
6
A New Approach of Texts and Writing Normalization for Arabic Knowledge Organization
6.1. Introduction
The normalization of the Arabic language and its writing are a necessity for its automatic processing. This mainly concerns the linguistic composition elements: syntactic, semantic, stylistic and orthographic structures (Fadili 2020a, 2020b). In order to contribute in this context, we propose an unsupervised approach based on deep learning implementing a normalization support system of writing in general, and in the context of written Arabic texts.
The approach is based mainly on the improvement of the Bi-RNN (bidirectional recurrent neural network) model and its contextual implementation Bi-LSTM (bidirectional long short-term memory) for sequence prediction. We have implemented mechanisms to capture the writing signals encoded through the different layers of the network for optimizing the prediction of the next structures and the next words completing the sentences in writing progress or transforming texts already written into their normalized forms. The latent structures and the reference spelling are those learned from the training corpus considering their importance and relevance: integration of the notions of attention and point of view in Bi-LSTM.
This chapter is structured as follows: section 6.3 presents the learning model, section 6.4 defines the methodological and technological elements implementing the approach, section 6.5 is devoted to the generation of the dataset for learning and, finally, section 6.6 presents the tests and the results obtained.
6.2. Motivation
The language writing normalization that we are talking about concerns all aspects related to syntactic, semantic, stylistic and orthographic structures (Fadili 2020a, 2020b). This is a complex task, especially in the case of languages used on the Internet, such as Arabic. Proposing solutions that can help authors and new users of such languages to respect and popularize their standards could be an important element in the process of standardizing their writings.
The rapid return and development of artificial intelligence makes such solutions possible: unsupervised approaches that do not require prerequisites or preprocessed data can be used to code the latent science contained in the studied corpora as the basis of machine learning and as references for normalization.
These are the elements that motivated us to study and propose an unsupervised approach, allowing us to detect and use the “NORMALIZATION” coded and contained in “well-written” texts in terms of spelling, composition and structure language.
Our contribution consists, on the one hand, of adapting and instantiating the contextual data model (see Fadili 2017) and, on the other hand, of making improvements to the basic Bi-LSTM in order to circumvent their limits in the management of “contextual metadata”.
6.3. Using a machine learning model
Several studies have shown that deep learning has been successfully exploited in many fields, including that of automatic natural language processing (NLP). One of the best implementations is the generation of dense semantic vector spaces (Mikolov 2013).
Other networks such as RNN (recurrent neural networks) have also been improved and adapted to support the recurrent and sequential nature of NLP: each state is calculated from its previous state and new entry. These networks have the advantage of propagating information in both directions: towards the input and output layers, thus reflecting an implementation of neural networks, close to the functioning of the human brain where information can be propagated in all directions by exploiting the memory principle (see the LSTM version of RNN in the following), via recurrent connections propagating the information of ulterior learning (the memorized information).
These are the characteristics that allow them to take better care of several important aspects of natural language. Indeed, they have this ability to capture latent syntactic, semantic, stylistic and orthographic structures, from the order of words and their characteristics, unlike other technologies such as those based on the concept of bag of words (BOW) where the order is not considered, obviously involving loss of the associated information.
In serial RNNs, each new internal and output state simply depends on the new entry and the old state.
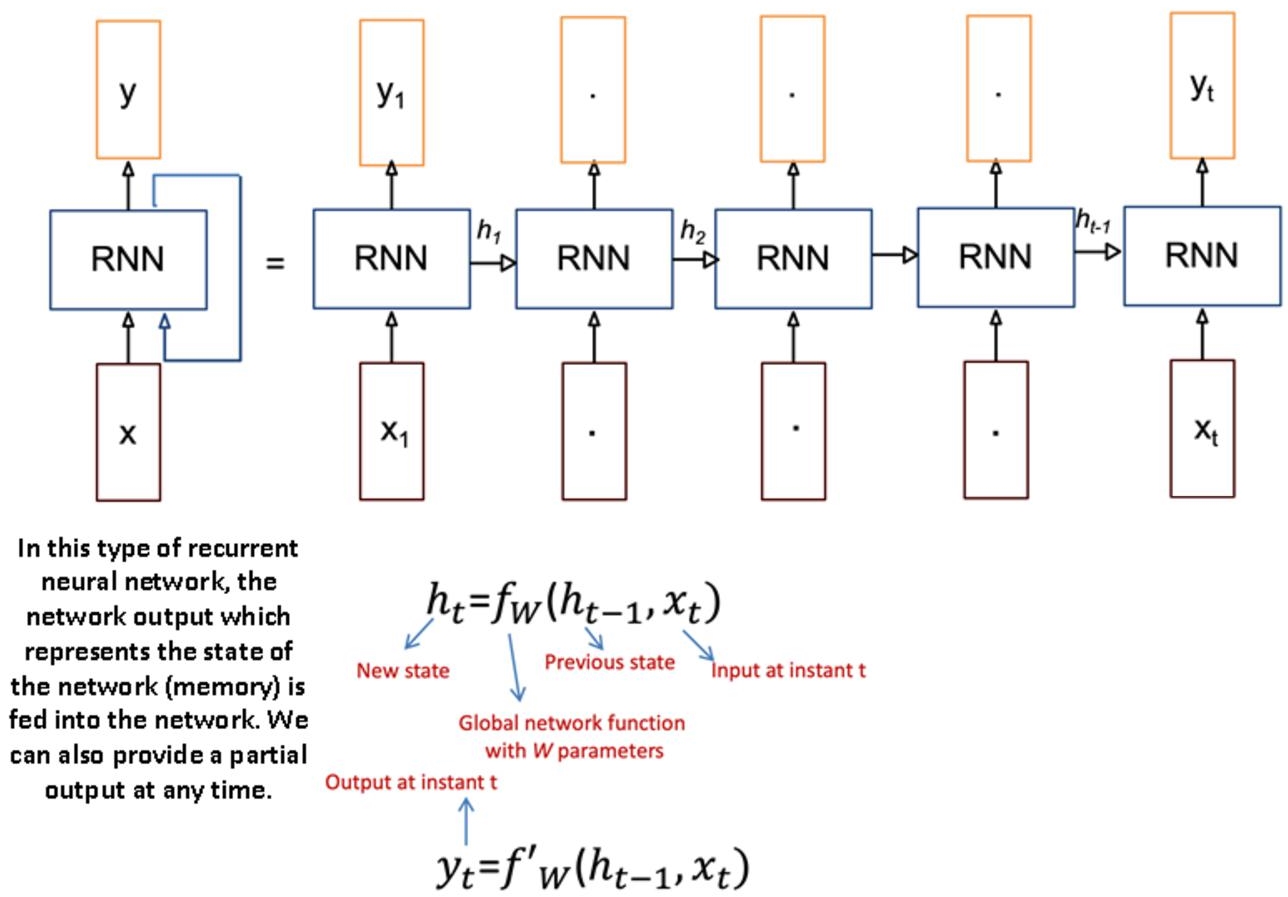
Figure 6.1 How an RNN works.
RNNs can also be stacked and bidirectional, and the simple equations shown in Figure 6.1 can be redefined for the two learning directions according to the model presented below.
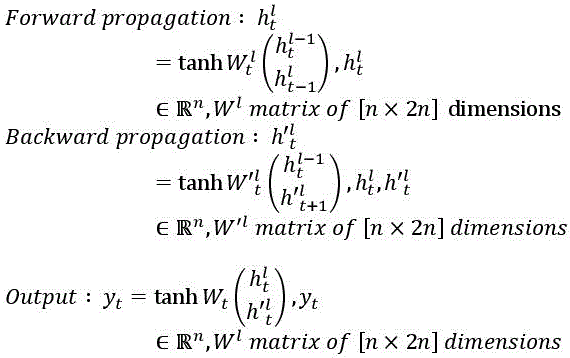
The training of multi-layer RNNs is done, as for the other types of networks, by minimizing the error (difference between the desired output and the output obtained), which can be obtained by the back-propagation of the error and the descent of the gradient. It can be demonstrated mathematically that the depth of RNNs, which can be high, because of sequential nature of paragraphs, texts, documents, etc., generally depends on the number of words to be processed at a time; this can provoke:
– either the Vanishment of Gradient in the first layers and the end of learning from a certain depth. When we must multiply the gradient, a maximum number of times, by a weight w/|w|<1;
– or the Explosion of Gradient always in the first layers and the end of learning from a certain depth. When we must multiply the gradient, a maximum number of times, by a weight w/|w|>1.
The LSTM architecture makes it possible to remedy these problems (Hochreiter and Schmidhuber 1997). It is based on finer control of the information flow in the network, thanks to three gates: the forget gate, which decides what to delete from the state (ht-1, xt); the input gate, which chooses what to add to the state; and the output gate, which chooses what we must keep from the state (see equations shown in Figure 6.2).
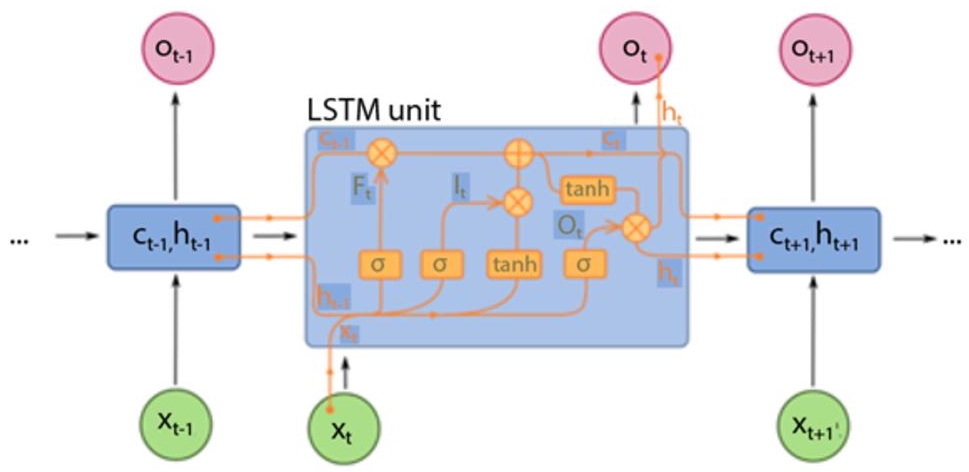
Figure 6.2 How a basic LSTM works.
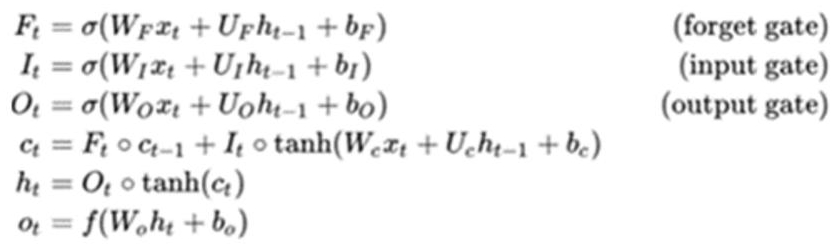
These equations that define the learning process of an LSTM express the fact that this kind of network makes it possible to cancel certain useless information and to reinforce others having a great impact on the results. We can also show by mathematical calculations that this architecture, in addition to the optimization of the calculations in the network, makes it possible to solve the problems linked to the vanishing and explosion of the gradient. This is what motivated our choice to use and improve this model by adapting it to our needs. We also integrated the notion of perspective or point of view of analysis as well as the notion of attention in the general process.
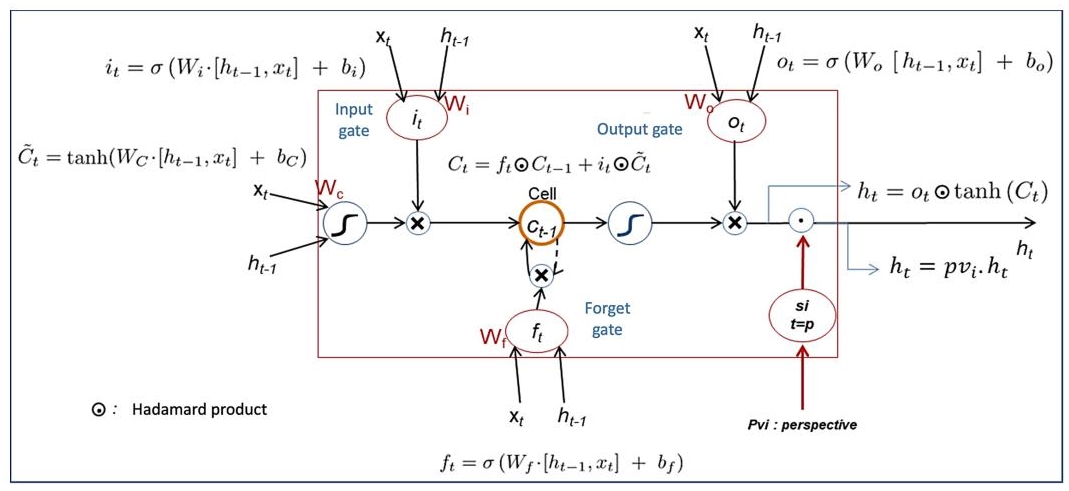
Therefore, our model allows us to control the flow in the “Context” i.e.:
- what to forget from the state;
- what to use from the state;
- what to send to the next state;
- according to a point of view or perspective;
- by paying attention to relevant information.
The latter notion is represented outside the internal architecture of the LSTM model.
6.4. Technological elements integration
Our approach has two main objectives:
– help users/authors to normalize their writing during the writing process;
– normalize already written texts as an early preprocessing step in an automatic analysis.
In the first case, our approach aims to predict and suggest supplementing the sentences being written with the most relevant words in their standardized orthographic forms and following a very specific linguistic structure (learned from texts of the training corpus). In other words, to a sequence of words that the user is typing, the system proposes a sequence of words, sentences or parts of standardized sentences.
In the second case, our approach aims to normalize the already written texts as an early pretreatment step in a semantic automatic analysis process. This is performed by transforming the texts, sentences and words into their normalized forms according to the orthographic, linguistic, stylistic structures, etc. learned from the training corpus.
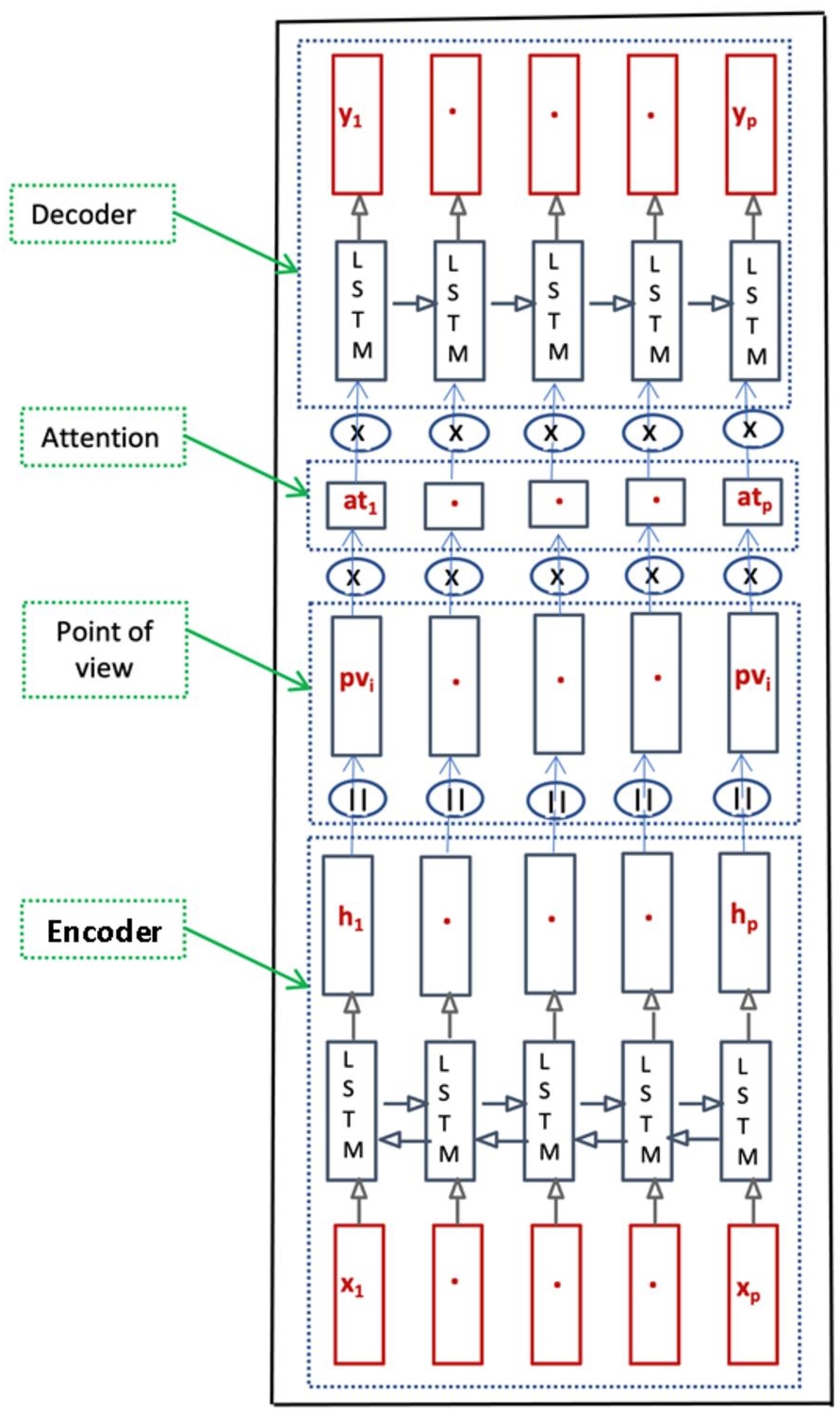
In both cases, this requires the use of the sequence-to-sequence or seq2seq version of Bi-LSTMs.
The proposed architecture consists of the following main layers:
- encoding:
- pretreatment,
- internal representation,
- domain (point of view);
- – decoding:
- new internal representation (calculated),
- attention,
- prediction.
A perspective is a set of words characterizing an analysis point of view (multidimensional space).
Let p be the number of words in the current sentence
Let i be the current perspective index
Let P be a perspective defined by the dimensions ![]()
Let H be the matrix composed by the hidden representations ![]() generated by the
generated by the ![]()
Consider ![]() where
where ![]() and
and 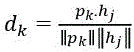
– ![]() is a first weight in the prediction calculation, based on the sum of the cosine distances between the hidden representations generated by the LSTM and the dimensions of the targeted analysis perspective.
is a first weight in the prediction calculation, based on the sum of the cosine distances between the hidden representations generated by the LSTM and the dimensions of the targeted analysis perspective.
This makes it possible to obtain a first transformation, weighted by the comparison to the view considered, of the internal representations of the meanings of the sentence:

6.5. Corpus and dataset
The corpus was built up by the collection of many documents in Arabic, obtained mainly from “well-written” institutional websites. The learning data model was obtained from a simplified version of the language model and the extended semantic model (Fadili 2017) and projections of the initial vector representations of the words, relating to a space of large dimensions (vocabulary size), in a reduced dimension semantic space using the Word2vec technology (w2v). The goal is to create an enriched model of instances adapted to the context of language normalization, with a reasonable size vector representation, essential for optimizing calculations and processing. The instantiation of the model was done by splitting the texts into sentences, and the generation of the enriched n-grams context windows for each word:
- 2-grams;
- 3-grams;
- 4-grams;
- 5-grams.
This first version of the instances is enriched with other parameters to support the syntactic structures and the thematic distributions. We associated each word in the dataset with its grammatical category (Part Of Speech – POS) as well as its thematic distribution (Topics) obtained by LDA (Latent Dirichlet Allocation) (Bei et al. 2003).
The other latent structures are integrated by the coding of the sequential nature of the texts by the LSTM. Similarly, the spelling is coded from the training corpus. It is this dataset that is provided to our augmented and improved Bi-LSTM model.
This model has the advantage of considering, in fine, the local context (n-grams) and the global context (themes), long-term and word order memories, which encode the latent structures of the texts (syntactic, semantic, etc.).
6.6. Experiences and evaluations
We have developed several modules and programs, implementing the elements of the general process, including mainly:
– automatic extraction of the various characteristics (Features);
– implementation of a deep learning system based on Bi-LSTM endowed with attention and domain mechanisms.
We have also designed an environment centralizing access to all modules:
– integration of all the elements in a single workflow implementing all the processing modules.
Feature extraction
We have developed and implemented three modules that run in the same “Python-Canvas” environment and exploited a process based on a “General MetaJoint” of the same environment to make the link between different components.
Without going into detail, the three modules consist, in order, of extracting the following characteristics:
– The first module allows us to extract the “linguistic context” of each word through a sliding window of size n.
– The second module allows us to grammatically annotate all the words in the text: perform POS Tagging (Part Of Speech Tagging).
– The third implements the “Topic modeling and LDA” technology in order to automatically extract the studied domain(s).
Workflow
The implementation of the workflow was done in the Orange-Canvas platform. It automates the chaining of results from previous modules for the extraction of characteristics and the instances ready to be used for learning.
Improved Bi-LSTM neural network
We developed from scratch a personalized Bi-LSTM neural network and adapted it to our needs. It is a neural network (multi-layer and recurrent Bi-LSTM) endowed with attention and domain mechanisms.
In order to ensure the honesty of the system, we separated the generated learning data into three parts:
– The first part was for validation on 20% of the dataset, in order to optimize the hyper-parameters of the system: the learning step, the type of the activation function and the number of layers.
– The rest of the dataset was divided into two parts:
- 60% for training, in order to estimate the best coefficients (wi) of the function of the neural network, minimizing the error between the actual and desired outputs;
- 20% for tests, in order to assess the performance of the system.
During all the learning phases, the system is autonomous, which can generate the features of the text (Features) for training and perform the learning process (validation, training and tests).
6.6.1. Results

After training the system on the constituted corpus, we conducted tests on a small text of 543 words. The system succeeded in correctly predicting the location and the punctuation of 455 words in the different sentences of the text, considering the latent structures coded from the training texts. The system, however, failed on the remaining 88 words and punctuation.
For more information on these results, refer to WEKA (Hall et al. 2009).
6.7. Conclusion
Our approach is an important contribution to the field of Arabic NLP, on the one hand, and to the organization of textual knowledge of the same language, on the other.
The knowledge generated today on the Web is poorly written, organized, structured, etc., since web users have the freedom to express themselves without any orthographic, stylistic and syntactic constraints. Hence, we need sophisticated and innovative tools, especially in the case of Arabic, to conduct its treatments. In addition, the organization of such knowledge is an even more complex problem, especially in the context of Big Data where processing by a human is almost impossible to achieve.
Our approach, which was designed to respond to all these problems, enabled us to obtain good results, as evidenced by the various statistics provided in section 6.6 (Fadili 2020a, 2020b).
As described above, we adjusted several hyper-parameters to optimize the system and generate all the parameters of the instances. On the entire corpus obtained, we validated the approach on 20% of the corpus, trained the system on approximately 60% and tested on approximately 20%. The various measurements show the good performance of the approach in terms of accuracy and loss.
This is mainly due to improvements made to the integration of certain aspects of the language and to extensions implemented for Bi-LSTM:
– language model and its instantiation;
– introduction of the concepts of attention and domain.
6.8. References
- Agarwal, A., Biadsy, F., Mckeown, K.R. (2009). Contextual phrase-level polarity analysis using lexical affect scoring and syntactic n-grams. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, Lascarides, A., Gardent, C., Nivre, J. (eds). Association for Computational Linguistics, Athens.
- Amiri, H. and Chua, T.S. (2012). Sentiment classification using the meaning of words. Twenty-Sixth AAAI Conference on Artificial Intelligence, July 22–26.
- Augenstein, I. (2012). LODifier: Generating linked data from unstructured text. In The Semantic Web: Research and Applications, Simperl, E., Cimiano, P., Polleres, A., Corcho, O., Presutti, V. (eds). Springer, Berlin, Heidelberg.
- Besag, J. (1986). On the statistical analysis of dirty pictures. Journal of the Royal Statistical Society. Series B (Methodological), 48(3), 259–302.
- Boudia, M.A., Hamou, R.M., Amine, A. (2016). A new approach based on the detection of opinion by Sentiwordnet for automatic text summaries by extraction. International Journal of Information Retrieval Research (IJIRR), 6(3), 19–36.
- Boury-Brisset, A.-C. (2013). Managing semantic big data for intelligence. In Stids, Laskey, K.B., Emmons, I., da Costa, P.C.G. (eds) [Online]. Available at: CEUR-WS.org.
- Cambria, E., Schuller, B., Xia, Y., Havasi, C. (2013). New avenues in opinion mining and sentiment analysis. IEEE Intelligent Systems, 28(2), 15–21.
- Chan, J.O. (2014). An architecture for big data analytics. Communications of the IIMA, 13.2(2013), 1–13.
- Christian, B., Tom, H., Kingsley, I., Tim, B.L. (2008). Linked data on the web (LDOW2008). Proceedings of the 17th International Conference on World Wide Web, 1265–1266.
- Curran, J.R., Clark, S., Bos, J. (2007). Linguistically motivated large-scale NLP with C&C and boxer. Proceedings of the ACL 2007 Demonstrations Session (ACL-07 Demo), Prague.
- Das, T.K. and Kumar, P.M. (2013). Big data analytics: A framework for unstructured data analysis. International Journal of Engineering and Technology, 5(1), 153–156.
- DBpedia (2022). Global and Unified Access to Knowledge Graphs [Online]. Available at: http://wiki.dbpedia.org/.
- Denecke, K. (2008). Using sentiwordnet for multilingual sentiment analysis. IEEE 24th International Conference on Data Engineering Workshop, ICDEW, 7–12 April.
- Dimitrov, M. (2013). From big data to smart data. Semantic Days [Online]. Available at: https://pt.slideshare.net/marin_dimitrov/from-big-data-to-smart-data-22179113.
- Duan, W., Cao, Q., Yu, Y., Levy, S. (2013). Mining online user-generated content: Using sentiment analysis technique to study hotel service quality. 46th Hawaii International Conference on System Sciences, 7–10 January.
- Esuli, A. and Sebastiani, F. (2007). SentiWordNet: A high-coverage lexical resource for opinion mining. Evaluation. 5th Conference on Language Resources and Evaluation (LREC’06), January.
- Fadili, H. (2013). Towards a new approach of an automatic and contextual detection of meaning in text: Based on lexico-semantic relations and the concept of the context. IEEE-AICCSA, 27–30 May.
- Fadili, H. (2016a). Towards an automatic analyze and standardization of unstructured data in the context of big and linked data. MEDES, 223–230.
- Fadili, H. (2016b). Le machine Learning : numérique non supervisé et symbolique peu supervisé, une chance pour l’analyse sémantique automatique des langues peu dotées. TICAM, Rabat.
- Fadili, H. (2017). Use of deep learning in the context of poorly endowed languages. 24e Conférence sur le Traitement Automatique de la Langue Naturelle (TALN), Orléans.
- Fadili, H. (2020a). Semantic mining approach based on learning of an enhanced semantic model for textual business intelligence in the context of big data. OCTA Multi-conference Proceedings: Information Systems and Economic Intelligence (SIIE) 208 [Online]. Available at: https://multiconference-octa.loria.fr/multiconference-program/.
- Fadili, H. (2020b). Deep learning of latent textual structures for the normalization of Arabic writing. OCTA Multi-conference Proceedings: International Society for Knowledge Organization (ISKO-Maghreb), 170 [Online]. Available at: https://multiconference-octa.loria.fr/multiconference-program/.
- Fan, J., Han, F., Liu, H. (2014). Challenges of big data analysis. National Science Review, 1(2), 293–314.
- Frijda, N.H., Mesquita, B., Sonnemans, J., Van Goozen, S. (1991). The duration of affective phenomena or emotions, sentiments and passions. In International Review of Studies on Emotion, Strongman, K.T. (ed.). Wiley, New York.
- Gupta, A., Viswanathan, K., Joshi, A., Finin, T., Kumaraguru, P. (2011). Integrating linked open data with unstructured text for intelligence gathering tasks. Proceedings of the Eighth International Workshop on Information Integration on the Web, March.
- Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., Witten, I.H. (2009). The WEKA data mining software: An update. SIGKDD Explorations, 11(1).
- Hiemstra, P.H., Pebesma, E.J., Twenhofel, C.J.W., Heuvelink, G.B.M. (2009). Real-time automatic interpolation of ambient gamma dose rates from the Dutch radioactivity monitoring network. Computers & Geosciences, 35(8), 1711–1721.
- Hochreiter, S. and Schmidhuber, J. (1997). LSTM can solve hard long time lag problems. In Advances in Neural Information Processing Systems 9, Mozer, M.C., Jordan, M.I., Petsche, T. (eds). MIT Press, Cambridge, MA.
- Hopkins, B. (2016). Think you want to be “data-driven”? Insight is the new data [Online]. Available at: https://go.forrester.com/blogs/16-03-09-think_you_want_to_be_data_driven_insight_is_the_new_data/.
- Hu, M. and Liu, B. (2004). Mining and summarizing customer reviews. Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 168–177.
- Hung, C. and Lin, H.K. (2013). Using objective words in SentiWordNet to improve sentiment classification for word of mouth. IEEE Intelligent Systems, 1.
- Kamp, H. (1981). A theory of truth and semantic representation. In Formal Semantics – the Essential Readings, Portner, P. and Partee, B.H. (eds). Blackwell, Oxford.
- Khalili, A., Auer, S., Ngonga, Ngomo, A.-C. (2014). conTEXT – Lightweight Text Analytics using Linked Data. Extended Semantic Web Conference (ESWC 2014), 628–643.
- Khan, E. (2013). Addressing big data problems using semantics and natural language understanding. 12th Wseas International Conference on Telecommunications and Informatics (Tele-Info ‘13), Baltimore, 17–19 September.
- Khan, E. (2014). Processing big data with natural semantics and natural language understanding using brain-like approach. International Journal of Computers and Communication, 8.
- Le, Q. and Mikolov, T. (2014). Distributed representations of sentences and documents. Proceedings of the 31st International Conference on Machine Learning (ICML-14), 32(2), 1188–1196.
- Mikolov, T. (2013). Statistical language models based on neural networks. PhD Thesis, Brno University of Technology.
- Miller, G.A. (1995). WordNet: A lexical database for English. Communications of the ACM, 38(11), 39–41.
- Minelli, M., Chambers, M., Dhiraj, A. (2013). Big Data, Big Analytics: Emerging Business Intelligence and Analytic Trends for Today’s Businesses. Wiley, New York.
- Nassirtoussi, A.K., Aghabozorgi, S., Wah, T.Y., Ngo, D.C.L. (2014). Text mining for market prediction: A systematic review. Expert Systems with Applications, 41(16), 7653–7670.
- Neelakantan, A., Shankar, J., Passos, A., McCallum, A. (2014). Efficient non-parametric estimation of multiple embeddings per word in vector space. Conference on Empirical Methods in Natural Language Processing, October.
- Paltoglou, G. and Thelwall, M. (2012). Twitter, MySpace, Digg: Unsupervised sentiment analysis in social media. ACM Transactions on Intelligent Systems and Technology (TIST), 3(4), 66.
- Park, C. and Lee, T.M. (2009). Information direction, website reputation and eWOM effect: A moderating role of product type. Journal of Business Research, 62(1), 61–67.
- Rao, D. and Ravichandran, D. (2009). Semi-supervised polarity lexicon induction. Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, 675–682.
- Rusu, D., Fortuna, B., Mladenić, D. (2011). Automatically annotating text with linked open data. 4th Linked Data on the Web Workshop (LDOW 2011), 20th World Wide Web Conference.
- Shand, A.F. (2014). The Foundations of Character: Being a Study of the Tendencies of the Emotions and Sentiments. HardPress, Miami.
- Singh, V.K., Piryani, R., Uddin, A., Waila, P. (2013). Sentiment analysis of textual reviews. Evaluating machine learning, unsupervised and SentiWordNet approaches. 5th IEEE International Conference on Knowledge and Smart Technology (KST), January 31–February 1.
- Taboada, M., Brooke, J., Tofiloski, M., Voll, K., Stede, M. (2011). Lexicon-based methods for sentiment analysis. Computational Linguistics, 37(2), 267–307.
- Tao, C., Song, D., Sharma, D., Chute, C.G. (2003). Semantator: Semantic annotator for converting biomedical text to linked data. Journal of Biomedical Informatics, 46(5), 882–893. DOI: 10.1016/j.jbi.2013.07.003.
- Tumasjan, A., Sprenger, T.O., Sandner, P.G., Welpe, I.M. (2010). Predicting elections with twitter: What 140 characters reveal about political sentiment. ICWSM, 10(1), 178–185.
- Wang, H., Can, D., Kazemzadeh, A., Bar, F., Narayanan, S. (2012). A system for real-time Twitter sentiment analysis of 2012 US presidential election cycle. Proceedings of the ACL 2012 System Demonstrations, Jeju Island, July.
- Zhang, W. and Skiena, S. (2009). Improving movie gross prediction through news analysis. Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology-Volume 01, 15–18 September.
- Zhao, J., Dong, L., Wu, J., Xu, K. (2012). Moodlens: An emoticon-based sentiment analysis system for Chinese tweets. Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August.
- Zhou, X., Tao, X., Yong, J., Yang, Z. (2013). Sentiment analysis on tweets for social events. 17th IEEE International Conference on Computer Supported Cooperative Work in Design (CSCWD), June.
Note
- Chapter written by Hammou FADILI.