
Chapter 8: C++ – The Quest for Microsecond Latency
In this chapter, we discuss some features and constructs available in C++. One disclaimer before we start is that covering a lot/most of what modern C++ (C++ 11/14/17) offers is beyond the scope of a single chapter (and often a single book), so we will focus on a few aspects that are important to developing, maintaining, and improving multi-threaded and ultra-low runtime latency HFT applications. Before starting to dig into this chapter, we recommend you to be fluent in C++. We recommend a couple of books to serve this purpose such as Programming: Principles and Practice Using C++ written by Bjarne Stroustrup.
We will start out by looking into modern C++ memory models, which specify how shared memory interactions work in a multi-threaded environment, then look at static analysis, which is an important aspect of application development, testing, and maintenance. Then we will dive into how to optimize applications for runtime performance, before finally dedicating an entire section to templates, which are super important for top-tier HFT ecosystems.
In this chapter, we will cover the following topics:
- C++ memory model
- Removing runtime decisions
- Dynamic memory allocation
- Template for reducing runtime
- Static analysis
By the end of this chapter, you will be capable of optimizing your C++ code for HFT systems. Finally, we will review an industry use case. We will talk about the technology that we used to build a Foreign Exchange (FX) high-frequency hedge fund.
Important Note
In order to guide you through all the optimizations, you can refer to the following list of icons that represent a group of optimizations lowering the latency by a specific number of microseconds:
![]() : Lower than 20 microseconds
: Lower than 20 microseconds
![]() : Lower than 5 microseconds
: Lower than 5 microseconds
![]() : Lower than 500 nanoseconds
: Lower than 500 nanoseconds
You will find these icons in the headings of this chapter.
Let's first start by talking about the C++ memory model.
C++ 14/17 memory model 
In this section, we will explore the definition and specification of the memory model for modern C++ (11, 14, and 17). We will investigate what it is, why it is needed for multi-threaded applications, and the important principles of the C++ memory model.
What is a memory model?
A memory model, a.k.a. a memory consistency model, specifies the allowed and expected behavior of multi-threaded applications that interact with shared memory. The memory model is the foundation of the concurrency semantics of shared memory systems. If there are two concurrent programs, one writing to and another reading from a shared memory space, the memory model defines the set of values that a read operation is allowed to return for any combination of reads and writes.
Implementation of the memory models (C++ or otherwise) must be constrained by the rules specified by the memory models, because if the outcome cannot be inferred from the order of reads and writes, then it is not an unambiguous memory model. Another way to think about the restrictions enforced by a memory model is that they define which instruction reordering is allowed by the compiler, the processor, and the architecture (the memory). Most research on memory models tries to maximize freedom for compiler, processor, and architecture optimizations.
Even if the optimizations become more and more complicated and complex, they must keep the semantics of what the developer wants to do. They should never break the constraints of the memory model.
At this point, let's formally define a few terms.
- Source code order
This is the order of instructions and memory operations that the programmer has specified in the programming language of their choice. This is the code or set of instructions as it exists before the compiler has compiled the code.
- Program order
This is the order of instructions and memory operations in the machine code that will be executed on the CPU after the compilation of the source code. The order of instructions and/or memory operations can be different here since, as mentioned previously, compilers will try to optimize and reorder instructions as part of the optimization process.
- Execution order
This is the order of actual execution of instructions and memory references as executed on the CPU. This is different from the compiled program order because at this stage, the CPU and the architecture in general are allowed to reorder the instructions in the machine code generated by the compiler. The optimizations here depend on the memory model of the specific CPU and its architecture.
We will now discuss the need for a memory model.
The need for a memory model
Let's discuss why we need a well-defined memory model at all. The fundamental reason comes down to the fact that the code we wrote is not exactly the code that is output after the compilation process and also not the code that is run on the hardware. Modern compilers and CPUs are allowed to execute instructions out of order to maximize performance and resource utilization.
In a single-threaded environment, this does not matter but in a multi-threaded environment running over a multi-core (multi-processor) architecture, different threads trying to read and write to a shared memory location causes race conditions and can lead to undefined and unexpected behavior in the presence of instruction reordering. As we saw in Chapter 4, HFT System Foundations – From Hardware to OS, scheduling and context switching are non-deterministic. They can be controlled but when context switching occurs at extremely specific places, it is possible that the optimizations cause the instructions to be executed and the memory accesses to occur in an order that causes results to be different depending on the sequence of events.
Having a memory model gives optimizing compilers a high degree of freedom when applying optimizations. The memory model dictates the synchronization barriers that use synchronization primitives (mutexes, locks, synchronized blocks, barriers, and so on), which we saw in the previous Chapter 7, HFT Optimization – Logging, Performance, and Networking. When shared variables change, the change needs to be made visible to other threads when a synchronization barrier is reached; that is, the reordering cannot break this invariant. We will now describe in detail how the C++ memory model works.
The C++ 11 memory model and its rules
Before we investigate the details of the C++ 11 memory model, let's recap the previous two sections. A memory model is meant to do the following:
- Specify the possible outcomes of the interactions of threads through shared memory.
- Check whether a program has well-defined behavior.
- Specify constraints for compiler code generation.
The C++ memory model has minimal guarantees about memory access semantics. As expected, there is a limit on the acceptable effects of compiler processing and optimizations (optimizations that reorder instructions and memory accesses) and CPU/architecture that executes instructions and memory accesses out of order. The guarantees about memory access semantics in the C++ memory model itself are quite weak – weaker than you would expect and weaker than what is typically implemented in practice. The memory model in practice mirrors the rules the system imposes, such as total store ordering (TSO) for x86_64 or a relaxed ordering with ARM.
For the C++ memory model, there are three rules with regard to transferring data between main memory (shared) and memory per-thread. We will discuss those three rules as follows. We will address memory ordering along with Sequential Consistency in the next section.
Atomicity
We have seen this before in Chapter 6, HFT Optimization – Architecture and Operating System, in the Lock-free data structures section. It needs to be clear which operations are indivisible when working with global/static/shared variables/data structures.
Let's introduce some constructs available from C++ 11 onward to support atomicity that can be generalized to different types of objects (templates) and support atomic loads and stores. We will quickly introduce the memory ordering support that C++ 11 provides and will take a closer look at it later in the Memory ordering section under C++ memory ordering principles.
std::lock_guard
std::lock_guard is a simple mutex wrapper that uses the principle of resource acquisition is initialization (RAII) for owning a mutex within the scoped block. It tries to take ownership of the mutex as soon as it is created and the scope in which it was created is finished, the lock_guard destructor is called, which releases the mutex. For convenience C++ 11 provides the std::atomic<T> template class to support atomic loads and stores for objects of type T.
std::atomic
The generic class std::atomic<T> we mentioned before to support atomic operations on generic objects supports the following atomic operations (there are more but we list the most important ones):
- load(std::memory_order order), which loads and returns the current value but does so atomically
- store(T value, std::memory_order order), which saves the current value atomically
- exchange(T value, std::memory_order order), which does a similar job as store but performs a read-modify-write operation
For integral and pointer types it also provides the following operations:
- fetch_add(T arg, std::memory_order order), which takes an additional argument arg and atomically sets the value to the arithmetic addition of the value and arg
- fetch_sub(T arg, std::memory_order order), which is like fetch_add except it subtracts instead of adding
And exclusively for integral types, it provides the following additional logical operations:
- fetch_and(T arg, std::memory_order order), which is like fetch_add except it performs the bitwise AND operation.
- fetch_or(T arg, std::memory_order order), which is like fetch_and except it performs the bitwise OR operation.
- fetch_xor(T arg, std::memory_order order), which is like fetch_and except it performs the bitwise XOR operation.
The default value for the std::memory_order order parameter is std::memory_order_seq_cst (Sequential Consistency). There are other values that can be specified here instead of Sequential Consistency to define a weaker memory model. The different options and their effects will be discussed in the Memory ordering section of C++ memory model principles.
Properties of atomic operations
The properties of atomic operations are as follows:
- Operations can be performed concurrently from multiple threads without risking undefined behavior.
- Atomic load sees either the initial value of a variable or the value written to it via an atomic store.
- Atomic stores for the same object are ordered identically in all threads.
Visibility
We briefly touched upon visibility in the prior section, where we mentioned that when there are read and write operations happening on shared data, the effects of one thread writing to the variable needs to be made visible to threads reading from it at the boundary of the synchronization barrier.
Let's discuss the rules with regard to visibility of changes made by one thread to another thread. Changes made by one thread are visible to other threads under the following conditions:
- The writing thread releases the synchronization lock, and the reading thread acquires it after that. Releasing the lock flushes all writes and acquiring the lock loads or reloads the values.
- For atomic variables, values written to it are flushed immediately before the next memory operation on the writer's side, but readers must call a load instruction before each access.
- When a writing thread terminates, all written variables are flushed, so threads that have synchronized with this thread's termination (join) will see the correct values written by this thread.
The following are some additional items to be cautious of with regard to visibility:
- When there are long stretches of code that use no synchronization with other dependent threads, the threads can be quite out of sync with the values of shared data members.
- Loops that wait or check against values written by other threads are wrong unless they use atomic or synchronization.
- Visibility failures and safety violations in the absence of correct synchronization are not guaranteed or required, merely a possibility. It might not happen in practice, only extremely rarely, or only on certain architectures or due to some specific external factors. Overall, it is almost impossible to be a 100% confident that there are no visibility-based errors.
We will now discuss instruction ordering.
Ordering
Since memory accesses are reordered by the compiler or CPU, the memory model needs to define when the effects of the assignment operations can appear out of order to a given thread:
- Sequential Consistency is a C++ machine memory model that requires that all instructions from all threads appear like they are being executed in an order consistent with the program or source code order on each thread.
- Memory ordering is another concept we will explore shortly in some detail. It describes the sequence of memory access instructions. The term can be used to refer to memory access ordering during compile time or runtime. Memory ordering allows the compiler and CPU to reorder memory operations, so they are out of order and that leads to optimal utilization of the different layers of the memory hierarchy (registers, caches, main memory, and so on) as well maximizing the use of the data transfer architecture and its bandwidth.
Let's learn about the principles of the C++ memory model and memory order concepts in the following section.
C++ memory model principles
In this section, we will look at the different options available to us in the modern C++ memory model paradigm with regard to accessing and writing to shared data structures in a multi-threaded and multi-processing environment.
Memory order concepts
The memory model is important to understand when using threads in HFTs since we may modify the semantics of a piece of software if we are not using the model accurately. We start by introducing some notations and concepts in the following list, and then dive into the different control options:
- Relaxed memory order: In the default system, memory operations are ordered quite loosely, and the CPU has a lot of leeway to reorder them. Compilers can likewise arrange the instructions they output in whatever sequence they choose, as long as it doesn't impair the program's apparent execution. Memory operations executed on the same memory region by the same thread are not reordered according to the modification order.
- Acquire/Release: All load-acquire operations reading the stored value synchronize with a store-release action. Any activities in the releasing thread that occur before the store-release occur before all operations in the acquiring thread that occur after the load-acquire.
- Consume: Consume is Acquire/Release's lighter variant. If X depends on the value loaded, all operations in the releasing thread before the store-release happen before an operation X in the consuming thread.
We looked at some features of memory ordering in this section. We will now focus on defining memory ordering in C++.
Memory ordering
Table 1 provides a quick introduction to the different memory ordering tags, which we will explore in greater detail in the subsequent sections.

Figure 8.1 – C++ memory model
These memory order tags allow four different memory ordering modes: Sequential Consistency, Relaxed and Release-Acquire, and the similar Release-Consume. Let's explore those next.
Sequential Consistency
Sequential Consistency (SC) is the principle that states that all threads involved in a multi-threaded application agree on the order in which memory operations have occurred or will occur. Another requirement is that the order is consistent with the order of operations in the source program. The technique to achieve this in modern C++ is to declare the shared variables as C++ 11 atomic types with memory ordering constraints. The result of any execution should be the same as if the operations of all processors were executed in sequential order.
Additionally, operations executed on each processor also follow program order. SC in a multi-threaded and multi-processor environment means that all threads are on the same page with regard to the order in which memory operations occurred and that this is consistent each time the program is run.
One way to achieve this in, say, Java is to declare shared variables as volatile and the C++ 11 equivalent would be to declare shared variables as atomic types with memory ordering constraints. When this is done, the compiler takes care of enforcing these ordering constraints by introducing additional instructions behind the scenes like memory fences (please check the Fences section in this chapter). The default memory order for atomic operations is sequential consistency, which is the std::memory_order_seq_cst operation.
Note
Although this mode is easy to understand, it will lead to the maximum performance penalty because it prevents compiler optimizations that might try to reorder operations past the atomic operations.
Relaxed Ordering
Relaxed Ordering is the opposite of SC, activated using the std::memory_order_relaxed tag. This mode of atomic operation will impose no restrictions on memory operations. However, the operation itself is still atomic.
Release-Acquire Ordering
In the Release-Acquire Ordering design, atomic store or write operations, a.k.a. store-release, use std::memory_order_release, and atomic load or read operations, a.k.a. load-acquire, use std::memory_order_acquire. The compiler is not allowed to move store operations after a store-release operation, and it is not allowed to move load operations before load-acquire operations. When the load-acquire operation sees values written by a store-release operation, the compiler makes sure that all the operations before the store-release happen before the load operations after the load-acquire.
Release-Consume Ordering
Release-Consume Ordering is like Release-Acquire Ordering but here the atomic load uses std::memory_order_consume and becomes an atomic load-consume operation. The behavior of this mode is the same as Release-Acquire except that the load operations that come after the load-consume operation and depend on the value loaded by the load-consume operation are ordered/sorted correctly.
We have seen that atomic objects have store and load methods for atomically writing to and reading from shared data and the default mode is Sequential Consistency. Under the hood, the compiler adds additional instructions to create memory fences after each store. We also discussed that adding a lot of memory fences creates inefficient code by preventing compiler optimizations. These fences are also not necessary for publication safety, in which case the question becomes how do we write code that generates minimal fencing operations (and hence much more efficient code)?
Here is what the compiler knows when it comes to memory access and operations on shared data:
- All memory operations in each thread and what they do, as well as any data dependencies
- Which memory locations are shared and which variables are mutable variables, that is, could change asynchronously due to memory operations in another thread.
So, then the solution to minimizing memory fences is to simply tell the compiler which operations on mutable and shared locations can be reordered and which cannot. Independent memory operations can be performed in random order with no implications as before.
Fences
Fences in programming are a sort of barrier instructions. They force the processor to enforce a specific ordering on memory operations. These operations will be modified based on the fences. Memory operations can be ordered between threads using fences. A fence can be either Release or Acquire. If the Acquire fence comes before the Release fence, then the stores take place before the loads following the acquire fence. We employ other synchronization primitives that allow atomic operations to ensure that the release fence comes before the acquire fence.
Like operations on atomic objects, the atomic_thread_fence operation has a memory_order parameter, which can take on the following values:
- If memory_order is memory_order_relaxed, this has no effects.
- If memory_order is memory_order_acquire or memory_order_consume, then it is an acquire fence.
- If memory_order is memory_order_release, then it is a release fence.
- If memory_order is memory_order_acq_rel, then it is both an acquire fence and a release fence.
- If memory_order is memory_order_seq_cst, then it is a sequentially consistent acquire and release fence.
We reviewed the order of the operation for fences. We will now finish off this section by talking about the changes in C++20.
C++ 20 memory model changes
There are some minor changes in C++ 20 as far as memory models are concerned. Some issues were discovered after the formalization of the C++ 11 memory model. The old model was defined with the objective that different regimes of memory access could be implemented on common architectures using costly hardware instructions. Specifically, memory_order_acquire and memory_order_release were supposed to be implementable on ARM and Power CPU architectures using lightweight fence instructions. Unfortunately, it turns out that they cannot, and this is also true for NVIDIA GPUs, although those were not really targeted a decade ago.
So that fundamentally leaves us with two options:
- Implement the standard as is. This is possible but will suffer from performance degradation, which goes against the purpose of why we have these memory models in the first place, and would degrade the efficiency of C++.
- Fix the standard to better handle the new architecture without messing up the concepts and ideas of memory models.
Option 2 being the more sensible choice was finally chosen by the C++ standards committee as the solution
In this section about memory models, we reviewed the different models. Since HFT processes run concurrently, it is important to know how the memory model works in the context of multi-threaded software. As part of our journey toward achieving peak performance for HFTs, we now need to learn how to reduce the execution time by removing the decision which could happen during runtime. That's going to be the topic for our next section.
Removing runtime decisions 
As C++ is a compiled language, it can optimize the source code during the compilation process and generate machine code with as much code and data resolved at compile time. In this section, we will look at the motivation for removing runtime decisions, consider some C++ constructs that are resolved at runtime, and see how an ultra-low latency HFT application tries to minimize or substitute runtime decisions.
Motivation for removing runtime decisions
The more code that lies on the critical path and can be resolved at compile time (instead of being resolved at runtime), the better the application performance – a key element in optimizing HFT applications. Here we discuss the advantages obtained by the compiler, CPUs, and memory architecture in terms of performance when the application has minimal runtime decisions and most of the code can be resolved at compile time.
Compiler optimizations
If the compiler can resolve the source and constant/static data at compile time, it opens up the possibility of a lot of compile-time optimization. Resolving at compile time means it knows at compile time what each object type is, which method/functions/subroutines are called at each invocation, how much memory is required and where when executing each method, and so on. Compile-time resolution allows the compiler to apply a lot of optimizations, including the following:
- Inlining: This is where the compiler replaces the function call with the body of the called function.
- Dead code removal: The compiler removes code that doesn't affect the program result.
- Instruction reordering: This allows us to break dependencies and run a code faster.
- Replacing compile time macros: These are very similar to inlining except technically, uses of macros are replaced by the actual code for the macros in the pre-processing step that precedes the compiler optimization steps.
This leads to the generation of machine code that is massively faster than if the compiler was unable to optimize due to a failure of compile-time resolution.
CPU and architecture optimizations
Not only is the machine code generated by the compiler significantly more optimized, but it works much better with the prefetching and branch prediction optimizations at the CPU, pipeline, and architecture hardware levels.
Due to the CPU pipeline, modern CPUs prefetch instructions and data that will be required to be accessed and executed shortly. This works significantly better when the data and instructions are known at compile time – think about inlined versus non-inlined methods. If the objects that will be accessed and/or the methods that will be needed are not known at compile time (because they're resolved at runtime), this process is hard to do correctly and often ends up prefetching the incorrect data and instructions from caches or main memory.
Another prefetching-related optimization is the branch prediction optimization, where the CPUs try to predict which branch will be taken (conditional switches, function calls, and so on). This is harder in the presence of dynamic resolution, as is the case when C++ applications use virtual functions, Run Time Type Identification (RTTI), and so on. This is because it is either impossible to predict the branches that will be taken since the type of object might not be known, and/or the method body might not be known or is just super difficult to get right most of the time. When the branch prediction is incorrect, it incurs a penalty since the data and code that was prefetched now needs to be evicted from the CPU pipeline, caches, memory, and so on. And then the correct data and code needs to be fetched at the call. We recommend reading the book Computer Architecture: A Quantitative Approach if you would like to know more about the theory of branch prediction.
Virtual functions
Virtual functions are key to one of C++'s particularly important features – dynamic polymorphism. This is an excellent feature that reduces code duplication, lends semantics to control and data flow program design, and lets us have generic interfaces that can be overridden and customized for specific object types. It is an important principle in Object-Oriented Programming (OOP) design, but unfortunately it comes with a runtime performance penalty. Due to the runtime resolution of virtual functions and the associated runtime performance penalty, HFT applications are typically extremely careful with regard to when and where virtual functions are used and try to eliminate unnecessary virtual functions. This section explores C++ virtual function performance in more detail.
How they work
Let's discuss how virtual functions are implemented from the compiler and operating system's perspective. When the compiler is compiling the source code, it knows which functions are virtual and their addresses. For each object that is created that has at least one virtual function, a table (called the virtual table, or vtable for short) is created that holds pointers to the virtual functions the type has. Objects of types that have virtual functions have a pointer referred to as a vptr that points to the virtual table for that object. When virtual functions are overridden by a derived class, the vtable entries for those overridden virtual functions point to the derived class implementation. At runtime, calling virtual functions requires a few additional steps over non-virtual functions: the runtime accesses the vptr, finds the vtable for that corresponding object type, figures out the address of the function it needs to call, and performs the virtual function call.
Performance penalties
In the previous section, we described how virtual functions are set up and how they are called. Since the runtime needs to access the vtable, virtual function calls have a little bit more overhead than non-virtual functions, but in this section, we will explore the biggest performance penalties that are incurred in the presence of virtual functions.
Compiler optimizations
One big source of performance penalty when using virtual functions is that it prevents compiler optimizations. To recap, the address of the virtual function depends on the type of the object, which is often not known till runtime. What that means is that the address and body of the virtual function that needs to be called are also not known till runtime. So, the compiler has no chance of inlining the function. That would save a few instructions for the call to the function and the return from it. Additionally, inlining would eliminate unused parameters and variables, often then eliminating operations before the call to the function. This becomes significantly worse when there are multiple objects with different virtual functions being called in a loop. In that case not only is inlining the calls not possible, but unrolling the loop is also impossible, as is exploiting the hardware for performance. We will discuss this in another section shortly, but this also kills the CPU pipeline and cache performance.
Prefetching and branch prediction
We mentioned before how the hardware tries to prefetch data and code that might be accessed and executed shortly. It also tries to predict which branches might be taken (a.k.a. speculative execution) and tries to prefetch the data and code from the branch that might be taken. In the case of objects with virtual functions and virtual function calls, it does not know the jump destination till the actual object type and virtual function address are resolved at runtime.
By this time, it has already prefetched instructions based on the branch it predicted and started executing those instructions already. If it happened to have predicted the branch correctly then it is all good, but if not then all the work done from the prefetch has to be stopped and reversed, and the correct instructions must now be fetched and executed after the fetch finishes.
This makes the program slower on branch mispredictions due to not only having to fetch the instructions once the correct addresses are resolved, but also since it must undo the effect of incorrect instructions being prefetched and executed. Also, the shorter the virtual function, the greater the slowdown observed since the overhead of branch misprediction becomes a larger fraction of total function call time.
Cache evictions and performance
We discussed the design and performance benefits derived from having different cache layers in the Memory hierarchy section in Chapter 6, HFT Optimization – Architecture and Operating System. We have also mentioned that L1 and L2 caches have instruction caches that cache frequently and recently used instructions. There is another cache that holds the comparison results for branch instructions – it is used to predict the destination branch from the previous executions of the same instructions and speed up computations by prefetching instructions and speculatively executing them.
Cache performance is best when the required instructions and branch results are in the appropriate caches, but virtual functions (especially large virtual functions with different implementations for each object type) are problematic here. This is especially bad if, say, there is a container of base class pointers and each one of them is pointing to potentially different object types or is randomly arranged (that is, the container is not sorted by type). This is bad because most calls to the virtual functions will result in calls to a different function in a potentially random memory location.
So, if the functions are large enough, each call to a virtual function will cause the cache to evict the data and instructions from the previous function call and load data and instructions for the new one. This is on top of the branch prediction penalties being paid (quite frequently). Virtual functions may cause a lot of cache evictions and cache misses and significantly hurt performance. But this is not always the case since if we have a function invocation through a vtable, and we perform this in a tight loop, the CPU will cover up the latency from accessing the vtable through the power of branch prediction and cache locality. It is always important to analyze where the performance issues of code occur.
Figure 8.2 describes this situation better. Let's assume the following class structure where a single base class with a virtual function gets derived by different implementations that override the virtual function.
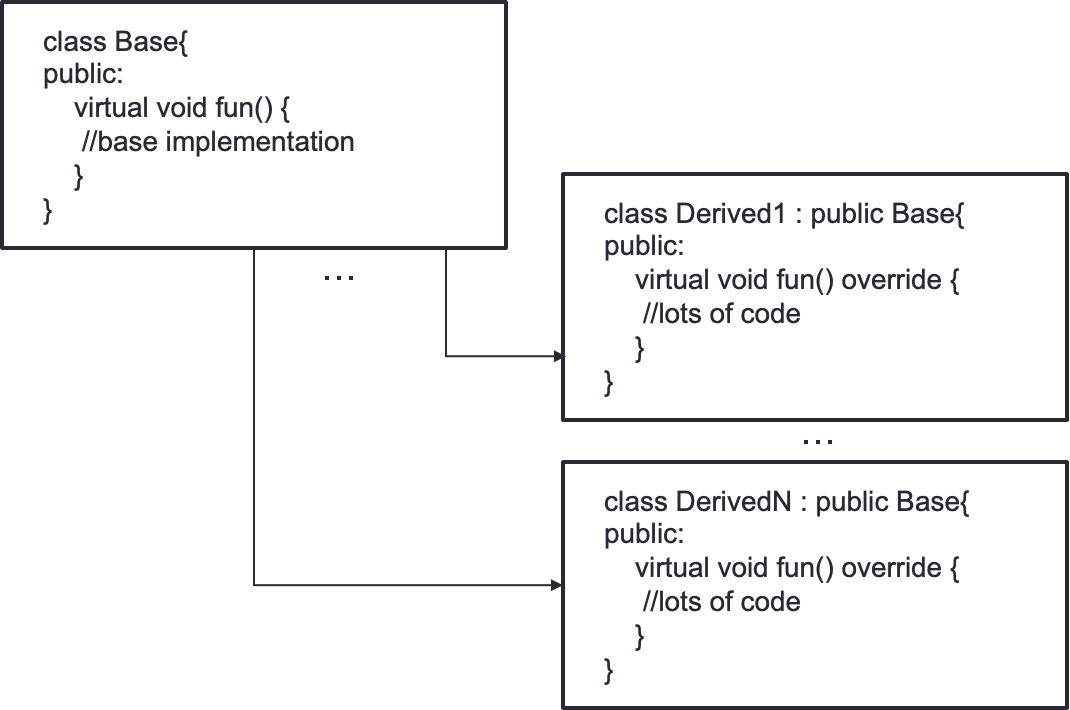
Figure 8.2 – Virtual function: class structure with a single base class and multiple derivations
Let's say there is a container of base class pointers that point to different derived class implementations that are potentially in different memory locations. If the code tries to loop through this container and call the virtual function, it will lead to a lot of cache evictions, cache misses, and overall terrible runtime performance. This is on top of the compiler not being able to unroll the loop and the branch misprediction penalties.
Figure 8.3 shows how the vtable can impact the performance by having different memory locations for the different virtual functions.

Figure 8.3 – Container of base pointers pointing to different derived objects at random memory locations
Since we saw that using virtual functions can be detrimental to performance, we will now talk about a method to remove them: the curiously recurring template pattern (CRTP).
Curiously recurring template pattern (CRTP)
We often oppose the CRTP method with virtual functions. We should first say that the virtual functions discover interface implementation at runtime, which is not the case for the CRTP. The CRTP is an example of static polymorphism as opposed to virtual functions, which are examples of dynamic polymorphism. The CRTP is a compile-time construct, which means it has no runtime overhead. It is used with a base class exposing an interface and the derived classes implementing that interface. As we saw in this section, invoking a virtual function via a base class reference frequently necessitates a call via a pointer to function, incurring indirection costs and preventing inlining.
In summary, we learned how to remove the latency that might be introduced by virtual functions. The use of virtual functions needs to be done very carefully. The CRTP is a way to avoid using virtual functions by opting for static polymorphism.
We will now introduce another type of latency that could cause slowdowns at runtime.
Run Time Type Identification (RTTI) 
The previous section on virtual functions outlined the impact of having objects and function calls that are resolved at runtime on performance. Most of the performance penalties outlined in that section apply to all object types resolved at runtime. In C++, Run Time Type Identification (RTTI) is the term used to describe the feature by which the types of objects are checked at runtime for objects where the types are not known at compile time.
What is RTTI?
C++'s RTTI is the mechanism that tracks and extracts information about an object's type when required at runtime. This only makes sense for classes that have at least one virtual function, meaning there is a possibility of base class pointers pointing to different types of derived class objects at runtime. So RTTI allows you to find the type of an object dynamically at runtime from the available pointer or reference of the base class type. This was introduced into C++ when exceptions and exception handling were added to C++ because knowing the runtime type of an object was critical to exception handling. Thus, RTTI allows applications to explicitly check for runtime types instead of relying on dynamic polymorphism, which implicitly deals with runtime type resolution.
C++ provides the dynamic_cast built-in operator for safely downcasting base class objects in an inheritance hierarchy. When downcasting pointers, it returns a valid pointer of the converted type on success and a nullptr on failure. dynamic_cast<Derived*>(base_ptr) attempts to convert the value of base_ptr to type Derived*. When downcasting references, it returns a valid reference of the converted type on success and raises an exception on failure. We will cover this in the Exceptions impeding performance section later in this chapter.
Another C++ built-in operator typeid is used fetch the runtime information of an object and returns it as a std::type_info object. The std::type_info object contains information about the type, type name, check equality between two object types, and so on. For polymorphic types, the typeid operator provides additional information about the derived types. typeid(*base_ptr) == typeid(Derived) returns true if base_ptr points to an object of type Derived.
Performance penalties
Let's discuss the performance penalties associated with the C++ RTTI mechanism.
- There is some additional space allocated per class and object, which is not a huge deal, but can become an issue if there are a lot of objects, and causes reduced cache performance.
- The typeid call can be quite slow as it usually involves fetching type information that is not often accessed.
- The dynamic_cast operation can be extremely slow. It involves fetching type information and checking for casting rules, which can lead to exceptions that are extremely expensive themselves (we will discuss that shortly).
In the following section, let's understand dynamic memory allocation.
Dynamic memory allocation
Allocation in the heap (or dynamic allocation) is common in programming. We need dynamic allocation for the flexibility to allocate at runtime. The operating system implements the dynamic memory management structures, algorithms, and routines. All dynamically allocated memory goes to the heap section of main memory. The OS maintains a few linked lists of memory blocks, primarily the free list to track contiguous blocks of free/unallocated memory and the allocated list to track blocks that have been allocated to the applications. On new memory allocation requests (malloc()/new), it traverses the free list to find a block free enough, then updates the free list (by removing that block) and adds it to the allocated list and then returns the memory block to the program. On memory deallocation requests (free()/delete), it removes the freed block from the allocated list and moves it back to the free list.
Runtime performance penalty
Let's recap the performance penalties associated with dynamic memory management that makes it unfit for use on the critical/hot path, especially for super latency-sensitive HFT applications.
Heap tracking overhead
Serving dynamic memory allocation/deallocation requests requires traversing lists of free memory blocks, which is not as efficient as using already available CPU registers or pushing additional variables onto a stack. So, the heap tracking mechanism adds some overhead and often the latencies are non-deterministic depending on the contents of the free list, how fragmented the memory is, the memory block size requested, and so on. In summary, metadata created by heap memory management can get quite involved to manage, and a lot of operations are performed just to free that block of memory.
Heap fragmentation
Over the course of many allocations and deallocations of varying sizes, the heap memory can get fragmented, meaning there are many small memory blocks with holes in between, which makes the free list long and can make it difficult and time-consuming, and in the worst case, impossible to service a memory allocation request that is larger than any of the free blocks, even though there is plenty of free memory available across the different free blocks. The OS employs some heap de-fragmentation techniques to manage these potential issues, but again that comes at a performance cost.
Cache performance
Dynamically allocated memory blocks can often be randomly distributed in heap memory. This can lead to significant cache performance degradation, higher cache evictions, and cache misses, among others. Application developers should be conscious of this and try to request dynamic memory in a cache-friendly way – often by requesting a large block of contiguous memory and then managing the objects in that memory to improve cache performance.
Alternatives/solutions for dynamic memory allocation
Not all parts of an HFT system are time critical. So, we need to be concerned about the speed of dynamic allocation and deallocation only on the time-critical hot paths.
Most high-performance dynamic memory allocation techniques come down to moving dynamic memory allocations off the critical path either by pre-allocating huge blocks of memory or managing them in the application themselves (Memory pools). Memory pools are basically data structures where an application allocates a huge chunk of memory at startup and then manages the use of this memory in critical code paths. The advantage here is that this allows the application to use very specialized allocation and deallocation techniques that maximize performance for the specific use case the applications are built for.
Another technique is to thoroughly inspect dynamic memory management uses and minimize them as much as possible, often at the cost of some assumptions that might make the application less flexible or generic.
We can also redefine the C++ new and delete operators, although this is not the recommended approach – it is better to have custom new and delete methods (my_new() and my_delete() methods would be examples) and call them explicitly. We can also talk about placement new, which gives us most of the semantic benefits of invoking new / delete, but with control over where the operator places the object. The downside is that you have to manage the memory life cycle separately.
Using constexpr efficiently
constexpr in C++ is used to make functions run at compile time – not as a guarantee, but it provides the possibility. There are a few restrictions to constexpr functions – they must not use static or thread_local variables, exception handling, or goto statements, and all variables must be of literal types and must be initialized – in short, everything the compiler needs to resolve the entire function body at compile time.
As we mentioned, declaring a constexpr function does not mean that it must run at compile time. It means that the function has the potential to be run at compile time. A constexpr function must be executed at compile time if used in a constant expression – for instance, if the result of the function call is assigned to a constexpr variable, then it must be evaluated at compile time.
The benefits of constexpr functions are along the same lines as has been discussed so far. Allowing the compiler to resolve and evaluate the function at compile time means no runtime costs for evaluating that function.
Exceptions impeding performance
Exceptions are the modern C++ mechanism for error handling and seek to improve upon the traditional error-code and if/else statement-based error handling from C. In this section, we will investigate what advantages they bring, what drawbacks and performance penalties they impose, and why that is suboptimal for HFT applications.
Why use exceptions?
Let's discuss the reasons for and benefits of using C++ exceptions for error handling:
- Using exceptions for error handling makes the source code simpler, cleaner, and better at handling errors. It is a more elegant solution to a long-nested list of if-else statements that grow over time and lead to spaghetti code, require tests for each scenario, and so on. Overall, requiring handling for each error code (and associated tests) leads to slower development.
- There is some code that cannot be done elegantly or cleanly without exceptions. The classic example is an error in a constructor – since it returns no value, how do we report the error? The elegant solution is to throw an exception and that serves as the basis for the Resource Acquisition Is Initialization (RAII) principle in modern C++ design. The alternative would be to set an error flag that needs to be checked each time an object is created after the constructor returns, which is ugly and requires a lot more code to check each time any object is created. Similar ideas apply even to regular functions, where you would have to return an error code or set a global variable. Returning error codes works but every time we add a new failure case, it requires updating code in a bunch of locations and leads to the if-else spaghetti code mentioned before. Setting global variables comes with its own set of issues – the variable must be checked after the function returns, would take on different values for different failures, is hard to maintain, and fails in a multi-threaded application.
- Exceptions are difficult to ignore, unlike return error codes, which often get ignored if application developers are not careful. Failure to catch an exception leads to program termination.
- Exceptions propagate automatically over method boundaries – that is, they can be caught and re-thrown up the caller stack.
We now know why exceptions should be used from the software engineering point of view. Next, we will explain what the performance impact is.
Drawbacks and performance penalties
Let's discuss some complexities, drawbacks, and performance penalties related to the use of C++ exceptions for error handling:
- Exception handling takes discipline and practice, especially for developers used to a more traditional error-code, if-else statement-driven type of error handling. So, as with any other programming construct, it needs good developers and careful consideration during application design.
- As far as performance is concerned, the good thing with C++ exceptions is that on the path where exceptions are not raised, there is no additional cost. However, when exceptions are thrown, it has an extremely prohibitive cost compared to, say, a function call and requires thousands of CPU cycles.
For HFT, if the applications are designed carefully so that exceptions are raised only for the rarest and most critical errors where it is unsafe to continue normally anyway, then the additional performance penalty is not an issue. However, if exceptions are treated lightly and raised as part of the normal functioning of the algorithm, then that can lead to major performance issues and what was initially thought to be rare might end up being performed quite frequently, leading to major performance degradation.
To continue with the runtime decision impacting performance, we will now talk about templates whose goal is to actually replace any runtime decision by generating multiple specialized versions of code.
Templates reducing the runtime
In this section, we will continue our discussion on removing or minimizing runtime decisions on the critical or hot path by introducing another important C++ feature. We will discuss what templates are, the motivation for using them, their advantages and disadvantages, and their performance relative to the alternatives.
What are templates?
Templates are the C++ mechanism to implement generic functions and classes. Generic programming is when generic types are used as arguments in algorithms and classes for compatibility with different data types. This eliminates code duplication and the need to repeatedly write similar or shared code that is independent of data type. Templates not only work with different data types, but based on what different types are needed at compile time, the source code for the classes and methods for those data types is generated automatically at compile time, just as with C macros. Unlike macros, however, the compiler can check for types instead of blindly substituting as with macros.
There are a few different types of templates:
- Function templates: Function templates are like normal C++ functions, except with a key difference. Normal functions work only with the defined data types inside the function, whereas function templates are designed to make them independent of data types, so they can work with any data type.
- Class templates: Class templates are also like regular classes, except they have members of one or more generic types passed as template parameters. These class templates can be used to store and manage any type of data. Instead of creating a new class each time for a different type, we define a generic class template that can work with most data types. This helps with code reusability, runs faster, and is more efficient.
- Variadic templates: This is another important template type and applies to both functions and classes. It supports a variable number of arguments, as opposed to non-variadic templates, which support only a fixed number of arguments. Variadic templates are usually used to create functional, list-processing constructs with template metaprogramming.
We will now talk about another advanced template-related technique, template specialization.
Template specialization
So far, we have been discussing the idea that a single template class or function can handle all data types. But it is also possible to have customized behavior based on some specific data types, which is known as template specialization. Template specializations are mechanisms by which we can customize function, class, and variadic templates for specific types. When the compiler encounters a template instantiation with specific data types, it creates a template instance for that type or set of types. If a template specialization exists, then the compiler uses that specialized version by matching the passed-in parameters with the data types specified. If it cannot match it to a template specialization, then it uses the non-specialized template to create an instance.
Why use templates?
Let's discuss the motivation behind using C++ templates to reduce latency at runtime.
Generic programming
The main advantage of using templates is obviously generic programming and producing code that is efficient, reusable, and extensible. One particularly good implementation of the generic programming paradigm using templates is the Standard Template Library (STL). This supports a wide range of data containers, algorithms, iterators, functors, and so on that are generic and operate on all data types.
Compile-time substitution
The substitution takes place during compile time and only the class or function bodies needed in the program are generated – that is, only the data types for which the template has been used in the application produce an instance of this template class at compile time. Knowing the parameters at compile time also makes template classes significantly more type-safe compared to runtime-resolved objects or functions.
Development cost, time, and lines of code (LOC)
Since we can implement a class or a function a single time that works with all data types, it cuts down on development effort, time, and source code complexity. It also makes debugging easy because there is less code, and it is contained in a single class or function.
Better than C macros and void pointers
C used preprocessor macros and void pointers to support some form of generic programming. But templates are a much better solution in each case as they are significantly more readable, type-safe, and less error prone. Macros are also always expanded inline, but with templates, the compiler has the choice to expand inline only when appropriate, which is useful for preventing code bloat. Macros are also clunky and hard to write due to the need to fit onto a single logical line of code, but templates appear as regular functions in their implementation.
Compile-time polymorphism
This is one of the most important applications at least for HFT applications (on top of everything else that has been mentioned here). We discussed in detail how virtual functions and dynamic polymorphism have significant performance penalties. Templates and the generic compile-time polymorphism they offer are often used to eliminate virtual inheritance and dynamic polymorphism as much as possible. By moving the code resolution and construction to compile time instead of runtime, and more importantly allowing compiler, CPU, and architecture optimizations to kick in, the performance is improved significantly.
Template metaprogramming
This is a more advanced use of C++ templates and is often either not understood well or is abused (by converting existing code constructs to use template metaprogramming unnecessarily and prematurely). Template metaprogramming gives us the ability to write code that is expanded at compile time to yield the actual machine code that will be used at runtime, essentially using templates to pre-compute a results table that can be referenced later. Expression templates are another similar advanced use of templates that are used to evaluate mathematical expressions at compile time to produce more efficient code executed at runtime.
Disadvantages of templates
Now let's look at some of the disadvantages and drawbacks of using templates.
Compiler support
Historically, a lot of compilers have had poor support for templates and can lead to reduced code portability. Also, it is not clear what compilers should do when they detect template errors, which can increase development time when using templates. Some compilers still do not support nesting of templates.
Header only
Templates are header only, which means all the code sits in the header files and none in any compiled libraries. When changes are made, it requires a complete rebuild of all pieces of the project. Also, there is no way to hide code implementation information since it is all exposed in the header file.
Increased compilation times
As mentioned before, templates reside entirely in headers and cannot be compiled into a library; they are linked during the application compilation and linking process. The advantage we gain from compiled libraries is that when a change is made, only the components that are affected need to be rebuilt. However, with templates that is not true, so each time changes are made, all the templated code has to be rebuilt. This leads to increased compilation times and as application complexity grows and template usage increases, this can go up significantly and become a problem. However, this is manageable and a non-issue.
Difficult to understand
Templates confuse a lot of developers (advanced C++ programmers included) because the rules around their use are complex. Issues such as name resolution in templates, template specialization matching, and template partial ordering can be confusing to understand and implement correctly. In general, generic programming is a different programming paradigm and requires time, effort, and practice to get used to – it does not come naturally if you are used to imperative programming in C++ (which is what 90% of C++ programmers use regularly). Overall, templates have a lot of advantages including development and debugging speed, but it takes a while to get to that point as there is quite a learning curve to understand templates properly.
Tough to debug
Debugging code that has a lot of templates can be difficult. Since the compiler replaces the template instantiation and calls with the substituted implementation, it is difficult for the debugger to find the actual code at runtime. This is similar in nature to how it can be difficult to debug inlined methods at runtime since the source code does not match what the debugger sees exactly. Error messages are extremely verbose and very confusing and time-consuming to understand. Even most modern compilers produce large, unhelpful, and confusing error messages.
Code bloat
Templates are expanded at the source code level and compiled into the source code. The compiler generates additional code for each template type or instance. If we have a lot of templated classes and functions or a lot of different data types that generate instances, the code generated by the compiler can grow quite large. This is known as code bloat, which also contributes to increased compilation times. The more subtle issue that hurts runtime performance from over-templated code bases is that since the size of the application itself is so large, it can have poor cache performance since there is a greater chance of cache evictions, misses, and so on.
Performance of templates
Fundamentally, the runtime performance of templates is as efficient and low latency as possible since it moves away from runtime object resolution and function calls to compile-time resolution. As mentioned before, this opens up a world of compiler optimization opportunities, such as inlining (among many others), and when executed, works much better with CPU and architecture optimizations such as prefetching and branch prediction to yield particularly superior performance.
It's important to avoid using the template and virtual keywords in the same class declaration. When a class template is used for the first time, it creates a copy of all member functions (applied to that new type). Having virtual functions means that even the vtable and RTTI will be duplicated, leading to additional code bloat (on top of what templates already cause).
Standard Template Library (STL)
Let's explore the C++ STL, which has become quite common among recent C++ applications. There are also some variants and libraries that operate similarly to the STL but improve upon some issues and add some functionalities.
What is the STL?
The STL is a very widely used library that provides containers and algorithms using templates for all data types. The STL is a repository of template classes that implement commonly used algorithms and data structures and work well with user-defined types as well as built-in types, and its algorithms are container independent. They are implemented as compile-time polymorphism, not runtime polymorphism.
Commonly used containers
Let's explore the most popular and commonly used C++ STL containers and when they are used:
- vector: This is the default go-to for a lot of applications, has the simplest data structure (C-array-style contiguous memory layout), and provides random access.
- deque: deque implements a double linked list and has better performance than a vector when elements are inserted and removed from the beginning or the end. deque is also efficient with memory and usually uses only as much memory as needed based on the number of elements. Accessing random elements is slower since it involves traversing the list and walking over potentially random memory locations (poor cache performance).
- list: list is like deque in that it is also implemented as a linked list and has similar benefits and drawbacks as deque. The difference here is that list does not invalidate iterators that refer to elements when elements are added or removed, unlike vector and deque.
- set, unordered_set, and multiset: These are associative containers that are used to track whether an element exists in the container or not. Associative containers are basically ones that are designed specifically to support quick and easy storage and retrieval of values referred to by keys. unordered_set uses hashes on the elements to perform lookup in amortized constant time but have no ordering. Amortized constant time lookup means under normal conditions, it takes constant time to perform the operation regardless of the size of the container. set and multiset on the order hand have keys that are ordered/sorted. multiset and set are identical except the former allows multiple elements with the same value to be saved.
- unordered_map and map, and unordered_multimap and multimap: These are also associative containers as discussed in the previous point, except they track key-value pairs. unordered_map and map save single key-value pairs, with the difference being that the former has no ordering on keys and the latter is ordered by key values. Unordered_multimap and multimap are like unordered_map and map respectively, except they allow multiple values per key.
Performance at runtime
Let's look at the performance of the STL at runtime:
- The STL, being a templated library, has particularly good runtime performance compared to C-style solutions or dynamic polymorphism-based solutions. Another way to squeeze performance from the STL is to optimize the user-defined structures to work exactly as we need them in the context of the HFT application.
- Using the STL effectively to build low-latency HFT applications requires the developers to understand the working of the STL properly and design programs carefully. Often developers misuse the STL and without understanding the computational complexity involved, they blame the library.
- Another problem with the STL is that many calls to STL library functions allocate memory internally, and without being careful to build and pass allocators to the STL containers, non-deterministic performance can result, especially for HFT applications (if they use the default dynamic memory allocators).
In this section, we studied data structures that can help to reduce latency because they are already optimized for performance. In this next section, we will learn how to improve performance by doing static analysis.
Static analysis
In this section, we will look at the development and testing techniques of static analysis. This is a set of tools and techniques to aid in the software development/testing/maintenance life cycle. It applies to all software application development processes in general, but especially to HFT applications where it is important to make changes quickly (adapting to changing market conditions and inefficiencies is key to being profitable) but very carefully without breaking existing expected functionality (bugs/errors/mistakes can lead to significant monetary losses).
What is C++ static analysis?
Static code analysis means debugging software applications by examining the code and using tools to automatically detect errors without actually executing the application or providing inputs. This can also be thought of as a code review-style debugging process that examines the code and tries to check the code structure and coding standards. Having automated tools and processes in place that can do this means we can make significantly more thorough checks for vulnerabilities while validating the code than a team of developers could. The algorithms and techniques used to analyze the source code and automatically spit out errors and warnings are similar in spirit to compiler warnings, except taken a few steps forward to find issues that dynamic testing at runtime would have revealed. There has been a good amount of progress with static analysis tools, from basic syntax checkers to something that can find even subtle bugs.
Static analysis aims to find software development issues such as programming errors, coding guideline violations, syntax violations, buffer overflow type issues, and security vulnerabilities, among others.
Let's explain why we need static analysis.
The need for static analysis
The motivation behind static analysis is to find errors and issues explained previously that dynamic analysis (unit tests/test environments/simulations that seek to uncover errors when the program is executed) does not find. Thus static analysis can uncover an issue that might have caused a major problem down the road when the system encounters data and scenarios that were not encountered during dynamic testing, triggering a failure (potentially a huge failure). Note that static analysis is just the first step in a large list of tools and practices to enforce software quality control.
In addition to static analysis, dynamic analysis relies on setting up enough test scenarios and feeding enough input and data to hopefully cover all the use cases for the application. Some coding errors might not surface during dynamic analysis (since we did not think of them when writing or carrying out the unit tests). These are the defects that dynamic analysis would miss, and the hope is that static analysis would find them.
Types of static analysis
One way of classifying types of static analysis based on the errors they aim to find is as follows:
- Control flow analysis: Here, the focus is on the caller-callee relationships and the flow of the control in the calling structure, such as process, thread, method, function, subroutine, instructions, and so on.
- Data flow analysis: Here, the focus is on the input, intermediate, and output data – the structure, the validation of types, and correct and expected operation.
- Failure analysis: This tries to understand faults and failures in different components (that do not fall into the first two categories).
- Interface analysis: This aims to make sure the components fit in with the overall pipeline – that they implement interfaces comprehensively and correctly. In HFT, this means a trading strategy process is correctly implemented with all the interfaces it needs to operate correctly and optimally in simulations and live trading.
Another way to break down static analysis types is as follows:
- Formal: The goal here is to answer the question, is the code correct?
- Cosmetic: The question here is, does the code look consistent? Does it align with the coding standards to the required degree?
- Design: The question here is, based on established firm-wide standards, have the components (such as class structures, method sizes, and organization) been designed correctly?
- Error checking: This is self-explanatory and focuses on faults, failures, and code violations.
- Predictive: This is more advanced, but the goal is to predict how the application will behave when executed, preparing for dynamic analysis.
In the following section, we will give a walkthrough of static analysis.
Steps in static analysis
The goal of static analysis is to automate it so that it is easy, fast, and thorough when applied to large code bases. Hence the process itself needs to be simple and algorithmic enough to be automated. Once the source code is ready or semi-ready from the developer's perspective, a static code analyzer runs through the code and flags compilation issues, issues with coding standards, code or data flow errors, design warnings, and so on. False positives are common, so the output of the static code analyzer is analyzed manually (by the developers) and once all real (true positive) issues are fixed, it is run through the static code analyzer again and then progresses to the dynamic analysis phase.
Static analysis is nowhere near perfect – it produces false positives and misses issues as well – but it is a good orthogonal debugging and troubleshooting tool that can save developers and code reviewers time and thus yield a more efficient work environment.
Benefits and drawbacks of static analysis
Let's look at the benefits and drawbacks of static analysis. The benefits have been discussed before, so we simply formalize and list them in this section. You can also likely guess what some of the drawbacks might be, but we will formally discuss them here as well.
Benefits
We present the list of the benefits of static analysis:
- Standardized and uniform code: Static analyzer tools started out as linters, so they are extremely good at flagging when new code does not meet coding guidelines and design standards. This yields a uniform code base that complies with established (firm-wide or industry-wide) coding standards and design patterns.
- Speed: Manual code reviews are extremely time consuming for the entire team of developers. Automated static analysis can help eliminate a lot of the issues before the code goes into code review. Additionally, it finds these issues early on, when errors are always easier and faster to fix. Overall, this leads to higher development, review, and maintenance speed across the entire software development life cycle for the entire team.
- Depth: We have mentioned this before, but building unit tests or running dynamic analysis such that they cover all edge cases and all code execution paths is downright impossible. Static code analyzers do much better in these cases as they can check for bugs and errors that are non-trivial or deep.
- Accuracy: Another obvious advantage of having an automated static analysis approach is that it is extremely accurate where manual code reviews and dynamic analysis cannot be. Accuracy helps with both thoroughness and quality.
- Offline: In most real-world applications (especially HFT applications), there are many moving pieces, so dynamic analysis in a simulated, test, or lab environment requires a lot of setup and resources. For HFT, this means different processes and components (feed handlers, order gateways, simulated exchanges, and loggers), along with network, IPC, and disk resources. That can be painful, expensive, and time consuming. Static code analysis on the other hand is performed offline in the absence of all these moving pieces so it is easy, cheap, and quick.
We described in detail what the benefits of static analysis are, so we will now talk about its weaknesses.
Drawbacks
The drawbacks of static analysis are as follows:
- Understanding semantics/developer intent is difficult
Consider the following code:
int area(int l, int w) {
return l + w;
}
A static analyzer here can detect that for some combination of l and w int values, their sum will yield an overflow, but it cannot determine that the function is incorrect to compute area.
- Coding rules are complex
A lot of coding rules are too complex for a static analyzer to statically enforce or detect. They might depend on external documentation, be subjective, depend on the firm or the application, and so on.
- False positives
We mentioned this before: false-positive detections can occur, and waste developers' time.
- Static analysis is not free or instantaneous
Like the compilation process, it takes time to run a static analyzer on the entire application. The larger and more complex the code base is, the longer it takes to run.
- Static analysis can never replace dynamic analysis
Despite their utility, static analyzers can never guarantee what will happen when the application is executed, so static analysis can supplement but never replace dynamic analysis, unit testing, simulations, or testbeds.
- System and third-party libraries
These often throw off static analyzers since the source might not be easily available or accessible.
We have seen the benefits and weaknesses of static analysis, so we will now consider the tools used to perform this kind of analysis.
Tools for static analysis
Let's quickly introduce some of the best and well known static code analyzers available for C and C++:
- Klocwork by Perforce
Klocwork is one of the best C++ static code analyzers out there. It works well with large code bases, has an enormous number of checkers, allows the customization of checkers, supports differential analysis (to help analysis times when only a small amount of code in a large code base has changed), and integrates with many IDEs and CI/CD tools.
- Cppcheck
Cppcheck is a free, open source, cross-platform static code analyzer for C and C++.
- CppDepend by CoderGears
CppDepend is a commercial C++ static code analyzer. Its strengths are in analyzing and visualizing the code base architecture (dependencies, control, and data flow layers). It has a dependency graph feature and monitoring capabilities to report differences between builds. It also supports rule checker customization.
- Parasoft
Parasoft has a commercial set of testing tools for C and C++ featuring a static code analyzer and supporting dynamic code analysis, unit tests, code coverage, and runtime analysis. It has a large, rich set of techniques and rules for static code analysis. It also lets you manage the analysis results in an organized manner, thus offering a comprehensive set of tools for the software development process.
- PVS Studio
This is another commercial tool that supports a lot of programming languages, C and C++ included. It detects non-trivial bugs, integrates with popular CI tools, and is well documented.
- Clang Static Analyzer
The Clang C and C++ compiler comes with a static analyzer that can be used to find bugs using path-sensitive analysis.
Finding a single recipe that works for all aspects of an HFT system is impossible. Learning how to analyze performance and run static analysis helps you to avoid the biggest mistakes we can make when coding in C++. By removing the biggest issues our code can have, we can focus on things that are critical for performance.
By combining static analysis and the runtime optimizations we talked about, such as using a proper memory model and reducing the number of function calls, we will reach an acceptable level of performance for an HFT system.
Use case - Building an FX high-frequency trading system
A company needs an HFT system capable of sending an order within 20 microseconds. To do this, the company can follow this approach:
- Choose a multi-process architecture over a multi-core architecture.
- Ensure each process is pinned to a specific core to reduce context switches.
- Have processes communicating over a circular buffer (lock-free data structure) in shared memory.
- Design the network stack using Solarflare OpenOnload for network acceleration.
- Increase the page size to reduce the number of TLB cache misses.
- Disable hyperthreading to get more control over the concurrency execution of the processes.
- Use the CRTP to reduce the number of virtual functions.
- Remove runtime decisions by using templated data structures.
- Pre-allocate data structures to avoid any allocation on the critical path.
- Send fake orders to keep caches hot and allow an order to go out at the last moment.
In any trading system, the number of orders is way lower than the amount of market data received. The critical path from getting market data to sending an order is exercised very infrequently. The cache will be overtaken by non-critical path data and instructions. That's why it is very important to run a dummy path to send orders through the entire system to keep the data cache and instruction cache primed. This will also keep the branch predictors hot.
The main idea of all these optimizations is to reduce the number of costly operations. Removing function calls, using lock-free data structures, and reducing the number of context switches are a part of this strategy.
Additionally, any decision taken at runtime is costly. That's why templated functions and inlining will be part of the common code in any HFT system. The most costly operations are those involving networking communications. Using an end-to-end kernel bypass such as Solarflare optimizes the network latency within the trading system. By using these optimizations, this company could achieve 20 microseconds for the tick-to-trade. The latency distribution is very important to measure. We need to be sure that 20 microseconds is the latency upper bound. We should never consider the average values because it is difficult to assess high latency with this value.
In HFTs, some strategies are very profitable when a lot of trades occur. If most of the time a trading system works as expected, there is no guarantee that the system will always perform well. When a trading system receives a lot of data, if it is not built correctly, the maximum latency can be 10 times more than the average. We should keep in mind that any optimization is not guaranteed to be faster if we have not measured it ourselves in production.
Summary
In this chapter, we covered a lot of modern C++ 14, 17, and 20 features for multi-threaded and ultra-low latency applications that deal with shared memory interactions. We also covered static analysis for application development. Finally, we discussed runtime performance optimization techniques that move as much decision, code evaluation, and code branching away from runtime into compile time as possible. The contents of this chapter address the major design and development decisions and techniques critical to the development and performance of C++ HFT applications.
We also saw how to build an HFT system for a small hedge fund specialized in FX. In the next chapter, we will learn about the usage of Java in an ultra-low-latency system such as an HFT system.