
Chapter 11. Oozie Operations
We covered all the functional aspects of Oozie in Chapters 4 through 8. We learned how to write workflows, coordinators, and bundles, and mastered the fundamentals of Oozie. Chapters 9 and 10 covered advanced topics like security and developer extensions. In this final chapter, we will cover several operational aspects of Oozie. We will start with the details of the Oozie CLI tool and the REST API. We will look at the Oozie server and explore some tips on administering and tuning it for better stability and performance. We will also cover typical operational topics like retry and reprocessing of Oozie jobs. Last but not the least, we will look at debugging techniques and resolutions for some common failures. We will also sprinkle in a few topics that are useful but don’t quite fit in any of the previous chapters.
Oozie CLI Tool
The primary interface for managing and interacting with Oozie is oozie, the command-line utility that we have
used throughout this book (e.g., to submit jobs, check their status, kill
them, etc.). Internally, it actually uses Oozie’s web service (WS) API,
which we will look at in detail in the next section. The CLI is available
on the Oozie client node, which is also typically the Hadoop edge node
with access to all the Hadoop ecosystem CLI clients and tools like Hadoop,
Hive, Pig, Sqoop, and others. This edge node is also usually configured to
talk to and reach the Hadoop cluster, Hive meta-store, and the Oozie
server. The Oozie client only needs to talk to the Oozie server and it’s
the server’s responsibility to interact with the Hadoop cluster.
Consequently, the CLI has an -oozie option that lets you specify the location
of the server, which is also the end point for reaching the Oozie server’s
web service. The CLI also takes the Unix environment variable OOZIE_URL as the default value for the server.
It’s convenient and recommended to define this environment variable on the
Oozie client machine to save yourself the effort of passing in the
-oozie with every command you type on
the Unix terminal. Example 11-1 shows how to invoke
the CLI command with and without the environment variable. This option
lists all the jobs in the system.
Tip
The CLI executable oozie is
available in the bin/ subdirectory
under the oozie client deployment directory. For the remainder of this
chapter, we will assume we have the oozie executable available in our Unix path
and we will skip the absolute path in our examples for invoking the
CLI.
Example 11-1. Using the OOZIE_URL environment variable
$ oozie jobs -oozie http://oozieserver.mycompany.com:11000/oozie ... $ export OOZIE_URL=http://oozieserver.mycompany.com:11000/oozie $ oozie jobs ...
Tip
The Oozie CLI tool can be finicky when it comes to the order of
the arguments. This is a common issue with a lot of the CLI tools in the
Hadoop ecosystem. So if you get some unexplained invalid command errors, always pay attention
to the sequence of the arguments in your command line. For instance,
with this example, you might get different results with oozie jobs -oozie <URL> and oozie -oozie <URL> jobs.
In addition to the OOZIE_URL
environment variable, OOZIE_TIMEZONE
and OOZIE_AUTH are two other variables
that can make using the CLI tool easier, though most users don’t need it
as often as the server URL.
CLI Subcommands
The oozie CLI tool is feature
rich and supports a lot of options. It’s covered extensively in
the Oozie
documentation.These options are organized into many subcommands.
The subcommands are logical groupings of the different actions and
options that the CLI supports, and are listed here (some of these have
only one command option that serves one specific function, while the
others have several options):
oozie versionPrints client version
oozie jobAll job-related options
oozie jobsBulk status option
oozie adminAdmin options that deal with server status, authentication, and other related details
oozie validateValidate the job XML
oozie slaSLA-related options
oozie infoPrint detailed info on topics like supported time zone
oozie mapreduceSpecial option to submit standalone MapReduce jobs via Oozie
oozie pigSpecial option to submit standalone Pig jobs via Oozie
oozie hiveSpecial option to submit standalone Hive jobs via Oozie
oozie helpGet help on the CLI and its subcommands
Users can also get help on the CLI tool or specific subcommands by typing in the following commands on the Oozie client machine’s Unix terminal.
$ oozie help $ oozie help job $ oozie help sla
Useful CLI Commands
In this section, we will touch on some of the more useful and
interesting CLI commands that can make the user’s life easier. We will
assume that the OOZIE_URL is set up
appropriately in our environment and hence skip the -oozie option in all of the CLI examples we
cover the rest of the way.
The validate subcommand
One of the primary complaints about Oozie is that the code-test-debug cycle
can be a little complicated with too many steps. Specifically, every
time the job XML is modified, it has to be copied to HDFS and users
often forget this step and end up wasting a lot of time. Even if they
remember to do it, these steps can get annoyingly repetitive if they
find errors in the XML after executing the workflow and have to fix
the XML and iterate a few times to get it right. The validate command can be used to do some
basic XML validation on the job file before copying it to HDFS. This
won’t catch all the errors in the job definition, but it is definitely
recommended for every job XML file that users write. Although this
only catches some basic syntax errors in the XML, it can and will save
some time:
$ oozie validate my_workflow.xml $ oozie validate my_coordinator.xml
The job subcommand
The most commonly used CLI options are for submitting and checking the
status of jobs as we have seen in earlier chapters. The CLI has been
designed for simplicity, and it doesn’t matter whether the job in
question is a workflow, coordinator, or a bundle; the command tends to
be the same. Following are the CLI commands to submit a job (-submit) or to submit and run it in one shot
(-run). The job ID is returned as
shown here if the command succeeds:
$ oozie job -config ./job.properties –submit job: 0000006-130606115200591-oozie-joe-W $ oozie job -config ./job.properties –run job: 0000007-130606115200591-oozie-joe-W
It’s the following property during submission, usually defined in the job.properties file, that tells the Oozie server what kind of job is being submitted or run. Only one of these three properties can be defined per job submission, meaning a job can be either a workflow, a coordinator, or a bundle:
oozie.wf.application.pathoozie.coord.application.pathoozie.bundle.application.path
The following commands are commonly used for monitoring as well
as managing running jobs. The -info
option gives you the latest status information on the job and the
other options like -kill and
-suspend are self-explanatory. You
will need the job ID for all of these commands. We have already seen
many of these commands in action throughout this book:
$ oozie job -info 0000006-130606115200591-oozie-joe-W Job ID : 0000006-130606115200591-oozie-joe-W ----------------------------------------------------------------- Workflow Name : identity-WF App Path : hdfs://localhost:8020/user/joe/ch01-identity/app Status : RUNNING Run : 0 User : joe Group : - Created : 2013-06-06 20:35 GMT Started : 2013-06-06 20:35 GMT Last Modified : 2013-06-06 20:35 GMT Ended : - CoordAction ID: - Actions ----------------------------------------------------------------- ID Status ----------------------------------------------------------------- 0000006-130606115200591-oozie-joe-W@:start: OK ----------------------------------------------------------------- 0000006-130606115200591-oozie-joe-W@identity-MR RUNNING ----------------------------------------------------------------- $ oozie job –suspend 0000006-130606115200591-oozie-joe-W $ oozie job –resume 0000006-130606115200591-oozie-joe-W $ oozie job –kill 0000006-130606115200591-oozie-joe-W
The -info option for a
coordinator job could print pages and pages of output depending on how
long it has been running and how many coordinator actions it has
executed so far. So there is a -len
option to control the amount of output dumped onto the screen. The
default len is 1,000 and the
coordinator actions are listed in chronological order (oldest action
first). However, this order is reversed and actions are listed in
reverse chronological order (newest action first) on the Oozie web UI
for better usability:
$ oozie job -info 0000084-141219003455004-oozie-joe-C -len 10
The other useful option under the job subcommand of the CLI is
the -dryrun. It is another form of
validating the job XML, with the property file taken into account. It
might not look like it’s telling you much about a workflow, but it is
still a good practice to run it before submitting a job. For the
coordinators, it tells you things like how many actions will be run
during the lifetime of the job, which can be useful information. Here
is some sample output:
$ oozie job -dryrun -config wf_job.properties OK $ oozie job -dryrun -config coord_job.properties ***coordJob after parsing: *** <coordinator-app xmlns="uri:oozie:coordinator:0.2" name="test-coord" frequency="1" start="2014-12-22T02:47Z" end="2014-12-23T02:49Z" timezone="UTC" freq_timeunit="DAY" end_of_duration="NONE"> ... </coordinator-app> ***actions for instance*** ***total coord actions is 2 *** ...
Tip
Adding the -debug flag to
the -job command can generate a
lot of useful information that can help with debugging. One great
benefit of the -debug option is
that it prints the actual web services API that the CLI command
calls internally. This can come in handy for users who are trying to
develop Oozie client apps using the web services API.
Sometimes users want to tweak and change a few properties of a
running coordinator or a bundle job. The -change option helps achieve this.
Properties like the end-time and
concurrency of a coordinator are
ideal for the -change option, which
only accepts a handful of properties. For instance, users may not want
to stop and restart a coordinator job just to extend the endtime.
Starting with version 4.1.0, Oozie also supports an -update option, which can update more
properties of a running job via the job.properties file than the -change option. Following are a few example
commands showcasing both options. Using the -dryrun with the -update spits out all the changes for the
user to check before updating:
$ oozie job -change 0000076-140402104721144-oozie-joe-C -value
endtime=2014-12-01T05:00Z
$ oozie job -change 0000076-140402104721144-oozie-joe-C -value
endtime=2014-12-01T05:00Z;concurrency=100;2014-10-01T05:00Z
$ oozie job -config job.properties -update
0000076-140402104721144-oozie-joe-C -dryrunWe recommend becoming conversant with the job –rerun option, as it helps with the
important task of reprocessing jobs (we will cover it in detail
in “Reprocessing”).
The jobs subcommand
The oozie CLI also provides a -jobs
subcommand. This is primarily intended to be a monitoring option. It
handles jobs in bulk unlike the -job option that handles a specific job. The
basic -jobs command lists all the
jobs in the system with their statuses. By default, this lists only
the workflow jobs in reverse chronological order (newest first, oldest
last) based on the job’s creation time. You can add the -jobtype flag to get the coordinator or
bundle jobs listed. If you print the coordinator jobs using the
jobtype=coordinator option, the
different coordinators will be listed in reverse chronological order
based on the next materialization time of the next action in each one
of them. This command also takes the -len command to control the output printed
on to the screen and provides a rich set of filters. You can list the
jobs filtered by a specific user, job status, creation time, or some
other criteria.
There is also a special -bulk
option specifically meant for bundles. Oozie bundles in large
enterprises can get really hairy to monitor with multiple
coordinators. -bulk helps monitor
the bundles with a variety of filters to organize the information
better. This option requires a bundle name, but the rest of the
filters are optional.
Listed here are several useful examples of the -jobs subcommand:
$ oozie jobs $ oozie jobs -jobtype coordinator $ oozie jobs -jobtype=bundle $ oozie jobs -len 20 -filter status=RUNNING $ oozie jobs -bulk bundle=my_bundle_app $ oozie jobs -bulk 'bundle=my_bundle_app;actionstatus=SUCCEEDED' $ oozie jobs -bulk bundle=test-bundle;actionstatus=SUCCEEDED
Tip
The -bulk option requires
bundle name and not the bundle job ID. Also, only the FAILED or
KILLED jobs are listed by default. Use the actionstatus filter to look at jobs that
are in other states, as shown in the preceding example. When using
the CLI, escape the ; or quote
the entire filter string.
More subcommands
The admin subcommand
provides users with support for some system-wide
administrative actions. One interesting option with this subcommand is
the -queuedump flag that dumps all
the elements in the server queue. The MapReduce, Pig, and Hive subcommands are available for
submitting MapReduce, Pig, and Hive jobs right from the command line
without having to write a workflow job. These will run as standalone
actions and Oozie generates the workflow XML internally, saving some
work for the user. All the required JARs, libraries, and supporting
files have to be uploaded to HDFS beforehand as always. These jobs are
created and run right away. Although these CLI features (which are
meant to submit action types) can come in handy occasionally.
Tip
The sla subcommand has been
deprecated starting with Oozie version 4.0 since the new SLA
framework explained in “JMS-Based Monitoring” has
been implemented. Also, the hive
subcommand is a recent addition to the CLI to go with the
pig and mapreduce commands. As always,
double-check the Oozie documentation online to see what options are
supported by the particular version of the Oozie CLI you are
using.
Oozie REST API
Oozie supports an HTTP-based REST API. This web service API is JSON-based and all responses are in UTF8. Any HTTP client that can make web service calls can submit and monitor Oozie jobs. There is library support in most programming languages like Python for making HTTP REST calls. As you can guess, this API is useful for interacting programmatically with Oozie. The use cases for this include automating the monitoring of your Oozie jobs and building custom web UIs to render all that information. Oozie’s own internal services like the Oozie CLI, Oozie’s web UI, and the Java client API that we will discuss in “Oozie Java Client” use this REST API. Oozie documentation covers this API well, but we will get you up to speed in this section with useful examples, tips, and tricks.
As mentioned earlier, if you run the oozie
–job with the -debug flag,
you will actually see the exact REST API call printed for your reference
as shown in Example 11-2.
Example 11-2. The -debug option
$ oozie job -info 0000025-140522211231058-oozie-joe-C@80 -debug GET http://oozieserver.mycompany.com:11000/oozie/v2/job/0000025- 140522211231058-oozie-joe-C@80?show=info ID : 0000025-140522211231058-oozie-joe-C@80 -------------------------------------------------------------------------------- Action Number : 80 Console URL : - Error Code : - Error Message : - External ID : 0000273-140814212041682-oozie-joe-W External Status : - Job ID : 0000025-140522211231058-oozie-joe-C Tracker URI : - Created : 2014-12-18 01:14 GMT Nominal Time : 2014-12-18 01:15 GMT Status : SUCCEEDED Last Modified : 2014-12-18 03:13 GMT First Missing Dependency : - --------------------------------------------------------------------------------
The URI http://oozieserver.mycompany.com:11000/oozie is the OOZIE_URL where the Oozie server is running. As of Oozie version 4.1.0, the server supports three different versions of the REST API. Versions v0, v1, and v2 may have slightly different features, interfaces, and responses. The following endpoints are supported in the latest version v2 and the previous versions are not too different, but do check the documentation for the specific details. Readers should be familiar with the listed subcommands from the previous section on CLI.
/versions
/v2/admin
/v2/job
/v2/jobs
/v2/sla
Tip
Since the Oozie CLI, REST API, and the Java client are all different ways to do the same thing, the examples covered might have some duplicate content. We do try to use different use cases in these examples to minimize overlap and repetition.
Most readers are probably familiar with curl, the common command-line tool used on many
Unix systems to transfer data to and from a URL. Curl supports the HTTP
protocol among several other protocols and is often used for making web
service calls from the command line and from scripts on Unix systems. Run
man curl on your Unix box if you need
more information on curl. In this
section, we will mostly use curl for
showcasing the Oozie REST API. Following are some simple examples using
curl with the server’s response printed
as well to give you a flavor of what’s returned by Oozie:
$ curl "http://oozieserver.mycompany.com:11000/oozie/versions"
[0,1,2]
$ curl "http://oozieserver.mycompany.com:11000/oozie/v2/admin/status"
{"systemMode":"NORMAL"}Since one of the primary uses for the web services API is enabling programmatic access to the Oozie services, let’s take a look at a short and sweet example program in Python that accesses a job status of a particular coordinator action and prints the results:
#!/usr/bin/python import json import urllib2 url = 'http://oozieserver.mycompany.com:11000/oozie/v2/job/ 0000084-141219003455004-oozie-joe-C?show=info' req = urllib2.Request(url) print urllib2.urlopen(req).read()
Most of the responses from the Oozie web server are in JSON format.
So readers are advised to use JSON formatting and printing utilities to
print the server’s response in more readable formats. On most Unix
systems, piping the JSON output through python -m
json.tool on the command line generates a readable output, as
shown in Example 11-3.
Example 11-3. Handling JSON output
$ curl "http://oozieserver.mycompany.com:11000/oozie/v2/jobs?jobtype=bundle"
| python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
104 2187 104 2187 0 0 146k 0 --:--:-- --:--:-- --:--:-- 237k
{
"bundlejobs": [
{
"acl": null,
"bundleCoordJobs": [],
"bundleExternalId": null,
"bundleJobId": "0000083-141219003455004-oozie-joe-B",
"bundleJobName": "test-bundle",
...
...
"createdTime": "Thu, 01 Jan 2015 08:39:10 GMT",
"endTime": null,
"group": null,
"kickoffTime": "Thu, 25 Dec 2014 01:25:00 GMT",
"pauseTime": null,
"startTime": null,
"status": "SUCCEEDED",
"timeOut": 0,
"timeUnit": "NONE",
"toString": "Bundle id[0000083-141219003455004-oozie-joe-B]
status[SUCCEEDED]",
"user": "joe"
}
],
"len": 50,
"offset": 1,
"total": 1
}The examples so far have shown how to read status and other
information from the server using HTTP GET. Let’s now look at an example that submits
or writes something to the server using HTTP POST. Oozie’s REST API can be used to start and
run jobs.
Tip
When we submit a workflow or a coordinator (or even an action)
using the REST API, we have to send the job configuration as the XML
payload via the HTTP POST. Similar to
what we do with the CLI, artifacts like the JARs for UDFs, other
libraries, and job XML like the workflow.xml and the coordinator.xml have to be copied to HDFS and
be in place ahead of the submission. In that sense, the Oozie REST API
is not a complete solution for job submissions. However, users can use
HttpFS,
the REST HTTP gateway for HDFS to upload the files.
We will see a complete example of submitting a Pig action via the REST API. Users can submit Pig, MapReduce, and Hive actions as individual jobs without having to write a workflow.xml, which Oozie will generate internally for running the job. This is called proxy job submission and for a Pig job, the following configuration elements are mandatory:
fs.default.namemapred.job.trackeruser.nameThe username of the user submitting the job
oozie.pig.scriptoozie.libpathoozie.proxysubmission
Let’s now build an XML payload with the required configuration for our example Pig job submission (we will keep the job simple with no UDF JARs or other special requirements):
$ cat pigjob.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://nn.mycompany.com:8020</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>jt.mycompany.com:8032</value>
</property>
<property>
<name>user.name</name>
<value>joe</value>
</property>
<property>
<name>oozie.pig.script</name>
<value>
A = load '/user/joe/rest_api/pig/input/pig.data' using
PigStorage(',') AS (name:chararray, id:int);
B = foreach A generate $0 as name;
store B into '/user/joe/rest_api/pig/output';
</value>
</property>
<property><name>oozie.libpath
</name>
<value>/user/oozie/share/lib/pig/</value>
</property>
<property>
<name>oozie.proxysubmission</name>
<value>true</value>
</property>
</configuration>Given this configuration and the Pig code, let’s make the REST API call for the proxy job submission—if it’s successful, you will get a job ID returned as shown here:
$ curl -X POST -H "Content-Type: application/xml;charset=UTF-8" -d @pigjob.xml
”http://oozieserver.mycompany.com:11000/oozie/v1/jobs?jobtype=pig"
{"id":"0000082-141219003455004-oozie-joe-W"}Oozie Java Client
In addition to the REST API, Oozie also supports a Java client API for easy integration with Java code. It supports the same kind of operations and is actually a wrapper on top the REST API. We won’t spend a lot of time explaining it here, but readers can refer to the Oozie documentation for more details. The brief example should give you a feel for the client code and the key classes in the Java package (the code shown here should be self-explanatory for most Java programmers):
import java.util.Properties;
import org.apache.oozie.client.OozieClient;
import org.apache.oozie.client.WorkflowJob;
import org.apache.oozie.client.WorkflowAction;
OozieClient myOozieClient
= new OozieClient(“http://oozieserver.mycompany.com:11000/oozie");
// Create job configuration and set the application path
Properties myConf = myOozieClient.createConfiguration();
myConf.setProperty(OozieClient.APP_PATH,
"hdfs://nn.mycompany.com:8020/user/joe/my-wf-app");
myConf.setProperty("jobTracker", "jt.mycompany.com:8032");
myConf.setProperty("inputDir", "/user/joe/input");
myConf.setProperty("outputDir", "/user/joe/output
// Submit and start the workflow job
String jobId = myOozieClient.run(conf);
// Wait until the workflow job finishes printing the status every 30 seconds
while (myOozieClient.getJobInfo(jobId).getStatus() == Workflow.Status.RUNNING) {
System.out.println("Workflow job running ...");
Thread.sleep(30 * 1000);
}
System.out.println("Workflow job completed ...");
System.out.println(myOozieClient.getJobInfo(jobId));If users want to write a client to connect to a secure Hadoop
cluster, Oozie’s Java API provides another client class (org.apache.oozie.client.AuthOozieClient) that
they can plug in seamlessly. The client needs to be
initialized as shown here:
AuthOozieClient myOozieClient = new
AuthOozieClient(“http://oozieserver.mycompany.com:11000/oozie");This client supports Kerberos HTTP SPNEGO authentication, pseudo/simple authentication, and anonymous access for client connections. Users can also create their own client that supports custom authentication (refer to the Oozie documentation for more details).
The oozie-site.xml File
As is customary with all the tools in the Hadoop ecosystem, Oozie has its own “site” XML file on the server node, which captures numerous settings specific to operating Oozie. A lot of the settings that define operational characteristics and Oozie extensions are specified in this oozie-site.xml file. We have been covering a lot of those settings across many chapters of this book if and when the context presented itself; for example, many of the security settings were covered in detail in “Oozie Security”. But there are several more settings available for tuning various aspects of Oozie. The defaults work well in most cases and users will never have to tune most of these settings. But some settings are more useful than others.
Also, following normal Hadoop conventions, an oozie-default.xml is deployed that captures all the default values for these settings and also serves as reference documentation for what the server is actually running. These settings can be overridden with your own setting in the oozie-site.xml. Be sure to review the sample oozie-default.xml available as part of the Apache Oozie documentation to familiarize yourself with the various settings and options available. We will cover some more of those settings in this chapter, but not all.
Tip
It can be very educational to browse through the oozie-default.xml file. It can be a quick reference to a lot of the features, options, limits, and possible extensions. Users sometimes are not aware of the options available to them or the system limits that are configurable. So just browsing these “default” files and values can be eye opening for new users of any Hadoop tool in general and Oozie in particular.
The best source of truth for all server configuration is the Oozie
web UI of the operational Oozie system (Figure 11-1). Clicking on the System Info tab on the
UI lets users see the current configuration that the server is running
with. And clicking on the + sign next
to the setting of interest expands it and shows the value. This is way
easier than fumbling through the site and default XML files trying to
figure out which property is where and what value it is set to. The figure
below shows the relevant part of the UI. This information is also
available via the REST API, though not available through the CLI.
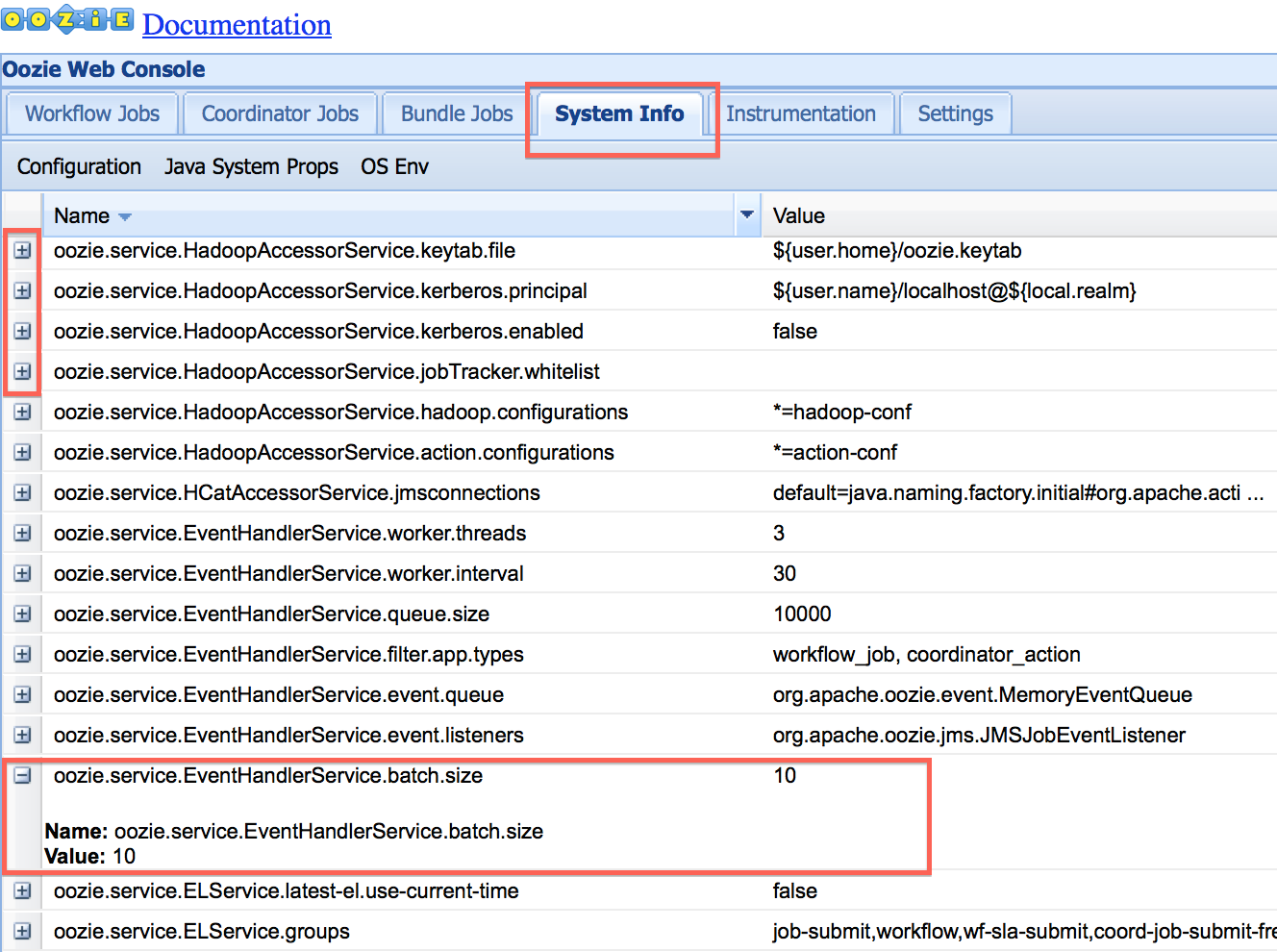
Figure 11-1. Server configuration
One basic setting is the oozie.services property. Example 11-4 shows the complete list of services
supported by Oozie. You should turn on or off the services of your choice
in the oozie-site.xml file. This is
for the Oozie administrator to define and manage.
Example 11-4. List of Oozie services
<property>
<name>oozie.services</name>
<value>
org.apache.oozie.service.SchedulerService,
org.apache.oozie.service.InstrumentationService,
org.apache.oozie.service.MemoryLocksService,
org.apache.oozie.service.UUIDService,
org.apache.oozie.service.ELService,
org.apache.oozie.service.AuthorizationService,
org.apache.oozie.service.UserGroupInformationService,
org.apache.oozie.service.HadoopAccessorService,
org.apache.oozie.service.JobsConcurrencyService,
org.apache.oozie.service.URIHandlerService,
org.apache.oozie.service.DagXLogInfoService,
org.apache.oozie.service.SchemaService,
org.apache.oozie.service.LiteWorkflowAppService,
org.apache.oozie.service.JPAService,
org.apache.oozie.service.StoreService,
org.apache.oozie.service.CoordinatorStoreService,
org.apache.oozie.service.SLAStoreService,
org.apache.oozie.service.DBLiteWorkflowStoreService,
org.apache.oozie.service.CallbackService,
org.apache.oozie.service.ShareLibService,
org.apache.oozie.service.CallableQueueService,
org.apache.oozie.service.ActionService,
org.apache.oozie.service.ActionCheckerService,
org.apache.oozie.service.RecoveryService,
org.apache.oozie.service.PurgeService,
org.apache.oozie.service.CoordinatorEngineService,
org.apache.oozie.service.BundleEngineService,
org.apache.oozie.service.DagEngineService,
org.apache.oozie.service.CoordMaterializeTriggerService,
org.apache.oozie.service.StatusTransitService,
org.apache.oozie.service.PauseTransitService,
org.apache.oozie.service.GroupsService,
org.apache.oozie.service.ProxyUserService,
org.apache.oozie.service.XLogStreamingService,
org.apache.oozie.service.JvmPauseMonitorService
</value>
<description>
All services to be created and managed by Oozie Services singleton.
Class names must be separated by commas.
</description>
</property>
<property>
<name>oozie.services.ext</name>
<value>
</value>
<description>
To add/replace services defined in 'oozie.services' with custom
implementations. Class names must be separated by commas.
</description>
</property>The Oozie Purge Service
One of Oozie’s many useful services that can be managed through
the settings in the oozie-site.xml is
the database purge service. As you know, Oozie uses a database for its metadata and state management. This database has to be
periodically cleaned up so that we don’t bump into database-related
performance issues. This service—the purge service—can be
turned on by enabling org.apache.oozie.service.PurgeService. The
server allows users to tune several aspects of the purge
service (e.g., how soon to purge workflow jobs, how often the purge
service should run, etc.). Do keep in mind that the purge service removes
only completed and successful jobs; it never touches the failed, killed,
suspended, or timed-out jobs. Table 11-1 shows some
of the settings that can be tuned to manage the purge service.
| Setting | Default value | Description |
|---|---|---|
oozie.service.PurgeService.older.than | 30 | Completed workflow jobs older than this value, in days, will be purged by the PurgeService. |
oozie.service.PurgeService.coord.older.than | 7 | Completed coordinator jobs older than this value, in days, will be purged by the PurgeService. |
oozie.service.PurgeService.bundle.older.than | 7 | Completed bundle jobs older than this value, in days, will be purged by the PurgeService. |
oozie.service.PurgeService.purge.old.coord.action | false | Whether to purge completed workflows and their corresponding coordinator actions of long-running coordinator jobs if the completed workflow jobs are older than the value specified in oozie.service.PurgeService.older.than |
oozie.service.PurgeService.purge.limit | 100 | Completed Actions purge: limit each purge to this value. This will make sure the server is not spending too much time and resources purging and overloading the server for other operations. |
oozie.service.PurgeService.purge.interval | 3600 | Interval at which the purge service will run, in seconds. This and the previous setting lets you decide whether you want to run short purges more often or run long purges less often. |
Tip
With long-term coordinator jobs like the ones that run for a year
or two, the purge service by default does not purge completed workflows belonging to that job even past the purge time limits for workflows as
long as the coordinator job is still running. This used to be a common
source of confusion and problem for users. The solution was to end the
coordinator jobs and recycle them every week or month or whatever the DB
load dictated. So the setting oozie.service.PurgeService.purge.old.coord.action
was introduced in version 4.1.0 to allow users to purge successfully
completed actions even if they belong to running coordinators.
Job Monitoring
Job monitoring is an integral part of any system for effective operation and management. For a system like Oozie that often deals with time- and revenue-critical jobs, monitoring those jobs is paramount. For instance, if a job fails or runs longer than expected, it is important to know what happened and take remedial action in a timely fashion. Oozie provides multiple ways to monitor the jobs:
- User Interface
Oozie web UI displays the jobs and the associated status and timelines. This UI is very basic and users can only browse jobs.
- Polling
Users can write their own custom monitoring system and poll Oozie using the REST API or Java API that we covered earlier in this chapter to get the latest job information.
Oozie workflow supports an
Emailaction that can send an email when a workflow action finishes.- Callback
Oozie provides a callback framework where a user can pass the callback URL during workflow submissions. When a job/action finishes, Oozie notifies through the user-defined callback URL and passes the status as payload. This notification service follows a best effort approach and provides no guarantees. More details on this notification feature can be found in the Apache Oozie documentation for both workflows and coordinators.
These approaches implement some parts of an effective job monitoring system, but there are significant shortcomings with each. So the Oozie community decided to implement a monitoring system based on JMS to tackle this problem from the ground up. This is a recent initiative starting with Oozie version 4.0.0.
JMS-Based Monitoring
Oozie supports publishing job information through any JMS-compliant message bus and the consumer can asynchronously receive the messages and handle them using custom processing logic. There are two types of notifications: job and SLA. The first one publishes the job status information that includes when the job started, completed, and so on. Currently, Oozie only supports status change notification for coordinator actions and workflow jobs. There is no support yet for coordinator jobs, workflow actions, and bundle jobs.
The second notification type addresses SLA monitoring. SLAs are very important for mission-critical applications and that information usually feeds daily executive dashboards and other operational reports in large enterprises. Oozie’s SLA notifications primarily include various kinds of SLA “met” and “missed” messages. Until version 4.0.0, Oozie supported SLA monitoring in a rather passive way where clients had to poll Oozie to get the SLA information and then determine the status themselves. In post 4.0.0 versions, users can define the expected SLA and the subsequent behavior through workflow and coordinator definition. Oozie pushes the SLA messages through JMS as soon as it is determined. There is also support for a REST API for clients to poll for the status. Moreover, Oozie can send an email when an SLA event occurs. Users can also visually view the SLA status through the new SLA tab of the Oozie UI.
Installation and configuration
The Oozie administrator has to install the JMS-based message bus to support this feature. After the message bus is properly installed, the Oozie server needs to be configured through the oozie-site.xml file. The configuration details are covered in the official Apache Oozie documentation.
Tip
Most of the testing in Oozie for this feature happened with
ActiveMQ, but it should work well
with any other JMS-compliant message bus. With that said, readers
will probably be better off sticking with ActiveMQ to the extent possible.
Consuming JMS messages
The main tenet of the JMS-based notification system is that Oozie makes the job and SLA status messages available through a push-based model. The primary focus of this feature is not the presentation or the UI layer. Although Oozie provides a basic and generic UI for all, users are encouraged to design their own UI based on these JMS messages because monitoring UI requirements tends to be quite varied and specific at every deployment.
In order to consume the JMS messages, clients needs to write a conventional JMS consumer. Oozie provides the JMS topic name, message format, and message selectors. Oozie is also flexible in that it allows the users to configure the JMS topic name and selectors. JMS selector is a feature by which the clients can skip the messages they are not interested in. More details on this subject can also be found in the Apache Oozie documentation.
Oozie Instrumentation and Metrics
Oozie code is very well instrumented and it can be used to closely monitor the performance of the server. Several samplers, timers, and counters are generated by this instrumentation, and it can be enabled by turning on the org.apache.oozie.service.InstrumentationService service. These metrics are available
through the instrumentation log on the server and the web services API
using the admin/instrumentation
endpoint (refer to the documentation
for more details). Listed here are some sample JVM variables that can help
you manage Oozie server’s Java process:
free.memory
max.memory
total.memoryStarting with Oozie version 4.1.0, a new and improved metrics service
has been implemented with the intention of eventually replacing the
existing instrumentation service. It is turned off by default in 4.1.0,
but will become the primary and only source of metrics over the course of
the next few releases. This new service is based on the codahale metrics package and is
API-compatible with the existing instrumentation service. The newer
metrics are a lot more accurate and detailed and come with very little
changes to the output format. The biggest drawback of the existing
instrumentation service is that the metrics are accumulated over time
going all the way back to when the Oozie server was started. This can
become stale over time. The new metrics don’t suffer from this limitation
and support a sliding time window for its calculations. Users can turn
these metrics on by enabling the following service:
<property>
<name>oozie.services.ext</name>
<value>
org.apache.oozie.service.MetricsInstrumentationService
</value>
</property>Caution
The two metrics services don’t work in parallel and users have to
pick one or the other. If the new metrics package is enabled, the
admin/instrumentation REST endpoint
and the Instrumentation tab on the UI will be replaced by the admin/metrics endpoint and the Metrics tab,
respectively.
Reprocessing
Reprocessing is an important operational undertaking in any complex system. We briefly touched on how bundles help with managing and reprocessing pipelines in Chapter 8. We will now look at reprocessing in detail and see how Oozie supports it at the workflow, coordinator, and bundle levels. In a production environment, job reprocessing is a very common and critical activity. There are three scenarios when a user needs to rerun the same job:
The job failed due to a transient error.
The job succeeded but the input data was bad.
The application logic was flawed or there was a bug in the code.
As you can see, the second and third scenarios can force
reprocessing even when the jobs have succeeded. Oozie provides convenient
ways to reprocess completed jobs through the CLI or the REST API.
Reprocessing is driven through the job
-rerun subcommand and option of the Oozie CLI. Let’s first look
at workflow reprocessing.
Workflow Reprocessing
Rerunning a workflow job is fairly straightforward and much simpler compared to the
coordinator or the bundle. But Oozie does enforce a few constraints for
reprocessing. Workflow jobs should be in a SUCCEEDED, FAILED, or KILLED state to be eligible for reprocessing.
Basically it should be in a terminal state. The following command will
rerun a workflow job that is already done:
$ oozie job -rerun 0000092-141219003455004-oozie-joe-W -config job.properties
Tip
In order to rerun a workflow on Oozie versions before 4.1.0, you have to specify all of the workflow properties (in the job.properties file). This is slightly different from the coordinator and bundle reprocessing, which reuses the original configuration as explained later in this section. This inconsistency has been fixed in Oozie 4.1.0 and workflows can also reuse the original properties now.
While the previous example will try to rerun the workflow, there are a few more details that will determine what exactly happens with that command. We cover some of the key aspects here:
It’s the user’s responsibility to make sure the required cleanup happens before rerunning the workflow. As you know, Hadoop doesn’t like the existence of an output directory and the
prepareelement introduced in “Action Types” exists just for this reason. It’s always a good idea to use theprepareelement in every action in all workflows to make the actions retryable. This may not be useful for normal processing, but will be a huge help during reprocessing.There are two configuration properties relevant to rerunning workflows,
oozie.wf.rerun.skip.nodesandoozie.wf.rerun.failnodes. We can use one or the other, not both. As always, they can be added to the job.properties file or passed in via the-Doption on the command line.The property
oozie.wf.rerun.skip.nodesis used to specify a comma-separated list of workflow action nodes to be skipped during the rerun.By default, workflow reruns start executing from the failed nodes in the prior run. That’s why if you run the command in the preceding example on a successfully completed workflow, it will often return without doing anything. The property
oozie.wf.rerun.failnodescan be set tofalseto tell Oozie that the entire workflow needs to be rerun. This option cannot be used with theoozie.wf.rerun.skip.nodesoption.There is a workflow EL function named
wf:run()that returns the number of the execution attempt for this workflow. Workflows can make some interesting decisions based on this run number if they want to.
Tip
One of the advantages of the workflow retries requiring the job properties is that you could potentially give it a different workflow application path and different parameters. This can help with one-off fixes for one retry of the workflow without affecting the other runs. But this feature comes with a lot of caveats, so be careful to match up the old and new workflow pretty closely.
Here are a couple of examples (the first command will rerun a workflow that succeeded during the first try; the second command will skip a couple of nodes during reprocessing):
$ oozie job -rerun 0000092-141219003455004-oozie-oozi-W -config job.properties -Doozie.wf.rerun.failnodes=false $ oozie job -rerun 0000092-141219003455004-oozie-oozi-W -config job.properties -Doozie.wf.rerun.skip.nodes=node_A,node_B
Coordinator Reprocessing
Coordinator actions can be reprocessed as long as they are in a completed
state. But the parent coordinator job itself cannot be in a FAILED or KILLED state. Users can select the coordinator
action(s) to rerun using either date(s) or action number(s). In
addition, a user also has the option to specify either contiguous or
noncontiguous actions to rerun. To rerun the entire coordinator job, a
user can give the actual start time and end time as a range. However, a
user can only specify one type of option in one retry attempt, either
date or action number. For the coordinator reruns, Oozie reuses the
original coordinator definition and configuration.
During reprocessing of a coordinator, Oozie tries to help the
retry attempt by cleaning up the output directories by default. For
this, it uses the <output-events> specification in the
coordinator XML to remove the old output before running the new attempt.
Users can override this default behavior using the –noCleanup option.
Moreover, a user can also decide to reevaluate the instances of
data (current()/latest()) using the
–refresh option. In this case, Oozie
rechecks all current() instances
and recalculates/rechecks the latest().
For example, the following command shows how to rerun a set of
coordinator actions based on date. It also removes the old files and
recalculates the data dependencies. This command reruns the actions with
the nominal time between 2014-10-20T05:00Z to 2014-10-25T20:00Z and individual actions with
nominal time 2014-10-28T01:00Z and
2014-10-30T22:00Z:
$ oozie job -rerun 0000673-120823182447665-oozie-hado-C -refresh -date 2014-10-20T05:00Z::2014-10-25T20:00Z, 2014-10-28T01:00Z, 2014-10-30T22:00Z
The next command demonstrates how to rerun coordinator actions using action numbers instead of dates. It also doesn’t clean up the old output data files created in the previous run and doesn’t recalculate the data dependencies. The command reruns the action number 4 and 7 through 10:
$ oozie job -rerun 0000673-120823182447665-oozie-hado-C -nocleanup -action 4,7-10
Bundle Reprocessing
Bundle reprocessing is basically reprocessing the coordinator actions that have
been run under the auspices of this particular bundle invocation. It
does provide options to rerun some of the coordinators and/or actions
corresponding to some of the dates. The options are -coordinator and -date. It’s easier to explain the usage
through examples. Refer to the following examples with the responses
captured to show what happens when a bundle is reprocessed:
$ oozie job -rerun 0000094-141219003455004-oozie-joe-B -coordinator test-coord Coordinators [test-coord] of bundle 0000094-141219003455004-oozie-joe-B are scheduled to rerun on date ranges [null]. $ oozie job -rerun 0000094-141219003455004-oozie-joe-B -coordinator test-coord -date 2014-12-28T01:28Z Coordinators [test-coord] of bundle 0000094-141219003455004-oozie-joe-B are scheduled to rerun on date ranges [2014-12-28T01:28Z]. $ oozie job -rerun 0000094-141219003455004-oozie-joe-B -coordinator test-coord -date 2014-12-28T01:28Z::2015-01-06T00:30Z Coordinators [test-coord] of bundle 0000094-141219003455004-oozie-joe-B are scheduled to rerun on date ranges [2014-12-28T01:28Z::2015-01-06T00:30Z]. $ oozie job -rerun 0000094-141219003455004-oozie-joe-B -date 2014-12-28T01:28Z All coordinators of bundle 0000094-141219003455004-oozie-joe-B are scheduled to rerun on the date ranges [2014-12-28T01:28Z].
Tip
With bundle reprocessing, you are actually rerunning a specific
bundle ID, but the -coordinator
option just needs the coordinator names of interest, not IDs. Oozie
will find the specific coordinator action IDs to rerun. As for the
-date option, enter the exact
nominal time of the coordinator action you want to rerun or a date
range using the X::Y syntax to
cover all nominal times in that range. In some versions of Oozie,
using a comma-separated list of dates results in some strange
behaviors.
Server Tuning
An Oozie server running on decent-sized hardware usually performs well in most deployments. With that said, like any legitimate software service, there are various limits and performance issues that Oozie bumps into once in a while. There are several configurations and settings that can be tuned through the oozie-site.xml file that we introduced in “The oozie-site.xml File”.
JVM Tuning
As we already covered, the Oozie server is a Tomcat web server that runs on a Java Virtual Machine (JVM). Like any JVM application, memory is a major tunable for the Oozie server. By default, the server is configured to run with 1 GB of memory. This is controlled by the following line in the file oozie-env.sh under the <INSTALLATION_DIR>/conf directory. Oozie administrators can modify and upgrade the memory allocation by editing this line and restarting the server:
export CATALINA_OPTS="$CATALINA_OPTS -Xmx1024m"
Tip
In case of performance issues, monitoring the load on the Oozie server process and analyzing the JVM performance metrics will help. All of the typical JVM concerns (e.g., memory, threads, garbage collection, etc.) apply to the Oozie server as well. The instrumentation and metrics covered in “Oozie Instrumentation and Metrics” can be a huge help in debugging these issues.
Service Settings
Oozier server is implemented using the Service Layers Pattern. The server is composed of many distinct services as listed in “The oozie-site.xml File”. One of the advantage of this design is that these logical services can be independently configured and tuned. Oozie has exposed many settings through oozie-site.xml for each of these services. We will look at few important services and their settings in this section.
The CallableQueueService
Of the many services that make up the Oozie service, the CallableQueueService is the most important
from a performance perspective. This is the core work queue that
drives all server-side activity. There are a handful of settings for
this specific service in the oozie-site.xml file, and Table 11-2 captures the most important ones from a
tuning perspective.
| Setting | Default value | Description |
|---|---|---|
oozie.service.CallableQueueService.queue.size | 10000 | Max callable queue size. |
oozie.service.CallableQueueService.threads | 10 | Number of threads used for executing callables |
oozie.service.CallableQueueService.callable.concurrency | 3 | Maximum concurrency for a given callable type. Each command is a callable type (submit, start, run, signal, job, jobs, suspend, resume, etc.). Each action type is a callable type (MapReduce, Pig, SSH, FS, sub-workflow, etc.). All commands that use action executors (action-start, action-end, action-kill and action-check) use the action type as the callable type. |
Tip
The Queue in the service
name might be slightly misleading. This is not a user-facing queue
that manages just the job submissions and other user requests. This
is an internal queue that’s used by Oozie code during processing.
The queue items are various callables, which is an Oozie
implementation primitive. User actions like scheduling a coordinator
or submitting a workflow gets translated into many callables internally and that’s what this
queue manages.
The default value for oozie.service.CallableQueueService.queue.size
is 10,000, which is a decent size that works for most use cases. But
if you notice some poor response times and unsatisfactory performance
from Oozie, you can use the -admin
subcommand of the CLI to look at the queue. The commands here tell us
the current size of the queue, in addition to listing all the items
that are occupying the queue. There are 549 items in this
queue:
$ oozie admin -queuedump | wc -l 549 $ oozie admin -queuedump [Server Queue Dump]: delay=0, elements=org.apache.oozie.command.coord.CoordActionInput CheckXCommand@71ab437d delay=64, elements=org.apache.oozie.command.coord.CoordActionInput CheckXCommand@e1995a0 delay=26829, elements=org.apache.oozie.command.coord.CoordActionInput CheckXCommand@6661ee03 delay=7768, elements=org.apache.oozie.command.coord.CoordActionInput CheckXCommand@3c246ecb ... ... ****************************************** [Server Uniqueness Map Dump]: coord_action_input_0005771-141217180918836-oozie-oozi-C@241= Sat Jan 10 23:58:21 UTC 2015 suspend_0056165-140725012140409-oozie-oozi-W= Fri Jan 09 07:56:57 UTC 2015 action.check_0056171-140725012140409-oozie-oozi-W@pig-node1= Sat Jan 10 18:31:30 UTC 2015 coord_action_input_0005792-141217180918836-oozie-oozi-C@113= Sat Jan 10 23:58:52 UTC 2015 suspend_0055992-140725012140409-oozie-oozi-W= Sat Jan 10 04:05:17 UTC 2015 coord_action_input_0005902-141217180918836-oozie-oozi-C@109= Sat Jan 10 23:57:57 UTC 2015 action.check_0056156-140725012140409-oozie-oozi-W@pig-node1= Sat Jan 10 18:31:30 UTC 2015 ... ...
While the queue size is rarely the problem, Oozie’s setting for
the number of threads is rather conservative because Oozie cannot make
any assumptions about the hardware size and resources at its disposal.
In real production systems, users often bump the oozie.service.CallableQueueService.threads
from 10 to 50 or even 100 depending on the server capacity. For best
results, increasing the number of callable queue threads should also
be accompanied by increasing the Oozie server’s VM heap size and GC parameters. Closely related to the number of threads is the oozie.service.CallableQueueService.callable.concurrency
setting. Oozie’s callables have a
notion of a callable type. This setting controls the maximum
concurrency for any one callable type. The default of 3 means only 3
out of the 10 threads at any give time can be dedicated to any one
type of callable. You could potentially list and browse the queue and
understand the callable types and tune this concurrency number
accordingly. In most cases, just proportionally increasing this to go
with the thread count will suffice. For example, if you bump the
number of threads to 100, increase the concurrency to 30. There are
few more things to tune with the CallableQueueService, but these three
settings will get you over the performance hump in most deployments.
The RecoveryService
The other interesting service is the Oozie RecoveryService. This is also an internal
service, is not meant to be user facing, and has nothing to do with
user-level job recovery or reprocessing. As you can tell, Oozie is a
complicated distributed system that manages jobs on Hadoop, an even
more complex system. There are many signaling, notification, and
callback systems in place that Oozie leverages for dependency
management, data availability checks, and the like. It’s almost
inevitable that things will go wrong and notifications will be missed
or signals will be lost given all the moving parts in play. So Oozie
has implemented a recovery service, which keeps an eye on the jobs and
the queue and recovers actions and jobs that appear to be hung or lost
in space. The service itself runs every 60 seconds and looks for
actions older than the configured number of seconds.
Table 11-3 shows the interesting settings
that drive the recovery service. In real low-latency pipelines, it
might be worthwhile to tune these default numbers down so the recovery
happens quicker. Users sometimes complain about how the coordinator is
still in the RUNNING state for a few minutes even after the
corresponding workflow has completed successfully. If these delays
bother the user, the following settings are the ones they have to look
at closely.
| Setting | Default value | Description |
|---|---|---|
oozie.service.RecoveryService.interval | 60 | Interval at which the RecoveryService will run, in seconds. |
oozie.service.RecoveryService.wf.actions.older.than | 120 | Age of the actions which are eligible to be queued for recovery, in seconds. |
oozie.service.RecoveryService.coord.older.than | 600 | Age of the coordinator jobs or actions which are eligible to be queued for recovery, in seconds. |
oozie.service.RecoveryService.bundle.older.than | 600 | Age of the bundle which that are eligible to be queued for recovery, in seconds. |
Tip
The other thing to keep an eye on from a performance perspective is the database statistics and tuning. We can’t get into the details here (because a lot of it depends on the particular DB system chosen), but having a DBA tune the MySQL or Oracle server and optimize things like DB connections can have a big impact on Oozie’s performance.
Oozie High Availability
Oozie introduced high availability (HA) in version 4.1. The idea of the HA feature is to remove the single point of failure, which is the Oozie server. The Oozie server, as you might have noticed throughout this book, is stateless. It stores all state information in the database. When the server process or the server machine goes down, the existing jobs on Hadoop obviously continue to work, but all the new requests to the Oozie server will fail and not get processed. This is where an HA setup helps. In Oozie HA, another Oozie server or a bank of multiple Oozie servers can run in parallel and if one server is down, the system continues to work with the other server handling the requests. These servers work in a true hot-hot fashion and any server can handle any client request.
The multiple Oozie servers are usually fronted by a software load-balancer or a virtual IP or a DNS round-robin solution so that the Oozie CLI or the REST API can use a single address to access the server and the multiple HA servers are hidden behind it. Otherwise, if the clients were talking to one specific server in this HA setup, it would require code or configuration change to switch the server to another when that server fails. This is not desirable nor practical. Using a load-balancer type architecture means that Oozie HA has the added benefit of distributing the load across two or more servers in addition to being fault tolerant.
Oozie HA makes sense only if the database runs in a different machine than the Oozie server and also supports multiple, concurrent connections. The derby database that is shipped with Oozie by default does not work for HA, as it does not support multiple connections. If the crash of an Oozie server also takes down the DB, the Oozie system will be down regardless. That’s why it’s recommended that the DB runs on other machines and also runs in the database HA mode so the system does not have any single points of failure.
Oozie HA is built on top of Apache Zookeeper, which is an open source server that helps with distributed coordination and Apache Curator, which simplifies the use of Zookeeper. It’s beyond the scope of this book to get into the details of these systems.
Tip
Apache Zookeeper can be a complicated service to manage and maintain. It is another distinct piece of software that Oozie HA introduces into your environment and some readers may have concerns around that. We recommend that readers gain some working knowledge of Zookeeper if they are interested in running Oozie HA.
While most Oozie client calls are independent requests that can go
to any server and the server can respond after consulting the DB, the
oozie job –log presents some
interesting challenges in the HA mode. The Oozie logs are stored on the
server where the job runs. So if the -log request goes to a specific server, it may
or may not find the logs locally. It has to then talk to the other servers
to fetch the relevant logs. This feature is also implemented using
Zookeeper.
Caution
The other problem with -log is
this: what if the server with the logs is down or unreachable? This
scenario has not been handled yet in Oozie 4.1, and can only be solved
with a major change to Oozie’s logging subsystem in a future release. So
even with HA, be prepared to see some failures with -log if a server or two are down.
Given the stateless nature of the Oozie server, even in the non-HA mode, a crashed server can be brought back up with very limited loss of functionality except for the requests submitted during the time the server was down. The server can start from where it left off as long as it has access to the DB when it comes back up. There are several approaches to running a couple of Oozie servers in a hot-warm or a hot-cold setup with the DB server deployed on a different box that has been implemented successfully in various enterprises for fault tolerance. Readers are encouraged to understand and evaluate the various trade-offs before jumping all in and enabling Oozie HA.
Example 11-5 shows the required and optional configuration settings for enabling Oozie HA. These settings must be added to the oozie-site.xml file on all the Oozie servers running HA (refer to the Oozie documentation for more details on the HA setup).
Example 11-5. Oozie HA settings
<property>
<name>oozie.services.ext</name>
<value>
org.apache.oozie.service.ZKLocksService,
org.apache.oozie.service.ZKXLogStreamingService,
org.apache.oozie.service.ZKJobsConcurrencyService,
org.apache.oozie.service.ZKUUIDService
</value>
</property>
...
<property>
<name>oozie.zookeeper.connection.string</name>
<value>localhost:2181</value>
</property>
...
<property>
<name>oozie.zookeeper.namespace</name>
<value>oozie</value>
</property>
...
<property>
<name>oozie.base.url</name>
<value>http://my.loadbalancer.hostname:11000/oozie</value>
</property>
...
<property>
<name>oozie.instance.id</name>
<value>hostname</value>
</property>Debugging in Oozie
Debugging Oozie can be a challenge at times. While Hadoop itself is
notoriously complicated when it comes to debugging and error logging,
Oozie adds another layer on top and manages jobs through a launcher. New
users often find this confusing as most Hadoop actions redirect their
stdout/stderr to the launcher mapper,
but those actions also run their own MapReduce jobs.
In reality, tracking down the job logs is not that hard once users get comfortable with Oozie’s execution model, but there is a steep learning curve. Hopefully, this book in general and this section in particular helps clarify and simplify things. The Oozie web UI actually has rich content when it comes to monitoring, though some users may complain that it takes to many clicks and windows to get to the required information. But at least everything is there.
The landing page of the Oozie UI has status information on all the
jobs with the focus being on the workflow Jobs tab by default. Users can click and switch to the
coordinator or bundle tab and see those jobs as well. This gives a nice overview
of all the jobs running in the system. This information is similar to what
users can see with oozie job –info (as
covered in “Oozie CLI Tool”). This UI also has the System Info
tab (as explained in “The oozie-site.xml File”). Let’s look at the
job information. Figure 11-2 shows the main Oozie
UI.
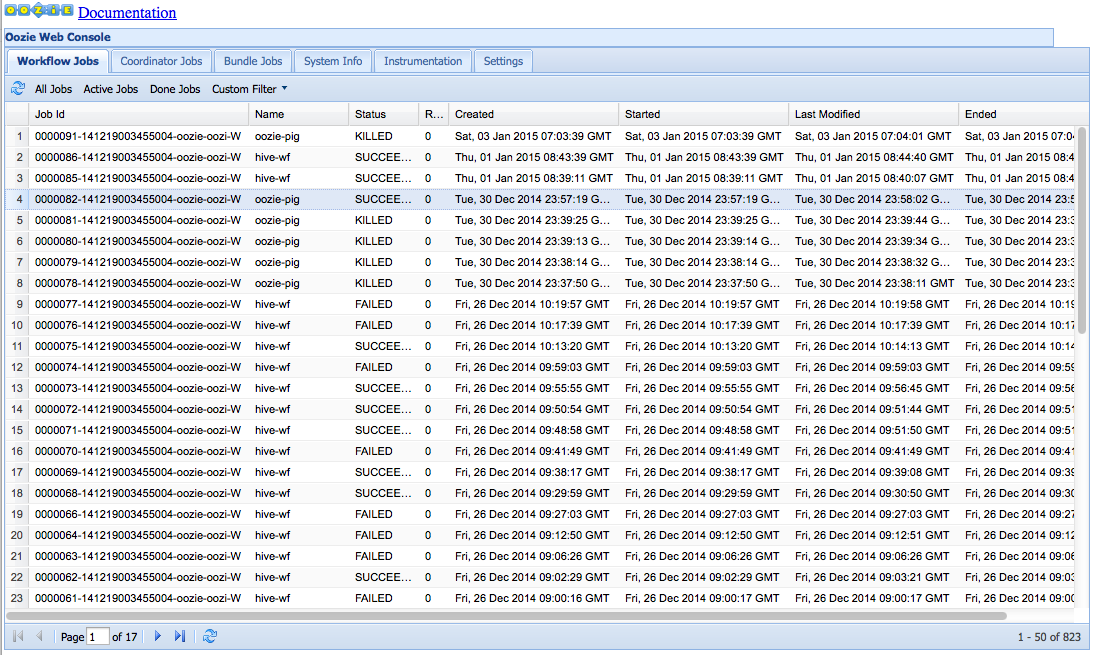
Figure 11-2. Job status
All jobs are clickable, and clicking on a workflow brings up a window with more interesting information. In this page, you are seeing all the information concerning this workflow job. You see the status of all the actions that make up this workflow. You can also see the Job Definition and Job Configuration tabs, which capture the workflow.xml and job.properties, respectively. This is very convenient, as users have all job-related information in one place. The Job Log tab has Oozie-level job logging and might not be too useful for debugging Hadoop jobs. And the Job DAG tab captures the workflow DAG in a visual fashion. This UI is captured in Figure 11-3 with the main action highlighted.
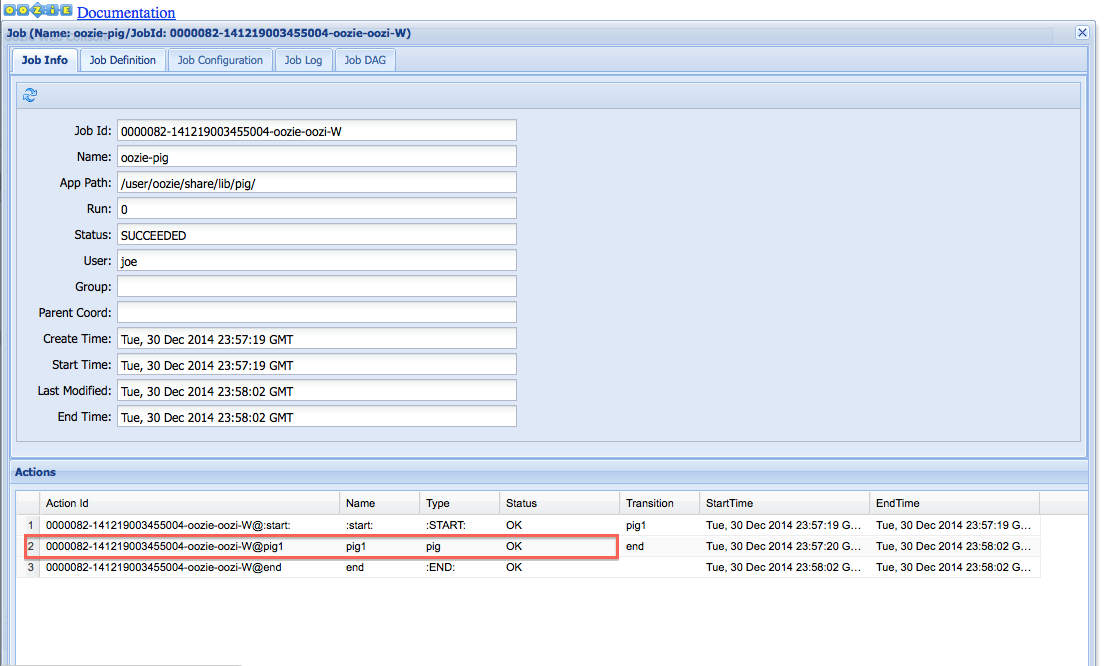
Figure 11-3. Workflow job details
The individual workflow actions are also clickable, and by clicking on the specific action, you get to the most useful action logs. The action-specific UI is captured in Figure 11-4.

Figure 11-4. Workflow action details
The Console URL is our window into action-level debugging. That’s
the URL that takes us to the launcher mapper on the Hadoop ResourceManager
(RM), the JobTracker (JT), or the Hadoop Job History Server (JHS) if the
job has already completed. You can get to the launcher mapper by clicking
on the lens icon highlighted in Figure 11-4.
Once you are on the Hadoop UI, then the normal Hadoop log analysis begins.
What we need to look at is the log of the single map task (launcher
mapper) corresponding to this job. Both stdout and stderr are captured in those logs.
In the same Action UI, we can see
a Child Job URLs tab, which contains the Hadoop job URLs for all the child
MapReduce jobs that the launcher kicks off to execute the actual action,
whether it is Hive, Pig, or something else. Clicking on the lens icon in
this UI also takes us to the corresponding Hadoop UI for the job. Users
should look at both the launcher mapper logs and the logs for the actual
MapReduce job(s) spawned for the action as part of debugging. Figure 11-5 shows the child URL for an example
action.

Figure 11-5. Action child URL
Basically, debugging a Hadoop action might involve debugging two (or more) Hadoop jobs, and users can use the Oozie UI as the starting point to get to them. This UI also has all the information about the bundle, coordinator, workflow, action, job properties, and so on. Users should get comfortable navigating through all this information on the Oozie UI and that will make debugging job failures a lot easier.
Oozie Logs
In “Debugging in Oozie”, we saw how to get to all the job and action information. In
this section, we will see where to find Oozie-level logs on the server.
All the Oozie server-side logs can be found under the <INSTALLATION_DIR>/logs/ subdirectory.
The main server log is called oozie.log and it gets rotated hourly. The
instrumentation log covered in “Oozie Instrumentation and Metrics”
is another useful resource and it gets rotated daily. The catalina.* files capture the web-server-level
logging and can come in handy for problems related to the Tomcat web
server. Following is a sample ls from
the logs/ directory showing some of
the key logs, both current and rotated logs:
$ ls catalina.2015-01-09.log catalina.out oozie-instrumentation.log.2015-01-09 oozie-instrumentation.log oozie.log-2015-01-10-20 oozie.log-2015-01-10-21 oozie.log
Tip
The Oozie logs are also available via the CLI command oozie job –log and the Oozie web UI. Those
logs are just filtered versions of the oozie.log file sent to the client for the
particular job ID(s).
Developing and Testing Oozie Applications
Given the complexity of deploying and debugging Oozie applications, coming up with an efficient develop-test-debug process is very important. Following are some recommendations on how to approach development of Oozie applications (some of these are just best practices and common sense tips, and you will do well to incorporate these into your development processes):
Develop Oozie applications in an incremental fashion. It might be too much to expect to write a workflow with 15 actions and test and get it running in one shot. Start with the first action and make sure it works via the workflow. Then expand incrementally.
Detach Oozie job development from the individual action development. It is a bad idea to debug Hive and Pig issues via Oozie workflows. Make sure you first develop the Hive or Pig code separately and get it working before trying to put it into an Oozie workflow. It is extremely inefficient to write a brand-new Hive or Pig script and test it through Oozie for the first time. It’s a lot easier to catch simple Hive and Pig errors using their respective CLI clients.
Expanding on the previous suggestion, when you are developing bundles with many coordinators interconnected by data dependencies or complex workflows with many fork/joins, it might be better to make sure the Oozie application logic works as intended before adding complex, long-running actions. In other words, build the shell of your Oozie application with fake actions and see if the control flow works the way you want it to. A simple shell action that just does an
echo Hellois often good enough to test the Oozie parts of your application. You can then replace these fake shell actions with real actions.Develop your job XMLs using an XML editor instead of a text editor. Use the
validateanddryrunoptions of the Oozie CLI liberally to catch simple errors.Write scripts to automate simple steps during development and testing. For example, every time you change your workflow XML, your script could run a validate command, remove the existing file/dir from HDFS, and copy the new file/directory to HDFS and run the app (if that’s required). Forgetting to copy the files to HDFS is a common oversight that costs users many minutes during every iteration.
Parameterize as much as possible. This makes the jobs very flexible and saves time during testing. For example, if you are developing a bundle and have to run it many times to test and fix during development, parameterize the
kick-off-timecontrol setting. This saves you time because you don’t have to reload the bundle XML to HDFS every time just for changing thekick-off-time. It can and should be controlled externally, outside the XML, using parameterization.
Application Deployment Tips
As you know, Oozie applications are deployed to HDFS. There are not a whole lot of rules on how the deployment should look except for a couple of conventions that we’ve already covered in the book. For instance, the workflow, coordinator, and bundle specification files are usually named a certain way and are under the application root directory. The job JARs are usually deployed under the lib/ subdirectory under the app root and get added to the CLASSPATH automatically. Other than these, there are not a whole lot of rules. New Oozie users always have many questions like whether the bundle, coordinator, and workflow files should be at the top level under the app root directory or should they be under multiple nested directory levels.
We can make it work with any deployment structure we choose, but certain organizing principles are recommended. Ideally, all files can be at the top level for simple bundles with just a handful of files. If the bundle is complex with many coordinators and if each coordinator in turn has many workflows with many JARs, it may be better to organize them in separate multilevel directories to reduce clutter. There may also be cases where the same coordinator might be part of different bundles and the same workflows may be part of different coordinators. Also, JARs are often shared between multiple workflows. For these scenarios, it’s important that we don’t duplicate and copy files and directories all over HDFS. So a mix of central directories at the top level for the shared components and nested directories for nonshared components will work well. These layouts are captured in Figure 11-6.

Figure 11-6. Application deployment on HDFS
Common Errors and Debugging
In this section, we cover some common errors and give various tips and solutions. We hope this section will save you some time by being a quick reference guide for some of the common mistakes we have seen repeated on Oozie.
Tip
A lot of the Oozie-level errors that the server throws are usually E0710 or E0701. You will see these errors in the Oozie UI and these errors usually mean it’s not a Hadoop issue, but something in the Oozie system.
Hive action and/or DistCp action doesn’t
work: Oozie’s out-of-the-box workflow actions are segregated as core actions and action
extensions. The extension actions are <hive>, <shell>, <email>, <distcp>, and <sqoop>; they are all enabled by default
on most recent Oozie deployments. But if you do see strange errors
running these extension actions, make sure the following setting is
enabled in oozie-site.xml (you can
check this on the Oozie UI as well, like we saw in “The oozie-site.xml File”):
<property>
<name>oozie.service.ActionService.executor.ext.classes</name>
<value>
org.apache.oozie.action.email.EmailActionExecutor,
org.apache.oozie.action.hadoop.HiveActionExecutor,
org.apache.oozie.action.hadoop.ShellActionExecutor,
org.apache.oozie.action.hadoop.SqoopActionExecutor,
org.apache.oozie.action.hadoop.DistcpActionExecutor
</value>
</property>
<property>
<name>oozie.service.SchemaService.wf.ext.schemas</name>
<value>
shell-action-0.1.xsd,shell-action-0.2.xsd,email-action-0.1.xsd,
hive-action-0.2.xsd,hive-action-0.3.xsd,hive-action-0.4.xsd,
hive-action-0.5.xsd,sqoop-action-0.2.xsd,sqoop-action-0.3.xsd,
ssh-action-0.1.xsd,ssh-action-0.2.xsd,distcp-action-0.1.xsd,
oozie-sla-0.1.xsd,oozie-sla-0.2.xsd
</value>
</property>Some actions work, others don’t:
The Hive query or DistCp works fine on the command line and the
workflow XML looks perfect, but the action still fails. This could be a
library issue, so make sure the following setting to use the sharelib is set to true in your job.properties file (you might see a JA018 error in the Oozie UI for this
issue):
oozie.use.system.libpath=true
Workflow XML schema errors: Always be aware of the XML schema version and features. When you see errors like the one shown here, check the schema:
Error: E0701 : E0701: XML schema error, cvc-complex-type.2.4.a:
Invalid content was found starting with element 'global'. One of
'{"uri:oozie:workflow:0.3":credentials, "uri:oozie:workflow:0.3":start}'
is expected.Issues with the <global>
section: The example error previously shown relates to support for
the <global> section. It’s only
supported in workflow XML version 0.4 or higher, as shown here:
<workflow-app xmlns="uri:oozie:workflow:0.4" name="my-test-wf">
Also, with some of the extension actions like hive or shell, the <global> section might not work.
Remember that the action definitions have their own schema version as
well and confirm that you are using supported features both at the
workflow level and the action level.
Schema version errors with action types: The action schema versions are different and often a lower number than the workflow schema version. Sometimes, users cut and paste the same version from the workflow header and that may not be the right version number. If you see the following error with a Hive action for instance, you should check the version number (it is probably too high):
Error: E0701 : E0701: XML schema error, cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be found for element 'hive'.
Syntax error with the HDFS
scheme: Another annoyingly common error is a typo and syntax
error in the workflow.xml or the
job.properties file while
representing the HDFS path URIs. It is usually represented as ${nameNode}/${wf_path} and users often end up
with a double slash (//) following
the NameNode in the URI. This could
be because the NameNode variable has
a trailing / or the path variable has
a leading / or both. But read the
error messages closely and catch typos and mistakes with the URI. For
instance, you will see the following error message if the job.properties file has a typo in the
workflow app root path:
Error: E0710 : E0710: Could not read the workflow definition, File does not exist: //user/joe /oozie/my_wf/workflow.xml
Workflow is in a perpetual RUNNING
state: You see that all the actions in a workflow have completed
either successfully or with errors including the end states (end or kill), but the workflow is not exiting and is
hung in the RUNNING state. This can
happen if you have a typo or a syntax error in the aforementioned end
states. This usually happens due to some error in the message section in
the kill node as shown here:
<kill name="fail">
<message>Hive failed, error message[${$$wf:errorMessage
(wf:lastErrorNode())}]</message>
</kill>Workflow action is running long after the
completion of its launcher mapper: Most of the workflow
actions utilize a map-only Hadoop job (called launcher
mapper) to launch the actual action. In some instances, users
might find that the launcher mapper has completed successfully according
to the ResourceManager or the JobTracker UI. However, the corresponding
action in the Oozie UI might still be in a running state long after the
launcher mapper has finished. This inconsistency can exist for as long
as 10 minutes. In other words, the subsequent actions in the workflow
might not be launched for 10 minutes. The possible reason for this delay
is some issue with Hadoop’s callback that Oozie uses to get the status
of the launcher mapper. More specifically, the root cause can be Hadoop
not being able to invoke the callback just after the launcher mapper
finishes or Oozie missing the Hadoop callback. The more common reason is
Hadoop missing the callback due to security/firewall or other reasons. A
quick check on the ResourceManager or JobTracker log will show the root
cause. Oozie admins can also decrease the value of the oozie.service.ActionCheckerService.action.check.delay
property from the default 600 seconds to 180 seconds or so in oozie-site.xml. This property determines the
interval between two successive status checks for any outstanding
launcher mappers. The reduction of this interval will definitely reduce
the duration of the inconsistency between Oozie and the RM/JT. But it
will also increase the load on the Oozie server due to more frequent
checks on Hadoop. Therefore, it should only be used as an interim
solution while the root cause is found and ultimately fixed.
MiniOozie and LocalOozie
There are ways to test and verify Oozie applications locally in a development environment instead of having to go to a full-fledged remote server. Unfortunately, these testing frameworks are not very sophisticated, well maintained, or widely adopted. So users have not had great success with these tools and these approaches may never substitute real testing against a real Oozie server and a Hadoop cluster. But it might still be worthwhile to try to get it working for your application. These approaches should work at least for simple workflows and coordinators:
- MiniOozie
Oozie provides a
junittest class called MiniOozie for users to test workflow and coordinator applications. IDEs like Eclipse and IntelliJ can directly import the MiniOozie Maven project. Refer to the test case in the Oozie source tree under minitest/src/test/java for an example of how to use MiniOozie. MiniOozie usesLocalOozieinternally.- LocalOozie
We can think of LocalOozie as embedded Oozie. It simulates an Oozie deployment locally with the intention of providing an easy testing and debugging environment for Oozie application developers. The way to use it is to get an
Oozieclientobject from a LocalOozie class and use it like a normal Java Oozie API client.
Tip
Another alternative when it comes to testing and debugging is to run an Oozie server locally against a pseudodistributed Hadoop cluster and test everything on one machine. We do not recommend spending too much time trying to get these approaches working if you bump into issues.
The Competition
You might wonder what other products are available for solving the problem of job scheduling and workflow management for Hadoop. Oozie is not the only player in this field and we briefly introduce a few other products in this section. The overall consensus in the Hadoop community is that these alternatives are not as feature-rich and complete as Oozie, though they all have their own strengths and do certain things well. Most of these products do not have the same widespread adoption and community support that Oozie enjoys. The list is by no means exhaustive or complete:
- Azkaban
The product that’s closest to Oozie in terms of customer adoption is Azkaban, an open source batch workflow scheduler created at LinkedIn. It has a lot of usability features and is known for its graphical user interface.
- Luigi
Spotify’s Luigi is another open source product that supports workflow management, visualization, and building complex pipelines on Hadoop. It’s known for its simplicity and is written in Python.
- HAMAKE
Hadoop Make or HAMAKE is a utility that’s built on the principles of dataflow programming. It’s client-based and is supposed to be lightweight.
A thorough comparison and analysis of these products are beyond the scope of this book. We do believe Oozie’s rich feature set, strong user community, and solid documentation set it apart, but we encourage you to do your own research on these products if interested. Oozie is often accused of being complex and having a steep learning curve, and we hope this book helps address that particular challenge.