


Planning your directory
The first sections in this chapter describe some guidelines on how the design and implementation of the data and directory tree structure should be done. Then security planning is described, followed by implementing such a directory in a physical infrastructure having scalability, availability, manageability, and maintenance aspects of an LDAP directory deployment in mind.
Discussing low-level details of designing a directory implementation, such as detailed performance tuning aspects or product selection criteria, is beyond the scope of this book. However, this chapter gives you an introductory understanding of what has to be considered when LDAP is to be introduced in an organization.
The discussions that follow in this chapter often refer to typical White Pages directory implementations for people directories. This approach was chosen for the sake of simplicity. Please bear in mind, LDAP is not only suitable for people directories. An LDAP directory can hold almost any kind of information and can therefore be used for a much broader range of applications. The Directory-Enabled Networks Initiative (DEN) is just one example where an LDAP directory is being used for storing network configuration and topology data.
Creating a design that has the flexibility to accommodate changes within the organization is probably the single most important task in implementing a directory service. This will help save time and money as the directory service grows. When designing the directory service, the project can be divided into several smaller projects:
•Surveying the directory service contents
•Creating access control strategies
•Replication and partitioning strategies
•Network planning (physical planning)
This chapter discusses the four main planning phases when designing an LDAP directory and briefly discusses implementation issues:
•The first phase, defining directory content, has two components. The first component, defining directory requirements, is about a careful analysis of the main purpose of the directory and the associated considerations to arrive at an overall approach to the directory plan. The second component, data design, is then about understanding the sources and nature of the data, deciding the scope of the data within the directory, and planning the way in which it will integrate with external data.
•The second phase, organizing your directory, also has two components. The first component, schema design, determines the format in which the data is to be stored. This is analogous to the field data definitions in a relational database. The second component, namespace design, determines the hierarchical structure of the directory. This is analogous to the relationship between individual files and their access paths in a relational database.
•The third phase, securing directory entries, is all about privacy and security design to ensure that the data in the directory is protected, as well as about allowing applications themselves to be secured by use of the directory. This aspect of the design affects all other aspects.
•The fourth phase, designing your server and network infrastructure, has two components. The first component, topology design, helps to determine the number and location of directory servers and how the data is distributed among them. The second, optional component, replication design, enables multiple copies of the data to be deployed, which can aid performance.
Surprising as it may seem, with the exception of security, the various major dimensions of design are largely independent of each other.
Some aspects of the design process allow for flexibility when requirements may change in the future. Others are less forgiving and can involve a major upheaval. It is essential to undergo a thorough planning process before starting the live implementation. Do not be misled into thinking, for instance, that because the directories’ servers such as ITDS are included with various IBM Operating Systems, for example, included in the price of AIX®, it is a lightweight piece of infrastructure. Nothing could be further from the truth. In building an LDAP-enabled directory you are laying the framework for generations of software that are even now beginning to emerge. The directory, like the database, is one of the major building blocks of your infrastructure and some attention to planning at the initial stages will reap rich rewards in the future.
We have discussed here some aspects of directory design. However, it needs to be pointed out that there is no single correct way to design a directory. To be able to build a more objective picture of the naming methodology, we recommend that several sources of information are compared. Often, vendors will have their own implementation guides that reflect different angles of views for this aspect.
3.1 Defining the directory content
The first phase, defining the directory content, is concerned with what it is that your proposed directory project sets out to achieve and what data is available to help it do so.
3.1.1 Defining directory requirements
This section discusses the directory definition requirements that need to be considered when planning a directory implementation.
Application needs
What type of application(s) will use the directory? Determine what directory-enabled applications are to be deployed and what are their data needs. Determine the organization's other mission-critical applications. Find out if those applications can directly access and/or update the directory. What are the requirements for manageability and scalability? Will the LDAP service be participating with an X.500 directory service?
User needs
Determine who needs access to the data as a user. Find out if those users can directly access or even update the directory. Determine the location of clients (users or applications). What expectations are there for privacy concerns? How accurate and up-to-date must the directory content be?
Deployment issues
What resources will be available for deployment? What people and skills are available? Can this be done as part of another project, for example, messaging migration, or will it require dedicated resources?
Infrastructure constraints
What hardware configurations are already in use and which, if any, are available to the project? What operating systems, middleware, and applications are in use? Specifically, what directory applications are already available? Obtain a network diagram. Is the directory to be protected behind a firewall or exposed to the Internet?
3.2 Data design
Planning the directory's data is the most important aspect of the directory planning activities, and it is probably the most time-consuming aspect as well. A considerable amount of the time spent planning the directory data will most likely be spent surveying the organization to locate all the data stores where directory information is managed. As this survey is performed, expect to find that some kinds of data are not well-managed; some processes may be inefficient, inadequate, or non-existent; and some kinds of data may not be available at all. All of these issues should be addressed before finishing a data-planning phase.
However, we start by looking at the requirements on the data to be used in the directory service. The scope of information required will largely be driven by the application requirement. However, some types of data are better suited for a directory service than others. Ideal candidates in a directory service have some of the following characteristics:
•A directory service is not a file system, a file server, an FTP server, a Web server, or a relational database. Therefore, large, unstructured objects of data should not be put in the directory. For that kind of data, a server more appropriate for the task should be used. However, it is appropriate to store pointers to these kinds of applications within the directory service through the use of FTP, HTTP, or other types of accesses.
•The data should typically be read much more often than it is written. This is because directory services usually are tuned for read operations; write operations are more expensive in terms of resource utilization than reads, and they may impact the directory server's performance in typical directory server implementations.
•Another "rule of thumb" is that the data should typically be accessed from more than just one system or client. For example, an employee's preference settings for a specific application may not be meaningful to put in the directory if that application is only run on the employee's single workstation. If the user wants to run this application on different systems, such as a mail client application, then the application would certainly benefit from a central directory for storing user preferences. This would allow the employee to use the same setup on multiple systems or even platforms within the organization.
Having in mind the types of data suitable and unsuitable for use in a directory, it is now possible to survey what the directory service data will be.
3.2.1 Sources for data
Planning the directory content includes deciding which existing data to store in the directory. Survey the organization and identify where the data comes from (such as Windows NT® domains, RACF®, application-specific directories, human resources databases, e-mail systems, and so forth).
When deciding on what to put into the directory, all the owners of data relevant to the contents of the directory should be identified. It is very probable that the information you will be choosing to put in the LDAP directory already resides on some other system in your organization. For example, the Personnel Department most likely already has databases with personnel information. Also be sure to make adequate use of processes already in place to administer that data even in the planned directory service.
Data management and access control are both important when maintaining a directory service. Plans must be made to identify resources for keeping the data up-to-date and identifying resources with the authority to decide on access control policies regarding the data residing in the directory tree.
If data is going to be imported from other sources, develop a strategy for both bulk imports and incremental updates. Try to limit the number of applications that can change the data. Doing this will help ensure the data integrity while reducing the organization's administration.
Identify duplications and data that is not actually used or required. Harmonize the data by eliminating such duplications and discard unnecessary data.
3.2.2 Characteristics of data elements
Data is made up of data elements, which possess several characteristics such as format, size, frequency, ownership, relationship with other data elements, etc. For instance, the data element e-mail address has a format of text, has many characters, has possible multiple values, is owned by the IT department, is used by both users and applications, and is related to the user's entry. Examine each planned data element to determine its characteristics and which are shared with other elements.
For each piece of data, determine the location where it will be mastered and who owns the data—that is, who is responsible for ensuring that the data is up-to-date.
3.2.3 Related data
Remember to plan for related data sources that contain directory-related data but which may not, initially at least, use the directory itself. For example, the human resources database must bear a close relationship to entries in a directory containing staff data. Consider appropriate replication and synchronization techniques and procedures to maintain the relationships.
3.3 Organizing your directory
Having decided on the type of data to use in the directory service, what the directory will be used for, and how the data will be updated, it is possible to start structuring the data. Structuring data is done by designing both a schema and a namespace. We explain these activities in the sections that follow.
3.3.1 Schema design
The schema design plays an important role in your directory implementation and helps you organize the data within a directory.
Directory schema
A schema is the collection of attribute-type definitions and object class definitions. A server uses these to determine how to match a filter or attribute against the attributes of a specific entry and whether to permit given attribute(s) to be added. This is similar to the data definitions of a relational database system. For more information on schemas, refer to “LDAP schema” on page 37.
Purpose
The purpose of a schema is to control the nature and format of the data stored in the directory. This means that schemas can be used for data validation and to control redundant data. A schema is also used by users and applications as the basis for directory search criteria.
Elements of LDAP schemas
LDAP directory schemas consist of attributes and object classes. A more detailed discussion on schema elements can be found in “LDAP schema” on page 37.
Design overview
Schema design involves several stages. First, identify any schemas provided by the applications you have in plan, plus any standard and vendor-supplied schemas. Secondly, select any predefined schemas that meet your needs. Thirdly, plan for any schema extensions.
For each piece of data, determine the name of the attribute(s) that you will use to represent the data in the directory and the object class(es) (the type of entry) that the data will be stored on.
Predefined schemas
When deciding on the design of the schema, there are a few things to consider. The LDAP specifications include a standard schema for a typical White Pages directory (RFC 2256, A Summary of the X.500(96) User Schema for use with LDAPv3). Vendors ship schemas with their LDAP server products that may include some extensions to support special features they feel are common and useful to their client applications. Work at the Internet Engineering Task Force (IETF) is in progress to create standard schemas for a broad range of applications.
Regardless of the type of information contained in the directory server, the standard schema, some of which is based on the X.500 standard, should not be modified. If this standard schema proves to be too limiting for the intended use, it can be extended to support the unique requirements. Standard schema elements, however, should not be deleted. Doing so can lead to inter-operability problems between different directory services and LDAP clients.
It is important to use a consistent schema within the directory server because LDAP-enabled application clients locate entries in the directory by searching for object classes or attributes and their associated values. If the schemas are inconsistent, then it becomes virtually impossible to locate information in the directory tree efficiently. An example of an inconsistent schema is a situation where an attribute is used to store a specific kind of information, and then later a different attribute is used to store the exact same kind of data, for example, when both attributes, telephoneNumber and phone, contain the same data.
Most LDAP-enabled application clients are designed to work with a specific, well-defined schema. Shrink-wrapped standard applications usually only work with a standard schema. These are important reasons why LDAP-based Directory Services should support at least the standard LDAP schema. Then the schema may be extended as the site discovers site-specific needs that are not met by the standard schema.
New schema elements
The use of a standard schema is beneficial, and specific changes can be made so long as they are additions. You may, however, create your own, private schema. But when doing so, you must take into consideration that compatibility to any other LDAP service may be lost and that your application clients have to be aware of that private schema.
3.3.2 Namespace design
Namespace design is a very important task in planning the directory. It is one of the most difficult to change at a later stage. A namespace is the means by which directory data is uniquely named and referenced. It is the equivalent of the unique key field for the entry. The structure of an LDAP namespace is described in Chapter 2, “LDAP concepts and architecture” on page 27.
Purpose
The namespace provides a way to organize the data. It can be used to partition (group) the data and to provide a basis for replication. It can affect your access control methods. Finally, it is the basic support for directory-enabled applications.
Analyzing needs
Before designing your namespace you need to understand the requirements for it. Do you need a flat namespace or a hierarchical one? What attributes can be used to name entries? Do you anticipate replication or partitioning? Does a corporate taxonomy (hierarchical map of the organization) exist, and could or should it be used? Might your requirements change over time, for example, with company mergers and acquisitions?
Namespace design approach
Namespace design is done by choosing a directory suffix, branching the directory tree, and finally creating a naming style for the directory entries.
Choosing a suffix
When deciding on suffixes, where a suffix is the root DN of a directory tree, it is a good idea to use the same naming structure for LDAP as is used for X.500. Using the X.500 methodology would lead to choosing a suffix like o=ibm,c=us or ou=raleigh,o=ibm.
This method will set the root of the directory tree to a specific organization in a specific country or to a specific organization and organizational unit. However, it is not necessary to do this, unless there are plans to participate in an X.500 directory service, since LDAP does not require any specific format for the DN naming convention. In LDAP, the directory suffix can be chosen freely to reflect the organizations distinct name. Another method that you can use, if the X.500 method does not seem appropriate, is the DNS naming model when choosing the directory suffix. This would result in a suffix using the domainComponent attribute, for example, dc=server,dc=company,dc=com.
The design of the directory schema and definition of the suffix makes it possible to start populating the tree. But, before doing so, the naming structure must be put in place. We have divided the discussion on naming structure creation into the two sections that follow:
•Branching of the directory tree
•Naming style for the entries
Branching the directory tree
Choosing to branch a directory tree based on the organizational structure, such as departments, can lead to a large administrative overhead if the organization is very dynamic and changes often. On the other hand, branching the tree based on geography may restrict the ability to reflect information about the organizational structure. A branching methodology that is flexible, and which still reflects enough information about the organization, must be created.
Because the structure of organizations often changes considerably over time, the aim should be to branch the tree in such a way as to minimize the number of necessary changes to the directory tree once the organization has changed. Note that renaming a department entry, for example, has the effect of requiring a change of the DNs of all entries below its branch point. This has an undesirable impact on the service for several reasons. Alias entries and certain attributes or ordinary entries, such as seeAlso and secretary, use DNs to maintain links with other entries. These references are one-way only, and LDAP currently offers no support to automatically update all references to an entry once its DN changes. The impact of renaming branches is illustrated in the following example.
When adding employees to their respective departments, it would be possible to create distinguished names (DN) like cn=John Smith, ou=Marketing, l=se, and dc=xyz.com. If John Smith should at a later time move to another department, his DN will have to change. This results in changing all entries regarding access rights and more. If John Smith's DN had been set to cn=John Smith, ou=employees, l=se, dc=xyz.com, then this would not be a problem. An attribute describing which department he belongs to (ou=marketing) could be added to his entry to include this information.
Other criteria that may or should be considered when branching the directory tree include physical or cultural splits in the organization and the nature of the client (human or application).
If your organization has separate units that are either physically separated or have their own management authorities, you might have a natural requirement to split and separate parts of the DIT.
A general rule of thumb says that the DIT should be reasonably shallow unless there are strong reasons to design deep branching levels down the directory tree. If the directory information is primarily searched and read by human users (that is, if users manually type in search criteria), the DIT should provide the information in an intuitive manner so that finding information is not limited to system specialists. If, on the other hand, the information is primarily retrieved from programs, other rules more suitable for that application can be followed.
3.3.3 Naming style
The first goal of naming is to provide unique identifiers for entries. Once this is achieved, the next major goal should be to make querying of the directory tree intuitive. Support for a naming structure that enables the use of user-friendly naming is desirable. Other considerations, such as accurately reflecting the organizational structure of an organization, should be disregarded if it has a negative effect of creating complex DNs, thus making normal querying non-intuitive. If we take a look at the X.500 view on naming, we see that the X.501 standard specifies that "RDNs are intended to be long-lived so that the users of the Directory can store the distinguished names of objects...", and "it is preferable that distinguished names of objects which humans have to deal with be user-friendly" (excerpt from The Directory - Overview of Concepts, Models and Services, CCITT 1988, cited in RFC 1617).
Multicomponent relative distinguished names can be created by using more than one component selected from the set of the attributes of the entry to be named. This is useful when there are, for example, two persons named John Smith in one department. The use of multicomponent relative distinguished names allows one to avoid artificial naming values such as cn=John Smith 1 or cn=John Smith 2. Attributes that could be used as the additional naming attribute include title, room number, telephone number, and user ID, resulting in a RDN, like title=Dr, cn=John Smith, creating a more user-friendly naming model.
A consistent approach to naming people is especially important when the directory stores information about people. Client applications will also be better able to assist users if entries have names conforming to a common format, or at least to a very limited set of formats. It is practical if the RDN follows such a format.
In general, the standard attribute types should be used as documented in the standards whenever possible. It is important to decide, within the organization, which attributes to use for what purpose and not to deviate from that structure.
It is also important that the choice of a naming strategy not be made on the basis of the possibilities of the currently available client applications. For example, it is questionable to use commonName of the form surname firstname merely because a client application presents results in a more satisfactory order by doing so. Use the best structure for people's names, and adapt or design the client applications accordingly.
Please refer to “LDAP distinguished name syntax (DNs)” on page 43 for a more detailed explanation of LDAP Distinguished name syntax.
3.4 Securing directory entries
Having designed the directory tree, we now need to decide on a security policy.
The degree of security controls you require will depend on the nature of the information you are storing. If it is just e-mail addresses then the worst danger of unlimited read capability is spam e-mail, and the worst danger of uncontrolled editing is misdirected e-mail. However, if the directory contains gender, home addresses, and social security numbers then the dangers are more extensive.
The degree of security you require will also reflect the ways in which clients will be accessing the directory and the methods that will be used to update and manage the directory.
Finally, it needs to reflect an acceptable level of administration effort for security. A security policy should be strong enough to prevent sensitive information from being modified or retrieved by unauthorized users, while simple enough that administration is kept simple so authorized parties can easily access it. Ease of administration is very important when it comes to designing a security policy. Too complex a security policy can lead to mistakes that either prevent people from accessing information that they should have access to, or allow people to modify or retrieve directory information that they should not have access to.
3.4.1 Purpose
The most basic purpose of security is to protect the data in your directory. It needs to be protected against unauthorized access, tampering with information, and denial of service.
3.4.2 Analysis of security requirements
Try to find answers to the following sorts of questions. Will your directory be read-only? How sensitive is the data? Is replication to multiple locations planned? What privileges might administrators have? How reliable are the users? How will they react to different levels of security? Will they require access across the Internet? Is your network itself secure? How about the machine room?
3.4.3 Design overview
To plan for the required level of security, two basic areas must be considered to answer the following questions: What level of security is needed when clients identify themselves to the directory server, and what methodology will be used when authorizing access to the different kinds of information in the directory? These areas are authentication and authorization.
3.4.4 Authentication design
Conceptually, directory authentication can be thought of as logging into the directory. LDAP terminology, however, usually refers to this operation as binding to the directory.
Generally, bind operations consist of providing the equivalent of a user ID and a password. However, in the case of an LDAP directory, the user ID is actually a distinguished name (or a distinguished name derived from a user ID). The distinguished name used to access the directory is referred to as the bind DN.
So, what level of authentication should be considered? There are, generally speaking, three different approaches:
•No authentication: This is the simplest approach, which might be perfectly suitable for most directories when all users are equally granted read (or even write) access to all data. There is no need for user authentication when this is the case.
•Basic authentication: This lets the client bind by entering a DN and a password. Using basic authentication will not ensure integrity and confidentiality of the login data since it is being sent over the network in a readable form.
•Secure authentication: Simple Authentication and Security Layer (SASL) is an extensible authentication framework. It was added to LDAP Version 3, and it supports Kerberos and other security methods, like S/Key. SASL provides the ability to securely authenticate LDAP clients and LDAP directory servers. There is an external mechanism in SASL that allows the use of authentication identity information from security layers external to the SASL layer. One possibility is to use the authentication information from SSL. SSL is generally used to secure the connection between a client and a server through the exchange of certificates. The client certificate can be used through SASL as authentication identity. SASL is already used within several Internet protocols including IMAP4 and POP3 (mail server protocols).
It is possible that there is a need for both basic and secure authentication. The choice will be dependent on the security policies in the organization's networks and what type of access rights the different types of clients will have when communicating with the server. For example, when setting up server-to-server communication, it may be valuable to use strong, secure authentication since server-to-server communication will often rely on unrestricted access to each other's tree structures, including individual entry's access settings. On the other hand, for client-to-server communication, where clients only have read access to names, phone numbers, and mail addresses, there is most likely no need for anything but basic authentication.
When using secure authentication, it is possible to choose from different methods depending on the vendors' implementations, for example, Kerberos or SSL. If Kerberos is not already deployed in the organization's intranet, then it will probably be sensible to use SSL, since support for SSL is included in most popular LDAP clients. When using SSL, it is possible for the server to authenticate the client by using its server certificate. A server certificate can be thought of as a secure, digital signature that uniquely identifies a server. It has been generated and registered with a trusted certifying authority, also known as a Certificate Authority (CA), such as VeriSign or the IBM World Registry™ CA. Also, when using server certificates, an encrypted communication can be established between the client and server, enabling a secure basic authentication of the client to the server.
Using SSL server certificates will be particularly interesting when setting up LDAP services on insecure networks, such as the Internet/extranet. This will enable the clients to verify the identity of the server and to encrypt communication of the basic authentication from the clients to the server on the insecure networks.
When using basic authentication, administration of passwords on the directory server will be necessary and may impose some administration overhead. If SSL client certificates are used, then an appropriate infrastructure will be needed to support the certificate generation and administration. This is usually done by separate certificate servers. Client certificate deployment is beyond the scope of this book, but it ought to be mentioned that LDAP supports storing client public keys and certificates in the entries allowing you also to use the directory by mail clients to encrypt e-mail.
3.4.5 Authorization design
The data in the directory tree will have to be protected in different ways. Certain information must be searchable for everybody, some must be readable, and most of it will be write protected. In LDAP Version 3, there are no defined attributes to handle this. As a result, vendors support their own implementations of authorization. This is done by different implementations of access control lists (ACLs).
ACLs are used to define access rules to the different entries in the directory tree. As an example of an ACL implementation, Example 3-1 on page 71 shows the IBM ITDS implementation of ACL attribute entries. The pertinent control attributes used here are aclsource, aclpropagate, and aclentry, where the latter, for example, is the attribute that specifies who has access to the entry and what level of access he or she has. In Example 3-1, cn=John Arnold,ou=employees,o=iseriesshop has read, write, search, and compare (rwsc) rights for normal, sensitive and critical data (the entry is highlighted and split into three lines in the example).
Example 3-1 Sample ACL attribute entry
dn: ou=employees, o=ibm, c=us
objectclass: top
objectclass: organizationalUnit
ou: employees description: Employees of IBM Corporation
entryowner: access-id:cn=admin,o=ibm, c=us
inheritoncreate: TRUE
ownerpropagate: TRUE
aclpropagate: TRUE
ownersource: default
aclsource: OU=employees,o=ibm, c=us
aclentry: access-id:CN=John Arnold,OU=employees,o=ibm,c=us:object:a:normal:rwsc: sensitive:rwsc:critical:rwsc aclentry: group:CN=ANYBODY:normal:rsc
When setting up access control lists, it is important to do it with the goal of minimizing the administration later on. It is good to try and delegate the access control hierarchically. An example of this could be the following: An individual, say John Arnold, needs to protect sensitive information. Two groups have been created for this purpose, owned by John Arnold (shown in Table 3-1). Entries can be added and deleted by John Arnold to his own groups without intervention of the directory service administrators.
Table 3-1 ACL structure for Web content administration using two groups
|
Group name
|
Owner
|
Group members
|
|
cn=editor
|
cn=Debbie Smith
|
cn=user1
cn=user2
|
|
cn=readers
|
cn=Brian Arnold
|
cn=user3
ou=techsupport
|
According to the table, John Arnold has added user1 and user2 to the editor group and user3 and the group called techsupport to the readers group, thus enabling user1 and user2 to edit the contents, and enabling user3 and the people in the techsupport organizational unit to read the contents.
3.4.6 Non-directory security considerations
Other security considerations that are not directly related to directory design but that can help to protect your data include encryption.
You should also ensure that your organization's security audit procedures are updated to reflect the new directory plan.
3.5 Designing your server and network infrastructure
Physical design involves building a network and server infrastructure to support availability, scalability, and manageability. Methods to do this in LDAP are partitioning and replication. Replication is actually not standardized in LDAP Version 3, but all directory vendors implement replication within their products. In this section we concentrate on deployment issues regarding when partitioning and/or replication is appropriate when trying to reach the goals of availability, scalability, and manageability, and what the trade-offs are.
In sizing the directory service, consideration must be given to which clients will be accessing what data, from where, and how often. If there are client applications that use the directory extensively, consideration must be given to ensuring that the network availability and bandwidth are sufficient between the application servers and the directory servers. If there are network bottlenecks, they must be identified because there may be a need to replicate data into remote LANs.
3.5.1 Availability, scalability, and manageability requirements
Availability for a directory service may not be a hot issue in cases where the directory is not business critical. However, if the use of the service becomes mission critical, then there is a need to design a highly available system. Designing a highly available system involves more than is supported in LDAP. The components from LDAP that are needed are partitioning and replication. Since high availability involves eliminating single points of failure or reducing their impact, it is necessary to have redundant hardware, software, and networks to spread the risk.
As more and more applications use and rely on a directory service, the need to scale the directory for high-load tolerance increases. Scaling up directory servers is done much the same way, either by increasing availability or by upgrading hardware performance. As is the case when increasing availability, we have to rely on functions outside the LDAP standard as well as LDAP replication and partitioning. The round-robin DNS or the load-balancing router, such as the IBM WebSphere Edge Server, are good tools to scale an LDAP server site.
Manageability aspects involve almost all parts of a directory design. Here is where trade-offs may have to be made regarding scalability, availability, flexibility, and manageability. The level of scalability and availability are both related to cost in hardware and software and, as a drag-along, cost of overall systems management. One important question to ask in a directory design about manageability is whether and how all information providers are able to furnish reliable, correct, and consistent directory data to the LDAP service. If this cannot be assured, there will be a chance for errors and inconsistencies in the LDAP directory data. If such problems are considered critical for the clients using the LDAP service, tools must be provided that can detect and maybe even correct these errors.
3.5.2 Topology design
Topology design concerns the distribution of directory servers. The first choice is between a centralized or a distributed approach. The second choice is between a partitioned and a replicated approach.
Centralized or distributed
You can choose to centralize in a single master directory or to distribute the data to additional directory servers.
A simple approach to create a highly available directory service is to create a master and a replica directory server, each one on its own physical machine. By replicating the data, we have eliminated the single point-of-failure for both hardware and software failures. This solution with a master and one or more replica servers normally provides for high availability for read functions to the LDAP servers. Write requests can only be directed to the master server. If high availability is required for write access, additional effort is necessary. Neither read-only nor read/write replication is supported natively by the LDAP standards, but vendors may have implemented their own mechanisms. Replication solutions can also be constructed using the export/import facilities of LDAP servers or with additional, custom-designed software tools. Also the OS/400® Directory server has its own replication mechanism that is constantly being enhanced.
A mechanism must be added to handle client redirection if one server fails. This can be done manually or semi-automatically by a DNS switchover, or automatically with a load-balancing technique by using a router designed for this. Such a router forwards client requests to one of the servers based on configurable criteria. It is important that the router supports stateful protocols; that is, subsequent requests from the same client need to be forwarded to the same server. There are several products on the market from different vendors to do this, such as IBM's WebSphere Edge Server. This function is also built into IBM Lotus Domino. The IBM Eserver iSeries of course allows multiple Domino server instances to run within a single operating system instance.
There is also the issue of network bandwidth and its reliability to take into consideration. In some cases, it may be necessary to distribute a replica into another LAN with slow network connections to the master. This can also be done with any means of replicating an LDAP server (remember that replication is not included in the LDAP standards, thus you have to use vendor product support or your own methods). The primary server for a particular client may be the directory server on the client's own LAN, and the secondary will then be the central master server, accessed over the WAN.
If the method of spreading the risk is used to create high availability, it is possible to partition the directory tree and to distribute it to different locations, LANs, or departments. As a side-effect, depending on how the directory tree is branched and distributed to these servers, each location, department, or LAN administrator could then easily manage their own part of the directory tree on a local machine, if this is a requirement. If a single server failed in such a configuration, then only a portion of the whole directory would be affected.
A combination of these methods could be used to create a dynamic, distributed, highly available directory service.
Partitioned or replicated
The second choice for topology design is only applicable when a distributed approach has been selected for the first choice. The options are between a partitioned and a replicated approach. The decision criteria are usually based on performance and availability issues and will be influenced by the size of the directory.
To create a high-availability environment, it is necessary to replicate and/or partition the directory, as discussed in the previous sections. Although not directly related to LDAP, it should be mentioned that adequate systems management tools and skills must be available to run such a fairly complex environment. In addition, one of the manageability concerns regarding replication might be the need to ensure an ample level of consistency. A master LDAP server might have been updated with new information, while a replica server still runs with the old, outdated information. The required level of consistency is largely dependent on the needs of the client applications using the service. If there is a requirement for currency and consistency among replicated servers, additional means must be provided to ensure this.
Replication will also affect back up and disaster/recovery procedures. Processes will be needed to handle recovery of master servers and how synchronization of replicas will be handled. Since replication is outside the current standard for LDAP, it is necessary to study the vendor's implementation in order to find adequate solutions.
Partitioning the directory enables local servers to own their own data, depending on schema and branching design. This increases flexibility when maintaining data, but increases the complexity of referral handling. A clear method of linking the name space together will have to be formulated to ensure consistent referrals in the directory service name space such that the logical name space is still a whole. Also, each local server may have to be administered and maintained locally, requiring staff with operating system and LDAP knowledge.
You should consider partitioning if the directory is very large, if your applications only require local workgroup data, if replication volumes would otherwise be too big, if your WAN is not suited to high volumes, and where future expansion of the service might trigger one of these considerations in the future.
The optimal topology design depends on the applications, the server, the physical network, and the directory namespace.
Remember that each partition needs a partition root, which is the DN of the entry at the top of the naming context, and hence occurs at a branching point in your directory. You may need to revisit your namespace design.
3.5.3 Replication design
Replication is a technique used by directory servers to improve performance, availability, and reliability. The replication process keeps the data in multiple directory servers synchronized.
Replication provides three main benefits:
•Redundancy of information: Replicas back up the content of their supplier servers.
•Faster searches: Search requests can be spread among several different servers, instead of a single server. This improves the response time for the request completion.
•Security and content filtering: Replicas can contain subsets of the data in a supplier server.
The replication design stage is only required when, firstly, a distributed approach is chosen to server deployment and, secondly, a replicated approach is chosen over a partitioned approach. Replication aims to improve the reliability and performance of your directory service.
Concepts
By making directory data available in more than one location you improve the reliability of the service in the event of server or network failure. You also improve the performance by distributing the load across multiple servers and reducing network traffic.
Designing replication
Consider first the unit of replication. This concerns which entries and which of their attributes are to be replicated. A subtree of the DIT might form a suitable selection basis. Now think about how consistent the data has to be. Must every change be replicated instantly to all servers? Due to the nature of directory data, for example people's phone numbers, it is not usual to impose such a tight restriction, but you might take a different view of removing the entry for a dismissed member of staff. Think about the sort of replication schedules that might be appropriate for your directory and network. Also, if you replicate Certificate Revocation Lists (CRLs) you may want to replicate information about a revoked certificate instantly.
To ensure initial copies are in place we might use LDAP Data Interchange Format (LDIF) files to import volumes of data in batch. A more incremental approach might be used for subsequent updates.
What sort of replication strategy is appropriate? Is a master-replica approach suitable, with all changes being driven out from the center? The alternative is a peer-to-peer approach, which allows all servers to update their own data and subsequently to exchange it.
The replication capabilities of various vendor’s LDAPv3 directory servers widely vary. It is advisable to look at your particular vendors documentation on replication to understand what features and capabilities exist in each respective product. Nearly all of the existing directory server implementations support the following three types of replication topologies in one form or another.
Master-Replica Replication
The basic relationship in replication is that of a master server and its replica server. The master server can contain a directory or a subtree of a directory. The master is writable, which means it can receive updates from clients for a given subtree. The replica server contains a copy of the directory or a copy of part of the directory of the master server. The replica is read only; it cannot be directly updated by clients. Instead it refers client requests to the master server, which performs the updates and then replicates them to the replica server.
The most simple example of the Master-Replica topology can be seen in Figure 3-1 on page 77. The Master Server in this example is replicating all of its data to the Replica server.

Figure 3-1 Master-replica replication topology (single consumer)
A master server can have several replicas. Each replica can contain a copy of the master's entire directory, or a subtree of the directory. In Figure 3-2, Replica 2 contains a copy of the complete directory of the Master Server; Replica 1 and Replica 3 each contain a copy of a subtree of the Master Server's directory.

Figure 3-2 Master-replica replication topology (multiple consumers)
The relationship between two servers can also be described in terms of roles, either supplier or consumer. In Figure 3-2, the Master Server is a supplier to each of the replicas. Each replica in turn is a consumer of the Master Server.
Cascading replication
Cascading replication is a topology that has multiple tiers of servers. A master server replicates to a set of read-only (forwarding) servers that in turn replicate to other servers. Some vendors call these forwarding servers replication hubs. Such a topology off-loads replication work from the master server. In the example of this type of topology, the master server is a supplier to the two forwarding servers. The forwarding servers serve two roles. They are consumers of the master server and suppliers to the replica servers associated with them. The replica servers are consumers of their respective forwarding servers. This is shown in Figure 3-3.

Figure 3-3 Cascading replication topology
Peer-to-peer replication
There can be several servers acting as masters for directory information, with each master responsible for updating other master servers and replica servers. This is referred to as peer replication. Some vendors also refer to this replication topology as multi-master. Peer replication can improve performance, availability, and reliability. Performance is improved by providing a local server to handle updates in a widely distributed network. Availability and reliability are improved by providing a backup master server ready to take over immediately if the primary master fails. Peer master servers replicate all client updates to the replicas and to the other peer masters, but do not replicate updates received from other master servers. Peer replication is shown in Figure 3-4 on page 79.
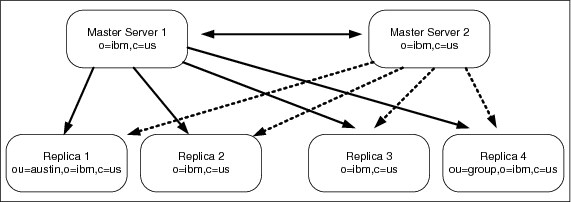
Figure 3-4 Peer-to-peer replication topology
3.5.4 Administration
In this section we show the tools for administering the directory, then we present a brief review of who should perform administrative tasks.
The LDAP specifications contained in the pertinent RFCs include functions for directory data management. These include functions to create and modify the Directory Information Tree (DIT) and to add, modify, and delete data stored in the directory.
Vendor products, however, most likely include additional tools for configuring and managing an LDAP server environment. These include such functions as:
•Server setup (initial creation)
•Configuring a Directory Information Tree
•Content management
•Security setup
•Replication and referrals management
•Access control management
•Logging and log file management
•Resource management and performance analysis tools
Depending on specific needs and preferences, LDAP directory administration can be performed several ways. Different vendors offer different administration tools. Although not all vendors provide tools for all methods, in general there are three tools to manage LDAP directories:
•Graphical administration tools
•Command line utilities
•Custom-written applications
Graphical tools features are specific to each vendor, when provided.
Command line tools are based on the LDAP Software Development Kit (SDK), which is mainly a set of libraries and header files. Depending on vendors, most SDKs come with a set of simple command line applications, either in source code or as ready-to-use executable programs. These tools were built using the LDAP API functions and thus can serve as sample applications. They enable you to do basic operations, such as searching the directory and adding, modifying, or deleting entries within the LDAP server. Each basic operation is accomplished with a single program such as ldapsearch or ldapmodify. By combining these tools using, for example a scripting language such as Perl, you can easily build up more complex applications. In addition, they are easily deployable in Web-based CGI programs.
As an alternative to using the administration utilities, custom-written administration tools can be used. A developer has several options for accessing LDAP. An API library for both C and Java languages is available. Another approach for custom-written tools is to use the Java Naming and Directory Interface (JNDI) client APIs. Such administration tools might be desirable when typical data administration, such as adding or modifying employee data, is done by non-technical staff. Writing directly to the API layer may also be necessary for applications that need to control the bind/unbind sequence, or, perhaps, want to customize the referral behavior. This is a more difficult approach because the developer must deal with the conversion of the data to the structures that are sent over the LDAP protocol. Additionally, the developer must be aware of a particular security setup, such as SSL.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.