


Introduction to LDAP
Today people and businesses rely on networked computer systems to support distributed applications. These distributed applications might interact with computers on the same local area network, within a corporate intranet, within extranets linking up partners and suppliers, or anywhere on the worldwide Internet. To improve functionality and ease-of-use, and to enable cost-effective administration of distributed applications, information about the services, resources, users, and other objects accessible from the applications needs to be organized in a clear and consistent manner. Much of this information can be shared among many applications, but it must also be protected in order to prevent unauthorized modification or the disclosure of private information.
Information describing the various users, applications, files, printers, and other resources accessible from a network is often collected into a special database that is sometimes called a directory. As the number of different networks and applications has grown, the number of specialized directories of information has also grown, resulting in islands of information that are difficult to share and manage. If all of this information could be maintained and accessed in a consistent and controlled manner, it would provide a focal point for integrating a distributed environment into a consistent and seamless system.
The Lightweight Directory Access Protocol (LDAP) is an open industry standard that has evolved to meet these needs. LDAP defines a standard method for accessing and updating information in a directory. LDAP has gained wide acceptance as the directory access method of the Internet and is therefore also becoming strategic within corporate intranets. It is being supported by a growing number of software vendors and is being incorporated into a growing number of applications. For example, the two most popular Web browsers, Netscape Navigator/Communicator and Microsoft Internet Explorer, as well as application middleware, such as the IBM WebSphere Application Server or the IBM HTTP server, support LDAP functionality as a base feature.
This chapter introduces the fundamentals of directories and the most commonly used protocol to access directories, the LDAP protocol. You will also learn about the various components that make up a directory.
Part of the information covered in this chapter and further information on LDAP directory concepts and implementations can be found in the following publications:
•Implementation and Practical Use of LDAP on the IBM iSeries™ Server, SG24-6193
•Using LDAP for Directory Integration, SG24-6163
Another book that contains good information about directory concepts and architecture is e-Directories Enterprise Software, Solutions, and Services, ISBN 0-201-70039-5.
1.1 Directories
A directory is a listing of information about objects arranged in some order that gives details about each object. Common examples are a city telephone directory and a library card catalog. For a telephone directory, the objects listed are people; the names are arranged alphabetically, and the details given about each person are address and telephone number. Books in a library card catalog are ordered by author or by title, and information such as the ISBN number of the book and other publication information is given.
In computer terms, a directory is a specialized database, also called a data repository, that stores typed and ordered information about objects. A particular directory might list information about printers (the objects) consisting of typed information such as location (a formatted character string), speed in pages per minute (numeric), print streams supported (for example PostScript or ASCII), and so on.
Directories allow users or applications to find resources that have the characteristics needed for a particular task. For example, a directory of users can be used to look up a person's e-mail address or fax number. A directory could be searched to find a nearby PostScript color printer. Or a directory of application servers could be searched to find a server that can access customer billing information.
The terms white pages and yellow pages are sometimes used to describe how a directory is used. If the name of an object (person, printer) is known, its characteristics (phone number, pages per minute) can be retrieved. This is similar to looking up a name in the white pages of a telephone directory. If the name of a particular individual object is not known, the directory can be searched for a list of objects that meet a certain requirement. This is like looking up a listing of hairdressers in the yellow pages of a telephone directory. However, directories stored on a computer are much more flexible than the yellow pages of a telephone directory because they can usually be searched by specific criteria, not just by a predefined set of categories.
1.1.1 Directory versus database
A directory is often described as a database, but it is a specialized database that has characteristics that set it apart from general-purpose relational databases. One special characteristic of directories is that they are accessed (read or searched) much more often than they are updated (written). Hundreds of people might look up an individual's phone number, or thousands of print clients might look up the characteristics of a particular printer, but the phone number or printer characteristics rarely change.
Because directories must be able to support high volumes of read requests, they are typically optimized for read access. Write access might be limited to system administrators or to the owner of each piece of information. A general-purpose relational database, on the other hand, needs to support applications, such as airline reservations and banking applications, with relatively high-update volumes.
Because directories are meant to store relatively static information and are optimized for that purpose, they are not appropriate for storing information that changes rapidly. For example, the number of jobs currently in a print queue probably should not be stored in the directory entry for a printer because that information would have to be updated frequently to be accurate. Instead, the directory entry for the printer can contain the network address of a print server. The print server can be queried to get the current queue length if desired. The information in the directory (the print server address) is static, whereas the number of jobs in the print queue is dynamic.
Another difference between directories and general-purpose relational databases is that most directory implementations still do not support transactions. However, transactions are supported in LDAP and are limited to transactions within the LDAP directory, and do not include other transactions (for example, database operations). Transactions are all-or-nothing operations that must be completed in total or not at all. For example, when transferring money from one bank account to another, the money must be debited from one account and credited to the other account in a single transaction. If only half of this transaction completes or someone accesses the accounts while the money is in transit, the accounts will not balance. General-purpose relational databases usually support such transactions, which complicates their implementation.
Because general-purpose relational databases must support arbitrary applications such as banking and inventory control, they allow arbitrary collections of data to be stored. Directories may be limited in the type of data they allow to be stored (although the architecture does not impose such a limitation). For example, a directory specialized for customer contact information might be limited to storing only personal information such as names, addresses, and phone numbers. If a directory is extensible, it can be configured to store a variety of types of information making it more useful to a variety of programs.
Another important difference between a directory and a general-purpose relational database is in the way information can be accessed. Most databases support a standardized, very powerful access method called Structured Query Language (SQL). SQL allows complex update and query functions at the cost of program size and application complexity. Directories, such as an LDAP directory, on the other hand, use a simplified and optimized access protocol that can be used in slim and relatively simple applications.
Because directories are not intended to provide as many functions as general-purpose relational databases, they can be optimized to economically provide more applications with rapid access to directory data in large distributed environments. If your intended use of the directory is to be read, mostly in a non-transactional environment, both the directory client and directory server can be simplified and optimized.
A request is typically performed by the directory client, and the process that looks up information in the directory is called the directory server. In general, servers provide a specific service to clients. Sometimes a server might become the client of other servers in order to gather the information necessary to process a request.
A directory service is only one type of service that might be available in a client/server environment. Other common examples of services are file services, mail services, print services, Web page services, and so on. The client and server processes may or may not be on the same machine. A server is capable of serving many clients. Some servers can process client requests in parallel. Other servers queue incoming client requests for serial processing if they are currently busy processing another client's request.
An API defines the programming interface a particular programming language uses to access a service. The format and contents of the messages exchanged between client and server must adhere to an agreed-upon protocol.
1.1.2 LDAP: Protocol or directory
The Lightweight Directory Access Protocol (LDAP) defines a message protocol used by directory clients and directory servers.The LDAP protocol uses different messages. For example, a bindRequest may be sent from the client to the LDAP server at the beginning of a connection. A searchRequest is used to search for a specific entry in the directory.
There are also associated LDAP APIs for the C language and ways to access LDAP from within a Java™ application. Additionally, within the Microsoft development environment, you can access LDAP directories through its Active Directory Service Interface (ADSI) In general with LDAP, the client is not dependent upon a particular implementation of the server, and the server can implement the directory however it chooses.
LDAP is an open industry standard that defines a standard method for accessing and updating information in a directory. LDAP has gained wide acceptance as the directory access method of the Internet and is therefore also becoming strategic within corporate intranets. It is being supported by a growing number of software vendors and is being incorporated into a growing number of applications.
LDAP defines a communication protocol. That is, it defines the transport and format of messages used by a client to access data in an X.500-like directory. LDAP does not define the directory service itself. When people talk about the LDAP directory, that is the information that is stored and can be retrieved by the LDAP protocol.
All modern LDAP directory servers are based on LDAP Version 3. You can use a Version 2 client with a Version 3 server. However, you cannot use a Version 3 client with a Version 2 server unless you bind as a Version 2 client and use only Version 2 APIs.
All LDAP servers share many basic characteristics since they are based on the industry standard Request for Comments (RFCs). However, due to implementation differences, they are not all completely compatible with each other when there is not a standard defined.
1.1.3 Directory clients and servers
Directories are usually accessed using the client/server model of communication. An application that wants to read or write information in a directory does not access the directory directly. Instead, it calls a function or application programming interface (API) that causes a message to be sent to another process. This second process accesses the information in the directory on behalf of the requesting application via TCP/IP. The default TCP/IP ports are 636 for secure communications and 389 for unencrypted communications. The results of the read or write action are then returned to the requesting application, as shown in Figure 4-1 on page 84.
The request is performed by the directory client, and the process that maintains and looks up information in the directory is called the directory server. In general, servers provide a specific service to clients. Sometimes, a server might become the client of other servers in order to gather the information necessary to process a request.
The client and server processes may or may not be on the same machine. A server is capable of serving many clients. Some servers can process client requests in parallel. Other servers queue incoming client requests for serial processing if they are currently busy processing another client’s request.
An API defines the programming interface that a particular programming language uses to access a service. The format and contents of the messages exchanged between client and server must adhere to an agreed-upon protocol. LDAP defines a message protocol used by directory clients and directory servers. There are also associated LDAP APIs for C and Java languages, and ways to access the directory from a Java application using Java Naming and Directory Interface (JNDI). The client is not dependent on a particular implementation of the server, and the server can implement the directory however it chooses.
1.1.4 Distributed directories
The terms local, global, centralized, and distributed are often used to describe a directory. These terms mean different things in different contexts. In this section, we explain how these terms apply to directories.
In general, local means nearby, and global means that something is spread across the universe of interest. The universe of interest might be a company, a country, or the Earth. Local and global are two ends of a continuum. That is, something may be more or less global or local than something else. Centralized means that something is in one place, and distributed means that something is in more than one place. As with local and global, something can be distributed to a greater or lesser extent.
The information stored in a directory can be simultaneously local and global in scope. For example, a directory that stores local information might consist of the names, e-mail addresses and so on of members of a department or workgroup. A directory that stores global information might store information for an entire company. Here, the universe of interest is the company.
The clients that access information in the directory can be local or remote. Local clients may all be located in the same building or on the same LAN. Remote clients might be distributed across the continent or planet.
The directory itself can be centralized or distributed. If a directory is centralized, there may be one directory server at one location or a directory server that hosts data from distributed systems. If the directory is distributed, there are multiple servers, usually geographically dispersed, that provide access to the directory.
When a directory is distributed, the information stored in the directory can be partitioned or replicated. When information is partitioned, each directory server stores a unique and non-overlapping subset of the information. That is, each directory entry is stored by one and only one server. One of the techniques to partition the directory is to use LDAP referrals. LDAP referrals enable users to refer LDAP requests to a different server. When information is replicated, the same directory entry is stored by more than one server. In a distributed directory, some information may be partitioned while some may be replicated.
The three dimensions of a directory (scope of information, location of clients, and distribution of servers) are independent of each other. For example, clients scattered across the globe can access a directory containing only information about a single department, and that directory can be replicated at many directory servers. Or, clients in a single location can access a directory containing information about everybody in the world that is stored by a single directory server.
The scope of information to be stored in a directory is often given as an application requirement. The distribution of directory servers and the way in which data is partitioned or replicated often can be controlled to affect the performance and availability of the directory.
1.2 Advantages of using a directory
An application-specific directory stores only the information needed by a particular application and is not accessible by other applications. Because a full-function directory service is complex to build, application-specific directories are typically very limited. They probably store only a specific type of information, do not have general search capabilities, do not support replication and partitioning, and probably do not have a full set of administration tools. An application-specific directory could be as simple as a set of editable text files, or it could be stored and accessed in an undocumented, proprietary manner.
In such an environment, each application creates and manages its own application-specific directory, which quickly becomes an administrative nightmare. The same e-mail address stored by the calendar application might also be stored by a mail application and by an application that notifies system operators of equipment problems. Keeping multiple copies of information up-to-date and synchronized is difficult, especially when different user interfaces and even different system administrators are involved.
What is needed is a common, application-independent directory. If application developers could be assured of the existence of a directory service, then application-specific directories would not be necessary. However, a common directory must address the problems mentioned above. It must be based on an open standard that is supported by many vendors on many platforms. It must be accessible through a standard API. It must be extensible so that it can hold the types of data needed by arbitrary applications, and it must provide full functionality without requiring excessive resources on smaller systems. Since more users and applications will access and depend on the common directory, it must also be robust, secure, and scalable.
When such a directory infrastructure is in place, application developers can devote their time to developing applications instead of application-specific directories. In the same way that developers rely on the communications infrastructure of TCP/IP and remote procedure call (RPC) to free them from low-level communication issues, they will be able to rely on powerful, full-function directory services. LDAP is the protocol to be used to access this common directory infrastructure. Like HTTP (hypertext transfer protocol) and FTP (file transfer protocol), LDAP has become an indispensable part of the Internet's protocol suite.
When applications access a standard common directory that is designed in a proper way, rather than using application-specific directories, redundant and costly administration can be eliminated, and security risks are more controllable. For example, the telephone directory, mail, and Web application as shown in Figure 1-1 can all access the same directory to retrieve an e-mail address or other information stored in a single directory entry. The advantage is that the data is kept and maintained in one place. Various applications can use individual attributes of an entry for different purposes permitting that the they have the correct authority. New uses for directory information will be realized, and a synergy will develop as more applications take advantage of the common directory.

Figure 1-1 Several applications using attributes of the same entry
Storing data in a directory and sharing it amongst applications saves you time and money by keeping administration effort and system resources down. Many IBM applications also utilize directories to centrally store and share information. The number of applications that support LDAP directories is constantly increasing. For example, LDAP directory support, such as for authentication and configuration management, is provided in various IBM operating systems, IBM WebSphere Application Server, IBM WebSphere Portal Server, IBM Tivoli Access Manager, IBM Tivoli Directory Server, IBM HTTP server, IBM Lotus® Domino®, and so forth.
1.3 LDAP history and standards
In the 1970s, the integration of communications and computing technologies led to the development of new communication technologies. Many of the proprietary systems that were developed were incompatible with other systems. It became apparent that standards were needed to allow equipment and systems from different vendors to interoperate. Two independent major standardizations efforts developed to define such standards.
1.3.1 OSI and the Internet
One standards drive was lead by the CCITT (Comite Consultatif International Telephonique et Telegraphique, or International Consultative Committee on Telephony and Telegraphy), and the ISO (International Standards Organization). The CCITT has since become the ITU-T (International Telecommunications Union - Telecommunication Standardization Sector). This effort resulted in the OSI (Open Systems Interconnect) Reference Model (ISO 7498), which defined a seven-layer model of data communication with physical transport at the lower layer and application protocols at the upper layers.
The other standards drive grew up around the Internet and developed from research sponsored by DARPA (the Defense Advanced Research Projects Agency) in the United States. The Internet Architecture Board (IAB) and its subsidiary, the Internet Engineering Task Force (IETF), develop standards for the Internet in the form of documents called Request for Comments (RFCs), which after being approved, implemented, and used for a period of time, eventually become standards (STDs). Before a proposal becomes an RFC, it is called an Internet Draft.
The two standards processes approach standardization from two different perspectives. The OSI approach started from a clean slate and defined standards using a formal committee process without requiring implementations. The Internet uses a less formal engineering approach, where anybody can propose and comment on RFCs, and implementations are required to verify feasibility.
The OSI protocols developed slowly, and because running the full protocol stack, is resource intensive, they have not been widely deployed, especially in the desktop and small computer market. In the meantime, TCP/IP and the Internet were developing rapidly and being put into use. Also, some network vendors developed proprietary network protocols and products.
1.3.2 X.500 the Directory Server Standard
However, the OSI protocols did address issues important in large distributed systems that were developing in an ad hoc manner in the desktop and Internet marketplace. One such important area was directory services. The CCITT created the X.500 standard in 1988, which became ISO 9594, Data Communications Network Directory, Recommendations X.500-X.521 in 1990, though it is still commonly referred to as X.500.
X.500 organizes directory entries in a hierarchal name space capable of supporting large amounts of information. It also defines powerful search capabilities to make retrieving information easier. Because of its functionality and scalability, X.500 is often used together with add-on modules for interoperation between incompatible directory services.
|
Note: An excellent online resource on X.500 is the book, Understanding X.500 - The Directory. While dated (1996), this book, which is now out of print (but available online) is considered one of the original “gospels” of the directory world. It describes and defines the X.500 directory model in great detail. Much of the material is still very much relevant in today’s current family of LDAP directory servers. It can be found here:
|
X.500 specifies that communication between the directory client and the directory server uses the directory access protocol (DAP). However, as an application layer protocol, the DAP requires the entire OSI protocol stack to operate. Supporting the OSI protocol stack requires more resources than are available in many small environments. Therefore, an interface to an X.500 directory server using a less resource-intensive or lightweight protocol was desired.
1.3.3 Lightweight Access to X.500
LDAP was developed as a lightweight alternative to DAP. LDAP requires the lighter weight and more popular TCP/IP protocol stack rather than the OSI protocol stack. LDAP also simplifies some X.500 operations and omits some esoteric features.
Two precursors to LDAP appeared as RFCs issued by the IETF, Directory Assistance Service (RFC 1202) and DIXIE Protocol Specification (RFC 1249). These were both informational RFCs which were not proposed as standards. The directory assistance service (DAS) defined a method by which a directory client could communicate to a proxy on a OSI-capable host which issued X.500 requests on the client’s behalf. DIXIE is similar to DAS, but provides a more direct translation of the DAP.
The first version of LDAP was defined in X.500 Lightweight Access Protocol (RFC 1487), which was replaced by Lightweight Directory Access Protocol (RFC 1777). LDAP further refines the ideas and protocols of DAS and DIXIE. It is more implementation neutral and reduces the complexity of clients to encourage the deployment of directory-enabled applications. Much of the work on DIXIE and LDAP was carried out at the University of Michigan, which provides reference implementations of LDAP and maintains LDAP-related Web pages and mailing lists.
RFC 1777 defines the LDAP protocol itself. RFC 1777, along with:
•The String Representation of Standard Attribute Syntaxes (RFC 1778)
•A String Representation of Distinguished Names (RFC 1779)
•An LDAP URL Format (RFC 1959)
•A String Representation of LDAP Search Filters (RFC 1960)
Define the original LDAPv2 version of the language.
LDAP Version 2 has reached the status of draft standard in the IETF standardization process, one step from being a standard. All of today’s directory server implementations are based on the LDAPv3 specification.
LDAP Version 3 is defined by Lightweight Directory Access Protocol (v3) (RFC 2251). Related RFCs that are new or updated for LDAP Version 3 are:
•Lightweight Directory Access Protocol (v3): Attribute Syntax Definitions (RFC 2252)
•Lightweight Directory Access Protocol (v3): UTF-8 String Representation of Distinguished Names (RFC 2253)
•The String Representation of LDAP Search Filters (RFC 2254)
•The LDAP URL Format (RFC 2255)
•A Summary of the X.500(96) User Schema for use with LDAPv3 (RFC 2256)
•Authentication Methods for LDAP (RFC 2829)
•LDAPv3: Extension for Transport Layer Security (RFC 2830)
•Lightweight Directory Access Protocol (v3): Technical Specification (RFC 3377)
RFC 2251 is a proposed standard, one step below a draft standard. LDAP V3 extended LDAP V2 in the following areas:
•Referrals: A server that does not store the requested data can refer the client to another server.
•Security: Extensible authentication using Simple Authentication and Security Layer (SASL) mechanism.
•Internationalization: UTF-8 support for international characters.
•Extensibility: New object types and operations can be dynamically defined and schema published in a standard manner.
In this book, the term LDAP refers to LDAP Version 3 unless LDAP Version 2 is specifically stated. Differences between LDAP Version 2 and LDAP Version 3 are noted when necessary.
1.3.4 Beyond LDAPv3
Recently, the push for encapsulating LDAP operations within XML for use within Web Services has spawned a new language called the Directory Services Markup Language (DSML). The most recent of the specification is DSMLv2. DSML is an XML schema for representing directory information, it's a generic import / export format for directory information. Directory information in DSML can be shared between DSML-aware applications without exposing the LDAP protocol.
XML provides an effective way to present and transfer data; Directory services allow you to share and manage data, and are thus a necessary prerequisite for conducting online business; DSML is designed to make directory service more dynamic by employing XML. DSML is an XML schema for working with directories, it is defined using a Document Content Description (DCD). Thus, DSML allows XML programmers to access LDAP-enabled directories without having to write to the LDAP interface or use proprietary directory-access APIs, and provides one consistent way to work with multiple dissimilar directories
More information on DSML can be found in Appendix A, “DSML Version 2” on page 635.
Various directory integration technologies have emerged in recent years that utilize LDAP and directory concepts to centralize and/or sychronize data between disparate directories as well as other disparate non-directory data sources. Two of the more prominent technologies in this directory integration space are Meta-Directories and Virtual Directories. These technologies are covered in greater detail in Appendix B, “Directory Integration - IBM Tivoli Directory Integrator” on page 681.
1.4 Directory components
A directory contains a collection of objects organized in a tree structure. The LDAP naming model defines how entries are identified and organized. Entries are organized in a tree-like structure called the Directory Information Tree (DIT). Entries are arranged within the DIT based on their distinguished name (DN). A DN is a unique name that unambiguously identifies a single entry. DNs are made up of a sequence of relative distinguished names (RDNs). Each RDN™ in a DN corresponds to a branch in the DIT leading from the root of the DIT to the directory entry. A DN is composed of a sequence of RDNs separated by commas, such as cn=thomas,ou=itso,o=ibm.
You can organize entries, for example, after organizations and within a single organization you can further split the tree into organizational units, and so forth. You can define your DIT based on your organizational needs as shown in Figure 1-2 on page 17. If you have, for example, one company with different divisions, you may want to start with your company name under the root as the organization (o) and then branch into organizational units (ou) for the individual divisions. In case you store data for multiple organizations within a country, you may want to start with a country (c) and then branch into organizations. For more information on planning a DIT, refer to Chapter 3, “Planning your directory” on page 57.
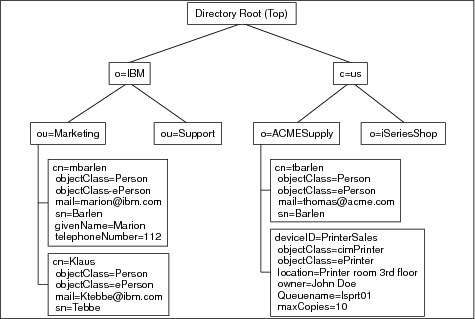
Figure 1-2 Example of a Directory Information Tree (DIT)
Each object also referred to as an entry in a directory belonging to one or more object classes. An object class describes the content and purpose of the object. It also contains a list of attributes, such as a telephone number or surname, that can be defined in an object of that class. You can publish entries of different object classes under another object as shown in Figure 1-2 where an ePrinter object and a Person object is published under the organization ACMESupply.

Figure 1-3 ePrinter object class
The object class also defines which of the attributes must be defined (required) when creating an object of this class and which attributes are optional. As shown in Figure 1-3, the object class with the name ePrinter has a required attribute deviceID and three optional attributes that may or may not be filled in when creating an ePrinter object. Object classes can also inherit characteristics, such as attributes from other object classes. In the example of the ePrinter, the class inherits all the attributes that are defined in class cimPrinter. That means, when you create an ePrinter object you have to define the deviceID and optionally you can specify the location, owner, and queuePtr attribute of ePerson and all attributes of cimPrinter.
Also attributes themselves have certain characteristics as shown in Figure 1-4 on page 19. The surname attribute name, for example, is defined as sn and surName, and describes a person's family name. The attribute definition specifies also the syntax rules for the attribute value. A telephone number may only contain numbers and hyphens while the surname consists of alpha characters. Other specifications include whether this attribute can contain only one or many values, the matching rules, the Object Identifier (OID), and so forth. The IBM Tivoli Directory Server (ITDS) product also includes some IBM proprietary extensions to each attribute. Other manufactures, such as Microsoft, have similar extensions. The IBM extensions include also an access class, which is used in combination with access control lists (ACLs) to control who can perform a certain action on the attribute value, such as read, write, search, or compare operations.
All the objects and attributes with their characteristics are defined in schemas. The schema specifies what can be stored in the directory. Schema-checking ensures that all required attributes for an entry are present before an entry is stored. Schema-checking also ensures that attributes not in the schema are not stored in the entry. Optional attributes can be filled in at any time. A schema also defines the inheritance and subclassing of objects and where in the DIT structure (hierarchy) objects may appear. Information about the ITDS schema can be found at:

Figure 1-4 Attribute definition example
As you have seen in Figure 1-3 on page 18 and Figure 1-4, object classes and attributes including their specifications are defined as OIDs in an ASN.1 notation format. All these OIDs are registered with a public organization, such as the ANSI organization (http://www.ansi.org) for the United States. The number notation refers to a hierarchy. For example, the OID 2.5.4.4 resolves into a surName attribute as shown in Figure 1-5 on page 20.

Figure 1-5 Example of object identifiers as defined by the ANSI organization
1.5 LDAP standards
Several standards in the form of IETF RFCs exist for LDAP. The following is a brief list of RFCs that apply for LDAP Version 2 and Version 3:
•RFC 1274 The COSINE and Internet X.500 Schema
•RFC 1777 Lightweight Directory Access Protocol (V2)
•RFC 1778 String Representation of Standard Attribute Syntaxes
•RFC 1779 String Representation of Distinguished Names
•RFC 1823 LDAP Application Program Interface (V2)
•RFC 2052 A DNS RR for Specifying the Location of Services (DNS SRV)
•RFC 2219 Use of DNS Aliases for Network Services
•RFC 2222 Simple Authentication and Security Layer (SASL)
•RFC 2247 Using Domains in LDAP/X.500 Distinguished Names
•RFC 2251 Lightweight Directory Access Protocol (V3)
•RFC 2252 Lightweight Directory Access Protocol (V3): Attribute Syntax Definitions
•RFC 2253 Lightweight Directory Access Protocol (V3): UTF-8 String Representation of Distinguished Names
•RFC 2254 The String Representation of LDAP Search Filters
•RFC 2255 The LDAP URL Format
•RFC 2256 A Summary of the X.500(96) User Schema for use with LDAPv3
•RFC 2596 Use of Language code in LDAP
•RFC 2696 LDAP Control Extension for Simple Paged Results Manipulation
•RFC 2829 Authentication Methods for LDAP
•RFC 2849 The LDAP Data Interchange Format (LDIF) - Technical Specification
•RFC 2891 LDAP Control Extension for Server Side Sorting of Search Results
•The Open Group schema for liPerson and liOrganization (NAC/LIPS)
•Oasis Directory Services Markup Language (DSML) 2.
1.6 IBM’s Directory-enabled offerings
Many of IBM’s products are directory enabled in one way or another. Some products have their own LDAP server component (that is, they can respond to queries from LDAP clients), some products require that an LDAP directory exist for them to work at all, and finally some products optionally can take advantage of a LDAP based directory service.
IBM Tivoli Directory Server (ITDS)
ITDS is IBM’s LDAPv3 Directory offering. ITDS implements the Internet Engineering Task Force (IETF) LDAP V3 specifications. It also includes enhancements added by IBM in functional and performance areas. This version uses IBM DB2® as the backing store to provide per LDAP operation transaction integrity, high performance operations, and on-line backup and restore capability. ITDS interoperates with the IETF LDAP V3 based clients. Please refer to Chapter 4, “IBM Tivoli Directory Server overview” on page 83, for a more detailed overview of ITDS.
IBM Lotus Domino
IBM Lotus Domino is an enterprise-class messaging and collaboration system, designed to take full advantage of the e-business revolution. It runs on a variety of different hardware platforms and operating systems. IBM Lotus Domino server supports industry standards like Simple Mail Transfer Protocol (SMTP), Multipurpose Internet Mail Extensions (MIME), Post Office Protocol (POP3), LDAP, and SSL.
IBM Lotus Domino is designed to simplify integration into a multi-directory environment. With IBM Lotus Domino (Domino) 6 (or later), you have the option of moving from a distributed directory architecture and making Domino the central directory. This allows you to take advantage of a centralized directory configuration that provides added control and less overhead and is easier to manage. Domino Server comes with the Domino Upgrade Services tool. This tool is used to import users from a server-based foreign directory and register those users in the Domino Directory. Domino Upgrade Services migrates data from many different systems, some of which include LDAP Data Interchange Format (LDIF) files, LDAP-compliant foreign directories (such as IBM Tivoli Directory Server), Microsoft Windows® NT Server, and Microsoft Active Directory.
IBM Lotus Domino 6.5 also has enhanced the implementation of LDAP capabilities and improved the performance of LDAP directory access. A new Domino LDAP Schema database allows you to maintain and extend the schema.
Other directory schemas can be imported via LDIF files.
Other Domino R6 features include:
•Support for X.500 naming conventions, including hierarchical naming and extensible attributes, for maximum flexibility in configuring the namespace.
•LDAP protocol support in both the client and the server providing lookup (read), add, delete, and modify (write) support for non-Notes clients (for example Web browsers) and servers.
•Rule-based domain relationships for faster lookups across large namespaces.
•Hierarchical naming and trust between domains to support the relationship of entries across domains.
•Support for a Public Key Infrastructure.
•A dynamically extensible directory schema ideal for customizing the directory to meet specific business requirements.
•Multi-master replication, a key element for reliable directory synchronization and maximum availability.
•The LDAP service schema support for LDAP RFCs 2252, 2256, 2798, 2247, 2739, 2079, 1274; the new Domino LDAP Schema database (SCHEMA.NSF) used as a tool for maintaining and extending the schema; an automatic schema maintenance process, true object class inheritance; faster schema loading; and support for the namingContext operational attribute defined in LDAP standard RFC 2251.
•An open architecture that can easily incorporate support for emerging standards.
IBM Tivoli Directory Integrator (ITDI)
With the Version 5.2 release of ITDI, ITDI now has the capability, via its LDAP Event Handler, to act as a pseudo LDAP directory server and handle LDAP transactions from various LDAP enabled clients. While ITDI is primarily a meta-directory data synchronization product, the ability to act as an LDAP server can be very useful in many integration scenarios.
ITDI synchronizes identity data residing in directories, databases, collaborative systems, applications used for human resources (HR), customer relationship management (CRM), and Enterprise Resource Planning (ERP), and other corporate applications.
By serving as a flexible, synchronization layer between a company's identity structure and the application sources of identity data, ITDI eliminates the need for a centralized datastore. For those enterprises who do choose to deploy an enterprise directory solution, ITDI can help ease the process by connecting to the identity data from the various repositories throughout the organization.
Please refer to Appendix B, “Directory Integration - IBM Tivoli Directory Integrator” on page 681, for more information about ITDI.
IBM software products that require a directory
These are:
•IBM Tivoli Access Manager
•IBM Tivoli Identity Manager
•IBM Tivoli Privacy Manager
•IBM WebSphere Portal Server
•IBM Lotus Sametime® Server
IBM software products that can take advantage of a directory
These are:
•IBM WebSphere Application Server
•IBM DB2 Universal Database™
•IBM Lotus Notes® Client
1.7 Directory resources on the Web
OpenLDAP is a very active open source LDAPv3 directory server (and associated client tools) project that has been around since 1998. It is derived from the original University of Michigan slapd server. The OpenLDAP suite includes:
•Stand-alone LDAP server (slapd)
•Stand-alone LDAP replication server (slurpd)
•Libraries implementing the LDAP protocol
•Utilities, tools, and sample clients
The OpenLDAP site is also the home of a the JLDAP Java LDAP Class Libraries and the JDBC-LDAP LDAP Bridge Driver.
The Apache Directory Project is a new Open Source project that is developing an embeddable Java based LDAPv3 directory server.
The University of Michigan LDAP Mailing List ([email protected] mail list) is a popular vendor neutral site used by LDAP developers and system administrators to resolve questions relating to use of LDAP. You can subscribe to the mailing list using the following information
SMTP Address: [email protected]
subject=SUBSCRIBE
Recent messages are archived and can be access directly at:
The LDAPZone is a general purpose site dedicated to directory issues. It has a number of useful forums dealing with development and directory administration.
The Directory Interoperability Forum (DIF) is the Open Group’s directory related working group focused on promotion of directory standards and standard compliance certification.
The Mozilla site contains a number of LDAP SDKs that have been popular since the early days of LDAP development. These include the LDAP C SDK, the Mozilla Java SDK, and PerLDAP.
Net::LDAP is a pure Perl LDAP module available from CPAN. It is actively maintained and provides the most comprehensive set of capabilities for accessing LDAP directories via Perl.
The Java Naming and Directory Interface (JNDI) is a standard component of Java. It provides the components required to build directory-enabled applications in Java.
The Active Directory Service Interfaces (ADSI) provides Microsoft based applications the ability to query and manipulate directories.
The DirectoryMark is a benchmarking suite designed to measure the performance of directory servers.
The Java LDAP Browser is a very good cross platform (pure Java) LDAP Browser/Editor. It is available for download at:
JXplorer is another good cross platform (pure Java) LDAP Browser/Editor. It also includes very good support for SSL-based LDAP connections.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.