
Chapter 5. Troubleshooting BGP Convergence
The following topics are covered in this chapter:
![]() Understanding BGP route convergence
Understanding BGP route convergence
![]() Troubleshooting convergence Issues
Troubleshooting convergence Issues
![]() BGP slow peer
BGP slow peer
![]() Troubleshooting BGP route churns
Troubleshooting BGP route churns
Understanding BGP Route Convergence
Every network design needs to be planned and tested before it is deployed and ready for use. There are various tests that should be performed, such as load test, failure test, convergence test, and so on before the network is ready to carry production traffic. The main problem faced when testing any network design is during convergence testing. The purpose of the convergence testing is to identify how convergent the network is when it is brought into production and actual production traffic will be carried over it. It is challenging when it comes to defining how convergent the network is. Routing convergence can be broadly defined as how quickly a routing protocol can become stable after changes occur in the network—for example, a protocol or link flap. In terms of Border Gateway Protocol (BGP), it can be defined as converged when all BGP neighbor sessions have been established and neighbors have been updated, routes have been learned from all neighbors and installed into the routing table, and all routing tables across the network are consistent after a network event or any change in the network.
Faster convergence leads to higher availability and improved network stability. Thus it is important that before the network is deployed in production, convergence time is properly calculated with thorough testing. But what is convergence time? Consider the topology shown in Figure 5-1. There are multiple paths from the source router in order to reach the destination router, but for simplicity, consider the two paths—primary and secondary. The primary extends from R1 to R2 to R4 to R6, whereas the secondary path extends from R1 to R3 to R5 to R6. If a link on primary path fails, the best path is impacted and leads to a traffic loss. Because of the failure event, a next-best path is computed. The amount of time during which there was a traffic loss in the network while the alternate path was not available to forward the traffic to the point where traffic starts flowing again is called the convergence time.

Like any other dynamic routing protocol, BGP accepts routing updates from its neighbors. It then advertises those updates to its peers except to the one from which it received, only if the route is a best route. BGP uses an explicit withdrawal section in the update message to inform the peers on loss of the path so they can update their BGP table accordingly. Similarly, BGP uses implicit signaling to check if there is an update for the learned prefix and to update the existing path information in case newer information is available. Looking closely at the BGP update message as shown in Figure 5-2, it can be seen that new BGP update message is bounded with a set of BGP attributes. Thus, any update with different set of attributes needs to be formatted as a different update message to be replicated to its peers.

As the networks grow larger, this could eventually pose scalability challenges and convergence issues especially to the service provider and enterprise networks to maintain an ever-increasing number of Transmission Control Protocol (TCP) sessions and routes. If the scale of the network has increased, the BGP process will have to process all the routes present in the BGP table and update its peers. In addition, the router processing the updates in such a scaled environment demand more memory and CPU resources. Because BGP is a key protocol for the Internet, it is important to ensure that BGP is highly convergent even with increased scale.
BGP convergence depends on various factors. BGP convergence is all about the speed of the following:
![]() Establishing sessions with a number of peers
Establishing sessions with a number of peers
![]() Locally generate all the BGP paths (either via network statement, redistribution of static/connected/IGP routes), and/or from other component for other address-family for example, Multicast Virtual Private Network (MVPN) from multicast, Layer 2 Virtual Private Network (L2VPN) from l2vpn manager, and so on.)
Locally generate all the BGP paths (either via network statement, redistribution of static/connected/IGP routes), and/or from other component for other address-family for example, Multicast Virtual Private Network (MVPN) from multicast, Layer 2 Virtual Private Network (L2VPN) from l2vpn manager, and so on.)
![]() Send and receive multiple BGP tables; that is, different BGP address-families to/from each peer
Send and receive multiple BGP tables; that is, different BGP address-families to/from each peer
![]() Upon receiving all the paths from peers, perform the best-path calculation to find the best path and/or multipath, additional-path, backup path
Upon receiving all the paths from peers, perform the best-path calculation to find the best path and/or multipath, additional-path, backup path
![]() Installing the best path into multiple routing tables, such as the default or Virtual Routing and Forwarding (VRF) routing table
Installing the best path into multiple routing tables, such as the default or Virtual Routing and Forwarding (VRF) routing table
![]() Import and export mechanism
Import and export mechanism
![]() For another address-family, like l2vpn or multicast, pass the path calculation result to different lower layer components
For another address-family, like l2vpn or multicast, pass the path calculation result to different lower layer components
BGP uses lot of CPU cycles when processing BGP updates and requires memory for maintaining BGP peers and routes in the BGP table. Based on the role of the BGP router in the network, appropriate hardware should be chosen. The more memory a router has, the more routes it can support, much like how a router with a faster CPU can support a larger number of peers.
BGP updates rely on TCP, optimization of router resources such as memory and TCP session parameters such as maximum segment size (MSS), path MTU discovery, interface input queues, TCP window size, and so on help improve convergence.
BGP Update Groups
An update group is a collection of peers with an identical outbound policy. The update groups are dynamically formed during the time of the configuration. Two peers will be part of same update group if one of the following conditions is met:
![]() Peers are in same peer group.
Peers are in same peer group.
![]() Peers are having the same template.
Peers are having the same template.
![]() If the peers are not part of any of the preceding two, they will be in same update group if they have the same outbound policy.
If the peers are not part of any of the preceding two, they will be in same update group if they have the same outbound policy.
After an update group is formed, a peer within the update group is selected as a group leader. The BGP process walks the BGP table of the leader and then formats the messages that are then replicated to the other members of the update group. This is so because the router needs to format the update only once and replicate the formatted update to all the peers in the update group because they all need to have the same information. Because the messages are not required to be formatted for all the peers but only for the leader of the update group, this saves lot of resources and processing time on the router.
On IOS, an update group is verified using the command show bgp ipv4 unicast update-group [group-index]. This command displays the update group index, the address-family under which the update group is formed, messages formatted in the update group, the messages replicated to the peers in the update group, and all the peers in the update group. If a particular peer is in process of being replicated or not yet converged, an asterisk (*) is seen beside the peer, indicating that the peer is still being updated. The topology in Figure 5-3 is used for understanding the update groups and the update generation process. In this topology, R1, R10, and R20 are the three route reflectors (RR) whereas R2, R3, R4, and R5 are the RR clients.

Example 5-1 displays the command output of show bgp ipv4 unicast update-group and previously discussed information. Also, this command shows the BGP update version, which generally matches the update version in the show bgp ipv4 unicast summary command. If the peers of the update group are configured as route-reflector clients, it is displayed in the command output. This command also displays any outbound policy attached to the update group.
Example 5-1 BGP Update Group on IOS
R1# show bgp ipv4 unicast update-group
BGP version 4 update-group 2, internal, Address Family: IPv4 Unicast
BGP Update version : 7/0, messages 0, active RGs: 1
Route-Reflector Client
Route map for outgoing advertisements is dummy
Topology: global, highest version: 7, tail marker: 7
Format state: Current working (OK, last not in list)
Refresh blocked (not in list, last not in list)
Update messages formatted 4, replicated 16, current 0, refresh 0, limit 1000
Number of NLRIs in the update sent: max 1, min 0
Minimum time between advertisement runs is 0 seconds
Has 4 members:
10.1.12.2 10.1.13.2 10.1.14.2 10.1.15.2
R1# show bgp ipv4 unicast summary | in table
BGP table version is 7, local router ID is 192.168.1.1
Use the command clear bgp ipv4 unicast update-group group-index [soft] to clear or soft clear the neighbors in the update group. The debug command debug bgp ipv4 unicast groups is used to see the events happening in the update group. Example 5-2 demonstrates a neighbor being added to peer group and the debug output during the event.
Example 5-2 debug bgp ipv4 unicast groups Command Output
R1(config)# router bgp 65530
R1(config-router)# neighbor 10.1.15.2 peer-group group1
R1# debug bgp ipv4 unicast groups
! Output generated by debug command
11:19:24.459: BGP-DYN(0): 10.1.15.2 cannot join update-group 2
due to an outbound route-map mismatch
11:19:24.459: BGP(0): Scheduling withdraws and update-group
membership change for 10.1.15.2
11:19:24.459: BGP-DYN(0): 10.1.15.2 cannot join update-group 2
due to an outbound route-map mismatch
11:19:24.459: BGP-DYN(0): Initializing the update-group 2 fields
with 10.1.15.2
11:19:24.459: BGP-DYN(0): Merging update-group 2 into update-group 4
11:19:24.459: BGP-DYN(0): Removing 10.1.15.2 from update-group 2
11:19:24.459: BGP-DYN(0): Adding 10.1.15.2 to update-group 4
11:19:24.475: %BGP-5-ADJCHANGE: neighbor 10.1.15.2 Down Member added to peergroup
11:19:24.475: BGP-DYN(0): 10.1.15.2's policies match with update-group 4
Update groups on IOS XR are a bit different. In IOS XR, there is a concept of hierarchical update group. At the top of the hierarchy is a parent update group with multiple child subgroups beneath it. Each subgroup is a subset of neighbors within an update group that have the same version and are running at a same pace for sending updates. Figure 5-4 illustrates how BGP updates are replicated in IOS XR using update groups and subgroups. The update groups have multiple subgroups. Each subgroups points to multiple neighbors in that subgroup and also to the formatted update messages for that update group. Each neighbor then maintains the pointer toward the current message that is being processed and written on the socket.

Barring desynchronization, an update group can contain multiple subgroups if neighbors having the same outbound behavior are configured at different times. Because the previous neighbors have already advanced to a table version, the neighbors being configured now are put in a new subgroup, and after they catch up to the other subgroup’s update version number, the subgroups are merged. Example 5-3 displays the output of command show bgp update-group on IOS XR. A new neighbor that is configured later is put into a different subgroup, and once that neighbor has synchronized the update and reaches the same table version, its moved to the other subgroup where all the other peers are present.
Example 5-3 show bgp update-group Command Output
RP/0/0/CPU0:R10# show bgp update-group
Update group for IPv4 Unicast, index 0.2:
Attributes:
Neighbor sessions are IPv4
Internal
Common admin
First neighbor AS: 65530
Send communities
Send extended communities
Route Reflector Client
4-byte AS capable
Non-labeled address-family capable
Send AIGP
Send multicast attributes
Minimum advertisement interval: 0 secs
Update group desynchronized: 0
Sub-groups merged: 0
Number of refresh subgroups: 0
Messages formatted: 6, replicated: 23
All neighbors are assigned to sub-group(s)
! Sub-Group 0.2 is for a new neighbor that was configured later
Neighbors in sub-group: 0.2, Filter-Groups num:1
Neighbors in filter-group: 0.2(RT num: 0)
10.1.105.2
Neighbors in sub-group: 0.1, Filter-Groups num:1
Neighbors in filter-group: 0.1(RT num: 0)
10.1.102.2 10.1.103.2 10.1.104.2
! Output after the neighbor 10.1.105.2 has synchronized
RP/0/0/CPU0:R10# show bgp update-group
Update group for IPv4 Unicast, index 0.2:
Attributes:
Neighbor sessions are IPv4
Internal
Common admin
First neighbor AS: 65530
Send communities
Send extended communities
Route Reflector Client
4-byte AS capable
Non-labeled address-family capable
Send AIGP
Send multicast attributes
Minimum advertisement interval: 0 secs
Update group desynchronized: 0
Sub-groups merged: 1
Number of refresh subgroups: 0
Messages formatted: 11, replicated: 28
All neighbors are assigned to sub-group(s)
Neighbors in sub-group: 0.2, Filter-Groups num:1
Neighbors in filter-group: 0.2(RT num: 0)
10.1.102.2 10.1.103.2 10.1.104.2 10.1.105.2
Two peers can be part of same update group within a particular address-family but can be in different update groups in a different address-family. Thus you need to ensure that a correct update group is being looked at while troubleshooting convergence issues.
Note
At the time of writing, the update group feature is not present in NX-OS.
BGP Update Generation
Update generation is the process of generating the update messages that need to be replicated to peer(s). The update generation process starts when one of the following events takes place:
![]() When a session is established with the peer
When a session is established with the peer
![]() When the import scanner is run with the importing prefixes
When the import scanner is run with the importing prefixes
![]() When there is a change in the network
When there is a change in the network
![]() Whenever there is an addition or removal of neighbor ip-address soft-reconfiguration inbound configuration
Whenever there is an addition or removal of neighbor ip-address soft-reconfiguration inbound configuration
![]() Whenever the BGP table is repopulated or the clear bgp ipv4 unicast * soft command is used
Whenever the BGP table is repopulated or the clear bgp ipv4 unicast * soft command is used
![]() When a route refresh message is received from a neighbor
When a route refresh message is received from a neighbor
The BGP update generation process varies as to whether the peer is part of an update group or not. Without peer groups or update groups, BGP walks the table of each peer, filters the update based on the outbound policy, and generates the update that is then sent to that neighbor. In the case of update group, a peer group leader is elected for each peer group or update group. BGP walks the table for the leader only; the prefixes are then filtered through the outbound policies. Updates are then generated and sent to the peer group or update group leader and are then replicated for peer group or update group members that are synchronized with the leader.
Before the messages are replicated, the update messages are formatted and stored in an update group cache. The size of the cache depends on variables; thus it can change over time. The cache has a maximum upper limit to help the following:
![]() Control the maximum transient memory BGP would use to generate update messages
Control the maximum transient memory BGP would use to generate update messages
![]() Throttling the update group messages in case of the cache getting full
Throttling the update group messages in case of the cache getting full
In earlier Cisco IOS software, the cache size was calculated based on the number of peers within the update group. The following criteria was used to calculate the cache size:
![]() For route refresh groups, always set the cache size to 1000
For route refresh groups, always set the cache size to 1000
![]() For update group of RR clients with more than half the BGP peers on the router having max queue size configured, the cache size is the max queue size
For update group of RR clients with more than half the BGP peers on the router having max queue size configured, the cache size is the max queue size
Table 5-1 shows the queue depth (cache) calculation methodology:

The new behavior was introduced with an enhancement—CSCsz49626. For the newer IOS releases, the cache size is calculated based on the following:
![]() Number of peers in an update group
Number of peers in an update group
![]() Installed system memory
Installed system memory
![]() Type of peers in an update group
Type of peers in an update group
![]() Type of address-family (for example, vpnv4 have a larger cache size)
Type of address-family (for example, vpnv4 have a larger cache size)
Table 5-2 shows the calculation method for cache size in newer releases:

The mem_multiply_factor or memory multiply factor variable in Table 5-2 is calculated based on the system memory. Table 5-3 shows the memory multiplier factor calculation based on system memory.

The cache size and number of messages within it can be seen with the help of the command show bgp ipv4 unicast replication. Example 5-4 shows the output of show bgp ipv4 unicast replication. From the output it can be noticed that the cache size (Csize) column is in a format of x/y, where x is the current number of messages in cache and y is the dynamically calculated cache size. It also displays the number of messages formatted and replicated for the update group.
Example 5-4 BGP Replication show Command
R1# show bgp ipv4 unicast replication
Current Next
Index Members Leader MsgFmt MsgRepl Csize Version Version
1 4 10.1.12.2 10 28 0/1000 10/0
! Output omitted due to brevity
In IOS XR, there is no cache size. In IOS XR, there is a write limit, which can be treated as a cap on the number of messages per update generation walk. The write limit has a maximum value of 5,000 messages. There is also a total limit, which refers to the maximum number of outstanding messages in the system across all subgroups or update groups. It has a max value of 25,000 messages. The update generation process is described in the following steps:
Step 1. Whenever there is a table change, the Minimum Router Advertisement Interval (MRAI) is started.
Step 2. When the timer expires, a subgroup within the update group is selected.
Step 3. After a subgroup is selected, update messages are generated up to the value of write limit or until the total number of messages is less than the total limit. These messages are stored in the hash table in the system. The io write thread is then invoked to write the messages to each neighbor’s socket.
Step 4. Return to Step 2 to find another subgroup.
Step 5. If there are a few subgroups for which the messages could not be generated, and the walk is completed, the update generation process is rescheduled for that update group, which is based on the MRAI value.
To verify the update generation process, use the debug command debug bgp update. Example 5-5 demonstrates the BGP update generation process in IOS XR with the help of debug output. It can be seen that when the prefix is received, the update message is then replicated to all the peers in the update group. One important thing to notice in the output is [default-iowt]. This indicates the io write thread as mentioned in Step 3 of the update generation process.
Example 5-5 IOS XR Update Generation Process
RP/0/0/CPU0:R10# debug bgp update level detail
! Truncating timestamp in the debug output
bgp[1052]: [default-rtr] (ip4u): Received UPDATE from 10.1.102.2 with attributes:
bgp[1052]: [default-rtr] (ip4u): nexthop 10.1.102.2/32, origin i, localpref 100,
metric 0
bgp[1052]: [default-rtr] (ip4u): Received prefix 192.168.2.2/32 (path ID: none)
from 10.1.102.2
! Output omitted for brevity
bgp[1052]: [default-upd] (ip4u): Created msg elem 0x10158ffc (pointing to message
0x100475b8), for filtergroup 0.1
bgp[1052]: [default-upd] (ip4u): Generated 1 updates for update sub-group 0.1
(average size = 70 bytes, maximum size = 70 bytes)
bgp[1052]: [default-upd] (ip4u): Updates replicated to neighbor 10.1.104.2
bgp[1052]: [default-upd] (ip4u): Updates replicated to neighbor 10.1.103.2
bgp[1052]: [default-upd] (ip4u): Updates replicated to neighbor 10.1.105.2
bgp[1052]: [default-upd] (ip4u): Updates replicated to neighbor 10.1.102.2
bgp[1052]: [default-iowt]: 10.1.104.2 send UPDATE length (incl. header) 70
bgp[1052]: [default-iowt]: 10.1.103.2 send UPDATE length (incl. header) 70
bgp[1052]: [default-iowt]: 10.1.105.2 send UPDATE length (incl. header) 70
bgp[1052]: [default-iowt]: 10.1.102.2 send UPDATE length (incl. header) 70
The update generation process on NX-OS is a bit different than on both IOS and IOS XR because there is no update group concept as of yet. BGP processes receive route update messages from its peers, runs the prefixes and attributes through any configured inbound policy, and installs the new paths in the BGP Routing Information Base (BRIB). BRIB is same as Loc-RIB, also known as BGP table. After the route has been updated in the BRIB, BGP then marks the route for further update generation. Before the prefixes are packaged, they are processed through any configured outbound policies. The BGP puts the marked routes into the update message and sends them to peers. Example 5-6 illustrates the BGP update generation on NX-OS. To understand the update generation process, enable debug commands debug ip bgp update and debug ip bgp brib. From the debug output shown, notice that the update received from peer 10.1.102.2 (withdraw message for prefix 192.168.2.2/32) is updated into the BRIB and then further updates are generated for the peers.
Example 5-6 BGP Update Generation on NX-OS
R20# debug logfile bgp
R20# debug ip bgp update
R20# debug ip bgp brib
R20# show debug logfile bgp
2015 Oct 11 14:26:33.613109 bgp: 65530 [7046] (default) UPD: Received UPDATE mes
sage from 10.1.202.2
2015 Oct 11 14:26:33.613332 bgp: 65530 [7046] (default) UPD: 10.1.202.2 parsed U
PDATE message from peer, len 28 , withdraw len 5, attr len 0, nlri len 0
2015 Oct 11 14:26:33.613381 bgp: 65530 [7046] (default) BRIB: [IPv4 Unicast] Mar
king path for dest 192.168.2.2/32 from peer 10.1.202.2 as deleted, pflags = 0x11
, reeval=0
! Output omitted for brevity
2015 Oct 11 14:26:33.616412 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] cons
ider sending 192.168.2.2/32 to peer 10.1.203.2, path-id 1, best-ext is off
2015 Oct 11 14:26:33.616437 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] 10.1
.203.2 192.168.2.2/32 path-id 1 withdrawn from peer due to: no bestpath
2015 Oct 11 14:26:33.616466 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] 10.1
.203.2 Created withdrawal (len 28) with prefix 192.168.2.2/32 path-id 1 for peer
2015 Oct 11 14:26:33.616495 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] (#66
) Finished update run for peer 10.1.203.2 (#66)
2015 Oct 11 14:26:33.616528 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] Star
ting update run for peer 10.1.204.2 (#65)
2015 Oct 11 14:26:33.616560 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] cons
ider sending 192.168.2.2/32 to peer 10.1.204.2, path-id 1, best-ext is off
2015 Oct 11 14:26:33.616585 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] 10.1
.204.2 192.168.2.2/32 path-id 1 withdrawn from peer due to: no bestpath
2015 Oct 11 14:26:33.616612 bgp: 65530 [7046] (default) UPD: [IPv4 Unicast] 10.1
.204.2 Created withdrawal (len 28) with prefix 192.168.2.2/32 path-id 1 for peer
! Output omitted for brevity
The BGP update generation process is helpful in understanding and troubleshooting convergence issues due to BGP.
Troubleshooting Convergence Issues
A BGP speaker faces convergence issues primarily because of a large BGP table size and an increase in the number of BGP peers. The different dimensional factors while investigating BGP convergence issues that need to be considered include the following:
![]() Number of peers
Number of peers
![]() Number of address-families
Number of address-families
![]() Number of prefixes/paths per address-family
Number of prefixes/paths per address-family
![]() Link speed of individual interface, individual peer
Link speed of individual interface, individual peer
![]() Different update group settings and topology
Different update group settings and topology
![]() Complexity of attribute creation and parsing for each address-family
Complexity of attribute creation and parsing for each address-family
While troubleshooting convergence issues, the first and foremost thing to verify is the time when the problem started happening, and whether there have been any recent changes that happened in the network that led to slow convergence. The changes could be an addition of single or multiple new customers, hardware or software changes, recent increase in size of the routing table or BGP table, and so on. If there has been addition of new customers or a new BGP session, it is important to understand what the scale is of BGP sessions that a BGP speaker can handle on a router. Sometimes, a single peer might be added physically, but it might be forming a BGP neighbor relationship in multiple address-families. Remember that if the new peer is forming a neighbor relationship in multisession mode, then a session is established for each address-family respectively.
While performing the convergence testing, collect statistical data to serve as the baseline for future tests. Perform the baseline convergence test during deployment followed by periodic retesting. This process helps uncover various convergence and other problems in the network and identifies the root cause of any outage situation. Without a baseline, it is hard to know when a problem started, which increases the scope of investigation for finding the root cause.
Another variable that has the most impact on the convergence is how big the BGP table is and how many paths are available in the network. In the present day world, redundancy is the need of the hour. Thus, it is being noticed that lot of designs not only have one or two redundant paths, but multiple redundant paths, and these redundant paths have a cost attached to it. Where multipath is good for providing redundancy, there is an additional overhead added on CPU and memory for calculating and holding multiple redundant paths.
While designing a network, the network operators should also consider providing enough capacity for optimal operation, not just enough to meet requirements. It has been seen many times that a link is overstretched for the amount of traffic it can handle, or a lower speed link is used than what is required, just to save some cost. Such compromises can cost the organizations a lot more than they can anticipate. If the link is over utilized, it is very likely that it can impact convergence and can impact critical traffic. For example, if there is excess traffic on the link, it is likely to drop the excess traffic that it cannot handle. In such situations, if any BGP update gets dropped, those packets have to be retransmitted back to the peer, thus adding to the delay in processing an update by the peer. Overutilized links can also cause the BGP sessions to flap because the BGP peer might be looking for a BGP keepalive or BGP update packet, but it never receives it. To overcome such issues, quality-of-service (QoS) policies can be applied on the interface as a workaround to give more preference to important traffic, such as control-plane traffic or high IP precedence traffic.
Last but not least is the BGP attribute. If multiple set of attributes are being applied or being received for BGP prefixes, it causes multiple update packets to be generated, and if the BGP table is huge—for example, having one million prefixes that need to be updated with various attributes—this can cause delay in the update generation process along with consumption of a lot of CPU cycles. Also, if there is complex regex or filtering applied on the inbound policy for a peer, the updates can take a longer time to converge.
Faster Detection of Failures
One of the biggest factors leading to slower convergence is the mechanism to detect failures. The capability to detect failures quickly is an often overlooked aspect of fast convergence. Unless you are able to quickly detect a failure, you cannot achieve fast convergence. Most of the network operators try to figure out a solution for improvising on convergence but stay behind on detecting failures and thus are never able to achieve faster convergence. A stable and reliable network should have three primary features:
![]() Faster convergence
Faster convergence
![]() Availability
Availability
![]() Scalability
Scalability
When talking about failure detection, the failures should be detected not just at the control-plane level but also at the data plane level.
Bidirectional Fast Detection (BFD) is a detection protocol that is used for subsecond detection of data plane (forwarding path) failures. BFD is used in conjunction with BGP to help detect failures in the forwarding path that significantly increase BGPs reconvergence time. BFD is a single, common standardized mechanism that is independent of media and routing protocols. It can be used in place of fast-hellos for multiple protocols. A single BFD session provides fast detection for multiple client protocols, thus reducing the control-plane overhead. BFD does not replace the protocol hello packets; it just provides a method for failure detection.
Another feature that helps in faster detection of failures for BGP sessions is fast peering session deactivation. BGP fast peering session deactivation improves BGP convergence and response time to adjacency changes with BGP neighbors. This feature introduces an event-driven interrupt system that allows the BGP process to monitor the peering based on the adjacency. When there is an adjacency change detected, it triggers the termination of BGP sessions between the default or configured BGP scanning interval. Enable this feature on Cisco IOS using neighbor ip-address fall-over [bfd] command. Example 5-7 illustrates the configuration for implementing the fast peering session deactivation feature.
Example 5-7 BGP Fast Peering Session Deactivation Feature Configuration
R1(config)# router bgp 65530
R1(config-router)# neighbor 10.1.12.2 fall-over ?
bfd Use BFD to detect failure
route-map Route map for peer route
<cr>
R1(config-router)# neighbor 10.1.12.2 fall-over bfd
R1(config-router)# end
With the fall-over option, BGP reacts immediately to any adjacency change detected locally. With the fall-over BFD option, not only faster convergence can be achieved but also a faster reaction. BFD can also help detect failures where the line protocol remains up, but peer reachability is lost.
Jumbo MTU for Faster Convergence
It is a well-known fact that the default MSS value without Path MTU discovery for BGP session is 536 bytes. In modern networks, an MSS of 536 results in an inefficient exchange of information because more packets are required to send the same amount of update data than if the MSS was 1460. This can be improved using Path maximum transmission unit (MTU) Discovery, which allows sending the update of size 1460 bytes with default MTU setting of 1500 across the path. So ~3 updates of 536 bytes can be packaged in the update and sent over to the peer. But the update can still be improved with Jumbo MTU of 9216 bytes. If the MTU is set to 9216 bytes and Path MTU discovery is enabled, as discussed in Chapter 3, “Troubleshooting Peering Issues,” 9176 byte update messages can be sent to the neighbors instead of the default 536 byte update messages. This increases the efficiency because fewer update messages need to be sent to the peer. In case slow convergence is seen, it may be worth checking the TCP MSS negotiation and verify if Path MTU Discovery is enabled or not. If Path MTU Discovery is not enabled on one of the devices in the path, it will cause the TCP to negotiate with default MSS value of 536 bytes.
Slow Convergence due to Periodic BGP Scan
In case of convergence issues, IOS devices seem to show a symptom of high CPU or a high memory utilization condition on the routers. This is because the IOS platforms are not distributed and multithreaded platforms, like IOS XR and NX-OS. But the first distinct part that makes BGP convergence slow is the periodic validity check mechanism of next-hop reachability performed by the traditional BGP Scanner process in each BGP node. The default BGP scan time is 60 seconds. Thus, if the next-hop becomes unreachable, it is not updated until the BGP Scanner process is invoked to verify if the next-hop is valid.
Figure 5-5 demonstrates an ineffective BGP next-hop validity check with BGP Scanner. In this topology, R1 is the route reflector and R2, R3, and R4 are the route-reflector clients. The routers R3 and R4 are advertising the same prefix 192.168.5.5/32 toward the route reflector (RR) with the respective next-hop values. Because of the lower router-id, path via R3 is selected as the best path on the RR for prefix 192.168.5.5/32. When the next-hop advertised by R3 becomes unreachable, the update is still not advertised to the RR. This causes a black hole of traffic for that destination until the next-hop is updated. The RR must wait for the BGP scan time to pass before it detects that the next-hop learned via R3 is not valid anymore. This is explained with outputs in Example 5-8.

Example 5-8 Ineffective NH Validity Check with BGP Scanner
! Output before 10.1.35.1 becomes unreachable
R2# show bgp ipv4 unicast
BGP table version is 60, local router ID is 192.168.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* i 192.168.5.5/32 10.1.45.1 0 100 0 ?
*>i 10.1.35.1 0 100 0 ?
!Output after 10.1.35.1 becomes unreachable
R2# show bgp ipv4 unicast 192.168.5.5
BGP routing table entry for 192.168.5.5/32, version 60
Paths: (2 available, best #2, table default)
Advertised to update-groups:
2
Refresh Epoch 9
Local, (Received from a RR-client), (received & used)
10.1.45.1 (metric 41) from 192.168.4.4 (192.168.4.4)
Origin incomplete, metric 0, localpref 100, valid, internal
rx pathid: 0, tx pathid: 0
Refresh Epoch 7
Local, (Received from a RR-client), (received & used)
10.1.35.1 (metric 31) from 192.168.3.3 (192.168.3.3)
Origin incomplete, metric 0, localpref 100, valid, internal, best
rx pathid: 0, tx pathid: 0x0
R2# show bgp ipv4 unicast
Network Next Hop Metric LocPrf Weight Path
* i 192.168.5.5/32 10.1.45.1 0 100 0 ?
*>i 10.1.35.1 0 100 0 ?
! Output after BGP Scan time expires
R2# show bgp ipv4 unicast
BGP table version is 61, local router ID is 192.168.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*>i 192.168.5.5/32 10.1.45.1 0 100 0 ?
* i 10.1.35.1 0 100 0 ?
R2# show bgp ipv4 unicast 192.168.5.5
BGP routing table entry for 192.168.5.5/32, version 61
Paths: (2 available, best #1, table default)
Advertised to update-groups:
2
Refresh Epoch 9
Local, (Received from a RR-client), (received & used)
10.1.45.1 (metric 41) from 192.168.4.4 (192.168.4.4)
Origin incomplete, metric 0, localpref 100, valid, internal, best
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 7
Local, (Received from a RR-client), (received & used)
10.1.35.1 (Inaccessible) from 192.168.3.3 (192.168.3.3)
Origin incomplete, metric 0, localpref 100, valid, internal
rx pathid: 0, tx pathid: 0
To overcome this issue, the BGP scan time is reduced by using the command bgp scan-time time-in-seconds, where the timer can be set to any value between 5 seconds and 60 seconds. But this is not an effective solution, because it still does not resolve the essential characteristic of the BGP Scanner process. Also, this could cause an impact on the router if the router is having a large BGP table, and scanning through all the prefixes frequently to validate the next-hop can continuously degrade the router’s performance. Thus it is always recommended to have BGP scan time set to its default value. A better way to overcome this issue is by using the BGP next-hop tracking (NHT) feature, which is discussed later in the chapter.
Slow Convergence due to Default Route in RIB
Default route makes the configuration simpler by allowing all traffic, but it is very important to understand where the default route needs to be advertised in the network and what impact it can potentially have. Although at times a default route is required, if configured inappropriately, it can lead to convergence issues and traffic black hole problems. Referring to the same topology as shown in Figure 5-5, R1 advertises a default route using default-originate command option toward the RR. Now taking Example 5-8, 192.168.5.5/32 has a best path through next-hop 10.1.35.1, but if that next-hop becomes unreachable, the BGP table still selects the best path for that path but with a lower metric because the RR now thinks that 10.1.35.1 is reachable via a default route which has a lower metric. Example 5-9 shows the output when this issue happens. Notice that the later output shows that the next-hop is still 10.1.35.1, but the next-hop has actually become unreachable. Thus, any traffic forwarded towards 192.168.5.5/32 will be black holed and dropped.
Example 5-9 Traffic Black Hole due to Default Route in RIB
! Output before 10.1.35.1 becomes unreachable
R2# show bgp ipv4 unicast
Network Next Hop Metric LocPrf Weight Path
*>i 0.0.0.0 192.168.1.1 0 100 0 i
* i 192.168.5.5/32 10.1.45.1 0 100 0 ?
*>i 10.1.35.1 0 100 0 ?
R2# show bgp ipv4 unicast 192.168.5.5
BGP routing table entry for 192.168.5.5/32, version 65
Paths: (2 available, best #2, table default)
Advertised to update-groups:
2
Refresh Epoch 9
Local, (Received from a RR-client), (received & used)
10.1.45.1 (metric 41) from 192.168.4.4 (192.168.4.4)
Origin incomplete, metric 0, localpref 100, valid, internal
rx pathid: 0, tx pathid: 0
Refresh Epoch 7
Local, (Received from a RR-client), (received & used)
10.1.35.1 (metric 31) from 192.168.3.3 (192.168.3.3)
Origin incomplete, metric 0, localpref 100, valid, internal, best
rx pathid: 0, tx pathid: 0x0
! Output after 10.1.35.1 becomes unreachable
R2# show bgp ipv4 unicast 192.168.5.5
BGP routing table entry for 192.168.5.5/32, version 66
Paths: (2 available, best #2, table default)
Advertised to update-groups:
2
Refresh Epoch 9
Local, (Received from a RR-client), (received & used)
10.1.45.1 (metric 41) from 192.168.4.4 (192.168.4.4)
Origin incomplete, metric 0, localpref 100, valid, internal
rx pathid: 0, tx pathid: 0
Refresh Epoch 7
Local, (Received from a RR-client), (received & used)
10.1.35.1 (metric 2) from 192.168.3.3 (192.168.3.3)
Origin incomplete, metric 0, localpref 100, valid, internal, best
rx pathid: 0, tx pathid: 0x0
Similar issues can be seen when there is a summarized route in IP RIB. These kind of issues can be resolved using the BGP Selective Next-Hop Tracking feature, which is discussed later in the chapter.
BGP Next-Hop Tracking
The BGP NHT feature was designed to overcome some of the challenges of the BGP Scanner process and convergence issues that are seen with default or summarized routes in RIB. BGP NHT feature is designed on Address Tracking Filter (ATF) infrastructure, which enables event-driven NEXT_HOP reachability updates. ATF provides a scalable event-driven model for dealing with IP RIB changes. A standalone component, ATF allows for selective monitoring of IP RIB updates for registered prefixes. The following actions are taken after ATF tracks all prefixes that are registered:
![]() Notify client about route changes.
Notify client about route changes.
![]() Client, in this case BGP, is responsible for taking action based on ATF notifications.
Client, in this case BGP, is responsible for taking action based on ATF notifications.
For event-driven NEXT_HOP reachability, BGP registers its next-hops from all available paths with ATF during the best-path calculation. ATF maintains all the information regarding the next-hops and tracks any IP RIB events in a dependency database. When a route for BGP next-hop changes (add/modify/delete) in the RIB, ATF notifies BGP about the change of its next-hop. Upon notification, BGP triggers a table walk to compute the best path for each prefix. This table walk is known as a lightweight “BGP Scanner” run. Figure 5-6 illustrates the interaction between BGP, ATF, and the IP RIB.
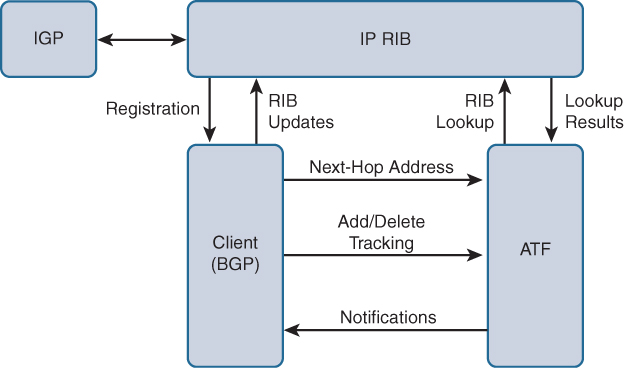
Because BGP is capable of holding a large number of prefixes, and each prefix can have multiple paths, reacting to each notification from ATF could be costly for BGP. For this reason, the table walk is scheduled after a calculated time.
BGP NHT feature is enabled by default in almost all releases where the feature is supported, unless it is explicitly disabled on the router using the command no bgp nexthop trigger enable under the BGP address-family on Cisco IOS. BGP NHT cannot be disabled on IOS XR and NX-OS platforms. On Cisco IOS devices, a list of next-hops that are registered with ATF is viewed using the hidden command show ip bgp attr nexthop. Example 5-10 displays the output of all next-hops registered with ATF on the route-reflector router in Figure 5-5.
Example 5-10 Next-Hops Registered with ATF
R2# show ip bgp attr nexthop
Next-Hop Metric Address-Family Table-id rib-filter
10.1.13.3 0 ipv4 unicast 0 0x10B624C3
10.1.45.5 3 ipv4 unicast 0 0x10B62400
10.1.35.5 2 ipv4 unicast 0 0x10B62493
10.1.14.4 0 ipv4 unicast 0 0x10B62433
After an ATF notification is received, BGP waits 5 seconds (by default) before triggering the next-hop scan. This timer is called the NHT trigger delay. The NHT trigger delay is changed for an address-family by using the command bgp nexthop trigger delay seconds on Cisco IOS. IOS XR and NX-OS platforms categorize the delay timers differently. The RIB notifications are classified based on the severity—critical and noncritical. The delay timers on IOS XR are configured by using the address-family command nexthop trigger-delay [critical | non-critical] seconds. NX-OS only provides command-line interface (CLI) to configure a trigger delay just for critical notifications using the address-family command nexthop trigger-delay critical seconds.
Note
The trigger delay is 5 seconds by default in almost all releases, except for 12.0(30)S or earlier (it is 1 second).
Selective Next-Hop Tracking
BGP NHT overcomes the problem faced because of periodic BGP scan by introducing the event-driven quick scan paradigm, but it still does not resolve the inconsistencies caused by default route or summarized route present in the RIB. To overcome these problems, a new enhancement was introduced in BGP NHT called the BGP Selective Next-Hop Tracking or BGP Selective Next-Hop Route Filtering.
A route map is used during best-path calculation and is applied on the routes in IP RIB that cover the next-hop of BGP prefixes. If the route to the next-hop fails the route-map evaluation during a BGP NHT scan triggered by a notification from ATF, the route to the next-hop is marked as unreachable. Selective Next-Hop Tracking is configured per address-family; this allows for different route maps to be applied for next-hop routes in different address-families.
Selective NHT is enabled using the command bgp nexthop route-map route-map-name on Cisco IOS software. Examine the Selective NHT feature configuration in Example 5-11.
Example 5-11 Selective NHT Configuration
router bgp 100
address-family ipv4 unicast
bgp nexthop route-map Loop32
!
ip prefix-list le-31 seq 5 per 0.0.0.0/0 le 31
!
route-map Loop32 deny 10
match ip address prefix-list le-31
!
route-map Loop32 permit 20
On Cisco IOS XR, use the command nexthop route-policy route-policy-name to implement the Selective Next-Hop Tracking feature.
The IOS XR implementation for BGP Next-Hop Tracking and Selective Next-Hop Tracking supports every address-family identifier (AFI)/subaddress-family identifier (SAFI), whereas IOS supports only IPv4/VPNv4 and VPNv6.
Slow Convergence due to Advertisement Interval
BGP neighbor advertisement interval or MRAI causes delays in update generation if set to a higher value configured manually. It is a good practice to have the same MRAI timer at both ends of the neighbor and also across different platforms. Cisco IOS has advertisement interval of 0 seconds for IBGP as well as EBGP session in a VRF and 30 seconds for EBGP session, whereas IOS XR and NX-OS has the advertisement interval of 0 seconds for both IBGP and EBGP sessions. Thus if there is an IOS router and an IOS XR router both having EBGP sessions, then IOS router advertises any update after the MRAI timer has passed, which is 30 seconds, whereas IOS XR advertises the update immediately. The higher advertisement interval can cause slow convergence because the updates are not replicated before the MRAI timer expires.
The advertisement interval or MRAI value is modified using the command neighbor ip-address advertisement-interval time-in-seconds on Cisco IOS and the command advertisement-interval time-in-seconds under the neighbor configuration mode on IOS XR. The MRAI value is not configurable on the NX-OS platform.
Computing and Installing New Path
By default, BGP always selects only one best path (assuming BGP multipath is not configured). In case of failure of the best path, BGP has to go through the path selection process again to compute the alternative best path. This takes time and thus impacts convergence time. Also, features such as BGP NHT help improve the convergence time by providing fast reaction to IGP events, but that is still not significant because it depends on the total number of prefixes to be processed for best-path selection. With the BGP multipath feature, equal cost paths can be used for both redundancy and faster failover.
The question is, what happens when there are unequal cost paths available in the network? Can the backup path be programmed in the forwarding engine (that is, Cisco Express Forwarding in case of Cisco devices) of the router? And how can multiple paths be received across a route reflector? There have been new enhancements in past few years in this area with which all these problems can be resolved. Features such as BGP Best External, BGP Add Path, and BGP Prefix Independent Convergence (PIC) are a few of the features that are answers to all these questions. These features highly enhance the convergence for BGP and provide high availability in the network. Backup paths are now precomputed and installed in the forwarding engine. Thus in case of any failure, the traffic switches to the installed backup path.
Troubleshooting BGP Convergence on IOS XR
BGP convergence troubleshooting techniques that are specific to IOS XR are covered. When troubleshooting IOS XR BGP convergence issues, the first thing you need to do is to verify whether the issue is seen right after the router boots or if it’s seen after a link or protocol flap, if fast convergence features are enabled, availability of an alternate path, and how fast the other supporting infrastructure functions (Label Switch Database (LSD), RIB, forwarding information base (FIB), and the like) are updated. It is also important to verify if any route policy is implemented or a route map on the peer router is attached to the BGP peer. Other possible scenarios that could lead to slow convergence on IOS XR could be a memory leak condition on the BGP process or by any critical application running in the system. This may cause the BGP to either converge slowly or hinder the BGP process from processing messages in a timely manner.
Verifying Convergence During Initial Bring Up
Verification needs to be performed when the router is rebooted, the BGP process has restarted or crashed, or BGP is configured for the first time. The following actions confirm convergence:
![]() BGP process state: Ensure that the BGP process is in Run state when it is started or restarted. If it is in a different state or is continuously restarting, then it needs further investigation and a Technical Assistance Center (TAC) case has to be opened.
BGP process state: Ensure that the BGP process is in Run state when it is started or restarted. If it is in a different state or is continuously restarting, then it needs further investigation and a Technical Assistance Center (TAC) case has to be opened.
![]() bgp update-delay configuration: Sometimes the BGP update-delay parameter is modified as part of the design requirements. BGP stays in Read-Only (RO) mode until the update-delay time elapses, unless it receives End of Row (EoR) from all peers.
bgp update-delay configuration: Sometimes the BGP update-delay parameter is modified as part of the design requirements. BGP stays in Read-Only (RO) mode until the update-delay time elapses, unless it receives End of Row (EoR) from all peers.
![]() Non-Stop Routing (NSR): If NSR is configured, a Stateful Switchover (SSO) is achieved by using the nsr process-failures switchover configuration knob. Verify the state using the command show redundancy on the IOS XR platforms.
Non-Stop Routing (NSR): If NSR is configured, a Stateful Switchover (SSO) is achieved by using the nsr process-failures switchover configuration knob. Verify the state using the command show redundancy on the IOS XR platforms.
![]() Verify BGP process performance statistics: Check BGP performance statistics, such as when the first BGP peer was established, what time it moved out of RO mode, and so on. This is checked by using the command show bgp process. When a new session is established and when the router begins exchanging OPEN messages, the router enters into BGP RO mode.
Verify BGP process performance statistics: Check BGP performance statistics, such as when the first BGP peer was established, what time it moved out of RO mode, and so on. This is checked by using the command show bgp process. When a new session is established and when the router begins exchanging OPEN messages, the router enters into BGP RO mode.
![]() performance-statistics detail: This command is AFI/SAFI aware and should be checked for relevant AFI/SAFI.
performance-statistics detail: This command is AFI/SAFI aware and should be checked for relevant AFI/SAFI.
Example 5-12 demonstrates the verification of the preceding points to troubleshoot any BGP convergence issue on the router.
Example 5-12 Troubleshooting Convergence on IOS XR
RP/0/0/CPU0:R10# show process bgp | include Process state
Process state: Run
! Verifying bgp update-delay configuration
RP/0/0/CPU0:R10# show run router bgp | include update-delay
bgp update-delay 360
! Verifying BGP in RO mode or Normal mode
RP/0/0/CPU0:R10# show bgp process detail | include State
State: Normal mode.
RP/0/0/CPU0:R10# show bgp process performance-statistics detail | begin First nei
First neighbor established: Oct 13 23:40:05
Entered DO_BESTPATH mode: Oct 13 23:46:09
Entered DO_IMPORT mode: Oct 13 23:46:09
Entered DO_RIBUPD mode: Oct 13 23:46:09
Entered Normal mode: Oct 13 23:46:09
Latest UPDATE sent: Oct 13 23:46:14
Note
The difference between the first established neighbor and update sent should be approximately the same as the update-delay time.
Verifying BGP Reconvergence in Steady State Network
To troubleshoot BGP reconvergence in steady state, always wait for the BGP application to be in RW (read/write) or Normal mode. After the BGP is in any of these states, check the router to see whether it exhibits any of the following symptoms:
![]() Check whether the router is not exceeding maximum allowed BGP peers and prefixes.
Check whether the router is not exceeding maximum allowed BGP peers and prefixes.
![]() Check for memory leaks by BGP application or any critical process.
Check for memory leaks by BGP application or any critical process.
![]() Check for constant link/peer flaps and troubleshoot based on that.
Check for constant link/peer flaps and troubleshoot based on that.
![]() Check whether the slow convergence is noticed for a particular peer or multiple peers. Compare the peers converging at a slower pace to the ones converging faster.
Check whether the slow convergence is noticed for a particular peer or multiple peers. Compare the peers converging at a slower pace to the ones converging faster.
![]() Check for any inefficiently configured route policy.
Check for any inefficiently configured route policy.
![]() Ensure whether Path MTU Discovery is enabled.
Ensure whether Path MTU Discovery is enabled.
![]() Check for any issues with RIB/FIB/BCDL infrastructure that are adding to the convergence delay
Check for any issues with RIB/FIB/BCDL infrastructure that are adding to the convergence delay
Ensure there is no memory leak on the router by any process that could be impacting BGP convergence. Troubleshooting memory leaks is covered in Chapter 6, “Troubleshooting Platform Issues Due to BGP.”
Check the logging buffer for any exception events, such as link flaps, peer flaps, BGP notifications, and core dumps for any process crashes. All these events can cause the BGP process to constantly calculate the best path for a given prefix that is learned from the flapping peer or across the flapping link. Consider configuring route dampening (applicable for prefixes learned from an external BGP peer) or interface dampening. In such situations, it might also be worth disabling fast-external-fallover knob under router bgp configuration, which is enabled by default.
Path maximum transmission unit (MTU) Discovery (PMTUD) was discussed in detail in Chapter 3. It is recommended to use PMTUD for improving convergence time in the network. While troubleshooting convergence issues, check the negotiated MSS value and current rx/tx queue size for the socket connection.
In Example 5-13, TCP stats show the details for this socket for the tx/rx toward application and toward netio/XIPC queue. TCP Non-Stop Routing (NSR) statistics are also listed for the protocol control block (PCB) associated with the BGP peer. Check the TCP PCB stats and NSR stats for the PCB on both the Active and Standby Route Processor (RP).
Example 5-13 Verifying Any Drops on the TCP Session
RP/0/8/CPU0:R10# show tcp brief | include 10.1.102.2
0x10146a20 0x60000000 0 0 10.1.102.1:62233 10.1.102.2:179 ESTAB
RP/0/8/CPU0:R10# show tcp statistics pcb 0x10146a20 location 0/8/CPU0
==============================================================
Statistics for PCB 0x10146a20, vrfid 0x60000000
Send: 0 bytes received from application
0 segment instructions received from partner
0 xipc pulses received from application
0 packets sent to network (v4/v6 IO)
722 packets sent to network (NetIO)
0 packets failed getting queued to network (v4/v6 IO)
0 packets failed getting queued to network (NetIO)
0 write operations by application
1 times armed, 0 times unarmed, 0 times auto-armed
Last written at: Wed Oct 14 05:20:19 2015
Rcvd: 722 packets received from network
380 packets queued to application
0 packets failed queuing to application
0 send-window shrink attempts by peer ignored
0 read operations by application
0 times armed, 0 times unarmed, 0 times auto-armed
Last read at: Wed Oct 14 05:19:43 2015
AsyncDataWrite: Data Type Data
380 successful write operations to XIPC
0 failed write operations to XIPC
7318 bytes data has been written
AsyncDataRead: Data Type Data
343 successful read operations from XIPC
0 failed read operations from XIPC
6968 bytes data has been read
AsyncDataWrite: Data Type Terminate
0 successful write operations to XIPC
0 failed write operations to XIPC
0 bytes data has been written
AsyncDataRead: Data Type Terminate
0 successful read operations from XIPC
0 failed read operations from XIPC
0 bytes data has been read
! Output omitted for brevity
RP/0/8/CPU0:R10# show tcp nsr statistics pcb 0x10146a20 location 0/8/CPU0
--------------------------------------------------------------
Node: 0/8/CPU0
--------------------------------------------------------------
==============================================================
PCB 0x10146a20
Number of times NSR went up: 1
Number of times NSR went down: 0
Number of times NSR was disabled: 0
Number of times switch-over occured : 0
IACK RX Message Statistics:
Number of iACKs dropped because SSO is not up : 0
Number of stale iACKs dropped : 0
Number of iACKs not held because of an immediate match : 0
TX Messsage Statistics:
Data transfer messages:
Sent 118347, Dropped 0, Data (Total/Avg.) 2249329/19
IOVAllocs : 0
Rcvd 0
Success : 0
Dropped (Trim) : 0
Dropped (Buf. OOS): 0
Segmentation instructions:
Sent 6139724, Dropped 0, Units (Total/Avg.) 6139724/1
Rcvd 0
Success : 0
Dropped (Trim) : 0
Dropped (TCP) : 0
NACK messages:
Sent 0, Dropped 0
Rcvd 0
Success : 0
Dropped (Data snd): 0
Cleanup instructions :
Sent 118346, Dropped 0
Rcvd 0
Success : 0
Dropped (Trim) : 0
Last clear at: Never Cleared
A complex route policy applied for a specific BGP peer can cause slowdown of BGP convergence. In Example 5-14, examine a complex route policy for a peer advertising 400K prefixes. The route policy performs multiple if-else statements, where each if statement tries to match either an as-path-set or prefix sets. If every prefix out of 400K prefixes goes through one of these if statements, it consumes a lot of CPU resources and slows BGP performance. This in turn can cause serious convergence issues. Complex route policies can be used for neighbors that are not advertising huge numbers of prefixes. The simpler the route policy, the faster the convergence for that BGP neighbor.
Example 5-14 Complex BGP Route Policy
as-path-set match-ases
ios-regex '^(.*65531)$',
ios-regex '^(.*65532)$',
ios-regex '^(.*65533)$',
! Output omitted for brevity
!
prefix-set K1-routes
10.170.53.0/24
end-set
!
prefix-set K2-routes
10.147.4.0/24
end-set
!
prefix-set K3-routes
198.168.44.0/23,
198.168.46.0/24
end-set
!
route-policy Inbound-ROUTES
if destination in K1-routes then
pass
elseif destination in K2-routes then
pass
elseif destination in K3-routes then
pass
elseif as-path in match-ases then
drop
else
pass
endif
end-policy
!
router bgp 65530
neighbor-group IGW
remote-as 65530
cluster-id 10.1.110.2
address-family ipv4 unicast
multipath
route-policy Inbound-ROUTES in
If BGP has not converged after it has come out of RO mode, use the show bgp all all convergence command to identify in which AFI/SAFI the BGP is not converged, and troubleshooting can be performed accordingly. Example 5-15 shows the output of the show bgp all all convergence command. It displays how few address-families are in not converged state.
Example 5-15 show bgp all all convergence Command
RP/0/0/CPU0:R10# show bgp all all convergence
Address Family: IPv4 Labeled-unicast
====================================
Not converged.
Received routes may not be entered in RIB.
One or more neighbors may need updating.
Address Family: IPv4 Unicast
============================
Not converged.
Received routes may not be entered in RIB.
One or more neighbors may need updating.
Address Family: IPv6 Unicast
============================
Converged.
All received routes in RIB, all neighbors updated.
All neighbors have empty write queues.
The convergence can also be verified for respective AFI/SAFI by using the CLI on the AFI/SAFI of interest. For instance, the command show bgp vpnv4 unicast convergence is used to verify the convergence state for the vpnv4 address-family. If a particular AFI/SAFI is flagged as not converged, further checks can be done to ascertain the reasons. One of the conditions that can lead to not converged state is that not all the configured peers in the address-family are in established state. If a peer is not expected to be in established state, the peer should be administratively shut down under the router bgp configuration. Another reason for a peer not being converged could be because either the local or remote peer router is busy and is not able to catch up with the processing of the incoming update message, or the transport is busy and not able to send the message out to the peer.
If a remote peer is not receiving an update in a timely manner, verify the update group performance statistics for the update group that the peer is member of. Example 5-16 shows the output of the command show bgp ipv4 unicast update-group performance-statistics. Use this command to verify how many messages have been formatted and how many replications have happened. Although it becomes a bit complex if the update group has a huge number of members, this command is really helpful for convergence issues seen for a set of peers.
Example 5-16 Update Group Performance Statistics
RP/0/0/CPU0:R10# show bgp ipv4 unicast update-group 0.2 performance-statistics
Update group for IPv4 Unicast, index 0.2:
Attributes:
Neighbor sessions are IPv4
Internal
Common admin
First neighbor AS: 65530
Send communities
Send extended communities
Route Reflector Client
4-byte AS capable
Non-labeled address-family capable
Send AIGP
Send multicast attributes
Minimum advertisement interval: 0 secs
Update group desynchronized: 0
Sub-groups merged: 0
Number of refresh subgroups: 0
Messages formatted: 0, replicated: 0
All neighbors are assigned to sub-group(s)
Neighbors in sub-group: 0.1, Filter-Groups num:1
Neighbors in filter-group: 0.1(RT num: 0)
10.1.102.2 10.1.103.2 10.1.104.2 10.1.105.2
Updates generated for 0 prefixes in 10 calls(best-external:0)
(time spent: 10.000 secs)
Update timer last started: Oct 13 23:42:12.404
Update timer last stopped: not set
Update timer last processed: Oct 13 23:42:12.434
If the update group is showing 0 messages formatted, and 0 updates generated, there seems to be some problem. One possible reason could be the route policy configuration. It might have a deny statement blocking all the updates from being sent to the peer.
Troubleshooting BGP Convergence on NX-OS
Like IOS XR, NX-OS also provides CLI for verifying convergence. There is a process that should be followed to verify if the BGP has converged and the routes are installed in the BRIB.
If there is a traffic loss, after BGP has completed its convergence for a given address-family, the routing information in the Unicast RIB (URIB) and the forwarding information in the FIB should be verified. Example 5-17 demonstrates a BGP route getting refreshed. The command show bgp afi safi ip-address can be used to validate that the prefix is installed in the BRIB table, and the command show ip route bgp can be used to check that the route has been installed in the URIB. In the URIB, verify the timestamp of when the route was downloaded to the URIB. If the prefix was recently downloaded to the URIB, there might have been an event that caused the route to get refreshed.
In Example 5-17, notice that the prefix 192.168.2.2 was installed two days and eleven hours ago, but the other prefixes were installed more than five days ago.
Example 5-17 Verifying BGP and Routing Table for Prefix
R20# show bgp ipv4 unicast 192.168.2.2
BGP routing table information for VRF default, address family IPv4 Unicast
BGP routing table entry for 192.168.2.2/32, version 67
Paths: (1 available, best #1)
Flags: (0x08001a) on xmit-list, is in urib, is best urib route
Advertised path-id 1
Path type: internal, path is valid, is best path
AS-Path: NONE, path sourced internal to AS
10.1.202.2 (metric 0) from 10.1.202.2 (192.168.2.2)
Origin IGP, MED 0, localpref 100, weight 0
Path-id 1 advertised to peers:
10.1.203.2 10.1.204.2 10.1.205.2
R20# show ip route bgp
IP Route Table for VRF "default"
'*' denotes best ucast next-hop
'**' denotes best mcast next-hop
'[x/y]' denotes [preference/metric]
'%<string>' in via output denotes VRF <string>
192.168.2.2/32, ubest/mbest: 1/0
*via 10.1.202.2, [200/0], 2d11h, bgp-65530, internal, tag 65530,
192.168.3.3/32, ubest/mbest: 1/0
*via 10.1.203.2, [200/0], 5d12h, bgp-65530, internal, tag 65530,
192.168.4.4/32, ubest/mbest: 1/0
*via 10.1.204.2, [200/0], 5d12h, bgp-65530, internal, tag 65530,
192.168.5.5/32, ubest/mbest: 1/0
*via 10.1.205.2, [200/0], 5d12h, bgp-65530, internal, tag 65530,
If the route is a vpnv4 prefix, that route has an associated label and a labeled next-hop. This is verified by using the command show forwarding route prefix vrf vrf-name. BGP convergence for the relevant address-family is checked by using the command show bgp convergence detail vrf all. Example 5-18 shows the output of the show bgp convergence details vrf all command. This command shows when the best-path selection process was started and the time to complete it.
Example 5-18 show bgp convergence detail vrf all Command
R20# show bgp convergence detail vrf all
Global settings:
BGP start time 5 day(s), 13:55:45 ago
Config processing completed 0.119865 after start
BGP out of wait mode 0.119888 after start
LDP convergence not required
Convergence to ULIB not required
Information for VRF default
Initial-bestpath timeout: 300 sec, configured 0 sec
BGP update-delay-always is not enabled
First peer up 00:09:18 after start
Bestpath timer not running
IPv4 Unicast:
First bestpath signalled 00:00:27 after start
First bestpath completed 00:00:27 after start
Convergence to URIB sent 00:00:27 after start
Peer convergence after start:
10.1.202.2 (EOR after bestpath)
10.1.203.2 (EOR after bestpath)
10.1.204.2 (EOR after bestpath)
10.1.205.2 (EOR after bestpath)
! Output omitted for brevity
Note
If the BGP best-path has not run yet, the problem is likely not related to BGP on that node.
If the best-path runs before EOR is received, or if a peer fails to send the EOR marker, it can lead to traffic loss. In such situations, enable debug for bgp updates with relevant debug filters for VRF, address-family, and peer, as shown in Example 5-19.
Example 5-19 debug Command with Filter
debug bgp events updates rib brib import
debug logfile bgp
debug-filter bgp vrf vpn1
debug-filter bgp address-family ipv4 unicast
debug-filter bgp neighbor 10.1.202.2
debug-filter bgp prefix 192.168.2.2/32
From the debug output, check the event log to look at the timestamp when the most recent End of RIB (EOR) was sent to the peer. This also shows how many routes were advertised to the peer before the sending of the EOR. A premature EOR sent to the peer can also lead to traffic loss if the peer flushes stale routes early.
If the route in URIB has not been downloaded, it needs to be further investigated because it may not be a problem with BGP. The following commands can be run to check the activity in URIB that could explain the loss:
![]() show routing internal event-history ufdm
show routing internal event-history ufdm
![]() show routing internal event-history ufdm-summary
show routing internal event-history ufdm-summary
![]() show routing internal event-history recursive
show routing internal event-history recursive
BGP Slow Peer
A BGP slow peer is a peer that cannot keep up with the rate at which the sender is generating update messages. The slow peer condition doesn’t happen in one or two updates, but this condition occurs over a prolonged period of time (usually minutes). There are several reasons for a peer to exhibit this problem, including the following:
![]() The peer is not having enough CPU capacity to process the incoming updates.
The peer is not having enough CPU capacity to process the incoming updates.
![]() The CPU is running high on the peer router and cannot service the TCP connection at the required frequency.
The CPU is running high on the peer router and cannot service the TCP connection at the required frequency.
![]() The throughput of the BGP TCP connection is very low as the result of excess traffic or traffic loss on the link.
The throughput of the BGP TCP connection is very low as the result of excess traffic or traffic loss on the link.
For further understanding the problem of BGP slow peer, it is important to understand the TCP Flow Control mechanism. The receiving side of the TCP application has a receive buffer that stores the data it received for reading it and processing it. If the receiver’s application doesn’t read the data fast enough, the buffer may fill up. Figure 5-7 illustrates the correlation between the RcvBuffer and RcvWnd.

The TCP Flow Control mechanism prevents the sender from sending more data than the receiver can store. The receiver sends the information of spare room in the buffer using the RcvWindow field as part of each TCP segment.
RcvWindow = RcvBuffer – (LastByteReceived – LastByteRead)
How does this impact the BGP update processing in the update group? When an update group peer is slow in processing the TCP updates, the update group’s number of updates pending transmission builds up and thus starts filling up the cache size (CSize). When that quota limit is reached, the BGP process does not format any new update messages for the update group leader. Because of this, even peers that are processing updates normally are not able to receive updates. Therefore, if there are any new updates to advertise new prefixes or any withdrawals, none of the peers in the update group receive the update. Thus, when one of the peers that is slow in consuming or processing the updates stops the formatting and replication of messages for all other peers in the update group, it is known as a slow peer condition.
Note
At the time of writing, BGP slow peer condition is not applicable for IOS XR and NX-OS platforms. The reason is on IOS XR, because of the concept of subgroups within update groups, slow peer issues are overcome. The slow peer condition does not apply to NX-OS because there is no concept of update groups in NX-OS.
BGP Slow Peer Symptoms
There are two common symptoms when the BGP slow peer condition is seen:
![]() High CPU due to BGP Router process
High CPU due to BGP Router process
![]() Prefixes not getting replicated and traffic black hole
Prefixes not getting replicated and traffic black hole
High CPU due to BGP Router Process
Often a BGP slow peer condition is not identified because of the high CPU condition on the router. The problem is reported as a high CPU condition due to BGP Router process.
Traffic Black Hole and Missing Prefixes in BGP table
No BGP update messages are formatted until the cache is freed up, which causes the other neighbors that are processing updates normally to miss all the newer updates that might have been there. Thus if a prefix is withdrawn from one peer, it does not get replicated to rest of the other peers that are interested in that update. Therefore, all the other remaining peers still maintain that prefix in their BGP table and thus the routing table (RIB). This situation can lead to traffic black holing.
In Figure 5-8, R1 is acting as a RR, R2 is a slow peer, and R3 through R10 are other peers that are part of the same update group. Because of the slow peer condition, the CSize has filled up for the update group, and a lot of updates are pending to be replicated to router R2.

R10 had a locally learned prefix (10.1.100.0/24) that becomes unreachable. R10 sends the withdraw message to R1 for this prefix. R1 updates that information in its BGP table, but it doesn’t format the update for any of the RR clients because it is still waiting for the CSize to have room for new messages. This information is thus not replicated to R3. R3 has a host locally connected to it that is sending traffic for the hosts in subnet 10.1.100.1.0/24. The traffic is forwarded from R3 out, but it gets dropped because the upstream device doesn’t have any information about the prefix 10.1.100.0/24 in its BGP table or routing table. This causes black holing of the traffic.
BGP Slow Peer Detection
BGP slow peer condition can be easily detected with the help of show commands. The following steps help identify a BGP slow peer:
Step 1. Verify OutQ in show bgp ipv4 unicast summary output.
Step 2. Verify SndWnd field in the show bgp ipv4 unicast neighbor ip-address command.
Step 3. Verify CSize along with Current Version and Next Version fields in show bgp ipv4 unicast replication output.
Step 4. Verify CPU utilization due to BGP Router process.
Verifying OutQ value
The show bgp ipv4 unicast summary or show bgp vpnv4 unicast all summary is a very useful command during troubleshooting BGP slow peer issues. The most important field to look in this output is the OutQ value, which should be high against a slow peer. Example 5-20 displays two neighbors with high OutQ value.
Example 5-20 High OutQ for BGP Slow Peer
R1# show bgp ipv4 unicast summary
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.1.12.2 4 109 42 87065 0 0 1000 00:10:00 3000
10.1.14.2 4 109 42 87391 0 0 674 00:10:00 2000
10.1.13.2 4 109 42 87391 0 0 0 00:10:00 1000
!Output omitted for brevity
The show bgp ipv4 unicast summary output is useful when the slow peer condition is seen in regular IPv4 BGP setup. But if there is a MPLS VPN setup, check the show bgp vpnv4 unicast all summary command as the peers are establishing neighbor relationship in the vpnv4 address-family. Also, it’s important to note that the BGP slow peer condition is mostly seen in RR deployments unless it’s a full-mesh BGP deployment. This is because the RR is peering with all its clients, most commonly using peer-group and with the same outbound policy, forming a single update group.
Verifying SndWnd
Now verify the show bgp ipv4 unicast neighbor ip-address command on both the sender and the receiver router. This command not only contains information related to BGP but also related to TCP. It shows the SndWnd/RcvWnd field based on the output on sending and the receiving routers, respectively. The sending side has the SndWnd value, which is very low or equal to 0. The RcvWnd field on the receiving router is very low or equal to 0. Example 5-21 demonstrates the low send window on the sending router and the low receive window in the receiving router. In this example, the sending router R1 is having the SndWnd as 0 and the receiving router R2 (the slow peer) is having the RcvWnd value as 0.
Example 5-21 show bgp ipv4 unicast neighbor ip-address Output
! Output from Sender side
R1# show bgp ipv4 unicast neighbor 10.1.12.2
! Output omitted for brevity
iss: 3662804973 snduna: 3668039487 sndnxt: 3668039487 sndwnd: 0
irs: 1935123434 rcvnxt: 1935222998 rcvwnd: 16003 delrcvwnd: 381
SRTT: 300 ms, RTTO: 303 ms, RTV: 3 ms, KRTT: 0 ms
minRTT: 0 ms, maxRTT: 512 ms, ACK hold: 200 ms
Status Flags: passive open, gen tcbs
Option Flags: nagle, path mtu capable
Datagrams (max data segment is 1436 bytes):
Rcvd: 3556 (out of order: 0), with data: 117, total data bytes: 99563
Sent: 5229 (retransmit: 17 fastretransmit: 0),with data: 5105, total data bytes:
5234513
! Output from Receiver side
R2# show bgp ipv4 unicast neighbor 10.1.12.1
! Output omitted for brevity
iss: 1935123434 snduna: 1935223160 sndnxt: 1935223160 sndwnd: 15841
irs: 3662804973 rcvnxt: 3668039487 rcvwnd: 0 delrcvwnd: 0
SRTT: 304 ms, RTTO: 338 ms, RTV: 34 ms, KRTT: 0 ms
minRTT: 0 ms, maxRTT: 336 ms, ACK hold: 200 ms
Status Flags: none
Option Flags: higher precendence, nagle, path mtu capable
Verifying Cache Size and Pending Replication Messages
As stated, the cache size of the update group keeps increasing without returning to zero when the formatted update messages keep building up for transmission. This is verified by using the show ip bgp replication command. Example 5-22 displays the show ip bgp replication output. In this output, the update group 1 has 348 members and the cache size (CSize) of 1000, but the cache is almost full because there are 999 messages in the cache. Another important thing to note is that for the same update group, there is a huge difference between the Current Version and the Next Version values. If this difference is temporary, then this can be ignored, but if the difference in version remains for a long period of time along with high Csize utilization, then this indicates a slow peer. Ideally, both the Current Version and Next Version fields should be equal or 0.
Example 5-22 show ip bgp replication Output
R1# show bgp ipv4 unicast replication
Current Next
Index Members Leader MsgFmt MsgRepl Csize Version Version
1 348 10.1.20.2 1726595727 1938155978 999/1000 1012333000/1012351142
2 2 192.168.78.19 79434677 79398843 0/200 1012351503/1012351503
3 1 10.37.187.24 0 0 0/100 0/0
4 2 10.19.30.249 79219618 97412908 0/200 1012351504/1012351504
The neighbors having the high OutQ value are also part of the same update group that is having high CSize usage. Remember that if it is a MPLS VPN setup, use the command show bgp vpvn4 unicast all replication to verify the CSize for an update group.
Workaround
A simple workaround to mitigate the slow peer condition and prevent it from impacting the other peers is to move the slow peer into a separate update group. There are three manual ways to accomplish this:
![]() Changing the outbound policy of that neighbor can move the neighbor to a separate update group.
Changing the outbound policy of that neighbor can move the neighbor to a separate update group.
![]() Change the advertisement interval from the default value.
Change the advertisement interval from the default value.
![]() BGP Slow Peer feature.
BGP Slow Peer feature.
Changing Outbound Policy
If the outbound policy of all the peers is the same, then creating a new outbound policy different from the one being used for the other peers moves the slow peer into a different update group.
Example 5-23 demonstrates moving a neighbor from one update group to another update group by changing the outbound policy using route-map.
Example 5-23 Changing Outbound Route Policy
R1# show bgp ipv4 unicast update-group
BGP version 4 update-group 5, internal, Address Family: IPv4 Unicast
BGP Update version : 18/0, messages 0, active RGs: 1
Topology: global, highest version: 18, tail marker: 18
Format state: Current working (OK, last not in list)
Refresh blocked (not in list, last not in list)
Update messages formatted 9, replicated 11, current 0, refresh 0, limit 1000
Number of NLRIs in the update sent: max 2, min 0
Minimum time between advertisement runs is 0 seconds
Has 4 members:
10.1.12.2 10.1.13.2 10.1.14.2 10.1.15.2
R1(config)# route-map R5_Out permit 10
R1(config-route-map)# set community 65530:5
R1(config-route-map)# exit
R1(config)# router bgp 65530
R1(config-router)# address-family ipv4
R1(config-router-af)# neighbor 10.1.15.2 route-map R5_Out out
R1(config-router-af)# end
R1# show bgp ipv4 unicast update-group
BGP version 4 update-group 5, internal, Address Family: IPv4 Unicast
BGP Update version : 19/0, messages 0, active RGs: 1
Topology: global, highest version: 19, tail marker: 19
Format state: Current working (OK, last not in list)
Refresh blocked (not in list, last not in list)
Update messages formatted 9, replicated 11, current 0, refresh 0, limit 1000
Number of NLRIs in the update sent: max 2, min 0
Minimum time between advertisement runs is 0 seconds
Has 3 members:
10.1.12.2 10.1.13.2 10.1.14.2
BGP version 4 update-group 6, internal, Address Family: IPv4 Unicast
BGP Update version : 19/0, messages 0, active RGs: 1
Route map for outgoing advertisements is R5_Out
Topology: global, highest version: 19, tail marker: 19
Format state: Current working (OK, last not in list)
Refresh blocked (not in list, last not in list)
Update messages formatted 4, replicated 4, current 0, refresh 0, limit 1000
Number of NLRIs in the update sent: max 3, min 0
Minimum time between advertisement runs is 0 seconds
Has 1 member:
10.1.15.2
If the members are part of a peer group, then removing the slow peer from that peer group moves it to a separate update group. Alternatively, if the peer group or peers already have a route map, create a route map with the same functionality but with a different name and apply it to the slow peer. This moves the slow peer to a separate update group.
Advertisement Interval
The BGP advertisement interval or MRAI is a measure to limit the advertisement of routes. Rather than having flash updates, the router waits for the advertisement interval to expire and then it sends the update to its peers. The advertisement interval was 5 seconds for IBGP peers and 30 seconds for EBGP peers. But this was later updated to 0 seconds for IBGP peers and 30 seconds for EBGP peers on Cisco IOS software. Changing the MRAI value moves the peer to a separate update group because the update is not packaged at the same time as compared to the other neighbors. Example 5-24 demonstrates how changing the advertisement interval moves the peer to a separate update group. In the first output, it is seen that the advertisement interval is 0 seconds for all the members in the update group 5, but after changing the advertisement interval to 6 for neighbor 10.1.13.2, it was moved to a separate update group.
Example 5-24 MRAI and Update Groups
R1# show bgp ipv4 unicast update-group
BGP version 4 update-group 5, internal, Address Family: IPv4 Unicast
BGP Update version : 24/0, messages 0, active RGs: 1
Topology: global, highest version: 24, tail marker: 24
Format state: Current working (OK, last not in list)
Refresh blocked (not in list, last not in list)
Update messages formatted 16, replicated 25, current 0, refresh 0, limit 1000
Number of NLRIs in the update sent: max 2, min 0
Minimum time between advertisement runs is 0 seconds
Has 4 members:
10.1.12.2 10.1.13.2 10.1.14.2 10.1.15.2
R1(config)# router bgp 65530
R1(config-router)# address-family ipv4
R1(config-router-af)# neighbor 10.1.13.2 advertisement-interval 6
R1(config-router-af)# end
R1# show bgp ipv4 unicast update-group
BGP version 4 update-group 8, internal, Address Family: IPv4 Unicast
BGP Update version : 5/0, messages 0, active RGs: 1
Topology: global, highest version: 5, tail marker: 5
Format state: Current working (OK, last not in list)
Refresh blocked (not in list, last not in list)
Update messages formatted 0, replicated 0, current 0, refresh 0, limit 1000
Number of NLRIs in the update sent: max 0, min 0
Minimum time between advertisement runs is 0 seconds
Has 3 members:
10.1.12.2 10.1.14.2 10.1.15.2
BGP version 4 update-group 9, internal, Address Family: IPv4 Unicast
BGP Update version : 5/0, messages 0, active RGs: 1
Topology: global, highest version: 5, tail marker: 5
Format state: Current working (OK, last minimum advertisement interval)
Refresh blocked (not in list, last not in list)
Update messages formatted 0, replicated 0, current 0, refresh 0, limit 1000
Number of NLRIs in the update sent: max 0, min 0
Minimum time between advertisement runs is 6 seconds
Has 1 member:
10.1.13.2
Both methods mentioned are manual methods of moving the slow peer to a separate update group.
BGP Slow Peer Feature
Starting with the 12.2(33)SRE release, Cisco IOS software introduced the slow peer detection feature that automatically detects and moves the slow peer into its own update group. The three mechanisms available are as follows:
![]() Static slow peer
Static slow peer
![]() Dynamic slow peer detection
Dynamic slow peer detection
![]() Slow peer protection
Slow peer protection
Static Slow Peer
Static slow peer is a configuration option to move a peer into its own update group, similar to the manual methods mentioned previously. When enabled, this feature moves the statically configured peer to a separate update group. The command neighbor [ip-address | peer-grp-name] slow-peer split-update-group static allows statically setting a neighbor as a slow peer. The benefit of the static slow peer feature is that it takes less overhead on the system resources. If there are two or more neighbors marked as slow peer, all of them are part of the same update group and progress at the pace of the slowest peer of them all.
Dynamic Slow Peer Detection
The feature is enabled by default on the newer IOS releases that has support for slow peer detection. When this feature is enabled, the router monitors its peers to see if any exhibit the symptoms shared before. If a peer is found to be having those symptoms, it is marked as slow and dynamically moved to a separate update group. At this point, a syslog message is printed indicating the peer that is found to be slow. When the neighbor recovers from the slow peer condition, it is then moved back to the existing update group along with a syslog message indicating the recovery of the peer.
The bgp slow-peer detection [threshold seconds] command is used to enable the dynamic slow peer detection feature. The threshold value in this command defines the time to detect a peer as a slow peer. The default value is 300 seconds.
Example 5-25 displays a syslog message generated for a slow peer detection and recovery.
Example 5-25 BGP Slow Peer Syslog Message
Sept 24 22:54:32.982 IST: %BGP-5-SLOWPEER_DETECT: Neighbor IPv4 Unicast 10.1.12.2
has been detected as a slow peer
! Output omitted for brevity
Sept 24 22:57:28.816 IST: %BGP-5-SLOWPEER_RECOVER: Slow peer IPv4 unicast 10.1.12.2
has recovered.
Slow Peer Protection
This feature depends on the dynamic BGP slow peer detection. When this feature is enabled, the peer after recovering from slow peer state is not moved back automatically to the default update group. Rather, it is marked permanently to remain in the new update group. After the root cause of the slow peer condition is identified, the peer can then be moved to the default update group by using the clear bgp ip-address slow command. If there are multiple address families, the clear command has to be used within the affected address-family. The slow peer protection feature is enabled by using the bgp slow-peer split-update-group dynamic [permanent] configuration command. The permanent keyword is the one that enables slow peer protection.
Slow Peer Show Commands
The CLI for show commands for slow peer is no different from the regular BGP show commands, but the output can be filtered to slow peers using the slow keyword at the end of the command. The CLI is applicable when the IOS slow peer configuration is being used. To verify the update group created for the slow peer, use the show bgp ipv4 unicast update-group slow command. To verify the summary information of all slow peers, use the show bgp ipv4 unicast summary slow command. The slow keyword is available for both show and clear commands.
Troubleshooting BGP Route Flapping
In a huge enterprise or in service provider deployments, it’s very common to see flapping routes. For example, a customer shuts down some servers at its end, and it causes the route to be updated on the service provider edge router and also on the remote customer router. These expected flaps are not cause for worry because they do not create a large table version update on the routers, but if there are 100K prefixes getting updated every few seconds, this can cause serious performance issues in the network and especially with BGP, because such route churns causes the CPU to spike up due to the BGP router process and slow down BGP convergence.
To investigate BGP route churn issues, the troubleshooting has to be performed on a hop-by-hop basis. Figure 5-9 shows the topology where the route reflector is seeing a huge amount of route churns. In this topology, R2, R3, and R4 are the route-reflector clients of router R1. R2 is peering with an ISP through which it is learning the Internet routing table.

The initial problem is, in most cases, reported as high CPU due to BGP Router process. Example 5-26 shows the high CPU utilization on the router due to BGP Router process. If the BGP prefixes are supposed to get installed in the routing table (RIB), the IP RIB Update process may also consume the CPU utilization.
Example 5-26 High CPU due to BGP Router Process
R1# show process cpu sorted
CPU utilization for five seconds: 99%/4%; one minute: 98%; five minutes: 98%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
3 1892358 1306768 1448 50.65% 58.59% 63.87% 0 BGP Router
198 101510 566 179346 34.61% 23.68% 21.04% 0 IP RIB Update
100 1118683 1274370 877 6.81% 2.56% 1.03% 0 BGP I/O
137 1752230 1275486 1373 1.86% 0.74% 0.67% 0 IP Input
82 157775 41329 3817 0.40% 0.39% 0.39% 0 Per-Second Jobs
339 8417 690 12198 0.32% 0.81% 0.20% 0 BGP Task
104 110554 640268 172 0.16% 0.13% 0.12% 0 VRRS Main thread
To verify whether the route flapping is happening, the BGP table version and the routing table need to be checked. Because the routes learned over BGP are flapping, it causes the BGP table version to continuously increase by a huge number (a small increase is not much of a concern and is expected in a large network).
To verify the table version, use the show ip bgp summary command multiple times to see how frequently the table version is incrementing. It’s better to capture this output along with the show clock command so as to understand the number of flaps that occurred since the last execution of the command. Example 5-27 demonstrates how to check the BGP table for flapping routes. The output shows that in 6 seconds the BGP table version has increased by 10,000. This output needs to be captured multiple times to understand how frequently the route churn is happening.
Example 5-27 Verifying BGP Table Version
R1# show clock
*14:54:24.240 UTC Sun Oct 25 2015
R1# show bgp ipv4 unicast summary
BGP router identifier 192.168.1.1, local AS number 65530
BGP table version is 277142, main routing table version 276802
39499 network entries using 5687856 bytes of memory
39499 path entries using 3159920 bytes of memory
3952/3952 BGP path/bestpath attribute entries using 600704 bytes of memory
! Output omitted for brevity
R1# show clock
*14:54:30.500 UTC Sun Oct 25 2015
R1# show bgp ipv4 unicast summary | include table
BGP table version is 289662, main routing table version 281302
If the routes are flapping in the global routing table, verify the routing table for flapping routes using the show ip route | include 00:00:0 command. To verify the routes for the vpnv4 prefixes, use the show ip route vrf * all | include 00:00:0 | Routing Table: command. The command displays the routes that got installed in the routing table in last 10 seconds. Example 5-28 shows the routing table having flapped routes in last 10 seconds. From this output it is seen that the next-hop 10.1.12.2 is the node from where all the prefixes were received that are flapping.
Example 5-28 Verifying Flapping Routes in RIB
R1# show ip route | in 00:00:0
B 172.31.117.0 [200/2373] via 10.1.12.2, 00:00:09
B 172.31.118.0 [200/2373] via 10.1.12.2, 00:00:09
B 172.31.119.0 [200/2373] via 10.1.12.2, 00:00:09
B 172.31.120.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.121.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.122.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.123.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.124.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.125.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.126.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.127.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.128.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.129.0 [200/1324] via 10.1.12.2, 00:00:09
B 172.31.130.0 [200/2964] via 10.1.12.2, 00:00:09
! Output omitted for brevity
Verify the next-hop for the flapping prefixes. In most cases, the flapping routes are coming from a common next-hop. Check the next-hop for a few of the flapping prefixes and track down that next-hop in the network. Go to that next-hop router and perform the preceding steps again by checking the table version, and then checking the routing table. If that router is receiving the prefixes from another eBGP peer, or those prefixes are learned via redistribution, then check the peer router to understand why those prefixes are flapping. One common reason could be a flapping link that is causing the BGP session or redistributing IGP to flap and create a route churn. Example 5-29 demonstrates how to track down the flapping prefixes. On the RR, a high amount of churn is noticed and further understood that the prefixes are learned via the next-hop 10.1.12.2. On the 10.1.12.2 router, those prefixes are being learned via another eBGP peer 10.1.26.2 from where those prefixes are being received. Further checking on the BGP peer shows that a BGP session has been flapping continuously, causing the BGP route churn.
Example 5-29 Verifying the Prefixes on the Next-Hop Router
R2# show ip route | in 00:00:0
B 172.47.117.0 [20/2370] via 10.1.26.2, 00:00:09
B 172.47.118.0 [20/2370] via 10.1.26.2, 00:00:09
B 172.47.119.0 [20/2370] via 10.1.26.2, 00:00:09
B 172.47.120.0 [20/2370] via 10.1.26.2, 00:00:09
B 172.47.121.0 [20/2370] via 10.1.26.2, 00:00:09
B 172.47.122.0 [20/2370] via 10.1.26.2, 00:00:09
B 172.47.123.0 [20/2370] via 10.1.26.2, 00:00:09
B 172.47.124.0 [20/2430] via 10.1.26.2, 00:00:09
B 172.47.125.0 [20/2430] via 10.1.26.2, 00:00:09
B 172.47.126.0 [20/2430] via 10.1.26.2, 00:00:09
B 172.47.127.0 [20/2430] via 10.1.26.2, 00:00:09
B 172.47.128.0 [20/2430] via 10.1.26.2, 00:00:09
B 172.47.129.0 [20/2430] via 10.1.26.2, 00:00:09
! Output omitted for brevity
R2# show logging
*Oct 25 06:03:45.585: %BGP-5-ADJCHANGE: neighbor 10.1.26.2 Up
*Oct 25 14:23:01.331: %BGP-5-NBR_RESET: Neighbor 10.1.26.2 reset (Peer closed the
session)
*Oct 25 14:23:03.093: %BGP-5-ADJCHANGE: neighbor 10.1.26.2 Down Peer closed the
session
*Oct 25 14:23:03.094: %BGP_SESSION-5-ADJCHANGE: neighbor 10.1.26.2 IPv4 Unicast
topology base removed from session Peer closed the session
*Oct 25 14:25:01.052: %BGP-5-ADJCHANGE: neighbor 10.1.26.2 Up
*Oct 25 14:28:01.122: %BGP-5-NBR_RESET: Neighbor 10.1.26.2 reset (Peer closed the
session)
*Oct 25 14:28:05.354: %BGP-5-ADJCHANGE: neighbor 10.1.26.2 Down Peer closed the
session
*Oct 25 14:28:05.354: %BGP_SESSION-5-ADJCHANGE: neighbor 10.1.26.2 IPv4 Unicast
topology base removed from session Peer closed the session
*Oct 25 14:28:15.183: %BGP-5-NBR_RESET: Neighbor 10.1.26.2 active reset (BGP
Notification sent)
! Output omitted for brevity
There can be situations in which the router is receiving continuous route churns from the next-hop router, but the routing table of the next-hop router shows that those prefixes have been stable. This could be an indication that there is something more to the problem than just a flapping link. At this point, the update group and replication needs to be verified. Use the debug bgp ipv4 unicast update debug command to verify why the update is being generated.
Until the actual reason for the route churn is identified, apply a temporary patch on the devices running BGP using the dampening feature. With the use of BGP dampening, flapping routes can be avoided to be installed in the BGP table back and forth until those routes become stable. If the churn is happening due to a flapping link, in that case, the interface dampening feature can be applied along with BGP dampening. Another benefit of dampening is that it provides a nice view of which prefixes are flapping frequently by using the command show bgp afi safi ip-address or the command show bgp afi safi [dampened-paths | flap-statistics].
Summary
This chapter discussed various BGP convergence problems that could severely degrade network performance or can cause traffic black holes. The chapter explains in detail the BGP update groups and the BGP update generation process on various Cisco platforms. The chapter then describes various scenarios that lead to BGP convergence issues, such as the problems faced because of periodic BGP scan, slow convergence due to default route in the RIB, and so on. The chapter then discussed various steps to troubleshoot BGP convergence issues on IOS XR and NX-OS platforms. On Cisco IOS platforms, slow convergence issues due to a BGP slow peer problem are discussed along with the methods to resolve them. Finally, the chapter discussed techniques to troubleshoot flapping BGP routes issues.
Reference
RFC 7747, Basic BGP Convergence Benchmarking Methodology for Data-Plane Convergence, R. Papneja, B., Parise, S. Hares, D. Lee, I. Varlashkin, IETF, https://tools.ietf.org/html/rfc7747, April 2016.