
Chapter 2. Oozie Concepts
This chapter covers the basic concepts behind the workflow, coordinator, and bundle jobs, and how they relate to one another. We present a use case for each one of them. Throughout the book, we will elaborate on these concepts and provide more detailed examples. The last section of this chapter explains Oozie’s high-level architecture.
Oozie Applications
In Unix, the /bin/echo file is
an executable. When we type /bin/echo
Hello in a terminal session, it starts a process that prints
Hello. Oozie applications are analogous
to Unix executables, and Oozie jobs are analogous to Unix processes. Oozie users
develop applications, and one execution of an application is called a
job.
Note
Throughout the book, unless explicitly specified, we do not differentiate between applications and jobs. Instead, we simply call them a workflow, a coordinator, or a bundle.
Oozie Workflows
An Oozie workflow is a multistage Hadoop job. A workflow is a collection of action and control nodes arranged in a directed acyclic graph (DAG) that captures control dependency where each action typically is a Hadoop job (e.g., a MapReduce, Pig, Hive, Sqoop, or Hadoop DistCp job). There can also be actions that are not Hadoop jobs (e.g., a Java application, a shell script, or an email notification).
The order of the nodes in the workflow determines the execution
order of these actions. An action does not start until the previous action in the
workflow ends. Control nodes in a workflow are used to manage the
execution flow of actions. The start and end control
nodes define the start and end of a workflow. The
fork and join control nodes
allow executing actions in parallel. The decision
control node is like a switch/case
statement that can select a particular execution path within the
workflow using information from the job itself. Figure 2-1 represents an example workflow.
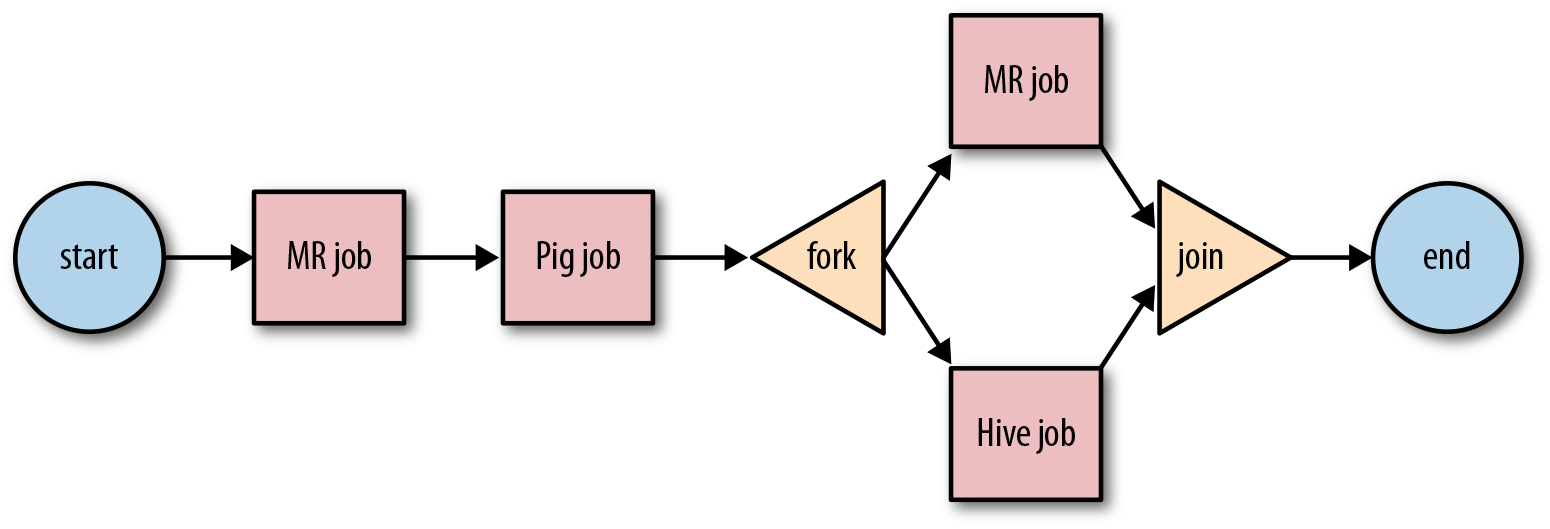
Figure 2-1. Oozie Workflow
Note
Because workflows are directed acyclic graphs, they don’t support loops in the flow.
Workflow use case
For this use case, we will consider a site for mobile applications that keeps track of user interactions collecting the timestamp, username, and geographic location of each interaction. This information is written to log files. The logs files from all the servers are collected daily. We would like to process all the logs for a day to obtain the following information:
ZIP code(s) for each user
Interactions per user
User interactions per ZIP code
First, we need to convert geographic locations into ZIP codes.
We do this using a to-ZIP MapReduce
job that processes the daily logs. The input data for the job is
(timeStamp, geoLocation, userName).
The map phase converts the geographic location into ZIP code and emits
a ZIP and username as key and 1 as value. The intermediate data of the
job is in the form of (ZIP + userName,
1). The reduce phase adds up and emits all the occurrences
of the same ZIP and username key. Each output record of the job is
then (ZIP, userName,
interactions).
Using the (ZIP, userName,
interactions) output from the first job, we run two
additional MapReduce jobs, the user-ZIPs job and user-interactions job.
The map phase of the user-ZIPs job emits (userName, ZIP) as intermediate data. The
reduce phase collects all the ZIP codes of a userName in an array and emits (userName, ZIP[]).
For the user-interactions
job, the map phase emits (userName,
1) as intermediate data. The reduce phase adds up all the
occurrences for the same userName
and emits (userName,
number-of-interactions).
The to-ZIP job must run
first. When it finishes, we can run the user-ZIPs and the user-interactions MapReduce jobs. Because
the user-ZIPs and user-interactions jobs do not depend on each
other, we can run both of them in parallel.
Figure 2-2 represents the daily-logs-workflow just described.
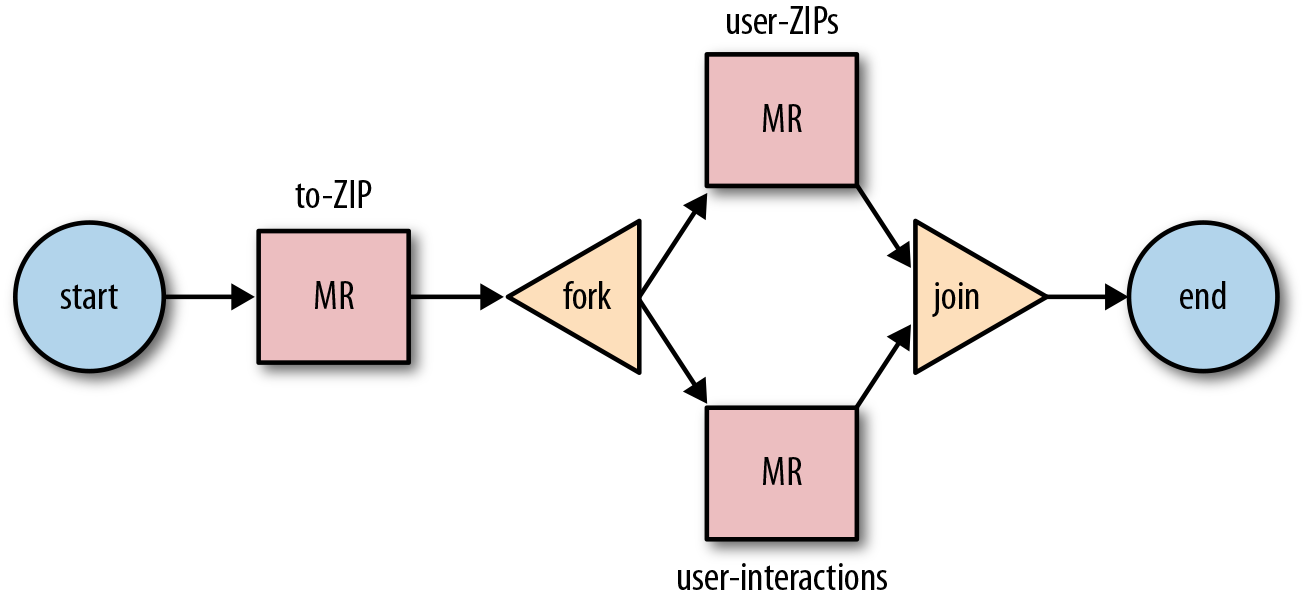
Figure 2-2. The daily-logs-workflow Oozie workflow
Oozie Coordinators
An Oozie coordinator schedules workflow executions based on a start-time and a frequency parameter, and it starts the workflow when all the necessary input data becomes available. If the input data is not available, the workflow execution is delayed until the input data becomes available. A coordinator is defined by a start and end time, a frequency, input and output data, and a workflow. A coordinator runs periodically from the start time until the end time, as shown in Figure 2-3.
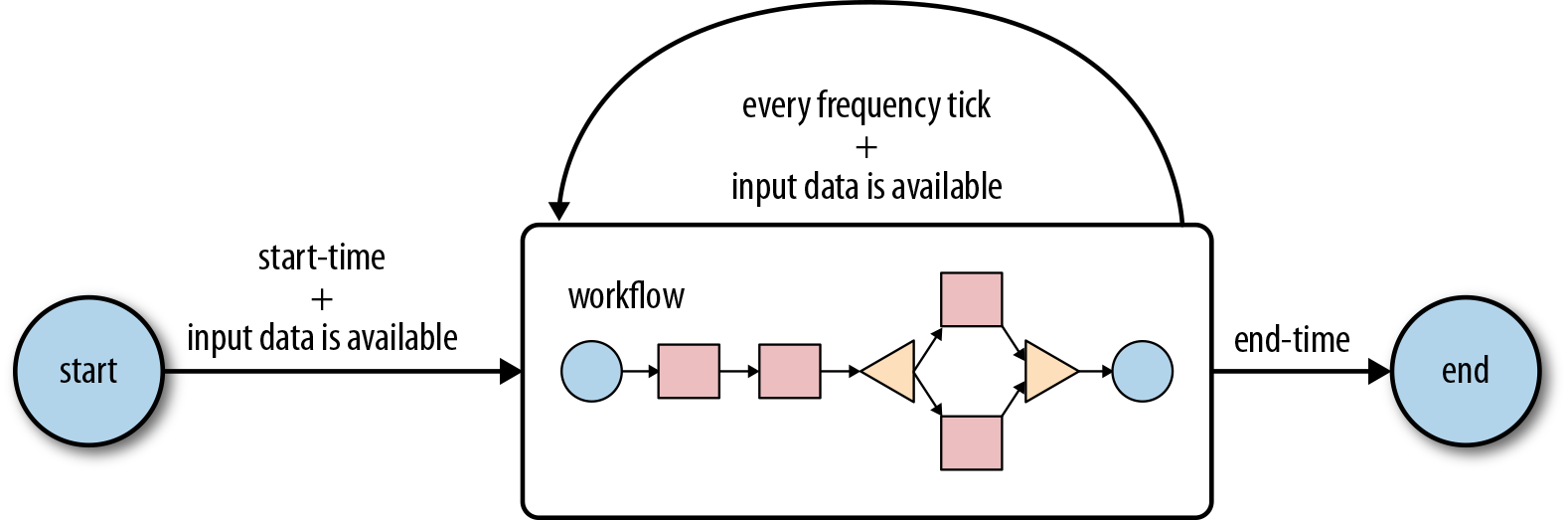
Figure 2-3. Lifecycle of an Oozie coordinator
Beginning at the start time, the coordinator job checks if the required input data is available. When the input data becomes available, a workflow is started to process the input data, which on completion, produces the corresponding output data. This process is repeated at every tick of the frequency until the end time of the coordinator job. If the input data is not available for a workflow run, the execution of the workflow job will be delayed until the input data becomes available. Normally, both the input and output data used for a workflow execution are aligned with the coordinator time frequency. Figure 2-4 shows multiple workflow jobs run by a coordinator job based on the frequency.

Figure 2-4. An Oozie coordinator job
It is possible to configure a coordinator to wait for a maximum amount of time for the input data to become available and timeout if the data doesn’t show up.
If a coordinator does not define any input data, the coordinator job is a time-based scheduler, similar to a Unix cron job.
Coordinator use case
Building on the “Workflow use case”, the
daily-logs-workflow needs to run on
a daily basis. It is expected that the logs from the previous day are
ready and available for processing at 2:00 a.m.
To avoid the need for a manual submission of the daily-logs-workflow every day once the log
files are available, we use a coordinator job, the daily-logs-coordinator job.
To process all the daily logs for the year 2013, the coordinator job must run every day at 2:00 a.m., starting on January 2, 2013 and ending on January 1, 2014.
The coordinator defines an input data dependency on logs files:
rawlogs. It produces three datasets as output data: zip_userName_interactions, userName_interactions, and userName_ZIPs. To differentiate the input
and output data that is used and produced every day, the date of the
logs is templatized and is used as part of the input data and output
data directory paths. For example, every day, the logs from the mobile
site are copied into a rawlogs/YYYYMMDD/ directory. Similarly, the
output data is created in three different directories: zip_userName_interactions/YYYYMMDD/,
userName_interactions/YYYYMMDD/,
and userName_ZIPs/YYYYMMDD/. For
both the input and the output data, YYYYMMDD is the day of the logs
being processed. For example, for May 24, 2013, it is 20130524.
When the daily-logs-coordinator job is running and
the daily rawlogs input data is
available at 2:00 a.m. of the next day, the workflow is started
immediately. However, if for any reason the rawlogs input data is not available at 2:00
a.m., the coordinator job will wait until the input data becomes
available to start the workflow that processes the logs. If the daily
rawlogs are not available for a few
days, the coordinator job keeps track of all the missed days. And when
the rawlogs for a missing day shows
up, the workflow to process the logs for the corresponding date is
started. The output data will have the same date as the date of the
input data that has been processed. Figure 2-5 captures some of these
details.

Figure 2-5. daily-logs-coordinator Oozie coordinator
Oozie Bundles
An Oozie bundle is a collection of coordinator jobs that can be started, stopped, suspended, and modified as a single job. Typically, coordinator jobs in a bundle depend on each other. The Output data produced by a coordinator job becomes input data for other coordinator jobs. These types of interdependent coordinator jobs are also called data pipelines.
Bundle use case
We will extend the “Coordinator use case” to explain the concept of a bundle. Specifically, let’s assume that in addition to the daily processing, we need to do a weekly and a monthly aggregation of the daily results.
For this aggregation, we use an aggregator-workflow workflow job that takes
three different inputs for a range of dates: zip_userName_interactions, userName_interactions, and userName_ZIPs.
The weekly aggregation is done by the weekly-aggregator-coordinator coordinator
job with a frequency of one week that aggregates data from the
previous week.
The monthly aggregation is done by the monthly-aggregator-coordinator coordinator
job with a frequency of one month that aggregates data from the
previous month.
We have three coordinator jobs: daily-logs-coordinator, weekly-aggregator-coordinator, and monthly-aggregator-coordinator. Note that we
are using the same workflow application to do the reports aggregation.
We are just running it using different date ranges.
A logs-processing-bundle
bundle job groups these three coordinator jobs. By running the bundle
job, the three coordinator jobs will run at their corresponding
frequencies. All workflow jobs and coordinator jobs are accessible and
managed from a single bundle job.
This logs-processing-bundle
bundle job is also known as a data pipeline job.
Parameters, Variables, and Functions
Most jobs running on a regular basis are parameterized. This is very typical for Oozie jobs. For example, we may need to run the same workflow on a daily basis, each day using different input and output directories. In this case, we need two parameters for our job: one specifying the input directory and the other specifying the output directory.
Oozie parameters can be used for all type of Oozie jobs: workflows, coordinators, and bundles. In “A Simple Oozie Job”, we specified the parameters for the job in the job.properties file used to submit the job:
nameNode=hdfs://localhost:8020
jobTracker=localhost:8032
exampleDir=${nameNode}/user/${user.name}/ch01-identity
oozie.wf.application.path=${exampleDir}/appIn “Oozie Coordinators”, we saw a coordinator that triggers a daily workflow to process the logs from the previous day. The coordinator job needs to pass the location of the logs to process for the corresponding day to each workflow. This is done using parameters as well.
Variables allow us to use the job parameters within the application definition. For example, in “A Simple Oozie Job”, the MapReduce action uses the three parameters of the job to define the cluster URIs as well as the input and output directories to use for the job:
...
<action name="identity-MR">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${exampleDir}/data/output"/>
</prepare>
<configuration>
...
<property>
<name>mapred.input.dir</name>
<value>${exampleDir}/data/input</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${exampleDir}/data/output</value>
</property>
</configuration>
</map-reduce>
...
</action>
...In addition to variables, Oozie supports a set of functions that can be used to carry out sophisticated logic
for resolving variable values during the execution of the Oozie job. For
example, the ${wf:id()} function
resolves to the workflow job ID of the current job. The
${hadoop:counters('identity-MR')}
function returns the counters of the MapReduce job run by the
identity-MR action. We cover these
functions in detail in Chapters 5, 6, and 7.
Application Deployment Model
An Oozie application is comprised of one file defining the logic of the application plus other files such as configuration and JAR files and scripts. A workflow application consists of a workflow.xml file and may have configuration files, Pig scripts, Hive scripts, JAR files, and more. Coordinator applications consist of a coordinator.xml file. Bundle applications consist of a bundle.xml file.
Tip
In most of our examples, we use the filename workflow.xml for the workflow definition.
Although the default filename is workflow.xml, you can choose a different name
if you wish. However, if you use a different filename, you’ll need to
specify the full path including the filename as the workflow app path
in job.properties. In
other words, you can’t skip the filename and only specify the directory.
For example, for the custom filename my_wf.xml, you would need to define oozie.wf.application.path=${exampleDir}/app/my_wf.xml. The same convention is true for
coordinator and bundle filenames.
Oozie applications are organized in directories, where a directory contains all files for the application. If files of an application need to reference each other, it is recommended to use relative paths. This simplifies the process of relocating the application to another directory if and when required. The JAR files required to execute the Hadoop jobs defined in the action of the workflow must be included in the classpath of Hadoop jobs. One basic approach is to copy the JARs into the lib/ subdirectory of the application directory. All JAR files in the lib/ subdirectory of the application directory are automatically included in the classpath of all Hadoop jobs started by Oozie. There are other efficient ways to include JARs in the classpath and we discuss them in Chapter 9.
Oozie Architecture
Figure 2-6 captures the Oozie architecture at a very high level.

Figure 2-6. Oozie server architecture
When Oozie runs a job, it needs to read the XML file defining the application. Oozie expects all application files to be available in HDFS. This means that before running a job, you must copy the application files to HDFS. Deploying an Oozie application simply involves copying the directory with all the files required to run the application to HDFS. After introducing you to all aspects of Oozie, additional advice is given in “Application Deployment Tips”.
The Oozie server is a Java web application that runs in a Java servlet container. By default,
Oozie uses Apache Tomcat,
which is an open source implementation of the Java servlet
technology. Oozie clients, users, and other applications interact with the
Oozie server using the oozie
command-line tool, the Oozie Java client API, or the Oozie HTTP REST API.
The oozie command-line tool and the Oozie Java API ultimately use the Oozie HTTP REST API to communicate with the Oozie
server.
The Oozie server is a stateless web application. It does not keep any user or job information in memory between user requests. All the information about running and completed jobs is stored in a SQL database. When processing a user request for a job, Oozie retrieves the corresponding job state from the SQL database, performs the requested operation, and updates the SQL database with the new state of the job. This is a very common design pattern for web applications and helps Oozie support tens of thousands of jobs with relatively modest hardware. All of the job states are stored in the SQL database and the transactional nature of the SQL database ensures reliable behavior of Oozie jobs even if the Oozie server crashes or is shut down. When the Oozie server comes back up, it can continue to manage all the jobs based on their last known state.
Oozie supports four types of databases: Derby, MySQL, Oracle, and PostgreSQL. Oozie has built-in purging logic that deletes completed jobs from the database after a period of time. If the database is properly sized for the expected load, it can be considered maintenance-free other than performing regular backups.
Within the Oozie server, there are two main entities that do all the
work, the Command and the ActionExecutor classes.
A Command executes a well-defined task—for example, handling the submission of a
workflow job, monitoring a MapReduce job started from a workflow job, or
querying the database for all running jobs. Typically, commands perform a
task and produce one or more commands to do follow-up tasks for the job.
Except for commands executed directly using the Oozie HTTP REST API, all
commands are queued and executed asynchronously. A queue consumer executes
the commands using a thread pool. By using a fixed thread pool for
executing commands, we ensure that the Oozie server process is not
stressed due to a large number of commands running concurrently. When the
Oozie server is under heavy load, the command queue backs up because
commands are queued faster than they can be executed. As the load goes
back to normal levels, the queue depletes. The command queue has a maximum
capacity. If the queue overflows, commands are dropped silently from the
queue. To handle this scenario, Oozie has a background thread that
re-creates all dropped commands after a certain amount of time using the
job state stored in the SQL database.
There is an ActionExecutor for
each type of action you can use in a workflow (e.g., there
is an ActionExecutor for MapReduce
actions, and another for Pig actions). An ActionExecutor knows how to start, kill,
monitor, and gather information about the type of job the action handles.
Modifying Oozie to add support for a new type of action in Oozie requires
implementing an ActionExecutor and a
Java main class, and defining the XML syntax for the action (we cover this
topic in detail in Chapter 10).
Given this overview of Oozie’s concepts and architecture, you should now feel fairly comfortable with the overall idea of Oozie and the environment in which it operates. We will expand on all of these topics as we progress through this book. But first, we will guide you through the installation and setup of Oozie in the next chapter.