
In this section, we will explore the application of a Kohonen neural network to customer clustering on the basis of the customer information collected from Proben1 (Card dataset).
The Card dataset is composed of 16 variables in total. Fifteen are inputs, and one is an output variable. For security reasons, all variable names have been changed to meaningless symbols. This dataset brings a good mix of variable types (continuous, categorical with small values, and categorical with larger values). The following table shows a summary of the data:
|
Variable |
Type |
Values |
|---|---|---|
|
V1 |
OUTPUT |
-1; 1 |
|
V2 |
INPUT #1 |
b, a |
|
V3 |
INPUT #2 |
continuous |
|
V4 |
INPUT #3 |
continuous |
|
V5 |
INPUT #4 |
u, y, l, t. |
|
V6 |
INPUT #5 |
g, p, gg |
|
V7 |
INPUT #6 |
c, d, cc, i, j, k, m, r, q, w, x, e, aa, ff |
|
V8 |
INPUT #7 |
v, h, bb, j, n, z, dd, ff, o |
|
V9 |
INPUT #8 |
continuous |
|
V10 |
INPUT #9 |
t, f |
|
V11 |
INPUT #10 |
t, f |
|
V12 |
INPUT #11 |
continuous |
|
V13 |
INPUT #12 |
t, f |
|
V14 |
INPUT #13 |
g, p, s |
|
V15 |
INPUT #14 |
continuous |
|
V16 |
INPUT #15 |
continuous |
For simplicity, we didn't use the inputs V5–V8 and V14 in order to not inflate the number of inputs too much. Further, we applied the following transformation:
|
Variable |
Type |
Values |
Conversion |
|---|---|---|---|
|
V1 |
OUTPUT |
-1; 1 |
- |
|
V2 |
INPUT #1 |
b, a |
b = 1, a = 0 |
|
V3 |
INPUT #2 |
continuous |
- |
|
V4 |
INPUT #3 |
continuous |
- |
|
V9 |
INPUT #8 |
continuous |
- |
|
V10 |
INPUT #9 |
t, f |
t = 1, f = 0 |
|
V11 |
INPUT #10 |
t, f |
t = 1, f = 0 |
|
V12 |
INPUT #11 |
continuous |
- |
|
V13 |
INPUT #12 |
t, f |
t = 1, f = 0 |
|
V15 |
INPUT #14 |
continuous |
- |
|
V16 |
INPUT #15 |
continuous |
- |
The proposed neural net topology is shown in the following figure:
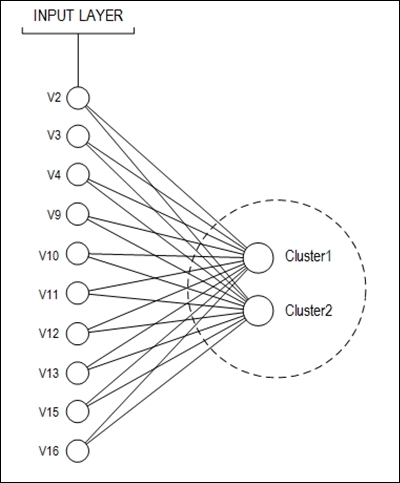
The number of examples stored is 690, but 37 of them have missing values. These 37 records were discarded. Therefore, 653 examples were used to train and test the neural network. The dataset division was made as follows:
- Training: 583 records
- Test: 70 records
The Kohonen training algorithm to cluster similar behavior depends on some parameters, such as the following:
- Normalization type
- Learning rate
It is important to note that the Kohonen training algorithm is unsupervised. So, this algorithm is used when the output is not known. In the card example, there are output values in the dataset and they will be used here only to attest clustering.
In this specific case, because the output is known, as classification, the clustering quality may be attested as follows:
- Sensitivity (true positive rate)
- Specificity (true negative rate)
- Accuracy
In a Java project, the calculations of these values are done through the Classification class, previously developed in Chapter 6, Classifying Disease Diagnosis.
It is a good practice to perform many experiments to try to find the best neural net for clustering customer profiles. Ten different experiments will be conducted, and the quality rates will be analyzed for each, as mentioned earlier. The following table summarizes the strategy that will be followed:
|
Experiment |
Learning Rate |
Normalization Type |
|---|---|---|
|
1 |
0.1 |
MIN_MAX |
|
2 |
MAX_MIN_EQUALIZED | |
|
3 |
0.3 |
MIN_MAX |
|
4 |
MAX_MIN_EQUALIZED | |
|
5 |
0.5 |
MIN_MAX |
|
6 |
MAX_MIN_EQUALIZED | |
|
7 |
0.7 |
MIN_MAX |
|
8 |
MAX_MIN_EQUALIZED | |
|
9 |
0.9 |
MIN_MAX |
|
10 |
MAX_MIN_EQUALIZED |
The Card class was created to run each experiment. Regarding the training, we applied the Euclidian distance, as previously explained in Chapter 4, Self-Organizing Maps.
The following piece of code shows a bit of its implementation:
Data cardDataInput = new Data("data", "card_inputs_training.csv");
Data cardDataInputTestRNA = new Data("data", "card_inputs_test.csv");
Data cardDataOutputTestRNA = new Data("data", "card_output_test.csv");
NormalizationTypesENUM NORMALIZATION_TYPE = Data.NormalizationTypesENUM.MAX_MIN;
try {
double[][] matrixInput = cardDataInput.rawData2Matrix( cardDataInput );
double[][] matrixInputTestRNA = cardDataInput.rawData2Matrix( cardDataInputTestRNA );
double[][] matrixOutput = cardDataInput.rawData2Matrix( cardDataOutputTestRNA );
double[][] matrixInputNorm = cardDataInput.normalize(matrixInput, NORMALIZATION_TYPE);
double[][] matrixInputTestRNANorm = cardDataInput.normalize(matrixInputTestRNA, NORMALIZATION_TYPE);
NeuralNet n1 = new NeuralNet();
n1 = n1.initNet(10, 0, 0, 2);
n1.setTrainSet( matrixInputNorm );
n1.setValidationSet( matrixInputTestRNANorm );
n1.setRealMatrixOutputSet( matrixOutput );
n1.setMaxEpochs(100);
n1.setLearningRate(0.1);
n1.setTrainType(TrainingTypesENUM.KOHONEN);
n1.setKohonenCaseStudy( KohonenCaseStudyENUM.CARD );
NeuralNet n1Trained = new NeuralNet();
n1Trained = n1.trainNet( n1 );
System.out.println();
System.out.println("---------KOHONEN TEST---------");
ArrayList<double[][]> listOfArraysToJoin = new ArrayList<double[][]>();
double[][] matrixReal = n1Trained.getRealMatrixOutputSet();
double[][] matrixEstimated = n1Trained.netValidation(n1Trained);
listOfArraysToJoin.add( matrixReal );
litOfArraysToJoin.add( matrixEstimated );
double[][] matrixOutputsJoined = new Data().joinArrays(listOfArraysToJoin);
//CONFUSION MATRIX
Classification classif = new Classification();
double[][] confusionMatrix = classif.calculateConfusionMatrix(-1.0, matrixOutputsJoined);
classif.printConfusionMatrix(confusionMatrix);
//SENSITIVITY
System.out.println("SENSITIVITY = " + classif.calculateSensitivity(confusionMatrix));
//SPECIFICITY
System.out.println("SPECIFICITY = " + classif.calculateSpecificity(confusionMatrix));
//ACCURACY
System.out.println("ACCURACY = " + classif.calculateAccuracy(confusionMatrix));
} catch (IOException e) {
e.printStackTrace();
}After running each experiment using the Card class and saving the accuracy rates, it is possible to observe that experiments 1 and 6 have the same accuracy. Data from the first experiment was normalized with the MIN_MAX method and data from the second experiment with MAX_MIN_EQUALIZED.
|
Experiment |
Accuracy |
|---|---|
|
1 |
0.9142857142857143 |
|
2 |
0.6285714285714286 |
|
3 |
0.3714285714285714 |
|
4 |
0.6000000000000000 |
|
5 |
0.5857142857142857 |
|
6 |
0.9142857142857143 |
|
7 |
0.0857142857142857 |
|
8 |
0.3714285714285714 |
|
9 |
0.4142857142857143 |
|
10 |
0.5857142857142857 |
The following table displays the confusion matrix, sensitivity, and specificity of experiments 1 and 6. Again, please note that it is possible to observe the equivalence between the neural nets in both experiments. Only 6 patterns from 70 (less than 10%) could not be clustered correctly.
|
Experiment |
Confusion Matrix |
Sensitivity |
Specificity |
|---|---|---|---|
|
1 |
31.0 | 2.0 4.0 | 33.0
|
0.8857142857142 |
0.9428571428571 |
|
6 |
31.0 | 2.0 4.0 | 33.0
|
0.8857142857142 |
0.9428571428571 |