
XML Component Architecture (as it relates to DM)
Introduction
When people discuss XML, it is sometimes unclear exactly what they are referring to. XML consists of a growing number of architectural components that we will describe in this chapter. We start off with a description of the design goals, and how these goals influenced XML’s development. Understanding these design goals gives data managers insight into how XML is different, and how it has avoided some of the drawbacks associated with other technologies. Next, in a section called “What XML Is Not,” we further explore the most common issue that have caused confusion about XML. The next section describes the overall organization of the components, and how they evolved. The rest of the chapter is devoted to individual descriptions of the various components. Covered in this chapter are DTD, XML Schema, DOM, XPath, XLink, XPointer, XSL, XSLT, RDF, SOAP, WSDL, UDDI, and ADML—a veritable alphabet soup of XML acronyms. At the end of the chapter, you will have a more complete picture of the constellation of components, and you will understand what is meant when “XML” is referred to in various contexts, along with a solid list of capabilities it brings to the table.
Like many other technologies, XML tends to build on itself—the syntax acts as the foundation of the component architecture, which is built up through multiple levels, each addressing an area of functional need. Nearly all the various XML components are either built on the core XML syntax, or with it in mind. This is a very important point that will be illu-minated throughout the chapter. Building these new component technologies on top of an XML language-based foundation has a number of advantages:
1. Since XML is an open standard, new developments have something stable, open, and accepted to use as a foundation.
2. Since XML is a powerful data representation language, new technologies have ready-made facilities for expressing business rules, programming code structures, data structures, and for that matter any type of information that can be represented digitally.
3. The wide availability of XML-processing software means that if new technologies are constructed using XML, existing software such as parsers and processors may be of use in working with the newly created XML-based technologies.
4. XML tools and technologies that are created using XML will retain the advantages of XML as well as its stability and flexibility.
5. Vendors are discouraged from creating proprietary versions of XML because tools and technologies built on top of XML will not work. This will effectively prevent XML from suffering the fate of Java.
Since XML is widely used and still growing, the component list presented here does not cover every component that currently exists, but concentrates on the most important items as they relate to data management technologies. New development in the future will likely be centered on two distinct areas-refining existing components to better address evolving requirements, and creating components in areas where new needs are being discovered. In order to better understand where XML is coming from and how it avoids some of the pitfalls of other systems, it is a good idea to explore the design goals and how they affect the overall component architecture.
XML Design Considerations
When the core XML standard was created, mindful of the Java controversies, the creators began with a number of important design goals.* These design goals describe something akin to an “XML philosophy,” and help explain why XML was designed to permit developers a more stable basis on which to plan their development. The following are some of the ideas that went into the development of XML from a very early stage that have greatly affected how XML is used and the advantages it provides. XML’s design goals include the following:
![]() XML shall be straightforwardly usable over the Internet.
XML shall be straightforwardly usable over the Internet.
![]() It shall be easy to write programs that process XML documents.
It shall be easy to write programs that process XML documents.
![]() The number of optional features in XML is to be kept to the absolute minimum, ideally zero.
The number of optional features in XML is to be kept to the absolute minimum, ideally zero.
![]() XML documents should be human legible and reasonably clear.
XML documents should be human legible and reasonably clear.
![]() The XML design should be prepared quickly.
The XML design should be prepared quickly.
![]() The design of XML shall be formal and concise.
The design of XML shall be formal and concise.
Each of these goals is explained in the sections below.
XML shall be straightforwardly usable over the Internet
XML was designed in the era of the Internet, and its designers wisely decided that one way to maximize its usefulness was to make sure it was easily usable over the Internet. That meant taking steps to minimize the changes that would be required for server-side software to serve up XML. Today’s web servers require very little work in terms of additional configuration to serve up XML documents. The impact of this design principle on data managers is twofold. First, existing web-based data delivery systems will also require few or no architectural changesunless they were badly architected in the first place. Second, unimplemented XML-based data delivery systems will find that today’s servers are likely already equipped with tools and technologies that will greatly facilitate delivery of XML-based data structures.
Additionally, XML documents use a number of conventions that are already widespread in web-based information delivery. A good example of this is the use of URIs (Uniform Resource Identifiers). Rather than inventing a new way of referring to hosts on the Internet and to particular resources found on those hosts, as well as referring to which protocols allow access to the resources, the designers avoided reinventing the wheel by aiding Internet compatibility using existing tools, techniques and constructs. In many XML documents today, indicators that look much like World Wide Web URLs can be found. This means that XML can be implemented in existing delivery architectures without significant rearchitecting or recoding.
It shall be easy to write programs that process XML documents
In order for a language to gain widespread adoption, it must be as easy as possible to implement in just about any type of computing device. Much of the early experimental XML software was originally written in the Java programming language, but today, libraries or toolkits exist for XML processing and manipulation for just about every programming language in existence. Developers aggressively reuse these (often freely) available toolkits. As a result it is now very easy to “XML-enable” applications by simply reusing software that does most of the heavy lifting for the devel-oper automatically.
Figure 3.1 illustrates the role of the parser. “Parsers” may also be called XML “processors,” which can be confusing. To help clarify, we will describe two types of parsers. The first is typically used for low-level technical purposes, by taking XML-wrapped data and converting it into some internal data structure that can then be dealt with by a programmer. Generally, though, when we use the term parser, we are referring to a slightly higher abstraction of software—a software component that can be put on top of an existing system and that acts as something of an “XML gateway.” In this figure, we see that a parser might take data and wrap it in XML (as the case would be if the user were trying to export a volume of data for interoperability). The parser might also take existing XML documents that are intended for the system, and convert them into individual data items that would then be inserted at a lower level. For now it is sufficient to say that XML parsers permit data structures from an existing application to be wrapped in XML so that it can be reused by other applications that understand the XML structures. The implications of these capabilities for data managers are truly profound. This parsing technology forms the basis for enterprise application integration (EAI), and a number of other fundamental technologies. Still, it is important to keep in mind that the strength of the parser will be directly related to the strengths of the data structures with which it works.

XML has succeeded admirably with this design goal—software that processes it is proliferating rapidly. Software built around XML is currently running on supercomputers, desktop pes, and even embedded devices such as mobile phones and PDAs. The easier it is to write software for a language, the more compact the software tends to be, which makes it possible to deploy the software on just about any platform, from embedded devices with limited memory, to huge parallel machines. This proliferation of XML-enabled software means that the reach of data managers now extends to virtually any machine that can understand XML.
What constitutes a language that is easy to process? In the case of XML, it has several features that give it this property. First, XML is simply plain text represented in Unicode. Unlike some binary data formats that require reference books to indicate byte offsets and code numbering interpretations, since XML is plain text, users already have a text editor they can use to create sample documents for testing. Second, the grammar or organizing constructs of XML, or the elements that are considered legal in the language, are very simple. This makes it easy to create compact and easy-to-maintain software programs that parse and manip-ulate XML. This item is intimately related to another design goal, that XML should have as few optional features as possible, which will be discussed next.
The number of optional features in XML is to be kept to the absolute minimum, ideally zero.
This particular design goal came predominantly from XML’s heritage as the successor of SGML. Standard Generalized Markup Language had a reputation for containing many optional features, which tended to complicate the use of the language. The more optional features a language contains, the more difficult it is to create a working software implementation to deal with that language. While it’s true that optional features may provide multiple ways of doing the same or similar things, programmers and people who are interested in computer languages often refer to these options as “syntactic sugar”—they are sweet, and may be convenient to work with for a while, but they eventually rot teeth.
The similarities between XML and SGML prompt many people to comment that the base XML specification is essentially SGML relabeled with a new acronym and without many of the arcane features of the original. XML is a subset of SGML that is less complex to use. SGML processing has been around for a long time, so there is a wealth of experience and information from which to draw—ranging from programmers to the processing systems themselves. The inherent simplicity of XML creates opportunities for implementing uncomplicated, well-structured XML applications. It also encourages the XML itself to be processed in a straightforward manner.
When using XML, there is only one way to express an attribute name and value within a particular element. The author of the document has ultimate control over which elements and attributes appear in the document, but attributes and elements have to be specified in a particular way. When there is only one way to do something, it tends to be clear and unambiguous—the software does not have to choose between many different possibilities for representing the same structure. The learning curve is also important; the fewer optional structures a language has, the easier it is to learn. When a new structure or concept is learned, it can be reused in many different contexts. The one notable exception to this is the XML singleton tag, or empty tag. If an XML tag contains no child elements, it can be written either as “<tagname></tagname>” or as “<tagname/>”—both have the same meaning. This simplicity is a welcome development for data managers who can easily transfer what they know of data and information representation concepts to XML. They are then free to concentrate on getting the semantics correct—often the more difficult task.
XML documents should be human legible and reasonably clear
Documents encoded in XML have the unique and curious property of being understandable both to humans and machines. Since the documents are just plain text files, humans can usually open them using a variety of different software packages and read their contents quite easily. Furthermore, since the element names typically correspond to words in human language that hold meaning for human readers, it is usually quite easy for a human to read and understand an XML document, even if he or she is not previously familiar with the tagging structure. While there are some exceptions to this rule, such as when the author of an XML document uses a less common character encoding, many documents can be read using the simplest of tools.
As a design goal, the results of this are that XML documents are easy to create, test, and interpret for humans. Clarity of formatting also makes it easy for newcomers to quickly pick up the technology and start work instead of spending large amounts of time with reference books, documentation, and obscure examples. This design goal is critical for the adoption of XML—one of the reasons that HTML spread as quickly as it did was because it had this same readability and ease of use. Even people who would not necessarily consider themselves very computer savvy could quickly pick up HTML and start creating their own web pages. In the same way, users can quickly pick up and begin using XML for their own tasks.
There are two considerations of this design goal that are important for data managers. First, it will enable you to get the business users to finally agree on data names. Just tell them you cannot make their application use XML unless they first give you a name for the XML tags required. As an important related issue, data managers should adopt a proactive approach to XML adoption in organizations. In situations where they have not done this, it often happens that multiple groups implement XML differently, adding to an already confusing mess. None of the above addresses another obvious advantage—that XML tagged structures are much easier to read than structures that are not delivered with their own metadata.
One final item on XML readability—there is a lot of current hype about a subject called “XML security.” Certainly if an organization sends its data, and the meaning of that data, unencrypted over a variety of transmission devices, it will be much easier for industrial spies to “see” what is going on internally. But this is not an XML security problem—it is a bad system design. Many security concerns can be addressed with the judicious application of existing security measures. Because security is such an important topic, though, it should be pointed out that not everyone would agree with the authors on this point. There are many possible scenarios where XML security could be important; for example, what if most of a document was fine for everyone to see, but there were a few crucial elements that should remain protected? For these and other situations, a host of new security-related XML standards are being worked on to provide data managers with the necessary tools. Security is part of a process, rather than something that is attached to a final product. That process might include where the data comes from, where it is going, and how it is used, which are topics outside the scope of those who are simply interested in presenting data in XML. More than anything, security should be considered its own topic that needs to be addressed in depth, both within the context of XML representation and independent of XML.
The XML design should be prepared quickly
The XML standard is an evolving technology. The base components that are most frequently used have been stable since 2000. The W3C web site* maintains a list of various XML standards and their status for those who need specific information about a particular technology. The technology is far from stagnant; it is growing rapidly. One of the original design goals was that the design should be prepared quickly, since the need for the technology was immediate. The developers of XML have done an astounding job at putting together a number of world-class technologies in record time. That they were able to put it together quickly while still producing a high-quality product is a testament to the wisdom of the architectural and design decisions that went into the front end of the development process. And as the adoption rates of XML increase, the growth and development rate increases as well. Best of all, the XML design process complements everything that data managers already know about good data design.
The design of XML shall be formal and concise
The official syntax guidelines for XML are simple and easy to understand. While some languages are specified in terms of examples, counterexamples, and “how things should look,” the XML definition is formalized, that is, it is written out in terms of a scientific grammar (or the formal definition of the syntactic structure of a language). The grammar specifies exactly what is allowed and what is not in every context, so there is never any question about how XML operates. With some languages, when everything is not made explicit, the people who implement the software are left with some wiggle room to determine how the software should behave in certain circumstances. If a particular type of error is not thoroughly described and there is no specific method for handling it, some software writers will choose to handle it in one way, while others will do it in another way that happens to be more convenient for them. This results in odd differences of behavior between software programs dealing with the same input data. Users should never be in a situation where a particular document will work with one XML parser, but generate many warnings or errors when using another. It is because of this undesirable behavior that XML specified a grammar along with the description of the language, to eliminate ambiguity from the start.
To take another example specific to XML, we can look at the way elements are encoded in documents. The language dictates exactly which characters are allowed to be part of an element name, along with rules about how they must occur. Attribute specification is laid out exactly, along with how white space in documents is processed, and so on. The XML grammar does everything it can to ensure that software using it will be reliable, predictable, and robust. Leaving no loopholes in the language, no “what-if” questions unanswered, is the way XML accomplishes this.
For data managers, this formality and conciseness complements existing data designs, especially good data designs. In XML, language formality is akin to the rules of normalization for relational structures, and is equally important. One small difference is that XML directly supports hierarchical data structures, while it is somewhat more difficult to express the same structures in a relational context. That is not to say that XML cannot work with the relational world; it can. But since more than half of all organizational data is still stored directly in hierarchical databases, this is not as much of a problem as you might think.
XML documents shall be easy to create
It certainly would not do to develop a new data format that had to be created using a particular expensive software package, since that would defeat one of the purposes of an open standard. The ease of creating XML documents is largely related to the fact that it is done using plain text. As a result, every computer user that has a program capable of editing text already possesses the ability to create XML documents. Since the language is simple and software for processing it is ubiquitous, developers can also easily create XML documents inside of programs.
Ensuring that XML documents are easy to create is yet another aspect of a common theme running through XML’s design goals—that it should have a minimal learning and application curve. XML developers want users to spend their time solving problems with the technology rather than tearing their hair out over learning it.
XML documents should be thought of by data managers as datasets containing metadata. Now instead of sending obscure bits and bytes of data over a line or on a bus, data managers can send the data and its meaning to applications that will be able to interpret it. While the true implications of this simultaneous transmission of data and metadata are not covered in detail until later in this book, experienced data managers should begin to see the possibilities.
Terseness in XML markup is of minimal importance
If the decision has to be made between having a language that is clear, and a language that is very terse and occupies the minimum number of bytes on a computer, it is often wise to choose clarity over size. This is one of the areas where XML has traditionally been criticized. When dealing with very large XML documents, users see long element names repeated thousands of times, and notice that the XML document is quite a bit larger than the same data represented in some other way. While it is true that XML documents are generally larger than other representations, a number of points are important to keep in mind:
![]() The size difference is a trade-off, not a penalty. When inflating the size of documents, users see a number of benefits. First, data can be expressed in a way that is clear and that leaves no doubt as to what the document means. Second, XML allows metadata to be encoded along with the source data. So even though XML tends to be larger, users are gaining extra benefits in exchange.
The size difference is a trade-off, not a penalty. When inflating the size of documents, users see a number of benefits. First, data can be expressed in a way that is clear and that leaves no doubt as to what the document means. Second, XML allows metadata to be encoded along with the source data. So even though XML tends to be larger, users are gaining extra benefits in exchange.
![]() Document sizes are still bounded. XML documents tend to be larger than other representations by some multiple of the original size, often a small multiple. The implications of this are that if a 5000-character document is represented in XML with twice as many characters, a 40,000-character document will also be represented in twice as many characters, not 5 times or 100 times as many characters. The size of the resulting XML document is relative to the size of the source data, and typically does not get out of hand with respect to the original document’s size.
Document sizes are still bounded. XML documents tend to be larger than other representations by some multiple of the original size, often a small multiple. The implications of this are that if a 5000-character document is represented in XML with twice as many characters, a 40,000-character document will also be represented in twice as many characters, not 5 times or 100 times as many characters. The size of the resulting XML document is relative to the size of the source data, and typically does not get out of hand with respect to the original document’s size.
![]() Computer storage is cheap; human intelligence is not. This argument is frequently used in situations where technologies viewed as less efficient are being defended, but it is true. Extra disk space to store XML documents can be very cheaply acquired, if it is needed at all. But the human time and effort necessary to cope with poorly represented and unclear data are often hugely expensive. The real question about the difference in size between XML and other formats is whether or not the added benefits of the larger format are worth the difference. In the case of XML, the answer is clearly yes.
Computer storage is cheap; human intelligence is not. This argument is frequently used in situations where technologies viewed as less efficient are being defended, but it is true. Extra disk space to store XML documents can be very cheaply acquired, if it is needed at all. But the human time and effort necessary to cope with poorly represented and unclear data are often hugely expensive. The real question about the difference in size between XML and other formats is whether or not the added benefits of the larger format are worth the difference. In the case of XML, the answer is clearly yes.
![]() Finally, judicious use of data compression techniques can help to offset larger file sizes. We have worked with an organization that felt it was worthwhile to encode a single character of data in a 255-character tag. This represented a large multiple in file size but was for all practical purposes eliminated when the file was compressed from 5 megabytes to 70 kilo-bytes!
Finally, judicious use of data compression techniques can help to offset larger file sizes. We have worked with an organization that felt it was worthwhile to encode a single character of data in a 255-character tag. This represented a large multiple in file size but was for all practical purposes eliminated when the file was compressed from 5 megabytes to 70 kilo-bytes!
From an operational perspective, elimination of strange abbreviations, acronyms, and other technological quirks that serve to obfuscate the data from users typically pays off in greater user comprehension, faster system diagnostics, and user affinity with their data.
Design Goal Summary
In short, the XML design goals serve to complement and even reinforce good data management practices and perhaps more importantly, they also become useful when transforming data from an existing use to a new use.
Looking at the ideas that went into the creation of XML is like looking from the inside to the outside of the technology, from the perspective of the designers. Now, let us take a look from the outside into XML, namely, some of the confusions that have arisen about it, where they came from, and in some cases the kernel of truth that lies at their core.
What XML Should Not Be Used For
Since its inception, XML has received a huge amount of hype as the next big thing that will solve all problems for all people. While some of XML’s hype is well deserved, like with any other technology, hype is one part fiction and one part fact. No technology will solve all problems for all people, but XML is built on a solid foundation with substantial architectural thought that went into it from the ground up, which makes us confident in saying that it can in fact help solve many problems for many people. There are a number of common misconceptions about what it is, and what it is not, which we will cover here. The discussion that follows owes a debt to both Robert Cringely and Fabian Pascal.
The purpose of this section is to make an attempt at separating the wheat from the chaff in terms of what is claimed about XML. Effective application of XML for data managers requires a thorough understanding of what it is and is not. This knowledge allows savvy users to call vendors on the carpet when they make questionable claims, and to understand the situations in which the use of XML might be akin to pounding a square peg into a round hole. Given the amount of interest, press, and discussion that the technology has generated, this section clearly could not hope to present the total picture of inaccurate claims about XML, but the most frequently overheard will be addressed.
XML Is Not a Type of Database
The common misconception that XML is a type of database is based on a misunderstanding of what XML is, along with a somewhat inaccurate definition of what a database is. XML is not a relational database like Oracle or DB2. At its core, an XML document is simply a text document, and should not be considered any more of a database than a regular email message, which is also a text document.
Still, this area can get fairly fuzzy. First, many relational database engines are starting to incorporate XML components that allow for quick loading and dumping of data to and from XML formats. This does not make XML a database, but it becomes easier to see where the confusion stems from. In the past few years, a number of software packages have also come into the market that call themselves “XML databases,” which further adds to the confusion. In fact, these “XML databases” are excellent at storing XML documents, fragments of documents, and even individual elements. Many even employ a storage and retrieval method that is modeled after the structure of an XML document. XML databases are real database packages that work with XML, but a distinction must be made between the XML language, and the external technologies that arise around the core language, which are intended to be used in conjunction with the actual XML language.
XML Is Not a Replacement for Data Modeling
XML is a powerful way of representing data, which has led many people to confuse it for a tool that helps with data modeling. In many cases, the critical aspects of data modeling involve making the decisions about which pieces of data should be stored in which places, how they should be stored, and the justification for those decisions—basically, the “where,” the “how,” and the “why.” However, this inevitably involves application of at least one person’s intelligence—people often find that completely computer-generated data models are woefully inadequate in many situations. XML does not automate the process of data modeling. Rather, one could think of XML as a giant container with infinite racks and shelves that can be configured in whichever way suits the user. The container provides a staggering number of possibilities in terms of how the data might be stored within, but of course it is still possible to choose an inefficient way to store that data that makes it hard to find and access at a later date.
Data modeling is best done by a smart human who knows his or her trade, the data, and the business for which the data is being stored—inside and out. Not only does XML not do one’s data modeling automatically, even if it could, one probably would not want it to. XML descriptions of the data modeling process might be generated as a way of documenting the “wheres,” “hows,” and “whys” of the modeling effort, but the thoughts must be entered by a person. Once the data modeling effort is completed, of course, XML can be brought back into the picture as a representational language that allows documentation, archiving, and publishing of the knowledge that was created as a result of the effort.
XML Is Not Something with which You Should Replace Your Web Site
In discussions of technology, particularly at a sales level, one of the most common confusions arises when a technology that aids with a particular process is subsequently claimed to replace the need for the process, or make that process obsolete. This is unique to technology—after all, no one would confuse the help that a hammer lends in the construction of a house with the actual house itself. From the earliest days of the development of XML, it has been used on web sites in a number of different forms, to aid in the process of delivering the right documents to the right people. But just as a hammer is not a house, nor can a house be built of nothing but hammers, XML is not a web site, nor can web sites be built of nothing but XML. A web site is a large and complicated operation, frequently involving aspects of data, display, networking, hardware, and software.
XML helps substantially with issues of data storage and display, through some of the various components discussed later in the chapter. What it does not help with, however, is the software that actually delivers the documents to users, or coordination of the entire effort. The use of XML on web sites is growing substantially with time, from organizations that store most of their web documents in a content management system that uses XML internally, to plain XML documents converted to a display format using eXtensible Stylesheet Language Transformations (XSLT) discussed in the next section, to special formats of XML that allow web site operators to syndicate their content to other sites. This is an exciting and promising area where many efficiencies and benefits can be realized, but it is important to keep the component concepts that go into the entirety of a “web site” separate.
XML Is Not a Replacement for Electronic Data Interchange
This confusion is somewhat related to the confusion about web sites being replaced with XML. A number of electronic data interchange (EDI) applications and systems rely heavily on XML in order to do their work. The key is to identify the business reasons for replacing EDI transactions with XML; in many instances, XML can reduce the per-transaction expense typically incurred by EDI users.
Within some EDI systems, XML acts as the format in which the data is represented. It still requires additional software in order to get from place to place, however—in some ways it is easy to see how EDI confusion has arisen around XML. Thinking of XML as EDI or as a replacement for EDI is like confusing a hammer with the act of using a hammer to drive a nail. XML is like the hammer—it is a tool, but it requires action and usage in order to accomplish a task, just as a hammer does not drive nails by itself.
There are two tasks typically involved in the design of any EDI sys-tem—determining exactly how transactions should proceed, and how that information should be encoded. Quite a bit of good work has been done in the area of designing how the transactions operate. This means that using XML as the encoding portion of the EDI system allows its authors to really leverage all of their hard work in the transaction design phase and express their design decisions in terms of XML.
Since we have taken a look at a number of different confusions surrounding XML, the next step would be an attempt to trace these confusions to the misunderstanding that they arise from. Tying these confusions together by their common threads allows users to separate the legitimate claims from the baseless hype.
Confusion Conclusion
There is a pattern in the types of confusion that arise when discussing XML. This pattern is by no means specific to XML, but applies to most other technologies that benefit from heavy “buzz” for any period of time. Understanding and recognizing these confusions can help with the effective evaluation of applications of XML, as well as that of other technologies. If users were to replace the word “XML” with another technology in each of these confusions, would they recognize familiar claims about the other technology?
1. Confusing XML with a process, when XML merely aids the process—XML aids the process of delivering web content by providing methods of representing data and presentation, but XML is not a web site or web server.
2. Claims that XML does something “automatically”—Software can perform tasks automatically, and many software applications provide support and extensive use of XML, but it is important to distinguish between something being accomplished by application of the language, and something that is accomplished by application of some software package that uses the XML language. Nothing inherent in XML eliminates the need for solid data design skills, and failure to incorporate data design principles can result in a situation in which XML can make an existing mess worse.
3. Claims that XML replaces something outside of its target domain—These confusions are sometimes tricky to recognize. In some situations, it is appropriate and correct to claim that XML can replace another technology, for example, other binary-only data representation formats. But to say that XML replaces data modeling or that it accomplishes data modeling by itself is a bit too optimistic. If a particular field or practice such as data modeling is not referred to or even alluded to in the design goals of a technology, it is unlikely that the field can be replaced by the technology in question. Again, it is important to distinguish between the technology itself and applications that utilize it.
XML Component Architecture (Parts & Pieces)
Sometimes reference is made to the XML community when discussing the development of various standards and new technologies. One of the drivers of the community is the W3C (The World Wide Web Consortium), an organization founded by Tim Berners-Lee, the technical inventor of the web. The W3C has over 400 organizational members, and strives for vendor neutrality in the way that it is organized. The group is consensus driven, and before decisions are made there is typically a period of public comment on various proposals. Given the eclectic membership, the technical community considers the W3C to be an organization that is extremely comprehensive in background and expertise, and fairly representative of whose who use W3C-created technologies.
Many of the XML standards and technologies that will be discussed in this chapter were originally drafted, written, and published by the W3C. One key difference that the W3C brings to the table is a standard process that is faster than traditional processes used by other organizations. But other professional and trade organizations also exist that come together and publish their own standards, so the XML community is even broader than just the W3C. Early in the development of the language, individual hobbyist contributors played an important part in the creation of the technology foundations; they created many of the first available XML software packages.
Next, we will take a look at the way the various components fit together; their logical categories, relationships, and the real meat: what they are good for.
XML Component Organization
As a family of components, XML is extraordinarily rich and diverse. Many individuals and organizations have seized the open technology that was given them and begun to build a number of different components, most of which are related to the core XML language. These components extend XML to provide additional functionality and representational power. To have a complete picture of XML, it is a good idea to take a brief look at the parties that originally created it, and how they mesh together.
Examining the organization of the community is often the factor that convinces people that XML is a solid standard that is here to stay, rather than a temporary fad that is bound to fade.
With many different organizations and individuals creating their own XML-based technologies, it might come as a surprise to some that there has not been much duplication of effort in the XML community. Typically, the standards that have been developed are comprehensive and robust not only for the target area of the original developers, but for other areas as well—this is a theme that will be seen again and again in the review of the various components.
We put forward a method of organizing the various XML components that we will discuss in this chapter, grouped by each component’s function and purpose. Some of these technologies are rather low-level standards that often are being used whether the end user knows it or not—for example, DOM and SAX. Others are much higher-level standards that are intended to facilitate complex processes, such as ADML (Architectural Definition Markup Language). Still others fall somewhere in the middle and are geared toward solving a specific problem, such as the presentation of data encoded in XML (XSL and XSLT).
Our first version of this articulation is pictured in Figure 3.2. This version had the advantage of being easy to PowerPoint audiences with. We also developed a second iteration of the XML component architecture in an attempt to simplify the message. This is shown in Figure 3.3.
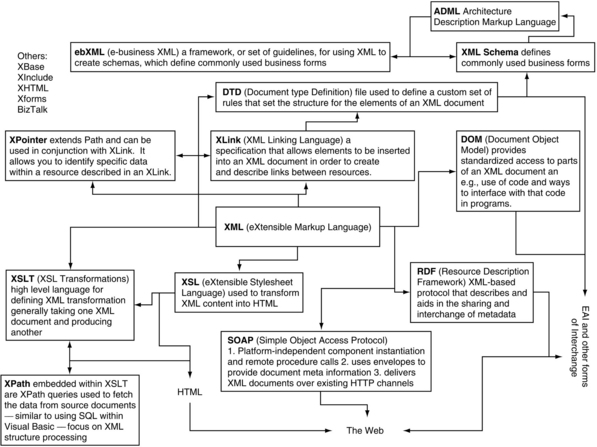
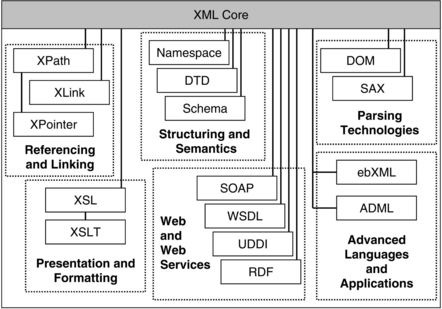
Figure 3.3 shows one possible organization of a number of different XML components, grouped by purpose and relationship. As indicated by lines connecting different components, some technologies are actually descendants or extensions of other components, such as the relationship between XSL and XSLT. Not all relationships between components are diagrammed here—the interconnections between and reuse of various technologies are extensive. For example, the schema and DTD components could realistically be linked to most of the other technologies. Rather than display the almost endless numbers of connections, we will provide a thorough description of each component from which most of the connections can be inferred.
The groupings in Figure 3.3 correspond to the way users typically apply various XML technologies. If the overall XML component architecture is likened to all of the hand tools that are available at your local hardware store, certainly there will be subgroups of carpentry tools, plumbing tools, landscaping tools, and so on. Similarly, users who are interested in XML for aiding presentation and formatting tend to look to XSL and XSLT, while people who are interested in providing automated services through networks tend to look to WSDL, UDDI, and SOAP.
Now it is time to describe each component listed in Figure 3.3, generally moving from components closest to the core near the top of the diagram, toward the most advanced components furthest from the core, shown at the bottom of the diagram. The first one we will look at is XML Namespaces, one of the components that aids in the structuring of complex documents.
XML Namespaces
XML documents do not exist in a vacuum, but are often part of more complicated systems where multiple systems are being used. One interesting consequence of this is seen in the way systems handle elements that have identical names, but different definitions. For example, if the “name” element is defined in two different ways, how is the system to tell which definition of “name” applies to a particular instance? In light of the earlier discussion of how the same terms might have different meanings in different locations within the same organization, this issue can come up quite frequently.
XML namespaces provide a way of associating element and attribute names with a particular URI. Users can choose a prefix along with a particular URI to disambiguate elements from one another. If the accounting and manufacturing departments have a different concept of the same element name “customerID,” then a prefix can be used for each to make them clear. For example, if the prefix for the accounting department was defined to be “acct,” and “mfg” was used for manufacturing, then the “customerID” element would be written as either “acctcustomerID” or “mfg:customerID” depending on which was meant in a particular context. This allows XML processors and systems to tell the difference between elements, even when using two different sets of overlapping definitions of elements and attributes.
As more XML “languages” begin to proliferate, XML namespaces are being used more and more. At first, they were not strictly necessary since multiple document types were seldom used together. The number of types of XML documents is growing rapidly though, and many common words have been used in several different places for element names, so the use of XML namespaces has become more important to ensure that the correct element is being referred to.
From a data management perspective, the use of namespaces permits organizations a means of controlling the scope of various data-standardization efforts within the organization and among cooperating organizational partners. By incorporating namespaces in the rollout of various element “vocabularies,” data managers can easily disambiguate individual vocabularies. XML namespaces allow users to separate those different groups of terms—the next component, DTDs, describes how XML users can actually define those groups of terms.
DTD: Document Type Definition
The DTD is frequently the first XML-related technology with which users of XML come into contact. Earlier, we stated that when organizations and individuals create their own tags, it is very important to have some type of idea about the order in which those tags should appear, and the meaning associated with the tags. The Document Type Definition was the first attempt at creating a technology that allowed users to express these ideas about their XML documents.
When discussing XML documents, people say that a document is either well formed, valid, or both. A well-formed document is one that conforms to all of the syntactic rules of XML, all elements have a corresponding closing tag, attributes are properly specified, and so on. Valid documents, on the other hand, are those that have a set of associated rules that specify which elements are valid, which are not valid, and what the appropriate tag nesting structure should be. Since the job of the DTD is essentially to specify those rules, an XML document must generally be associated with a particular DTD in order to be valid. Document Type Definitions are not the only way to specify legal elements and nesting structures; an XML schema, which is discussed in the next section, is one of many options that can also perform this job.
Basically, a DTD is a series of definitions. Users are able to define four types of items that appear in XML documents that give them structure and meaning; these correspond to existing data management concepts already practiced by most organizations. The first and most important type of item that is defined in the DTD is the element.
Element Names
Which elements occur in the document, and what are their names? Elements form the core vocabulary of a document and should be relatively descriptive of the data that is contained inside them. Optionally, documentation about particular elements can be placed near the element’s definition to allow for easy reference to what the element should mean. Element names frequently contain the context of a particular piece of data that makes it meaningful. Without context, the number “102.5” does not mean much. With an appropriate element name-wrapped around it such as “radio frequency” or “temperature,” the small piece of data takes on context and meaning, transforming it into information. Elements are also frequently referred to as “tags,” although there is a subtle difference. The element is the name that occurs within a tag. In other words, given the example “<XMLTag />,” the element is “XMLTag,” while the tag is “<XMLTag />.”
When defining elements, not only the name must be defined, but also a list of valid attributes for the element, as well as potential sub-elements. When taken together, this gives a more complete picture of the element’s meaning and place within larger data structures. Elements go hand in hand with attributes, which is why the next function of a DTD is also critical: defining the attribute names and values.
Attribute Names
Optionally, some elements may have attribute names along with values for those attributes. Which attributes are allowed inside of which elements? A DTD allows users to specify not only which attributes are allowed, but also which ones are optional, potential default values for attributes if they are not specified, and which attributes are required. In many cases, it makes sense to require attributes. Consider an example using a travel industry vocabulary, if an element called “flight” was used, it would be useful to require an attribute called “number” to be present, and hold the value of the flight number of the particular flight in question. On the other hand, in an ordering system it might be a good idea to make the “quantity” attribute of a particular ordered item optional. If the quantity is not specified, then a quantity of 1 is assumed.
Attributes frequently represent aspects of metadata around a particular data item. Given a “temperature” element, an associated attribute might contain information such as “measurement=‘Fahrenheit’” to allow the user to understand more about the information being presented. Depending on the way the data is modeled, attributes can function as metadata, or almost as the data equivalent of a parenthetical comment.
Still, attributes and elements by themselves are not enough. For any real level of complexity or power to be achieved in XML documents, we need entire groups, families, and hierarchies of elements and attributes—data structures, not just single lonely elements. Toward this end, the DTD defines the way the elements and attributes relate to one another—the nesting rules.
Nesting Rules
From a structural perspective, the most critical responsibility of the DTD is to describe which elements are allowed to occur inside of which other elements. While it makes sense for a human to see a price element inside of another element that makes clear that the price refers to a particular product, the same price element might not make any sense in a different context without being associated with a product. A properly written DTD allows the author to make sure that valid documents will only contain a price element underneath a product element, and nowhere else.
The nesting rules of a DTD are the order brought to the otherwise soupy chaos of large numbers of interacting elements and attributes. Together with elements and attributes, the nesting rules almost complete the picture of what can occur in an XML document. One last small piece is missing though–the XML entity.
Entities
An entity is a particular symbol or glyph that appears in an XML document, and acts as a stand-in for something else. It might also be a full text string, or even a full DTD. As an example, take the angle brackets. Since the characters “<” and “>” are frequently used inside of XML documents to represent the beginning of an element, some special way of expressing the “<” character must be used when it is intended literally rather than as the beginning of an element. For these two characters, the most frequently used entity names are “>” for the “<” character, and “<” for the “<” character, where “gt” stands for “greater than” and “It” for “less than.”
When looking at the specific element for the “>” sign, “gt” is referred to as the entity name, while “>” is called an entity reference. In fact, since the ampersand character “&” itself is used as a special character for entity referencing, it too must be defined as entity in order to be used literally. In most situations, it is referenced as “&”.
Entity names and values are declared as part of the DTD. XML users are not restricted to particular names or values for XML entities, but the facility is there to allow any type of entity to be declared. In practice, though, many DTDs contain a very similar set of entities since the same types of characters and entities are frequently needed. The entity conventions that are seen in XML documents borrow heavily from XML’s SGML and HTML precursors, providing a bit of continuity for those already familiar with the other languages.
Now that we have had a look at all of the facilities of the DTD, there are a few places where the DTD is somewhat lacking. The limitations of DTDs themselves are quite interesting.
Limitations
While using DTDs to describe XML document structure is quite sufficient for many users, DTDs do have a number of drawbacks. First and fore-most, they are something of an oddity with regard to other XML technologies since DTDs are not written using standard element and attribute syntax – that is, DTDs are not written in XML and cannot be processed as XML documents themselves. There is nothing wrong with this per se, but they are different from regular XML entities. Another limitation of DTDs is that they are good only for defining attributes, entities, elements, and nesting order. They do not provide support for data typing, or allow the user to restrict the values of data that can be contained in certain elements.
When using XML documents as a method of modeling and expressing data, this is a serious drawback. It is obvious to human users that the “price” attribute of a particular element should contain numeric data, and should not ever contain somebody’s name, or just plain character data. But a DTD has no way of expressing which types of data are allowed in particular places, and as a result, a document can be considered valid even if it contains data that is clearly incorrect. To a DTD, the concept of document validity ends when the document has met the DTD’s constraints in terms of clements, attributes, entities, and nesting order.
What is needed is something more powerful that will let us accomplish the same things that a DTD can do, but with more features and flexibility.
These facilities are provided by the successor to the DTD, the XML schema.
XML Schema
As the limitations of DTDs began to show, the need for a replacement grew. The facilities provided by DTDs are very useful, but fall somewhat short of ideal. In addition, the fact that DTDs were not written using XML elements made them a bit more difficult to learn than necessary, and made extensibility of the format somewhat limited. One of the overarching design goals of XML, embodied in its name, is that of extensibility. Wherever possible, it is usually a good idea to make the facilities of XML extensible. This is because no one has the ability to foresee which features will be indispensable in the future. The best the designers of any technology can do is to design it in such a way as to make it as flexible as possible, so that when the technology inevitably has to change and adapt, it can do so without the feeling that the new features were crudely “tacked on.”
The XML schema standard (implemented as a recommendation in May 2001) has a number of advantages that rightfully make it the best choice for modeling data structures in XML.
XML Schemas Are Written Using XML Elements and Attributes
In contrast to DTDs, XML schemas are written using actual XML elements and attributes. This comes with all of the attendant benefits of XML. Users do not have to learn a new language—schemas can be incorporated as parts of other documents, and they can be manipulated by just about any XML-capable program or technology. Most importantly, like the core XML language itself, XML schemas are extensible. A number of new features have been added to XML schemas that were not present in DTDs, but since schemas themselves are written in XML, future releases of the schema specification will be able to add new features as needed, rather than requiring a different specification altogether, as was required in the DTD-to-schema process.
XML Schemas Support Data Types
The major new feature that was the most lacking from DTDs was the ability to model data types within elements. By specifying a data constraint on a particular element, XML users can further narrow down the definition of what a “valid” document really means. Specifying and enforcing data types is also the most rudimentary step in attempting to ensure data quality. Without knowing the general form of acceptable data, it is difficult to quickly tell whether a particular piece of data is useful or not.
The data type specification that XML schemas allow falls into two categories. First, the schema author can specify an actual data type, and second, the author can define an acceptable range of values, or a domain. XML schemas by default recognize a number of different common data types, such as strings, integers, boolean, URIs, and so on. In addition, facilities are provided to allow users to define their own data types. For example, authors can define a special integer data type called “score,” which ranges exactly from 0 to 100. That data type can then be associated with a particular element, so that the data in the element can only be an integer value in that range. If the data is anything else, the document will not be considered valid. Aside from simple numeric ranges, actual domains can also be specified. For example, data inside of an element that expresses a product name might be limited to a list of products that a company actually produces.
When constraints like this are put on the data, and valid documents are required, data managers can be sure that orders are not being placed for nonexistent items, and that scores represented in documents will be within the valid range. This reduces the amount of complexity that must be present in the system that actually does the processing of the data on the other end. Invalid documents will be rejected, and valid documents can allow the system to focus on processing the data in a meaningful way rather than spending excessive effort doing data validation.
XML Schemas Support Namespaces
Standard DTD definitions did not readily allow authors to use namespaces as part of their elements. XML schemas have fixed this situation by including support for namespaces. In fact, namespaces are so common in schemas that most examples that are used include the prefix “xsi” for all elements within the schema language itself. Of course, this naturally allows authors of XML schemas to reuse even the names of schema elements in their own documents. In fact, the XML schema language itself has a corresponding schema.
After the schema standard had been developed, users rapidly saw that it represented an advance, and wanted to use it. The next question was, “How do we get all of our old DTDs moved to schemas?”
Transitioning From DTDs to XML Schemas
While schemas are meant as the replacement for DTDs, the number of DTDs already in existence is large enough that they will be around for quite some time. The ability to use DTDs with existing XML documents is not going to disappear, but users are encouraged to move toward XML schemas for future use. Where possible, it may be desirable to transition DTDs toward XML schemas, but it is not strictly necessary.
A number of applications and tools are already available that provide mechanisms for automatically converting old DTDs into newer XML schemas. This is a straightforward task to perform since both languages specify much of the same information. It is particularly easy to convert from a DTD to a schema because schemas provide more information about elements and entities than DTDs do. It is important to note, however, that when translating DTDs to schemas, the only information that will be included is what was in the original DTD. Without further modification, the schema will not provide any extra benefit that the DTD did not.
Looking at the situation from the other direction, converting XML schemas to DTDs is a potentially difficult task, since converting the information in a schema to a DTD requires an application to drop information about data types and constraints from the resulting DTD. This is not desirable, and should be avoided unless absolutely necessary. Fortunately, conversion of XML schemas to DTDs is not much of an issue since almost all XML-capable software now supports schemas.
At this point, we have covered several different components that describe the structure and semantics of a document. Now we will move into a description of how programs actually get access to data within XML documents, starting with a discussion of the Document Object Model.
DOM: Document Object Model
The Document Object Model (DOM) is a way of thinking about and addressing XML documents. At its core, the DOM represents an entire XML document as a tree in a computer’s memory. The advantage of tree representation is that it makes any piece of information in an XML document accessible at any point, and allows for navigation through the document along paths of parent/child elemental relationships. Documents can be formally searched like hierarchical data structures, and just about any algorithm that deals with tree data structures can be applied to XML documents represented in the document object model.
Unlike some of the other items discussed in this chapter, the DOM is not a technology that is written using the XML language, but rather it is a way of dealing with and thinking about XML documents.
In Figure 3.4, we see on the left-hand side a simple XML document, and on the right-hand side a picture of how the data might be organized inside of a computer, in a tree structure. Notice that lines moving from particular nodes in the tree on the right-hand side correspond directly to the nesting depth seen on the left-hand side. For the sake of simplicity, the actual data inside the XML elements is represented in the tree form inside parentheses. This figure illustrates two points about the DOM; first, it organizes an XML document in memory as a tree, and second, it provides access to the actual data items inside XML elements.
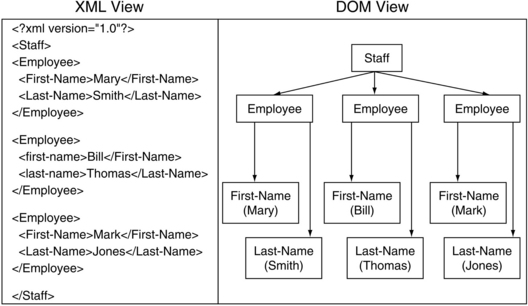
The DOM represents the entire document as a tree. But what if the document is very large, or if we are only interested in a very small subset of the elements in the document? The next component, XPath, addresses this requirement and provides a facility for arbitrary selectivity of data in documents.
XPath
The XPath component of XML is a simple language that allows for an arbitrary group of elements and attributes to be selected from a document. When dealing with very complex or large XML documents, it is often useful to be able to refer to a very specific set of elements and attributes. Maybe the set in question is the “first name” element underneath every single “employee” element in the document. Maybe the set in question is the value of every “age” attribute in the “employee” elements. Frequently the set is simply one element, for example, the “employee” element that surrounds Bill Richard’s XML record.
Often, when the set being referred to is just one single element, users choose to think of an XPath expression as identifying a pathway through an XML document down to the element in question. Frequently this is how XPath is used-for example, in many situations, users who are writing XSLT style sheets will use an XPath expression to refer to and extract data from a particular element in the document.
In Figure 3.5, we illustrate the same XML document, represented in its visual DOM form as a tree, and illustrate the two different ways of thinking of XPath expressions and how they relate to XML documents. In the first instance, the interesting element is the “last name” element associated with the employee Mary Smith. In this XML document, there is a way to refer to that element and only that element. This comes in handy when the data from that particular element is needed for some external processing, or when the element is being used as a reference point for some other data. In the second situation, XPath allows the user to select a set of nodes, in this case, every single “first name” element in the document. This is accomplished by effectively crafting an XPath expression that refers to the “first name” element underneath the “employee” element. Since there is more than one, the result of the XPath expression is a set of nodes in the tree.
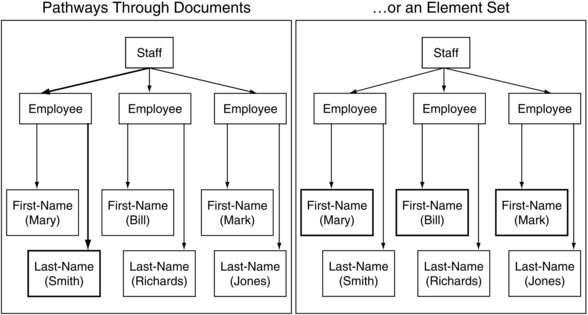
XPath allows users to develop quite powerful expressions for referring to data within an XML document. The syntax of XPath is put together in a way that is sufficiently flexible for just about any referencing that would need to be done. XPath is something of an anomaly compared to other pieces of the XML component architecture, because in its most common form, it is not a set of attributes or elements as other components are, but simple text strings. While the learning curve is quite good for those new to XPath, it cannot be learned solely through the addition of new elements and attributes to an existing XML document. But it is used often enough to make the time it takes to learn and apply the component worthwhile in light of its utility.
The DOM and XPath allow users to access various items within XML documents. What about cases where we are more interested in referencing other data items, but not actively finding out the value? The next section discusses how references can be made between documents via a component called XLink.
XLink: XML Linking
Links are the data concepts that really created the web. Without hyperlinking between documents, the web would not be anything more than an extremely large collection of standalone documents. The ability to instantaneously jump from one resource to another on the web is one of its “killer features” that made such tremendous growth and interest possible. Given how indispensable the linking feature is, the designers of XML wanted to provide a flexible framework for the same feature in XML documents.
Hyperlinks as they exist on the web have a number of problems though. They still work quite well for what they actually do, but all you need to do to investigate the weaknesses of regular HTML hyperlinks is to ask the maintainer of a large HTML-based web site what he or she thinks about the challenges involved with maintaining such monstrous “link farms.” Ever since HTML-based sites reached a fairly large size, the problems with the original concept of the hyperlink were fairly apparent. Since XML itself is rather new, the designers fortunately had the accumulated experience and knowledge to begin the creation of a new linking facility that would not encounter the problems experienced with traditional hyperlinking.
Specifically, here are a few of the drawbacks associated with HTML links:
1. Hyperlinks may only have one target. A link goes from one page to another page, or to another location within the same page. If the destination page is mirrored on anyone of 10 different systems, 10 links are needed even though the document being pointed at is the same on all of the systems.
2. Linking requires a special element. It is not possible to put a link inside a different element—the link must be an element unto itself.
3. No link-traversal strategy is provided. There are many potential ways that links could be processed and followed, but since no additional information comes with the link, there really is only one way to follow it.
4. No metadata about the link is provided. Metadata could be very useful; for example, who created the link, and when was it created? If the resource has an expiration date on it, perhaps the link should point elsewhere or cease to exist after a certain date.
The XLink XML architectural component was a result of an analysis of these issues, and the desire to fix them. Like other XML components, it was designed from the start to be human readable, and to represent all relevant data for the link in a way that conformed to the rules of base XML—that is, XML links can be added to existing well-formed XML documents, and the documents will still be well formed.
A link that is specified with XLink can support multiple destinations, define link endpoints and traversal rules, and even allow the author to have some control over the direction of travel involved with a particular link. Finally, given the huge amount of HTML that is already out there, one vital feature of XML linking is that it is compatible with HTML-linking structures.
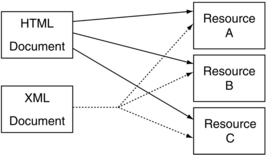
The construction of an XML link actually has three distinct parts. Separating the concept out from a link into three constituent pieces that interact allows users to avoid the limitations of the overly simplistic HTML link. The three pieces are the participating resources, the actual link definition, and the arcs.
Participating Resources
The participating resources of a link are simply the document or documents that are on either end of a link. Given the original linking structure in HTML, there was no need for a concept like this because the participating resources were either implied or explicit–the document being pointed at was explicitly labeled in the link, and the document that was linked from was obviously the document in which the link occurred. The problem with this strategy is that it forces users into a situation where links can only represent one-to-one relationships. Why not provide a mechanism for producing links that can represent one-to-many or many-to-many linking relationships? XLink is in fact a very useful capability, but in order to be used, it must be clear which resources are on either side of the link. Specifying the participating resources of a link does just that.
As described earlier, these links provide the capability for having more than one target for a given link. With HTML, in order to connect three resources, three links are needed, each of which has its own element in its own location. Using XLink, it is possible to create a single link that “forks” to three different resources. This forking is simply a result of using more than one participating resource on the destination end of a link (as shown in Figure 3.6).
Link Definition
As part of a link, additional information might be included that helps users of the link understand its relevance. It is often useful to have a title for links, authors associated with them, or a brief description of the resource on the other end of the link. Automated programs that are processing XML documents can use this type of information, or people inspecting some presented form of the document might use it. There are ways of accomplishing this type of thing in HTML, but they tend to be very limited, clunky, unreliable, and non-standard. XLink took the approach of assuming from the start that extra definition information about the link would be useful, and built it in from the beginning so that the data looks as if it belongs there, rather than shoehorned in after the fact.
Link definitions also allow link “locators” to be defined. In many situations, the actual address of a particular resource might be long and cumbersome. In addition, if a particular resource is referred to many times, it is useful to be able to label that resource with some name, and then use that name whenever the resource is being referred to. This allows the actual resource address to be changed only in one place and for all of the references to that resource to change accordingly. Link definitions found in XLink constructs provide just this capability.
Arcs
Arcs specify the direction of travel of the link in question. They are also occasionally referred to as traversal rules, and there are three basic types, shown in Figure 3.7. Outbound arcs mean that the link in question goes from a local resource to some other non-local resource. Inbound arcs are links that go from a non-local resource to a local resource. Finally, third-party arcs are present in links that connect two non-local resources. These three possibilities effectively cover every situation in which links might be needed, by categorizing the resources in terms of whether or not they are local.
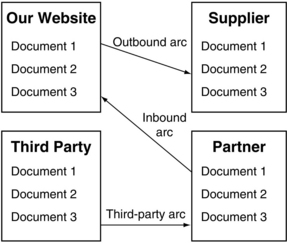
One of the interesting consequences of being able to describe links in these three different ways is that the user does not have to be capable of writing a document in order to produce a link with that document as the source. Using old HTML links, the user must have the ability to actually modify the file in question if he or she wishes to create a link from that document to some other document. Using XLink, the source of the link is as flexible as the destination. Another interesting point is that the concept of the inbound link means that documents can be aware (possess self-knowledge) of who is creating links with the document in question as an endpoint.
XLink is a good starting point for creating references to other resources, but it is not the end of the story. Just as DOM and XPath both exist to satisfy different needs for access to data according to the level of granularity needed, XPath dovetails with the next component, XPointer, to provide two different levels of granularity for linking.
XPointer
XLink provides a very useful mechanism for pointing to particular resources, but it does not allow users to link to particular snippets of data. XPointer, on the other hand, does allow XML documents and elements to point to specific snippets of data within other resources, along with any potential contextual information that might be needed. Given the fact that essentially XPointer is pointing at other XML data, it does have one limi-tation; the data being pointed to must be XML.
Based on this description, it might sound as if XPointer is similar to XPath, since XPath allows users to refer to particular elements and attributes within a document. In fact, XPointer is very similar to XPath, and was based on XPath. This again illustrates the architectural trend in XML to build on existing technologies and to extend them with new capabilities rather than creating a completely different technology for a slightly different purpose. XPointer extends many of the concepts in XPath and adds a few new tricks to the bag. From the start, XPointer was intended as a solution that should be able to point at any user selectable region of a document, by encoding the selection criteria into the XPointer expression. As with XPath, powerful expressions can be built that make reference to human concepts, such as “the second section of the fifth chapter” or “all elements that contain the text ‘Mary Smith,’” rather than referring to elements specifically by name, or worse, by some arcane unique identifier. Conversely, if elements are tagged with unique identifiers, XPointer provides a mechanism for referring to them as well.
These descriptions mean that the data is not even required to be in the place where the user might expect it. The actual XPointer expression provides a bit of “context” around the data—the element or attribute in question must be surrounded by a certain structure in order to satisfy the XPointer statement. As long as the context around the data remains the same, the actual document being referred to may freely change.
When combined with XLink, XPointer further extends the ability of users to connect multiple documents in interesting and powerful ways. The original hyperlink concept in HTML was astonishing for many people, due to the huge range of possibilities it provided with regard to connecting different types of information. Imagine then the possibilities provided by combining XLink and XPointer to provide linking without limits.
While facilities for linking are indispensable, it would not be terribly useful to have a beautiful set of interlinked documents that no one could read. Given this issue, what follows is a discussion of components related to document formatting and presentation. This allows us to transform documents for other purposes, or to bring them entirely out of the database and onto paper.
XSL and XSLT
The two components described in this section are the Extensible Style sheet Language (XSL) and XSL Transformations (XSLT). From an architectural perspective, these are actually two different components, but they will both be dealt with together since, correctly or not, the terms are often used interchangeably.
One of the things many users take away from our seminars on XML-based data management is that “XML is to data what Java was supposed to be to programming languages.” Using XML, organizations can manage their data in XML form and then “pour” that data into a variety of other forms. XML style sheets and style sheet-based transformation are used to repurpose the information—these transformations can then be managed using existing technologies just like other XML documents.
The purpose of both of these components is to create a flexible system for presentation of XML documents. Up until now, all of the XML components discussed have focused on data representation, access, inter-change, and other aspects of the actual data that is in XML documents. XSL and XSLT provide methods of taking XML documents as input, and outputting something different—XSL is used for paginated output, while XSLT allows for transformation from one XML dialect to another (which may include presentation in XHTML form on the web).
Like many other XML components, the brainstorming and creation of this particular component was partially a result of looking out at the landscape of current styling technologies in use, and attempting to find ways to improve on their good spots while avoiding their bad spots. The most frequently used styling language is probably CSS, which stands for Cascading Style Sheets, and is used in conjunction with HTML documents. In many situations, the user only needs to write a short CSS description of how each HTML element should be presented, and the rest is left to the browser. For example, the author of a page might want to make sure that all text within a paragraph tag was rendered as 12-point Arial. CSS makes this easy, but even goes a step further and allows users to define their own classes of tags by inserting special attributes into their HTML elements, and then using the specific class of a tag as a basis for how it should be marked up.
While these same features can be used in XSL, it is a much more general mechanism for displaying data. In HTML, the number of elements is restricted, and their meaning is well understood. On the other hand, in XML, users can define their own elements, so even the most basic display properties of elements are unknown to browsers and other software. XSL is the method by which users can define exactly how each of the elements should work. But that is only part of it. There are two primary differences between CSS and XSL. First, XSL can actually use XSLT to reorganize the document tree completely, which CSS is unable to do. In addition, while XSL provides the concept of pagination and physical page layout, CSS does not. Those who only display documents on the web often do not need the pagination feature, so some elect to use XSLT and CSS together.
XSL has three main subcomponents that it uses, depending on what type of transformation is being accomplished:
![]() XPath. Described earlier, this component aids in referencing particular portions of documents for presentation.
XPath. Described earlier, this component aids in referencing particular portions of documents for presentation.
![]() XSL Formatting Objects. This component allows far more fine-grained control over presentation than CSS, including top-to-bottom and right-to-left text formatting, headers and footers, and page numbers.
XSL Formatting Objects. This component allows far more fine-grained control over presentation than CSS, including top-to-bottom and right-to-left text formatting, headers and footers, and page numbers.
![]() XSLT. This component allows XML documents of one form to be transformed into a different form of XML.
XSLT. This component allows XML documents of one form to be transformed into a different form of XML.
Of these three components, XPath and XSLT are the most frequently used. XSL Formatting Objects is an extremely powerful component that can accomplish fine-tuning of presentation in ways that are not possible using the other two. But for most presentation tasks, formatting objects are not needed. Use of XSL formatting objects are most frequently encountered in places where more control over presentation is a requirement, such as when XML documents must be transformed into PDF files. Since PDF files and certain other formats require more advanced information about spacing and layout of documents, which is not needed in an (X)HTML document, XSL formatting objects are often used in those situations (see Figure 3.8).
XSLT
When most people think of display of XML documents, they normally think of XSLT, since it is the primary tool used when transforming XML documents into HTML and XHTML for display on the web. In actuality, it is a subcomponent of XSL, and works in concert with XSL much like other components such as XPath and XSL formatting objects. The core mission of XSLT is quite simple—it transforms documents from one form of XML to some other form. The new form could be HTML, XML, or even comma-delimited text. The way it accomplishes this is by taking a set of user-defined rules and applying them to a given XML document to produce a resulting document that must also be well-formed XML. Given the DOM view of XML documents, sometimes XSLT is spoken of as having an input tree and a result tree.
XSLT is rule driven. This means that when users want to translate documents from one form of XML to another, rules are specified as to what should be done with each element in the document. This can range from quite simple, to quite complex. For example, if the only difference between two forms of XML is that one uses an “employee” element, while the other uses “emp” for the same purpose, an XSLT program can quickly be developed that converts from one to the other. On the other hand, XSLT also contains sophisticated functions and capabilities that allow users to insert extra elements, transform only some of the source document’s elements, perform limited mathematical operations on data, string manipulation, and much more. While it should not be used as a full-featured programming language, XSLT does contain quite a few features that are normally found in professional programming languages. The difference between XSLT and a generic programming language is that XSLT is extremely well suited to its particular problem domain, and its syntax is something users are already familiar with—straight XML.
XSLT and the fact that it is written entirely in XML creates a number of benefits. Up until now, XML has been discussed as a data-representation language, but with the addition of XSLT, it now has the ability to model business rules, transformation processes, and to a limited extent, programming code. Although XSLT is often used to transform entire documents into new documents, it can also work with small subsections of a document (as shown in Figure 3.9). The implications of this are quite interesting. In programming terms, one of the reasons that object-oriented programming is so powerful is that it provides methods of operating on the data together with the data itself, bundled into a useful package referred to as an object. XSLT allows users to construct their own “XML objects,” which can then be used in much the same way as objects in a programming language. This rests on three important capabilities:

1. XSLT programs are XML documents, and as such they can be embedded inside other XML documents.
2. XSLT programs can operate on a portion of the tree if they choose-it need not always be a straight document-to-document conversion process.
3. XML provides an ideal way to represent the information that comes along with objects.
As of this writing, there does not appear to be a widely available or used implementation of this “XML object” concept-it is intended to serve as an example of what is possible when combining the capabilities of several XML components with architectural thinking.
What is of particular interest to data managers is the fact that stylesheet transformations allow data transformation without requiring application code, and are managed using modern data management technologies. By storing transformations written in XML inside of databases, the transformation process is easier to manage, because the transformations can be managed properly as the data that they are, instead of managing lines of programming code (which is traditionally very difficult and expensive). Furthermore, as these transformations become better understood, data managers have unique opportunities to eliminate other code applications and replace them with XML-based transformations. After all, what do applications do but transform data from one form to another? The potential to reduce the organizational application code base to one-fifth of its original size will be explored in more detail in later chapters on the more advanced applications of XML technologies.
XSLT Browser and Web Integration
As XML has caught on, a number of different ways to use XSL and XSLT have come along. At this point, most recent browsers support XSLT for transforming XML documents into XHTML. This is quite convenient since it means that essentially all the content publisher has to do is insert a reference to the relevant XSLT prozram inside of an XML file, and serve
the XML file directly to the browser. A simple example of this can be seen in Figure 3.10, which shows an XML file describing flights from Richmond, Virginia, to London displayed in a Mac browser window. The browser will recognize that an external stylesheet is needed in order to present the document, and will download it and apply it before the user sees the page in question. This is much the same model that HTML uses—many HTML pages make reference to an external file containing CSS instructions for the presentation of an HTML page.

Still, these implementations are not yet perfect. There are some differences between software packages as to what type of reference they require for the XSLT program, and how the resulting interpreted XML comes out. Because of these differences, some content providers who wish to control as much of the presentation as possible will occasionally choose to apply the XSLT to the XML on the server side, and serve only the resulting document to the client. In this way, the content provider can be sure that all browsers will see the same result, and that small differences in XSLT implementation between browsers will not cause unexpected presentation. This approach is likely to be used for a while to come. Mixed approaches are also often employed; for example, using XSLT on the server side, and CSS on the client side to handle other presentation issues.
We have talked a bit about how the presentation technology fits into the web, but that is not the end of XML’s applicability to the web. In the next sections, we will discuss other XML components and their relationship to the web, starting with a facility to help us overcome the information overload—The Resource Description Framework.
RDF: Resource Description Framework
As the web has grown, the need to be able to summarize the contents of entire sites has grown as well. There are a number of different Internet portals out there that attempt to bring together the best resources from a number of different sites into one place where they can all be perused and potentially used. Individual documents often have metadata about them that is used to summarize the resource (author, title, publishing date, key words, etc.) and entire sites or collections of documents can as well. The way these sites and collections are summarized and categorized is through the use of the Resource Description Framework (RDF).
The most common application of RDF is the concept of site syndication. Many Internet sites allow users to add to their gateway page a summary of the headlines on other sites. For example, a user who has a gateway page with one of the more popular portals might be able to see at a glance the leading headlines with four different news carriers, sports results, and links to local entertainment listings all in one place. Generally, the way this is actually implemented is by using RDF.
These days, most large sites regularly create and publish an RDF description of the data that is available on their site. News sites keep a running list of the top stories, software sites keep lists of the latest downloads, and so on. All that the Internet portal has to do is to regularly update their copy of the RDF document for a number of different sites. This provides the portal with the ability to deliver the latest headlines and links directly to the user.
RDF actually started life as a generic framework for metadata. Its creator’s goal was to provide a system that could allow automated sharing of semantic information by programs over the web. It allows resource discovery, cataloging, and content aggregation. Resource discovery is the process of finding resources on a particular topic, through whatever means; cataloging is simply storing many RDF descriptions for later searching based on the metadata; and content aggregation is taking several information resources in different places and documents and combining them into a new composite document to meet a specific need. As a more specific example of content aggregation, RDF makes it possible to build software that can automatically create a composite document that contains all news reports from that day in which a particular organization is mentioned. By using RDF, the software knows where the documents are, which topics the documents deal with, and when they were published. This is yet another example of the powerful possibilities of effectively using metadata (in this case, article locations, topic descriptions, and publishing dates).
Many people make reference to the fact that XML will help improve Internet searching. The idea is that as more data comes tagged along with metadata describing its content, search engines will have more specific information to tailor search results. Currently, if a user searches for the name of a particular popular author, the user might potentially see thousands of results. On the other hand, if it were possible to search for a particular name only in situations where the name occurred as the author of a resource, the results would be limited to articles and books that the author had actually written. At the moment, RDF is the XML architectural component that best provides these facilities.
As with other XML technologies, efforts were made to make RDF general enough that it would be applicable in many situations, not just syndication of web content. So RDF also contains the ability to use different existing ontologies, and other ways of hierarchically categorizing information according to its essential qualities. This feature is what allows RDF to live up to its original goal—to be a method of publishing and searching machine processable information to allow as much information on the Internet as possible to be machine processable.
Currently, RDF is being used is primarily in the area of traditional web sites. However, web services is a new topic area in which XML figures in heavily. SOAP, the next component that we will discuss, is at the very center of the relationship between XML and web services.
SOAP: Simple Object Access Protocol
SOAP is one of the XML components that had had the most buzz surrounding it for the past few years, mostly due to the fact that it is a corner-stone technology of the new push toward web services. At its core, SOAP is an XML-encoded method by which programs or services on two completely different systems can communicate. This type of technology has quite a history—a number of technologies have been created to allow this type of facility, but not all of them caught on very well. Because SOAP is XML-based, it is the ideal candidate for this type of technology, because it provides an easy method of understanding what is being sent down the wire. Since there are readily available XML toolkits for just about every programming language in use, almost any language can speak SOAP and communicate with other technologies elsewhere. In this case, the base XML language can be thought of as the platform, while SOAP is something of an application running on that platform. Since a large number of technologies already are capable of processing XML, using SOAP to open up lines of communication between technologies is not that much of a leap.
SOAP is also often associated with the HTTP network protocol, which is best known for its role in serving up the web pages of the world. By piggybacking SOAP on top of HTTP, the designers took advantage of a number of benefits:
1. HTTP is already widely deployed, quite stable, and mature. Rather than setting out to design networking and data interchange technologies, the SOAP designers were able to stick to the important parts and let the issue of networking, which had already been solved by HTTP, be handled by a protocol that had already proven itself capable.
2. HTTP is well understood. Again in the spirit of the XML developers striving to reuse existing open technologies rather than reinventing the wheel, HTTP was used because many people, from web designers to programmers, are already comfortable with HTTP, reducing the learning curve.
3. The protocol, which was originally used for the web, tends to easily permeate firewalls and existing technology within organizations. This is an important point, since almost all organizations have their own unique security patterns, blocking some traffic and allowing other traffic. Almost all sites let web traffic through, so piggybacking SOAP on top of HTTP maximizes the chances that it will be useful in as many places as possible.
From a technology perspective, SOAP provides a way of encoding a particular request to a service somewhere on the network, and sending information along with that request. For example, take a particular manufacturing company that provides an electronic catalog of all of its materials through a web service to its customers. Customers can connect to the company’s server and send SOAP messages indicating a price query on a particular part. The server will then respond with the item name, description, price, and ordering information. All of this is done automat-ically—customers can even place orders through a SOAP interface automatically. Figure 3.11 shows how each of the statements made is understood by the other party, along with the parameters that come with them This is what SOAP enables programs to do.
SOAP documents that are sent back and forth contain what is called the SOAP “envelope.” The envelope in turn is composed of two parts, the header and the body. The header, which is optional, can contain metadata about the request, or instructions for various intermediate programs that might process the data in the document. The body, on the other hand, which is mandatory, contains the content of the request that is intended for the last program that will process the request. In some situations, SOAP documents may be passed through multiple systems and/or services before they reach their destination.
To take a concrete example, if a customer were querying a supplier’s site about product prices, the header of the SOAP document might contain a bit of metadata, and a statement that requires the server to understand a particular version of the SOAP protocol in order to process the request and ensure compatibility. The body would contain just a few simple elements whose meaning would amount to a price query on a particular item number. The item number would be contained within the body of the SOAP request. When encoding the information in this way, it is crystal clear to the supplier exactly what the customer is looking for. On the other end, the server looks up the price for that particular item, adds extra information about availability, purchasing, and whatever else is needed, wraps the entire chunk of information up into a SOAP envelope, and sends it back to the customer.
SOAP services are wonderful to use, if people know how to use them. The issue of figuring out how to use someone else’s web service is addressed using WSDL, the next component we will discuss.
WSDL: Web Services Definition Language
The WSDL specification often goes hand in hand with SOAP. When describing SOAP, we mentioned that systems can communicate with one another by exchanging SOAP documents with particular elements that describe the request being made, along with any parameter information that might be necessary to complete the request, such as the item number of an item whose price is being requested. What we did not discuss in the SOAP section is how exactly the client system is supposed to know what format the server expects the request to be sent in. The client cannot simply make up its own elements and hope that the server will understand—it must send the server the request according to how the server expects it. The Web Services Definition Language (WSDL) fills this need. The main purpose of this XML component is to let clients know how to communicate with a particular web service. Ideally, each unique web service that provides a set of capabilities will have its own dedicated WSDL document that is publicly available and details to the client how to actually use the SOAP-based service.
WSDL definitions generally contain a number of different pieces of information about the web service, all of which are needed in order to use it effectively. First, the actual address or URL of the service is provided. Next, a description of what protocol is needed to communicate with the service is given. Many web services communicate over HTTP as described in the section on SOAP, but HTTP is not the only way to exchange SOAP messages; FTP (File Transfer Protocol) and SHTTP (Secure HTTP) may also be used. If another protocol is needed, that can be noted in the WSDL description.
Next, the semantics of the service are described. There are three types of transactions—request only, request and response, and response only, each of which has its own use. Request only might be useful when the client only wants to send data to the server, and no response is needed. The utility of request and response is fairly clear–in many web services situations, the client asks for something, and the server responds with an answer, such as in the price inquiry example given earlier. The response-only transaction may also be useful if no input parameters are needed. For example, if a web service provides the temperature in Richmond, Virginia, then no request is actually needed. The fact that the client connected is the request.
Finally, the WSDL document contains a description of the messages that can be passed between machines. In this case, it has to actually lay out which elements are expected and what order they might occur in. Given the patterns of reuse that we have seen in the XML architecture, it is no surprise that schemas are used for this purpose, and are actually embedded in the WSDL document.
WSDL descriptions are frequently exchanged between partners in various businesses, or individuals who want to use services. But given that the web is so huge, invariably users would be missing out on many opportunities if they were to stick to the services they already know about. More importantly, WSDL allows an interface to be broken down into the “what” of the interface and the “how.” Sometimes, applications may need to accomplish a particular “what,” but might not care about the “how,” in which case a different but equivalent web service is used depending on what is most convenient and available.
But how does an organization find out about new web services and how to interact with them? The next component allows users to discover new services to fit specific needs.
UDDI: Universal Description, Discovery, and Integration
UDDI is another important component in the overall area of XML-enabled data and metadata interchange. The most commonly used metaphor to describe UDDI is that it acts as the virtual yellow pages of organizations and the services that they offer. It can be thought of as a catalog of web services along with where the corresponding WSDL documents can be found for each web service. One of the larger goals that XML technologies have been working toward is making machine navigation of semantic content on the Internet as easy and understandable as possible. Perhaps after a number of years, people will say that standardized XML components did for data interchange and systems communication what the set of networking protocols (i.e., TCP/IP) did for the Internet in its early years. We have taken a look at SOAP and WSDL, which focus on how machines actually carry out conversations (SOAP), and how they know which language to use when communicating with one another (WSDL), but we have not discussed a technology that helps these machines find each other in the first place. That gap is filled by UDDI.
UDDI is most often used inside a repository. This repository is the actual electronic yellow pages, and contains a number of XML documents that can describe various services that are available. The services need not be strictly tied to SOAP and web services, although in practical implementations they often are. This is another example of how the various XML components were architected for generic rather than specific situations. WSDL provides the ability to describe more services than what are strictly thought of when SOAP/HTTP is mentioned. The approach was to create a generic technology that could describe a wide range of possibilities, and then to specialize the technology for current implementations. UDDI functions in the same way, in that the services described in a UDDI registry do not have to be “normal” web services—UDDI merely contains the representational power to refer to web services quite conveniently.
Universal Description, Discovery, and Integration repositories can be public, meaning that the entries in the repository are available to the wider Internet, or private, meaning available on a more limited basis according to the desires of the publishers. Each type of registry contains four types of data about services in the registry:
1. The Organization. This comprises information about the organization—its name, where it might be located on a map, and even contact information. UDDI also has the ability to categorize this information for specific searching, so that when users use a repository, they can choose to look at organizations by name, location, etc.
2. The Service. In this section, a brief description of the service is given, along with technical information about the service, such as a category, or a business process that the service is associated with. Again, providing this extra metadata about the service provides UDDI publishers the flexibility to allow advanced searches for various services in the repository.
3. The Template. This section contains information that is intended for applications that need to use the service, rather than the other pieces of data mentioned earlier, which tend to be more useful to humans. Included in this section is the actual location of the service on the Internet, as well as load-balancing and/or routing information.
4. The Model. This area holds rather advanced information about what model the given service may conform to. For example, since each service would potentially want clients to speak a different type of XML, it would be useful to be able to categorize various services and put them in a taxonomy according to what type of structure they use for communication. If a program knows that using certain formatted XML messages are required to communicate with one service, it is often helpful to know what other services might be used with the same format.
Model information stored in the repository is particularly interesting, since it begins the process of aggregating disparate services into larger categories based on what types of formats are required to communicate with them. Further aggregation is inherently possible based on other metadata fields in the registry. For example, aggregation of services by company, by business process, or by specific information output could be very useful, depending on the situation.
Given all of the information in the repository, generally three types of searches are possible—white pages searches, yellow pages searches, and green pages searches. White pages searches allow services to be located based on a specific piece of information that the user already knows, much like in a telephone book. If the name or unique identifier of a business is known, that business can be rapidly located. Yellow pages searches work just like searches in the standard yellow pages—rather than aggregating entries by name, they are aggregated according to various taxonomies, such as by industry. If a service is needed within a particular industry without specific knowledge of the name of the service or an organization that provides it, yellow pages searches are often best. Finally, green pages searches allow the location of services based on technical information about the services, such as specifications for interfaces, and so on.
Now let us take a look at the way the SOAP, WSDL, and UDDI XML components can be combined. In Figure 3.12, we see the process that a client might go through to accomplish a particular task. First, the client needs to locate a particular service that can provide some information or facility to the client. In order to do this, the client connects to a UDDI repository, issues a search, and successfully locates a particular service that will provide pricing information for bulk purchasing of widgets. Next, using the information from the UDDI repository, the client connects to another server, which returns a WSDL description of how exactly the client should interact with the particular service. After consulting the WSDL description, the client has all the information that it needs to connect to the actual service, issue legal requests, and collect the information that comes back.

In some ways, this is an extreme example. It does seem rather complicated that a client would have to do this many steps just to fetch pricing information. It is worth keeping in mind that this is a special case where the client had no previous knowledge of any service that would fill its needs. For all subsequent uses of the service, of course, there would be no need to reconnect to the UDDI repository, or even to re-fetch the WSDL description—the client could simply connect to the service and conduct its business. The point of this diagram and discussion is to illustrate that the XML components discussed here not only provide a flexible method for data and metadata encoding, but also provide the building blocks for very useful facilities. The main problem with the Internet today is that it contains too much information that is understandable only by humans. Automated programs have no intelligence, and need their own way to make sense of the information they are getting, as well as a method of getting around on the Internet on their own. The combination of WSDL, SOAP, and UDDI provides just that.
Using SOAP, UDDI, and web services, organizational data managers can re-architect some legacy applications into smaller, more compact, easier to maintain services that cost less, perform better, and are far easier to integrate than was previously thought possible. This is partly due to the fact that many components of this architecture are already freely available to be used, but also because the architecture forces the designer to think of the overall structure in terms of the form of the data and how it is supplied to users of the data, rather than focusing on platform-specific details.
SOAP, WSDL and UDDI comprise a higher level system on top of the core XML language. Rather than simply representing data, they are meant to describe activities—the use of a particular service, or invocation of another process. The next component, ADML, goes to an even higher level, attempting to use XML’s structure to represent a second level of structure—that used in the architectural process.
ADML: Architecture Description Markup Language
Given the architectural possibilities that XML has, and the work that has gone into architecting the XML components themselves, it was pretty much inevitable that someone would use XML to describe those and other architectural activities. That is indeed what the Architecture Description Markup Language has done. The function of this component is exactly what one might guess from its name—it allows the description of architectural concepts in XML. This type of XML format is often not used directly by a person, but its benefit is derived from tool support. In the past, many organizations have been locked into a particular set of design tools because they were not able to transition the data out of those tools into something else. Tools that are able to encode information in an ADML format will be more easily integrated into open systems.
Rather than storing architectural information in arcane binary-only files, or in stacks of paper documentation, it makes sense to encode this information and start using it in other ways. Making architectural documents available and highly usable via their XML format will likely allow other system designers to understand more about the architectural context that their new system must fit into, including existing interconnections and standard ways of accomplishing particular tasks. In order to effectively apply an enterprise-wide architecture, it must be formalized and able to be communicated. XML again fits the bill as a format everyone can understand (even if they only have a lowly text editor) and promotes use of and reference to the information in the document. From an architectural perspective, many concepts are necessarily reused in the architectural process to give the entire architecture a uniformity that lessens the learning curve and eases maintenance. Encoding architectural information in ADML allows chunks to be reused in the right places, as necessary.
One traditional confusion about ADML deals with its relationship to UML, or the Unified Modeling Language. While UML is meant as a systems design language that allows the user to specify aspects of the way one particular system will be constructed, ADML focuses on the way multiple systems interact, and therefore could be said to be one conceptual level higher than UML. Sometimes, though, the line between architecture and design is not always perfectly clear, and there are some concepts that carryover between the two.
Conclusion
The XML Component Architecture contains a number of components to accomplish a variety of tasks. Of the components that are described in this chapter, the related tasks can be broken down into the following categories:
![]() Structuring and Semantics. The Namespace, DTD, and Schema components described handle the ways that document assembly and meaning is conveyed to users and to other computer systems.
Structuring and Semantics. The Namespace, DTD, and Schema components described handle the ways that document assembly and meaning is conveyed to users and to other computer systems.
![]() Parsing Technologies. DOM and SAX are two different methods of parsing XML documents and gaining access to the underlying data that they represent.
Parsing Technologies. DOM and SAX are two different methods of parsing XML documents and gaining access to the underlying data that they represent.
![]() Referencing and Linking. XLink and XPath provide mechanisms for creating links between and across XML documents to help tie resources together and minimize duplication of data in different places.
Referencing and Linking. XLink and XPath provide mechanisms for creating links between and across XML documents to help tie resources together and minimize duplication of data in different places.
![]() Presentation and Formatting. XSL, XSLT, and XSL-FOP handle the transformation of XML documents into both visually
Presentation and Formatting. XSL, XSLT, and XSL-FOP handle the transformation of XML documents into both visually
oriented final products meant for humans, and different forms of XML for subsequent processing.
![]() Web and Web Services. RDF, SOAP, UDDI, and WSDL allow users to invoke foreign applications directly, and exchange metadata descriptions of information.
Web and Web Services. RDF, SOAP, UDDI, and WSDL allow users to invoke foreign applications directly, and exchange metadata descriptions of information.
![]() Advanced Languages and Applications. ADML and ebXML (which will be covered more thoroughly in the XML Frameworks chapter) are two examples of higher-level systems and languages built on top of the core XML standard for specific functionality.
Advanced Languages and Applications. ADML and ebXML (which will be covered more thoroughly in the XML Frameworks chapter) are two examples of higher-level systems and languages built on top of the core XML standard for specific functionality.
Effective use of XML requires that the user know about the various options that XML presents, so that the right tool can be used for the right job. Almost all of these components are based on the core XML standard, and frequently one finds relationships between various components. The number of XML components is likely to expand with the needs of the user community, as well as the number of organizations that use it on all manner of critical tasks.
*For more information on XML design goals, please see Bosak and Bray’s Scientific American feature article: XML and the Second Generation Web: May 1999 http://www.sciam.com/1999/0599issue/0599bosak.html