
10 Putting it all together: Designing a privacy-enhanced platform (DataHub)
- Requirements for a privacy-enhanced platform for collaborative work
- The different components of a research collaboration workspace
- Privacy and security requirements in real-world applications
- Integrating privacy and security technologies in a research data protection and sharing platform
In previous chapters we’ve looked at privacy-enhancing technologies that serve different purposes. For instance, in chapters 2 and 3 we looked into differential privacy (DP), which covered the idea of adding noise to data query results to ensure the individual’s privacy without disturbing the data’s original properties. In chapters 4 and 5 we looked at local differential privacy (LDP), which is a local setup for differential privacy, utilizing a locally deployed data aggregator. In essence, LDP eliminates the trusted data curator that we used in the original DP techniques. Then, in chapter 6 we discussed techniques and scenarios where synthetic data generation would be helpful instead of the aforementioned privacy techniques. In chapters 7 and 8 we looked into protecting data privacy, particularly in data mining and management, when data is stored in database applications and released for different data mining tasks. Finally, in chapter 9 we walked you through different compressive privacy (CP) strategies that project the data into a lower-dimensional space. We also discussed the benefits of using CP approaches, particularly for machine learning (ML) algorithms.
Now we are at the final chapter in this book. Here we’ll walk you through applying privacy-enhancing technologies and methods to implement a real-world application, a platform for research data protection and sharing—we’ll call it DataHub. In this chapter we’ll look at the functions and features of this hypothetical system. Our goal here is to walk you through the design process of a practical application where privacy and security enhancement technologies play a vital role.
10.1 The significance of a research data protection and sharing platform
There are many application scenarios where privacy-enhancing technologies need to be applied to real-world applications to protect the privacy of individuals. For example, as we discussed in previous chapters, private data, such as age, gender, zip code, payment patterns, and so on, collected from e-commerce or banking applications needs to be protected so that it cannot be traced back by other parties to identify the original users.
Similarly, in a healthcare application you must ensure all the necessary privacy protections. Patient records and medication details must not be exposed, even for research purposes, without the patient’s consent. In such situations, the best approach when utilizing this private information for purposes such as research is to apply some sort of privacy-enhancing mechanism and perturb the original data. But which mechanism works best? Can we use any mechanism in all the different use cases? This chapter will answer those questions by putting the different mechanisms together in a collaborative task.
Let’s consider a scenario where different healthcare institutions work independently on finding a cure for a particular disease, such as skin cancer. Each institution works closely with its patients to develop advanced research studies. Let’s assume that they are using an ML algorithm to classify skin cancer based on dermoscopic images to aid the research process. However, instead of each institute working independently, they could work collaboratively to improve the accuracy of the ML model. Different institutions could contribute varying types of data, which provides a more diverse dataset and, hence, better accuracy.
However, as you know, data collected from human subjects specifically for research purposes must be maintained securely and usually cannot be shared with other parties due to privacy concerns. This is where privacy-enhancing technologies come into play. As this is a collaborative effort, we have to pick the most suitable technology to ensure the data privacy guarantees.
This chapter will explore how we can allow different stakeholders to collaborate (in this case, various healthcare institutions). We will essentially be designing an end-to-end platform using a set of security and privacy-enhancing technologies to protect and share research data. The idea is to show how you can apply the technologies we’ve discussed in previous chapters in a real-world scenario. Our use case will be DataHub—the research data protection and sharing platform.
10.1.1 The motivation behind the DataHub platform
Researchers from different institutes, organizations, or countries work collaboratively to achieve a common scientific goal. They usually collect a large amount of data from various sources and analyze it to answer specific research questions. For example, suppose a cancer institute is doing research to prevent and treat mesothelioma, a type of cancer rarely seen in the US population. Since this is a rare cancer type, the data provided by mesothelioma patients at the institute is minimal. Hence, the researchers in this institute need more patient data from other cancer institutes, but other institutes may not be willing to share patient data due to privacy policies. Aggregating private data from multiple data owners is a significant problem in collaborative research.
Let’s consider another scenario. Let’s say a researcher is surveying individuals’ political attitudes. The researcher may conduct a traditional face-to-face survey or use an online survey tool, but in either case the researcher obtains raw data containing private information about individuals. This raw data is vulnerable to misuse, as happened in the Facebook-Cambridge Analytica data scandal, which we briefly discussed in chapter 1—the data collected by Cambridge Analytica was used to attempt to influence voter opinions. As a result, there is increasing demand for systems that allow data sharing and aggregation while protecting security and privacy.
This chapter’s DataHub is a hypothetical system that will accomplish those objectives. In such a system, we need to provide data storage security, eliminate data misuse, and maintain the integrity of research processes. Since human beings are the subjects of many research fields, such as medicine, biology, psychology, anthropology, and sociology, protecting the privacy of individuals is a fundamental requirement for researchers using data containing personal information. The DataHub platform we will design will solve this problem by providing privacy-preserving mechanisms for analyzing aggregated data from multiple data owners. Moreover, this platform will contain tools for conducting privacy-preserving surveys that collect perturbed data from individuals, with privacy guarantees. Essentially, we can improve survey participation and eliminate privacy breaches with these privacy guarantees.
10.1.2 DataHub’s important features
There will be many different stakeholders for this application—data owners, data users, algorithm providers, and so on—so collaboration between the platform users needs to be facilitated through data or technology contributions and sharing, with privacy access controls specified by the data owners.
Let’s look at the key features that we need in such an application:
-
Ensure the protection of data . The collected data needs to be protected through security and privacy-enhancing techniques. Security can be ensured through data encryption/decryption and integrity checks during data storage and retrieval. Integrity verification can guarantee that the data is not altered unintentionally or maliciously. Privacy can be ensured by perturbing the data or analysis results using the privacy protection techniques, including synthetic data generation and privacy-preserving ML, that we discussed in previous chapters.
-
Allow the application to scale . Once deployed, the system should leverage the advances in cloud computing and emerging distributed data processing techniques in database systems to scale the computations with the growing data and application requirements. The security and privacy techniques should be implemented through the data protection as a service deployed on virtual machines (VMs). More VM resources could be deployed dynamically as the amount of data and number of users increases.
-
Enable collaboration and participation of stakeholders . The platform should facilitate collaboration through at least four roles: data owner, data provider, data user, and algorithm provider. In addition to research data, algorithms for data analytics and protection can be gathered and shared across institutes. Accessing the data and algorithms can be enabled through different role-based access control mechanisms.
Even within the context of data protection and sharing, there are many different application use cases. We already mentioned two: an application for data aggregation across multiple collaborating institutions, and an online survey tool to facilitate the data collection process. There could be many other use cases involving storing, analyzing, collecting, and sharing research data.
If you are wondering whether there are any established solutions similar to this, the answer is yes. For example, BIOVIA ScienceCloud (www.sciencecloud.com) is a cloud-based infrastructure that enables solutions for research collaboration. HUBzero (https://hubzero.org) is another open source software platform for hosting analytical tools, publishing data, sharing resources, collaborating, and building communities. Open Science Data Cloud (OSDC; www.opensciencedatacloud.org) is another cloud platform facilitating storing, sharing, and analyzing terabyte- and petabyte-scale scientific datasets. However, none of the existing solutions allow privacy-preserving queries or the analysis of protected data from multiple sources, which is what we are looking for. In addition, none of them provides a tool for conducting privacy-preserving surveys, which is a fundamental way of collecting information from individuals, especially in social sciences. This lack of privacy-preserving technologies means that the current platforms do not sufficiently support research collaboration. We will fill this gap by facilitating a secure, shared workspace where multiple organizations and the scientific research community can collaboratively work on a cloud-based system that caters to all the needs of the scientific community under one roof, with privacy assurances.
10.2 Understanding the research collaboration workspace
We’ll now elaborate on the design of the research collaboration workspace. DataHub will facilitate four different user groups on the platform: the data owner, data provider, data user, and algorithm provider, as depicted in figure 10.1. These different users can be configured through different user roles with a role-based access control mechanism. A platform user may also have more than one role in the system. For instance, a data owner may want to utilize the data of other data owners. In that case, the data owner could run a privacy-preserving algorithm as a data user.
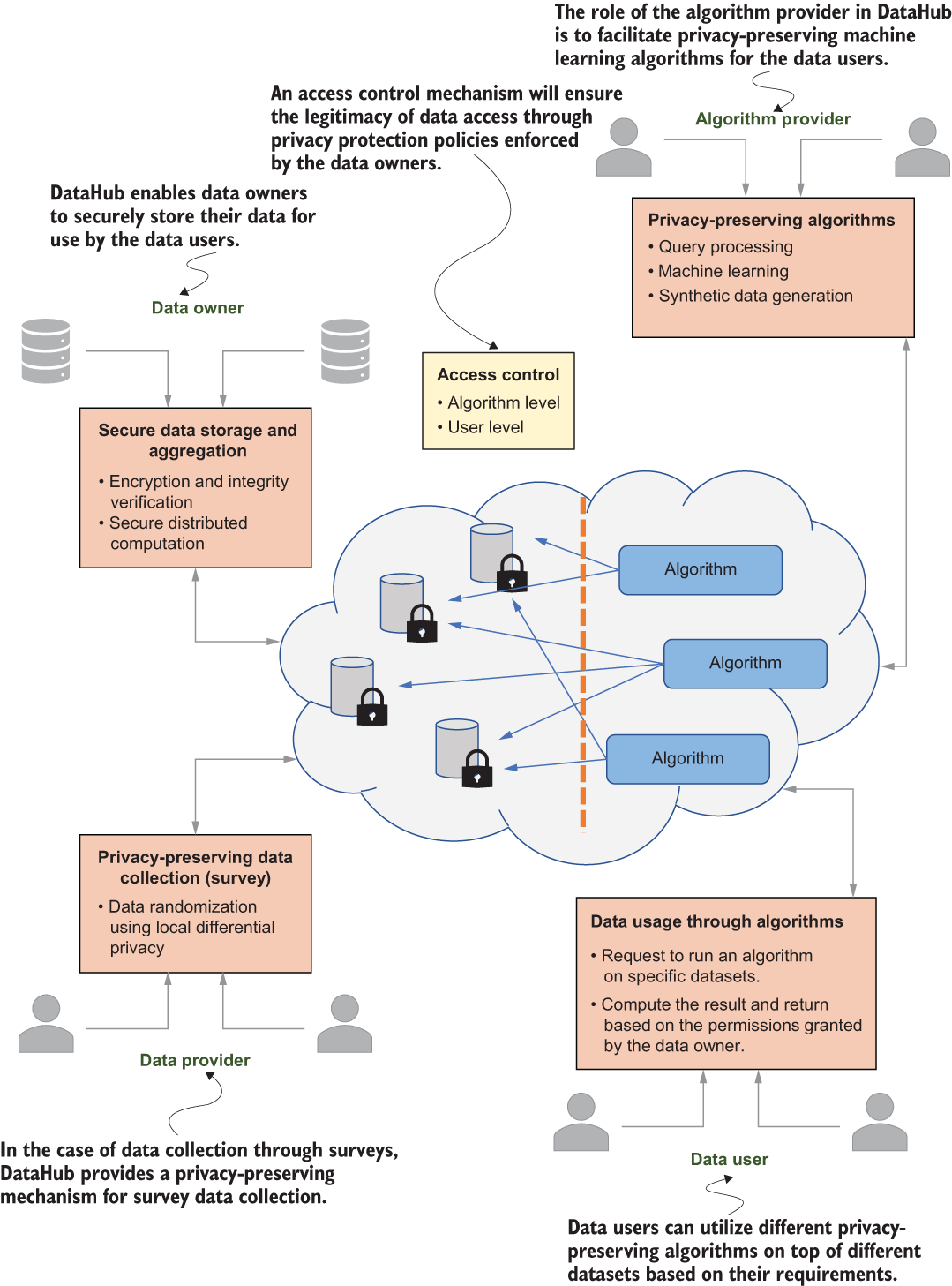
Figure 10.1 Overview of the different user roles in the DataHub system
As you can see in figure 10.1, data owners aim to allow researchers to use their datasets while protecting the security and privacy of these datasets. One way to achieve the security and privacy of a dataset is by integrating a scalable cloud-based secure NoSQL database solution called SEC-NoSQL [1] into the architecture.
Whenever a data owner submits their data to DataHub, it is stored securely in a database. To facilitate that, one solution would be for the data owner to encrypt that information and put it in the database. However, whenever we wanted to query even a single data tuple from that dataset, the data owner would have to decrypt the whole database, which is not practical or efficient in multiparty applications. As a solution to this problem, the research community came up with a SQL-aware encryption concept [2]. The idea is that data will be encrypted in such a way that querying encrypted data is possible without decrypting the whole database. This can be achieved with layers of different property-preserving encryption. The SEC-NoSQL framework will provide data security through data encryption mechanisms and data integrity verification during data storage and retrieval. Integrity verification prevents data from being altered by any party unintentionally or maliciously. We will look into the details in section 10.3.1, but as a quick high-level overview, data security operations can be implemented in two trust models for data owners to protect their data from the rest of the DataHub:
-
A semi-trusted third party called the crypto service provider (CSP) will provide the public key for encryption.
-
The algorithms will be executed between data owners and DataHub without the help of the crypto service provider.
In this platform, data owners will control how their data can be used and who can access or use it by defining different protection policies through the access control mechanism.
DataHub will also have a component for collecting data through privacy-preserving surveys (see figure 10.1). As we discussed in chapter 4, local differential privacy (LDP) allows data users to aggregate information about a population while protecting the privacy of each individual (the data owners) by using a randomized response mechanism (see section 4.1.2).
Moreover, data users can utilize data possessed by data owners by running privacy-preserving algorithms in DataHub. These algorithms could be privacy-preserving ML, query processing, synthetic data generation, and so on. In general, the data users will only learn the result of an algorithm if access is granted. The results of the algorithms will guarantee differential privacy, which is a commonly used standard for quantifying individual privacy, as we discussed in chapters 2 and 3.
Finally, DataHub can be extended by algorithm providers adding new algorithms (figure 10.1). This promotes collaboration between different institutions.
10.2.1 The architectural design
As a scalable system for the scientific community, DataHub will be a platform that manages all data and algorithms on a public cloud. As illustrated in figure 10.1, the main functionality of DataHub will be running privacy-preserving algorithms on protected datasets. NoSQL databases will be used for data storage because they provide better performance and high scalability for big data, and especially for increasing workloads. The detailed deployment architecture is shown in figure 10.2.

Figure 10.2 System deployment architecture of DataHub
Let’s quickly go through the components shown in figure 10.2. As you can see, DataHub can be implemented on top of different commercially available, open source tools and technologies. The data owners and data users connect to the DataHub platform through the public internet, as they would access any web page. The access gateway will enforce the access policies during the login process to identify the privileges assigned to each user. If access is granted, the load balancer will distribute the load appropriately, and the request will be forwarded to the relevant DataHub service application based on the request type. We will be looking at the different service offerings later in the chapter. Each function performed by DataHub is offered as a service application (resource as a service). For example, ML is offered as machine learning as a service. Finally, to facilitate the secure delivery of some services, a crypto service provider is integrated.
NOTE Figure 10.2 identifies some of the most popular open source software products to give you an idea of their functions. This is just for reference. You can use your preferred software products.
In terms of deployment, we can pick the semi-honest trust model for DataHub. In the semi-honest trust model, each party in the system is assumed to follow the protocols correctly, but they might be curious about the data being exchanged and may try to obtain additional information by analyzing the values received during the execution of the protocols. Data owners cannot fully trust a cloud-based service provider, so DataHub will not require original data from data owners while running the algorithms.
We can develop privacy-preserving algorithms for two variations on the semi-honest trust model. The first trust model requires a semi-trusted third party, the crypto service provider (CSP), which will provide the public key for encryption. The algorithms for this model are more efficient in terms of communication costs. The second trust model does not need the CSP, but the algorithms require more communication between data owners and DataHub during their execution. In both models, it is possible to analyze aggregated data from multiple data owners, promoting collaborative research.
Now let’s look at these trust models in detail.
10.2.2 Blending different trust models
As mentioned in the preceding section, we are using two different semi-honest trust models in our design architecture.
In this model, the idea is to use a semi-trusted third party, the crypto service provider (CSP) [3], to develop more efficient algorithms. The CSP first generates a key pair and provides the public key to be used by data owners for encryption. Since data owners do not want to share their raw data with DataHub, they encrypt their data and share the encrypted data with DataHub.
To perform computations over the encrypted data, we can use encryption schemes such as homomorphic encryption (we discussed a similar protocol in section 9.4). When DataHub performs the computation over several encrypted datasets for an algorithm, it needs to decrypt the results by interacting with the CSP before sharing them with the data user. This approach is practical since it does not require data owners to be online during the execution of the algorithms. However, it involves some assumptions, such as there being no collusion between the CSP and DataHub.
Figure 10.3 shows how an algorithm is executed in DataHub with the CSP. Each data owner first encrypts their data with the CSP’s public key and sends it to the DataHub platform. Whenever a data user wants to access the data, such as to run an ML task on that data, DataHub will run the task on the encrypted data and obtain the results. Those results will then be blinded and sent to the CSP for decryption. Since the data is blinded, there is no way for the CSP to infer the data. Once the decrypted data is received, DataHub will remove the blind and send it back to the data user to fulfill the request.

Figure 10.3 Executing a privacy-preserving algorithm for the CSP-based trust model in DataHub
This model does not require the CSP to execute the algorithms. When an algorithm is being executed, DataHub directly interacts with data owners. There can be several solutions for this model. For instance, secure multiparty protocols between DataHub and the data owners can be developed, or each data owner can use their own keys for encryption and decryption.
We could use distributed differential privacy (discussed in chapter 3) as another possible solution for this model. When there is a request from a data user to run an algorithm over several datasets, DataHub could distribute the request among the owners of these datasets. Using the DataHub plugin, each dataset owner would compute its own share locally and apply differential privacy to the computed share. When DataHub collects all the differentially private shares from data owners, the result for the data user’s request could be computed using private shares.
Figure 10.4 illustrates the execution of this distributed differentially private algorithm. Compared to the CSP-based model, this approach requires the data owners to be online during the execution of the algorithm, which requires more communication between DataHub and data owners.

Figure 10.4 Executing a privacy-preserving algorithm (distributed DP approach) for the non-CSP-based trust model in DataHub
10.2.3 Configuring access control mechanisms
Identity and access management is an extremely vital part of any system for information security. Generally, an access control mechanism is a framework that helps manage an application’s identity and access management. It is important that we use a proper access control mechanism in this system both to protect the system assets (the data and privacy-preserving algorithms) from unauthorized external parties and to manage how different assets can be accessed by internal users (the data owner, data provider, data user, or algorithm provider).
Access control policies usually can be described with reference to objects, subjects, and operations. The object represents specific assets to be protected in the system, such as the data owner’s data and the algorithms. The subject refers to particular system users. The operation describes specific actions performed by the system users (subjects) on system assets (objects), such as CREATE, READ, UPDATE, and DELETE. One access control policy defines how a subject operates on a certain object.
Four main types of access control are employed in today’s applications:
-
Discretionary access control (DAC)—In the DAC model, the resource owner specifies which subjects can access specific resources. For instance, in operating systems like Windows, macOS, or Ubuntu, when you create a folder, you can easily add, delete, or modify the permissions (like full control, read-only, etc.) that you want to give to other users. This model is called discretionary because the access control is based on the discretion of the owner of the resource.
-
Mandatory access control (MAC)—In the MAC model, users cannot determine who can access their resources. Instead, the system’s security policies will determine who can access the resources. This is typically used in environments where the confidentiality of the information is of utmost importance, such as in military institutions.
-
Role-based access control (RBAC)—In the RBAC model, instead of granting each subject access to different objects, access is granted to a role. Subjects associated with roles will be granted the corresponding access to those objects.
-
Attribute-based access control (ABAC)—The ABAC model is an advanced implementation of RBAC, where access is based on different attributes of the objects in the system. These attributes can be almost any characteristic of users, the network, devices on the network, and so on.
DataHub is a role-based collaborative data sharing platform (as you saw earlier in figure 10.1), and it involves a large number of users (the subjects) accessing data (the objects). It would not be practical to individually manage the access of each subject to the many different objects. As such, we will design and implement an RBAC mechanism in our platform.
Now let’s look at how RBAC can help us implement access control policies in DataHub. As shown in figure 10.5, there is a set of objects (e.g., dataset D1, algorithm A1), a set of subjects (e.g., user U1, U2, and U3), and a set of operations (e.g., query processing, performing ML algorithms). For each object, we define different access control policies with different roles (e.g., R1, R2). Each role is described with certain attributes and rules. The attributes define the subjects associated with the corresponding role, and the rules define the corresponding policies. For instance, in figure 10.5 U1 and U2 are associated with R1 defined within D1, which also defines the rule “allow access to query processing.” In this case, U1 and U2 are allowed to perform query processing on D1. Similarly, U3 is allowed to perform an ML algorithm A1 on the dataset D1.
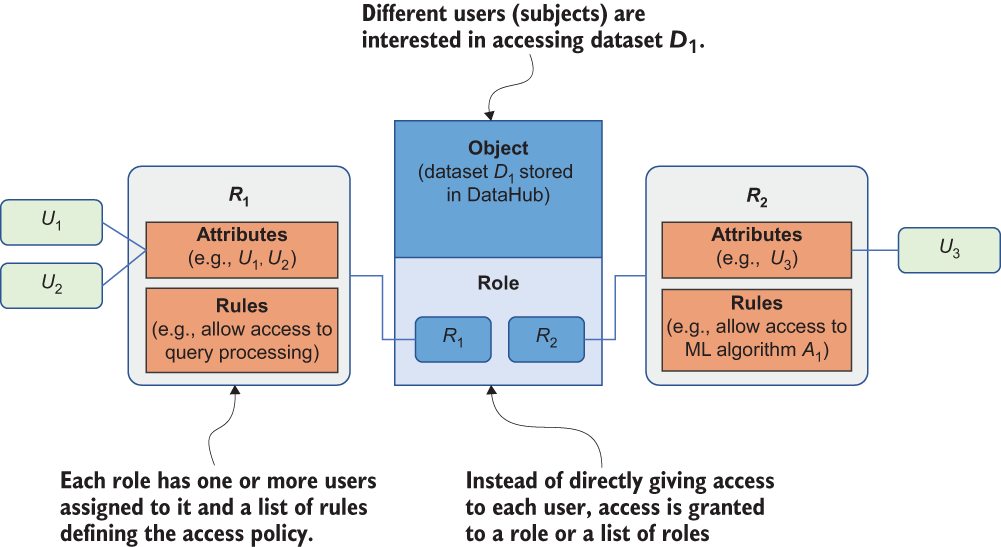
Figure 10.5 How role-based access control (RBAC) works
In this design, an access control policy can also be submitted to DataHub by the corresponding users (e.g., data owners or data providers) along with their data. In this way, the data owners and data providers can have full control over their submitted data. They also have the option to control and monitor the algorithms that have access to their data. When new data users are added to DataHub, they can request access permission to a particular dataset. The data owner of the requested dataset can decide whether to add that user to one of the roles associated with that dataset. This is how the access gateway in figure 10.2 is facilitated.
Now that you have a basic understanding of DataHub’s architecture, let’s look at how the privacy technologies work together to protect this platform.
10.3 Integrating privacy and security technologies into DataHub
As we mentioned earlier in this chapter, our goal is to show you how to combine different privacy-enhancing technologies in a real-world scenario. In this section we are going to look into the technical aspects of integrating these different technologies. First, we’ll cover the data storage options, and then we’ll extend our discussion to the ML mechanisms.
10.3.1 Data storage with a cloud-based secure NoSQL database
In chapters 7 and 8 we discussed how privacy-enhancing technologies can be used in data mining tasks and in database applications. As a quick recap, regardless of the data model we are using (whether relational or non-relational), security is a major concern in any datastore. But most modern database systems (especially NoSQL database systems) are more concerned about performance and scalability than about security.
Security-aware database systems based on different approaches have been researched for many years [2], [4]. One approach to ensure security for sensitive data in a cloud environment is to encrypt the data on the client side. CryptDB [2] is one such system developed for a relational database. It utilizes a middleware application to rewrite the original query issued by the client, so those queries are executed on the encrypted data at the database level. With this approach as a basis, we have explored the possibilities and implemented a framework called SEC-NoSQL [1], as depicted in figure 10.6. It ensures the security and privacy of NoSQL databases while preserving database performance for big data analytics.
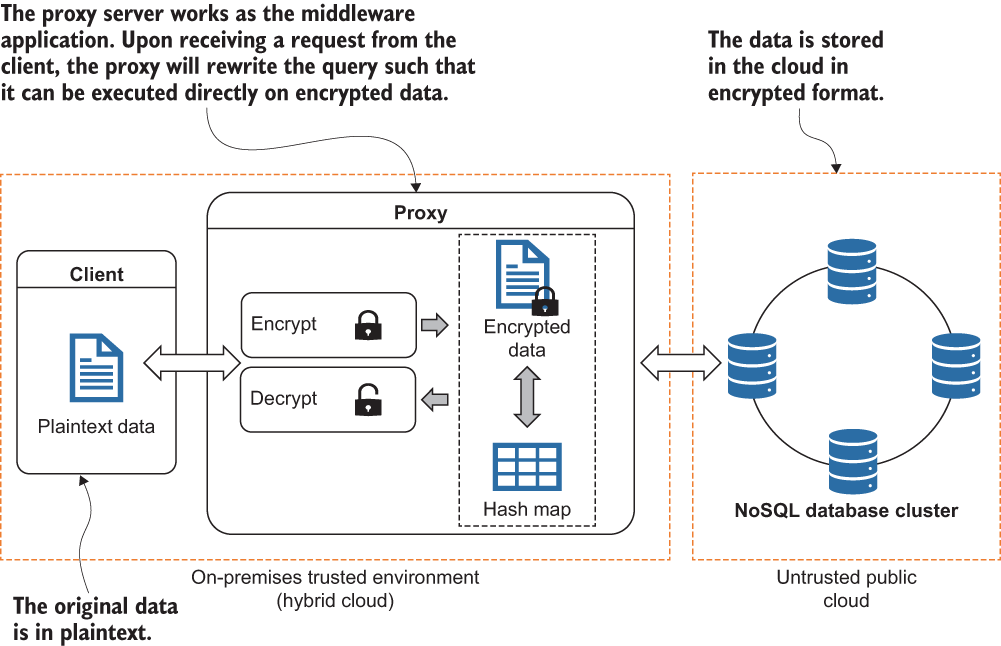
Figure 10.6 The architecture of SEC-NoSQL
The main idea behind the SEC-NoSQL framework is to implement a practical and security-aware NoSQL database solution that operates on the cloud with a guaranteed level of performance and scalability. In this design, clients only communicate with the proxy server as they would when directly storing data to or retrieving it from the database. First, the data owner issues a request to the proxy for database schema creation. The proxy transforms the schema by anonymizing the column names and executes that schema in the database. When a request appears at the proxy for a data write, it goes through the encryption mechanism, and the proxy generates a hash value (HMAC) of that record using the HMAC-SHA256 algorithm. This value will then be stored in a hash table maintained by the proxy. In the event of a read request, the proxy retrieves the encrypted record from the database, generates the hash value, and compares the corresponding entry in the hash table to ensure data integrity. If the integrity check is passed, the record will then be decrypted, and the corresponding results will be sent back to the client.
To facilitate queries over encrypted records, we need to implement cryptographic techniques that allow us to perform basic read/write operations over encrypted data. Different encryption algorithms provide different security guarantees. A more secure encryption algorithm can ensure indistinguishability against a powerful adversary, and some schemes allow different operations to be performed over encrypted data.
By following the approach suggested by CryptDB, we have implemented a different set of encryption algorithms to facilitate a different set of SQL queries over encrypted data. Based on different cryptographic operations such as random encryption, deterministic encryption, order-preserving encryption, and homomorphic encryption, SEC-NoSQL can operate and process various queries over encrypted data without much affecting the level of database performance.
With that basic understanding of how SEC-NoSQL works, let’s quickly look at a simple example of how the query operations work. Suppose we are using MongoDB as our backend database, and we need to insert the ID and name of an employee in the table_emp table in the database. In MongoDB, we can do so by executing something like the following:
db.table_emp.insertOne({col_id: 1, col_name: 'xyz'})However, when this query is received by the middleware application in SEC-NoSQL, it will be translated to something like the following:
db.table_one.insertOne({col_one: DET(1), col_two: RND('xyz')})As you can see, all the table and column names will be anonymized, and the data will be encrypted (here, DET means deterministic encryption). This is how a simple INSERT operation works. A similar approach can be followed to implement the READ, UPDATE, and DELETE operations.
10.3.2 Privacy-preserving data collection with local differential privacy
We discussed the fundamentals and applications of local differential privacy (LDP) in chapters 4 and 5. One potential use case for LDP is for online surveys. Researchers use surveys for various purposes, such as analyzing behavior or assessing thoughts and opinions.
Collecting survey information from individuals for research purposes is challenging for privacy reasons. Individuals may not trust the data collector enough to share sensitive information. Although an individual may participate in a survey anonymously, it is still be possible to identify the person by using the information provided [5]. LDP is one solution to this problem. As you’ll probably recall, LDP is a way of ensuring individual privacy when the data collector is not trusted. LDP aims to guarantee that when an individual provides a value, it should be difficult to identify what the original value is.
So how can we use LDP in our DataHub platform? Before we answer that, let’s quickly revisit the fundamentals of LDP. LDP protocols consist of three main steps. First, each user encodes their values (or data) using an encoding scheme. Then, each user perturbs their encoded values and sends them to the data collector. Finally, the data collector aggregates all the reported values and estimates privacy-preserving statistics. Figure 10.7, which you saw earlier in chapter 4, illustrates this LDP process.
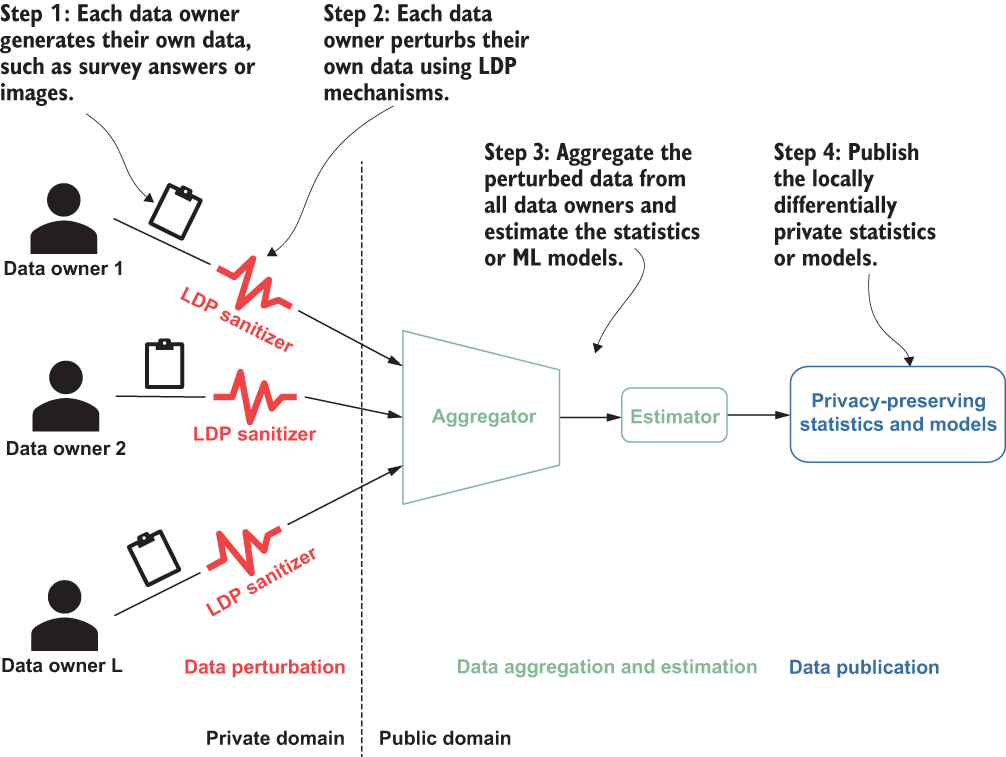
Figure 10.7 How local differential privacy works
We will design an online survey tool for our DataHub platform, as shown in figure 10.8, by implementing the existing LDP methods for collecting data from individuals (data providers) and estimating statistics about the population. Since each value will be perturbed before it is sent to DataHub, the data providers will not be concerned about their privacy.

Figure 10.8 Privacy-preserving survey mechanism of DataHub
Most of the existing LDP implementation schemes assume that a single ϵ value is determined by the data collector and used by individuals. However, individuals may have different privacy preferences. In our approach, we plan to allow data providers to select a privacy level for each piece of information submitted to DataHub. For instance, an individual may share their age with the data collector, while another may prefer to hide it. Researchers will be able to collect data from individuals for different purposes by guaranteeing each individual’s privacy under LDP. Each individual will control the level of their privacy when they share information with researchers through DataHub.
The same architecture can be used not just for fundamental problems such as frequency estimation but also for other analyses such as classification and regression. As discussed in section 5.3, we can use the perturbed data to train a naive Bayes classifier, which can then be used for different tasks.
10.3.3 Privacy-preserving machine learning
Machine learning relies heavily on the underlying data, and data privacy becomes a critical concern when that data is coming from multiple parties. For instance, data may be distributed among several parties, and they may want to run an ML task without revealing their data. Or a data owner may want to run an ML task on their data and share the learned model with other parties. In that case, the model shouldn’t reveal any information about the training data.
There are different approaches to addressing this problem, and these approaches can be broadly grouped into two categories: cryptographic-based approaches and perturbation-based approaches.
Cryptographic-based approaches
In cryptographic-based privacy-preserving machine learning (PPML) solutions, homomorphic encryption, garbled circuits, and secret-sharing techniques are the widely used mechanisms for protecting privacy.
In the case study in section 9.4, we discussed a hybrid system utilizing additive homomorphic encryption and garbled circuits to perform principal component analysis (PCA) without leaking information about the underlying data. As figure 10.9 shows, data owners compute and encrypt summary statistics and send them to the data user. The data user then aggregates all the encrypted shares from the data owners, adds a random blinding value to the results, and passes them to the CSP. The CSP uses its private key to decrypt the blinded data, constructs garbled circuits, and transfers them back to the data user. Finally, the data user executes the garbled circuits to obtain outputs.

Figure 10.9 Privacy-preserving ML protocol for cryptographic-based approach
In the case of DataHub, we can slightly modify this protocol. For instance, since the encrypted datasets will be stored in NoSQL databases, DataHub can compute the local share of each data owner using homomorphic properties and follow the protocol. In the trust model with the CSP, DataHub does not need to interact with the data owners and can decrypt the results with the help of the CSP.
We discussed the use of differential privacy (DP) in chapters 2 and 3. As a quick recap, DP aims to protect the privacy of individuals while releasing aggregate information from the database, preventing membership inference attacks by adding randomness to the algorithm’s outcome. We will use DP with our perturbation-based approaches.
Several different privacy-preserving ML algorithms have been developed to satisfy DP. Among these, the research community has investigated differentially private PCA with different approaches. Some approaches estimate the covariance matrix of the data by adding a symmetric Gaussian noise matrix, while others have used the Wishart distribution to approximate the covariance matrix. Both approaches assume the data has already been collected. In section 3.4 we explored a highly efficient and scalable differentially private distributed PCA protocol (DPDPCA) for horizontally partitioned data. We will use that protocol here in DataHub.
As shown in figure 10.10, each data owner encrypts their share of data and sends it to the proxy, a semi-trusted party between the data user and data owners. The proxy aggregates the received encrypted share from each data owner. To prevent the inference from PCA, a noise matrix is added to the aggregated result by the proxy, which makes the approximation of the scatter matrix satisfy (ε, δ)-differential privacy. The aggregated result is sent to the data user, which decrypts the result, constructs an approximation of the scatter matrix, and proceeds to PCA.
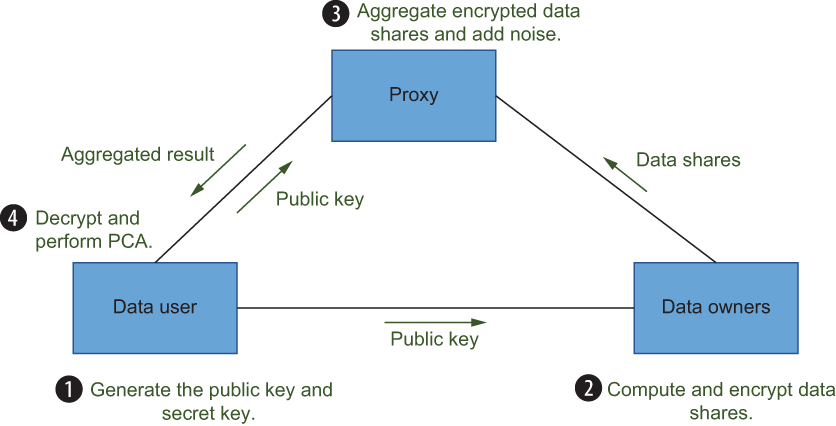
Figure 10.10 Privacy-preserving ML protocol for the perturbation-based approach
10.3.4 Privacy-preserving query processing
Now let’s look at how query processing can be facilitated with DataHub. As we discussed in section 10.2.2, the DataHub platform will support two trust models: the CSP-based trust model and the non-CSP-based trust model, where the CSP is a semi-honest third party. Therefore, we will develop algorithms to process queries on one or more protected datasets for both trust models. This query-processing functionality can be enabled with two different approaches. The first enables query processing through the SEC-NoSQL framework, while the other enables differentially private query processing. Each approach has its own merits and demerits, so let’s review the technical aspects of these approaches in detail.
Our current SEC-NoSQL framework supports the main CRUD operations (CREATE, READ, UPDATE, and DELETE). By using other encryption schemes, such as homomorphic and order-preserving encryption, we can extend this framework to support different types of statistical queries, such as SUM, AVERAGE, and ORDER BY. In the CSP-based trust model, data owners will encrypt their data using homomorphic encryption with the CSP’s public key and submit the encrypted data to DataHub, which can process aggregation queries with the help of the CSP. Using the SEC-NoSQL framework for processing queries under the non-CSP-based trust model is also possible. Each data owner can use their own public key and send the encrypted data to DataHub. However, when a data user wants to process a query, DataHub will need to interact with the data owners for decryption. This will reduce the practicality of query processing because data owners need to be online during query processing, and more communication between DataHub and each data owner is required.
A CSP is not required for differentially private query-processing approaches in the distributed setting. To satisfy differential privacy in numeric queries, we just need to add the required level of noise to the query results. However, when the data is distributed among several parties, deciding how much noise each party should add is not trivial. We discussed this matter in section 3.4.2. As a solution, Goryczka et al. [6] introduced a distributed differentially private setting for the secure sum aggregation problem. In the distributed Laplace perturbation algorithm (DLPA), each data owner generates a partial noise sampled from a Gauss, Gamma, or Laplace distribution, and the accumulated noise in the aggregator will follow the Laplace distribution, which satisfies DP. In practice, using the Laplace distribution for partial noise is more efficient for secure distributed data aggregation with privacy, and it adds less redundant noise. Therefore, DataHub will use DLPA for differential privacy in the distributed model.
10.3.5 Using synthetic data generation in the DataHub platform
In chapter 6 we discussed different use cases for synthetic data generation and why synthetic data is so important. Privacy-preserving query processing and ML algorithms are important, but sometimes researchers want to execute new queries and analysis procedures. When there is no predefined algorithm for the operation, we have to request original data from data owners so we can utilize it locally. That’s where privacy-preserving data sharing methods such as k-anonymity, l-diversity, t-closeness, and data perturbation come into play. We discussed these privacy-preserving data sharing and data mining techniques in chapters 7 and 8. However, another promising solution for data sharing is to generate synthetic yet representative data that can be safely shared. Sharing a synthetic dataset in the same format as the original data gives us much more flexibility in how data users can use the data, with no concerns for data privacy. Let’s look at how synthetic data generation mechanisms can be utilized in the DataHub platform.
DataHub will include a private synthetic data generation algorithm as a service, as was shown in figure 10.11. This algorithm will combine attribute-level micro-aggregation [7] and a differentially private multivariate Gaussian generative model (MGGM) to generate synthetic datasets that satisfy differential privacy. As discussed in chapter 6, the noise required to achieve DP for synthetic data is less than for other algorithms. Data users will be able to perform aggregation queries on a synthetic dataset, or they can use synthetic data with ML algorithms in DataHub.
To better capture the statistical features from the actual data, we can divide the attributes into independent attribute subsets. Attributes in the same subset will be correlated to each other and uncorrelated to the attributes in different attribute subsets. For each attribute subset, we can assign a synthetic data generator that includes micro-aggregation and differentially private MGGM. You can refer to section 6.4 for more about the implementation and technical details.
Our solution will be well suited for both trust models (with the CSP and without), which we discussed earlier. In the CSP-based trust model, DataHub generates the synthetic data with the help of the CSP. In the non-CSP-based trust model, the data owners generate the synthetic data and release it to DataHub. Figure 10.11 shows the steps involved in generating and using the synthetic data in DataHub for the non-CSP-based trust model.

Figure 10.11 DataHub’s synthetic data generation mechanism without a CSP
This concludes our discussion of the different features in the DataHub platform. We have explored possible ways of implementing and productionizing the privacy-enhancing techniques we discussed throughout this book by deploying them in a real-world scenario. DataHub is just one application scenario. You can use the same concepts, techniques, and technologies in your application domain. The relevant source code for each chapter is available in the book’s GitHub repository, so you can apply any of the concepts we’ve discussed. Implement them, experiment with them, and make good use of them. Good luck!
Summary
-
Throughout the book we’ve discussed various privacy-enhancing technologies that can serve privacy protection as a whole.
-
These different concepts have their own merits, demerits, and use cases. When you want to implement privacy, it is important to look at the broader picture and choose the appropriate technologies wisely.
-
Our privacy-enhanced platform for research data protection and sharing (DataHub) is a real-world application scenario that showcases how we can align different privacy-enhancing technologies toward a common goal.
-
There are two main trust models—CSP-based and non-CSP-based—that we can integrate into DataHub’s architectural design.
-
Data privacy and security are essential when designing an application, especially for distributed, collaborative environments.
-
We can store data in the DataHub platform with a cloud-based secure NoSQL database.
-
DataHub can facilitate privacy-preserving data collection with local differential privacy and privacy-preserving machine learning in two different settings: using cryptographic-based and perturbation-based approaches.
-
DataHub also provides synthetic data generation in both trust models (with CSP and without).