
Chapter 1. Understanding brownfield applications
- Defining brownfield applications
- Inheriting an application
- Facing challenges in brownfield applications
An industrial brownfield is a commercial site contaminated by hazardous waste that has the potential to be reused once it’s cleaned up. To a software developer, a brownfield application is an existing project, or codebase, that may be contaminated by poor practices, structure, and design, but that has the potential to be revived through comprehensive and directed refactoring.
Many of the established applications you’ll encounter fit this description. By the time you start working on them, the core technology and architectural decisions have already been made, but architectures and technologies are still more easily repaired than replaced. In this chapter, we’ll explore the various components of a brownfield application. We’ll talk about the challenges inherent in taking on brownfield applications, particularly the social and political aspects surrounding your work. We’ll include in our discussion ways you can convince your boss that the effort is worthwhile and that it will result in lower costs and higher productivity in the long run. We’ll also look at the unique benefits working on brownfield apps offers to you as a developer.
As you move through this book, you’ll learn (or relearn) numerous techniques for dealing with brownfield applications. Many are the same techniques you should be applying to new development projects to prevent the “contamination” characteristic of brownfields. But they can present some interesting challenges when you apply them to established code.
To set the stage, we’ll open with an anecdote—contrived, to be sure, but very much based on personal experience and observations.
1.1. Welcome to Twilight Stars!
“Welcome to Twilight Stars! Where fading stars can shine again!”
So claims the welcome package you receive on your first day. You’ve just started as a consultant for Twilight Stars, a company that provides bookings for bands of fading popularity. The website that manages these bookings has had a storied past, and you’ve been told that your job is to turn that site around. This is your first gig as an independent consultant, so your optimism runs high!
1.1.1. Reality check
Then Michael walks in. He props himself up against the door and watches you unpack for a while. You exchange introductions and discover he’s one of the senior programmers on the team. As you explain some of your ideas, Michael’s smirk becomes increasingly prominent.
“How much do you really know?” he says. Without waiting for an answer, he launches into a diatribe that he has clearly recounted many times before...
“Did they tell you our delivery date is in 6 weeks? Didn’t think so. That’s a hard deadline, too; they’ll miss their window of opportunity if we don’t deliver by then. The big shots still cling to the hope that we’ll meet it but the rest of us know better. If we hold to that date, this app is going to have more bugs than an entomology convention. As it is, the client has zero confidence in us. He stopped coming to the status meetings months ago.
“Anyway, you’ll be hard pressed just to keep up since Huey and Lewis both left last week. They’re only the latest to go, too. Despite what he may have told you about refactoring, the PM, Jackson, had to bring you in just to get this sucker out the door on time. Yeah, we know it’s a mess and we need to clean it up and all, but I’ve seen guys like you come through here on a regular basis. It’ll be all you can do just to keep up with the defects. Which, by the way, we’re mandated to resolve before delivery. Each and every one of them.”
With that, Michael excuses himself after suggesting (somewhat ominously) that you review the defect list. You locate the Excel file on the server that stores them and are taken aback. There are some 700 open defects, some more than 2 years old! Some are one-liners like “Can’t log in” and many were reported by people who no longer work on the project.
Without knowing what else to do, you scan the list for a seemingly simple bug to fix: display an appropriate page title in the title bar of the window. “That should be an easy one to pick off,” you think.
Luckily, your welcome package contains instructions on getting the latest version of the code. Unluckily, the instructions are out of date and it’s a good 45 minutes before you realize you’re looking at the wrong code.
After retrieving the latest version, you open the solution and do what comes naturally: compile. Errors abound. References to third-party controls that you haven’t installed and code files that don’t exist. As you investigate, you also discover references to local web services and databases that you have yet to install. In one case, it even appears unit tests are running against a production database. (Upon further investigation, you realize the tests are being ignored. Phew!)
You spend the rest of the day tracking down the external dependencies and missing code from various team members’ machines. As you drive home, you realize that the entire day was spent simply getting the application to compile. “No matter,” you say to yourself, “now I’m in a position to be productive.”
1.1.2. Day two
You arrive early on day two ready to do some coding. As you settle in to find that elusive line of code that sets the window title, you realize the code itself is going to be a significant obstacle to cramming the work required into the remaining time before release.
Eventually, you find the code to change a window title. It’s buried deep in what appears to be a half-finished generic windowing framework. Tentatively, you “fix” the bug and test it the only way you can at the moment: by pressing F5. Crash!
Fast-forward to two o’clock. In the intervening hours, you’ve touched every major layer of the application after you discovered that the window title was being stored in the database (explained one team member, “At one point, we were going to offer the app in Spanish.”). Near as you can tell, the new title you were trying to set is too big for the corresponding database column.
Stop us if any of this starts to sound familiar.
In the meantime, you still aren’t able to even fix the bug because key files have been checked out by others (including the recently departed Huey) and the version control system doesn’t allow files to be modified by more than one person. Also, though some areas appear to be protected by automated tests, these tests are ignored, not testing what they claim, or outright failing. Clearly the team doesn’t run them often. One class containing over 10,000 lines of code is “covered” by a single test. Disturbingly, it passes.
1.1.3. Settling in
Over the ensuing weeks, the longer you spend working with the code, the more questions you have. The architecture looks as though it’s in the process of moving to a new UI pattern. The architect behind it steadfastly refuses requests for meetings to explain it, claiming it should be self-explanatory. The designers of the original code are long gone, so you’re left to cobble together solutions that make use of both the original and the new patterns. You know it’s not the best you can do, but you’re scared to even suggest to the PM that it needs to be revamped.
Eventually, you’re told that you’ll be taking over the test-fix-test cycle for one area of the application (or as some developers call it, fix-release-pray-fix). Changes to the code have indeterminate impacts. Verifying any change requires a full release and testing cycle that involves the end users. The result is uncontrollable code, sliding morale, and no confidence among the parties involved.
In the end your team makes the deadline, but at a cost. More developers have left for greener fields and lower stress. Management begins a process of imposing crippling accountability practices on the team. As you sit down to start on phase 2, you pause to reflect on your initial optimism in the project. An email notification interrupts your reverie:
Issue #3,787 Created: Window title incorrect.
1.1.4. Taking stock
Twilight Stars may be a fictional company, but the issues facing it are real. We’ve touched on only a scant few of the problems here that often face a brownfield application. We’ll come back to our intrepid hero again in chapter 13 after he’s had a chance to peruse the book and implement some of the solutions he encounters. In the meantime, let’s see what makes up a brownfield application.
1.2. The components of a brownfield application
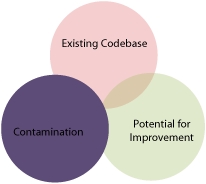
Like the industrial definition, the salient components of a brownfield application are
- Existing codebase
- Contamination by poor practices
- Potential for reuse or improvement
Figure 1.1 shows the three components and as you can see, they’re interrelated.
Figure 1.1. Brownfield applications have three components that distinguish them from greenfield and legacy applications.

It’s easy to distinguish brownfield applications from greenfield ones. Greenfield applications have no previous project or technical history, whereas brownfield applications are typically burdened with it. Similarly, we make a distinction between brownfield and legacy applications as well. We’ll come back to legacy code-bases shortly, but for now consider them to be applications that are long forgotten and that are worked on only when absolutely necessary.
Brownfield applications generally fall between greenfield and legacy. Table 1.1 compares the three types of projects.
Table 1.1. A comparison of the major project concerns and how they relate to greenfield, brownfield, and legacy applications
|
Concern |
Greenfield |
Brownfield |
Legacy |
|---|---|---|---|
|
Project state |
Early in the development lifecycle; focuses on new features |
New feature development and testing and/or production environment maintenance |
Primarily maintenance mode |
|
Code maturity |
All code actively being worked on |
Some code being worked on for new development; all code actively maintained for defect resolution |
Very little code actively developed, except for defect resolution |
|
Architectural review |
Reviewed and modified at all levels and times as the codebase grows |
Only when significant changes (business or technical) are requested |
Rarely, if ever, reviewed or modified |
|
Practices and processes |
Developed as work progresses |
Mostly in place, though not necessarily working for the team/project |
Focused on maintaining the application and resolving critical defects |
|
Project team |
Newly formed group that is looking to identify the direction of its processes and practices |
Mix of new and old, bringing together fresh ideas and historical biases |
Very small team that maintains the status quo |
In short, brownfield applications fall into that gray area between when an application is shiny and new and when it’s strictly in maintenance mode. Now that we’ve provided the criteria for a brownfield application, let’s examine the components from figure 1.1 in more detail.
1.2.1. Existing codebase
One of the defining characteristics of a greenfield application is that there’s little or no prior work. There’s no previous architecture or structure to deal with. By contrast, brownfield projects are ones that have a significant codebase already in place.
We don’t mean that when you leave work after the first day, your greenfield application magically turns into a brownfield one overnight. Typically, it has been in development for some period of time (or has been left unattended) and now has some concrete and measurable work that needs to be done on it. Often, this work takes the form of a phase of a project or even a full-fledged project.

There are a couple of points worth mentioning with respect to existing codebases, even if they’re a little obvious:
- You must have access to the code.
- The code should be in active development.
Your brownfield application may already be in production
Because you’re dealing with an existing codebase, there’s a chance it has already been released into production. If so, this will have some bearing on your project’s direction but not necessarily on the techniques we’ll talk about in this book. Whether you’re responding to user requests for new features, addressing bugs in the existing version, or simply trying to complete an existing project, the methods in this book still apply.
These two points disqualify certain types of applications from being brownfield ones—for example, an application that requires occasional maintenance to fix bugs or add the odd feature. Perhaps the company doesn’t make enough money on it to warrant more than a few developer hours a week, or maybe it’s not a critical application for your organization. This application isn’t being actively developed. It’s being maintained and falls more into the category of a legacy application.
Instead, a brownfield codebase is an active one. It has a team assigned to it and a substantial budget behind it. New features are considered and bugs tracked.
The next component of a brownfield application is the degree to which it’s contaminated. Let’s see why this is an important aspect of the definition.
1.2.2. Contaminated by poor programming practices
Besides being an existing, actively developed codebase, brownfield applications are defined by their level of contamination, or smell—that is, how bad the code is. This determination is subjective in the best of cases, but in many instances, everyone agrees that something is wrong, even if the team can’t quite put their finger on it or agree on how to fix it.
Different levels of contamination exist in any codebase. It’s a rare application indeed that’s completely free of bad code and/or infrastructure. Even if you follow good coding practices and have comprehensive testing and continuous integration, chances are you’ve accrued technical debt to some degree.
Technical debt
Technical debt is a term used to describe the quainter areas of your code. They’re pieces that you know need some work but that you don’t have the time, experience, or staff to address at the moment. Perhaps you’ve got a data access class with hand-coded SQL that you know is ripe for a SQL injection attack. Or each of your forms has the same boilerplate code cut and pasted into it to check the current user. Your team recognizes that it’s bad code but isn’t able to fix it at the moment.
It’s akin to the to-do list on your refrigerator taunting you with tasks like “clean out the garage” and “find out what that smell is in the attic.” They’re easily put off but need to be done eventually.
The nasty side effect of technical debt is the bad design and code decisions. They’re like the weekend you had that one time in college. It seemed like a good idea at the time, but now you constantly have to deal with it. In code, at some point you’ve made decisions about design and architectures that may have made sense at the time but now come back to haunt you regularly. It may now take an inordinate amount of time to add a new screen to the application, or it might be that you have to change something in several different places instead of just one. Like that weekend in college, these are painful, and regular, reminders of your past transgression. But unlike your college past, you can change code.
Along the same lines, contamination means different things to different people. You’ll need to fight the urge to call code contaminated simply because it doesn’t match your coding style.
The point is that you need to evaluate the degree to which the code is contaminated. If it already follows good coding practices and has a relatively comprehensive set of tests but you don’t like the way it’s accessing the database, you could argue that it isn’t a full-fledged brownfield application—merely one that needs a new data access strategy.
Although it may be hard to pinpoint the exact degree of contamination, you can watch for warning signs that might give you a gut feeling:
- How quickly are you able to fix bugs?
- How confident do you feel when bugs are fixed?
- How easy is it to extend the application and add new features?
- How easy would it be to change how you log error messages in the application?
If your answer to any or all of these questions is a chagrined “Not very,” chances are you have a lot of contamination.
Bear in mind that every application can be improved upon. Often, all it takes is a new perspective. And like any homeowner will tell you, you’re never truly finished renovating until you leave (or the money runs out).
So far we’ve discussed the nature of the application and talked about its negative aspects. With the final core component of a brownfield application, we’ll look at the positive side of things and see what can be done to make our app better.
1.2.3. Potential for reuse or improvement
The final criterion, potential for reuse or improvement, is important. It means that despite the problems you’ve identified, you’re confident that the application can be improved. Your application isn’t only salvageable but you’ll be making an active effort to improve it. Often, it’s an application that you’re still actively developing (perhaps even still working toward version 1). Other times, it’s one that has been put on hold for some time and that you’re resurrecting.

Compare this with a traditional legacy application. Projects that have aged significantly, or that have been moved into maintenance mode, fall into the legacy category. Such applications aren’t so much maintained as they are dealt with. These applications are left alone and resurrected only when a critical bug needs to be fixed. No attempts are made to improve the code’s design or to refactor existing functionality.
Note
In his book Working Effectively with Legacy Code (Prentice Hall PTR, 2004), Michael Feathers defines legacy code as any code that doesn’t have tests. This definition works for the purpose of his book, but we’re using a more traditional definition: really, really old code.
As you can see, it isn’t hard to come up with an example of a brownfield application. Any time you work on an application greater than version 1.0, you’re two-thirds of the way to the core definition of a brownfield application. Often, even applications working toward version 1.0 fall into this category.
Our next step is to crystallize some of the vague notions we feel when dealing with brownfield applications.
1.3. Inheriting an application
The idea of working in a codebase that has been thrown together haphazardly, patched up on the fly, and allowed to incur ongoing technical debt doesn’t always inspire one to great heights. So consider this section of the book your rallying cry. Dealing with someone else’s code (or even your own code, months or years later) is rarely easy, even if it does follow good design practices. And in many cases, you’ll be making changes that end users, and even your own managers, don’t notice. The person who will truly benefit from your work is either you or the developer who comes after you.
Reasons to be excited about brownfield applications
- Business logic already exists in some form.
- You can be productive from day one.
- Fixing code is easier than writing it.
- The project may already be in use and generating revenue.
It’s the contaminated nature of the code that makes your task exciting. Software developers, as a group, love to solve problems, and brownfield applications are fantastic problems to solve. The answers are already there in the existing code; you just need to filter out the noise and reorganize.
The nice thing about brownfield applications is that you see progress almost from day one. They’re great for getting quick wins—expending a little effort for a big gain. This is especially true at the beginning of the project where a small, obvious refactoring can have a huge positive effect on the overall maintainability of the application. And right from the start, we’ll be making things easier by encouraging good version control practices (chapter 2) and implementing a continuous integration process (chapter 3), two tasks that are easier to accomplish than you might think.
In addition, most developers find it much easier to “fix” code than to write it from scratch. How many times have you looked at code you’ve done even 6 months ago and thought, “I could write this so much better now”? It’s human nature. Things are easier to modify and improve than they are to create, because all the boring stuff (project setup, form layout) has already been done.
Compare this with greenfield applications, where the initial stages are spent setting up the infrastructure for code not yet written. Or compare it with writing tests at a relatively granular level and agonizing over whether you should create a separate Services project to house that new class you’re testing.
Finally, the application may already be in production and may even be generating revenue for your company! That alone should be reason enough to make a concerted effort to improve it.
In short, brownfield applications shouldn’t be viewed as daunting. Quite the contrary. Throughout this book, you’ll find that once you start improving an application and its ecosystem, the process becomes addictive.
But before we go any further, this is a good point to lay some groundwork for the brownfield revitalization task that lies ahead of you. To do that, we’ll talk about some concepts that will be recurring themes throughout the remainder of the book, starting with the concept of pain points. Although pain points are only a sampling of problems that you may encounter on your brownfield project, they’ll show you how to identify and act on issues.
1.3.1. Pain points
A pain point is a process that’s causing you grief—one that causes you to search for a solution or alternative. For example, if every test in a certain area requires the same code to prime it, it may signal that the common code needs to be either moved to the test’s setup or, at the very least, into a separate method.
Pain points come in all sizes. The easy ones are those that can be codified or for which solutions can be purchased. These include refactorings like Extract to Method or Introduce Variable (which can be done with a couple of keystrokes within Visual Studio).
The harder ones take more thought and might require drastic changes to the code. Don’t shy away from these—they’ve been identified as pain points. But always keep in mind the cost-benefit ratio before undertaking major changes.
One of the things that differentiate a brownfield application from a greenfield application is that pain points are more prevalent at the start. Pain points in greenfield applications don’t stick around long because you remove them as soon as you discover them—which is easier because there isn’t as much code. In brownfield applications, pain points have been allowed to linger and fester and grow.
Pain points are especially relevant to brownfield applications because they define areas in need of improvement. Without pain points, there’s no need to make changes. It’s only when you’re typing the same boilerplate code repeatedly, or having to cut and paste more than once, or are unable to quickly respond to feature requests, and so on and so forth, that you need to take a look at finding a better way.
Be on the lookout for pain
Very often, we aren’t even aware of pain points, or we accept them as a normal part of the development process. For example, we might have a web application that restricts access to certain pages to administrators. In these pages, you’ve peppered your code with calls to IsAdmin() to ensure regular users can’t access them. But after you’ve made this call for the third time, your “hack alert” should trigger you to find out if this problem can be solved some other way (like, say, with a <location> tag in your web.config).
We’ll talk about pain points throughout this book. Almost every piece of advice is predicated on solving some common pain point. Each remaining chapter will begin with a scenario describing at least one pain point (and usually several) that we’ll address in that chapter.
Identifying pain points is normally the result of some kind of productivity friction, which we’ll discuss next.
1.3.2. Identifying friction
Another thing you’ll encounter when inheriting a brownfield application is friction. Anything that gets in the way of a developer’s normal process causes friction. Things that cause friction aren’t necessarily painful but they’re a noticeable burden, and you should take steps to reduce friction.
An example of friction is if the build process is excessively long. Perhaps this is due to automated tests dropping and re-creating a database (we’ll cover automated builds and integration tests in chapters 3 and 4, respectively). Perhaps it’s calling out to an unreliable web service. Whatever the reason, building the application is a regular event in a developer’s day-to-day process, and if left unchecked, this friction could add up to quite a bit of money over the length of the project.
Like pain points, friction may go unnoticed. You should constantly be on the alert when anything distracts you from your core task: developing software. If anything gets in your way, it must be evaluated to see if the process can be improved upon. Very often, we can get so wrapped up in our work that we forget computers can automate all but the most complex of tasks.
Noticing and acting on friction and pain points takes a clarity of thought that often subsides as your involvement in a project lengthens. As a result you have to explicitly expend effort thinking outside your current box, or as we like to say, challenging your assumptions.
1.3.3. Challenging your assumptions
When you inherit a brownfield application, you’re at a unique point in its development in that you’re actively trying to improve it. It behooves you to challenge the way you have thought about certain techniques and practices in the past in order to deliver on that promise.
Challenge your assumptions
Throughout the book, we’ll call attention to ideas that may be unintuitive or that may not be commonly known. These won’t be traditional pieces of advice that you should follow heedlessly. Rather, they should be taken as a new perspective—an idea worth considering that might fit in with your style or that might solve a particular problem you’re having.
Examples of challenging your assumptions can range from the mundane to the far-reaching. It could be as simple as raising your monitor to eye level to reduce strain. Or it could be reexamining your data access layer to see if it can be refactored to an object-relational mapper (see chapter 11). Do you find yourself typing the same code over and over again? Maybe you can create a code snippet for it. Or maybe it’s the symptom of some design flaw in your application. Whatever the case, developers, more than anyone, should recognize that doing the same thing over and over again is a sign that something can be improved.
Challenging assumptions is a good practice in any project but more so in brownfield applications. There’s a good chance that some questionable assumptions led to the code being contaminated in the first place. Usually, bad assumptions are the root cause of pain points and friction.
But by the same token, there’s a fine line between critical thinking and outright irreverence. You should be practical with your challenges. At all times, you should weigh the costs and benefits of any major changes you make. Although we developers would rather not consider it most of the time, the expectations of clients and management need to play into our decision-making process.
1.3.4. Balancing the client’s expectations
There’s a common metaphor in the software industry: the Iron Triangle. It’s depicted in figure 1.2.
Figure 1.2. The Iron Triangle. Changes in any of the three vertices will affect the project’s overall quality.

Here’s one way the triangle has been summed up: the project can be done on time, on budget, and feature complete. Which two do you want? The idea is that in order to increase the quality (the area of the triangle), one or more of the other aspects will need to give. Conversely, if we reduce the resources, for example, without changing anything else, quality will suffer.
The Iron Triangle metaphor is somewhat flawed. One example is that if you reduce the scope of an application without reducing anything else, it implies the quality will go down.
Instead, we feel the relationship is more akin to a scale, as shown in figure 1.3. On the left, we have (estimated) time and resources, representing things we want to keep low. On the right are quality and features, which we want to be high. The important thing to remember is that the scale must remain balanced at all times. If you want to add a new feature, you must add an appropriate amount of time and resources to keep the balance. If you lose some funding, you have a decision to make: sacrifice quality or features in order to rebalance.
Figure 1.3. Generally speaking, your job will be to balance time and resources against code quality and features.

The development team has influence in all aspects of this equation except cost. We have the ability to work in ways that will ensure that we provide the functionality that the client wants. We can also use different tools, techniques, and practices that will enhance the quality of the application. Although more limited, the development team does have the ability to meet or miss deadlines. More effective, though, is our ability to influence deadlines and set realistic and attainable expectations.
The relationship between time/resources and quality/scope is of particular interest in a brownfield application. This is because the scale needs constant adjustment as time goes on. As you progress, you may discover that your estimates were off and need adjustment. You may not be physically able to deliver the application at the current scope and quality within the existing timeframe and budget. In effect, external factors have shifted the balance so that the left side of the scale is too light. You need to either increase the schedule or resources, or lower the quality or scope, in order to balance it out.
As developers, we’re often focused on one aspect of the scale: quality. By contrast, project managers and clients typically need to balance all four. Brownfield applications, in particular, may require some radical decisions. Almost by definition, you’ll be affecting the quality of the code. As you outline the changes that have to be made, be sure you consider their impact on the scale, especially from the standpoint of your client.
In itself, balancing the scale is a complex task. Management courses and development methodologies exist by the dozens simply to try to address it. With a brownfield application, subtle complexities come into play. One of those subtleties is the decision to refactor or to do a big rewrite.
1.3.5. The big rewrite
When you inherit a brownfield project, at some point someone will ask the question: “Should we just rewrite this thing from scratch?” Often, the obvious answer is no. The codebase might be too large, the current problems with it too small, and/or the benefit of the work too minor.
But on rare occasions, you’ll encounter a project where the answer should be yes. In our experience, this is dictated by a few factors. For example, the current brownfield codebase may not address the client’s desired goals. Perhaps it’s a completely synchronous system and the need is for an asynchronous one. In this case, trying to shoehorn asynchronous, or messaging-based, practices and patterns into the existing codebase would probably lead to maintainability issues, and possibly even a failure to achieve the stated architecture. As a result, the disconnect between the current architectures and the desired one will probably dictate that we perform a major rewrite of the application.
Be cautious when evaluating whether a brownfield codebase should be rewritten. As a rule, developers often prematurely jump to the conclusion that an application is unmaintainable simply because we don’t want to deal with “someone else’s” problems. We feel like the guy in the parade who has to follow behind the horses with a shovel.
But in many cases, issues such as poor coding practices, lack of a good ecosystem, and defect-ridden code can be overcome through strong and focused refactoring, not from a ground-up rewrite. We refer to Joel Spolsky’s still-relevant article from 2000 titled “Things You Should Never Do”[1] on the dangers of rewriting from scratch.
That said, if you perform your due diligence and decide that rewriting the application is more cost-effective than refactoring and tweaking the existing one, you’ll face some unique challenges. In some ways, it’s easier than a straight greenfield project because you’re starting from scratch, yet you still have a reference application that defines the functionality. At the same time, you’re essentially rebooting an application that, from the users’ perspective, may work. Maybe it has some quirks but few users will trade the devil they know for the devil they don’t.
In the end, the refactor/rewrite decision should come down to business value. Will it cost less over the long term to maintain the current application versus creating a whole new one? It may be hard for us to put aside emotion and not inflate the cost of maintenance for the current application, but it’s even more detrimental to ignore the economics of any project.
Now that we’ve looked at some aspects of inheriting an application, let’s explore some of the challenges you’ll face as you start your brownfield project.
1.4. The challenges of a brownfield application
Your task won’t be an easy one. There will be technical and not-so-technical challenges ahead.
Unlike with a greenfield project, there’s a good chance your application comes with some baggage. Perhaps the current version has been released to production and has been met with a less-than-enthusiastic response from the customers. Maybe there are developers who worked on the original codebase and they aren’t too keen on their work being dissected. Or maybe management is pressuring you to finally get the application out the door so it doesn’t look like such a blemish on the IT department.
These are but a few of the scenarios that will affect the outcome of your project (see figure 1.4). Unfortunately, they can’t be ignored. Sometimes they can be managed, but at the very least, you must be cognizant of the political and social aspects of the project so that you can try to stay focused on the task at hand.
Figure 1.4. There are many challenges to a brownfield application. As developers, we often focus only on the technical ones.

We’ll start the discussion with the easy ones: technical factors.
1.4.1. Technical factors
Almost by definition, brownfield applications are rife with technical problems. The deployment process might be cumbersome. The web application may not work in all browsers. Perhaps it doesn’t print properly on the obscure printer on the third floor. You likely have a list of many of the problems in some form already. And if you’re new to the project, you’ll certainly find more. Rare is the project that holds up well under scrutiny by a new pair of eyes.
In many ways, the technical challenges will be easiest to manage. This is, after all, what you were trained to do. And the good thing is that help is everywhere. Other developers, user groups, newsgroups, blogs—virtually any problem has already been solved in some format, save those in bleeding-edge technology. Usually, the issue isn’t finding a solution exists—the issue is finding one that works in your environment.
One of the keys to successfully overcoming the technical factors that you inherit is to focus on one at a time and to prioritize them based on pain. Trying to solve all the technical issues on a project is impossible. Even trying to solve many of them at one time is overwhelming. Instead of trying to take on two, three, or more technical refactorings at one time, focus on one and be sure to complete that task as best as you possibly can.
Stay focused!
When you start looking for problems in a brownfield application, you’ll find them. Chances are they’ll be everywhere. You may face a tendency to start down one path, then get distracted by another problem. Call it the “I’ll-just-refactor-this-one-piece-of-code-first” syndrome.
Fight this impulse if you can. Nothing adds technical debt to a project like several half-finished refactorings. Leaving a problem partially solved is more a hindrance than a solution. Not only does the problem remain, but you have introduced inconsistency. This makes it that much harder for the next developer to figure out what’s going on.
Working on some technical factors will be daunting. Looking to introduce something like inversion of control and dependency injection (see chapter 9) into a tightly coupled application can be an overwhelming experience. This is why it’s important to bite off pieces that you can chew completely. Occasionally, those pieces will be large and require a significant amount of mastication. That’s when it’s crucial to have the motivation and drive to see the task through to completion. For a developer, nothing is more rewarding than completing a task, knowing that it was worthwhile and, subsequently, seeing that the effort is paying off.
Unfortunately, technical problems aren’t the only ones you’ll face. Unless you work for yourself, you’ll at least need to be aware of political issues. We’ll discuss political factors next.
1.4.2. Political factors
Whether or not you like it, politics plays a factor in all but the smallest companies. Brownfield applications, by their very nature, are sure to come with their own brand of political history. By the time an application has become brownfield, the politics can become entrenched.
Political factors can take many forms, depending on the nature of the application, its visibility within the organization, and the personality of the stakeholders. And it doesn’t take much to create a politically charged situation. The application could be high profile and several months late. It could be in production already but so unstable that the customers refuse to use it. The company may be going through a merger with another company that makes similar software. All of these situations will have an effect on you.
Political factors exist mostly at a macro level. Rarely do politics dip into the daily domain of the individual programmer. But programmers will usually feel the ramifications of politics indirectly.
One of the most direct manifestations is in the morale of the team, especially the ones who have been on the project longer. Perhaps you have a highly skilled senior programmer on the team who has long stopped voicing her opinions out of resignation or frustration. Alternatively, there’s the not-so-skilled developer who has enough political clout to convince the project manager that the entire application’s data storage mechanism should be XML files to make it easier to read them into typed datasets. Sure, you could make the case against this particular issue, and possibly win, but the root cause (the misinformed developer) is still running rampant through the project.
Another common example is when management, project sponsors, or some component of the organization has soured to your project and they’ve decided, rightly or wrongly, to point the blame at the technology being used. As the implementers of the technology, the developers are often dragged into the fray. In such cases, we’re almost always on the defensive, having to explain every single decision we make, from the choice of programming language to the number of assemblies we deploy.
Regardless of the forces causing them to influence a project, politics are the single most difficult thing to change when on the project. They’re usually based on longstanding corporate or business relationships that have a strong emotional backing to them, and this is difficult to strip away. It’s nearly impossible to meet these situations head on and make changes.
Dealing with political situations is never an easy undertaking. Our natural tendency is to hide in the code and let others worry about the political landscape. Indeed, if you’re able to safely ignore these problems, we highly recommend doing so. But we have yet to encounter a situation in a brownfield application where we’ve been able to disregard them completely. And in our experience, burying your head in the sand tends to make things worse (or at the very least, it certainly doesn’t make things better).
Instead, subtlety and patience are often the best ways to address politically charged situations. Tread lightly at first. As when working in code, learning the pain points is the key to success. In the case of negative politics, learning what triggers and fuels the situation sets the foundation for solving the problem. Once you know the reasoning for individual or group resistance, you can begin appealing to those points.
Tales from the trenches: “Get it done with fewer defects”
One of the projects we worked on had a poor track record of releasing new features that were littered with defects and/or missed functionality. This had continued to the point where management and clients intervened with the mandate that the team must “...get it done with fewer defects.” And they were right—we had to.
At the time, one of our first suggestions was to implement a policy of test-driven design (TDD) to force the development team to spend more time defining the requirements, designing their code around those requirements, and generating a set of lasting artifacts that could be used to verify the expectations of the requirements. As is often the case when proposing TDD to management, the added coding effort was perceived as a drain on resources and a problem for meeting schedules or deadlines. The idea of doing more work up-front to ensure successful implementation—rather than doing more after-the-fact work to fix defects—didn’t compute well with them.
As we backed away from the (heated) conversations, it became quite apparent to us that there was a historically based set of prejudices surrounding TDD. Past experience and the ensuing politics surrounding a visible failure were creating a great deal of resistance to our ideas.
Instead of selling a technique known as test-driven design, we proposed a combination of practices that would allow us to specifically address the quality problems the project was seeing, without boring the client about what they were. With the implementation of these practices, delivered quality improved and management’s confidence in our abilities increased.
To this day we’re not sure if that management team understood that we were doing TDD on their project, but that didn’t matter. The political charge around the term was so high that it was never going to succeed when packaged in that manner. Research into the reasoning behind that level of negativity pointed to a past implementation and execution experience. By rebundling the practices, we were able to circumvent the resistance and still deliver what was requested of us by management.
In the end, your goal in a project that has some political charge isn’t to meet the politics directly. Instead, you should be looking to quell the emotion and stay focused on the business problems being solved by your application. Strike a happy balance between groups who have interests they want addressed. You’ll never make everyone fully happy all the time, but if you can get the involved parties to rationally discuss the project, or specific parts of the project, you’re starting to succeed.
That was kind of a superficial, Dr. Phil analysis of politics, but this is a technical book, after all. And we don’t want to give the impression that we have all the answers with regard to office politics ourselves. For now, we can only point out the importance of recognizing and anticipating problems. In the meantime, we’ll continue our talk on challenges with a discussion on morale.
1.4.3. Team morale
When you first start on a brownfield project, you’ll usually be bright eyed and bushy tailed. But the existing members of that team may not share your enthusiasm. Because this is a brownfield application, they’ll have some history with the project. They’ve probably been through some battles and lost on occasion. In the worst situations, there may be feelings of pessimism, cynicism, and possibly even anger among the team members. This type of morale problem brings with it project stresses such as degradation in quality, missed deadlines, and poor or caustic communication.
It’s also a self-perpetuating problem. When quality is suffering, the testing team may suffer from bad morale. It’s frustrating to feel that no matter how many defects you catch and send back for fixing, the returned code always has a new problem caused by fixing the original problem. The testing team’s frustration reflects on the developers and the quality degrades even more.
Because every team reacts differently to project stresses, resolving the issues will vary. One thing is certain, though: for team morale to improve, a better sense of “team” has to be built.
One of the most interesting problems that we’ve encountered is Hero Programmer Syndrome (HPS). On some teams, or in some organizations, there are a few developers who will work incredible numbers of hours to meet what seem like impossible deadlines. Management loves what these people do. They become the go-to guys when times are tough, crunches are needed, or deadlines are looming.
It may seem counterintuitive (and a little anticapitalist), but HPS should be discouraged. Instead of rewarding individual acts of heroism, look for ways to reward the team as a whole. Although rewarding individuals is nice, having the whole team on board will usually provide better results both in the short and long terms.
Note
The project will run much smoother if the team feels a sense of collective ownership. The team succeeds and faces challenges together. When a bug is encountered, it’s the team’s fault, not the fault of any one developer. When the project succeeds, it’s due to the efforts of everyone, not any one person.
One of the benefits you get from treating the team as a single unit is a sense of collective code ownership. No one person feels personally responsible for any one piece of the application. Rather, each team member is committed to the success of the application as a whole. Bugs are caused by the team, not a team member. Features are added by the team—not Paul, who specializes in data access, or Anne, who’s a whiz at UI.
When everyone feels as if they have a stake in the application as a whole, there’s no “Well, I’m pulling my weight but I feel like the rest of the team is dragging me down.” You can get a quick sense of how the project is going by talking to individual members of the team. If they use the words we and our a lot, their attitude is likely reflected by the rest of the team. If they say, I and my, you have to talk to other members to get their side of the story.
HPS is of particular importance in brownfield applications. A pervasive individualistic attitude may be one of the factors contributing to the project’s existing political history. If you get the impression that it exists on your team, you have that much more work ahead of you moving toward collective code ownership.
It isn’t always an easy feat to achieve. Team dynamics are a topic unto themselves. At best, we can only recognize that they’re important here and relate them to brown-field applications in general.
Unfortunately, the development team members aren’t the only people you have to worry about when it comes to morale. If your team members are disenchanted, imagine how your client feels.
1.4.4. Client morale
It’s easy to think of morale only in terms of the team doing the construction of the software. As developers, we’re most in touch with this group. But we’re also heavily influenced by the morale of our clients. Their feeling toward the project and working on it will ebb and flow just as it does for a developer and the team in general.
Because the client is usually outside our sphere of direct influence, there’s little that we can do to affect their overall morale. The good news is that the biggest way we can affect their mood is simply by doing what we were trained to do: build and deliver software.
Clients have fairly simple concerns when it comes to software development projects. They want to get software that works the way they need it to (without fail), when they need it, and for a reasonable cost. This doesn’t change between projects or between clients.
The great thing for developers is that many of the things that will make working in the code easier will also address the concerns of the client. Introducing automated testing (see chapter 4) will help to increase quality. Applying good object-oriented (OO) principles to the codebase (chapter 7) will increase the speed with which changes and new features can be implemented with confidence. Applying agile principles, such as increased stakeholder/end user involvement, will show clients firsthand that the development team has their interests at heart.
Any combination of these things will increase the morale of the client at the same time as, and possibly correlated to, increasing their confidence in the development team. The increased confidence that they have will significantly reduce friction and increase communication within the team. Those are two things that will positively influence the project’s success.
To relate this again back to brownfield applications, remember that the client likely is coming into the project with some preconceived notions of the team and the project based on direct experience. If some bad blood exists between the client and the development team, you have your work cut out for you. In our experience, constant and open communication with the client can go a long way to rebuilding any broken relationships.
Whatever bad blood has existed in the past, you should make every attempt to repair damaged relationships. Don’t be afraid to humble yourself. It’s helpful to remember that you’re there for your client’s benefit, not the other way around.
Tales from the trenches: Involving the client
For one of our clients, quality assurance (QA) testing had historically been a bottleneck on projects. Without a dedicated QA team, the business analyst was taking on these duties...whenever she could fit it in with her regular duties. Development charged ahead at full steam but nothing could be taken off our “completed features” list until the QA had been completed.
Unfortunately, the business analyst wasn’t receptive when we suggested she work an 80-hour week. So our alternate solution was to engage the end users directly for the QA testing. Three people who were going to use the application dedicated a certain number of hours each week to QA testing.
The advantages were so quick and so numerous, we felt foolish for not thinking of it sooner. Not only did our QA bottleneck all but disappear, but also the users provided invaluable feedback on the direction of the features, they got “on-the-job” training on how the application worked, and each team gained a greater appreciation for the needs of the other. The business users became much more interested in the development process because their feedback was being heard and they got responses quickly. Because of this, the relationship between the developers and the client flourished, setting the stage for a much smoother experience in the next project.
We cannot overstate this: involving the client is A Good Thing.
So far, we’ve psychoanalyzed our team and our client. That just leaves the management team in the middle. Let’s talk about how they feel.
1.4.5. Management morale
We’ve discussed the morale of the team and the client. In between those two usually sits a layer of management. These are the people tasked with herding the cats. Like everyone else, they can fall victim to poor morale. From the perspective of the developer, management morale problems manifest themselves in the same way that client morale problems do.
It’s helpful to think of management as another client for the development team, albeit one with slightly different goals. They have deliverables that they expect from the development team, but they’re happiest when the client is happiest. As such, you can influence their morale the same way you influence the client’s: by building quality software on time and on budget.
A good method we’ve found for improving management morale is to keep open communication lines. This is true for your client as well, but nothing saps a project manager’s energy like a problem that has been allowed to fester unchecked until it bubbles over. Even if there is nothing actionable, most managers like to know what’s going on, both good and bad. At the beginning of the project there may be more bad than good, but as long as you stay focused on the goal of improving the application, managers can help navigate to where the effort should be focused.
That covers everybody. In the next section, we’ll focus on change.
1.4.6. Being an agent for change
As a software developer, you likely don’t have a problem embracing change at a personal level. After all, change is one of the defining characteristics of our industry. The challenge will be effecting change on a broader level in your project.
This being a brownfield application, change must be inevitable. Clearly, the path that led to the codebase being a brownfield application didn’t work too well, and the fact that you’re reading this book probably indicates that the project is in need of some fresh ideas.
Not everyone has the stomach for change. Clients dread it and have grown accustomed to thinking that technical people are only concerned with the cool new stuff. Management fears it because it introduces risk around areas of the application that they’ve become comfortable with assuming are now risk free. Testers loath it as it will add extra burden to their short-term workload. Finally, some developers reject it because they’re comfortable having “always done it this way.” (See section 1.2.3 earlier in this chapter.)
Tales from the trenches: Dealing with skepticism
Over the course of our careers, we’ve heard countless excuses from people who, for one reason or another, simply don’t want to learn anything new. Examples include “I don’t have time to learn, I’m too busy getting work done” and “How is a college summer student going to support this?” and “This is too different from the way we’re used to” and “We’ve never had a problem with the old way of doing things.”
On one project where we met considerable skepticism, the response required some planning and more than a little good fortune. We sought out others on the team who were more receptive to our goals. We worked directly with them to train them on different techniques and help instill a sense of continuous improvement.
The good fortune came in the form of a manager with a long-term goal that the team would be trained within the next 3 to 5 years. Whenever we met with particularly strong resistance, he’d act as the arbitrator to decide the direction the team should go. Sometimes he would decide in our favor; sometimes he wouldn’t. But whatever the final decision, it was always explained clearly that it was in support of the long-term goal.
If this sounds a little too “mom-and-apple-pie,” that’s because we’re sugarcoating it. Success wasn’t total and the team didn’t look the same way at the end of the project as it did at the beginning. But over time, we were able to introduce some useful tools into their arsenal and get most of them into the mind-set of continuous improvement.
In the end, it was a measured response and more than a little support from above that helped.
Even with all these barriers to change, people in each of those roles will be thankful after the fact that change has taken place. We do assume that the change was successful and, just as important, that the team members can see the effects of the change. If change happens and there is nothing that can be used for comparison, or nothing that can be trotted out in a meeting that indicates the effect of the change, it will be hard for team members to agree that the effort required was worth the gain received. It might be as simple as creating a report, such as the one shown in figure 1.5, which visually describes the progress being made in different areas of the project’s work effort.
Figure 1.5. Before starting any change, be sure you can measure how successful it will be when you’re done.

As a person who thinks of development effort in terms of quality, maintainability, timeliness, and completeness, you have all the information and tools to present the case for change, both before and after it has occurred. Remember, you’ll have to convince people to allow you to implement the change (whether in its entirety or in isolation) and to get the ball rolling. You’ll also be involved in providing the proof that the effect(s) of the change were worth the effort. You have to be the agent for change.
This ability will come with experience, but in the meantime here are a couple of tactics you can try. The first is “It’s better to beg forgiveness than to ask permission.” Now, we’re not espousing anarchy as a way of getting things done, but if you can defend your actions and you feel the consequences are reasonable, going ahead and, say, adding a unit-test project to your application can get things rolling. If your decision is easily reversible, that’s all the better.
Also, be efficient. Talk only to the people you need to talk to and tell them only pertinent details. Users don’t care if you want to implement an object-relational mapper (see chapter 11). If you aren’t talking about cash dollars, leave them and your VPs out of the conversation.
Challenge your assumptions: Making change
When talking about working on poorly performing projects, a developer we both highly respect said to us, “Change your environment, or change your environment.” That is, if you can’t change the way things are done in your organization, consider moving on to a new environment.
Sometimes you’ll find environments where, no matter how well you prepare, present, and follow through on a proposed change, you won’t be able to implement it. If you can’t make changes in your environment, you’re not going to make it any better, and that’s frustrating. No matter how change resistant your current organization may be, you can always make a change in your personal situation. That could be moving to a different team, department, or company. Regardless of what the change ends up being, make sure that you’re in the situation that you can be most comfortable in.
Acting as an agent is similar to how a business analyst or client works for the business needs. You have to represent the needs of your project to your team. But change doesn’t just happen; someone has to advocate it, to put their neck on the line (sometimes a little, sometimes a lot). Someone has to get the ball rolling. It takes a special kind of personality to achieve this. You have to be confident in the arguments you make. You need to inspire others on the project team where change needs to occur. You don’t necessarily have to orate at the same level as Martin Luther King Jr., JFK, or Mahatma Gandhi, but you need to inspire some passion from people. If you can, you should be that person.
If you’re joining a brownfield project, you’re in the perfect situation to advocate change. You’re looking at the code, the process, and the team with fresh eyes. You’re seeing what others with more time on the project may have already become numb to. You may have fresh ideas about tools and practices that you bring from other projects. You, above all else, can bring enthusiasm and energy to a project that’s simply moving forward in the monotony of the day to day.
As we’ve mentioned before, you’ll want to tread lightly at the start. First, get the lay of the land and find (or create) allies within the project. More than anything, you’ll want to proceed with making change.
During our time talking about change with different groups and implementing it in our own work, we have come up with one clear thought: the process of change is about hearts and minds, not shock and awe. Running into a new project with your technical and process guns blazing will alienate and offend some of the existing team. They’ll balk at the concepts simply because you’re the new person. Negativity will be attached to your ideas because the concerned parties will, without thought, think that they’re nothing more than fads or the ideas of a rogue or cowboy developer. Once you’ve entered a project in this fashion, it’s extremely difficult to have the team think of you in any other way.
Hearts and minds is all about winning people over. Take one developer at a time. Try something new with a person who’s fighting a pain point and, if you’re successful at solving the problem area, you’ll have a second advocate spreading ideas of change. People with historical relevance on the project usually carry more weight than a new person when proposing change. Don’t be afraid to find and use these people.
Tales from the trenches: Don’t get emotionally involved
In one project we were on, tensions started to run high as the team fragmented into a consultants-versus-employees mentality. On the one side were the consultants who wanted to “throw in a bunch of advanced code that the others couldn’t understand or support.” On the other were the employees who were “so far behind in their skills, they may as well be coding in COBOL.” The frustration culminated in an email from one employee to one of us copied to not only the current team but everyone in the entire group as well as a couple of managers. Some of the complaints in the email were valid; some less so. Among the rational ones: we removed code that we had thought wasn’t being called, not counting on direct calls made to it from an Active Server Pages Framework (ASPX) page.
The first off-the-cuff email response we made sat in our draft box for a couple of hours before we deleted it. We took a deep breath and wrote a second one. The cc list was reduced only to the direct team. We included a sincere apology for removing the code and a request that we keep our focus on delivering value to the client. This was followed up with a telephone call reiterating the apology.
In this case, there are many reasons we could’ve given to defend ourselves: Why are we calling code directly from an ASPX page? Why does the app still compile and pass all its tests? And why does something like this warrant such a melodramatic response?
All of these are subjective and would have prolonged, and likely escalated, the situation. By admitting wrongdoing, we were able to diffuse the situation and get back on track quickly.
Emotionally charged situations will arise in your brownfield projects. As tough as it will be at the time, it’s imperative that you keep your wits about you and stay focused on the goal: delivering an application the client is happy with.
Being an agent of change is about playing politics, suggesting ideas, formulating reasoning for adoption, and following through with the proposals. In some environments, none of these things will be simple. The problem is, if someone doesn’t promote ideas for change, they’ll never happen. That’s where you (and, we hope, this book) come in. One of the common places that you’ll have to sell these changes is to management. Let’s take a look at what can happen there.
1.5. Selling it to your boss
There may be some reluctance and possibly outright resistance to making large-scale changes to an application’s architecture and design. This is especially true when the application already “works” in some fashion. After all, users don’t typically see any noticeable difference when you refactor. It’s only when you’re able to deliver features and fix defects much quicker that the efforts get noticed.
Often, managers even recognize that an application isn’t particularly well written but are still hesitant. They will ease developers’ concerns by claiming that “We’ll refactor it in the next release but for the time being, let’s just get it done.”
The technical debt phase
As mentioned in section 1.1.2, technical debt is the laundry list of items that eventually should get done but that are easy to put off. Every project incurs technical debt, and many projects deal with it through a big push phase (if they deal with it at all). This is some major undertaking where all work on the application stops until you’ve worked through at least a good chunk of your technical debt.
This isn’t the way to go. Instead, we promote the idea of a time-boxed task every, or every other, coding cycle (whether that be development iterations or releases to testing). The sole purpose of this task is to pay down some technical debt.
This doesn’t have to be a team-wide task. It may take only one person working half a day a week. And it’s limited by time, not by tasks. The person working on technical debt works on it for the allotted time, then stops, regardless of how much is left on the technical debt list. (The person should finish what she’s started and plan accordingly.)
This sentiment is understandable and may even be justified. Just as there are managers who ignore the realities of technical debt, many developers ignore the realities of basic cost-benefit equations. As a group, we have a tendency to suggest changes for some shaky reasons:
- We want to learn a new technology or technique.
- We read a white paper/blog post suggesting this is the thing to do.
- We don’t want to take the time to understand the current codebase.
- We believe that doing it another way will make all our problems go away and not introduce a different set of issues.
- We’re bored with the tasks that have been assigned to us.
So before we talk about how to convince your boss to undertake a massive rework in the next phase of the project, it’s worth taking stock of the reasons why we’re suggesting it. Are we doing it for the client’s benefit? Or is it for ours?
The reason we ask is that there are many valid business reasons why you shouldn’t undertake this kind of work. Understanding them will help put your desires to try something new in perspective:
- The project’s shelf life is short.
- The application does follow good design patterns—just not ones you agree with.
- The risk associated with the change is too large to mitigate before the next release.
- The current team or the maintenance team won’t be able to technically understand the changed code and need training first.
- Significant UI changes may risk alienating the client or end user.
Warning
Be cautious when someone suggests a project’s shelf life will be short. Applications have a tendency to outlive their predicted retirement date. Like shelf life, people often minimize the perceived technical complexity of a project. Don’t let this fool you. We’ve seen many “simple” applications turn into monstrous beasts that have required advanced technical implementations to achieve the goals and needs of the business. Never buy this line of rhetoric. Instead, prepare yourself and your codebase for the likely eventuality of increasing technical complexity.
Note
Lack of time and money are two common reasons given for choosing not to perform a large-scale refactoring. Neither one is valid unless the person making the decision outright admits they’re hoping for a short-term gain in exchange for long-term pain.
You won’t have an easy time trying to justify the expense of large-scale changes. It’s hard to find good solid information on this that’s written in a way meant to convince management to adopt. Even if you do find a good piece of writing, it’s common for management to dismiss the article on the grounds that the writer doesn’t have a name known to them, or that the situation doesn’t apply.
By far, the best way to alter management’s opinion is to show concrete results with clear business value. Attempt to convince them to let you try a prototype in a small and controlled situation. This will give them the comfort that if the trial goes sour, they’ll have protected the rest of the project and not spent a lot of money. And if it goes well, they now have the data to support their decision to go ahead.
For these same reasons, you shouldn’t be looking at the proof of concept solely as a way to convince your management that you are right. You should always consider that your suggestion may not be the best thing for the project and approach the trial objectively. This allows you to detach yourself from any one technology and focus on the success of the project itself. If the experiment succeeds, you now have a way of helping the project succeed. If it fails, at least you didn’t go too far down the wrong road.
In figure 1.6, we show something akin to a mockup but with notes on how it can work within our existing infrastructure.
Figure 1.6. Proofs of concept and mockups can help convince your boss of the value of a concept and can help you work out kinks before implementing it large-scale.

Another advantage of proofs of concept is that because you’re constrained to a small area, you can be protected from external factors. You can then focus on the task at hand and increase your chances to succeed—which is your ideal goal.
When you’re discussing change with decision makers, it’s a good idea to discuss benefits and costs in terms of cash dollars whenever possible. Doing so may not be as difficult as it first sounds.
Previously, we discussed the concept of pain points and friction. This is the first step in quantifying the money involved: isolate the pain point down to specific steps that can be measured. The steps that are causing pain for the development team can then be translated into business terms.
There are two kinds of cost savings you can focus on. The first is direct savings from being able to work faster. If you spend 2 hours implementing a change and that change saves half a day for each of four developers on the project, the task can be justified.
Another way to look at this method of cost savings is as an opportunity cost. How much money is the company forgoing by not completing a particular cost-saving task?
The second method of cost savings is what keeps insurance companies in business: How much money will it cost if we don’t implement a certain task and things go wrong? Can we spend a little money up front to reduce our risk exposure in the event something goes horribly wrong?
In the end, the discussion points for selling management or clients on the idea of reworking the codebase are going to include the concepts of cost and risk. By using prototypes and proofs of concept, along with examples of inefficiency and risk, you’ll be more likely to address significant points of concern held by your audience.
Once we’ve addressed the concerns of management and clients, it’s time to start doing some work. That’s a great point for us to get you into the technology. Chapter 2 starts at a seemingly innocuous part of the process: version control.
1.6. Summary
Like so many in software development, you’ll spend more time on projects that are incomplete or in ongoing development than you will on projects that aren’t. It’s much more common for projects to need our services once they’ve been started and resource shortages or inadequacies have bubbled to the surface.
With these projects, we inherit all the problems that come with them. Problems will include technical, social, and managerial concerns, and in some way you’ll be interacting with all of these. The degree of influence that you have over changing them will vary depending on both the project environment and the position that you have in it.
Remember that you probably won’t solve all the problems all the time. Don’t get wrapped up in the magnitude of everything that’s problematic. Instead, focus on little pieces where the negative impact on the project, at whatever level, is high and where you’re in a position to make or direct the change. These pain points are the ones that will provide the biggest gain.
Positive change works wonders on the project, no matter what the change is. Remember to look at pain points that have cross-discipline benefits. Implementing a solution for a problem that’s felt by developers, management, testers, and the clients will have a positive influence on each of those disciplines. More importantly, positive cross-discipline improvements will increase the communication and rapport between the groups that may exist within the project team.
No matter the effect that you have said that a change will have on a project team, there will still be people who resist. Convincing these people will become a large part of the work that you do when trying to implement a new technique or process. One of the most effective ways is to sell the change using terms and conditions that will appeal to the resister. If part of their role, as in management, is to be concerned with money and timeline, then sell to those points. For technical people, appeal to the sense of learning new techniques and bettering their craft.
Even with the tactical use of this technique, you’ll often run into people and topics that take more selling. If you feel as if you’re at a dead end, ask for a time-boxed task where you can prove the technique or practice on a small scale and in an isolated environment. Often, results from these trial or temporary implementations will speak volumes to the person who’s blocking their use.
The changes that you, as a developer, make to a project, whether permanently or on a trial basis, will fall into two different concerns: ecosystem and code. No matter how well schooled a project is in one of those two areas, deficiencies in the other can still drag it down. Don’t concentrate on one over the other. Instead, focus on the areas in the project where the most significant pain points are occurring. Address those first and then move on to the next largest pain point.
As we step through this book, you’ll see a number of categories that pain points will occur in. Although we have tried to address them in a specific order, and each builds on the previous, your project may need an order of its own. This is fine. Adapt what you see in the book and the sample project that provides the best results for you.
With that, let’s move on to addressing some common pain points.