
6. Text Analytics and Sentiment Analysis
The information age that we are living in is characterized by rapid growth in the amount of data and information collected, stored, and made available in electronic format. A vast majority of business data is stored in text documents that are virtually unstructured. According to a study by Merrill Lynch and Gartner, 85% of all corporate data is captured and stored in some sort of unstructured form (McKnight, 2005). The same study also stated that this unstructured data is doubling in size every 18 months. Because knowledge is power in today’s business world, and knowledge is derived from data and information, businesses that effectively and efficiently tap into their text data sources will have the necessary knowledge to make better decisions, leading to a competitive advantage over those businesses that lag behind. This is where the need for text analytics and text mining fits into the big picture of today’s businesses.
Even though the overarching goal for both text analytics and text mining is to turn unstructured textual data into actionable information through the application of natural language processing (NLP) and analytics, their definitions are somewhat different, at least to some experts in the field. According to many, text analytics is a broader concept that includes information retrieval (e.g., searching and identifying relevant documents for a given set of key terms) as well as information extraction, data mining, and web mining, whereas text mining is primarily focused on discovering new and useful knowledge from textual data sources.
Figure 6.1 illustrates the relationships between text analytics and text mining, along with other related application areas. The bottom of the figure lists the main disciplines (the foundation of the house) that play critical roles in the development of these increasingly more popular application areas.

Compared to text mining, text analytics is a relatively new term. With the recent emphasis on analytics, many related technical application areas (e.g., consumer analytics, completive analytics, visual analytics, social analytics) have jumped on the analytics bandwagon. While the term text analytics is more commonly used in business application context, text mining is frequently used in academic research circles. Even though these terms may be defined somewhat differently at times, text analytics and text mining are usually used synonymously.
Text mining (also known as text data mining or knowledge discovery in textual databases) is the semiautomated process of extracting patterns (i.e., useful information and knowledge) from large amounts of unstructured data. Remember that data mining is the process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data stored in structured databases, where the data are organized in records structured by categorical, ordinal, or continuous variables. Text mining is the same as data mining in that it has the same purpose and uses the same processes, but with text mining the input to the process is a collection of unstructured (or less structured) data files, such as Word documents, PDF files, text excerpts, XML files, and so on. In essence, text mining can be thought of as a process (with two main steps) that starts with imposing structure on the text-based data sources followed by extracting relevant information and knowledge from this structured text-based data by using data mining techniques and tools.
The benefits of text mining are obvious in areas where very large amounts of textual data are being generated, such as law (e.g., court orders), academic research (e.g., research articles), finance (e.g., quarterly reports), medicine (e.g., discharge summaries), biology (e.g., molecular interactions), technology (e.g., patent files), and marketing (e.g., customer comments). For example, free-form text-based interactions with customers in the form of complaints (or praises) and warranty claims can be used to objectively identify product and service characteristics that are deemed to be less than perfect and can be used as input to improve product development and service allocations. Likewise with market outreach programs and focus groups that generate large amounts of data. By not restricting product or service feedback to a codified form, customers can present, in their own words, what they think about a company’s products and services.
Another area where the automated processing of unstructured text has had a lot of impact is in email and other electronic communications. Text mining not only can be used to classify and filter junk email, but it can also be used to automatically prioritize email based on importance level as well as generate automatic responses (Weng & Liu, 2004). The following are some of the most popular application areas of text mining:
• Information extraction. Text mining can identify key phrases and relationships within text by looking for predefined objects and sequences in text by using pattern matching. Perhaps the most commonly used form of information extraction is entity extraction. Named entity extraction includes named entity recognition (recognition of known entity names—for people and organizations, place names, temporal expressions, and certain types of numeric expressions, using existing knowledge of the domain), co-reference resolution (detection of co-reference and anaphoric links between text entities), and relationship extraction (identification of relationships between entities).
• Topic tracking. Based on a user profile and documents that a user views, text mining can predict other documents that might be of interest to the user.
• Summarization. Text mining can be used to summarize a document to save the reader time.
• Categorization. Text mining can be used to identify the main themes of a document and then place the document into a predefined set of categories, based on those themes.
• Clustering. Text mining can be used to group similar documents without having a predefined set of categories.
• Concept linking. Text mining can be used to connect related documents by identifying their shared concepts and, by doing so, help users find information that they perhaps would not find by using traditional search methods.
• Question answering. Text mining can be used to find the best answer to a given question through knowledge-driven pattern matching.
Text mining has its own language, with many technical terms and acronyms. Following is a list of some of the terms and concepts that are commonly used in the context of text mining:
• Unstructured data (versus structured data). Structured data has a predetermined format. It is usually organized into records with simple data values (categorical, ordinal, and continuous variables) and stored in databases. In contrast, unstructured data does not have a predetermined format and is stored in the form of textual documents. In essence, the structured data is for the computers to process, while the unstructured data is for humans to process and understand.
• Corpus. In linguistics, a corpus (plural corpora) is a large and structured set of texts (now usually stored and processed electronically), prepared for the purpose of conducting knowledge discovery.
• Terms. A term is a single-word or multiword phrase extracted directly from the corpus of a specific domain by means of natural language processing (NLP) methods.
• Concepts. Concepts are features generated from a collection of documents by means of manual, statistical, rule-based, or hybrid categorization methodologies. Concepts result from higher-level abstraction than do terms.
• Stemming. Stemming is the process of reducing inflected words to their stem (or base or root) form. For instance, stemmer, stemming, and stemmed are all based on the root stem.
• Stop words. Stop words (or noise words) are words that are filtered out prior to or after processing of natural language data (i.e., text). Even though there is no universally accepted list of stop words, most natural language processing tools use a list that includes articles (a, am, the, of, etc.), auxiliary verbs (is, are, was, were, etc.), and context-specific words that are deemed not to have differentiating value.
• Synonyms and polysemes. Synonyms are syntactically different words (i.e., spelled differently) with identical or at least similar meanings (e.g., movie, film, and motion picture). In contrast, polysemes, also called homonyms, are syntactically identical words (i.e., spelled exactly the same) but have different meanings (e.g., bow can mean “to bend forward,” “the front of a ship,” “a weapon that shoots arrows,” or “a kind of tied ribbon”).
• Tokenizing. A token is a categorized block of text in a sentence. The block of text corresponding to the token is categorized according to the function it performs. This assignment of meaning to blocks of text is known as tokenizing. A token can look like anything; it just needs to be a useful part of the structured text.
• Term dictionary. A term dictionary is a collection of terms specific to a narrow field that can be used to restrict the extracted terms within a corpus.
• Word frequency. The number of times a word is found in a specific document is called the word frequency.
• Part-of-speech tagging. This is the process of marking up the words in a text that correspond to a particular part of speech (e.g., nouns, verbs, adjectives, adverbs), based on each word’s definition and the context in which it is used.
• Morphology. Morphology is a branch of the field of linguistics and a part of natural language processing that studies the internal structure of words (patterns of word formation within a language or across languages).
• Term-by-document matrix (occurrence matrix). This type of matrix is a common representation schema for the frequency-based relationship between terms and documents in tabular format, where terms are listed in rows, documents are listed in columns, and the frequency between the terms and documents is listed in cells as integer values.
• Singular-value decomposition (latent semantic indexing). This dimensionality reduction method is used to transform a term-by-document matrix to a manageable size by generating an intermediate representation of the frequencies using a matrix manipulation method similar to principal-component analysis.
Natural Language Processing
Some of the early text mining applications used a simplified representation called bag-of-words when introducing structure to a collection of text-based documents in order to classify them into two or more predetermined classes or to cluster them into natural groupings. In the bag-of-words model, text—such as a sentence, paragraph, or complete document—is represented as a collection of words, disregarding the grammar or the order in which the words appear. The bag-of-words model is still used in some simple document classification tools. For instance, in spam filtering, an email message can be modeled as an unordered collection of words (a bag of words) that is compared against two different predetermined bags. One bag is filled with words found in spam messages and the other is filled with words found in legitimate emails. Although some of the words are likely to be found in both bags, the “spam” bag will contain spam-related words such as stock market, Viagra, and buy much more frequently than the legitimate bag, which will contain more words related to the user’s friends or workplace. The level of match between a specific email’s bag of words and the two bags containing the descriptors determines the characterization of the email as either spam or legitimate.
Naturally, we humans do not use words without some order or structure. We use words in sentences, which have semantic as well as syntactic structure. Thus, automated techniques (e.g., text mining) need to look for ways to go beyond the bag-of-words interpretation and incorporate more and more semantic structure into their operations. The current trend in text mining is toward including many of the advanced features that can be obtained using natural language processing.
It has been shown that the bag-of-words method may not produce good enough information content for text mining tasks (e.g., classification, clustering, association). A good example of this can be found in evidence-based medicine. A critical component of evidence-based medicine is incorporating the best available research findings into the clinical decision-making process, which involves appraisal of the information collected from the printed media for validity and relevance. Several researchers from University of Maryland developed evidence assessment models using a bag-of-words method (Lin & Demner-Fushman, 2005). They employed popular machine learning methods along with more than half a million research articles collected from MEDLINE (Medical Literature Analysis and Retrieval System). In their models, they represented each abstract as a bag of words, where each stemmed term represented a feature. Despite using popular classification methods with proven experimental design methodologies, their prediction results were not much better than simple guessing, which may indicate that the bag-of-words method is not generating a good enough representation of the research articles in this domain; hence, more advanced techniques such as natural language processing are needed.
Natural language processing (NLP) is an important component of text mining and is a subfield of artificial intelligence and computational linguistics. It studies the problem of understanding natural human language, with the view of converting depictions of human language (e.g., textual documents) into more formal representations (in the form of numeric and symbolic data) that are easier for computer programs to manipulate. The goal of NLP is to move beyond syntax-driven text manipulation (which is often called “word counting”) to a true understanding and processing of natural language that considers grammatical and semantic constraints as well as the context.
The definition and scope of the word understanding is one of the major discussion topics in NLP. Considering that the natural human language is vague and that a true understanding of meaning requires extensive knowledge of a topic (beyond what is in the words, sentences, and paragraphs), will computers ever be able to understand natural language the same way and with the same accuracy that humans do? Probably not! NLP has come a long way from the days of simple word counting, but it has an even longer way to go to really understanding natural human language. The following are just a few of the challenges commonly associated with the implementation of NLP:
• Part-of-speech tagging. It is difficult to mark up terms in a text as corresponding to a particular part of speech (e.g., nouns, verbs, adjectives, adverbs) because the part of speech depends not only on the definition of the term but also on the context within which the term is used.
• Text segmentation. Some written languages, such as Chinese, Japanese, and Thai, do not have single-word boundaries. In these instances, the text-parsing task requires the identification of word boundaries, which is often difficult. Similar challenges in speech segmentation emerge when analyzing spoken language because sounds representing successive letters and words blend into each other.
• Word sense disambiguation. Many words have more than one meaning. Selecting the meaning that makes the most sense can only be accomplished by taking into account the context within which the word is used.
• Syntactic ambiguity. The grammar for natural languages is ambiguous; that is, multiple possible sentence structures often need to be considered. Choosing the most appropriate structure usually requires a fusion of semantic and contextual information.
• Imperfect or irregular input. Foreign or regional accents and vocal impediments in speech and typographical or grammatical errors in texts make the processing of language an even more difficult task.
• Speech acts. A sentence can often be considered a request for action. The sentence structure alone may not contain enough information to define the action. For example, “Can you pass the class?” requests a simple yes/no answer, whereas “Can you pass the salt?” is a request for a physical action to be performed.
It is a longstanding dream of the artificial intelligence community to come up with algorithms that are capable of automatically reading and obtaining knowledge from text. By applying a learning algorithm to parsed text, researchers from Stanford University’s NLP lab have developed methods that can automatically identify concepts and relationships between those concepts in text. By applying a unique procedure to large amounts of text, their algorithms automatically acquire hundreds of thousands of items of world knowledge and use them to produce significantly enhanced repositories for WordNet. WordNet is a laboriously hand-coded database of English words, their definitions, sets of synonyms, and various semantic relationships between synonym sets. It is a major resource for NLP applications, but it has proven to be very expensive to build and maintain manually. By automatically inducing knowledge into WordNet, the potential exists to make WordNet an even greater and more comprehensive resource for NLP at a fraction of the cost.
One prominent area where the benefits of NLP and WordNet are already being harvested is in customer relationship management (CRM). Broadly speaking, the goal of CRM is to maximize customer value by better understanding and effectively responding to their actual and perceived needs. An important area of CRM, where NLP is making a significant impact, is sentiment analysis. Sentiment analysis is a technique used to detect favorable and unfavorable opinions toward specific products and services, using large numbers of textual data sources (customer feedback in the form of Web postings). Detailed coverage of sentiment analysis is given later in this chapter.
NLP has successfully been applied to a variety of domains for a variety of tasks via computer programs to automatically process natural human language that previously could be done only by humans. Following are among the most popular of these tasks:
• Question answering. NLP can be used to automatically answer a question posed in natural language—that is, to produce a human-language answer to a human-language question. To find the answer to a question, the computer program may use either a prestructured database or a collection of natural language documents (a text corpus such as the World Wide Web).
• Automatic summarization. A computer program can be used to create a shortened version of a textual document that contains the most important points of the original document.
• Natural language generation. Systems can convert information from computer databases into readable human language.
• Natural language understanding. Systems can convert samples of human language into more formal representations that are easier for computer programs to manipulate.
• Machine translation. Systems can automatically translate one human language to another.
• Foreign language reading. A computer program can assist a nonnative language speaker in reading a foreign language with correct pronunciation and accents on different parts of the words.
• Foreign language writing. A computer program can assist a nonnative language user in writing in a foreign language.
• Speech recognition. Systems can convert spoken words to machine-readable input. Given a sound clip of a person speaking, such a system produces a text dictation.
• Text-to-speech. A computer program can automatically convert normal language text into human speech. This is also called speech synthesis.
• Text proofing. A computer program can read a proof copy of a text in order to detect and correct any errors.
• Optical character recognition. A system can automatically translate images of handwritten, type-written, or printed text (usually captured by a scanner) into machine-editable textual documents.
The success and popularity of text mining depends greatly on advancements in NLP in both generation as well as understanding of human languages. NLP enables the extraction of features from unstructured text so that a wide variety of data mining techniques can be used to extract knowledge (novel and useful patterns and relationships) from it. In that sense, simply put, text mining is a combination of NLP and data mining.
Text Mining Applications
As the amount of unstructured data collected by organizations increases, so do the value proposition and popularity of text mining tools. Many organizations are now realizing the importance of extracting knowledge from their document-based data repositories through the use of text mining tools. Following are only a small subset of the exemplary application categories of text mining.
Marketing Applications
Text mining can be used to increase cross-selling and up-selling by analyzing the unstructured data generated by call centers. Text generated by call-center notes as well as transcriptions of voice conversations with customers can be analyzed by text mining algorithms to extract novel, actionable information about customers’ perceptions about a company’s products and services. In addition, blogs, user reviews of products at independent Websites, and discussion board postings are gold mines of customer sentiments. This rich collection of information, properly analyzed, can be used to increase satisfaction and the overall lifetime value of a customer.
Text mining has become invaluable for customer relationship management. Companies can use text mining to analyze rich sets of unstructured text data, combined with relevant structured data extracted from organizational databases, to predict customer perceptions and subsequent purchasing behavior. For instance text mining can be used to meaningfully improve the ability of a mathematical model to predict customer churn (i.e., customer attrition) so that those customers identified as most likely to leave a company could be accurately identified for retention tactics.
Treating products as sets of attribute–value pairs rather than as atomic entities can potentially boost the effectiveness of many business applications, including demand forecasting, assortment optimization, product recommendations, assortment comparison across retailers and manufacturers, and product supplier selection. Ghani et al. (2006) used text mining to develop a system capable of inferring implicit and explicit attributes of products to enhance retailers’ ability to analyze product databases. The proposed system allows a business to represent its products in terms of attributes and attribute values without much manual effort. The system learns these attributes by applying supervised and semi-supervised learning techniques to product descriptions found on retailers’ Websites.
Security Applications
One of the largest and most prominent text mining applications in the security domain is the highly classified ECHELON surveillance system. As rumor has it, ECHELON is capable of identifying the content of telephone calls, faxes, emails, and other types of data, intercepting information sent via satellites, public switched telephone networks, and microwave links.
In 2007, EUROPOL developed an integrated system capable of accessing, storing, and analyzing vast amounts of structured and unstructured data sources in order to track transnational organized crime. Called the Overall Analysis System for Intelligence Support (OASIS), this system aims to integrate the most advanced data and text mining technologies available in today’s market. The system has enabled EUROPOL to make significant progress in supporting its law enforcement objectives at the international level (EUROPOL, 2007).
The U.S. Federal Bureau of Investigation (FBI) and the Central Intelligence Agency (CIA), under the direction of the Department for Homeland Security, are jointly developing a supercomputer data and text mining system. The system is expected to create a gigantic data warehouse along with a variety of data and text mining modules to meet the knowledge-discovery needs of federal, state, and local law enforcement agencies. Prior to this project, the FBI and CIA each had its own separate databases, with little or no interconnection.
Another security-related application of text mining is in the area of deception detection. Applying text mining to a large set of real-world criminal (person-of-interest) statements, Fuller et al. (2008) developed prediction models to differentiate deceptive statements from truthful ones. Using a rich set of cues extracted from the textual statements, the model predicted the holdout samples with 70% accuracy, which is believed to be a significant success considering that the cues are extracted only from textual statements (with no verbal or visual cues). Furthermore, compared to other deception-detection techniques, such as polygraph, this method is nonintrusive and widely applicable to not only textual data but also (potentially) to transcriptions of voice recordings. A more detailed description of text-based deception detection is provided at the end of this chapter as an application example.
Biomedical Applications
Text mining holds great potential for the medical field in general and biomedicine in particular for several reasons. First, the published literature and publication outlets (especially with the advent of open source journals) in the field are expanding exponentially. Second, compared to most other fields, the medical literature is more standardized and orderly, making it a more “minable” information source. Finally, the terminology used in this literature is relatively constant, having a fairly standardized ontology. A few exemplary studies have successfully used text mining techniques in extracting novel patterns from biomedical literature.
Experimental techniques such as DNA microarray analysis, serial analysis of gene expression (SAGE), and mass spectrometry proteomics, among others, are generating large amounts of data related to genes and proteins. As in any other experimental approach, it is necessary to analyze this vast amount of data in the context of previously known information about the biological entities under study. The literature is a particularly valuable source of information for experiment validation and interpretation. Therefore, the development of automated text mining tools to assist in such interpretation is one of the main challenges in current bioinformatics research.
Knowing the location of a protein within a cell can help elucidate its role in biological processes and determine its potential as a drug target. Numerous location-prediction systems are described in the literature; some focus on specific organisms, whereas others attempt to analyze a wide range of organisms. Shatkay et al. (2007) proposed a comprehensive system that uses several types of sequence- and text-based features to predict the locations of proteins. The main novelty of their system lies in the way in which it selects its text sources and features and integrates them with sequence-based features. Shatkay et al. (2007) tested the system on previously used data sets and on new data sets devised specifically to test the predictive power of the system. The results showed that their system consistently beat previously reported results.
Chun et al. (2006) described a system that extracts disease–gene relationships from literature accessed via MEDLINE. They constructed a dictionary for disease and gene names from six public databases and extracted relationship candidates by using dictionary matching. Because dictionary matching produces a large number of false positives, Chun et al. developed a method of machine learning–based named entity recognition (NER) to filter out false recognitions of disease/gene names. They found that the success of relation extraction is heavily dependent on the performance of NER filtering and that the filtering improved the precision of relation extraction by 26.7%, at the cost of a small reduction in recall.
Figure 6.2 shows a simplified depiction of a multilevel text analysis process for discovering gene–protein relationships (or protein–protein interactions) in the biomedical literature (Nakov et al., 2005). This simplified example uses a simple sentence from biomedical text. As shown in the figure, first (at the bottom three levels), the text is tokenized using part-of-speech tagging and shallow parsing. The tokenized terms (words) are then matched (and interpreted) against the hierarchical representation of the domain ontology to derive the gene–protein relationship. Application of this method (and/or some variation of it) to the biomedical literature offers great potential for decoding the complexities in the Human Genome Project.

The issue of text mining is of great importance to publishers that hold large databases of information requiring indexing for better retrieval. This is particularly true in scientific disciplines, in which highly specific information is often contained in written text. Initiatives have been launched, such as Nature’s proposal for an Open Text Mining Interface (OTMI) and the National Institutes of Health’s Journal Publishing Document Type Definition (DTD), that would provide semantic cues to machines to answer specific queries contained within text without removing publisher barriers to public access.
Academic institutions have also launched text mining initiatives. For example, the National Centre for Text Mining, a collaborative effort between the Universities of Manchester and Liverpool in the United Kingdom, provides customized tools, research facilities, and advice on text mining to the academic community. With an initial focus on text mining in the biological and biomedical sciences, research has since expanded into the social sciences. In the United States, the School of Information at the University of California, Berkeley, is developing a program called BioText to assist bioscience researchers in text mining and analysis.
The Text Mining Process
In order to be successful, text mining studies should follow a sound methodology based on best practices. Remember from Chapter 3, “The Data Mining Process,” that CRISP-DM is the industry standard for data mining projects; likewise, a standardized process model is needed for text mining. Even though most parts of CRISP-DM are also applicable to text mining projects, a specific process model for text mining would include much more elaborate data preprocessing activities. Figure 6.3 depicts a high-level context diagram of a typical text mining process (Delen & Crossland, 2008). This context diagram presents the scope of the process, emphasizing its interfaces with the larger environment. In essence, it draws boundaries around the specific process to explicitly identify what is included in (and excluded from) the text mining process.

As the context diagram indicates, the input (the inward connection to the left edge of the box) into the text-based knowledge discovery process is the unstructured as well as structured data collected, stored, and made available to the process. The output (the outward extension from the right edge of the box) of the process is the context-specific knowledge that can be used for decision making. The controls, also called the constraints (the inward connection to the top edge of the box), of the process include software and hardware limitations, privacy issues, and difficulties related to processing the text that is presented in the form of natural language. The mechanisms (the inward connection to the bottom edge of the box) of the process include proper techniques, software tools, and domain expertise. The primary purpose of text mining (within the context of knowledge discovery) is to process unstructured (textual) data (along with structured data, if relevant to the problem being addressed and available) to extract meaningful and actionable patterns for better decision making.
At a very high level, the text mining process can be broken down into three consecutive tasks, each of which has specific inputs to generate certain outputs (see Figure 6.4). If, for some reason, the output of a task is not what was expected, a backward redirection to the previous task execution is necessary.
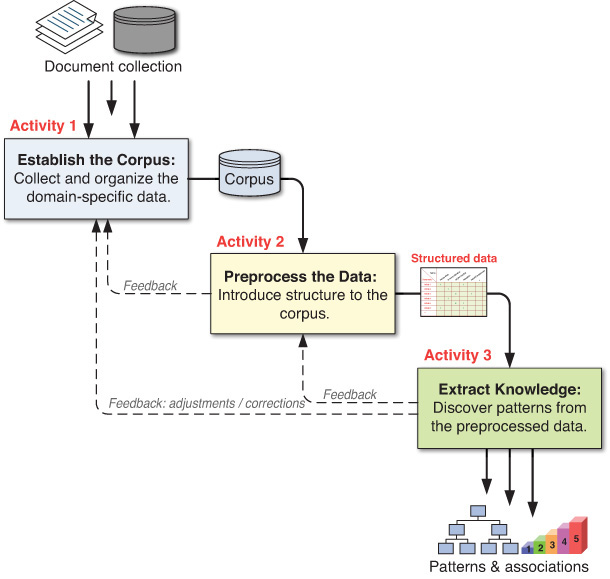
Task 1: Establish the Corpus
The main purpose of the first task in the text mining process is to collect all the documents related to the context (i.e., domain of interest) being studied. This collection may include textual documents, XML files, emails, Web pages, and short notes. In addition to the readily available textual data, voice recordings may also be transcribed using speech-recognition algorithms and made a part of the text collection.
Once collected, the text documents are transformed and organized in a manner such that they are all in the same representational form (e.g., ASCII text files) for computer processing. The organization of the documents can be as simple as a collection of digitized text excerpts stored in a file folder, or it can be a list of links to a collection of Web pages in a specific domain. Many commercially available text mining software tools could accept these as input and convert them into a flat file for processing. Alternatively, the flat file can be prepared outside the text mining software and then presented as the input to the text mining application.
Task 2: Preprocess the Data: Create the Term–Document Matrix
In task 2 of the text mining process, the digitized and organized documents (the corpus) are used to create the term–document matrix (TDM). In the TDM, rows represent the documents, and columns represent the terms. The relationships between the terms and documents are characterized by indices (i.e., a relational measure that can be as simple as the number of occurrences of the term in respective documents). Figure 6.5 shows a typical example of a TDM.

The goal is to convert the list of organized documents (the corpus) into a TDM where the cells are filled with the most appropriate indices. The assumption is that the essence of a document can be represented with a list of the frequency of the terms used in that document. However, are all terms important when characterizing documents? Obviously, the answer is “no.” Some terms, such as articles, auxiliary verbs, and terms used in almost all the documents in the corpus, have no differentiating power and therefore should be excluded from the indexing process. This list of terms, commonly called stop terms or stop words, is specific to the domain of study and should be identified by the domain experts. On the other hand, the experts might choose a set of predetermined terms under which the documents are to be indexed (called include terms or a dictionary). In addition, synonyms (pairs of terms that are to be treated the same) and specific phrases (e.g., “Eiffel Tower”) can also be provided so that the index entries are more accurate.
Another filtration that should take place to accurately create the indices is stemming, which refers to the reduction of words to their roots so that, for example, different grammatical forms or declinations of a verb are identified and indexed as the same word. For example, stemming would ensure that modeling and modeled will be recognized as the word model.
The first generation of a TDM includes all the unique terms identified in the corpus (as its columns), excluding the ones in the stop term list; all the documents (as its rows); and the occurrence count of each term for each document (as its cell values). If, as is commonly the case, the corpus includes a rather large number of documents, then there is a very good chance that the TDM will have a very large number of terms. Processing such a large matrix might be time-consuming and, more importantly, might lead to extraction of inaccurate patterns. At this point, one has to decide the following: (1) What is the best way to represent the indices? and (2) How can we reduce the dimensionality of this matrix to a manageable size?
What Is the Best Way to Represent the Indices?
Once the input documents are indexed and the initial word frequencies (by document) are computed, a number of additional transformations can be performed to summarize and aggregate the extracted information. The raw term frequencies generally reflect on how salient or important a word is in each document. Specifically, words that occur with greater frequency in a document are better descriptors of the contents of that document. However, it is not reasonable to assume that the word counts themselves are proportional to their importance as descriptors of the documents. For example, if a word occurs one time in document A but three times in document B, then it is not necessarily reasonable to conclude that the word is three times as important a descriptor of document B as of document A. In order to have a more consistent TDM for further analysis, these raw indices need to be normalized. As opposed to showing the actual frequency counts, the numeric representation between terms and documents can be normalized using a number of alternative methods. The following are a few of the most commonly used normalization methods (StatSoft, 2014):
• Log frequencies. The raw frequencies can be transformed using the log function. This transformation “dampens” the raw frequencies and how they affect the results of subsequent analysis.
• Binary frequencies. An even simpler transformation than log frequencies can be used to enumerate whether a term is used in document binary frequencies. The resulting TDM matrix will contain only 1s and 0s to indicate the presence or absence of the respective words. Again, this transformation dampens the effect of the raw frequency counts on subsequent computations and analyses.
• Inverse document frequencies. Another issue to consider related to the indices used in further analyses is the relative document frequencies (df) of different terms. For example, a term such as guess may occur frequently in all documents, whereas another term, such as software, may appear only a few times. The reason is that one might make guesses in various contexts, regardless of the specific topic, whereas software is a more semantically focused term that is only likely to occur in documents that deal with computer software. A common and very useful transformation that reflects both the specificity of words (i.e., document frequencies) and the overall frequencies of their occurrences (i.e., term frequencies) is the so-called inverse document frequency (Manning et al. 2008).
How Can We Reduce the Dimensionality of the TDM Matrix?
Because the TDM is often very large and rather sparse (with most of the cells filled with zeros), an important question is “How can we reduce the dimensionality of this matrix to a manageable size?” Several options are available for managing matrix size:
• A domain expert can go through the list of terms and eliminate those that do not make much sense for the context of the study (this is a manual, labor-intensive process).
• We can eliminate terms with very few occurrences in very few documents.
• We can transform the matrix by using singular value decomposition.
Singular value decomposition (SVD), which is closely related to principal-component analysis, reduces the overall dimensionality of the input matrix (i.e., the number of input documents by the number of extracted terms) to a lower dimensional space, where each consecutive dimension represents the largest degree of variability (between words and documents) possible (Manning et al. 2008). Ideally, an analyst might identify the two or three most salient dimensions that account for most of the variability (i.e., differences) between the words and documents, thus identifying the latent semantic space that organizes the words and documents in the analysis. Once such dimensions are identified, the underlying meaning of what is contained (discussed or described) in the documents has been extracted.
Task 3: Extract the Knowledge
Using a well-structured TDM, potentially augmented with other structured data elements, novel patterns are extracted in the context of the specific problem being addressed. The main categories of knowledge extraction methods are classification, clustering, association, and trend analysis. A short description of these methods follows.
Classification
Arguably the most common knowledge discovery topic in analyzing complex data sources is the classification (or categorization) of certain objects. The task is to classify a given data instance into a predetermined set of categories (or classes). As it applies to the domain of text mining, the task is known as text categorization, where for a given set of categories (subjects, topics, or concepts) and a collection of text documents, the goal is to find the correct topic (subject or concept) for each document, using models developed with a training data set that includes both the documents and actual document categories. Today, automated text classification is applied in a variety of contexts, including automatic or semiautomatic (interactive) indexing of text, spam filtering, Web page categorization under hierarchical catalogs, automatic generation of metadata, and detection of genre.
Clustering
Clustering is an unsupervised process whereby objects are classified into “natural” groups called clusters. In categorization, a collection of preclassified training examples is used to develop a model based on the descriptive features of the classes in order to classify a new unlabeled example; on the other hand, in clustering, the problem is to group an unlabeled collection of objects (e.g., documents, customer comments, Web pages) into meaningful clusters without any prior knowledge.
Clustering is useful in a wide range of applications, from document retrieval to better Web content searching. In fact, one of the prominent applications of clustering is the analysis and navigation of very large text collections, such as Web pages. The basic underlying assumption is that relevant documents tend to be more similar to each other than to irrelevant ones. If this assumption holds, the clustering of documents based on the similarity of their content improves search effectiveness.
Association
A formal definition and detailed description of association was provided in Chapter 4, “Data and Methods in Data Mining.” The main idea in generating association rules (or solving market-basket problems) is to identify the sets that frequently go together. In text mining, associations specifically refer to the direct relationships between concepts (terms) or sets of concepts. The concept set association rule, relating two frequent concept sets A and C, can be quantified by the two basic measures support and confidence. In this case, confidence is the percentage of documents that include all the concepts in C within the same subset of those documents that include all the concepts in A. Support is the percentage (or number) of documents that include all the concepts in A and C. For instance, in a document collection, the concept software implementation failure may appear most often in association with enterprise resource planning and customer relationship management, with significant support (4%) and confidence (55%), meaning that 4% of the documents had all three concepts represented together in the same document, and of the documents that included software implementation failure, 55% of them also included enterprise resource planning and customer relationship management. Text mining with association rules was used to analyze published literature (news and academic articles posted on the Web) to chart the outbreak and progress of bird flu (Mahgoub et al., 2008). The idea was to automatically identify the associations among the geographic areas, spread across species, and countermeasures (treatments).
Trend Analysis
Recent methods of trend analysis in text mining have been based on the notion that the various types of concept distributions are functions of document collections; that is, different collections lead to different concept distributions for the same set of concepts. It is therefore possible to compare two distributions that are otherwise identical except that they are from different subcollections. One notable direction of this type of analyses is having two collections from the same source (e.g., from the same set of academic journals) but from different points in time. Delen and Crossland (2008) applied trend analysis to a large number of academic articles published in the three highest-rated academic journals to identify the evolution of key concepts in the field of information systems. Following is a description of this text mining application.
Application Example: Text Mining of Research Literature

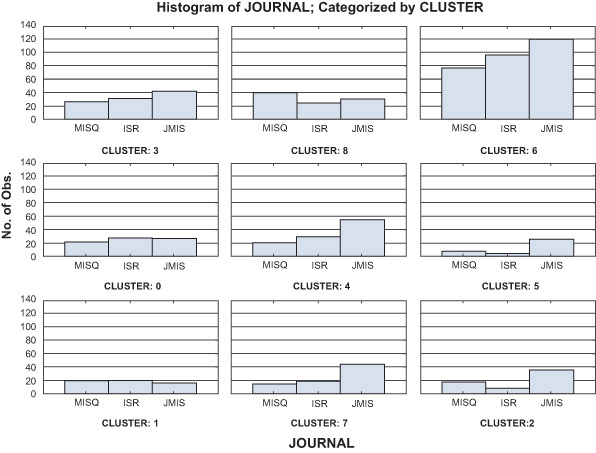

Source: Delen & Crossland, 2008.
Figure 6.8 Time-Dependent Changes in the Number of Articles Published in Each Cluster
Text Mining Tools
As more and more organizations are realizing the value of text mining, the number of software tools offered by software companies and nonprofits is also increasing. The following sections describe some of the popular text mining tools, which we classify as commercial software tools and free (and/or open source) software tools.
Commercial Software Tools
The following are some of the most popular software tools used for text mining. Note that many of these companies offer demonstration versions of their products on their Websites:
• ClearForest offers text analysis and visualization tools.
• IBM offers SPSS Modeler and Data and Text Analytics Toolkit.
• Megaputer Text Analyst offers semantic analysis of free-form text, summarization, clustering, navigation, and natural language retrieval with search-dynamic refocusing.
• SAS Text Miner provides a rich suite of text processing and analysis tools.
• KXEN Text Coder (KTC) is text analytics solution for automatically preparing and transforming unstructured text attributes into a structured representation for use in KXEN Analytic Framework.
• The Statistica Text Mining engine provides easy-to-use text mining functionally with exceptional visualization capabilities.
• VantagePoint provides a variety of interactive graphical views and analysis tools with powerful capabilities to discover knowledge from text databases.
• The WordStat analysis module from Provalis Research analyzes textual information such as responses to open-ended questions and interviews.
• Clarabridge text mining software provides an end-to-end solution for customer experience professionals wishing to transform customer feedback for marketing, service, and product improvements.
Free Software Tools
Free software tools, some of which are open source, are available from a number of nonprofit organizations:
• RapidMiner has a graphically appealing user interface and is one of the most popular free, open source software tools for data mining and text mining.
• Open Calais is an open source toolkit for including semantic functionality within your blog, content management system, Website, or application.
• GATE is a leading open source toolkit for text mining. It has a free open source framework (or SDK) and graphical development environment.
• LingPipe is a suite of Java libraries for linguistic analysis of human language.
• S-EM (Spy-EM) is a text classification system that learns from positive and unlabeled examples.
• Vivisimo/Clusty is a Web search and text-clustering engine.
Often, innovative application of text mining comes from the collective use of several software tools.
Sentiment Analysis
We humans are social beings. We are adept at utilizing a variety of means to exchange ideas. We often consult financial discussion forums before making an investment decision, we ask our friends for their opinions on a newly opened restaurant or a newly released movie, and we conduct Internet searches and read consumer reviews and expert reports before making a big purchase like a house, a car, or an appliance. We rely on others’ opinions to make better decisions, especially in an area where we don’t have a lot of knowledge or experience. Thanks to the growing availability and popularity of opinion-rich Internet resources such as social media outlets (e.g., Twitter, Facebook), online review sites, and personal blogs, it is now easier than ever to find opinions of others (thousands of them, as a matter of fact) on everything from the latest gadgets to political and public figures. Even though not everybody expresses opinions on the Internet, due to fast-growing numbers and capabilities of social communication channels, the numbers are increasing exponentially.
Sentiment is a difficult word to exactly define. It is often linked to or confused with other terms, like belief, view, opinion, and conviction. Sentiment suggests a subtle opinion reflective of one’s feelings (Mejova, 2009). Sentiment has some unique properties that sets it apart from other concepts that we might want to identify in text. Often we want to categorize text by topic, which may involve dealing with whole taxonomies of topics. Sentiment classification, on the other hand, usually deals with two classes (positive versus negative), a range of polarity (e.g., star ratings for movies), or even a range in strength of opinion (Pang & Lee, 2008). These classes span many topics, users, and documents. Although dealing with only a few classes may seem like an easier task than standard text analysis, it is far from the reality.
As a field of research, sentiment analysis is closely related to computational linguistics, natural language processing, and text mining. Sentiment analysis has many names. It’s often referred to as opinion mining, subjectivity analysis, and appraisal extraction, with some connections to affective computing (computer recognition and expression of emotion). The sudden upsurge of interest and activity in the area of sentiment analysis, which deals with the automatic extraction of opinions, feelings, and subjectivity in text, is creating opportunities and threats for business and individuals alike. The ones who embrace and take advantage of it will greatly benefit from it. Every opinion put on the Internet by an individual or a company will be accredited back to the originator (good or bad) and will be retrieved and mined by others (often automatically by computer programs).
Sentiment analysis tries to answer the question “What do people feel about a certain topic?” by digging into opinions of many, using a variety of automated tools. Bringing together researchers and practitioners in business, computer science, computational linguistics, data mining, text mining, psychology, and even sociology, sentiment analysis aims to expand traditional fact-based text analysis to new frontiers to realize opinion-oriented information systems. In a business setting, especially in marketing and customer relationship management, sentiment analysis seeks to detect favorable and unfavorable opinions toward specific products and/or services, using a large numbers of textual data sources (e.g., customer feedback in the form of Web postings, tweets, blogs, etc.).
Sentiment that appears in text comes in two flavors: explicit, where the text directly expresses an opinion (“It’s a wonderful day”), and implicit, where the text implies an opinion (“The handle breaks too easily”). Most of the earlier work done in sentiment analysis focused on the first kind of sentiment, since it is was easier to analyze. Current trends are to implement analytical methods to consider both implicit and explicit sentiments. Sentiment polarity is a particular feature of text that sentiment analysis primarily focuses on. It is usually dichotomized into two areas—positive and negative—but polarity can also be thought of as a range. A document containing several opinionated statements would have a mixed polarity overall, which is different from not having a polarity at all (being objective) (Mejova, 2009).
Sentiment Analysis Applications
Traditional sentiment analysis methods were survey based or focus group centered; they were costly and time-consuming and, hence, were driven from a small sample of participants. In contrast, the new face of text analytics–based sentiment analysis is a limit breaker. Current solutions automate very large-scale data collection, filtering, classification, and clustering methods via natural language processing and data mining technologies that handle both factual and subjective information. Sentiment analysis is perhaps the most popular application of text analytics, tapping into data sources like tweets, Facebook posts, online communities, discussion boards, blogs, product reviews, call center logs and recordings, product rating sites, chat rooms, price comparison portals, search engine logs, and newsgroups. The following sections discuss applications of sentiment analysis to illustrate the power and the widespread coverage of this technology.
Voice of the Customer (VOC)
VOC is an integral part of an analytic CRM and customer experience management systems. As the enabler of VOC, sentiment analysis can access a company’s product and service reviews (either continuously or periodically) to better understand and better manage customer complaints and praises. For instance, a motion picture advertising/marketing company might detect negative sentiments toward a movie that is about to open in theaters (based on its trailers) and quickly change the composition of the trailers and its advertising strategy (on all media outlets) to mitigate the negative impact. Similarly, a software company may detect negative buzz regarding the bugs found in its newly released product early enough to release patches and quick fixes to alleviate the situation.
Often, the focus of VOC is individual customers and their service- and support-related needs, wants, and issues. VOC draws data from the full set of customer touchpoints, including emails, surveys, call center notes/recordings, and social media postings, and it matches customer voices to transactions (e.g., inquiries, purchases, returns) and individual customer profiles captured in enterprise operational systems. VOC, mostly driven by sentiment analysis, is a key element of customer experience management initiatives, where the goal is to create an intimate relationship with the customer.
Voice of the Market (VOM)
VOM is about understanding aggregate opinions and trends. It’s about knowing what stakeholders—customers, potential customers, influencers, whoever—are saying about your, and your competitors’, products and services. A well-done VOM analysis helps companies with competitive intelligence and product development and positioning.
Voice of the Employee (VOE)
Traditionally, VOE has been limited to employee satisfaction surveys. Text analytics in general and sentiment analysis in specific are huge enablers of assessing VOE. Using rich, opinionated textual data is an effective and efficient way to listen to what employees are saying. As we all know, happy employees empower customer experience efforts and improve customer satisfaction.
Brand Management
Brand management focuses on listening to social media, where anyone (e.g., past/current/prospective customers, industry experts, other authorities) can post opinions that can damage or boost a reputation. A number of relatively newly launched startup companies offer analytics-driven brand management services. Brand management is product and company focused rather than customer focused. It attempts to shape perceptions rather than to manage experiences, using sentiment analysis techniques.
Financial Markets
Predicting the future values of individual (or a group of) stocks has been an interesting and seemingly unsolvable problem. What makes a stock (or a group of stocks) move up or down is anything but an exact science. Many believe that the stock market is mostly sentiment driven, making it anything but rational (especially for short-term stock movements). Therefore, use of sentiment analysis in financial markets has gained significant popularity. Automated analysis of market sentiments using social media, news, blogs, and discussion groups seems to be a proper way to compute market movements. If done correctly, sentiment analysis can identify short-term stock movements based on the buzz in the market, potentially impacting liquidity and trading.
Politics
As we all known, opinions matter a great deal in politics. Because political discussions are dominated by quotations, sarcasm, and complex references to persons, organizations, and ideas, politics is one of the most difficult—and potentially fruitful—areas for sentiment analysis. By analyzing the sentiment on election forums, it may be possible to predict who is more likely to win or lose. Sentiment analysis can help understand what voters are thinking and can clarify a candidate’s position on issues. Sentiment analysis can help political organizations, campaigns, and news analysts better understand which issues and positions matter the most to voters. The technology was successfully applied by both parties to the 2008 and 2012 U.S. presidential election campaigns.
Government Intelligence
Government intelligence is another application of sentiment analysis. For example, it has been suggested that one could monitor sources for increases in hostile or negative communications. Sentiment analysis can allow the automatic analysis of the opinions that people submit about pending policy or government-regulation proposals. Furthermore, monitoring communications for spikes in negative sentiment may be of use to agencies like the Department of Homeland Security.
Other Interesting Areas
Sentiments of customers can be used to better design ecommerce sites (e.g., product suggestions, up-sell/cross-sell advertising), better place advertisements (e.g., placing dynamic advertisement of products and services that consider the sentiment on the page the user is browsing), and mine opinion- or review-oriented search engines (i.e., opinion-aggregation Websites, as alternatives to sites like Epinions, to summarize user reviews). Sentiment analysis can help with email filtration by categorizing and prioritizing incoming emails (e.g., it can detect strongly negative or flaming emails and forward them to a proper folder), as well as citation analysis, where it can determine whether an author is citing a piece of work as supporting evidence or as research that he or she dismisses.
The Sentiment Analysis Process
Because of the complexity of the problem of sentiment analysis (e.g., underlying concepts, expressions in text, the context in which text is expressed), there is not a readily available standardized process for conducting sentiment analysis. However, based on the published work in the field of sentiment analysis so far (both on research methods and range of applications), a multistep, simple, logical process, as shown in Figure 6.9, seems to be an appropriate methodology for sentiment analysis. These logical steps are iterative (i.e., feedbacks, corrections, and iterations are part of the discovery process) and experimental in nature, and once completed and combined, capable of producing desired insight about the opinions in the text collection.
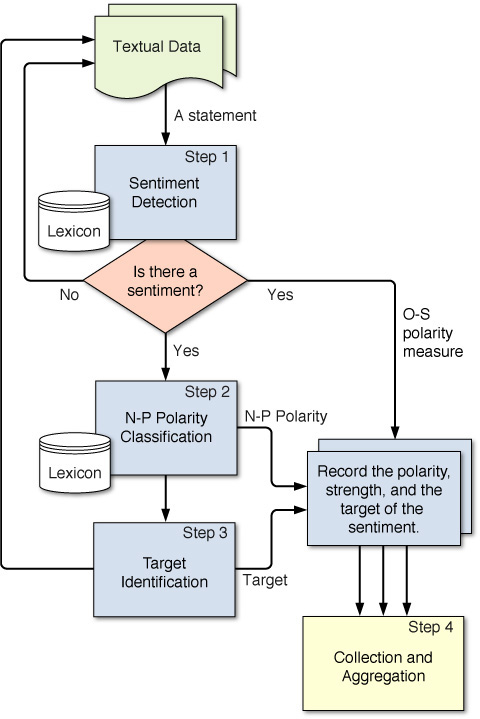
Step 1: Sentiment Detection
After the retrieval and preparation of the text documents, the first main task in sensitivity analysis is the detection of objectivity. Here the goal is to differentiate between a fact and an opinion, which may be viewed as classification of text as objective or subjective. This may also be characterized as calculation of O-S polarity (objectivity–subjectivity polarity, which may be represented with a numeric value ranging from 0 to 1). If the objectivity value is close to 1, then there is no opinion to mine (i.e., it is a fact), and therefore the process goes back and grabs the next text data to analyze. Usually opinion detection is based on the examination of adjectives in text. For example, the polarity of “what a wonderful work” can be determined relatively easily by looking at the adjective.
Step 2: N-P Polarity Classification
The second main task is polarity classification. Given an opinionated piece of text, the goal is to classify the opinion as falling under one of two opposing sentiment polarities or locate its position on the continuum between these two polarities (Pang & Lee, 2008). When viewed as a binary feature, polarity classification is the binary classification task of labeling an opinionated document as expressing either an overall positive opinion or an overall negative opinion (e.g., thumbs up/thumbs down). In addition to the identification of N-P polarity, one should also be interested in identifying the strength of the sentiment; as opposed to just positive, it may be expressed as mildly, moderately, strongly, or very strongly positive. A lot of research has been done on product or movie reviews where the definitions of “positive” and “negative” are quite clear. Other tasks, such as classifying news as “good” or “bad,” present some difficulty. For instance, an article may contain negative news without explicitly using any subjective words or terms. Furthermore, these classes usually appear intermixed when a document expresses both positive and negative sentiments. Then the task can be to identify the main (or dominating) sentiment of the document. Still, for lengthy texts, the tasks of classification may need to be done at several levels: term, phrase, sentence, and perhaps document level. For those, it is common to use the outputs of one level as the inputs for the next higher layer.
Step 3: Target Identification
The goal of this step is to accurately identify the target of the expressed sentiment (e.g., a person, a product, an event). The difficulty of this task depends largely on the domain of the analysis. Even though it is usually easy to accurately identify the target for product or movie reviews, because the review is directly connected to the target, it may be quite challenging in other domains. For instance, lengthy, general-purpose text such as Web pages, news articles, and blogs do not always have predefined topics that they are assigned to, and they often mention many objects, any of which may be deduced as the target. Sometimes there is more than one target in a sentiment sentence, which is the case in comparative texts. A subjective comparative sentence orders objects in order of preferences, such as “This laptop computer is better than my desktop PC.” Such sentences can be identified using comparative adjectives and adverbs (e.g., more, less, better, longer), superlative adjectives (e.g., most, least, best) and other words, such as same, differ, win, prefer, etc. Once the sentences have been retrieved, the objects can be put in an order that is most representative of their merits, as described in text.
Step 4: Collection and Aggregation
Once the sentiments of all text data points in the document are identified and calculated, in this step, they are aggregated and converted to a single sentiment measure for the whole document. This aggregation may be as simple as summing up the polarities and strengths of all texts or as complex as using semantic aggregation techniques from natural language processing to come up with the ultimate sentiment.
The Methods Used for Polarity Identification
As mentioned in the previous section, polarity identification can be made at the word, term, sentence, or document level. The most granular level for polarity identification is the word level. Once the polarity identification is made at the word level, it can be aggregated to the next higher level, and then the next until the level of aggregation desired from the sentiment analysis is reached. There seem to be two dominant techniques used for identification of polarity at the word/term level, each of which has advantages and disadvantages:
• Using a lexicon as a reference library—either developed manually or automatically, by an individual for a specific task or developed by an institution for general use
• Using a collection of training documents as the source of knowledge about the polarity of terms within a specific domain (i.e., inducing predictive models from opinionated textual documents)
Application Example: Text-Based Deception Detection

Sources: C. M. Fuller, D. Biros, & D. Delen, “Exploration of Feature Selection and Advanced Classification Models for High-Stakes Deception Detection,” Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS), Big Island, HI, IEEE Press, pp. 80–99, 2008; and C. F. Bond & B. M. DePaulo, “Accuracy of Deception Judgments,” Personality and Social Psychology Reports, 10(3): 214–234, 2006.
References
Bond C. F., & B. M. DePaulo. (2006). “Accuracy of Deception Judgments,” Personality and Social Psychology Reports, 10(3): 214–234.
Chun, H. W., Y. Tsuruoka, J. D. Kim, R. Shiba, N. Nagata, T. Hishiki, & Jun’ichi Tsujii. (2006, January). “Extraction of Gene-Disease Relations from Medline Using Domain Dictionaries and Machine Learning,” Pacific Symposium on Biocomputing, 11: 4–15.
Delen, D., & M. Crossland. (2008). “Seeding the Survey and Analysis of Research Literature with Text Mining,” Expert Systems with Applications, 34(3): 1707–1720.
Etzioni, O. (1996). “The World Wide Web: Quagmire or Gold Mine?” Communications of the ACM, 39(11): 65–68.
EUROPOL. (2007). EUROPOL Work Program 2007, state-watch.org/news/2006/apr/europol-work-programme-2007.pdf (accessed October 2008).
Feldman, R., & J. Sanger. (2007). The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data. Boston: ABS Ventures.
Fuller, C. M., D. Biros, & D. Delen. (2008). “Exploration of Feature Selection and Advanced Classification Models for High-Stakes Deception Detection,” Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS), Big Island, HI: IEEE Press, pp. 80–99.
Ghani, R., K. Probst, Y. Liu, M. Krema, & A. Fano. (2006). “Text Mining for Product Attribute Extraction,” SIGKDD Explorations, 8(1): 41–48.
Grimes, S. (2011, February 17). “Seven Breakthrough Sentiment Analysis Scenarios,” InformationWeek.
Kanayama, H., & T. Nasukawa. (2006). Fully Automatic Lexicon Expanding for Domain-Oriented Sentiment Analysis, EMNLP: Empirical Methods in Natural Language Processing, http://trl.ibm.com/projects/textmining/takmi/sentiment_analysis_e.htm (accessed February 2014).
Lin, J., & D. Demner-Fushman. (2005). “‘Bag of Words’ Is Not Enough for Strength of Evidence Classification,” AMIA Annual Symposium Proceedings, pp. 1031–1032. http://pubmedcen-tral.nih.gov/articlerender.fcgi?artid=1560897 (accessed December 2013).
Mahgoub, H., D. Rösner, N. Ismail, & F. Torkey. (2008). “A Text Mining Technique Using Association Rules Extraction,” International Journal of Computational Intelligence, 4(1): 21–28.
Manning, C. D., P. Raghavan & H. Schutze. (2008). Introduction to Information Retrieval. Cambridge, MA: MIT Press.
Masand, B. M., M. Spiliopoulou, J. Srivastava, & O. R. Zaïane. (2002). “Web Mining for Usage Patterns and Profiles,” SIGKDD Explorations, 4(2): 125–132.
McKnight, W. (2005, January 1). “Text Data Mining in Business Intelligence,” Information Management Magazine. http://information-management.com/issues/20050101/1016487-1.html (accessed May 2009).
Mejova, Y. (2009). Sentiment Analysis: An Overview, www.cs.uiowa.edu/~ymejova/publications/CompsYelenaMejova.pdf (accessed February 2013).
Miller, T. W. (2005). Data and Text Mining: A Business Applications Approach. Upper Saddle River, NJ: Prentice Hall.
Nakov, P., A. Schwartz, B. Wolf, & M. A. Hearst. (2005). “Supporting Annotation Layers for Natural Language Processing.” Proceedings of the ACL, interactive poster and demonstration sessions. Ann Arbor, MI: Association for Computational Linguistics, pp. 65–68.
Pang, B., & L. Lee. (2008). Opinion Mining and Sentiment Analysis, http://dl.acm.org/citation.cfm?id=1596846.
Peterson, E. T. (2008). The Voice of Customer: Qualitative Data as a Critical Input to Web Site Optimization, http://foreseeresults.com/Form_Epeterson_WebAnalytics.html (accessed May 2009).
Shatkay, H., et al. (2007). “SherLoc: High-Accuracy Prediction of Protein Subcellular Localization by Integrating Text and Protein Sequence Data,” Bioinformatics, 23(11): 1410–1417.
StatSoft. (2014). Statistica Data and Text Miner User Manual. Tulsa, OK: StatSoft, Inc.
Weng, S. S., & C. K. Liu. (2004) “Using Text Classification and Multiple Concepts to Answer E-mails,” Expert Systems with Applications, 26(4): 529–543.
Zhou, Y., et al. (2005). “U.S. Domestic Extremist Groups on the Web: Link and Content Analysis,” IEEE Intelligent Systems, 20(5): 44–51.