
Chapter 7. Managing flow
- What continuous flow is and why you want it
- Eliminating waste to achieve flow
- Managing flow with kanban
- Using daily standups to help the work flow
- Choosing what to work on next
- Managing bottlenecks using the Theory of Constraints
Flow, or rather one-piece continuous flow, has been the cornerstone in Toyota’s[1] production vision for decades. A one-piece continuous flow is a system in which each part of work that creates value for the customer moves from one value-adding step in the process directly to the next, and so on until it reaches the customer, without any waiting time or batching between those steps. Instead of building up inventories just in case, things are produced only when needed, just in time—at the right place and in the right quantity: no more, no less.
1 Toyota is the company that pioneered the Toyota Production System (TPS), which Lean is based on.

This continuous flow turns every process into a tightly linked chain in which everything is connected. There is nowhere for a problem to hide, no inventory of other work or products to work on if something stops or breaks; so when things break, you immediately know what’s happened, and you’re forced to solve the problem together. It forces people to think, and through this they become better team members and people.
In this chapter, we’ll take a closer look at the benefits of the flow approach to organizing your work. You’ll learn about waste elimination and cycle time, but also how to actually manage the flow by keeping the work moving and by using models such as the Theory of Constraints to improve your process. We’ll take a look at some common practices that can help you focus and improve the flow in your process, such as reducing waiting time, removing blockers, and using cross-functional teams. There are some practices that many teams use that can further help you focus on flow, such as daily standups and policies around what to work on next; we’ll check into those as well.
But let’s start at the beginning and see why flow is something that’s worth striving for and focusing your attention on.
7.1. Why flow?

Toyota is by no means the only, or even the first, company to chase the continuous-flow ideal. People and companies have been striving toward this vision for centuries. And why wouldn’t they? If one-piece continuous flow is achieved, you have no delays, no queues, no batches, no inventory, no waiting. You have no over-production; you only deliver what is actually requested and needed by the customer, and you deliver it immediately when it’s needed.
You’ve seen in previous chapters that this gives you flexibility and responsiveness, better risk management, faster feedback leading to improved quality (building the right thing and building it right), increased predictability leading to increased trust, fewer expedite requests, and faster continuous delivery of value.
As if that isn’t enough, flow also exposes improvement opportunities and provides you with a vision for your improvement efforts: faster flow.
What can you do to get a faster flow, then? Let’s look at a strategy that has helped Toyota for a long time: eliminating waste.
7.1.1. Eliminating waste
Toyota has spent more time perfecting, and has come closer to the vision of, one-piece continuous flow than any other company. An important part of that journey has been a focus on eliminating waste.

All we are doing is looking at the time line from the moment the customer gives us an order to the point when we collect the cash. And we are reducing that time line by removing the non-value-added wastes.
Taiichi Ohno[2]
2 Taiichi Ohno, Toyota Production System: Beyond Large-Scale Production (Productivity Press, 1988, http://amzn.com/0915299143), p. ix.
Another way of expressing this is to ask, “What’s stopping the work from flowing?” Applying this perspective, you examine your processes from the customer’s point of view. What does the customer want from this process? The customer can be the end customer or the internal customer in the next phase of production. What the customer wants has value. Everything else is waste. Some steps in a process add value, others don’t. This is true for all processes.
Early on, Toyota identified seven categories of waste that applied to manufacturing; and later the company applied the same thinking to other areas, such as product development. Different industries have since then made similar categories of waste for their particular contexts. Mary and Tom Poppendieck did this for software development through their seminal works Lean Software Development: An Agile Toolkit (Addison-Wesley Professional, 2003) and Implementing Lean Software Development: From Concept to Cash (Addison-Wesley Professional, 2006).
7.1.2. The seven wastes of software development
Let’s take a closer look at the seven different kinds of wastes that Mary and Tom Poppendieck have identified:
- Partially done work— Work that isn’t completely done is in reality just work in process. It lies around waiting for you to complete it and adds to your WIP. See chapter 5 for more on this.
- Extra features— Taiichi Ohno famously said, “There’s no greater waste than overproduction.” A lot of the software being produced in the world isn’t really used or valued by the customer. According to the famous CHAOS report performed by The Standish Group in the early 2000s, 45% of the features of software applications were never used. This suggests that a lot of waste could be avoided with better understanding of what the customer needs: that is, building the right thing. On an individual level, if you’ve ever thought “This may come in handy” or “Maybe they want this to be configurable,” you know what we mean.
- Relearning— Software development is, to a great extent, learning. Failing to remember mistakes you’ve made before and having to redo them (and relearn the solution) is a great waste. This can happen both in teams and for individuals.
- Handoffs— When you hand work from one person to another, a lot of extra work is created in order to convey necessary information to the next person. Even with that extra work, a lot of information will be lost in the handoff.
- Delays— Delays create extra work, remember? No? Go read section 5.2.2, “Delay causes extra work,” without delay.
- Task switching— We talked earlier about context switching (see chapter 5) and the wasteful effect it can have on your focus and capacity.
- Defects— Defects are work that comes back to you because you did something wrong the first time around. Not only does this create extra work, but typically that kind of work comes at a bad time, slowing down the things you’re working on right now. See section 5.2.5, “Lower quality.”
A Word from the Coach

Some people in the kanban community think there has been an unhealthy obsession with waste within Lean software development and that waste is a red herring. According to them, you should instead be focusing on reducing time to delivery and risk management; waste will be identified and removed as a part of this process. We’re not sure we see the conflict, but you should of course avoid unhealthy obsessions and heavily faith-based approaches in general. Part of the confusion comes when people look to see if certain actions are waste.
For example, is a daily standup meeting to coordinate team activities adding value, or is it waste? If it’s a value-adding activity, why don’t you do more of it? Why not just meet all day long? The answer is that the activity in itself isn’t a value-add or waste; it’s the return of time invested (ROTI) to help you improve your understanding or deliver customer value that determines if it’s waste or not.

Eliminating waste and limiting WIP are different ways of achieving flow. But how do you apply these principles in practice to help the work to flow?
7.2. Helping the work to flow
One of the core practices of kanban is to manage the flow of work through each state in the workflow. This means monitoring and measuring how the work flows, but also keeping the work moving. You can take several different approaches to help the work to flow.
7.2.1. Limiting work in process
Limiting WIP is of course an essential practice when it comes to keeping the work moving. The fewer things in process, the faster the work will flow and the more improvement opportunities you’ll discover. You might remember Little’s law, which states that the more WIP you have, the longer the lead time for each item is. You can read much more about this in chapter 5.
Limiting your WIP gives you better flow. But is that what you want? Optimizing for flow is a strategy decision. That decision is a trade-off; to achieve better flow, you might end up with people sitting idle from time to time. Is that acceptable in order to get better flow through your process?
There are types of work and situations for which the opposite is true: you strive to use your resources optimally instead. One example is a mill for aluminum. That kind of equipment operates at extreme heat and takes a long time to heat up. It’s expensive to turn off the mill. You want the melting furnace to be running all the time, and you want to have a lot of material ready for the furnace to handle (lots of WIP). You might even want it running when no customers are waiting for the aluminum. You’re optimizing for resource utilization.
In the other case, optimizing for flow, an example is the fire department. They have a lot of slack (waiting, preparing, and training) in order to be ready to go immediately and put out a fire when it happens. We, as a society, accept that and are paying firefighters to sit idle, because we don’t want them busy when we call and ask them to put out a fire. To optimize for flow, we’re accepting the fact that they’re not busy all the time. That kind of behavior is typically found in high-risk environments.
Optimizing for flow over resource utilization is a strategy decision, but by focusing on flow efficiency you can reduce a lot of superfluous work and waste and actually improve resource efficiency too. In the book This Is Lean: Resolving the Efficiency Paradox (Rheologica, 2012), researchers Niklas Modig and Pär Åhlström define Lean as an operations strategy that aims to increase resource efficiency through focusing on increasing flow efficiency.
7.2.2. Reducing waiting time
Do you have work items sitting in the board’s Done columns, waiting to be pulled to the next state? Are items sitting in states like Waiting to Deploy or Todo? It isn’t unusual to see work spending more time waiting to be worked on than actually being worked on. How can this waiting time be reduced?
If you don’t already have an explicit way of showing that work is done in a particular state and ready for the next, this should be your first step. This makes the waiting visible and signals to others that the work item is ready to be pulled. It also makes it easier to track and measure the amount of time spent in waiting. Collecting this data and analyzing it may give you insight into what can be improved. If you have a hard time convincing others that time is wasted in waiting, measuring it like this can serve as an eye opener.
Do you start the work from scratch, or is it started or prepared somewhere else (what we typically call upstream from the kanban board)? Maybe the work is sitting there, waiting for you to start it. Are you the last people to touch the work before it reaches the customer? In order to reduce waiting time, it’s often necessary to go outside of your own workflow and your kanban board.
Ensuring that work is ready
An excellent way to avoid waiting is to take steps to make sure the work is always ready for the next state. This can be done by planning and breaking work down to minimize dependencies, maybe having external people or resources prepared and standing by so that you don’t get blocked, or designing the work for collaboration so that team members who have finished something can easily chip in on what you’re doing instead of waiting or pulling new work.
Being clear on the expected outcome and making sure it’s communicated clearly to everyone before work starts go a long way toward avoiding misunderstandings and confusion that result in delays and waiting.
One of the best ways to make sure you understand each other is to practice specification by example.[a] This means you write your specification in the form of acceptance criteria or concrete examples (real numbers and real data used) of how a feature will be used. The feature will be complete when the example is fulfilled: nothing more, nothing less.
a Read more in Specification by Example: How Successful Teams Deliver the Right Software, by Gojko Adzic (Manning, 2011, www.manning.com/adzic/).
Sometimes it actually makes sense to increase the amount of WIP in a queue, particularly in front of a bottleneck (see section 7.5.1), in order to avoid unnecessary waiting.
Making the work items smaller and similarly sized
Another way of designing and preparing work to reduce waiting is to make the work items smaller and similarly sized. Smaller work items reduce lead times and lower the amount of WIP. Large work items are often harder to estimate and sometimes hide issues that will be visible once you start breaking them down. Instead of creating a full use case (like buying books, for example) you could try user stories (such as put book into basket, fill out checkout information, and perform checkout).
If you can make the work items more similar in size, you’ll get a more even flow and increased predictability, which in turn can help you build trust and avoid needing to expedite “special requests.” In practice it also removes the cost part of the equation because all work now is of the same cost, at least time-wise.
A great way of reducing waiting is of course to limit WIP: the lower the WIP, the faster you’ll be able to pull work items to the next state. A lot of waiting is caused by being blocked, a kind of waiting that demands a section of its own.
7.2.3. Removing blockers
Blockers belong to a special class of waiting. They’re things that block you but that are outside of your immediate control, such as third-party dependencies, waiting for external code reviews, or waiting for information. In our experience, blockers like these are often accepted as the natural order of things as something “we can’t do anything about,” but more often than not the opposite turns out to be true.

Robert C. Martin, a.k.a. Uncle Bob, the guy who called the meeting that produced the Agile Manifesto, claims that to never be blocked is the prime directive for any agile developer:[a]
a “The Prime Directive of Agile Development,” http://mng.bz/NT5s.
Like a good pool player who always makes sure the shot he is taking sets up the next shot he expects to take, every step a good agile developer takes enables the next step. A good agile developer never takes a step that stops his progress, or the progress of others.
The main idea is that all the areas that interface with other systems should be handled in such a way that you can continue with your work even though the other parties aren’t done with theirs. For coding, for example, this could mean creating an interface to code against for external systems. If the other parties don’t deliver on time, you can always supply your own implementation—a stub or fake as it’s called—and continue to work until the real implementation is completed.
But the prime directive isn’t just for the individual developer:
The prime directive extends to all levels of the team and organization. Never being blocked means you set up your development environment such that blockages don’t happen.... If the core group is building a reusable framework for us, and we need some function that isn’t ready yet, we’ll write it ourselves and use the core team’s function later, when (and if) it arrives. If the enterprise architecture supports our needs in such a convoluted and obtuse way that we’ll have to spend days just understanding, then we’ll avoid the enterprise architecture and get the features working in a simpler way. We won’t be blocked.
For other types of work, you can make sure you do all the work you can to not end up waiting for others.
That you’ve filed a ticket in the support system or sent an email to someone doesn’t mean you’ve done what you can to not be blocked. Could you give them a call, or maybe even walk up to them and talk to them? Did you explain how this is affecting you and how it would help your work advance if you could get assistance? Is there someone else who could solve the problem for you? Maybe there’s a workaround you can live with for now. Try to be creative and find a way to not be blocked.

If you’ve tried everything and still find yourself blocked, avoid starting new work. Picking up new work will increase your WIP and result in a slowdown of all your other work, as you’ll recall from chapter 5. Maybe there is something that you can help finish while you wait to be unblocked. Are there any bottlenecks or other problems in your workflow that you can help to resolve? More on this in section 7.5.1.
You can save some tasks that are useful to do when you’re blocked. Some teams even create special classes of services for this (see chapter 8): that is, special work that you as a team see as important, but that may not be immediately important to other stakeholders. It could be things like upgrading a build server or automating some manual work—things that will improve your future quality and speed. This kind of work can be picked up when you’re blocked and dropped quickly as the blocker is cleared.
A blocker is also an opportunity to learn how you can improve your work. What caused the blocker? Is there anything you could have done to foresee and work around it that you can apply to future situations? Can blockers be avoided completely if you change how you work? Or if someone else changes how they work? Some teams create the habit of always applying root-cause analysis to every blocker or issue that stops the flow, to learn and improve from the root cause of the problem (read more about root-cause analysis in chapter 10).
Tracking blockers
Tracking blockers and how they affect you is often a good start for reducing them. If you put start and end dates on the blockers, or put a dot on their stickies for every day they sit there, you can see how much of a work item’s total cycle time is spent being blocked, just as we suggested with waiting time in the previous section. Use this data to understand how blockers affect you and what you can do about it. The data can also be useful to explain to the people blocking you how it would help you if you were unblocked.
Tracking how the number of blockers varies and what the average time to remove them is can also drive improvement. For more on tracking blockers, see section 11.1.3.
Swarming

A behavior that emerges in many kanban teams is what has been referred to as swarming. The focus on limiting WIP and helping the work flow leads the team to act together when a WIP limit is reached, when a difficult blocker arises, or when a work item is too big, too late, or too complex to be handled by a single person or a few team members. People swarm around the issue to resolve it more quickly[3] and to get back to the normal flow.
3 Of course, sometimes more hands can slow you down rather than help you. The key here is that people are available to help you, like an “all hands on deck” situation. Maybe you don’t need everyone to solve the problem, but for starters everyone is there to help analyze the issue and propose a solution. Implementing the solution might engage only a few people.
Some teams make this an explicit policy when they get blocked, or even when they find a defect. Every time they encounter a blocker or a defect, everyone swarms in to remove it. Swarming can also be a policy assigned to a specific class of service (see chapter 8).
Swarming can also be used to describe the general behavior of working outside your specialization to help high-risk or high-value work get done faster or to reduce the total amount of WIP, a behavior held in high regard by many kanban teams.
7.2.4. Avoiding rework

Sometimes a defect will escape from one state of the workflow, only to be found in a later one. This causes the work item to move backward in the workflow, which increases the cycle time both for that item and for other work items, because it increases the amount of WIP. Avoiding rework can have a big effect on flow and cycle time.
It’s no coincidence that one of the key principles of Lean software development[4] is to build quality in from the start. A good way to accomplish this is to invest in technical practices such as pair programming, test-driven development, continuous integration, and test automation.[5]
4 Coined by Mary and Tom Poppendieck.
5 More on this in the excellent pair of books Clean Code: A Handbook of Agile Software Craftsmanship (Prentice Hall, 2008, http://amzn.com/0132350882) and The Clean Coder: A Code of Conduct for Professional Programmers (Prentice Hall, 2011, http://amzn.com/0137081073) by Robert C. Martin.
Another important practice for building quality in is to minimize the time between introducing and fixing a defect. If the code is tested as soon as it’s developed, and any defects are fixed immediately after they’re found, you’ll save time logging defects and won’t have to spend so much time figuring out where they were introduced. This is of course easier the fewer things you work on at the same time and the smaller they are: that is, if the amount of WIP is low.
Value demand and failure demand
Defects aren’t the only things that cause rework. John Seddon has introduced the concept of failure demand to describe “demand on a system caused by failure to do something or do something right for the customer.”

All requests coming in to your workflow that aren’t requests for new things, but rather requests generated because something isn’t working the way it was expected to, because something is too difficult to understand, because something is missing, and so on, fall into the failure demand category. Examples in software development are faulty design that doesn’t take user experience into account, bad requirements generated without real user involvement or feedback, and rework because of misunderstandings and miscommunication.
You don’t gain much by making failure demand flow faster; instead you want to eliminate as much failure demand as possible to make room for more value demand, which is what you’re (hopefully!) here to produce. Finding out what the customer needs and values and delivering just that also builds quality in.
In the book Freedom from Command and Control: A Better Way to Make the Work Work (Vanguard Consulting Ltd., 2003, http://amzn.com/0954618300), John Seddon tells the story of a call center for which about 40% of calls were questions about invoices.
The failure to create a clear and understandable invoice caused a lot of demand on the system that easily could be avoided. And sure enough—when the company changed the layout and structure of the invoice, the failure demand went down, and the call center got a lot fewer calls in total.
A Word from the Coach
One simple and useful practice is to start tracking and visualizing the failure demand. This can be done by putting a little red dot on each sticky that represents failure demand as it enters the board. When it exits the board, you can do a root-cause analysis (see chapter 10) on how to avoid that in the future.
7.2.5. Cross-functional teams
A cross-functional team is a team with different functional specialties or multidisciplinary skills. When a team has all the skills and resources needed to fulfill the requests put to it, it’s said to be truly cross-functional. This means it’s less dependent on handoffs with other teams and less likely to be waiting for others or to be blocked. If, for example, a product owner or business analyst is on the team, what to build can be decided just in time instead of work not being ready or work to be done piling up; if the team is skilled in both coding and testing, code won’t have to be handed over to someone else to be tested.
Striving to make teams cross-functional helps reduce waiting, makes avoiding and removing blockers easier, and can help avoid rework. It’s also likely to reduce WIP. In other words, it’s a great way to make work flow faster.
When we think about cross-functional teams, one in particular stands out: The A-Team!
This has to be the best cross-functional team ever assembled. They have all the skills for any job:
- The leader and the brains of any operation: Colonel John “Hannibal” Smith
- Mr. Good Looking: Lieutenant Templeton “Face” Peck
- The muscle: Bosco “B.A.” Baracus
- And finally, what every good team needs: a mad helicopter pilot, Captain “Howlin’ Mad” Murdock

Although they’re all specialists in their own fields, they always end up working together to solve the tasks at hand.
Feature teams vs. component teams
A common way to organize a cross-functional team is to make it responsible for a feature. Some refer to this as a feature team. The team takes responsibility for a certain feature from start to finish. To complete a feature, the team might need to do a vertical slice of the complete system, touching all the parts of the system and, therefore, needing to have a mix of competencies within the team in order to be able to complete the feature.
Consider, as a contrast, a component team that creates just the data-access layer or just the user-interface layer. When structuring teams like this, you run the risk of having teams waiting for each other to be able to complete features. A complete feature might involve several teams: the UI team, the business-logic team, and the data-layer team. If any of them are late, the complete feature is delayed. Information is lost, and miscommunication happens in handoffs between teams. Hence it’s a greater risk to the overall schedule and quality of the result.
A Word from the Coach
One giant project organization map that Marcus briefly looked at had about 250 people layered in a big five-level-deep hierarchical map. The teams at the lowest level were called things like Integration, Data Access, UI Mobile, and so on. From this it was easy to conclude that the project (which was running well into the second year already) was set up in a way that no one could be done until all the teams were done. The slowest team was dictating the speed for the whole project—just by virtue of the project’s organization.
Organizing your teams by feature sits well with a kanban flow and can even be visualized on a common board as separate swim lanes.
7.2.6. SLA or lead-time target
Some teams find that their service-level agreements (SLAs) give them a clear target to strive toward, and other teams like to set a target themselves—for example, average lead time (or why not a little less?)—to track their progress against. This helps foster a mindset that time is of the essence, to flow the work faster. It can also give you the benefits of timeboxing.
Timeboxing is a simple technique that is used in many agile software development methods to manage risk and to focus on doing the things that matter most first. These methods often use iterations of a set length (for example, two weeks) to plan and review work. When the size of the team and the time allotted are both fixed, scope needs to be flexible, and you have to prioritize and build the most important things first. See chapter 9 for more on using iterations with kanban.
Using a timebox also makes you aware of how much time you’re spending on a task and helps you avoid gold plating: continuing to work on a task past the point where the extra effort is worth the value it adds.

7.3. Daily standup
One way to help the work to flow is to talk about, and do something about, the problems that hinder the work to flow—daily, or even more often. The daily standup meeting (a.k.a. morning meeting, daily, morning call, or standup) was made popular in the software development community in the early agile years with methods such as Scrum and XP. Scrum has the daily standup as a core meeting that’s called Daily Scrum. We think that a daily standup meeting is a great tool to get everyone in the team up to date with the current situation in the team and the status of your work.
Just because the agile methods we mentioned made this practice popular doesn’t mean it’s only when using those methods that a daily standup can prove useful. Many teams use some sort of daily standup even when not using agile methods. It’s one of those practices that just seems to make sense to everyone. Together with visualizing your workflow on a board, it’s probably the practice that many teams get the most immediate effect from when they start using it.
7.3.1. Common good practices around standups
Running a daily standup doesn’t take much; running a good daily standup is harder. But in a great standup, you can help the work to flow more smoothly and handle things like blockers and other problems that hinder flow. There are a few general tips on how to succeed with standups, and in this section we check out a few of them.
A standup is short

Keep the meeting short; 5–15 minutes seems to be the norm. A short timeboxed meeting pushes you into talking about what is important and makes you think about what can be discussed elsewhere. The exact time limit isn’t what’s important; keeping the meeting focused and the energy up is.
The “standup” in standup meetings is there for this reason. You stand up to keep the meeting short and energized rather than yet another status report in the conference room. Stand next to your visualized workflow (your board) to be able to see and talk about your items (more on this later).
A standup starts (and ends) on time
Keeping the meeting short also means it needs to start on time. There are all kinds of ways to try to get people to be on time,[6] but for most teams this doesn’t seem to be a problem as long as the things that are discussed in the meeting are important and engaging.
6 Including fines, people standing silently to wait for latecomers, and other things that feel pretty awkward when you think about it. We’re most likely dealing with adults; why not talk about the pros and cons of coming on time and pick a time that suits everyone, instead?

How you get the meeting to start on time will probably vary in different organizations. For some teams, just deciding on a time is all that’s needed; but others might need a booking in the calendar system to make sure the time slot isn’t taken for other meetings.
A standup is focused
Make sure you talk about things that are important for the team attending the meeting. If a discussion starts to drag and it’s only engaging two people, kindly ask them to continue after the daily standup.
There’s no point in having a person stand around waiting for others to talk about things that aren’t interesting. Make sure your precious time together is well invested for everyone who comes to the meeting.

A standup is regular
Conduct the standup at the same time and the same place every day. This creates a rhythm to the day and will soon be second nature to the team.

Many teams start their days with a daily standup (it’s often referred to as a morning meeting) because it gives a good and focused start to the day, but that’s not mandatory. Run the standup at a time that feels appropriate for all team members.
We think starting the day by getting together and checking what’s up is great, but you might disagree. Ask the team.

7.3.2. Kanban practices around daily standups
As kanban teams have started to practice standups, a few practices or ideas have emerged that differ from how standups traditionally have been done.
Focus on the baton—not the runners
The first thing that often differentiates a daily standup in a kanban team from other standup meetings is that a kanban team tends to focus on the work on the board rather than on the individual people in the team.
This can be contrasted with focusing on each person in the team, as in the Scrum practice of letting each person answer “the three questions”:
- What did you do yesterday?
- What are you going to do today?
- Do you have any impediments that hinder you from doing that?
This is a good practice that makes everyone talk at the meeting, and you get a great status overview for each person in the team. But you might miss the opportunity to talk about the work at hand. Maybe there’s one item that’s blocked, and it could be worth spending the entire meeting talking about how to clear it up. Or maybe nothing is blocked, and work is flowing along as expected; then you can close the meeting early and not drag it out more than needed.

Finally and maybe most importantly, the focus isn’t on what individual people have or haven’t done but rather on whether there are any problems in the flow, in your process, or with individual work items. It helps you understand that you’re a team whose members help each other get the work done together.
Walk the board
Kanban teams often enumerate their work from right to left, starting from the Done column and moving upstream. This is to emphasize the pull principle: you’re pulling work to you, pulling features into production, not pushing work over to the next state.

We make sure to honor the good practices around standup meetings and hence keep to our timebox of 15 minutes, for example. This means we might not be able to run through all the work items on the board. By enumerating the work on the board from right to left, this means we might not have time to talk about the far left. This might be OK because that work is also the furthest from being done.
To further increase the focus on progressing the work toward Done, you can ask two questions for each work item:
- What do we need to do to move the work item closer to done?
- Who is going to do it?
If you end up missing part of the board often (the leftmost columns when working from right to left, for example), due to the timebox, you might look into another strategy, such as focusing on things that don’t follow your policies, or things that smell, for example.
Focusing on smells
Many of the visualizations we have talked about in the book help you see when work isn’t behaving as expected, is blocked, or breaks some of your policies. These indicators and visualizations can help you see the work items that are not following your policies—the smells (see the sidebar “Process smells” in chapter 4)—on the board.
Here’s the Kanbaneros board at one daily standup. It has lots of things that don’t follow the visual, explicit policies for the team. Can you spot them all?

Here are the things that the team saw and talked about in their daily standup:
- We have two items in the Urgent lane. Didn’t our policy state that there could be only one in there? What should we do about the second item? Does that urgent item have our full attention?
- In the Done column, Eric is still working on work that is completed. Unless he is still working in a parallel universe, we probably need to talk about that. Is that work done? If not, what kind of work is taking place, and should the sticky be moved? Maybe we’re missing a column like Deploying.
- In the Test column, we have exceeded our WIP limit of two, because we have three items in the column. That might be OK, but in this case the team didn’t notice that it happened. Breaking the WIP limit should at least trigger a discussion: Could Adam help out somewhere else instead of pulling new work? Are we ready to pay the toll of higher WIP? Does this happen a lot? Do we need to change the way we work or maybe change the limit?
- In the Test column, there’s work that has been waiting a long time that no one is working on. This is indicated with dots, one for each day in the Test column. Why is Adam testing other stuff? Is there a blocker we should escalate?
- Take a look at all that work that is ready for test, in the Development/Done column. There’s a bottleneck building up before Test. Maybe it’s better that the developers stop working to put more stuff into that queue and start helping Adam to test instead. Creating a big pile of untested work doesn’t make the untested work any more complete.
- Daphne is hoarding a lot of items in the Development column. Is that OK? Why is she doing that? Will that be a problem? Does she need help?
- In the Analyze column, there’s some sort of Important indicator on the only work item that no one is working on. Why? Is that item important, then? Who will start looking into that? What happens with the other work in that column?
You probably found more as well (we’ve left a few for you to discover), but we hope that we’ve shown that by focusing on the things that deviate from your normal flow, you can spend the daily standup time on the work items that need your attention. The use of visualizations and explicit policies helps you to find these things pretty easily.
7.3.3. Get the most out of your standup
Here are some other things worth considering if you want to get the most out of a daily standup.
Question of conscience
“Is there anything you’re working on that isn’t on the board?” This is a great question to ask each other during a standup meeting. It’s quite easy to have a “little work on the side” that you need to do. This not only takes time from what you were supposed to do, but also has a tendency to become a habit, which in the long run means the board becomes less relevant. Before long you might end up with people having private backlogs and maybe even a private board with their on-the-side tasks. Try to make the board reflect reality as far as possible.

Working on the wrong thing
“Are we working on the most important things right now? How do we know that? Is the prioritization clear?” We often hear of teams working hard on items that might not be the things that are giving the most value right now. This of course has to be balanced with long-term work such as paying off technical debt. One way to handle this is with different classes of service (see chapter 8).
If you start hearing people say that they don’t know what to do next or they feel that they’re working on the wrong things, you might have to revisit the policies around your prioritization. This could be a trigger to make them more explicit; can the prioritization policies be visualized, or can they be clearer?
Not understanding the work
As the board evolves, a lot of policies and enhancements are added to the board with the best of intentions. But after a while, these policies can be hard to understand and see, even for people in the team. For outsiders, the rules to which the work adheres can be difficult to follow.
Try to always find simpler ways to describe your work. Remember that your visualization can also inform others around you who might pass by your board. Would an outsider understand how this works? Do you?
Spontaneous kaizen

Just focusing on smells, deviations, and problems on the board isn’t useful, of course, if you don’t try to do something about them. When the daily standup ends, you’ll sometimes see some people linger around the board, forming groups and starting to talk about the work that you mentioned during the meeting. This has been called spontaneous kaizen by some, as in, spontaneous improvement meetings. The team is starting to discuss and improve their work.
This kind of behavior should be encouraged, and you can trigger discussions and conversations like this by postponing discussions under the standup until afterward. When a couple of people start going off on a tangent during the standup, you could, for example, say
- “Can we meet right after this meeting and talk more?” (See the sidebar “Sticky questions” for one example.)
- “Let’s find a solution for that work item right after this meeting. We’ll do it here at the board.”
- “Could you guys work out a better way to solve that problem after the meeting?”
Offer help, and encourage them to involve the people needed to clear out the problem or improve the situation if they want to.
At Spotify in New York, one team came up with a great way to visualize that a question should be talked about more after the standup. The topic was written down on a small sticky and stuck onto the person who wanted to talk about it. She kept the sticky on her until the discussion was held, which usually took place directly after the meeting.
Another, more formalized way to create a constant improvement focus is to use the Kanban Kata[7] (see chapter 10) in the standups. By using the kata, you get help on how to approach the improvement work and a guide that helps you ask the right questions.
7 Kanban Kata is a way to apply formal steps around doing improvement work to help you make small experiments that guide you toward a better future.
When the team has taken policies and ways of working and made them their own, you’ll often find that the daily standups don’t have many smells like the ones described in this section. The daily standups can then go by pretty quickly, or your focus can change to an improvement mindset, which you can see in section 10.3.

7.3.4. Scaling standups

The daily standup is, as we wrote at the outset of this section, a practice that is easy, often highly appreciated, and rewarding. This is the reason that many teams pick up this practice, even though they might not be doing XP, Scrum, or any named method at all.
A question we have encountered more than once is how to scale daily standups. That is, “We have more than one team working together on the same product or project, and we need a way to coordinate the group of teams as well. How have other teams used kanban to do that?”
Why?
It’s much more difficult to keep a big meeting with a lot of participants short, focused, and energized, especially if it happens daily. That is why the first question you should ask yourself is, “Why do we want to do a multiteam daily standup?” What is the reason for having these meetings? What kinds of problems do you solve with these meetings? What should you not talk about at these meetings?
At one client, Marcus was brought in as they split a big team (about 40 people) into five smaller teams. The big team had met each morning, and hence it felt natural to meet not only in the smaller teams but also in a “Big Daily” with all the teams. All the teams had a lane on the bigger board with copies of their work items underway, often in a coarser form than on their own board.
Pretty soon they realized that they had already talked about status in the smaller teams, so it felt strange to recap that at the Big Daily. Keeping the big board and the local team boards’ statuses in sync became a hassle. They therefore decided to tweak the Big Daily into Daily Sync, in which they only talked about things that needed to be synced around more than one team. They also removed the swim lanes for the teams and just had them report orally about what they were up to.
After a few weeks of doing that, they realized that they mostly talked about deploying and releasing, and the meeting became Release Sync with a single focus: “What are we releasing today?” They created a simple board with just a Release queue to which each team brought their items to be released, and that was what they talked about. Most days that meeting was over in about two to three minutes.
We always ended the meeting with the question, “Anything else that all teams need to know?” to leave room for other information. More often than not there was nothing to inform everybody about, but when information needed to be shared with everyone, this meeting was a good opportunity to do so.
Tips on doing multiteam standups
Here are a few things to consider when you create a daily standup for more than one team (let’s call it big daily for lack of a better term):
- Should the big daily be run before or after the team standups? If you run the big daily before the team dailies, you can send information to the teams, but you might miss out on the latest status from the teams. Running it afterward gives you the status of the teams, but you miss the opportunity to send information to the team daily standups.
- Who is attending the big daily meeting? You probably want at least one person from each team in your group in order to make the meeting interesting. That person needs to be able to make decisions if required (for example, if some extra work should be added to the team backlog). We suggest that you let anyone interested attend the meeting, but require at least one person from each team.
- What kind of visualization should this meeting have to support its decisions? Are you going to have a board for your big daily? What kind of information do you want to show there? What kind of questions, statuses, and progress do you want to show on the board? Whom are you creating the board for?
- Are you displaying the status of each team on the big daily board too? If you have a board for all the teams, how do you communicate the status of each team? Beware of putting too much detail on the big board, because that means duplicating information and that the teams have to keep their work synchronized over two boards. An aggregated status is probably better.
As you can see, there are a lot of things to consider when you set up a big daily meeting. But if you start out thinking about what you, as a group, want to get out of this meeting, you can often start narrowing it down and focusing on those questions. A big daily standup can be a great boost and information-sharing opportunity, but you have to balance it carefully, or you might run into some of the problems we’ve talked about in this section.
Bottom up or top down?
The approach we’ve just described is suitable when you have teams that feel the need to synchronize their work to an aggregate board. But the reverse can also be true: you may have a big team that splits out into smaller teams (or teamlets as some companies call them) that need to synchronize their work.
You can use a coarse-grained board, without the details, and focus on the baton/work, using all of the good practices we’ve described around the daily standup. If there are small teams within the team that need to exchange detailed information and coordinate after that, they can have their own boards and/or standups where they focus on a smaller part of the workflow and their smaller tasks.
A good kanban board and the practices described here make it possible to scale a kanban daily beyond a small single team. And taking the practices a bit further (coarser-grained board, and so on) makes it scale a little more.
If you get everyone to meet often, you also foster collaboration that is needed in a bigger group. You get to know who works on what, who to talk to, who is waiting for you, and so on. This increases the likelihood of resolving blockers, minimizing waiting time, and sharing valuable information, because everyone is involved in the same workflow.
Just as with almost all practices, constantly asking yourself if this meeting is providing value for the time you put into it is one way of making sure that you don’t fall into those traps. If not, find other ways to keep everyone synced among the teams; great team visualizations might be one way, frequent demos might be another. Make the tool work for you—not the other way around.

Let’s leave the daily standup meeting for now and instead focus on a question that often arises in the meeting: “What should I do now?” Several of the kanban practices we have described so far can help you and your team to answer that question. Let’s dive in and see how.
7.4. What should I be doing next?
If you want a fast and smooth flow of work, you don’t want to be blocked by not knowing what to do next. A common question that comes up quite often around the board is what someone should be doing next. It’s a fair question, of course, but also something that you as a team want to be able to answer yourselves. You don’t want your flow to be slowed down by having to wait for someone else to tell you what to do next.

Many of the visualization techniques and our discussion of explicit policies in this book try to move you toward being more and more self-organized, to get a smoother flow in the process: for example, ordering the columns for prioritization, using classes of service with different colors, using blocked or urgent indicators, adding swim lanes for work that is to be expedited, and having WIP limits. All these small things help you answer the question “What should I be doing next?”
Let’s look at a concrete example of these practices at work. Here’s a situation that Adam, the tester, found himself in a couple of days ago:

In order to keep the work flowing along, what is a good choice for Adam to do now?
First he should check whether there’s any work going on in the Test column (his column) right now. To achieve a better flow, this should always be at the top of your mind: “Can I help finish work in progress?” You might remember the Kanbaneros’ motto: “Stop starting, start finishing.” Here’s a situation where this is put into practice.
Adam can practice this opportunity right away because Beth is testing another item. He helps her to finish that item and thereby clears the Test column. Good for them.

Now what? There’s no more work in the Test column, but there are two items stacked up in the Development/Done queue. What should Adam (and Beth) do now? They could pull both of those items into testing. There’s room for that, according to the WIP limit, so it seems like a good idea. Or maybe they want to take the top-priority item (at the top of the Development/Done column) first and work together to keep the WIP down and finish that faster. Which item they go after is up to the team and the policies the team has for how they work. In this case, Beth and Adam each take one item and finish it.

Next, consider the situation that happens a couple of days later. Adam is now the sole tester,[8] and he finds himself in a situation in which there’s no other work to be worked on in his column. Not only that—there’s no new work to pull in and start working on. What should Adam do now?
8 Beth is first and foremost a business analyst, you know.
The first knee-jerk reflex might be to suggest that he help one of the developers. That would ensure that their items are completed and moved into the Development/Done column, from which Adam could pick them up and start to test them. Sadly, Adam totally lacks the development skills needed for this particular work item, so he wouldn’t be helpful writing code.[9] Not all people can do all tasks, no matter how much we want that to be the case.
9 Let us be the first ones to object to that statement. A tester is often excellent to pair up with as you write code. It’s a great way to produce high-quality code. This is just an example in which we allowed ourselves to make Adam impossible to work with in development. It’s rarely the case in real life.
So what should Adam do, then? If you look in the earlier columns on the board, you can see a little situation starting to build up in the form of a step that is starved for work (a bottleneck, if you will). It’s in Analyze; can you see it?
Both Frank and Beth are working on one item each, but nothing is finished. Not only that, but as the developers finish their work, they won’t have any new work to pull because the Analyze/Done queue is empty. This is a bottleneck that needs your attention. Maybe Adam can help out there. In fact, a tester’s view can be valuable in analyzing features. He goes over and asks Beth if he can help out, and together they finish the feature.

Let’s say for the sake of argument that Adam couldn’t (or wasn’t allowed to) help out with analysis. Maybe those work items weren’t suitable for sharing. What should he have done then? He should resist the urge to pull new work that increases WIP and instead try to find other interesting work, something that can be dropped when new work is available on the board: when new work is ready to test, for example. This kind of work can be one of those things that you’ve postponed for so long: getting that new test server upgraded, cleaning up the databases in the staging environment, or finally updating the documentation of the old API. It should not, however, be work that needs to go through the normal workflow that would increase WIP and slow down everything in the process.
This could be an excellent opportunity to work on improvements or invent or learn new things that help you move faster in the future. Yes, this is slack time when you’re not producing value for your customer, but that is needed in order to be able to improve.
Without slack there cannot be improvements.
Dr. Arne Roock (@arneroock)
Summing up: what should I be working on next?
Let’s leave the example that we’ve been following for a while, and try to sum up how you could reason around what you should be working on next:[10]
10 This list was suggested by David Joyce.
- Can you help finish work that is already in process? Do that.
- Do you not have the skills needed for that? Look for bottlenecks or other things that slow down your flow, and help resolve them.
- Do you not have the right skills to help resolve a bottleneck or remove a blocker? Pull new work into the system, as long as you don’t exceed your WIP.
- If you still find yourself without work, find something interesting that you think will help the team, and do that.[11]
11 Ok—you can’t allow yourself to be idle forever, of course. Just doing “other, interesting work” won’t pay the bills. If that happens often, maybe you could see if you can start to cooperate more, or design your work so that it can be split in smaller pieces.
A Word from the Coach
These guidelines for what to work on next are rules of thumb that will help a team new to kanban and a flow focus to understand the principles. They aren’t to be used as rules. You may have other policies in place that take precedence over these guidelines. Depending on the context, it might, for example, make more sense to try to resolve a bottleneck before helping someone complete work.

7.5. Managing bottlenecks
The queues and the WIP limits work together to create a leading indicator of the problems in your workflow while you’re experiencing them. They tell you where the bottlenecks are and also show you where they’re building up even before they happen. Let’s look at an example. At the beginning of the day, the board looks like this. All of the steps are filled with work, and people are working away.
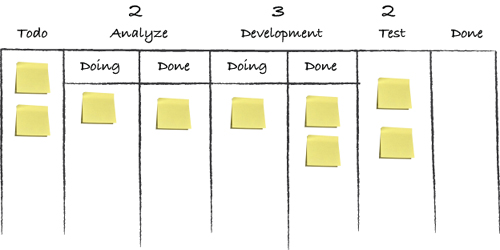
After a little while, the developers want to pull in new work. There’s only one item in Development/Doing. The developers pull a new work item from the Analyze/Done column; it’s just sitting there waiting.

But wait a minute; the Development column is already at maximum capacity. Items are apparently not moving fast enough from the Development column and through Test; we have a bottleneck in testing. What should we do about it?

If we do nothing and just keep pulling new development work—that is, ignoring the WIP limits—Test will be flooded with work sitting there waiting. This will increase the lead times of everything in the workflow and result in all the bad things associated with a higher WIP that we talked about in chapter 5.
We need to free up people to fix the problem, and fortunately the developers that were about to start new work apparently have capacity to spare. In many cases, this will only be a short-term solution; for example, testing might require special skills that make it difficult for a developer to be as efficient as needed. If Test is a recurring bottleneck, it makes sense to work on a long-term solution such as hiring more testers or perhaps automating more of the testing.
7.5.1. Theory of Constraints: a brief introduction
The Theory of Constraints[12] is a management philosophy that is based around the idea that the throughput of all systems is limited by at least one constraint: a bottleneck that slows production. With no constraints in a system, the throughput would be instant and infinite; the car would appear in your driveway at the same time as you clicked Buy, or a new software feature would be in production the moment you said you wanted it.
12 Eliyahu M. Goldratt and Jeff Cox formulated the Theory of Constraints in the excellent business novel The Goal: Excellence in Manufacturing (North River Press, 1984, http://amzn.com/B0006EI69C).
That also means the constraint slows down the whole system. Any improvement you do to help work to flow better through the constraint is an improvement for the whole system. Any improvement you do to another part of the system isn’t really an improvement because the bottleneck constraint is what is setting the pace for the entire workflow.
The Theory of Constraints, as an advanced theory of managing bottlenecks, would classify these solutions as elevation improvements because they focus on elevating, or increasing, the capacity at the bottleneck. This is the solution most people intuitively think of when faced with a bottleneck: adding more people or machines, more training, better tools, and better technologies. These solutions are often difficult because they require an expensive investment that takes time to produce results.
According to the Theory of Constraints, you often have another, simpler, and less expensive, option: to exploit the bottleneck. This means you first make sure the bottleneck is used to its maximum capacity. Are the people working at the bottleneck doing other kinds of work than the bottleneck activity? Could someone else do that work instead of them? In our previous example, maybe the developers can fill out the testers’ time reports and do their expenses for them. Any idle time in the bottleneck, any time where they can’t do bottleneck-activity work, reduces the output of the entire system.
Discovering a bottleneck
Bottlenecks often reveal themselves by having work piling up in front of them and steps after the bottleneck being starved for things to do. In the board below, you can see that there’s a lot of work waiting to be tested and nothing that is ready to be deployed.

In this example, the developers are blocked from pulling new work because that would break their WIP limit of four. All four development items are waiting to be tested. The testing step in turn is up to its WIP limit of two and should not pull more work either. Finally, we see that the step after testing (Deploy) has nothing to do because no work is flowing from the testing step.
With the queue the team has put in front of the testing step, you get a leading indicator of a problem happening: you can see it build up over time. This gives you an opportunity to react and start doing something about the bottleneck before it becomes a real problem.
Exploiting a bottleneck: the tester
Of course, testing[13] is just used as an example because it’s common and easy to understand. The bottleneck could be anywhere: yes, even with the developers!
13 Adam is a great tester, and we love him dearly. He’s not always the bottleneck but rather is used as an example in this section. Sorry, Adam.
In The Goal, Mr. Goldratt also teaches the Five Focusing Steps as a way to continuously improve the throughput of your system:
- Identify the constraint of the system: for example, a single machine that all the parts in a factory need to pass through.
- Exploit the constraint to get the most out of it. For example, make sure the machine is running all the time.
- Subordinate all other work to support the exploitation of the constraint. For example, make sure you don’t send faulty parts to the machine; that would be a waste of time for the constraint.
- Elevate the constraint. For example, buy another machine to share the workload.
- Rinse and repeat. Go over your system again, and see if the constraint is still the biggest constraint in the system. You don’t want “resistance to change” to be the constraint; we’re continuously learning and improving.
Here are some things you can do to exploit a bottleneck:
- Make sure the people/role that constitutes the bottleneck resource (the testers in our example) always have work to do: for example, by building up a queue of work in front of them.
- Build in quality to minimize the workload.
- Remove or at least limit interruptions.
- Remove impediments that hinder them in their work or leave them waiting.
- Carefully prioritize the bottleneck’s work so that they always work on the most important tasks. You don’t want the constraint to be wasting time on unimportant tasks, now do you? Remember that the constraint is slowing production for the entire system.
- Let them work at a steady pace by evening out the arrival rate of work.
Examples
To make sure the testers always have work, try to divide the work items into small deliverables that can be tested individually so that work is quickly ready for them and arrives at a steady pace, rather than in spikes.

Have the testers work closely with the developers and other upstream people (product owners, analysts, designers, and so on) early to build in quality and better understand the work they’re testing.
Warning

A common antipattern we have seen is that testers working in non-agile environments expect to do the testing in batches at the end of iterations or releases. A lot of time is spent on preparing, planning, administration, and similar activities. They even get involved in other activities like planning the next release or another project. This increases their WIP and decreases the amount of time they can spend on the bottleneck activity.
Another warning
As you make changes to your system, the bottleneck might move. That’s the last part of the five focusing steps (“Rinse and repeat”) and should be evaluated continuously; where is the bottleneck now? Are you working on the right bottleneck? Remember that an improvement to a non-bottleneck step in your process isn’t really an improvement.

There’s a lot more that can be said about and learned from studying the Theory of Constraints, and this has only been a short introduction to the topic. Read more about the Theory of Constraints in Tame the Flow: Hyper-Productive Knowledge-Work Management by our friends Steve Tendon and Wolfram Müller (Leanpub, 2013, https://leanpub.com/tame-the-flow), which deep-dives into the subject and its applications.
7.6. Summary
In this chapter we talked about ways to manage your work flow:
- Flow (or continuous flow) is an ideal state that describes a process in which every step in the process creates value, with no interruptions or waiting time.
- Pursuing this ideal state is a never-ending quest that will help you not only get a smoother, faster flow but also find problems in your process.
- Everything that isn’t value in the eyes of the customer is waste. Eliminating waste leads to better flow.
- “Managing flow” is one of the principles of kanban, and there are a lot of things you can do to help the work flow:
- Limit WIP.
- Reduce waiting times in your process: for example, by ensuring that the work is always ready for the next step or by making the work items smaller so that they move faster through the process. Remove blockers as fast as possible. Or why not strive to “never be blocked”?
- Avoid rework by building quality into your process from the start. How much of the demand you have in your system today is failure demand? How can you have less failure demand and more value demand?
- Create cross-functional teams that can minimize waiting times.
- Use goals and targets like SLAs to get clear timeboxes and objectives to strive toward.
- Many teams use the daily standup to collaborate well together. Here are some practices to help make a standup great:
- Keep it short and energized: never more than 15 minutes (that’s why you stand up).
- Keep it regular: same time and place every day.
- Keep it disciplined: start and end on time.
- Keep it focused: complete discussions afterward.
- Many kanban teams have some practices that they follow:
- Focus on the work, not the workers.
- Walk through the items on the board from right to left.
- Focus on deviations—the smells in your process.
- Here are some other things to think about to get the most out of your standup:
- Is all the work visible on the board?
- Are we working on the right thing?
- Do we understand the work?
- Encourage spontaneous kaizen meetings after the standup in which small improvements are made every day.
- Standups can be scaled to more than one team, but make sure each layer adds value and isn’t just another reporting instance.
Think about the following:
- Run before or after smaller team standups?
- Who attends?
- What kinds of visualizations are needed?
- How will statuses be synchronized between local team boards and other boards?
- “What should I be doing next?” is a common question at standups. With explicit policies on how to handle that question, you minimize the risk of hindering the flow of work.
- A bottleneck is something that slows down production. With queues, you can get leading indicators and discover the bottlenecks.
- The Theory of Constraints is a management theory built around finding and eliminating bottlenecks in a process.