
Chapter 15. Solving Tomorrow’s Problems Today
Software testing is a growing field that will continue to mature for many years. Many of the innovations and new approaches in test have been reactions to the problems test teams have run into. The creation of software testing jobs occurred after programmers discovered that they couldn’t find all of their own bugs. Implementation of many test automation solutions occurred after management discovered that testing would require either more testers or a more efficient method of conducting some segments of testing.
It seems that there is always another obstacle to overcome in software testing. For the most part, testers wait until the problem is big enough so that a solution for the problem is imperative. For the art, craft, and science of testing to continue to advance and expand, we need to be able to anticipate some of these problems before their burden becomes overwhelming. This chapter covers some of the testing problems that Microsoft is currently facing and the direction we are taking in solving those problems.
Automatic Failure Analysis
If a tester runs 100 test cases and 98 percent of them pass, the tester might need only a few minutes to investigate the two failures and either enter the bugs into the bug tracking system or correct the errors in the test. Now, consider the case where the tester has 1,000 different tests that run across 10 different configurations and 5 different languages. That same 98 percent pass rate on an “exploded” test matrix of 50,000 test points[1] results in 1,000 failures for investigation. With an increasing number of product configurations available, it is becoming common for small teams to have a million test points, where even a tiny percentage of failures can result in enough needed investigation to cause “analysis paralysis”—a situation where the test team spends as much time investigating test failures as they do testing.
Overcoming Analysis Paralysis
Just as automated testing is one solution for testing a countless number of different product configurations, automatic failure analysis (AFA) is a solution for dealing with a large number of test failures. The most effective way to avoid paralysis is to anticipate it—in other words, don’t wait until you have an overwhelming number of failures to investigate before considering the impact the investigation will have on the test team. It is easy for a test team to become stuck in an infinite loop between creating automation and investigating failures (or, as I have sometimes heard it said, creating failures and investigating automation). Living in this loop rarely results in well-tested software.
In the best circumstances, analyzing hundreds or thousands of failures merely takes time. In other scenarios, much worse things can happen. Consider this conversation between a manager and his employee John:
Manager: John, how far did you get investigating those test failures?
John: I investigated some of the results and identified these four bugs in the product. I haven’t had time to get to the rest, but I recognize several tests among those that have been failing because of known issues that won’t be fixed until the next release.
Manager: OK, I want you to get back to work on automating tests for our next new feature.
...two months pass...
Manager: John, we have a serious problem with the release. Customers are reporting serious issues.
John: Yeah... it turns out that the failures I didn’t investigate failed in a different way than they had before and there was actually a serious issue. It’s unfortunate, but I don’t have time to look at every single failure, and it made sense at the time not to look further....
In this example, John didn’t finish the analysis for a few reasons. He skipped some of the investigation because in his mind the failures were already understood. Furthermore, even his manager thought that the best investment of John’s time was to move on to creating new automated tests.
If you run a test twice and it fails twice, you cannot assume that it failed the same way both times. Similarly, if you run the same test on five different configurations of the software and it fails all five times, you don’t know that the configurations all failed in the same way unless you investigate all five failures. Performing this analysis manually is tedious, error prone, and keeps testers from doing what they need to be doing—testing software!
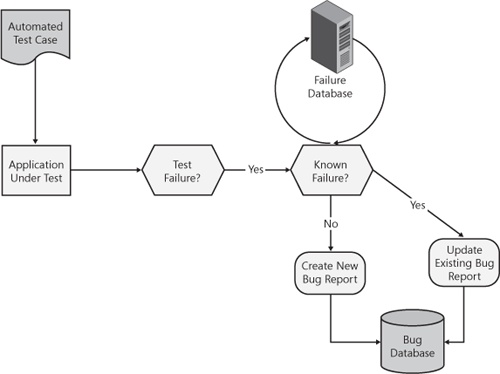
Successful AFA requires several critical components. Figure 15-1 shows a basic architecture of an AFA implementation.
The Match Game
The most critical piece of an AFA system is failure matching. If I’m running a manual test (scripted or exploratory) and it fails, I log a bug containing specific information on the environment and scenario that led me to the bug. Poorly constructed automated tests might merely report that a “failure occurred in test case 1234” and move on to test case 1235. For AFA to work, the automated tests need to report consistent information about the environment, scenario, and steps that lead to the error occurring. Good logging practices (discussed in the following section) are the backbone of reliable failure analysis. If the test logs are unstructured or contain insufficient information, there is no way failure matching will work.
On the back end, a failure database contains information about every known test failure. When a test fails, a comparison against known failures occurs, and the system either creates a new bug report or updates an existing report. Implementation of the analysis engine can be complex. At a minimum, it would compare log files or stack traces or both. A more extensive and reliable implementation should include a sophisticated matching algorithm to allow for flexibility and growth. For example, the two logs in Example 15-1 should match as being the same failure despite the minor differences, and should not show up as two distinct failures.
Log file 1 Test Case 1234: SysInfo(MyDevBox) DateTime.Now Test Input Boundaries [int foobits(int)] Testing lower boundary [0] Testing lower boundary passed. Testing upper boundary [32768] Expected result -1 Actual result 0 Result: Test Failed. Log file 2 Test Case 1234: SysInfo(MyTestBox) DateTime.Then Test Input Boundaries [INT FOOBITS(INT)] Testing lower boundary [0] Testing lower boundary passed. Testing Upper Boundary [32768] Expected -1 Actual 0 Result: Test Upper Boundary Failed.
A smart and flexible failure-matching algorithm allows for minor changes in the logging information as well as the changes commonly introduced by data-driven variations or test generation techniques.
Good Logging Practices
Good logging is essential for analyzing and matching failures. Logging is too often an ad hoc and unreliable “tax” that testers add to their automation. As trivial as it might sound, high-quality and consistent logging practices can be the difference between “throw-away” automated tests and those that run reliably for 10 years or more. Table 15-1 lists some things to consider when writing log files.
Anatomy of a Log File
What information is beneficial in a log file? Table 15-2 breaks down the log file from Example 15-1.
Log entry | Purpose |
Test Case 1234 | Unique name |
SysInfo(MyDevBox) | Placeholder for environment data |
DateTime.Now | Contextual data (this will never match another test) |
Test Input Boundaries [int foobits(int)] | Identifies what is being tested |
Testing lower boundary [0] | What was the value? If a crash occurs, we’ll never get to trace it later |
Testing lower boundary passed | (Last) Known good execution |
Testing upper boundary [32768] | Record the current input value |
Expected result –1 | What did we want to observe? |
Actual result 0 | What did we observe? (fail state observation) |
Result: Test Failed | Formal summary of test case status |
Integrating AFA
An excellent return on investment for large-scale test automation requires integration in all stages of the automation, check-in, and bug tracking systems. A successful solution greatly reduces the need for manual intervention analyzing test results and failures. Another use of AFA is in analyzing trends in test failures. For example, analysis can indicate that parameter validation errors contributed to 12 percent of the test pass failures over the last six months, or that UI timing issues contributed to 38 percent of the test pass failures over the last six months. This data can be used effectively to understand and target risk areas of the product.
With AFA, the team can focus on new issues as they occur. Much of the risk in analysis of test results is in losing important variations in the noise of expected variations. When investigating a series of failures it is natural (and common) to make evaluations such as “This test point failed last week; this week’s failure is probably the same as last week’s.” An AFA system is capable of removing the tedium from test pass analysis and removing avoidable analysis errors by using rules of analysis when deciding whether a failure has been previously observed. Furthermore, these rules are not relaxed because of familiarity with the tests or frequency of the observed test point failure.
Machine Virtualization
Microsoft test teams use massive labs filled with desktop computers and walls of rack-mounted systems. The computers are a finite resource and are in demand for use as build machines or for nightly or weekly manual and automated test passes. Microsoft Hyper-V (formerly known as Windows Server Virtualization) is quickly gaining ground as an alternative that is allowing test teams to use virtual machines. (The most simple definition of a virtual machine, or VM, is an implementation of a computer that runs as a program on a host system.) Hypervisor-based virtualization (like Hyper-V) has much better performance and security than does hosted virtualization (where the VM runs as a program inside the host operating system).
Virtualization Benefits
Virtual machine usage for testing is rapidly being adopted. One of the main benefits for the individual tester is convenience—maintenance of one physical computer and a library of virtual machines is much simpler than maintaining several physical computers. Another big benefit is that a whole set of virtual machines can be easily run by one tester on a single computer, whereas traditionally, testers might need several computers in their office or access to a large lab. Cost savings is another benefit that virtual machines provide. Costs are reduced by using fewer computers and by getting better usage out of the existing hardware as a result of the parallelization benefits of VMs. These savings are beneficial in a tester’s or developer’s individual office as well as in a test lab.
In the Office
Testers and developers often need multiple computers in their office. For example, they might need to test on different hardware architectures or on multiple computers at once. Rather than fill their office with computers (in my career as a tester, I have had as many as 10 physical test computers in my office), each office can have one Hyper-V server with several different VMs running on it. By using virtualization, testers and developers can create VMs with various specifications at the same time, and configuration is relatively fast and simple. This flexibility allows testers and developers to get much greater test coverage without adding additional hardware to their offices.
Test Lab Savings
Test lab managers can use the server consolidation application of Hyper-V to make their existing hardware more efficient and get the most out of new investments. Most test groups at Microsoft have large labs full of computers responsible for automated tests, stress tests, performance tests, and builds; these labs are prime candidates for consolidation. Test labs rarely run anywhere near full capacity. By using virtual machines, lab administrators can get the same work done on far fewer computers. This saves valuable lab space as well as power costs.
Reducing server machine count also saves time for lab managers. Every lab computer has a time cost that results from the work that must be done to install, rack, and configure it. Management overhead is also associated with a server, including tasks such as upgrading and troubleshooting hardware. Some overhead will always exist, but VM usage greatly reduces this overhead. Virtualization reduces the number of physical computers that need this time commitment. Although many of these same tasks are still necessary on virtual machines, the work is easier because of the potential for automation. It is impossible to automate some aspects of the physical setup of a computer, but scripting through the Windows Management Instrumentation (WMI) can perform the equivalent work for a virtual machine. For example, virtual networks allow lab managers to dynamically modify the network topology programmatically rather than by manually unplugging cables.
Because Hyper-V allows virtual machines of different types to run on the same physical computer, it is no longer necessary to have a wide variety of servers in a lab. Of course, it is still valuable to have computers to represent esoteric hardware, and for this reason, we would never recommend that VM testing replace physical testing entirely. But virtual machines can easily represent simple differences such as processor or core count, 32- versus 64-bit, and memory configurations.
Test Machine Configuration Savings
Virtualization use is saving more than money, power, and space. Development time is an enormously valuable resource, and virtualization can make developers and testers more efficient by reducing two major engineering time sinks: test machine setup time and test recovery time.
Testers and developers both spend a great deal of time setting up computers to test and validate their code. By using virtualization solutions, users can create test images once, and then deploy them multiple times. For example, a tester could create a virtual machine and store it on a file server. When it is time to run a test, testers just copy the VM to a host server and execute the test, rather than take the time to install the operating system and other software. Testers and administrators often create entire libraries of virtual machines with different configurations that serve this purpose. Testers and developers can then choose the exact virtual machine they need instead of setting up a machine manually. Need to run a test on the German build of the Windows Vista operating system with Microsoft Office XP preinstalled? The environment to run this test is only a file copy away.
Test computers often enter an unrecoverable state during testing. After all, the point of most tests is to find bugs, and bugs in complex applications and system software can cause a computer to fail. Virtual machines provide two different solutions to this problem. The first, and simplest, is the fact that a VM is not a physical computer. When a VM fails, the physical hardware is not compromised, data in the parent partition is not lost, and other VMs are unaffected. The impact of a catastrophic failure is greatly reduced.
The other time-saving benefit and the second recovery solution provided by virtualization is the ability to take snapshots of the system. (Snapshot is the term used by Microsoft Hyper-V. Other virtualization methods might use a different name for this feature.) A snapshot is a static “frozen” image of the VM that can be taken at any time. After taking a snapshot, the VM continues to run, but the state at the time of the snapshot is saved. Snapshots can help developers and testers quickly recover from errors. By taking a snapshot before the test, testers can quickly and easily roll back the VM to a point before it failed. They can then run the test again or move on with other tests without the need to re-create the VM or reinstall its operating system.
There are a few things to keep in mind before going too wild with snapshots. Although it might seem perfectly logical to create a massive number of snapshots to have a “repro case” for every bug imaginable, this would lead to poor performance in Hyper-V. Each snapshot adds a level of indirection to the VM’s disk access, so it would get very slow after several hours of frequent snapshots. It is also worth noting that snapshots are not a portable copy but a set of differences between the original VM and the snapshot—meaning that snapshots cannot be used outside of the VM they belong to.
Virtual Machine Test Scenarios
Virtual machine use is advantageous in a variety of testing scenarios. Discussions of some of the more common scenarios are in the following section, but the usage scenarios are limitless, and many additional test scenarios can benefit from virtual machines, such as API tests, security tests, and setup and uninstall scenarios.
Daily Build Testing
Many testers are responsible for testing an assortment of service packs, updates, and new versions of products. For example, consider an application that can run on various releases of the Windows operating system. The first version of the product has shipped, and the test team is beginning to test version 2. Table 15-3 lists a typical hardware/operating system matrix for such a product.
32-bit | 64-bit | |||
Single-proc | Dual-proc | Single-proc | Dual-proc | |
Windows XP SP2 | To be tested | |||
Windows Server 2003 SP2 | To be tested | To be tested | To be tested | To be tested |
Windows Vista SP1 | To be tested | |||
Windows Server 2008 | To be tested | To be tested | ||
[2] Because the Windows Server 2008 operating system adjusts the kernel between multi-proc and single-proc, a reinstall of the operating system for multi-proc is unnecessary. It is necessary for operating systems prior to and including Windows Vista. | ||||
Typically, a tester would have three or more test computers to support this matrix (depending on the number of test cases). It is certainly possible for a tester to test the variations with one computer by testing one operating system after another; however, this would be much less efficient and consume substantial time in installing and configuring the test environments. Installations of the operating system and updates, as well as the associated restarts, are extremely time-consuming tasks. Because three or more virtual machines can run on a single physical computer, virtualization can transform three test computers into nine or more virtual test machines while cutting test machine setup time in half. This is possible by using features such as snapshots and the scripting interface exposed by Hyper-V.
In the preceding matrix, the tester would usually install eight different versions of the Windows operating system across the physical computers throughout the test pass. By using a virtualized solution, testers can install all eight versions in virtual machines using three (or fewer) physical computers. The setup time for an automated test pass completes in a fraction of the time, and manual test coverage increases because the tester can stay focused on testing the product instead of setting up environments to get to the next test case. Compatibility and upgrade testing also benefit immensely from this approach of using virtual machines.
Network Topology Testing
Hyper-V facilitates creating complex networking topologies without the hassle of configuring masses of wires and physical switches.
The diagrams in Figure 15-2 and Figure 15-3 illustrate how machine virtualization can be used to create a complex networking environment. The entire network topology in the diagram can be created on one physical server.

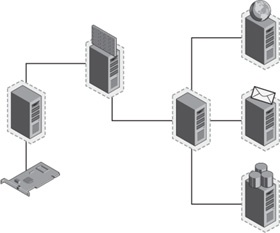
In this scenario, three subnets are created and bridged together by two servers acting as routers. Subnet A contains all the typical infrastructure people rely on to get onto the network. Subnet A also holds a deployment server that deploys windows images. The client on subnet C represents a computer that is expected to start from the network and install the latest release of the Windows Vista operating system.
In Figure 15-3, three virtual servers are behind a fourth that is acting as a firewall. The firewall VM is connected to the host’s physical network interface through a virtual switch, but the other three servers are not. They are connected to the firewall server through a second virtual switch that does not provide direct connectivity to the outside network.
The exciting part of this scenario is that creation of all these machines, switches, and subnets can take place through automation and run on a single physical computer. Prior to virtualization, test beds like these would have required several physical computers and all the wires and routers necessary to create the network topology—not to mention the human resources to actually do all of the work!
When a Failure Occurs During Testing
Failures found during testing can be a time-consuming road block for testers. Time is often lost waiting for a developer to debug the issue or answer a question about the error. This can delay testers from getting more testing done if they need to hold a computer for hours or days waiting for a response.
Some failures are so uncommon that they can take several hours or even days to reproduce. This takes time from testers as well as developers, especially if the developers want to observe state on the computer before the failure actually occurs.
The following two examples are common occurrences in a test organization. Virtualization has the potential to help an engineering team be more efficient by utilizing export and import and snapshots.
Export and Import
When using virtual machines, the tester does not need to wait for a developer to debug a failure. Instead, the tester can save the virtual machine and export it to a network share. Saving the virtual machine causes the entire state of the virtual machine to be saved to disk. Export packages up the virtual machine’s configuration and stores it in a specified location.
A developer can then import that virtual machine at her convenience. Because the virtual machine was paused before it was exported, the virtual machine will then be opened in the paused state. All that a developer needs to do is resume the virtual machine and debug the failure just as if she were sitting in front of a physical computer. This allows the tester to regain control of his test computers faster than if he had been executing a test on the host. It also allows the developer to prioritize the investigation of the issue correctly, and the tester can create and save multiple snapshots of difficult-to-reproduce errors for additional debugging.
Snapshots
Snapshots can help reduce the time it takes to reproduce bugs that only seem to happen after running for several hours or even days. For example, a tester could write a script that takes a snapshot of the virtual machine every hour. As that script is running, test would execute in the virtual machine. After a failure occurs, the tester can investigate and find the snapshot that occurred prior to the failure. Then, the tester can revert to the snapshot, start the virtual machine from that point, and hit the bug in no more than 60 minutes. Snapshots make it possible for the tester to do this repeatedly without having to wait hours and even days for the bug to reproduce. Some nondeterministic bugs might not be immediately reproducible by this method, but this method can work for bugs that appear after a known period of running time.
Test Scenarios Not Recommended
Despite all the advantages of virtualization, there are some cases where it is not advisable. If host computers are going to be used for hosting only one or two virtual machines, the cost benefit will be much less because this setup does not provide a significant efficiency gain in hardware usage. However, in some cases benefits such as rapid deployment and snapshots outweigh the overhead introduced by virtualization.
Because Hyper-V provides its own device drivers to the guest operating system, it is not possible to test device drivers inside virtual machines. Likewise, tests that require specific hardware or chipsets will not have access to hardware installed on the host. The Hyper-V video driver is designed for compatibility and is optimized for remote desktop usage. Therefore, high-performance video and 3-D rendering will not work on VMs. Hyper-V dynamically allocates processor resources to VMs as needed, so low-level power-management software will not have any effect inside a VM.
More Info
For more information about virtualization and Microsoft Hyper-V technology, see the Microsoft Virtualization page at http://www.microsoft.com/virtualization.
Code Reviews and Inspections
Code reviews are an integral part of the engineering process. After I finish a draft of the chapter you are reading, I will ask several colleagues and subject matter experts to review what I’ve written before I submit the chapter to the editors for further review. This is one of the best ways to get the “bugs” out of the prose and unearth any errors in my data or samples. Code reviews provide the same service for code and can be extremely effective in finding bugs early.
Code reviews are part of the development process for every team at Microsoft but remain an area where improvements and increases in effectiveness are under way.
Types of Code Reviews
Code reviews range from lightweight (“can you take a quick look at my code”) to formal (team meeting with assigned roles and goals). Pair programming, an Agile approach where two developers share one workstation, is another form of code review. Different approaches vary in their effectiveness, as well as in the comfort of participation of those involved. Many testers at Microsoft are actively involved in reviewing product code, and many teams have the same code review requirements for test code as they do for product code.
Formal Reviews
The most formal type of inspection is the Fagan inspection (named after the inventor of the process, Michael Fagan). Fagan inspections are group reviews with strict roles and process. Reviewers are assigned roles such as reader or moderator.(The author of the code attends the session but does not take on any of the other roles.) The moderator’s job is to ensure that everyone attending the review session is prepared and to schedule and run the meeting. There is an expectation that reviewers have spent a considerable amount of time prereviewing the code before the meeting, and they often use checklists or guidelines to focus their review efforts.
Fagan inspections require a large time investment but are extremely effective in finding bugs in code. One team at Microsoft using Fagan inspections was able to reduce the number of bugs found by the test team and customers from 10 bugs per thousand lines of code (KLOC) to less than 1 bug per KLOC. Despite the potential for finding errors, the biggest obstacle blocking teams from using Fagan inspections is how much time they take (inspection rate is approximately 200 lines per hour) followed closely by the fact that most developers don’t like to spend 25 percent to 30 percent of their time in formal inspection meetings. For these reasons, despite the effectiveness, Fagan-style inspections are not widely used at Microsoft.
Informal Reviews
The challenge in developing a solution for effective code reviews is identifying a level of formality that is both time-efficient and effective in finding critical issues during the coding phase. “Over the shoulder” reviews are fast but usually find only minor errors. The “e-mail pass-around” review has the benefit of multiple reviewers, but results vary depending on who reads the e-mail message, how much time reviewers spend reviewing, and how closely they look at the changes.
The best solution appears to be to find a process that is both collaborative and time efficient. Programmers need the benefit of multiple peer reviews with assigned roles but without the overhead of a formal meeting. Companies such as Smart Bear Software have conducted and published case studies[3], http://www.smartbearsoftware.com. with these same premises in mind and have shown success in creating a lightweight review process that is nearly as effective as a formal inspection. Studies internal to Microsoft have shown similar results, and many teams are experimenting to find the perfect balance between formality and effectiveness when conducting code reviews.
Checklists
I think it’s fair to say that most people do better work when they know what to do. When an employee arrives at work, she probably accomplishes more if she has a list of tasks to address (regardless of whether she created the list herself or a superior created it for her) rather than if she is simply told “go do some work.” Yet many code reviews start with a request to “please look at my code.” Some reviewers can do a fine job reviewing code without any guidelines, but for most, a checklist or guideline can be highly beneficial.
Checklists guide the reviewer toward finding the types of bugs that are easiest to detect during code review and the bugs that are most critical to find during the review phase. An example checklist might look like this:
Functionality Check (Correctness)
Testability
Check Errors and Handle Errors Correctly
Resources Management
Thread Safe (Sync, Reentry, Timing)
Simplicity/Maintainability
Security (INT Overflow, Buffer Overruns, Type Mismatches)
Run-Time Performance
Input Validation
Other types of checklists might focus entirely on a single area such as performance or security so that multiple reviewers can focus on different aspects of the code under review.
Other Considerations
The funny thing about code reviews is that relatively few teams directly monitor the effectiveness of reviews. This might seem silly—why would you put effort into something without knowing what the return on the investment was? An indirect measure of effectiveness is to monitor the bugs that are tracked; that is, if, after implementing a new code review policy, there are fewer bugs found by the test team and customers, you could say that the code reviews were effective... but how effective were they? If you really want to know, you, of course, need to measure the effort and effect. An accurate ROI measurement of code reviews, or any improvement process for that matter, requires that the time investment is measured and that the bugs found during review are tracked in some manner.
Activities
Table 15-4 lists two hypothetical products of similar size and scope. In Product A, only bugs found by the test team or bugs found post release (by the customer) are tracked. Product B also tracks bugs found through developer testing and code reviews.
Product A | Product B | ||
Bugs found through developer testing | ? | Bugs or rework found through developer testing | 150 |
Bugs found through code review | ? | Bugs or rework found through code review | 100 |
Bugs found by test team | 175 | Bugs found by test team | 90 |
Bugs found by customer | 25 | Bugs found by customer | 10 |
Total bugs found | 200 | Total bugs found | 350 |
Product A has 200 known bugs, and Product B has 350. Product B also has fewer bugs found by the customer—but there isn’t really enough data here to say that one product is “buggier” than the other is. What we do know about Product B, however, is which types of activities are finding bugs. Coupled with data from planning or any tracking of time spent on these tasks, we can begin to know which early detection techniques are most effective, or where improvements might need to be made.
Taking Action
In addition to the number of issues found by activity, it can be beneficial to know what kinds of issues code reviews are finding. For example, a simple lightweight root-cause analysis of the bugs found by the customer or test team might reveal that detection of a significant portion of those bugs could have occurred through code review and indicate an action of updating checklists or stricter policy enforcement.
Furthermore, classifying issues by the type of rework necessary to fix the issue identifies where additional early detection techniques might be implemented. Table 15-5 lists a sample of some common rework items found during code review, along with an example technique that could be used to detect that issue before code review.
Detection/prevention technique(s) | |
Duplicate code, for example, reimplementing code that is available in a common library | Educate development team on available libraries and their use; hold weekly discussions or presentations demonstrating capabilities of libraries. |
Design issue, for example, the design of the implementation is suboptimal or does not solve the coding problem as efficiently as necessary | Group code reviews can catch these types of errors while educating all review participants on good design principles. |
Functional issue, for example, the implementation contains a bug or is missing part of the functionality (omission error) | Functional bugs can lead to implementation of new guidelines or techniques to be applied in developer testing. |
Spelling errors | Implement spell checking in the integrated development environment (IDE). |
Time Is on My Side
An accurate measurement of code review effectiveness requires accurate knowledge of the time spent on reviews. You could just ask the team how much time they spent reviewing code, but the answers, as you’d guess, would be highly inaccurate. This is one of the reasons teams that want to measure the value of code reviews use some type of code review tool for all of their code reviews. If the reviews are conducted in the framework of a review tool, time spent on the review task can be tracked more easily. There are, of course, some difficulties in measuring time spent on review as part of application usage. One mostly accurate solution is to monitor interaction with the application (keystrokes, mouse movements, and focus) to determine whether the reviewer is actively reviewing code or merely has the code review window open.
Time spent on code reviews can be an interesting metric in the context of other metrics and can answer the following questions:
What percentage of our time did we spend on code review versus code implementation?
How much time do we spend reviewing per thousand lines of code (KLOC)?
What percentage of our time was spent on code reviews this release versus the last release?
What is the ratio of time spent to errors discovered (issues per review hour)?
What is the ratio of issues per review hour to bugs found by test or customer?
And so on...
The preceding questions are samples. To determine the right answers for a particular situation, you need to ask yourself what the goals of code review are for your team. If the goals are to spot-check code before check-in, the time on task measurement might not be very interesting. But if you are interested in improving effectiveness or efficiency, some of these questions might help you determine whether you are reaching your goals.
More Review Collateral
Much more happens in a code review other than identifying rework. An important part of the process that is often lost over time is the conversations and comments about a piece of code. For example, when I have some code ready for review, I don’t say, “Here’s my code—take a look.” Instead, I put together an introductory e-mail message with a few sentences or a paragraph describing what the code is doing (for example, fixing a bug or adding a feature), and I might describe some of my implementation decisions. This information helps the reviewers do a better job, but when the review is over, that information is lost. The loss gets worse when considering that the follow-up conversations—whether they are in e-mail, in a team review, or face to face—are also lost. Over time, this lost information can lead to difficulties in knowledge transfer and maintainability issues.
Another way a review tool can aid with code reviews is by tracking some of this collateral data. A code review tool can contain questions, comments, conversations, and other metadata and link them with the code. Anyone on the team can look at a source file and view the changes along with explanations and conversations regarding any change. If someone on the team needs to ramp up quickly on the background pertaining to a single file or component (for example, a new developer on the team), a tool could queue up all of the changes and related review comments and play them back in a movie or slide show. This movie wouldn’t win an Oscar, but it would have phenomenal potential for preparing new team members (or existing team members taking on new responsibilities) quickly.
Two Faces of Review
For most people, the primary benefit of review is detecting bugs early. Reviews are, in fact, quite good at this, but they provide another benefit to any team that takes them seriously. Reviews are a fantastic teaching tool for everyone on the team. Developers and testers alike can use the review process to learn about techniques for improving code quality, better design skills, and writing more maintainable code. Conducting code reviews on a regular basis provides an opportunity for everyone involved to learn about diverse and potentially superior methods of coding.
Tools, Tools, Everywhere
A big advantage of working at a company with so many programmers is the number of software tools written by employees that are available to help solve any problem you might be facing.
A big disadvantage of working at a company with so many programmers is the number of software tools written by employees that you have to sort through to solve the problem you might be facing.
Microsoft’s internal portal for engineering and productivity tools has been a tremendous asset for many years, and the number of tools available has grown substantially every year. One drawback to the growth has been the number of disparate tools that solve a single problem, albeit all in slightly different manners. Searches on the portal for “test harness” and “test framework” return 25 and 51 results, respectively. Although many of these tools have unique features or purposes, there is a considerable amount of duplication in functionality.
Reduce, Reuse, Recycle
The concept of code reuse (reusing sections of code or components) has always been a topic in software engineering. A software library, such as the common dialog library shipped with Windows, is a good example of code reuse. This library (comdlg32.dll) contains all of the dialog boxes and related functions used for opening and saving files, printing, choosing colors, and other common user interaction tasks. Programmers don’t need to write their own functions or create their own UI to open or save files; they can just use the functions in the common dialog library.
Several years ago, when Office made the shift from being merely a group of applications geared toward people who needed spreadsheet and word processing functionality to a unified suite of applications for the business user, the team discovered that many functions were duplicated across the different applications. Because of this, mso.dll, the shared Office library, was born. With the shared library, programmers on the Office team can easily access common functions and implement consistent functionality and user interface across applications. A bigger benefit is that the test team needs to test these functions only in one place—everyone benefits.
Shared libraries work well in Windows and Office mainly because they are development platforms; that is, they are designed with the intent that programmers will use the exposed functionality to add to or enhance the baseline platform architecture. Code reuse also works well in Office because it’s one product line. The challenge in taking better advantage of code reuse in tools and utilities is that most divisions or product lines have their own solution developed without knowledge of the other solutions. For the most part, there’s no motivation and little benefit to share code.
What’s the Problem?
On many levels, there is no problem. There are far worse problems a company can have than having too many lightweight XML parsers in the library. Additionally, the tools are shared in a central repository where everyone in the company can search for utilities and download whatever is appealing to them. More choices should lead to a better selection for everyone, but the opposite is generally true. In The Paradox of Choice,[4] Barry Schwartz discusses how having too many options to consider makes the ultimate decision much more difficult; that is part of the problem, but there’s more to it.
One of the great things about Microsoft is that every product group sets their own goals, their own vision, and they determine their own way to solve the engineering problems they face from day to day. There’s not much motivation other than saving time to adopt or reuse code for tools and utilities.
But still, there is a prevalent worry that code reuse isn’t used as much as it should be, and that duplication of efforts and the not-invented-here (NIH) syndrome are prime targets as areas of improvement. To make tool adoption work across groups in a company the size of Microsoft, it is not enough to share just the tool—the code needs to be shared as well.
Open Development
Sharing code and tools between teams relies on meeting the unique needs of each team. If an individual or team cannot customize code or a tool themselves, or if the owner of the code cannot make the needed changes for them, their only remedy is to create their own copy or start from scratch. Unless, of course, the code is available for anyone to contribute to or modify.
In 2007, Microsoft launched a new internal portal named CodeBox, which is shown in Figure 15-4. With CodeBox, Microsoft engineers can create, host, and manage collaborative projects. Built by the Engineering Excellence team, CodeBox is an internally shared application with a look and feel similar to CodePlex (http://www.codeplex.com). CodeBox includes support for source control, which enables anyone to make additions and enhancements to any of the projects. The owners of the projects have complete control over which changes they accept, while those who are making changes remain free to work in a branch or fork (a branch or fork is a distinct copy of the original source that retains the same history) in case they need to retail special features that have not yet been accepted.

CodeBox use is growing quickly. Many of the popular tools from the previous tool portal have already been migrated to the shared source model on CodeBox. From January 2007 to March 2008, contributions grew from 50 to 400 per week. In addition to the shared tools and utilities, larger groups are using CodeBox as a workspace for developing applications that will someday grow to be new Microsoft products.
It’s too early to tell the long-term benefit CodeBox is going to have on increasing code reuse, but the initial prognosis is good. As adoption and usage grow, shared code and tools will benefit the entire company in terms of reduced development costs, higher quality tools, and replacement of constant reinvention with building on the knowledge and experience of an entire engineering community.
Summary
Software engineering continues to grow in advancements as well as in complexity. With this advancement and complexity, new and bigger challenges consistently appear. To many software engineers, these challenges are a big part of the excitement and draw of the profession. Keeping one eye on the problems of today while anticipating and acting on the emerging problems of the future is a crucial attribute of great technical leaders at Microsoft and in the software industry. Improvements in failure analysis, code reviews, virtual machine usage, and code reuse are only four of the dozens of big challenges Microsoft engineers are confronting. These challenges, along with a continuing effort to improve software engineering, are an exciting part of the Microsoft culture.