
4
The Conversation Analytic Approach to Transcription
1 Introduction
In 1965, as an undergraduate student enrolled in Harvey Sacks’ lecture course and later in her position of ‘clerk/typist’, Gail Jefferson undertook the task of typing out everything that was said in the tape-recorded conversations Sacks had collected (Lerner, 2004c). By the late 1960s, this apparently simple task had generated most of the comprehensive system1 for transcribing talk and other conduct in talk-in-interaction that conversation analysts now rely on.
A key insight of conversation analytic research is that various features of the delivery of talk and other bodily conduct are basic to how interlocutors build specific actions and respond to the actions of others (see Drew, this volume, on turn design; Levinson, this volume, on action). It is for this reason that Jefferson developed, and other conversation analysts continue to develop, ways of representing talk and other conduct that capture the rich subtlety of their delivery. Jefferson’s system of conventions evolved side by side with, and was informed by the results of, interaction analysis, which continues to show that there are many significant things going on in talk that parties to the interaction treat as relevant, and that simple orthographic representation misses. However, transcripts are necessarily selective in the details that are represented and thus are never treated by conversation analysts as a replacement for the data.
Conversation analysts’ insistence on capturing not only what is said but also details of how something is said, including interactants’ visible behaviors, is based on the assumption that “no order of detail in interaction can be dismissed a priori as disorderly, accidental, or irrelevant” (Heritage, 1984b: 241).2 Conversation analytic transcripts need to be detailed enough to facilitate the analyst’s quest to discover and describe orderly practices of social action in interaction.
In this chapter, we first discuss the key conventions used in transcribing, with illustrations of the importance of using them. We then explore new frontiers and emerging challenges for transcription. To conclude, we engage with some of the criticisms that have been made about the conversation analytic approach to transcription.
2 Transcription Conventions
In the following, we discuss the most commonly used conventions for transcribing vocal conduct in talk-in-interaction (see Jefferson, 2004b). Jefferson transcription conventions are intended to build intuitively on familiar forms of literary notation (underlining for emphasis, capital letters for volume, arrows for pitch movement, and so on), which makes learning transcription conventions relatively straightforward. The conventions are organized into the following five categories:
We will take each of these in turn and briefly illustrate their interactional significance.
2.1 Transcript Layout
As seen in this chapter and elsewhere in this volume, conversation analysts use a standard layout for setting out transcripts, which illustrates three key features (illustrated in Excerpt (1)): speakers are identified at each point where speaker transition is relevant (Sacks, Schegloff & Jefferson, 1974); talk is represented as it is produced, not as it might have been intended or as it ‘should’ have been produced; and a fixed width font is used to align overlapping talk and/or visible behavior.

Note also the use of line numbers: each line of the transcript is numbered to facilitate reference to specific points in the interaction during analysis.
2.2 Temporal and Sequential Relationships
One of the most consequential contributions of CA to the study of talk and social action was the introduction of timing and sequential position in interaction. CA research has amply demonstrated the incredible precision with which interlocutors coordinate their talk (e.g. Jefferson, 1973, 1984a, 1986b, 1989b; Sacks, Schegloff & Jefferson, 1974; Schegloff, 2000b). Timing is therefore taken very seriously in CA transcription conventions.
2.2.1 Overlapping Talk
Simultaneous talk by two or more interlocutors is represented by lining the overlapping talk up and marking it with square brackets.3 Overlap onset is marked with the left square bracket ([); overlap offset, when marked, is indicated with the right square bracket (]), as in Excerpt (2):
There are a number of reasons why marking overlap is important (relatedly, see Clayman, this volume, on the transition-relevance place). Careful transcription of overlaps and gaps facilitated the discovery that turn-taking is not a result of speakers simply waiting for one another to finish talking. Rather speakers project possible completions of turn-constructional units, aiming to start their talk at a transition-relevance place (Sacks, Schegloff & Jefferson, 1974):
When they get this wrong, speakers tend to drop out of overlap very quickly (Schegloff, 2000b). Overlap therefore provides evidence for the rules of turn-taking and also exposes a range of practices that speakers employ to subvert those rules (cf. Sacks, Schegloff & Jefferson, 1974). A careful transcription of the onset of overlap is necessary for a grounded analysis of the interactional consequences of simultaneous talk. This illustrates the symbiotic relationship between careful transcription and new analytic insight.
2.2.2 Latching
Latching (represented by equals signs) marks the absence of any discernible silence between two turns or between parts of one turn. Latching indicates that an ordinary ‘beat of silence,’ which represents a normal transition space (or an unmarked next position) between one turn and another, is not there (Jefferson, 1984a; Schegloff, 2000b). Latching can therefore occur between different speakers’ turns:
Or within the same speaker’s turn, as when a speaker ‘rushes through’4 to extend his/her turn after a possibly complete TCU has been produced (see Walker, this volume):
Latched production can be critical for understanding what is being accomplished interactionally. For instance, Local (2004) shows how the latched together unit and=uh(m) can mark any subsequent talk as not related to immediately prior talk, but rather resuming an earlier topic.
Equals signs can also show that a speaker’s talk, broken up into separate lines on the transcript to accommodate the placement of overlapping talk, is nevertheless ‘through produced’, as in Excerpt (6) (lines 3/6 and 4/7):

2.2.3 Gaps and Pauses
Conversation analysts distinguish between gaps, which are silences that occur between TCUs, and pauses, silences within a TCU (Sacks, Schegloff & Jefferson, 1974). Silences are measured to the nearest tenth of a second and placed in parentheses: between lines of talk for gaps and on the same line as the preceding talk for pauses. A period in parentheses indicates a micropause, a hearable silence that is less than two-tenths of a second.
The transcription conventions were developed measuring silence relative to speech rhythm so that silence is understood relative to the tempo of the talk. To time silences following this method, one acclimates to the pacing of the talk and then, when the silence is reached, begins counting by saying a counting phrase at the pace of the preceding talk (Auer, Couper-Kuhlen & Müller, 1999; T. Wilson & Zimmerman, 1986). For example, some people use ‘none one thousand, one one thousand…’, and so on to time the silence as following: if the silence is broken immediately following ‘none’, a 0.2 second silence is indicated; if the silence is broken at ‘none one’, a 0.5 second silence is marked; if the silence is broken at ‘none one thou-’, a 0.7 second silence is indicated; if the silence is broken at ‘none one thousand’, the silence is a full second in length, and so on. If there is a noticeable silence but it is shorter than ‘none’, it is a micropause. If it occurs between TCUs, then it is most likely a ‘beat of silence’—the normal amount of time left between TCUs—and therefore will remain an unmarked transition.
Some CA studies (Couper-Kuhlen, 2012; Stivers, et al., 2009) rely on absolute measures of silences, often obtained through computer-aided methods, and here it is important to listen for the beat of silence between TCUs and leave it unmarked.
There are many reasons why marking silences is important. For example, whether a turn transition space is compressed (e.g. when the next turn is latched as shown above), extended (gap), or unmarked, has interactional consequences for interlocutors. For instance, in Excerpt (7) below, the gap at line 2 alerts A to an upcoming dispreferred response (Pomerantz, 1984a; Schegloff, 2007b) to her suggestion to have partners at a bridge game they are organizing, which is evident by A backing off at line 3:

Speakers also show an orientation to the length of silence. For example, Jefferson (1989b) noted that a silence of approximately one second might be a ‘standard maximum’ allowance for silence, at which point interlocutors begin some activity designed to resolve the problem (e.g. lines 2–3 of Excerpt (12)). Moreover, precise measures of silence have been used as evidence for a cyclical application of the turn-allocation rules (M. Wilson & T. Wilson, 2005; T. Wilson & Zimmerman, 1986), as well as to investigate possible cross-cultural variability in turn-taking (Stivers, et al., 2009).
2.3 Speech Delivery and Intonation
In this section we will discuss how to represent unit-final intonation, stretches of words and phrases, cut-offs and jump-starts, emphasis, volume, and pitch change, and will focus on their interactional relevance.
2.3.1 Unit-Final Intonation
CA transcripts use punctuation marks (period, comma, question mark, inverted question mark) to represent TCU-final intonation, not grammatical punctuation. Specifically:
- A period (.) indicates a falling intonation contour, not necessarily an assertion (see lines 1, 3 and 5 of (7)).
- A question mark (?) indicates strongly rising intonation, but not necessarily an interrogative (see line 4 of (16)).5
- A comma (,) indicates slightly rising intonation, not necessarily a clause boundary and not necessarily marking that the speaker is continuing (e.g. line 1 of (4)).
- Some transcriptionists have used the inverted question mark (¿) or a question mark followed by a comma (?,) to indicate a pitch rise that is stronger than a comma but weaker than a question mark.
- An underscore (e.g. “it_”) at a turn ending represents level intonation.6
Note that many researchers discuss TCU-final intonation by making reference to this punctuation notation. Thus, one may describe the end of line 5 in Excerpt (7) above as displaying falling or period intonation. Earlier in the same line, “well,” may be identified as having slightly rising or comma intonation. These terms (e.g. falling and period) are used interchangeably.
Unit-final intonation conveys important information about actions accomplished by the turn-constructional unit, for example, in terms of the speaker’s epistemic stance relative to that of the recipient (see Drew, this volume, on turn design; Levinson, this volume, on action formation). Similarly to interrogative morpho-syntax, unit-final rising intonation may indicate the speaker’s low epistemic access or entitlement to what is being said (as in an intonational question), while falling intonation may convey a higher degree of access/entitlement (cf. Bolden, 2010; Raymond, 2010). Unit-final intonation also plays an important role in turn-taking and specifically in projecting and indicating a TCU’s possible completion point (cf. Couper-Kuhlen & Ford, 2004; Fox, 2001a). In fact, due to the importance of prosody in talk-in-interaction, and the difficulty some transcriptionists have in transcribing it accurately, some (interactional linguists) advocate more sophisticated methods than the symbols outlined above (e.g. Couper-Kuhlen & Selting, 1996b). For example, some projects may benefit from speech analysis software that can create graphical representations of prosodic contours.7 Note, however, that a contour that appears to rise or fall on a graph may, in conjunction with other phonetic cues, be perceived by the human ear differently (on phonetics more generally, see Walker, this volume).
2.3.2 Volume
Underlining (e.g. “Why”) is used to indicate some form of stress or emphasis, either by increased amplitude or by higher pitch (often both). The more underlining within a word, the greater the emphasis.8 For example, in (7), line 1, “pa::rtners” carries greater emphasis than “Why.”
When marking emphasis, it is important to think about the natural stress that words carry with them. For example, words like information or interruption are typically pronounced with a mild stress (on the -may- and -rup- syllables, respectively), so no marking is required unless the speaker makes further emphasis.
Especially loud talk (e.g. shouting) is indicated by upper-case letters (e.g. “a MOMENT”). Competing in overlap is a common environment for this (Schegloff, 2000b).
Degree signs (e.g. “°yes°”) are placed around talk that is markedly quiet or soft. Double degree signs (e.g. “°°yes°°”) indicate a particularly quiet voice, such as sotto voce, or whispering, or mouthing (i.e. forming words with one’s mouth, with very little sound emerging), which may accompany extreme upset (Hepburn, 2004).
2.3.3 Pitch Variations
Intonation contours that lack the more marked shift in pitch represented by arrows (see below) are marked by underlining, sometimes in combination with colon signs (which alone indicate sound stretching; see the following section). An underlined element followed by a colon indicates an up-down contour through the word: for example, in line 1 of Extract (8) below, pitch moves up then down through the production of the word “pa:ssing.” A colon underlined indicates pitch movement sliding up through the work—e.g. “les’n:s” (line 5 of (8)):

These markings can be especially useful where speakers’ intonation slides up and down throughout a word. For example, starting up, sliding down and then back up (as in “No:::,”) allows speakers to inflect their talk with ‘warning’ intonation (Hepburn & Potter, 2011b).9
Even relatively slight variations in pitch (and volume) may be interactionally significant. For example, Schegloff (1998b: 238, emphasis in original) shows that “a speaker can regularly project by a pitch-peak . . . the next possible completion at which the turn-unit or the turn has been designed to end.”
It is useful to try to distinguish sharper rises or falls in pitch from variations in intonation contour marked by underlines and colon/underlines. Such sharp changes upward in pitch are indicated with an up arrow (↑) (or, alternatively, by a caret (∧)), while downward shifts are marked with a down arrow (↓) (a breve (![]() ) or a pipe (|)). Arrows may also mark resetting of the pitch register at which the talk is being produced. Pitch variations can be marked within a word, as with “matt:↓ress:” below, or across a string of words (surround the string with the appropriate symbols) as with “↑we pl’se bring↑” below:
) or a pipe (|)). Arrows may also mark resetting of the pitch register at which the talk is being produced. Pitch variations can be marked within a word, as with “matt:↓ress:” below, or across a string of words (surround the string with the appropriate symbols) as with “↑we pl’se bring↑” below:
Doubled symbols (e.g. (↑↑ and ↓↓ or ∧∧ or ||) can also be used for particularly sharp pitch resets (line 10 of Excerpt (18).
Pitch shifts play an important role in accomplishing a wide range of actions in conversation. Elevated pitch is often associated with heightened emotion as discussed below (see Ruusuvuori, this volume, on emotion). It can also accompany laughter (as in (6) above) and contribute to an enactment of ‘surprise’ (Selting, 1996b; Wilkinson & Kitzinger, 2006). Pitch, together with other aspects of prosody, has been found to play a role in delivering and receiving news as ‘good’ or ‘bad’ (Freese & Maynard, 1998).
2.3.4 Speed/Tempo of Speech
The combination of greater-than and less-than symbols (> <) indicates that a stretch of talk is compressed or rushed (line 3 of (10) below).

Speeding up talk can display that it may be slightly superfluous—at line 3 Mum’s second TCU is hearably doing a ‘note to self’. Used in the reverse order (< >), the signs indicate that the talk between the symbols is slower or more drawn out than the surrounding talk (lines 1/3 of (11) below). This can add emphasis to talk; here it surrounds reported speech.
The less-than symbol by itself (<) indicates that the immediately following talk is jump-started: “a practice by which speakers bring off a start to the following talk that sounds earlier than it is, and seems to be produced by an over-loud first syllable” (Schegloff, 2005b: 473; for a phonetic account, see Local & Walker, 2004). This is also known as a left push. The left push is one way of holding on to the turn that has come to a possible completion (a rush through, discussed above, is another practice):
Here, in her first TCU, Mum is disagreeing with a prior turn and then quickly jump-starts into a change of topic.
Colons (:) are used to indicate the prolongation or stretching of the sound just preceding them (e.g. recall line 3 of (7)). The more colons, the longer the stretching.10 Stretching talk can be implicated in overlap, for example when a speaker’s stretch on the last syllable and the next speaker’s start on the current TCU’s projected completion lead to terminal overlap (Jefferson, 2004d).
A hyphen (-) after a word or part of a word indicates a cut-off (phonetically a glottal stop):
Cut-offs are used, for example, to initiate self-repair (Schegloff, Jefferson & Sacks, 1977; see also Kitzinger, this volume ) as in (13), where Mum starts to produce “bla[ck]” but cuts this word off and replaces it with “very dark skinned” (line 2).
2.3.5 Voice Quality
Aside from various forms of pitch, stretch, volume and emphasis, there are other features of the delivery of talk that are transcribed. For example:
- Smiley voice, or suppressed laughter, marked or enclosed by the British pound sign (£). Jefferson (2004d) notes its role in acknowledging, but not joining in with, laughter;
- Creaky voice (#) can appear during upset or turn endings (Local, Wells & Sebba, 1985);
- Tremulous voice (∼) can signal upset, even where no other signs are present (Hepburn, 2004).
2.4 Transcriptionist’s Comments and Uncertain Hearings
Double parentheses are used to mark a transcriptionist’s description of events rather than representations of them: e.g. ((cough)) or ((telephone rings)). When the transcriptionist is uncertain about a hearing, single parentheses are used to represent a possible hearing, as in line 1 below:
If there are two possible hearings, they are separated with a forward slash within the parentheses:
2.5 Features Accompanying Talk
This section will focus on the transcription of aspiration, laughter and crying.
2.5.1 Aspiration
Hearable aspiration (breathing) is shown by the letter h—the greater the number, the longer the aspiration. Hearable inhalation (in-breath) is shown with a period before the letter(s) (e.g. .hh).11
Aspiration may be involved in conveying a range of emotions, such as extreme upset or hysteria. Whalen and Zimmerman (1998) showed that call takers in 911 calls (CT) use the term ‘hysteria’ to account for failing to collect required information. Here is a selection from their transcript of a caller subsequently classified as ‘hysterical’:

Kidwell (2006) shows that common features of ‘hysteria’ include crying, panting and sobbing.
2.5.2 Laughing
Gail Jefferson showed that laughter is organized in fine detail to coordinate with and sometimes sustain ongoing actions (Jefferson, 1984c, 1985a, 2004c; Jefferson, Sacks & Schegloff, 1987). For example, in her paper on laughter in troubles-telling, she notes that laughter may display the teller’s “good spirits” and bravery, so is “troubles-resistive” (Jefferson, 1984b: 367). Other researchers have focused on the appearance and coordination of laughter in different settings (see Glenn, 2003, for a review; see also Haakana, 2002; Lampert & Ervin-Tripp, 2006).
Laughter is typically made up of tokens such as huh/hah/heh/hih, meaning that there can be different voiced vowels within the aspiration, and, as line 2 below shows, the same interlocutor may use a variety of forms.

These elements may have elevated volume and pitch (line 4), and may contain differing degrees of aspiration. They may also contain consonants such as “g” in “.hhugh” on line 9 (see Jefferson, 2010).
Laughter may interlace speech so that laughter particles are produced simultaneously with talk. Laughter particles may be one or more elements of plosive aspiration (indicated in parentheses, such as in “thi(h)nk” in line 9). They may also be simply breathy (as in “yeahh” in line 8 of (17) above).12
2.5.3 Crying
Hepburn (2004) described a range of features of crying that can alert interlocutors to upset. Excerpt (18) below, taken from a reality television show, illustrates some typical features:
- reduced volume or ‘mouthing’ (line 1) indicating trouble with speaking;
- sniffs (line 5);
- other embodied features including touching face/wiping eyes (line 4), and hiding face/avoiding eye contact (line 12);
- silence where other talk might be due (lines 9/11);
- increased pitch (line 10); and
- increased aspiration (line 13).

Preliminary studies (e.g. Hepburn, 2004; Hepburn & Potter, 2007) suggest that interlocutors can respond empathetically even when only one or two of these signs of upset are present.
In this section, the focus has been on vocal conduct in English language talk-in-interaction. More recently, conversation analysts have started to tackle different kinds of data—e.g. recordings in other languages and video-recordings—which have raised new transcription challenges. In the following section, we discuss some of these new developments.
3 Transcribing Talk in Languages Other Than English
While English transcription conventions are well established, conversation analysts working in other languages face unique challenges. The following is a very brief discussion of some of the issues involved in transcribing talk in other languages and presenting it to audiences unfamiliar with the language.
3.1 Orthographic Representation
If the language under study is not written with the Roman alphabet, the transcriptionist needs to decide how to represent the language orthographically. The options include using: (a) the writing system of the target language (for languages that have a standard written form), (b) a standard phonetic system, such as a simplified version of the International Phonetic Alphabet (e.g. Enfield, 2007b; Moerman, 1988), or (c) a Roman transliteration system (e.g. for Russian, Bolden, 2008a; for Korean, Lee, 2006). The latter, commonly adopted option has a number of advantages, including relative accessibility of the transcripts to English-speaking audiences and the ease of publication in English-language venues.
3.2 Transcribing Tonal Languages
Approximately 42% of word languages are tonal (Maddieson, 2008). In tonal languages (such as Mandarin Chinese and Thai), pitch variations (tones) are phonemic (i.e. pitch contours change word meanings) rather than pragmatic (as they are in English). Because conversation analytic transcription was developed for a nontonal language (English), there are no standard ways of representing tones. Lexical tones may be represented using a number system (see, for example, Enfield, 2007b, for Lao), or—especially for languages with simpler tonal systems—diacritics (e.g. Hanks, 2007, for Yucatec Maya; Moerman, 1988, for Thai).
Furthermore, a transcriptionist working on a tonal language must decide whether (and how) unit-final intonation is to be marked. In English, unit final prosody is an important aspect of the transcription system (as discussed above) because final intonation contours carry important pragmatic information about the action(s) accomplished by the turn-constructional unit. However, in tonal languages, final pitch contours can be affected by the lexical tone of the final word (e.g. Tao, 1996), which raises the question of how unit-final intonation is to be transcribed.
3.3 Presenting Data to English-Speaking Audiences
When presenting transcripts of talk in languages other than English to English-speaking audiences, typically a multi-linear transcription is used (e.g. Sidnell, 2009b). The most common practice is to provide a three-line transcription (as in (19) below), where the first line represents the original talk (in the adopted orthography), the second line is a morpheme-by-morpheme English gloss of the original (a combination of word translations and grammatical information in an abbreviated way13), and the third line is an idiomatic English translation that attempts to capture the local, interactional meaning of the original.

The advantage of a three-line transcription (especially for languages that do not follow the English word order) is that it allows an English speaker some understanding of the talk as it unfolds, such as providing information about when (relative to what has been said) overlaps occur.14 A two-line transcription—that is, one containing only an orthographic representation of the original talk and an idiomatic English translation—is typically used for languages that closely follow the English word order.
Presenting data to an audience unfamiliar with the language under investigation involves translation of the original talk, which is difficult and fraught with problems (see, for example, Bilmes, 1996; Moerman, 1988; Schegloff, 2002d). Schegloff (2002d: 263) warns that translation inevitably suggests analysis and points out an additional burden that conversation analysts working on languages other than English have when presenting their data to English audiences:
The translation needs to be rendered in a fashion sensitive not only to the detail and nuance of the material being studied in its language-of-occurrence, but also sensitive to the detail and nuance in comparable English language interactions as revealed in the already extant literature.
In other words, translation is not just a perfunctory step in the transcription process, but is part of the analysis of the original talk that has to be informed by what is known about English.
4 Transcribing Visible Conduct
Conversation analytic transcription conventions were developed primarily on audio-recorded data (such as, telephone conversations), and thus capture interlocutors’ vocal conduct only. The use of video in conversation analytic research, pioneered by Charles Goodwin in the 1970s (C. Goodwin, 1981), is widespread today (see Heath & Luff, this volume). In face-to-face interactions, participants’ visible conduct is instrumental to how social actions are accomplished and coordinated, which means that it has to be represented on a transcript. Although the transcription of both talk and visible behavior is necessarily selective, the transcription of visible behavior may be even more so due to the substantial number of parameters. Moreover, visible behavior involving facial expressions, body posture, gestures and gaze can occur in overlap with each other and with talk.
Conversation analytic studies have relied on various methods (sometimes in combination) for transcribing visible conduct:
- transcriptionist comments;
- specialized notational systems (see chapters in this volume by Heath & Luff, Mondada, and Rossano); and
- visual representations, such as drawings and video frame grabs.
Using transcriptionist comments—in double parenthesis, such as ((A looks at B))—is, perhaps, the simplest way of transcribing visible conduct (see excerpt (20) below). However, limited information about how visible behaviors unfold incrementally over time can be presented in this way, as comments can provide only a simplified gloss of the observable behavior.15

Specialized notational systems—such as those developed for eye gaze (C. Goodwin, 1981; Rossano, Brown & Levinson, 2009) and gestures (Heath, 1986; Streeck, 1993)—are designed to capture such details. For example, Goodwin’s conventions for representing eye-gaze facilitate the analysis of the coordination of gaze and talk, and the coordination of gaze between the participants. (This has led to a number of fascinating findings; see Rossano, this volume.)
Visual representations (e.g. drawings and digital video frames) accompanying a transcript of vocal conduct have the advantages of being easily interpretable and more holistic in representation. Moreover, digital frame grabs can be selected to capture, with a high degree of precision, the temporal unfolding of visible conduct in coordination with speech. With the advent of digital video, frame grabs can be quite easily produced and edited for clarity of presentation (and, if desired, to disguise participants’ identifiable features).
For one example of the use of video frame grabs, see Excerpt (21): Alex is on the left; Bob on the right.
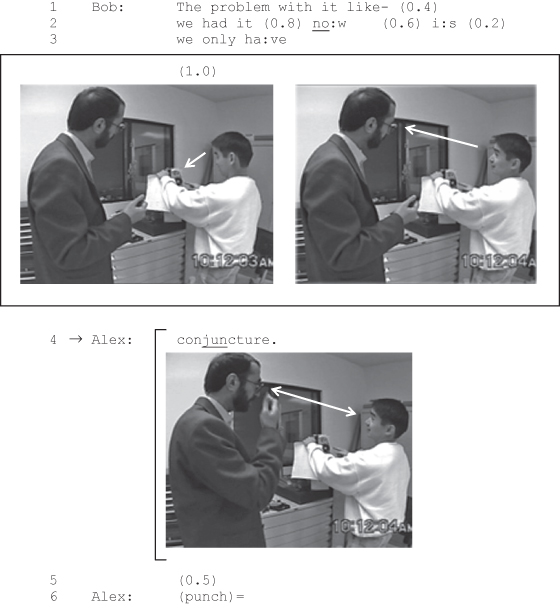
Here, eye gaze is represented visually and in relation to the vocal conduct. Additionally, other visible aspects, such as body orientations, gestures, and the surrounding environment, can be seen and taken into an account. When material objects become relevant to the interaction, the transcriptionist may need to represent them as well. The following Excerpt (22) attempts to capture Bob’s manipulation of the machine he is talking about.
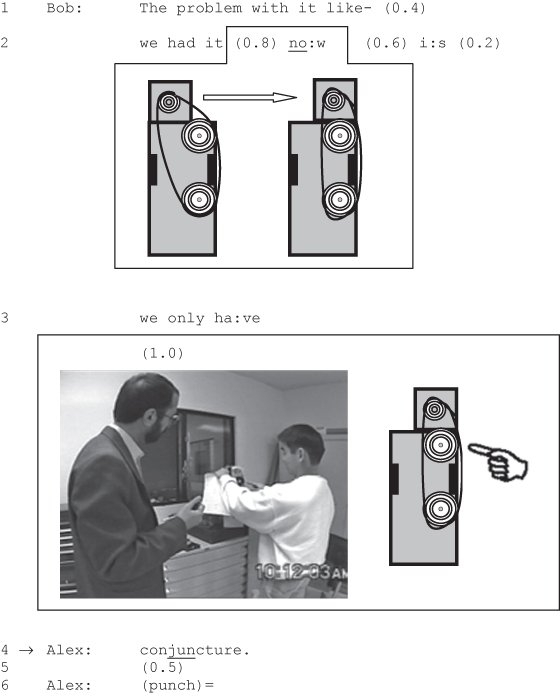
Visual representations are sometimes the most accessible way of representing video data in public presentations and in print. However, as seen from the two excerpts above, this way of representing data is very space consuming, so only very short transcripts can be included in publications.
Note that both (21) and (22) represent the same stretch of interaction but selectively highlight different aspects of the participants’ visible conduct. This illustrates the fact that decisions about how to present visual data (at conferences and in publications) have to be guided by the researchers’ analytic goals. However, the video-recording itself (and not its inevitably selective transcript) has to remain the object of the analysis.
We have focused up to now on some of basic principles and practices of transcription, and on the different ways that transcription continually evolves. Part of that evolution must involve opening ourselves up to scrutiny by other researchers outside CA, and below we outline some critical concerns that have been raised.
5 Concerns With the CA Approach to Transcription
We can differentiate two types of (often overlapping) concerns about transcription which we call epistemological and practical. The following subsections outline and assess these concerns.
5.1 Epistemological Concerns
Epistemological objections to transcription have to do with whether transcription is a valid research tool and to what degree transcription embodies researchers’ theoretical orientations.
5.1.1 Criticisms
Some critics (e.g. Bogen, 1992; Mishler, 1991) object to detailed transcription as a research tool. They claim that most researchers would be better off doing different styles of research, as all the detail in the transcript gets in the way of what is analytically important. Other critics accept the importance of transcribing the specifics of interaction, but focus on the need for transcriptionists to be more reflexive about the product. For example, Ochs (1979) suggests that there are assumptions about the world wired into transcription, and that transcriptionists should consider the way they work and be cautious about these assumptions (see Ashmore & Reed, 2005, for a more critical version of this). Similarly, Bucholtz (2000) advocates a reflexive transcription practice that highlights the assumptions made in the process.
5.1.2 Conversation Analysts’ Response
The idea that the transcript is theorized is unproblematic if it is taken as a reminder that there are different things that can be encoded in a transcript and that what the researcher chooses to encode will depend on their research questions and analytic perspective. However, wherever researchers are concerned in one way or another with talk as action, arguments would need to be developed, grounded in materials, to show that the lack of attention to such features of talk would not be analytically consequential (see Potter & Hepburn, 2005, in debate with Smith, Hollway & Mishler, 2005).
5.2 Practical Concerns: Inadequacy of CA Transcription
One of the most striking features of conversation analytic transcription is its representation of talk in non-standard orthography. This approach has been criticized from two sides: those who prefer the ease of using standard English language orthography (typically qualitative social scientists) and those who prefer using a standard phonetic transcription system, such as the International Phonetic Alphabet (typically linguists).
5.2.1 Criticisms
On the one hand, advocates of the orthographic transcription claim that CA transcription is too difficult to read, transcriptionist-dependent and presents speech in a caricatured fashion of ‘comic book’ orthography, which makes speakers look stupid (see Jefferson, 1983a, for a response to these critics). Furthermore, some critics argue that the complexity of CA transcription is not necessary if conversation is not the primary object of study (e.g. Du Bois, 1991 and Ochs, 1979 develop this argument). On the other hand, linguists often criticize conversation analytic transcription for being unsystematic in its representation of phonetic details and advocate the adoption of a standard phonetic transcription system, such as the International Phonetic Alphabet (IPA).
5.2.2 Conversation Analysts’ Response
Orthographic transcription imposes the conventions of written language designed to be broadly independent of specific speakers. Such a transformation systematically wipes out evidence of intricate coordination, talk as action and recipient design. It encourages the analyst to interpret talk by reference to an individual speaker (e.g. perceptions) or focus on abstract relations between word and world (e.g. discourses). If talk is a medium for action, then forms of representation that try to capture elements of action rather than ‘just the words’ are needed.
On the other hand, using the International Phonetic Alphabet or a similar system in Conversation Analysis would highlight a range of features of speech production at the expense of information about overlap, delay, prosody, gesture and so on. The point is that the IPA is tuned to the theoretical concerns of certain areas of linguistics and speech pathology but not designed to capture talk as action (cf. Kelly & Local, 1989b; Ochs, 1979). The basic principle of conversation analytic transcription is “to get as much of the actual sound as possible into [the] transcripts, while still making them accessible to linguistically unsophisticated readers” (Sacks, Schegloff & Jefferson, 1974: 734).
The bottom line here is that everyone involved in CA has the opportunity to highlight the limitations of the transcription system and contribute to a better one.
6 Conclusions
Jeffersonian transcription provides a shared, standard system for rendering talk-in-interaction in a way that can be textually reproduced. It is compact, transportable and reproducible, and provides for easy random access unlike audio or video records. CA transcription is a fundamental resource for data sessions, presentations and journal articles, and, as such, it is often the medium through which analysts encounter and evaluate each other’s work. It is therefore at the center of the epistemic culture of Conversation Analysis. CA transcription has evolved, and will continue to evolve, with the gradual progression of conversation analytic studies of interaction.
NOTES
We would like to thank Tanya Stivers for excellent editorial input, Jonathan Potter for some useful discussion of critical perspectives, and Kathryn Howard, Roi Estlein, Makoto Hayashi and Estefania Guimaraes for assistance with the non-English transcription section.
1 One of the first full descriptions of the conversation analytic transcription system can be found in Sacks, Schegloff and Jefferson (1974); its modern incarnation in, for example, Jefferson (2004b).
2 Sacks’ (1984a: 22) refers to this notion as “order at all points.”
3 Older transcripts represent the beginning of overlapping talk with two forward slashes (//) on the line being overlapped by an incoming speaker.
4 “In a ‘rush-through’ a speaker who is approaching upcoming possible turn completion increases the pace of the talk, does not decelerate, talks through the momentary silence which regularly intervenes between the end of a turn and the start of a next, and launches a next turn-constructional unit” (Schegloff, 1998b: 241). See the following section on how speech tempo is marked.
5 In English, questions (especially, wh-interrogatives) may be produced with falling or only slightly rising intonation (Couper-Kuhlen, 2012; Geluykens, 1988). For example, the two interrogatives in Excerpt (7) (lines 1 and 3) are produced with falling intonation.
6 Some transcriptionists leave this intonation contour unmarked; however, the use of the underline makes it clearer that the intonation was transcribed as flat rather than simply left out.
7 Praat is one commonly used program, available for free download at: http://www.fon.hum.uva.nl/praat/. ToBI (Tones and Break Indices) conventions may also be useful (see http://www.ling.ohio-state.edu/∼tobi/).
8 There are different practices about placement of underlines: the first letter of the word adds some emphasis to the whole word; underlining only the vowel sound means emphasis is not retained in the rest of the word.
9 Currently not all CA transcriptionists use a combination of colon and underline for representing pitch movement; some rely on the caret and pipe, or arrows, for all pitch changes (both pitch resets and within-word pitch changes). However it is notable that Jefferson found this an important element in her transcripts up to her most recent output in the Nixon tapes (Jefferson, 2004b) and Schegloff (2007b) also employs the colon/underline notation. As indicated, it has been indispensible when adequately transcribing interaction between parents and young children.
10 Graphically stretching a word on the page by inserting blank spaces between letters does not indicate how it was pronounced; it is used to allow alignment with overlapping talk (cf. line 4 of Excerpt (16)).
11 In older transcript, the period is superscripted.
12 Potter and Hepburn (2010) suggest that the category laughter may be over-interpretative and propose replacing the laughter terminology with interpolated particles of aspiration.
13 For the interlinear gloss, researchers adopt glossing practices that accord with the linguistic properties of the language under study. The glosses may follow disciplinary conventions (such as the Leipzig Glossing Rules for linguistics: http://www.eva.mpg.de/lingua/resources/glossing-rules.php) and/or reflect the study’s objectives (e.g. be more or less specific with regard to the identified linguistic features).
14 Although, as Bilmes (1996) observes, this might be of limited use since the reader unfamiliar with the language under study will still be unable to assess accurately the TCU’s projectability, for example.
15 Some researchers (e.g. Kidwell, 2005; Kidwell & Zimmerman, 2006) combine transcriptionist comments with one or several of the more sophisticated representation systems discussed below.