
In This Chapter
Understanding the silo concept
Optimizing and managing the data center
Handling hardware, software, and work processes
We have spent a lot of time talking about the fact that a business itself is a set of services focused on achieving the right customer experience. In the case of an automated teller machine (ATM), the customer wants to walk up to the machine and in quick order get a wad of cash. If the customer has the right card, the right security code, and enough money in the bank account, everything works like magic.
If only magic were possible! Reality is much more complicated. When we speak of managing the data center, what we really mean is managing the whole corporate IT resource − which, for the vast majority of organizations, has its heart in the data center.
In this chapter, we focus on the optimization of all the service management processes that constitute the operational activities of the data center. An inherent conflict exists between highly efficient use of assets and a guaranteed customer or user experience.
A data center isn't a neatly packaged IT system; it's a messy combination of hardware, software, data storage, and infrastructure. The typical data center has myriad servers running different operating systems and a large variety of applications. In addition, many organizations have created multiple data centers over time to support specific departments or divisions in different geographic locations.
As long as hardware, energy, and physical space were relatively cheap, no one really bothered to think about the need to manage data center resources closely. If something broke, replacing it often was easier than figuring out where the problem was. If performance slowed, adding a couple more servers was a simple way to keep users from complaining. Over the past couple of years, however, three events changed everything:
Data centers became expensive in terms of space and energy.
The number of servers and other devices in use grew very large, making management of data and applications more complex and labor intensive.
Compliance requirements, both external and internal, made oversight a business requirement.
Taken together, these events shifted organizations' approach from management of individual application silos (which could be added to the data center as new applications were requested) to overall management of data centers, based on the need to consolidate a broad set of services.
Organizations always had an incentive to optimize many aspects of data center activity, but the focus now is on managing a data center as a single coherent set of resources. This approach means managing a broad but poorly integrated IT ecosystem that spans the corporate supply chain from suppliers to customers while attempting to satisfy a series of competing demands, from the directives of corporate governance to energy efficiency.
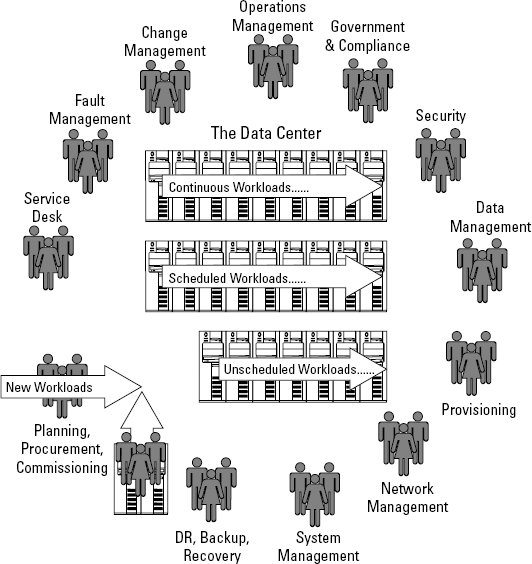
In many ways, you can think of a data center as being a factory. It resembles a factory in the sense that it has staff members who need to carry out regular, well-defined activities. It also has purpose-built machinery for processing a regular scheduled set of work. From an organizational perspective, the management goals include ensuring the quality of processes, having very few breakdowns, and holding down costs. The efficient and effective operation of the factory is critical to the success of the business.
Differences exist between a data center and a traditional factory, however. Specifically, in a data center the raw material being processed is information, and the mechanisms that process this raw material are business applications. All the activities of the data center involve catering to the needs of those business applications so that they perform as expected and are available when needed. The various types of management software are the tools that help data center staff keep the production line in good order.
Figure 11-1 illustrates this idea, with the data center running various workloads. Because this figure fundamentally depicts how a data center operates, it may make managing a data center appear to be relatively easy. A multitude of processes are involved, however.
Ultimately, what a data center does is run workloads. A workload is what it sounds like: a set of tasks required to meet customer or user demand (or possibly to complete tasks behind the scenes). As with everything else in the complex world of the data center, you find different types of workloads:
Continuous workloads keep important business applications running all the time. An application that manages the transactions from hundreds of ATMs, for example, must run all the time.
Scheduled workloads are put in place for tasks such as backups.
Unscheduled workloads are intended to run only when a user requests service.
Optimization is a balancing act. If you want to provide a specific service level for an application, you must devote enough resources to ensure that the service level will be met. If you provide too many resources, however, you waste some of them. If you had no financial constraints, you could provide all the resources anyone could possibly need to cater to every possible level of application activity. In such a world, every server could have a duplicate server just in case of an outage. You could give every department twice the storage it needed just in case data volumes grew at dramatic rates.
That approach wasn't feasible even in the days of siloed computing, however, and it isn't at all desirable if you want to get the best possible value from the computer resources that are deployed.
Optimizing an entire data center is far more complex than optimizing for a specific application. Many things can be optimized in a way that provides adequate support for defined service levels yet keeps costs down.
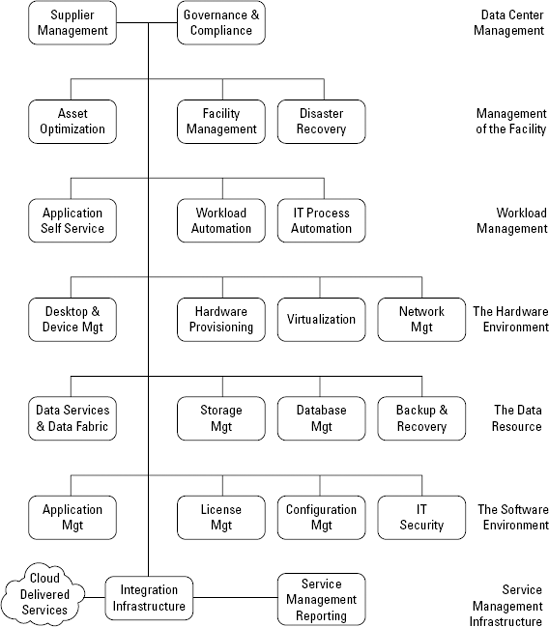
Figure 11-2 represents the service management processes or activities that inevitably take place in management of the corporate IT resource. The processes shown in the figure are the ones that are relevant to optimization activity.
The figure separates these processes into groups, or layers, that can be considered together. We drew the figure as though it were a network connecting many applications, because it is quite likely that service management applications will relate to most of the processes depicted here and connect with one another via integration infrastructure.
Optimizing the data center as a whole is complicated because all the capabilities − facilities, workloads, hardware environments, data resources, software environments, and the infrastructure itself − have traditionally been handled as independent disciplines. The data center is rarely managed as a single unified environment, and the different areas typically don't orchestrate their activities.
The lack of integration generally is the result of explosive growth. IT management never expected that data centers would grow so large, and many of the problems that now exist were mild irritations or nonexistent when data centers were much smaller. The structure of the IT organization, combined with the service management software in use, reflects this lack of integration. Just as there are application silos, there are service management silos. This reality is compounded by the fact that many data centers are running out of space or seeing their costs escalate uncontrollably.
Several distinct factors mandate a holistic approach to data center management:
Compliance, governance, and security requirements emanating from multiple sources
Escalating power requirements and inefficient hardware use
The advent of compelling virtualization technologies coupled with the need to implement them effectively to improve resource productivity
Accelerated technology change (new technologies usually are difficult to integrate and tend to be disruptive)
The automation of business processes across highly distributed environments encouraged by the introduction of a service oriented architecture (SOA)
The need for service management to manage processes to support corporate goals directly
The need for this approach is even more urgent than you may think, because the needs of businesses change constantly. An organization often has a network of relationships with partners, suppliers, and customers that must be managed in a holistic manner. As companies become more and more dependent on these networks, it is imperative to manage the underlying technology that supports them in a predictable and dynamic manner.
What organizations now want most from their data centers are efficiency and predictability: predictable costs, staffing levels, and performance service levels for IT users and customers bound together in an efficient integrated operation.
In Figure 11-2, earlier in this section, we present a set of service management processes. In the following sections, we discuss these processes and explain how they may participate in the optimization of data center activities.
At the highest level, organizations have to take a businesscentric view of optimizing the data center. You may have the best-looking data center in the world, but if it doesn't meet the performance needs of the organization or support the right customer experience, it will be a failure.
The top layer of Figure 11-2 (refer to "Optimizing the Data Center," earlier in this chapter) is data center management, containing two processes: supplier management, and governance and compliance. These two activities tend to strongly influence all the activities in the layers below to some degree.
Supplier management is about determining and maintaining relationships and contracts with key IT suppliers. Depending on how much money your company spends with these vendors, you can establish significant discounts for both purchases and support. Normally, any given business area works with more than one vendor, using a secondary supplier to provide a credible negotiating position with the primary supplier, for example. The conundrum in supplier management is that commitment to one supplier's strategic technology direction may make it impossible to implement alternative innovative technology in the data center when that technology comes from other sources.
Supplier management isn't a technology-supported activity (beyond the use of office software) and isn't likely ever to be well defined; generally, it's an art form. Who can know which vendors and what technology will dominate the market in five years' time? If the chief information officer (CIO) and his team are good at choosing technology winners and negotiating contracts, they will do well in this activity. The CIO might also work with vendors to establish a more predictable schedule for maintenance releases, patches, and back version support. Normally, however, they also need the confidence and assistance of the chief financial officer and chief executive officer to acquit themselves well. The decisions they make determine or constrain many technology choices at lower levels, and these constraints need to be known and understood when decisions are made.
The key performance indicators (KPIs) for supplier management are expressed in terms of the unit cost of specific units of technology, the discount the company achieves against list price, and the actual useful life cycle of the technology purchased.
Governance and compliance is the other key issue that has a big effect on data center strategy and many data center activities.
Depending on your industry and even your subsection of your industry, you need to focus on different compliance initiatives.
Warning
Compliance can be awkward because it imposes rules and processes that may be expensive and rarely pay for themselves. You may incur criminal penalties for failing to abide by some regulations. Your CEO won't thank you when you tell her, as she walks away in handcuffs, that you saved thousands of dollars by ignoring regulations. For that reason, all compliance processes should be mandated by the board of directors, and all costs should be clear and visibly accounted for. The board will mandate specific costs and impose some constraints on how flexible some processes are, but these processes are mandatory.
IT governance is about implementing, maintaining, and improving IT management and support processes. In theory, it doesn't necessarily involve automation, although in practice, implementing IT governance effectively is difficult without a good deal of help from software. IT governance involves setting policy in all areas of IT activity. Especially in highly technical areas such as software security, not automating the implementation of policy is ineffective.
In many areas of IT, Information Technology Infrastructure Library (ITIL) standards can be implemented with little variance, and the implementation of the standard can be partly or wholly automated. (For more information on ITIL, see Chapter 5.)
It would be ideal if all IT policies and processes could be defined in a central repository and their implementation automated with little human intervention. Reality is far from that ideal, but in most data centers, much more could be done in this area. Typically, only a few elements of IT governance are automated. We discuss governance in greater depth in Chapter 10.
The second layer in Figure 11-2 (refer to "Optimizing the Data Center," earlier in this chapter) depicts service management processes that concern the data center facility as a whole. This layer contains three primary processes: asset optimization, facility management, and disaster recovery.
This service management process is served by the asset management application that we discuss as part of the service management infrastructure in Chapter 9. There, we focus on the need to capture accurate information about the assets that are deployed in the corporate IT network or possibly used on a cloud basis, which is part of what the application is intended to do. (We discuss clouds in Chapter 15.)
The application's role is much bigger than just data gathering, however. Such an application also should be able to record and monitor the whole life cycle of any element of hardware or software, or combination of the two. In some organizations, this information is made freely available to at least some IT users so that they appreciate the costs and are able to calculate the return on investment associated with specific projects.
Ultimately, the IT asset management application (depending on what it does and how it's used) can contribute information to many important activities, including the creation and implementation of specific policies or service levels. It can also help with the assessment of risk and with meeting specific performance objectives of the business.
All these activities can be counted as asset optimization activities of a kind. Multiple dimensions are involved in the use of any given asset; hence, other KPIs may be associated with asset optimization.
Traditionally, optimizing physical assets, such as in manufacturing environments, has been viewed as being entirely separate from optimizing digital assets. That situation is changing under the umbrella of service management. As IT begins to align more closely with business processes, the management of IT assets and business assets is likely to merge into a single activity. Data centers are becoming part of a larger ecosystem of service management; therefore, they need to integrate with sensor-based systems and process automation systems.
Facility management is the activity of caring for and feeding the physical data center. It embraces everything from disaster protection (such as sprinkler systems and fire-retardant materials) to environmental controls (such as air conditioning and power management) to physical security.
Speaking of physical security, an increasingly important innovation is for organizations to tie their physical security (such as doors with passcodes) to a systems-based security system. If an employee is fired, for example, automated systems typically are in place to remove that employee's passwords and prevent him from accessing systems. That same alert should trigger a change in the passcodes for the data center, as well as access to other physical environments that may need protection.
Warning
Significant economies of scale are involved in running a data center. When a data center runs out of space, the organization incurs a sudden, large, and unwelcome change in costs caused by the need to acquire a new, appropriately built facility to house more servers, which will need communications connections, power supply, air conditioning, security, and so on.
Note
Data center space is the most expensive type of office space, so optimizing its use is important.
Tip
A good KPI for keeping an eye on facility costs and efficiency is average workload per square foot of floor space. There are many ways of defining workload in terms of hardware resources. Maintaining a KPI of this sort is useful for many purposes, particularly when you examine the cost of using a hosting provider or cloud computing (see Chapter 15).
The ability to recover from disasters is vitally important, and most organizations have rules of governance that dictate the provision of specific disaster-recovery capabilities. If a disaster befalls the corporate data center, which has no disaster-recovery capability, the company is unlikely to survive. Therefore, having business continuity procedures is a necessity. From a service management perspective, disaster recovery is a combination of the process, corporate policies, and readiness to act when the data center fails.
Disaster recovery can be expensive, especially in very large data centers with thousands of servers. Full disaster recovery mandates having an identical data center somewhere, ready to go into action immediately, complete with staff, operating procedures, preloaded applications, and up-to-data data. For most organizations, however, this plan is neither affordable nor feasible. Consequently, disaster-recovery plans normally provide for recovering only critical systems.
Disaster recovery can be complex, because as systems change and are upgraded, the disaster-recovery systems need to stay in step. The advent of SOA, for example, has posed some awkward problems for disaster-recovery systems. SOA-based systems typically are composed of services that are reused in different situations. Therefore, IT has to know the dependencies of these services across the organization. A related nuance is that disaster-recovery systems are rarely tested and sometimes not tested at all until a disaster occurs.
Luckily, technology developments make it increasingly easy to provide disaster recovery through the use of either cloud services or dual sites, with each data center providing disaster recovery for the other. (For details on clouds and virtualization, take a look at Chapter 15.)
Like any other IT activity, disaster recovery involves optimization issues. A company needs to link its service-level agreements and its asset optimization activities with the need for disaster recovery. As with everything in the service management world, compromises are likely to occur in terms of the disaster-recovery service-level targets and the necessary systems.
A disaster-recovery plan should cover issues such as e-commerce processes that touch suppliers and customers; e-mail, which is often the lifeblood of business operations; online customer service systems; customer and employee support systems; various systems that support the corporate infrastructure, such as sales, finance, and human resources; and research and development. Depending on the company's resources and income sources, management may need to consider other factors in a disaster-recovery plan.
The third layer in Figure 11-2 (refer to "Optimizing the Data Center," earlier in this chapter) groups those processes that relate to managing workloads: from an IT perspective, managing the corporate IT resource. Being simplistic, we could say that you have applications that you need to run and resources to run them, so all you're really doing is managing those workloads.
A few decades ago, in the age of the mainframe, workload management really was like that. It boiled down to scheduling jobs (often by writing complex job-control instructions) and monitoring the use of the computer resource. In those days few, if any, workloads ran around the clock; thus, workload management was a scheduling activity involving queuing up jobs to run and setting priorities between jobs. Some workloads had dependencies − a specific outcome from one program might alter what needed to be done next − but all dependencies usually could be automated via the job-control language.
In today's far more complex world, many more applications need to run, and many more computers exist to run them. Some workloads are permanent, running all the time. In most companies, e-mail is such an application. Quite a few companies also have Web-facing applications with resource requirements that can fluctuate dramatically. Virtualization capabilities make it possible (to some degree) to create virtual resource spaces. On its own, the World Wide Web increased the number of dependencies among applications, and when Web Services standards were created, the number of dependencies increased. SOA makes matters worse.
So workload management involves recording known dependencies among programs and applications − an activity that provides useful information to the configuration management database (CMDB), as noted in Chapter 9 − and scheduling those workloads to run within the available resources. This process has to be flexible so that an application's resources can be boosted when transaction rates escalate and reduced as those rates decline. In addition, a host of support functions have to run in conjunction with the business applications, including monitoring software and (where appropriate) backup jobs.
Increasingly, companies are giving users, customers, and partners direct access to applications that support everything from ordering to status inquiries. Customers and users really like to be able to access these resources directly, but this type of direct interaction with applications complicates workload management because it makes predicting future workloads harder. Behind self-service applications, you need the usual well-orchestrated set of service management capabilities.
Application self-service normally is automatic − that is, whenever the user requests a service, the process happens instantaneously, without any human intervention. To realize this level of sophistication, application self-service has to have three processes happening behind the scenes:
Identity management capability (to make sure that the user has the authority to access the application)
A portal interface (to make it easier for the user to access specific components or data elements)
Resource provisioning capability to execute the user request (to bring the requested application resource to the right place at the right time)
If you're familiar with SOA, you may recognize the focus on components − and indeed, self-service applications are similar. Most SOA implementations work precisely this way. In such cases, services usually are recorded and made available in some sort of service catalog, perhaps called a service registry/repository in SOA. This catalog may simply be a list of what applications a user can choose to run, and it may be automated to the point where the user simply selects a capability that is immediately made available through a portal. The service catalog could work in many ways, perhaps providing pointers to applications. If an application were sitting in a portal interface, the catalog could direct a user to that application.
Tip
If you want to know a lot more about SOA, we recommend that you take a look at Service Oriented Architecture For Dummies, 2nd Edition (Wiley). We think it's a great book, even if we did write it!
One risk in implementing self-service capabilities is creating an unexpected level of demand for resources, especially when Web-based applications are readily available to customers. If a major weather situation causes customers to reschedule flights online, for example, airline systems may experience a major unanticipated spike in access. As more and more customers rely on self-service applications, the workload management environment supporting application self-service needs to be highly automatic and sophisticated.
Implementing an efficient flow of work among people working on the same service management activity and teams working on related activities is one of the primary keys to optimizing the efficiency of the data center. We refer to the design and implementation of these workflows as IT process automation.
It's difficult to understate the contribution that the intelligent use of IT process automation can make. We can draw a clear parallel between this process and integration infrastructure, which we discuss in Chapter 9. The function of integration infrastructure is integrating all the service management software applications so that they can share data effectively and don't suffer the inherent inefficiencies of silo applications. Similarly, the function of IT process automation is integrating service management activities and processes so that they work in concert.
From the automation perspective, IT process automation implements workflows that schedule the progress of activities, passing work and information from one person to another, but it also involves integrating those workflows with the underlying service management applications that are used in some of the tasks.
To continue our analogy of the data center as a factory (refer to "Seeing the Data Center As a Factory," earlier in this chapter), IT process automation is about designing the flow of activities so that they happen in a timely manner and keep the production line rolling, whether those activities involve fixing problems that have occurred or commissioning new hardware and software to add to the data center. The ideal situation would be not only to have all important service management processes occurring as automated workflows, but also to have a dashboard-based reporting system that depicts all the activities in progress in the data center, providing alerts if bottlenecks arise.
Tip
Such a reporting system could also report on the data center's important KPIs, providing a real-time picture of the health of the whole data center.
Figure 11-2 (refer to "Optimizing the Data Center," earlier in this chapter) groups the following service management processes on the hardware-environment level:
Desktop and device management
Hardware provisioning
Virtualization
Network management
Most of these processes are discussed in other chapters, so except for the last two, we intend only to introduce them in the following sections.
The desktop traditionally has been managed as almost a separate domain by a separate team outside the data center, with the primary KPI being the annual cost of ownership (including support costs). This situation has changed recently, for two reasons:
Desktop virtualization is feasible now.
Increasing need exists to manage mobile devices − whether those devices are laptops, smartphones, or mobile phones − as extensions of the corporate network.
Traditionally, hardware provisioning was relatively simple. Hardware was bought, commissioned, and implemented with the knowledge that it would be designated for a specific application for most, if not all, of its useful life. Eventually, it would be replaced.
With the advent of virtualization, the provisioning of hardware became more complex but also more economical. Today, virtualization and hardware provisioning are inextricably bound together.
Network management constitutes the set of activities involved in maintaining, administering, and provisioning resources on the corporate network. The corporate network itself may embrace multiple sites and involve communications that span the globe.
The main focus of network management activity is simply monitoring traffic and keeping the network flowing, ideally identifying network resource problems before they affect the service levels of applications. In most cases, the primary KPI is based on network performance, because any traffic problems on the network will affect multiple applications.
An asset discovery application (which we mention in Chapter 9 in connection with the CMDB), if it exists, normally is under the control of the network management team because the application is likely to provide important data. The network management team is likely to work closely with the IT security team because members of IT security will be the first responders to any security attacks that the organization suffers.
Recent innovations in network technology are likely to change some network management processes. Previously, for example, the capacity of a network was controlled by the capacity of the physical network. Now, major network technology vendors such as Cisco and Brocade provide highly sophisticated network switches that can be configured as networks in a box. These switches make it possible to virtualize a network to reduce or increase bandwidth. Suppose that you have an exceptionally large data warehouse that needs to be backed up. If you virtualize the network, this typically complicated process is simplified dramatically and made more efficient. In such a case, bandwidth can be increased to speed the task and decreased when the task is finished.
In the longer term, bandwidth is likely to be provisioned automatically, just as virtual servers are provisioned automatically, just as virtual servers are provisioned automatically.
Network management is about to become more complicated with the addition of unified communications. In the vast majority of companies, voice communications, videoconferencing, and other forms of collaboration are separate from IT systems. This situation is slowly changing, inevitably making network management more complex.
Voice over IP (VoIP) is in the ascendancy, and companies are gradually adopting it, although not always in highly integrated ways. Nevertheless, adoption of VoIP is a move in the direction of unified communications, in which e-mail, Short Message Service (SMS) messages, chat, voice communications, and all forms of collaboration become computer applications.
Managing highly distributed data has emerged as one of the most important issues for service management. This task has always been complex because of the vast volume of data that has to be managed in most corporations. The problem is exacerbated when data is managed as a service across departments and across partners and suppliers.
We devote Chapter 14 to data management, so in the following list, we simply define the processes included in it, as illustrated in Figure 11-2 (refer to "Optimizing the Data Center," earlier in this chapter). What has started to happen is that data itself has been packaged so that it can be transported with greater ease.
Data services and data fabric: These processes move data around the network to make it available to the applications or services that need it (particularly business intelligence services).
Storage management: This process manages data storage in all its forms.
Database management: This process involves the specific tasks of managing database configuration and performance for critical applications and services.
Backup and recovery: This process involves the management of backup and recovery, including the management of all dependencies among systems.
Tip
The primary KPI that an organization will want to measure is the cost per gigabyte of data stored in various strata of availability, from online to archived and stored.
The processes that we group on the software-environment level in Figure 11-2 (refer to "Optimizing the Data Center," earlier in this chapter) are covered elsewhere in this book, so we only introduce them here:
Application management: This process normally involves specific software designed to monitor the performance of a specific application. The activity could also be described as performance monitoring at the application level.
License management: The management of software licenses can be considered to be a separate activity or part of asset or supplier management. Either way, the primary KPI is expressed in terms of cost per user per application.
Configuration change management: In its broadest definition, software configuration management covers the management of software releases and the management of changes in all configurations, complete with an audit trail (who did what, when, and how).
IT security: IT security is a particularly complex activity, made more complex by the fact that currently, no security platform can be implemented to provide comprehensive IT security across a network.
With respect to optimization, the ultimate goal in the corporate environment is to use software efficiently in terms of resource consumption while delivering agreed-on service levels at both the business level and the application level.
The final layer in Figure 11-2 (refer to "Optimizing the Data Center," earlier in this chapter) is service management infrastructure, which we discuss in Chapter 9. In the following sections, we discuss two additional elements: cloud computing and service management reporting.
A cloud is a computing model that makes IT resources such as servers, middleware, and applications available as a service to business organizations in a self-service manner. We include cloud computing in Figure 11-2 simply to indicate that workloads (or perhaps parts of workloads) may be run in the cloud. In fact, all the layers we discuss in this chapter could be augmented from the cloud. We expect that this approach will become necessary over time, as organizations migrate some of their applications to the cloud or sign up to run new applications from the cloud. For more information on cloud computing, take a look at Chapter 15.
The idea of a central console initially grew out of the fact that in the old days of the mainframe, a single screen reported the progress of all workloads to the computer operator. That setup was impossible in large networks. Instead, several consoles aggregated information from various parts of the network. In addition, purpose-specific consoles reported on activities such as network management or IT security.
A central service management reporting capability depends on a functional CMDB and integration infrastructure that support the gathering of data from multiple sources and the passing of messages among service management applications. Such a capability can exist even if only some level of integration is available.
When this capability exists, it's a relatively simple matter to add reporting software to provide specific reporting capabilities that give insight into the behavior of any part of the IT network. Such reporting capabilities can easily be added to the service catalog and made available to anyone in the data center as self-service options.
The general strategic direction for service management, as we describe in Chapter 6, is evolution from system management through service management. This journey enables organizations to move from managing systems to managing the application services that run on those systems. The next stage of the journey is moving business service management (BSM) where it enables IT to be aligned with the goals of the business. As its name implies, BSM manages business services.
In this chapter, we look at the data center from an optimization perspective, highlighting various KPIs and specific areas of data center activity where optimization can be applied. Most of the optimization we discuss is already carried out within the data center in some way, in many cases informally. The nature of these optimizations will not change dramatically as an organization moves closer toward the goal of direct BSM, but the optimizations will have to be reconciled with the optimization of business services. When BSM is reality, it governs all other optimizations. We discuss BSM in more detail in Chapter 18.
In Figure 6-2 in Chapter 6, we define maturity in terms of this progression:
Fragmented services→Standardized services→Integrated services→Optimized services
As with strategy, the optimizations we discuss in this chapter are likely to be carried out in some way irrespective of the level of maturity. All such optimization activity becomes more effective as the industry moves to integrated services. The holistic optimization of the data center is possible only when the service management environment is fully integrated.