
C H A P T E R 3
Hybrid Columnar Compression
Hybrid Columnar Compression (HCC) is probably one of the least understood of the features that are unique to Exadata. The feature was originally rolled out in a beta version of 11gR2 and was enabled on both Exadata and non-Exadata platforms. The production release of 11gR2 restricted the feature to Exadata platforms only. Ostensibly this decision was made because the additional processing power available on the Exadata storage servers. Because the feature is restricted to Exadata, the recent documentation refers to it as Exadata Hybrid Columnar Compression (EHCC).
This chapter will first present basic information on both of Oracle’s older row-major format compression methods (BASIC and OLTP). We will then explore in detail the mechanics of Oracle’s new HCC feature—how it works, including how the data is actually stored on disk, where and when the compression and decompression occur, and when its use is appropriate. Finally we’ll provide some real world examples of HCC usage.
Oracle Storage Review
As you probably already know, Oracle stores data in a block structure. These blocks are typically 8K and from a simplistic point of view they consist of a block header, a row directory, row data and free space. The block header starts at the top of a block and works its way down, while the row data starts at the bottom and works its way up. The free space generally sits in the middle. Figure 3-1 shows a representation of a traditional Oracle block format.

Figure 3-1. The standard Oracle block format (row-major storage)
Rows are stored in no specific order, but columns are generally stored in the order in which they were defined in the table. For each row in a block there will be a row header, followed by the column data for each column. Figure 3.2 shows how the pieces of a row are stored in a standard Oracle block. Note that we called it a row piece, because occasionally a row’s data may be stored in more than one chunk. In this case, there will be a pointer to the next piece.

Figure 3-2. The standard Oracle row format (row-major storage)
Note that the row header may contain a pointer to another row piece. We’ll come back to this a little later, but for now, just be aware that there is a mechanism to point to another location. Also note that each column is preceded by a separate field indicating the length of the column. Nothing is actually stored in the Column Value field for nulls. The presence of a null column is indicated by a value of 0 in the column length field. Trailing nulls don’t even store the column length fields, as the presence of a new row header indicates that there are no more columns with values in the current row.
PCTFREE is a key value associated with blocks; it controls how space is used in a block. Its purpose is to reserve some free space in each block for updates. This is necessary to prevent row migration (moving rows to new blocks) that would be caused by lack of space in the row’s original block when a row increases in size. When rows are expected to be updated (with values that require more space), more space is generally reserved. When rows are not expected to increase in size because of updates, values as low as 0 may be specified for PCTFREE. With compressed blocks it is common to use very low values of PCTFREE, because the goal is to minimize space usage and the rows are generally not expected to be updated frequently (if ever). Figure 3-3 shows how free space is reserved based on the value of PCTFREE.

Figure 3-3. Block free space controlled by PCTFREE
Figure 3-3 shows a block that reserves 20 percent of its space for updates. A block with a PCTFREE setting of 0 percent would allow inserts to fill the block almost completely. When a record is updated, and the new data will not fit in the available free space of the block where the record is stored, the database will move the row to a new block. This process is called row migration. It does not completely remove the row from the original block but leaves a reference to the newly relocated row so that it can still be found by its original rowid (which basically consists of a file number, block number, and row number within the block). This ability of Oracle to relocate rows will become relevant when we discuss what happens if you update a row that has been compressed. Note that the more generic term for storing rows in more than one piece is row chaining. Row migration is a special case of row chaining in which the entire row is relocated. Figure 3-4 shows what a block with a migrated row might look like.
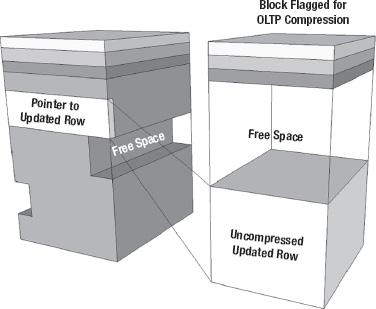
Figure 3-4. Row migration
This diagram represents a situation where the entire row has been relocated, leaving behind only a pointer to the new location.
Oracle Compression Mechanisms
Oracle provides several compression mechanisms in addition to HCC. The naming is somewhat confusing due to the common marketing terms and some changes in nomenclature along the way. Here we’ll refer to the three main flavors of compression used by Oracle as BASIC, OLTP, and HCC.
BASIC
This compression method is a base feature of Oracle Database 11g Enterprise Edition. It compresses data only on direct path loads. Modifications force the data to be stored in an uncompressed format, as do inserts that do not use the direct path load mechanism. Rows are still stored together in the normal row-major form. The compression unit is a single Oracle block. BASIC is the default compression method, from a syntax standpoint. For example, BASIC compression will be used if you issue the following command:
CREATE TABLE … COMPRESS;
Basic compression was introduced in Oracle Database version 9i. This form of compression was also referred to as DSS Compression in the past. The syntax COMPRESS FOR DIRECT_LOAD OPERATIONS can still be used to enable BASIC compression, although this syntax has now been deprecated.
OLTP
The OLTP compression method allows data to be compressed for all operations, not just direct path loads. It is part of an extra-cost option called Advanced Compression and was introduced in Oracle Database version 11g Release 1. The storage format is essentially the same as BASIC, using a symbol table to replace repeating values. OLTP compression attempts to allow for future updates by leaving 10 percent free space in each block via the PCTFREE setting (BASIC compression uses a PCTFREE value of 0 percent). Therefore, tables compressed for OLTP will occupy slightly more space than if they were compressed with BASIC (assuming direct path loads only and no updates). The syntax for enabling this type of compression is
CREATE TABLE … COMPRESS FOR OLTP;
Alternatively, the syntax COMPRESS FOR ALL OPERATIONS may be used, although this syntax is now deprecated. OLTP compression is important because it is the fallback method for tables that use HCC compression. In other words, blocks will be stored using OLTP compression in cases where HCC cannot be used (non-direct path loads for example). One important characteristic of OLTP compression is that updates and non-direct path inserts are not compressed initially. Once a block becomes “full” it will be compressed. We’ll revisit this issue in the performance section of this chapter.
HCC
HCC is only available for tables stored on Exadata storage. As with BASIC compression, data will only be compressed in HCC format when it is loaded using direct path loads. Conventional inserts and updates cause records to be stored in OLTP compressed format. In the case of updates, rows are migrated to new blocks. These blocks are marked for OLTP compression, so when one of these new blocks is sufficiently full, it will be compressed using the OLTP algorithm.
HCC provides four levels of compression, as shown in Table 3-1. Note that the expected compression ratios are very rough estimates and that the actual compression ratio will vary greatly depending on the data that is being compressed.


Tables may be compressed with HCC using the following syntax:
CREATE TABLE ... COMPRESS FOR QUERY LOW;
CREATE TABLE ... COMPRESS FOR QUERY HIGH;
CREATE TABLE ... COMPRESS FOR ARCHIVE LOW;
CREATE TABLE ... COMPRESS FOR ARCHIVE HIGH;
You may also change a table’s compression attribute by using the ALTER TABLE statement. However, this command has no effect on existing records unless you actually rebuild the segment using the MOVE keyword. Without the MOVE keyword, the ALTER TABLE command merely notifies Oracle that future direct path inserts should be stored using HCC. By the way, you can see which form of compression a table is assigned, if any, using a query like this:
SYS@SANDBOX1> select owner, table_name, compress_for
2 from dba_tables
3 where compression = ‘ENABLED’
4 and compress_for like nvl('&format',compress_for)
5* order by 1,2;
OWNER TABLE_NAME COMPRESS_FOR
------------------------------ ------------------------------ ------------
KSO SKEW2_BASIC BASIC
KSO SKEW2_HCC1 QUERY LOW
KSO SKEW2_HCC2 QUERY HIGH
KSO SKEW2_HCC3 ARCHIVE LOW
KSO SKEW2_HCC4 ARCHIVE HIGH
KSO SKEW2_OLTP OLTP
6 rows selected.
Of course, the current assignment may have nothing to do with the storage format in use for any or all of the blocks that store data for a given table. Here is a quick example:
SYS@SANDBOX1> !cat table_size2.sql
compute sum of totalsize_megs on report
break on report
col owner for a20
col segment_name for a30
col segment_type for a10
col totalsize_megs for 999,999.9
select s.owner, segment_name,
sum(bytes/1024/1024) as totalsize_megs, compress_for
from dba_segments s, dba_tables t
where s.owner = t.owner
and t.table_name = s.segment_name
and s.owner like nvl('&owner',s.owner)
and t.table_name like nvl('&table_name',segment_name)
group by s.owner, segment_name, compress_for
order by 3;
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW 1,460.3
--------------
sum 1,460.3
1 row selected.
Elapsed: 00:00:00.31
SYS@SANDBOX1> alter table kso.skew compress for ARCHIVE HIGH;
Table altered.
Elapsed: 00:00:00.02
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW 1,460.3 ARCHIVE HIGH
--------------
sum 1,460.3
1 row selected.
Elapsed: 00:00:00.02
SYS@SANDBOX1> -- It says ARCHIVE HIGH, but obviously the data has not been compressed.
SYS@SANDBOX1>
SYS@SANDBOX1> alter table kso.skew move compress for query low parallel 32;
Table altered.
Elapsed: 00:00:09.60
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW 301.3 QUERY LOW
--------------
sum 301.3
Elapsed: 00:00:00.02
You could probably guess that the first ALTER command (without the MOVE keyword) didn’t really do anything to the existing data. It only took a few hundredths of a second, after all. And as you can see when we looked at the size of the table, it did not compress the existing data, even though the data dictionary now says the table is in ARCHIVE HIGH mode. When we added the MOVE keyword, the table was actually rebuilt with the new compression setting using direct path inserts and as you can see, the data has been compressed from the original 1,406MB to 301MB.
In this section we briefly described each of the three types of compression available in Oracle. Since this chapter is focused on HCC, we won’t discuss the other methods further except as they relate to how HCC works.
HCC Mechanics
HCC works by storing data in a nontraditional format—nontraditional for Oracle, anyway. Data stored using HCC still resides in Oracle blocks, and each block still has a block header. But the data storage has been reorganized. In the first place, the blocks are combined into logical structures called compression units, or CUs. A CU consists of multiple Oracle blocks (usually adding up to 32K or 64K). Figure 3-5 shows a logical representation of how CUs are laid out.

Figure 3-5. Layout of an HCC Compression Unit
Notice that the rows are no longer stored together. Instead the data is organized by column within the compression unit. This is not a true column oriented storage format but rather a cross between column oriented and row oriented. Remember that the sorting is done only within a single CU. The next CU will start over with Column 1 again. The advantage of this format is that it allows any row to be read in its entirety by reading a single CU. With a true column oriented storage format you would have to perform a separate read for each column. The disadvantage is that reading an individual record will require reading a multi-block CU instead of a single block. Of course full table scans will not suffer, because all the blocks will be read. We’ll talk more about this trade-off a little later but you should already be thinking that this limitation could make HCC less attractive for tables that need to support lots of single row access.
The sorting by column is actually done to improve the effectiveness of the compression algorithms, not to get performance benefits of column oriented storage. This is where the name “Hybrid Columnar Compression” comes from and why Exadata has not been marketed as a column oriented database. The name is actually very descriptive of how the feature actually works.
HCC Performance
There are three areas of concern when discussing performance related to table compression. The first, load performance, is how long it takes to compress the data. Since compression only takes place on direct path loads, this is essentially a measurement of the impact of loading data. The second area of concern, query performance, is the impact of decompression and other side effects on queries against the compressed data. The third area of concern, DML performance, is the impact compression algorithms have on other DML activities such as Updates and Deletes.
Load Performance
As you might expect, load time tends to increase with the amount of compression applied. As the saying goes, “There is no such thing as a free puppy.” When you compare costs in terms of increased load time with the benefit provided by increased compression ratio, the two Zlib-based options (QUERY LOW and ARCHIVE HIGH) appear to offer the best trade-off. Here’s a listing showing the syntax for generating compressed versions of a 15G table along with timing information.
SYS@SANDBOX1> @hcc_build3
SYS@SANDBOX1> set timing on
SYS@SANDBOX1> set echo on
SYS@SANDBOX1> create table kso.skew3_none nologging parallel 8
2 as select /*+ parallel (a 8) */ * from acolvin.skew3 a;
Table created.
Elapsed: 00:00:42.76
SYS@SANDBOX1> create table kso.skew3_basic nologging parallel 8 compress
2 as select /*+ parallel (a 8) */ * from acolvin.skew3 a;
Table created.
Elapsed: 00:01:35.97
SYS@SANDBOX1> create table kso.skew3_oltp nologging parallel 8 compress for oltp
2 as select /*+ parallel (a 8) */ * from acolvin.skew3 a;
Table created.
Elapsed: 00:01:24.58
SYS@SANDBOX1> create table kso.skew3_hcc1 nologging parallel 8 compress for query low
2 as select /*+ parallel (a 8) */ * from acolvin.skew3 a;
Table created.
Elapsed: 00:00:56.57
SYS@SANDBOX1> create table kso.skew3_hcc2 nologging parallel 8 compress for query high
2 as select /*+ parallel (a 8) */ * from acolvin.skew3 a;
Table created.
Elapsed: 00:01:56.49
SYS@SANDBOX1> create table kso.skew3_hcc3 nologging parallel 8 compress for archive low
2 as select /*+ parallel (a 8) */ * from acolvin.skew3 a;
Table created.
Elapsed: 00:01:53.43
SYS@SANDBOX1> create table kso.skew3_hcc4 nologging parallel 8 compress for archive high
2 as select /*+ parallel (a 8) */ * from acolvin.skew3 a;
Table created.
Elapsed: 00:08:55.58
SYS@SANDBOX1> set timing off
SYS@SANDBOX1> set echo off
SYS@SANDBOX1> @table_size2
Enter value for owner:
Enter value for table_name: SKEW3
Enter value for type:
OWNER SEGMENT_NAME TYPE TOTALSIZE_MEGS
-------------------- ------------------------------ ------------------ --------------
ACOLVIN SKEW3 TABLE 15,347.5
--------------
sum 15,347.5
1 row selected.
SYS@SANDBOX> !cat comp_ratio.sql
compute sum of totalsize_megs on report
break on report
col owner for a10
col segment_name for a20
col segment_type for a10
col totalsize_megs for 999,999.9
col compression_ratio for 999.9
select owner, segment_name, segment_type type,
sum(bytes/1024/1024) as totalsize_megs,
&original_size/sum(bytes/1024/1024) as compression_ratio
from dba_segments
where owner like nvl('&owner',owner)
and segment_name like nvl('&table_name',segment_name)
and segment_type like nvl('&type',segment_type)
group by owner, segment_name, tablespace_name, segment_type
order by 5;
SYS@SANDBOX1> @comp_ratio
Enter value for original_size: 15347.5
Enter value for owner: KSO
Enter value for table_name: SKEW3%
Enter value for type:
OWNER SEGMENT_NAME TYPE TOTALSIZE_MEGS COMPRESSION_RATIO
---------- -------------------- ------------------ -------------- -----------------
KSO SKEW3_NONE TABLE 15,370.8 1.0
KSO SKEW3_OLTP TABLE 10,712.7 1.4
KSO SKEW3_BASIC TABLE 9,640.7 1.6
KSO SKEW3_HCC1 TABLE 3,790.1 4.0
KSO SKEW3_HCC3 TABLE 336.9 45.6
KSO SKEW3_HCC2 TABLE 336.7 45.6
KSO SKEW3_HCC4 TABLE 274.3 55.9
--------------
sum 25,091.4
7 rows selected.
The listing shows the commands used to create compressed versions of the SKEW3 table. We also loaded an uncompressed version for a timing reference. Note also that the SKEW3 table is highly compressible due to many repeating values in a small number of columns. It’s a little hard to pick out the information from the listing, so Table 3-2 summarizes the data in a more easily digested format.

So as you can see, QUERY HIGH and ARCHIVE LOW compression levels resulted in almost exactly the same compression ratios (45.6) for this dataset and took roughly the same amount of time to load. Loading is definitely slower with compression and for this dataset was somewhere between 2 and 3 times slower (with the exception of ARCHIVE HIGH, which we’ll come back to). Notice the huge jump in compression between QUERY LOW and QUERY HIGH. While the load time roughly doubled, the compression ratio improved by a factor of 10. For this dataset, this is clearly the sweet spot when comparing load time to compression ratio.
Now let’s turn our attention to the ARCHIVE HIGH compression setting. In the previous test we did not attempt to maximize the load time. Our choice of 8 is actually a rather pedestrian setting for parallelism on Exadata. In addition, our parallel slave processes were limited to a single node via the PARALLEL_FORCE_LOCAL parameter (we’ll talk more about that in Chapter 6). So our load process was using a total of eight slaves on a single node. Here’s some output from the Unix top command showing how the system was behaving during the load:
===First HCC4 run (8 slaves)
top - 19:54:14 up 2 days, 11:31, 5 users, load average: 2.79, 1.00, 1.09
Tasks: 832 total, 9 running, 823 sleeping, 0 stopped, 0 zombie
Cpu(s): 50.5%us, 0.6%sy, 0.0%ni, 48.8%id, 0.1%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 74027752k total, 29495080k used, 44532672k free, 111828k buffers
Swap: 16771852k total, 2120944k used, 14650908k free, 25105292k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
19440 oracle 25 0 10.1g 86m 55m R 99.9 0.1 0:21.25 ora_p001_SANDBOX1
19451 oracle 25 0 10.1g 86m 55m R 99.9 0.1 0:21.21 ora_p002_SANDBOX1
19465 oracle 25 0 10.1g 86m 55m R 99.9 0.1 0:21.34 ora_p003_SANDBOX1
19468 oracle 25 0 10.1g 87m 55m R 99.9 0.1 0:20.22 ora_p004_SANDBOX1
19479 oracle 25 0 10.1g 86m 55m R 99.9 0.1 0:21.21 ora_p005_SANDBOX1
19515 oracle 25 0 10.1g 86m 54m R 99.9 0.1 0:21.18 ora_p006_SANDBOX1
19517 oracle 25 0 10.1g 88m 50m R 99.9 0.1 0:27.59 ora_p007_SANDBOX1
19401 oracle 25 0 10.1g 87m 54m R 99.5 0.1 0:21.31 ora_p000_SANDBOX1
Clearly, loading data into an ARCHIVE HIGH compressed table is a CPU-intensive process. But notice that we’re still only using about half the processing power on the single Database Server. Adding more processors and more servers should make it go considerably faster. By the way, it’s usually worthwhile to look at the CPU usage during the uncompressed load for comparison purposes. Here’s another snapshot from top taken during the loading of the uncompressed version of the SKEW3 table; in this and similar snapshots, we’ve highlighted output items of particular interest:
===No Compression Load
top - 19:46:55 up 2 days, 11:23, 6 users, load average: 1.21, 0.61, 1.20
Tasks: 833 total, 2 running, 831 sleeping, 0 stopped, 0 zombie
Cpu(s): 22.3%us, 1.4%sy, 0.0%ni, 75.9%id, 0.1%wa, 0.1%hi, 0.2%si, 0.0%st
Mem: 74027752k total, 29273532k used, 44754220k free, 110376k buffers
Swap: 16771852k total, 2135368k used, 14636484k free, 25074672k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15999 oracle 16 0 10.0g 72m 64m S 54.8 0.1 0:04.89 ora_p000_SANDBOX1
16001 oracle 16 0 10.0g 72m 64m S 51.5 0.1 0:04.72 ora_p001_SANDBOX1
16024 oracle 16 0 10.0g 69m 61m S 48.5 0.1 0:03.97 ora_p007_SANDBOX1
16020 oracle 16 0 10.0g 70m 61m S 44.6 0.1 0:04.16 ora_p006_SANDBOX1
16003 oracle 16 0 10.0g 71m 62m S 43.6 0.1 0:04.42 ora_p002_SANDBOX1
16014 oracle 16 0 10.0g 71m 62m S 42.9 0.1 0:04.26 ora_p005_SANDBOX1
16007 oracle 16 0 10.0g 69m 61m S 40.9 0.1 0:04.28 ora_p004_SANDBOX1
16005 oracle 15 0 10.0g 72m 64m R 38.3 0.1 0:04.45 ora_p003_SANDBOX1
Notice that while the number of active processes is the same (8), the CPU usage is significantly less when the data is not being compressed during the load. The other levels of compression use somewhat less CPU, but are much closer to HCC4 than to the noncompressed load.
To speed up the ARCHIVE HIGH loading we could add more processes or we could allow the slaves to run on multiple nodes. Here’s a quick example:
SYS@SANDBOX1> alter system set parallel_force_local=false;
System altered.
Elapsed: 00:00:00.09
SYS@SANDBOX1> create table kso.skew3_hcc4 nologging parallel 32 compress for archive high
2 as select /*+ parallel (a 32) */ * from kso.skew3 a;
Table created.
Elapsed: 00:03:18.96
Setting the PARALLEL_FORCE_LOCAL parameter to FALSE allowed slaves to be spread across both nodes. Setting the parallel degree to 32 allowed 16 slaves to run on each of the two nodes in our quarter rack test system. This effectively utilized all the CPU resources on both nodes. Here’s one last snapshot of top output from one of the nodes during the load. The other node showed the same basic profile during the load.
===Second HCC4 run (32 slaves)
top - 18:32:43 up 2:10, 2 users, load average: 18.51, 10.70, 4.70
Tasks: 862 total, 19 running, 843 sleeping, 0 stopped, 0 zombie
Cpu(s): 97.3%us, 0.4%sy, 0.0%ni, 2.2%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 74027752k total, 35141864k used, 38885888k free, 192548k buffers
Swap: 16771852k total, 0k used, 16771852k free, 30645208k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21657 oracle 25 0 10.1g 111m 72m R 99.1 0.2 5:20.16 ora_p001_SANDBOX2
21663 oracle 25 0 10.1g 113m 80m R 99.1 0.2 5:11.11 ora_p004_SANDBOX2
26481 oracle 25 0 10.1g 89m 54m R 99.1 0.1 3:07.37 ora_p008_SANDBOX2
26496 oracle 25 0 10.1g 89m 54m R 99.1 0.1 3:06.88 ora_p015_SANDBOX2
21667 oracle 25 0 10.1g 110m 73m R 98.5 0.2 5:16.09 ora_p006_SANDBOX2
26483 oracle 25 0 10.1g 89m 53m R 98.5 0.1 3:06.63 ora_p009_SANDBOX2
26488 oracle 25 0 10.1g 90m 52m R 98.5 0.1 3:08.71 ora_p011_SANDBOX2
26485 oracle 25 0 10.1g 90m 54m R 97.9 0.1 3:04.54 ora_p010_SANDBOX2
26490 oracle 25 0 10.1g 90m 54m R 97.9 0.1 3:04.46 ora_p012_SANDBOX2
21655 oracle 25 0 10.1g 105m 70m R 97.3 0.1 5:13.22 ora_p000_SANDBOX2
26494 oracle 25 0 10.1g 89m 52m R 97.3 0.1 3:03.42 ora_p014_SANDBOX2
21661 oracle 25 0 10.1g 106m 73m R 95.4 0.1 5:12.65 ora_p003_SANDBOX2
26492 oracle 25 0 10.1g 89m 54m R 95.4 0.1 3:08.13 ora_p013_SANDBOX2
21659 oracle 25 0 10.1g 114m 79m R 94.8 0.2 5:13.42 ora_p002_SANDBOX2
21669 oracle 25 0 10.1g 107m 72m R 90.5 0.1 5:10.19 ora_p007_SANDBOX2
21665 oracle 25 0 10.1g 107m 67m R 86.2 0.1 5:18.80 ora_p005_SANDBOX2
Query Performance
Of course, load time is not the only performance metric of interest. Query time is more critical than load time for most systems since the data is only loaded once but queried many times. Query performance is a mixed bag when it comes to compression. Depending on the type of query, compression can either speed it up or slow it down. Decompression certainly adds overhead in the way of additional CPU usage, but for queries that are bottlenecked on disk access, reducing the number of blocks that must be read can often offset and in many cases more than make up for the additional overhead. Keep in mind that depending on the access mechanism used, the decompression can be done on either the storage cells (smart scans) or on the database nodes. Here’s an example of running a CPU-intensive procedure:
SYS@SANDBOX1> !cat gather_table_stats.sql
begin
dbms_stats.gather_table_stats(
'&owner','&table_name',
degree => 32,
method_opt => 'for all columns size 1'
);
end;
/
SYS@SANDBOX1> @gather_table_stats
Enter value for owner: ACOLVIN
Enter value for table_name: SKEW3
PL/SQL procedure successfully completed.
Elapsed: 00:00:12.14
SYS@SANDBOX1> @gather_table_stats
Enter value for owner: KSO
Enter value for table_name: SKEW3_OLTP
PL/SQL procedure successfully completed.
Elapsed: 00:00:12.75
SYS@SANDBOX1> @gather_table_stats
Enter value for owner: KSO
Enter value for table_name: SKEW3_BASIC
PL/SQL procedure successfully completed.
Elapsed: 00:00:12.60
SYS@SANDBOX1> @gather_table_stats
Enter value for owner: KSO
Enter value for table_name: SKEW3_HCC1
PL/SQL procedure successfully completed.
Elapsed: 00:00:14.21
SYS@SANDBOX1> @gather_table_stats
Enter value for owner: KSO
Enter value for table_name: SKEW3_HCC2
PL/SQL procedure successfully completed.
Elapsed: 00:00:14.94
SYS@SANDBOX1> @gather_table_stats
Enter value for owner: KSO
Enter value for table_name: SKEW3_HCC3
PL/SQL procedure successfully completed.
Elapsed: 00:00:14.24
SYS@SANDBOX1> @gather_table_stats
Enter value for owner: KSO
Enter value for table_name: SKEW3_HCC4
PL/SQL procedure successfully completed.
Elapsed: 00:00:21.33
And again for clarity, Table 3-3 shows the timings in a more readable format.


Gathering statistics is a very CPU-intensive operation. Spreading the stat-gathering across 16 slave processes per node almost completely utilized the CPU resources on the DB servers. As you can see, the compression slowed down the processing enough to outweigh the gains from the reduced number of data blocks that needed to be read. This is due to the CPU-intensive nature of the work being done. Here’s a snapshot of top output to verify that the system is CPU-bound:
top - 14:40:50 up 4 days, 6:17, 10 users, load average: 10.81, 4.16, 4.53
Tasks: 841 total, 21 running, 820 sleeping, 0 stopped, 0 zombie
Cpu(s): 96.1%us, 0.7%sy, 0.0%ni, 2.9%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st
Mem: 74027752k total, 34494424k used, 39533328k free, 345448k buffers
Swap: 16771852k total, 568756k used, 16203096k free, 29226312k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
16127 oracle 25 0 40.3g 146m 106m R 97.6 0.2 10:19.16 ora_p001_POC1
16154 oracle 25 0 40.3g 145m 119m R 97.6 0.2 10:11.75 ora_p014_POC1
16137 oracle 25 0 40.3g 144m 113m R 96.9 0.2 10:14.20 ora_p006_POC1
16125 oracle 25 0 40.3g 139m 108m R 96.6 0.2 10:24.11 ora_p000_POC1
16133 oracle 25 0 40.3g 147m 109m R 96.6 0.2 10:27.14 ora_p004_POC1
16145 oracle 25 0 40.3g 145m 117m R 96.2 0.2 10:20.25 ora_p010_POC1
16135 oracle 25 0 40.3g 154m 112m R 95.9 0.2 10:16.51 ora_p005_POC1
16143 oracle 25 0 40.3g 135m 106m R 95.9 0.2 10:22.33 ora_p009_POC1
16131 oracle 25 0 40.3g 156m 119m R 95.6 0.2 10:16.73 ora_p003_POC1
16141 oracle 25 0 40.3g 143m 115m R 95.6 0.2 10:18.62 ora_p008_POC1
16151 oracle 25 0 40.3g 155m 121m R 95.6 0.2 10:11.54 ora_p013_POC1
16147 oracle 25 0 40.3g 140m 113m R 94.9 0.2 10:17.92 ora_p011_POC1
16139 oracle 25 0 40.3g 155m 114m R 94.6 0.2 10:13.26 ora_p007_POC1
16149 oracle 25 0 40.3g 156m 124m R 93.9 0.2 10:21.05 ora_p012_POC1
16129 oracle 25 0 40.3g 157m 126m R 93.3 0.2 10:09.99 ora_p002_POC1
16156 oracle 25 0 40.3g 141m 111m R 93.3 0.2 10:16.76 ora_p015_POC1
Now let’s look at a query that is I/O-intensive. This test uses a query without a WHERE clause that spends most of its time retrieving data from the storage layer via cell-smart table scans:
SYS@SANDBOX1> @hcc_test3
SYS@SANDBOX1> set timing on
SYS@SANDBOX1> select /*+ parallel (a 32) */ sum(pk_col) from acolvin.skew3 a ;
SUM(PK_COL)
-----------
6.1800E+15
1 row selected.
Elapsed: 00:00:06.21
SYS@SANDBOX1> select /*+ parallel (a 32) */ sum(pk_col) from kso.skew3_oltp a ;
SUM(PK_COL)
-----------
6.1800E+15
1 row selected.
Elapsed: 00:00:05.79
SYS@SANDBOX1> select /*+ parallel (a 32) */ sum(pk_col) from kso.skew3_basic a ;
SUM(PK_COL)
-----------
6.1800E+15
1 row selected.
Elapsed: 00:00:05.26
SYS@SANDBOX1> select /*+ parallel (a 32) */ sum(pk_col) from kso.skew3_hcc1 a ;
SUM(PK_COL)
-----------
6.1800E+15
1 row selected.
Elapsed: 00:00:03.56
SYS@SANDBOX1> select /*+ parallel (a 32) */ sum(pk_col) from kso.skew3_hcc2 a ;
SUM(PK_COL)
-----------
6.1800E+15
1 row selected.
Elapsed: 00:00:03.39
SYS@SANDBOX1> select /*+ parallel (a 32) */ sum(pk_col) from kso.skew3_hcc3 a ;
SUM(PK_COL)
-----------
6.1800E+15
1 row selected.
Elapsed: 00:00:03.36
SYS@SANDBOX1> select /*+ parallel (a 32) */ sum(pk_col) from kso.skew3_hcc4 a ;
SUM(PK_COL)
-----------
6.1800E+15
1 row selected.
Elapsed: 00:00:04.78
Table 3-4 shows the timings for the unqualified query in a tabular format.

The query does not require a lot of CPU resources on the DB server. As a result, the savings in I/O time more than offset the increased CPU. Note that the rather significant CPU requirements of the ARCHIVE HIGH decompression caused the elapsed time to increase for this test over the less CPU-intensive algorithms. Nevertheless, it was still faster than the uncompressed run. Here’s a snapshot of top output while one of these queries was running.
top - 15:37:13 up 4 days, 7:14, 9 users, load average: 5.00, 2.01, 2.50
Tasks: 867 total, 7 running, 860 sleeping, 0 stopped, 0 zombie
Cpu(s): 25.2%us, 0.9%sy, 0.0%ni, 73.4%id, 0.5%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 74027752k total, 35193896k used, 38833856k free, 346568k buffers
Swap: 16771852k total, 568488k used, 16203364k free, 29976856k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
25414 oracle 16 0 10.0g 40m 31m S 33.0 0.1 0:13.75 ora_p001_SANDBOX1
25474 oracle 15 0 10.0g 39m 30m S 32.4 0.1 0:13.54 ora_p012_SANDBOX1
25472 oracle 15 0 10.0g 37m 29m S 28.8 0.1 0:13.45 ora_p011_SANDBOX1
25420 oracle 16 0 10.0g 35m 28m R 27.8 0.0 0:13.71 ora_p004_SANDBOX1
25418 oracle 15 0 10.0g 39m 31m R 27.4 0.1 0:13.78 ora_p003_SANDBOX1
25435 oracle 15 0 10.0g 38m 30m S 27.4 0.1 0:13.46 ora_p008_SANDBOX1
25478 oracle 15 0 10.0g 38m 30m S 27.1 0.1 0:13.75 ora_p014_SANDBOX1
25428 oracle 15 0 10.0g 38m 31m S 24.8 0.1 0:13.81 ora_p005_SANDBOX1
25437 oracle 15 0 10.0g 38m 30m R 24.5 0.1 0:13.88 ora_p009_SANDBOX1
25416 oracle 15 0 10.0g 39m 32m S 24.1 0.1 0:13.81 ora_p002_SANDBOX1
25430 oracle 15 0 10.0g 39m 31m R 22.8 0.1 0:13.00 ora_p006_SANDBOX1
25433 oracle 16 0 10.0g 40m 32m S 22.8 0.1 0:12.94 ora_p007_SANDBOX1
25470 oracle 15 0 10.0g 38m 30m R 22.8 0.1 0:13.73 ora_p010_SANDBOX1
25484 oracle 15 0 10.0g 38m 30m S 20.2 0.1 0:13.23 ora_p015_SANDBOX1
25476 oracle 15 0 10.0g 37m 30m S 18.5 0.1 0:13.30 ora_p013_SANDBOX1
25411 oracle 15 0 10.0g 38m 30m R 13.2 0.1 0:12.67 ora_p000_SANDBOX1
DML Performance
Generally speaking, records that will be updated should not be compressed. When you update a record in an HCC table, the record will be migrated to a new a block that is flagged as an OLTP compressed block. Of course, a pointer will be left behind so that you can still get to the record via its old rowid, but the record will be assigned a new rowid as well. Since updated records are downgraded to OLTP compression you need to understand how that compression mechanism works on updates. Figure 3-6 demonstrates how non-direct path loads into an OLTP block are processed.
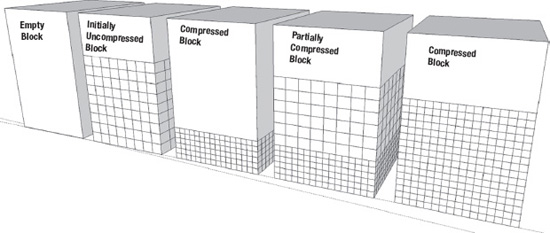
Figure 3-6. The OLTP compression process for non-direct path loads
The progression of states moves from left to right. Rows are initially loaded in an uncompressed state. As the block fills to the point where no more rows can be inserted, the row data in the block is compressed. The block is then placed back on the freelist and is capable of accepting more uncompressed rows. This means that in an OLTP-compressed table, blocks can be in various states of compression. All rows can be compressed, some rows can be compressed, or no rows can be compressed. This is exactly how records in HCC blocks behave when they are updated. A couple of examples will demonstrate this behavior. The first will show how the size of a table can balloon with updates.
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW 1,460.3
--------------
sum 1,460.3
1 row selected.
SYS@SANDBOX1> create table kso.skew_hcc3 nologging parallel 16 compress for archive low
2 as select * from kso.skew a;
Table created.
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW_HCC3
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW_HCC3 23.0 ARCHIVE LOW
--------------
sum 23.0
1 row selected.
SYS@SANDBOX1> update /*+ parallel (a 32) */ kso.skew_hcc3 a set col1=col1;
32000004 rows updated.
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW_HCC3
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW_HCC3 916.0 ARCHIVE LOW
--------------
sum 916.0
1 row selected.
SYS@SANDBOX1> -- Check how this compares to direct path load OLTP table.
SYS@SANDBOX1>
SYS@SANDBOX1> create table kso.skew_oltp nologging parallel 16 compress for oltp
2 as select /*+ parallel (a 16) */ * from kso.skew a;
Table created.
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW_OLTP
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW_OLTP 903.1 OLTP
--------------
sum 903.1
1 row selected.
SYS@SANDBOX1> @comp_ratio
Enter value for original_size: 1460.3
Enter value for owner: KSO
Enter value for table_name: SKEW%
Enter value for type:
OWNER SEGMENT_NAME TYPE TOTALSIZE_MEGS COMPRESSION_RATIO
---------- -------------------- ------------------ -------------- -----------------
KSO SKEW TABLE 1,460.3 1.0
KSO SKEW_HCC3 TABLE 916.0 1.6
KSO SKEW_OLTP TABLE 903.1 1.6
--------------
sum 3,279.4
3 rows selected.
This output shows that updating all the records in an HCC ARCHIVE LOW table expanded it to a slightly larger footprint than an OLTP-compressed (via direct path load) version of the same table. Interestingly enough, the update statement spent most of its time waiting on BUFFER BUSY WAITS. Apparently there is not a specific wait event for when a process is waiting while a block is being compressed. Here is the complete set of events that the update statement waited on (from a 10046 trace file processed with tkprof), along with per-second session statistics (both from one of the parallel slave processes):
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
cursor: pin S wait on X 1 0.01 0.01
PX Deq: Execution Msg 16 67.43 68.15
cell multiblock physical read 14 0.00 0.02
resmgr:cpu quantum 90 0.01 0.14
buffer busy waits 2077 3.54 139.84
latch: cache buffers chains 2068 0.34 6.75
enq: TX - contention 66 0.27 0.33
enq: HW - contention 142 1.55 16.56
latch: redo allocation 361 0.25 1.51
global enqueue expand wait 19 0.00 0.00
gc current multi block request 67 0.00 0.03
KJC: Wait for msg sends to complete 16 0.00 0.00
log buffer space 230 0.28 12.44
latch: enqueue hash chains 28 0.00 0.01
latch: ges resource hash list 20 0.01 0.05
log file switch completion 5 0.30 0.88
enq: FB - contention 61 0.03 0.12
enq: US - contention 439 3.98 82.64
Disk file operations I/O 110 0.00 0.02
control file sequential read 720 0.17 1.64
cell single block physical read 131 0.05 0.26
db file single write 72 0.06 0.23
KSV master wait 431 2.10 5.24
ASM file metadata operation 144 0.00 0.01
kfk: async disk IO 36 0.09 0.35
cell smart file creation 4779 0.08 1.05
CSS operation: action 1 0.00 0.00
enq: CF - contention 36 0.19 0.24
control file parallel write 108 0.09 0.95
DFS lock handle 252 0.38 3.06
undo segment extension 163 1.02 9.95
L1 validation 2 0.01 0.01
reliable message 50 0.00 0.05
latch: row cache objects 1 0.00 0.00
gc cr grant 2-way 1 0.00 0.00
gc cr multi block request 4 0.00 0.00
log file switch (checkpoint incomplete) 6 3.29 4.15
latch: undo global data 3 0.00 0.00
latch free 7 0.05 0.07
latch: gc element 4 0.00 0.00
wait list latch free 2 0.00 0.00
log file sync 1 0.00 0.00
latch: object queue header operation 3 0.00 0.00
Stat Name Events/Sec
--------------------------------------- ----------
HSC OLTP Space Saving 30,485
HSC OLTP Compressed Blocks 10
HSC Compressed Segment Block Changes 8,314
STAT, HSC Heap Segment Block Changes 8,314
STAT, HSC OLTP Non Compressible Blocks 10
STAT, HSC OLTP positive compression 20
HSC OLTP inline compression 20
The second example demonstrates that a row is migrated from an HCC block when it is updated. Basically we’ll update a single row, see that its rowid has changed, verify that we can still get to the record via its original rowid, and check to see if the TABLE FETCH CONTINUED ROW statistic gets updated when we access the row via its original rowid.
SYS@SANDBOX1> @table_size2
Enter value for owner: KSO
Enter value for table_name: SKEW_HCC3
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO SKEW_HCC3 18.6 ARCHIVE LOW
--------------
sum 18.6
SYS@SANDBOX1> select count(*) from kso.skew_hcc3 where pk_col=16367;
COUNT(*)
----------
1
SYS@SANDBOX1> select rowid, old_rowid(rowid) old_rowid_format
2 from kso.skew_hcc3 where pk_col=16367;
ROWID OLD_ROWID_FORMAT
------------------ --------------------
AAATCBAAIAAF8uSFc9 8.1559442.22333
SYS@SANDBOX1> -- So our row is in file 8, block 1559442, row 22333
SYS@SANDBOX1>
SYS@SANDBOX1> update kso.skew_hcc3 set col1=col1 where pk_col=16367;
1 row updated.
SYS@SANDBOX1> select rowid, old_rowid(rowid) OLD_ROWID_FORMAT
2 from kso.skew_hcc3 where pk_col=16367;
ROWID OLD_ROWID_FORMAT
------------------ --------------------
AAATCBAAHAAMGMMAAA 7.3171084.0
SYS@SANDBOX1> -- Ha! The rowid has changed – the row moved to file 7
SYS@SANDBOX1>
SYS@SANDBOX1> -- Let's see if we can still get to it via the original rowid
SYS@SANDBOX1>
SYS@SANDBOX1> select pk_col from kso.skew_hcc3 where rowid = 'AAATCBAAIAAF8uSFc9';
PK_COL
----------
16367
SYS@SANDBOX1> -- Yes we can! – can we use the new rowid?
SYS@SANDBOX1>
SYS@SANDBOX1> select pk_col from kso.skew_hcc3 where rowid = 'AAATCBAAHAAMGMMAAA';
PK_COL
----------
16367
SYS@SANDBOX1> -- That works too! – It’s a migrated Row!
SYS@SANDBOX1> -- Let’s verify with “continued row” stat
SYS@SANDBOX1>
SYS@SANDBOX1> @mystats
Enter value for name: table fetch continued row
NAME VALUE
---------------------------------------------------------------------- ---------------
table fetch continued row 2947
SYS@SANDBOX1> -- select via the original rowid
SYS@SANDBOX1>
SYS@SANDBOX1> select pk_col from kso.skew_hcc3 where rowid = 'AAATCBAAIAAF8uSFc9';
PK_COL
----------
16367
SYS@SANDBOX1> @mystats
Enter value for name: table fetch continued row
NAME VALUE
---------------------------------------------------------------------- ---------------
table fetch continued row 2948
SYS@SANDBOX1> -- Stat is incremented – so definitely a migrated row!
So the row has definitely been migrated. Now let’s verify that the migrated row is not compressed. We can do this by dumping the block where the newly migrated record resides. But before we look at the migrated row let’s have a look at the original block.
SYS@SANDBOX1> !cat dump_block.sql
@find_trace
alter system dump datafile &fileno block &blockno;
SYS@SANDBOX1> @dump_block
TRACEFILE_NAME
------------------------------------------------------------------------------------
/u01/app/oracle/diag/rdbms/sandbox/SANDBOX1/trace/SANDBOX1_ora_5191.trc
Enter value for fileno: 7
Enter value for blockno: 3171084
System altered.
Now let’s look at the trace file produced in the trace directory. Here is an excerpt from the block dump.
Block header dump: 0x01f0630c
Object id on Block? Y
seg/obj: 0x13081 csc: 0x01.1e0574d4 itc: 3 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1f06300 ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x002f.013.00000004 0x00eec383.01f2.44 ---- 1 fsc 0x0000.00000000
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
bdba: 0x01f0630c
data_block_dump,data header at 0x2b849c81307c
===============
tsiz: 0x1f80
hsiz: 0x14
pbl: 0x2b849c81307c
76543210
flag=--------
ntab=1
nrow=1
frre=-1
fsbo=0x14
fseo=0x1f60
avsp=0x1f4c
tosp=0x1f4c
0xe:pti[0] nrow=1 offs=0
0x12:pri[0] offs=0x1f60
block_row_dump:
tab 0, row 0, @0x1f60
tl: 32 fb: --H-FL-- lb: 0x1 cc: 5
col 0: [ 4] c3 02 40 44
col 1: [ 2] c1 02
col 2: [10] 61 73 64 64 73 61 64 61 73 64
col 3: [ 7] 78 6a 07 15 15 0b 32
col 4: [ 1] 59
end_of_block_dump
The block is not compressed and conforms to the normal Oracle block format. Notice that there is only one row in the block (nrows=1). Also notice that the data_object_id is included in the block in hex format (seg/obj: 0x13081). The table has five columns. The values are displayed, also in hex format. Just to verify that we have the right block, we can translate the data_object_id and the value of the first column as follows:
SYS@SANDBOX1> !cat obj_by_hex.sql
col object_name for a30
select owner, object_name, object_type
from dba_objects
where data_object_id = to_number(replace('&hex_value','0x',''),'XXXXXX'),
SYS@SANDBOX1> @obj_by_hex
Enter value for hex_value: 0x13081
OWNER OBJECT_NAME OBJECT_TYPE
------------------------------ ------------------------------ -------------------
KSO SKEW_HCC3 TABLE
SYS@SANDBOX1> desc kso.skew_hcc3
Name Null? Type
----------------------------- -------- --------------------
PK_COL NUMBER
COL1 NUMBER
COL2 VARCHAR2(30)
COL3 DATE
COL4 VARCHAR2(1)
SYS@SANDBOX1> @display_raw
Enter value for string: c3 02 40 44
Enter value for type: NUMBER
VALUE
--------------------------------------------------
16367
As you can see, this is the record that we updated in the SKEW_HCC3 table. Just as an aside, it is interesting to see how the compressed block format differs from the standard uncompressed format. Here is a snippet from the original block in our example that is compressed for ARCHIVE LOW.
===============
tsiz: 0x1f80
hsiz: 0x1c
pbl: 0x2b5d7d5cea7c
76543210
flag=-0------
ntab=1
nrow=1
frre=-1
fsbo=0x1c
fseo=0x30
avsp=0x14
tosp=0x14
r0_9ir2=0x0
mec_kdbh9ir2=0x0
76543210
shcf_kdbh9ir2=----------
76543210
flag_9ir2=--R----- Archive compression: Y
fcls_9ir2[0]={ }
0x16:pti[0] nrow=1 offs=0
0x1a:pri[0] offs=0x30
block_row_dump:
tab 0, row 0, @0x30
tl: 8016 fb: --H-F--N lb: 0x2 cc: 1
nrid: 0x0217cbd4.0
col 0: [8004]
Compression level: 03 (Archive Low)
Length of CU row: 8004
kdzhrh: ------PC CBLK: 2 Start Slot: 00
NUMP: 02
PNUM: 00 POFF: 7974 PRID: 0x0217cbd4.0
PNUM: 01 POFF: 15990 PRID: 0x0217cbd5.0
CU header:
CU version: 0 CU magic number: 0x4b445a30
CU checksum: 0xf0529582
CU total length: 21406
CU flags: NC-U-CRD-OP
ncols: 5
nrows: 32759
algo: 0
CU decomp length: 17269 len/value length: 1040997
row pieces per row: 1
num deleted rows: 1
deleted rows: 0,
START_CU:
00 00 1f 44 1f 02 00 00 00 02 00 00 1f 26 02 17 cb d4 00 00 00 00 3e 76 02
17 cb d5 00 00 00 4b 44 5a 30 82 95 52 f0 00 00 53 9e eb 06 00 05 7f f7 00
Notice that this block shows that it is compressed at level 3 (ARCHIVE LOW). Also notice that one record has been deleted from this block (migrated would be a more accurate term, as this is the record that we updated earlier). The line that says deleted rows: actually shows a list of the rows that have been migrated. Remember that we updated the record with rowid 7.3171084.0, meaning file 7, block 3171084, slot 0. So this line tells us that the one deleted row was in slot 0.
![]() Kevin Says: I like to remind people to be mindful of the potential performance irregularities that may occur should a table comprised of EHCC data metamorphose into a table that is of mixed compression types with indirection. There should be no expected loss in functionality; however, there is an expected, yet unpredictable, impact to the repeatability of scan performance. The unpredictable nature is due to the fact that it is completely data-dependent.
Kevin Says: I like to remind people to be mindful of the potential performance irregularities that may occur should a table comprised of EHCC data metamorphose into a table that is of mixed compression types with indirection. There should be no expected loss in functionality; however, there is an expected, yet unpredictable, impact to the repeatability of scan performance. The unpredictable nature is due to the fact that it is completely data-dependent.
Expected Compression Ratios
HCC can provide very impressive compression ratios. The marketing material has claimed 10× compression ratios and believe it or not, this is actually a very achievable number for many datasets. Of course the amount of compression depends heavily on the data and which of the four algorithms is applied. The best way to determine what kind of compression can be achieved on your dataset is to test it. Oracle also provides a utility (often referred to as the Compression Advisor) to compress a sample of data from a table in order to calculate an estimated compression ratio. This utility can even be used on non-Exadata platforms as long as they are running 11.2.0.2 or later. This section will provide some insight into the Compression Advisor and provide compression ratios on some sample real world datasets.
Compression Advisor
If you don’t have access to an Exadata but still want to test the effectiveness of HCC, you can use the Compression Advisor functionality that is provided in the DBMS_COMPRESSION package. The GET_COMPRESSION_RATIO procedure actually enables you to compress a sample of rows from a specified table. This is not an estimate of how much compression might happen; the sample rows are inserted into a temporary table. Then a compressed version of that temporary table is created. The ratio returned is a comparison between the sizes of the compressed version and the uncompressed version. As of Oracle Database version 11.2.0.2, this procedure may be used on a non-Exadata platform to estimate compression ratios for various levels of HCC as well as OLTP compression. The Advisor does not work on non-Exadata platforms running Database versions prior to 11.2.0.2, although there may be a patch available to enable this functionality.
The Compression Advisor may also be useful on Exadata platforms. Of course you could just compress a table with the various levels to see how well it compresses, but if the tables are very large this may not be practical. In this case you may be tempted to create a temporary table by selecting the records where rownum < X and do your compression test on that subset of rows. And that’s basically what the Advisor does, although it is a little smarter about the set of records it chooses. Here’s an example of its use:
SYS@SANDBOX1> !cat get_compression_ratio.sql
set sqlblanklines on
set feedback off
accept owner -
prompt 'Enter Value for owner: '
accept table_name -
prompt 'Enter Value for table_name: '
accept comp_type -
prompt 'Enter Value for compression_type (OLTP): ' -
default 'OLTP'
DECLARE
l_blkcnt_cmp BINARY_INTEGER;
l_blkcnt_uncmp BINARY_INTEGER;
l_row_cmp BINARY_INTEGER;
l_row_uncmp BINARY_INTEGER;
l_cmp_ratio NUMBER;
l_comptype_str VARCHAR2 (200);
l_comptype number;
BEGIN
case '&&comp_type'
when 'OLTP' then l_comptype := DBMS_COMPRESSION.comp_for_oltp;
when 'QUERY' then l_comptype := DBMS_COMPRESSION.comp_for_query_low;
when 'QUERY_LOW' then l_comptype := DBMS_COMPRESSION.comp_for_query_low;
when 'QUERY_HIGH' then l_comptype := DBMS_COMPRESSION.comp_for_query_high;
when 'ARCHIVE' then l_comptype := DBMS_COMPRESSION.comp_for_archive_low;
when 'ARCHIVE_LOW' then l_comptype := DBMS_COMPRESSION.comp_for_archive_low;
when 'ARCHIVE_HIGH' then l_comptype := DBMS_COMPRESSION.comp_for_archive_high;
END CASE;
DBMS_COMPRESSION.get_compression_ratio (
scratchtbsname => 'USERS',
ownname => '&owner',
tabname => '&table_name',
partname => NULL,
comptype => l_comptype,
blkcnt_cmp => l_blkcnt_cmp,
blkcnt_uncmp => l_blkcnt_uncmp,
row_cmp => l_row_cmp,
row_uncmp => l_row_uncmp,
cmp_ratio => l_cmp_ratio,
comptype_str => l_comptype_str
);
dbms_output.put_line(' '),
DBMS_OUTPUT.put_line ('Estimated Compression Ratio using '||l_comptype_str||': '|| round(l_cmp_ratio,3));
dbms_output.put_line(' '),
END;
/
undef owner
undef table_name
undef comp_type
set feedback on
SYS@SANDBOX1> @get_compression_ratio.sql
Enter Value for owner: KSO
Enter Value for table_name: SKEW3
Enter Value for compression_type (OLTP):
Estimated Compression Ratio using "Compress For OLTP": 1.4
Elapsed: 00:00:07.50
SYS@SANDBOX1> @get_compression_ratio.sql
Enter Value for owner: KSO
Enter Value for table_name: SKEW3
Enter Value for compression_type (OLTP): QUERY LOW
Compression Advisor self-check validation successful. select count(*) on both Uncompressed and EHCC Compressed format = 1000001 rows
Estimated Compression Ratio using "Compress For Query Low": 4
Elapsed: 00:01:04.14
SYS@SANDBOX1> @get_compression_ratio.sql
Enter Value for owner: KSO
Enter Value for table_name: SKEW3
Enter Value for compression_type (OLTP): QUERY HIGH
Compression Advisor self-check validation successful. select count(*) on both Uncompressed and EHCC Compressed format = 1000001 rows
Estimated Compression Ratio using "Compress For Query High": 42.4
Elapsed: 00:01:01.42
SYS@SANDBOX1> @get_compression_ratio.sql
Enter Value for owner: KSO
Enter Value for table_name: SKEW3
Enter Value for compression_type (OLTP): ARCHIVE LOW
Compression Advisor self-check validation successful. select count(*) on both Uncompressed and EHCC Compressed format = 1000001 rows
Estimated Compression Ratio using "Compress For Archive Low": 43.5
Elapsed: 00:01:01.70
SYS@SANDBOX1> @get_compression_ratio.sql
Enter Value for owner: KSO
Enter Value for table_name: SKEW3
Enter Value for compression_type (OLTP): ARCHIVE HIGH
Compression Advisor self-check validation successful. select count(*) on both Uncompressed and EHCC Compressed format = 1000001 rows
Estimated Compression Ratio using "Compress For Archive High": 54.7
Elapsed: 00:01:18.09
Notice that the procedure prints out a validation message telling you how many records were used for the comparison. This number can be modified as part of the call to the procedure if so desired. The get_compression_ratio.sql script prompts for a table and a Compression Type and then executes the DBMS_COMPRESSION.GET_COMPRESSION_RATIO procedure. Once again the pertinent data is a little hard to pick out of the listing, so Table 3-5 compares the actual compression ratios to the estimates provided by the Compression Advisor.

The estimates are fairly close to the actual values and while they are not 100 percent accurate, the tradeoff is probably worth it in cases where the objects are very large and a full test would be too time-consuming or take up too much disk space. The ability to run the Compression Advisor on non-Exadata platforms is also a real plus. It should be able to provide you with enough information to make reasonable decisions prior to actually migrating data to Exadata.
Real World Examples
As Yogi Berra once said, you can learn a lot just by watching. Marketing slides and book author claims are one thing, but real data is often more useful. Just to give you an idea of what kind of compression is reasonable to expect, here are a few comparisons of data from different industries. The data should provide you with an idea of the potential compression ratios that can be achieved by Hybrid Columnar Compression.
Custom Application Data
This dataset came from a custom application that tracks the movement of assets. The table is very narrow, consisting of only 12 columns. The table has close to 1 billion rows, but many of the columns have a very low number of distinct values (NDV). That means that the same values are repeated many times. This table is a prime candidate for compression. Here are the basic table statistics and the compression ratios achieved:
==========================================================================================
Table Statistics
==========================================================================================
TABLE_NAME : CP_DAILY
LAST_ANALYZED : 29-DEC-2010 23:55:16
DEGREE : 1
PARTITIONED : YES
NUM_ROWS : 925241124
CHAIN_CNT : 0
BLOCKS : 15036681
EMPTY_BLOCKS : 0
AVG_SPACE : 0
AVG_ROW_LEN : 114
MONITORING : YES
SAMPLE_SIZE : 925241124
TOTALSIZE_MEGS : 118019
===========================================================================================
Column Statistics
===========================================================================================
Name Analyzed Null? NDV Density # Nulls # Buckets
===========================================================================================
PK_ACTIVITY_DTL_ID 12/29/2010 NOT NULL 925241124 .000000 0 1
FK_ACTIVITY_ID 12/29/2010 NOT NULL 43388928 .000000 0 1
FK_DENOMINATION_ID 12/29/2010 38 .000000 88797049 38
AMOUNT 12/29/2010 1273984 .000001 0 1
FK_BRANCH_ID 12/29/2010 NOT NULL 131 .000000 0 128
LOGIN_ID 12/29/2010 NOT NULL 30 .033333 0 1
DATETIME_STAMP 12/29/2010 NOT NULL 710272 .000001 0 1
LAST_MODIFY_LOGIN_ID 12/29/2010 NOT NULL 30 .033333 0 1
MODIFY_DATETIME_STAMP 12/29/2010 NOT NULL 460224 .000002 0 1
ACTIVE_FLAG 12/29/2010 NOT NULL 2 .000000 0 2
FK_BAG_ID 12/29/2010 2895360 .000000 836693535 1
CREDIT_DATE 12/29/2010 549 .001821 836693535 1
===========================================================================================
SYS@POC1> @table_size2
Enter value for owner:
Enter value for table_name: CP_DAILY_INV_ACTIVITY_DTL
OWNER SEGMENT_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- ------------------------------ -------------- ------------
KSO CP_DAILY_INV_ACTIVITY_DTL 118,018.8
--------------
sum 118,018.8
SYS@POC1> @comp_ratio
Enter value for original_size: 118018.8
Enter value for owner: KSO
Enter value for table_name: CP_DAILY%
Enter value for type:
OWNER SEGMENT_NAME TYPE TOTALSIZE_MEGS COMPRESSION_RATIO
---------- -------------------- ------------------ -------------- -----------------
KSO CP_DAILY_HCC1 TABLE 7,488.1 15.8
KSO CP_DAILY_HCC3 TABLE 2,442.3 48.3
KSO CP_DAILY_HCC2 TABLE 2,184.7 54.0
KSO CP_DAILY_HCC4 TABLE 1,807.8 65.3
--------------
sum 13,922.8
As expected, this table is extremely compressible. Simple queries against these tables also run much faster against the compressed tables, as you can see in this listing:
SYS@POC1> select sum(amount) from kso.CP_DAILY_HCC3 where credit_date = '01-oct-2010';
SUM(AMOUNT)
------------
4002779614.9
1 row selected.
Elapsed: 00:00:02.37
SYS@POC1> select sum(amount) from kso.CP_DAILY where credit_date = '01-oct-2010';
SUM(AMOUNT)
------------
4002779614.9
1 row selected.
Elapsed: 00:00:42.58
This simple query ran roughly 19 times faster using the ARCHIVE LOW compressed table than when it was run against the uncompressed table.
Telecom Call Detail Data
This table contains call detail records for a telecom company. There are approximately 1.5 billion records in the table. Many of the columns in this table are unique or nearly so. In addition, many of the columns contain large numbers of nulls. Nulls are not compressible since they are not stored in the normal Oracle block format. This is not a table we would expect to be highly compressible. Here are the basic table statistics and the compression ratios:
==========================================================================================
Table Statistics
==========================================================================================
TABLE_NAME : SEE
LAST_ANALYZED : 29-SEP-2010 00:02:15
DEGREE : 8
PARTITIONED : YES
NUM_ROWS : 1474776874
CHAIN_CNT : 0
BLOCKS : 57532731
EMPTY_BLOCKS : 0
AVG_SPACE : 0
AVG_ROW_LEN : 282
MONITORING : YES
SAMPLE_SIZE : 1474776874
TOTALSIZE_MEGS : 455821
===========================================================================================
SYS@POC1> @comp_ratio
Enter value for original_size: 455821
Enter value for owner: KSO
Enter value for table_name: SEE_HCC%
Enter value for type:
OWNER SEGMENT_NAME TYPE TOTALSIZE_MEGS COMPRESSION_RATIO
---------- -------------------- ------------------ -------------- -----------------
KSO SEE_HCC1 TABLE 168,690.1 2.7
KSO SEE_HCC2 TABLE 96,142.1 4.7
KSO SEE_HCC3 TABLE 87,450.8 5.2
KSO SEE_HCC4 TABLE 72,319.1 6.3
--------------
sum 424,602.1
Financial Data
The next table is made up of financial data, revenue accrual data from an order entry system to be exact. Here are the basic table statistics.
=====================================================================================
Table Statistics
=====================================================================================
TABLE_NAME : REV_ACCRUAL
LAST_ANALYZED : 07-JAN-2011 00:42:47
DEGREE : 1
PARTITIONED : YES
NUM_ROWS : 114736686
CHAIN_CNT : 0
BLOCKS : 15225910
EMPTY_BLOCKS : 0
AVG_SPACE : 0
AVG_ROW_LEN : 917
MONITORING : YES
SAMPLE_SIZE : 114736686
TOTALSIZE_MEGS : 120019
=====================================================================================
So the number of rows is not that great, only about 115 million, but the table is wide. It has 161 columns and the average row length is 917 bytes. It is a bit of a mixed bag with regards to compressibility though. Many of the columns contain a high percentage of nulls. On the other hand, many of the columns have a very low number of distinct values. This table may be a candidate for reordering the data on disk as a strategy to improve the compression ratio. At any rate, here are the compression rates achieved on this table at the various HCC levels.
SYS@POC1> @comp_ratio
Enter value for original_size: 120019
Enter value for owner: KSO
Enter value for table_name: REV_ACCRUAL_HCC%
Enter value for type:
OWNER SEGMENT_NAME TYPE TOTALSIZE_MEGS COMPRESSION_RATIO
---------- -------------------- ------------------ -------------- -----------------
KSO REV_ACCRUAL_HCC1 TABLE 31,972.6 3.8
KSO REV_ACCRUAL_HCC2 TABLE 17,082.9 7.0
KSO REV_ACCRUAL_HCC3 TABLE 14,304.3 8.4
KSO REV_ACCRUAL_HCC4 TABLE 12,541.6 9.6
--------------
sum 75,901.4
Retail Sales Data
The final table is made up of sales figures from a retailer. The table contains about 6 billion records and occupies well over half a Terabyte. There are very few columns, and the data is highly repetitive. In fact, there are no unique fields in this table. This is a very good candidate for compression. Here are the basic table statistics:
==========================================================================================
Table Statistics
==========================================================================================
TABLE_NAME : SALES
LAST_ANALYZED : 23-DEC-2010 03:13:44
DEGREE : 1
PARTITIONED : NO
NUM_ROWS : 5853784365
CHAIN_CNT : 0
BLOCKS : 79183862
EMPTY_BLOCKS : 0
AVG_SPACE : 0
AVG_ROW_LEN : 93
MONITORING : YES
SAMPLE_SIZE : 5853784365
TOTALSIZE_MEGS : 618667
==========================================================================================
Column Statistics
==========================================================================================
Name Analyzed Null? NDV Density # Nulls # Buckets Sample
==========================================================================================
TRANS_ID 12/23/2010 389808128 .000000 0 1 5853784365
TRANS_LINE_NO 12/23/2010 126 .007937 0 1 5853784365
UNIT_ID 12/23/2010 128600 .000008 0 1 5853784365
DAY 12/23/2010 3 .333333 0 1 5853784365
TRANS_SEQ 12/23/2010 22932 .000044 0 1 5853784365
BEGIN_DATE 12/23/2010 4 .250000 0 1 5853784365
END_DATE 12/23/2010 4 .250000 0 1 5853784365
UNIT_TYPE 12/23/2010 1 1.000000 0 1 5853784365
SKU_TYPE 12/23/2010 54884 .000018 0 1 5853784365
QTY 12/23/2010 104 .009615 0 1 5853784365
PRICE 12/23/2010 622 .001608 0 1 5853784365
==========================================================================================
Here are the compression ratios achieved for this table. As expected they are very good.
SYS@DEMO1> @comp_ratio
Enter value for original_size: 618667
Enter value for owner: KSO
Enter value for table_name: SALES_HCC%
Enter value for type:
OWNER SEGMENT_NAME TYPE TOTALSIZE_MEGS COMPRESSION_RATIO
---------- -------------------- ------------------ -------------- -----------------
KSO SALES_HCC1 TABLE 41,654.6 14.9
KSO SALES_HCC2 TABLE 26,542.0 23.3
KSO SALES_HCC3 TABLE 26,538.5 23.3
KSO SALES_HCC4 TABLE 19,633.0 31.5
--------------
sum 114,368.1
Summary of the Real World Examples
The examples in this section came from real applications. They show a fairly extreme variation in data compressibility. This is to be expected, as the success of compression algorithms is very dependent on the data being compressed. Table 3-6 presents the data from all four examples.


Hopefully this data gives you some feel for the range of compression ratios that you can expect from HCC and the types of datasets that will benefit most. Of course the best way to predict how compressible a particular table may be is to actually test it. This fact cannot be overemphasized.
Restrictions/Challenges
There are a few challenges with using HCC. Many of them have to do with the fact that HCC is not available on non-Exadata platforms. This fact poses challenges for recovery and high availability solutions. The other major challenge is that HCC doesn’t play well with data that is being actively updated. In particular, systems characterized by lots of single-row updates, which we often describe as OLTP workloads, will probably not work well with HCC.
Moving Data to a non-Exadata Platform
Probably the largest hurdle with using HCC has been moving the data to non-Exadata platforms. For example, while RMAN and Dataguard both support the HCC block format, and will happily restore data to a non-Exadata environment, a database running on such an environment will not be able to do anything with the data until it is decompressed. This can mean a lengthy delay before being able to access the data in a case where a failover to a standby on a non-Exadata platform occurs. The same issue holds true for doing an RMAN restore to a non-Exadata platform. The restore will work but the data in HCC formatted blocks will not be accessible until the data has been moved into a non-HCC format. This can be done with the ALTER TABLE MOVE NOCOMPRESS command, by the way.
![]() Note The ability to decompress HCC data on non-Exadata platforms only became available in Oracle database version 11.2.0.2. Attempting this on version 11.2.0.1 would result in an error. (Check with Oracle Support for a patch that may enable this behavior on 11.2.0.1)
Note The ability to decompress HCC data on non-Exadata platforms only became available in Oracle database version 11.2.0.2. Attempting this on version 11.2.0.1 would result in an error. (Check with Oracle Support for a patch that may enable this behavior on 11.2.0.1)
In addition to the lengthy delay associated with decompressing data before being able to access it, there is also the issue of space. If HCC is providing a 10× compression factor, you will need to have 10 times the space you are currently using available on the target environment to handle the increased size of the data. For these reasons, Dataguard is rarely set up with a standby on a non-Exadata platform.
Disabling Serial Direct Path Reads
As we discussed in Chapter 2, Serial Direct Path Reads allow nonparallelized scan operations to use the direct path read mechanism, which is a prerequisite for enabling the Smart Scan features of Exadata. Serial Direct Path Reads are enabled based on a calculation that depends on the size of the object being scanned relative to the available buffer cache. In simplistic terms, only large objects will be considered for Serial Direct Path Reads. HCC’s effectiveness can actually work against it here. Since the compression reduces the size of the objects so drastically, it can cause statements that would normally benefit from a Smart Scan to use the standard read mechanism, disabling many of Exadata’s optimizations. This is generally not a huge problem, because the number of blocks is considerably reduced by HCC and the database is making this decision at run time. The problem comes in, though, when an object is partitioned. The calculation is based on the size of the object being scanned; in the case of a partitioned object this means the size of the partition. So in cases where partitioning is used with HCC, we often see some partitions using Smart Scans and some unable to use Smart Scans. Keep in mind that this also means decompression cannot be done at the storage layer, as this capability is enabled only when performing Smart Scans.
![]() Kevin Says: Compression also has a lot to do with the often-overlooked In-Memory Parallel Query feature of Oracle Database 11g. Very effective compression combined with modern large memory servers makes In-Memory Parallel Query a usable feature for production purposes. Customers would do well to consider the best compression technology that suits their DML processing requirements while potentially exploiting the power of In-Memory Parallel Query.
Kevin Says: Compression also has a lot to do with the often-overlooked In-Memory Parallel Query feature of Oracle Database 11g. Very effective compression combined with modern large memory servers makes In-Memory Parallel Query a usable feature for production purposes. Customers would do well to consider the best compression technology that suits their DML processing requirements while potentially exploiting the power of In-Memory Parallel Query.
Locking Issues
The Exadata documentation says that updating a single row of a table compressed with HCC locks the entire compression unit containing the row. This can cause extreme contention issues for OLTP-type systems. This is the main reason that HCC is not recommended for tables (or partitions) where the data will be updated. Here’s a demonstration of the locking behavior:
KSO@SANDBOX1> select rowid, old_rowid(rowid) old_rowid , pk_col from kso.skew_hcc3
2 where rownum < 10;
ROWID OLD_ROWID PK_COL
------------------ ------------------------------ ----------
AAATCBAAHAAMkyXAAA 7.3296407.0 27999409
AAATCBAAHAAMkyXAAB 7.3296407.1 27999408
AAATCBAAHAAMkyXAAC 7.3296407.2 27999407
AAATCBAAHAAMkyXAAD 7.3296407.3 27999406
AAATCBAAHAAMkyXAAE 7.3296407.4 27999405
AAATCBAAHAAMkyXAAF 7.3296407.5 27999404
AAATCBAAHAAMkyXAAG 7.3296407.6 27999403
AAATCBAAHAAMkyXAAH 7.3296407.7 27999402
AAATCBAAHAAMkyXAAI 7.3296407.8 27999401
9 rows selected.
KSO@SANDBOX1> update kso.skew set col1=col1 where pk_col = 27999409;
1 row updated.
SYS@SANDBOX1> select col1 from kso.skew_hcc3 where pk_col = 27999409 for update nowait;
select col1 from kso.skew where pk_col = 16858437 for update nowait
*
ERROR at line 1:
ORA-00054: resource busy and acquire with NOWAIT specified or timeout expired
SYS@SANDBOX1> -- Expected because this row has been updated by another process
SYS@SANDBOX1>
SYS@SANDBOX1> select col1 from kso.skew_hcc3 where pk_col = 27999401 for update nowait;
select col1 from kso.skew where pk_col = 16858429 for update nowait
*
ERROR at line 1:
ORA-00054: resource busy and acquire with NOWAIT specified or timeout expired
SYS@SANDBOX1> -- Not normal Oracle locking behavior
Clearly this behavior would be disastrous to many OLTP systems. Especially when you consider the large number of records that can be stored in an HCC block. In this case that number is approximately 13,500 rows per block. This means that a single update could lock well over 50,000 rows.
Single Row Access
HCC is built for full table scan access. Decompression is a CPU-intensive task. Smart Scans can distribute the decompression work to the CPU’s on the storage cells. This makes the CPU-intensive task much more palatable. However, Smart Scans only occur when Full Scans are performed. This means that other access mechanisms, index access for example, must use the DB server CPUs to perform decompression. This can put an enormous CPU load on DB servers in high volume OLTP-type systems. In addition, since data for a single row is spread across multiple blocks in a CU, retrieving a complete row causes the entire CU to be read. This can have a detrimental effect on the overall database efficiency for systems that tend to access data using indexes, even if the access is read-only.
Common Usage Scenarios
HCC provides such high levels of compression that it has been used as an alternative to traditional ILM strategies, which generally involve moving older historical data off the database entirely. These ILM strategies usually entail some type of date range partitioning and a purge process. This is done to free storage and in some cases to improve performance. Often the data must be retained in some backup format so that it can be accessed if required at some later date. With HCC, it is possible in many cases to retain data indefinitely by compressing the oldest partitions. This approach has many advantages over the traditional approach of moving the data.
First and foremost, the data remains available via the standard application interfaces. No additional work will need to be done to restore a backup of old data before it can be accessed. This advantage alone is often enough to justify this approach. This approach typically entails leaving active partitions uncompressed while compressing old partitions more aggressively. Here’s a short example of creating a partitioned table with mixed compression modes.
SYS@DEMO1> CREATE TABLE "KSO"."CLASS_SALES_P"
2 ( "TRANS_ID" VARCHAR2(30),
3 "UNIT_ID" NUMBER(30,0),
4 "DAY" NUMBER(30,0),
5 "TRANS_SEQ" VARCHAR2(30),
6 "END_DATE" DATE,
7 "BEGIN_DATE" DATE,
8 "UNIT_TYPE" VARCHAR2(30),
9 "CUST_TYPE" VARCHAR2(1),
10 "LOAD_DATE" DATE,
11 "CURRENCY_TYPE" CHAR(1)
12 ) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOLOGGING
13 STORAGE(
14 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
15 TABLESPACE "CLASS_DATA"
16 PARTITION BY RANGE ("BEGIN_DATE")
17 (PARTITION "P1" VALUES LESS THAN (TO_DATE
18 (' 2008-09-06 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN'))
19 SEGMENT CREATION IMMEDIATE
20 PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS NOLOGGING
21 STORAGE(INITIAL 8388608 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
22 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT
23 FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
24 TABLESPACE "CLASS_DATA" ,
25 PARTITION "P2" VALUES LESS THAN (TO_DATE
26 (' 2008-09-07 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN'))
27 SEGMENT CREATION IMMEDIATE
28 PCTFREE 0 PCTUSED 40 INITRANS 1 MAXTRANS 255 COMPRESS FOR QUERY HIGH NOLOGGING
29 STORAGE(INITIAL 8388608 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
30 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT
31 FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
32 TABLESPACE "CLASS_DATA" ,
33 PARTITION "P3" VALUES LESS THAN (TO_DATE
34 (' 2008-09-08 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN'))
35 SEGMENT CREATION IMMEDIATE
36 PCTFREE 0 PCTUSED 40 INITRANS 1 MAXTRANS 255 COMPRESS FOR ARCHIVE LOW NOLOGGING
37 STORAGE(INITIAL 8388608 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
38 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT
39 FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
40 TABLESPACE "CLASS_DATA" ) ;
Table created.
SYS@DEMO1> @part_size2.sql
Enter value for owner: KSO
Enter value for table_name:
OWNER SEGMENT_NAME PART_NAME TOTALSIZE_MEGS COMPRESS_FOR
-------------------- -------------------- -------------------- -------------- ------------
KSO CLASS_SALES_P P1 24.0
P2 24.0 QUERY HIGH
P3 24.0 ARCHIVE LOW
******************** ******************** --------------
sum 72.0
Summary
Introduced in Oracle 11g R2, Hybrid Columnar Compression provides exceptional compression capabilities that are far beyond anything available in prior releases. This is thanks in large part to the adoption of industry-standard compression algorithms and an increase in the size of the compression unit from a single database block (typically 8K) to a larger unit of 32K or 64K. The feature is only appropriate for data that is no longer being modified, though, because of locking issues and the fact that updated rows are moved into a much less compressed format (OLTP compression format). For this reason, HCC should only be used with data that is no longer being modified (or only occasionally modified). Since compression can be defined at the partition level, it is common to see tables that have a mixture of compressed and uncompressed partitions. This technique can in many cases replace ILM approaches that require moving data to alternate storage media and then purging it from the database.