
Chapter 8. Using AOP as an architectural tool
- Aspect initialization
- Aspect validation
- Improving a threading aspect using validation and initialization
- Dealing with architectural constraints
- Using architectural constraints to help with NHibernate
- Working with multicasting attributes
AOP’s own architecture and its effect on the architecture of a large code base are important concepts to understand in order to use AOP effectively. When you’re designing and implementing an architecture, failing earlier in the process may reduce costs from rework, and PostSharp can help you quickly and automatically identify failures at compile time.
Until this point, we’ve been looking at PostSharp and AOP in a narrow way: one aspect and one class at a time. Let’s look at PostSharp through the eyes of an architect, viewing an entire system and how it fits together. PostSharp contains tools to make an architect’s job easier, as well as tools to make sure that the aspects themselves are well-architected.
One thing about PostSharp that may have concerned you at some point is that all of my examples involve putting attributes on individual methods and properties, which may seem tedious and repetitive, and if you had to do that with a large code base, it would be. Fortunately, PostSharp doesn’t require that you always do that. We’ll look at ways in which we can multicast aspect attributes so that we can reuse aspects without a lot of attribute repetition.
Because PostSharp is implemented as a compile-time tool (as explored in the previous chapter), it opens the door for us to write code that can run immediately after the normal compile time. We can use this opportunity to write code that validates that aspects are being used in the right places and won’t cause problems during runtime, as well as the structure and architecture of a project as a whole. This approach allows problems to be identified earlier (or, as I like to call it, to fail faster).
We’ll also take this opportunity to perform aspect initialization. If you have an expensive operation (such as the use of Reflection), better to get that out of the way during the build than wait until runtime.
8.1. Compile-time initialization and validation
Let’s review the PostSharp build process (illustrated in figure 8.1 [a repeat of figure 7.6]) from the previous chapter and look at how it fits into the normal .NET build process. Recall that you have the compile-time phase (in which code is compiled into CIL) and the runtime phase (in which CIL is compiled to machine instructions just in time to be executed). Compile-time AOP tools like PostSharp add one more step (the post compiler) and modify the CIL after it’s compiled but before it’s executed.
Figure 8.1. Build process with PostSharp
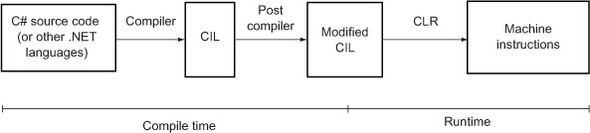
The post-compiler portion of the previous diagram is where PostSharp does its work. Let’s zoom into the post-compiler step of the build process (shown in figure 8.2).
Figure 8.2. Zooming into the post-compiler steps of PostSharp aspects
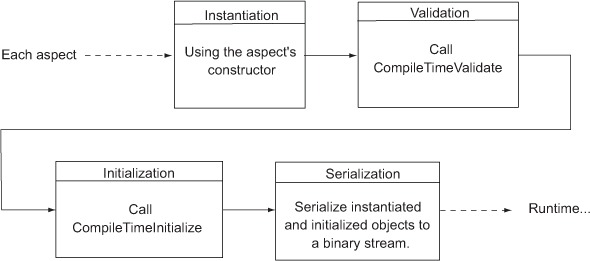
PostSharp performs several steps for each aspect that you write. Each aspect is instantiated using the aspect’s constructor. PostSharp can then perform a validation step (calling a CompileTimeValidate method in your aspect) to check whether the aspect is being used properly. Then PostSharp can perform an initialization step (calling a CompileTimeInitialize method in your aspect) to perform any expensive computations now instead of waiting until runtime. Finally, PostSharp will take the aspect instance and serialize it (to a binary stream) so that it can be deserialized and executed later at runtime.
This section focuses on the validation and initialization steps of the process. Until this chapter, I hadn’t defined any CompileTimeValidate or CompileTimeInitialize code in the examples in order to keep them simple. All of these steps are still performed, but because we didn’t define CompileTimeValidate or CompileTimeInitialize, those steps didn’t do anything.
Note
Aspects are serialized by default, but unless you use CompileTimeInitialize, you can turn serialization off at the individual aspect level to get an improvement in runtime performance.
With CompileTimeValidate, PostSharp lets us fail faster. If we can validate something at compile time, we don’t have to wait until runtime to find a bug or get an exception. CompileTimeInitialize lets us do costly work ahead of time. If we can do a (potentially costly) operation before running the program, let’s get it out of the way.
8.1.1. Initializing at compile time
Often, an aspect needs to know some information about the code to which it’s being applied, such as a method name, some parameter information, or other information. All of this information can be supplied by the PostSharp API, which uses Reflection to populate the information that is passed to your aspect (for example, the args parameters). Reflection information is the most common thing I’ve seen initialized, but any other costly information that can be obtained and instantiated before the entire program is executed is also fair game.
For a quick example, let’s look at a basic logging aspect (of which you’ve seen multiple examples in the book so far). Instead of logging a string, let’s log the name of the method. If I used a PostSharp OnMethodBoundaryAspect, and did this at runtime, the next listing shows how I could log that MyMethod was being executed.
Listing 8.1. Logging the method that was called

If you examine args.Method, you’ll notice that it’s an object of the type MethodBase, which is in System.Reflection. Although it’s not a big deal for our example, which has only one bounded method, using Reflection every time the aspect is used could add up in terms of performance in a large application.
But paying this performance price at runtime shouldn’t be necessary. The method name won’t change when the program is running, so why not interrogate the method names at compile time instead, within PostSharp’s post compiler process? In the following listing, we override CompileTimeInitialize in this aspect and store the method name in a private string field. In OnEntry, use that string field instead of args.Method.Name.
Listing 8.2. Using Initialize to get the method name at compile time

One note about PostSharp licensing: this initialization won’t have much effect on performance if you’re using the Express (free) edition because it doesn’t do any optimization and args.Method will still be populated for OnEntry using Reflection regardless of whether OnEntry uses it. But it’s still a good idea to follow this practice of using CompileTimeInitialize in case you end up needing the aspect optimization, which the full version of PostSharp can give you.
Use of Reflection is only one type of operation that can be performed at compile time instead of runtime. If you want to perform other slow or costly operations, CompileTimeInitialize is the place to do it.
Because PostSharp is already running this initialization code at compile time, why not also take the opportunity to run some validations on the aspect while you’re at it?
8.1.2. Validating the correct use of an aspect
The use of CompileTimeValidate in PostSharp allows us to check the context of where and how an aspect is applied to make sure that it will work correctly at runtime. To use CompileTimeValidate, override it in an aspect—for instance, a LocationInterceptionAspect.
Let’s start with a simplistic example, shown in the next listing, and then I’ll show you a more realistic scenario in the next section. I have a Program class with one string property called MyName. I’ll apply an aspect to it called MyAspect, which will log to Console whenever the property’s getter is used.
Listing 8.3. A LocationInterceptionAspect to log usage of get

But as the author of this aspect, I have a (strange) rule that I only want the aspect to be used on properties that are named Horse. Otherwise, the aspect is being used improperly, and therefore the project shouldn’t compile. I’ll override the CompileTimeValidate method (see the next listing) and check the location’s name. If it’s not "Horse", then I’ll use the PostSharp API’s Message class to write an error message.
Listing 8.4. Using CompileTimeValidate to check the location name

When I create this aspect and try to compile my project, because my property name isn’t 'Horse', I’ll get an error message. And because I’m using Visual Studio, it’ll appear to be a normal compiler error message (figure 8.3).
Figure 8.3. CompileTimeValidate-generated error message
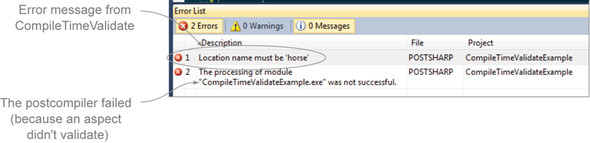
I’m not going to comprehensively document this PostSharp feature here, but I will point out a couple of interesting things. First, notice that CompileTimeValidate returns a bool. If CompileTimeValidate returns false, the aspect won’t be applied to that particular location. If I put the aspect attribute on 100 properties, and only one of them is named 'horse', the aspect will only be applied once.
Second, notice that the SeverityLevel I chose was “Error.” By doing this, I’m telling PostSharp to write a compiler error, and thus Visual Studio will treat it as such. If I instead used a SeverityLevel like “Warning,” the message would be shown as a warning and wouldn’t keep the project from being compiled. In my experience, warnings are often ignored, so generally I like to stick with “Error.” One other thing to mention about errors: the post compiler will not stop at the first error it finds—it will continue to process all aspects and write out each Message.
Finally, the error code and the message are strings that can be whatever you want. It’s a good idea to make these as descriptive and as useful as possible so that anyone encountering these CompileTimeValidate errors can find the offending code easily, as line number and filename are not included by PostSharp in the Message. Including the full class name, full property type, and property name in your error message and creating meaningful error codes are good ideas (and use similar information for method aspects, of course).
Now you’ve seen a few basic examples of CompileTimeInitialize and CompileTimeValidate. Let’s put CompileTimeValidate to work in a real aspect.
8.1.3. Real-world example: Threading revisited
Let’s revisit the threading example from chapter 3. Recall that we created a WorkerThread aspect to spin up another thread, and a UIThread aspect to make sure that any UI code called from that thread will be run on the UI thread. Let’s take another look at UIThread in particular, and look for anything that might be a problem with the way that aspect was written:
[Serializable]
public class UIThread : MethodInterceptionAspect {
public override void OnInvoke(MethodInterceptionArgs args) {
var form = (Form) args.Instance;
if (form.InvokeRequired)
form.Invoke(new Action(args.Proceed));
else
args.Proceed();
}
}
This aspect depends on args.Instance being an object of type Form. What if it’s not? Casting args.Instance to Form would then cause an InvalidCastException to be thrown. We could add runtime checks to avoid that. Instead of hard casting the object, we could use the C# as operator to soft cast the object and then check to make sure the cast is valid before trying to call InvokeRequired and Invoke. When using as, if the cast isn’t able to be performed, then a null is returned and no exception is thrown, as shown here.
Listing 8.5. Runtime checks on casting

Doing that would at least keep the aspect from throwing exceptions. But it still raises a question: why was UIThread being used on a class that didn’t inherit from Form in the first place? Is there some code that was moved to another class? Is there a new team member who’s unfamiliar with how threading works? Is someone trying to use this aspect with a UI framework other than Windows Forms? If we put in that runtime check, it solves the exception issue, but it kicks those other questions down the road.
Instead of enabling procrastination, let’s make this aspect force us to deal with such an issue immediately. Instead of that soft cast, let’s use CompileTimeValidate to ensure, at compile time, that the UIThread aspect is always being used on methods in a Form class (see the next listing). If it’s not, we’ll write an error message with information about where UIThread is being used incorrectly and prevent the build from succeeding.
Listing 8.6. Threading aspect of compile-time validation

I wrote out a message explaining the error, as well as the assembly, class, and method name where the aspect is failing to validate (see figure 8.4 for an example error message). You could also write out parameters or any other information you think might be helpful to find the problem.
Figure 8.4. UIThread validation error message

If you’re following along with a Windows Forms application, make sure that you don’t confuse System.Windows.Forms.Message with PostSharp.Extensibility.Message. For clarity, I’ve written the full name in the previous example.
Now, instead of waiting for a crash or another consequence, you can use this CompileTimeValidate code to fail faster. I’ll put the aspect on a class that doesn’t inherit from Form (I’ll put a UIThread attribute on a method in class NotAWindowsForm called MyMethod) and see what happens when I try to build, as shown in figure 8.4.
The use of CompileTimeValidate doesn’t eliminate the need for communication and teamwork around the use of AOP; it will cause that communication to happen sooner, when it’s easier and cheaper to fix. The last thing you want to do is have the discussion the day before deploying to production (or even afterwards).
Compile-time validation is one of the more interesting and powerful features available in all versions of PostSharp. In fact, it led many developers to write aspects that contained only compile-time validation. These validation aspects could be used to examine the code of the project and treat any mistakes it finds as compiler errors. They have no pointcut and contain no code that will run after the program starts. This was such a common technique that the PostSharp developers decided to make it a first-class feature called architectural constraints (compile-time validation still remains its own feature, though).
8.2. Architectural constraints
In PostSharp, the architectural constraint feature helps you to write sanity checks for your project. Think of it as a unit test for your project’s architecture.
Before we get too far into this chapter, let’s address some licensing and technical concerns. This feature (architectural constraints) isn’t strictly related to AOP. It’s also not available in the free Express edition of PostSharp. But it’s still an interesting way to demonstrate the power of post-compiler IL manipulation, so that’s why I’ve decided to leave it in the book. Compile-time validation from the previous section is available in all versions of PostSharp, including the free version.
In this section, I’ll give you an overview of the types of constraints that PostSharp allows you to create, and I’ll show you a real-world example of how architectural constraints might come in handy if you’re using NHibernate.
8.2.1. Enforcing architecture
The main idea behind architectural constraints is that you can examine the code in your project in an automated way by writing other code. We all know that even though a project compiles, that doesn’t mean it won’t fail. If we can build in additional checks to run when compiling, then we’ll know about problems sooner (continuing the theme of this chapter of failing faster).
PostSharp gives us the ability to write two different types of architectural constraints: scalar and referential. This separation is partially a semantic one and partially a technical one. Both types of constraints can enforce rules at compile time that the C# compiler itself doesn’t give you, but referential constraints are checked on all assemblies processed by PostSharp that reference the code element.
Scalar constraints
A scalar constraint is a simple constraint that’s meant to affect a single piece of code written in isolation. This is most like using a CompileTimeValidate method in an aspect (except without the aspect part).
For instance, when you use NHibernate, all of the properties of entities must be marked as virtual (which was covered in an earlier chapter—NHibernate uses Castle DynamicProxy). I often forget to make properties virtual, and when I do, I don’t find out until I run the program and use the entity, which might not happen right away.
I’d rather get an error message when compiling. We’ll look at that in more detail in the next section, with a real-world example of an NHibernate virtual constraint.
Examples aren’t limited to NHibernate. If you’ve used Windows Communication Foundation (WCF) before, then maybe you’ve created a DataContract class, added a new property, and forgotten to put the DataMember attribute on it. Or, have you created a ServiceContract interface and forgotten to put the OperationContract attribute on a new method that you’ve added to it? These are frustrating issues that the normal C# compiler won’t detect but that a scalar constraint can detect early.
Referential constraints
A referential constraint is a more wide-reaching form of architectural constraint. Referential constraints are meant to enforce architectural design across assemblies, references, and relationships. This form of constraint can be useful for architects, particularly if you’re developing an API.
PostSharp comes with three out-of-the-box constraints that you can use for some specific scenarios: ComponentInternal, InternalImplements, and Internal. In table 8.1, I don’t go into too much documentation-level detail, but in addition to being useful, they serve as good examples for when you can use referential constraints.
Table 8.1. PostSharp out-of-the-box architectural constraints
|
Constraint |
What does it do? |
Why would I use it? |
|---|---|---|
| ComponentInternal | Enforces that the code it’s applied to can’t be used outside of its own C# namespace | Allows you to simulate the behavior of C# internal at the namespace level for more organizational control |
| InternalImplements | Enforces that an interface can be implemented only by classes inside its own assembly | Allows you to expose an interface to API consumers, who might find it useful (in unit tests, for instance) without allowing them to write their own implementations |
| Internal | Enforces that a public item will remain public, but can’t be used by another assembly | Allows you to keep an item of code as visible as a public item and still restrict its use as with C# internal |
Of course, the door is wide open for you to write your own custom referential constraints. One annoyance I often come across is that sealed can be overused and that it limits extensibility. Sometimes there is a good reason to use sealed, but not often. It can make testing difficult, too. Therefore, in order to prevent sealed from sneaking into a project, I created a referential constraint called Unsealable.
To write this constraint, I created a class called Unsealable, which inherits from PostSharp’s ReferentialConstraint base class (see the next listing). Inside this class, I override the ValidateCode method, which receives a target object as well as an Assembly. I scan the entire assembly to look for classes that are sealed and derived from the target class. I also need to use an attribute (MulticastAttributeUsage) to tell PostSharp to exactly which items this constraint should be applied.
Listing 8.7. Unsealable referential constraint

Any class that I mark Unsealable with that attribute means that any other class that inherits from it can’t be sealed and will cause an error that prevents the build from completing.
A demonstration of this constraint is shown next. Write a class called MyUnsealableClass; put the Unsealable attribute on it; write another class that inherits from MyUnsealableClass called TryingToSeal; make TryingToSeal a sealed class; and try to compile.
Listing 8.8. Unsealable demonstration

When I try to compile, because I was trying to make the class sealed, I’ll get an error message in Visual Studio (as in figure 8.5).
Figure 8.5. Error caused by trying to seal an Unsealable class

Again, these architectural constraints don’t eliminate the need for communication on your team. As an architect, if you don’t want developers sealing their classes, this makes the conversation about appropriate use of C#’s sealed keyword happen sooner. The faster the fail, the better.
And speaking of failing fast, let’s look at creating a scalar constraint to deal with the virtual keyword in NHibernate entity classes.
8.2.2. Real-world example: NHibernate and virtual
Each property of an NHibernate entity must be virtual. But often when creating new properties and making changes to data access code, I forget to put virtual on properties.
You can have an NHibernate entity property that isn’t virtual, if you disable lazy loading. But lazy loading is an important feature of NHibernate, so by default, NHibernate will assume that you want lazy loading unless you configure things otherwise in your .hbm mapping files.
The C# compiler doesn’t care (nor should it) and lets me continue compiling and running the code. But over time it catches up to me, and when I try to build a session factory, I’ll get the all-too-familiar InvalidProxyTypeException (as in figure 8.6).
Figure 8.6. The InvalidProxyTypeException of death
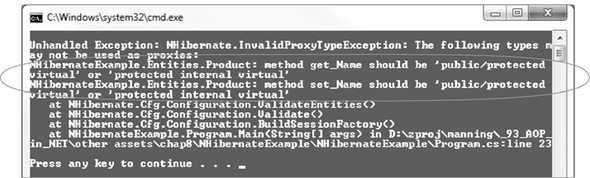
Now I have to stop what I was doing—whatever feature I was trying out or website I was demo’ing—and add virtual to a property. And hope that I didn’t forget any other properties. Because if I did, then I’ll have to do it all over again.
I want to avoid this annoyance; I’d rather fail fast. Let’s create a PostSharp scalar constraint so that I’m made aware of these mistakes right when I’m compiling.
Writing a ScalarConstraint is similar to writing a ReferentialConstraint. In figure 8.9, I create a class that inherits from the PostSharp ScalarConstraint base class. Override the ValidateCode method. In that method, get all of the properties from the targeted item(s) (in our case, the target(s) will be each of the entity class Types). For each property of the target type, check to make sure that it’s virtual. If it’s not, write a Message. Again, use a MulticastAttributeUsage attribute to indicate to which items this constraint can be applied.
Figure 8.9. Multicasting at the class level

Listing 8.9. NHibernate ScalarConstraint

To use this constraint, you could put an [NHEntity] attribute on each entity class in your domain model. But what if you create a new entity and forget to put an attribute on it? Instead, I’m going to use another feature of PostSharp: attribute multicasting. This feature allows me to specify more than one class at a time.
We’ll explore how multicasting works more in the next section, but here’s a little preview. If I put all of my NHibernate model entities into the same namespace (for instance, NHibernateExample.Entities), I can multicast this NHEntity scalar constraint with one assembly directive:
[assembly: NHEntity(AttributeTargetTypes =
"NHibernateExample.Entities.*")]
You could add this to the standard AssemblyInfo.cs file in your project, but it might be a better idea to put it into its own file, such as AspectInfo.cs. Now every single class that’s in the NHibernateExample.Entities namespace will have the NHEntity scalar constraint applied to it at runtime. Create a Book class in the NHibernateExample.Entities namespace, as shown in this listing, but don’t make one of the members virtual.
Listing 8.10. An NHibernate entity with a nonvirtual property

When I try to compile, I’ll get an informative error message like the one shown in figure 8.7 that gives me a chance to fix the code before executing the program.
Figure 8.7. Result of NHEntity scalar constraint

Attribute multicasting isn’t limited to architectural constraints and can be useful with normal PostSharp aspects to maximize reuse as it minimizes repetition. And unlike architectural constaints, attribute multicasting is a feature that’s available in the free Express edition.
8.3. Multicasting
In chapter 1, I defined a pointcut as the “where” of an aspect. Think of a pointcut as a sentence describing where an aspect could be placed (I described it by adding extra arrows to a flowchart, shown in figure 8.8 and repeated from chapter 1).
Figure 8.8. Pointcuts on a low-level flowchart
They can be simple, as “before every method in a class”, or they can be complex, as “before every method in a class in the namespace MyServices except for private methods and method DeleteName”.
Up until now, the examples in this book have had simple and narrow pointcuts: a member or two, or possibly a whole class. So to keep it simple, I put a couple of attributes in the code and call it a day. In reality, many aspects will have much broader pointcuts, and using attributes on every single class or method can be another form of scattered boilerplate (albeit less intrusive and less tangled). If you have a lot of code on which to use aspects, or the code changes often, I recommened you don’t keep using attributes over and over.
This is where the PostSharp attribute multicasting feature helps (some other AOP tools have a feature called dynamic pointcuts, which is similar). We can apply PostSharp aspects at three levels:
- At the individual method/location level (most of the examples in the rest of the book)
- At the class level (will be applied to all members in the class)
- At the assembly level (will be applied to multiple classes/members in the assembly)
You’ve already seen plenty of examples of the first level. Putting attributes on individual properties or methods gives you maximum control and flexibility over where aspects are applied. For the next section, let’s start at the class level and work our way up to the assembly level.
8.3.1. At the class level
If you write a LocationInterceptionAspect and apply it at the class level, by default it will intercept all of the locations in that class.
If you write a method aspect (OnMethodBoundaryAspect or LocationInterceptionAspect) and apply it at the class level, by default it will be applied to all of the methods in that class. This approach would be equivalent to using the attribute four times, once on each method (see figure 8.9).
When using an aspect as an attribute, you’ll have a lot of configuration options available for multicasting in the attribute’s constructor. These are all covered in the PostSharp documentation, but here are a few notable examples:
- AttributeExclude— Selectively exclude methods from receiving a multicasted attribute
- AspectPriority— Define what order the aspects are applied (in C#, attribute order isn’t inherently deterministic)
- AttributeTargetElements— Choose what type of targets the aspect is applied to
To demonstrate, let’s write the LogAspect class, which will only report on which method(s) the aspect is being applied to. Once we have this aspect, we can change the configuration options and see what happens. I’ll use a Console project to keep it simple:
[Serializable]
public class LogAspect : OnMethodBoundaryAspect {
public override void OnEntry(MethodExecutionArgs args) {
Console.WriteLine("Aspect was applied to {0}",
args.Method.Name);
}
}
class Program {
static void Main(string[] args) {
var m = new MyClass();
m.Method1();
m.Method2();
}
}
Apply this aspect as shown in figure 8.10 and execute the program. You should see that the aspect is being applied to the constructor and Method1/2/3.
Figure 8.10. Aspect applied to the constructor and three methods

Let’s suppose that I want the aspect to be applied to everything in the class, except for Method3. I’d use the AttributeExclude setting, as in this listing.
Listing 8.11. Excluding a member with AttributeExclude

Compile and run, and—as you can see in figure 8.11—Method3 has not had the aspect applied to it.
Figure 8.11. No aspect applied to Method3

Using multiple aspects can be a common scenario. The order the aspects are applied can be important. You may want to use an aspect for caching and an aspect for security on the same class, for instance. In the next listing, I demonstrate how to create another aspect and use it on MyClass.
Listing 8.12. AspectPriority for ordering

When you use the C# compiler, you don’t have any guarantee that the attributes will be applied in the order that you specify them (I mentioned this in chapter 2). To enforce the order, you can use the AspectPriority setting, as shown in figure 8.10. LogAspect has a higher priority than AnotherAspect, so it will be applied first. If I swap those numbers, AnotherAspect would be applied first instead.
Figure 8.12. Swapping AspectPriority

With AttributeTargetElements, you can indicate in more detail to which elements to multicast. This setting (see the following listing) uses the MulticastTargets enumeration, which includes choices such as Method, InstanceContructor, and StaticConstructor. If I choose InstanceConstructor, the aspect is applied only to constructor(s).
Listing 8.13. AttributeTargetElements to target only the instance constructor

With multicasting at the class level, you get a sensible default (apply to everything) and flexible configuration, down to the individual member if you need it. You can use these same configuration options when multicasting at the assembly level.
8.3.2. At the assembly level
Earlier in this chapter, you saw a sneak peek on how to use attribute multicasting at the assembly level. We set up PostSharp to apply the NHEntity scalar constraint attribute to every class in a certain namespace:
[assembly: NHEntity(AttributeTargetTypes =
"NHibernateExample.Entities.*")]
Although that wasn’t an aspect, because aspects and constraints are both attributes, they both can be multicasted.
Let’s start with the basics. To apply an aspect to an entire assembly, use the syntax [assembly: MyAspect]. This syntax would apply the aspect to every valid target in the entire assembly.
To narrow it down, use the PostSharp configuration options in the attribute constructor. You have the same options available to you at the assembly level as at the class level. But at the assembly level, the AttributeTargetTypes setting becomes much more useful, because you can use it to apply an aspect to multiple classes and/or namespaces.
In the NHEntity example, I set the target to be a namespace with a wildcard (NHibernateExample.Entities*). In addition to that wildcard (the *), you can use regular expressions or exact names of classes.
You can use wildcards for any part of a namespace or type hierarchy. If I had multiple Entities namespaces (Sales.Entities and Support.Entities, for instance), I could also use a wildcard for the first part of the namespace:
[assembly: MyAspect(AttributeTargetTypes = "*.Entities.*)]
Using regular expressions can be helpful when you want to use conventions to determine where aspects are applied. If I establish a convention that every class that accesses the database is named with Repository at the end (InvoiceRepository, TerritoryRepository, and so on) and I want to apply transactional aspects to every repository class, I can use regex to do that:
[assembly: TransactionAspect(AttributeTargetTypes
= "regex:.*Repository$")]
Don’t abuse regular expressions—keep them simple. Use clear and sensible conventions, and be certain that expressions won’t pick up any targets that they aren’t supposed to. If a regular expression gets much more complex than this example, you may want to rethink your architecture/organization.
You can also multicast to individual members that have a certain name by using the AttributeTargetMembers configuration. The same rules apply: you can use an exact name, wildcards, or regular expressions.
If I want to apply a logging aspect to all methods that contain Delete in the name, I could do so with AttributeTargetMembers:
[assembly: LogAspect(AttributeTargetMembers="*Delete*")]
If your architecture contains a good structure with the use of namespaces and/or judicious use of conventional naming, you’ll have total control over where aspects are applied through the use of these assembly-level aspects. With all the configuration options, you can also define some complex pointcuts if necessary.
The benefits to using assembly-level attributes to help define pointcuts are that you don’t need to clutter your code by using attributes everywhere. Additionally, you have all of your pointcuts defined in one convenient file (such as AspectInfo.cs), which makes it easier to see where aspects are being used.
8.4. Summary
In this chapter, we dived into PostSharp’s architectural functionality. Castle DynamicProxy and other runtime AOP tools have some clear benefits that PostSharp (and comparable compile-time AOP frameworks) can’t match. But when it comes to raw power, PostSharp is hard to match.
In the past three chapters, I’ve highlighted the key differences between the two approaches to AOP using the two leading tools in .NET. They’re both amazing frameworks, and comparing and contrasting them helps illuminate the underlying concept of AOP and the significant trade-offs between approaches.
In this chapter, I briefly touched on the idea of multiple aspects being applied to the same code. We used an AspectPriority to determine the order of application. In the next chapter, we’ll get back to looking at both tools, and I’ll show how you’d do this with DynamicProxy, as well as a potentially more robust and less ambiguous way to do it with PostSharp.