
C H A P T E R 1
Getting Started: Transitioning to HTML5
HTML5 is the first major update to the HTML specification in more than a decade. A decade! And what an update it is! Exciting new features such as multimedia support, interactivity, smarter forms, and better semantic markup are present, but the slate is not being wiped clean and started from scratch. The HTML you know and love is still there for you to play with, as is XHTML. With HTML5, you are free to code your pages in (almost) any way you are familiar with, but mastery of your craft comes from understanding the history, conventions, and semantics (meaning) of what you are coding and from creating informed decisions that drive your authoring style.
This chapter will untangle the foundations of HTML5 so that you can see where it has come from; this is followed by an overview of fundamental HTML terminology and concepts. Next, the major changes of HTML5 are summarized, and the state of XHTML is explained. Finally, some tools for using HTML5 features today are summarized, followed by a listing of other web developer tools.
HTML5 = HTML  HTML5
HTML5
What does HTML stand for? “Hypertext Markup Language.” This is likely not new to you. Well, what then does HTML5 stand for? “HyperText Markup Language, version 5” sounds reasonable. It's a reasonable assumption indeed, but HTML5 has a convoluted history that makes the term not as clear as it first seems. It may mean the most recent draft of the HTML specification to some, a stable snapshot of a larger specification to others, or a label to describe a whole suite of new and not-so-new technologies that aim to make the Web a richer, more engaging place to interact with.
Before HTML5
Remember Web 2.0? The term that rose to prominence in the mid-2000s became synonymous with a transition from a read-only mentality toward the Web to one that allowed active participation in its content: the read/write Web. As the term popped up at more and more conferences and elsewhere, eventually becoming a common catchphrase in mainstream media, its exact meaning became less than defined. Companies such as YouTube seemed to have it, yet undoubtedly web developers the world over were presented with the headache of explaining to confused clients that the old and antiquated HTML of their websites could not be supplanted with Web 2.0. The term became largely symbolic of what was possible, what was hip, and what was new. In practice, it encompassed old technologies that were repackaged in new ways, such as the asynchronous loading of content with JavaScript and XML (which became known as Ajax). In actuality, the ability to interact with a website in a read/write context had been around for years.
Perhaps more than anything, this period signified the desire to bring new life to the Web. The World Wide Web Consortium (W3C), the organization behind the direction of HTML at the time, had not released a recommendation for the HTML specification since 1999, when HTML 4.01 was released. For years after, the W3C was busy at work on XHTML 1.0 and then XHTML 2.0, a reworked XML-based flavor of HTML that sought to implement a stricter, more consistent coding practice. Since XHTML was based on XML, web page authors needed to adhere to the specification exactly; otherwise, the page would not load when it was not valid. The hope was the world's website authors would adopt this new standard, flushing the Web of malformed markup. But there was one problem. The world didn't switch.
Why XHTML 2.0 died and HTML5 thrived
By the time Web 2.0 was coined, there was mounting criticism toward the use of XHTML. In an effort to accommodate browsers that did not support XHTML, web page authors were writing XHTML markup but continued to serve the pages from their web servers using the Internet MIME type “text/html,” instead of the proper “application/xhtml+xml,” which would tell the browser it was viewing XML. The authors would build what they thought were valid XHTML pages, yet without delivering the pages as XML. They would not see any coding mistakes materializing in the browsers they were building against. The point became lost. The XHTML syntax did not matter if it was not being checked as such. In 2004 a group formed named the Web Hypertext Application Working Group (WHATWG), which aimed to evolve good old HTML instead of focusing on XHTML, as the W3C was doing at the time. The WHATWG began developing a specification named “Web Applications 1.0,” which would eventually become HTML5!
The WHATWG philosophy
The WHATWG took a different approach from the W3C in developing the HTML specification. Instead of pushing what some saw as a draconian overhaul of web standards, the WHATWG aimed to evolve HTML incrementally, maintaining backward-compatibility with previous versions of HTML. This made sense because web browsers did not operate on a versioning approach to rendering HTML; they attempted to render whatever HTML was thrown at them, independent of which version of the specification the web page author attempted to adhere to (HTML 3.2, HTML 4.01, and so on). The WHATWG developed a specification that was largely driven by what was practically in use—what web browser vendors were implementing and what web page authors were using. In 2007 three web browser manufacturers, Mozilla Foundation, Apple, and Opera Software, requested that the W3C adopt the work of WHATWG as a starting point for further development of HTML. Soon after, the W3C took the suggestion, and after nearly a decade of keeping HTML in hibernation, the next version, HTML 5 (with a space), was underway. In 2009, after eight Working Drafts and no Release Candidate, the W3C decided to bring XHTML 2 to a close and concentrate on HTML 5 (which was eventually shortened to HTML5). (Refer to Figure 1-1 for a chart of this convoluted history.) Additionally, XHTML lives on as XHTML5, which adheres to XML syntactic rules, as opposed to the HTML rules. Bits of XML syntax are permissible in HTML syntax (trailing slashes on empty elements, such as <br />, for instance); however, these are not true XHTML documents unless they are explicitly delivered from a server as such using the MIME type “application/xhtml+xml” or “application/xml” (more on this later).

Figure 1-1. The convoluted evolution of HTML. Note that the HTML2 specification appeared prior to the formation of the W3C.
The current state of HTML5
“The specification is never complete because it is continuously evolving.”
WHATWG FAQ
Is HTML5 done? No! Is it ready to use? Yes! The WHATWG and W3C continue to develop the HTML5 specification in conjunction with each other; however, WHATWG no longer refers to its specification as HTML5 (and you just thought you were wrapping your head around the history!). In addition to focusing on codifying what is already in practice, another philosophical difference between the WHATWG and the W3C HTML Working Group is that the WHATWG will no longer be developing a version of HTML that will at some point be closed for further revision. The W3C treats each version as a “snapshot” of the current state of development, while the WHATWG aims to have one specification for HTML that gets updated as needed. This reflects a move away from developing web applications that rely on the features of a particular version of HTML and instead relies on checking for support of the features directly, regardless of the “version” of the HTML specification used.
In the eyes of WHATWG, the W3C HTML5 specification (http://w3.org/TR/html5/) is a snapshot of the most stable features of the “living specification” WHATWG is overseeing. This specification is simply named HTML (http://whatwg.org/html/). The HTML specification is nested further as a subset of Web Applications 1.0 (Figure 1-2), which includes specifications related to web development that are separate from HTML, such as Web Workers (concurrent JavaScript threads), Web Storage (used for storing data in a web application), and others. You can view the full Web Applications specification at www.whatwg.org/specs/web-apps/current-work/complete.html.

Figure 1-2. How HTML/HTML5 fit together
This brings me back to the beginning of this trip through HTML's history. What is HTML5? Depending on the context:
- It is the most recent version of the HTML specification.
- It is a stable snapshot of an earlier version of the HTML specification.
- It is a label used to describe the contemporary state of open web technologies.
As far as the meaning of HTML5 referred to in this book, what is covered here is by its very nature a snapshot of the current specification. This means it may be ahead of W3C's HTML5 specification but will likely be behind the WHATWG's “living specification” by the time this goes to print. That is the nature of the Web. It's continuously evolving. For what is covered in this book, the third bullet point shown earlier possibly works the best. This book is a look at the contemporary state of web development. HTML5 is the new hip state of the Web, like the Web 2.0 that came before it. Where appropriate, associated APIs and technologies are included, regardless of the exact specification they draw from, but the overarching framework they work under is the next version of HTML—HTML5! (Or however you want to refer to it.)
Anatomy of an HTML5 document
Now that you are sufficiently versed in the path toward HTML5, let's look at a simple document so you can see how things have changed. Open your preferred code editor, create a new HTML file, save it as index.html, and type the following:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>HTML5 Apprentice</title>
</head>
<body>
<p>Hello World</p>
</body>
</html>
Surprise! You will notice that this document is not only familiar but also simpler than the HTML you may have seen before. Pretty clean and compact, huh? OK, feel free to open this in your preferred web browser to see that the text Hello World will in fact display on your page. If you can name every term in the previous code, feel free to skip the next section; otherwise, read on to get a refresher on fundamental HTML terminology and concepts.
HTML terminology and concepts
To avoid confusion on what is being referred to within this text as well as what you may read or hear spoken elsewhere, it is important that you know some fundamental terminology and concepts. Using the correct terminology is important both to avoid confusion and to aid your own and others' understanding.
Three fundamental building blocks make up an HTML document: elements, attributes, and text (content). Consider the following HTML code snippet for creating a link:
<a href="about.html">About Us</a>
The element is the a (which stands for anchor) element, which generates a clickable link to another HTML page or other resource. The element is composed of two tags: the starting tag (<a>) and the ending tag (</a>), which are also known as the start and end tag or the opening and closing tag. The attribute is the text that appears inside the starting tag as a name/value pair. Finally, the text content (which appears in the web page when this code is viewed in the browser) appears between the opening and closing tags (see Figure 1-3).
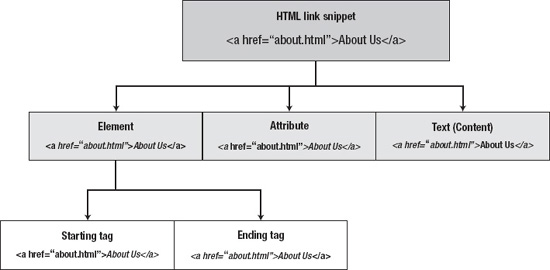
Figure 1-3. Fundamental components of a typical HTML snippet showing element, attribute, content, and tags.
Elements
Elements are the M in HTML; they are the markup instructs a web browser on how to handle some content. Each element has a keyword, such as body, p, a, img, and so on, that defines what it is (body element, paragraph element, anchor element, and image element, respectively). Different elements define different types of behaviors, such as creating links, embedding images, and so on. You may hear of an element being referred to synonymously with tags, but elements and tags have slightly different meanings. Tags are part of elements, as Figure 1-5 shows. The majority of elements consist of an opening tag, some content, and a closing tag, but depending on the tag, one or more of these three components may be absent. Many elements can contain any number of further elements nested inside of them, which are, in turn, made up of tags and content. The following example shows two elements: the p element, which is everything from the first opening angle bracket (<) to the very last closing angle bracket (>), and the em element, which encompasses the opening <em> tag, the closing </em> tag, and the content in between.
<p>Here is some text, some of which is <em>emphasized</em></p>
Notice that the <em></em> element is entirely enclosed in the <p></p> element; it would not be proper syntax to nest them any other way, as follows:
<p>Here is some text, some of which is <em>emphasized</p></em>
There is not a clear hierarchy of what is inside of what, which is problematic when a web browser is deciding how to display this text. A web browser will still parse and attempt to display this code, but it is not code that conforms to the HTML specification.
Empty elements
Not all elements contain text content. For example, the img, br, and hr elements insert, respectively, an image, new line, and horizontal rule into the page. What they don't do is modify some content on the page, beyond taking up space for themselves. Such elements are not container elements—that is, you would not write <hr>some content</hr> or <br>some content</br>. Instead, any content or formatting is dealt with via attribute values (explained in the next section). In HTML, an empty element (also known as a void element) is written simply as <img>, <br>, <meta>, or <hr>, without a closing tag. In the XML form of HTML, XHTML, an empty element requires a space and a trailing slash, like <img />,1 <br />, <meta />1, or <hr />; these are referred to as self-closing tags. Because of HTML5's flexible syntax, either form is acceptable to use. I tend to lean toward the XHTML syntax because the presence of the slash makes it clearer that the tag is an opening and closing tag merged together.
Attributes
Attributes appear within the starting tag of an element. A particular element often contains a mixture of attributes that are unique to that element along with attributes that are valid on a broad range of different elements. They are used to modify the behavior of the element in some respect. They can be thought of as key/value pairings, like key="value", where a particular element will have a number of defined attributes (the key) that can be set to some value. For instance:
__________
1 In practice, the img and meta elements will have attributes as well.
The attribute href appears in the opening tag and is set to a custom value that changes the behavior of the HTML element. Depending on the attribute, it may contain multiple, space-separated values. Other attributes you may have already encountered might include alt, src, and title, but there are many more attributes. As with elements, HTML5 supports both HTML and XHTML syntax when writing attributes; in HTML syntax they would not need to be in quotes, so <a href=contact.html> would be acceptable, but, as with elements, I believe the XHTML syntax is clearer, because the quotes let you know the value is a custom value, like a quotation of something you have said. An exception to the clarity of XHTML syntax may be the way it handles certain attributes known as Boolean attributes. Boolean attributes provide an effect solely based on their presence or absence within an element. In XHTML, which requires that each attribute have a value, their value either is left empty or is set to a text string that is the same as the attribute name. For instance, the video element contains an attribute called autoplay; in XHTML syntax, this would look like <video autoplay=""> or <video autoplay="autoplay">. However, in the more forgiving HTML syntax, this could be written as <video autoplay>. In this case, the HTML format is clearer. Since HTML5 supports either syntax, which way you write it is up to you!
DOM
With the descriptions of elements, tags, and attributes safely behind us, let's turn our attention to another concept related to HTML that you should know: the DOM. The Document Object Model (DOM) is a term that crops up particularly when discussing JavaScript's relationship to a page, and as a web designer/developer, it is an important term to be aware of. What is it? It is a standard way of representing a document, in this case an HTML page, as a treelike data structure composed of connected nodes. The nodes represent the elements, attributes, and text content in the page. Through its branching, tree-like structure, the DOM describes how the nodes are nested inside of each other.
The DOM and the nodes it contains are represented in JavaScript as objects, which describe what a particular node contains and can do. Using JavaScript, individual components on the page can be accessed using dot notation to traverse the tree structure. If you are not familiar with dot notation, it simply means that one node in the DOM tree that is nested inside another can be accessed through its containing nodes (known as objects in this context) by supplying the node (object) name separated by a period. For example, the HTML page is represented in the DOM as an object named document, which contains the actual HTML page contents. Since the HTML page contains a head and a body, there is a head and a body object inside the document object. So, to access the HTML page's body element, the following would be written in JavaScript: document.body. This won't actually do anything; the body element is just being accessed from JavaScript, but it isn't being processed in any way. The point is that the structure of the page is represented by nested objects, each of which can be accessed using a dot (period).
Once you get down to the specific HTML elements, the commands get more generalized, because it is unknown in advance what elements are on your particular page. JavaScript contains a number of commands that can be used for accessing the contents inside the body of the HTML page, for dynamically updating content, for responding to events, and so on. For instance, to access the first HTML element shown on the page, you would use document.body.firstElementChild. To access the first attribute of that element, you would use document.body.firstElementChild.attributes[0]. The zero in brackets just refers to the number of the attribute to access; 0 refers to the first of the attributes in the HTML element, 1 to the second attribute, and so forth. Lastly, to access the contents of this element, you would use the following: document.body.firstElementChild.firstChild.
Figure 1-4 shows the structure of a simple web page with only a link in the body area. Looking at this diagram, you'll notice an extra object at the top, called window. While the DOM is accessible through the document object, document is actually contained in this window object, which represents the web browser window the page content is contained in. Technically, accessing the DOM would be done through the window object first, which is the “root” object through which all other aspects of the web page are accessible from JavaScript. Accessing the page's body, for instance, could be done with window.document.body or document.body (in which case, a reference to window at the beginning is implied).

Figure 1-4. Accessing the DOM through the document object reveals the inverted tree-like structure of a simple web page (which in this case, only contains a link in the body)
What's new in HTML5?
At this point, you may be asking yourself, “What, really, is new in HTML5?” To begin with, it's worth noting that HTML was originally conceived of as a markup language for presenting text documents, not as an application development platform. However, over time, more and more functionality has been squeezed into the web browser. HTML5 has first and foremost attempted to consolidate, document, and add to the features added to the language over the past decade. Some of the main changes are described in the following sections.
Backward-compatibility
HTML5 is compatible in most cases with previous forms of HTML syntax and tags. How is this new? Well, for years a “standards-based” approach to web authoring was emphasizing a transition away from HTML syntax toward XHTML syntax. As discussed in the history section, HTML5 has moved the emphasis away from a syntactically “pure” XML-based approach and instead moves the emphasis toward better documentation of the practices already in use.
Error handling
While web page authors may write documents any way they are familiar with, pretty much, a major change in HTML5 has been directed toward user agents (web browser manufacturers), not authors. Web browsers attempt to render HTML code, whatever it may look like. Because of the flexibility of HTML in practice, the code can be ambiguous in its structure at times. In the past, web browser manufacturers approached ambiguous code differently and implemented different algorithms for how to handle the ambiguous HTML (termed tag soup). This led to inconsistencies in appearance across different browsers. One obvious approach toward solving this issue is to make the language stricter so web page authors are forced to structure their pages a certain way. This was the thought and effort behind XHTML1.x; however, another approach is to standardize how errors are handled on the browser implementator's side. This is what HTML5 seeks to do. It seeks to finally document how variations in syntax should be handled. Web browsers have two choices when dealing with a parsing error: either implement the rules specified in the HTML5 specification or abort processing the document at the first error. The idea is that different browsers will consistently handle the same errors, and those that do not implement the error-handling behavior will stop parsing the HTML, thus notifying the author of an issue with their syntax.
Obviously, it will be apparent to the web developer that something is wrong if the page does not render, but it will be far less apparent if the page renders fine, even if there is an error the browser is handling. In such situations, the page is being handled, but it is considered nonconforming with the HTML5 specification. This is why it is of utmost importance that web developers are familiar with what has changed in HTML and which elements and attributes they should not use (see the “Obsolete Features” section later in this chapter). If in doubt, however, there are conformance-checking services such as http://html5.validator.nu or http://validator.w3.org that will check supplied HTML code against the HTML5 specification.
Simplified doctype
HTML often begins with a doctype declaration. In the past this has looked something like this:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
or
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
A doctype declaration provides an indication as to what Document Type Definition (DTD) you're going to be writing your markup against. A DTD is basically a page detailing the rules and grammar of the markup. So, the difference in the two lines of the code listed earlier is that they are specifying a DTD for different versions of (X)HTML, one HTML 4.01 and the other XHTML 1.0. Wait a minute! This heralds from a worldview of HTML that sees it as broken into different versions. Since we are talking about HTML5, which is backward-compatible with previous versions of the specification, all that needs to be done is say the page is displaying HTML. Therefore, the doctype has been simplified to the following:
<!DOCTYPE html>
How's that for simplification of the doctype? It really couldn't be any simpler. Well, actually it could; it could be absent, and your HTML page will still load if it is omitted, but don't erase this line from your web pages just yet!
Doctypes in HTML serve two important purposes. First, they inform user agents and validators what DTD the document is written against. This action is passive—that is, your browser isn't going and downloading the DTD every time a page loads to check that your markup is valid; it's only when you manually validate a page that it kicks in.
The second and, for practical purposes, most important purpose is that doctypes inform browsers which parsing algorithm to use to read a document. Web browsers commonly have three ways they can parse an HTML document:
- No-quirks (or “standards”) mode
- Quirks mode
- Limited-quirks (or “almost standards”) mode
To render documents in one mode over another, the browser depends on the presence, absence, or value of the doctype string. This is known as doctype switching, and it was included in browsers as a way of determining how to render a document. The assumption is that if an author has included a doctype, then that author knows what he or she is doing, and the browser tries to interpret the strict markup in a strict way (in other words, standards mode). The absence of a doctype triggers quirks mode, which renders the markup in old and incorrect ways; the assumption here is that if the author hasn't included a doctype, then he or she probably is not writing standard markup, and therefore the markup will be treated as if it has been written in the past for buggier browsers. Whether no-quirks or limited-quirks mode is triggered is subtler and depends on the doctype chosen as well as the browser the document is viewed in.
![]() Tip Do you want to convince yourself that the browser switches parsing modes based on the presence or absence of the doctype? If you open a page in Mozilla Firefox 4 and select Tools
Tip Do you want to convince yourself that the browser switches parsing modes based on the presence or absence of the doctype? If you open a page in Mozilla Firefox 4 and select Tools ![]() Page Info, under the General tab you will see a Render Mode listing that will show the current mode being used to view the page. If you add and remove the doctype declaration from a web page and check the Page Info during each state, you will see that the browser is triggering different parsing modes. Alternatively, if you are familiar with JavaScript, insert the following script into the head section of an HTML page:
Page Info, under the General tab you will see a Render Mode listing that will show the current mode being used to view the page. If you add and remove the doctype declaration from a web page and check the Page Info during each state, you will see that the browser is triggering different parsing modes. Alternatively, if you are familiar with JavaScript, insert the following script into the head section of an HTML page:
<script type="text/javascript">
alert(document.compatMode);
</script>
When loading the page, this will show a pop-up with either “CSS1Compat” or “BackCompat.” The former means the mode is set to no-quirks mode; the latter means it is set to quirks mode.
One last note in regard to doctypes: in order to be compatible with legacy systems that generate HTML code and therefore require the doctype syntax to look more like it previously has, the following alternative doctype declaration for HTML5 is acceptable:
<!DOCTYPE html SYSTEM "about:legacy-compat">
This is provided only for systems producing HTML, so it is unlikely that you, as a web page author, would use this declaration unless you wanted to give your fingers an additional workout or show your friends that you are a master of the smallest nuances of HTML5.
Simplified character encoding
The HTML you type is text, right? Well, to you it is, but to the computer it is stored as a series of bits: 1s and 0s. Therefore, a particular character is actually stored as a particular binary number. A computer program (such as a web browser) reading a text document needs to know two things fundamentally:
- That what it is reading is supposed to be text
- Which convention is being used to map the bits it reads to the representation of a particular character of text
This second point is referred to as the character encoding for the document. Think of it as like the old telegraph system of communicating, where messages were sent as Morse code and subsequently translated into letters and words. To successfully transmit text using Morse code, the sender and the receiver both need to know how the clicks being sent map to particular letters. The character encoding tells the computer how to translate the bits and bytes it reads into letters for display or other purposes.
The HTML5 specification strongly recommends that all HTML documents have a character encoding set. The recommended way is to have the server send this as part of the response headers, in the HTTP Content-Type header, but if this is not possible, the meta HTML element can be used in the head section of the HTML document. The most widely used character encoding system in use on the Web is UTF-8, which can encode more than 1 million characters covering most written language scripts in use around the world.
In HTML 4.01, the meta element looked like this:
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
This is still supported in HTML5 for backward-compatibility, but the preferred syntax is shorter and includes a new attribute, charset:
<meta charset="UTF-8">
Ahh, this is much more succinct! Remember, you don't need this at all if your server sends the character encoding as part of its HTTP response header.
New content model categories
A content model is used to specify the kinds of content that specific HTML elements are expected to contain. Different HTML elements that can contain the same kinds of content can be grouped together into categories. Traditionally, HTML elements have fallen under two categories: block and inline. In HTML5 these have been significantly expanded to seven major categories:
- Metadata content
- Flow content
- Sectioning content
- Heading content
- Phrasing content
- Embedded content
- Interactive content
The block category roughly corresponds to “flow content,” while the inline category corresponds to “phrasing content” to make a distinction between this category and the display:inline; property used in CSS. These will be explored further in the next chapter.
New elements
HTML5 introduces a large number of new elements to help give greater meaning (semantics) to the structure of your web pages. New elements such as header, nav, and footer describe areas where the title and logo of the page may appear, where the main navigational menu appears, and where the copyright and legal information would be found, respectively. This standardizes the common practice of creating these areas of a web page using elements such as a div element with an id attribute. For example, previously a footer section might have been created with this:
<div id="footer">copyright 2011</div>
Using the new section tags, this could be rewritten as follows:
<footer>copyright 2011</footer>
Using these new structural tags is clearer and standardizes the identifier for this tag, since an id attribute could be written “page-footer,” “thefooter,” and so on, by different authors. The “Semantic Web” aims to provide clearly defined content that is readable by machines for better data mining/search purposes. The old format makes it impossible for a machine to pick out the footer consistently on several different web pages, while the HTML5 syntax makes it totally predictable—assuming, of course, the author in fact was using the footer tag for the appropriate section of their web page.
In addition to new structural elements, there have been major upgrades to the element types available in web forms, introducing new input types for entering dates, URLs, e-mail addresses, phone numbers, and so on. Also introduced is a number of new elements for embedded and interactive content, such as the video, audio, and canvas (a scriptable drawing surface). There have also been changes to existing elements, such as redefining the meaning (semantics) of the b, i, and small elements so that they are no longer presentational in nature. The new elements and changes to existing elements will be explored in greater detail in upcoming chapters.
Microdata
This new addition is based on the idea of annotating HTML elements for the purposes of adding metadata to the page's content so that it may more easily, and in a standardized way, be processed by external applications, aggregators, and search engines. This idea isn't new. Microformats and RDFa are two formats for annotating HTML for this purpose, but HTML5 introduces a third format: Microdata (itself based on RDFa). Microdata uses a set of global attributes that may be used to add additional semantic structure to the content on a page.
Embedded MathML and SVG
Mathematical Markup Language (MathML) and Scalable Vector Graphics (SVG) are both XML-based markup languages that are described in different specifications than HTML. As the name implies, MathML is for describing and presenting math equations using correct mathematical notation. SVG is used for describing interactive and static (noninteractive) vector-based graphics. Neither of these languages is new, but since HTML5 may include XML-style syntax, both of these languages can be embedded within a regular HTML page. These will be touched on further in Appendix A.
APIs
In the spirit of creating a platform for web application development, HTML5 introduces a number of scripting application programming interfaces (APIs). These include additions to the JavaScript API that allow elements to be selected via their classes. For example, using array syntax, the first element on a page with the class attribute set to aClass could be retrieved via JavaScript with the following:
document.getElementsByClassName("aClass")[0]
Also added are APIs associated with the new elements, such as a means to control video and audio playing within the new video and audio elements. Additional functionality added includes handling drag-and-drop user interaction, getting access to the web browser history state, and storing web page data in a cache for later retrieval in an offline state. There are also a number of related APIs that work with HTML5 but actually fall under separate specifications. A notable one in this category is the Geolocation API, which provides a means to handle location data within a web context. Later chapters will explore these APIs in greater detail.
No longer SGML conforming (again!)
Well, frankly you are unlikely to notice this change at all. HTML in its purest form originally developed from Standard Generalized Markup Language (SGML), a much older markup language. However, the HTML implemented by web browsers did not fully comply with the SGML specification, and HTML5 has simply codified that fact. HTML5 has syntactic elements borrowed from SGML, HTML, and XHTML1.x, making it an amalgamated language distinct in its own right.
Obsolete features
There is a bit of a catch-22 in HTML5, in that it must remain compatible with old features of HTML, while discouraging the use of certain elements that are no longer considered acceptable to use. For instance, HTML contains certain markup that is presentational in nature, meaning the effect it has on its content is to stylize its appearance in some way (the font element, for example). Presentational markup has long since been usurped by Cascading Style Sheets (CSS), so the majority of these features have been deprecated. Authors should not use these elements any longer, even though they still appear in the HTML specification. These elements are not simply removed from the specification so that user agents (web browsers) will know how to handle them when they are encountered (such as in older web pages); however, such pages are said to be nonconforming. The web browser will render them, but they do not adhere to the current HTML specification. Table 1-1 shows the list of obsolete elements and the alternatives to their use.


In addition to the deprecated elements, many attributes have been filed under obsolete as well, and many are presentational in nature and are easily emulated using CSS. See Table 1-2 for a list of attributes that have been marked obsolete in HTML5. They should not be used.



Is XHTML gone?
Short answer: no. It is now known as XHTML5. However, the HTML5 specification states that XHTML must no longer be served with the MIME type “text/html,” as was commonly done with XHTML 1.x. A major reason this came into practice was that Internet Explorer would not parse a page served as XML and would instead attempt to download the page to disk instead of displaying it. This was not the only reason, however. XML is very strict in its syntax, and the smallest validation error would cause the web page to break and become unusable, with the error visible for the entire world to see. So, XHTML syntax was often used but still delivered as HTML as a precaution.
What's all this noise about MIME types?
Multipurpose Internet Mail Extensions (MIME) types, also known as the media type, tell a web page what kind of data it is receiving. Obviously, the web browser would want to handle an image vs. a text document very differently, so it is important to have the means to tell it what kind of data it is being sent. Since XHTML and HTML look very similar, the web browser needs to be told which it is dealing with. If it is XHTML, it needs to parse it using an XML parser that adheres to the XML specification; if it is HTML, it needs to parse it using an HTML parser that adheres to the HTML specification.
Before I continue, let me clarify the major difference between XHTML and HTML. Although they share a common vocabulary, XHTML has several theoretical advantages over HTML, including the following:
- XHTML that is not well-formed will be immediately spotted, because browsers will refuse to display the page and will display an error instead.
- XHTML provides a guarantee of a well-formed2 document.
Neither of the preceding points is true, however, unless the pages are serving XHTML with a MIME type of “application/xhtml+xml” or “application/xml.” If your web server is serving your web pages with a MIME type of “text/html,” then you will not be taking full advantage of XHTML.
Deciding between HTML and XHTML
So, which should you use, HTML5 or XHTML5? It depends on your syntactic preferences and how important the guarantee of well-formedness in your documents is to you. XML-style syntax can still be used in HTML, but don't expect it to have the implications of XHTML unless it is served as such. Ultimately, it's a judgment call entirely dependent on your own circumstances. Just don't make the mistake of thinking that by serving a page as XHTML you've done all you need to do to create a professional, well-structured, semantically meaningful document.
Web browser support
Whichever syntax you use, let's turn to how you see the fruits of your labor. As features of HTML5 become stable, they are—in a perfect world—expected to appear in the latest version of your preferred web browser. But how do you know which features are actually supported and which are not? Testing code in the browser you are developing against is the surest option, but there are also websites such as http://caniuse.com available that give you an idea of what your preferred browser supports. Another site, http://html5test.com, detects whether certain features are available in the browser used to visit the site (Figure 1-5). Use a different browser, and you may see a different score and summary, highlighting that not all features will work on all major browsers.
__________
2 I should point out that “well-formed” does not mean the same as “valid.” For instance, a tag with an attribute mymadeupattribute=“true” is well-formed but still invalid.

Figure 1-5. http://html5test.com results for Google Chrome 11
Since not all features of HTML5 are supported on current web browsers, it is a good idea to detect for support of any features that do not fail gracefully. Modernizr (http://modernizr.com) is a JavaScript library that is worth investigating for this purpose. The library detects the availability of HTML5 (and CSS3) features, whose presence or absence are stored as Boolean values in a JavaScript object the Modernizr library creates.3 These values can be checked using conditional JavaScript code to add functionality if the features are present or, otherwise, handle the page if they are not. For example, to detect whether the audio element is supported, you could write the following in your page's JavaScript code:
// Check Modernizr object for audio Boolean value of true
if (Modernizr.audio) {
// Enable functionality on page for audio controls
}
else
{
// Handle lack of audio element support on the page
}
__________
3 If you want to know more about creating custom methods of detecting HTML5 features, check out Mark Pilgram's excellent summary at http://diveintohtml5.org/detect.html.
![]() Note Paul Irish (
Note Paul Irish (http://paulirish.com) is a lead developer on the Modernizr project, as well as a project called the HTML5 Boilerplate (http://html5boilerplate.com), which is worth checking out as well. The Boilerplate provides a default bare-bones starting template for HTML5 web projects. It includes the Modernizr and jQuery JavaScript libraries, as well as a default web page structure and attached CSS style sheet.
Web browser developer tools
Each web browser uses software known as a layout engine to parse HTML and CSS and render it on-screen. Unsurprisingly, these are often different for each (though Google Chrome and Apple's Safari both use WebKit), which explains the differences in support of HTML5 features, even among the most recent releases of different web browsers. Since they are different, it's good to have a solid in-browser developer tool in order to explore and manipulate the HTML/CSS. Each browser has a set of tools for aiding web development in this regard. Typically, these tools, when enabled, allow content on the page to be right-clicked, and an “Inspect Element” or similar option will be present in the contextual menu. Inspecting the HTML element will reveal its structure and CSS styling, which can be explored and manipulated (nonpermanently) in the browser. These tools also feature some sort of “console” where JavaScript code can log commands using the code console.log("message"); or similar. See Table 1-3 for a list of major browser's respective layout engines and developer tools.

__________
4 Visit http://getfirebug.com to download this Firefox extension.
5 Enabled through the Develop menu, which is enabled by checking the box in Preferences… ![]() Advanced.
Advanced.
Summary
It's been a convoluted road—years in the making—that now brings us HTML5. More and more new features are finding their way into web browsers, and certainly the majority is here for us to use today! Now that you have gotten your head around how HTML5 fits into the larger picture and explored what has changed and what has stayed the same, it is time to head off into the details of how to most effectively use the new features. You have only just scratched the surface!