errors and often are not available with the very first call. Using a retry ensures that your application logic can withstand such scenarios and will not break because of an error, which can be safely ignored.
With the common patterns covered, let's switch our focus to more advanced scenarios available when using Durable Functions.
Eternal and singleton orchestrations, stateful entities, and task hubs
Let's now focus on some more advanced features of Durable Functions. In this section, we will cover things such as infinite orchestrations, entity functions, and aggregating all the components into a single hub.
Eternal orchestrations
By default, in Durable Functions, each orchestration ends at some point. You can think about it as a line from point A to point B – between those points, you will have multiple activities, which can be called and replayed. Once you reach point B, the workflow ends, and you must start from the beginning.
To overcome that problem, you could probably implement an infinite loop. While the idea is correct, you need to take into consideration the history of your orchestration. If you leverage a loop inside your orchestration, the history will grow infinitely. As this is undesirable, eternal orchestrations were introduced to grant you the possibility to run an orchestration, which never ends.
Eternal orchestrations have one additional advantage, As they very often represent fire-and-forget scenarios, you do not need to implement a scheduler to keep the work going. You can simply start your orchestration and then focus on monitoring instead of scheduling. An example of eternal orchestration looks like this:
[FunctionName("Infinite_Loop")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context)
{
await context.CallActivityAsync("DoPeriodicTasks", null);
DateTime waitTime = context.CurrentUtcDateTime.AddHours(1);
await context.CreateTimer(waitTime, CancellationToken.None);
context.ContinueAsNew(null);
}The preceding example represents a simple orchestration, which performs a task, waits for an hour, and then starts again. There is no need for loops and custom code – it is up to Durable Functions to wait for the timer to fire and then start the process from the beginning.
Singleton orchestrations
I mentioned in this chapter that there are scenarios where multiple orchestrations can run in the same moment. In many cases, this will not be a problem, but you may face requirements that will force you to implement a singleton orchestration to have the process run correctly. Fortunately, Durable Functions offers a pattern that can fix that problem.
As you probably remember, orchestrations in Durable Functions have their IDs assigned. These IDs can be either autogenerated or user-generated. To implement a singleton orchestration, you need to leverage the latter – ask the Durable Functions API for the running orchestrations and search for the ID you assigned previously. The code for that functionality can look like this:
[FunctionName("HttpStartSingle")]
public static async Task<HttpResponseMessage> RunSingle(
[HttpTrigger(AuthorizationLevel.Function, methods: "post", HttpRequestMessage req,
[DurableClient] IDurableOrchestrationClient starter,
ILogger log)
{
var existingInstance = await starter.GetStatusAsync(instanceId);
}Here, we are using the GetStatusAsync() method to fetch the status of an orchestration having the given ID. There are multiple ways to obtain the ID of an orchestration:
- It can be passed via a URL if your function is triggered via HTTP requests.
- It can be fetched from a database.
- It can be generated based on the set of coded parameters.
Once the status is downloaded, you can use a simple if/else statement to implement your logic:
if (existingInstance == null
|| existingInstance.RuntimeStatus == OrchestrationRuntimeStatus.Completed
|| existingInstance.RuntimeStatus == OrchestrationRuntimeStatus.Failed
|| existingInstance.RuntimeStatus == OrchestrationRuntimeStatus.Terminated)
{
// Start new
}
else
{
// Orchestration already exists
}Simply put, we are checking whether orchestration has been completed – if not, we are assuming that it is active and skip the creation of a new one.
Stateful entities
As opposite to standard orchestrator functions, which manage state implicitly (via control flow), Durable Functions offer an alternative approach called entity functions. They leverage a special kind of trigger called an entity trigger, which looks like this:
[FunctionName("Counter")]
public static void Counter([EntityTrigger] IDurableEntityContext ctx)
{
// Function code
}The difference between orchestrator and entity functions is the way in which a state is managed – for entity functions, you manage your state explicitly by using the SetState() function. The state we are referring to is set for an object, which is called a durable entity. Each durable entity has some important traits worth mentioning:
- Each entity has its own ID, which can be used to find it.
- Entities can be unloaded from memory if not used.
- Each entity is lazily created when needed.
- When operations are performed on an entity, they are called serially.
The operation of setting the state for an entity looks like this:
ctx.SetState(<state value>);
You can also use the IDurableEntityClient.SignalEntityAsync() method for communication from a client (function) to an entity, or IDurableOrchestrationContext.SignalEntity() for one-way communication from an orchestration. You can find more information in the Further reading section.
Task hubs
A task hub is a logical container used by your orchestrations and activities. Technically, hub implementation relies on your storage provider – if you are using storage accounts, the task hub structure will be different from the one for MSSQL. However, the concept of a hub is always the same – if your function apps share the same storage account, they need to be configured with separate task hubs. The name of your hub can be configured inside the host.json file:
{
"version": "2.0",
"extensions": {
"durableTask": {
"hubName": "MyTaskHub"
}
}
}The reason why you need separate task hubs for each function app is related to how Durable Functions are managed under the hood. To cut a long story short, if you fail to give your apps different task hubs, your orchestration may end up corrupted because different functions will try to access the same resources. This may cause distractions in your application or even lead to incorrect results.
As we have discussed most of the low-level functionalities, let's now check how you can work with Durable Functions on an architecture level.
Advanced features – instance management, versioning, and high availability
Besides the purely technical stuff, such as different kinds of orchestrations, handling infinite loops, and managing state, Durable Functions offer a bunch of high-level capabilities that can help you manage your services according to more advanced business requirements. In the final section of this chapter, we will cover some additional topics that you may find interesting, such as managing different instances of orchestrations, versioning your orchestrations, and achieving high availability.
Instance management
We talked about unique IDs in this chapter, which are assigned to each instance of your orchestration. Those IDs can be used for various functionalities, including singleton orchestrations, monitoring, and inter-orchestration communication. Additionally, Durable Functions offer a dedicated API, which can be used to manage different instances of orchestration functions. This API is accessible via the IDurableOrchestrationClient object, which is available in your trigger function:
[FunctionName("HelloWorldQueueTrigger")]
public static async Task Run(
[QueueTrigger("queue")] string input,
[DurableClient] IDurableOrchestrationClient starter,
ILogger log)
{
}Now, when we have access to the object, we can perform many different operations by accessing its methods. For example, if you would like to start an orchestration, you simply need to call the StartNewAsync() method like this:
string instanceId = await starter.StartNewAsync("HelloWorld", input);The preceding method will start a new instance of "HelloWorld" orchestration and return its instanceId string, which can be used for further management. Optionally, you could specify your own ID for an instance – in that scenario, you would receive the same instanceId string as the one you set.
When talking about singleton orchestrations, we discovered that there is a method called GetStatusAsync(), which allows us to fetch an orchestration status. Let's recall its syntax:
DurableOrchestrationStatus status = await client.GetStatusAsync(instanceId);
All we need is to use the previously obtained instanceId string of our orchestration – once we have the status returned, we can perform additional actions based on the value:
- Let the process continue and check the status later.
- Terminate the orchestration if it takes too long to complete.
- Notify operators regarding the current state of an orchestration.
Additionally, if you wish to just load all the instances and query on your own, you can simply use the ListInstancesAsync() method to get them and iterate through the returned collection.
Tip
Listing all the instances of orchestrations can be achieved with or without a filter. To introduce a filter, use the OrchestrationStatusQueryCondition class and pass it as the first parameter of the ListInstancesAsync() method.
In Durable Functions, orchestration can also be terminated. Termination is achieved via TerminateAsync() like this:
client.TerminateAsync(instanceId, reason);
As you can see, to terminate an orchestration, you will need both its ID and a reason, which will be saved to the orchestration history. A reason can be by any string you wish – it is only important to pass a self-explanatory value in case you ever had to come back to the orchestration.
To check even more functionalities related to instance management, check the Further reading section. Durable Functions documentation presents additional scenarios that you may find helpful, such as sending an event to an instance of orchestration, purging history, or even deleting a task hub. In the meantime, let's check how we can implement versioning for the orchestrations to prevent problems when updating our system.
Versioning
The idea of versioning is important in many computer systems and its proper implementation is often a prerequisite to building a well-maintained system. In Durable Functions, this concept is also present – when developing orchestrations, sooner or later you will face a need to change something while preserving backward compatibility (at least for some time).
You may wonder why you need to preserve compatibility. Well, let's consider the following scenario – you have a working process, which is constantly scheduled with new instances. At the same moment, you need to introduce new functionality or a new element, which affects how your orchestrations handle part of the results. To help us visualize the scenario, let's use the following code snippet:
int result = await context.CallActivityAsync<int>("Foo");Our orchestration can call the "Foo" activity at any moment and, if it is currently running, it will expect an integer value as the result.
Note
Remember that orchestrations call activities by using their name – this is a dynamic dependency, and it cannot be guaranteed at compilation time.
Now, let's assume we are introducing the following change – the "Foo" activity will start returning a Boolean value instead:
bool result = await context.CallActivityAsync<bool>("Foo");If we have running orchestrations at this moment, they will probably fail as they will expect an integer instead of a true/false value (remember that even though the code base changed, an orchestration that is already active will use the old one until unloaded). The same problematic scenario can arise if you change the logic inside your orchestration or reorder activities inside it. As orchestrations can be resumed and replayed, changing the order of activities can render an orchestration inconsistent. In that scenario, Durable Functions will report a NonDeterministicOrchestrationException error and the whole workflow will stop.
To avoid that kind of error, some strategy for versioning must be implemented. While it is possible to just do nothing (and to be honest, this is a viable strategy for all those cases where you see no value in implementing more sophisticated approaches for your functions), in general, it is not advised as it can even lower the performance of your functions. Instead, you can leverage two alternative approaches:
- Wait for all the orchestrations to stop.
- Deploy new code as separate orchestrations/activities.
Both strategies have their pros and cons, but ultimately lead to a much better experience than the "do nothing" strategy. The first one can be implemented with proper instance management – you need to pause the creation of new orchestrations and wait until existing instances are finished. Then you can restart the process (for example, using an external event).
Deploying a separate code is straightforward – you just copy some part of your code base as a new orchestration and introduce changes there. This approach can quickly allow you to run your orchestrations, but if applied incorrectly, can lead to increasing your technical debt.
High availability
As with all cloud services, at some point, you will consider increasing the availability of your systems and making sure they can withstand possible errors and outages. By default, Durable Functions uses Storage Account as its storage mechanism and relies on that service when replication is considered. In general, there are three main scenarios for availability when using Durable Functions:
- Shared storage
- Individual storage
- Replicated storage
When using the shared storage approach, you deploy two function apps in two regions, but the storage behind them is deployed only to the single region:

Figure 8.3 – Shared architecture
This approach will allow you to run your functions in an active-passive model, but still, the single point of failure will be the storage account used for your functions. This model, however, will help you in running all the orchestrations, even if the main region fails. An alternative approach to that is deploying a storage individually:

Figure 8.4 – Architecture with individual storage accounts
The difference here is mostly related to the individual storage accounts, which are deployed for each function app. While this will defend you against regional errors, the downside of this approach is being unable to replay all the orchestrations, which are stuck in the region where an outage occurs. In that scenario, you will have to wait until the main region works again. An alternative is to use a storage solution with Geo-redundant storage (GRS)

Figure 8.5 – GRS replication
This approach will allow you to combine two previously described patterns. Here you are using the native approach for data replication and if an outage occurs, you are enabling failover in the main region to start running your process from the secondary region. The main downside to this solution is waiting for the failover process to complete.
Those three ideas for high availability should help you in discovering even more ways to implement replication for your Durable Functions. Remember that those concepts may need additional components if, for example, your functions are triggered by an HTTP request. If that is the case, you will need to add a load-balancing component to distribute the traffic properly.
That is all as regards the topic of Durable Functions for this book. I hope you liked it and remember that the Further reading section offers some additional information about different aspects of working with those functions.
Summary
In this chapter, you learned about Durable Functions, including implementing your own workflows and using both basic and advanced features. This knowledge should help you when designing and developing your own solutions based on serverless/Function-as-a-Service components.
In the next chapter, you will learn about Azure Logic Apps, which offers similar functionality to Durable Functions but with a different audience and way of development.
Questions
- How can you achieve singleton orchestrations in Durable Functions?
- What is the difference between an orchestrator function and an entity function?
- Can you set a custom ID for an orchestration instance?
- Can you use a custom storage provider for Durable Functions?
- Can you use infinite loops in Durable Functions?
- What are the differences between orchestrations and activities?
Further reading
- HTTP features – consumer pooling: https://docs.microsoft.com/en-us/azure/azure-functions/durable/durable-functions-http-features?tabs=csharp
- Entity functions: https://docs.microsoft.com/en-us/azure/azure-functions/durable/durable-functions-entities?tabs=csharp
- Instance management: https://docs.microsoft.com/en-us/azure/azure-functions/durable/durable-functions-instance-management?tabs=csharp
- Durable Functions repository: https://github.com/Azure/azure-functions-durable-extension
- Azure Functions code examples: https://docs.microsoft.com/en-us/samples/browse/?products=azure-functions