
7
Learning to Recognize Others: The Effect of Vocal Emotions
Virginie BEAUCOUSIN
CRFDP, Université de Rouen Normandie, France
“There are as many movements in the voice as there are movements in the mind, and the mind is deeply affected by the voice.”
(Cicero, De oratore)
Everyday we meet other people. We are able to identify these individuals when we have met them before and to recall information about them more or less accurately depending on their familiarity (celebrity or acquaintance): who they are, what their name is, when we last met them, whether we like them, what we last talked about, etc. This identification depends mainly on the person’s voice, face and body. This process allows for effective interpersonal interactions: we do not have to introduce ourselves every time in order to start a conversation.
This identification process can be impaired, leading to varying degrees of difficulty: it gives the impression of talking to strangers at the beginning of an interaction. There are two distinct syndromes: prosopagnosia, which is the inability to recognize a person from their face, and phonagnosia, which is the inability to identify individuals from their voice. The double dissociation between these two syndromes indicates that facial identification and voice identification are separate processes. Thus, these difficulties are often compensated for by these patients through the use of the cues that lead to preserved identification (facial or vocal), so that identification is preserved to facilitate recognition. However, the difficulties reported by these patients show that compensation by the other modality is not sufficient to make interactions satisfactory (Campanella and Belin 2007; Schweinberger et al. 2014).
The interactions between these identification processes have received little attention from the scientific community (Campanella and Belin 2007; Schweinberger et al. 2014). This may be because in face-only identification models, even in revised models, voice has been mentioned succinctly as participating in identification (Bruce and Young 1986; Burton et al. 1990). The study of speaker1 identification by voice is much more recent (Campanella and Belin 2007; Schweinberger et al. 2014). However, more recent models consider the voice/face interaction as fundamental in the process of speaker recognition (Belin et al. 2004; von Kriegstein et al. 2005; von Kriegstein 2012). Yet, it is not so rare to encounter situations where only the voice allows for identifying one’s interlocutor2 (e.g. during telephone conversations). We will see that these new models are based on studies that show that voice, just like faces, actively participates in the recognition of a person during communication.
The voice conveys a lot of information about the person’s identity and the context of enunciation, which can facilitate interactions. In particular, we will see that it can transmit emotional information. This type of information can facilitate the memorization of the person’s identity. We have all experienced this before. For example, we remember more easily the teachers who greeted us in the morning with a smile and a cheerful “good morning”, than those who addressed us with a neutral tone and an expressionless face. Although each of us is able to cite several examples of this type, the influence of emotions on recognition is still very little explored in cognitive science.
In this chapter, we will focus on the voice as a carrier of information about the speaker’s identity and emotional states. Based on a communication model, we will define the information conveyed by the voice that allows us to recognize and also to judge people before developing several arguments in favor of the importance of vocal emotions in the memorization and recognition of the speaker.
7.1. Communicating with others: the role of the voice
Interaction between two individuals is based on the decoding of verbal and non-verbal elements. Albert Mehrabian’s work (1972) has shown that interpersonal interactions are mainly based on the decoding of non-verbal information, especially in an emotional situation (93%, see Figure 7.1). Verbal elements (7%) still participate in the success of the interaction thanks to the ortholinguistic functions3 that lead to the decoding of the verbal content (from phonological processing to syntactic-semantic integration). Non-verbal cues conveyed by the faces (Burton et al. 1990; George and Conty 2008; Zebrowitz and Montepare 2008), the body (de Gelder 2006), the body odors (Demattè et al. 2007; Leleu et al. 2015) and the emotion-related voice modulation, i.e. emotional prosody (Belin et al. 2004; Beaucousin et al. 2007; Bruck et al. 2011), provide paralinguistic information about the communicative context that will structure and organize the interpersonal interaction. The voice, face and body convey information about the interlocutor such as identity, gender, age, socio-cultural background, personality traits and internal emotional states (Lacheret-Dujour and Beaugendre 1999; Van Lancker Sidtis 2006; George and Conty 2008).
The ability to read these non-verbal social cues, such as voice or gaze, is a basic process that ensures social adaptation and leads to the recognition of emotional mental states, to our capacity for empathy and to social coordination (Lakin et al. 2003; George and Conty 2008; Schwartz and Pell 2012). A difficulty in perceiving non-verbal speech cues greatly diminishes the quality of social exchanges, as it is the case in schizophrenia (Box 7.1) (Brazo et al. 2014), neurodegenerative diseases (Speedie et al. 1990; Drapeau et al. 2009; Obeso et al. 2012) or in patients with brain injury such as aprosody4 (Ross 2000).

Figure 7.1. Cognitive processes involved in understanding emotional speech. For a color version of this figure, see www.iste.co.uk/habib/emotional.zip
COMMENT ON FIGURE 7.1.– In an interaction between two individuals, the interlocutor perceives verbal and non-verbal elements (emotional prosody, facial expression, etc.). Verbal elements are analyzed through ortholinguistic functions (phonological, lexical and syntactic-semantic integration). From the non-verbal elements, the paralinguistic functions provide the interlocutor with information about the identity, personality, mental state and communicative intentions of the speaker. Depending on the situation, up to 95% of non-verbal information is thought to contribute to the speaker’s message comprehension (Mehrabian 1972), thus ensuring optimal social adaptability and coordination (Beaucousin et al. 2007; George et al. 2008).
Box 7.1. Deficits in the perception of emotional prosody in schizophrenia?
In this chapter, we are particularly interested in the voice as a vehicle for non-verbal information about the person, and thus in emotional prosody. Within the framework of the model we have just posed, it seems interesting to clarify the role of emotional prosody in communication from a phylogenetic and ontogenetic perspective because, although we have the impression that communication is essentially based on verbal content, this does not seem to be the case at all ages of life and even throughout human history. These data allow us to have a better understanding of the place of emotional prosody in interactions.
From a phylogenetic perspective, researchers suggest that the protolanguage of hunter-gatherer tribes, i.e. the form of communication existing before the appearance of a language5, could have corresponded to intonational nuances similar to emotional prosody (Locke 1997; Falk 2004). Indeed, it would have allowed, for example, women to calm the cries of their children during harvesting or men during hunting to coordinate their actions in order to kill a large prey. This protolanguage would therefore have allowed the direct transmission of simple information. Gradually, a system of vocal signs (minimal verbal content) organized syntactically would have complexified this protolanguage leading to the emergence of a language allowing an increasingly elaborated communication. In the course of human history, the importance of emotional prosody in the understanding of language would thus have decreased, to the benefit of the decoding of verbal content (Rousseau 1781). But can its contribution be considered as secondary? Before answering this question, let us look at what happens during development.
This precedence of verbal content over prosodic content for language comprehension changes also during development. During in utero development, the baby is able to perceive the sound environment from the third trimester of pregnancy. Intrauterine recordings show that it is mainly prosody that is transmitted through the abdominal wall and the amniotic fluid (Querleu et al. 1988). The verbal content is difficult to distinguish, giving the impression to an adult listening to these recordings that they are hearing through a door. After birth, adults use an adapted mode of communication to interact with the young child, called Child-directed speech – or motherese6. This mode of communication is based on the exaggeration of emotional prosody (slowing down, more pronounced intonational modulation, etc.) but without modification of lexical units compared to speech directed toward the adult (Monnot et al. 2005). Child-directed speech conveys information about communication intentions (Fernald and Kuhl 1987; Fernald 1989). Indeed, an adult is able to identify the communicative intentions of delexicalized child-directed speech (without identifiable verbal content) and children can modify their behavior accordingly before the acquisition of the lexical-syntactic code, which appears around the age of 2 years (Boysson-Bardies 1996).
In adults, although some researchers consider that verbal content is more involved in understanding the interaction than emotional prosody (Kotz and Paulmann 2007), studies of brain-damaged patients show that emotional prosody plays an important role in understanding the emotional content (Monnot et al. 2003; Beaucousin et al. 2006), especially for social coordination (Beaucousin et al. 2007; Dickey et al. 2010). The inability to produce or understand emotional prosody, i.e. aprosody (not to be confused with dysprosody, see Box 7.2), leads to a definite disadvantage in interactions with others, insofar as a loss of family support7 or a loss of profession8 can be observed (Heilman et al. 1975; Ross 2000). Thus, in adults, emotional prosody is used to interpret communication intentions. However, case studies of patients with aprosody have been the subject of only 18 scientific publications9 since the first case reported in 1947 by Monrad-Krohn, as compared to more than 6,000 for aphasia. Currently, aprosody is rarely assessed, due to the lack of standardized tests in different languages such as French (to our knowledge, only Elliot Ross’s Aprosodia Battery exists in English; translated but non-standardized versions are used in other languages, raising the question of the quality of translations). Moreover, a neutral prosody during an interview with a health professional, such as a psychologist, or at the beginning of an illness, can be interpreted, sometimes wrongly, as a distancing in order to protect oneself against an emotional outburst (copying strategy).
But, beyond providing valuable information on the context of enunciation, the voice transmits clues that contribute to the recognition of the interlocutor. Indeed, it is essential to know who we are dealing with in order to achieve completely the objective of each person during the interaction.
Box 7.2. The different functions of prosody: a classification based on a study in neuropsychology (Ross 2000)
7.2. Learning to recognize the other person through their voice
Some authors refer to the voice as a sound face (Révis 2017). The face and voice provide valuable elements for speaker identification, and even a redundancy allowing for ambiguities to be removed in degraded interaction conditions (noise or darkness) (Campanella and Belin 2007). We have seen that the voice has only integrated a place in recognition models very late on (Campanella and Belin 2007). Why did this happen?
The first well-documented case of phonagnosia in the literature is recent, dating from 2009 (Garrido et al. 2009), although similar cases had been described before (Neuner and Schweinberger 2000). As we have seen in the introduction to this chapter, phonagnosia is the inability to recognize a person’s voice without any sensory impairment. Unlike the cases described in 2000, the 2009 case is described through a battery of assessments that show a selective impairment in recognizing a (famous and/or familiar) person from their voice. This patient is able to identify environmental sounds, other types of information from the voice, such as the gender of the speaker, or emotions conveyed by the voice, indicating that primary auditory processing is preserved, as well as secondary auditory processing. Furthermore, this case of congenital phonagnosia (without identifiable neurological impairment in adulthood) indicates that identifying a person by voice is a separate process from identifying faces, as this person is perfectly capable of identifying the faces of celebrities, people around them or even people they did not know before (ability to learn to recognize new faces). What impact does this alteration have on the person’s daily life? The article mentions very little information on this subject: the patient is nevertheless described as having a “lifelong social problem” (Garrido et al. 2009). She takes an antidepressant, but the article does not mention whether this is related to her social interaction problem (indication not mentioned). The authors mention that the patient came to the clinic because, upon discovering the description of prosopagnosia10, she rightly thought that she had found an explanation for her problem. We can therefore legitimately infer that this problem causes a certain form of handicap in her daily life to lead her to seek information and consultation.
Thus, the voice can be used to identify a person. It provides both perceptual (pitch, intensity, etc.) and semantic (person’s name, verbal content, emotional information, etc.) information (O’Mahony and Newell 2012). As with faces, perceptual information forms a unique signature, i.e. unique to each individual (except for monozygotic twins). This is not the case for semantic information, which is variable and not unique to a given individual (O’Mahony and Newell 2012). Moreover, we saw earlier that decoding of this semantic information is acquired later (between 1 and 2 years) than perceptual decoding (possible before birth because perceptual systems are functional in utero).
So we are experts in perceptual decoding, but how does perceptual information allow for identifying an individual as unique? Since the last century, we have known that the voice carries information that identifies the gender, age and socio-cultural background of the speaker. Some authors refer to this as idiosyncratic prosody (Monrad-Krohn 1947). Indeed, depending on the individual’s size, their voice will be more or less acute: the smaller the individual is, the higher their voice will be because the vocal cords are shorter (Révis 2017). We have all experienced this phenomenon when speaking with children. Since women are smaller than men, it is also possible to understand why they also have a higher pitched voice than men.
Size is not the only factor explaining sexual vocal dimorphism; some studies also show that sex hormones modify the elasticity of the vocal cords (Révis 2017). Gender also seems to modulate other acoustical parameters, such as speech rate: women speak more slowly and articulate more than men.
The voice also evolves with age: we have seen that the child’s voice is higher pitched than the adult’s, ensuring a very good discrimination between these ages (much less so within these age groups). During normal aging, the change in voice differs between men and women: women’s voices become deeper and men’s higher than in young adults of the same sex. This phenomenon is called presbyopia and occurs around the age of 60 years (Révis 2017).
Finally, the voice bears the traces of a person’s individual history. For example, excessive smoking and/or alcohol consumption will lead to a voice that is known as “hoarse” in everyday language. The intonation nuances are less harmonious, the voice becomes deeper and deeper and a loss of vocal power can be observed. These substances alter the elasticity of the vocal cords (Révis 2017). But beyond these effects, the voice also conveys territorial and national accents that sometimes identify the geographical origin or socio-cultural belonging of interlocutors. We have seen that dysprosody can lead to the emergence of an accent that is not developmentally specific to a given socio-educational environment (Box 7.2) (Monrad-Krohn 1947). While this information can be changed voluntarily, it is more difficult for biometric information (age, sex).
This information, decoded from the voice, ensures the interlocutor’s recognition. But is it effective? The recognition rate of voice identity is low, compared to facial identity recognition, but a higher inter-individual variability is observed (von Kriegstein 2012; Schweinberger et al. 2014; Révis 2017). However, apart from our own voice, which we find very difficult to identify when exposed to it via a recording, our ability to recognize familiar voices increases with the frequency of exposure (Kensinger and Corkin 2004) and the duration of the presented recording. The recognition rate increases from a chance threshold to over 66% when a sentence is spoken rather than a word (Ladefoged and Ladefoged 1980).
A final element can enhance this recognition ability: the presence of a face (Belin et al. 2004; Campanella and Belin 2007; von Kriegstein 2012; Schweinberger et al. 2014). The ability to correctly associate a voice and a face develops between 4 and 7 months of life (Campanella and Belin 2007). It is therefore an extremely early learning ability. In adults, one study shows that the presence of a face can serve as a primer for recognizing a person’s voice (O’Mahony and Newell 2012). Indeed, we make more errors and go more slowly to identify a voice when it is presented with a face that has not been learned as belonging to that same person. On the other hand, the presentation of a face previously associated with a voice will subsequently facilitate its recognition. This is true even if the voice-face association is new (voice and face unknown to the participant before the experiment). This effect is not present if, instead of the face, the first name is presented with the voice (O’Mahony and Newell 2012). This beneficial effect of faces on speech recognition may be selectively achieved in prosopagnosia, even though the presence of a face in these patients may improve language comprehension (von Kriegstein 2012). Moreover, the voice-face association is robust and rapid, as a brief simultaneous presentation is sufficient for the two to be linked (von Kriegstein et al. 2005; von Kriegstein and Giraud 2006).
To date, there are two models of person recognition that integrate speech and facial information (Campanella and Belin 2007; von Kriegstein 2012). Both models are supported by behavioral, brain imaging and neuropsychological data, but here we will only detail the cognitive processes. The main difference between the two models is that one postulates that sensory decoding will activate the individual’s memory trace (Campanella and Belin 2007), while the other assumes that percept will lead to the formation of predictions about the origin of sensory information and will constrain the interpretation of the sensory signal with respect to certain signal regularities (von Kriegstein 2012). Regardless of the model, identification is based on the decoding of speech information on the one hand and facial information on the other hand. These are then integrated to activate the speaker’s identity (Figure 7.2). It should be noted, however, that although identification is based on idiosyncratic information (allowing the speaker’s age, gender, etc., to be determined), there is a distinction between the decoding and identification stages since patients with phonagnosia or prosopagnosia are able to decode this information. The decoding of vocal and facial information takes place in distinct brain regions11 but in parallel (before 100 ms). The networking of these regions leads to the identification around 170–220 ms.
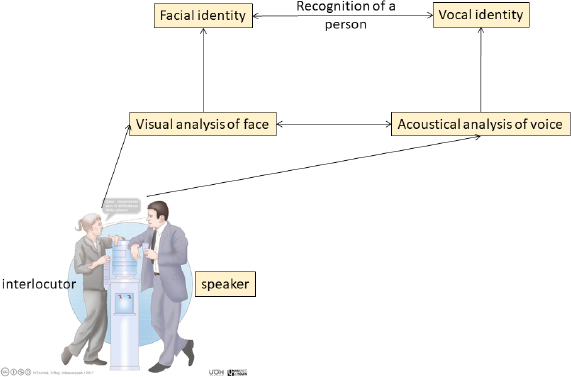
Figure 7.3. The interlocutor’s recognition. Adaptation of the models by Campanella and Belin (2007) (Model of face and voice processing) and von Kriegstein (2012) (Audiovisual model for human communication). For a color version of this figure, see www.iste.co.uk/habib/emotional.zip
COMMENT ON FIGURE 7.3. – During an exchange between two people, the speaker will perceive the interlocutor’s face and voice. The speaker will define a facial and vocal identity from the visual analysis of the face and the auditory analysis of the voice, which will allow them to recognize their speaker. At each level of analysis, interactions can be observed between the specific face processing pathway and the voice processing pathway, even in the case of a unimodal interaction (such as a telephone conversation).
Finally, it seems that the ability to recognize an interlocutor increases when they are encountered in a strong emotional context (Kensinger and Corkin 2004). The importance of emotions conveyed by the voice is not yet well integrated into existing models but we will see that it could be of importance in the case of memory pathologies.
7.3. Emotions and the recognition of others
During a social interaction, a lived experience encoding will modify subsequent experiences (Feldman Barrett et al. 2011). Voice can therefore help define an enunciation context that will modify future interactions because it conveys different types of information, as we have just seen. We will first define what we mean by context. There are several types of context, but in this chapter we will only be interested in the one related to the environment (or the experimental stimulation). It is called “stimulus-dependent context” (Feldman Barrett et al. 2011). For example, we were able to show that gaze contact with a face alters the memory of the face and the judgment of the individual (Lopis et al. 2017). This stimulus-dependent context evoked by emotional language stimuli, including voice, can alter the memory trace of a face and the person’s judgment.
Emotional expression from the face is a prolific field of research with a long history (for a review of the literature, see George (2013)). But the study of emotional contextual effects on facial perception is more recent and still very underdeveloped (for a review, see Feldman Barrett et al. (2007) and Wieser and Brosch (2012)). Most work has focused on emotional facial expressions but very little has focused on emotional cues outside of faces. Yet these can alter the way faces are perceived, judged and remembered. For example, the presence of emotional prosody facilitates the decoding of emotional facial expressions (Schwartz and Pell 2012). This facilitative effect is likely related to the activation of emotion conveyed by the voice (Hietanen et al. 1998; Magnee et al. 2007).
But beyond the emotional evaluation, a linguistic emotional context can modify the neural trace of the face previously perceived in the emotional context evoked by the voice (Morel et al. 2012) or evoked in writing (Todorov et al. 2007). In particular, early effects evoked by a vocal emotional context have been observed through audio recordings of voices evoking emotional situations (Beaucousin et al. 2006, 2007). Participants in a magnetoencephalography (MEG) protocol perceived faces expressing no facial emotion while listening to these recordings. When these same faces were presented a second time alone (without recordings), we observed that the neural trace of faces perceived after a single presentation in a positive context was different from that of faces presented in a neutral or negative context around 50 ms (Morel et al. 2012). Thus, the single presentation between an emotional voice and a face is sufficient to alter early brain activity in response to that face presented alone. Why was this change in prior experience only observed for the positive context? We hypothesized that a negative context, because of its perceptual salience, may have diverted attention from the face (Vuilleumier 2005). Moreover, positive emotions have a particular social salience for humans, promoting the association of emotional voice and face (Sander et al. 2005; Grandjean et al. 2008). For the first time, extrinsic stimulus-dependent context effects on the face were demonstrated in early steps. Prior to this work, it was accepted that emotional processes could modify the perception of the visual environment as early as 100 ms after stimulus presentation (Galli et al. 2006; Pourtois et al. 2012; Wieser and Brosch 2012), but now we know that these modifications appear as early as 50 ms (Morel et al. 2012).
However, it remains important to know whether these early brain effects shape people’s behavior. Indeed, a language context is considered as an ecological context because it is part of our daily experiences (Feldman Barrett et al. 2007). However, the experimental constraints, especially in MEG (large number of trials, positioning of the participant in a chair with a heavy device to place the magnetometers around the head, etc.), do not allow direct inference of possible impacts at the behavioral level. By reproducing this protocol but outside of MEG, Shasha Morel was able to show that this prior experience modifies the judgment of the person’s mood (Morel 2009). Thus, faces previously perceived in a positive vocal context are judged as being in a good mood, whereas a neutral or negative context induces an evaluation of bad mood on faces that do not express any emotional expression (Morel 2009). This effect remains present even if the person does not voluntarily report having noted the association between the face and the voice.
These results show that the information conveyed by a face is not only constructed from the immediate context of presentation (Feldman Barrett 2011). It is not only the emotional meaning evoked by the face that is constructed from the context but also the value of that face for the individual. This value constructed by the stimulus and its environment thus comes to modify the judgment on this person. Thus, it seems conceivable to use the emotional context to modify the value of a person’s face in order to improve its learning (Box 7.3), as is the case for other non-verbal social cues (Lopis et al. 2017). But further studies will need to confirm these observations in order to generalize the results, before a new and more integrative model can be proposed.
Box 7.3. Alzheimer’s disease and recognition of the other person in a vocal emotional context
7.4. Conclusion
The voice carries different types of information: idiosyncratic, emotional and linguistic. This information actively participates in the recognition of individuals. In particular, the emotional dimension of the voice could play a contextual role in facilitating the memorization of people’s identity, thus opening up paths to remediation program for memory pathologies (e.g. Alzheimer’s disease) or communication pathologies (e.g. schizophrenia).
7.5. References
Alzheimer’s Association (2018). Alzheimer’s disease facts and figures. Alzheimer’s & Dementia, 14, 367–429. doi.org/10.1016/j.jalz.2018.02.001.
Amlerová, J., Laczó, J., Nedelska, Z., Parizkova, M., Vyhnalek, M., Zhang, B., Andel, R., Sheardova, K., Hort, J. (2017). Recognition of emotions from voice in mild cognitive impairment and Alzheimer’s disease dementia. Alzheimer’s & Dementia, 13, 1148. doi.org/10.1016/j.jalz.2017.06.1677.
Baltazar, M. and Conty, L. (2016). Les effets du contact par le regard : un enjeu thérapeutique ? L’Encéphale, 42, 547–552. doi.org/10.1016/j.encep.2015.11.005.
Baltazar, M., Hazem, N., Vilarem, E., Beaucousin, V., Picq, J.L., Conty, L. (2014). Eye contact elicits bodily self-awareness in human adults. Cognition, 133, 120–127. doi.org/10. 1016/j.cognition.2014.06.009.
Banse, R. and Scherer, K.R. (1996). Acoustic profiles in vocal emotion expression. J. Pers. Soc. Psychol., 70, 614–636.
Beaucousin, V., Geronikola, N., Lopis, D., Millox, V., Baltazar, M., Picq, J.L., Conty, L. (submitted). How to successfully convey emotional meaning to Alzheimer patients: Use prosody! Neuropsychology.
Beaucousin, V., Lacheret-Dujour, A., Tzourio-Mazoyer, N. (2003). La prosodie. In Cerveau et Langage, Etard, O., Tzourio-Mazoyer, N. (eds). Hermes-Lavoisier, Paris.
Beaucousin, V., Lacheret, A., Turbelin, M.R., Morel, M., Mazoyer, B., Tzourio-Mazoyer, N. (2006). FMRI study of emotional speech comprehension. Cerebral Cortex, 17, 339–352. doi.org/10.1093/cercor/bhj151.
Beaucousin, V., Turbelin, M.R., Tzourio-Mazoyer, N. (2007). Le rôle de l’hémisphère droit dans la compréhension du langage : exemple de la prosodie affective. Revue de Neuropsychologie, 17, 149–180.
Belin, P., Fecteau, S., Bedard, C. (2004). Thinking the voice: Neural correlates of voice perception. Trends Cogn. Sci., 8, 129–135.
Boysson-Bardies, B. (1996). Comment la parole vient aux enfants. Odile Jacob, Paris.
Brazo, P., Beaucousin, V., Lecardeur, L., Razafimandimby, A., Dollfus, S. (2014). Social cognition in schizophrenic patients: The effect of semantic content and emotional prosody in the comprehension of emotional discourse. Frontiers in Psychiatry, 5, 1–7. doi.org/10. 3389/fpsyt.2014.00120.
Bruce, V. and Young, A. (1986). Understanding face recognition. Br. J. Psychol., 77 (Pt 3), 305–327. doi.org/10.1111/j.2044-8295.1986.tb02199.x.
Bruck, C., Kreifelts, B., Wildgruber, D. (2011). Emotional voices in context: A neurobiological model of multimodal affective information processing. Phys. Life Rev., 8, 383–403. doi.org/10.1016/j.plrev.2011.10.002.
Bucks, R.S. and Radford, S.A. (2004). Emotion processing in Alzheimer’s disease. Aging & Mental Health, 8, 222–232. doi.org/10.1080/13607860410001669750.
Burton, A.M., Bruce, V., Johnston, R.A. (1990). Understanding face recognition with an interactive activation model. British Journal of Psychology, 81, 361–380. doi.org/10. 1111/j.2044-8295.1990.tb02367.x.
Cadieux, N.L. and Greve, K.W. (1997). Emotion processing in Alzheimer’s disease. J. Int. Neuropsychol. Soc., 3, 411–419.
Cadieux, N.L., Greve, K.W., Hale, M.A. (1994). Emotion processing and caregiver stress in Alzheimer’s disease: A preliminary report. Clinical Gerontologist, 15, 75–78.
Campanella, S. and Belin, P. (2007). Integrating face and voice in person perception. Trends Cogn. Sci., 11, 535–543.
Caramelli, P., Mansur, L.L., Nitrini, R. (1998). Language and communication disorders in demantia of the Alzheimer type. In Handbook of Neurolinguistics, Stemmer, B., Whitaker, H.A. (eds). Academic Press, San Diego.
Castro, A. and Pearson, R. (2011). Lateralisation of language and emotion in schizotypal personality: Evidence from dichotic listening. Personality and Individual Differences, 51, 726–731. doi.org/10.1016/j.paid.2011.06.017.
Condray, R., van Kammen, D.P., Steinhauer, S.R., Kasparek, A., Yao, J.K. (1995). Language comprehension in schizophrenia: Trait or state indicator? Biological Psychiatry, 38, 287–296. doi.org/10.1016/0006-3223(95)00378-T.
Costa, H., de Souza, W.C., Mulholland, T. (2011). Recognition of facial expression and emotional prosody in Alzheimer’s disease. Alzheimer’s & Dementia, 7, S241. doi.org/10.1016/j.jalz.2011.05.684.
Demattè, M.L., Osterbauer, R., Spence, C. (2007). Olfactory cues modulate facial attractiveness. Chem. Senses, 32, 603–610. doi.org/10.1093/chemse/bjm030.
Dickey, C.C., Morocz, I.A., Minney, D., Niznikiewicz, M.A., Voglmaier, M.M., Panych, L.P., Khan, U., Zacks, R., Terry, D.P., Shenton, M.E., McCarley, R.W. (2010). Factors in sensory processing of prosody in schizotypal personality disorder: An fMRI experiment. Schizophr. Res., 121, 75–89. doi.org/10.1016/j.schres.2010.03.008.
Drapeau, J., Gosselin, N., Gagnon, L., Peretz, I., Lorrain, D. (2009). Emotional recognition from face, voice, and music in dementia of the Alzheimer type. Annals of the New York Academy of Sciences, 1169, 342–345. doi.org/10.1111/j.1749-6632.2009.04768.x.
Dubois, B., Feldman, H.H., Jacova, C., Dekosky, S.T., Barberger-Gateau, P., Cummings, J., Delacourte, A., Galasko, D., Gauthier, S., Jicha, G., Meguro, K., O’Brien, J., Pasquier, F., Robert, P., Rossor, M., Salloway, S., Stern, Y., Visser, P.J., Scheltens, P. (2007). Research criteria for the diagnosis of Alzheimer’s disease: Revising the NINCDS-ADRDA criteria. Lancet Neurol., 6(8), 734–746. https://doi.org/10.1016/S1474-4422(07)70178-3.
Edwards, J., Pattison, P.E., Jackson, H.J., Wales, R.J. (2001). Facial affect and affective prosody recognition in first-episode schizophrenia. Schizophrenia Research, 48, 235–253. doi.org/10.1016/S0920-9964(00)00099-2.
Edwards, J., Jackson, H.J., Pattison, P.E. (2002). Emotion recognition via facial expression and affective prosody in schizophrenia: A methodological review. Clinical Psychology Review, 22, 789–832.
Falk, D. (2004). Prelinguistic evolution in early hominins: Whence motherese? The Behavioral and Brain Sciences, 27, 491–503.
Feldman Barrett, L. (2011). Constructing emotion. Psychological Topics, 20, 359–380.
Feldman Barrett, L., Lindquist, K.A., Gendron, M. (2007). Language as context for the perception of emotion. Trends Cogn. Sci., 11, 327–332. doi.org/10.1016/j.tics.2007.06.003.
Feldman Barrett, L., Mesquita, B., Gendron, M. (2011). Context in emotion perception. Current Directions in Psychological Science, 20, 286–290. doi.org/10.1177/0963721411422522.
Fernald, A. (1989). Intonation and communicative intent in mothers’ speech to infants: Is the melody the message? Child Dev., 60, 1497–1510. doi.org/10.2307/1130938.
Fernald, A. and Kuhl, P. (1987). Acoustic determinants of infant preference for motherese speech. Infant Behav. Dev., 10, 279–293.
Galli, G., Feurra, M., Viggiano, M.P. (2006). “Did you see him in the newspaper?” Electrophysiological correlates of context and valence in face processing. Brain Research, 1119, 190–202.
Garrido, L., Eisner, F., McGettigan, C., Stewart, L., Sauter, D., Hanley, J.R., Schweinberger, S.R., Warren, J.D., Duchaine, B. (2009). Developmental phonagnosia: A selective deficit of vocal identity recognition. Neuropsychologia, 47, 123–131. doi.org/10.1016/j. neuropsychologia.2008.08.003.
Garcia-Rodriguez, B., Fusari, A., Rodriguez, B., Hernandez, J.M., Ellgring, H. (2009). Differential patterns of implicit emotional processing in Alzheimer’s disease and healthy aging. J. Alzheimers Dis., 18(3), 541–551 [Online]. Available at: https://doi.org/10.3233/JAD-2009-1161.
de Gelder, B. (2006). Towards the neurobiology of emotional body language. Nature reviews. Neuroscience, 7, 242–249. doi.org/10.1038/nrn1872.
George, N. (2013). The facial expression of emotions. In The Cambridge Handbook of Human Affective Neuroscience, Armony, J., Vuilleumier, P. (eds). Cambridge University Press, Cambridge.
George, N. and Conty, L. (2008). Facing the gaze of others. Neurophysiol. Clin., 38, 197–207. doi.org/10.1016/j.neucli.2008.03.001.
George, N., Morel, S., Conty, L. (2008). Visages et électrophysiologie. In Traitement et reconnaissance des visages : du percept à la personne, Barbeau, E., Joubert, S., Felician, O. (eds). Solal, Marseille.
Grandjean, D., Sander, D., Scherer, K.R. (2008). Conscious emotional experience emerges as a function of multilevel, appraisal-driven response synchronization. Conscious Cogn., 17, 484–495. doi.org/10.1016/j.concog.2008.03.019.
Heilman, K.M., Scholes, R., Watson, R.T. (1975). Auditory affective agnosia. Disturbed comprehension of affective speech. J. Neurol. Neurosurg. Psychiatry, 38, 69–72.
Hietanen, J.K., Surakka, V., Linnankoski, I. (1998). Facial electromyographic responses to vocal affect expressions. Psychophysiology, 35, 530–536. doi.org/10.1017/S0048577298970445.
Hoekert, M., Kahn, R.S., Pijnenborg, M., Aleman, A. (2007). Impaired recognition and expression of emotional prosody in schizophrenia: Review and meta-analysis. Schizophrenia Research, 96, 135–145. doi.org/10.1016/j.schres.2007.07.023.
Horley, K., Reid, A., Burnham, D. (2010). Emotional prosody perception and production in dementia of the Alzheimer’s type. J. Speech Lang. Hear Res., 53, 1132–1146. doi.org/10.1044/1092-4388(2010/09-0030).
Hsieh, S., Foxe, D., Leslie, F., Savage, S., Piguet, O., Hodges, J.R. (2012). Grief and joy: Emotion word comprehension in the dementias. Neuropsychology, 26, 624–630. doi.org/10.1037/a0029326.
Karpf, A. (2008). La voix : un univers invisible. Autrement, Paris.
Kensinger, E.A. and Corkin, S. (2004). Two routes to emotional memory: Distinct neural processes for valence and arousal. Proc. Natl. Acad. Sci., 101, 3310–3315.
Koff, E., Zaitchik, D., Montepare, J., Albert, M.S. (1999). Emotion processing in the visual and auditory domains by patients with Alzheimer’s disease. J. Int. Neuropsychol. Soc., 5, 32–40. doi.org/10.1017/S1355617799511053.
Kotz, S.A. and Paulmann, S. (2007). When emotional prosody and semantics dance cheek to cheek: ERP evidence. Brain Res., 1151, 107–118.
Kotz, S.A., Meyer, M., Paulmann, S. (2006). Lateralization of emotional prosody in the brain: An overview and synopsis on the impact of study design. Prog. Brain Res., 156, 285–294. doi.org/10.1016/S0079-6123(06)56015-7.
von Kriegstein, K. (2012). A multisensory perspective on human auditory communication. In The Neural Bases of Multisensory Processes, Frontiers in Neuroscience, Murray, M.M., Wallace, M.T. (eds). CRC Press/Taylor & Francis, Boca Raton.
von Kriegstein, K. and Giraud, A.-L. (2006). Implicit multisensory associations influence voice recognition. PLoS Biol., 4, e326. doi.org/10.1371/journal.pbio.0040326.
von Kriegstein, K., Kleinschmidt, A., Sterzer, P., Giraud, A.L. (2005). Interaction of face and voice areas during speaker recognition. Journal of Cognitive Neuroscience, 17, 367–376.
Kucharska-Pietura, K., David, A.S., Masiak, M., Phillips, M.L. (2005). Perception of facial and vocal affect by people with schizophrenia in early and late stages of illness. The British Journal of Psychiatry, 187, 523–528. doi.org/10.1192/bjp.187.6.523.
Lacheret-Dujour, A. (2015). Prosodic clustering in speech: From emotional to semantic processes. In Emotion in Language: Theory – Research – Application, Lüdtke, U. (ed.). John Benjamins Publishing Company, Amsterdam.
Lacheret-Dujour, A. and Beaugendre, F. (1999). La prosodie du français. CNRS, Paris.
Ladefoged, P. and Ladefoged, J. (1980). The ability of listeners to identify voices. UCLA Working Papers in Phonetics, 49, 43–51.
Lakin, J., Jefferis, V.E., Cheng, C.M., Chartrand, T.L. (2003). The chameleon effect as social glue: Evidence for the evolutionary significance of nonconscious mimicry. Journal of Nonverbal Behavior, 27, 145–162.
Lakshminarayanan, K., Ben Shalom, D., van Wassenhove, V., Orbelo, D., Houde, J., Poeppel, D. (2003). The effect of spectral manipulations on the identification of affective and linguistic prosody. Brain and Language, 84, 250–263. doi.org/10.1016/S0093-934X(02)00516-3.
Lecardeur, L., Stip, E., Champagne-Lavau, M. (2010). Cognitive remediation therapy of social cognition in schizophrenia: A critical review. Current Psychiatry Reviews, 6, 280–287. doi.org/10.2174/157340010793499369.
Leleu, A., Demily, C., Franck, N., Durand, K., Schaal, B., Baudouin, J.-Y. (2015). The odor context facilitates the perception of low-intensity facial expressions of emotion. PLoS One, 10, e0138656. doi.org/10.1371/journal.pone.0138656.
Locke, J.L. (1997). A theory of neurolinguistic development. Brain Lang., 58, 265–326. doi.org/10.1006/brln.1997.1791.
Lopis, D., Baltazar, M., Geronikola, N., Beaucousin, V., Conty, L. (2017). Eye contact effects on social preference and face recognition in normal ageing and in Alzheimer’s disease. Psychological Research. doi.org/10.1007/s00426-017-0955-6.
Magnee, M.J., Stekelenburg, J.J., Kemner, C., de Gelder, B. (2007). Similar facial elec tromyographic responses to faces, voices, and body expressions. Neuroreport, 18, 369–372.
Martin, A. and Fedio, P. (1983). Word production and comprehension in Alzheimer’s disease: The breakdown of semantic knowledge. Brain Lang., 19, 124–141.
Mehrabian, A. (1972). Nonverbal Communication. Aldine-Atherton, Chicago.
Monnot, M., Orbelo, D., Riccardo, L., Sikka, S., Rossa, E. (2003). Acoustic analyses support subjective judgments of vocal emotion. Annals of New York Academy of Science, 1000, 288–292.
Monnot, M., Foley, R., Ross, E.D. (2005). Affective prosody: Whence motherese. Commentary/Falk: Prelinguistic evolution in early hominins: Whence motherese? The Behavioral and Brain Sciences, 27, 518–519. doi.org/10.1017/S0140525X04390114.
Monrad-Krohn, G.H. (1947). Dysprosody or altered “melody of language”. Brain, 70, 405–415.
Morel, S. (2009). Effets de l’expérience préalable et de l’émotion sur la perception des visages et de leur état émotionnel : études comportementales et électrophysiologiques. PhD Thesis, Université Pierre et Marie Curie, Paris.
Morel, S., Beaucousin, V., Perrin, M., George, N. (2012). Very early modulation of brain responses to neutral faces by a single prior association with an emotional context: Evidence from MEG. NeuroImage, 61, 1461–1470. doi.org/10.1016/j.neuroimage.2012.04.016.
Naglie, G., Hogan, D.B., Krahn, M., Beattie, B.L., Black, S.E., Macknight, C., Freedman, M.,
Patterson, C., Borrie, M., Bergman, H., Byszewski, A., Streiner, D., Irvine, J., Ritvo, P., Comrie, J., Kowgier, M., Tomlinson, G. (2011). Predictors of patient self-ratings of quality of life in Alzheimer disease: Cross-sectional results from the Canadian Alzheimer’s Disease Quality of Life Study. Am. J. Geriatr. Psychiatry, 19(10), 881–890 [Online]. Available at: https://doi.org/10.1097/JGP.0b013e3182006a67.
Neuner, F. and Schweinberger, S.R. (2000). Neuropsychological impairments in the recognition of faces, voices, and personal names. Brain Cogn., 44, 342–366. doi.org/10.1006/brcg.1999.1196.
O’Mahony, C. and Newell, F.N. (2012). Integration of faces and voices, but not faces and names, in person recognition. Br. J. Psychol., 103, 73–82. doi.org/10.1111/j.2044-8295.2011.02044.x.
Obeso, I., Casabona, E., Bringas, M.L., Alvarez, L., Jahanshahi, M. (2012). Semantic and phonemic verbal fluency in Parkinson’s disease: Influence of clinical and demographic variables. Behav. Neurol., 25, 111–118. doi.org/10.3233/BEN-2011-0354.
Pourtois, G., Schettino, A., Vuilleumier, P. (2012). Brain mechanisms for emotional influences on perception and attention: What is magic and what is not. Biol. Psychol. doi.org/10.1016/j.biopsycho.2012.02.007.
Querleu, D., Renard, X., Versyp, F., Paris-Delrue, L., Crepin, G. (1988). Fetal hearing. Eur. J. Obstet. Gynecol. Reprod. Biol., 28, 191–212.
Révis, J. (2017). La voix et soi : ce que notre voix dit de nous. De Boeck Supérieur, Louvain-la-Neuve.
Roberts, V.J., Ingram, S.M., Lamar, M., Green, R.C. (1996). Prosody impairment and associated affective and behavioral disturbances in Alzheimer’s disease. Neurology, 47, 1482–1488.
Ross, E.D. (2000). Affective prosody and the aprosodias. In Principles of Behavioral and Cognitive Neurology, Mesulam, M. (ed.). Oxford University Press, Oxford.
Rousseau, J.-J. (1781). Essai sur l’origine des langues. Flammarion, Paris.
Roux, P. (2008). Étude du traitement implicite de la prosodie linguistique et émotionnelle dans la schizophrénie. PhD Thesis, Université Paris 5, Paris.
Roux, P., Christophe, A., Passerieux, C. (2010). The emotional paradox: Dissociation between explicit and implicit processing of emotional prosody in schizophrenia. Neuropsychologia, 48, 3642–2649. doi.org/10.1016/j.neuropsychologia.2010.08.021.
Russell, J.A. and Feldman Barrett, L. (1999). Core affect, prototypical emotional episodes, and other things called emotion: Dissecting the elephant. J. Pers. Soc. Psychol., 76, 805–819.
Sander, D., Grandjean, D., Pourtois, G., Schwartz, S., Seghier, M.L., Scherer, K.R., Vuilleumier, P. (2005). Emotion and attention interactions in social cognition: Brain regions involved in processing anger prosody. NeuroImage, 28, 848–858.
Savla, G.N., Vella, L., Armstrong, C.C., Penn, D.L., Twamley, E.W. (2013). Deficits in domains of social cognition in schizophrenia: A meta-analysis of the empirical evidence. Schizophrenia Bulletin, 39, 979–992. doi.org/10.1093/schbul/sbs080.
Scherer, K.R. (1998). Vocal affect expression: A review and a model for future research. Psychol. Bull., 99, 143–165.
Scherer, K.R. (2003). Vocal communication of emotion: A review of research paradigms. Speech Communication, 40, 227–256. doi.org/10.1016/S0167-6393(02)00084-5.
Schwartz, R. and Pell, M.D. (2012). Emotional speech processing at the intersection of prosody and semantics. PLoS One, 7, e47279. doi.org/10.1371/journal.pone.0047279.
Schweinberger, S.R., Kawahara, H., Simpson, A.P., Skuk, V.G., Zäske, R. (2014). Speaker perception: Speaker perception. Wiley Interdisciplinary Reviews: Cognitive Science, 5, 15–25. doi.org/10.1002/wcs.1261.
Small, J.A., Huxtable, A., Walsh, M. (2010). The role of caregiver prosody in conversations with persons who have Alzheimer’s disease. American Journal of Alzheimer’s Disease and Other Dementias, 24, 469–475. doi.org/10.1177/1533317509342981.
Speedie, L.J., Brake, N., Folstein, S.E., Bowers, D., Heilman, K.M. (1990). Comprehension of prosody in Huntington’s disease. J. Neurol. Neurosurg. Psychiatry, 53, 607–610.
Taler, V., Baum, S.R., Chertkow, H., Saumier, D. (2008). Comprehension of grammatical and emotional prosody is impaired in Alzheimer’s disease. Neuropsychology, 22, 188–195. doi.org/10.1037/0894-4105.22.2.188.
Templier, L., Chetouani, M., Plaza, M., Belot, Z., Bocquet, P., Chaby, L. (2015). Altered identification with relative preservation of emotional prosody production in patients with Alzheimer’s disease. Gériatrie et Psychologie Neuropsychiatrie du Viellissement, 106–115. doi.org/10.1684/pnv.2015.0524.
Testa, J.A., Beatty, W.W., Gleason, A.C., Orbelo, D.M., Ross, E.D. (2001). Impaired affective prosody in AD: Relationship to aphasic deficits and emotional behaviors. Neurology, 57, 1474–1481. doi.org/10.1212/WNL.57.8.1474.
Todorov, A. and Uleman, J.S. (2002). Spontaneous trait inferences are bound to actors’ faces: Evidence from a false recognition paradigm. J. Pers. Soc. Psychol., 83, 1051–1065.
Todorov, A., Gobbini, M.I., Evans, K.K., Haxby, J.V. (2007). Spontaneous retrieval of affective person knowledge in face perception. Neuropsychologia, 45, 163–173.
Van Lancker Sidtis, D.V. (2006). Does functional neuroimaging solve the questions of neurolinguistics? Brain and Language, 98, 276–290.
Vuilleumier, P. (2005). How brains beware: Neural mechanisms of emotional attention. Trends Cogn. Sci., 9, 585–594. doi.org/10.1016/j.tics.2005.10.011.
Wieser, M.J. and Brosch, T. (2012). Faces in context: A review and systematization of contextual influences on affective face processing. Front. Psychol., 3, 471. doi.org/10.3389/fpsyg.2012. 00471.
Zebrowitz, L.A. and Montepare, J.M. (2008). Social psychological face perception: Why appearance matters. Soc. Personal. Psychol. Compass., 2, 1497. doi.org/10.1111/j.1751-9004.2008.00109.x.
- 1 The one who speaks in an exchange between two individuals.
- 2 The one addressed by the speaker in an exchange between two individuals.
- 3 Ortholinguistic functions ensure the decoding of the acoustic (or visual) message from the verbal content. There are five of them. The phonetic function concerns the language sounds; the phonological function represents the organization of these sounds within the message to form morphemes (the smallest units of sound that carry meaning); the morphological function corresponds to the combination of morphemes to form elements of the lexicon (which corresponds to all the words); the syntactic function represents the level of organization of words to form meaningful statements; and finally the semantic function ensures the association of the signifieds (or concepts) with the signifiers that constitute the lexical units (Van Lancker-Sidtis 2006).
- 4 Inability to understand or produce emotional prosody, i.e. modulation of vocal intonation in relation to internal emotional states (Box 7.3).
- 5 Ability to express and transmit thoughts through a system of vocal signs.
- 6 Child-directed speech does not mean using different words from adult language, but it is the way of speaking, the prosody, that differs.
- 7 One man’s production aprosody, following a stroke, led to his divorce because his partner complained that he no longer felt attached to her because of the “way” he addressed her (Ross 2000). It was the lack of emotional prosody in intimate exchanges that most affected this woman.
- 8 A teacher was forced to retire from her job following a production aprosody because she was no longer able to maintain order in her classroom because of her “neutral” way of calling school children to order (Ross 2000).
- 9 Search conducted on the pubmed database with the term aprosodia in the title of the article.
- 10 Inability to recognize a person from their face alone.
- 11 The face-selective area in the right fusiform gyrus (the so-called fusiform face area, FFA) and the voice-selective in the anterior part of the right superior temporal gyrus (the so-called temporal voice area, TVA).