
C H A P T E R 11
PL/SQL Programming in the Large
Most business applications are data-centric and therefore require a database at their core. These applications are commonly used for years or even decades. During this time, the user interface is sometimes completely replaced or extended to keep it state of the art. The data model and the business logic, on the other hand, usually evolve more steadily along with the supported business processes. Many of these applications end up large, whether they start small (such as an APEX replacement of a spreadsheet) or are complex from the onset. Thus, we need an architecture and a programming language suitable for developing and maintaining data-centric business logic for years. PL/SQL in the Oracle database ideally fits these requirements.
Business logic in PL/SQL can lead to lots of PL/SQL code; my company's flagship application, for example, has 11 million lines and is maintained by 170 developers. This is true programming in the large. Effective and efficient programming in the large in any language requires good modularization and high uniformity based on strict adherence to programming conventions. PL/SQL provides solid foundations to implement and enforce these aspects. Furthermore, it allows for object-oriented programming, which significantly increases reuse and thereby leads to a cost reduction and quality increase.
This chapter first describes when and why business logic in PL/SQL is a good option, then explains ways to master the key success factors for PL/SQL programming in the large.
The Database as PL/SQL-Based Application Server
Software architectures and programming languages must be chosen to best satisfy business requirements. Therefore, the most convincing argument for coding business logic in PL/SQL is a long-term successful application based on this architecture. The Avaloq Banking System is such an application and serves as case study. From this case study, I deduce the strengths of this architecture. Because no architecture is universally applicable, it is also important to know its limits.
Case Study: The Avaloq Banking System
The Avaloq Banking System (ABS) is a complete core banking system with payment, investment, and financing functionality. It provides an end-user GUI and batch processing of messages and files. Over 65 banks with 20 to 5,000 concurrent end users each use it in seven countries. Real-time OLTP and reporting are implemented in the same database.
The ABS has a physical three-tier architecture, as depicted in Figure 11-1. The thin rich client implemented in .NET provides for efficient user interaction with optimal Windows integration. The middle tier is responsible for telephony integration, external authentication, and protocol conversion between Oracle Net and Windows Communication Foundation, so that no Oracle client is required on desktops, firewalls can prohibit direct SQL access from end-user PCs, and network encryption in the client network is available for free. Neither the client nor the middle tier contains any business logic; in fact, they could be used as-is for an arbitrary ERP application.
The business logic resides in the backend—that is, the Oracle database. The database serves as a PL/SQL-based application server and is based on a logical three-tier architecture with data access, business logic, and presentation layers. The same PL/SQL business logic code is executed in batch processing and GUI sessions. For example, a payment transaction is handled the same way whether it is read into the system from a file or entered by a clerk on the GUI.
In the Avaloq Banking System, the state of GUI sessions is stored in PL/SQL package body global variables. Every field value is sent to the server for validation and calculation of derived fields. Business transactions are built up in PL/SQL memory and are persisted upon finalization by the user. The best location of the session state (database tables, database server memory, middle tier, or client) is an often emotional topic of debate. Because large parts of the business logic can be implemented in PL/SQL even if the session state is not kept in the database, this chapter is relevant no matter where your application stores the session state.

Figure 11-1. Avaloq Banking System technical architecture
Development of the Avaloq Banking System started in 1993 with Oracle 7. The basic architecture with the business logic in the Oracle database has been the same since the beginning. The original GUI was written in HyperCard; it has since been replaced three times by Java AWT, Java Swing, and .NET based implementations and may well become a Web GUI in the future.
Avaloq is a commercial company that wants to maximize profit. We have chosen the described architecture to maximize customer satisfaction and developer productivity and periodically reevaluate it. Admittedly, no commercial application servers existed in 1993 when development of the Avaloq Banking System started. However, we keep the current architecture because it works very well and not because a migration to an application server would be very expensive. In fact, we chose a similar architecture for our database provisioning and continuous integration system, which was designed in 2006 by an engineer with JEE background and Java certification. We sometimes have to explain the reasons for our architecture choice, but we haven't lost a single sales case in the past 17 years because of our architecture.
Many other ERP and banking applications, including IFS Applications, Oracle E-Business Suite, and Oracle Fusion Applications contain several million lines of PL/SQL. Oracle's strong commitment to PL/SQL is manifested by its implementation of Application Express (APEX) in PL/SQL and by the continuous enhancements of PL/SQL, such as edition-based redefinition in 11gR2.
Strengths of Business Logic in the Database with PL/SQL
Avaloq profits from the following strengths of coding the business logic in the database:
- Simplicity: Most developers need to code in only one language for a single tier. They can code complete business functions without losing time coordinating with and waiting for developers of other tiers to do their jobs. Furthermore, the concurrency model makes it easy to develop programs that run parallel to others.
- Performance: Data access including bulk operations is fastest directly in the database. It's the same basic idea as in Exadata: bring the processing closer to the data and send only the minimum over the network. For batch processing, which is the majority of the OLTP banking activity, all processing can be done in the database.
- Security: Definer rights procedures make it easier to ensure that no critical information can be accessed by unauthorized persons from outside the database. All data can reside in locked schemas and external access can be restricted to a few packages. No direct table or view access needs to be granted. If the business logic is outside the database, there are (at least after some time) multiple applications that directly access the database. This makes it hard to enforce consistent security. Passwords stored in application servers can be easily misused to directly access data. Furthermore, the session state in the server prevents spoofing attacks.
- Consistency: I trust Oracle's read consistency. I wouldn't sleep well if I had to display real-time customer portfolios based on middle-tier caches simultaneous with heavy OLTP activity.
- Availability from any environment: Many applications need to interface with others. Stored procedures can be invoked from any language through JDBC, OCI, ODBC, etc. Of course, this is true for web services as well.
- Participation in distributed transactions: Distributed transactions are crucial for interfaces in business systems to ensure once and only once execution. Distributed transactions with Oracle as transaction participant are simple to set up and are supported by most transaction coordinators. Setting up distributed transactions for arbitrary interfaces over a Web service or CORBA middle tier connected to a database in a multi-vendor environment, on the other hand, is a nightmare.
- Centralized, single-tier deployment: Most enhancements and bug fixes require a change on only a single tier, even if tables and business logic need to be modified.
- Scalability: The Oracle database scales nicely in the box thanks to ever more powerful servers and horizontally outside the box with Real Application Cluster.
- Stability and reliability: The Oracle database is an exceptionally stable and reliable execution environment.
Most benefits of three-tier architectures stem from the logical rather than the physical separation of data access, business logic, and presentation. The logical separation, and therefore the benefits, can also be achieved with modularization inside the database, as described later.
Stored procedures can be coded in PL/SQL, in Java, in .NET, or in almost any language as external procedures. PL/SQL is my default.
PL/SQL Stored Procedures
PL/SQL, an imperative 3GL designed specifically for seamless processing of SQL, provides additional benefits for coding business logic. Selected key benefits are illustrated in Figure 11-2.

Figure 11-2. Selected key benefits of PL/SQL
Furthermore, edition-based redefinition provides for online application upgrades of PL/SQL code together with other object types. PL/SQL also runs in the TimesTen in-memory database, thereby bringing the same advantages to data cached in memory for even high performance.
Java Stored Procedures
Java stored procedures don't provide the same seamless SQL integration as PL/SQL. In fact, Java doesn't have any of the benefits listed in Figure 11-2. Furthermore, as of Oracle 11gR2, the performance of SQL calls from within a Java stored procedure is significantly worse than those from PL/SQL or Java running outside the database. This may well improve given that with the JDBC performance from outside the database is excellent. The algorithmic performance with the 11g just-in-time compiler, on the other hand, is better than that of PL/SQL and almost on par with Java outside the database.
Avaloq uses Java if something is not possible in PL/SQL, such as OS calls prior to Oracle 10g, or where an existing Java library greatly simplifies the work. For example, the Avaloq installer checks the signature of ZIP files using Java and the database provisioning system transfers LOBs between databases using Java over JDBC—rather than PL/SQL over database links, which only support LOBs in DDL and not DML. The availability of many libraries is definitely a strength of the Java ecosystem. This fact is, however, often overrated. For business applications, often only infrastructure libraries are useful, and even those might be insufficient. For example, none of the Java logging frameworks support per-entry security, grouping of log calls of the same problem into a single entry, or a workflow on entries. Furthermore, the constant appearance of new libraries can lead to Compulsive Latest Framework Adoption Disorder, which commonly manifests itself in many similar libraries being used in a single product because the effort for a complete refactoring of large products is prohibitive. Last but not least, PL/SQL also comes with a formidable number of libraries: the PL/SQL Packages and Types Reference has grown to 5,900 pages in 11gR2.
A benefit of Java is that the same code, such as data validation, can run in the database and in another tier. An alternative for the latter case is the generation of code in PL/SQL and another language from a domain-specific language. In the Avaloq Banking System, over half of the PL/SQL code is generated from higher-level domain-specific languages.
Whereas Oracle lets the developer decide between PL/SQL and Java as implementation language on a subprogram (procedure or function) by subprogram basis, I try to avoid a difficult-to-maintain wild mix.
Java stored procedure is actually a misnomer. The Oracle database includes a complete Java Virtual Machine (JVM). It is, therefore, possible to write stored procedures in any of the dozens of language with a compiler that generates Java byte code. From aspect-oriented programming with AspectJ to functional programming with Scala, however, none of the languages sport a seamless SQL embedding.
SQLJ, a preprocessor-based extension of Java, adds syntactic sugar for simpler SQL integration and automatic bind variables. However, it lacks compile-time checking of embedded SQL and dependency tracking for automatic invalidation after modifications of referenced objects. Automatic invalidation would require an enhancement of the JVM and cannot be added by means of a language extension.
SQLJ support is spotty. Few IDEs support SQLJ. Oracle itself ceased supporting SQLJ in the original 10g release. Following customer complaints, SQLJ reappeared in the 10.1.0.4 patch set.
.NET and C-Based External Procedures
External procedures, or subprograms as they are interchangeably called in the Oracle documentation, are subprograms with a PL/SQL call specification and an implementation in another language. By coding stored procedures in .NET, you restrict yourself to running the Oracle database on Windows. External procedures, written in C or another language callable from C, hamper portability. Furthermore, they run in their own processes. Thus, C-based external procedures have no significant advantage over business logic in a middle tier except that they can be called through the database.
Limits of the Database as PL/SQL-Based Application Server
If you are a hammer, everything looks like a nail. As a software engineer, on the other hand, you should be aware of the applicability limits of an architecture blueprint. The described business logic in PL/SQL in the database solution is an excellent fit for data centric ERP applications. On the other hand, it is not a good fit for computationally intensive applications requiring little data interaction.
Furthermore, PL/SQL is not my first choice for the following tasks:
- CPU intensive tasks: PL/SQL’s algorithmic performance is below that of C and Java. Furthermore, Oracle license costs apply to PL/SQL. Java in commercial application servers incurs similar license costs, whereas no runtime license is required to run C or standalone Java programs. In the Avaloq Banking System, less than 50 percent of the CPU usage is PL/SQL; the rest is SQL.
- Programs using very large collections in memory: PL/SQL collections may require significantly more memory than their C counterparts. I take an in-depth look at memory usage later in this chapter.
- Very complex data structures: PL/SQL collections and records are sufficient for most tasks. However, others can be more easily expressed in a language with generic types, in-memory references, and automated garbage collection.
![]() Note Vendor independence is sometimes cited as a reason against proprietary stored procedure languages. This argument is invalid because most applications are never ported to another database and because achieving good performance and correct concurrency handling on different databases requires multiple specific implementations rather than a single generic implementation. Tom Kyte argues this point in detail in Expert Oracle Database Architectures (Apress, 2005). I support every word he says on this topic in his book (and my paycheck doesn't come from Oracle). It's a different point if you don't like a particular database vendor. But you should make the best use of the database you choose.
Note Vendor independence is sometimes cited as a reason against proprietary stored procedure languages. This argument is invalid because most applications are never ported to another database and because achieving good performance and correct concurrency handling on different databases requires multiple specific implementations rather than a single generic implementation. Tom Kyte argues this point in detail in Expert Oracle Database Architectures (Apress, 2005). I support every word he says on this topic in his book (and my paycheck doesn't come from Oracle). It's a different point if you don't like a particular database vendor. But you should make the best use of the database you choose.
Soft Factors
Even though Java may have more sex appeal than PL/SQL, I’ve found that it is not harder (and, unfortunately, not easier) to hire PL/SQL programmers than to hire their Java counterparts. The learning curve is not much different. PL/SQL is easy to learn. The big challenges, especially for new graduates, are to understand the business requirements, learn programming in the large, grasp the application-specific frameworks and patterns, and write efficient SQL.
SQL is also a problem if the business logic is written in Java. Of course, the trivial SQL statements can be generated by an object relation mapper. But the SQL statements that follow a few simple patterns are not the problem in PL/SQL either—it’s the complex statements that must be hand coded for optimal performance.
Making the start easy for a new hire in a company with a multimillion line application is one of the main requirements of successful programming in the large.
Requirements of Programming in the Large
Having established the case for business logic in the database, let’s see how best to master all the PL/SQL you will write. Programming in the large can involve programming by larger groups of people or by smaller groups over longer time periods. Often the people maintaining a software solution change. As a case in point, none of the creators of PL/SQL in Oracle 6 work in the PL/SQL group anymore. Because it is common for over two thirds of the lifetime cost of a piece of software to go to maintenance, efficiency in maintenance is a key requirement.
Programming in the large requires an approach that delivers in time, budget, and external product quality to the users during the initial creation and future maintenance of software. Ignoring the process aspects, which are largely independent of the architecture and programming language, you need a high internal product quality to achieve the external goals. The main factors of internal product quality are simplicity, ease of understanding, extendibility, and reusability. The business-logic-in-the-database architecture is the cornerstone for simplicity. The other goals are achieved with naming and coding conventions, modularization, and object-oriented programming. The implementation of these aspects differs among programming languages. In this chapter, I explain how to implement these aspects in PL/SQL. Due to space constraints, I omit other relevant aspects of programming in the large, such as tooling, and of handling the usually associated large data volumes, such as information lifecycle management and design for performance and scalability.
Successful programming in the large requires successful programming in the small. If code that somebody else wrote five years ago crashes, you will be thankful if she or he followed proper exception handling and error logging practices (which I omit in this chapter for brevity). Likewise, you'll be glad if the code you modify contains unit tests or contracts in the form assertions, so you know you aren't likely to break any of the 200 callers of the subprogram you change to fix the bug. Any type of programming requires logical thinking and pedantic exactness.
Uniformity through Conventions
Uniformity is a necessity for programming in the large because it allows developers to understand each other’s code quickly and thoroughly. For example, if the primary key column of every table is called id and every reference to it is <table>_id, anybody who comes across a foo_id knows immediately that it references foo.id. Uniformity also ensures that developers don't constantly reformat someone else’s code and thereby waste time, introduce regressions, and create diffs in which it is hard to distinguish the semantic changes from the cosmetic changes.
Uniformity can be achieved through conventions. In most cases, no conventions are better or worse than others; their sole value lies in providing the foundation for uniformity. For example, driving on the right-hand side of the road is as good as driving on the left-hand side. The choice is arbitrary. But every country must adopt one of the two conventions to avoid chaos. Likewise, there is no advantage in using trailing commas rather than leading commas to separate parameters. However, mixing the two in a single program impedes readability.
Unfortunately, there are no standard naming and formatting conventions for PL/SQL as there are for Java. Chapter 14 provides a set of coding conventions and Steven Feuerstein has three sets of PL/SQL coding conventions at http://bit.ly/8WPRiy. Whether you adopt one of the aforementioned conventions or make up your own is unimportant as long as you have a convention to which everybody in your organization adheres.
There are three ways to guarantee adherence to a convention. The best is to use an IDE that automatically establishes the convention either as you type or upon selecting auto format. Whatever cannot be handled in this manner must be enforced—ideally, through automatic tools rather than reliance on manual reviews. The last option to guarantee adherence is hope, which might work with a small project but not when programming in the large.
Sometimes large applications contain sources that, for historical reasons, adhere to different conventions. In this case, you must decide whether it is worth the effort to make all sources comply with one standard; if you want to keep multiple standards for different, clearly separated parts of the application; or if all new sources should adhere to a single standard. In any case, every source must consistently follow a single convention. If the chosen approach is to move to a single convention, complete sources must be adapted at once. Syntactic adaptations to adhere to a different convention must not be mixed with semantic changes, such as bug fixes, in a single repository check in. Otherwise, code auditing becomes very difficult.
The rationale behind a convention can be rendered obsolete by a new Oracle release or other changes. For example, before Oracle 10g, the PL/SQL compiler accepted different default values for input parameters in the package specification and body and just used the values provided in the package specification. To avoid wrong assumptions, the Avaloq convention was not to specify any default values for exported subprograms in the package body. Starting in 10g, the compiler checks that the default values are the same if listed in both the specification and the body. Thus, you can duplicate the default values without risk so that the developer doesn't have to open the specification when working in the body. The moral of the story is that you should periodically check the rationale behind every convention, especially if the convention also has disadvantages.
For most aspects regulated by conventions, it doesn't matter what the convention says because the sole benefit of the convention is the resulting uniformity. There are, however, aspects for which good reasons exist to go one way rather than another. For example, if your IDE supports only auto-formatting with leading commas, it doesn't make sense if your convention prescribes trailing commas. I present here selected aspects specific to PL/SQL for which there is a strong rationale to follow a particular practice.
Abbreviations
Identifiers in SQL and PL/SQL can be only 30 bytes long. To make a descriptive name fit these requirements, you need to omit unnecessary words (such as “get”) and abbreviate long words. You can achieve consistency in abbreviations by maintaining a list of abbreviations and checking all names against that list. You must also add to that list those words which you specifically choose never to abbreviate. You can even add a synonym list against which you check new entries to avoid multiple entries for the same concept.
To check consistent abbreviation usage, all identifiers must be split into their parts and checked against the abbreviation registry. The identifiers to be checked can be found in the Oracle data dictionary, in views such as user_objects and user_tab_columns. From Oracle 11g onward, all identifiers used in PL/SQL programs are stored in user_identifiers if the unit is compiled with plscope_settings="identifiers:all". You may want to enable this new feature called PL/Scope at the system level by issuing
SQL> alter system set plscope_settings="identifiers:all";
and recompiling all user PL/SQL units. The view user_plsql_object_settings shows for which objects this setting is in effect.
Because lower-case and mixed-case identifiers require double quotes in SQL and PL/SQL, they are not used. Instead, identifier parts are usually separated by an underscore.
The following code listing shows a simplified version of an abbreviation checker. The table abbr_reg holds the registered abbreviations. The package abbr_reg# provides a procedure ins_abbr to insert a new abbreviation and chk_abbr to check whether only registered abbreviations are used as identifier parts. You can populate the registry with calls such as abbr_reg#.ins_abbr('abbr', 'abbreviation') and check consistent usage with abbr_reg#.chk_abbr.
create table abbr_reg(
abbr varchar2(30) primary key -- Abbreviation, e.g., ABBR
,text varchar2(100) not null -- Abbreviated text, e.g., ABBREVIATION
,descn varchar2(400) -- Description, explain concept
) organization index;
create unique index abbr_reg#u#1 on abbr_reg(text);
create or replace package abbr_reg#
is
------------------------------------------------------------------------------
-- Registry of abbreviations for SQL and PL/SQL identifier parts, such as
-- ABBR for ABBREVIATION and REG for REGISTRY. All identifiers must be made up
-- of registered abbreviations separated by underscores, e.g. abbr_reg.
-- Contains also terms not to be abbreviated.
------------------------------------------------------------------------------
------------------------------------------------------------------------------
-- Insert an abbreviation into the registry.
------------------------------------------------------------------------------
procedure ins_abbr(
i_abbr varchar2
,i_text varchar2
,i_descn varchar2 := null
);
------------------------------------------------------------------------------
-- Check whether only registered abbreviations are used as identifier parts.
------------------------------------------------------------------------------
procedure chk_abbr;
end abbr_reg#;
create or replace package body abbr_reg#
is
procedure ins_abbr(
i_abbr varchar2
,i_text varchar2
,i_descn varchar2
)
is
begin
insert into abbr_reg(abbr, text, descn)
values(upper(trim(i_abbr)), upper(trim(i_text)), i_descn);
end ins_abbr;
------------------------------------------------------------------------------
procedure chk_ident(
i_ident varchar2
,i_loc varchar2
)
is
l_start_pos pls_integer := 1;
l_end_pos pls_integer := 1;
l_abbr_cnt pls_integer;
l_part varchar2(30);
c_ident_len constant pls_integer := length(i_ident);
begin
while l_start_pos < c_ident_len loop
-- DETERMINE NEXT PART --
while l_end_pos <= c_ident_len
and substr(i_ident, l_end_pos, 1) not in ('_', '#', '$')
loop
l_end_pos := l_end_pos + 1;
end loop;
l_part := upper(substr(i_ident, l_start_pos, l_end_pos - l_start_pos));
-- CHECK WHETHER THE PART IS A REGISTERED ABBREVIATION --
select count(*)
into l_abbr_cnt
from abbr_reg
where abbr = l_part;
if l_abbr_cnt = 0 then
dbms_output.put_line('Unregistered part ' || l_part || ' in ident ' || i_ident
|| ' at ' || i_loc || '.'),
end if;
-- INIT VARIABLES FOR NEXT LOOP --
l_end_pos := l_end_pos + 1;
l_start_pos := l_end_pos;
end loop;
end chk_ident;
------------------------------------------------------------------------------
procedure chk_abbr
is
begin
-- PL/SQL USING PL/SCOPE --
for c in (
select name
,object_type
,object_name
,line
from user_identifiers
where usage = 'DECLARATION'
order by object_name, object_type, line
) loop
chk_ident(
i_ident => c.name
,i_loc => c.object_type || ' ' || c.object_name || ' at line ' || c.line
);
end loop;
-- OTHER ITEMS: USER_OBJECTS, USER_TAB_COLUMNS, ... --
-- ...
end chk_abbr;
end abbr_reg#;
Since only one hundred lines of PL/SQL code are needed to build the checker, there is no excuse not to build one. PL/Scope makes this process much easier than trying to parse your source from user_source or your source code repository.
![]() Note Oracle does not use abbreviations consistently in the data dictionary. For example, the term “index” is spelled out once and abbreviated differently twice in the views user_indexes and user_ind_columns and the column idx of user_policies. Presumably, Oracle doesn't fix this because backward compatibility in public APIs is more important than consistent abbreviations.
Note Oracle does not use abbreviations consistently in the data dictionary. For example, the term “index” is spelled out once and abbreviated differently twice in the views user_indexes and user_ind_columns and the column idx of user_policies. Presumably, Oracle doesn't fix this because backward compatibility in public APIs is more important than consistent abbreviations.
Pre- and Suffixes for PL/SQL Identifiers
Many PL/SQL developers add prefixes to identifiers to indicate their scope or type. For example, local variables are prefixed with l_, constants with c_, input parameters with i_, and types with t_. There are two good reasons to add a prefix or a suffix to every PL/SQL identifier. Both have to do with avoiding scope capture.
PL/SQL automatically turns PL/SQL variables in static SQL statements into bind variables. Consider the following function, which should return the employee name for the specified employee number from the emp table of the SCOTT schema created by demobld.sql script from Oracle. In this example, I don't use any prefixes for the parameter empno and the local variable ename.
create or replace function emp#ename(empno emp.empno%type)
return emp.ename%type
is
ename emp.ename%type;
begin
select ename
into ename
from emp
where empno = empno;
return ename;
end emp#ename;
The function doesn't do what I would like it to do. Both occurrences of empno in the where clause refer to the table column empno rather than to the input parameter because every identifier is resolved to the most local declaration. In this case, the most local scope is the SQL statement with the table emp. Hence, the where condition is equivalent to emp.empno = emp.empno, which is the same as emp.empno is not null. Unless I have exactly one entry in the table emp, the function will throw an exception.
SQL> truncate table emp;
Table truncated.
SQL> insert into emp(empno, ename) values (7369, 'SMITH'),
1 row created.
With exactly one row in the table, the function returns the name of this row independent of the actual parameter. I ask for the name of the employee with empno 21 and get the name of the employee with empno 7369.
SQL> select emp#ename(21) from dual;
EMP#ENAME(21)
-----------------------------------------------------------------
SMITH
1 row selected.
With two or more rows in the table, the function always returns an ORA-01422.
SQL> insert into emp(empno, ename) values (7499, 'ALLEN'),
1 row created.
SQL> select emp#ename(7369) from dual;
select emp#ename(7369) from dual
*
ERROR at line 1:
ORA-01422: exact fetch returns more than requested number of rows
ORA-06512: at "K.EMP#ENAME", line 5
You can avoid scope capture by adding a prefix or a suffix to the input parameter empno, such as i_empno. Let’s generalize this rule to say that every PL/SQL identifier should have a prefix or a suffix that is not used in column names. The minimum length for the prefix or suffix is two bytes—that is, a letter and an underscore as separator. You can use this prefix to convey additional semantics, such as the scope of a variable or the mode of a parameter without wasting another precious one of the thirty bytes.
An alternative to the prefix is to qualify all PL/SQL variables inside SQL statements with the name of the declaring block, e.g., empno = emp#ename.empno. The advantage of this approach is that it prevents unnecessary invalidation when a column is added to the table because the compiler knows that no scope capture can occur. Bryn Llewellyn describes this aspect of Oracle 11g fine-grained dependency tracking in http://bit.ly/dSMfto. I don't use this approach because edition-based redefinition is the better solution to prevent invalidation during online upgrades and because I find the syntax clumsy.
Of course, adding an l_ prefix to every local variable does not avoid scope capture in nested PL/SQL blocks. Fully qualified notation for all PL/SQL identifiers in all nested blocks would solve this at the cost of wordiness.
The second reason for including prefixes or suffixes in PL/SQL identifiers is to avoid confusion with the large number of keywords in SQL and PL/SQL and the built-in functions declared in standard and dbms_standard. As of Oracle 11gR2, there are 1,844 SQL keywords such as table and names of built-in functions such as upper, which are listed in v$reserved_words.
SQL> select count(distinct keyword)
2 from v$reserved_words;
COUNT(DISTINCTKEYWORD)
----------------------
1844
1 row selected.
The PL/SQL keywords are listed in appendix D of the PL/SQL Language Reference, but not available in a view. If you’re not careful in the selection of your own identifiers, you shadow the Oracle implementation. In the following example, the implementation of upper, which returns the argument in lowercase rather than the Oracle-provided standard function with the same name, is executed:
create or replace procedure test
authid definer
is
function upper(i_text varchar2) return varchar2
is
begin
return lower(i_text);
end upper;
begin
dbms_output.put_line(upper('Hello, world!'));
end test;
SQL> exec test
hello, world!
PL/SQL procedure successfully completed.
What appears artificial in this small example may well occur in practice in a large package maintained by someone other than the original author. For example, the original author may have implemented a function regexp_count when the application still ran under 10g. After the upgrade to 11gR2, the new maintainer may have added a call to regexp_count somewhere else in the package, expecting the newly added SQL built-in function with the same name (but possibly different semantics) to be invoked.
Oracle provides warnings to prevent the abuse of keywords. Unfortunately, warnings are usually disabled. If you enable all and recompile the test procedure, you get the desired error or warning, depending upon whether you set plsql_warnings to error:all or enable:all.
SQL> alter session set plsql_warnings='error:all';
Session altered.
SQL> alter procedure test compile;
Warning: Procedure altered with compilation errors.
SQL> show error
Errors for PROCEDURE TEST:
LINE/COL ERROR
-------- ----------------------------------------------------------------------------
4/12 PLS-05004: identifier UPPER is also declared in STANDARD or is a SQL built-in
In summary, adding a prefix or a suffix to every PL/SQL identifier can solve problems with scope capture. I use prefixes for variables and parameters to avoid scope capture in static SQL, but I don't bother to add prefixes or suffixes to functions or procedures because clashes with keywords are rare and because scope capture cannot occur in SQL with functions with parameters.
To differentiate between lists and elements thereof, it is common to add a plural suffix to lists such as associative arrays. Alternatively, suffixes to indicate the type, such as _rec for record and _tab for associative array types, are used to distinguish between elements and lists and at the same time convey additional semantic information at the cost of several characters. I use the type suffix notation in this chapter for clarity because I will be comparing implementations using different types. I use the hash sign as suffix for packages to avoid name clashes with tables of the same name.
![]() Note The proper usage of prefixes and suffixes can also easily be checked with PL/Scope. Lucas Jellema has an example of this at
Note The proper usage of prefixes and suffixes can also easily be checked with PL/Scope. Lucas Jellema has an example of this at http://technology.amis.nl/blog/?p=2584.
Modularization of Code and Data
Proper modularization is the foundation for scalability of the development team and maintainability of an application. Modularization brings the benefits of “divide and conquer” to software engineering. The key aspects of modularization are the following:
- Decomposability: It must be possible to decompose every complex problem into a small number of less complex subproblems that can be worked on separately.
- Modular understandability: In a large application, it must be possible to understand any part in isolation without knowing much or anything at all about the rest of the application. This property is called modular understandability. Programming in the large often means that a person works on an application with several million lines of code that already existed before she or he joined the company. Clearly, this can be done in an efficient manner only if the application satisfies modular understandability.
- Modular continuity: Continuity has two aspects. First, a small change to the specification must lead to a change in only one or a few modules. Second, a change in a module must easily be shown not to cause a regression in other modules. Modular continuity is especially important for interim patches that, due to their frequency and urgency, may not be as well tested as major releases.
- Reusability: A solution to a problem in one part of an application must be reusable in another part. The more general goal of composability (that is, the construction of new, possibly very different systems out of existing components) is commonly required only for basis frameworks.
![]() Note Decomposability and composability are often conflicting goals. Decomposability is achieved by top-down design. It leads to specific modules, which may be unsuitable for composition in general. Composability, on the other hand, is based on bottom-up design, which leads to general designs that are often inefficient and too costly for special cases (unless a module can be reused many times, justifying a large investment).
Note Decomposability and composability are often conflicting goals. Decomposability is achieved by top-down design. It leads to specific modules, which may be unsuitable for composition in general. Composability, on the other hand, is based on bottom-up design, which leads to general designs that are often inefficient and too costly for special cases (unless a module can be reused many times, justifying a large investment).
These aspects of modularization can be achieved with modules by adhering to the following rules:
- Information hiding (abstraction): Every module explicitly separates the public interface for its clients from its private implementation. This can be compared to a TV: its interface is a remote control with a few buttons and its implementation consists of complex circuits and software. TV viewers don't need to understand the implementation of the TV.
- Small interfaces: The interfaces are as small as possible in order not to restrict future improvements of the implementation.
- Few interfaces and layering: Every module uses as few interfaces from other modules as possible to reduce collateral damage if an interface needs to be changed in an incompatible way and to generally improve modular continuity. Most architectures are layered, where modules from higher layers, such as the business logic, may call modules from lower layers, such as data access, but not vice versa.
- Direct mapping: Each module represents a dedicated business concept and encompasses the data and operations necessary to do a single task and to do it well.
How do these general requirements and design principles translate to PL/SQL? A module maps on different levels of granularity to a subprogram, a package, a schema, or sets of any of the previous items. Subprograms as units of abstraction are the same in PL/SQL and most other procedural language and therefore not discussed here in more detail.
I restrict the discussion to technical modularization and ignore modularization in source code versioning, deployment, customization, marketing, and licensing, for which the technical modularization is often a precondition. I start with packages and then describe how to implement larger modules with and without schemas.
Packages and Associated Tables as Modules
PL/SQL explicitly provides packages to be used as modules that meet the previously mentioned requirements. Information hiding is supported by separating the package specification from its implementation. To ensure that the clients need to consult only the specification and don't rely on implementation details that may change, the package specification must be properly documented. A brief description of the semantics and intended usage of the overall package and each interface element (such as subprograms and types) suffices. The fact that there is no standard HTML API generation tool similar to JavaDoc available for PL/SQL is no excuse not to document package specifications. Users won't mind reading the documentation in the package specification. In fact, in an ad-hoc survey, most Java developers told me that they look at JavaDoc in the Java sources rather than the generated HTML.
Information hiding can even be implemented literally by wrapping the body but not the specification. Oracle does this for most public APIs, such as dbms_sql. Be aware, though, that wrapped code can be unwrapped, losing only comments in the process.
Every element exposed in a package specification can be used by any other program in the same schema and in another schema that has been granted execute privilege on the package. PL/SQL does not support protected export like Java or read-only export of variables like Oberon-2. This is not needed: APIs for different types of clients can be implemented by different packages.
Packages also provide for efficient development with separate, type-safe compilation. Clients can be compiled against the package specification and are never invalidated if only the body is modified. With the introduction of fine-grained dependency tracking in 11g, clients are invalidated only if the package specification changes in a relevant way. The drawback of this approach is that without a just-in-time compiler (which PL/SQL doesn't have) no cross-unit inlining is possible (except for standalone procedures, which PL/SQL doesn't currently support either).
![]() Note To keep the interface small, most procedures should be declared only in the package body and not exported through the specification in production code. To test them, they can be exported in test builds using conditional compilation, as described by Bryn Llewellyn at
Note To keep the interface small, most procedures should be declared only in the package body and not exported through the specification in production code. To test them, they can be exported in test builds using conditional compilation, as described by Bryn Llewellyn at http://bit.ly/eXxJ9Q.
To extend modularization from PL/SQL code to table data, every table should be modified by only a single package. Likewise, all select statements referencing only a single table should be contained in this single package. On the other hand, select statements referencing multiple tables associated with different packages are allowed to break the one-to-one mapping. Views may be used to introduce an additional layer of abstraction. However, it is usually not practical to introduce a view for every join between two tables associated with different packages.
There are multiple approaches to detect violations of the previously mentioned rules for table accesses. All approaches described here must be viewed as software engineering tools to find bugs during testing and not as means to enforce security. Except for the trigger and the fine-grained auditing approaches, a transitive closure (e.g., with a hierarchical query) is required to drill down through views to the underlying tables.
I describe two compile-time approaches in summary form in a single section and three runtime approaches in detail under separate headings. The runtime approaches are more complex and contain techniques of interest beyond the specific cases. The main problem with the runtime approaches is that they require test cases that trigger the execution of all relevant SQL statements.
Detecting Table Accesses by Static Analysis
There are two compile-time approaches based on static analysis:
- Searching in the source text: This approach is usually surprisingly quick with a good tool, unless there are lots of views whose occurrences also need to be searched. However, this approach requires a PL/SQL parser to be automated.
- Dependencies: The view user_dependencies lists only static dependencies and does not distinguish between DML and read-only access. PL/Scope does not contain information on SQL statements.
Detecting Table Accesses by Probing the Shared Pool
The view v$sql contains recently executed SQL that is still in the shared pool. The column program_id references the PL/SQL unit that caused the hard parse. For example, the following statement shows all PL/SQL sources that issued DML against the above table abbr_reg. To also see select statements, simply remove the condition on command_type.
SQL> select ob.object_name
2 ,sq.program_line#
3 ,sq.sql_text
4 from v$sql sq
5 ,all_objects ob
6 where sq.command_type in (2 /*insert*/, 6 /*update*/, 7 /*delete*/, 189 /*merge*/)
7 and sq.program_id = ob.object_id (+)
8 and upper(sq.sql_fulltext) like '%ABBR_REG%';
OBJECT_NAME PROGRAM_LINE# SQL_TEXT
-------------------- ------------- ------------------------------------------------------
ABBR_REG# 10 INSERT INTO ABBR_REG(ABBR, TEXT, DESCN) VALUES(UPPER(:
1 row selected.
The shared pool probing approach has several shortcomings.
- Only the PL/SQL unit that caused the hard parse is returned. If the same SQL occurs in multiple units (even though it shouldn't in hand-written code), you won't find the others. If the hard parse is triggered by an anonymous block, you don't get any relevant information.
- You have to catch the SQL before it is flushed out of the shared pool. The Statspack, ASH, and AWR views on SQL don't contain the column program_id.
- You need to use an approximate string match, which may return too much data, because the target table of a DML is visible only in the SQL text. Tables from a select clause can be matched exactly by joining v$sql_plan. Alternatively, you can create on-the-fly wrapper procedures containing the SQL texts, get the references from all_dependencies, and drop the wrapper procedures again.
- Truncates are listed as generic lock table in the SQL text.
Detecting Table Accesses with Triggers
Triggers are another option to log or block access. The following trigger checks that all DML to the table abbr_reg is made from the package abbr_reg# or a subprogram called from it:
create or replace trigger abbr_reg#b
before update or insert or delete or merge
on abbr_reg
begin
if dbms_utility.format_call_stack not like
'%package body% K.ABBR_REG#' || chr(10) /*UNIX EOL*/|| '%' then
raise_application_error(-20999,'Table abbr_reg may only be modified by abbr_reg#.'),
end if;
end;
As expected, DML from abbr_reg# is tolerated, but direct DML or DML from another package is not.
SQL> exec abbr_reg#.ins_abbr('descn', 'description')
PL/SQL procedure successfully completed.
SQL> insert into abbr_reg(abbr, text) values('reg', 'registry'),
insert into abbr_reg(abbr, text) values('reg', 'registry')
*
ERROR at line 1:
ORA-20999: Table abbr_reg may only be modified by abbr_reg#.
ORA-06512: at "K.ABBR_REG#B", line 3
ORA-04088: error during execution of trigger 'K.ABBR_REG#B'
Instead of calling the expensive dbms_utility.format_call stack, you can use a package body global variable in abbr_reg#, set the variable to true before accesses to the table abbr_reg and false after, and call from the trigger a procedure in abbr_reg# that checks whether the variable is true or not.
Detecting Table Accesses with Fine-Grained Auditing
Since Oracle doesn't provide on-select triggers, you have to use a workaround to detect read access. The three options are fine-grained auditing, RLS predicates, and Database Vault. All require the Enterprise Edition. Database Vault is an additionally priced option. Here is the approach with fine-grained auditing. I log all distinct callers into the table call_log.
create table call_log(
object_schema varchar2(30)
,object_name varchar2(30)
,policy_name varchar2(30)
,caller varchar2(200)
,sql_text varchar2(2000 byte)
,constraint call_log#p primary key(object_schema, object_name, policy_name
,caller, sql_text)
) organization index;
![]() Note Oracle puts a limit onto the maximum size of an index entry based on the block size as described in My Oracle Support (MOS) Note 136158.1. I ran this example on a database with 8K block size and AL32UTF8 character set, in which each character can occupy up to 4 bytes. To get the most information into the index, which is used to avoid duplicate entries upon creation, I specify the length semantics of the column sql_text to be byte.
Note Oracle puts a limit onto the maximum size of an index entry based on the block size as described in My Oracle Support (MOS) Note 136158.1. I ran this example on a database with 8K block size and AL32UTF8 character set, in which each character can occupy up to 4 bytes. To get the most information into the index, which is used to avoid duplicate entries upon creation, I specify the length semantics of the column sql_text to be byte.
The table gets filled by the procedure call_log_ins, which is called by the fine-grained auditing framework for every SQL statement execution, corresponding roughly to a statement-level trigger.
create or replace procedure call_log_ins(
i_object_schema varchar2
,i_object_name varchar2
,i_policy_name varchar2
)
is
pragma autonomous_transaction;
l_caller call_log.caller%type;
l_current_sql call_log.sql_text%type;
----------------------------------------------------------------------------------
-- Returns the call stack below the trigger down to the first non-anonymous block.
----------------------------------------------------------------------------------
function caller(
i_call_stack varchar2
) return varchar2
as
c_lf constant varchar2(1) := chr(10);
c_pfx_len constant pls_integer := 8;
c_head_line_cnt constant pls_integer := 5;
l_sol pls_integer;
l_eol pls_integer;
l_res varchar2(32767);
l_line varchar2(256);
begin
l_sol := instr(i_call_stack, c_lf, 1, c_head_line_cnt) + 1 + c_pfx_len;
l_eol := instr(i_call_stack, c_lf, l_sol);
l_line := substr(i_call_stack, l_sol, l_eol - l_sol);
l_res := l_line;
while instr(l_line, 'anonymous block') != 0 loop
l_sol := l_eol + 1 + c_pfx_len;
l_eol := instr(i_call_stack, c_lf, l_sol);
l_line := substr(i_call_stack, l_sol, l_eol - l_sol);
l_res := l_res || c_lf || l_line;
end loop;
return l_res;
end caller;
begin
l_caller := nvl(substr(caller(dbms_utility.format_call_stack), 1, 200), 'external'),
l_current_sql := substrb(sys_context('userenv','current_sql'), 1, 2000);
insert into call_log(
object_schema
,object_name
,policy_name
,caller
,sql_text
) values (
i_object_schema
,i_object_name
,i_policy_name
,l_caller
,l_current_sql
);
commit;
exception
when dup_val_on_index then
rollback;
end call_log_ins;
Finally, I need to add the policy. I want the procedure call_log_ins to be called for every access to the table abbr_reg in a select statement. To audit DML as well, I must add the parameter statement_types => 'select,insert,update,delete' to the call or create separate policies for select and for DML.
begin
dbms_fga.add_policy(
object_name => 'ABBR_REG'
,policy_name => 'ABBR_REG#SELECT'
,handler_module => 'CALL_LOG_INS'
);
end;
/
I test the implementation by calling abbr_reg#.chk_abbr from my running example, like so:
SQL> exec abbr_reg#.chk_abbr
PL/SQL procedure successfully completed.
SQL> select object_name, policy_name, caller, sql_text from call_log;
OBJECT_NAME POLICY_NAME CALLER SQL_TEXT
----------- --------------- ------------------------------ ---------------------------------
ABBR_REG ABBR_REG#SELECT 35 package body K.ABBR_REG# SELECT COUNT(*) FROM ABBR_REG WHE
1 row selected.
Neither the DML trigger nor the fine-grained auditing fires on truncate of a table or partition. To log or block these, a DDL trigger is required.
Modules Containing Multiple Packages or Submodules
Subprograms and packages are necessary building blocks. Yet higher level modules are required to group the thousands of packages in large programs. For example, the Avaloq Banking System is divided functionally into core banking, execution & operation, and front modules. Each module is further subdivided, such as execution & operation into finance and payment. On each modularization level, accepted dependencies are declared.
Orthogonally, the system is divided technically into data access, business logic, and presentation layers. The two modularizations can be treated separately or be combined as shown on the left side of Figure 11-3. Atomic modules, such as Finance UI, are defined as intersections of the two modularizations. Technical modules are shown as enclosing boxes, first-level functional modules by identical shading and name prefixes of the atomic modules belonging together.
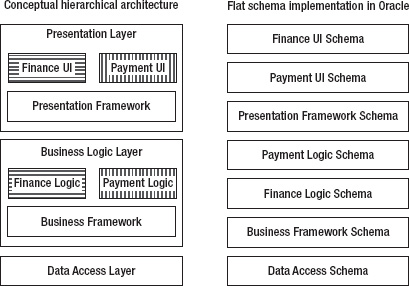
Figure 11-3. Nested layer and module architecture and a flat implementation with schemas
Modules as sets of packages and other object types can be represented in Oracle with schemas and grants. Both schemas and grants are very flexible, yet low level. For example, schemas cannot be nested. Thus the conceptual hierarchical architecture on the left side of Figure 11-3 must be mapped to a flat set of schemas, as shown on the right side. Furthermore, interfaces have to be implemented as individual grants to each client schema.
Therefore, the introduction of a modularization model with a higher abstraction level than Oracle schemas and grants improves the understandability by reducing the number of items. Oracle schemas and grants can be generated from this model if desired or the model can be used to check the modularization within a schema.
The precise requirements for the metamodel depend upon the chosen modularization. Typically, the model must meet the following requirements:
- Represent the modules of the system, such as Payment Logic and Business Framework in Figure 11-3.
- Map every database object to exactly one module, such as the PL/SQL package pay_trx# to the module Payment Logic.
- Declare the dependencies between modules, such as Payment Logic using Business Framework but not vice versa. Only acyclic dependencies should be permitted.
- Declare the interfaces (APIs) of each module—that is, which objects may be referenced from depending modules.
Provide an extension/upcall mechanism that allows a module to be extended by another module that depends on it. For example, the Presentation Framework may declare an extension point for menu items and the Payment UI may create a menu item. When this menu item is selected, the Presentation Framework must make an upcall to the Payment UI. This call is termed upcall because it goes against the dependency chain: the Payment UI depends on the Presentation Framework and not the other way around.
In PL/SQL, upcalls are usually implemented with generated dispatchers or dynamic SQL as described in the section on object-oriented programming. If modules are implemented with schemas, the appropriate execute object privilege must be granted.
Grants derived from dependencies and grants required for upcalls can be separated by placing generated code, such as upcall dispatchers, into a separate schema.
No additional privileges are required at all if upcalls are implemented with dynamic dispatch as provided by user defined types.
Optionally, the metamodel can provide the following:
- Support hierarchical nesting of modules along one or more dimensions, such as functionality and technical layering. Alternatively, dedicated entities, such as layers and functional components, can be introduced. Dedicated entities can be defined with specific semantics, such as layers allowing only downward dependencies.
- Allow for friend modules, which may use additional APIs not available to normal client modules. For example, the Payment Logic module may provide additional APIs only for the Payment UI module. Likewise, it may be justified to widen the interface between selected modules for performance reasons. Friendship can be declared individually or be derived from other entities, such as functional domain modules.
- Manage exceptions. Upon the introduction of a (new) target modularization, it may not be feasible to immediately remove all illegal dependencies, yet no additional illegal dependencies must be created going forward. Therefore, the temporarily tolerated illegal dependencies must be managed.
The target architecture model of an application can be defined centrally in a single file and/or on a per-module basis. The central definition is suited for global high-level entities, such as layers. The per-module configuration is more scalable and is required for multiple independent module providers. The manifest files of OSGi modules (called bundles in OSGi terminology) are examples of a per-module declaration.
Figure 11-4 shows a possible metamodel in form of an entity-relationship diagram. I list the previously mentioned requirements in parentheses behind the element that satisfies it. At the top of Figure 11-4 are the modules (requirement 1) and the module types. Hierarchies of modules (requirement 6) and dependencies between modules (requirement 3) are shown below. With these entities you can model the architecture depicted on the left in Figure 11-3.
The objects (such as PL/SQL units, tables, and views) come next. Each object belongs to exactly one module (requirement 2). Each object is either private to its containing module or is an interface of some type (requirement 4). In the example are several types of interfaces: interfaces for other atomic modules with the same functional module parent, interfaces for other modules in the same application, and public interfaces that can be used by external applications. The additional code table code_object_intf_mode is used to differentiate between read-only access and read-write access to tables.
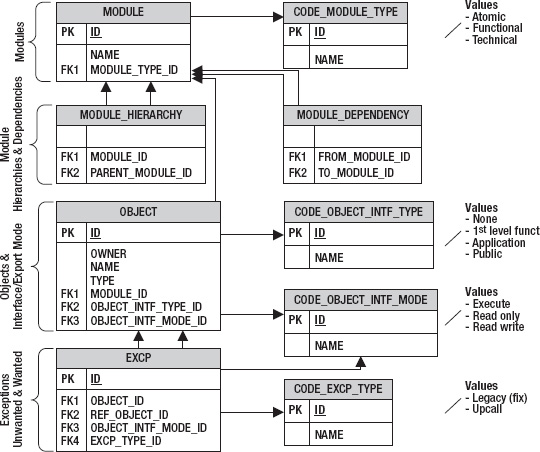
Figure 11-4. Metamodel for target modularization
At the bottom of Figure 11-4 are the structures to represent the two types of exceptions as described by the two values at the bottom right.
- Legacy bugs to be fixed (requirement 8). These should occur only temporarily if an application is newly modularized or if the target modularization is changed.
- Accepted exceptions for upcalls (requirement 5).
Friend modules (requirement 7) are only supported implicitly by functional modules. Explicit friend modules could be supported by introducing different module dependency types or by modeling friends as additional exception type.
Modules as groups of PL/SQL packages and other object types can be implemented with database schemas or within schemas. The two approaches can be combined, such as schemas for the top level modules and grouping within schemas for the submodules.
Schemas as Modules
Schemas provide a common modularization for all types of objects from PL/SQL units to tables at a higher granularity than packages. Every object belongs to a schema. Schemas can be used to divide an application into parts. For example, an application could be divided into three schemas containing the data access, business logic, and presentation layer, respectively.
Schemas are synonymous with users in Oracle. I create the schemas for the three-layer architecture as follows:
SQL> create user data_access identified by pwd account lock;
User created.
SQL> create user business_logic identified by pwd account lock;
User created.
SQL> create user presentation identified by pwd account lock;
User created.
Grants for Object Privileges
To access objects in another schema, the respective object privilege needs to be granted. I first create a table and a procedure in the data_access schema to have a concrete example.
SQL> create table data_access.t(x number);
Table created.
SQL> create or replace procedure data_access.d(
2 i_x number
3 )
4 is
5 begin
6 insert into t(x) values (abs(i_x));
7 end d;
8 /
![]() Note To create these objects, you must log on with a user that has the “Create any table” and “Create any procedure” privileges or grant create session, table, and procedure to data_access.
Note To create these objects, you must log on with a user that has the “Create any table” and “Create any procedure” privileges or grant create session, table, and procedure to data_access.
Without an explicit grant, the procedure data_access.d cannot be accessed from a subprogram in the schema business_logic:
SQL> create or replace procedure business_logic.b(
2 i_x number
3 )
4 is
5 begin
6 data_access.d(trunc(i_x));
7 end b;
8 /
Warning: Procedure created with compilation errors.
SQL> show error
Errors for PROCEDURE BUSINESS_LOGIC.B:
LINE/COL ERROR
-------- ------------------------------------------------------
6/3 PL/SQL: Statement ignored
6/3 PLS-00201: identifier 'DATA_ACCESS.D' must be declared
After granting the execute privilege, I can successfully compile the procedure.
SQL> grant execute on data_access.d to business_logic;
Grant succeeded.
SQL> alter procedure data_access.d compile;
Procedure altered.
Grants are a flexible, yet low-level construct:
- Grants are always on individual items. A separate grant is required for each of the interface packages.
- Grants are always to a specific schema. Just because business_logic can access data_access.d doesn't mean that presentation can access data_access.d. By granting presentation privileges only on business_logic and not on data_access, you could enforce a strict layering in which all calls from presentation to data_access must go through business_logic. Grants provide selective information hiding whereas a package exports an item either for all clients or for none.
- If two schemas should be granted the same privileges on a set of objects (such as Finance Logic and Payment Logic on Business Framework in Figure 11-3), the grants must be made individually because roles are not considered in definer rights procedures.
- It is not possible to grant a schema (for example, one containing generated code) access to all objects of another schema. Separate grants for each object are required.
- For tables, the select, insert, update, and delete privileges can be granted separately. Thus, schemas make it possible to enforce data consistency by restricting DML to a single schema and allowing other modules direct read access for optimal performance. There is no performance overhead for accessing object in other schemas with definer rights procedures.
Because grants are so low level and because a large application may require thousands of grants, it is best to generate the grants from a metamodel, as in Figure 11-4.
![]() Note All privileges on individual objects are visible in the view all_tab_privs. System, role, and column privileges can be found in all_sys_privs, all_role_privs, and all_column_privs, respectively.
Note All privileges on individual objects are visible in the view all_tab_privs. System, role, and column privileges can be found in all_sys_privs, all_role_privs, and all_column_privs, respectively.
Accessing Objects in Other Schemas
Like packages, schemas introduce namespaces. There are two options to reference an object in another schema. The fully-qualified notation requires the schema name in each reference (such as data_access.d in the previous example). Alternatively, you can create a synonym for the procedure d in the schema business_logic and then access the procedure directly as d.
SQL> create or replace synonym business_logic.d for data_access.d;
Synonym created.
Some developers prefer the synonym approach to reduce the amount of typing and to avoid strong coupling. Because interfaces should be few and explicit, I prefer the fully-qualified notation, which prevents name clashes.
![]() Note If a schema contains an object of the same name as another schema, it becomes impossible to reference objects in this other schema using the fully-qualified notation because the scoping rules of PL/SQL resolve the reference to the object. For example, if you add a table data_access to the schema business_logic, you can no longer reference any objects in PL/SQL from data_access in business_logic except through synonyms.
Note If a schema contains an object of the same name as another schema, it becomes impossible to reference objects in this other schema using the fully-qualified notation because the scoping rules of PL/SQL resolve the reference to the object. For example, if you add a table data_access to the schema business_logic, you can no longer reference any objects in PL/SQL from data_access in business_logic except through synonyms.
Optimal Usage of Schemas
The ideal number of schemas for an application depends upon the architecture. For hand-written code, 20–100 packages might be a desirable average size for a schema. With fewer packages, the number of modules as well as the sizes and number of interfaces may become too high, which violates the aforementioned rules for modularization and causes administration overhead for grants and structural changes. With more packages, the units of modular understandability are too big.
Schemas have several additional features that should be considered during design. They are useful for deploying third-party components because their namespaces prevent name clashes. Schemas can be used to enforce security because the security is checked in all cases (including dynamic SQL) by the database. Beyond the object privileges described previously, schemas can be used to centralize critical operations into a small, “micro-kernel”-like schema with many system privileges. Furthermore, schemas have various properties (such as quotas on tablespaces) and are units of enabling editioning.
The Road to Modularization with Schemas
In spite of all these benefits, most large applications that I know use only one or a handful of schemas. The reasons seem to be nontechnical or historic and unrelated to any problems with schemas in current versions of Oracle. The aforementioned synonym approach for referencing objects in other schemas provides a relatively simple migration path to using schemas for modularization. Only DDL statements and queries against the data dictionary might have to be adapted, and dynamic SQL needs to be checked to find missing grants. Of course, such a migration provides only a starting point for future cleanup and yields no magic modularization improvement.
After the migration to schemas, no additional modularization violations referencing previously unreferenced schema private objects are possible. For example, if there is no reference from the new schema business_logic to the table data_access.t before the migration, no object privilege needs to be granted for the migration. If a developer later tries to reference data_access.t in a package in business_logic, the PL/SQL compiler will catch the error. On the other hand, additional references to already-used schema private objects are possible because grants are to schemas rather than to individual objects therein. If, in this example, an existing package body of business_logic accessed data_access.t before the migration, the grant would have been required for the one-to-one migration, and additional violations would not be flagged by the compiler. It is therefore necessary keep a list of pre-existing violations and check for new violations. The check can be fine granular using all_identifiers for references between PL/SQL units and using all_dependencies for references involving other object types.
Modularizing an existing application is very expensive because if the modularization was not enforced in the past, the application is full of illegal references to non-referenceable modules and to non-interface objects. The high cost of changing these reference is attributed to past sins and not to any shortcomings of schemas. The lessons to be learned are that new applications must be modular from the beginning and that modularity must be enforced.
Modularization within Schemas
If an application is confined to a single schema for backward compatibility or organizational reasons or if schemas are only to be used for top-level modules, the application can still be subdivided into logical modules inside a schema.
Modules within schemas are often implicitly represented by name prefixes, such as da_ for objects in the data access layer. The correct usage of module prefixes can be checked as previously described for scope prefixes.
Since modularization without enforcement is worthless and because the database doesn't help with enforcement of modularization within schemas, you need to create your own checks. For the checks you need the target and the actual modularization. The target modularization is given by an instance of the metamodel of Figure 11-4 (shown earlier). The actual modularization is in the code. Static dependencies are listed in all_dependencies and all_identifiers. I have already discussed the detection of references to tables in dynamic SQL. For references to PL/SQL in dynamic SQL and PL/SQL, you can use the SQL area or Database Vault.
Database Vault is a security option that restricts access to specific areas in an Oracle database from any user, including users who have administrative access. You use access restrictions to catch modularization violations—that is, direct accesses of non-interface units of other modules. In the example, I assume that every PL/SQL unit has a module prefix in its name and that interface units have a _intf# suffix. Database Vault provides the option to execute a custom PL/SQL function to check the validity of each PL/SQL call (or other object usage) in a rule. The function gets the call stack and verifies that the topmost caller/callee pair of units in the schema to be checked (in the example k) satisfies the modular reference requirements. To avoid checks for the checking function, I create the latter in a separate schema x.
create or replace function x.valid_call
return pls_integer
is
c_lf constant varchar2(1) := chr(10); -- UNIX
c_intf_like constant varchar2(8) := '%\_INTF#'; -- Interface unit suffix
c_owner_like constant varchar2(5) := '% K.%'; -- Schema to be checked
c_module_sep constant varchar2(1) := '_'; -- Separator of module prefix
c_head_line_cnt constant pls_integer := 4; -- Ignored lines in call stack
l_call_stack varchar2(4000); -- Call stack
l_sol pls_integer; -- Start pos of current line
l_eol pls_integer; -- End pos of current line
l_callee varchar2(200); -- Called unit
l_caller varchar2(200); -- Calling unit
l_res boolean; -- Valid call?
begin
l_call_stack := dbms_utility.format_call_stack;
l_sol := instr(l_call_stack, c_lf, 1, c_head_line_cnt);
l_eol := instr(l_call_stack, c_lf, l_sol + 1);
l_callee := substr(l_call_stack, l_sol, l_eol - l_sol);
-- ONLY CALLS TO NON INTERFACE UNITS OF K MAY BE INVALID --
if l_callee like c_owner_like and l_callee not like c_intf_like escape '' then
l_callee := substr(l_callee, instr(l_callee, '.') + 1);
-- FIND TOPMOST CALLER OF SCHEMA K, IF ANY, AND CHECK FOR SAME MODULE PREFIX --
loop
l_sol := l_eol + 1;
l_eol := instr(l_call_stack, c_lf, l_sol + 1);
l_caller := substr(l_call_stack, l_sol, l_eol - l_sol);
if l_caller like c_owner_like then
l_caller := substr(l_caller, instr(l_caller, '.') + 1);
l_res := substr(l_callee, 1, instr(l_callee, c_module_sep))
= substr(l_caller, 1, instr(l_caller, c_module_sep));
end if;
exit when l_eol = 0 or l_res is not null;
end loop;
end if;
return case when not l_res then 0 else 1 end;
end valid_call;
The Database Vault schema needs to be granted the execute privilege on this function so it can be used in rules.
SQL> grant execute on x.valid_call to dvsys;
Grant succeeded.
Then I create the rule set, rule, and command rule to execute the function valid call on the execution of each PL/SQL unit logged in as Database Vault Owner.
declare
c_rule_set_name varchar2(90) := 'Modularization within schema check';
c_rule_name varchar2(90) := 'CHKUSER';
begin
-- RULE SET: CHECK RULES AND FLAG VIOLATIONS
dvsys.dbms_macadm.create_rule_set(
rule_set_name => c_rule_set_name
,description => null
,enabled => dvsys.dbms_macutl.g_yes
,eval_options => dvsys.dbms_macutl.g_ruleset_eval_all
,audit_options => dvsys.dbms_macutl.g_ruleset_audit_off
,fail_options => dvsys.dbms_macutl.g_ruleset_fail_show
,fail_message => 'Modularization check failed'
,fail_code => -20002
,handler_options => dvsys.dbms_macutl.g_ruleset_handler_off
,handler => null
);
-- RULE: CHECK WHETHER CALL IS VALID
dvsys.dbms_macadm.create_rule(
rule_name => c_rule_name
,rule_expr => 'X.VALID_CALL = 1'
);
-- ADD RULE TO RULE SET
dvsys.dbms_macadm.add_rule_to_rule_set(
rule_set_name => c_rule_set_name
,rule_name => c_rule_name
);
-- MATCH CRITERIA: EXECUTE RULE SET ON PL/SQL EXECUTE OF OBJECTS OWNED BY USER K
dvsys.dbms_macadm.create_command_rule(
command => 'EXECUTE'
,rule_set_name => c_rule_set_name
,object_owner => 'K'
,object_name => '%'
,enabled => dvsys.dbms_macutl.g_yes
);
commit;
end;
/
With this in place, a call from k.m1_2 to k.m1_1 is legal because both units have the same module prefix of m1. On the other hand, a call from k.m2_3 to k.m1_1 is blocked because the caller belongs to module m2 and the callee to module m1.
SQL> create or replace procedure k.m1_1 is begin null; end;
2 /
Procedure created.
SQL> create or replace procedure k.m1_2 is begin execute immediate 'begin m1_1; end;'; end;
2 /
Procedure created.
SQL> exec k.m1_2
PL/SQL procedure successfully completed.
SQL> create or replace procedure k.m2_3 is begin execute immediate 'begin m1_1; end;'; end;
2 /
Procedure created.
SQL> exec k.m2_3
BEGIN k.m2_3; END;
*
ERROR at line 1:
ORA-01031: insufficient privileges
ORA-06512: at "K.M1_1", line 1
ORA-06512: at "K.M2_3", line 1
ORA-06512: at line 1
This approach works for both static and dynamic SQL (native and dbms_sql). Instead of blocking violations, they could also be permitted and logged.
![]() Note To install Database Vault you must relink the binaries, as explained in appendix B of the Database Vault Administrator's Guide, and add the Oracle Label Security (precondition) and Oracle Database Vault options with the Database Creation Assistant dbca. As of 11.2.0.2, there are few gotchas with the installation. The option must be installed with dbca as the SQL*Plus scripts don't install NLS properly. The required special character in the password for the DV Owner must not be the last character. If you use deferred constraints, patch 10330971 is required. With AL32UTF8 as database character set, a tablespace with 16K or bigger block size is required because of the aforementioned maximum size of an index entry based on the block size. If your default block size is smaller, set db_16k_cache_size and create a tablespace with 16 K block size for database vault. Furthermore, Database Vault purposely introduces some restrictions, which you may need to lift again for your application to work properly.
Note To install Database Vault you must relink the binaries, as explained in appendix B of the Database Vault Administrator's Guide, and add the Oracle Label Security (precondition) and Oracle Database Vault options with the Database Creation Assistant dbca. As of 11.2.0.2, there are few gotchas with the installation. The option must be installed with dbca as the SQL*Plus scripts don't install NLS properly. The required special character in the password for the DV Owner must not be the last character. If you use deferred constraints, patch 10330971 is required. With AL32UTF8 as database character set, a tablespace with 16K or bigger block size is required because of the aforementioned maximum size of an index entry based on the block size. If your default block size is smaller, set db_16k_cache_size and create a tablespace with 16 K block size for database vault. Furthermore, Database Vault purposely introduces some restrictions, which you may need to lift again for your application to work properly.
Modularization with Schemas vs. within Schemas
Table 11-1 summarizes the pros and cons of modularization with and within schemas. An abstract model of the target modularization is required in both cases.

Object-Oriented Programming with PL/SQL
With modularization you are still missing two important pieces to efficiently create large programs. First, all your memory structures have been restricted to the representation of singletons. However, most applications must support multiple instances of a kind, such as multiple banking transactions. Second, reuse has been restricted to reuse exactly as is. In practice, though, reuse commonly requires adaptations—without having to duplicate the source code and maintain multiple copies going forward. For example, payment and stock-exchange transactions in a banking system share many commonalities but differ in other aspects, such as their booking logic. The goal is to have only a single implementation of the shared functionality rather than just reuse of ideas and developers. Object-oriented programming addresses these issues.
Reuse brings many benefits: it reduces the time to market, the implementation cost, and the maintenance effort because there is only one implementation to maintain. Because there is only one implementation, more expert resources can be spent on making it correct and efficient.
Object-oriented programming increases reuse in two ways.
- Reuse with adaptations: Inheritance and subtype polymorphism allow you to extend a data type and treat instances of its subtypes as if they were instances of the supertype. In the example, you can define a generic banking transaction type as supertype and subtypes for payment and stock exchange transactions. Dynamic binding (also called late binding, dynamic dispatch, and virtual methods) adds the final piece to the puzzle. You can declare, possibly abstract without an implementation, a procedure book on the supertype banking transaction and adapt it for the two subtypes. The generic framework calls the procedure book, and each banking transaction executes the logic corresponding to its actual subtype.
- Reuse of data and associated functionality: Object-oriented analysis promotes decomposition based on data rather than functionality. Because data is longer lived than the particular functionality provided on it, this typically provides for better reuse.
Bertrand Meyer summarizes both aspects in his book Object-Oriented Software Construction: “Object-oriented software construction is the building of software systems as structured collections of possibly partial abstract data type implementations.”
![]() Note Generic types (F-bounded polymorphism) are sometimes mistakenly considered to be a requirement for object-oriented programming, especially since their addition to Java 5. However, generic types are an orthogonal concept that is, for example, also present in the original version of Ada, which is not object-oriented. Generic types are most commonly used for collections. PL/SQL supports strongly typed collections, such as associative arrays, as built-in language construct. This suffices in most cases.
Note Generic types (F-bounded polymorphism) are sometimes mistakenly considered to be a requirement for object-oriented programming, especially since their addition to Java 5. However, generic types are an orthogonal concept that is, for example, also present in the original version of Ada, which is not object-oriented. Generic types are most commonly used for collections. PL/SQL supports strongly typed collections, such as associative arrays, as built-in language construct. This suffices in most cases.
Whereas PL/SQL is not an object-oriented programming language per se, it is possible to program in an object-oriented way using user-defined types (UDT) or PL/SQL records. Multiple instances and reuse with adaptations are implemented as follows:
- PL/SQL does not support in-memory references (pointers) directly. The only way to create an arbitrary number of instances of an object at runtime is to store the instances in collections, such as associative arrays. References are represented as collection indexes.
- UDTs support dynamic binding out of the box. With records, you can implement dynamic dispatch yourself using dynamic SQL or a static dispatcher.
I start with UDTs because their alternate name object types suggests that they are the natural choice for object-oriented programming and then explain why records are the better option in most cases.
Object-Oriented Programming with User-Defined Types
Oracle added user-defined types (UDT) in Oracle 8 amid the object hype, addressing mostly storage aspects and leaving out some useful programming features. UDTs are schema-level objects. I can create a base type for banking transactions as follows:
![]() Note Oracle uses two synonymous terms for user-defined types (UDT). In the Database Object-Relational Developer's Guide, they are called object types because Oracle wanted to support object orientation in the database. The same term object type has been used for much longer as the type of an entry in all_objects, such as packages and tables. The second synonym abstract data type (ADT) is used in the PL/SQL Language Reference, because UDTs can be used to implement the mathematical concept of an ADT—that is, a data structure defined by a list of operations and properties of these operations. I use the unambiguous term UDT in this chapter. UDTs include varrays and nested tables, which I don't discuss here. UDTs are useful as types of parameters for subprograms called externally.
Note Oracle uses two synonymous terms for user-defined types (UDT). In the Database Object-Relational Developer's Guide, they are called object types because Oracle wanted to support object orientation in the database. The same term object type has been used for much longer as the type of an entry in all_objects, such as packages and tables. The second synonym abstract data type (ADT) is used in the PL/SQL Language Reference, because UDTs can be used to implement the mathematical concept of an ADT—that is, a data structure defined by a list of operations and properties of these operations. I use the unambiguous term UDT in this chapter. UDTs include varrays and nested tables, which I don't discuss here. UDTs are useful as types of parameters for subprograms called externally.
create or replace type t_bank_trx_obj is object (
s_id integer
,s_amount number
------------------------------------------------------------------------------
-- Returns the amount of the transaction.
------------------------------------------------------------------------------
,final member function p_amount return number
------------------------------------------------------------------------------
-- Books the transaction.
------------------------------------------------------------------------------
,not instantiable member procedure book(
i_text varchar2
)
) not instantiable not final;
The type t_bank_trx_obj has two attributes s_id and s_amount to hold the state. In addition, it has two methods. The function p_amount is declared as final, meaning that it cannot be overridden in subtypes. The procedure book is declared as non-instantiable (abstract), meaning that it just declared and specified, but not implemented. The syntax for the type body is PL/SQL extended by the modifiers for subprograms, like so:
create or replace type body t_bank_trx_obj is
final member function p_amount return number
is
begin
return s_amount;
end p_amount;
end;
Inheritance and Dynamic Dispatch with UDTs
UDTs provide for inheritance. I can define a payment transaction type as a specialization of the general banking transaction type.
create or replace type t_pay_trx_obj under t_bank_trx_obj (
------------------------------------------------------------------------------
-- Creates a payment transaction. Amount must be positive.
------------------------------------------------------------------------------
constructor function t_pay_trx_obj(
i_amount number
) return self as result
,overriding member procedure book(
i_text varchar2
)
);
I can also add an explicit constructor to prohibit payment transactions with negative amounts. The constructor only takes the amount as input parameter, assuming that the ID gets initialized from a sequence. The keyword “self” denotes the current instance, like “this” in other languages.
![]() Note Oracle creates a default constructor with all attributes in the order of declaration and the names of the attributes as input parameters. To prevent that, the default constructor creates a loophole (e.g., allowing the caller to create a payment with a negative amount), an explicit constructor with the same signature as the default constructor must be declared.
Note Oracle creates a default constructor with all attributes in the order of declaration and the names of the attributes as input parameters. To prevent that, the default constructor creates a loophole (e.g., allowing the caller to create a payment with a negative amount), an explicit constructor with the same signature as the default constructor must be declared.
create or replace type body t_pay_trx_obj is
constructor function t_pay_trx_obj(
i_amount number
) return self as result
is
begin
if nvl(i_amount, -1) < 0 then
raise_application_error(-20000, 'Negative or null amount'),
end if;
self.s_amount := i_amount;
return;
end t_pay_trx_obj;
------------------------------------------------------------------------------
overriding member procedure book(
i_text varchar2
)
is
begin
dbms_output.put_line('Booking t_pay_trx_obj "' || i_text || '" with amount '
|| self.p_amount);
end book;
end;
I can now use the two types to illustrate the dynamic dispatch. I assign a payment transaction to a variable of type t_bank_trx_obj and call the procedure book. Even though the static type of the variable is t_bank_trx_obj, the implementation of the actual type t_pay_trx_obj is executed.
SQL> declare
2 l_bank_trx_obj t_bank_trx_obj;
3 begin
4 l_bank_trx_obj := new t_pay_trx_obj(100);
5 l_bank_trx_obj.book('payroll January'),
6 end;
7 /
Booking t_pay_trx_obj "payroll January" with amount 100
PL/SQL procedure successfully completed.
Limitations of UDTs
So far, you have seen the good aspects of UDTs for object-oriented programming. Unfortunately, UDTs also have two major shortcomings.
- UDTs can use only SQL types, but not PL/SQL types (such as record and Boolean) in their specification because UDTs can be persisted in SQL.
- Unlike PL/SQL packages, UDTs don't support information hiding. It is not possible to declare any attributes or methods as private, or to add more attributes and methods in the body. Any client can access all members, as shown in the following example, in which I directly modify the amount:
create or replace procedure access_internal
is
l_bank_trx_obj t_bank_trx_obj;
begin
l_bank_trx_obj := new t_pay_trx_obj(100);
l_bank_trx_obj.s_amount := 200;
l_bank_trx_obj.book('cheating'),
end;
At least PL/Scope gives you a way to detect such accesses. The following select lists all static accesses to attributes and private methods, indicated by the prefix p_, from outside the declaring type and its subtypes:
SQL> select us.name, us.type, us.object_name, us.object_type, us.usage, us.line
2 from all_identifiers pm
3 ,all_identifiers us
4 where pm.object_type = 'TYPE'
5 and (
6 pm.type = 'VARIABLE'
7 or (pm.type in ('PROCEDURE', 'FUNCTION') and pm.name like 'P\_%' escape '')
8 )
9 and pm.usage = 'DECLARATION'
10 and us.signature = pm.signature
11 and (us.owner, us.object_name) not in (
12 select ty.owner, ty.type_name
13 from all_types ty
14 start with ty.owner = pm.owner
15 and ty.type_name = pm.object_name
16 connect by ty.supertype_owner = prior ty.owner
17 and ty.supertype_name = prior ty.type_name
18 );
NAME TYPE OBJECT_NAME OBJECT_TYPE USAGE LINE
-------- -------- --------------- ----------- ---------- ----
S_AMOUNT VARIABLE ACCESS_INTERNAL PROCEDURE ASSIGNMENT 6
1 row selected.
PL/Scope distinguishes between assignment and reference. Unfortunately, hidden assignments in the form of passing an attribute as actual parameter for an out or in out parameters are visible only as references.
Persistence of UDTs
Object types can be persisted as table columns or as object tables. For example, all transactions can be stored in the following table:
create table bank_trx_obj of t_bank_trx_obj(s_id primary key)
object identifier is primary key;
This table can store objects of any subtype, such as payment transaction.
SQL> insert into bank_trx_obj values(t_pay_trx_obj(1, 100));
1 row created.
What looks easy at the beginning becomes very complex and cumbersome when type specifications change. The details are beyond the scope of this chapter. Furthermore, edition-based redefinition of types (and as of 11gR2, type bodies) is impossible for types with table dependents and subtypes thereof. Storing UDTs in tables is bad practice that may be justified only in Advanced Queuing tables and for some varrays. Of course, it is also possible to store the content of UDTs into relational tables with a table column per UDT attribute as described for records below.
Object-Oriented Programming with PL/SQL Records
PL/SQL record types provide an alternative implementation basis to UDTs for object-oriented programming in PL/SQL. Most people I know who do object-oriented programming in PL/SQL use records for object-oriented programming. Using records instead of UDTs solves several problems.
- PL/SQL types are allowed as types of fields and as parameters of subprograms.
- Multiple inheritance and subtyping are possible.
The disadvantage of using records is that you have to implement the dynamic dispatch yourself. Before I get to the dynamic dispatch, I will describe how to create an arbitrary number of object instances at runtime in memory and how to reference them.
Multiple Instances and In-Memory References with Collections
The object instances are stored in a collection. The collection and the record type are declared in the package body to implement information hiding. References are indexes into the collection. The index type is declared as subtype of pls_integer in the package specification because the references are used as arguments to exported subprograms. The following example shows the implementation of a heap using an associative array of bank transactions. I intersperse the code with explanatory text.
create or replace package bank_trx#
is
------------------------------------------------------------------------------
-- Type for references to t_bank_trx and subtypes thereof.
------------------------------------------------------------------------------
subtype t_bank_trx is pls_integer;
I need to keep track of the actual type of each banking transaction instance.
------------------------------------------------------------------------------
-- Type for subtypes of t_bank_trx.
------------------------------------------------------------------------------
subtype t_bank_trx_type is pls_integer;
The constructor takes the type of the transaction as well as the individual elements. I prefix the subprograms with the name of the type. This allows me to wrap multiple types with a single package and give the types direct access to each other's internal representation.
------------------------------------------------------------------------------
-- Creates a banking transaction.
------------------------------------------------------------------------------
function bank_trx#new(
i_bank_trx_type_id t_bank_trx_type
,i_amount number
) return t_bank_trx;
All other subprograms take the self reference i_bank_trx as the first argument. The procedure bank_trx#remv is required because there is no automatic garbage collection.
------------------------------------------------------------------------------
-- Removes (deletes) the banking transaction.
------------------------------------------------------------------------------
procedure bank_trx#remv(
i_bank_trx t_bank_trx
);
------------------------------------------------------------------------------
-- Returns the amount of the transaction.
------------------------------------------------------------------------------
function bank_trx#amount(
i_bank_trx t_bank_trx
) return number;
------------------------------------------------------------------------------
-- Books the transaction.
------------------------------------------------------------------------------
procedure bank_trx#book(
i_bank_trx t_bank_trx
,i_text varchar2
);
end bank_trx#;
![]() Note The index of the associative array must not be confused with the ID stored inside the banking transaction. The index is the current in-memory “address” which can change if the transaction is persisted and read again. The ID is the unique and immutable identifier of the transaction. Using the ID as the index wouldn't work because the index is of type pls_integer, which has a smaller range than ID. Changing the associative array to be indexed by varchar2(38) instead of pls_integer to store any positive integer would result in higher memory usage and lower performance. For added type safety, a record with a single pls_integer element could be used as type of t_bank_trx instead.
Note The index of the associative array must not be confused with the ID stored inside the banking transaction. The index is the current in-memory “address” which can change if the transaction is persisted and read again. The ID is the unique and immutable identifier of the transaction. Using the ID as the index wouldn't work because the index is of type pls_integer, which has a smaller range than ID. Changing the associative array to be indexed by varchar2(38) instead of pls_integer to store any positive integer would result in higher memory usage and lower performance. For added type safety, a record with a single pls_integer element could be used as type of t_bank_trx instead.
The implementation of the package body bank_trx# is straightforward.
create or replace package body bank_trx#
is
The state of an object is represented in a record. The set of records is stored in an associative array.
type t_bank_trx_rec is record (
bank_trx_type_id t_bank_trx_type
,id integer
,amount number
);
type t_bank_trx_tab is table of t_bank_trx_rec index by t_bank_trx;
b_bank_trx_list t_bank_trx_tab;
The function bank_trx#new assigns the record to the next free index.
function bank_trx#new(
i_bank_trx_type_id t_bank_trx_type
,i_amount number
) return t_bank_trx
is
l_bank_trx t_bank_trx;
begin
l_bank_trx := nvl(b_bank_trx_list.last, 0) + 1;
b_bank_trx_list(l_bank_trx).bank_trx_type_id := i_bank_trx_type_id;
b_bank_trx_list(l_bank_trx).amount := i_amount;
return l_bank_trx;
end bank_trx#new;
The procedure bank_trx#remv deletes the element.
procedure bank_trx#remv(
i_bank_trx t_bank_trx
)
is
begin
b_bank_trx_list.delete(i_bank_trx);
end bank_trx#remv;
The function bank_trx#amount has the same implementation for all types of banking transactions, which can be given in the base type.
function bank_trx#amount(
i_bank_trx t_bank_trx
) return number
is
begin
return b_bank_trx_list(i_bank_trx).amount;
end bank_trx#amount;
The overridable procedure bank_trx#book has a different implementation for each type of banking transaction. The implementation in bank_trx# needs to call the code of the subtypes.
procedure bank_trx#book(
i_bank_trx t_bank_trx
,i_text varchar2
)
is
begin
<Dynamic dispath according to b_bank_trx_list(i_bank_trx).bank_trx_type_id>
end bank_trx#book;
end bank_trx#;
Subtypes
Before I illustrate the implementation of the dynamic dispatch, I will introduce the payment transaction subtype. As with the UDT implementation, the subtype in form of a package contains a constructor and its specialized implementation of the procedure book. Here is the code for the subtype:
create or replace package body pay_trx#
is
function pay_trx#new(
i_amount number
) return bank_trx#.t_bank_trx
is
begin
if nvl(i_amount, -1) < 0 then
raise_application_error(-20000, 'Negative amount'),
end if;
return bank_trx#.bank_trx#new(
i_bank_trx_type_id => bank_trx_type#.c_pay_trx
,i_amount => i_amount
);
end pay_trx#new;
------------------------------------------------------------------------------
procedure bank_trx#book(
i_bank_trx bank_trx#.t_bank_trx
,i_text varchar2
)
is
begin
dbms_output.put_line('Booking t_pay_trx "' || i_text || '" with amount '
|| bank_trx#.bank_trx#amount(i_bank_trx));
end bank_trx#book;
end pay_trx#;
The package body pay_trx# references the list of banking transaction subtypes. The constant declaration package bank_trx_type# can be hand coded or generated.
create or replace package bank_trx_type#
is
-- LIST OF SUBTYPES OF BANKING TRX. HAS NO BODY. --
c_pay_trx constant bank_trx#.t_bank_trx_type := 1;
end bank_trx_type#;
Dynamic Dispatch
UDTs natively support dynamic dispatch. With objects as records, you need to implement dynamic dispatch yourself. This can be done with dynamic SQL or a static dispatcher.
Dynamic Dispatch with Dynamic SQL
The statement to be invoked for bank_trx#book for each type of bank transaction is stored in a table.
SQL> create table bank_trx_dsp(
2 method_name varchar2(30)
3 ,bank_trx_type_id number(9)
4 ,stmt varchar2(200)
5 ,primary key(method_name, bank_trx_type_id)
6 ) organization index;
Table created.
SQL> begin
2 insert into bank_trx_dsp(
3 method_name
4 ,bank_trx_type_id
5 ,stmt
6 ) values (
7 'bank_trx#book'
8 ,bank_trx_type#.c_pay_trx
9 ,'begin pay_trx#.bank_trx#book(i_bank_trx => :1, i_text => :2); end;'
10 );
11 commit;
12 end;
13 /
PL/SQL procedure successfully completed.
The implementation of the procedure bank_trx#.bank_trx#book executes the correct dynamic SQL based on the bank_trx_type_id:
procedure bank_trx#book(
i_bank_trx t_bank_trx
,i_text varchar2
)
is
l_stmt bank_trx_dsp.stmt%type;
begin
select stmt
into l_stmt
from bank_trx_dsp
where method_name = 'bank_trx#book'
and bank_trx_type_id = b_bank_trx_list(i_bank_trx).bank_trx_type_id;
execute immediate l_stmt
using i_bank_trx, i_text;
end bank_trx#book;
With all pieces in place, I can create and book a payment transaction.
SQL> declare
2 l_my_payment bank_trx#.t_bank_trx;
3 begin
4 l_my_payment := pay_trx#.pay_trx#new(100);
5 bank_trx#.bank_trx#book(l_my_payment, 'payroll'),
6 end;
7 /
Booking t_pay_trx "payroll" with amount 100
PL/SQL procedure successfully completed.
The call with dynamic SQL is slower and less scalable than a static PL/SQL call. Thanks to single statement caching in 10g and newer, the differences are small if every session uses mostly one type of banking transactions. Another difference to the static call is that if a dynamic call returns an exception, a rollback is performed to the savepoint set implicitly before the call.
Dynamic Dispatch with a Static Dispatcher
A static dispatcher in form of an if statement is the alternative to dynamic SQL. Such a dispatcher can be generated from metadata or coded by hand. The procedure bank_trx#.bank_trx#book calls the dispatcher with the type of the transaction.
procedure bank_trx#book(
i_bank_trx t_bank_trx
,i_text varchar2
)
is
begin
bank_trx_dsp#.bank_trx#book(
i_bank_trx => i_bank_trx
,i_bank_trx_type_id => b_bank_trx_list(i_bank_trx).bank_trx_type_id
,i_text => i_text
);
end bank_trx#book;
The dispatcher, of which I only show the body, simply calls the correct implementation based on the type.
create or replace package body bank_trx_dsp#
is
procedure bank_trx#book(
i_bank_trx bank_trx#.t_bank_trx
,i_bank_trx_type_id bank_trx#.t_bank_trx_type
,i_text varchar2
)
is
begin
if i_bank_trx_type_id = bank_trx_type#.c_pay_trx then
pay_trx#.bank_trx#book(
i_bank_trx => i_bank_trx
,i_text => i_text
);
else
raise_application_error(-20000, 'Unknown bank_trx_type_id: ' || i_bank_trx_type_id);
end if;
end bank_trx#book;
end bank_trx_dsp#;
If there are very many subtypes, the if statement in the dispatcher has many branches. A binary search with nested if statements provides the best runtime performance in this case. If the dispatcher is coded by hand, it can be implemented in bank_trx# instead of a separate package.
Additional Attributes and Methods in Subtypes
If payment transactions require additional methods not present in general banking transactions, I just add them to the package pay_trx#. If payment transactions require an additional attribute (say, a settlement type), I create a corresponding record type and associative array in the body of pay_trx#, show in bold here:
create or replace package body pay_trx#
is
type t_pay_trx_rec is record (
settle_type_id t_settle_type
);
type t_pay_trx_tab is table of t_pay_trx_rec index by bank_trx#.t_bank_trx;
b_pay_trx_list t_pay_trx_tab;
function pay_trx#new(
i_amount number
,i_settle_type_id t_settle_type
) return bank_trx#.t_bank_trx
is
l_idx bank_trx#.t_bank_trx;
begin
if nvl(i_amount, -1) < 0 then
raise_application_error(-20000, 'Negative amount'),
end if;
l_idx := bank_trx#.bank_trx#new(
i_bank_trx_type_id => bank_trx_type#.c_pay_trx
,i_amount => i_amount
);
b_pay_trx_list(l_idx).settle_type_id := i_settle_type_id;
return l_idx;
end pay_trx#new;
To free the additional state I also need bank_trx#.bank_trx#remv to call a remove method in pay_trx# through the dispatcher.
Persistence of Objects as Records
To persist banking transactions implemented in memory with the record approach, I create a plain vanilla table with the respective columns.
create table bank_trx(
id integer
,bank_trx_type_id integer
,amount number
,constraint bank_trx#p primary key(id)
);
The additional attributes of subtypes, such as the settlement type of payment transactions, can be stored in supplementary tables.
create table pay_trx(
bank_trx_id integer
,settle_type_id integer
,constraint pay_trx#p primary key(bank_trx_id)
,constraint pay_trx#f#1 foreign key(bank_trx_id) references bank_trx(id)
);
The disadvantage of this approach is that multiple tables must be accessed. Alternatively, you can store the additional fields in the base table, a fine solution if there are few fields and you don't mind the conceptual ugliness. A third approach is to get rid of the base table bank_trx and store all attributes in pay_trx. The disadvantages of this form of object-relational mapping are two-fold: you have to create a union-all view over all subtypes to find a transaction if you know only its ID, and Oracle cannot enforce unique IDs over all types of transactions stored in multiple tables using a simple primary key constraint.
Assessment
The good news is that it is possible to do object-oriented programming in PL/SQL as well as in C and most other procedural programming languages. The bad news is that getting all the features requires some additional glue code. Fortunately, the glue code may largely be generated.
If an application requires only a handful of type hierarchies and if they are just a few levels deep, PL/SQL is suitable. If, on the other hand, hundreds of different types with subtypes are required, I'd look for a different solution. The Avaloq Banking System described at the beginning of this chapter has two type hierarchies: banking transactions and static data objects. Each hierarchy has only two levels: a base type and hundreds of subtypes. In addition, there are dozens of standalone types without any subtypes. For these standalone types, no dispatchers are required, resulting in an implementation as simple as in an object-oriented language.
Memory Management
Large programs commonly require lots of memory, whether objects are stored in collections as described earlier or whether other patterns are used. Therefore, you need to know how to measure memory usage to detect problems, such as memory leaks. Collections consume most of the PL/SQL memory; therefore you need to understand how they allocate memory.
Most large PL/SQL applications use dedicated rather than shared server processes. Therefore, I focus on dedicated server processes and ignore shared server processes, in which the UGA (and, therefore, most PL/SQL memory) resides in the SGA.
![]() Note With PL/SQL variables you can allocate more memory than defined by pga_aggregate_target, which specifies the target aggregate PGA memory available to all server processes attached to the instance. PL/SQL memory is considered untunable. Oracle simply allocates memory as requested as long as the OS provides it.
Note With PL/SQL variables you can allocate more memory than defined by pga_aggregate_target, which specifies the target aggregate PGA memory available to all server processes attached to the instance. PL/SQL memory is considered untunable. Oracle simply allocates memory as requested as long as the OS provides it.
Measuring Memory Usage
There are multiple ways to measure the memory usage of processes, corresponding one-to-one to connections and in most cases also sessions. The view v$process is often used as a starting point.
SQL> select se.sid
2 ,se.username
3 ,round(pr.pga_used_mem / power(1024, 2)) pga_used_mb
4 ,round(pr.pga_alloc_mem / power(1024, 2)) pga_alloc_mb
5 ,round(pr.pga_freeable_mem / power(1024, 2)) pga_freeable_mb
6 ,round(pr.pga_max_mem / power(1024, 2)) pga_max_mb
7 from v$session se
8 ,v$process pr
9 where se.paddr = pr.addr
10 and se.type != 'BACKGROUND'
11 order by pr.pga_alloc_mem desc;
SID USERNAME PGA_USED_MB PGA_ALLOC_MB PGA_FREEABLE_MB PGA_MAX_MB
----- -------- ----------- ------------ --------------- ----------
173 K 35 39 3 39
91 K 16 28 10 28
50 K 19 23 3 24
376 K 13 13 0 13
The first three memory figures denote the currently used, allocated, and freeable memory, where used plus freeable roughly equals allocated. The column pga_max_mem returns the maximum size the process ever had. Note that your system may show slightly different values for all experiments in this section as memory usage depends upon the exact Oracle release and operating system.
The view v$process_memory, introduced in 10g but buggy prior to 11g, provides a drill-down. I illustrate this with a procedure that prints the current memory usage of the session.
create or replace procedure print_session_mem
is
begin
dbms_output.put_line('Category Allocated KB Used KB Max all KB'),
dbms_output.put_line('----------------------------------------------'),
for c in (
select pm.*
from v$session se
,v$process pr
,v$process_memory pm
where se.sid = sys_context('userenv', 'sid')
and se.paddr = pr.addr
and pr.pid = pm.pid
) loop
dbms_output.put_line(rpad(c.category, 10)
|| to_char(round(c.allocated / 1024), '999G999G999')
|| to_char(round(c.used / 1024), '999G999G999')
|| to_char(round(c.max_allocated / 1024), '999G999G999'));
end loop;
end print_session_mem;
I then print the initial memory usage.
SQL> set serveroutput on
SQL> exec print_session_mem
Category Allocated KB Used KB Max all KB
----------------------------------------------
SQL 44 38 44
PL/SQL 38 33 38
Other 982 982
PL/SQL procedure successfully completed.
To allocate memory, I create a package with a global associative array.
create or replace package mem#
is
type t_char1000_tab is table of varchar2(1000) index by pls_integer;
g_list t_char1000_tab;
end mem#;
Next, I fill the global variable with data and print the memory usage again.
SQL> begin
2 select lpad('x', 1000, 'x')
3 bulk collect into mem#.g_list
4 from dual
5 connect by level <= 100000;
6 end;
7 /
PL/SQL procedure successfully completed.
SQL> exec print_session_mem
Category Allocated KB Used KB Max all KB
----------------------------------------------
SQL 58 46 4,782
PL/SQL 114,052 113,766 114,056
Other 7,594 7,594
PL/SQL procedure successfully completed.
The PL/SQL memory usage jumped from 33 KB to 113,766 KB. The category Other, which contains miscellaneous structures, also increased. Next, I delete the associative array and measure the memory usage once more.
SQL> exec mem#.g_list.delete
PL/SQL procedure successfully completed.
SQL> exec print_session_mem
Category Allocated KB Used KB Max all KB
----------------------------------------------
SQL 58 45 4,782
PL/SQL 114,060 45 114,060
Other 7,586 7,586
PL/SQL procedure successfully completed.
The used PL/SQL memory decreased almost back to the initial value. The allocated memory stayed the same. Freeable memory can be returned to the operating system by calling the procedure dbms_session.free_unused_user_memory in the session. Because of the cost of deallocation and allocation, it should not be called too frequently.
SQL> exec dbms_session.free_unused_user_memory
PL/SQL procedure successfully completed.
SQL> exec print_session_mem
Category Allocated KB Used KB Max all KB
----------------------------------------------
SQL 50 37 4,782
PL/SQL 58 49 114,068
Freeable 1,024 0
Other 1,084 1,830
PL/SQL procedure successfully completed.
The view v$process_memory_detail provides even more detail for a single process at a time. A snapshot is created by executing alter session set events 'immediate trace name pga_detail_get level <pid>', where pid is obtained from v$process. The usefulness of v$process_memory_detail for PL/SQL developers is limited, because the returned heap names are not fully documented and because the breakdown is not by PL/SQL type or compilation unit. A detailed description is given in MOS Notes 822527.1 and 1278457.1.
The procedure dbms_session.get_package_memory_utilization, introduced in 10.2.0.5 and 11gR1, allows you to drill down to the PL/SQL units using the memory. This is perfect for finding memory leaks. This example shows the memory utilization after filling mem#.g_list:
SQL> declare
2 l_owner_names dbms_session.lname_array;
3 l_unit_names dbms_session.lname_array;
4 l_unit_types dbms_session.integer_array;
5 l_used_amounts dbms_session.integer_array;
6 l_free_amounts dbms_session.integer_array;
7 begin
8 dbms_session.get_package_memory_utilization(
9 owner_names => l_owner_names
10 ,unit_names => l_unit_names
11 ,unit_types => l_unit_types
12 ,used_amounts => l_used_amounts
13 ,free_amounts => l_free_amounts
14 );
15 for i in 1..l_owner_names.count loop
16 dbms_output.put_line(
17 case l_unit_types(i)
18 when 7 then 'PROCEDURE '
19 when 8 then 'FUNCTION '
20 when 9 then 'PACKAGE '
21 when 11 then 'PACKAGE BODY'
22 else 'TYPE ' || lpad(l_unit_types(i), 3)
23 end || ' '
24 || rpad(l_owner_names(i) || '.' || l_unit_names(i), 26)
25 || ' uses ' || to_char(round(l_used_amounts(i) / 1024), '999G999G999')
26 || ' KB and has ' || to_char(round(l_free_amounts(i) / 1024), '999G999G999')
27 || ' KB free.'),
28 end loop;
29 end;
30 /
PACKAGE BODY SYS.DBMS_SESSION uses 2 KB and has 1 KB free.
PACKAGE SYS.DBMS_SESSION uses 0 KB and has 1 KB free.
PACKAGE BODY SYS.DBMS_OUTPUT uses 2 KB and has 1 KB free.
PACKAGE SYS.DBMS_OUTPUT uses 0 KB and has 1 KB free.
PACKAGE K.MEM# uses 108,035 KB and has 5,414 KB free.
PACKAGE BODY SYS.DBMS_APPLICATION_INFO uses 1 KB and has 0 KB free.
PACKAGE SYS.DBMS_APPLICATION_INFO uses 0 KB and has 1 KB free.
PL/SQL procedure successfully completed.
The downside is that the procedure can analyze the memory usage of only the session it runs in.
The hierarchical profiler dbms_hprof provides an undocumented method for profiling memory allocation and deallocation in 11g. The procedure start_profiling has two new parameters, profile_pga and profile_uga. The following example shows how the latter can be used:
SQL> create or replace directory hprof_dir as '/tmp';
Directory created.
SQL> begin
2 dbms_hprof.start_profiling(
3 location => 'HPROF_DIR'
4 ,filename => 'hprofuga'
5 ,profile_uga => true
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
SQL> declare
2 procedure alloc
3 is
4 begin
5 select lpad('x', 1000, 'x')
6 bulk collect into mem#.g_list
7 from dual
8 connect by level < 100000;
9 end alloc;
10 procedure dealloc
11 is
12 begin
13 mem#.g_list.delete;
14 dbms_session.free_unused_user_memory;
15 end dealloc;
16 begin
17 alloc;
18 dealloc;
19 end;
20 /
PL/SQL procedure successfully completed.
SQL> exec dbms_hprof.stop_profiling
PL/SQL procedure successfully completed.
To analyze the generated profile, you can either use the same undocumented parameters in DBMS_HPROF.ANALYZE (which stores the byte output in the _TIME columns of DBMSHP_PARENT_CHILD_INFO) or pass the parameter -pga or -uga to plshprof.
oracle@af230d:af230d > $ORACLE_HOME/bin/plshprof -uga -output hprofuga hprofuga
PLSHPROF: Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production
[10 symbols processed]
[Report written to 'hprofuga.html']
This produces a HTML report, as shown in Figure 11-5.
Figure 11-5. UGA allocation and deallocation memory profile
The profile shows allocation and deallocation of memory for the UGA rather than allocation and deallocation within the UGA. Comparable information can be gathered by tracing OS calls with truss or similar utilities. Remember that this usage of the hierarchical profiler is undocumented and not supported by Oracle.
I have seen several cases where the memory reported by Oracle's dynamic performance views did not correspond to the figures reported by the OS. If you experience memory issues, it's always worthwhile to check on the OS as well. Help for analyzing out of process memory error can be found in MOS Notes 1088267.1 and 396940.1.
Historic PGA and UGA snapshot values of V$SYSSTAT and V$SESSTAT can be found in the workload repository and in Statspack views DBA_HIST_SYSSTAT, PERFSTAT.STATS$SESSTAT, and PERFSTAT.STATS$SYSSTAT. In my experience, this information is insufficient to analyze problems. Therefore, it is worthwhile to check the memory usage of long-running processes in an outer loop and log detailed information if a specified threshold is exceeded. If possible, processes should periodically restart themselves to recover from memory leaks and unreleased locks.
Collections
Because collections usually consume the majority of the PL/SQL memory, it is important to understand how memory is allocated for them and how to reduce their footprint. Oracle does not document the implementation of collections to allow for modifications in future releases. Therefore, you must measure the memory allocation yourself and be aware that information gathered this way may be rendered obsolete by a future Oracle release.
Many data types use up to double the space on 64bit versions of Oracle as compared to the 32bit versions. My measurements were made on Solaris 10 x86-64.
I illustrate the following points that may be relevant for your coding with associative arrays indexed by pls_integer:
- Associative arrays have an overhead of roughly 27 bytes for the key. This overhead is significant for an array of pls_integer or Boolean, but not for a larger payload (such as a complex record or a large string). In most cases it is better in terms of memory usage, performance, and conceptual clarity to use an associative array of a record instead of several associative arrays of basic types as in dbms_session.get_package_memory_utilization. With out-of-line allocation of the payload, the total overhead per element may be significantly larger than the 30 bytes for the key.
- Space for roughly 20 consecutive indices is allocated at once. Thus, in terms of memory usage and performance, it is better to use consecutive indices.
- As of 11.2.0.2, memory is freed for other usage or returned to the OS only upon deletion of the last element of an array. This holds true for the keys and small payloads stored inline. Memory for large payloads that are stored out of line is usually freed immediately.
- There may be a benefit in defining elements, such as varchar2, only as large as needed to avoid overallocation.
Associative arrays indexed by varchar2 differ in all but the last point. The overhead of the key is larger and depends on the actual length of the string. Space is allocated for only one element at a time and, in some cases, freed immediately upon deletion. Furthermore, arrays indexed by varchar2 are significantly slower than their counterparts indexed by pls_integer.
In terms of memory usage and performance, there is no benefit in using other collection types (namely varrays and nested tables).
So let me prove the above claims with the following procedure. I use conditional compilation to vary the length of the strings in the collection and to use the procedure with different collection types.
create or replace procedure coll_mem_usage(
i_step pls_integer := 1
,i_elem_cnt pls_integer := 1000000
)
is
$IF $$COLL_TYPE = 0 $THEN
type t_char_tab is table of varchar2($$string_len) index by pls_integer;
$ELSIF $$COLL_TYPE = 1 $THEN
type t_char_tab is table of varchar2($$string_len) index by varchar2(10);
$ELSIF $$COLL_TYPE = 2 $THEN
type t_char_tab is table of varchar2($$string_len);
$ELSIF $$COLL_TYPE = 3 $THEN
type t_char_tab is varray(2147483647) of varchar2($$string_len);
$END
c_string_len constant pls_integer := $$string_len;
l_str constant varchar2($$string_len) := lpad('x', c_string_len, 'x'),
l_list t_char_tab;
------------------------------------------------------------------------------
procedure print_plsql_used_session_mem(
i_label varchar2
)
is
l_used number;
begin
$IF DBMS_DB_VERSION.VERSION < 11 $THEN
select pr.pga_used_mem
$ELSE
select pm.used
$END
into l_used
from v$session se
,v$process pr
,v$process_memory pm
where se.sid = sys_context('userenv', 'sid')
and se.paddr = pr.addr
and pr.pid = pm.pid
and pm.category = 'PL/SQL';
dbms_output.put_line(rpad(i_label, 18) || ' PL/SQL used '
|| to_char(round(l_used / 1024), '999G999G999') || ' KB'),
end print_plsql_used_session_mem;
begin
-- INIT --
dbms_output.put_line(i_elem_cnt || ' elements of length ' || c_string_len || ' step '
|| i_step || ' type ' || $$coll_type);
print_plsql_used_session_mem('Init'),
-- ALLOCATE ELEMENTS --
$IF $$COLL_TYPE = 2 OR $$COLL_TYPE = 3 $THEN /* NESTED TABLE, VARRAY */
l_list := t_char_tab();
l_list.extend(i_elem_cnt * i_step);
$END
for i in 1..i_elem_cnt loop
l_list(i * i_step) := l_str;
end loop;
print_plsql_used_session_mem('Allocated'),
-- REMOVE ALL BUT 1 ELEMENT --
for i in 2..i_elem_cnt loop
$IF $$COLL_TYPE != 3 $THEN /* ASSOCIATIVE ARRAYS, NESTED TABLE */
l_list.delete(i * i_step);
$ELSE /* NO SINGLE ELEMENT DELETE IN VARRAY */
l_list(i * i_step) := null;
$END
end loop;
print_plsql_used_session_mem('1 element left'),
-- ADD ANOTHER c_element_cnt ELEMENTS --
$IF $$COLL_TYPE = 2 OR $$COLL_TYPE = 3 $THEN /* NESTED TABLE, VARRAY */
l_list.extend(i_elem_cnt * i_step);
$END
for i in (i_elem_cnt + 1)..(2 * i_elem_cnt) loop
l_list(i * i_step) := l_str;
end loop;
print_plsql_used_session_mem('Allocated on top'),
-- DELETE ALL --
l_list.delete;
print_plsql_used_session_mem('All deleted'),
end coll_mem_usage;
The procedure is invalid upon creation. It needs to be compiled with valid conditional compilation flags, such as collection type “associative array index by pls_integer”, denoted by coll_type equal to 0, and string_len 10.
SQL> alter procedure coll_mem_usage compile plsql_ccflags='coll_type:0,string_len:10';
Procedure altered.
The valid procedure can be executed.
SQL> exec coll_mem_usage
1000000 elements of length 10 step 1 type 0
Init PL/SQL used 0 KB
Allocated PL/SQL used 36,144 KB
1 element left PL/SQL used 36,144 KB
Allocated on top PL/SQL used 72,272 KB
All deleted PL/SQL used 16 KB
PL/SQL procedure successfully completed.
This output shows that the overhead for the key is 27 bytes. 36,144 KB divided by 1,000,000 entries gives 37 bytes per entry, of which 10 bytes are used by the string array element. Deleting all but one element doesn't free up any space, as shown by the column “1 element left” being unchanged from the column “Allocated.” New elements cannot reuse the space of deleted elements, as show by “Allocated on top” doubling the used memory.
Table 11-2 summarizes the results of running the procedure with different parameters. The second row shows that by using only every tenth index, ten times as much memory is used. Increasing the step further would show that space for about twenty consecutive elements is allocated at once.
With a string length of 100, the strings are allocated out of line and the freed memory of the strings, but not the indices, can be reused as shown on the third row. In this case, there is an overhead and alignment loss of 37 bytes per entry for the out-of-line storage.
For consecutive indices, associative arrays indexed by varchar2 are six times slower and use more than double the memory than their pls_integer counterparts. On the other hand, their memory usage is independent of the step.
The memory usage and performance of nested table and varrays is roughly the same as for associative arrays index by pls_integer.

Summary
Business logic of data-centric applications belongs in the database. This claim is supported by both technical reasons and successful practical examples. There are plenty of technical benefits for this practice, such as simplicity of the design, high performance, and increased security. Furthermore, many concrete examples of ERP systems that use this design have been successful for many years, and new systems are built based on this design.
Business logic in PL/SQL in the database leads to a large PL/SQL code base. Naturally, the question arises of how to deliver to users an initial version that meets time, budget, and external product quality parameters and that can be maintained in the future. On an abstract level, the answers are the same for any architecture. The concrete implementation in PL/SQL is unique in four areas that I covered in this chapter.
- Uniformity allows developers to understand each other’s code more quickly and thoroughly. Uniformity is more important than the concrete convention. Still, there are good reasons to incorporate certain aspects into your PL/SQL coding conventions.
- Modularization is the foundation for scalability of the development team and maintainability of an application. Modularization brings the benefits of divide and conquer to software engineering. PL/SQL provides strong modularization constructs in the form of subprograms, packages, and schemas as well as excellent analysis capabilities based on dependency views and PL/Scope.
- Object-oriented programming allows for increased reuse, which is key to reducing cost and time to market and improving quality in programming in the large. Whereas reuse as-is has a limited applicability, reuse with adaptations as provided by object-oriented programming enables reuse in more cases. PL/SQL is not an object-oriented language but can be used to program in an object-oriented way via the set of described patterns.
- The memory requirements of large applications must be measured and optimized using the described techniques. There are many good resources on design for scalability and performance, including several chapters of this book.