
Chapter 12. Other Tools
Every professional employs a trusted set of tools. A good carpenter needs and uses dozens of tools and knows how to use each of these tools best to accomplish a specific task effectively. The detectives I see on television rely on an endless supply of tools, each used for just the right situation to solve crimes (nearly always within 60 minutes, too). I have always considered testing similar to many other lines of work in the use of tools. To be successful in almost any endeavor, you need substantial knowledge of the area as well as tools that can assist with complex tasks.
A tester’s tools are applications to help testers do some part of their job more efficiently or more effectively. Testers at Microsoft use countless numbers of test tools throughout the testing process. Tools run tests, probe the system, track progress, and assist in dozens of other situations. Previous chapters have mentioned a few of the tools used by testers at Microsoft, but there are others that many testers consider essential. This chapter discusses a few more of the tools that testers at Microsoft find to be effective and beneficial.
Code Churn
Churn is a term used to describe the amount of changes that happen in a file or module over a selected period. Several measurements can be used to calculate code churn. The most common include the following:
Count of Changes. The number of times a file has been changed
Lines Added. The number of lines added to a file after a specified point
Lines Deleted. Total number of lines deleted over a selected period
Lines Modified. Total number of lines modified over a selected period
Microsoft Visual Studio Team System calculates a Total Churn metric by summing the total of Lines Added, Lines Deleted, and Lines Modified, as shown in Table 12-1.
Similar to the complexity metrics discussed in Chapter 7, code churn measurements can be indicative of where more bugs are likely to be located. In a sense, this is an intuitive metric. Other than writing new code to add features, the reason for code changing (churning) is most often a result of fixing a known bug. Significant percentages of bug fixes either don’t actually fix the problem or cause another error to occur. Both of these situations require additional code changes (churn) to fix the new (or remaining) failures. Often, this scenario repeats; if the code is particularly complex, the cycle can continue for several iterations until all known bugs are fixed, and no new failures are found (odds are, however, that highly churned code will have even more bugs remaining).
Keep in mind that churn is another metric that falls into the “smoke-alarm” category; excessive churn doesn’t always mean that there are dozens of new bugs to be found, but it is an indicator that you might need to take a closer look at the area of the product that is changing.
Keeping It Under Control
Source control, the ability to track changes in source code, is as important an asset to testers at Microsoft as it is to developers. Almost all development teams in the software industry use a source code management (SCM) system, and Microsoft development teams certainly aren’t an exception. Every test team at Microsoft uses source control to some extent—both for traditional uses as well as for specific testing tasks.
Tracking Changes
Similar to typical SCM usage, the primary use of source control on test teams is for tracking changes to code written for test tools and test automation. Entire teams, and sometimes teams spanning all of Microsoft, share test tools. When more teams adopt a tool, it becomes more important to track changes so that any bugs or unexpected behavior caused by the change can be more easily identified. This usage is equivalent to SCM usage in development environments, with the fundamental difference being that the “customer” of the tool is another tester or test team in the company.
It is also beneficial to track changes in test automation or test cases. In addition to tracking changes in tests over the lifetime of a product, with SCM systems teams can create and re-create the state of the entire body of source code and related documents at any arbitrarily selected point in time. The most common use of this is to generate snapshots of the system from key milestones in the product life cycle. A common example is creating a snapshot of all product code and test code at the moment the product was released to manufacturing. By having a copy of the tests used to ship the product, sustained engineering teams can make changes to the product code with confidence. This is the same concept adopted by developers who use a suite of unit tests to help ensure that any changes they make to a module do not cause a regression. Sustained engineering teams use the tests to help them assess risk of a code change causing an unforeseen bug in another part of the system.
What Changed?
The Hocus-Focus comic strip by Henry Boltinoff ran in the newspaper my family received while I was growing up. If you’re not familiar with the comic, it was a simple two-panel strip where the two panels looked identical, but the text in between the panels asked the reader to “Find at least six differences in details between panels.” It usually took me only a few minutes to find all six differences, but my strategy was consistent. I cycled through each object or feature in the first picture and compared its shape, size, and other attributes with the same object in the second picture. Sometimes the difference was in part of the object, and sometimes I had to look at an entire area at once to see the difference. Over time, I got better and better (faster and more accurate) until I reached a point where I could spot all six in a few seconds every time.
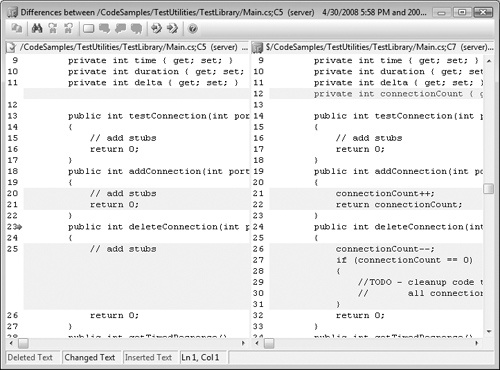
Similarly, as a software tester, I use a SCM system and diff tools (utilities that show the differences between two files) to isolate coding errors. Figure 12-1 shows the comparison of two files using a diff tool. Because the SCM system records every change made to the product source code, when a tester discovers a bug while testing a scenario that previously worked, he often turns to the SCM system to help isolate the problem. Source control can show all changes made to a file, module, feature, or entire application between any points in time. If a tester discovers a bug that didn’t occur on a test pass two weeks earlier, she can easily identify all source code changes and examine the differences to investigate which change might have caused the error. Note that on some teams, developers can be the team members who go through this process. (See the sidebar titled "Who wears what hat?" that follows for more information on this topic.)
Monitoring changes isn’t unique to source code. It is also important to track changes made to specifications and other documents. Many applications can track the changes made to a document. The chapters in this book, for example, pass from authors to reviewers to editors and back again. At each stage, a reviewer might make several edits and suggestions. All changes are tracked within Microsoft Office Word so that each of the authors can track progress as well as document and refer to the discussions leading up to wording or content decisions.
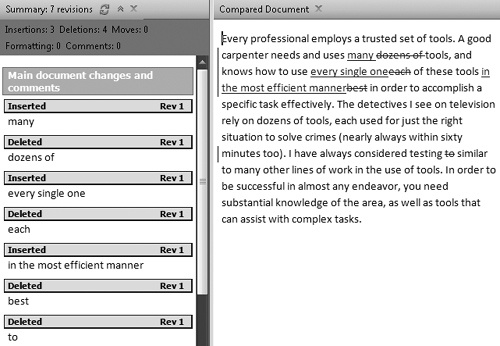
Word can also compare two documents even if the reviewer forgets to activate the Track Changes feature, as shown in Figure 12-2. This is convenient for checking the changes made between two versions of a document and for reviewing the changes, for example, when reviewing edits made simultaneously by several reviewers.
Why Did It Change?
Sometimes when I’m playing hocus focus with source code changes I can see the change, but I have no idea why the change was made.
===================================================================
--- math.cs;8 (server) 5/2/2008 5:24 PM
+++ math.cs;9 (server) 5/6/2008 7:25 PM
***************
*** 20,26 ****
}
else
{
! return value;
}
--- 20,26 ----
}
else
{
! return value * 2;
}
===================================================================In the preceding code, it is obvious what this change does—it changes the returned value by a factor of 2! But why was this change made? Source control systems give testers a few key pieces of information in their detective work. One useful type of information is access to the names of each developer who has changed the code along with exact descriptions and records of the code the individual has changed. If you know who made a change that you don’t understand, you can walk down the hall, call, or e-mail that person and ask him or her about it.
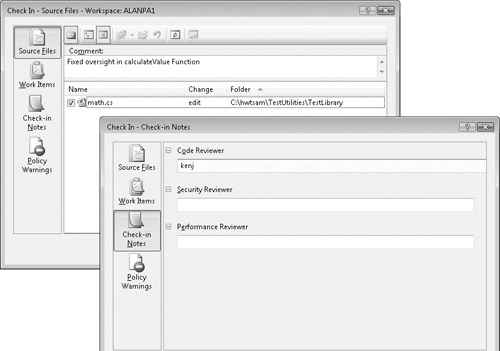
Tracking down a developer for quick communication is often a great solution for understanding recent changes or changes made to a current version of a product, but what do you do if the developer has gone home, has left the group, or has left the company? The source control system often houses many points of highly relevant data, including developer comments and a bug number or link to the issue fixed by the change in the bug management system. When code is committed (a working copy is merged into the master source control system), the author of the change is generally required to fill in several fields in a submission form including the bug fixed by the change (or in the case of new code, an ID associated with the particular feature). Other fields might include such items as the name of the code reviewer and a short description of the details of the change, as shown in Figure 12-3. All of these items are clues that aid testers and developers alike in bug investigations.
A Home for Source Control
The use of source control among test teams at Microsoft has evolved and grown with the company. In my early days at Microsoft, source control for the test teams I worked on was quite informal to say the least! Most of the test teams used source control for their test code or data files, but each part of the team used a separate source control server. The fact that we used source control on managed servers ensured that the test source code was backed up and revisions were tracked.
As long as you didn’t want to share or view source from another team, there were no problems with this system. On my team, it was the tester’s responsibility to compile the test source code, and then copy the resulting binaries to a common share where other testers or the automation system could find them when they were needed. This system worked most of the time, but errors occurred occasionally when a copy failed or someone accidentally deleted a file.
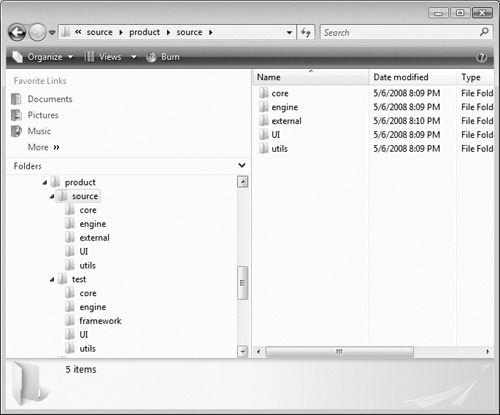
Over time, more teams began to consolidate test source into single servers and systems for their entire team. The structure and layout became more formal and far less ad hoc. These days, most teams store test source code next to product source code on the same servers and systems, as shown in Figure 12-4. Then, a build lab (a single person or small team dedicated to creating daily builds for the team) builds product code and test code daily and propagates the test binaries to servers automatically.
A source control layout such as the one shown in the figure has several advantages. One of the most important features is that code is easy to find. If a developer wants to run some of the test team’s tests, he knows where to go. Similarly, if a tester wants to understand a bit more about the implementation of the code she is testing, she can find the product code easily. It also makes it much easier for the build team to investigate any build errors caused by inconsistencies between product and test code. Finally, if the build team is building both product and test code as part of the same process, it is simpler for the team to add consistent version information to the test code and product code. Consistent versioning allows for easier management of test binaries and product binaries, and can facilitate better regression analysis.
Build It
The build, along with the many related activities that stem from the build process, is an integral part of the daily work of every team at Microsoft. Source control, bug management, and test passes all stem from the build process:

The Daily Build
For most teams, the entire product is compiled from source code at least once a day. Microsoft has performed daily builds for years, and continuous integration (continuous builds along with frequent code check-in) is strongly supported by the Agile community. The build process includes compiling the source (transforming the source code to binary format), linking (the act of combining binaries), and any other steps required to make the application usable by the team such as building the setup program and deploying the build to a release server.
More often than not, the daily build process also includes a suite of smoke tests. A smoke test is a brief test to make sure the basic functionality of the application works. It’s similar to driving a borrowed car around the block to check for obvious faults before driving all the way across town. Test teams usually run a suite of smoke tests. Most often, these are known as build acceptance tests (BATs) or build verification tests (BVTs). Some definitions of these terms denote BATs to be a smaller suite of tests than BVTs, but in most cases, the terms are interchangeable. A good set of BVTs ensures that the daily build is usable for testing. Table 12-2 lists several BVT attributes.
BVT attribute | Explanation |
Automate Everything | BVTs run on every single build, and then need to run the same every time. If you have only one automated suite of tests for your entire product, it should be your BVTs. |
Test a Little | BVTs are non-all-encompassing functional tests. They are simple tests intended to verify basic functionality. The goal of the BVT is to ensure that the build is usable for testing. |
Test Fast | The entire BVT suite should execute in minutes, not hours. A short feedback loop tells you immediately whether your build has problems. |
Fail Perfectly | If a BVT fails, it should mean that the build is not suitable for further testing, and that the cause of the failure must be fixed immediately. In some cases, there can be a workaround for a BVT failure, but all BVT failures should indicate serious problems with the latest build. |
Test Broadly—Not Deeply | BVTs should cover the product broadly. They definitely should not cover every nook and cranny, but should touch on every significant bit of functionality. They do not (and should not) cover a broad set of inputs or configurations, and should focus as much as possible on covering the primary usage scenarios for key functionality. |
Debuggable and Maintainable | In a perfect world, BVTs would never fail. But if and when they do fail, it is imperative that the underlying error can be isolated as soon as possible. The turnaround time from finding the failure to implementing a fix for the cause of the failure must be as quick as possible. The test code for BVTs needs to be some of the most debuggable and maintainable code in the entire product to be most effective. Good BVTs are self-diagnosing and often list the exact cause of error in their output. Great BVTs couple this with an automatic source control lookup that identifies the code change with the highest probability of causing the error. |
Trustworthy | You must be able to trust your BVTs. If the BVTs pass, the build must be suitable for testing, and if the BVTs fail, it should indicate a serious problem. Any compromises on the meaning of pass or fail for BVTs also compromises the trust the team has in these tests. |
Critical | Your best, most reliable, and most trustworthy testers and developers create most reliable and most trustworthy BVTs. Good BVTs are not easy to write and require time and careful thought to adequately satisfy the other criteria in this table. |
An example of a BVT suite for a simple text editor such as Windows Notepad could include the following:
Create a text file.
Write some text.
Verify basic functionality such as cut, copy, and paste work.
Test file operations such as save, open, and delete.
A daily (or more frequent) build and BVT process reduces the chance of errors caused by large integrations or sweeping changes. Keeping the product in a state where it will build and where it will run every day is critical to a healthy software organization. Test teams at Microsoft have the same need for daily builds as product teams. For this reason, source code for automated tests and test tools are also built daily, typically as part of the same process used to build the product code.
Breaking the Build
The most minimum effect of a daily build is ensuring that compilation errors (also known as build errors) are caught within 24 hours of check-in. Compilation errors are rare but can stop the engineering flow if the test team is waiting for the daily build to begin testing. The most common reason for a compilation error is also the most preventable: syntax errors by the developer. Anyone who has ever compiled any code or run a script has made a syntax error. A missing semicolon, a mistyped keyword, or an errant keystroke can cause an error when the program is compiled or when the script is run. These sorts of errors are inevitable, but they only cause a problem if the broken code is checked into source control. I don’t know any programmers who deliberately check in broken code, but some still make these mistakes through carelessness. Usually it’s “just a little change” that the developer forgets to double check by recompiling the local source code. A simple prevention method could be to require developers to build before checking in source code, but this might be difficult to enforce, and some mistakes could potentially still slip through.
Build breaks are often caused by reasons other than syntax errors. “Forgetting to check in a file” is one of the most common reasons I have seen that triggers a build break. When working with large, complex systems, it is also quite common to see build errors caused by a dependency changing in another part of the system. Think of the core Windows SDK header files (the files containing definitions of Windows data types and functions). A small change to one of these files can often cause build errors in far-reaching components. On a smaller scale, changing an interface name in a COM library or other shared components can just as easily cause compilation errors in dependent components.
Stopping the Breaks
I don’t know anyone who has worked with daily builds who hasn’t experienced a build break on their team. At Microsoft, we use several techniques to minimize the number and impact of build errors. Two of the most popular and effective techniques are rolling builds and check-in systems.
In its simplest form, a rolling build is an automatic continuous build of the product based on the most current source code. Several builds might occur in one day, and build errors are discovered sooner. The fundamental steps in a rolling build system include these:
The easiest way to implement a rolling build is with a simple Windows command script (cmd) file. Scripting tools such as Sed, Awk, and Perl are also commonly used. An example of what a rolling build script might look like is in Example 12-1.
rem RollingBuild.cmd rem sync, build, and report errors rem The following two commands record the latest change number rem and obtain the latest source changes :BEGINBUILD rem clean up the build environment call cleanbuild.cmd changes -latest sync -all rem build.cmd is the wrapper script used for building the entire product call build.cmd rem if ANY part of the build fails, a build.err file will exist rem notify the team of the rolling build status IF EXIST "build.err" ( call reporterror.cmd ) ELSE ( call reportsuccess.cmd ) goto BEGINBUILD
Some Microsoft teams also include some or all BVTs in a rolling build and automatically report the results to the team. Teams that conduct several rolling builds each day often pick one—for example, the last successful build before 13:00—and conduct additional testing and configuration on that build before releasing it to the team as the daily build.
Another method of preventing build breaks and increasing code quality is the use of a check-in system. Years ago, when developers had changes to check in to SCM, they would check the code directly into the main source tree. Any mistakes they made—either syntax errors or bugs—would immediately affect every build. You can get away with a system like this for small projects, but for larger software projects, a staged check-in can be quite beneficial.
Figure 12-5 shows the basic architecture of a check-in system. Instead of checking the code directly into the main SCM, when programmers are ready to submit changes, they submit them to an interim system. At a minimum, the interim computer verifies that the code builds correctly on at least one platform, and then submits the code on behalf of the programmer to the main source control system. Most such systems build for multiple configurations and targets—something that is nearly impossible for a single developer to do on her own.
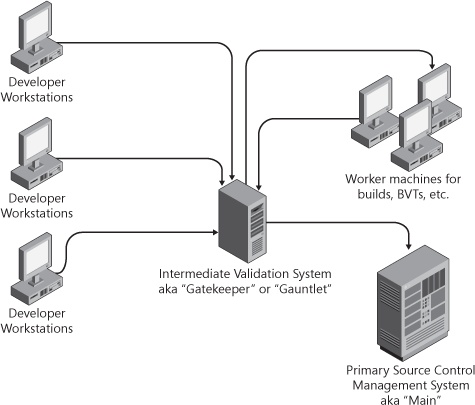
The interim system (sometimes referred to as a gauntlet or gatekeeper) will also typically run a selection of automated tests against the change to watch for regressions. Depending on the implementation of the system, the set of tests can be static, can be selectable by the programmer at the time of submission, or is created dynamically based on which parts of the code are changed.
Any selection of pre- or postbuild tests can be added at any time to the system. To the developer, it feels the same as checking directly into main (the main source tree), but a substantial number of bugs are found before they ever get a chance to cause problems for the entire team.
Static Analysis
When a test team begins writing software to test software, a funny question comes up: “Who tests the tests?” The question is easy to ignore, but it pays to answer it. A tremendous amount of coding effort goes into writing test code, and that code is susceptible to the same sorts of mistakes that occur in product code. In a number of ways, running the tests and examining failures are a test for the tests, but that approach can still miss many bugs in test code. One effective method for finding bugs in test code (or any code, for that matter) is to use tools for automatic static analysis. Static analysis tools examine the source code or binary and identify many classes of errors without actually executing the code.
Native Code Analysis
A number of different tools are available for analysis of native code (that is, code written in C or C++). Traditional tools include commercial products such as PC-Lint,[2] KlocWork,[3] and Coverity,[4] as well as the static Code Analyzer included with Visual Studio Team System.
Every team at Microsoft uses code analysis tools. Since 2001, the primary tool used at Microsoft for native code analysis is a tool named PREfast. This is the same tool available for native code analysis in Visual Studio Team System.
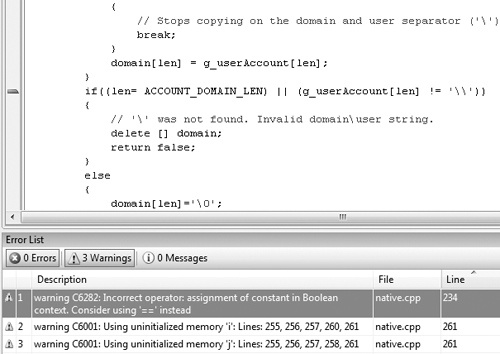
PREfast scans source code, one function at a time, and looks for coding patterns and incorrect code usage that can indicate a programming error. When PREfast finds an error, it displays a defect warning and provides the line number of the offending source code, as shown in Figure 12-6.
Managed Code Analysis
FxCop is an application that analyzes managed code and reports a variety of information such as possible design, localization, performance, and security improvements, as shown in Figure 12-7. In addition to detecting many common coding errors, FxCop detects many violations of programming and design rules (as described in the Microsoft Design Guidelines for Class Library Developers). Anyone creating applications in managed code will find the tool beneficial.
FxCop is available as a stand-alone tool or integrated into Visual Studio. Testers can use the stand-alone tool to examine a managed binary for errors, but most testers and developers use the integrated version of the tool for analysis.

Note
The Code Analysis Team Blog at http://blogs.msdn.com/fxcop contains a wealth of information on analysis tools in Visual Studio Team System.
Just Another Tool
FxCop and PREfast are both powerful tools that should be used by every software team. Static analysis tools are great for finding certain classes of errors well before the test team sees the code, but they do not replace testing. It is certainly possible (and probable) to write code that is free of code analysis–detected defects that is still filled with bugs. However, fixing these bugs earlier does give the test team more time—and a much better chance—to find a huge number of more critical bugs throughout the entire product cycle.
Test Code Analysis
Many types of errors are specific to test automation. One such area is environmental sensitivity. This refers to the reliance of tests on noninvariant environmental factors. This issue can reveal itself in a variety of forms, which are best represented by example. Consider a test of a user control called a FileSaveWidget, which accepts an input file path and saves data to the specified file. A simple test of this component is listed in sample code for a FileSaveWidget test here.
1 void TestFileSaveWidget()
2 {
3 // this file contains the expected output of the file save widget
4 string baselineFilePath = @"\test-serverTestDataaseline.txt";
5
6 // the local path for the save file
7 string outputFilePath = @"D:datafile.txt";
8
9 FileSaveWidget widget = new FileSaveWidget();
10 widget.SetDataFile(outputFilePath);
11 widget.Save();
12 try
13 {
14 VerifyDataFile(baselineFilePath, outputFilePath);
15 WriteTestResult("PASS");
16 }
17 catch (Exception e)
18 {
19 String errorMessage = e.Message;
20 if (errorMessage.Contains("File not found"))
21 {
22 WriteTestResult("FAIL");
23 }
24 }
25 }The code looks straightforward enough, but there are at least three issues in this example. On line 4, notice the use of a remote file share on a computer called test-server. There is no guarantee that this server will be visible when the test runs on a network or user account different from the one the tester originally intended. Line 7 contains a hard-coded reference to drive D. Perhaps all computers that this tester has encountered so far have writeable partitions on D, but this assumption will likely lead to failures later on (D could be a CD-ROM drive or simply nonexistent).
Line 19 hides a more subtle but important issue. The expected error message in the case that the save operation fails might indeed be “File not found”—if the test is running on an English-language operating system or English-language build of the product. However, a Spanish localized build might return “Archivo no encontró” in this case, which would not be caught by this test. Many test teams at Microsoft use scanning tools to find issues that can cause problems with test code. Sample output from a test code–scanning tool is in Table 12-3.
Issue | Location | Owner | Details |
Hard-coded share path | Test.cs:4 | Chris Preston | A hard-coded share path was found in a test source file. Hard-coded paths to specific file shares can make the test unportable. |
Hard-coded local path | Test.cs:7 | Michael Pfeiffer | A hard-coded local path was found in a test source file. Hard-coded local paths can make tests unportable. Consider putting any hard-coded paths into a configuration file. |
Hard-coded string | Test.cs:19 | Michael Pfeiffer | Hard-coded exception string “File not found”; please use ResourceLibrary to comply with localization testing. |
Invalid user name | Test Case ID 31337 | (N/A) | Test case assigned to invalid user “Nobody”; please assign to a current team member. |
Analysis tools often go beyond analyzing code and look for errors in the test cases or almost anyplace else where testers might make errors. Some examples of the biggest improvements to test code as a result of analysis such as this include the following:
Improved success running localized test passes as a result of proactively catching and reporting usages of hard-coded English strings
Improved test reliability resulting from checking for potential race conditions (usage of Thread.Sleep), invalid configuration files, and so on
Improved completeness of test coverage by checking for “orphaned” tests (code that was checked in but not enabled in automated runs, incorrectly marked in the TCM, and so on)
The bigger value added by analysis is that it preempts issues from occurring by flagging them on a daily basis. Every day, testers get feedback on the quality of their tests and test cases, and they use the feedback to improve the quality of their tests and, ultimately, the quality of the product.
Test Code Is Product Code
These errors might not be important for production code, but they are critical for test code reliability and maintainability. Error-prone test code is one of the biggest concerns I hear from test managers throughout the industry. Even at Microsoft, where many of our SDETs are top-notch programmers, we rely on these tools to help us create tests that can run reliably and report accurate results for a decade or more and through thousands of executions. By now it should be clear that testers at Microsoft commonly use many traditional development tools. What this really means is that at Microsoft, source code is treated the same as product code regardless of whether the code ships or not.
Even More Tools
There is no end to the number of tools testers use. Microsoft employees consistently take advantage of any efficiency or effectiveness gains achieved through the aid of software, and they are careful to ensure that using a tool rather than a manual process doesn’t affect the final output. Continuing the toolbox analogy used at the beginning of this chapter, using software to aid testing is similar to using a power tool rather than a hand tool. In many cases, the power tool is faster and achieves better results, but some jobs still make sense to complete by hand.
Tools for Unique Problems
Most of the previously discussed tools are ones that almost every tester uses. Countless others solve big problems for smaller groups of people. Screen recorders, file parsers, add-ons for automation tools, and even the font display tool shown in Chapter 10 are all examples of software programs written to solve specific testing problems.
In addition to tools, testers customarily share libraries (reusable functionality that can be added to any application) in their team so that everyone on the team can solve similar problems using a consistent, well-tested solution. For example, the Office team has shared libraries that are used to help automated tests access the window controls common to all Office applications, and the Windows Mobile team has shared libraries to simulate cellular data. These are both areas where a common solution helps the entire test team do their jobs better.
Tools for Everyone
Microsoft employees love to create tools. Thousands of tools ranging from test helper libraries to Outlook add-ins to productivity enhancers are available in an easy-to-access repository. Engineers love to use software that helps them do their job better, and many employees share their applications with their teams across the entire company.
Note
The Microsoft internal tool repository contains nearly 5,000 different tools written by Microsoft employees.
Employees can search the tools in this repository (the ToolBox), as shown in Figure 12-8, and they can subscribe to RSS feeds to notify them of new tool submissions. Each tool entry lists information about the tool and the name of the tool owner in case more information is needed. Finally, every tool can be rated and comments can be added to aid future toolbox browsers in their tool-choosing decisions.
Summary
One of the qualities I’ve noticed in great testers is that they are extremely efficient in their testing. They are not hurried in their testing activities; rather they all seem to know exactly the point where software can help solve their current testing problem faster than their brain can. When software is a potential solution for their current situation, they are able to find or repurpose an existing tool to their needs or, when necessary, create a new tool to solve a problem.
Testers need to use new tools when appropriate and reexamine their current toolbox periodically to be most effective. As is the case with source code management, testers should also examine their toolset and determine whether existing tools can be used in a different way. An adequately filled toolbox, along with the skill and knowledge to use those tools, is one of the biggest assets a tester can have.
[1] Nachiappan Nagappan and Thomas Ball, Use of Relative Code Churn Measures to Predict System Defect Density (Association for Computing Machinery, 2005), http://research.microsoft.com/~tball/papers/ICSE05Churn.pdf.
[2] See http://www.gimpel.com.
[3] See http://www.klocwork.com.
[4] See http://www.coverity.com.
[5] James Q. Wilson and George L. Kelling. “Broken Windows: The Police and Neighborhood Safety,” Atlantic Monthly, 1992.
[6] Andrew Hunt and David Thomas, The Pragmatic Programmer (Boston, MA: Addison-Wesley Professional, 1999).