
In this chapter
| Introduction |
| Temporary tables |
| Surrogate keys |
| Alternate keys |
| Table relations |
| Table inheritance |
| Unit of Work |
| Date-effective framework |
| Full-text support |
| The QueryFilter API |
| Data partitions |
The Microsoft Dynamics AX 2012 application run time provides robust database features that make creating an enterprise resource planning (ERP) application much easier. Many new and powerful database features have been added to Microsoft Dynamics AX 2012. This chapter focuses on several of these new capabilities. The information provided here introduces the features, provides information about how to use them in an application, and, when appropriate, explains in detail how each feature works.
Many database features, such as optimistic concurrency control (OCC), transaction support, and the query system, have been available in Microsoft Dynamics AX for several releases. For detailed information about these and other database features in Microsoft Dynamics AX, see the “Database” section in the Microsoft Dynamics AX 2012 software development kit (SDK) at http://msdn.microsoft.com/en-us/library/aa588039.aspx.
You can also refer to previous editions of “Inside Microsoft Dynamics AX,” which contain useful information about database functionality that still applies to Microsoft Dynamics AX 2012.
By default, any table that is defined in the Application Object Tree (AOT) is mapped in a one-to-one relationship to a permanent table in the underlying relational database. Microsoft Dynamics AX also supports the functionality of temporary tables. In previous releases, Microsoft Dynamics AX provided the capability to create InMemory temporary tables that are mapped to an indexed sequential access method (ISAM) file-based table that is available only during the run-time scope of the Application Object Server (AOS) or a client. Microsoft Dynamics AX 2012 provides a new type of temporary table that is stored in the TempDB database in Microsoft SQL Server.
The ISAM file that represents an InMemory temporary table contains the data and all of the indexes that are defined for the table in the AOT. Because working on smaller datasets is generally faster than working on larger datasets, the Microsoft Dynamics AX run time monitors the size of each InMemory temporary table. If the size is less than 128 kilobytes (KB), the temporary table remains in memory. If the size exceeds 128 KB, the temporary table is written to a physical ISAM file. Switching from memory to a physical file affects performance significantly. A file with the naming syntax $tmp<8 digits>.$$$ is created when data is switched from memory to a physical file. You can monitor the threshold limit by noting when this file is created.
Although InMemory temporary tables don’t map to a relational database, all of the data manipulation language (DML) statements in X++ are valid for tables that operate as InMemory temporary tables. However, the Microsoft Dynamics AX run time executes some of the statements in a downgraded fashion because the ISAM file functionality doesn’t offer the same functionality as a relational database. For example, set-based operators always execute as record-by-record operations.
When you declare a record buffer for an InMemory temporary table, the table doesn’t contain any records. You must insert records to work with the table. The InMemory temporary table and all of the records are lost when no declared record buffers point to the temporary dataset.
Memory and file space aren’t allocated to the InMemory temporary table until the first record is inserted. The temporary table is located on the tier where the first record was inserted. For example, if the first insert occurs on the server tier, the memory is allocated on this tier, and eventually the temporary file will be created on the server tier.
Important
Use temporary tables carefully to ensure that they don’t cause excessive round trips between the client and the server, resulting in degraded performance. For more information, see Chapter 13.
A declared temporary record buffer contains a pointer to the dataset. If you use two temporary record buffers, they point to different datasets by default, even though the table is of the same type. To illustrate this, the X++ code in the following example uses the TmpLedgerTable temporary table defined in Microsoft Dynamics AX 2012. The table contains four fields: AccountName, AccountNum, CompanyId, and LedgerDimension. The AccountNum and CompanyId fields are both part of a unique index, AccountNumIdx, as shown in Figure 17-1.

The following X++ code shows how the same record can be inserted in two record buffers of the same type. Because the record buffers point to two different datasets, a “duplicate value in index” failure doesn’t result, as it would if both record buffers pointed to the same temporary dataset, or if the record buffers were mapped to a database table.
static void TmpLedgerTable(Args _args)
{
TmpLedgerTable tmpLedgerTable1;
TmpLedgerTable tmpLedgerTable2;
tmpLedgerTable1.CompanyId = 'dat';
tmpledgerTable1.AccountNum = '1000';
tmpLedgerTable1.AccountName = 'Name';
tmpLedgerTable1.insert(); // Insert into tmpLedgerTable1's dataset.
tmpLedgerTable2.CompanyId = 'dat';
tmpledgerTable2.AccountNum = '1000';
tmpLedgerTable2.AccountName = 'Name';
tmpLedgerTable2.insert(); // Insert into tmpLedgerTable2's dataset.
}To have the record buffers use the same temporary dataset, you must call the setTmpData method on the record buffer, as illustrated in the following X++ code. In this example, the setTmpData method is called on the second record buffer and is passed in the first record buffer as a parameter.
static void TmpLedgerTable(Args _args)
{
TmpLedgerTable tmpLedgerTable1;
TmpLedgerTable tmpLedgerTable2;
tmpLedgerTable2.setTmpData(tmpLedgerTable1);
tmpLedgerTable1.CompanyId = 'dat';
tmpledgerTable1.AccountNum = '1000';
tmpLedgerTable1.AccountName = 'Name';
tmpLedgerTable1.insert(); // Insert into shared dataset.
tmpLedgerTable2.CompanyId = 'dat';
tmpledgerTable2.AccountNum = '1000';
tmpLedgerTable2.AccountName = 'Name';
tmpLedgerTable2.insert(); // Insert will fail with duplicate value.
}The preceding X++ code fails on the second insert operation with a “duplicate value in index” error because both record buffers point to the same dataset. You would notice similar behavior if, instead of calling setTmpData, you simply assigned the second record buffer to the first record buffer, as illustrated here:
tmpLedgerTable2 = tmpLedgerTable1;
However, the variables would point to the same object, which means that they would use the same dataset.
When you want to use the data method to copy data from one temporary record buffer to another, where both buffers point to the same dataset, write the code for the copy operation as follows:
tmpLedgerTable2.data(tmpLedgerTable1);
Warning
The connection between the two record buffers and the dataset is lost if the code is written as tmpLedgerTable2 = tmpLedgerTable1.data. In this case, the temporary record buffer points to a new record buffer that has a connection to a different dataset.
As mentioned earlier, if no record buffer points to the dataset, the records in the temporary table are lost, the allocated memory is freed, and the physical file is deleted. The following X++ code example illustrates this situation, in which the same record is inserted twice using the same record buffer. But because the record buffer is set to null between the two insert operations, the first dataset is lost, so the second insert operation doesn’t result in a duplicate value in the index because the new record is inserted into a new dataset.
static void TmpLedgerTable(Args _args)
{
TmpLedgerTable tmpLedgerTable;
tmpLedgerTable.CompanyId = 'dat';
tmpledgerTable.AccountNum = '1000';
tmpLedgerTable.AccountName = 'Name';
tmpLedgerTable.insert(); // Insert into first dataset.
tmpLedgerTable = null; // Allocated memory is freed
// and file is deleted.
tmpLedgerTable.CompanyId = 'dat';
tmpledgerTable.AccountNum = '1000';
tmpLedgerTable.AccountName = 'Name';
tmpLedgerTable.insert(); // Insert into new dataset.
}Notice that none of these InMemory temporary table examples uses the ttsbegin, ttscommit, and ttsabort statements. These statements affect only ordinary tables that are stored in a relational database. For example, the following X++ code adds data to an InMemory temporary table. Because the table is an InMemory temporary table, the value of the accountNum field is printed to the Infolog even though the ttsabort statement executes.
static void TmpLedgerTableAbort(Args _args)
{
TmpLedgerTable tmpLedgerTable;
ttsbegin;
tmpLedgerTable.CompanyId = 'dat';
tmpledgerTable.AccountNum = '1000';
tmpLedgerTable.AccountName = 'Name';
tmpLedgerTable.insert(); // Insert into table.
ttsabort;
while select tmpLedgerTable
{
info(tmpLedgerTable.AccountNum);
}
}To cancel the insert operations on the table in the preceding scenario successfully, you must call the ttsbegin and ttsabort methods on the temporary record buffer instead, as shown in the following example:
static void TmpLedgerTableAbort(Args _args)
{
TmpLedgerTable tmpLedgerTable;
tmpLedgerTable.ttsbegin();
tmpLedgerTable.CompanyId = 'dat';
tmpledgerTable.AccountNum = '1000';
tmpLedgerTable.AccountName = 'Name';
tmpLedgerTable.insert(); // Insert into table.
tmpLedgerTable.ttsabort();
while select tmpLedgerTable
{
info(tmpLedgerTable.AccountNum);
}
}When you work with multiple temporary record buffers, you must call the ttsbegin, ttscommit, and ttsabort methods on each record buffer because there is no correlation between the individual temporary datasets.
When working with InMemory temporary tables, keep the following points in mind:
When exceptions are thrown and caught outside the transaction scope, if the Microsoft Dynamics AX run time has already called the ttsabort statement, temporary data isn’t rolled back. When you work with temporary datasets, make sure that you’re aware of how the datasets are used both inside and outside the transaction scope.
The database-triggering methods on temporary tables behave almost the same way as they do with ordinary tables, but with a few exceptions. When insert, update, and delete are called on the temporary record buffer, they don’t call any of the database-logging or event-raising methods on the application class if database logging or alerts have been set up for the table.
Delete actions are also not executed on InMemory temporary tables. Although you can set up delete actions, the Microsoft Dynamics AX application run time doesn’t try to execute them.
Microsoft Dynamics AX lets you trace Transact-SQL statements, either from within the Microsoft Dynamics AX Windows client, or from the Microsoft Dynamics AX Configuration Utility or the Microsoft Dynamics AX Server Configuration Utility. However, Transact-SQL statements can be traced only if they are sent to the relational database. You can’t trace data manipulation in InMemory temporary tables with these tools. However, you can use the Microsoft Dynamics AX Trace Parser to accomplish this. For more information, see the section, Microsoft Dynamics AX Trace Parser in Chapter 13.
You can query a record buffer to find out whether it is acting on a temporary dataset by calling the isTmp record buffer method, which returns a value of true or false depending on whether the table is temporary.
The application code in Microsoft Dynamics AX often uses temporary tables for intermediate storage. This requires performing joins with regular tables and in some cases, executing set-based operations. But InMemory temporary tables provide restricted support for joins. These joins are performed by the data layer in the AOS, which does not give ideal performance. Also, as mentioned earlier, set-based operations are always downgraded to row-by-row operations for InMemory tables. TempDB temporary tables have been added to Microsoft Dynamics AX to provide a high-performance solution for these scenarios. Because these temporary tables are stored in the SQL Server database, database operations such as joins can be used.
TempDB temporary tables use the same X++ programming constructs as InMemory temporary tables. The key difference is that they are stored in the SQL Server TempDB database. The following code example shows the usage of a TempDB temporary table:
void select2Instances()
{
TmpDBTable1 dbTmp1;
TmpDBTable1 dbTmp2;
dbTmp1.Field1 = 1;
dbTmp1.Field2 = 'First';
dbTmp1.insert();
dbTmp2.Field1 = 2;
dbTmp2.Field2 = 'Second';
dbTmp2.insert();
info("First Instance.");
while select * from dbTmp1
{
info(strfmt("%1 - %2", dbTmp1.Field1, dbTmp1.Field2));
}
info("Second Instance.");
while select * from dbTmp1
{
info(strfmt("%1 - %2", dbTmp2.Field1, dbTmp2.Field2));
}
}This example uses a table called TmpDBTable1 that contains two fields. The TableType property for the TmpDBTable1 table is set to TempDB. Similar to an InMemory temporary table, the TempDB temporary table is created only when the data is inserted into the table buffer. To see the data in the temporary table, insert a breakpoint before the first select statement in the X++ code, and then open SQL Server Management Studio (SSMS) to examine the tables that are created in the TempDB system database. Each table buffer instance for the temporary table has a corresponding table in the database in the following format: t<table_id>_GUID. In the example, the table ID of the TmpDBTable1 table is 101420. This means that two tables were created in the TempDB database, with one of them having the table name t101420_E448847EACA4482997F4CD8BCAAAE0CE. After the method runs and the table buffers are destroyed, these two tables are truncated. The Microsoft Dynamics AX run time uses a pool to keep track of these tables in the TempDB database. The run time will reuse one of these table instances when a TmpDBTable1 table buffer is created again in X++.
You can create temporary tables in the following ways:
The following sections describe each method.
To define a table as temporary, you must set the appropriate value in the TableType property for the table resource. By default, the TableType property is set to Regular. To create a temporary table, choose one of the other two options: InMemory or TempDB, as shown in Figure 17-2. The temporary tables are created in memory, and are backed by a file or created in the TempDB database when needed.

Tip
Tables that you define as temporary at design time should have Tmp inserted as part of the table name instead of at the beginning or end of the name; for example, InventCostTmpTransBreakdown. This improves readability of the X++ code when temporary tables are explicitly used. In previous versions of Microsoft Dynamics AX, the best practice was to prefix temporary tables with Tmp, which is why a number of temporary tables still use this convention.
When you define a table by using the AOT, you can attach a configuration key to the table by setting the ConfigurationKey property on the table. The property belongs to the Data category of the table properties.
When the Microsoft Dynamics AX run time synchronizes the tables with the database, it synchronizes tables for all modules and configurations, regardless of whether they’re enabled except the SysDeletedObjects configuration keys. Whether a table belongs to a licensed module or an enabled configuration depends on the settings in the ConfigurationKey property. If the configuration key is disabled, the table is disabled and behaves like a TempDB temporary table. Therefore, no run-time error occurs when the Microsoft Dynamics AX run time interprets X++ code that accesses tables that aren’t enabled. For more information about the SysDeletedObjects configuration key, see “Best Practices: Tables” at http://msdn.microsoft.com/en-us/library/aa876262.aspx.
You can use X++ code to turn an ordinary table into an InMemory temporary table by calling the setTmp method on the record buffer. From that point forward, the record buffer is treated as though the TableType property on the table is set to InMemory.
Note
You can’t define a record buffer of a temporary table type and turn it into an ordinary table, partly because there is no underlying table in the relational database.
The following X++ code illustrates the use of the setTmp method, in which two record buffers of the same type are defined; one is temporary, and all records from the database are inserted into the temporary version of the table. Therefore, the temporary record buffer points to a dataset that contains a complete copy of all of the records from the database belonging to the current company.
static void TmpCustTable(Args _args)
{
CustTable custTable;
CustTable custTableTmp;
custTableTmp.setTmp();
ttsbegin;
while select custTable
{
custTableTmp.data(custTable);
custTableTmp.doInsert();
}
ttscommit;
}Notice that the preceding X++ code uses the doInsert method to insert records into the temporary table. This prevents execution of the overridden insert method. The insert method inserts records in other tables that aren’t switched automatically to temporary mode just because the custTable record buffer is temporary.
Caution
Use great care when changing an ordinary record buffer to a temporary record buffer because application logic in overridden methods that manipulates data in ordinary tables could execute inadvertently. This can happen if the temporary record buffer is used in a form and the form application run time calls the database-triggering methods.
The introduction of surrogate keys is a significant change to table keys in Microsoft Dynamics AX 2012. A surrogate key is a system-generated, single-column primary key that does not carry domain-specific semantics. It is specific to the Microsoft Dynamics AX installation that generates the key. A surrogate key value cannot be generated in one installation and used in another installation. The natural choice for a surrogate key in Microsoft Dynamics AX is the RecId column. However, in Microsoft Dynamics AX 2009 and earlier, the RecId index is still paired with the DataAreaId column for company-specific tables. In Microsoft Dynamics AX 2012, the RecId index does not contain the DataAreaId column and becomes a single-column unique key.
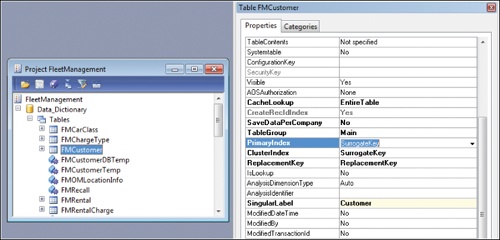
Surrogate key support is enabled when you create a new table the AOT. To use the surrogate key pattern for a table, set the PrimayIndex property to SurrogateKey, as shown in Figure 17-3.
Note
The SurrogateKey value is not available for tables that were created in an earlier version of Microsoft Dynamics AX. If you want to implement a surrogate key for an existing table, you must re-create the table in the AOT.
Defining a surrogate key on a table in Microsoft Dynamics AX has several benefits. The first benefit is performance. When a surrogate key and the foreign key that references it are used to join two tables, performance is improved when compared to joins created with other data types. The benefit is more prominent when compared to Microsoft Dynamics AX 2009 and earlier versions because the kernel automatically adds the DataAreaId column to any key defined for any company-specific table. You identify these company-specific tables through the SaveDataPerCompany property. Without a surrogate key, the join must be based on at least on two columns, with one of them being the DataAreaId column.
The second benefit of using a surrogate key is that a surrogate key value never changes, which eliminates the need to change the values of foreign keys. For example, the Currency table (Figure 17-4) uses the CurencyCodeIdx index as the primary index, which contains the CurrencyCode column. The Ledger table has two foreign keys in the Currency table that are based on the CurrencyCode column. If there is ever a need to change the CurrencyCode value for a record in the Currency table, the corresponding records in the Ledger table also must be updated. But if a surrogate key were used for the Currency table and the Ledger table holds the surrogate foreign key, you could update the CurrencyCode value in the Currency table without affecting the key relationship between the row in the Currency table and the rows in the Ledger table.

The third benefit of using a surrogate key is that it is always a single-column key. Some features of SQL Server, such as full-text search, require a single-column key. Using a surrogate key lets you take advantage of these features.
Surrogate keys do have some drawbacks. The most prominent drawback is that the key value is not human-readable. When you look at the foreign keys on a related table, it is not easy to determine what the related row is. To display meaningful information that identifies the foreign key, some human-readable information from the related entity must be retrieved and displayed instead. This requires a join to the related table, and the join adds performance overhead.
For a table, a candidate key is a minimal set of columns that uniquely identifies each row in the table. An alternate key is a candidate key for a table that is not a primary key. In Microsoft Dynamics AX 2012, you can mark a unique index to be an alternate key.
Because Microsoft Dynamics AX already has the concept of a unique index, you might wonder what the value is of having the concept of an alternate key. Developers create unique indexes for various reasons. Typically, one unique index serves as the primary key. Sometimes, additional unique indexes are created for performance reasons, such as to support a specific query pattern. When you look at the unique indexes for a table, it is not always obvious which index is used for the primary key and which have been added for other reasons. For example, if you were to extract your data model and present it to a business analyst, you would not want the analyst to see the keys that were created solely for performance reasons. You need a way to separate your semantic model from your physical data model for this purpose. Being able to designate the additional unique indexes as alternate keys helps you to achieve this.
Figure 17-5 shows a unique index that was added to the FMVehicleModel table of the Fleet Management sample application. This is not the primary index for the table, so the AlternateKey property for the index is set to Yes.

Relationships between tables (called relations in Microsoft Dynamics AX) are key to the data model and run-time behavior. They are used in the following run-time scenarios in Microsoft Dynamics AX:
Join conditions in the query or form data source and form dynalink
Delete actions on tables
Lookup conditions for bound (backed by a data source) or unbound controls on forms
Several changes and enhancements have been made for table relations in Microsoft Dynamics AX 2012.
In Microsoft Dynamics AX, table relations can be explicitly defined on tables, or they can be derived from relation properties that are defined on extended data types (EDTs) associated with table fields. The Microsoft Dynamics AX kernel looks up the relation properties for EDTs, and then for table relations. The order may be switched, depending on the scenario.
There are several issues with defining the relation properties on EDTs and mixing them with the relations defined on tables. First, EDT relations capture relations on only a single field. They cannot be used to capture multiple-field relations, which leads to incomplete relationships that are used in join or delete actions. Second, most of the properties for the relation depend on the context in which the relation is used. This context cannot be captured for EDT relations because they are stored in a central location in the AOT. For example, the role and related role name and cardinality and related cardinalities could be different for relations on different tables. Third, it is difficult to figure out how many relations are actually available for a table because the table relations give you only a partial view. You need to also look at relations that are defined on EDTs for the fields in the table and their base EDTs.
To address these issues, Microsoft Dynamics AX 2012 has migrated most of the EDT relations to table relations. To begin deprecating the Relations node under individual EDTs, the addition of new relations is not allowed. If an EDT has no nodes defined under the Relations node, the node is not displayed in Microsoft Dynamics AX 2012. An EDT has a new Table References node for cases where a control is bound directly to an EDT, and not through a table field. To reduce the work of manually adding a table relation that can be used in place of the EDT relation, you are prompted to create the table relation automatically when an EDT with a valid foreign key reference is used on a table field.
Because the Microsoft Dynamics AX run time performs lookups for EDT relations and table relations in a specific order, you need to ensure that the same relation gets picked up before and after the migration in all scenarios. This is especially important when migrating EDT relations in multiple table relations between two tables. The Microsoft Dynamics AX run time achieves backward compatibility by examining some properties that were set on table fields and table relations. These properties enable the run time to determine whether a table relation was created from an EDT relation that existed before. These properties are explained in Table 17-1.
Table 17-1. Properties of table fields.
You do not have to migrate an EDT relation manually to a table relation and then set the properties described in Table 17-1. The EDT Relation Migration tool can help with this process. You can access this tool from Tools > Code Upgrade > EDT Relation Migration Tool, as shown in Figure 17-6. For information about how to use this tool, see the topic “EDT Relation Migration Tool” at http://msdn.microsoft.com/en-us/library/gg989788.aspx.

After you migrate the EDT relations to table relations, verify that delete actions, query joins, and lookups work the same way they did before the migration. Focus on cases in which the migration of an EDT relation resulted in multiple table relations between two tables. The EDT Relation Migration tool lists the artifacts that are affected.
The following are some examples of the artifacts that might be affected. For example, the SalesTable table and the CustTable table have two relations between them defined on SalesTable. One of them was migrated from an EDT relation because it did not exist as a table relation before. The two relations are based on the fields CustAccount and InvoiceAccount. For delete actions, the relation based on CustAccount should be picked up before and after the migration. The SalesHeading query has a join between the SalesTable table and the CustTable table with the Relations property set to Yes on the data source for the SalesTable table. This query should pick up the relation based on CustAccount instead of the relation based on InvoiceAccount before and after the migration.
A goal for Microsoft Dynamics AX 2012 was to make the data model more consistent. This includes using surrogate key patterns when appropriate. It also includes using only primary keys as your foreign key references whenever possible. To facilitate the latter, Microsoft Dynamics 2012 introduces a special type of foreign key relation that you can use when creating relations between tables, as shown in Figure 17-7. A foreign key relation allows only two kinds of references to the related table. The first is a reference to the primary key. The second is a reference to a single-column alternate key of the related table. This reference to the single-column alternate key is provided to reduce the number of surrogate foreign key joins that were discussed in the Surrogate keys section, earlier in this chapter.

If you use a human-readable alternate key as your foreign key, you can display the foreign key on forms without the need for a join. You might wonder why only single-column alternate keys are allowed for foreign key references. This is to balance performance for a different usage pattern, when you actually want to join between the two tables (not for purposes of the user interface). Joins that are based on smaller columns (both the size of the columns and the number of columns) perform faster. By restricting the pattern to only single-column alternate keys, the performance degradation of the join is limited.
A consistent table relation pattern can result in performance benefits, too. For example, if one table references the CustTable table by using keyA, and another table references the CustTable table by using keyB, both tables must be joined to the CustTable table to correlate the rows in these two tables. However, if both of them use the same key, they can correlate directly, eliminating the need for joins.
Foreign key relations have some capabilities that other relations do not. For example, you can use them as join conditions in queries. This saves you from having to manually enter the field join conditions, which can be prone to error. Navigation property methods can also be generated for foreign key relations, as discussed in the next section.
When you expand the Relations node for a table defined in the AOT, you can see the table relationships that are defined. The CreateNavigationPropertyMethods property, which is available only for foreign key relations, has special significance. Setting this property to Yes, as shown in Figure 17-8, causes kernel-generated methods on a table buffer to be created. You can use these methods to set, retrieve, and navigate to the related table buffer through the relation specified. The examples later in this section show the method signatures and usage patterns.

The navigation setter method links two related table buffers together. It is frequently used with the UnitOfWork class to create rows in the database from those table buffers. This effectively allows you to create an in-memory object graph with a related table buffer so that you can push them into the database with the proper relationship established among the rows. For more information, see the Unit of Work section later in this chapter.
The navigation getter method retrieves the related table buffer if a setter method has set it. Otherwise, the method retrieves the related table buffer from the database. This can effectively replace the find method pattern that is commonly used on tables. In the latter case, the table buffer that is returned is not linked to the table buffer on which the method was called. This means that the method will try to retrieve data from the database again. Note that when the navigation property getter method queries the database to get the related record, it selects all fields for that record. This can affect performance, particularly in cases where you had selected a smaller field list to achieve a performance benefit.
The following code uses the DirPartyTable_FK method to retrieve the related DirPartyTable table record for a customer with an account number of 1101 and prints the customer’s name to the Infolog:
static void NavigationPropertyMethod(Args _args)
{
CustTable cust;
select cust where cust.AccountNum == '1101';
// The DirPartyTable_FK() methods retrieves the related DirPartyTable record
// through the DirPartyTable_FK role defined on the CustTable
info(strFmt('Customer name for %1 is %2',cust.AccountNum, cust.DirPartyTable_FK().Name));
}Figure 17-9 shows the output of this example in the Infolog.

However, if the navigation property setter method is used to set the related DirPartyTable record, that record is always returned and the run time does not query the database:
static void NavigationPropertyMethodSetter(Args _args)
{
CustTable cust;
DirPartyTable dp;
select cust where cust.AccountNum == '1101';
dp.Name = 'NotARealCustomer';
// Set the related DirPartyTable record
cust.DirPartyTable_FK(dp);
// The DirPartyTable_FK() methods retrieves the DirPartyTable record set above and
// does not retrieve from the database.
info(strFmt('Customer name for %1 is %2',cust.AccountNum, cust.DirPartyTable_FK().Name));
}Figure 17-10 shows the output from this example in the Infolog.

Each navigation method must have a name. Like any other method on the table, its name cannot conflict with other methods. By default, the RelatedTableRole property is used for the method name. An error is thrown during table compilation if a conflict with another method name is detected. If a conflict occurs, use the NavigationPropertyMethodNameOverride property to specify the name to use.
Table inheritance has long been part of extended entity relationship (ER) modeling, but there was no built-in support for this in earlier versions of Microsoft Dynamics AX. Any inheritance or object-oriented characteristics had to be implemented manually by the developer. Microsoft Dynamics AX 2012 supports table inheritance natively from end to end, including modeling, language, run time, and user interface.
To model table inheritance in Microsoft Dynamics AX 2012, you must first create a root table and then create a derived table. These tasks are described in the following sections. Later sections describe how to work with existing tables, view the type hierarchy, and specify table behavior.
First, you must create the table that is the root of the table hierarchy. Before you create any fields for the table, set the SupportInheritance property to Yes. For the root table, you must add an Int64 column that is named InstanceRelationType, which holds the information about the actual type of a specific row. This column should have the ExtendedDataType property set to RelationType, and the Visible property set to No. After you create this field, you must set the InstanceRelationType property for the base table to the field that you just added. From this point, you can model the root table as you normally would.
Next, create a derived table, and set the SupportInheritance property to Yes. Set the Extends property to point to the table on which the derived table is based. Set these properties before you create any fields for the table. This will help ensure that all fields in tables in the hierarchy have unique names and IDs, which is necessary for the run time to work correctly. It also makes it possible to choose different storage models, such as storing all types in a single table, without causing name collisions. Storage is discussed later in this section.
If tables already have fields before you add the tables to an inheritance hierarchy, you might need to update the field names and IDs in both metadata and code. If the tables already contain data, the existing data will need to be upgraded to work with the new table hierarchy. These are nontrivial tasks. For these reasons, creating a new table inheritance hierarchy from existing tables is not supported.
You can use the Type Hierarchy Browser to view a table inheritance hierarchy. To do so, right-click a table in the AOT, and then click Add-Ins > Type Hierarchy Browser. Figure 17-11 shows the hierarchy for the FMVehicle table.

Tables in an inheritance hierarchy share some property settings, so that table behavior is consistent throughout the hierarchy. These settings include the cache lookup mode, the OCC setting, and the save-data-per-company setting.
Configuration keys should be consistent with the table inheritance hierarchy. In other words, if a configuration key is disabled for the base table, the configuration key for the derived table should not be enabled. This condition is checked when you compile a table in the hierarchy, and errors are reported if the condition is found. For more information about configuration keys, see Chapter 11.
You can specify whether a table in an inheritance hierarchy is concrete or abstract. By default, tables are concrete. This means that you can create a row that is of that table type. Specifying that a table is abstract means that you cannot create a row that is of that table type. Any row in the abstract table must be of a type of one of the derived tables (further up in the hierarchy) that is not marked as abstract. This concept aligns with the concept of an abstract class in an object-oriented programming language.
The table inheritance model in Microsoft Dynamics AX 2012 is a discrete model. Any row in the table hierarchy can be of only one concrete type (a table that is not marked as abstract). You cannot change the type of a row from one concrete type to another concrete type after the row is created.
In some implementations of object-relational (OR) mapping technologies, you can choose how the table inheritance hierarchy is mapped to data storage. The choices typically are one table for every modeled type, one table for every concrete type, or one table for every hierarchy. Microsoft Dynamics AX 2012 creates one table for every modeled type. Like a regular table, a table in a table inheritance hierarchy maps to a physical table in the database. Records in the inheritance hierarchy are linked through the RecId field. The data for a specific row of a type instance may be stored in multiple tables in the hierarchy, but they share the same RecId.
Every table in an inheritance hierarchy automatically has a system column that is named RELATIONTYPE. You will see this column in SQL Server, but not in the AOT. This column acts as a discriminator. The data for a concrete type is stored in multiple tables that make up the inheritance chain for that type. For a row in one of the tables, the discriminator column identifies the next table in the chain.
Figure 17-12 shows some rows in the FMVehicle table and the corresponding table IDs for its derived tables. The value of the InstanceRelationType field for cars equals the table ID of the FMCarClass table; for SUVs, the InstanceRelationType field equals the table ID of the FMSUV table; and for trucks, the InstanceRelationType field equals the table ID of the FMTrucks table. These represent the concrete type of each row in the FMVehicle table. The value of the RelationType field for both cars and SUVs equals the table ID of the FMCarClass table because FMCarClass is the next directly derived table for those rows. For trucks, the value of the RelationType field equals the table ID of the FMTruck table.

When you issue a query on a table that is part of a table inheritance hierarchy, the Microsoft Dynamics AX run time provides the type fidelity by default. This means that if a select * statement is performed for a table, all of the rows of that table type are returned. For example, if you issue the query select * from DirPartyTable, all instances of DirParty are returned, including DirPerson, OperatingUnit, and so on. Morever, because select * is used, the query returns complete data. This means that the DirPartyTable table must be joined to all of its derived tables.
When a select * is performed for a table that is part of a table inheritance hierarchy, that table is joined with an inner join to all of its base tables (all the way up to the root table), and then joined with an outer join to all of its derived tables (including derived tables at all levels). The reason for this is that any row in that table must have a corresponding row in all of its base tables, but could have matching rows in any of the concrete type paths. This ensures that, no matter what concrete type a row is, complete data for that row is always retrieved. Similar to the polymorphic behavior in object-oriented programming, this mechanism provides polymorphic data retrieval for a table that is part of a table inheritance hierarchy. In cases where you need to have all of the data for a row, this behavior is very convenient. You can use the dynamic method binding feature of table inheritance to write code that is clean and extensible.
For example, in the Fleet Management project, the FMVehicle table has a doAnnualMaintenance method that simply throws an exception. This happens because FMVehicle is an abstract table and any concrete table that is derived from it must override this method. The tables FMCarClass, FMTruck, and FMSUV all override this method, as shown in Figure 17-13. Note that each overridden method accesses a field that is not accessible from the base table.

The following code queries the FMVehicle table and calls the doAnnualMaintenance method:
static void PolyMorphicQuery(Args _args)
{
FMVehicle vehicle;
while select vehicle
{
vehicle.doAnnualMaintenance();
}
}If you run the code as a job, you would get results that look similar to those shown in Figure 17-14.

As you can see, even though the select statement executes on the FMVehicle table, the statement returns fields in the derived tables. The actual select statement for this query looks like the following:
SELECT <all fields from all tables in the hiearchy> FROM FMVEHICLE T1 LEFT OUTER JOIN FMTRUCK T2 ON (T1.RECID=T2.RECID) LEFT OUTER JOIN FMCARCLASS T3 ON (T1.RECID=T3.RECID) LEFT OUTER JOIN FMSUV T4 ON (T3.RECID=T4.RECID)
When the inheritance hierarchy is very wide, very deep, or both, a polymorphic query can result in numerous table joins, which can degrade query performance. For example, the query select * from DirPartyTable produces eight table joins.
Exercise caution when using the table inheritance feature. Determine whether you really need all of the data from every derived type instance. If the answer is no, you should list the fields that you need explicitly in the field list. (Note that you can also list fields from derived tables when you model a query in the AOT or use the query object in X++ code. But you can only list fields from current and base tables when you write the X++ select statement.) The Microsoft Dynamics AX run time then adds joins to only the tables that contain the fields in the list. For example, if you change the query on the DirPartyTable table to select name from DirpartyTable, only the DirPartyTable table is included in the query. No joins to other tables in the hierarchy are created because no data is being accessed from them. Careful query construction can improve query performance significantly.
Listing only the fields that are needed is not only beneficial here, but it is a good practice in general. This may allow SQL Server to use a covering index when processing the query and reduce the network load. A common concern about this practice is passing the table buffer to another function in another module, because you need to ensure that the other function does not use fields that were not selected to be returned. When an attempt is made to read fields that are not in the field list, Microsoft Dynamics AX 2009 and earlier versions does not produce an exception. You get whatever value is on the table buffer, which in most cases is an empty value. In Microsoft Dynamics AX 2012, an attempt to access an unavailable field raises an exception, but only if the field is included in a table that is part of a table inheritance hierarchy. A configuration setting is available to raise either a warning or exception for all tables that encounter this issue. To change this setting, do the following:
Click System Administration > Setup > System > Server Configuration.
On the Performance Optimization FastTab, under Performance Settings, click the drop-down list next to Error On Invalid Field Access to change the setting.
To maintain backward compatibility and to reduce run-time overhead, this setting is turned off by default. It is recommended that you activate this setting for testing purposes only.
Maintaining referential integrity is important for any ERP application. Microsoft Dynamics AX 2012 lets you model table relations with richer metadata and express referential integrity in your data model more precisely. However, the application is still responsible for making sure that referential integrity is maintained. Microsoft Dynamics AX table relations are not implemented as database foreign key constraints in the SQL Server database. Implementing these constraints would add performance overhead in SQL Server. Also, for performance and other reasons, application code might violate referential integrity rules temporarily and fix the violations later.
Maintaining referential integrity requires performing data operations in the correct order. This is most prominent in cases where records are created and deleted. The parent record must be created first, before the child record can be inserted with the correct foreign key. But child records must be deleted before the parent record. Ensuring this manually in code can be error-prone, especially with the more normalized data model in Microsoft Dynamics AX 2012. Also, data operations are often spread among different code paths. This leads to extending locking and transaction spans in the database.
Microsoft Dynamics AX 2012 provides a programming concept called Unit of Work to help with these issues. Unit of Work is essentially a collection of data operations that is performed on related data. Application code establishes relationships between data in memory, modifies the data, registers the operation request with the Unit of Work framework, and then requests that the Unit of Work perform all of the registered data operations in the database as a unit. Based on the relationships established among the entities in the in-memory data, the Unit of Work framework determines the correct sequence for the requested operations and propagates the foreign keys, if necessary.
The following code example shows Unit of Work in use:
public static void fmRentalAndRentalChargeInsert()
{
FMTruck truck;
FMRental rental;
FMRentalCharge rentalCharge;
FMCustomer customer;
UnitofWork uoW;
// Populate rental and RentalChange in UoW. 3 types of Rental Charge Records
// for the same Rental.
// Getting the customer and the truck that the customer is renting
// These records are referred to from the rental record
select truck where truck.VehicleId == 'co_wh_tr_1';
select customer where customer.DriverLicense == 'S468-3184-6541';
uoW = new UnitofWork();
rental.RentalId = 'Redmond_546284';
// This links the rental record with the truck record.
// During insert, rental record will have the correct foreign key into the truck record.
rental.fmVehicle(truck);
// This links the rental record with the customer record.
// During insert, rental record will have the correct foreign key into the
// customer record.
rental.fmCustomer(customer);
rental.StartDate = DateTimeUtil::newDateTime(112008,0);
rental.EndDate = DateTimeUtil::newDateTime(1012008,0);
rental.StartFuelLevel = 'Full';
// Register the rental record with unit of work for save.
// Unit of work makes a copy of the record.
uoW.insertonSaveChanges(rental);
uoW.saveChanges();
}It is important to understand that Unit of Work copies the data changes into its own buffer when the registration method executes. After that, the original buffer is disconnected from Unit of Work. Any changes made to the table buffer after that will not be picked up by Unit of Work. If you want to save these changes through Unit of Work, you need to call the corresponding registration method again.
When you register multiple changes on the same record with Unit of Work, the last changes that are registered overwrite all previous changes.
In the previous code example, the code runs on the server because Unit of Work is a server-bound construct and cannot be instantiated or used on the client.
The form run time in Microsoft Dynamics AX uses the Unit of Work framework in its internal implementation to handle data operations on form data sources, where several form data sources are joined together directly. These scenarios did not work in previous releases of Microsoft Dynamics AX. When the form run time uses the Unit of Work framework, it is not accessible through X++.
Many business scenarios require tracking how data changes over a period of time. Some of the requirements include viewing the value of a record as it was in the past, viewing the value at the current time, or being able to enter a record that will become effective on a future date. A typical example of this is employee data in an application that is used by the Human Resources team of a company. Some questions that such an application will help answer might be as follows:
What position did a specific employee hold on a specific date?
What is the current salary for the employee?
What is the current contact information for the employee?
In addition to answering these questions, there might also be a requirement to allow users to enter new data and change existing data. For example, a user could change the contact information for Employee C and make the new information effective on September 15, 2012. Such data is often referred to as date-effective data. Microsoft Dynamics AX 2012 supports creating and managing date-effective data in the database. The date-effective framework provides a number of features that include support for modeling entities, programmatic access for querying and updating date-effective data, run time support for maintaining data consistency, and user interface support. Core Microsoft Dynamics AX features, such as the Global Address Book and modules like Human Resources, use date-effective tables extensively in their data models.
Microsoft Dynamics AX provides support for modeling date-effective entities at the table level. The ValidTimeStateFieldType property of a table indicates whether the table is date-effective. This information is stored in the metadata for the table and is used at run time.
Figure 17-15 shows the DirPersonName table, which is used to track the history of a person’s name. The table is date-effective because the ValidTimeStateFieldType property is set to UtcDateTime. When you set this property on a table, the date-effective framework automatically adds the columns ValidFrom and ValidTo, which are required for every date-effective table. The data type of these columns is based on the value chosen for the ValidTimeStateFieldType property. Two data types are available:
Date Tracking takes place at the day level. Records are effective starting from the ValidFrom date through the ValidTo date.
UtcDateTime Tracking takes place at the second level. In this case, multiple records can be valid within the same day.

In addition to the fields each date-effective table is required to have, the table must have at least one alternate key that is implemented as a unique index. This alternate key is referred to as the validtimestate key in the date-effective framework, and it is used to enforce the time period semantics that are enabled by a date-effective table. The validtimestate key must contain the ValidFrom column and at least one other column other than the ValidTo column. The validtimestate key has an additional property that indicates whether gaps (missing records for a period of time) are allowed in the data. In Figure 17-16, the DirPersonName table is used track changes to the Person column. The validtimestate key contains the Person column and the ValidFrom column. When the ValidTimeStateKey property is set to Yes for an index, the index also needs to be a unique index and is required to be an alternate key.

In Table 17-2, the records reflect the changing names over a period of time for two people. The table must have a unique index with the following columns: Person and ValidFrom. The ValidTo column can be part of the index, but it is optional. This index has the ValidTimeStateKey property set to Yes. Because the objective is to track the history of a person, the column that represents the person is also part of the validtimestate key. The validtimestate key enables the date-effective framework to indicate the field for which the history is being tracked.
This scenario has a requirement not to allow gaps in each person’s name data. To implement this requirement, the ValidTimeStateMode property is set to NoGap. For other scenarios, gaps in the data might be acceptable. This is also implemented by using the ValidTimeStateMode property. The date-effective framework also enforces that a person cannot have more than one name at the same time. This is called prevention of overlaps in the data. If the ValidTo column for a record contains the maximum value allowed (12/31/215423:59:59), it indicates that the record does not expire.
Business application logic that is written in X++ may need to retrieve data that is stored in date-effective tables. To support this, the framework has three modes of data retrieval:
Current Returns the record that is currently active by default, when you use a select statement or an application programming interface (API) to retrieve data from the table.
AsOfDate Retrieves the record that is valid for the passed-in date or the UtcDateTime parameter. This can be in the past, current, or future. The ValidFrom column of the retrieved record is less than or equal to the value passed in. The ValidTo column is greater than or equal to the value passed in.
Range Returns the records that are valid for the passed in range.
The X++ language supports a syntax that is similar to the Transact-SQL syntax that is used when querying relational databases. The date-effective framework enhances this syntax by adding the validtimestate keyword to indicate the type of query. The modes described earlier translate to the following queries.
Note
The ValidFrom and ValidTo columns in these examples use the Date data type. If they used the UtcDateTime data type, the dates passed in would have to be in UtcDateTime format.
This query retrieves the current emergency contact information for Employee A. There is no need to specify any values for the ValidFrom and ValidTo columns in the where clause because the Microsoft Dynamics AX run time automatically adds them:
select * from EmployeeEmergencyContact where EmployeeEmergencyContact.Employee == 'A';
This query retrieves the record that was in effect on April 21, 1986:
select validtimestate (21�41986) * from EmployeeEmergencyContact where EmployeeEmergencyContact.Employee == 'A';
This query retrieves all of the records for Employee A for the time period that is passed into the statement:
select validtimestate(01�11985, 31122154) * from EmployeeEmergencyContact where EmployeeEmergencyContact.Employee == 'A';
X++ also exposes a Query API to retrieve data from tables. This API has been extended with the following methods to allow different forms of querying:
validTimeStateAsOfDate(date);
validTimeStateAsOfDateTime(utcdatetime);
validTimeStateDateRange(date);
validTimeStateDateTimeRange(utcdatetime);
The date-effective framework uses these methods and transforms them by adding additional predicates on the ValidFrom and ValidTo columns to fetch the data that meets the requirement of the query.
The data that is stored in a date-effective table must conform to the following consistency requirements:
Because the data that is stored in the table can be added to or changed, the date-effective framework ensures that these consistency requirements are enforced. The date-effective framework implements these requirements by adjusting other records using the following rules:
If ValidFrom is being updated, retrieve the previous record, and then update the ValidTo of the previous record to a value of ValidFrom -1 to ensure that there is no overlap or gap. If the ValidFrom of the edited record is less than the ValidFrom of the previous record, display an error. The error is displayed because further action is required to delete the previous record to avoid overlaps. The date-effective framework does not delete automatically records during adjustments.
If ValidTo is being updated, retrieve the next record, and then update the ValidFrom of the next record to a value of ValidTo + 1 to ensure that there is no overlap or gap. If the ValidTo of the edited record is greater than the ValidTo of the next record, display an error.
The date-effective framework does not allow simultaneous editing of ValidTo and ValidFrom columns.
The date-effective framework does not allow editing of any other columns that are part of the validtimestate key.
When a new record is inserted, the ValidTo of the existing record is updated to a value of ValidFrom -1 of the newly inserted record. New records cannot be inserted in the past or future if records already exist for that time period.
When a record is deleted, the ValidTo of the previous record is adjusted to a value of ValidFrom -1 of the next record, but only if the system requires that there should be no gaps. If gaps are allowed, no adjustment is performed.
The date-effective framework allows regular updates of records in a date-effective table. It also provides additional modes that are typical for the types of changes that are made to date-effective tables. The date-effective framework provides the following three modes:
Correction This mode is analogous to regular updates to data in a table. If the ValidFrom or ValidTo columns are updated, the system updates additional records if necessary to guarantee that the data does not contain gaps or overlaps.
CreateNewTimePeriod The date-effective framework creates a new record with updated values, and updates the ValidTo of the edited record to a value of ValidFrom -1 of the newly inserted record. By default, the ValidFrom column of the newly inserted record has the current date for the Date data type columns or the current time for UtcDateTime data type columns. This mode does not allow editing of records in the past. This mode hides the date-effective characteristics of the data from the user. The user edits the records as usual, but internally a new record is created to continue tracking the history of changes made to the record.
EffectiveBased This mode is a hybrid of the other two modes. Records in the past are prevented from being edited. Current active records are edited by using the same semantics as CreateNewTimePeriod mode. Records in the future are updated by using the same semantics as Correction mode.
The update mode must be specified by calling the validTimeStateUpdateMode(ValidTimeStateUpdate _validTimeStateUpdateMode) method on the table buffer that is being updated. This method takes a value from the ValidTimeStateUpdate enumeration as a parameter. This enumeration has the list of the various update modes.
When the user updates a record in a date-effective table, other records might be updated as a consequence. The date-effective framework first provides a dialog box that informs the user about the additional updates and asks the user to confirm whether the action should proceed. The user’s actions are simulated without actually updating the data. After the user chooses to update the data, the user interface is refreshed by retrieving all of the updated records.
Microsoft Dynamics AX 2012 has the capability to execute full-text search queries against the database. Full-text search functionality is provided by SQL Server and allows the ability to perform linguistic searches against text data stored in the database. For more information, see “Full-Text Search (SQL Server)” at http://msdn.microsoft.com/en-us/library/ms142571.aspx.
Microsoft Dynamics AX provides the capability to create a full-text index on a table. New methods that are available in the Query class that let you write queries that use this index. Figure 17-17 shows a full-text index that has been created for the VendTable table in the AOT.

Only one full-text index can be created for a table. Only fields that have the string data type can be used as fields for the full-text index. When the table is synchronized, a corresponding full-text index is created in the database. Microsoft Dynamics AX also requires that the table be part of either the Main table group or the Group table group. You cannot create a full-text index for temporary tables.
The following example shows how full-text queries can be executed by using the Query API:
Query q;
QueryBuildDataSource qbds;
QueryBuildRange qbr;
QueryRun qr;
VendTable vendTable;
q = new Query();
qbds = q.addDataSource(tablenum(VendTable));
qbr = qbds.addRange(fieldnum(VendTable, AccountNum));
qbr.rangeType(QueryRangeType::FullText);
qbr.value(queryvalue('SQL'));
qr = new QueryRun(q);
while (qr.next())
{
vendTable = qr.get(tablenum(VendTable));
print vendTable.AccountNum;
}The QueryRangeType::FullText enumeration used by the rangeType method causes the data layer to generate a full-text search query in the database. Microsoft Dynamics AX uses the FREETEXT keyword provided by SQL Server when it generates a full-text query that is executed on the database. For the previous code example, the following Transact-SQL query is generated:
SELECT T1.ACCOUNTNUM,T1.INVOICEACCOUNT,... FROM VENDTABLE T1 WHERE (((PARTITION=?) AND (DATAAREAID=?)) AND (FREETEXT(ACCOUNTNUM,?))) ORDER BY T1.ACCOUNTNUM
For more information about the FREETEXT keyword, see “Querying SQL Server Using Full-Text Search” on MSDN at http://msdn.microsoft.com/en-us/library/ms142559.aspx.
You can also use the extended query range syntax to generate a full-text query. This is shown in the following example. The freetext keyword specifies that the data layer should generate a full-text query.
qbrCustDesc = qsbdCustGrp.addRange(fieldnum(VendTable, AccountNum));
qbrCustDesc.value('((AccountNum freetext "bike") || (AccountNum freetext "run"))'),A favorite Transact-SQL interview question is to ask a candidate to explain the difference between the on clause and the where clause in a select statement that involves joins. You can find the long version of the answer on MSDN, which talks about the different logical phases of query evaluation. The short answer is that there is no difference between the two for an inner join. For an outer join, rows that do not satisfy the on clause are included in the result set, but rows that do not satisfy the where clause are not.
So you might wonder when to use on and when to use where. An example will help illustrate. The following polymorphic query finds all DirParty instances with the name John. There are two kinds of predicates here. The first one matches the individual rows with their corresponding base or derived type:
<baseTable>.recID == <derivedTable>.recid.
The second predicate matches the name:
DirPartyTable.name == 'John'
To start with the first predicate, when you take a specific row from the root table, it may have a matching row in any one of the derived tables. Because the goal is to retrieve complete data for all types, you do not want to discard a row just because it does not match one of the derived tables. For this reason, you want to use the on clause. For the second predicate, you want only the rows that qualify the predicate. Thus, you want to use the where clause. The Transact-SQL for the query looks like this:
SELECT * FROM DIRPARTYTABLE T1 LEFT OUTER JOIN DIRPERSON T2 ON (T1.RECID=T2.RECID) LEFT OUTER JOIN DIRORGANIZATIONBASE T3 ON (T1.RECID=T3.RECID) LEFT OUTER JOIN DIRORGANIZATION T4 ON (T3. RECID=T4.RECID) LEFT OUTER JOIN OMINTERNALORGANIZATION T5 ON (T3.RECID=T5.RECID) LEFT OUTER JOIN OMTEAM T6 ON (T5.RECID=T6.RECID) LEFT OUTER JOIN OMOPERATINGUNIT T7 ON (T5.RECID=T7.RECID) LEFT OUTER JOIN COMPANYINFO T8 ON (T5.RECID=T8.RECID) WHERE (T1.NAME='john')
You might notice that the on clause is specified immediately after the table join, and the where clause is specified at the end of the query after all of the table joins and on clauses. This matches the order in which the query is evaluated. The where clause predicates are evaluated after all of the joins have been processed. The following X++ select statement produces a similar query:
static void Job3(Args _args)
{
SalesTable so;
SalesLine sl;
select so where so.CustAccount == '1101'
outer join sl where sl.SalesId == so.SalesId;
}The Transact-SQL for the query looks like this:
SELECT * FROM SALESTABLE T1 LEFT OUTER JOIN SALESLINE T2 ON ((T2.DATAAREAID=N'ceu') AND (T1. SALESID=T2.SALESID)) WHERE ((T1.DATAAREAID=N'ceu') AND (T1.CUSTACCOUNT=N'1101'))
There is something of a mix here. The keyword is where, but it is specified after each table join. So where does the predicate go in the Transact-SQL? If you use SQL trace, you’ll see that for an outer join, the predicates appear in the on clause. For an inner join, it shows in the where clause. To understand this, keep in mind that the X++ where is actually the on clause in Transact-SQL. Because there is no difference between on and where for inner joins, the Microsoft Dynamics AX run time simply moves those to the where clause. The X++ Query programming model has the same behavior. Query ranges that you specify by using the QueryBuildRange clause go in the on clause.
So how do you specify where clause predicates? For the X++ select statement, you may be able to attach these where clause predicates on one of the tables that are inner-joined. Alternatively, you could add these to the where clause of the first table if all the other tables are outer-joined. The solution is more difficult with the Query programming model because you cannot specify QueryBuildRange on another data source without using the extended query range feature. To solve this problem, Microsoft Dynamics AX 2012 added support for the QueryFilter API.
Because the where clause is evaluated at the query level after all of the joins have been evaluated, the QueryFilter API is available at the query level. You can refer to any query data source that is not part of an exists/notexists subquery. The following example shows the use of QueryFilter:
public void setFilterControls()
{
Query query = fmvehicle_qr.query(); // Use QueryRun's Query so that the filter can be
cleared
QueryFilter filter;
QueryBuildRange range;
boolean useQueryFilter = true; // Change to false to see QueryRange on outer join
if (useQueryFilter)
{
filter = this.findOrCreateQueryFilter(
query,
query.dataSourceTable(tableNum(FMVehicleMake)),
fieldStr(FMVehicleMake, Make));
makeFilter.text(filter.value());
}
else
{
// Optional code to illustrate behavior difference
// between QueryFilter and QueryRange
range = SysQuery::findOrCreateRange(
query.dataSourceTable(tableNum(FMVehicleMake)),
fieldNum(FMVehicleMake, Make));
makeFilter.text(range.value());
}
}
public QueryFilter findOrCreateQueryFilter(
Query _query,
QueryBuildDataSource _queryDataSource,
str _fieldName)
{
QueryFilter filter;
int i;
for(i = 1; i <= _query.queryFilterCount(); i++)
{
filter = _query.queryFilter(i);
if (filter.dataSource().name() == _queryDataSource.name() &&
filter.field() == _fieldName)
{
return filter;
}
}
return _query.addQueryFilter(_queryDataSource, _fieldName);
}QueryFilter has similar grouping rules about how individual predicates are constructed with AND or OR operators. First, QueryFilters are grouped by query data source and the results are combined by using the AND operator. Next, within a group for a specific query data source, the same rules for QueryRange are applied: predicates on the same fields use the OR operator first and then the AND operator.
If you run the following X++ code and look at the Transact-SQL trace, you will see CROSS JOIN in the Transact-SQL statement. You may think that it misses the join condition and is doing a Cartesian product of the two tables. The join condition is actually in the where clause. A cross join like this is equivalent to an inner join with the join condition. The cross join is needed because the two tables must be listed before the outer join tables, because they appear as outer join conditions. Transact-SQL does not allow you to reference tables before they are used in the query.
static void CrossJoin(Args _args)
{
CustTable cust;
SalesTable so;
SalesLine sl;
select generateonly cust where cust.AccountNum == '*10*'
join so where cust.AccountNum == so.CustAccount
outer join sl where so.SalesId == sl.SalesId;
info(cust.getSQLStatement());
}The Transact-SQL for the query looks like this:
SELECT * FROM CUSTTABLE T1 CROSS JOIN SALESTABLE T2 LEFT OUTER JOIN SALESLINE T3 ON (((T3. PARTITION=?) AND (T3.DATAAREAID=?)) AND (T2.SALESID=T3.SALESID)) WHERE (((T1.PARTITION=?) AND (T1.DATAAREAID=?)) AND (T1.ACCOUNTNUM=?)) AND (((T2.PARTITION=?) AND (T2.DATAAREAID=?)) AND (T1. ACCOUNTNUM=T2.CUSTACCOUNT))
In previous releases of Microsoft Dynamics AX, the DataAreaId column in a table was used to provide the data security boundary. It was also used to define legal entities through the concept of a company. As part of the organizational model and data normalization changes, a large number of entities like Products and Parties that were previously stored per-company, have been updated to be shared (through global tables) in Microsoft Dynamics AX 2012. This was done primarily to enable sharing of data across legal entities and to avoid data inconsistencies.
But in some deployments of Microsoft Dynamics AX, data is not expected to be shared across legal entities. In such deployments, the DataAreaId column is primarily used as a security boundary to segregate data into various companies. Such customers want to share the deployment, implementation, and maintenance cost of Microsoft Dynamics AX, but they have no other shared data or shared business processes. There are also holding companies that grow by acquiring independent businesses (subsidiaries), but the data and processes are not shared among these subsidiaries.
Microsoft Dynamics AX 2012 R2 provides a solution to these requirements. This release of Microsoft Dynamics AX uses the concept of data partitioning by adding a Partition column to the tables in the database. This allows the data to be truly segregated into separate partitions. When a user logs into Microsoft Dynamics AX, he or she always operates in the context of a specific partition. The system ensures that data from only the specified partition is visible, and that all business processes run in the context of that specific partition.
The Partitions table contains the list of partitions that are defined for the system. During setup, Microsoft Dynamics AX creates a default partition called initial. A system administrator can create additional partitions by using the Partitions form in the System Administration module.
A new property named SaveDataPerPartition has been added for all tables in the AOT. By default, the value is set to Yes, and the property cannot be edited. This property can be edited only if the SaveDataPerCompany property is set to No and the table is marked as a SystemTable, or if the table belongs to the Framework table group. These checks are put in place to enable all application tables to be partitioned. Only specific tables that are used by the kernel can have data that is not partitioned.
All of the tables whose SaveDataPerPartition property is set to Yes have a Partition system column in the metadata. In the database, the table has a PARTITION column with a data type int64. It is a surrogate foreign key to the RECID column of the PARTITION table. This column always contains a value from one of the rows in the PARTITION table. The column has a default constraint with the RECID value of the initial partition. The kernel adds the PARTITION column to all the indexes in a partition-enabled table except for the RECID index.
The Microsoft Dynamics AX kernel framework handles the population and retrieval of the Partition column based on the partition that is specified for the current session. The various database operations provided by Microsoft Dynamics AX have the following functionality:
select statements All select statements are filtered automatically based on the current partition of the session. The Transact-SQL statement that is generated always has the Partition column in the WHERE clause.
insert statements The inserted buffer always has the Partition column set to the partition of the current session. Microsoft Dynamics AX displays an error if the application code sets the column to a value that is different from the current partition of the session.
update statements All updates are performed in the current partition. Updating the Partition column is not allowed.
Because of this functionality, you usually do not have to write code to handle the Partition column. However, an exception is any code that uses direct Transact-SQL. The Partition column will not be handled automatically, and the direct SQL code has to ensure that the WHERE clause contains the partition of the current session.
To provide strict data isolation, the framework does not provide the ability to change partitions programmatically at run time. To change the partition, a new session has to be created that is set to use the other partition. Certain framework components like Setup and Batch use the runAs method, which creates a new session to execute code in a different partition. This is not a common pattern and should not be used in non-framework application logic.
Similarly, the framework does not allow execution of database operations that span multiple partitions. This is a contrast from the cross-company functionality that allows execution of database statements across multiple legal entities.