
4. The Origins of Asserted Versioning
IT Best Practices
Contents
A Non-Temporal Table and a Basic Version Table77
Logical Delete Versioning83
Temporal Gap Versioning86
The Scope and Limits of Best Practice Versioning92
Glossary References93
Lots of things are important to us. That's why we keep data about them in our databases. In a non-temporal table, each one of them, i.e. each object, is represented by one and only one row. In a version table, however, each row represents a period of time in the life of an object, and is a description of what that object is like during that time. And so, in a version table, there can be any number of rows representing the same object, each describing what the object is like during a different period of time.
In an assertion table, on the other hand, each row represents an assertion about an object, and represents what we said, during a specific period of time, that object is like. And so, in an assertion table, there also can be any number of rows representing the same object, each describing what we said, at a different period of time, the object is like.
Bi-temporal tables contain both kinds of information. Their rows tell us what we once asserted as true, currently assert as true, or may at some future time assert as true, a statement about what an object used to be like, is like right now, or may be like at some time in the future.
Because each object is represented by exactly one row in a non-temporal table, when updates are applied, those updates overwrite the data that was there before the update. Such updates are called “updates in place”. But one problem with updates in place, of course, is that they lose information. They lose the information about what the object used to be like, about what it was like before the update. They lose historical information because they overwrite data.
Historical data can usually be found somewhere, of course, in archives and transaction logs if nowhere else. But if it is important to be able to quickly and easily access data about what objects used to be like, either by itself or together with data about what those objects are like now, then keeping that data in the same table that also contains data about the current state of those objects makes a lot of sense.
If we don't keep historical and current data in the same table, then query authors who need that data will need to be aware of the multiple table and column names, and the multiple different locations, where different subsets of historical data are kept; and, as we know, they often are not. Even if aware of all the places from which they will have to assemble the historical data they are interested in, they will also have to know which of possibly redundant copies of that data is the most current, and which the most reliable and complete; and, as we also know, they often don't.
They may need to rewrite queries, changing table and column names prior to pointing them to whichever copy of that data is chosen as the target for those queries; and in doing so, as we all know, they often make mistakes. And when tables of historical data are not kept column for column union-ably parallel with the corresponding tables containing current data, which is often the case, then the job of query authors becomes even more difficult and error-prone. They won't be able to simply copy production queries and change names. They will have to write new queries, perhaps joining data that the production queries did not have to join, perhaps assembling intermediate results and then combining those intermediate results in various complicated ways. In short, they may very quickly be taken into the realm of SQL queries that all but the most experienced query authors have no business writing.
Versioning is the IT community's way of providing queryable access to historical, current and future data. However, there are far too many variations of versioning to make an exhaustive review of them possible. So in this chapter, we will distinguish four main types of versioning, and will discuss one representative method of each type. Those four types are:
(i) Basic versioning;
(ii) Logical delete versioning;
(iii) Temporal gap versioning; and
(iv) Effective time versioning.
In this chapter, we will use several variations of a version table, and a corresponding non-temporal table, to present the basic mental model which we believe is essential to understanding how to manage versioned data. That mental model is that conventional and version tables of the same persistent objects (customers, policies, etc.) are related as follows.
An object is represented in a non-temporal table by a row which is put into that table at a certain point in time, may be updated during its tenure on the table, and may eventually be removed from that table. These three stages in the life history of an object as represented in a non-temporal table are inaugurated by, respectively, an insert transaction, zero or more update transactions, and zero or one delete transaction.
That same object is represented in a version table by a series of one or more temporally tagged rows. The object that is identified by a primary key in the non-temporal table is, in the corresponding basic version table, represented by that primary key plus a clock tick. So the primary key for the first row for an object to appear in a basic version table contains the object's unique identifier and the date the row was inserted. For each update to that object, a new row is inserted into the version table. That row has the same unique identifier for the object, but its date is different than the date of other rows for that object already on the table because its date is the date it is inserted into the table. As for a delete, some approaches to versioning carry it out as a physical delete, and others as a logical delete.
A Non-Temporal Table and a Basic Version Table
Figure 4.1 introduces the diagram we will use to compare a non-temporal table with various types of version tables.
 |
| Figure 4.1 Conventional and Basic Version Tables: An Insert Transaction. |
Two tables are shown. The one on top represents a non-temporal table of insurance policies. The one below it represents a basic version table of those same policies. Above each table is the SQL statement that inserted or most recently altered the data in that table.
In each table, primary key columns are indicated by underlining their column headings. In each table, the italicized column is a foreign key to a table which will make its first appearance in Chapter 11. Type and copay are the two business data columns in both tables. Create date and update date in the non-temporal table are, respectively, the date the row was inserted into the table, and the date the row was last updated.
In all sample tables, dates are shown in the format “mmmyy”. Thus, “Jan10” is short for January 1st, 2010, which is the start of the January 2010 clock tick. Since the clock used in most of these examples ticks once a month, the notation is unambiguous. The reason for the “mmmyy” representation is that it takes up minimal horizontal space on the page, which is important for the sample transactions, rows and tables used in illustrations throughout the book.
In the version table, there is no update date because rows are not physically updated. Instead, each logical update is carried out by copying the most current version, applying the update to the copy and inserting the result as the new most current version. As for a physical create date, that is the same thing as the version date in basic versioning.
The upper components of the diagram read as follows:
(i) The box in the upper left-hand corner of the diagram indicates what time it is now, in the example.
(ii) The row of vertical bars represents a timeline. Each vertical bar on that timeline represents one month. The month which is current, in the context of each example, is marked by filling in its vertical bar. This is a graphical representation of the same information provided in the clock tick box.
(iii) The open-ended rectangle located below the clock tick box and directly above the January 2010 bar indicates the effective time period of the single version of the policy object, P861. Rectangles which are open-ended will be used to represent versions with unknown end dates. As we will see in later diagrams, as soon as the end date for a version is known, the rectangle will be closed.
Basic Versioning
IT professionals have been using version tables for at least a quarter-century, when they want to keep track of changes that would otherwise be lost because of updating by overwriting data. The simplest versioning method is to add a date to the primary key of the table to be versioned, thus transforming it from a non-temporal into a uni-temporal table, i.e. into a table with one temporal dimension. This is the method we call basic versioning.
An Insert Transaction
Figure 4.1 shows the results of applying the same insert transaction to each table. In both cases, that result is a single row, as shown. An open-ended rectangle is situated directly above January 2010. This marks the start of the time period during which policy P861 is represented in the basic version table.
After the insert, the rectangle extends through to the end of the current month even though, on the date of the insert, we are at the beginning of that month, not at its end. This is because we are using a clock that ticks once a month and so that transaction, once applied, will remain in the database for at least that one month. Thus, our concept of a clock tick is a logical concept, not a physical one.
There is no upper limit to the length of a clock tick. The lower limit is the granularity of a full machine timestamp, as accessible by the DBMS. It is what we called, in the previous chapter, an atomic clock tick. Although it is possible to compare points in time and periods of time that use different size clock ticks, it is far simpler when all temporal tables use the same size clock ticks. In this book, as we said, we will manage temporal data with a clock that ticks once a month. Management of different size clock ticks can be left to the eventual implementation of temporal data management by vendors because it is a discrete technical issue whose absence from this discussion does not affect the discussion in any other way.
An Update Transaction
Figure 4.2 shows the results of applying the same update transaction to each table. In the case of the version table, the update is carried out as an insert, resulting in a new row which is a new version of the policy. In the case of the non-temporal table, the update is carried out as a simple update in place.
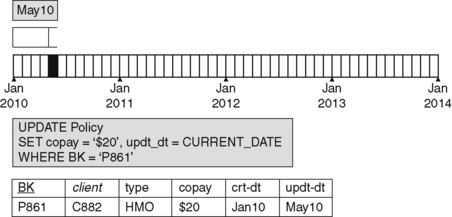 |
 |
| Figure 4.2 Conventional and Basic Version Tables: An Update Transaction. |
That transaction changes the copay amount on the policy from $15 to $20. The update was applied in May, so the rectangle for this update extends through the end of that month. Note also that the transaction closes the first rectangle, and closes it as of the same clock tick that begins the new version.
Now the information content of the two tables begins to diverge. The version table tells us that P861 had a copay of $15 from January to May, and a copay of $20 thereafter. The non-temporal table does tell us that an update was made in May, and that the copay for P861 is now $20, but it doesn't tell us what data the update changed, or how many updates have already been applied to the policy.
But the version table tells us all these things. We can determine what was changed by the update by comparing each non-initial version of the object with its immediate predecessor. We can tell what the policy was like before the change by looking at the previous version. We can tell how many updates have been applied to the policy by counting the versions, and we can tell when each one took place.
A Second Update Transaction
Figure 4.3 shows a second update transaction. This transaction updates the policy type from HMO (Health Maintenance Organization) to PPO (Preferred Provider Organization).
 |
 |
| Figure 4.3 Conventional and Basic Version Tables: A Second Update Transaction. |
After the transaction is applied to the version table, a third version is created. So we now know when the second version ended. It ended when the third version began. This is shown graphically, in Figure 4.3, by starting a third rectangle to show that the transaction has resulted in a third version of the object. Of course we don't know, at this point, if or when that third version will ever end.
The non-temporal table records the fact that an August 2010 update was applied. But it cannot tell us whether or not any previous updates were applied or, if any were, how many of them there were. Nor can it tell us what the August update changed, or what the prior state of the policy was at any time between January and August. The version table, on the other hand, can tell us all of these things.
A Delete Transaction
As shown in Figure 4.4, the result of applying the indicated delete transaction is that the row representing the policy is removed from the non-temporal table on December 2010, and that all the rows representing that policy are removed from the basic version table on that date. There remains no evidence, in either table, that policy P861 ever existed.
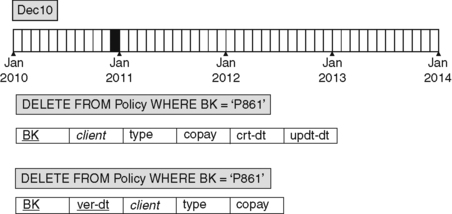 |
| Figure 4.4 Conventional and Basic Version Tables: A Delete Transaction. |
For a modest set of business requirements, basic versioning may be all that is needed. And by beginning with basic versioning, we have been able to present an uncluttered comparison of a non-temporal table and a version table. An object is represented by a single row in a non-temporal table. The equivalent representation of that object, in a version table, is a temporally contiguous set of one or more rows, all of them representing that object during some period of its existence. The one non-temporal row, and the set of version rows, cover exactly the same period of time.
But basic versioning is the least frequently used kind of versioning in real-world databases. The reason is that it preserves a history of changes to an object for only as long as the object exists in the database. When a delete transaction for the object is applied, all the information about that object is removed.
One type of versioning that is frequently seen in real-world databases is logical delete versioning. It is similar to basic versioning, but it uses logical deletes instead of physical deletes. As a result, the history of an object remains in the table even after a delete transaction is applied.
Logical Delete Versioning
In this variation on versioning, a logical delete flag is included in the version table. It has two values, one marking the row as not being a delete, and the other marking the row as being a delete. We will use the values “Y” and “N”.
After the same insert and the same update transactions, our non-temporal and logical delete version tables look as shown in Figure 4.5.
 |
| Figure 4.5 A Logical Delete Version Table: Before the Delete Transaction. |
We are now at one clock tick before December 2010, i.e. at November 2010. Although we have chosen to use a one-month clock in our examples primarily because a full timestamp or even a full date would take up too much space across the width of the page, a 1-month clock is not completely unrealistic. It corresponds to a database that is updated only in batch mode, and only at one-month intervals. Nonetheless, the reader should be aware that all these examples, and all these discussions, would remain valid if any other granularity, such as a full timestamp, were used instead.
Let us assume that it is now December 2010, and time to apply the logical delete transaction. The result is shown in Figure 4.6. However, the non-temporal table is not shown in Figure 4.6, or in any of the remaining diagrams in this chapter, because our comparison of non-temporal tables and version tables is now complete.
 |
| Figure 4.6 A Logical Delete Version Table: After the Delete Transaction. |
Note that none of policy P861's rows have been physically removed from the table. The logical deletion has been carried out by physically inserting a row whose delete flag is set to “Y”. The version date indicates when the deletion took place, and because this is not an update transaction, all the other data remains unchanged. The logical deletion is graphically represented by closing the open-ended rectangle.
At this point, the difference in information content between the two tables is at its most extreme. The non-temporal table has lost all information about policy P861, including the information that it ever existed. The version table, on the other hand, can tell us the state of policy P861 at any point in time between its initial creation on January 2010 and its deletion on December 2010.
These differences in the expressive power of non-temporal and logical delete version tables are well known to experienced IT professionals. They are the reason we turn to such version tables in the first place.
But version tables are often required to do one more thing, which is to manage temporal gaps between versions of objects. In a non-temporal table, these gaps correspond to the period of time between when a row representing an object was deleted, and when another row representing that same object was later inserted.
When only one version date is used, each version for an object other than the latest version is current from its version date up to the date of the next later version; and the latest version for an object is current from its version date until it is logically deleted or until a new current version for the same object is added to the table. But by inferring the end dates for versions in this way, it becomes impossible to record two consecutive versions for the same object which do not [meet]. It becomes impossible to record a temporal gap between versions.
To handle temporal gaps, IT professionals often use two version dates, a begin and an end date. Of course, if business requirements guarantee that every version of an object will begin precisely when the previous version ends, then only a single version date is needed. But this guarantee can seldom be made; and even if it can be made, it is not a guarantee we should rely on. The reason is that it is equivalent to guaranteeing that the business will never want to use the same identifier for an object which was once represented in the database, then later on was not, and which after some amount of time had elapsed, was represented again. It is equivalent to the guarantee that the business will never want to identify an object as the reappearance of an object the business has encountered before.
Let's look a little more closely at this important point. As difficult as it often is, given the ubiquity of unreliable data, to support the concept of same object, there is often much to be gained. Consider customers, for example. If someone was a customer of ours, and then for some reason was deleted from our Customer table, will we assign that person a new customer number, a new identifier, when she decides to become a customer once again? If we do so, we lose valuable information about her, namely the information we have about her past behavior as a customer. If instead we reassign her the same customer number she had before, then all of that historical information can be brought to bear on the challenge of anticipating what she is likely to be interested in purchasing in the near future. This is the motivation for moving beyond logical delete versioning to the next versioning best practice—temporal gap versioning.
Temporal Gap Versioning
Let's begin by looking at the state of a temporal gap version table that would have resulted from applying all our transactions to this kind of version table. We begin with the state of the table on November 2010, just before the delete transaction is applied, as shown in Figure 4.7.
 |
| Figure 4.7 A Temporal Gap Version Table: Before the Delete Transaction. |
We notice, first of all, that a logical delete flag is not present on the table. We will see later why it isn't needed. Next, we see that except for the last version, each version's end date is the same as the next version's begin date. As we explained in Chapter 3, the interpretation of these pair of dates is that each version begins on the clock tick represented by its begin date, and ends one clock tick before its end date.
In the last row, we use the value 9999 to represent the highest date the DBMS is capable of recording. In the text, we usually use the value 12/31/9999, which is that date for SQL Server, the DBMS we have used for our initial implementation of the Asserted Versioning Framework. Notice that, with this value in ver_end, at any time from August 2010 forward the following WHERE clause predicate will pick out the last row:
WHERE ver_dt <= Now() AND Now() < ver_end1
Or, at any time from May to August, the same predicate will pick out the middle row. In other words, this WHERE clause predicate will always pick out the row current at the time the query containing it is issued, no matter when that is.
Figure 4.8 shows how logical deletions are handled in temporal gap version tables.
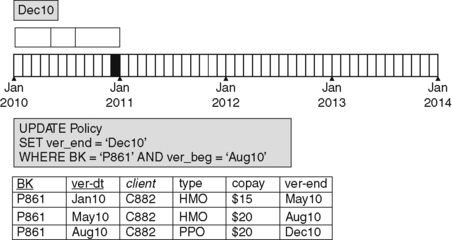 |
| Figure 4.8 A Temporal Gap Version Table: After the Delete Transaction. |
As we have seen, when an insert or update is made, the version created is given an end date of 12/31/9999. Since most of the time, we do not know how long a version will remain current, this isn't an unreasonable thing to do. So each of the first two rows was originally entered with a 12/31/9999 end date. Then, when the next version was created, its end date was given the same value as the begin date of that next version.
So when applying a delete to a temporal gap version table, all we need to do is set the end date of the latest version of the object to the deletion date, as shown in Figure 4.8. In fact, although the delete in this example takes effect as soon as the transaction is processed, there is no reason why we can't do “proactive deletes”, processing a delete transaction but specifying a date later than the current date as the value to use in place of 12/31/9999.
Effective Time Versioning
The most advanced best practice for managing versioned data which we have encountered in the IT world, other than our own early implementations of the standard temporal model, is effective time versioning. Figure 4.9 shows the schema for effective time versioning, and the results of applying a proactive insert, one which specifies that the new version being created will not take effect until two months after it is physically inserted.
 |
| Figure 4.9 Effective Time Versioning: After a Proactive Insert Transaction. |
Effective time versioning actually supports a limited kind of bi-temporality. As we will see, the ways in which it falls short of full bi-temporality are due to two features. First, instead of adding a second a pair of dates to delimit a second time period for version tables—a time period which we call assertion time, and computer scientists call transaction time—effective time versioning adds a single date. Next, instead of adding this date to the primary key of the table, as was done with the version begin date, this new date is included as a non-key column.
With effective time versioning, the version begin and end dates indicate when versions are “in effect” from a business point of view. So if we used the same schema for effective time versioning as we used for temporal gap versioning, we would be unable to tell when each version physically appeared in the table because the versioning dates would no longer be physical dates.
That information is often very useful, however. For example, suppose that we want to recreate the exact state of a set of tables as they were on March 17th, 2010. If there is a physical date of insertion for every row in each of those tables, then it is an easy matter to do so. However, if there is not, then it will be necessary to restore those tables as of their most recent backup prior to that date, and then apply transactions from the DBMS logfile forward through March 17th. For this reason, IT professionals usually include a physical insertion date on their effective time version tables.
Once the proactive insert transaction shown in Figure 4.9 has completed, then at any time from January 1st to the day before March 1st, the following filter will exclude this not yet effective row from query result sets:
WHERE ver_dt <= Now() AND Now()< ver_end
But beginning on March 1st, this filter will allow the row into result sets. So the use of this filter on queries, perhaps to create a dynamic view which contains only currently effective data, makes it possible to proactively insert a row which will then appear in the current view exactly when it is due to go into effect, and not a moment before or a moment after. The time at which physical maintenance is done is then completely independent of the time at which its results become eligible for retrieval as current data.
Proactive updates or deletes are just as straightforward. For example, suppose we had processed a proactive update and then a proactive delete in, respectively, April and July. In that case, our Policy table would be as shown in Figure 4.10.
 |
| Figure 4.10 Effective Time Versioning: After Three Proactive Transactions. |
To see how three transactions resulted in these two versions, let's read the history of P861 as recorded here. In January, we created a version of P861 which would not take effect until March. Not knowing the version end date, at the time of the transaction, that column was given a value of 12/31/9999. In April, we created a second version which would not take effect until May. In order to avoid any gap in coverage, we also updated the version end date of the previous version to May. Not knowing the version end date of this new version, we gave it a value of 12/31/9999.
Finally, in July, we were told by the business that the policy would terminate in August. Only then did we know the end date for the current version of the policy. Therefore, in July, we updated the version end date on the then-current version of the policy, changing its value from 12/31/9999 to August.
Effective Time Versioning and Retroactive Updates
We might ask what kind of an update was applied to the first row in April, and to the second row in July. This is a version table, and so aren't updates supposed to result in new versions added to the table? But as we can see, no new versions were created on either of those dates. So those two updates must have overwritten data on the two versions that are in the table.
There are a couple of reasons for overwriting data on versions. One is that there is a business rule that some columns should be updated in place whereas other columns should be versioned. In our Policy table, we can see that copay amount is one of those columns that will cause a new version to be created whenever a change happens to it. But we may suppose that there are other columns on the Policy table, columns not shown in the example, and that the changes made on the update dates of those rows are changes to one or more of those other columns, which have been designated as columns for which updates will be done as overwrites.
The other reason is that the data, as originally entered, was in error, and the updates are corrections. Any “real change”, we may assume, will cause a new version to be created. But suppose we aren't dealing with a “real change”; suppose we have discovered a mistake that has to be corrected. For example, let's assume that when it was first created, that first row had PPO as its policy type and that, after checking our documents, we realized that the correct type, all along, was HMO. It is now April. How do we correct the mistake?
We could update the policy and create a new row. But what version date would that new row have? It can't have March as its version date because that would create a primary key conflict with the incorrect row already in the table. But if it is given April as its version date, then the result is a pair of rows that together tell us that P861 was a PPO policy in March, and then became an HMO policy in April. But that's still wrong. The policy was an HMO policy in March, too.
We need one row that says that, for both March and April, P861 was an HMO policy. And the only way to do that is to overwrite the policy type on the first row. We can't do that by creating a new row, because its primary key would conflict with the primary key of the original row.
Effective Time Versioning and Retroactive Inserts and Deletions
Corrections are changes to what we said. And we have just seen that effective time versioning, which is the most advanced of the versioning best practices that we are aware of, cannot keep track of corrections to data that was originally entered in error. It does not prevent us from making those corrections. But it does prevent us from seeing that they are corrections, and distinguishing them from genuine updates.
Next, let us consider mistakes made, not in the data entered, but in when it is entered. For example, consider the situation in which there are no versions for policy P861 in our version table, and in which we are late in performing an insert for that policy. Let's suppose it is now May, but that P861 was supposed to take effect in March. What should we do? Well, by analogy with a proactive insert, we might do a retroactive insert, as shown in Figure 4.11.
| Figure 4.11 Effective Time Versioning: A Retroactive Insert Transaction. |
So suppose that it is now June, and we are asked to run a report on all policies that were in effect on April 10th. The WHERE clause of the query underlying that report would be something like this:
WHERE ver_dt <= ‘04/10/2010’ AND ‘04/10/2010’ < ver_end
Based on a query using this filter, run on June 1st, the report would include the version shown. But suppose now that we had already run the very same report, and that we did so back on April 25th, and the business intent is to rerun that report, getting exactly the same results. So it uses the same query, with the same WHERE clause. Clearly, however, the report run back on April 25th did not include P861, which didn't make its way into the table until May 1st.
If there is any chance that retroactive inserts may have been applied to a version table, the WHERE clause predicate we have been using is inadequate, because it only allows us to pick out a “when in effect” point in time. We also need to pick out a “when in the life of the data in the table” point in time. And for that purpose, we can use the create date.
With this new WHERE clause, we can do this. The filterwill return all versions in effect on 4/10/2010, provided those physical rows were in the table no later than 4/25/2010. And the filterwill return all versions in effect on 4/10/2010, provided those physical rows were in the table no earlier than 5/01/2010. Clearly, by using version dates along with create dates, effective time versioning can keep track of both changes to policies and other persistent objects, and also the creation and logical deletion of versions that were not done on time.
WHERE ver_dt <= ‘04/10/2010’ AND ‘04/01/2010’ < ver_end
AND crt_dt <= ‘04/25/2010’
WHERE ver_dt <= ‘04/10/2010’ AND ‘04/10/2010’ < ver_end
AND crt_dt > ‘05/01/2010’
The Scope and Limits of Best Practice Versioning
Versioning maintains a history of the changes that have happened to policies and other persistent objects. It also permits us to anticipate changes, by means of proactively creating new versions, creating them in advance of when they will go into effect. All four of the basic types of versioning which we have reviewed in this chapter provide this functionality.
Basic versioning is hardly ever used, however, because its deletions are physical deletions. But when a business user says that a policy should be deleted, she is (or should be) making a business statement. She is saying that as of a given point in time, the policy is no longer in effect. In a conventional table, our only option for carrying out this business directive is to physically delete the row representing that policy. But in a version table, whose primary purpose is to retain a history of what has happened to the things we are interested in, we can carry out that business directive by logically deleting the then-current version of the policy.
Logical delete versioning, however, is not very elegant. And the cost of that lack of elegance is extra work for the query author. Logical delete versioning adds a delete flag to the schema for basic versioning. But this turns its version date into a homonym. If the flag is set to “N”, the version date is the date on which that version became effective. But if the flag is set to “Y”, that date is the date on which that policy ceased to be effective. So users must understand the dual meaning of the version date, and must include a flag on all their queries to explicitly draw that distinction.
Temporal gap versioning is an improvement on logical delete versioning in two ways. First of all, it eliminates the ambiguity in the version date. With temporal gap versioning, that date is always the date on which that version went into effect. When the business says to delete a policy as of a certain date, the action taken is to set the version end date on the currently effective version for that policy to that date. No history is lost. The version date is always the date the version became effective. There is no flag that must be included on all the queries against that table.
Secondly, temporal gap versioning can record a situation in which instead of beginning exactly when a prior version ended, a version of a policy begins some time after the prior version of that policy ended. Expressed in business terms, this is the ability of the database to let us reinstate a policy after a period of time during which it was not in effect. In more general terms, it allows us to record the reappearance of an object after a period of non-effectivity.
Effective time versioning builds on temporal gap versioning. And it does so by providing limited support for bi-temporality. With temporal gap versioning, the two dates—the version begin and end dates—are what they say they are; they are version dates. They say when the version became effective and if and when it stopped being in effect. But effective time versioning has no way to make corrections to existing versions other than by overwriting the erroneous data on those versions. And this is a shortcoming common to all best practice forms of versioning.
When temporal gaps between adjacent versions of the same object must be supported, data designers usually use effective time versioning, not merely temporal gap versioning. One reason is that effective time versioning only requires one more column on the table, a row create date. And the maintenance of that column is trivial; whenever a row is physically created, the current date is put into its row create date column.
Both temporal gap versioning and effective time versioning also allow us to recognize the reappearance of an object as the same object we once kept track of, but one for which we no longer have a currently effective version.
In this chapter, we are not yet concerned with bi-temporality. But any form of versioning which supports the as-was vs. as-is distinction is bi-temporal. Effective time versioning starts us on the road to bi-temporality because it includes both (i) dates which designate a period of time that applies to the object itself, and also (ii) one date which describes a point in time that applies to the data about that object, i.e. to the row itself. But there is a lot more to bi-temporality than we have seen so far, and a lot of bi-temporal support which is lacking in effective time versioning. We need to move beyond existing best practices.
Glossary References
Glossary entries whose definitions form strong inter-dependencies are grouped together in the following list. The same glossary entries may be grouped together in different ways at the end of different chapters, each grouping reflecting the semantic perspective of each chapter. There will usually be several other, and often many other, glossary entries that are not included in the list, and we recommend that the Glossary be consulted whenever an unfamiliar term is encountered.
assertion table
assertion time
transaction time
atomic clock tick
clock tick
bi-temporal table
non-temporal table
object
persistent object
version data
version table
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.