
Chapter 10: Python – Interpreted but Open to High Performance
In this chapter, we will introduce you to using Python in the high-frequency trading (HFT) system. Getting an HFT system using Python is problematic since Python was not built for speed and low latency. Because Python is the most used language and provides all the necessary libraries for data analysis, this language is the go-to in algorithmic trading. We will learn how to use HFT libraries in Python in this chapter.
We will cover the following topics:
- Introducing Python
- Python limitations in the context of HFT
- How to use a C++ library in Python
We will provide you with the tools capable of transforming any C++ code into code that can be used by Python.
We will start by explaining why we should use Python, even in HFT.
Introducing Python
Python is the most used programming language on the planet (one-third of all new code is written in Python). This language is used in software development. Python is a relatively simple language to learn and it is a high-level programming language that uses type inference, which is interpreted. Unlike C/C++, which requires you to concentrate on memory management and the hardware aspects of the computer you're programming, Python handles the internal implementation, such as memory management. As a consequence, this language will make it easier to concentrate on writing trading algorithms.
Python is a flexible language that can construct applications in any sector. Python has been extensively used for years. The Python community is vast enough to provide many important libraries for your trading strategy, spanning from data analytics, machine learning, data extraction, and runtime, to communication; the list of open source libraries is enormous.
Python also contains concepts seen in other languages, such as object-oriented, functional, and dynamic types on the software engineering side. Python has an abundance of online resources and a wealth of books that will guide you through every subject where Python may be used. For example, you can read Learn Python Programming published by Packt and written by Romano and Kruger. In trading, Python isn't the only language used. To undertake data analysis and construct trading models, we'll want to utilize Python. We'll utilize C, C++, or Java in production code. Source code will be compiled into an executable or bytecode using these languages and as a result, the program will be 100 times quicker than Python or R. Even though all three languages are slower than Python, we will utilize them to build libraries. These libraries will be wrapped so that they may be used with Python.
Python is an appropriate language for data analytics, which makes this language adaptable to create trading strategies. In the Packt book, Learn Algorithmic Trading, written by the authors of this book, we describe how to leverage this language and the pandas and NumPy libraries to create trading strategies.
Making use of Python for analytics
Python has all the features for quantitative researchers to be proficient in data analysis, and Python with scrapy or beautifulsoup can scrape websites (data crawling). It has many string libraries and the regular expression library, which can help clean data (data cleaning). The sklearn and statsmodels libraries help developers create models (data modeling). Matplotlib will help with data visualization.
Python is the go-to language for many developers in finance. It is essential to talk about this language in this chapter as Python is the most used programming language in the world. Raising the question of whether Python can do HFT is a fair question to ask. However, as we saw, it is difficult to use Python as it is because of its speed. We can, therefore, think about using other language libraries to exploit their speed.
Figure 10.1 represents the steps for building a trading strategy:

Figure 10.1 – Steps to create a trading strategy
HFT strategies are also made the same way by following these steps:
- This part doesn't involve any programming since it just involves getting the trading idea which we will introduce in the market. In the case of an HFT strategy, we could use the example of a statistical arbitrage strategy. This strategy will assume that the derivative financial product and its underlying asset returns are correlated.
- In this step, we can start getting market data to validate Step 1. From this moment, the use of Python will be beneficial for data analysis.
- Any data transformations, such as normalizing and cleaning data to create the model, should be done with Python and the pandas and NumPy libraries.
- We can use the scikit-learn package to build models. It is an open source Python-based machine learning package, and it supports classification, regression, clustering, and dimensionality reduction. In the case of our HFT strategy example, we will be able to correlate returns between the two assets by using regression models.
- In Steps 5 and 6, we will implement a first model with the market data collected and backtest this model.
- Step 7 is essential to promote the need for speed in the trading strategy at this stage. Based on the prior data analytics done in the previous steps, we will be able to determine the time needed to enter and get out of a position to have a profitable trading strategy.
- Steps 8 and 9 are the final stage of the trading strategy, and will be an iteration between the actual profit and the predicted profit.
Looking at the last steps, we can observe that speed matters. We need to understand why Python has a slow execution; it will not be possible to use it for the last steps of the trading strategy.
Why is Python slow?
Python is a high-level language (higher than C or C++); therefore, it handles software such as memory allocation, memory deallocation, and pointers. Python memory management makes it easy for programmers to write Python programs. Figure 10.2 depicts the Python chain. Python code is converted into Python bytecode initially and internally, the bytecode interpreter conversion occurs, and most of it is hidden from the developer. Bytecode is a lower-level programming language that is platform agnostic. The purpose of bytecode compilation is to speed up source code execution. The source code is converted to bytecode and then run one after another in Python's virtual machine to carry out the operations. Python's virtual machine is a built-in feature. Python code is interpreted rather than compiled to native code during execution; therefore, it is a little slower:
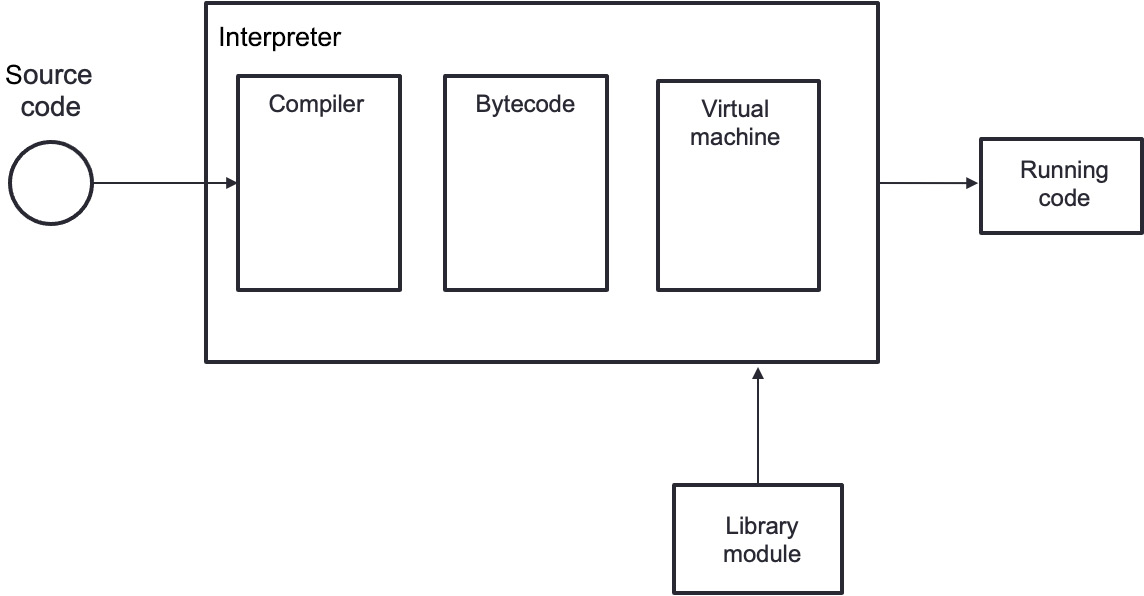
Figure 10.2 – Python chain
Python is first converted to bytecode. The Python virtual machine (PVM) then interprets and executes this bytecode.
Python is slow because of the following reasons:
- Python code is interpreted at runtime rather than converted to native code at compile time, unlike native languages such as C/C++. Python is an interpreted language, which means that the Python code we create must go through several abstraction steps before becoming machine code that can be executed.
- Compiler for Just-in-Time (JIT): Other interpreted languages, such as Java bytecode, run quicker than Python bytecode because they come with a JIT compiler that translates bytecode into native code at runtime, as explained in Chapter 9, Java and JVM for Low-Latency Systems. Python does not have a JIT compiler since it is challenging to create one due to the dynamic nature of the language. It's hard to predict what parameters will be supplied to a function, making optimization a difficult task.
- The Global Interpreter Lock (GIL) inhibits multi-threading by requiring the interpreter to run only one thread at a time inside a single process (that is, a Python interpreter instance).
Since we now understand why Python cannot achieve performance by itself, we will study how Python uses libraries in detail.
How do we use libraries in Python?
A library helps developers to reuse code that has been already created and tested for specific functionalities. We use libraries by downloading a pre-compiled version for a specific platform and by linking them to our software. By doing so, we don't have to rewrite code, and we increase the trust in our implementation by using tested code. Libraries can be statically linked to software, which increases the size of the executable. They can also be used dynamically, which means the executable will load the libraries when starting up. We can find these libraries with the dynamic load library (.dll) extension on Windows or with the Shared Object (.so) extension in the Linux world. Python uses dynamic libraries by using the import command.
Python standard modules are pretty numerous. The library includes built-in modules (written in C) that enable access to system capabilities such as file input/output (I/O) that would otherwise be unavailable to Python programmers, as well as Python modules that provide standardized solutions to many common programming issues. Some of these modules are specifically designed to promote and improve Python application portability by abstracting platform-specifics into platform-neutral application programming interface (APIs). Python has many other libraries that can help develop software. We introduce some of them here:
- Google's TensorFlow library was created in partnership with the Google Brain team. It's a high-level calculation library that's open source. It's also seen in deep learning and machine learning algorithms. There are a lot of Tensor operations in it.
- Matplotlib is a library that allows you to plot numerical data. This library is useful to display charts in data analytics. It is often used in designing trading strategies to visualize how they perform by having a visual presentation of important metrics such as profit and loss.
- pandas: For data scientists, pandas is an important library. It's an open source machine learning package with a range of analytic tools and configurable high-level data structures. It simplifies data analysis, processing, and cleansing. Sorting, re-indexing, iteration, concatenation, data conversion, visualizations, aggregations, and other operations are all supported by pandas.
- NumPy: Numerical Python is the name of the program. It is the most widely utilized library. It's a well-known machine learning package that can handle big matrices and multi-dimensional data. It has built-in mathematical functions for quick calculations. NumPy is used internally by libraries such as TensorFlow to conduct various Tensor operations. One of the most essential components of this library is the array interface.
- SciPy: Scientific Python is a high-level scientific computation package in Python that is open source. This library is based on a NumPy extension, and it uses NumPy to do complicated calculations. The numerical data code is kept in SciPy, whereas NumPy supports sorting and indexing array data. It is also commonly used by engineers and application developers.
- Scrapy is an open source toolkit for scraping information from web pages. It allows for highly rapid web crawling as well as high-level screen scraping. It's also suitable for data mining and automated data testing.
- Scikit-learn is a well-known Python toolkit for dealing with large amounts of data. Scikit-learn is a machine learning library that is open source. It supports a wide range of supervised and unsupervised methods, such as linear regression, classification, and clustering. NumPy and SciPy are often used in conjunction with this package.
We now know that Python can work efficiently with libraries. Let's now explain how C++ HFT libraries can work with Python.
Python and C++ for HFT
As we showed in the previous section, Python is too slow to be adequate for high-frequency trading. C++ is much faster and is the language of choice to get low latency. We are presenting in this section a means to integrate the two languages to unify both worlds. On one side, Python gives the developers ease and flexibility, and on the other side, C++ allows code to reach high performance and low latencies. In HFT, we need to have quantitative researchers and programmers build HFT strategies to run in the production environment. Having a Python ecosystem capable of using C++ libraries will allow quants (quantitative traders) to focus on their research and deploy code in production without the need for other resources. We will explain how to provide a standard interface to different C/C++ libraries. These C/C++ libraries will become Python modules. In other words, we will use them as dynamic libraries loaded in memory when we need them.
Let's first talk about motivation.
Using C++ in Python
We want to use C++ with Python for the following reasons:
- We already have a vast, well-tested, and reliable C++ library that we would like to use in Python. This might be a communication library or a library to help with a specific project goal, such as HFT.
- We want to transfer a vital portion of Python code to C++ to speed it up. C++ has a quicker execution speed, but it also lets us avoid the Python GIL restrictions.
- We wish to utilize Python test tools to test their systems on a wide scale.
We now know the motivation to use C++, and we will explain how we can achieve that next.
Using Python with C++
To use Python with C++, we have mainly two ways:
- Extending involves using C++ libraries with the import command. We will provide C++ libraries with a Python interface. The function prototypes are in Python and the implementation is in C++. It is equivalent to creating a shared C++ library that will be dynamically loaded when the software starts. This library will be used in a critical portion of a code.
- Embedding is a technique in which the end user runs a C++ application that calls the Python interpreter as a library procedure. It's the equivalent of adding scriptability to an existing program. Embedding is the process of adding calls into your C or C++ program after it has started up to set up the Python interpreter and invoke Python code later.
Extending modules is frequently the best approach to use highly performant code. The operation of creating a C++ library and using it will be the code solution to what we are proposing. Embedding requires more effort than simply extending. Unlike embedding, extending gives us more power and freedom. When we are embedding, many valuable Python tools and automation techniques become significantly more difficult, if not impossible, to employ.
A mapping of one object to another is referred to as binding. Binding is used to link one language with another one. For instance, if we create a library in C or C++, we can use this library with Python. The modification of these libraries requires their recompilation.
When an existing C or C++ library designed for a specific purpose has to be utilized from Python, Python bindings are employed.
To understand why Python bindings are necessary, consider how Python and C++ store data and the problems that this might generate. C or C++ saves data in memory in the most miniature feasible format. If you use uint8_t, the space required to store data is 8 bits if structure padding is not considered.
On the other hand, Python uses objects allocated in the heap. In Python, integers are large integers whose size varies depending on their data. This means that for each integer transmitted across the border, bindings convert a C integer to a Python integer.
When preparing data to be transported from Python to C or vice versa, Python bindings execute a method similar to marshaling by changing an object's memory representation to a data format acceptable for storage or transmission.
Boost.Python library
This library allows you to combine Python and C++. It enables you to use C++ objects and functions in Python and vice versa without using any further tools outside the C++ compiler. There is no need to modify the C++ code. The library is made to encapsulate C++ APIs without being intrusive:
- To illustrate how this tool works, we will work on this example. This example illustrates how to compile the add function using a C++ compiler and how to use it in Python code. Let's assume we want to use the C++ add function defined as follows:
int add(int x, int y)
{
return x+y;
}
- This function can be exposed to Python by writing a Boost.Python wrapper:
#include <boost/python.hpp>
BOOST_PYTHON_MODULE(math_ext)
{
using namespace boost::python;
def("add", add);
}
- We will build a shared library with the preceding code, which will create a .dll or .so file. We will be able to use this library with Python by using the import command:
>>> import math_ext
>>> print math_ext.add(1,2)
3
As seen in the preceding example, the Boost.Python library is pretty easy to use and is a comprehensive library. It allows us to perform practically anything the C-API provides but in C++. With this package, we do not have to write C-API code, and when we bind code, either it compiles perfectly or fails.
If we already have a C++ library to bind, it's undoubtedly one of the most acceptable options currently available. However, when we simply need to rebuild a simple C/C++ code, Cython is recommended.
Cython
The Cython programming language is a Python superset that enables programmers to run C/C++ functions and declare C/C++ types on variables and class properties. This allows the compiler to build C code from a highly efficient Cython code. The C code is created once and then compiled with all significant C/C++ compilers. Technically, we write code in .pyx files, and those files are translated into C code, then compiled into CPython modules. Cython code can resemble standard Python (and pure Python files are valid .pyx Cython files), but it includes additional information such as variable types. Cython can create speedier C code by using this optional type. Both pure Python functions and C and C++ functions (and C++ methods) can be called from code in Cython files.
We are going to illustrate how to convert the add function into a more optimized function. This function will be compiled by a C/C++ compiler, and then we will use the function in regular Python code:
- Let's reuse the same example we used earlier with the add function, and we will save this code to add.pyx:
def add(a,b):
return a+b
add(3,4)
- Then, we create the setup.py file, which works like a build automation tool such as Makefile:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("add.pyx")
)
- We will build the Cython file by using the command line:
$ python setup.py build_ext --inplace
It will create the add.so file in Unix or add.pyd in Windows.
- We can now use this file by using the import command:
>>> import add
7
That's an example of how to compile C/C++ code based on Python code.
When designing Python bindings for C or C++, Cython is a highly complex tool that may provide you with a lot of power. It gives a Python-like technique for building code that manually manages the GIL, which may significantly speed up certain issues, but we didn't explore it fully here. However, because that Python-like language isn't precisely Python, there's a slight learning curve for figuring out which bits of C and Python go where.
Using ctypes/CFFI to accelerate Python code
ctypes is a tool in the standard library for creating Python bindings.
With this tool, we load the C library, and we call the function in the Python program. To create the Python bindings in ctypes, we can follow these steps:
- Load your library.
- Wrap the input parameters.
- Indicate ctypes as the return type of the function.
The fact that ctypes is part of the standard library gives it a significant edge over the previous tools. It also doesn't necessitate any further steps because the Python application handles everything. Furthermore, the principles employed are simple. However, the absence of automation makes increasingly complicated jobs more complex, which was not the case with the previous tools we saw.
The C Foreign Function Interface for Python is known as CFFI. Python bindings are created using a more automated method. We design and utilize Python bindings in a variety of ways using CFFI. There are two modes to choose from:
- API versus ABI: API mode generates a complete Python module using a C compiler, but Application Binary Interface (ABI) mode imports the shared library and interacts with it directly. It's challenging to get the structures and arguments right without using the compiler, and the API model is strongly recommended in the manual.
- Out-of-line versus inline: The difference between these two modes is a speed versus convenience trade-off.
The Python bindings are compiled every time a script runs in inline mode. This is useful since it eliminates the need for a second construction phase; however, it will slow down the software.
Out-of-line mode necessitates an additional stage in which the Python bindings are generated once and then used each time the application is executed. This is far quicker, although that may not be a factor.
Ctypes appear to need less effort than CFFI. While this is true for simple use cases, due to the automation of most of the function wrapping, CFFI scales to more significant projects considerably better than ctypes. The user experience with CFFI is also pretty different. You can use ctypes to import a pre-existing C library into a Python application. CFFI, on the other hand, generates a new Python module that can be loaded in the same way as any other Python module.
SWIG
Simplified Wrapper and Interface Generator (SWIG) is not like any of the other tools listed previously. It's a comprehensive tool for creating C and C++ bindings for various languages, not just Python. In some applications, the ability to develop bindings for many languages might be pretty valuable. It does, of course, come at a cost in terms of complexity. The configuration file of SWIG is pretty cumbersome, and it takes some time to get it right.
We illustrate the use of SWIG with the following code. Suppose we have some C functions we want to be added to Python:
/* File : math.c */
int add_1(int n) {return n+1;
}
int add(int n, int m) {return n+m;
}
The configuration file of SWIG is made by an interface file. We will now describe this interface.
Writing an interface file
With this method, we write an interface file that SWIG will use.
This is an example of the interface file:
/* example.i */
%module math
%{/* Put header files here or function declarations like below */
extern int add_1(int n);
extern int add(int n, int m);
%}
extern int add_1(int n);
extern int add(int n, int m);
We will now build a Python module in the following section.
Building a Python module
The last step to turning C code into a Python module is as follows:
unix % swig -python math.i
unix % gcc -c math.c math_wrap.c
-I/usr/local/include/python3.7
unix % ld -shared example.o example_wrap.o -o _example.so
We will use this module by using the import command:
>>> import math
>>> math.add_1(5)
6
>>> math.add(5,2)
7
We can talk about many other ways of using C/C++ in Python. This part aims to build an exhaustive list of all the ways of accomplishing the migration of a C++ library for Python use but to tackle the problem of speed that Python has by using a high-speed library.
Improving the speed of Python code in HFT
The critical components we defined during the previous chapters must run at high speed. Using any of the tools we described previously will help you create C/C++-like code and create performant Python code using libraries. It is essential to begin constructing a new algorithm in Python utilizing NumPy and SciPy while avoiding looping code by leveraging the vectorized idioms of both libraries. In reality, this means attempting to replace any nested for loops with similar calls to NumPy array functions. The purpose is to prevent the CPU from wasting time on the Python interpreter instead of crunching numbers for trading strategies.
However, there are situations when an algorithm cannot be efficiently expressed in simple vectorized NumPy code. The following is the recommended method in this case:
- Find the primary bottleneck in the Python implementation and isolate it in a dedicated module-level function.
- If there is a small but well-maintained C/C++ version of the same algorithm, you may develop a Cython wrapper for it and include a copy of the library's source code. Or you can use any of the other techniques we talked about previously.
- Place the Python version of the function in the tests and use it to ensure that the built extension's results match the gold standard, easy-to-debug Python version.
- Check whether it is possible to create coarse-grained parallelism for multi-processing by utilizing the joblib.Parallel class once the code has been optimized (not a simple bottleneck spottable by profiling).
Figure 10.3 depicts the function calls to C++ when there is a need for low-latency functions for HFT:
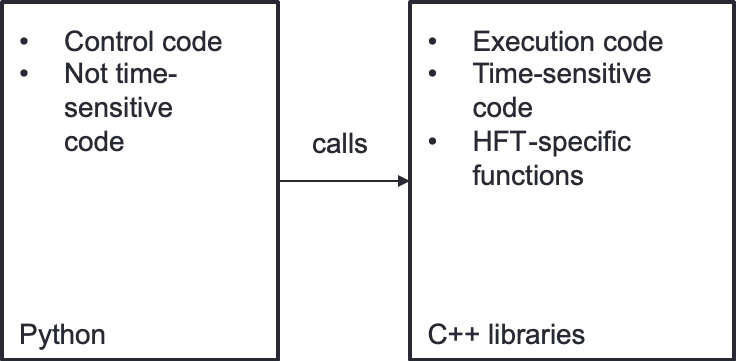
Figure 10.3 – Python and C++ interactions
The control code, which could be used to decide to liquidate a position, can be calculated in Python. C++ will be in charge of the execution of the liquidation by using the speed of these libraries.
The critical components include the following:
- Limit order book
- Order manager
- Gateways
- HFT execution algorithm
All these should be implemented in C/C++ or Cython.
Some companies that have compiler engineers invest in C++ code generation from Python. We will have a tool parsing Python code and generating C++ code in this situation. This C++ code will be compiled and run like any other code, and Python code, in general, can be used for coding trading strategies. Most people in charge of creating trading strategies have more Python skills than C++ knowledge. Therefore, it is easier for them to develop everything in Python than convert Python into C++ libraries used in the C++ trading system.
In this section, we learned how to improve Python code using C++. We will now wrap up this chapter.
Summary
In this chapter, we illustrated how to use Python in HFT. Python is not a language for performance and low latency, and we highlighted how to use other languages such as C++ to get to the same performance level. You are now capable of using any HFT-specific C/C++ code in your Python code.
We will now finish this book by opening up to some new topics in the next chapter, such as achieving less than 500 nanoseconds for tick-to-trade latency with Field Programmable Gate Array (FPGA), and opening HFT systems to cryptocurrencies.