
Many applications that exist today are written using unmanaged code, such a C, C++, and assembly, that runs directly on the system, meaning that the system has limited protection from what happens when the application executes. If the application wants to overwrite memory to which it doesn’t have access or leak all of the system resources, it can.
Managed code, on the other hand, is executed using the Microsoft .NET Framework Common Language Runtime (CLR). The CLR can protect the system by performing certain actions and verifications automatically for the application. For instance, it can handle the memory consumption by using a garbage collection, perform boundary checks on arrays, and guarantee type safety.
Using the .NET Framework and managed code greatly reduces exposure to some common security attacks, such as buffer overflows and memory leaks, but the key word is reduces, not eliminates. In no way does using managed code mean your application is free of security vulnerabilities. For instance, if the application written in managed code created a large array of Control objects, it could eventually consume all of the window handles on the machine.
Whereas several great books and other resources describe in detail .NET security, this chapter mainly focuses on specific security issues that can be found in managed code.
More Info
For more information about .NET security, see http://msdn.microsoft.com/library/en-us/dnanchor/html/anch_netsecurity.asp and the book .NET Framework Security by Brian LaMacchia, Sebastian Lange, Matthew Lyons, Rudi Martin, and Kevin T. Price.
In addition to discussing some of the myths surrounding managed code, we also briefly cover the basics of code access security (CAS), what to look for while performing code reviews, how to recognize luring attacks caused by using the AllowPartiallyTrustedCallers attribute, how privileges can be elevated by using exception filtering, and decompiling managed assemblies.
We have often heard developers and testers attest that their application is free of certain security vulnerabilities because it is written in managed code. Although using managed code can help reduce certain types of security vulnerabilities, it cannot guarantee that your application won’t have any. Several myths exist about preventing security issues by using managed code, and the following subsections show why these assumptions are not valid.
Whenever untrusted user data is supplied to an application, it can introduce security vulnerabilities. Testing for these vulnerabilities is covered in other chapters throughout this book. Even if the application uses managed code exclusively, basic security testing principles still apply. However, before we discuss the security issues that can be found in applications that use managed code, let’s dismiss some of the common myths about using managed code.
As discussed in Chapter 8, buffer overflows can lead to arbitrary execution of an attacker’s code. Although using managed code protects against the majority of buffer overflow issues found in applications, overflows in applications written in managed code are still be possible.
Managed code can have code that is unverifiable. Any code that is unverifiable has the potential of causing serious security problems like buffer overflows, garbage collection (GC) heap corruption, and violating the type system. When you use C#, the unsafe keyword must be used to declare a block of code as unverifiable. Other managed languages do not have an explicit unsafe keyword and may emit unverifiable code for some constructs by default.
Also, many applications are not written entirely in managed code. Instead, a managed application might interact with unmanaged code, such as by using a Component Object Model (COM) object. As such, an application written in managed code calling into unmanaged code using a COM interop, PInvoke, etc. can still cause buffer overflows, integer overflows, format string issues, and array indexing errors. Refer to the section titled Using Unverifiable Code later in this chapter for more information.
In Web application development, ASP.NET enables a programmer to design a Web page by using Web controls that automatically render the HTML, much like building a Microsoft Windows application. This enables the developer to create a complex Web page without having to write a lot of HTML. The developer can set properties on the Web controls that affect how the controls behave when users browse to the page. For example, the following code shows the values set for an image Web control.
this.exampleImage.ImageUrl = Request.QueryString("imageUrl");
this.exampleImage.AlternateText = Request.QueryString("imageText");It might seem that there are cross-site scripting (XSS) vulnerabilities in this code because the untrusted client input is used to set the value of the image’s properties. However, many of the ASP.NET controls automatically encode the values, such as the ImageUrl and AlternateText properties for an Image Web control. However, not all of the controls automatically encode the values. Take the following example:
this.exampleLink.NavigateUrl = Request.QueryString("linkUrl");
this.exampleLink.Text = Request.QueryString("linkText");If exampleLink is an ASP.NET HyperLink control, you might think that the control will automatically encode the values for NavigateUrl and Text like the image Web control did. However, the Text property for a HyperLink control does not automatically encode the value. Instead, the application should use the appropriate HtmlEncode method to prevent XSS vulnerabilities.
Chapter 10, goes into further detail on XSS attacks, and you can also refer to the book’s Web site for the list of ASP.NET controls and whether they encode or not. Use this list and the tips in Chapter 10 to help figure out where to look for these vulnerabilities—never assume that .NET controls don’t need to be tested for XSS bugs.
In programming languages such as C and C++, the developer must ensure any memory that was previously allocated is freed, which leads to many memory leaks in applications. Using the .NET Framework generally makes it easier to manage memory allocation and deallocation because both are handled by garbage collection. When resources aren’t needed any more, the CLR automatically frees the memory—or that is what might be expected to happen.
Managed code has the ability to call into unmanaged code to perform certain operations. For example, your application might call into a native Windows API to perform certain operations. If your managed assembly calls into unmanaged code that allocates memory for an object, how does the managed code know when or how to free the memory? It doesn’t, unless you explicitly handle cleaning up this memory.
Even if your application does not leak memory, managed code makes it easy to write badly designed code that could allow your assembly to consume all the system memory. These aren’t memory leaks, but could lead to poor application performance or denial of service attacks, such as those discussed in Chapter 14. Look at the following code example:
// Get untrusted data from user and split on semicolons.
string[] values = inputString.Split(';'),
foreach (string value in values)
{
// Create a new object and add to list.
AddToList(new HugeMemoryStructure(value));
}In this example, user input is used to create an array of strings by splitting the input on semicolons. The code then loops through the array of strings and constructs a new object and adds it to a list. Because each semicolon causes an object to be created and added to a list, it makes it easy for an attacker to consume a lot of memory by providing an input string of several semicolons. Do not assume using managed code obviates the need to test for resource starvation attacks.
The .NET Framework provides some really useful libraries that enable your code to access databases. SQL injection vulnerabilities are caused when user input is used when constructing SQL statements that allow the logic of the statement to be modified in undesirable ways. If your application is using managed code to access a database, it is still susceptible to SQL injection attacks. Chapter 16, explains and shows how to test for SQL injection, and includes examples that illustrate that managed code is still vulnerable.
Code access security (CAS) is an extremely effective way to help protect your application at the code level, but implementing CAS properly often can be a daunting task. Although an in-depth analysis of CAS is beyond the scope of this chapter, we do provide a basic description to enable you to understand the security vulnerabilities that are common in applications using managed code. If you are already familiar with CAS, you might want to skim through this section or skip to the next section.
Other than being able to develop a powerful application quickly, one of the benefits of using managed code is that the .NET Framework has the ability to protect resources by using CAS. Chapter 13, discusses granting users permissions to certain resources; however, CAS is able to remove privileges an application has to system resources. For instance, imagine an application that needs only to read and write to a single file. At the system level, permissions can be set on the file to grant only certain users access to the file. If the application is written in managed code, additional security measures could be used to grant the application Read and Write permissions to that single file. If there happens to be a canonicalization bug (covered in Chapter 12), the .NET Framework will prevent the code from accessing any other file than what is allowed.
Figure 15-1 illustrates the basic user security model using unmanaged (native) code. The operating system knows whether the user has permission to the binary executable file that is trying to be accessed to launch the application. When both the user and object permissions match, access is granted. If the user has permission, the unmanaged binary executable can be extremely powerful and potentially can run malicious code.

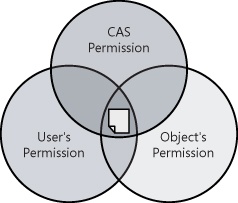
Using managed code, CAS can isolate a user from the effects of running potentially malicious code, even if the user is an administrator. Figure 15-2 shows that a user can have permissions to an object and the application’s CAS permissions can restrict access to that object. For the application to access other objects, such as a network resource, separate permissions for those resources must also be granted.
Once an assembly is compiled using the CLR and deployed to a location on the target machine, the next process is to execute the assembly. When the application is first launched, CAS is used to determine the permissions. Figure 15-3 gives a high-level overview of the interactions between an executing managed assembly and code access security.
The assembly in Figure 15-3 is loaded into the CLR when it is executed. CAS then determines all of the information about the assembly to construct evidence. The evidence and the policy the application is running under, which is set by the system administrator, are then used to figure out the code groups for the assembly. The CLR code group security authorization process (which is discussed in more depth in the section titled Code Groups later in the chapter) uses this information to finally determine which permissions are granted for the application. During the execution of the application, any resource or access that requires permission is verified by using CAS. Also, it is possible for an application to use CAS to further restrict or grant permissions for any code it then executes; however, it can grant only the permissions it has and no more.

Now let’s look at some of the individual components of the .NET Framework and CAS that are used to help secure an application.
Managed code is compiled into an assembly. In short, an assembly contains the assembly manifest, type metadata, Microsoft Intermediate Language (MSIL), and a set of resources. From a security perspective, permissions are granted and requested at an assembly level. You can read more about .NET assemblies at http://msdn.microsoft.com/library/en-us/cpguide/html/cpconcontentsofassembly.asp.
One of the great benefits of the .NET Framework is that a CPU-independent application can be written in any of the .NET languages, such as C#, VB.NET, and J#, because the application’s managed source code is compiled into MSIL. MSIL is similar to assembly language in that it has instructions for processes such as managing objects, calling methods, accessing memory, and performing arithmetic and logical operations. Before the application can start, the MSIL is converted to code that is specific to the CPU architecture—native code. This compiling is usually done by the just-in-time (JIT) compiler, which is available on multiple platforms.
An assembly can also be signed with a strong name key, which ensures the assembly is uniquely identifiable. The strong name consists of a name, version number, culture information if provided, and a public key. In the .NET Framework 2.0, the strong name also includes the processor architecture: MSIL, x86, amd64, or IA64. For example, the strong name for the System.Security.dll that is installed as part of the .NET Framework 1.1 is as follows:
System.Security, Version=1.0.5000.0, Culture=neutral,
PublicKeyToken=b03f5f7f11d50a3a, Custom=nullThe strong name is generated using the assembly and a private key. Unless the private key is compromised, the strong name of an assembly cannot be duplicated and the .NET Framework will perform security checks to guarantee the file has not been modified since it was built. Because of this integrity check, your application can use strong names as evidence to ensure they aren’t loading potentially Trojan assemblies that an attacker loaded onto the system.
After the assembly is loaded into the runtime, certain information, known as evidence, is extracted and presented as input to the system to determine the permissions the assembly is granted. Evidence is the characteristics that identify an assembly, much like a fingerprint identifies a person. The information that an assembly can provide as evidence include these:
Zone. Similar to the concept of zones used in Microsoft Internet Explorer (refer to Chapter 10 for more details on Internet Explorer zones)
URL. A specific URL or file location from which the assembly was downloaded, such as http://www.microsoft.com/downloads or file://C:Programs
Site. Site from which the assembly was downloaded, for example, www.microsoft.com
Strong name. An assembly’s strong identity
Hash. Hash value of an assembly using a hash algorithm such as MD5 or SHA1
Application directory. The directory from which the assembly was loaded
Authenticode signature. Digital signature with the publisher’s certificate
An assembly also can have custom evidence, such as a simple checksum of the assembly or the date the assembly was created. The custom evidence can be supplied by the host application or in any user code that loads the assembly. When the assembly is loaded, the evidence is computed in real time, meaning the evidence can change even if the assembly doesn’t. For instance, if you execute an assembly from a particular directory, it might result in different permissions than if you ran it from another directory.
The .NET Framework defines numerous permissions that are used to protect a resource or action. Here are several examples of common permissions that can be found in the .NET Framework:
EnvironmentPermission. Controls access to environment variables
FileIOPermission. Controls access to files and folders
PrintingPermission. Controls access to printers
ReflectionPermission. Controls access to an assembly’s metadata through reflection
RegistryPermission. Controls access to the registry
WebPermission. Controls access to HTTP resources
Most permissions can be further defined by using parameters. For example, instead of granting an application FileIOPermission, the application can also specify the type of access that is granted: Read, Write, Append, and PathDiscovery. In addition, the FileIOPermission allows the path of the file or folder to be specified, so you can restrict an application to being able to read only a single file, as the following C# example shows:
// Allow method to read only the file C: est.txt. [FileIOPermission(SecurityAction.PermitOnly, Read = "C:\test.txt")]
The example specifies the PermitOnly security action, which is discussed later in the chapter, and restricts the code to being able to read only the file located at C: est.txt. If the code attempts to read any other file, a SecurityException would be thrown. Also, the example uses the declarative style, which is expressed at compile time and is scoped to an entire method, class, or namespace. On the other hand, an imperative style can also be used to allow more flexibility because it is calculated at run time. For example, the path might need to be determined programmatically, such as by using the following C# code:
// Restrict the caller to reading only the temp file, which was
// determined at run time.
FileIOPermission filePerm =
new FileIOPermission(FileIOPermissionAccess.Read, tempFile);
filePerm.PermitOnly();
ReadFileData(tempFile); // Do some read operation on the file.
FileIOPermission.RevertPermitOnly(); // Remove the PermitOnly permission.Note
It is generally recommended that you use the declarative style if at all possible since it is expressed in the assembly’s metadata. Doing so makes it easier for tools to check the permissions in an assembly. Of course, if the permissions need to be calculated at run time or scoped to just a portion of the code, imperative style should be used.
A policy is actually an XML file that describes the permissions that are granted to assemblies. There are four policy levels, of which two can be configured by an administrator and used to determine the permissions that are granted to an assembly. Listed in order from highest to lowest they are as follows:
Enterprise. Used to set policy at the entire enterprise level
Machine. Used to set policy for code that runs on the machine
User. Used to set policy for the current user logged on to the machine
Application Domain. Used to set policy of an assembly loaded by an application
Generally, an administrator can only configure the Enterprise and Machine policies, but normally can’t control the User or Application Domain policy. When the policy is evaluated, it starts with the permissions granted at the Enterprise level, then intersects those permissions with the ones at the Machine level, then intersects the resulting permissions with the User level, and finally intersects the policy on the Application Domain (if used). An Application Domain (AppDomain) can be used by an application to control the permissions that are granted to any assemblies it might load. By combining the permissions at each level from high to low using an intersection, the resulting permissions will never be higher than that granted by the previous level.
Figure 15-4 shows an example of how permissions from each level are intersected to determine the resulting permissions. Each policy consists of code groups that are used to determine the resulting permissions granted to an assembly.

A code group is a building block for policy trees that consist of two parts:
Membership condition. A membership condition is the checks done on an assembly based on the evidence that was collected. For example, an ASP.NET Web application might have UrlMemberShipCondition that is based on the URL of the application. For additional membership conditions defined by the .NET Framework, refer to http://msdn.microsoft.com/library/en-us/cpguide/html/cpconCodeGroups.asp.
Permission set. The permission set is the collection of permissions that are granted to an assembly when its evidence matches the membership condition.
Because the code groups in a policy act like a filter, permissions are granted once the condition is met. However, what happens if more than one condition can be met? A policy is evaluated in hierarchal order as the code groups appear. If a policy has multiple code groups, the first one in the policy XML is evaluated before the last one is. If an earlier code group matches the condition first, the permission set for that code group will be granted. During the evaluation, the code group can also determine how the permission set can be granted to the existing permission set using the following code group classes:
FileCodeGroup. Returns a permission set that grants file access to the application’s directory
FirstMatchCodeGroup. Returns a permission set that is the union of the permissions of the root code group and the first child group that is also matched
NetCodeGroup. Returns a permission set that grants Web Connect access to the site from which the application is executed
UnionCodeGroup. Returns a permission set that is a union of all the pervious matching permission sets
To understand policy and how code groups are used to determine the permissions granted to an assembly, look at the following policy file:
<configuration>
<mscorlib>
<security>
<policy>
<PolicyLevel version="1">
<SecurityClasses>
<SecurityClass Name="NamedPermissionSet"
Description="System.Security.NamedPermissionSet"/>
</SecurityClasses>
<NamedPermissionSets>
<PermissionSet
class="NamedPermissionSet"
version="1"
Unrestricted="true"
Name="FullTrust"
/>
<PermissionSet
class="NamedPermissionSet"
version="1"
Name="Nothing"
Description="Denies all resources, including the right to execute"
/>
</NamedPermissionSets>
<CodeGroup
class="FirstMatchCodeGroup"
version="1"
PermissionSetName="Nothing">
<IMembershipCondition
class="AllMembershipCondition"
version="1"
/>
<CodeGroup
class="UnionCodeGroup"
version="1"
PermissionSetName="FullTrust">
<IMembershipCondition
class="UrlMembershipCondition"
version="1"
Url="$AppDirUrl$/bin/*"
/>
</CodeGroup>
</CodeGroup>
</PolicyLevel>
</policy>
</security>
</mscorlib>
</configuration>In this sample policy file, two permission sets, called Nothing and FullTrust, are defined in the System.Security.NamedPermissionSet assembly. The first code group in the policy sets the permission to Nothing on all of the assemblies by having the membership condition AllMembershipCondition. That root code group has a child code group that unions the current permission set, which is now Nothing, with the permission set FullTrust for any applications that have a URL starting with the bin folder in the application’s directory. For example, using the URL http://localhost/bin/sample.aspx, sample.aspx will be granted FullTrust. As you can see, the policy used the value $AppDirUrl$ to specify the application’s directory URL and the asterisk (*) to indicate a wildcard for any applications running under the bin directory.
Code that is fully trusted (FullTrust) means exactly what the name implies—you trust the code 100 percent. Managed code that is running as FullTrust has the ability to do anything on the system, such as call into unmanaged or native code, access random memory locations, use pointers, and manipulate any file. An assembly that is fully trusted can be called only by other managed code that is also fully trusted, unless the assembly is marked with the AllowPartiallyTrustedCallers attribute, which is discussed in the later section titled Understanding the Issues of Using APTCA. By default, applications that are installed locally are fully trusted.
The CLR provides a great security system for partially trusted code, which is essentially code that is running with reduced permissions. The level of permissions that partially trusted code has is somewhere between FullTrust and no trust. The system has several policies to control the trust level for an application. For example, if you attempt to execute an application from a network share or from the Internet, by default the application will be partially trusted and probably won’t execute unless it was designed to work in a partially trusted environment because it will attempt to access a resource it doesn’t have permission to.
The .NET Framework allows code to execute in a sandbox, meaning the assembly that is loaded is granted limited permissions. The main idea behind using a sandbox is to reduce what the code is capable of doing. After all, why allow code to access the registry if it does not need to? An administrator can use policy at run time or a developer can use an AppDomain at development time in order to reduce the granted permissions of an application. For example, applications running under the ASP.NET worker process are executed in an AppDomain. An ASP.NET Web application can run with less than full trust by using one of the predefined trust levels in a policy file. By default, ASP.NET has five security policies that grant different permissions: Full, High, Medium, Low, and Minimal. The concept of sandboxing is similar to running an application with least privileges, which is discussed in Chapter 13.
Important
Similar to running applications with least privileges, an application that grants only the minimal permissions it uses can help mitigate security risks. PermitOnly and Deny are often used to create a virtual sandbox, but they do not achieve this effectively. If you are sandboxing potentially hostile code, use a separate AppDomain with the Internet permission set or some subset thereof instead.
Systems with the CLR also have the global assembly cache (GAC), which stores .NET assemblies that are designated to be shared between several applications. For example, you might have a new and efficient compression library. Applications that use the compression library are responsible for deploying the library, but sometimes it might be more desirable to install all such libraries in a common place. The GAC can be this common repository of shared libraries, but it should be used only if it is absolutely needed. Assemblies that are installed to the GAC must be strong named and also must execute as FullTrust by default—meaning the code is highly trusted.
At this point, you might be wondering how the CLR ensures that the calling code has the correct permissions needed to access a resource or perform an operation. It does this by performing a stack walk and comparing the permissions of the caller and the AppDomain to the permission that is needed. This notion of checking the caller for a particular permission is known as a demand. The CLR can perform three types of demands: full demands, link demands, and inheritance demand.
A full demand performs an entire stack walk and checks each caller to make sure it has the permissions needed. Figure 15-5 shows how the CLR checks for Permission X in each caller.
Assembly A calls a method in Assembly B that eventually calls all the way into Assembly D, thus triggering the stack walk to check for Permission X.

Because a full demand can affect performance, the code can be optimized to perform fewer stack walks, such as by using a link demand. However, not checking all of the callers introduces a security risk that must be tested thoroughly, as discussed in the section “Problems with Link Demands” later in the chapter.
Unlike a full demand, link demands check the permissions only on the immediate caller. They are performed at JIT compilation, meaning you cannot imperatively do a link demand during code execution. In Figure 15-6, Assembly A is fully trusted and calls a method in Assembly B, which needs Permission X. Assembly B has a link demand for Permission X, so it checks whether the caller is granted Permission X. In this case, Assembly A also has the correct permission, so the link demand succeeds.
If Assembly A is partially trusted, it might not have Permission X, so when Assembly B performs the link demand for Permission X, it will fail, as shown in Figure 15-7.


Assembly A starts by calling a method in Assembly B. Because Assembly B has a LinkDemand on it, the demand is checked with Assembly A is JIT complied. Because Assembly A does not have Permission X, the call will not succeed.
An inheritance demand is applied to a class that wants to make sure any derived classes have the specified permission. This demand prevents malicious code from deriving from another class. For instance, if Class A is protected by an inheritance demand, Class B can not inherit from Class A if it is not granted that permission. You can use only the declarative style for an inheritance demand.
In the previous section, you saw how CAS can cause a stack walk to check whether callers have a particular permission. You can also alter the behavior of the security checks by using stack walk modifiers, which can cause the stack walk to stop for later callers, deny a particular permission, or allow only a particular permission. From a security perspective, a developer needs to use stack walk modifiers with caution because they can cause security vulnerabilities. The following methods are used to override the security checks during a stack walk:
Assert
Deny
PermitOnly
Using assert essentially stops the stack walk from checking the rest of the callers if they have the permission demanded. The code that asserts declares that any of the callers should be trusted with the permission asserted. The code cannot assert for a permission it does not have, and the asserting code must be granted the permission that is being asserted and also must have the Assertion flag for SecurityPermission; otherwise, the security check will fail. Figure 15-8 shows that a partially trusted Assembly A can call a method in Assembly B.

Using deny is a way to prevent code from accessing a resource or performing an action that requires a particular permission. When a deny is used, any callers downstream that cause a demand for that permission will not be granted access, even if all the callers have permissions for the resource. Figure 15-9 shows Assembly A calling a method in Assembly B, which then denies Permission X and calls a method in Assembly C. Assembly C does a demand for Permission X, so the CLR checks the callers, which fails because Assembly B denied Permission X.

However, denying permission does not block any downstream callers from asserting for that same permission. Thus, if a caller asserts for a permission that was previously denied, the security check will succeed and permission will be granted, as shown in Figure 15-10. Even though Assembly B denied Permission X, the assert in Assembly C for the permission causes the stack walk to stop there and the method call to succeed.

PermitOnly is similar to using deny, but instead of denying a particular permission, PermitOnly grants only the permission specified and denies all other permissions. Figure 15-11 shows how the method call in Assembly A fails because Assembly B uses PermitOnly for Permission X, but Assembly B does a demand for Permission X and Permission Y. Like deny, any callers downstream that have the correct permissions can also override the PermitOnly and grant more permission than the assembly doing the PermitOnly might expect. Rather than use PermitOnly, use policy and AppDomains to guarantee that all of the callers have only the specified permissions.

When performing a code review of managed code, you can look for several items to find security problems. In this section, we cover some of the most common security issues you might find during code reviews of managed code. Luckily, several available resources can help you perform a security code review, such as http://msdn.microsoft.com/library/en-us/dnpag2/html/SecurityCodeReviewIndex.asp. Many times, guides such as these are geared toward the developer. However, by knowing which guidelines a developer should follow, you can more easily detect security weaknesses when a developer doesn’t follow them.
In addition to manually performing code reviews, FxCop (http://www.gotdotnet.com/team/fxcop) is a tool that analyzes .NET managed code to make sure the assembly adheres to the Microsoft .NET Framework Design Guidelines. It can inspect assemblies for several types of flaws, and it also has some great security checks. If your developers aren’t already using FxCop during the development process, their applications are likely to have security issues that can be found easily using the tool. Of course, you can run this tool yourself to find the flaws—attackers certainly will.
Even if your developers are using FxCop, they can suppress warnings and even turn off entire rules. For instance, to disable a FxCop message, the SuppressMessage attribute can be used. But, FxCop can still be used to find the violations. Any place in code that a developer suppressed a message, especially a security message, you should take a closer look at the code to make sure the developer wasn’t suppressing the message to avoid having to figure out how to revise the code to be more secure.
The rest of this section discusses other security risks that can be found by reviewing the managed source code, such as the following:
Calling “unsafe” code
Problems with asserts
Problems with link demands
Poor exception handling
Any code with a security bug is considered unsafe. In this section, however, we refer to unsafe code specifically as code in which the following types of conditions occur:
Using unverifiable code
Using Win32 (APIs)
Marshaling data
If an application written in managed code calls unsafe code, the chances of a security problem increase because the CLR cannot adequately protect the system once unsafe or native code is introduced. When an attacker’s data is used when calling into unsafe code, the probability of a security vulnerability increases even more.
As mentioned earlier in the “Myth 1” section, an application written in managed code can actually define code that is unverifiable. Normally, managed code is verified by the CLR to check for such items as type safety and memory management. By declaring code as unsafe, the CLR will not verify the code. Thus, it is up to the developer to make sure the code does not introduce any security risks—and it’s up to the tester to verify this.
For the application to compile unverifiable C# code, the /unsafe compiler option must be specified. Then, an application can define a whole method using the unsafe modifier, such as this:
private unsafe void UnsafeFunction (byte[] data, int size)
{
// "Unsafe" code can cause a buffer overflow.
}Also, the application can define a block of code as unsafe using the following syntax:
private void AnotherUnsafeFunction(byte[] data)
{
unsafe
{
// "Unsafe" code block can also cause integer overflows.
}
}Any code inside the unsafe block is more susceptible to buffer overflows, integer overflows, format string problems, and even out-of-bound errors for arrays; however, it does not mean that it contains those bugs. An unsafe block just means that pointers can be used to access memory, which can lead to security problems.
Testing for buffer overflows is discussed in Chapter 8, but you can also see whether your application compiles using the /unsafe option and review all of the unsafe code blocks for security issues.
It is possible for managed code to call functions that are exported from an unmanaged dynamic-link library (DLL). The CLR also won’t verify any unmanaged code that your application might call into. Just like when using the unsafe code block, calling unmanaged APIs from managed code means your application could be vulnerable to attacks, such as buffer overflows. Unmanaged APIs are called through a platform invoke, also called PInvoke.
To PInvoke a Win32 API, System.Runtime.InteropServices.DllImport is used, such as in the following example:
[System.Runtime.InteropServices.DllImport("advapi32.dll")]
public static extern bool ConvertStringSidToSid(string stringSid,
out IntPtr sid);Because some APIs are designed under the assumption that the caller is responsible for the sanitization of the input, they might not handle untrusted input in a secure fashion. If the attacker can ever supply data to the APIs, appropriate data validation should be done prior to calling the API. If your application uses PInvoke to call a Win32 API, you should see whether data from a potential attacker is ever used when calling the API and test any data validation prior to calling the API. Normally, attacker-supplied code cannot call these APIs because there is a demand for the UnmanagedCode permission to make sure that all of the callers have the necessary permissions to call into these APIs. However, much like an assert can be used to stop a call stack from verifying all of the callers, the application can also use the Suppress-UnmanagedCodeSecurity attribute to disable the demand for the permission. If you find code that uses this attribute, investigate further. Managed code can also call into native code using COM interoperability or the “It Just Works” (IJW) mechanism. Refer to http://msdn2.microsoft.com/en-us/library/ms235282.aspx for more information on how to call native functions from managed code.
Any time data is going back and forth between COM objects and managed code or a PInvoke is used, there is an opportunity for the data to be handled improperly. When an attacker controls this data, a security vulnerability is highly probable. If you are familiar with different programming languages, you already know different data types can be used. Marshaling data refers to converting or copying the data so that something else can use it properly. For example, if your managed code uses a COM object that passes a complex data type in a method, the data needs to be represented in a way that both the managed code application and COM object will understand. Mixing programming languages means the data needs to be marshaled to convert from managed to unmanaged types.
Watch out for ways that data can become mangled when the wrong types are used in marshaling. For instance, if the API takes an int and the developer uses a System.UInt32, there is a chance of an integer overflow. You can also search the source for code that uses the Marshal class, which provides several powerful methods that can deal with unmanaged memory and types.
Pay special attention to any code that asserts a permission. Recall that an assert stops the CLR from walking the call stack to verify any additional callers. The following are a few issues you should look for when an assert is used:
Complement an assert with a demand
Don’t assert too much permission
Reduce the scope of the assert
If any of these items are not handled properly by the application, a security bug is likely.
Because an assert vouches for a permission of the calling code, the application should also verify the permission of the caller, which can be done by using a demand for another permission. However, it can be difficult to determine which permission to demand. Obviously, if the application demands a permission that is already granted (or that can easily be granted), the demand will not be effective.
For instance, which permission should the application demand if it needs to assert for the FileIOPermission? The answer varies, actually. Some applications will demand a custom defined permission specific to the application. Or an application might simply check to make sure the caller has a strong name identity. If you see an assert without an appropriate corresponding demand, be sure to check whether you can always trust the caller of the function where the assert is granted for the permission.
The following example can help clarify this issue:
[FileIOPermission(SecurityAction.Assert, Unrestricted=true)]
public void CopyFile(string source, string destination)
{
...
}If this method is in a public class on an assembly marked APTCA (which uses the AllowPartiallyTrustedCallers attribute), an attacker is able to call the CopyFile method from untrusted code to copy files. (APTCA issues are covered in more depth later in this chapter.) Here, you can see how a developer might protect untrusted callers from using the method. In the following code, a demand for a custom permission is made prior to asserting the FileIOPermission:
[CustomPermission(SecurityAction.Demand, Unrestricted=true)]
[FileIOPermission(SecurityAction.Assert, Unrestricted=true)]
public void CopyFile(string source, string destination)
{
...
}As long as CustomPermission is a subclass of a CodeAccessPermission object and implements the IUnrestrictedPermission, only callers that have been specifically granted that permission in their policy will be allowed to call CopyFile. By default, all FullTrust callers are granted the custom permission. Other demands can also be used, such as the StrongNameIdentityPermission; however, you should make sure the demand isn’t for a permission that is easily obtained. For example, the default Machine policy has a code group for assemblies executed from the Internet zone that grants the FileDialogPermission. Thus, if that permission protects CopyFile that is used by untrusted callers, it wouldn’t work well because code executing from the Internet zone is already granted the FileDialogPermission.
If your application’s code only needs to read a file, it shouldn’t assert permission for reading and writing to a file. Never assert more permissions than are needed. Imagine if there is a flaw in the application that allows an attacker to call into your assembly. Code that grants only the least permissions necessary reduces the scope of damage the attacker could cause.
A good indication that an application is granting too broad a permission is when any of the following assert attributes are used:
All
Unrestricted
Unmanaged
As mentioned earlier, an assert can be declarative or imperative. A declarative assert affects the entire method and indicates a problem. Typically, there is no reason for an assert to span multiple lines of code. Take a look at the following code that uses a declarative assert:
// Assert the RegistryPermission.
[RegistryPermission(SecurityAction.Assert, Unrestricted=true)]
public static void RegistryTest(string untrustedInput)
{
string keyPath = "Software/" + untrustedInput;
RegistryKey key = Registry.CurrentUser.OpenSubKey(keyPath);
DoSomethingWithRegistry(key);
key.Close();
}Aside from some of the fairly obvious problems with this code, such as untrustedInput not being checked for null, what else is wrong? Well, no exception handling is done when calling OpenSubKey, and an exception could occur in DoSomethingWithRegistry that would cause key.Close()not to be called. This situation would result in a leaked handled, and could cause a denial of service. Also, if any malicious code could be injected when calling DoSomethingWithRegistry, it would be granted the unrestricted RegistryPermission. This chapter discusses exception filtering later in the section called Recognizing Poor Exception Handling, which could be used to elevate the permissions of the calling code.
An imperative assert for the RegistryPermission could help avoid this security bug. Anytime you see an assert that is scoped to the entire method, question why and push for the scope to be reduced to just the code that actually needs the permissions. If imperative asserts are used, make sure the code calls CodeAccessPermission.RevertAssert.
As mentioned earlier, link demands check the immediate caller for the requested permission. A lot of times, for performance reasons developers use a link demand instead of a full demand that causes an entire stack walk. However, because a link demand does not verify all of the callers, it also poses a security risk. The main problem with using a link demand is that it can be bypassed easily and unknowingly. The following sections describe how.
Because a link demand enforces that only the immediate caller has the permission needed, another public method in the same or a fully trusted assembly might be able to expose the same functionality. The following C# code is an example:
public class SecurityHazard
{
...
[FileIOPermission(SecurityAction.LinkDemand, Unrestricted=true)]
public void WriteFile(string filename)
{
// Write data to the file.
...
}
}
public class BuggyClass
{
private string filename;
public BuggyClass(string filename)
{
this.filename = filename;
}
public void Initialize()
{
SecurityHazard hazard = new SecurityHazard();
hazard.WriteFile(this.filename);
}
}In this example, an attacker could bypass the link demand for the FileIOPermission by creating a BuggyClass object with a path to a file and then calling the Initialize method. Because BuggyClass is in the same assembly, the link demand will succeed as long as the assembly is granted the FileIOPermission. To prevent this bug, BuggyClass needs to promote the LinkDemand for the FileIOPermission or the access modifier for Initialize changed to internal if it shouldn’t be called by other assemblies.
To find these issues during a code review, do the following:
Look for all the link demands.
For each link demand, identify the member that is protected by the LinkDemand, and identify all code using the member.
If the code that uses the member with the LinkDemand is accessible to another assembly, ensure the member promotes the link demand or the caller has permission.
Obviously, this can be a fairly tedious task and can easily lead to an oversight. Instead of a manual code review, you can enable the FxCop rule UnsecuredMembersDoNotCallMembersProtectedByLinkDemands to catch these issues.
Similar to using a public method that calls the method that does the link demand, a method that implements an interface can allow the link demand to be bypassed if the method is accessed through the interface instead. For example, say an assembly has the following interface and class:
public interface IByPassLinkDemand
{
void DoSomething(string);
}
public class SecurityHazard : IByPassLinkDemand
{
...
[FileIOPermission(SecurityAction.LinkDemand, Unrestricted=true)]
public void DoSomething(string filename)
{
...
}
}Even if all of the callers of DoSomething promote the link demand, a malicious user can still bypass the permission check by accessing the method through the interface. The following code shows how this is accomplished:
public void DoSomethingMalicious()
{
SecurityHazard hazard = new SecurityHazard();
// If the following is uncommented, it throws a security exception.
//hazard.DoSomething();
// However, the following causes the link demand to succeed.
((IByPassLinkDemand)hazard).DoSomething();
}As you can see, using DoSomething by itself could not be called if DoSomethingMalicious is granted FileIOPermission. However, the malicious code is able to access DoSomething through using the IByPassLinkDemand interface. Because IByPassLinkDemand is defined in an assembly that has the FileIOPermission and does not LinkDemand the FileIOPermission for any of its callers, you can cast the hazard object to the interface and then call DoSomething.
For issues such as these, the method definitions in the interface must have the link demands as well. Alternatively, you can ensure that all the methods that implement the interface have a full demand on the methods. The FxCop rule VirtualMethodsAndOverridesRequireSameLinkDemands could be used to catch these issues.
Managed code generally uses exceptions to handle application errors. If an error occurs while a certain operation is performed, an exception is thrown. It is up to the application how the exception is handled. Exception handling is done using the try, catch, finally, and throw keywords. Look at the following ASP.NET example:
private void DoDivision()
{
string input = Request.QueryString("numerator");
// Ensure input has value.
if (String.IsEmptyOrNull(input))
{
// Throw an exception if argument is null.
throw new ArgumentNullException();
}
try
{
int result = Int32.Parse(input);
Response.Write("10 / {0} = {1}", input, result);
}
catch (Exception e)
{
Response.Write("Error occurred will trying to divide.");
}
finally
{
Response.Write("Finished calling DoDivision().");
}
}DoDivision gets a value from a URL QueryString, which an attacker could supply. It then does a simple check to make sure the value is not empty or null; if the value is empty or null, an ArgumentNullException is thrown. Next, the method attempts to parse the value as an integer. It will catch all of the exceptions that could have occurred during those operations and output an error message. Before the function returns, the code in the finally code block will always execute and print a message stating it is done.
Improperly handling exceptions can lead to different types of security vulnerabilities, such as these:
Elevation of privilege
Information disclosure
Improper exception handling can cause an elevation of privilege (EoP), not just of the user account the code is running as, but also of the permissions the code can execute. Remember, managed code offers code access security in addition to the user security provided by the system. For an exception to cause an EoP, the following conditions must be true:
The code must be elevating a certain privilege. For instance, the code could impersonate a different user to elevate user permissions.
An attacker must be able to cause an exception in the code that is elevating privileges.
For EoP of code access security, the attacker must also be able to execute code that calls into the application.
Suppose a piece of code changes the user context of the running code. This is commonly done by impersonating another account, or, in some cases, the application is already impersonating a user of low privileges and calls RevertToSelf to elevate its permissions to use the context of the running process. In either case, if the attacker is able to cause an exception when the application is running as a different user context, the attacker might cause an EoP. Look at the following sample code:
public void DoSomething(string untrustedInput)
{
SecurityContext securityContext = RevertToSelf();
try
{
PerformHighPrivilegeAction(untrustedInput);
}
catch (ArgumentException e)
{
LogException(e);
}
finally
{
securityContext.Undo();
}
}In this example, the code reverts to the identity of the process running (such as a service account) and performs an action that the user couldn’t have done. It also catches a specific exception and calls a method that logs it. But what happens if PerformHighPrivilegeAction throws a different exception other than ArgumentException? The finally code block that undoes the RevertToSelf is executed, right? Maybe. A technique known as exception filtering might allow the caller to handle the exception with its own code because the framework will walk up the call stack and look for the handler of the exception. For instance, an attacker might use the following code and handle the exception before the finally code block is called. Now, because the RevertToSelf isn’t undone, the attacker’s code is now running with the higher privileges.
public void MaliciousCode()
{
try
{
object.DoSomething(null);
}
catch
{
// Code execution is running at higher privileges.
...
}
}The same concept applies for EoP of code access security, and such EoP is probably more likely to occur, especially in a partially trusted environment like a Web application.
Look through the application’s source for places that elevate permissions, such as when changing the user context in which the code is running or when the application grants any permissions. Code that can cause an exception when the permissions are elevated must be reviewed to see whether the exception is handled by the application using a catch block. Otherwise, any malicious code that can cause the exception, will be able to catch the exception in their code—and the malicious code’s would have the elevated permissions.
An exception that is caught and logged out can contain a lot of useful information that, if disclosed, an attacker can take advantage of. Refer to Chapter 7, for more details on how an attacker might be able to use certain data for malicious purposes. For example, if a Web application catches all exceptions and does a Response.Write to output the error, the output might include sensitive information. Imagine if the Web application is making a database connection, and the SQL server connection information is disclosed if an exception occurs—especially if it outputs a connection string that includes the user name and password used to connect to the database.
Look at the exceptions that are caught and see what the application is doing with the exception information. Does it output the data to the user? Does the output contain sensitive information? Does it reveal the call stack? Because error cases aren’t always hit when testing an application, look through the code to determine what the error cases are doing and how an attacker might be able to trigger the code path to cause the exception.
As you know, the .NET Framework can protect certain resources, such as files or registry keys, from being accessed in managed code. Normally, an assembly that has a strong name and is fully trusted cannot be called by code that is not fully trusted—also known as partially trusted code—because the CLR automatically adds a link demand for the FullTrust permission on all public members in the assembly. This means only fully trusted callers are allowed to call the assembly. However, there are times when an application might want partially trusted code to call into the fully trusted code.
For instance, imagine you have a Web application that allows third-party customers to extend functionality by using your product’s fully trusted assembly, which is installed in the GAC. Although you could require the customer to install the third-party code into the GAC, doing so means that they must trust that those assemblies won’t do anything harmful to the system because code in the GAC has a lot of privileges. Instead, you might create a directory that is granted limited permissions in which third-party components can be installed. For those components to still be allowed to use your FullTrust assembly, your fully trusted and strong-named assembly must use the AllowPartiallyTrustedCallers attribute (APTCA) to suppress the link demand for the FullTrust permission.
Then, not only might your managed assemblies contain security flaws, but using APTCA allows partially trusted callers to call into your FullTrust assembly—meaning your code is more vulnerable to attackers. For example, an assembly that does not have file access might be able to use another assembly marked APTCA that does grant file access, allowing the assembly to be repurposed by the attacker. This type of attack is also known as a luring attack. Figure 15-12 shows how a partially trusted assembly attempts to access a file. As discussed earlier in this chapter, normally the CLR does not allow the partially trusted assembly to call the fully trusted assembly.

In this example, CAS prevents the luring attack because it checks whether Assembly B has permission for file access, and when that check passes, it checks next whether Assembly A has permissions for file access. The check fails because the partially trusted assembly doesn’t. However, recall the earlier discussion on stalk walk modifiers. Can you think of any ways that Assembly B can modify how CAS does the stack walk to grant file access permission to Assembly A? Assembly B could assert file access, which would stop the stack walk from checking whether Assembly A has permission, as shown in Figure 15-13.
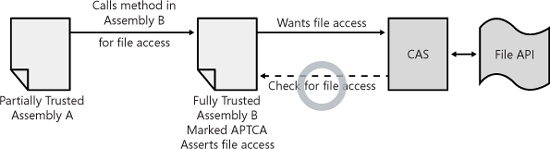
Figure 15-13. Fully trusted assembly marked APTCA asserts file access permission, allowing partially trusted assemblies to use the File API.
Also, the assembly might use only a link demand to protect the public method from being called. However, as discussed earlier, link demands can be bypassed. Figure 15-14 shows how Assembly C uses a link demand to ensure the caller has the needed permissions to perform an operation. Assembly B, which is marked APTCA, could wrap the operation in a public method that Assembly A could call. In this example, the partially trusted assembly is able to avoid the link demand and could potentially repurpose Assembly B to attack the system.

Figure 15-14. Fully trusted assembly using a link demand to check permission is bypassed when an assembly marked APTCA allows a partially trusted assembly to use the File API.
One of the biggest misconceptions about this type of luring attack is that it is difficult for an attacker to get a user to execute partially trusted code on the victim’s machine. After all, an attacker can’t place malicious code on the victim’s machine without the consent of the user or administrator, correct? Not exactly true! Walk through an example of how this can be done:
You install an application that installs an APTCA assembly into the GAC.
The APTCA assembly has a public method that allows it to write to a file on the hard disk drive that is used to store your music playlist of a given name.
That method does a declarative assert for the FileIOPermission using the Write security action so that any callers can also create the playlist file as expected, meaning the assert is scoped at the method level.
A malicious attacker realizes this common APTCA assembly has this public feature that writes the playlist file to the hard disk, but the public method appears that it only writes to a special path. After some further investigation, the attacker discovers there is a canonicalization bug (refer to Chapter 12) when the playlist name is specified that allows the attacker to write to any file or folder on the hard disk. Now, the attacker crafts the exploit.
The attacker creates a Windows UserControl using the .NET Framework. In the constructor, the attacker calls into the APTCA assembly to write a file of choice to the hard disk.
The attacker then sends you a link to the attacker’s Web site and lures you into browsing to it—with a little bit of social engineering, this isn’t as hard to do as you might think.
Upon visiting the malicious Web site, your browser automatically downloads the assembly containing the UserControl and instantiates the control by calling its constructor. Normally, a UserControl is run with very few privileges, especially without the FileIOPermission.
The attacker’s code in the constructor calls into the APTCA assembly, which asserted the FileIOPermission for write access, and the attacker can now write files to any place on your hard disk—not good! This bug might seem like a bug in the browser, but it is actually a bug in the APTCA assembly because it granted too many permissions to partially trusted code. Figure 15-15 illustrates how this happens.

Figure 15-15. APTCA assembly being loaded by a UserControl hosted in a browser, which allows an attacker to write any file to the victim’s machine
To understand this attack, consider why it actually works. First, any partially trusted code can call into an APTCA assembly. If no demands are done, the partially trusted code will have permissions to execute code. If the APTCA assembly does not assert the FileIOPermission, the demand for the FileIOPermission would not have been stopped from reaching the attacker’s assembly, thus preventing him in using the File API.
You might wonder how the code was even executed in the first place. Internet Explorer is capable of loading .NET UserControls into the browser, but normally these controls are granted the Internet permission set, which includes the Execute permission and a few more. The UserControl is automatically downloaded from a server and loaded in a Web page using the following syntax:
<OBJECT CLASSID="nameof.dll#namespace.class">
If the assembly is not already installed on the victim’s machine, it will be downloaded automatically as long as the DLL is located in the same folder as the Web page that caused it to load. The assembly can reference the APTCA assembly and just call its public methods. Do you think the browser will prompt the user to execute the assembly? Not in all cases, and even if it does, many people simply click Yes in most dialog boxes. As for managed controls, there is no prompting model; they either run or are blocked.
If your application has an APTCA assembly, look hard for luring attacks. This can be an extremely tedious and time-consuming task. Here are the questions to ask if your assembly is marked with APTCA:
How do you determine if an assembly is marked APTCA?
Why is the assembly marked APTCA?
What functionality does the public interface provide?
An assembly is marked APTCA by using the AllowPartiallyTrustedCallers attribute, so you could search the source for that string. It is declared using the following syntax:
[assembly: AllowPartiallyTrustedCallers]
Alternatively, if you don’t have access to the source code, you can use Microsoft IL Disassembler (ILDASM), which is included in the .NET Framework Software Development Kit (SDK), to look at the manifest information of the assembly. Figure 15-16 shows the manifest information for an APTCA assembly.
Really question why the assembly is marked APTCA, which by definition means that you intend for partially trusted callers to be able to use your assembly. If possible, APTCA assemblies should be avoided because they increase your attack surface and are challenging to test thoroughly.

If your application must have an APTCA assembly, carefully review the functionality that is available for an attacker to call into. For instance, FormatDrive should raise a huge flag if it is a public method on an APTCA assembly; however, that likely won’t happen. Think about what the method does and whether an attacker can potentially repurpose it for malicious uses. Refer to Chapter 18, and Chapter 19, for more information on repurposing attacks.
Also, often methods are marked with the public or protected access modifier because another class in the same assembly needs to use it. On the other hand, if the method is really intended only to be called by the same assembly, the method should be marked with the internal access modifier so it isn’t visible to other assemblies—unless the other assemblies can use ReflectionPermission, which is considered a high-privilege permission that should be granted only to trusted callers.
As mentioned earlier, testing APTCA assemblies can often be a tedious and time-consuming task. There really aren’t any tools that will indicate whether a method can lead to a luring attack. Instead, you need to find all of the places that attackers can call an APTCA assembly, and then determine whether a luring attack bug is present. Here are the basic steps to help you determine whether a luring attack bug exists:
Look for all the public objects on the APTCA assembly.
For each public interface, see if any permissions are being asserted. If so, this is an indicator that the method needs more attention because it is vouching for some permission for a partially trusted caller—which can potentially be attacker-supplied code. Methods that assert should also demand another permission.
For each public interface, determine whether there is any protection on calling the interface by using a link demand or a full demand. The permission that is being demanded shouldn’t be too generic where the attacker’s code might already be granted the case.
If the public method is using a link demand, see if the demand could be bypassed using the techniques discussed in the section Finding Problems with Link Demands.
Even if the public method might be demanding a permission, make sure no other callers expose the public method and end up granting the permission. For example, if the public method Class1::Foo() does a full demand for Permission X and public method Class2::Bar() ends up asserting Permission X, a vulnerability exists.
After checking all of the public interfaces and the call stack to see what an attacker has permission to access, think about what the attacker can do. Remember, a permission is used to protect a resource. If the attacker can gain access to the resource or cause a victim to perform operations, a luring attack bug exists that must be fixed.
You can also run the security FxCop rules on managed assemblies, which can catch most of the issues with an APTCA assembly. Luring attacks are a real security threat. Often, we have seen improper use of CAS that could lead to security bugs.
As mentioned earlier, .NET assemblies are compiled into MSIL. Because MSIL is then compiled by the CLR, generally it is easy to decompile an assembly to reveal something that almost resembles the original source code. When you are looking for certain types of security vulnerabilities, using a decompiler is extremely useful, for example, to find luring attacks by discovering which methods do a demand for a permission versus the ones that don’t. To make it harder for an application to be decompiled, the assembly can be obfuscated—a process that involves mangling the programming logic, but not changing the runtime behavior of the application. Chapter 17, discusses how a program can be reverse engineered to enable an attacker to discover the program logic that can be used to discover flaws in the software or even bypass certain security checks.
Since there isn’t just one type of attack that managed code introduces, below are several tips when security testing managed code that you should use when testing your application.
Run FxCop. FxCop is a great tool that can catch a lot of common coding errors. Be sure to enable all the security rules. Also, look at all of the places that use SuppressMessage to see whether the developer has a valid reason for suppressing the FxCop message.
Analyze all asserts. Because an assert stops the CLR from performing a stack walk on all the callers, determine whether an untrusted caller can call into the method doing the assert.
Limit the scope of an assert. There aren’t many reasons for an assert to span several lines of code. Sometimes developers use the permissions security attribute to apply the assert at the method level because that’s easier. If only one line of code needs the assert, scope it to just that one line. RevertAssert should also be used instead of allowing the assert to go out of scope.
Look for broad asserts. If possible, run with the least number of permissions needed for your application to execute. This tip is especially true for Web applications. If a Web application doesn’t need to run at FullTrust, choose another policy that reduces the permissions of the AppDomain. Also, most asserts can also limit access to resources. For instance, if you need to read only a single file, there is no reason to give all access to any file on the machine.
Look for luring attacks. If your application allows partially trusted callers to execute code, you should test for luring attacks. Start by analyzing all of the public interfaces that an attacker can call. If the method is protected by a link demand, see if the link demand can be bypassed. Methods that assert a permission should also demand a permission that trusted callers would have, but not an attacker, for instance, using a custom permission attribute.
Look for and review “unsafe” code. The /unsafe switch enables the application to use unsafe code when compiling. Review all unsafe code blocks.
Look for use of PermitOnly and Deny to sandbox code. Any code that uses PermitOnly and Deny in order to sandbox permissions should be considered a bug. Instead, the code should use a restricted AppDomain.
Verify that exceptions don’t disclose too much information. Because exception cases aren’t always hit when performing functionality testing, analyze the application’s exception code to see whether any sensitive data can be returned to malicious users.
Attempt exception filtering attacks. Look for places where permissions elevate an actual user’s privileges. Make sure that malicious code can not cause an exception in the code that can be handled in the attack’s code, which could cause elevating of permissions.
More Info
For more information about testing managed code, refer to the security checklist at http://msdn.microsoft.com/library/en-us/dnpag2/html/SecurityCodeReviewIndex.asp.
This chapter discusses the basics of code access security and some of the more common security vulnerabilities found in managed code. Applications written in managed code are not guaranteed to be free of security flaws. The security model of the .NET Framework definitely adds a layer of protection to the system by allowing an administrator to reduce the permissions for resources and limit the actions an application can perform. Code access security is a complement to the user security of the system; however, CAS also adds complexities that can introduce new security risks.