
Chapter 10. Concurrency and scalability
This chapter covers
- Camel’s threading model
- Configuring thread pools and thread profiles
- Using concurrency with EIPs
- Message synchronicity and concurrency
- Camel’s client concurrency API
- Scalability with Camel
Concurrency is another word for multitasking, and we multitask all the time in our daily lives. We put the coffee on, start up the computer, and while it’s booting grab the paper to glance at the news. Computers are also capable of doing multiple tasks—you may have multiple tabs open in your web browser while your mail application is fetching new email, for example.
Juggling multiple tasks is also very common in enterprise systems, such as when you’re processing incoming orders, handling invoices, and doing inventory management, and these demands only grow over time. With concurrency, you can achieve higher performance; by executing in parallel, you can get more work done in less time.
Camel processes multiple messages concurrently in Camel routes, and it leverages the concurrency features from Java, so we’ll first discuss how concurrency works in Java before we can move on to how thread pools work and how you define and use them in Camel. The thread pool is the mechanism in Java that orchestrates multiple tasks. After we’ve discussed thread pools, we’ll move on to how you can use concurrency with the EIPs, and we’ll dive into how message synchronicity works. We’ll then look at Camel’s client concurrency API, which makes it easier for clients to work with concurrency. The last section of this chapter focuses on how you can achieve high scalability with Camel and how you can leverage this in your custom components.
10.1. Introducing concurrency
As we’ve mentioned, you can achieve higher performance with concurrency. When performance is limited by the availability of a resource, we say it’s bound by that resource: CPU-bound, IO-bound, database-bound, and so on. Integration applications are often IO-bound, waiting for replies to come back from remote servers, or for files to load from a disk. This usually means you can achieve higher performance by utilizing resources more effectively, such as by keeping CPUs busy doing useful work.
Camel is often used to integrate disparate systems, where data is exchanged over the network. This means there’s often a mix of resources, which are either CPU-bound or IO-bound. It’s very likely you can achieve higher performance by using concurrency.
To help explain the world of concurrency, we’ll look at an example. Rider Auto Parts has an inventory of all the parts its suppliers currently have in stock. It’s vital for any business to have the most accurate and up-to-date information in their central ERP system. Having the information locally in the ERP system means the business can operate without depending on online integration with their suppliers. Figure 10.1 illustrates this business process.
Figure 10.1. Suppliers send inventory updates, which are picked up by a Camel application. The application synchronizes the updates to the ERP system.
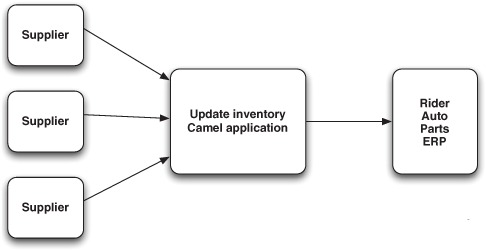
Figure 10.2 shows the route of the inventory-updating Camel application from figure 10.1. This application is responsible for loading the files and splitting the file content on a line-by-line basis using the Splitter EIP, which converts the line from CSV format to an internal object model. The model is then sent to another route that’s responsible for updating the ERP system. Implementing this in Camel is straightforward.
Figure 10.2. A route picks up incoming files, which are split and transformed to be ready for updating the inventory in the ERP system.

Listing 10.1. Rider Auto Parts application for updating inventory
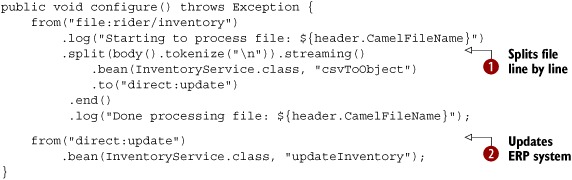
Listing 10.1 shows the configure method of the Camel RouteBuilder that contains the two routes for implementing the application. As you can see, the first route picks up the files and then
splits the file content line by line ![]() . This is done by using the Splitter EIP in streaming mode. The streaming mode ensures that the entire file isn’t loaded into memory; instead it’s loaded piece by piece on demand,
which ensures low memory usage.
. This is done by using the Splitter EIP in streaming mode. The streaming mode ensures that the entire file isn’t loaded into memory; instead it’s loaded piece by piece on demand,
which ensures low memory usage.
To convert each line from CSV to an object, you use a bean—the InventoryService class. To update the ERP system, you use the updateInventory method of the InventoryService, as shown in the second route ![]() .
.
Now suppose you’re testing the application by letting it process a big file with 100,000 lines. If each line takes a tenth of a second to process, processing the file would take 10,000 seconds, which is roughly 167 minutes. That’s a long time. In fact, you might end up in a situation where you can’t process all the files within the given timeframe.
In a moment, we’ll look at different techniques for speeding things up by leveraging concurrency. But first we’ll set up the example to run without concurrency to create a baseline to compare to the concurrent solutions.
10.1.1. Running the example without concurrency
The source code for the book contains this example (both with and without concurrency) in the chapter10/bigfile directory.
First, you need a big file to be used for testing. To create a file with 1000 lines, use the following Maven goal:
mvn compile exec:java -PCreateBigFile -Dlines=1000
A bigfile.csv file will be created in the target/inventory directory.
The next step is to start a test that processes the bigfile.csv without concurrency. This is done by using the following Maven goal:
mvn test -Dtest=BigFileTest
When the test runs, it will output its progress to the console.
BigFileTest simulates updating the inventory by sleeping for a tenth of a second, which means it should complete processing the bigfile.csv in approximately 100 seconds. When the test completes, it should log the total time taken:
[ad 0 - file://target/inventory] INFO - Inventory 997 updated
[ad 0 - file://target/inventory] INFO - Inventory 998 updated
[ad 0 - file://target/inventory] INFO - Inventory 999 updated
[ad 0 - file://target/inventory] INFO - Done processing big file
Took 102 seconds
In the following section, we’ll see three different solutions to run this test more quickly using concurrency.
10.1.2. Using concurrency
The application can leverage concurrency by updating the inventory in parallel. Figure 10.3 shows this principle by using the Concurrent Consumers EIP.
Figure 10.3. Using the Concurrent Consumers EIP to leverage concurrency and process inventory updates in parallel

As you can see in figure 10.3, the idea is to use concurrency ![]() after the lines have been split
after the lines have been split ![]() . By doing this, you can parallelize steps
. By doing this, you can parallelize steps ![]() and
and ![]() in the route. In this example, those two steps could process messages concurrently.
in the route. In this example, those two steps could process messages concurrently.
The last step ![]() , which sends messages to the ERP system concurrently, is only possible if the system allows a client to send messages concurrently
to it. There can be situations where a system does not permit concurrency, or it may only allow up to a certain number of concurrent messages. Check the SLA (service level agreement) for the system you integrate with. Another
reason to disallow concurrency would be if the messages have to be processed in the exact order they are split.
, which sends messages to the ERP system concurrently, is only possible if the system allows a client to send messages concurrently
to it. There can be situations where a system does not permit concurrency, or it may only allow up to a certain number of concurrent messages. Check the SLA (service level agreement) for the system you integrate with. Another
reason to disallow concurrency would be if the messages have to be processed in the exact order they are split.
Let’s try out three different ways to run the application faster with concurrency:
- Using parallelProcessing options on the Splitter EIP
- Using a custom thread pool on the Splitter EIP
- Using staged event-driven architecture (SEDA)
The first two solutions are features that the Splitter EIP provides out of the box. The last solution is based on the SEDA principle, which uses queues between tasks.
Using Parallelprocessing
The Splitter EIP offers an option to switch on parallel processing, as shown here:
.split(body().tokenize("
")).streaming().parallelProcessing()
.bean(InventoryService.class, "csvToObject")
.to("direct:update")
.end()
Configuring this in Spring XML is very simple as well:
<split streaming="true" parallelProcessing="true">
<tokenize token=" "/>
<bean beanType="camelinaction.InventoryService"
method="csvToObject"/>
<to uri="direct:update"/>
</split>
To run this example, use the following Maven goals:
mvn test -Dtest=BigFileParallelTest
mvn test -Dtest=SpringBigFileParallelTest
As you’ll see, the test is now much faster and completes in about a tenth of the previous time.
[Camel Thread 1 - Split] INFO - Inventory 995 updated
[Camel Thread 4 - Split] INFO - Inventory 996 updated
[Camel Thread 9 - Split] INFO - Inventory 997 updated
[Camel Thread 3 - Split] INFO - Inventory 998 updated
[Camel Thread 2 - Split] INFO - Inventory 999 updated
[e://target/inventory?n] INFO - Done processing big file
Took 11 seconds
What happens is that when parallelProcessing is enabled, the Splitter EIP uses a thread pool to process the messages concurrently. The thread pool is, by default, configured to use 10 threads, which helps explain why it’s about 10 times faster: the application is mostly IO-bound (reading files and remotely communicating with the ERP system involves a lot of IO activity). The test would not be 10 times faster if it were solely CPU-bound; for example, if all it did was “crunch numbers.”
Note
In the console output you’ll see that the thread name is displayed, containing a unique thread number, such as Camel Thread 4 - Split. This thread number is a sequential, unique number assigned to each thread as it’s created, in any thread pool. This means if you use a second Splitter EIP, the second splitter will most likely have numbers assigned from 11 upwards.
You may have noticed from the previous console output that the lines were processed in order; it ended by updating 995, 996, 997, 998, and 999. This is a coincidence, because the 10 concurrent threads are independent and they run at their own pace. The reason why they appear in order here is because we simulated the update by delaying the message for a tenth of a second, which means they’ll all take approximately the same amount of time. But if you take a closer look in the console output, you’ll probably see some interleaved lines, such as with order lines 954 and 953:
[Camel Thread 5 - Split] INFO - Inventory 951 updated
[Camel Thread 7 - Split] INFO - Inventory 952 updated
[Camel Thread 8 - Split] INFO - Inventory 954 updated
[Camel Thread 9 - Split] INFO - Inventory 953 updated
You now know that parallelProcessing will use a default thread pool to achieve concurrency. What if you want to have more control over which thread pool is being used?
Using a Custom Thread Pool
The Splitter EIP also allows you to use a custom thread pool for concurrency. You can create a thread pool using the java.util.Executors factory:
ExecutorService threadPool = Executors.newCachedThreadPool();
The newCachedThreadPool method will create a thread pool suitable for executing many small tasks. The pool will automatically grow and shrink on demand.
To use this pool with the Splitter EIP, you need to configure it as shown here:
.split(body().tokenize("
")).streaming().executorService(threadPool)
.bean(InventoryService.class, "csvToObject")
.to("direct:update")
.end()
Creating the thread pool using Spring XML is done as follows:
<bean id="myPool" class="java.util.concurrent.Executors"
factory-method="newCachedThreadPool"/>
The Splitter EIP uses the pool by referring to it, using the executorServiceRef attribute, as shown:
<split streaming="true" executorServiceRef="myPool">
<tokenize token=" "/>
<bean beanType="camelinaction.InventoryService"
method="csvToObject"/>
<to uri="direct:update"/>
</split>
To run this example, use the following Maven goals:
mvn test -Dtest=BigFileCachedThreadPoolTest
mvn test -Dtest=SpringBigFileCachedThreadPoolTest
The test is now much faster and completes within a few seconds:
[pool-1-thread-442] INFO - Inventory 971 updated
[pool-1-thread-443] INFO - Inventory 972 updated
[pool-1-thread-449] INFO - Inventory 982 updated
[e://target/invene] INFO - Done processing big file
Took 2 seconds
You may wonder why it’s now so fast. The reason is that the cached thread pool is designed to be very aggressive and to spawn new threads on demand. It has no upper bounds and no internal work queue, which means that when a new task is being handed over, it will create a new thread if there are no available threads in the thread pool.
You may also have noticed the thread name in the console output, which indicates that many threads were created; the output shows thread numbers 442, 443, and 449. Many threads have been created because the Splitter EIP splits the file lines more quickly than the tasks update the inventory. This means that the thread pool receives new tasks at a higher pace than it can execute them; new threads are created to keep up.
This can cause unpredicted side effects in an enterprise system—a high number of newly created threads may impact applications in other areas. That’s why it’s often desirable to use thread pools with an upper limit for the number of threads.
For example, instead of using the cached thread pool, you could use a fixed thread pool. You can use the same Executors factory to create such a pool:
ExecutorService threadPool = Executors.newFixedThreadPool(20);
Creating a fixed thread pool in Spring XML is done as follows:
<bean id="myPool" class="java.util.concurrent.Executors"
factory-method="newFixedThreadPool">
<constructor-arg index="0" value="20"/>
</bean>
To run this example, use the following Maven goals:
mvn test -Dtest=BigFileFixedThreadPoolTest
mvn test -Dtest=SpringBigFileFixedThreadPoolTest
The test is now limited to use 20 threads at most.
[pool-1-thread-13] INFO - Inventory 997 updated
[pool-1-thread-19] INFO - Inventory 998 updated
[ pool-1-thread-5] INFO - Inventory 999 updated
[ ntory?noop=true] INFO - Done processing big file
Took 6 seconds
As you can see by running this test, you can process the 1,000 lines in about 6 seconds using only 20 threads. The previous test was faster, as it completed in about 2 seconds, but it used nearly 500 threads (this number can vary on different systems). By increasing the fixed thread pool to a reasonable size, you should be able to reach the same timeframe as with the cached thread pool. For example, running with 50 threads completes in about 3 seconds. You can experiment with different pool sizes.
Now, on to the last concurrency solution, SEDA.
Using SEDA
SEDA (staged event-driven architecture) is an architecture design that breaks down a complex application into a set of stages connected by queues. In Camel lingo, that means using internal memory queues to hand over messages between routes.
Note
The Direct component in Camel is the counterpart to SEDA. Direct is fully synchronized, and it works like a direct method call invocation.
Figure 10.4 shows how you can use SEDA to implement the example. The first route runs sequentially in a single thread. The second route uses concurrent consumers to process the messages that arrive on the SEDA endpoint, using multiple concurrent threads.
Figure 10.4. Messages pass from the first to the second route using SEDA. Concurrency is used in the second route.
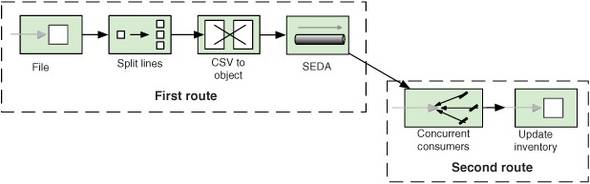
Listing 10.2 shows how to implement this solution in Camel by using the seda endpoints, shown in bold.
Listing 10.2. Rider Auto Parts inventory-update application using SEDA

By default, a seda consumer will only use one thread. To leverage concurrency, you use the concurrentConsumers option to increase the number of threads—to 20 in this listing ![]() .
.
To run this example, use the following Maven goals:
mvn test -Dtest=BigFileSedaTest
mvn test -Dtest=SpringBigFileSedaTest
The test is fast and completes in about 6 seconds.
[ead 20 - seda://update] INFO - Inventory 997 updated
[ead 18 - seda://update] INFO - Inventory 998 updated
[read 9 - seda://update] INFO - Inventory 999 updated
Took 6 seconds
As you can see from the console output, you’re now using 20 concurrent threads to process the inventory update. For example, the last three thread numbers from the output are 20, 18, and 9.
Note
When using concurrentConsumers with SEDA endpoints, the thread pool uses a fixed size, which means that a fixed number of active threads are waiting at all times to process incoming messages. That’s why it’s best to leverage the concurrency features provided by the EIPs, such as the parallelProcessing on the Splitter EIP. It will leverage a thread pool that can grow and shrink on demand, so it won’t consume as many resources as a SEDA endpoint will.
We’ve now covered three different solutions for applying concurrency to an existing application, and they all greatly improve performance. We were able to reduce the 11-second processing time down to 3 to 7 seconds, using a reasonable size for the thread pool.
In the next section, we’ll review thread pools in more detail and learn about the threading model used in Camel. With this knowledge, you can go even further with concurrency.
10.2. Using thread pools
Using thread pools is common when using concurrency. In fact, thread pools were used in the example in the previous section. It was a thread pool that allowed the Splitter EIP to work in parallel and speed up the performance of the application.
In this section, we’ll start from the top and briefly recap what a thread pool is and how it’s represented in Java. Then we’ll look at the default thread pool profile used by Camel and how to create custom thread pools using Java DSL and Spring XML. We’ll also look at how you can use a custom strategy to delegate the creation of thread pools to an external resource, such as a Java WorkManager on a JAVA EE server.
10.2.1. Understanding thread pools in Java
A thread pool is a group of threads that are created to execute a number of tasks in a task queue. Figure 10.5 shows this principle.
Figure 10.5. Tasks from the task queue wait to be executed by a thread from the thread pool.

Note
For more info on the Thread Pool pattern, see the Wikipedia article on the subject: http://en.wikipedia.org/wiki/Thread_pool.
Thread pools were introduced into Java 1.5 by the new concurrency API residing in the java.util.concurrent package. In the concurrency API, the ExecutorService interface is the client API that you use to submit tasks for execution. Clients of this API are both Camel end users and Camel itself, because Camel fully leverages the concurrency API from Java.
Note
Readers already familiar with Java’s concurrency API may be in familiar waters as we go further in this chapter. If you want to learn in depth about the Java concurrency API, we highly recommend the book Java Concurrency in Practice by Brian Goetz.
In Java, the ThreadPoolExecutor class is the implementation of the ExecutorService interface, and it provides a thread pool with the options listed in table 10.1.
Table 10.1. Options provided by thread pools
As you can see from table 10.1, there are many options you can use when creating thread pools in Java. To make it easier to create commonly used types of pools, Java provides Executors as a factory, which you saw in section 10.1.2. In section 10.2.3, you’ll see how Camel makes creating thread pools even easier.
When working with thread pools, there are often additional tasks you must deal with. For example, it’s important to ensure the thread pool is shut down when your application is being shut down; otherwise it can lead to memory leaks. This is particularly important in server environments when running multiple applications in the same server container, such as a JAVA EE or OSGi container.
When using Camel to create thread pools, the activities listed in table 10.2 are taken care of out of the box.
Table 10.2. Activities for managing thread pools
|
Activity |
Description |
|---|---|
| Shutdown | Ensures the thread pool will be properly shut down, which happens when Camel shuts down. |
| Management | Registers the thread pool in JMX, which allows you to manage the thread pool at runtime. We’ll look at management in chapter 12. |
| Unique thread names | Ensures the created threads will use unique and human-readable names. |
| Activity logging | Logs lifecycle activity of the pool. |
Another good practice that’s often neglected is to use human-understandable thread names, because those names are logged in production logs. By allowing Camel to name the threads using a common naming standard, you can better understand what happens when looking at log files (particularly if your application is running together with other frameworks that create their own threads). For example, this log entry indicates it’s a thread from the Camel File component:
[Camel Thread 7 - file://riders/inbox] DEBUG - Total 3 files to consume
If Camel didn’t do this, the thread name would be generic and wouldn’t give any hint that it’s from Camel, nor that it’s the file consumer.
[Thread 0] DEBUG - Total 3 files to consume
Tip
Camel uses a customizable pattern for naming threads. The default pattern is "Camel Thread ${counter} - ${name}". A custom pattern can be configured using ExecutorServiceStrategy. In Camel 2.6 the default pattern has been improved to include the Camel id "Camel (${camelId}) thread ${counter} - ${name}".
We’ll cover the options listed in table 10.1 in more detail in the next section, when we review the default thread profile used by Camel.
10.2.2. Camel thread pool profiles
Thread pools aren’t created and configured directly, but via the configuration of thread pool profiles. A thread pool profile is a profile that dictates how a thread pool should be created, based on a selection of the options listed earlier in table 10.1.
Thread pool profiles are organized in a simple two-layer hierarchy with custom and default profiles. There is always one default profile and you can optionally have multiple custom profiles.
The default profile is defined using the options listed in table 10.3.
Table 10.3. Settings for the default thread pool profile
|
Option |
Default value |
Description |
|---|---|---|
| poolSize | 10 | The thread pool will always contain at least 10 threads in the pool. |
| maxPoolSize | 20 | The thread pool can grow up to at most 20 threads. |
| keepAliveTime | 60 | Idle threads are kept alive for 60 seconds, after which they’re terminated. |
| maxQueueSize | 1000 | The task queue can contain up to 1000 tasks before the pool is exhausted. |
| rejectedPolicy | CallerRuns | If the pool is exhausted, the caller thread will execute the task. |
As you can see from the default values in table 10.3, the default thread pool can use from 10 to 20 threads to execute tasks concurrently. The rejectedPolicy option corresponds to the rejected option from table 10.1, and it’s an enum type allowing four different values: Abort, CallerRuns, DiscardOldest, and Discard. The CallerRuns option will use the caller thread to execute the task itself. The other three options will either abort by throwing an exception, or discard an existing task from the task queue.
There is no one-size-fits-all solution for every Camel application, so you may have to tweak the default profile values. But usually you’re better off leaving the default values alone. Only by load testing your applications can you determine that tweaking the values will produce better results.
Configuring the Default Thread Pool Profile
You can configure the default thread pool profile from either Java or Spring XML.
In Java, you access the ThreadPoolProfile starting from CamelContext. The following code shows how to change the maximum pool size to 50.
ExecutorServiceStrategy strategy = context.getExecutorServiceStrategy();
ThreadPoolProfile profile = strategy.getDefaultThreadPoolProfile();
profile.setMaxPoolSize(50);
The default ThreadPoolProfile is accessible from ExecutorServiceStrategy, which is an abstraction in Camel allowing you to plug in different thread pool providers. We’ll cover ExecutorServiceStrategy in more detail in section 10.2.4.
In Spring XML, you configure the default thread pool profile using the <threadPoolProfile> tag:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPoolProfile id="myDefaultProfile"
defaultProfile="true"
maxPoolSize="50"/>
...
</camelContext>
It’s important to set the defaultProfile attribute to true to tell Camel that this is the default profile. You can add additional options if you want to override any of the other options from table 10.3.
There are situations where one profile isn’t sufficient, so you can also define custom profiles.
Configuring Custom Thread Pool Profiles
Defining custom thread pool profiles is much like configuring the default profile.
In Java DSL, a custom profile is created using the ThreadPoolProfileSupport class:
ThreadPoolProfile custom = new ThreadPoolProfileSupport("bigPool");
custom.setMaxPoolSize(200);
context.getExecutorServiceStrategy().registerThreadPoolProfile(custom);
This example increases the maximum pool size to 200. All other options will be inherited from the default profile, which means it will use the default values listed in table 10.3; for example, keepAliveTime will be 60 seconds. Notice that this custom profile is given the name bigPool; you can refer to the profile in the Camel routes by using executorServiceRef:
.split(body().tokenize("
")).streaming().executorServiceRef("bigPool")
.bean(InventoryService.class, "csvToObject")
.to("direct:update")
.end()
When Camel creates this route with the Splitter EIP, it refers to a thread pool with the name bigPool. Camel will now look in the registry for an ExecutorService type registered with the ID bigPool. If none is found, it will fall back and see if there is a known thread pool profile with the ID bigPool. And because such a profile has been registered, Camel will use the profile to create a new thread pool to be used by the Splitter EIP. All of which means that executorServiceRef supports using thread pool profiles to create the desired thread pools.
When using Spring XML, it’s simpler to define custom thread pool profiles. All you have to do is use the <threadPoolProfile> tag:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPoolProfile id="bigPool" maxPoolSize="100"/>
</camelContext>
Besides using thread pool profiles, you can create thread pools in other ways. For example, you may need to create custom thread pools if you’re using a third-party library that requires you to provide a thread pool. Or you may need to create one as we did in section 10.1 to leverage concurrency with the Splitter EIP.
10.2.3. Creating custom thread pools
Creating thread pools with the Java API is a bit cumbersome, so Camel provides a nice way of doing this in both Java DSL and Spring XML.
Creating Custom Thread Pools in Java DSL
In Java DSL, you use org.apache.camel.builder.ThreadPoolBuilder to create thread pools, as follows:
ThreadPoolBuilder builder = new ThreadPoolBuilder(context);
ExecutorService myPool = builder.poolSize(5).maxPoolSize(25)
.maxQueueSize(200).build("MyPool");
The ThreadPoolBuilder requires CamelContext in its constructor, because it will use the default thread pool profile as the baseline when building custom thread pools. That means myPool will use the default value for keepAliveTime, which would be 60 seconds.
Creating Custom Thread Pools in Spring XML
In Spring XML, creating a thread pool is done using the <threadPool> tag:

As you can see, the <threadPool> is used inside a <camelContext> tag. This is because it needs access to the default thread profile, which is used as baseline (just as the ThreadPoolBuilder requires CamelContext in its constructor).
The preceding route uses a <threads> tag, that references the custom thread pool ![]() . If a message is sent to the direct:start endpoint, it should be routed to <threads>, which will continue routing the message using the custom thread pool. This can be seen in the console output that logs the
thread names:
. If a message is sent to the direct:start endpoint, it should be routed to <threads>, which will continue routing the message using the custom thread pool. This can be seen in the console output that logs the
thread names:
[Camel Thread 0 - Cool] INFO hello - Exchange[Body:Hello Camel]
Note
When using executorServiceRef to look up a thread pool, Camel will first check for a custom thread pool. If none are found, Camel will fall back and see if a thread pool profile exists with the given name; if so, a new thread pool is created based on that profile.
All thread pool creation is done using ExecutorServiceStrategy, which defines a pluggable API for using thread pool providers.
10.2.4. Using ExecutorServiceStrategy
The org.apache.camel.spi.ExecutorServiceStrategy interface defines a pluggable API for thread pool providers. Camel will, by default, use the DefaultExecutorServiceStrategy class, which creates thread pools using the concurrency API in Java. When you need to use a different thread pool provider, for example, a provider from a JAVA EE server, you can create a custom ExecutorServiceStrategy to work with the provider.
In this section, we’ll show you how to configure Camel to use a custom ExecutorServiceStrategy, leaving the implementation of the provider up to you.
Configuring Camel to Use a Custom ExecutorServiceStrategy
In Java, you configure Camel to use a custom ExecutorServiceStrategy via the setExecutorServiceStrategy method on CamelContext:
CamelContext context = ...
context.setExecutorServiceStrategy(myExecutorServiceStrategy);
In Spring XML, it’s easy because all you have to do is define a Spring bean. Camel will automatically detect and use it:
<bean id="myExecutorService"
class="camelinaction.MyExecutorServiceStrategy"/>
So far in this chapter, we’ve mostly used thread pools in Camel routes, but they’re also used in other areas, such as in some Camel components.
Using ExecutorServiceStrategy in a Custom Component
The ExecutorServiceStrategy defines methods for working with thread pools.
Suppose you’re developing a custom Camel component and you need to run a scheduled background task. When running a background task, it’s recommended that you use the ScheduledExecutorService as the thread pool, because it’s capable of executing tasks in a scheduled manner.
Creating the thread pool is easy with the help of Camel’s ExecutorServiceStrategy.
Listing 10.3. Using ExecutorServiceStrategy to create a thread pool

Listing 10.3 illustrates the principle of using a scheduled thread pool to repeatedly execute a background task. The custom component
extends DefaultComponent, which allows you to override the doStart and doStop methods to create and shut down the thread pool. In the doStart method, you create the ScheduledExecutorService using ExecutorServiceStrategy ![]() and schedule it to run the task
and schedule it to run the task ![]() once every second using the scheduleWithFixedDelay method.
once every second using the scheduleWithFixedDelay method.
The source code for the book contains this example in the chapter10/pools directory. You can try it using the following Maven goal:
mvn test -Dtest=MyComponentTest
When it runs, you’ll see the following output in the console:
Waiting for 10 seconds before we shutdown
[Camel Thread 0 - MyBackgroundTask] INFO MyComponent - I run now
[Camel Thread 0 - MyBackgroundTask] INFO MyComponent - I run now
You now know that thread pools are how Java achieves concurrency; they’re used as executors to execute tasks concurrently. You also know how to leverage this to process messages concurrently in Camel routes, and you saw several ways of creating and defining thread pools in Camel.
When modeling routes in Camel, you’ll often use EIPs to build the routes to support your business cases. In section 10.1, you used the Splitter EIP and learned to improve performance using concurrency. In the next section, we’ll take a look at other EIPs you can use with concurrency.
10.3. Using concurrency with EIPs
Some of the EIPs in Camel support concurrency out of the box—they’re listed in table 10.4. In this section, we’ll take a look at them and the benefits they offer.
Table 10.4. EIPs in Camel that supports concurrency
|
EIP |
Description |
|---|---|
| Aggregate | The Aggregator EIP allows concurrency when sending out completed and aggregated messages. We covered this pattern in chapter 8. |
| Multicast | The Multicast EIP allows concurrency when sending a copy of the same message to multiple recipients. We discussed this pattern in chapter 2, and we’ll use it in an example in section 10.3.2. |
| Recipient List | The Recipient List EIP allows concurrency when sending copies of a single message to a dynamic list of recipients. This works in the same way as the Multicast EIP, so what you learned there also applies for this pattern. We covered this pattern in chapter 2. |
| Splitter | The Splitter EIP allows concurrency when each split message is being processed. You saw how to do this in section 10.1. This pattern was also covered in chapter 8. |
| Threads | The Threads EIP always uses concurrency to hand over messages to a thread pool that will continue processing the message. You saw an example of this in section 10.2.3, and we’ll cover it a bit more in section 10.3.1. |
| Wire Tap | The Wire Tap EIP allows you to spawn a new message and let it be sent to an endpoint using a new thread, while the calling thread can continue to process the original message. The Wire Tap EIP always uses a thread pool to execute the spawned message. This is covered in section 10.3.3. We encountered the Wire Tap pattern in chapter 2. |
All the EIPs from table 10.4 can be configured to enable concurrency in the same way. You can turn on parallelProcessing to use thread pool profiles to apply a matching thread pool; this is likely what you’ll want to use in most cases. Or you can refer to a specific thread pool using the executorService option. You’ve already seen this in action in section 10.1.2, where you used the Splitter EIP.
In the following three sections, we’ll look at how to use the Threads, Multicast, and Wire Tap EIPs in a concurrent way.
10.3.1. Using concurrency with the Threads EIP
The Threads EIP is the only EIP that has additional options in the DSL offering fine-grained definition of the thread pool to be used. These additional options are listed in table 10.3.
For example, the thread pool from section 10.2.3 could be written as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<to uri="log:start"/>
<threads threadName="Cool" poolSize="5" maxPoolSize="15"
maxQueueSize="250">
<to uri="log:cool"/>
</threads>
</route>
</camelContext>
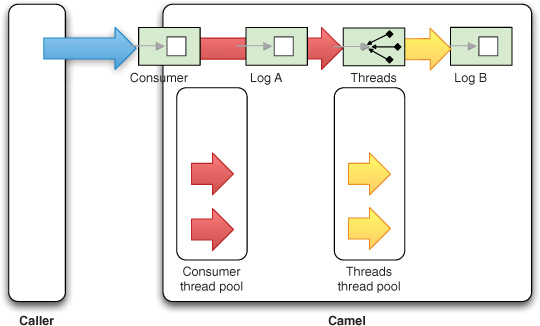
Figure 10.6 illustrates which threads are in use when a message is being routed using the Threads EIP.
Figure 10.6. Caller and pooled threads are in use when a message is routed.
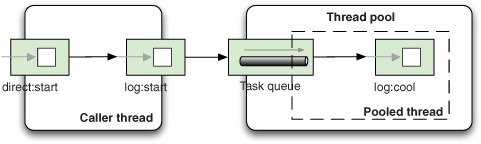
There will be two threads active when a message is being routed. The caller thread will hand over the message to the thread pool. The thread pool will then find an available thread in its pool to continue routing the message.
You can run this example from the chapter10/pools directory using the following Maven goal:
mvn test -Dtest=SpringInlinedThreadPoolTest
You’ll see the following in the console:
[main] INFO start - Exchange[Body:Hello Camel]
[Camel Thread 0 - Cool] INFO hello - Exchange[Body:Hello Camel]
The first set of brackets contains the thread name. You see, as expected, two threads in play: main is the caller thread, and Cool is from the thread pool.
Tip
You can use the Threads EIP to achieve concurrency when using Camel components that don’t offer concurrency. A good example is the Camel file component, which uses a single thread to scan and pick up files. By using the Threads EIP, you can allow the picked up files to be processed concurrently.
Let’s look at how Rider Auto Parts improves performance by leveraging concurrency with the Multicast EIP.
10.3.2. Using concurrency with the Multicast EIP
Rider Auto Parts has a web portal where its employees can look up information, such as the current status of customer orders. When selecting a particular order, the portal needs to retrieve information from three different systems to gather an overview of the order. Figure 10.7 illustrates this.
Figure 10.7. The web portal gathers information from three systems to compile the overview that’s presented to the employee.
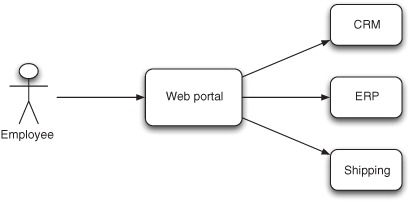
Your boss has summoned you to help with this portal. The employees have started to complain about poor performance, and it doesn’t take you more than an hour to find out why; the portal retrieves the data from the three sources in sequence. This is obviously a good use case for leveraging concurrency to improve performance.
You also look in the production logs and see that a single overview takes 4.0 seconds (1.4 + 1.1 + 1.5 seconds) to complete. You tell your boss that you can improve the performance by gathering the data in parallel.
Back at your desk, you build a portal prototype in Camel that resembles the current implementation. The prototype uses the Multicast EIP to retrieve data from the three external systems as follows:
<route>
<from uri="direct:portal"/>
<multicast strategyRef="aggregatedData">
<to uri="direct:crm"/>
<to uri="direct:erp"/>
<to uri="direct:shipping"/>
</multicast>
<bean ref="combineData"/>
</route>
The Multicast EIP will send copies of a message to the three endpoints and aggregate their replies using the aggregatedData bean. When all data has been aggregated, the combineData bean is used to create the reply that will be displayed in the portal.
You decide to test this route by simulating the three systems using the same response times as from the production logs. Running your test yields the following performance metrics:
TIMER - [Message: 123] sent to: direct://crm took: 1404 ms.
TIMER - [Message: 123] sent to: direct://erp took: 1101 ms.
TIMER - [Message: 123] sent to: direct://shipping took: 1501 ms.
TIMER - [Message: 123] sent to: direct://portal took: 4139 ms.
As you can see, the total time is 4.1 seconds when running in sequence. Now you enable concurrency with the parallelProcessing options:
<route>
<from uri="direct:portal"/>
<multicast strategyRef="aggregatedData"
parallelProcessing="true">
<to uri="direct:crm"/>
<to uri="direct:erp"/>
<to uri="direct:shipping"/>
</multicast>
<bean ref="combineData"/>
</route>
This gives much better performance:
TIMER - [Message: 123] sent to: direct://erp took: 1105 ms.
TIMER - [Message: 123] sent to: direct://crm took: 1402 ms.
TIMER - [Message: 123] sent to: direct://shipping took: 1502 ms.
TIMER - [Message: 123] sent to: direct://portal took: 1623 ms.
The numbers show that response time went from 4.1 to 1.6 seconds, which is an improvement of roughly 250 percent. Note that the logged lines aren’t in the same order as the sequential example. With concurrency enabled, the lines are logged in the order that the remote services’ replies come in. Without concurrency, the order is always fixed in the sequential order defined by the Camel route.
The source code for the book contains this example in the chapter10/eip directory. You can try the two scenarios using the following Maven goals:
mvn test -Dtest=MulticastTest
mvn test -Dtest=MulticastParallelTest
You have now seen how the Multicast EIP can be used concurrently to improve performance. The Aggregate, Recipient List, and Splitter EIPs can be configured with concurrency in the same way as the Multicast EIP.
The next pattern we’ll look at using with concurrency is the Wire Tap EIP. We encountered it the first time in chapter 2, section 2.5.5.
10.3.3. Using concurrency with the Wire Tap EIP
The Wire Tap EIP leverages a thread pool to process the tapped messages concurrently. You can configure which thread pool it should use, and if no pool has been configured, it will fall back and create a thread pool based on the default thread pool profile.
Suppose you want to use a custom thread pool when using the Wire Tap EIP. First you must create the thread pool to be used, and then you pass that in as a reference to the wire tap in the route, as highlighted in bold:
public void configure() throws Exception {
ExecutorService lowPool = new ThreadPoolBuilder(context)
.poolSize(1).maxPoolSize(5).build("LowPool");
from("direct:start")
.log("Incoming message ${body}")
.wireTap("direct:tap", lowPool)
.to("mock:result");
from("direct:tap")
.log("Tapped message ${body}")
.to("mock:tap");
}
The equivalent route in Spring XML is as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<threadPool id="lowPool"
poolSize="1" maxPoolSize="5" threadName="LowPool"/>
<route>
<from uri="direct:start"/>
<log message="Incoming message ${body}"/>
<wireTap uri="direct:tap" executorServiceRef="lowPool"/>
<to uri="mock:result"/>
</route>
<route>
<from uri="direct:tap"/>
<log message="Tapped message ${body}"/>
<to uri="mock:tap"/>
</route>
</camelContext>
The source code for the book contains this example in the chapter10/eip directory. You can run the example using the following Maven goals:
mvn test -Dtest=WireTapTest
mvn test -Dtest=SpringWireTapTest
When you run the example, the console output should indicate that the tapped message is being processed by a thread from the LowPool thread pool.
[main] INFO route1 - Incoming message Hello Camel
[Camel Thread 0 - LowPool] INFO route2 - Tapped message Hello Camel
You now have a better understanding of the overall concept of using thread pools for concurrency in Java. We’ll next look at how the synchronicity of messages impacts the way thread pools are leveraged.
10.4. Synchronicity and threading
A caller can invoke a service either synchronously or asynchronously. If the caller has to wait until all the processing steps are complete before it can continue, it’s a synchronous process. If the caller can continue before the processing has been completed, it’s an asynchronous process.
The service being invoked can leverage as many threads as it wants to complete the message. The number of threads doesn’t affect whether or not the caller is considered synchronous or asynchronous.
Now imagine from this point forward that the service being invoked is a Camel route. As just mentioned, the service can use multiple threads to process the message. In this section, we’ll focus on which factors affect how many threads are involved in processing messages in Camel.
These factors may affect the threading model:
- Component— The Camel component that originates the exchange is either based on a fire-and-forget or a request-response messaging style.
- EIPs— As you saw in section 10.3, some EIPs support concurrency.
- Configured synchronicity— Some components can be configured to be either synchronous or asynchronous.
- Transactions— If the route is transacted, the transactional context is limited to run within one thread only.
- Message exchange pattern (MEP)— MEP is information stored on the exchange that tells Camel whether the message is using a fire-and-forget or request-response messaging style. Camel uses the terminology from the Java Business Integration (JBI) specification (http://en.wikipedia.org/wiki/JBI): InOnly means fire-and-forget, and InOut means request-response.
In the next four sections (10.4.1 through 10.4.4), we’ll cover four different scenarios showing how synchronicity and MEP affect the threading model:
- Asynchronous caller, and Camel uses one thread to process the message
- Synchronous caller, and Camel uses one thread to process the message
- Asynchronous caller, and Camel uses multiple threads to process the message
- Synchronous caller, and Camel uses multiple threads to process the message
We’ll discuss the pros and cons of each scenario and give an example of where it may be used in a real-life situation.
The source code for the book contains these examples in the chapter10/synchronicity directory. You can use these Maven goals to run the examples:
mvn test -Dtest=AsyncOneThreadTest
mvn test -Dtest=SyncOneThreadTest
mvn test -Dtest=AsyncMultipleThreadsTest
mvn test -Dtest=SyncMultipleThreadsTest
10.4.1. Asynchronous caller using one thread
In figure 10.8, you’ll see that Camel uses the consumer thread all along the processing of the message. In this figure, an arrow represents a thread, and the consumer thread is shown as one long arrow.
Figure 10.8. In asynchronous InOnly mode, the caller doesn’t wait for a reply. On the Camel side, only one thread is used for all the processing of the message.

This scenario can be implemented in a simple Camel route:
from("seda:start")
.to("log:A")
.to("log:B");
You can try the route from a unit test by sending an InOnly message using the sendBody method from ProducerTemplate:
public void testSyncInOnly() throws Exception {
String body = "Hello Camel";
LOG.info("Caller calling Camel with message: " + body);
template.sendBody("seda:start", body);
LOG.info("Caller finished calling Camel");
}
If you run this example, you should see output to the console that shows the threads in use during routing:
[main] INFO Caller - Caller calling Camel with message: Hello Camel
[main] INFO Caller - Caller finished calling Camel
[Camel Thread 0 - seda://start] INFO A - InOnly, Hello Camel
[Camel Thread 0 - seda://start] INFO B - InOnly, Hello Camel
The first two log lines are the caller sending the message to Camel. The last two show that the consumer thread [Camel Thread 0 - seda://start] is used to process the message in the entire route.
The caller is sending in a fire-and-forget message (InOnly), which means the caller doesn’t expect a reply (and it doesn’t wait for a reply). As a result, the caller can continue while the message is being processed. We view the caller’s synchronicity as asynchronous.
From the Camel perspective, only one thread is involved in processing the message, which simplifies things. Table 10.5 outlines the pros and cons of this approach from the Camel perspective.
Table 10.5. Pros and cons of using one thread from the Camel perspective
|
Pros |
Cons |
|---|---|
|
|
The asynchronous InOnly scenario is often used with JMS messaging, where it’s common to use Camel to route messages from JMS queues to other destinations. Real-world systems might use this scenario when routing messages between JMS destinations, such as a new order queue that’s routed to a validated order queue if the order passes a sanity check. Orders that are invalid would be routed to an invalid order queue for further manual inspection.
In this example, the caller didn’t expect a reply because it sent an InOnly message. The next scenario shows what happens when the caller sends an InOut (request-response) message.
10.4.2. Synchronous caller using one thread
This scenario is only slightly different from the previous one. In figure 10.9 you can see that Camel is still only using one thread (represented as one arrow). The difference is that this time the caller expects a reply, which the consumer thread in Camel has to deliver back to the waiting caller.
Figure 10.9. In synchronous InOut mode, the caller waits for a reply. In Camel, the consumer thread is used for all the processing of the message, and it delivers the reply to the waiting caller.
The route in Camel is also a bit different, because you want to transform the message to return a reply to the caller: "Bye Camel".
from("seda:start")
.to("log:A")
.transform(constant("Bye Camel"))
.to("log:B");
You can test this by using the requestBody method from ProducerTemplate, which sends an InOut message:
public void testSyncInOut() throws Exception {
String body = "Hello Camel";
LOG.info("Caller calling Camel with message: " + body);
Object reply = template.requestBody("seda:start", body);
LOG.info("Caller received reply: " + reply);
}
If you run this example, you should see output to the console showing the threads in use during routing.
[main] INFO Caller - Caller calling Camel with message: Hello Camel
[Camel Thread 0 - seda://start] INFO A - InOut, Hello Camel
[Camel Thread 0 - seda://start] INFO B - InOut, Bye Camel
[main] INFO Caller - Caller received reply: Bye Camel
Notice how the caller waits for the reply while the consumer thread [Camel Thread 0 -seda://start] is used to process the message for the entire route. You can see that the caller is waiting—it will log to the console after Camel has processed the message. Because the caller waits for a reply, we consider it synchronous.
The pros and cons of this configuration from the Camel perspective are the same as in the previous section and are listed in table 10.5.
The synchronous InOut scenario can be used with JMS messaging because you can return replies if the JMSReply JMS property is provided on the incoming message. Real-world systems may want to use this approach with components that natively support request-response messaging, such as web services. A system could expose a web service that clients can call to query order status.
The next two scenarios we’ll cover show what happens when Camel uses multiple threads to process the messages.
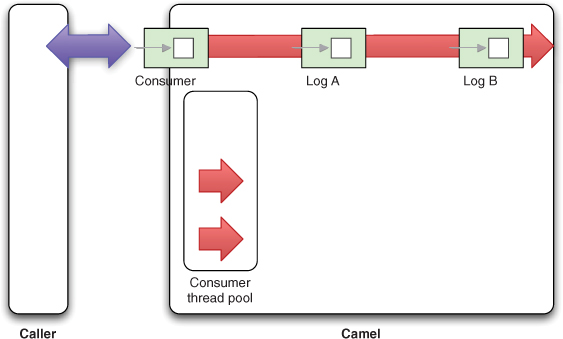
10.4.3. Asynchronous caller using multiple threads
The asynchronous InOnly scenario is illustrated in figure 10.10. This time you’re leveraging two threads in Camel to process the messages (represented by the two arrows).
Figure 10.10. In asynchronous InOnly mode, the caller doesn’t wait for a reply. On the Camel side, multiple threads are involved during the routing of the message.
This time there are two thread pools involved in Camel. The consumer thread will process the first part of the routing, and then the message is transferred to another thread pool, which continues routing the message.
The Camel route is yet again different. You use the Threads EIP to add the asynchronous behavior to the route:
from("seda:start")
.to("log:A")
.threads(5, 10)
.to("log:B");
By using threads(5, 10), you create a thread pool with a pool size of 5 and a maximum size of 10.
To test this scenario, you can use the following unit test:
public void testAsyncInOnly() throws Exception {
String body = "Hello Camel";
LOG.info("Caller calling Camel with message: " + body);
template.sendBody("seda:start", body);
LOG.info("Caller finished calling Camel");
}
If you run this example, you should see output to the console that shows the threads in use during routing:
[main] INFO Caller - Caller calling Camel with message: Hello Camel
[main] INFO Caller - Caller finished calling Camel
[Camel Thread 0 - seda://start] INFO A - InOnly, Hello Camel
[Camel Thread 1 - Threads] INFO B - InOnly, Hello Camel
The first two log lines indicate the caller sending the message to Camel. The last two lines show the other two threads involved in routing the message inside Camel.
In this scenario, the caller is asynchronous because it can continue without waiting for a reply.
This model has a different set of pros and cons from the Camel perspective, as listed in table 10.6.
Table 10.6. Pros and cons of using an asynchronous caller and having multiple threads, from the Camel perspective
|
Pros |
Cons |
|---|---|
|
|
In a real-world situation, you might want to use this scenario when consuming files, as we did in section 10.1. By not having the consumer thread process the file, it’s free to pick up new files. And by using multiple threads in Camel, you can maximize throughput as multiple threads can work simultaneously on multiple files.
Another use case when multiple threads can be an advantage is when you process big messages that can be split into smaller submessages for further processing. This is what we did in section 10.1 using the parallelProcessing option on the Splitter EIP.
The next scenario is similar to this one, but it uses a request-response messaging style.
10.4.4. Synchronous caller using multiple threads
The synchronous InOut scenario involving multiple threads inside Camel is illustrated in figure 10.11. In this scenario, the situation is a bit more complex because the caller is waiting for a reply and Camel is using multiple threads to process the message. This means the consumer thread that received the request must block until the routing is complete, so it can deliver the reply back to the waiting caller. If this sounds a bit confusing, don’t be alarmed. We’ll unlock how this works when we look at the asynchronous client API in section 10.5.
Figure 10.11. In synchronous mode, the caller waits for a reply. On the Camel side, multiple threads are involved during the routing of the message. The consumer thread has to block, waiting for the reply, which it must send back to the waiting caller.

The route you use for testing this scenario is as follows:
from("seda:start")
.to("log:A")
.threads(5, 10)
.transform(constant("Bye Camel"))
.to("log:B");
The unit test uses the requestBody method to send an InOut message to Camel:
public void testAsyncInOut() throws Exception {
String body = "Hello Camel";
LOG.info("Caller calling Camel with message: " + body);
Object reply = template.requestBody("seda:start", body);
LOG.info("Caller received reply: " + reply);
}
If you run this example, you should see output to the console that shows the threads in use during routing:
[main] INFO Caller - Caller calling Camel with message: Hello Camel
[Camel Thread 0 - seda://start] INFO A - InOut, Hello Camel
[Camel Thread 1 - Threads] INFO B - InOut, Bye Camel
[main] INFO Caller - Caller received reply: Bye Camel
These lines reveal that the caller waits for the reply and that two threads are involved during the routing of the message in Camel.
What the lines also reveal is that the caller received "Bye Camel" as the reply. This may seem a bit like magic, as the "Bye Camel" message was constructed in the last part of the route. That means the consumer thread somehow knew that it had to block until the reply message was ready.
Although this might seem like magic, there is no such magic in Camel or the Java language. It’s the Java concurrency API that allows you to wait for an asynchronous task to complete, using what is called a Future handle. We’ll cover this in more detail in section 10.5.
Table 10.7 presents the pros and cons of this scenario.
Table 10.7. Pros and cons of using a synchronous caller and having multiple threads, from the Camel perspective
|
Pros |
Cons |
|---|---|
|
|
This scenario can be used when you want to return an early reply to the waiting caller. Suppose you expose a web service and want to return an OK reply as quickly as possible. By dispatching the received messages asynchronously, you allow the consumer thread to continue and return the early reply to the caller. This may sound easy, but the MEP impacts how this can be done correctly. Let’s take a moment to map out the pitfalls.
10.4.5. Returning an early reply to a caller
Consider an example in which a caller invokes a Camel service in a synchronous manner—the caller is blocked while waiting for a reply. In the Camel service, you want to send a reply back to the waiting caller as soon as possible; the reply is an acknowledgement that the input has been received, so "OK" is returned to the caller. In the meantime, Camel continues processing the received message in another thread.
Figure 10.12 illustrates this example in a sequence diagram.
Figure 10.12. A synchronous caller invokes a Camel service. The service lets the wire tap continue processing the message asynchronously while the service returns an early reply to the waiting caller.

Implementing this example as a Camel route with the Java DSL can be done as follows:

You leverage the Wire Tap EIP ![]() to continue routing the incoming message in a separate thread. This gives room for the consumer to immediately reply
to continue routing the incoming message in a separate thread. This gives room for the consumer to immediately reply ![]() to the waiting caller.
to the waiting caller.
Here’s an equivalent example using Spring XML:

The source code for the book contains this example in the chapter8/synchronicity directory. You can run the example using the following Maven goals:
mvn test -Dtest=EarlyReplyTest
mvn test -Dtest=SpringEarlyReplyTest
When you run the example, you should see the console output showing how the message is processed:
11:18:15 [main] INFO - Caller calling Camel with message: Hello Camel
11:18:15 [Camel Thread 0 - WireTap] INFO - Incoming Hello Camel
11:18:15 [main] INFO - Caller finished calling Camel and received reply: OK
11:18:18 [Camel Thread 0 - WireTap] INFO - Processing done for Hello Camel
Notice in the console output how the caller immediately receives a reply within the same second it sent the request. The last log line shows that the Wire Tap EIP finished processing the message 3 seconds after the caller received the reply.
Note
In the preceding example, the route with ID "process", you need to convert the body to a String type to ensure that you can read the message multiple times. This is necessary because Jetty is stream-based, which causes it to only be able to read the message once. Or, instead of converting the body, you could enable stream caching—we’ll cover stream caching in chapter 13.
So far in this chapter, you’ve seen concurrency used in Camel routes by the various EIPs that support them. But Camel also has a strong client API, manifested in the ProducerTemplate and ConsumerTemplate classes (see appendix C). These classes have easy-to-use methods for sending messages to any endpoint you choose. In the next section, you’ll learn what those classes have to offer when it comes to concurrency.
10.5. The concurrency client API
You can use the concurrency client API directly from Java code, which means you’re in full control of what should happen. You don’t have to use Camel routes and EIPs to achieve concurrency.
To fully understand the concurrency API from the client point of view, we’ll look at how you can achieve concurrency with pure Java. Then we’ll look at the same example using Camel’s ProducerTemplate. We’ll end this section by looking at how the Camel client API allows you to easily submit concurrent messages to different endpoints and leverage a callback mechanism to gather the replies when they come back.
10.5.1. The concurrency client API in Java
The concurrency API in Java is located in the java.util.concurrent package, and it was introduced in Java 5 (aka JDK 1.5). All the concurrency behavior in Camel is built on top of this API. For example, the Camel thread pools are all ExecutorService instances, which are capable of executing tasks concurrently and asynchronously.
Java’s concurrency API includes the following classes that are interesting to learn about and understand from a developer’s point of view:
- ExecutorService—This is the foundation for executing tasks in an asynchronous manner.
- Callable—This represents an asynchronous task. Think of it as an improved Runnable that can return a result or throw an exception.
- Future—This represents the lifecycle of an asynchronous task and provides methods to test whether the task has completed or been cancelled, to retrieve its result, and to cancel the task.
Figure 10.13 is a sequence diagram that depicts how these three concepts are related and how they’re involved in a typical use case where an asynchronous task is being executed.
Figure 10.13. The client submits tasks (Callable) to be executed asynchronously by ExecutorService, which returns a Future handle to the client.
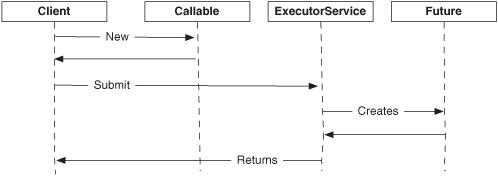
Figure 10.13 shows how a client creates a new Callable, which represents the tasks (the code) you want to be executed asynchronously. The task is then submitted to an ExecutorService, which is responsible for further processing the task. Before the task is executed, a Future is returned to the client. The Future is a handle that the client can use at any point later on to retrieve the result of the task.
Listing 10.4 shows how this works in Java code.
Listing 10.4. Asynchronous task execution using the Java API

The task to be executed is located within the call method of the Callable ![]() . Note that you can use generics to specify the result type as a String. The task is then submitted to the ExecutorService
. Note that you can use generics to specify the result type as a String. The task is then submitted to the ExecutorService ![]() , which returns a Future<String> handle; the generic type matches the type from the task. While the task is being processed, you can do other computations,
but in this example you just loop and wait for the task to be done
, which returns a Future<String> handle; the generic type matches the type from the task. While the task is being processed, you can do other computations,
but in this example you just loop and wait for the task to be done ![]() . At the end, you can retrieve the result using the get method
. At the end, you can retrieve the result using the get method ![]() .
.
The source code for the book contains this example in the chapter10/client directory. You can use the following Maven goal to run the example:
mvn test -Dtest=CamelFutureDoneTest
When you run the example, the console should output what’s happening:
07:29:30 [main] - Submitting task to ExecutorService
07:29:30 [main] - Task submitted and we got a Future handle
07:29:30 [pool-1-thread-1] - Starting to process task
07:29:30 [main] - Is the task done? false
07:29:32 [main] - Is the task done? false
07:29:34 [main] - Is the task done? false
07:29:35 [pool-1-thread-1] - Task is now done
07:29:36 [main] - Is the task done? true
07:29:36 [main] - The answer is: Camel rocks
As you can see from the console output, the task executes in a thread named "pool-1-thread-1" while the caller executes in the main thread. This output also proves that the client waits until the task is done.
There’s a smarter way to retrieve the result than by looping and testing whether the task is done—you can use the get method on the Future handle which will automatically wait until the task is done. Removing the while loop from the code in listing 10.4 and running the example will output the following:
07:37:20 [main] - Submitting task to ExecutorService
07:37:20 [main] - Task submitted and we got a Future handle
07:37:20 [pool-1-thread-1] - Starting to process task
07:37:25 [pool-1-thread-1] - Task is now done
07:37:25 [main] - The answer is: Camel rocks
As you can see, this time you don’t have to test whether the task is done. Invoking the get method on Future causes it to wait until the task is done and to react promptly when it is done.
The source code for the book contains this example in the chapter10/client directory. You can use the following Maven goal to run the example:
mvn test -Dtest=CamelFutureGetTest
You’ve seen how clients leverage Future to retrieve the result of tasks that have been submitted for asynchronous execution. Table 10.8 lists the most commonly used methods provided by Future.
Table 10.8. Commonly used methods in the java.util.concurrent.Future class
|
Method |
Description |
|---|---|
| get() | Waits, if necessary, for tasks to complete, and then returns the result. Will throw an ExecutionException if the tasks throw an exception. |
| get(timeout, TimeUnit) | Waits, if necessary, for at most the specified time for the task to complete, and then returns the result if available. Will throw an ExecutionException if the tasks throw an exception. TimeoutException is thrown if timed out. |
| isDone() | Returns true if the task is done; otherwise false is returned. |
Understanding the principle of Future is important because it’s the same mechanism Camel leverages internally when it processes messages asynchronously. Future also plays a role in the concurrency client API provided by Camel, which we’re going to take a look at now.
10.5.2. The concurrency client API in Camel
The client concurrency API in Camel is provided in the ProducerTemplate class. It offers a range of methods that Camel end users can leverage to submit messages to Camel to be further processed asynchronously.
Consider the following route:
from("seda:quote")
.log("Starting to route ${body}")
.delay(5000)
.transform().constant("Camel rocks")
.log("Route is now done");
You can see that this route will delay processing the message for 5 seconds, which means it will take at least 5 seconds for the reply to be returned. This is the same situation as in the previous example (section 10.5.1), where the Callable tasks also took 5 seconds to complete. This allows us to compare this example with the previous one to see how easy it is in Camel to use the concurrency client API.
Sending a message asynchronously to the "seda:quote" endpoint is easy to do in Camel by using the asyncRequestBody method as shown here:
public void testFutureWithoutDone() throws Exception {
LOG.info("Submitting task to Camel");
Future<String> future = template.asyncRequestBody("seda:quote",
"Hello Camel", String.class);
LOG.info("Task submitted and we got a Future handle");
String answer = future.get();
LOG.info("The answer is: " + answer);
}
The source code for the book contains this example in the chapter10/client directory. You can use the following Maven goal to run the example:
mvn test -Dtest=CamelFutureTest
If you run this example, the console should output something like the following:
11:02:49 [main] - Submitting task to Camel
11:02:49 [main] - Task submitted and we got a Future handle
11:02:49 [Camel Thread 0 - seda://quote] - Starting to route Hello Camel
11:02:54 [Camel Thread 0 - seda://quote] - Route is now done
11:02:54 [main] - The answer is: Camel rocks
What you should notice in this example is that the Camel concurrency client API also uses the Future handle to retrieve the result. This allows Camel end users to more easily learn and use the Camel concurrency API, as it’s based on and similar to the Java concurrency API.
Table 10.9 lists the most commonly used methods, provided by ProducerTemplate. All the methods listed will return a Future handle.
Table 10.9. Commonly used asynchronous methods in the ProducerTemplate class
|
Method |
Description |
|---|---|
| asyncSend(endpoint, exchange) | Sends the exchange to the given endpoint |
| asyncSendBody(endpoint, body) | Sends the body to the given endpoint using InOnly as the exchange pattern |
| asyncSendBodyAndHeader (endpoint, body, header) | Sends the body and header to the given endpoint using InOnly as the exchange pattern |
| asyncRequestBody(endpoint, body) | Sends the body to the given endpoint using InOut as the exchange pattern |
| asyncRequestBodyAndHeader (endpoint, body, header) | Sends the body and header to the given endpoint using InOut as the exchange pattern |
| asyncCallback (endpoint, exchange, callback) | Sends the exchange to the given endpoint and invokes the callback when the task is done |
| asyncCallbackSendBody (endpoint, body, callback) | Sends the body to the given endpoint using InOnly as the exchange pattern, and invokes the callback when the task is done |
| asyncCallbackRequestBody (endpoint, body, callback) | Sends the body to the given endpoint using InOut as the exchange pattern, and invokes the callback when the task is done |
Notice that all the methods listed in table 10.9 start with async in their method name. This makes them easy to remember when you need to send a message asynchronously.
The last three methods in table 10.9 support a callback mechanism, which makes sense in situations where you may need to use the same callback for several tasks. Let’s look at an example now, to make this all a bit clearer.
Using Asynccallback
Rider Auto Parts has a selected number of premium partners who are promoted exclusively on the Rider Auto Parts web store. Whenever a customer browses the items catalog, the partners are listening and can provide feedback about related items. For example, if you browse for bumper parts, the partners can suggest related items, such as bumper extensions or other car parts. The partners have to return their feedback within a given time period, so the user experience of browsing the website isn’t slowed down noticeably.
Implementing such a use case is possible using the Camel concurrency client API. You can use a callback to gather the partner feedback within the given time period.
The callback is defined in Camel as the org.apache.camel.spi.Synchronization interface:
public interface Synchronization {
void onComplete(Exchange exchange);
void onFailure(Exchange exchange);
}
The callback has two methods: the first is invoked when the Exchange is processed successfully, and the second is invoked if the Exchange fails.
Listing 10.5 shows how this can be implemented in Camel.
Listing 10.5. Using a callback to gather replies asynchronously

You use a CountDownLatch ![]() to let you know when you’ve received all the replies or the given time period is up. The callback is used to gather the replies
in the relates list.
to let you know when you’ve received all the replies or the given time period is up. The callback is used to gather the replies
in the relates list.
You use the org.apache.camel.impl.SynchronizationAdapter class to implement the callback logic ![]() . It allows you to override the onComplete and onFailure methods. The onComplete method is invoked when the message is routed successfully, so we get a valid reply for the business partner. The onFailure method is invoked if the routing fails. In both situations, you need to count down the latch to keep track of the number
of replies coming back.
. It allows you to override the onComplete and onFailure methods. The onComplete method is invoked when the message is routed successfully, so we get a valid reply for the business partner. The onFailure method is invoked if the routing fails. In both situations, you need to count down the latch to keep track of the number
of replies coming back.
Now you’re ready to send messages to the partners about which category the user is browsing. In this test, the category is
set to "bumper". You use the asyncCallbackRequestBody method ![]() , listed in table 10.9, to send the "bumper" message to the partners and have their replies gathered by the callback. This is done asynchronously, so you need to wait until the replies
are gathered or the time period is up. For that, you use the countdown latch
, listed in table 10.9, to send the "bumper" message to the partners and have their replies gathered by the callback. This is done asynchronously, so you need to wait until the replies
are gathered or the time period is up. For that, you use the countdown latch ![]() . In this example, you wait until all five replies have been gathered or the timeout is triggered.
. In this example, you wait until all five replies have been gathered or the timeout is triggered.
The source code for the book includes this example in the chapter10/client directory. You can run it by invoking the following Maven goal:
mvn test -Dtest=RiderAutoPartsCallbackTest
If you run this example, you should get the following output on the console:
11:03:23,078 [main] INFO - Send 5 messages to partners.
11:03:24,629 [main] INFO - Got 3 replies, is all? false
11:03:24,629 [main] INFO - Related item category is: bumper extension
11:03:24,630 [main] INFO - Related item category is: bumper filter
11:03:24,630 [main] INFO - Related item category is: bumper cover
In this example, you send to five different partners but only three respond within the time period.
As you’ve seen, the Camel concurrency client API is powerful, as it combines the power from Camel with an API resembling the equivalent concurrency API in Java. That’s all we have to say about the asynchronous client API. The next section covers what you can do in Camel to improve scalability.
10.6. The asynchronous routing engine
Camel uses its routing engine to route messages either synchronously or asynchronously. In this section we focus on scalability and learn that higher scalability can be achieved with the help of the asynchronous routing engine.
For a system, scalability is the desirable property of being capable of handling a growing amount of work gracefully. In section 10.1, we covered the Rider Auto Parts inventory application, and you saw you could increase throughput by leveraging concurrent processing. In that sense, the application was scalable, as it could handle a growing amount of work in a graceful manner. That application could scale because it had a mix of CPU-bound and IO-bound processes, and because it could leverage thread pools to distribute work.
In this section, we’ll look at scalability from a different angle. We’ll look at what happens when messages are processed asynchronously.
10.6.1. Hitting the scalability limit
Rider Auto Parts uses a Camel application to service its web store, as illustrated in figure 10.14.
Figure 10.14. The Rider Auto Parts web store communicates with the ERP system to gather pricing information.

A Jetty consumer handles all requests from the customers. There are a variety of requests to handle, such as updating shopping carts, performing searches, gathering production information, and so on—the usual functions you expect from a web store. But there’s one function that involves calculating pricing information for customers. The pricing model is complex and individual for each customer—only the ERP system can calculate the pricing. As a result, the Camel application communicates with the ERP system to gather the prices. While the prices are being calculated by the ERP system, the web store has to wait until the reply comes back, before it returns its response to the customer.
The business is doing well for the company, and an increasing number of customers are using the web store, which puts more load on the system. Lately there have been problems during peak hours, with customers reporting that they can’t access the web store or that it’s generally responding slowly.
The root cause has been identified: the communication with the ERP system is fully synchronous, and the ERP system takes an average of 5 seconds to compute the pricing. This means each request that gathers pricing information has to wait (the thread is blocked) an average of 5 seconds for the reply to come back. This puts a burden on the Jetty thread pool, as there are fewer free threads to service new requests.
Figure 10.15 illustrates this problem. You can see that the thread is blocked (the white boxes) while waiting for the ERP system to return a reply.
Figure 10.15. A scalability problem illustrated by the thread being blocked (represented as white boxes) while waiting for the ERP system to return a the reply.
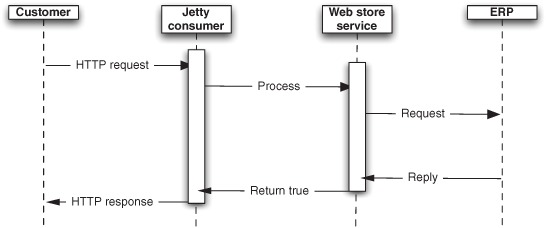
Figure 10.15 reveals that the Jetty consumer is using one thread per request. This leads to a situation where you run out of threads as traffic increases. You’ve hit a scalability limit. Let’s look into why, and look at what Camel has under the hood to help mitigate such problems.
10.6.2. Scalability in Camel
It would be much better if the Jetty consumer could somehow borrow the thread while it waits for the ERP system to return the reply, and use the thread in the meantime to service new requests. This can be done by using an asynchronous processing model. Figure 10.16 shows the principle.
Figure 10.16. The scalability problem is greatly improved. Threads are much less blocked (represented by white boxes) when you leverage asynchronous communication between the systems.
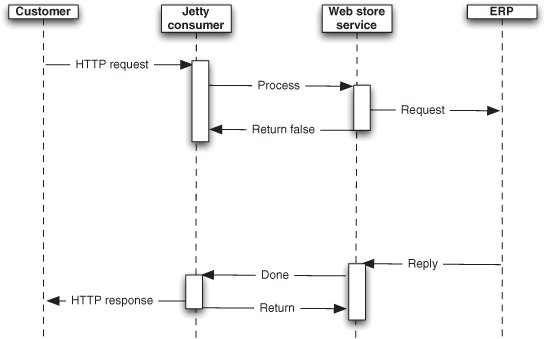
If you compare figures 10.15 and 10.16, you can see that the threads are much less blocked in the latter (the white boxes are smaller). In fact, there are no threads blocked while the ERP system is processing the request. This is a huge scalability improvement because the system is much less affected by the processing speed of the ERP system. If it takes 1, 2, 5, or 30 seconds to reply, it doesn’t affect the web store’s resource utilization as much as it would otherwise do. The threads in the web store are much less IO-bound and are put to better use doing actual work.
Figure 10.17 shows a situation in which two customer requests are served by the same thread without impacting response times.
Figure 10.17. The same thread services multiple customers without blocking (white and grey boxes) and without impacting response times, resulting in much higher scalability.
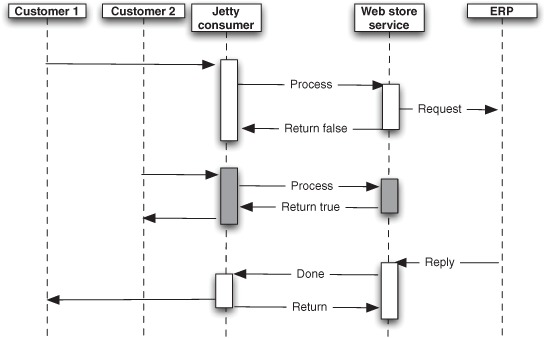
In this situation, customer 1 sends a request that requires a price calculation, so the ERP system is invoked asynchronously. A short while thereafter, customer 2 sends a request that can be serviced directly by the web shop service, so it doesn’t leverage the asynchronous processing model (it’s synchronous). The response is sent directly back to customer 2. Later, the ERP system returns the reply, which is sent back to the waiting customer 1.
In this example, you can successfully process two customers without any impact on their response time. You’ve achieved higher scalability.
Apache ServiceMix (http://servicemix.apache.org/) is an enterprise service bus (ESB) that can host your Camel application. In terms of high scalability, ServiceMix offers a message bus (the JBI and NMR components) for passing messages inside your application or between applications. The message bus supports the asynchronous processing model described in this chapter, which means it’s highly scalable.
In the next section, we’ll look under the hood to see how this is possible in Camel using the asynchronous processing model.
10.6.3. Components supporting asynchronous processing
The routing engine in Camel is capable of routing messages either synchronously or asynchronously. The latter requires the Camel component to support asynchronous processing, which in turn depends on the underlying transport supporting asynchronous communication. Table 10.10 lists the components in Camel 2.5 that support asynchronous communication.
Table 10.10. Components that support asynchronous processing
|
Description |
|
|---|---|
| camel-cxf | Supports asynchronous routing at both the consumer and producer levels. |
| camel-jbi | Supports asynchronous routing at both the consumer and producer levels. Requires Apache ServiceMix. |
| camel-jetty | Supports asynchronous routing at both the consumer and producer levels. |
| camel-jms | Supports asynchronous routing at the producer level when using request-response over JMS queues. |
| camel-netty | Supports asynchronous routing at the producer level. |
| camel-nmr | Supports asynchronous routing at both the consumer and producer levels. Requires Apache ServiceMix. |
Note
The Camel team will add support for additional components in the future. You can check the online documentation for an updated list of supported components: http://camel.apache.org/asynchronous-routing-engine.html.
In order to achieve high scalability in the Rider Auto Parts web store, you need to use asynchronous routing at two points. The communication with the ERP system and with the Jetty consumer must both happen asynchronously. The camel-jetty component already supports this.
The Jetty servlet engine uses continuations to achieve high scalability. It allows Camel to park a request and later retrieve the request and continue processing it. You can read more about continuations at the Jetty website: http://wiki.eclipse.org/Jetty/Feature/Continuations.
Communication with the ERP system must happen asynchronously too. To understand how this is possible with Camel, we’ll take a closer look at figure 10.16. The figure reveals that after the request has been submitted to the ERP system, the thread won’t block but will return to the Jetty consumer. It’s then up to the ERP transport to notify Camel when the reply is ready. When Camel is notified, it will be able to continue routing and let the Jetty consumer return the HTTP response to the waiting customer. To enable all this to work together, Camel provides an asynchronous API that the components must use. In the next section, we’ll walk through this API.
10.6.4. Asynchronous API
Camel supports an asynchronous processing model, which we refer to as the asynchronous routing engine. There are advantages and disadvantages of using asynchronous processing, compared to using the standard synchronous processing model. They’re listed in table 10.11.
Table 10.11. Advantages and disadvantages of using the asynchronous processing model
|
Advantages |
Disadvantage |
|---|---|
|
|
The asynchronous processing model is manifested by an API that must be implemented to leverage asynchronous processing. You’ve already seen a glimpse of this API in figure 10.16; the arrow between the Jetty consumer and the web store service has the labels Return false and Done. Let’s see the connection that those labels have with the asynchronous API.
AsyncProcessor
The AsyncProcessor is an extension of the synchronous Processor API:
public interface AsyncProcessor extends Processor {
boolean process(Exchange exchange, AsyncCallback callback);
}
The AsyncProcessor defines a single process method that’s similar to its synchronous Processor.process sibling.
Here are the rules that apply when using AsyncProcessor:
- A non-null AsyncCallback must be supplied; it will be notified when the exchange processing is completed.
- The process method must not throw any exceptions that occur while processing the exchange. Any such exceptions must be stored on the exchange’s exception property.
- The process method must know whether it will complete the processing synchronously or asynchronously. The method will return true if it completes synchronously; otherwise it returns false.
- When the processor has completed processing the exchange, it must call the callback.done(boolean doneSync) method. The doneSync parameter must match the value returned by the process method.
The preceding rules may seem a bit confusing at first. Don’t worry, the asynchronous API isn’t targeted at Camel end users but at Camel component writers.
In the next section, we’ll cover an example of how to implement a custom component that acts asynchronously. You’ll be able to use this example as a reference if you need to implement a custom component.
Note
You can read more about the asynchronous processing model at the Camel website: http://camel.apache.org/asynchronous-processing.html.
The AsyncCallback API is a simple interface with one method:
public interface AsyncCallback {
void done(boolean doneSync);
}
It’s this callback that’s invoked when the ERP system returns the reply. This notifies the asynchronous routing engine in Camel that the exchange is ready to be continued, and the engine can then continue routing it.
Let’s see how this all fits together by digging into the example and looking at some source code.
10.6.5. Writing a custom asynchronous component
The source code for the book contains the web store example in the chapter10/scalability directory. This example contains a custom ERP component that simulates asynchronous communication with an ERP system. Listing 10.6 shows how the ErpProducer is implemented.
Listing 10.6. ErpProducer using the asynchronous processing model
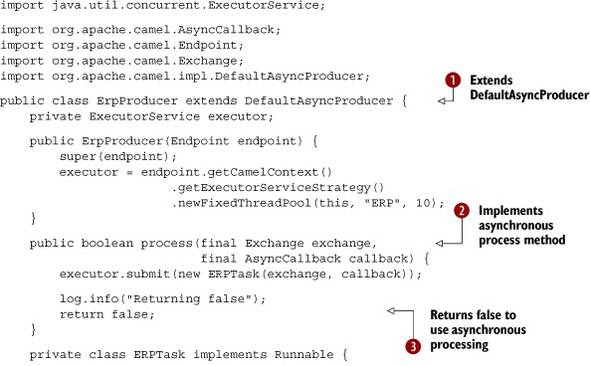
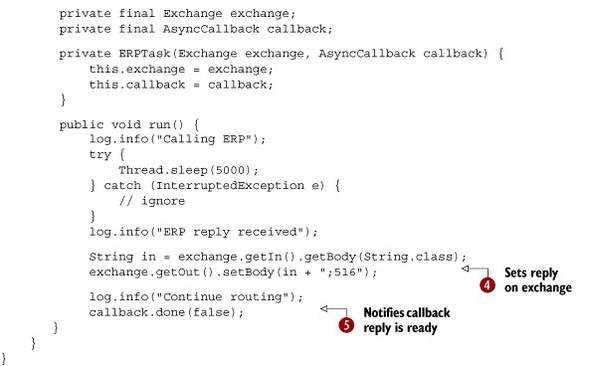
When implementing a custom asynchronous component, it’s most often the Producer that leverages asynchronous communication, and a good starting point is to extend the DefaultAsyncProducer ![]() .
.
To simulate asynchronous communication, you use a thread pool to execute tasks asynchronously; this means you need to create
a thread pool in the constructor. To support the asynchronous processing model, the ErpProducer must also implement the asynchronous process method ![]() .
.
To simulate the communication, which takes 5 seconds to reply, you submit ERPTask to the thread pool. When the 5 seconds are up, the reply is ready, and it’s set on the exchange ![]() .
.
According to the rules, when you’re using AsyncProcessor the callback must be notified when you’re done with a matching synchronous parameter ![]() . In this example, false is used as the synchronous parameter because the process method returned false
. In this example, false is used as the synchronous parameter because the process method returned false ![]() . By returning false, you instruct the Camel routing engine to leverage asynchronous routing from this point forward for the given exchange.
. By returning false, you instruct the Camel routing engine to leverage asynchronous routing from this point forward for the given exchange.
You can try this example by running the following Maven goal from the chapter10/scalability directory:
mvn test -Dtest=ScalabilityTest
This runs two test methods: one request is processed fully synchronously (not using the ERP component), and the other is processed asynchronously (by invoking the ERP component).
When running the test, pay attention to the console output. The synchronous test will log input and output as follows:
2010-07-16 11:41:42 [ qtp1444378545-11] INFO input
- Exchange[ExchangePattern:InOut, Body:1234;4;1719;bumper]
2010-07-16 11:41:42 [ qtp1444378545-11] INFO output
- Exchange[ExchangePattern:InOut, Body:Some other action here]
Notice that both the input and output are being processed by the same thread.
The asynchronous example is different, as the console output reveals:
2010-07-16 11:49:48 [ qtp515060127-11] INFO input
- Exchange[ExchangePattern:InOut, Body:1234;4;1719;bumper]
2010-07-16 11:49:48 [ qtp515060127-11] INFO ErpProducer
- Returning false (processing will continue asynchronously)
2010-07-16 11:49:48 [Camel Thread 0 - ERP] INFO ErpProducer
- Calling ERP
2010-07-16 11:49:53 [Camel Thread 0 - ERP] INFO ErpProducer
- ERP reply received
2010-07-16 11:49:53 [Camel Thread 0 - ERP] INFO ErpProducer
- Continue routing
2010-07-16 11:49:53 [Camel Thread 0 - ERP] INFO output
- Exchange[ExchangePattern:InOut, Body:1234;4;1719;bumper;516]
This time there are two threads used during the routing. The first is the thread from Jetty, which received the HTTP request. As you can see, this thread was used to route the message to the ErpProducer. The other thread takes over communication with the ERP system. When the reply is received from the ERP system, the callback is notified, which lets Camel highjack the thread and use it to continue routing the exchange. You can see this from the last line, which shows the exchange routed to the log component.
This concludes our coverage of scalability with Camel.
10.7. Summary and best practices
In this chapter, we looked at thread pools, which are the foundation for concurrency in Java. We saw how concurrency greatly improves performance and we looked at all the possible ways to create, define, and use thread pools in Camel. You saw how easy it was to use concurrency with the numerous EIPs in Camel, and you also saw how synchronicity affects the way threading occurs in Camel.
Java provides a concurrency API, which we compared to the Camel concurrency API. Both APIs offer you full control over submitting and executing asynchronous tasks.
Here are some best practices related to concurrency:
- Leverage concurrency if possible. Concurrency can greatly speed up your applications. Note that using concurrency requires business logic that can be invoked in a concurrent manner.
- Tweak thread pools judiciously. Only tweak the thread pools when you have a means of measuring the changes. It’s often better to rely on the default settings.
- Know the JDK API. Understand the asynchronous API from Java, such as Callable and the Future handle.
- Use asynchronous processing for high scalability. If you require high scalability, try using the Camel components that support the asynchronous processing model (listed in table 10.10).
In the next chapter we get more practical and learn how to develop with Camel. You will learn, among other things, how to start a new Camel project from scratch.