


Directory Integration - IBM Tivoli Directory Integrator
In this appendix we discuss the topic of directory integration and the IBM Tivoli Directory Integrator (ITDI). ITDI is a toolkit that simplifies integration of directories with a variety of other data stores. It includes "snap-in" components that support connectivity to many types of data stores, protocols for the reliable and secure transportation of data between them, and help automate the mapping of data between them. ITDI includes "event handlers" to help systems integrators automate data flows between data stores in near real time as data is changed or based on defined schedules. The ITDI architecture includes a framework for scripting business rules as data is exchanged between repositories. It even has special "plug-ins" for a variety of directories that enable it to securely capture and propagate passwords when they are changed. These include Active Directory, the iPlanet directory, the IBM Directory Server, and the HTTP password on Domino Servers.
Before we dive into how to use IBM Tivoli Directory Integrator for directory integration, we need to clarify why the topic is a critical success factor in enterprise directory projects so often that it deserves a chapter in this book. After all, directories based on the LDAP standards are now available from many vendors. They are embedded with modern operating systems, Internet security systems and application servers. Why is a directory solution not complete after a highly available LDAP directory service is in place with a well-designed directory tree and a replication strategy that delivers high availability and performance? Would the final step not be to enforce a corporate edict that all infrastructure services and applications use that directory service to maintain and access the identity and other data that it contains?
Why Directory Integration is important
Today nearly all modern network operating systems1, I/T infrastructure components, and applications that require user identity data are directory enabled "off the shelf." They can exploit an LDAP directory for user authentication and access control as soon as they are installed and properly configured. But the reality is that this technology has emerged only recently and was standardized over just the last few years. In the not too distant past, enterprise applications were often installed with their own application specific repositories to maintain the identities of users, their preferences and permissions to access application resources.
As the Internet was embraced to extend access to corporate IT resources and applications to customers and business partners, security software and Web application servers also needed a trusted repository for user identity data. As a result, most enterprises have in place many legacy repositories of identity data. Some of them may be based on modern standards and access protocols and others may not. Some may contain only internal users while other databases contain the data used to authenticate business partners and customers who access corporate Web sites. But there is a considerable investment in business processes and applications that keep these repositories populated with data and their contents up to date as users are added and removed, or their business roles change and affect access permissions to application functions and data.
The problem is not that most enterprises want another application specific repository but that they have too many already with maintenance responsibilities for them split between several departments with different, and sometimes conflicting, business objectives. The investments enterprises have in Human Resource (HR) systems, application databases, legacy application and LAN user directories means that those systems are not easily replaced and will remain the "authoritative sources" where the identity data for users of corporate applications is maintained for some time. This is also the case for the basic identity data for business partners and customers who use new Web-based applications to access corporate resources. The result is that in most directory deployments, corporate or enterprise LDAP directories do not immediately become the "authoritative source" for most of the data they contain. They need to become instead "trusted sources" that provide infrastructure components and applications a standard mechanism to access identity and other shared data for user authentication and access control. The data the corporate LDAP directory contains will mostly originate and be maintained elsewhere and must be kept up-to-date with several authoritative sources. These problems are shown in Figure B-1.
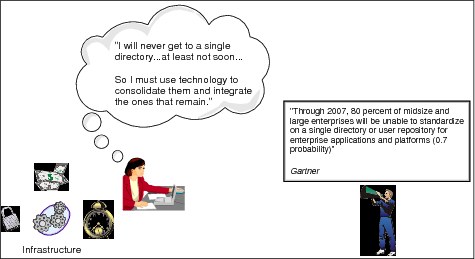
Figure B-1 Cost, security policy, complexity, and schedules drive requirements for directory integration
Directory Integration Services
So, by itself, the LDAP directory service installed with modern network operating systems, security and reduced sign-on services, or Web services applications will have limited business value to owners of legacy applications. Until it is connected to existing repositories, the information the LDAP directory contains about users and other IT resources will be stale, inaccurate, or inconsistent with user accounts in operating systems, mail systems, and databases used by line of business applications. The costs of revising legacy applications to exploit a new directory service and changing the current administration applications and procedures in several departments to maintain it is usually too high to offer a satisfactory return on investment. The lengthy project schedules can mean the directory services would be delivered too late to be of real value.
An alternative approach that extends the benefit of an enterprise directory immediately is to use directory integration services2 to reduce the number of application specific directories and the maintenance of redundant data stores. It may not be possible to completely eliminate application specific repositories or directories, but if they can be integrated and synchronized with each other, most of the legacy investment in maintenance of user identity data can be preserved and leveraged to populate and maintain an enterprise directory. The reduced maintenance costs and elimination of security exposures that are obtained by consolidating legacy directories3 and eliminating redundant data also offers a compelling return on investment for directory integration projects.
User provisioning applications
User provisioning applications automate the management of user accounts for employees, business partners, and customers. These have traditionally been paper-based and process-intensive tasks that are often slow and error prone. Provisioning applications provide administrative interfaces and support workflows within the enterprise associated with provisioning and de-provisioning user accounts on operating systems, email and other application directories. They also manage the permissions individual users have to access corporate resources and IT transactions. They streamline and automate these procedures, ensuring that business policies are enforced and an audit trail is maintained.
Automated provisioning is often an objective of many corporate directory and security projects for the reasons illustrated in Figure B-1 on page 684. Information Week did a study where they interviewed 4500 security professionals and asked them whom they suspected as the source of a security breach or espionage. Six of the top eight suspects in this survey were people who were actually granted accounts with the permissions needed to perform the activity by the enterprise itself. The fact that 30–60 percent of the active accounts in an enterprise may be orphans4 is obviously part of the problem. Perhaps the account should never have been created; maybe the user left the company or was promoted or transferred to a job with responsibilities that no longer require the account. The user may even have been a contractor whose contract has expired but who was never taken out of operating system or application directories.
Enterprises gain control of identity data by deploying provisioning systems. The security risks of orphan accounts are eliminated, and the business policies that govern the access permissions granted to the accounts are enforced. Accounts are turned on only for business purposes and are immediately turned off when the business reason for them is no longer valid.
However, a provisioning system is dependent on an underlying directory service or other database that is a trusted source of identity information about users and their enterprise roles. This identity data governs account management and the permissions that individual accounts are granted. The accuracy and currency of this identity data is crucial to the effectiveness of automating and enforcing enterprise account provisioning policies. You have to have a trusted source of information about who the valid users are and the enterprise roles and responsibilities they have before you can safely automate account provisioning and the assignment of permissions to accounts to execute transactions and access data5. A solid and well-integrated directory infrastructure is prerequisite to deploying a provisioning system.
Directory Integration technologies
With this background in why the directory integration is a crucial aspect of nearly every enterprise directory strategy, we should look at some of the different methods and technologies that have emerged to accomplish it. One solution that was used prior to the availability of tools better fitted to the purpose is to write scripts or small applications that synchronize information in one repository with another. This seems reasonable if all that is required is to synchronize a few data elements, or attributes, in a new enterprise directory with a single legacy system. No new infrastructure software need be purchased. If the synchronization does not need to be done immediately, it is usually possible to extract a few attributes from the source and periodically schedule a utility or application to update the directory.
But requirements are rarely that simple, and this approach can result in a solution that is error prone and difficult or impossible to maintain or extend over time. If we look at the tasks that must be accomplished to integrate heterogeneous repositories of data, it is easy to see why.
A robust directory synchronization strategy will usually require managing data flows between several systems. The solution design must incorporate a large amount of detail about bidirectional exchanges of information. The direction of updates must be consistent with the authoritative sources, so that data flows only from authoritative to non-authoritative sources. There are often requirements to detect changes that are made by a non-authoritative source, log the event, and possibly even rolling them back. Figure B-2 on page 687 illustrates many of the details that need to be understood and handled.
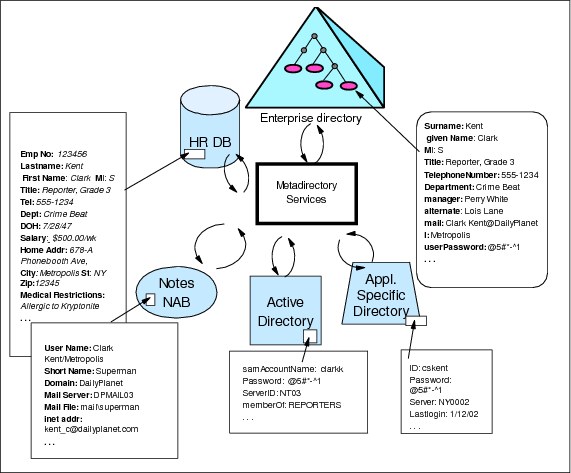
Figure B-2 Directory Integration requires handling many details
Data sources
Data sources are the systems and devices that are to communicate with each other. Since a repository may be authoritative for only some of the data it contains, and receive updates from other systems, the data flows are often bidirectional. For example, an HR system is usually authoritative for basic identity information of users such as name, address, the department to which an employee is assigned and their manager. An email or network operating system may receive information needed to create or delete accounts from the HR system, but be authoritative for other data such as login IDs and the groups to which users are assigned to provide access to network and other resources.
Matching rules
The chief goal of directory integration is to associate and synchronize data across various applications and data stores that use it. In doing so, the enterprise separates the management of shared (or enterprise) data from applications that work with it and maintain it. This is the essential first step in controlling identity data as a valuable corporate asset. Applications and infrastructure components such as security systems become consumers of corporate identity data, though legacy applications may remain the authoritative sources of the enterprise data.
However, it is not always easy to match up and associate the entries in one directory with those in another. For example, there may be no unique identifier, such as an employee or customer number for each user within an enterprise. The enterprise may have more than one HR system that assigns such numbers to employees in different divisions that have been acquired over time. And even if there is a unique identifier for each employee, it may not be currently stored as an attribute of the employee's entry in each of the directories and databases, and operating system platforms for which he or she has an account.
In Figure B-2 on page 687 for example, Clark Kent's key in the HR system is employee Number 123456. In Active Directory, Clark is assigned the sAMAccountName clarkk. He uses the shortName Superman in the corporate email system. The application specific directory may simply list two or three individuals with the name Clark Kent who have different user IDs. The only way to distinguish between them may be to look at the department they currently work in, or perhaps their office number or telephone numbers, and even this may not be enough to reliably associate them with our super hero. And, as we saw in the previous section if this is the organization's first directory project, there is a high probability that each of these systems may contain "orphan" accounts that cannot be matched with any individual or accounts in other repositories.
Entry and Attribute filtering and mapping
Each repository may contain information about many types of users or other resources. Some of this information is application specific or sensitive information that is stored in entries that business or privacy rules require should never be propagated to other systems. Within individual entries, there may be sensitive fields whose values should never be exposed while other attributes of the same entry must be frequently propagated to multiple destinations. For example, salary and medical information that is contained in the HR database should never be propagated to other directories while first name, last name, and department are propagated to several other systems. The requirements for which fields are propagated change periodically as new applications are added and business rules change, so the solution must be easy to re-configure to adapt.
Attributes will often have different names and syntaxes in source and target systems. In the figure for example, last name in HR is mapped to surname (sn) in the enterprise directory. Some attribute values for a target system don't have a direct mapping and may have to be computed from values in one or more source systems, as when first name, middle initial, and last name in an HR system are combined to create a cn (common name) attribute in an LDAP directory. This is a very simple example, but attribute mapping rules can be much more complex. For example, the users in LDAP directories are organized into a hierarchical directory tree with a distinguished name (DN) that specifies the precise location of their entry in the tree. When groups are synchronized between directories with different tree structures the groups contain the DNs of users in a member attribute. The DNs have to be mapped between the tree structures as the group entries are copied or synchronized between the directories.
Mechanisms to transport data between systems
Various standard protocols are used to transport data from source systems to a target systems. For some legacy systems, there is no standard protocol available to access or update the data they contain, and the systems integrator must use application specific programming interfaces or utilities provided by a vendor to import and export data. The data flows must be reliable, so that information is not lost due to system or network failures. Message queueing systems that guarantee delivery may have to be exploited.
When source and target systems communicate
Sometimes the systems need only be synchronized periodically, such as once a day or once an hour. This is often satisfactory when adding new hires into an employee database that will not actually become active or need access to systems right away. Other times, for example, when a user account must be revoked because of a possible security breach, or a user changes their password in the network operating system and it has to be propagated securely to other directories or applications, the communication must occur in near real time.
Change detection
Many systems have built-in mechanisms an integration system can exploit to detect changes. Directory servers have time stamps on the entries they contain. They can be configured with change logs and most support event notification or persistent search operations that enable a client application to register and receive modified entries when they are changed. Databases support triggers and stored procedures that can be exploited to detect and propagate changes. This is not always the case with legacy systems. For example, if the Application Specific Directory illustrated in the figure below is a spreadsheet or flat file, it is not so straightforward to look at a new version of the file and determine what entries have been added, deleted, or modified since the last version, and which have not changed.
Logging and error handling
There are usually requirements to log certain transactions and events in system logs and to interface with systems management tools when failures occur within the integration solution. External systems or network failures may prevent synchronization from occurring at the time changes are made in a source system or when they are scheduled to be propagated. The integration solution must be robust enough to find these changes and propagate them correctly when the error is corrected and connectivity is restored. Failures may occur during a batch process that synchronizes a large number of entries and checkpoint/restart capabilities may be required.
Metadirectories and virtual directories
Due to the complexity of these requirements, custom scripting or application development is not usually affordable or maintainable. It is viable only for solutions that involve only a few point-to-point data flows with minimal requirements for event handling, attribute mappings and minimal logging and error handling capabilities. Metadirectories are tools that have emerged to provide a complete set of services tailored to handling these issues. They enable integrators to quickly develop, deploy and maintain and extend a solution for integrating identity data for infrastructure components and applications.
A metadirectory is not another user directory. It is a toolkit that provides graphical tools systems integrators use to work with information about where data is located, how it can be accessed, how the entries in one store are linked with entries in another, and how the data should flow between different directories and databases. Metadirectory run-time services include connectors (agents) for collecting information from many operating system and application specific sources to integrate the data into a unified namespace. Metadirectories also enforce business rules that specify the authoritative source for attribute values, handle naming and schema discrepancies, and provide data synchronization services between information sources. One of the benefits of a metadirectory is that it can create and maintain a central repository consisting of entries and attributes that are "joined" or aggregated from many other sources. However, a central store for data other than the "metadata" is not required for a metadirectory to provide synchronization services.6
Virtual directories vs. metadirectory technology
Virtual directories implement relatively new, but closely related and complementary to metadirectory technology with similar services. They provide applications with "virtual views" of the data contained in a variety of data stores. These views can be tailored to the requirements of the application. An application that prefers to use LDAP protocol to access its data can do so, even though the data may be stored in a relational database. Virtual directories are essentially brokers that enable a single query to reference information in multiple data sources dynamically.
A virtual directory could assemble information from multiple sources, perhaps using attributes in a directory as pointers, and then present it to a client application in response to an LDAP query against a virtual directory tree that is defined in the virtual directories "metadata". In Figure 3, a virtual directory could receive a query for Clark Kent's data and assemble his phone number, e-mail address, Active Directory and Lotus Domino account IDs, and his physical address from the multiple directories to enable an application to present them on a single screen for centralized administration. A virtual directory provides a layer of abstraction between the applications accessing data and the various repositories where it is stored and managed.
A potential advantage of a virtual directory over a metadirectory, when data access is primarily read-only and there is no need to synchronize data at the various sources, is that data is not moved between sources in order to compose and permanently store an aggregate view. Instead, the data is aggregated as required by the applications that access it. Virtual directories could be appropriate when this is the fundamental requirement, rather than data synchronization, especially for large amounts of data that is mostly read and infrequently written.
In many situations the advantage of a virtual directory can be very difficult to achieve. Directories and databases achieve high performance for portals and security systems that must perform hundreds of authentications and other queries on directory data per second by caching data. Since they control all access to the data, the directory server or database engine can manage a cache efficiently by discarding or replacing cached data when updates are made. Virtual directories can also cache data, of course, but a highly efficient caching strategy is more difficult for them because they do not see updates to the underlying data stores by applications that bypass them and write directly to the data store. When the virtual directory must store cached data persistently due to memory limitations on the server hardware or to provide quick restarts of the server, the distinction between virtual directories and metadirectories is blurred.
Since virtual directories synthesize views of information that can physically reside in several stores with different schemas, they will include most of the functionality of a metadirectory. For this reason, it is likely that metadirectories will evolve to provide some virtual directory services over time. The IBM Tivoli Directory Integrator may be an example of the very early stages of this trend. The latest release of ITDI includes an LDAP server "event handler" that enables a configuration to act as an LDAP server to a client application or infrastructure component. An ITDI configuration can therefore be built to receive LDAP requests and run assembly lines to perform operations such as looking up data in various types of data sources and assembling a resulting view of data in heterogeneous stores to a client using LDAP protocol.7 It is likely that over the long term, both metadirectories and virtual directory approaches will have a role in directory integration.
Overview of IBM Tivoli Directory Integrator
IBM Tivoli Directory Integrator synchronizes identity data residing in directories, databases, and applications. By serving as a flexible, synchronization layer between a company's sources of identity data, Directory Integrator can eliminate the need for a centralized data store. For those enterprises that do need to deploy an enterprise directory, Directory Integrator can connect it to the identity data from various repositories throughout the organization to populate it and keep it up-to-date.
With many built-in connectors for managing the flow of data and events, an open-architecture Java development environment to extend or modify these connectors, and tools to apply logic to data as data is processed, Directory Integrator can be used for:
•Synchronizing and exchanging information between applications or directory sources.
•Managing data across a variety of repositories providing the consistent directory infrastructure needed for a wide variety of applications including security and provisioning.
•Creating the authoritative data bases needed to expose only trustworthy data to advanced software applications such as Web services.
•Building an Enterprise Directory that contains commonly used data about users. This data store can become the authoritative data store for these data elements for the enterprise.
The product architecture is illustrated in Figure B-3 on page 694. The key concept to understand about ITDI is that it implements an assembly line model in which components are configured to support data flows between data sources. The product includes a GUI toolkit environment for creating and modifying assembly lines and a run-time server with a management GUI for starting and stopping assembly lines, examining log files, and other functions required to support an infrastructure service.
The basic components used to compose ITDI assembly lines are described in this section. Complete documentation, including a tutorial that guides the new user through the creation and operation of a simple assembly line is available in the on-line publications packaged with the product. The online documentation also includes a number of sample configurations that illustrate the use of the connectors and event handlers packaged with the product.
ITDI configurations are stored in XML files that contain all of the static metadata about one or more assembly lines. There is no architectural limit to the number of assembly lines that can be defined and managed by a single configuration file. An ITDI server is started with a particular configuration file, so an instance of the ITDI server can run several assembly lines concurrently. ITDI is a Java application and does not have dependencies on other infrastructure services.8 It is possible to start multiple instances of the ITDI server on a single system, each with configuration files defining different sets of assembly lines.
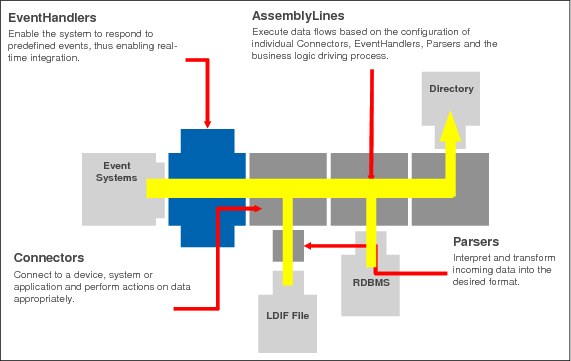
Figure B-3 IBM Tivoli Directory Integrator Product Architecture
Assembly lines
An assembly line collects information from connected information sources and performs operations on the data. An assembly line can create new entries altogether or update and delete entries in data sources. Assembly lines receive information from various data sources, perform operations on the input, and then map the collected information to other data sources. Assembly Lines work on one item at a time, for example, one data record, directory entry, registry key, and so forth. Multiple assembly lines may be running concurrently.
Connectors
Connectors support numerous protocols and access mechanisms. Many connectors are included with the product and ITDI architecture includes a framework that allows advanced users to create others. Connectors provide the input and output of an Assembly Line. Each Connector is linked to a data source, and is provides an environment specific to that type of source where data transformation and aggregation operations are easy to configure.
ITID connectors can be configured in several modes that determine how they operate. In iterator mode a connector is configured to read through the entries in a data source9 and pass each entry down the assembly line. In lookup mode, a connector is configured to find an entry in a data source based on search criteria and retrieve data from it. In update mode, a connector is configured to lookup an entry and may also update the entry after it has been located. In delete mode, a connector is configured to find and remove an entry from a data source. In add mode, a connector is configured to add entries to a data source.
In the current release the built-in connectors include:
•Btree Object DB Connector
•Command Line Connector
•Domino Users Connector
•File System
•FTP Client Connector
•Old HTTP Client Connector
•HTTP Client Connector
•Old HTTP Server Connector
•HTTP Server Connector
•IBM MQ Series (JMS)
•IBM Directory Changelog Connector
•JMS Connector
•JNDI
•LDAP
•Lotus Notes
•MailboxConnector Connector
•Memory Stream Connector
•Netscape/iPlanet Changelog Connector
•NT4
•Script Connector
•SNMP Connector
•TCP Connector (Generic)
•URL Connector (Generic)
•(runtime provided) Connector
•Web Service Connector
Event Handlers
ITDI includes an Event Handler framework that provides the integrator the ability to wait for, recognize and react to specific events that take place in the infrastructure. For example, changes in an LDAP or NOS directory, arriving e-mails, records updated in certain databases, incoming HTML requests for pages from a Web browser or Web services-based Simple Object Access Protocol (SOAP) messages can trigger assembly lines to run or other operations. The advanced user may also define new event handlers for site-specific events10.
ITDI Event Handlers are configured through the configuration GUI to examine the event11 and perform one or more actions based on the information received about the event. An action can be simple such as running a particular assembly line. More complex configurations for event handlers are also possible, such as selecting an assembly line to run based on data associated with the event, running a sequence of assembly lines, and executing scripts.
The built-in event handlers include:
•Active Directory Changelog.
•DSMLv2.
•Microsoft Exchange Changelog.
•HTTP.
•IBM Directory Server Changelog. This event handler is specifically designed to work efficiently with the Tivoli IBM Directory Server's changelog and event notification functionality.
•JMX.
•LDAP event handler for use with directories that support persistent search.
•LDAP server handler that enables ITDI to operate as an LDAP server to a client.
•SNMP.
•TCP Port.
•Timer.
•Web Service.
•zOS LDAP Changelog.
Parsers
Parsers interpret and translate information from a byte stream into a structured information object, where each piece of information is accessible by name. You can also translate a structured information object into a byte stream. You can select from the wide range of extensible parsers such as "comma separated values", "fixed column", LDAP Data Interchange Format (LDIF), Extensible Markup Language (XML), SOAP, and Directory Services Markup Language (DSML), or even create a new parser from scratch.
Hooks
Hooks enable the integrator to script actions to be executed under specific circumstances, or at desired points in the execution of the Assembly Line process. JavaScript is the preferred scripting language for ITDI because it can be used on every operating system platform for which ITDI is supported. Other scripting languages such as Perl can be used on some platforms.
ITDI provides a complete framework for scripting that handles all the details of invoking scripts at the appropriate point during assembly line operations and providing access to ITDI Java objects and their methods. The product's online documentation includes the complete set of APIs that users can call from scripts to access methods for controlling assembly lines, accessing data about them, calling the system utility functions provided with the product, and even executing methods on connectors.12
Link Criteria
Link Criteria are the attribute matching rules that locate entries in a directory for a connector to operate on when a connector is in lookup, update, or delete mode. When a connector is in one of these modes, ITDI automatically includes hooks in the scripting framework that enable the integrator to easily handle cases where the link criteria do not find a match in a data source or when multiple potential matches are found.
Link Criteria may be simple, such as linking two entries based on the value of a single attribute such as employeeNumber. More complex criteria are also easy to create by using scripts to perform data transformation if they are required for the comparison or to create complex search criteria that are specific to the data source. ITDI has built-in link comparison functions for the common "equals", "not equals", "contains", "starts with", and "ends with" comparison operations.
Work Entry
Work Entries are internal variables used to temporarily store values from directory entries. The values may be read directly from specific attributes, or may be computed by a script that performs data manipulation or transformation operations to compute a value for an attribute. Connectors are configured with input and output attribute maps that specify the mapping between the names and data types of attributes in the work object and the attribute values stored in a data source. ITDI also includes APIs that the systems integrator can call from scripts to create new attributes in the work entry and to examine and modify the values of the attributes that it contains.
Persistent store
The latest version of ITDI includes an embedded SQL database engine (IBM Cloudscape™) for Java that is useful for storing persistent metadata (not shown in the figure). Because of its lightweight, pure-Java, embeddable architecture Cloudscape is an excellent database engine for tools like ITDI because the database engine becomes part of the tool. The user never has to install or manage it and the database becomes invisible. The persistent store enables the integrator to persistently store information about data sources between runs of assembly lines. The Cloudscape persistent store can be set up so that the database is kept internal and accessible to only one ITDI configuration or put in a network mode that enables multiple ITDI configurations to share it.
ITDI automatically generates and uses a persistent store when a connector in iterator mode is configured to detect changes in a sequential file. When the file is processed, ITDI manages a persistent store that retains a record of the entries in the file that have been processed. This enables ITDI to recognize when new entries have been added or old entries have been deleted and efficiently return them to the connector with a flag indicating whether the entry is new, unchanged, or deleted. Connectors using this change detection mechanism have the option of indicating whether they want to receive unchanged entries, or only process adds and deletes from the file.
Older versions of ITDI include a bTree connector that can be used to provide a similar function. The bTree connector is retained in current versions, but the best practice is to use the more functional and Cloudscape based persistent store that relieves some constraints that affect the performance and scalability of the bTree connector.
Configuration of ITDI assembly lines
Directory Integrator provides a powerful graphical user interface (GUI) to configure the assembly lines and constituent connectors. Figure B-4 on page 699 illustrates that a configuration file can contain many different assembly lines that the system integrator can select to work with. In the figure, the assembly line named ITIMSearch has been selected. The top of the right hand panel provides a number of tabs the systems integrator may use to work with that assembly line, and the data flow tab has been selected.
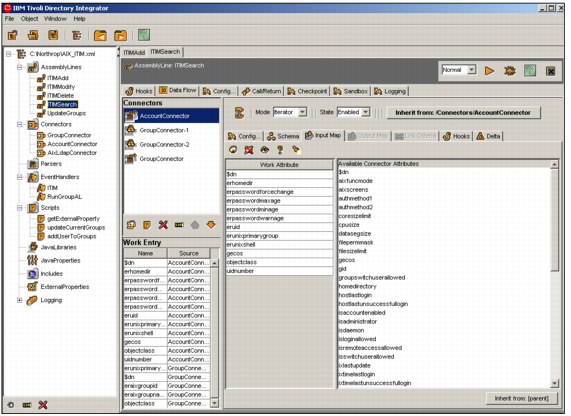
Figure B-4 ITDI Graphical Configuration Interface
The panel under the data flow tab is where the connectors in the ITIMSearch assembly line are configured and it shows the work object that flows between them. It has another row of tabs, and in the figure the input map tab has been selected. The panels on the data flow tab are:
•Connectors. This panel lists each of the connectors in the order they will be executed by the assembly line. In this example, the assembly line will run AccountConnector first, followed by the remaining connectors in the assembly line. Below the list of connectors are several icons to add or delete connectors from the assembly line, control the order of the connectors in the assembly line, and to add a configured connector to a connector library. Connectors in the connector library are available from the Connectors folder on the leftmost panel and can be selected and placed in other assembly lines. This is a powerful mechanism for re-use after a connector has been configured and tested.13
•Work Entry. This panel shows the contents of the work entry that flows between each of the connectors in the assembly line. Each of the attributes of the work entry is shown, along with the name of the connector that populates the work entry with the attribute value.
•When one of the connectors in the assembly line is selected, the configuration of that connector is displayed in the panel to the right of the Connectors panel. It contains another row of tabs for configuring the connector that has been selected.
In this example, the connector selected for configuration is in input mode and the Input Map tab for it has been selected. The panel below the tab shows the attributes that are available from the data source in the Available Connector Attribute list. The integrator may drag and drop attributes from the list into the Work Attribute list and control how they are mapped. For connectors in update or add mode, ITDI will provide an Output Map to configure how attributes are mapped from the work entry to the attributes available in the data source.
Notice the button labeled Inherit from: /Connectors/AccountConnector in the figure that shows the attribute map is being inherited from a connector definition in the Connectors folder. The integrator has the option of using this button to break this inheritance if some aspect of the inherited connector configuration needs to be handled in a specific way by selecting to inherit from another source, or no inheritance at all. It is typical, and a best practice, for connectors to be reused and extended in multiple assembly lines in ITDI deployments.14
Configuration of an ITDI Event Handler
ITDI Event Handlers are used to provide a framework to control how assembly lines are run. This framework is particularly useful when an event, such as a change event from an LDAP server, an HTTP message, or a JMS message is received. The incoming event can trigger several different assembly lines to run or other actions, depending on the content of the data received with the event.
Figure B-5 on page 702 illustrates how a typical ITDI event handler invokes an assembly line to process an event. The event handler in the figure is the ITDS changelog event handler. This event handler is configured on its configuration tab (not shown) to receive notification from an ITDS server whenever a change occurs in a part of the directory tree. The change notification event includes data about the change, such as the target DN, and the type of change.
Figure B-5 on page 702 shows the Action Map tab for the event handler that defines the processing that ITDI will perform each time a change event is received. An action map item, named ChangeDetected has been defined. For this item, two conditions based on the type of change received from the directory server will be evaluated to determine if the change is either an "add" or a "modify". The check box Match Any has been selected to indicate that if either of these conditions is true, the action items defined in the bottom panel's Condition True tab will be performed. In this case there are two action items. The first is to write a simple message to the console log file. The second is to run an assembly line named PropagatePwdChg. The Condition False tab may have action items that are performed if neither condition is evaluated as true. An ITDI Action Map may have multiple Action Items, each with their own set of conditions. They are evaluated in order.
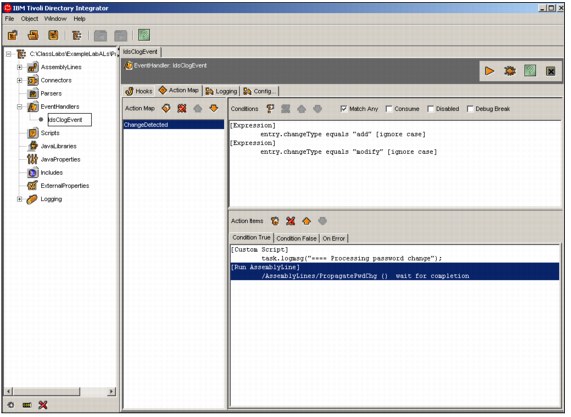
Figure B-5 ITDI Event Handler Action Map
A few Event Handlers have been pre-programmed to make things even easier. The DSMLV2 event handler shown in Figure B-6 on page 703 is an example. Here, the Configuration Tab contains all the information necessary to process DSML V2 events. Each of the possible DSML V2 events that can be received by the event handler are listed with a drop down list for selecting the particular assembly line that will be called to process that event. In this example, the DSML V2 compare and modify DN operations have not been associated with assembly lines, so these operations will be ignored by the event handler.
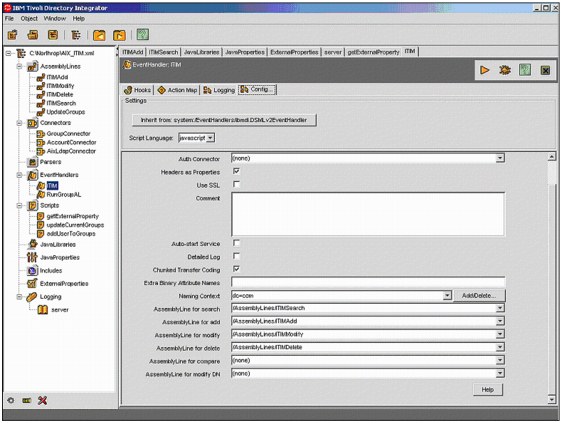
Figure B-6 ITDI DSML V2 Event Handler
ITDI solution example
With this background in directory integration technology and how it is used, we will take a look at a simplified, but typical corporate directory integration requirement and illustrate how an ITDI solution would be designed to solve it. This example has been taken from a few of the lab exercises for a training class offered by IBM for ITDI. To provide an idea of how easily integration solutions such as this can be implemented, in the training class students build all of the assembly lines described in this chapter and unit test them on the first day of class.
This solution is for an ITDI deployment to meet a mythical XYZ Company's requirement to integrate employee identity data in their HR system with Active Directory and Domino accounts. The initial objective is to load a new corporate directory with employee data from Active Directory and Domino and keep their user data synchronized. A future project will add business partners into the corporate directory for an IBM Tivoli Access Manager for eBusiness (ITAMeB) deployment to provide authentication and access control for WebSphere applications. The IBM Tivoli Directory Server (ITDS) will be the user and group registry for ITAMeB.
XYZ Company's initial requirements are to:
•Load a new ITDS enterprise directory with employee data from an extract from an HR system. The HR data is merged with data from the company's existing Active Directory and Domino servers. The initial loading of the database implements a business rule configured into the ITDI assembly lines to detect and report on "dirty" data that is discovered in the legacy Active Directory and Domino servers.
•Keep the enterprise directory, Domino server, and Active Directory synchronized with a daily extract of a simulated HR system.
– When a new user is added to the HR system, an Active Directory account is created. A Domino account can also be created with an email database and a Notes ID file for use with the Notes thick client. New Notes users are also provisioned with an HTTP password so they can access email using the Notes browser interface.
– When a user's status is changed from "Active" to "Inactive" in the simulated HR system, the user's Active Directory account is disabled. When a user's status is changed from "Inactive" to "Active" their existing Active Directory account is enabled.
•No significant changes will be made to XYZ Company's current business processes for maintaining identity data in the IT infrastructure. Current XYZ Company business processes may be streamlined, but administrative interfaces for managing user identities will not be modified or extended in this design.
•All XYZ Company employees will have an entry in the new corporate LDAP directory. They may also be given Active Directory and Domino accounts or added to static groups in the LDAP directory, based on their job code.
•When an XYZ Company HR administrator creates a new employee record in the HR system, the employee is assigned a unique employee User ID. The employee User ID will be the ID the employee authenticates with in the LDAP directory, Domino and Active Directory. Employees are never deleted from the HR system. Their status is changed from active to inactive on their termination date.
•User accounts will also be created in Active Directory, ITAMeB and Domino. Which accounts are created is based on the employee's job code.
– Users with a Job Code greater than 9 are knowledge workers. Knowledge workers always require Active Directory, ITAMeB, and Domino accounts.
– Users with a Job of 9 or less are production workers. Production workers do not need Domino accounts for email or to access other Domino applications. Production workers require an Active Directory account to access time and attendance and other shop floor applications that run on workstations or servers in the XYZ Company Windows domain. After the future ITAMeB deployment, they will require an ITAMeB account to access browser based HR applications from home, so they must also be in the LDAP directory.
•The XYZ Company Active Directory and Domino servers already contain entries for all current employees.
ITDI solution design
The ITDS LDAP directory is new at XYZ Company. It must be initially populated from the set of currently active employees in the HR system. There may be some "dirty" data in Domino and Active Directory. For example, employees that have job codes that require Domino accounts that do not have them or employees who do not have Active Directory accounts.
After the initial population of the LDAP directory, XYZ Company will use IDI to add new employees to the LDAP directory when they are added to the HR system. When employee information is changed in the HR system IDI will keep the directory, Domino, and Active Directory data synchronized. IDI assembly lines will support the following events.
•New Users. When new employees are added to HR, they must be added to the LDAP directory and assigned a Windows user ID and password. If the employee's job code is greater than 9, they are a knowledge worker, and a Domino account will be created.
•Account Revocation. When an employee leaves XYZ Company, their employee status is changed from an Active to Inactive in the HR system. ITDI must deactivate their Windows accounts.
•Employee Status Changes. When a user's job code changes, an ITDI assembly line must evaluate whether the employee needs a new Domino account created. If so, one will be created.
HR System Extract
The authoritative source for most identity information is an extract from the HR system. This extract is generated by a utility provided that produces a "comma delimited" flat file and contains the following data for each employee. The first record of the flat file is a header record containing the names of the fields in the following records. There is one record for each employee that contains:
•User ID
•Street address
•State
•City
•Zip code
•First name
•MI (middle initials)
•Last name
•Office fax number
•Full name
•Job code
•Employee number
•Employee status
•Dept number
•Telephone number
•Organizational title
Active Directory
Active Directory users are stored in the cn=Users,dc=xyz,dc=com container. The RDN is the cn attribute. XYZ Company has been using the full name as the value of this attribute but this has caused problems. They have decided to use the unique UID created by the HR system for new users. Active Directory will be the authoritative source for UserPrincipalName. This attribute in Active Directory will be the User [email protected]. For example, for the user with the ID jdoe, it will be [email protected]. It will be mapped to the description attribute in the IDS LDAP directory.
Another important attribute in Active Directory is userAccountControl. This Active Directory attribute controls the active or inactive status of a user account, among other things. If the second low order bit of this attribute is set on, the account is inactive.15
Domino
For the initial phase of the project the user's email address (the mail attribute) will be retrieved from the Domino server to populate the LDAP directory. When IDI creates new users in Domino, the basic attributes required by the Domino User connector to register a new user will be given values.
XYZ Company ITDS Directory Information Tree
The XYZ Company LDAP directory tree structure is illustrated in Figure B-7. The suffix of the directory is dc=XYZ Company,dc=com. The Directory Information Tree (DIT) is organized into a hierarchy of containers, or organizational units (ou's).
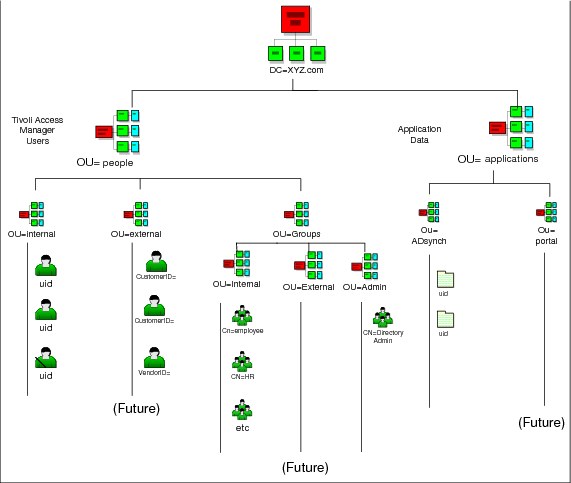
Figure B-7 XYZ Company Directory Information Tree (DIT)
User and group containers
The ou=Internal container will store entries for employees. under ou=people, dc=XYZ, dc=com. The subtree is flat to avoid embedding organizational structure into the Distinguished Names in the directory. The Relative Distinguished Name (RDN) for entries in this container will be the uid attribute that contains the user's Windows ID.
The ou=External container is reserved for future use. Only internal users (employees and contractors) will be stored in the directory in this phase of the XYZ Company directory integration solution. In the future, external users (customers and vendors) can be added under the container ou=External.
The ou=Groups container will store groups of users under the subtree ou=people, dc=XYZ,dc=com. The group subtree will be subdivided into containers for groups of internal users, external users, and administrative users. This enables the directory administrator to keep groups of administrators, internal users, and external users.
The RDN of the group entries in the directory is the cn attribute (the common name of the group). The three group containers are:
•ou=internal,ou=groups,ou=people,dc=xyz.com. ITAMeB will be deployed in the future to control access to resources based on the groups to which users belong. This container will contain the groups used by ITAMeB to control access to the resources it protects. In the figure, for example, the members of the group cn=employee, ou=internal, ou=groups, ou=people, dc=xyz, dc=com will be given access to the XYZ employee portal by ITAMeB.
•ou=external,ou=groups,ou=people,dc=xyz.com. This subtree is reserved. In the future groups containing external users may be defined in this subtree.
•ou=admin,ou=groups,ou=people,dc=xyz.com. This subtree contains administrative groups whose members are users given administrative rights for ITAMeB, applications, and the directory server.
Application container
Directory entries in the ou=Applications container will be used by directory enabled XYZ Company infrastructure components and applications.
•ou=ADsynch, ou=Applications,dc=XYZ, dc=com. In the future, after ITAMeB is installed, the ITDI Active Directory password interceptor will be installed on the Active Directory Domain Controller to synchronize passwords in the ITDS directory when users change their passwords in Active Directory. The ITDI interceptor will securely store the public key encrypted new password in this ITDS container. An ITDI assembly line will propagate new or changed values for password to the entry with the same uid in the ou=Internal, ou=People, dc=XYZ,dc=com container.
•ou=Portal, ou=Applications,dc=xyz.com. This container will be used in the future by the WebSphere Portal Server and portal applications.
LDAP Schema
In this design the schema and indexing information in the tables in this section are the default configuration of the IBM Directory Server "out of the box" after installation. The following attributes will be populated in the directory:
•cn (Common Name) - This multivalued attribute will contain two values, the user's full name in HR and the user's last name to facilitate LDAP directory searches based on the last name.
•businessCategory - This attribute will contain the employee's job code from HR.
•departmentNumber - From HR.
•description - This attribute will contain the userPrincipalName in Active Directory.
•displayName - The user's full name from HR.
•employeeNumber - From HR.
•employeeType - Mapped to employee status in HR.
•facsimileTelephoneNumber - From office fax number in HR.
•givenName - From first name in HR.
•initials - From MI in HR.
•l (location) - From the city attribute in HR.
•mail - The email address from Domino.
•postalCode - From zip code in HR.
•sn - From last name from HR.
•st - From state in HR.
•street - From street address in HR.
•telephoneNumber - From telephone number in HR.
•title - From organizational title in HR.
•uid - From user ID in HR.
Groups will be created in the ou=Groups,ou=People,dc=XYZ,dc=com container with the accessGroup objectclass. The future Access Manager deployment will use groups in ACLs that control user access to the resources it protects.
Solution components
The components of the XYZ Company Directory and future ITAMeB deployment are illustrated in Figure B-8.

Figure B-8 Solution architecture
Initial population of the LDAP Directory
This section describes how the LDAP directory will be initially loaded with entries for current XYZ Company employees. Once populated, the LDAP directory will be maintained by the procedures and ITDI assembly lines described in the next section.
The initial entries loaded into the directory will contain attributes that are populated from the XYZ Company HR System. The extract utility provided with the HR system will be used to export user data into an XML file. An extract is generated that contains the HR information for each current employee. The data flow through the assembly line for initial population of the LDAP directory is shown in Figure B-9 on page 711.16

Figure B-9 Initial Directory population data flow
This assembly line contains the following connectors:
•File System Connector - This connector will be configured in iterator mode to read the XML data exported from the HR System. Into the ITDI work object. It will pass the entry to the next connector.
•LDAP Connector (Domino) - This connector will be configured in Lookup mode. It will be configured to look up the employee's email address in Domino and add it to the work entry. Only employees with a job code of 10 or higher should have an email address. If "dirty data" is found, a passive state connector17 will be called to output an error message.
•LDAP Connector (Active Directory) - This connector will be configured in Lookup mode. It will lookup the user's userPrincipalName in Active Directory. If no Active Directory account information is found for an active employee, a passive state connector will be called to output an error message. An SSL connection will be configured to Active Directory in preparation for the requirement to add active directory users and set their passwords.18
•LDAP Connector (ITDS ou=internal, ou=People container) - This connector will be configured in Update mode. It will lookup the entry in the IDS directory for the employee with the data from the HR system19. If found, the connector will update the attributes in its attribute map with the values from the work entry. If not found, the connector will add the entry.
The first time the assembly line runs, the entry will not be found, since the LDAP directory is empty, and the connector will create a new entry from the HR data, email address from Domino, and the userPrincipalName from Active Directory. If the assembly line is run multiple times, the user entry will be found if it was created by a previous run. The entry will be updated if the current HR data differs from the data in the directory.
•File System Connector - This connector will be configured in passive state with an XML parser. It will be called by other connectors to write errors to an error log.
User Management
This section describes the IDI data flows that will keep the LDAP directory, and Active Directory synchronized. These data flows are triggered by new or changed entries in the HR system. The processes supporting these events are shown in the data flow diagram in Figure B-10 on page 713.

Figure B-10 User management data flow
This assembly line contains the following connectors:
•Flat file Connector - This connector will be configured in iterator mode to read the XML data exported from the HR System.
•Domino User Connector - This connector will be configured in Update Mode. If this is a potential new Domino user, and job code requires an email account, it will create a new Domino account for the user. Otherwise, the connector will update the entry if the HR Data has changed.
•LDAP Connector (Active Directory) - This connector will be configured in update mode. It will lookup the user's userPrincipalName in Active Directory. If no Active Directory account information is found for an active employee a new account will be created. The employee status attribute from the HR file will be mapped to the Active Directory userAccountControl attribute to enable or disable the Active Directory account based on their current status.
•LDAP Connector (ITDS ou=internal, ou=People container) - This connector will be configured in Update mode. It will lookup the entry in the ITDS directory for the employee with the data from the HR system.
Summary
In this chapter we have reviewed the reasons why it is usually critical to address directory integration requirements in any major directory deployment project. We reviewed several methodologies for integrating directories with heterogeneous legacy data stores and focused on metadirectories as currently providing the most robust and stable technology. Metadirectories were compared to the complementary technologies of provisioning systems and virtual directories. Finally we provided an overview of a particular metadirectory, the IBM Tivoli Directory Integrator and illustrated a solution design for deploying it to solve a set of relatively simple but realistic and common integration requirements.
1 While modern operating systems are directory enabled, they are not always installed and configured to exploit an LDAP directory for user accounts. For example, Unix and Linux servers are still configured to use flat files to maintain their user account and group information more often then they are set up to store user account information in a directory.
2 The term "directory integration services" is used to label various types of services that link heterogeneous repositories and provide a consistent view of the information they contain. Another popular label for these services is "metadirectory", which is a particular technology to accomplish this.
3 An internal study found IBM spends approximately $50 per user entry for each password directory it maintains. In a company with 200,000 employees, that offers significant savings in ongoing costs for each directory that can be consolidated or eliminated.
4 An orphan account is one that exists and is associated with access permissions but the individual who owns the account is not known. Orphan accounts are obviously fertile ground for security problems.
5 A provisioning system that automates account creation and access permissions based on erroneous user identity data may be worse and actually less secure than an inefficient manual one.
6 Some metadirectory vendors require that a proprietary product or database be used to store the metadata. This is not a characteristic of ITDI. ITDI stores its static metadata in XML configuration files and can store dynamic metadata in an embedded java database.
7 This is not yet a true virtual directory, of course. ITDI does not cache the virtual views created by the assembly lines and does not include tools specifically designed to create them.
8 This is an important point. Some metadirectories have dependencies on other services such as a particular vendor's LDAP server or relational database being installed with it. With ITDI, the hardware and software requirements to install and use it are lightweight and depend mainly on having connectivity to the data sources it is used to integrate.
9 The iteration can be filtered. For example an LDAP or database connector in iterator mode can be configured to read through all the entries returned by specific search criteria.
10 For example, ITDI includes a script event handler that enables the integrator to write a script to define a custom event.
11 As an example, ITDI includes LDAP changelog event handlers, which can react to changes in an LDAP directory server. The event handler could be configured to run one or more assembly lines, based on the DN of the entry that was changed and the type of change (add, modify, delete, rename).
12 Since ITDI is 100% Java, all its public objects and methods are easily accessible from a scripting language such as JavaScript. Documentation in Javadoc form is included in the online documentation library.
13 ITDI implements inheritance of connector configurations. There are several aspects of connector configuration, such as the location, account names and passwords used to connect to a data source, the source attributes retrieved or written, and hooks that implement site-specific business logic during connector processing, etc. Internally connectors are Java objects and each of these aspects can be inherited, extended, or replaced when a connector is reused from the library.
14 It is possible to select a connector from the Connectors folder in the leftmost panel and perform the configuration of a connector directly in the library. Once configured, the connectors in this folder can be placed and used in several assembly lines. The advantage is that as the configuration is tested and extended, changes made in the connector library can be inherited in each place the connector is used.
15 See Microsoft documentation for a complete description of the userAccountControl attribute.
16 In this and other data flow diagrams in this document, components, such as the HR Extract Utility in this figure that are external to this system are shown as rectangles.
17 A connector can be placed in an enabled, disabled, or passive state (see the drop down list for these states in Figure B-4 on page 699). In passive state, the ITDI framework does not automatically call the connector. The connector is typically called from a hook script when needed, such as in this case when an error condition occurs.
18 Active Directory requires an SSL session be used when setting user passwords.
19 It could also be configured in add mode, but existing entries need to be handled if the assembly line is run multiple times during testing.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.