
Chapter 3
Content Distribution Network
3.1. Motivation
Nowadays, the demand for content on the Internet is increasing rapidly. This needs an efficient and scalable content distribution solution. Implementing multiple servers placed at geographically distributed locations replaces using single-server schemes. The general idea of this evolution is to bring the servers geographically closer to clients. This new architecture, called CDN, will improve the performance of the system, reduce network load and provide better fault tolerance. Currently, there are many successful CDN providers such as Akamai [AKA 98] and Digital Island [DIG 96].
The general operation mechanism of a CDN service is depicted in Figure 3.1. When a customer (e.g. a Website and VoD service) subscribes to a CDN service, the customer provides data to the CDN provider. The latter will implement a distribution network in using replica server scheme. More precisely, a CDN provider replicates the content data from the origin server of the customer to the replica servers scattered over the Internet. The operation mechanism of a user’s request is described step by step as follows. First, the end user sends a request to the Website (step 1). Then, the Website forwards the request to the CDN service (step 2). Finally, the CDN provider uses several mechanisms to select the most appropriate server with which to serve the end user (step 3).
Figure 3.1. CDN service
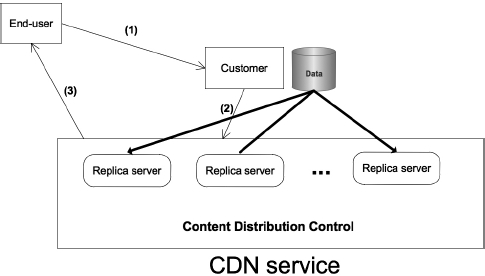
Figure 3.2 shows a detailed architecture of a CDN system [PEN 04, PAT 08]. The CDN focuses on serving both Web content and streaming media. We now present some main components of this architecture: origin server, replica servers, clients, access network, distribution network, content manager and redirector.
Figure 3.2. General architecture of CDN system
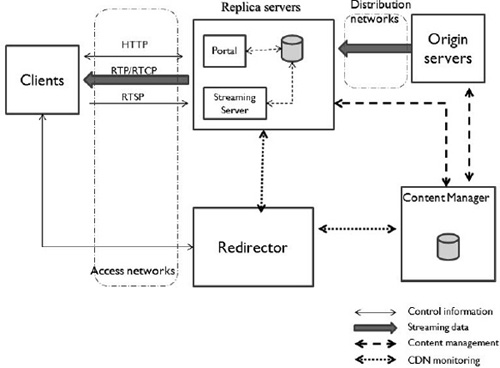
An origin server contains the information to be distributed or accessed by clients. It distributes the delegated content to the replica servers of the CDN through the distribution network. The replica servers act as proxy/cache servers with the ability to store and deliver content. The structure, number and location of replica servers are used to classify the CDN and the selection algorithm executed to determine the server who serves each issued request. Clients are represented by PCs or special set-top boxes that request and download a particular piece of content stored somewhere in the CDN. The CDN usually works with clusters of clients rather than individual clients. The clients access the service provided by the CDN through different access networks, depending on the ISP.
Distribution network interconnects the origin servers with the multimedia streaming servers (MSSs) to deliver media objects within the streaming media CDN. The content manager controls the media objects stored in each replica server, providing this information to the redirector in order to get each client served by the most suitable replica server. The redirector module provides intelligence to the system because it estimates the most adequate replica server for each different request and client.
A functional CDN architecture includes two key layers: the routing layer and meta-routing layer (Figure 3.3).
Figure 3.3. Two layers in a CDN architecture
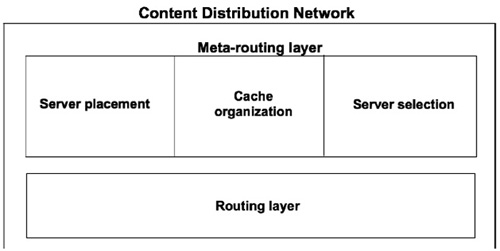
These two independent layers are the brain of a CDN architecture (Figure 3.3). While the routing layer takes into account the path finding process to optimize data delivery tasks, the meta-routing layer carries out some modules. In this book, we focus on the server selection module and propose a novel server selection policy based on user perception.
Definitively, for each layer, we propose a novel approach:
3.2. Routing layer
As a layer below the meta-routing layer in a CDN, the routing layer takes into account the routing process to transfer data between end user and selected server. The goal is to choose the best path that gives good user perception on end user side. For traditional routing process in CDN, providers usually use QoS routing systems, which are based on technical parameters and widely use routing protocols. In this section, first, we survey the QoS routing approaches they used in their CDN systems. Then, we present some classical routing algorithms. Finally, we discuss QoS routing with different protocols.
3.2.1. Routing in telecommunication network
Routing is one of the main features of the network layer, which is responsible for deciding on which output line an incoming packet must be retransmitted. In general, there is direct delivery, which corresponds to the transfer of a datagram between two computers on the same network, and indirect delivery, which is implemented as at least a router that separates the original sender and final recipient. Indirect delivery is necessary for determining to which router an IP datagram should be sent, according to its final destination. It is possible to use a specific routing table for each router to determine to which route a datagram output should be sent for any network. The main contents of a routing table consist of quadruples (destination, gateway, mask, interface).
There are many routing protocols, which can be divided into the following two categories:
In this section, we focus particularly on the intra-domain protocols that can be divided into two main categories: distance-vector protocols and link-state protocols.
3.2.2. Classical routing algorithms
3.2.2.1. Distance-vector routing
For distance-vector routing algorithm (Bellman-Ford routing) [HEI 08], each router has a routing table that indicates each destination, the best known distance and that line to reach it. This algorithm is used by the protocols RIPvl, RIPv2 [ATK 07] and IGRP [SHA 10b]. The estimated distance in the routing table assumes that a metric must be calculated locally for each router (e.g. the hop-count, packet number in the queue, routing time and link cost). The distance-vector routing algorithm can determine the optimal route by exchanging information in the list of metric distances. Furthermore, this information is exchanged between neighbor routers. First, each router starts registering, in its routing table, the links with neighbor routers indicating the line and the estimated distance. Then, periodically, each router sends this to all its neighbor tables extracted from its routing table containing the estimated distance for each destination, thereby updating the routing table. The principle idea of distance-vector routing is to find the shortest path following the imposed metric.
3.2.2.2. Link-state routing
With the link-state routing algorithms, each router maintains the same database of network topology. Each router executes the same algorithm in parallel, by building a tree, of which it is the root, to find the shortest path. This tree of the shortest path has the information of the entire path to any destination network, but only the next hop is stored in routing tables. After detecting the change of a link state, the router transmits information via a mechanism of broadcast to all other routers. Like distance-vector routing, the notion of shortest path uses a distance defined by a metric such as hop count and the number of packets in the queue. First, the link-state routing algorithm begins researching the neighbors and assessing the distances to reach them. Then, each estimated distance is sent to all routers in the network. Each router can include in its database the complete network topology, and then build the tree to calculate the shortest path. A typical link-state routing protocol is the OSPF [MOY 08, RÉT 09].
3.2.3. QoS-based routing
The user’s needs of telecommunications are characterized by an increase in bandwidth requirements (television services such as VoD, Internet access, telecommuting and video telephony). The use of next-generation network (NGN) as part of multimedia applications, services of guaranteed quality, mailing services, mobile services, etc., requires that the delivery service is guaranteed by a QoS control (throughput, delay, jitter, reliability, etc.). Certainly, the above-mentioned routing techniques do not meet these characteristics. Thus, it is necessary to design new routing mechanisms. Routing must take into account the real state of links and routers to perform QoS routing. Taking into account the QoS, routing is organized around three stages: (1) evaluating the state of network links; (2) collecting the information by the routers and (3) determining the routers satisfying these QoS constraints.
However, the authors of [WAN 95] and [MIC 79] proved that a QoS-based routing system met an NP-complete problem in finding a path satisfying more than two non-correlative constraints (e.g. delay, loss rate, jitter and cost) at the same time. Apart from the complexity problem, QoS-based routing faces another issue as follows. In fact, identifying a path for guaranteeing the QoS requirements needs accurate knowledge of the availability of network resources. Most existing routing algorithms assume the availability of precise state information. However, in many cases, this information may be inaccurate and insufficient. Another issue of QoS-based routing is that this kind of routing is no longer sufficient for the new types of content on the Internet: the high-quality multimedia content. Such content is sensitive to end-to-end delay, loss rate, etc., opposed to classic service-level agreements (SLAs) between network operators and service providers.
The approaches of QoS routing can be classified into four categories [HOC 04]:
We now present the four categories in detail.
3.2.3.1. Switching-based protocol: MPLS
MPLS [BOC 10] is a protocol that imposes a fixed route onto different flows to arrive at their destinations. It is based on the concept of label switching. Traffic characterization defining the required QoS is associated with each flow. It is not strictly a protocol of layer 3 (network layer), but rather an intermediary between layer 2 (link layer) and layer 3 (network layer) of the OSI model. MPLS is a technology that offers circuit mode to an IP, to the image of X25 or ATM. The advantages of MPLS can be summarized as follows:
The idea of label switching is to replace the search for the longest match between the destination address of IP packets, and present prefixes in the routing tables by inserting a label of fixed-length header between the network and link header of the packets. The determination of the next one is then made through the label. This solution is more advantageous, since it no longer relies on finding the longest match of prefixes of variable length, but on finding a fixed-length label.
Prospects for MPLS to improve the QoSs are numerous. Cisco contributed to the standardization of MPLS by offering the tag switching, which uses 3 bits in the Service Type field of the IPv4 header of incoming IP packets and places them in the field Class of Service (CoS) of the MPLS label. In the MPLS domain, the routing can be performed so as to favor the flow having the highest CoS. Moreover, one of the most interesting aspects of MPLS is the ability to build explicit end-to-end routing, the label-switched paths (LSP). These paths can be determined to meet the QoS constraints. Thus, multiple parallel paths can exist between two routers in the MPLS domain. Each path offers unique characteristics in terms of delay or bandwidth.
3.2.3.2. Protocols derived from existing protocols
We now survey some protocols that are derived from existing protocols. The first protocol is QOSPF [ZHA 07], an extension of OSPF. Combined with a reservation protocol, this routing protocol can inform all routers of the capacity of links to support the constraints of QoS. QOSPF is based on the use of two messages: the link resource advertisement (RES-LSA) message and the resource reservation advertisement (RRA) message. The purpose of the RES-LSA messages is to inform all the routers of the link state. This information is used to determine paths. This message type is used when a new router is added to the network or when the load of a link varies. The role of the RRA message is to indicate the resources used by a stream (or rather reserved for this flow). Each router is notified of the resources and the route taken by each flow. The number of RRA messages can become very high if the number of flows increases, which poses a problem of scale.
Classical routing algorithms use a single route to route packets from their source to their destination. To make best use of network resources, we should conduct a multipath routing [HE 08]. Indeed, the routing algorithms can find multiple paths with the same minimal cost. The choice of one of these paths is currently arbitrary. The techniques, namely equal cost multipath (ECMP) [GOJ 03], have been proposed in order to evenly distribute the traffic on these paths. Other techniques suggest an uneven distribution on different paths (optimized multipath (OMP)). There are also extensions to OSPF to perform routing on several paths. OSPF-ECMP can divide the traffic equally on optimal paths. Since these routing techniques are not sensitive to the load, there is no risk of oscillations.
3.2.3.3. Protocols based on multiple metrics
Metric combination is used to combine different metrics into a single metric and calculate the path that minimizes the resulting metric. Metric composition can use linear, nonlinear and Lagrange relaxation composition. The key idea in QoS routing is to find a path satisfying multiple constraints on routing metrics like desired bandwidth, delay time and end-to-end QoS. Nowadays, many studies have been introduced to integrate the QoS requirements which are problematic for the routing algorithm. However, only few proposed routing algorithms are suitable for today’s Internet such as QOSPF traffic engineering (TE) and the Wang Crowcroft algorithm (WCA). The Enhanced Interior Gateway Routing Protocol (EIGRP) [LEM 10] is also one of the multimetric routing algorithms.
In [GUE 99], the authors proposed the Guerin-Orda algorithm to solve both the bandwidth-constrained and delay-constrained problem with imprecise network states. The goal of the bandwidth-constrained routing is to find the path with the highest probability of accommodating a connection having a precise bandwidth requirement. The goal of the delay-constrained routing is to find a path having the highest probability of satisfying a given end-to-end delay. In fact, it is NP-hard to find the path satisfying these constraints at the same time. The idea of this algorithm is to transform a global constraint into local constraints. More precisely, the approach is to split the end-to-end delay constraint of intermediate links in such a way that all links in the path have the same probability of satisfying the local constraint.
Ma and Steenkiste [MA 97] presented a novel approach to solve the constraints on delay, jitter and buffer space in rate-based scheduling networks. In [WAN 96], the authors proposed a hop-by-hop distributed routing system. Every router predetermines a forwarding neighbor for every possible destination. This approach uses link-state protocol to maintain a complete global state, which is used to determine the shortest-widest path (i.e. the path that has maximum bandwidth and smallest delay).
3.2.3.4. Protocols based on learning techniques
In order to design adaptive algorithms for dynamic network routing problems, the researchers used different learning techniques. For RL, technique is defined as learning a policy, a converting of observations into actions, based on feedback from the environment. In RL, the network represents the environment whose state is determined by the number and relative position of nodes, the status of links between them and the dynamics of packets. Each node is considered as an agent who has a choice of actions. Another learning technique is based on the behavior of various biological entities such as an ant/bee colony [MEL 11a, BIT 10a]. Ant colony optimization (ACO) [DOR 06] is influenced by the foraging behavior of some ant species. These ants leave a pheromone on the ground to give information about a favorable path that should be followed by other members of the colony. ACO is widely used in routing systems. Di Caro et al. [DIC 05] proposed AntHocNet, an algorithm for routing in mobile ad hoc networks. This hybrid algorithm combines reactive route setup with proactive route probing, maintenance and improvement. At the start of a data session, it sets up paths when they are needed instead of maintaining routes to all destinations. Backward ants return to the source to set up paths in the form of pheromone tables indicating their quality as well.
Besides these techniques, there are also various routing algorithms based on a neural network for finding the optimal path [PAT 12, SCH 09]. In [SCH 09], the authors propose a hybrid intelligent method for routing combining Hopfield neural networks (HNNs) and simulated annealing (SA). The proposed method is considered as a modified version of the discrete time equation used to determine the new neuron input. The novel version of the equation improved the HNN convergence and decreased the computation cost. In addition, the SA algorithm is used to obtain the optimal parameters of the HNN. Gelenbe and Lent [GEL 04] propose cognitive packet networks (CPNs) that are based on random neural networks. These are store-and-forward packet networks in which the intelligence is constructed into the packets rather than at the routers or in the high-level protocols. CPN is a reliable packet network infrastructure that incorporates packet loss and delays directly into user QoS criteria and uses these criteria to do routing. The major drawback of algorithms based on cognitive packet networks is the convergence time, which is affected when the network is heavily loaded.
The Q-routing approach was first proposed by Boyan and Littman [BOY 94]. This is a technique where each node makes its routing decision based on the local routing information, represented as a table of Q-values that estimate the quality of the alternative routes. These values are updated each time the node sends a packet to one of its neighbors. However, when a Q-value is not updated for a long time, it does not necessarily reflect the current state of the network and hence a routing decision that is based on such an unreliable Q-value will not be accurate. The update rule in Q-routing does not take into account the reliability of the estimated or the updated Q-value because it depends on the traffic pattern and load levels. In fact, most of the Q-values in the network are unreliable.
Mellouk et al. [?] propose a continuous state-dependent routing algorithm based on a multipath routing approach exploiting the Q-routing algorithm. The global learning algorithm finds K best paths in terms of cumulative link cost and optimizes the residual bandwidth and the average delivery time on these paths. The technique used to estimate the residual bandwidth and the end-to-end delay is based on the RL approach to take into account dynamic changes in networks. The proposed system, called bandwidth delay K optimal paths Q-routing algorithms (BDKOQRA), takes into account static and dynamic QoS criteria and is based on inductive approaches with continuous learning of dynamic network parameters such as link capacity, end-to-end delay and residual bandwidth. A load balancing policy that depends on the traffic dynamic path probability distribution function is also supported.
In the last few decades, many research areas have been massively influenced by the behavior of various biological entities and phenomena. Hence, there are also routing algorithms inspired by bee life [BIT 10b]. Teodorovic and Dell’Orco proposed bee colony optimization (BCO) [TEO 05], which is an improvement and generalization of the bee system. This proposal is able to solve combinatorial problems characterized by uncertainty. The authors used a fuzzy bee system representing one of the possible BCOs on the ride-sharing problem. Inspired by BCO, Markovic et al. [MAR 07a] tailored BCO-RWA for the routing and wavelength assignment (RWA) problem in all-optical networks regardless of wavelength conversion in intermediate nodes. This proposal has been applied to a static case in which lightpath requests are known in advance. Authors proved that BCO-RWA can produce optimal or near-optimal solutions in a reasonable amount of computer time.
So, we can see that all approaches mentioned above have taken into account only the QoS criteria (technical parameters) in ignoring the QoE notion. This lack motivates us to integrate the QoE into a routing system. This work is described in Chapter 4. We work not only on the routing layer but also on the meta-routing layer, which is presented in the next section.
3.3. Meta-routing layer
The basic idea of a CDN is to move the content from the locations of origin servers to locations closer to end users, at the edge of the network. Apart from routing mechanisms in core networks (that is realized by routing layer modules), we explain in this section how the CDN provider places the replica servers, how they build caching policy and how they select the appropriate replica server to serve the user request. Among various modules of meta-routing layer, we survey in this section three main modules (Table 3.1): Server placement, cache organization and server selection. Then, we explain why we have chosen the server selection module among the three modules. Finally, we focus on the “server selection” module in proposing a new selection algorithm, which will be presented in Chapter 5.
Table 3.1. Approaches for meta-routing modules
|
Modules |
Approaches |
|
Server placement |
Minimum K-center problem [JAM 00] Facility location problem [QIU 01] k-hierarchically well-separated trees [BAR 96] Topology-informed placement strategy [JAM 01] |
|
Cache organization |
Caching techniques: [PAT 08] Query-based scheme Digest-based scheme Directory-based scheme Hashing-based scheme Cache update techniques: [PAT 08] Periodic update Update propagation On-demand update Invalidation |
|
Server selection |
Algorithms: Round-Robin [SZY 03] Globule project [PIE 06] [KAR 99] [AND 02] [ARD 01] Mechanisms: Client multiplexing [BHA 97, BEC 98] HTTP redirection DNS indirection Anycasting Peer-to-peer |
3.3.1. Server placement
In order to minimize the average content access latency perceived by end users and the network bandwidth consumption, CDN needs a server placement module to decide where on the network to place the servers, which store replicas of data. Intuitively, replica servers should be placed closer to the clients to reduce latency and bandwidth consumption. In this section, we give a survey of the approaches concerning server placement issues.
To resolve the server placement problem, there are some theoretical approaches such as minimum K-center problem [JAM 00], the facility location problem [QIU 01] or k-hierarchically well-separated trees [BAR 96]. For the minimum K-center problem, the goal is to minimize the maximum distance between a node and the nearest center with a given number of centers. Similar to the latter, the facility location problem has a given constraint that is the total cost in terms of building facilities and service clients. The third issue, k-hierarchically well-separated trees, is based on graph theory.
These theoretical approaches described above are not easy to implement in real CDN systems because they are computationally expensive and they do not consider the characteristics of the network. Therefore, some heuristic solutions have been developed. Qiu et al. [QIU 01] propose a server placement approach based on a greedy algorithm [KRI 00]. The goal of this algorithm is to choose M servers among N potential sites. One site is chosen at a time. First, to determine the suitability for hosting a server, each of the N sites is evaluated individually. The site having the lowest cost (e.g. bandwidth consumption) is chosen. Then, the iteration continues until M servers have been chosen. This algorithm assumes that users direct their accesses to the server which has the lowest cost. The l-backtracking greedy algorithm is discussed in [JAM 01]. The difference from the basic, algorithm is that in each iteration, the l-backtracking greedy algorithm verifies all the possible combinations by deleting l of the already placed servers and replacing them with l + 1 new servers.
Jamin et al. [JAM 01] propose a topology-informed placement strategy. The authors assume that the nodes with the highest outdegrees1 can reach more nodes with smaller latency. They place servers on candidate hosts in descending order of outdegrees. However, as one has no detailed information of network topology, each node represents a single AS. Each AS-level BGP peering corresponds to a node link.
The experiments of these above-mentioned strategies show that the topology-informed placement strategy can perform almost as well as the greedy placement. They show that using router-level topology information gives better performance than exploiting only AS-level topology. In addition, they proved that the performance improvement degrades with the increasing server number.
After placing servers in the network, another important task of a CDN service provider is to organize the server cache. This work is clarified in the next section.
3.3.2. Cache organization
We now present the cache organization of a CDN system. Cache organization includes caching techniques and cache update techniques. The goal is to guarantee the availability, freshness and reliability of content. The performance of a CDN system will be improved if the cache is well organized. In this section, we present cache organization in two parts: caching techniques and cache update techniques [PAT 08].
The content caching can be classified into two classes: intra-cluster and inter-cluster caching. The intra-cluster involves different schemes such as the query-based scheme, digest-based scheme, directory-based scheme and hashing-based scheme. In the query-based scheme [WES 97], CDN server broadcasts a query to other cooperating CDN servers for each cache miss. The CDN server has to wait for the last “miss” reply of their neighbors to conclude that there is no peer who has the requested content. Hence, the problems of this scheme are the significant query traffic and the delay. The digest-based scheme [ROU 98] focuses on the problem of the flooding queries in the query-based scheme. In the digest-based scheme, each CDN server maintains a digest of content stored by other cooperating replica servers. The updating CDN server informs the cooperating replica servers of content updates. Based on the content digest, a CDN server can decide which particular replica server should be used to route a content request. However, due to the frequent exchange of update messages to ensure having the correct information about each other, the update traffic overhead is a drawback of this scheme. The directory-based scheme [GAD 97] is introduced as a centralized version of the digest-based scheme. In this scheme, the centralized server has the information of all replica servers in a cluster. The CDN server only informs the directory server when local updates occur. If there is a local cache miss, CDN server will query the directory server. The directory server receives all the information from cooperating replica servers. The problems of this centralized scheme are potential bottlenecks and single points of failure. In the hashing-based scheme [KAR 99, VAL 98], all servers use the same hashing functions. The designated server keeps the content based on IP addresses of the CDN servers and the hashing function. This designated server carries out all requests for that particular content. Because of the smallest implementation overhead and highest content sharing efficiency, the hashing-based scheme is more efficient than other schemes.
The inter-cluster cooperative caching cannot apply the hashing-based scheme because representative servers of different clusters are normally distributed geographically. There is only the query-based scheme that can be applied to inter-cluster caching. A cluster will query its neighbor cluster if it fails to serve a content request. The neighbor will reply a hit message if it finds the requested content. On the contrary, if the neighbor does not find the requested content, it will forward this request to an other neighbor. The hashing-based scheme is used by all the servers of a cluster. A server only queries the designated server of that cluster to serve a content request.
To ensure the freshness of content, a CDN provider should take into account the cache update mechanism. Clearly, with the delays involved in propagating the content, the content may be inconsistent or expired. Hence, the CDN provider must address the problems about how long different content is to be considered fresh, when to check back with the origin server for updated content, etc. We now discuss some cache update techniques: periodic update, update propagation, on-demand update and invalidation.
In the periodic update technique, caches are updated regularly. The drawback of this approach is that significant levels of unnecessary traffic are generated from update traffic at each interval. With the update propagation technique, the active content is performed and pushed to the CDN cache servers. So, the updated version of a document is sent to all caches even if there is a change of document at the origin server. Due to the frequent changing of content, this approach creates excess update traffic. According to on-demand update, one propagates the latest copy of a document to the replica server based on the prior request for that content. This technique assumes that the content is not updated unless it is requested. The drawback of this technique is the back-and-forth traffic between the cache and origin server. In the invalidation technique, the invalidation message is broadcasted to all surrogate caches when a document is modified at the origin server. While the document is being modified, the surrogate caches are blocked. After that, the cache has to fetch an updated version of the document. The disadvantage of this technique is that it does not make full use of the distribution network for content delivery.
Because of the cache organization, CDNs help the content provider to ensure a freshness content and the consistency of CDN sites. In fact, the content providers themselves construct the policies and heuristics for caching policies. Then, the content providers give the caching policies to the CDN provider, which it will deploy to its caches. Based on these rules, the caches know how to maintain the freshness of content through ensuring consistency.
The tasks of server placement and cache organization are considered as preparation-related process of a CDN service. The first one, the server placement module, is used to place the replica servers in order to minimize the average content access latency and the network bandwidth consumption. The second one, the cache organization module, takes into account the cache management process to guarantee the availability, freshness and reliability of content. Despite this, these two modules are launched in the preparation phase where one designs the infrastructure for a CDN service. In this book, we focus on the module that appears in the main phase of a CDN: the server selection module.
3.3.3. Server selection
As explained earlier, we focus on the server selection module among the modules in the meta-routing layer. The server selection module is used to direct the user requests to the suitable replica server. It could direct the request to the closest replica server. However, the closest server may not be the best one for servicing this request. So, apart from hop-count criteria, they should consider other metrics such as network proximity, client perceived latency, distance and replica server load. In this section, we survey several server selection algorithms and mechanisms.
3.3.3.1. Server selection algorithms
Server selection algorithms are classified into two types [PAT 08]: adaptive and non-adaptive. The difference between these two types is the consideration of the current condition. In fact, while the adaptive algorithm considers the current condition of the environment to select the replica server, the non-adaptive algorithm only uses some heuristics to select the replica server.
The most common non-adaptive server selection algorithm is round-robin [SZY 03], which balances the load between the servers by sending all requests to replica servers in a round. This simple algorithm is efficient for clusters, where all the replica servers are installed in the same place. However, the round-robin server selection algorithm is not suitable for wide-area distributed systems. Another non-adaptive algorithm assumes that the replica server load and the client-server distance are the most influential factors. This algorithm takes into account the client-server distance to direct requests to the replica servers in such a way that load is balanced among them. The Cisco DistributedDirector [DEL 99] applied some non-adaptive server selection algorithms. They also consider the percentage of received client requests and assume that the server receiving more requests is more powerful. They support random request distribution that randomly chooses the replica server. In addition, there are other non-adaptive algorithms that direct requests to the closest replica.
According to adaptive server selection algorithms, we now survey some representative proposals. The Globule project [PIE 06] proposes an adaptive server selection algorithm that always chooses the server closest to the users in terms of network proximity. They use path length as an estimation metric that is updated periodically. This algorithm seems inefficient (that is proven in [HUF 02]) because the metric used is passive and it does not introduce any additional traffic to the network. In another proposal, Karger et al. [KAR 99] propose an algorithm to adapt to hotspots. They utilize URL content to generate a hashing function from various identifiers. They use this hashing function to route the user requests to a logical ring involving cache servers with IDs from the same space. This algorithm directs user requests to the cache server holding the smallest ID. In two proposals [AND 02, ARD 01], the authors use user-server latency as an evaluation metric. They use client access logs and passive server-side latency to measure the client-server latency. The replica server having the minimal latency is chosen. The drawback of this approach is that it needs the maintenance of central database measurements, which restricts the scalability of the system. In another approach, Cisco DistributedDirector [DEL 99] proposes an adaptive server selection algorithm, which carries out a weighted combination of three metrics: inter-AS distance, intra-AS distance and end-to-end latency. Using three metrics makes this approach flexible. However, the deployment for metric measurement is complex and costly. In addition, the active measurement technique gives more additional traffic to the system. Akamai [AKA 98, DIL 02] propose an adaptive algorithm to avoid the flash crowds problem. Their metrics used are: replica server load, the reliability of loads between the client and each replica server and also the available bandwidth of a server.
3.3.3.2. Server selection mechanisms
There are many techniques to direct the user requests to the appropriate server among various replica servers. These techniques are classified into five categories [PEN 04]:
3.4. Conclusion
This chapter has surveyed the general CDN architecture with its two principal layers: the routing layer and the meta-routing layer. In fact, over the last few years, CDN has actually become an efficient solution for the rapid growth and evolution of the Internet. The mechanism of replicating content from the origin server to replica servers can present short access delay and consume less network bandwidth of the Internet infrastructure. In fact, serving content from a local replica server typically has better performance (lower access latency, higher transfer rate) than from the origin server. This chapter plays an important role in clarifying our way of integrating the QoE model into the CDN architecture. This is also the basic premise to explain the need of applying the QoE model to a CDN.
1 The node outdegree is the number of other nodes it is connected to.