
Chapter 6. Oozie Coordinator
In the previous two chapters, we covered the Oozie workflow in great detail. In addition to the workflow, Oozie supports another abstraction called the coordinator that schedules and executes the workflow based on triggers. We briefly introduced the coordinator in Chapter 2. In this chapter, we will cover the various aspects of the Oozie coordinator in a comprehensive fashion using real-life use cases. We present multiple scenarios to demonstrate how the Oozie coordinator can be utilized to trigger workflows based on time. We also describe the various operational knobs that the coordinator provides to control the execution of the workflow. We will get into the data availability–based workflow trigger in Chapter 7.
Coordinator Concept
As described in Chapter 5, an Oozie workflow can be invoked manually and on demand using the Oozie command-line interface (CLI). This is sufficient for a few basic use cases. However, for most of the practical use cases, this is inadequate and very difficult to manage. For instance, consider a scenario where a workflow needs to be started based on some external trigger or condition. In other words, as soon as some predefined condition or predicate is satisfied, the corresponding workflow should be executed. For example, we could have a requirement to run the workflow every day at 2 a.m. It is very hard to achieve this behavior using just the CLI and basic scripting. There are two main reasons for this:
The specification of multifaceted predicates (such as time and data dependency) can often get very complex.
The scheduling of workflows based on such predicates is a challenging task.
Oozie coordinator helps handle these trigger-based workflow executions. First, Oozie provides a flexible framework to specify the triggers or predicates. Second, it schedules the workflow based on those predefined triggers. In addition, it enables administrators to monitor and control the workflow execution depending on cluster conditions and application-specific restrictions.
Triggering Mechanism
As of now, the Oozie coordinator supports two of the most common triggering mechanisms, namely time and data availability. These triggering mechanisms allow recurrent and interdependent workflow executions that can create an implied data pipeline application.
Time Trigger
Time-based triggers are easy to explain and resembles the Unix cron utility. In a time-aware coordinator, a workflow is executed at fixed intervals or frequency. A user typically specifies a time trigger in the coordinator using three attributes:
- Start time (ST)
Determines when to execute the first instance of the workflow
- Frequency (F)
- End time (ET)
Bounds the last execution start time (i.e., no new execution is permitted on or after this time)
In other words, the first execution occurs at the ST and subsequent executions occur at (ST + F), (ST + 2F), (ST + 3F) , and so on until the ET is reached.
Data Availability Trigger
Workflow jobs usually process some input data and produce new output data. Therefore, it is very common to hold off the workflow execution until all of the required input data becomes available. For instance, you want to execute a workflow at 1 a.m., but you also want to make sure the required input data is available before the workflow starts. You ideally want the job to wait even past 1 p.m. if any of the input data is missing.
The Oozie coordinator supports a very flexible data dependency–based triggering framework. It is important to note that the concept of data availability–based scheduling is a little more involved than time-based triggering. Therefore, we introduce the concept here but explain data triggers in detail in Chapter 7.
Coordinator Application and Job
A coordinator application is a template to define the triggers or predicates to launch a workflow. In particular, it has three components: triggers (time and/or data triggers), a reference to the workflow to be launched, and the workflow execution parameters. Coordinator applications are usually parameterized to allow flexibility. When a coordinator application is submitted to Oozie with all its parameters and configurations, it is called a coordinator job. A coordinator application can be submitted multiple times with the same or different parameters that create multiple and independent coordinator jobs. As explained in “Oozie Applications”, Oozie executes coordinator jobs whereas users write coordinator applications.
Coordinator Action
A coordinator job regularly creates/materializes a new coordinator action for each time instance based on its start time and frequency. For example, if a coordinator job has a start time of January 1, 2014, and an end time of December 31, 2014, with a frequency of one day, there will be a total of 365 actions, one created each day. More importantly, the coordinator action actually checks for data availability and ultimately submits the workflow.
Our First Coordinator Job
In this section, we describe a basic coordinator job that is very similar to a
Unix cron job. This example introduces the common terminologies and
concepts of a time-triggered coordinator job. As mentioned earlier, the
time-triggered coordinator launches the workflow starting from the
start time and continuously launches
one at every predefined interval (a.k.a. frequency) until it reaches the end time. In this example, we want to execute
the identity-WF (explained in Chapter 1) daily starting from 2 a.m., January 1, 2014 to
2 a.m., December 31, 2014. That means the first coordinator action will
start at 2014-01-01T02:00Z, the
second instance will start at 2014-01-02T02:00Z, and the last instance at
2014-12-31T02:00Z. Each of these time
instances is called the nominal time
of that specific action. In other words, each coordinator action must
have a nominal time. Here’s the formal XML definition of such a
coordinator:
<coordinator-app name="my_first_coord_job" start="2014-01-01T02:00Z "
end=“2014-12-31T02:00Z" frequency="1440" timezone="UTC"
xmlns="uri:oozie:coordinator:0.4">
<action>
<workflow>
<app-path>${appBaseDir}/app/</app-path>
<configuration>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>exampleDir</name>
<value>${appBaseDir}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>Tip
Nominal time specifies when a workflow execution should ideally start. For various reasons, it might not start on time but the nominal time of that coordinator action is unchanged regardless of when the workflow actually starts. In our example, nominal time for the first coordinator action is 2014-01-01T02:00Z and for the second action is 2014-01-02T02:00Z, irrespective of their actual execution time. It’s important that you have a clear understanding of nominal time.
For ease of explanation, we artificially divide the above coordinator XML into two segments: specification of the trigger(s) and definition of the triggered workflow. The first segment primarily describes the triggering conditions including both time and data dependencies.
As mentioned earlier, there are three main attributes required to
specify a coordinator job. The start
time defines when to start the execution and the value could
be some time in the future or some time from the past. The end time defines the time when a coordinator
should stop the creation of new coordinator actions. Both start and end
times are defined in a combined date and time format as defined
by ISO
8601. The frequency of the job is 1,440 minutes or one day.
Although the default unit of coordinator frequency is minutes, there are
other convenient ways to specify the frequency using EL functions that
we describe in “Parameterization of the Coordinator”. More
specifically, for daily jobs, we recommend you use ${coord:days(1)} instead of 1,440 minutes for
frequency.
In addition, there are two other self-explanatory attributes that
are not directly related to the triggering mechanism. The first
attribute is name with value my_first_coord_job that can later be used for
querying Oozie. The second attribute is xmlns, which specifies the coordinator
namespace used for coordinator XML versioning. The namespace plays a
critical role in ensuring backward compatibility of the coordinator. For
example, the new/updated features added for namespace oozie:coordinator:0.4 might break or modify
the functionality of a coordinator written with an older namespace
(e.g., oozie:coordinator:0.3).
Alternatively, if you want to use some of the new/updated features, the
new namespace should be used.
The next segment of the coordinator XML specifies what type of job to execute when the triggering conditions are met. As of now, Oozie coordinator only supports launching Oozie workflows and a coordinator application can only include one workflow application. In the future, the scope could be extended to other types of jobs as well.
The workflow tag here is the same as the one we used to define a standalone submission in “A Simple Oozie Job”. coordinator uses these values to parameterize and automate the workflow submission as we do with any standalone workflow submission. The main difference is in the representation. In a standalone workflow execution, we typically use a property file in key-value format, though the XML syntax is also supported. But for the workflow execution via a coordinator, we have to define it inline in XML format. In both cases, these key-value pairs are passed to the workflow at its start.
It is important to note that the propagation of coordinator
properties down to the workflow is not automatic; you need to define and
specify these key value pairs under <action> configuration. As shown in the
example, we specify app-path to
point to the workflow application path, whereas in a standalone
CLI-based workflow submission we define the property oozie.wf.application.path in the property file to specify the same thing. The rest of the
parameters are optional and defined as configuration properties. The
properties defined in this example are similar to the properties
defined in “A Simple Oozie Job”.
Coordinator Submission
There are multiple ways to submit a coordinator. In this section, we only
explain job submission using the oozie CLI.
Other approaches are described later in Chapter 11. At first, we will need to create a local
properties file (say job.properties) and pass this filename during
submission as an argument to the CLI:
$ cat job.properties
nameNode=hdfs://localhost:8020
jobTracker=localhost:8032
appBaseDir=${nameNode}/user/${user.name}/ch06-first-coord
oozie.coord.application.path=${appBaseDir}/appIn addition, we will need to upload the coordinator job definition to HDFS. It primarily includes the job’s XML definition (i.e., coordinator.xml):
$ hdfs dfs -put ch06-first-coord/ . $ hdfs dfs -ls -R ch06-first-coord/ drwxr-xr-x - joe supergroup 0 2014-03-29 12:24 ch06-first-coord/app -rw-r--r-- 1 joe supergroup 705 2014-03-29 12:24 ch06-first-coord/app/ coordinator.xml -rw-r--r-- 1 joe supergroup 2141 2014-03-29 12:24 ch06-first-coord/app/ workflow.xml drwxr-xr-x - joe supergroup 0 2014-03-29 12:24 ch06-first-coord/data drwxr-xr-x - joe supergroup 0 2014-03-29 12:24 ch06-first-coord/data/ input -rw-r--r-- 1 joe supergroup 25 2014-03-29 12:24 ch06-first-coord/data/ input/input.txt
Tip
Similar to the workflow XML convention explained in “Application Deployment Model”, the coordinator definition file doesn’t have to be named coordinator.xml. Using different names allows users to host multiple definitions in one directory, which has more of a practical value for coordinators than workflows.
The command in Example 6-1 submits the coordinator and returns a coordinator job ID if successful. The subsequent commands show the most common operations that users typically run for monitoring and managing the coordinator jobs through the Oozie CLI.
Example 6-1. Running and managing coordinator jobs
$ export OOZIE_URL=http://localhost:11000/oozie $ oozie job -run -config job.properties job: 0000003-140329120933279-oozie-joe-C $ oozie job -info 0000003-140329120933279-oozie-joe-C Job ID : 0000003-140329120933279-oozie-joe-C -------------------------------------------------------------------------------- Job Name : my_first_coord_job App Path : hdfs://localhost:8020/user/joe/ch06-first-coord/app Status : RUNNING Start Time : 2014-01-01 02:00 GMT End Time : 2014-12-31 02:00 GMT Pause Time : - Concurrency : 1 -------------------------------------------------------------------------------- ID Status Ext ID Err Code Created Nominal Time 0000003-140329120933279-oozie-joe-C@1 SUCCEEDED 0000004-140329120933279- oozie-joe-W - 2014-03-29 23:14 GMT 2014-01-01 02:00 GMT -------------------------------------------------------------------------------- 0000003-140329120933279-oozie-joe-C@2 SUCCEEDED 0000005-140329120933279- oozie-joe-W - 2014-03-29 23:16 GMT 2014-01-02 02:00 GMT -------------------------------------------------------------------------------- $ oozie job -info 0000003-140329120933279-oozie-joe-C@1 ID : 0000003-140329120933279-oozie-joe-C@1 -------------------------------------------------------------------------------- Action Number : 1 Console URL : - Error Code : - Error Message : - External ID : 0000004-140329120933279-oozie-joe-W External Status : - Job ID : 0000003-140329120933279-oozie-joe-C Tracker URI : - Created : 2014-03-29 23:14 GMT Nominal Time : 2014-01-01 02:00 GMT Status : SUCCEEDED Last Modified : 2014-03-29 23:15 GMT First Missing Dependency : - -------------------------------------------------------------------------------- $ oozie job -kill 0000003-140329120933279-oozie-joe-C $ oozie job -info 0000003-140329120933279-oozie-joe-C Job ID : 0000003-140329120933279-oozie-joe-C -------------------------------------------------------------------------------- Job Name : my_first_coord_job App Path : hdfs://localhost:8020/user/joe/ch06-first-coord/app Status : KILLED Start Time : 2014-01-01 02:00 GMT End Time : 2014-12-31 02:00 GMT Pause Time : - Concurrency : 1 -------------------------------------------------------------------------------- ID Status Ext ID Err Code Created Nominal Time 0000003-140329120933279-oozie-joe-C@1 SUCCEEDED 0000004-140329120933279- oozie-joe-W - 2014-03-29 23:14 GMT 2014-01-01 02:00 GMT -------------------------------------------------------------------------------- 0000003-140329120933279-oozie-joe-C@2 SUCCEEDED 0000005-140329120933279- oozie-joe-W - 2014-03-29 23:16 GMT 2014-01-02 02:00 GMT --------------------------------------------------------------------------------
Tip
Upon successful submission, Oozie returns a unique coordinator
job ID. Each coordinator ID has a -C at the end. At the start time for this
job, Oozie initiates the creation of the coordinator action. Oozie
also assigns an ID for each new action. coordinator action IDs are
generated by concatenating the coordinator job ID, the @ sign, and a sequentially incrementing
action number. For example, if the coordinator job ID is 0000003-140329120933279-oozie-joe-C, the
first two action IDs will be 0000003-140329120933279-oozie-joe-C@1
and
0000003-140329120933279-oozie-joe-C@2.
Oozie Web Interface for Coordinator Jobs
Oozie provides a basic, read-only user interface for coordinator jobs very similar to what it provides for workflows and bundles. Users can click on the Coordinator Jobs tab on the Oozie web interface at any time. It displays the list of recent coordinator jobs in a grid-like UI as shown in Figure 6-1. This UI captures most of the useful information about the coordinator jobs. The last column titled Next Materialization shows the nominal time for the next coordinator action to be materialized for any running coordinator job.
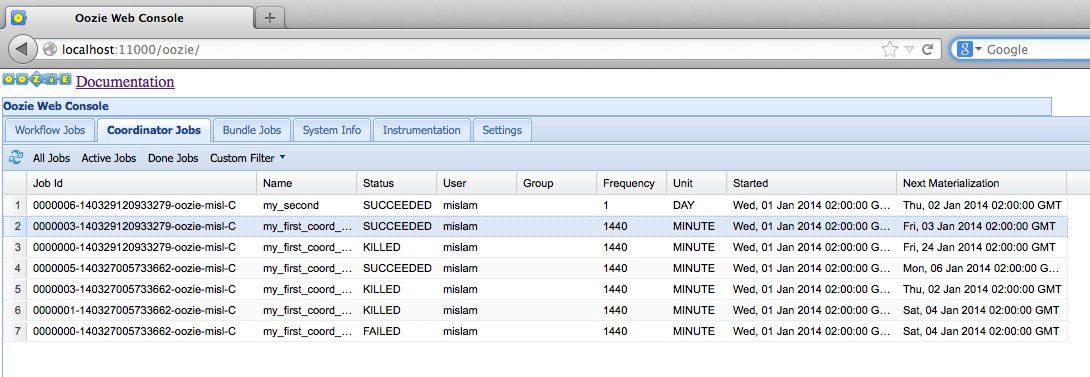
Figure 6-1. Oozie web interface for coordinator jobs
Users can drill down into a specific coordinator job by clicking on the row of that job. This will display a new window presenting the details of that coordinator job, as shown in Figure 6-2. As you can see, there are four tabs: Coord Job Info, Coord Job Definition, Coord Job Configuration, and Coord Job Log. You can select any of these tabs as necessary (the Coord Job Info tab is displayed by default). The first tab shows the current job status, including all the spawned coordinator actions listed in the bottom half of the window. Users can click on the reload icon located at the top-left of the window to refresh the contents. The second tab, Coord Job Definition, displays the original coordinator XML that you submitted.
All of the configuration settings passed as part of the CLI and the properties file are displayed in the third tab (the Coord Job Configuration tab). The fourth tab shows the Oozie log generated for this specific coordinator job. Since coordinator jobs typically create a lot of coordinator actions, they tend to be long running and the logs may be huge. It can take a long time to load all the logs from the Oozie backend. That’s why it is better to retrieve only the logs for a subset of coordinator actions. For this purpose, there is a “Retrieve log” button where the user can specify a set of coordinator action numbers such as “1,2” or “1-3,” and so on. This will ensure that Oozie retrieves the logs only for those actions.
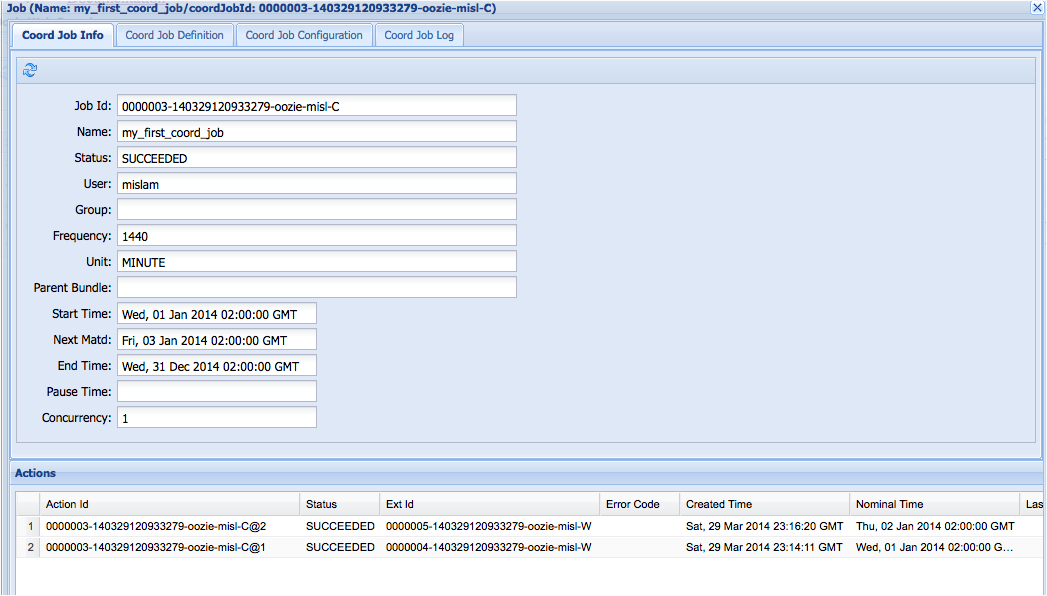
Figure 6-2. Oozie web interface for coordinator jobs
From the first tab (Coord Job Info) of the coordinator job window, users can further drill down to the corresponding workflow by clicking on the row of the coordinator action. This displays the workflow window shown in Figure 6-3. This window is essentially the same as the one explained in “A Simple Oozie Job”.
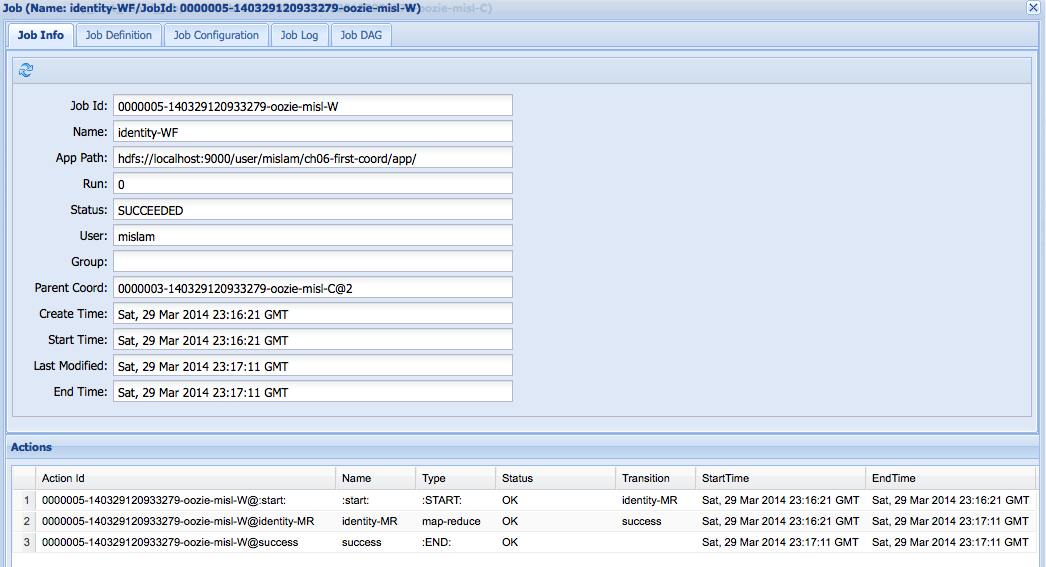
Figure 6-3. A workflow job launched by coordinator
Coordinator Job Lifecycle
So far we have discussed the details of coordinator jobs and how to submit and manage them. In this section, we will briefly describe the internals of a coordinator job’s execution. In particular, we describe the different states that a coordinator job goes through beginning with its submission. This will help users understand the various statuses shown at different stages of job execution and then act accordingly.
The main function of a coordinator job is to create (materialize) a coordinator action for a specific time instance (nominal time). coordinator jobs often run from the start time to the end time and materialize new coordinator actions periodically.
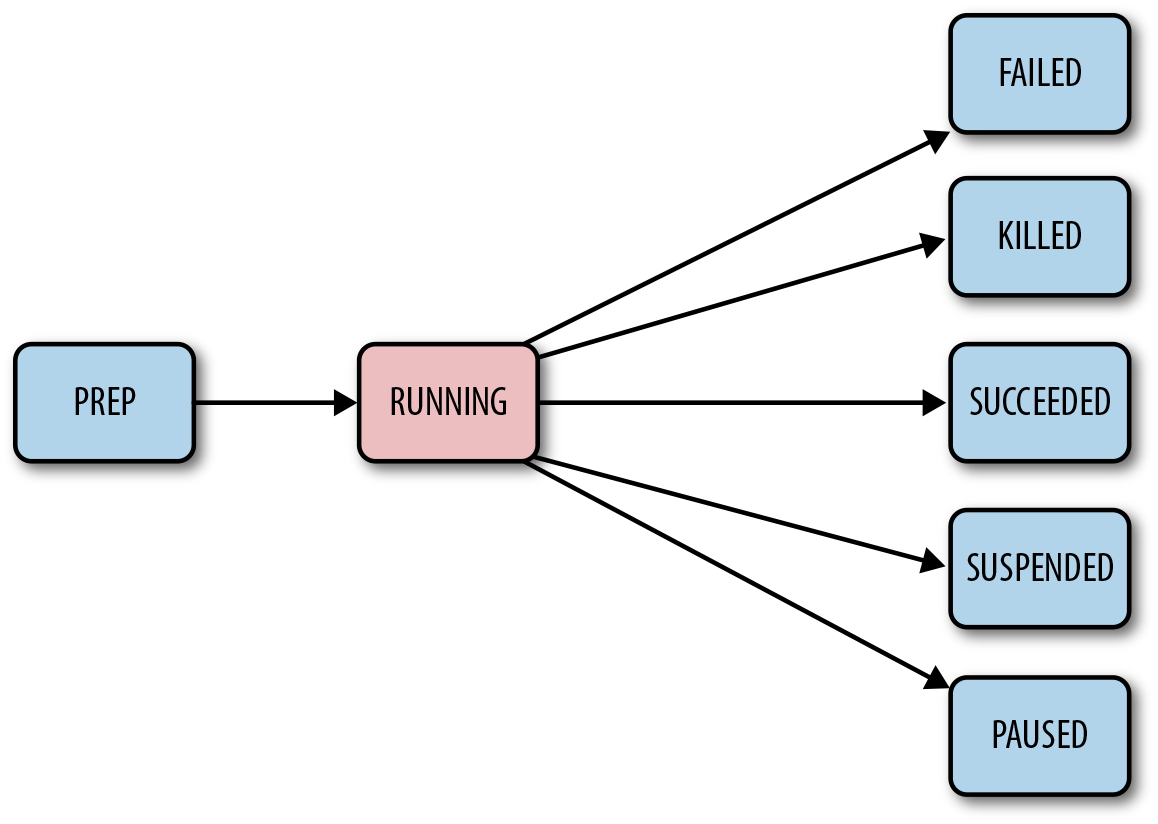
Figure 6-4. Coordinator job lifecycle
When a coordinator job is submitted to the Oozie service, Oozie
parses the coordinator XML and validates the configurations. After that,
Oozie returns a coordinator job ID and puts the job in PREP state. Because the coordinator job might have a future start time,
Oozie keeps the job in PREP state until it reaches the start time. As
shown in Figure 6-4, Oozie moves the job
into the RUNNING state as soon as the
start time is reached. In the RUNNING state, Oozie
continuously materializes coordinator actions if and when the nominal time
is reached. The coordinator job generally spends most of its time in the
RUNNING state from the start to its end
time. Users can suspend or pause the coordinator at any time for
operational reasons or otherwise, and that moves the job’s state to SUSPENDED or
PAUSED, respectively.
The final state of a coordinator job depends on the states of all
the spawned coordinator actions. For example, if and when all coordinator
actions are materialized and all actions complete successfully, Oozie
moves the job to the SUCCEEDED state.
Likewise, if all the actions end up in the FAILED state, the
coordinator job also moves to the FAILED state. Figure 6-4 shows the basic transition diagram.
The actual transitions are much more complex: if one of the coordinator
actions fails, times out, or is killed as the job is still running, Oozie
moves the job from RUNNING to RUNNING_WITH_ERROR. Similarly, there are other states such as DONE_WITH_ERROR,
SUSPENDED_WITH_ERROR, and PAUSED_WITH_ERROR. Also, it’s possible to
explicitly kill a coordinator job in any state, which transitions the job
to the KILLED state.
Coordinator Action Lifecycle
As mentioned earlier, a coordinator job creates or materializes a coordinator action for a specific time instance (a.k.a. nominal time). The coordinator action waits until the dependent data (if any) is available and then submits the actual workflow. In this section, we briefly describe the different coordinator action states and their transitions.
When a coordinator job materializes a coordinator action, Oozie
assigns the action to the WAITING state. In
this initial state, the action waits for any dependent data for the
duration of the timeout period (configurable and described in “Execution Controls”). If any of the dependent data is still
missing after the timeout period, Oozie transitions the action to
the TIMEDOUT state. On
the other hand, if all the data become available, Oozie moves the action’s
state to READY. At this state, Oozie enforces the throttling mechanism as
defined by the concurrency setting. This setting specifies the maximum
number of coordinator actions of a coordinator job that can run
simultaneously. If the action fits under the concurrency constraint, Oozie
just transfers the action to the SUBMITTED state. This
is when Oozie submits the corresponding workflow. Figure 6-5 captures all the important state
transitions.
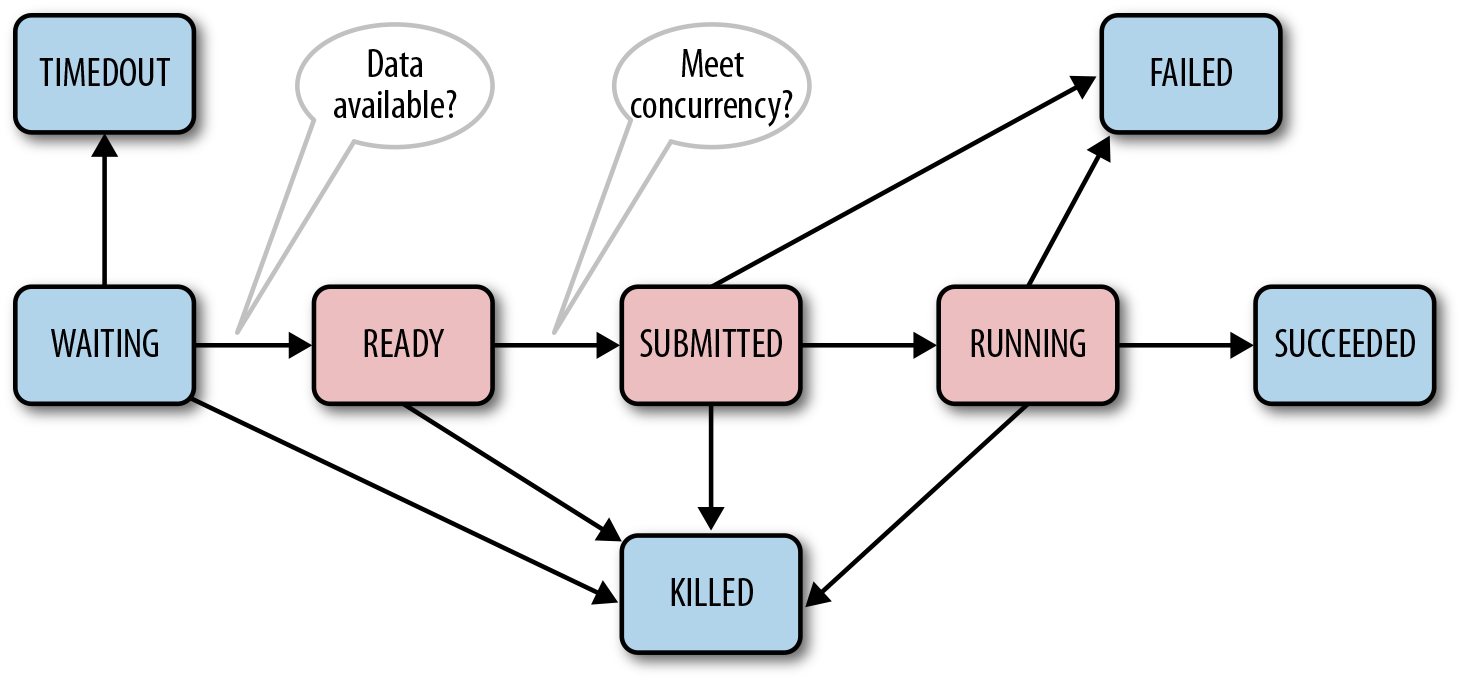
Figure 6-5. Coordinator action lifecycle
If the submission fails, Oozie moves the action to the FAILED state.
Otherwise, it moves it to the RUNNING state and
waits for the workflow to finish. At this stage, the state of the workflow
dictates the state of the corresponding coordinator action. More
specifically, depending on whether the workflow fails, succeeds, or gets
killed, Oozie transitions the state of the coordinator action to FAILED, SUCCEEDED, or KILLED, respectively. A user can kill a
coordinator action at any state and that transitions the action to the
KILLED state.
Parameterization of the Coordinator
The coordinator XML can be parameterized using the same techniques we discussed in “Parameterization” for the workflow. It supports both variable and function parameters in exactly the same way as seen before. In this section, we explain time- and frequency-related EL functions. We explain other EL functions as needed in subsequent sections.
EL Functions for Frequency
In “Our First Coordinator Job”, we used frequency="1440"
for daily jobs. This frequency was expressed in minutes. However, there
are some scenarios where frequencies can’t be easily expressed in
absolute minutes. For example, a frequency of one day may not always
translate to 24 hours. Some days could be 23 hours or 25 hours due to
Daylight Saving Time. Similarly, every month does not correspond to 30
days. It could be anything between 28 and 31 days. To help you handle
these intricacies easily, Oozie provides a set of functions to define
the frequency. We strongly encourage you to utilize those functions
instead of using absolute value in minutes.
In a nutshell, the advantages of using Oozie-defined EL functions include:
Transparent handling of Daylight Saving Time
Makes the application portable across time zones
Easy handling of Daylight Saving Time or any time-related policy changes in various countries
Day-Based Frequency
Oozie provides two EL functions to specify day-based frequencies. The first one, coord:days(N), means the number of minutes in
N days. The second one, coord:endOfDays(N), means the same thing as
coord:days(N). The only difference is
that endOfDays shifts the first
occurrence to the end of the day and then adds N days to get the next occurrence. Table 6-1 explains the different scenarios.
| EL function | Start time | Time zone | In minutes | First instance | Second instance |
|---|---|---|---|---|---|
| days(1) | 2014-01-01T08:00Z | UTC | 1440 | 2014-01-01T08:00Z | 2014-01-02T08:00Z |
| days(2) | 2014-01-01T08:00Z | America/Los_Angeles | 1440 X 2 | 2014-01-01T08:00Z | 2014-01-03T08:00Z |
| days(1) | 2014-03-08T08:00Z | UTC | 1440 | 2014-03-08T08:00Z | 2014-03-09T08:00Z |
| days(1) | 2014-03-08T08:00Z | America/Los_Angeles | 1380 | 2014-03-08T08:00Z | 2014-03-09T07:00Z |
| days(2) | 2014-03-08T08:00Z | America/Los_Angeles | 1380 +1440 | 2014-03-08T08:00Z | 2014-03-10T07:00Z |
| endOfDays(1) | 2014-01-01T08:00Z | UTC | 1440 | 2014-01-02T00:00Z | 2014-01-03T00:00Z |
| endOfDays(1) | 2014-01-01T08:00Z | America/Los_Angeles | 1440 | 2014-01-01T08:00Z | 2014-01-02T08:00Z |
| endOfDays(1) | 2014-01-01T09:00Z | America/Los_Angeles | 1440 | 2014-01-02T08:00Z | 2014-01-03T08:00Z |
| endOfDays(1) | 2014-03-07T09:00Z | America/Los_Angeles | 1380 | 2014-03-08T08:00Z | 2014-03-09T08:00Z |
Month-Based Frequency
Any month-based frequency also has its own issues similar to a day-based frequency. These include:
Number of days in a month is not a constant, but changes month to month. It also depends on whether the year is a leap year or not.
Number of hours in the individual days of a month might not be the same due to Daylight Saving Time.
There are two month-based EL functions for frequency. coord:months(N)
returns the number of minutes in N months starting from the current nominal
time. coord:endOfMonths(N) is
very similar to coord:months(N). The difference is that endOfMonths()
first moves the current nominal time to the end of this month
and then calculates the number of minutes for N months from that point. Table 6-2 demonstrates the various scenarios with real values.
| EL function | Start time | Time zone | In minutes | First instance | Second instance |
|---|---|---|---|---|---|
| months(1) | 2014-01-01T08:00Z | UTC | 1440 x 31 | 2014-02-01T08:00Z | 2014-02-01T08:00Z |
| months(2) | 2014-01-01T08:00Z | America/Los_Angeles | 1440 X (31 +28) | 2014-03-01T08:00Z | 2014-03-01T08:00Z |
| months(1) | 2014-03-01T08:00Z | UTC | 1440 x 31 | 2014-04-01T08:00Z | 2014-04-01T08:00Z |
| months(1) | 2014-03-01T08:00Z | America/Los_Angeles | 1440 x 30 + 1380 | 2014-04-01T07:00Z | 2014-04-01T08:00Z |
| endOfMonths(1) | 2014-01-01T08:00Z | UTC | 1440 x 31 | 2014-02-01T00:00Z | 2014-03-01T00:00Z |
| endOfMonths(1) | 2014-01-01T08:00Z | America/Los_Angeles | 1440 x 31 | 2014-01-01T08:00Z | 2014-02-01T08:00Z |
Execution Controls
A coordinator job continuously creates coordinator actions until it reaches the end time. In an ideal situation, a coordinator job will have only one active coordinator action in Oozie at any give time. Let’s assume that each action completes before the nominal time of the next action under normal processing conditions. However, there are still many circumstances that result in a lot of coordinator actions being concurrently active in the system. Let’s call this a “backlog,” which could occur for the following reasons:
- Delayed data
When any dependent data for a coordinator is not available, Oozie has to wait. This could build up a backlog.
- Reprocessing
It is very common to rerun the job after its original start time due to either bad input data or a bug in the processing logic. This reprocessing scenario could cause a significant backlog.
- Late submission
Users could submit the coordinator job late for various practical reasons. The size of the backlog of coordinator actions in such situations depends on how late the submission was. The system might take a long time to catch up to the current processing time depending on various factors.
Whatever the root cause is, this backlog creates potential system
instability for Oozie, as well as the Hadoop services. In particular, each
active coordinator action increases the load on Oozie and Hadoop system
resources, such as the database, memory, CPU, and the NameNode. To address
these catch-up scenarios, Oozie provides four control parameters for any
coordinator. Having a good understanding of the coordinator action
lifecycle explained in “Coordinator Action Lifecycle”
will help you comprehend the control parameters explained here:
throttleA coordinator job periodically creates coordinator actions. Therefore, if we can regulate this materialization, the ultimate number of outstanding actions can be controlled. Oozie provides a user-level control knob called
throttle, which a user can specify in her coordinator XML. This controls how many maximum coordinator actions can be in theWAITINGstate for a coordinator job at any instant. If no value is specified, the system default value of 12 is used. While a user can specify any value for this, there is also a system-level upper limit that an administrator can tune. This system-level limit is calculated by multiplying the throttling factor (propertyoozie.service.coord.materialization.throttling.factor) and the maximum internal processing queue size (propertyoozie.service.CallableQueueService.queue.size) defined in oozie-site.xml. In short, this setting can be tuned both at the system and the user level through the oozie-site.xml and coordinator XML, respectively.timeoutWhile
throttlerestricts how many actions can be in theWAITINGstate,timeoutenforces how long each coordinator action can be inWAITING. Likethrottle, there are both user- and system-level limits to thetimeoutvalue. A user can specify atimeoutin minutes in the coordinator XML. If notimeoutvalue is specified, Oozie defaults to 7 days. In addition, Oozie enforces the maximum value that a user can specify for thetimeout. Oozie system administrators can specify this using the propertyoozie.service.coord.default.max.timeoutin oozie-site.xml. The default maximumtimeoutis 60 days.execution orderIf there are multiple actions in the
READYstate, Oozie needs to determine which workflow to submit first. Thisexecutionknob specifies which order Oozie should follow. There are three possible values:FIFO,LIFO, andLAST_ONLY. The default isFIFO(First in First Out), which means start the earliest action first. TheLIFO(Last In First Out) asks Oozie to execute the latest action first.LAST_ONLYmeans execute only the last one and discard the rest.
Caution
As of the time of writing this book, FIFO is the only fully tested option.
concurrencyThis dictates how many coordinator actions of a job can run simultaneously. It restricts the maximum number of actions that can be in the
RUNNINGstate for a coordinator job at the same time. In other words, it regulates the transition from theREADYstate to theRUNNINGstate of a coordinator action. This setting primarily impacts the load on the Hadoop cluster. The default value is 1. A value of -1 means infinite.
An Improved Coordinator
Our initial example (“Our First Coordinator Job”) was very
simple and straightforward. In Example 6-2,
we extend it with more parameterization and by adding the <controls> section.
Example 6-2. Improved coordinator
<coordinator-app name="my_second" start="${startTime}" end="${endTime}"
frequency="${coord:days(1)}" timezone="UTC"
xmlns="uri:oozie:coordinator:0.4">
<controls>
<timeout>${my_timeout}</timeout>
<concurrency>${my_concurrency}</concurrency>
<execution>${execution_order}</execution>
<throttle>${materialization_throttle}</throttle>
</controls>
<action>
<workflow>
<app-path>${appBaseDir}/app/</app-path>
<configuration>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>exampleDir</name>
<value>${appBaseDir}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>$ cat job.properties
nameNode=hdfs://localhost:8020
jobTracker=localhost:8032
appBaseDir=${nameNode}/user/${user.name}/ch06-second-coord
startTime=2014-01-01T02:00Z
endTime=2014-12-31T02:00Z
my_timeout=60
my_concurrency=2
execution_order=FIFO
materialization_throttle=5
oozie.coord.application.path=${appBaseDir}/app
$ hdfs dfs -put ch06-second-coord .
$ hdfs dfs -ls -R ch06-second-coord
drwxr-xr-x - joe supergroup 0 2014-03-29 16:46 ch06-second-coord/app
-rw-r--r-- 1 joe supergroup 914 2014-03-29 16:46 ch06-second-coord/app/
coordinator.xml
-rw-r--r-- 1 joe supergroup 2141 2014-03-29 16:46 ch06-second-coord/app/
workflow.xml
drwxr-xr-x - joe supergroup 0 2014-03-29 16:48 ch06-second-coord/data
drwxr-xr-x - joe supergroup 0 2014-03-29 16:46 ch06-second-coord/data/input
-rw-r--r-- 1 joe supergroup 25 2014-03-29 16:46 ch06-second-coord/data/
input/input.txt
drwxr-xr-x - joe supergroup 0 2014-03-29 16:48 ch06-second-coord/data/output
-rw-r--r-- 3 joe supergroup 0 2014-03-29 16:48 ch06-second-coord/data/
output/_SUCCESS
-rw-r--r-- 3 joe supergroup 31 2014-03-29 16:48 ch06-second-coord/data/
output/part-00000
$ oozie job –run –config job.properties
<COORDINATOR-JOB ID>In this chapter, we covered the basic concepts of the coordinator with a primary focus on time-based triggers. The next chapter will continue to dig deeper into the coordinator framework with a focus on data dependencies.