
![]()
Chapter 11
Basics of Markov chain simulation
![]()
Many clever methods have been devised for constructing and sampling from arbitrary posterior distributions. Markov chain simulation (also called Markov chain Monte Carlo, or MCMC) is a general method based on drawing values of θ from approximate distributions and then correcting those draws to better approximate the target posterior distribution, p(θ![]() y). The sampling is done sequentially with the distribution of the sampled draws depending on the last value drawn; hence, the draws form a Markov chain. (As defined in probability theory, a Markov chain is a sequence of random variables θ1, θ2, …, for which, for any t, the distribution of θt given all previous θ’s depends only on the most recent value, θt-1.) The key to the method’s success, however, is not the Markov property but rather that the approximate distributions are improved at each step in the simulation, in the sense of converging to the target distribution. As we shall see in Section 11.2, the Markov property is helpful in proving this convergence.
y). The sampling is done sequentially with the distribution of the sampled draws depending on the last value drawn; hence, the draws form a Markov chain. (As defined in probability theory, a Markov chain is a sequence of random variables θ1, θ2, …, for which, for any t, the distribution of θt given all previous θ’s depends only on the most recent value, θt-1.) The key to the method’s success, however, is not the Markov property but rather that the approximate distributions are improved at each step in the simulation, in the sense of converging to the target distribution. As we shall see in Section 11.2, the Markov property is helpful in proving this convergence.
Figure 11.1 illustrates a simple example of a Markov chain simulation—in this case, a Metropolis algorithm (see Section 11.2) in which θ is a vector with only two components, with a bivariate unit normal posterior distribution, θ ~ N(0, I). First consider Figure 11.1a, which portrays the early stages of the simulation. The space of the figure represents the range of possible values of the multivariate parameter, θ, and each of the five jagged lines represents the early path of a random walk starting near the center or the extremes of the target distribution and jumping through the distribution according to an appropriate sequence of random iterations. Figure 11.1b represents the mature stage of the same Markov chain simulation, in which the simulated random walks have each traced a path throughout the space of θ, with a common stationary distribution that is equal to the target distribution. We can then perform inferences about θ using points from the second halves of the Markov chains we have simulated, as displayed in Figure 11.1c.
In our applications of Markov chain simulation, we create several independent sequences; each sequence, θ1, θ2, θ3, …, is produced by starting at some point θ0 and then, for each t, drawing θt from a transition distribution, Tt(θt![]() θt-1) that depends on the previous draw, θt-1. As we shall see in the discussion of combining the Gibbs sampler and Metropolis sampling in Section 11.3, it is often convenient to allow the transition distribution to depend on the iteration number t; hence the notation Tt. The transition probability distributions must be constructed so that the Markov chain converges to a unique stationary distribution that is the posterior distribution, p(θ
θt-1) that depends on the previous draw, θt-1. As we shall see in the discussion of combining the Gibbs sampler and Metropolis sampling in Section 11.3, it is often convenient to allow the transition distribution to depend on the iteration number t; hence the notation Tt. The transition probability distributions must be constructed so that the Markov chain converges to a unique stationary distribution that is the posterior distribution, p(θ![]() y).
y).
Markov chain simulation is used when it is not possible (or not computationally efficient) to sample θ directly from p(θ![]() y); instead we sample iteratively in such a way that at each step of the process we expect to draw from a distribution that becomes closer to p(θ
y); instead we sample iteratively in such a way that at each step of the process we expect to draw from a distribution that becomes closer to p(θ![]() y). For a wide class of problems (including posterior distributions for many hierarchical models), this appears to be the easiest way to get reliable results. In addition, Markov chain and other iterative simulation methods have many applications outside Bayesian statistics, such as optimization, that we do not discuss here.
y). For a wide class of problems (including posterior distributions for many hierarchical models), this appears to be the easiest way to get reliable results. In addition, Markov chain and other iterative simulation methods have many applications outside Bayesian statistics, such as optimization, that we do not discuss here.
The key to Markov chain simulation is to create a Markov process whose stationary distribution is the specified p(θ![]() y) and to run the simulation long enough that the distribution of the current draws is close enough to this stationary distribution. For any specific p(θ
y) and to run the simulation long enough that the distribution of the current draws is close enough to this stationary distribution. For any specific p(θ![]() y), or unnormalized density q(θ
y), or unnormalized density q(θ![]() y), a variety of Markov chains with the desired property can be constructed, as we demonstrate in Sections 11.1–11.3.
y), a variety of Markov chains with the desired property can be constructed, as we demonstrate in Sections 11.1–11.3.

Figure 11.1 Five independent sequences of a Markov chain simulation for the bivariate unit normal distribution, with overdispersed starting points indicated by solid squares. (a) After 50 iterations, the sequences are still far from convergence. (b) After 1000 iterations, the sequences are nearer to convergence. Figure (c) shows the iterates from the second halves of the sequences; these represent a set of (correlated) draws from the target distribution. The points in Figure (c) have been jittered so that steps in which the random walks stood still are not hidden. The simulation is a Metropolis algorithm described in the example on page 278, with a jumping rule that has purposely been chosen to be inefficient so that the chains will move slowly and their random-walk-like aspect will be apparent.
Once the simulation algorithm has been implemented and the simulations drawn, it is absolutely necessary to check the convergence of the simulated sequences; for example, the simulations of Figure 11.1a are far from convergence and are not close to the target distribution. We discuss how to check convergence in Section 11.4, and in Section 11.5 we construct an expression for the effective number of simulation draws for a correlated sample. If convergence is painfully slow, the algorithm should be altered, as discussed in the next chapter.
This chapter introduces the basic Markov chain simulation methods—the Gibbs sampler and the Metropolis-Hastings algorithm—in the context of our general computing approach based on successive approximation. We sketch a proof of the convergence of Markov chain simulation algorithms and present a method for monitoring the convergence in practice. We illustrate these methods in Section 11.6 for a hierarchical normal model. For most of this chapter we consider simple and familiar (even trivial) examples in order to focus on the principles of iterative simulation methods as they are used for posterior simulation. Many examples of these methods appear in the recent statistical literature and also in the later parts this book. Appendix C shows the details of implementation in the computer languages R and Stan for the educational testing example from Chapter 5.
11.1 Gibbs sampler
A particular Markov chain algorithm that has been found useful in many multidimensional problems is the Gibbs sampler, also called alternating conditional sampling, which is defined in terms of subvectors of θ. Suppose the parameter vector θ has been divided into d components or subvectors, θ = (θ1, …, θd). Each iteration of the Gibbs sampler cycles through the subvectors of θ, drawing each subset conditional on the value of all the others. There are thus d steps in iteration t. At each iteration t, an ordering of the d subvectors of θ is chosen and, in turn, each θjt is sampled from the conditional distribution given all the other components of θ:

Figure 11.2 Four independent sequences of the Gibbs sampler for a bivariate normal distribution with correlation ρ = 0.8, with overdispersed starting points indicated by solid squares. (a) First 10 iterations, showing the componentwise updating of the Gibbs iterations. (b) After 500 iterations, the sequences have reached approximate convergence. Figure (c) shows the points from the second halves of the sequences, representing a set of correlated draws from the target distribution.
![]()
where θ-jt-1 represents all the components of θ, except for θj, at their current values:
![]()
Thus, each subvector θj is updated conditional on the latest values of the other components of θ, which are the iteration t values for the components already updated and the iteration t - 1 values for the others.
For many problems involving standard statistical models, it is possible to sample directly from most or all of the conditional posterior distributions of the parameters. We typically construct models using a sequence of conditional probability distributions, as in the hierarchical models of Chapter 5. It is often the case that the conditional distributions in such models are conjugate distributions that provide for easy simulation. We present an example for the hierarchical normal model at the end of this chapter and another detailed example for a normal-mixture model in Section 22.2. Here, we illustrate the workings of the Gibbs sampler with a simple example.
Example. Bivariate normal distribution
Consider a single observation (y1, y2) from a bivariate normally distributed population with unknown mean θ = (θ1, θ2) and known covariance matrix (![]() ). With a uniform prior distribution on θ, the posterior distribution is
). With a uniform prior distribution on θ, the posterior distribution is
![]()
Although it is simple to draw directly from the joint posterior distribution of (θ1, θ2), for the purpose of exposition we demonstrate the Gibbs sampler here. We need the conditional posterior distributions, which, from the properties of the multivariate normal distribution (either equation (A.1) or (A.2) on page 580), are
![]()
The Gibbs sampler proceeds by alternately sampling from these two normal distributions. In general, we would say that a natural way to start the iterations would be with random draws from a normal approximation to the posterior distribution; such draws would eliminate the need for iterative simulation in this trivial example. Figure 11.2 illustrates for the case ρ = 0.8, data (y1, y2) = (0, 0), and four independent sequences started at (θ2.5, θ2.5).
11.2 Metropolis and Metropolis-Hastings algorithms
The Metropolis-Hastings algorithm is a general term for a family of Markov chain simulation methods that are useful for sampling from Bayesian posterior distributions. We have already seen the Gibbs sampler in the previous section; it can be viewed as a special case of Metropolis-Hastings (as described in Section 11.3). Here we present the basic Metropolis algorithm and its generalization to the Metropolis-Hastings algorithm.
The Metropolis algorithm
The Metropolis algorithm is an adaptation of a random walk with an acceptance/rejection rule to converge to the specified target distribution. The algorithm proceeds as follows.
1. Draw a starting point θ0, for which p(θ0![]() y) > 0, from a starting distribution p0(θ). The starting distribution might, for example, be based on an approximation as described in Section 13.3. Or we may simply choose starting values dispersed around a crude approximate estimate of the sort discussed in Chapter 10.
y) > 0, from a starting distribution p0(θ). The starting distribution might, for example, be based on an approximation as described in Section 13.3. Or we may simply choose starting values dispersed around a crude approximate estimate of the sort discussed in Chapter 10.
2. For t = 1, 2, …:
(a) Sample a proposal θ* from a jumping distribution (or proposal distribution) at time ![]() . For the Metropolis algorithm (but not the Metropolis-Hastings algorithm, as discussed later in this section), the jumping distribution must be symmetric, satisfying the condition
. For the Metropolis algorithm (but not the Metropolis-Hastings algorithm, as discussed later in this section), the jumping distribution must be symmetric, satisfying the condition ![]() , and t.
, and t.
(b) Calculate the ratio of the densities,
![]()
(c) Set
![]()
Given the current value θt-1, the transition distribution Tt(θt![]() θt-1) of the Markov chain is thus a mixture of a point mass at θt = θt-1, and a weighted version of the jumping distribution, Jt(θt
θt-1) of the Markov chain is thus a mixture of a point mass at θt = θt-1, and a weighted version of the jumping distribution, Jt(θt![]() θt-1), that adjusts for the acceptance rate.
θt-1), that adjusts for the acceptance rate.
The algorithm requires the ability to calculate the ratio r in (11.1) for all (θ, θ*), and to draw θ from the jumping distribution Jt(θ*![]() θ) for all θ and t. In addition, step (c) above requires the generation of a uniform random number.
θ) for all θ and t. In addition, step (c) above requires the generation of a uniform random number.
When θt = θt-1—that is, if the jump is not accepted—this still counts as an iteration in the algorithm.
Example. Bivariate unit normal density with normal jumping kernel
For simplicity, we illustrate the Metropolis algorithm with the simple example of the bivariate unit normal distribution. The target density is the bivariate unit normal, ![]() , where I is the 2 × 2 identity matrix. The jumping distribution is also bivariate normal, centered at the current iteration and scaled to 1/5 the size:
, where I is the 2 × 2 identity matrix. The jumping distribution is also bivariate normal, centered at the current iteration and scaled to 1/5 the size: ![]() . At each step, it is easy to calculate the density ratio
. At each step, it is easy to calculate the density ratio ![]() , I). It is clear from the form of the normal distribution that the jumping rule is symmetric. Figure 11.1 on page 276 displays five simulation runs starting from different points. We have purposely set the scale of this jumping algorithm to be too small, relative to the target distribution, so that the algorithm will run inefficiently and its random-walk aspect will be obvious in the figure. In Section 12.2 we discuss how to set the jumping scale to optimize the efficiency of the Metropolis algorithm.
, I). It is clear from the form of the normal distribution that the jumping rule is symmetric. Figure 11.1 on page 276 displays five simulation runs starting from different points. We have purposely set the scale of this jumping algorithm to be too small, relative to the target distribution, so that the algorithm will run inefficiently and its random-walk aspect will be obvious in the figure. In Section 12.2 we discuss how to set the jumping scale to optimize the efficiency of the Metropolis algorithm.
Relation to optimization
The acceptance/rejection rule of the Metropolis algorithm can be stated as follows: (a) if the jump increases the posterior density, set θt = θ*; (b) if the jump decreases the posterior density, set ![]() with probability equal to the density ratio, r, and set θt = θt-1 otherwise. The Metropolis algorithm can thus be viewed as a stochastic version of a stepwise mode-finding algorithm, always accepting steps that increase the density but only sometimes accepting downward steps.
with probability equal to the density ratio, r, and set θt = θt-1 otherwise. The Metropolis algorithm can thus be viewed as a stochastic version of a stepwise mode-finding algorithm, always accepting steps that increase the density but only sometimes accepting downward steps.
Why does the Metropolis algorithm work?
The proof that the sequence of iterations θ1, θ2, … converges to the target distribution has two steps: first, it is shown that the simulated sequence is a Markov chain with a unique stationary distribution, and second, it is shown that the stationary distribution equals this target distribution. The first step of the proof holds if the Markov chain is irreducible, aperiodic, and not transient. Except for trivial exceptions, the latter two conditions hold for a random walk on any proper distribution, and irreducibility holds as long as the random walk has a positive probability of eventually reaching any state from any other state; that is, the jumping distributions Jt must eventually be able to jump to all states with positive probability.
To see that the target distribution is the stationary distribution of the Markov chain generated by the Metropolis algorithm, consider starting the algorithm at time t - 1 with a draw θt-1 from the target distribution p(θ![]() y). Now consider any two such points θa and θb, drawn from p(θ
y). Now consider any two such points θa and θb, drawn from p(θ![]() y) and labeled so that
y) and labeled so that ![]() . The unconditional probability density of a transition from
. The unconditional probability density of a transition from ![]() is
is
![]()
where the acceptance probability is 1 because of our labeling of a and b, and the unconditional probability density of a transition from θb to θa is, from (11.1),

which is the same as the probability of a transition from θa to θb, since we have required that Jt(·![]() ·) be symmetric. Since their joint distribution is symmetric, θt and θt-1 have the same marginal distributions, and so p(θ
·) be symmetric. Since their joint distribution is symmetric, θt and θt-1 have the same marginal distributions, and so p(θ![]() y) is the stationary distribution of the Markov chain of θ. For more detailed theoretical concerns, see the bibliographic note at the end of this chapter.
y) is the stationary distribution of the Markov chain of θ. For more detailed theoretical concerns, see the bibliographic note at the end of this chapter.
The Metropolis-Hastings algorithm
The Metropolis-Hastings algorithm generalizes the basic Metropolis algorithm presented above in two ways. First, the jumping rules Jt need no longer be symmetric; that is, there is no requirement that ![]() . Second, to correct for the asymmetry in the jumping rule, the ratio r in (11.1) is replaced by a ratio of ratios:
. Second, to correct for the asymmetry in the jumping rule, the ratio r in (11.1) is replaced by a ratio of ratios:
![]()
(The ratio r is always defined, because a jump from θt-1 to θ* can only occur if both ![]() are nonzero.)
are nonzero.)
Allowing asymmetric jumping rules can be useful in increasing the speed of the random walk. Convergence to the target distribution is proved in the same way as for the Metropolis algorithm. The proof of convergence to a unique stationary distribution is identical. To prove that the stationary distribution is the target distribution, p(θ![]() y), consider any two points θa and θb with posterior densities labeled so that
y), consider any two points θa and θb with posterior densities labeled so that ![]() . If θt-1 follows the target distribution, then it is easy to show that the unconditional probability density of a transition from θa to θb is the same as the reverse transition.
. If θt-1 follows the target distribution, then it is easy to show that the unconditional probability density of a transition from θa to θb is the same as the reverse transition.
Relation between the jumping rule and efficiency of simulations
The ideal Metropolis-Hastings jumping rule is simply to sample the proposal, θ*, from the target distribution; that is, J(θ*![]() θ) ≡ p(θ*
θ) ≡ p(θ*![]() y) for all θ. Then the ratio r in (11.2) is always exactly 1, and the iterates θt are a sequence of independent draws from p(θ
y) for all θ. Then the ratio r in (11.2) is always exactly 1, and the iterates θt are a sequence of independent draws from p(θ![]() y). In general, however, iterative simulation is applied to problems for which direct sampling is not possible.
y). In general, however, iterative simulation is applied to problems for which direct sampling is not possible.
A good jumping distribution has the following properties:
• For any θ, it is easy to sample from J(θ*![]() θ).
θ).
• It is easy to compute the ratio r.
• Each jump goes a reasonable distance in the parameter space (otherwise the random walk moves too slowly).
• The jumps are not rejected too frequently (otherwise the random walk wastes too much time standing still).
We return to the topic of constructing efficient simulation algorithms in the next chapter.
11.3 Using Gibbs and Metropolis as building blocks
The Gibbs sampler and the Metropolis algorithm can be used in various combinations to sample from complicated distributions. The Gibbs sampler is the simplest of the Markov chain simulation algorithms, and it is our first choice for conditionally conjugate models, where we can directly sample from each conditional posterior distribution. For example, we could use the Gibbs sampler for the normal-normal hierarchical models in Chapter 5.
The Metropolis algorithm can be used for models that are not conditionally conjugate, for example, the two-parameter logistic regression for the bioassay experiment in Section 3.7. In this example, the Metropolis algorithm could be performed in vector form—jumping in the two-dimensional space of (α, β)—or embedded within a Gibbs sampler structure, by alternately updating α and β using one-dimensional Metropolis jumps. In either case, the Metropolis algorithm will probably have to be tuned to get a good acceptance rate, as discussed in Section 12.2.
If some of the conditional posterior distributions in a model can be sampled from directly and some cannot, then the parameters can be updated one at a time, with the Gibbs sampler used where possible and one-dimensional Metropolis updating used otherwise. More generally, the parameters can be updated in blocks, where each block is altered using the Gibbs sampler or a Metropolis jump of the parameters within the block.
A general problem with conditional sampling algorithms is that they can be slow when parameters are highly correlated in the target distribution (for example, see Figure 11.2 on page 277). This can be fixed in simple problems using reparameterization (see Section 12.1) or more generally using the more advanced algorithms mentioned in Chapter 12.
Interpretation of the Gibbs sampler as a special case of the Metropolis-Hastings algorithm
Gibbs sampling can be viewed as a special case of the Metropolis-Hastings algorithm in the following way. We first define iteration t to consist of a series of d steps, with step j of iteration t corresponding to an update of the subvector θj conditional on all the other elements of θ. Then the jumping distribution, Jj,t(·![]() ·), at step j of iteration t only jumps along the jth subvector, and does so with the conditional posterior density of θj given
·), at step j of iteration t only jumps along the jth subvector, and does so with the conditional posterior density of θj given ![]() :
:
![]()
The only possible jumps are to parameter vectors θ* that match θt-1 on all components other than the jth. Under this jumping distribution, the ratio (11.2) at the jth step of iteration t is and thus every jump is accepted. The second line above follows from the first because, under this jumping rule, θ* differs from θt-1 only in the jth component. The third line follows from the second by applying the rules of conditional probability to θ = (θj, θ-j) and noting that θ-j* = θ-jt-1.

Usually, one iteration of the Gibbs sampler is defined as we do, to include all d steps corresponding to the d components of θ, thereby updating all of θ at each iteration. It is possible, however, to define Gibbs sampling without the restriction that each component be updated in each iteration, as long as each component is updated periodically.
Gibbs sampler with approximations
For some problems, sampling from some, or all, of the conditional distributions p(θj![]() θ-j, y) is impossible, but one can construct approximations, which we label g(θj
θ-j, y) is impossible, but one can construct approximations, which we label g(θj![]() θ-j), from which sampling is possible. The general form of the Metropolis-Hastings algorithm can be used to compensate for the approximation. As in the Gibbs sampler, we choose an order for altering the d elements of θ; the jumping function at the jth Metropolis step at iteration t is then
θ-j), from which sampling is possible. The general form of the Metropolis-Hastings algorithm can be used to compensate for the approximation. As in the Gibbs sampler, we choose an order for altering the d elements of θ; the jumping function at the jth Metropolis step at iteration t is then
![]()
and the ratio r in (11.2) must be computed and the acceptance or rejection of θ* decided.
11.4 Inference and assessing convergence
The basic method of inference from iterative simulation is the same as for Bayesian simulation in general: use the collection of all the simulated draws from p(θ![]() y) to summarize the posterior density and to compute quantiles, moments, and other summaries of interest as needed. Posterior predictive simulations of unobserved outcomes
y) to summarize the posterior density and to compute quantiles, moments, and other summaries of interest as needed. Posterior predictive simulations of unobserved outcomes ![]() can be obtained by simulation conditional on the drawn values of θ. Inference using the iterative simulation draws requires some care, however, as we discuss in this section.
can be obtained by simulation conditional on the drawn values of θ. Inference using the iterative simulation draws requires some care, however, as we discuss in this section.
Difficulties of inference from iterative simulation
Iterative simulation adds two challenges to simulation inference. First, if the iterations have not proceeded long enough, as in Figure 11.1a, the simulations may be grossly unrepresentative of the target distribution. Even when simulations have reached approximate convergence, early iterations still reflect the starting approximation rather than the target distribution; for example, consider the early iterations of Figures 11.1b and 11.2b.
The second problem with iterative simulation draws is their within-sequence correlation; aside from any convergence issues, simulation inference from correlated draws is generally less precise than from the same number of independent draws. Serial correlation in the simulations is not necessarily a problem because, at convergence, the draws are identically distributed as p(θ![]() y), and so when performing inferences, we ignore the order of the simulation draws in any case. But such correlation can cause inefficiencies in simulations. Consider Figure 11.1c, which displays 500 successive iterations from each of five simulated sequences of the Metropolis algorithm: the patchy appearance of the scatterplot would not be likely to appear from 2500 independent draws from the normal distribution but is rather a result of the slow movement of the simulation algorithm. In some sense, the ‘effective’ number of simulation draws here is far fewer than 2500. We calculate effective sample size using formula (11.8) on page 287.
y), and so when performing inferences, we ignore the order of the simulation draws in any case. But such correlation can cause inefficiencies in simulations. Consider Figure 11.1c, which displays 500 successive iterations from each of five simulated sequences of the Metropolis algorithm: the patchy appearance of the scatterplot would not be likely to appear from 2500 independent draws from the normal distribution but is rather a result of the slow movement of the simulation algorithm. In some sense, the ‘effective’ number of simulation draws here is far fewer than 2500. We calculate effective sample size using formula (11.8) on page 287.
We handle the special problems of iterative simulation in three ways. First, we attempt to design the simulation runs to allow effective monitoring of convergence, in particular by simulating multiple sequences with starting points dispersed throughout parameter space, as in Figure 11.1a. Second, we monitor the convergence of all quantities of interest by comparing variation between and within simulated sequences until ‘within’ variation roughly equals ‘between’ variation, as in Figure 11.1b. Only when the distribution of each simulated sequence is close to the distribution of all the sequences mixed together can they all be approximating the target distribution. Third, if the simulation efficiency is unacceptably low (in the sense of requiring too much real time on the computer to obtain approximate convergence of posterior inferences for quantities of interest), the algorithm can be altered, as we discuss in Sections 12.1 and 12.2.
Discarding early iterations of the simulation runs
To diminish the influence of the starting values, we generally discard the first half of each sequence and focus attention on the second half. Our inferences will be based on the assumption that the distributions of the simulated values θt, for large enough t, are close to the target distribution, p(θ![]() y). We refer to the practice of discarding early iterations in Markov chain simulation as warm-up; depending on the context, different warm-up fractions can be appropriate. For example, in the Gibbs sampler displayed in Figure 11.2, it would be necessary to discard only a few initial iterations.1 We adopt the general practice of discarding the first half as a conservative choice. For example, we might run 200 iterations and discard the first half. If approximate convergence has not yet been reached, we might then run another 200 iterations, now discarding all of the initial 200 iterations.
y). We refer to the practice of discarding early iterations in Markov chain simulation as warm-up; depending on the context, different warm-up fractions can be appropriate. For example, in the Gibbs sampler displayed in Figure 11.2, it would be necessary to discard only a few initial iterations.1 We adopt the general practice of discarding the first half as a conservative choice. For example, we might run 200 iterations and discard the first half. If approximate convergence has not yet been reached, we might then run another 200 iterations, now discarding all of the initial 200 iterations.
Dependence of the iterations in each sequence
Another issue that sometimes arises, once approximate convergence has been reached, is whether to thin the sequences by keeping every kth simulation draw from each sequence and discarding the rest. In our applications, we have found it useful to skip iterations in problems with large numbers of parameters where computer storage is a problem, perhaps setting k so that the total number of iterations saved is no more than 1000.

Figure 11.3 Examples of two challenges in assessing convergence of iterative simulations. (a) In the left plot, either sequence alone looks stable, but the juxtaposition makes it clear that they have not converged to a common distribution. (b) In the right plot, the twosequences happen to cover a common distribution but neither sequence appears stationary. These graphs demonstrate the need to use between-sequence and also within-sequence information when assessing convergence.
Whether or not the sequences are thinned, if the sequences have reached approximate convergence, they can be directly used for inferences about the parameters θ and any other quantities of interest.
Multiple sequences with overdispersed starting points
Our recommended approach to assessing convergence of iterative simulation is based on comparing different simulated sequences, as illustrated in Figure 11.1 on page 276, which shows five parallel simulations before and after approximate convergence. In Figure 11.1a, the multiple sequences clearly have not converged; the variance within each sequence is much less than the variance between sequences. Later, in Figure 11.1b, the sequences have mixed, and the two variance components are essentially equal.
To see such disparities, we clearly need more than one independent sequence. Thus our plan is to simulate independently at least two sequences, with starting points drawn from an overdispersed distribution (either from a crude estimate such as discussed in Section 10.2 or a more elaborate approximation as discussed in the next chapter).
Monitoring scalar estimands
We monitor each scalar estimand or other scalar quantities of interest separately. Estimands include all the parameters of interest in the model and any other quantities of interest (for example, the ratio of two parameters or the value of a predicted future observation). It is often useful also to monitor the value of the logarithm of the posterior density, which has probably already been computed if we are using a version of the Metropolis algorithm.
Challenges of monitoring convergence: mixing and stationarity
Figure 11.3 illustrates two of the challenges of monitoring convergence of iterative simulations. The first graph shows two sequences, each of which looks fine on its own (and, indeed, when looked at separately would satisfy any reasonable convergence criterion), but when looked at together reveal a clear lack of convergence. Figure 11.3a illustrates that, to achieve convergence, the sequences must together have mixed.
The second graph in Figure 11.3 shows two chains that have mixed, in the sense that they have traced out a common distribution, but they do not appear to have converged. Figure 11.3b illustrates that, to achieve convergence, each individual sequence must reach stationarity.
Splitting each saved sequence into two parts
We diagnose convergence (as noted above, separately for each scalar quantity of interest) by checking mixing and stationarity. There are various ways to do this; we apply a fairly simple approach in which we split each chain in half and check that all the resulting half-sequences have mixed. This simultaneously tests mixing (if all the chains have mixed well, the separate parts of the different chains should also mix) and stationarity (at stationarity, the first and second half of each sequence should be traversing the same distribution).
We start with some number of simulated sequences in which the warm-up period (which by default we set to the first half of the simulations) has already been discarded. We then take each of these chains and split into the first and second half (this is all after discarding the warm-up iterations). Let m be the number of chains (after splitting) and n be the length of each chain. We always simulate at least two sequences so that we can observe mixing; see Figure 11.3a; thus m is always at least 4.
For example, suppose we simulate 5 chains, each of length 1000, and then discard the first half of each as warm-up. We are then left with 5 chains, each of length 500, and we split each into two parts: iterations 1–250 (originally iterations 501–750) and iterations 251–500 (originally iterations 751–1000). We now have m = 10 chains, each of length n = 250.
Assessing mixing using between- and within-sequence variances
For each scalar estimand ψ, we label the simulations as ψij (i = 1, …, n; j = 1, …, m), and we compute B and W, the between- and within-sequence variances:

The between-sequence variance, B, contains a factor of n because it is based on the variance of the within-sequence means, ![]() , each of which is an average of n values ψij.
, each of which is an average of n values ψij.
We can estimate var(ψ![]() y), the marginal posterior variance of the estimand, by a weighted average of W and B, namely
y), the marginal posterior variance of the estimand, by a weighted average of W and B, namely
![]()
This quantity overestimates the marginal posterior variance assuming the starting distribution is appropriately overdispersed, but is unbiased under stationarity (that is, if the starting distribution equals the target distribution), or in the limit n → ∞ (see Exercise 11.5). This is analogous to the classical variance estimate with cluster sampling.
Meanwhile, for any finite n, the ‘within’ variance W should be an underestimate of var(ψ![]() y) because the individual sequences have not had time to range over all of the target distribution and, as a result, will have less variability; in the limit as n → ∞, the expectation of W approaches var(ψ
y) because the individual sequences have not had time to range over all of the target distribution and, as a result, will have less variability; in the limit as n → ∞, the expectation of W approaches var(ψ![]() y).
y).
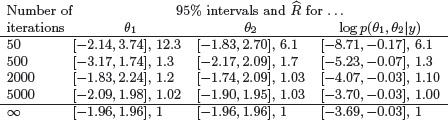
Table 11.1 95% central intervals and estimated potential scale reduction factors for three scalar summaries of the bivariate normal distribution simulated using a Metropolis algorithm. (For demonstration purposes, the jumping scale of the Metropolis algorithm was purposely set to be inefficient; see Figure 11.1.) Displayed are inferences from the second halves of five parallel sequences, stopping after 50, 500, 2000, and 5000 iterations. The intervals for ∞ are taken from the known normal and -![]() 22/2 marginal distributions for these summaries in the target distribution.
22/2 marginal distributions for these summaries in the target distribution.
We monitor convergence of the iterative simulation by estimating the factor by which the scale of the current distribution for ψ might be reduced if the simulations were continued in the limit n → ∞. This potential scale reduction is estimated by2
![]()
which declines to 1 as n → ∞. If the potential scale reduction is high, then we have reason to believe that proceeding with further simulations may improve our inference about the target distribution of the associated scalar estimand.
Example. Bivariate unit normal density with bivariate normal jumping kernel (continued)
We illustrate the multiple sequence method using the Metropolis simulations of the bivariate normal distribution illustrated in Figure 11.1. Table 11.1 displays posterior inference for the two parameters of the distribution as well as the log posterior density (relative to the density at the mode). After 50 iterations, the variance between the five sequences is much greater than the variance within, for all three univariate summaries considered. However, the five simulated sequences have converged adequately after 2000 or certainly 5000 iterations for the quantities of interest. The comparison with the true target distribution shows how some variability remains in the posterior inferences even after the Markov chains have converged. (This must be so, considering that even if the simulation draws were independent, so that the Markov chains would converge in a single iteration, it would still require hundreds or thousands of draws to obtain precise estimates of extreme posterior quantiles.)
The method of monitoring convergence presented here has the key advantage of not requiring the user to examine time series graphs of simulated sequences. Inspection of such plots is a notoriously unreliable method of assessing convergence and in addition is unwieldy when monitoring a large number of quantities of interest, such as can arise in complicated hierarchical models. Because it is based on means and variances, the simple method presented here is most effective for quantities whose marginal posterior distributions are approximately normal. When performing inference for extreme quantiles, or for parameters with multimodal marginal posterior distributions, one should monitor also extreme quantiles of the ‘between’ and ‘within’ sequences.
11.5 Effective number of simulation draws
Once the simulated sequences have mixed, we can compute an approximate ‘effective number of independent simulation draws’ for any estimand of interest ψ. We start with the observation that if the n simulation draws within each sequence were truly independent, then the between-sequence variance B would be an unbiased estimate of the posterior variance, var(ψ![]() y), and we would have a total of mn independent simulations from the m sequences. In general, however, the simulations of ψ within each sequence will be autocorrelated, and B will be larger than var(ψ
y), and we would have a total of mn independent simulations from the m sequences. In general, however, the simulations of ψ within each sequence will be autocorrelated, and B will be larger than var(ψ![]() y), in expectation.
y), in expectation.
One way to define effective sample size for correlated simulation draws is to consider the statistical efficiency of the average of the simulations ![]() , as an estimate of the posterior mean, E(ψ
, as an estimate of the posterior mean, E(ψ![]() y). This can be a reasonable baseline even though is not the only possible summary and might be inappropriate, for example, if there is particular interest in accurate representation of low-probability events in the tails of the distribution.
y). This can be a reasonable baseline even though is not the only possible summary and might be inappropriate, for example, if there is particular interest in accurate representation of low-probability events in the tails of the distribution.
Continuing with this definition, it is usual to compute effective sample size using the following asymptotic formula for the variance of the average of a correlated sequence:
![]()
where ρt is the autocorrelation of the sequence ψ at lag t. If the n simulation draws from each of the m chains were independent, then var![]() would simply be 1/mn var(ψ
would simply be 1/mn var(ψ![]() y) and the sample size would be mn. In the presence of correlation we then define the effective sample size as
y) and the sample size would be mn. In the presence of correlation we then define the effective sample size as
![]()
The asymptotic nature of (11.5)–(11.6) might seem disturbing given that in reality we will only have a finite simulation, but this should not be a problem given that we already want to run the simulations long enough for approximate convergence to the (asymptotic) target distribution.
To compute the effective sample size we need an estimate of the sum of the correlations ρ, for which we use information within and between sequences. We start by computing the total variance using the estimate ![]() from (11.3); we then estimate the correlations by first computing the variogram Vt at each lag t:
from (11.3); we then estimate the correlations by first computing the variogram Vt at each lag t:
![]()
We then estimate the correlations by inverting the formula, E(ψi - ψi-t)2 = 2(1 - ρt)var(ψ):
![]()
Unfortunately we cannot simply sum all of these to estimate neff in (11.6); the difficulty is that for large values of t the sample correlation is too noisy. Instead we compute a partial sum, starting from lag 0 and continuing until the sum of autocorrelation estimates for two successive lags ![]() is negative. We use this positive partial sum as our estimate of σt=1∞ ρt in (11.6). Putting this all together yields the estimate, where the estimated autocorrelations
is negative. We use this positive partial sum as our estimate of σt=1∞ ρt in (11.6). Putting this all together yields the estimate, where the estimated autocorrelations ![]() are computed from formula (11.7) and T is the first odd positive integer for which
are computed from formula (11.7) and T is the first odd positive integer for which ![]() is negative.
is negative.
![]()
All these calculations should be performed using only the saved iterations, after discarding the warm-up period. For example, suppose we simulate 4 chains, each of length 1000, and then discard the first half of each as warm-up. Then m = 8, n = 250, and we compute variograms and correlations only for the saved iterations (thus, up to a maximum lag t of 249, although in practice the stopping point T in (11.8) will be much lower).
Bounded or long-tailed distributions
The above convergence diagnostics are based on means and variances, and they will not work so well for parameters or scalar summaries for which the posterior distribution, p(![]()
![]() y), is far from Gaussian. (As discussed in Chapter 4, asymptotically the posterior distribution should typically be normally distributed as the data sample size approaches infinity, but (a) we are never actually at the asymptotic limit (in fact we are often interested in learning from small samples), and (b) it is common to have only a small amount of data on individual parameters that are part of a hierarchical model.)
y), is far from Gaussian. (As discussed in Chapter 4, asymptotically the posterior distribution should typically be normally distributed as the data sample size approaches infinity, but (a) we are never actually at the asymptotic limit (in fact we are often interested in learning from small samples), and (b) it is common to have only a small amount of data on individual parameters that are part of a hierarchical model.)
For summaries ![]() whose distributions are constrained or otherwise far from normal, we can preprocess simulations using transformations before computing the potential scale reduction factor
whose distributions are constrained or otherwise far from normal, we can preprocess simulations using transformations before computing the potential scale reduction factor ![]() and the effective sample size
and the effective sample size ![]() eff. We can take the logarithm of all-positive quantities, the logit of quantities that are constrained to fall in (0, 1), and use the rank transformation for long-tailed distributions. Transforming the simulations to have well-behaved distributions should allow mean and variance-based convergence diagnostics to work better.
eff. We can take the logarithm of all-positive quantities, the logit of quantities that are constrained to fall in (0, 1), and use the rank transformation for long-tailed distributions. Transforming the simulations to have well-behaved distributions should allow mean and variance-based convergence diagnostics to work better.
Stopping the simulations
We monitor convergence for the entire multivariate distribution, p(θ![]() y), by computing the potential scale reduction factor (11.4) and the effective sample size (11.8) for each scalar summary of interest. (Recall that we are using θ to denote the vector of unknowns in the posterior distribution, and
y), by computing the potential scale reduction factor (11.4) and the effective sample size (11.8) for each scalar summary of interest. (Recall that we are using θ to denote the vector of unknowns in the posterior distribution, and ![]() to represent scalar summaries, considered one at a time.)
to represent scalar summaries, considered one at a time.)
We recommend computing the potential scale reduction for all scalar estimands of interest; if ![]() is not near 1 for all of them, continue the simulation runs (perhaps altering the simulation algorithm itself to make the simulations more efficient, as described in the next section). The condition of
is not near 1 for all of them, continue the simulation runs (perhaps altering the simulation algorithm itself to make the simulations more efficient, as described in the next section). The condition of ![]() being ‘near’ 1 depends on the problem at hand, but we generally have been satisfied with setting 1.1 as a threshold.
being ‘near’ 1 depends on the problem at hand, but we generally have been satisfied with setting 1.1 as a threshold.
We can use effective sample size ![]() eff to give us a sense of the precision obtained from our simulations. As we have discussed in Section 10.5, for many purposes it should suffice to have 100 or even 10 independent simulation draws. (If neff = 10, the simulation standard error is increased by √1 + 1/10 = 1.05). As a default rule, we suggest running the simulation until
eff to give us a sense of the precision obtained from our simulations. As we have discussed in Section 10.5, for many purposes it should suffice to have 100 or even 10 independent simulation draws. (If neff = 10, the simulation standard error is increased by √1 + 1/10 = 1.05). As a default rule, we suggest running the simulation until ![]() eff is at least 5m, that is, until there are the equivalent of at least 10 independent draws per sequence (recall that m is twice the number of sequences, as we have split each sequence into two parts so that
eff is at least 5m, that is, until there are the equivalent of at least 10 independent draws per sequence (recall that m is twice the number of sequences, as we have split each sequence into two parts so that ![]() can assess stationarity as well as mixing). Having an effective sample size of 10 per sequence should typically correspond to stability of all the simulated sequences. For some purposes, more precision will be desired, and then a higher effective sample size threshold can be used.
can assess stationarity as well as mixing). Having an effective sample size of 10 per sequence should typically correspond to stability of all the simulated sequences. For some purposes, more precision will be desired, and then a higher effective sample size threshold can be used.
| Diet | Measurements |
| A | 62, 60, 63, 59 |
| B | 63, 67, 71, 64, 65, 66 |
| C | 68, 66, 71, 67, 68, 68 |
| D | 56, 62, 60, 61, 63, 64, 63, 59 |
Table 11.2 Coagulation time in seconds for blood drawn from 24 animals randomly allocated to four different diets. Different treatments have different numbers of observations because the randomization was unrestricted. From Box, Hunter, and Hunter (1978), who adjusted the data so that the averages are integers, a complication we ignore in our analysis.
Once ![]() is near 1 and
is near 1 and ![]() eff is more than 10 per chain for all scalar estimands of interest, just collect the mn simulations (with warm-up iterations already excluded, as noted before) and treat them as a sample from the target distribution.
eff is more than 10 per chain for all scalar estimands of interest, just collect the mn simulations (with warm-up iterations already excluded, as noted before) and treat them as a sample from the target distribution.
Even if an iterative simulation appears to converge and has passed all tests of convergence, it still may actually be far from convergence if important areas of the target distribution were not captured by the starting distribution and are not easily reachable by the simulation algorithm. When we declare approximate convergence, we are actually concluding that each individual sequence appears stationary and that the observed sequences have mixed well with each other. These checks are not hypothesis tests. There is no p-value and no statistical significance. We assess discrepancy from convergence via practical significance (or some conventional version thereof, such as ![]() > 1.1).
> 1.1).
11.6 Example: hierarchical normal model
We illustrate the simulation algorithms with a hierarchical normal model, extending the problem discussed in Section 5.4 by allowing an unknown data variance, σ2. The example is continued in Section 13.6 to illustrate mode-based computation. We demonstrate with the normal model because it is simple enough that the key computational ideas do not get lost in the details.
Data from a small experiment
We demonstrate the computations on a small experimental dataset, displayed in Table 11.2, that has been used previously as an example in the statistical literature. Our purpose here is solely to illustrate computational methods, not to perform a full Bayesian data analysis (which includes model construction and model checking), and so we do not discuss the applied context.
The model
Under the hierarchical normal model (restated here, for convenience), data yij, i = 1, …, nj, j = 1, …, J, are independently normally distributed within each of J groups, with means θj and common variance σ2. The total number of observations is ![]() . The group means are assumed to follow a normal distribution with unknown mean μ and variance τ2, and a uniform prior distribution is assumed for (μ, log σ, τ), with σ > 0 and τ > 0; equivalently, p(μ, log σ, log τ) ∝ τ. If we were to assign a uniform prior distribution to log τ, the posterior distribution would be improper, as discussed in Chapter 5.
. The group means are assumed to follow a normal distribution with unknown mean μ and variance τ2, and a uniform prior distribution is assumed for (μ, log σ, τ), with σ > 0 and τ > 0; equivalently, p(μ, log σ, log τ) ∝ τ. If we were to assign a uniform prior distribution to log τ, the posterior distribution would be improper, as discussed in Chapter 5.
The joint posterior density of all the parameters is
![]()
Starting points
In this example, we can choose overdispersed starting points for each parameter θj by simply taking random points from the data yij from group j. We obtain 10 starting points for the simulations by drawing θj independently in this way for each group. We also need starting points for μ, which can be taken as the average of the starting θj values. No starting values are needed for τ or σ as they can be drawn as the first steps in the Gibbs sampler.
Section 13.6 presents a more elaborate procedure for constructing a starting distribution for the iterative simulations using the posterior mode and a normal approximation.
Gibbs sampler
The conditional distributions for this model all have simple conjugate forms:
1. Conditional posterior distribution of each θj. The factors in the joint posterior density that involve θj are the N(μ, τ2) prior distribution and the normal likelihood from the data in the jth group, yij, i = 1, …, nj. The conditional posterior distribution of each θj given the other parameters in the model is
![]()
where the parameters of the conditional posterior distribution depend on μ, σ, and τ as well as y:
![]()
![]()
These conditional distributions are independent; thus drawing the θj’s one at a time is equivalent to drawing the vector θ all at once from its conditional posterior distribution.
2. Conditional posterior distribution of μ. Conditional on y and the other parameters in the model, μ has a normal distribution determined by the θj’s:
![]()
where
![]()
3. Conditional posterior distribution of σ2. The conditional posterior density for σ2 has the form corresponding to a normal variance with known mean; there are n observations yij with means θj. The conditional posterior distribution is
![]()
where
![]()
4. Conditional posterior distribution of τ2. Conditional on the data and the other parameters in the model, τ2 has a scaled inverse-![]() 2 distribution, with parameters depending only on μ and θ (as can be seen by examining the joint posterior density):
2 distribution, with parameters depending only on μ and θ (as can be seen by examining the joint posterior density):
![]()
![]()
Table 11.3 Summary of inference for the coagulation example. Posterior quantiles and estimated potential scale reductions are computed from the second halves of ten Gibbs sampler sequences, each of length 100. Potential scale reductions for σ and τ are computed on the log scale. The hierarchical standard deviation, τ, is estimated less precisely than the unit-level standard deviation, σ, as is typical in hierarchical modeling with a small number of batches.
with
![]()
The expressions for τ2 have (J - 1) degrees of freedom instead of J because p(τ) ∝ 1 rather than τ-1.
Numerical results with the coagulation data
We illustrate the Gibbs sampler with the coagulation data of Table 11.2. Inference from ten parallel Gibbs sampler sequences appears in Table 11.3; 100 iterations were sufficient for approximate convergence.
The Metropolis algorithm
We also describe how the Metropolis algorithm can be used for this problem. It would be possible to apply the algorithm to the entire joint distribution, p(θ, μ, σ, τ![]() y), but we can work more efficiently in a lower-dimensional space by taking advantage of the conjugacy of the problem that allows us to compute the function p(μ, log σ, log τ
y), but we can work more efficiently in a lower-dimensional space by taking advantage of the conjugacy of the problem that allows us to compute the function p(μ, log σ, log τ![]() y), as we discuss in Section 13.6. We use the Metropolis algorithm to jump through the marginal posterior distribution of (μ, log σ, log τ) and then draw simulations of the vector θ from its normal conditional posterior distribution (11.9). Following a principle of efficient Metropolis jumping that we shall discuss in Section 12.2, we jump through the space of (μ, log σ, log τ) using a multivariate normal jumping kernel centered at the current value of the parameters and variance matrix equal to that of a normal approximation (see Section 13.6), multiplied by 2.42/d, where d is the dimension of the Metropolis jumping distribution. In this case, d = 3.
y), as we discuss in Section 13.6. We use the Metropolis algorithm to jump through the marginal posterior distribution of (μ, log σ, log τ) and then draw simulations of the vector θ from its normal conditional posterior distribution (11.9). Following a principle of efficient Metropolis jumping that we shall discuss in Section 12.2, we jump through the space of (μ, log σ, log τ) using a multivariate normal jumping kernel centered at the current value of the parameters and variance matrix equal to that of a normal approximation (see Section 13.6), multiplied by 2.42/d, where d is the dimension of the Metropolis jumping distribution. In this case, d = 3.
Metropolis results with the coagulation data
We ran ten parallel sequences of Metropolis algorithm simulations. In this case 500 iterations were sufficient for approximate convergence (![]() < 1.1 for all parameters); at that point we obtained similar results to those obtained using Gibbs sampling. The acceptance rate for the Metropolis simulations was 0.35, which is close to the expected result for the normal distribution with d = 3 using a jumping distribution scaled by 2.4/√d (see Section 12.1).
< 1.1 for all parameters); at that point we obtained similar results to those obtained using Gibbs sampling. The acceptance rate for the Metropolis simulations was 0.35, which is close to the expected result for the normal distribution with d = 3 using a jumping distribution scaled by 2.4/√d (see Section 12.1).
11.7 Bibliographic note
Gilks, Richardson, and Spiegelhalter (1996) is a book full of examples and applications of Markov chain simulation methods. Further references on Bayesian computation appear in the books by Tanner (1993), Chen, Shao, and Ibrahim (2000), and Robert, and Casella (2004). Many other applications of Markov chain simulation appear in the recent applied statistical literature.
Metropolis and Ulam (1949) and Metropolis et al. (1953) apparently were the first to describe Markov chain simulation of probability distributions (that is, the ‘Metropolis algorithm’). Their algorithm was generalized by Hastings (1970); see Chib and Greenberg (1995) for an elementary introduction and Tierney (1998) for a theoretical perspective. The conditions for Markov chain convergence appear in probability texts such as Feller (1968), and more recent work such as Rosenthal (1995) has evaluated the rates of convergence of Markov chain algorithms for statistical models. The Gibbs sampler was first so named by Geman and Geman (1984) in a discussion of applications to image processing. Tanner and Wong (1987) introduced the idea of iterative simulation to many statisticians, using the special case of ‘data augmentation’ to emphasize the analogy to the EM algorithm (see Section 13.4). Gelfand and Smith (1990) showed how the Gibbs sampler could be used for Bayesian inference for a variety of important statistical models. The Metropolis-approximate Gibbs algorithm introduced at the end of Section 11.3 appears in Gelman (1992b) and is used by Gilks, Best, and Tan (1995).
Gelfand et al. (1990) applied Gibbs sampling to a variety of statistical problems, and many other applications of Gibbs sampler algorithms have appeared since; for example, Clayton (1991) and Carlin and Polson (1991). Besag and Green (1993), Gilks et al. (1993), and Smith and Roberts (1993) discuss Markov simulation algorithms for Bayesian computation. Bugs (Spiegelhalter et al., 1994, 2003) is a general-purpose computer program for Bayesian inference using the Gibbs sampler; see Appendix C for details.
Inference and monitoring convergence from iterative simulation are reviewed by Gelman and Rubin (1992b) and Brooks and Gelman (1998), who provide a theoretical justification of the method presented in Section 11.4 and discuss more elaborate versions of the method; see also Brooks and Giudici (2000) and Gelman and Shirley (2011). Other views on assessing convergence appear in the ensuing discussion of Gelman and Rubin (1992b) and Geyer (1992) and in Cowles and Carlin (1996) and Brooks and Roberts (1998). Gelman and Rubin (1992a,b) and Glickman (1993) present examples of iterative simulation in which lack of convergence is impossible to detect from single sequences but is obvious from multiple sequences. The rule for summing autocorrelations and stopping after the sum of two is negative comes from Geyer (1992).
Venna, Kaski, and Peltonen (2003) and Peltonen, Venna, and Kaski (2009) discuss graphical diagnostics for convergence of iterative simulations.
11.8 Exercises
1. Metropolis-Hastings algorithm: Show that the stationary distribution for the Metropolis-Hastings algorithm is, in fact, the target distribution, p(θ![]() y).
y).
2. Metropolis algorithm: Replicate the computations for the bioassay example of Section 3.7 using the Metropolis algorithm. Be sure to define your starting points and your jumping rule. Compute with log-densities (see page 261). Run the simulations long enough for approximate convergence.
3. Gibbs sampling: Table 11.4 contains quality control measurements from 6 machines in a factory. Quality control measurements are expensive and time-consuming, so only 5 measurements were done for each machine. In addition to the existing machines, we are interested in the quality of another machine (the seventh machine). Implement a separate, a pooled and hierarchical Gaussian model with common variance described in Section 11.6. Run the simulations long enough for approximate convergence. Using each of three models—separate, pooled, and hierarchical—report: (i) the posterior distribution of the mean of the quality measurements of the sixth machine, (ii) the predictive distribution for another quality measurement of the sixth machine, and (iii) the posterior distribution of the mean of the quality measurements of the seventh machine.
| Machine | Measurements |
| 1 | 83, 92, 92, 46, 67 |
| 2 | 117, 109, 114, 104, 87 |
| 3 | 101, 93, 92, 86, 67 |
| 4 | 105, 119, 116, 102, 116 |
| 5 | 79, 97, 103, 79, 92 |
| 6 | 57, 92, 104, 77, 100 |
Table 11.4: Quality control measurements from 6 machines in a factory.
4. Gibbs sampling: Extend the model in Exercise 11.3 by adding a hierarchical model for the variances of the machine quality measurements. Use an Inv-![]() 2 prior distribution for variances with unknown scale σ02 and fixed degrees of freedom. (The data do not contain enough information for determining the degrees of freedom, so inference for that hyperparameter would depend very strongly on its prior distribution in any case). The conditional distribution of σ02 is not of simple form, but you can sample from its distribution, for example, using grid sampling.
2 prior distribution for variances with unknown scale σ02 and fixed degrees of freedom. (The data do not contain enough information for determining the degrees of freedom, so inference for that hyperparameter would depend very strongly on its prior distribution in any case). The conditional distribution of σ02 is not of simple form, but you can sample from its distribution, for example, using grid sampling.
5. Monitoring convergence:
(a) Prove that ![]() as defined in (11.3) is an unbiased estimate of the marginal posterior variance of
as defined in (11.3) is an unbiased estimate of the marginal posterior variance of ![]() , if the starting distribution for the Markov chain simulation algorithm is the same as the target distribution, and if the m parallel sequences are computed independently. (Hint: show that
, if the starting distribution for the Markov chain simulation algorithm is the same as the target distribution, and if the m parallel sequences are computed independently. (Hint: show that ![]() can be expressed as the average of the halved squared differences between simulations
can be expressed as the average of the halved squared differences between simulations ![]() from different sequences, and that each of these has expectation equal to the posterior variance.)
from different sequences, and that each of these has expectation equal to the posterior variance.)
(b) Determine the conditions under which ![]() approaches the marginal posterior variance of
approaches the marginal posterior variance of ![]() in the limit as the lengths n of the simulated chains approach ∞.
in the limit as the lengths n of the simulated chains approach ∞.
6. Effective sample size:
(a) Derive the asymptotic formula (11.5) for the variance of the average of correlated simulations.
(b) Implement a Markov chain simulation for some example and plot ![]() eff from (11.8) over time. Is
eff from (11.8) over time. Is ![]() eff stable? Does it gradually increase as a function of number of iterations, as one would hope?
eff stable? Does it gradually increase as a function of number of iterations, as one would hope?
7. Analysis of survey data: Section 8.3 presents an analysis of a stratified sample survey using a hierarchical model on the stratum probabilities.
(a) Perform the computations for the simple nonhierarchical model described in the example.
(b) Using the Metropolis algorithm, perform the computations for the hierarchical model, using the results from part (a) as a starting distribution. Check by comparing your simulations to the results in Figure 8.1b.
1 In the simulation literature (including earlier editions of this book), the warm-up period is called burn-in, a term we now avoid because we feel it draws a misleading analogy to industrial processes in which products are stressed in order to reveal defects. We prefer the term ‘warm-up’ to describe the early phase of the simulations in which the sequences get closer to the mass of the distribution.
2 In the first edition of this book, ![]() was defined as
was defined as ![]() . We have switched to the square-root definition for notational convenience. We have also made one major change since the second edition of the book. Our current
. We have switched to the square-root definition for notational convenience. We have also made one major change since the second edition of the book. Our current ![]() has the same formula as before, but we now compute it on the split chains, whereas previously we applied it to the entire chains unsplit. The unsplit
has the same formula as before, but we now compute it on the split chains, whereas previously we applied it to the entire chains unsplit. The unsplit ![]() from the earlier editions of this book would not correctly diagnose the poor convergence in Figure 11.3b.
from the earlier editions of this book would not correctly diagnose the poor convergence in Figure 11.3b.