
Now, lets put all the pieces we have formed till now to implement training of the agent.
- step1 - Load the agent by calling the function 'agent()' and compile it with the loss as 'loss' and with optimizer as 'optimizer' which we have defined in the hyperparameters section.
- step2 - Reset the environment and reshape the initial state
- step3 - Call the agent_action function by passing the model, epsilon, and state information and obtain the next action that needs to be taken.
- step4 - Take the action obtained in step 3 using 'env.step' function. Store the resulting information in the training_data deque container by calling the memory function and passing the required arguments.
- step5 - Assign the new state obtained in step 4 to the state variable and increment the time step by 1 unit
- step6 - Until done resulting in step4 turns True, repeat step 3 through 5
- step7 - Call the 'replay' function to train the agent on a batch of the training data at the end of the episode/game.
- step8 - Repeat step2 through step7 until the target score has been achieved.
def train(target_score, batch_size, episodes,
optimizer, loss, epsilon,
gamma, epsilon_min, epsilon_decay, actions, render=False):
"""Training the agent on games."""
print('----Training----')
k.clear_session()
# define empty list to store the score at the end of each episode
scores = []
# load the agent
model = agent(states, actions)
# compile the agent with mean squared error loss
model.compile(loss=loss, optimizer=optimizer)
for episode in range(1, (episodes+1)):
# reset environment at the end of each episode
state = env.reset()
# reshape state to shape 1*4
state = state.reshape(1, states)
# set done value to False
done = False
# counter to keep track of actions taken in each episode
time_step = 0
# play the game until done value changes to True
while not done:
if render:
env.render()
# call the agent_action function to decide on an action
action = agent_action(model, epsilon, state, actions)
# take the action
new_state, reward, done, info = env.step(action)
reward = reward if not done else -10
# reshape new_state to shape 1*4
new_state = new_state.reshape(1, states)
# call memory function to store info in the deque container
memory(state, new_state, reward, done, action)
# set state to new state
state = new_state
# increment timestep
time_step += 1
# call the replay function to train the agent
epsilon = replay(epsilon, gamma, epsilon_min, epsilon_decay, model, training_data)
# save score after the game/episode ends
scores.append(time_step)
if episode % 100 == 0:
print('episode {}, score {}, epsilon {:.4}'.format(episode, time_step, epsilon))
print('Avg Score over last 100 epochs', sum(scores[-100:])/100)
if sum(scores[-100:])/100 > target_score:
print('------ Goal Achieved After {} Episodes ------'.format(episode))
# plot the scores over time
performance_plot(scores, target_score)
break
# Uncomment below line to plot score progress every 100 episodes
# performance_plot(scores, target_score)
return model
model = train(target_score=target_score, batch_size=batch_size, episodes=episodes, optimizer=optimizer, loss=loss, epsilon=epsilon, gamma=gamma, epsilon_min=epsilon_min, epsilon_decay=epsilon_decay, actions=actions, render=False)
To view the Cart-Pole game on your screen when training, set render argument to true inside the train function. Also, visualizing the game will slow down the training.

Figure 15.7: Scores output when training the agent
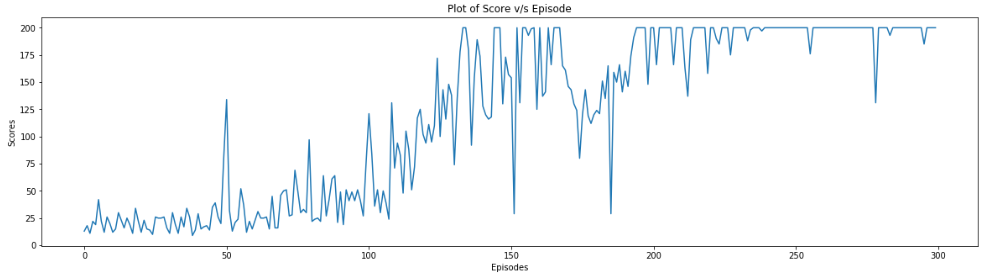
Figure 15.8: Plot of Scores v/s Episodes when training the agent
We see that when training the agent, our target score of 200 points averaging over 100 latest episodes was reached at the end of 300 games.
We have been using the epsilon-greedy policy to train the agent. Feel free to use other policies listed here https://github.com/keras-rl/keras-rl/blob/master/rl/policy.py once you have finished mastering the training of DQN.
It is not always necessary that when you give a try at training the agent, it would take you just 300 games. In some cases, it might even take more than 300. Refer to the notebook at https://github.com/PacktPublishing/Python-Deep-Learning-Projects/blob/master/Chapter%2015/DQN.ipynb to see at the 5 tries made at training the agent and the number of episodes it took to train it.