
Chapter 7. Data Trigger Coordinator
In Chapter 6, we primarily discussed how Oozie materialized coordinator actions at periodic intervals and subsequently executed the workflow. In other words, we only considered the time-based trigger to start workflows. However, time is not the only dependency that determines when to launch a workflow for many use cases. A common use case is to wait for input data. If a workflow is started before its required data is available, the workflow execution will either produce wrong results or fail. The Oozie coordinator allows users to express both data and time dependency together and to kick off the workflow accordingly. There are many diverse use cases based on data dependency that poses serious challenges to the design of the coordinator. In this chapter, we explain how to express both data and time dependency in a coordinator and how Oozie manages the workflow executions.
Expressing Data Dependency
It’s important to understand the three terms, dataset, input-events, and output-events, that Oozie uses to describe data
dependencies in a coordinator XML.
Dataset
A dataset is a logical entity to represent a set of data produced by an application. A user can define a dataset either using its directory location or using metadata. Oozie has always supported directory-based data dependency. Recently, Oozie introduced metadata-based data dependency as well. This book primarily focuses on the directory-based dataset, as that’s the most commonly used approach. The metadata-based dependency will be covered later, in “HCatalog-Based Data Dependency”.
Furthermore, the data in a dataset can be produced in two ways:
In a fixed interval
Ad hoc/random, without following any time pattern
In Oozie, the dataset produced in regular frequency is called synchronous and the dataset produced randomly is known as asynchronous. Oozie currently supports only the synchronous datasets, so this is the type we will focus on in this chapter. We will explore an approach to handle asynchronous datasets later in “Emulate Asynchronous Data Processing”. In a nutshell, a dataset in Oozie is a template to represent a set of directory-based data produced at fixed time intervals.
Defining a dataset
There are five attributes to define a dataset in Oozie:
nameThis specifies the logical name of a dataset. There can be more than one dataset in a coordinator. The name of a dataset must be unique within a coordinator.
initial-instanceThis specifies the first time instance of valid data in a dataset. This time instance is specified in a combined date and time format. Any reference to data earlier than this time is meaningless.
frequencyThis determines the interval of successive data instances. A user can utilize any EL functions mentioned in “Parameterization of the Coordinator” to define the frequency.
uri-templateThis specifies the template of the data directory in a dataset. The data directory of most batch systems often contains year, month, day, hour, and minute to reflect the effective data creation time. Oozie provides a few system-defined variables to specify the template. These are
YEAR,MONTH,DAY,HOUR, andMINUTE. These system variables are only valid in defininguri-template. During execution, Oozie replaces these using the timestamp of a specific dataset instance.Tip
In a synchronous dataset, every data instance is associated with a time instance. For example, if the time instance of a dataset is
2014-07-15T10:25Z, the variablesYEAR,MONTH,DAY,HOUR, andMINUTEwill be replaced with2014,07,15,10, and 25, respectively. However, it’s not required to utilize all these system variables to define auri-template.done-flagThis specifies the filename that is used to indicate whether the data is ready to be consumed. This file is used as a signal to prevent the dependent process from starting too early with only partial data as input. The
done-flagis optional and defaults to_SUCCESSif it’s not specified. Usually, a Hadoop MapReduce job creates a zero-size file called_SUCCESSat the end of processing to indicate data completeness. Ifdone-flagexists, but the value is specified as empty, Oozie just checks for the existence of the directory and uses that as a signal for completion.
The following example shows a dataset definition. The dataset
ds_input1 is produced by some other
application every six hours starting from 2 a.m. on December 29. The
first three instances of the ds_input1 dataset are in directories:
hdfs://localhost:8020/user/joe/revenue_feed/2014-12-29-02,
hdfs://localhost:8020/user/joe/revenue_feed/2014-12-29-08, and hdfs://localhost:8020/user/joe/revenue_feed/2014-12-29-14,
respectively. The producer of the data creates a file called _trigger (defined as done-flag) when the data for the previous
six hours is complete and ready. For example, if any coordinator
action depends of the first data instance, coordinator will
particularly wait for the file hdfs://localhost:8020/user/joe/revenue_feed/2014-12-29-02/_trigger.
Instead, if the done-flag contains
an empty value, the coordinator
will wait until the directory hdfs://localhost:8020/user/joe/revenue_feed/2014-12-29-02/
is created:
<dataset name="ds_input1" frequency="${coord:hours(6)}"
initial-instance="2014-12-29T02:00Z">
<uri-template>
${baseDataDir}/revenue_feed/${YEAR}-${MONTH}-${DAY}-${HOUR}
</uri-template>
<done-flag>_trigger</done-flag>
</dataset>In practice, there could be multiple datasets defined in a
coordinator. Oozie provides a <datasets> section where a user can
define all the relevant datasets. In addition, Oozie allows users to
include a separate XML file within
the <datasets> section that
includes a set of dataset definitions. This enables users to define
the datasets in one file and reuse them in multiple coordinators. If a
dataset with the same name is defined in both places, the one defined
in the coordinator XML supersedes the one in the other file. The
following example shows how to include a dataset file:
<datasets>
<include>hdfs://localhost:8020/user/joe/shares/common_datasets.xml</include>
<dataset name="ds_input1" frequency="${coord:hours(6)}"
initial-instance="2014-12-29T02:00Z">
<uri-template>
${baseDataDir}/revenue_feed/${YEAR}-${MONTH}-${DAY}-${HOUR}
</uri-template>
<done-flag>_trigger</done-flag>
</dataset>
</datasets>The example common_datasets.xml could be as follows:
<datasets>
<dataset name="ds_input2" frequency="${coord:hours(6)}"
initial-instance="2014-12-29T02:00Z">
<uri-template>
${baseDataDir}/revenue_feed/${YEAR}-${MONTH}-${DAY}-${HOUR}
</uri-template>
<done-flag>_trigger</done-flag>
</dataset>
</datasets>Tip
It’s becoming increasingly common to access datasets on Amazon S3 from Hadoop. To enable data dependency on datasets on S3 in Oozie, set the following property:
oozie.service.HadoopAccessorService. supported.filesystems
to value hdfs,s3,s3n in the oozie-site.xml file. Also add the jets3t JAR to the Oozie webapp during Oozie deployment.
Timelines: coordinator versus dataset
So far, we have introduced two independent timelines, one for the
coordinator and one for the datasets. These multiple time-based
terminologies might be confusing and overwhelming, so some
clarification will be helpful here. The notion of a coordinator itself
is founded on time and we have introduced a handful of concepts
related to time in the previous chapter. The time parameters explained
there helps to manage the workflow execution and controls things like
the start and stop of the action materialization and the frequency of
materialization. In contrast, the initial-instance and frequency, introduced in the dataset
definition in this chapter, controls a different timeline for the data
produced by upstream jobs. These dataset settings might not have any
direct association with the timeline defined for the coordinator
itself.
input-events
Whereas datasets declare data
items of interest, <input-events> describe the actual
instance(s) of dependent dataset for this coordinator. More
specifically, a workflow will not start until all the data instances
defined in the input-events are
available.
There is only one <input-events> section in a
coordinator, but it can include one or more data-in sections. Each data-in handles one dataset dependency. For
instance, if a coordinator depends on two different datasets, there
will be two data-in definitions in
the input-events section. In turn,
a data-in can include one or more
data instances of that dataset. Each data instance typically
corresponds to a time interval and has a direct association with one
directory on HDFS.
A data-in definition needs
the following three attributes:
nameCan be used to uniquely identify this
data-insection.datasetIndicates the name of a dataset that the application depends on. The referred dataset must be defined in the
<datasets>definition section.- The
instancedefinition Specifies the data instance that the application will wait for. There are two ways to denote the instance(s). A user can define each instance using an individual
<instance>tag. Alternatively, a user can specify the range of instances using<start-instance>and<end-instance>tags. Each instance is basically a timestamp that will eventually be used to replace the variables defined in the<uri-template>of a dataset definition. Defining an absolute timestamp is valid, but it is neither practical nor convenient for a long-running coordinator. Therefore, Oozie provides several EL functions (explained later in “Parameterization of Dataset Instances”) to conveniently specify the batch instance(s).
In summary, the input-events
allows a user to define the list of required datasets and the
corresponding data instances. Example 7-1
shows an <input-events>
section with one <data-in>
item. In this example, the data-in,
named event_input1, refers to the
last four instances of the dataset using the EL function current() (described in “Parameterization of Dataset Instances”). This means that the coordinator
will wait for the previous four batch instances of data coming from
the dataset named ds_input1.
Example 7-1. Input-events section
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<start-instance>${coord:current(-4)}</start-instance>
<end-instance>${coord:current(-1)}</end-instance>
</data-in>
</input-events>output-events
In an Oozie coordinator, <output-events> specifies the data instance produced by a coordinator action. It
is very similar to input-events.
The similarities and differences are explained in Table 7-1.
| Similarities | Differences |
|---|---|
There can be at most one <input-events> and one
<output-events> in a
coordinator. | There are one or more <data-in> sections under
input-events. On the other
hand, there can be only one <data-out> section under
output-events. |
There are two attributes (name and dataset) required to define a
data-in, as well as a
data-out. | Each data-in
contains a single instance or a range of instances.
Conversely, each data-out
can contain only one instance and multiple instances are not
allowed. |
Like input-events, a
user can pass the output directory to the workflow as
well. | Oozie waits for the data instances defined in
theinput-events. Oozie
expects and supports the passing of the dependent directories
to the launched workflow. However, Oozie generally doesn’t
perform any special processing like data availability checks
for the output-events.
Oozie refers to the output-events mostly for cleaning up
the output data during coordinator reprocessing (discussed in
“Coordinator Reprocessing”). |
The following example shows the declaration of output-events:
<output-events>
<data-out name="event_output1" dataset="daily-feed">
<instance>${coord:current(0)}</instance>
</data-out>
</output-events>Example: Rollup
This example is an extension of our previous time-triggered coordinator described in “Our First Coordinator Job” with data dependency added to it. The previous example executed a workflow once every day. In Example 7-2, we add a new condition. The workflow runs every day and waits for the previous four instances of a dataset produced every six hours by an upstream application. The workflow uses the preceding four instances of a “six-hourly” dataset as input and produces the daily output. These types of jobs are commonly known as rollup jobs where datasets produced in a smaller frequency are combined into a higher frequency.
Example 7-2. A rollup job
<coordinator-app name="my_first_rollup_job" start="2014-01-01T02:00Z"
end="2014-12-31T02:00Z" frequency="${coord:days(1)}"
xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:hours(6)}"
initial-instance="2014-12-29T02:00Z">
<uri-template>
${baseDataDir}/revenue_feed/${YEAR}-${MONTH}-${DAY}-${HOUR}
</uri-template>
<done-flag>_trigger</done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<start-instance>${coord:current(-4)}</start-instance>
<end-instance>${coord:current(-1)}</end-instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBaseDir}/basic-cron</app-path>
<property>
<name>nameNode</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>jobTracker</name>
<value>localhost:8032</value>
</property>
</workflow>
</action>
</coordinator-app>This example XML has two new sections <datasets>
and <input-events> that we
discussed in “Defining a dataset” and “input-events”, respectively. Each coordinator
action waits for four dataset directories produced for the times 2:00,
8:00, 14:00, and 20:00 of the previous day. Figure 7-1 captures these timelines. It’s worth
noting there are two independent timelines, one for the coordinator and
one for the dataset. The dataset timeline in Figure 7-1 shows that the data is produced every 6
hours by some other process at 2:00, 8:00, 14:00, and 20:00. On the other
hand, the coordinator timeline shows that the coordinator job runs every
day at 2:00 a.m. Each coordinator action depends on data from the previous
four instances of the dataset with respect to its nominal time. The
nominal time of the action acts as the bridge between the two timelines.
As shown in the figure, the coordinator action with nominal time 2014-01-01T02:00Z waits for the following
dataset instances:
hdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-02/_triggerhdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-08/_triggerhdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-14/_triggerhdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-20/_trigger
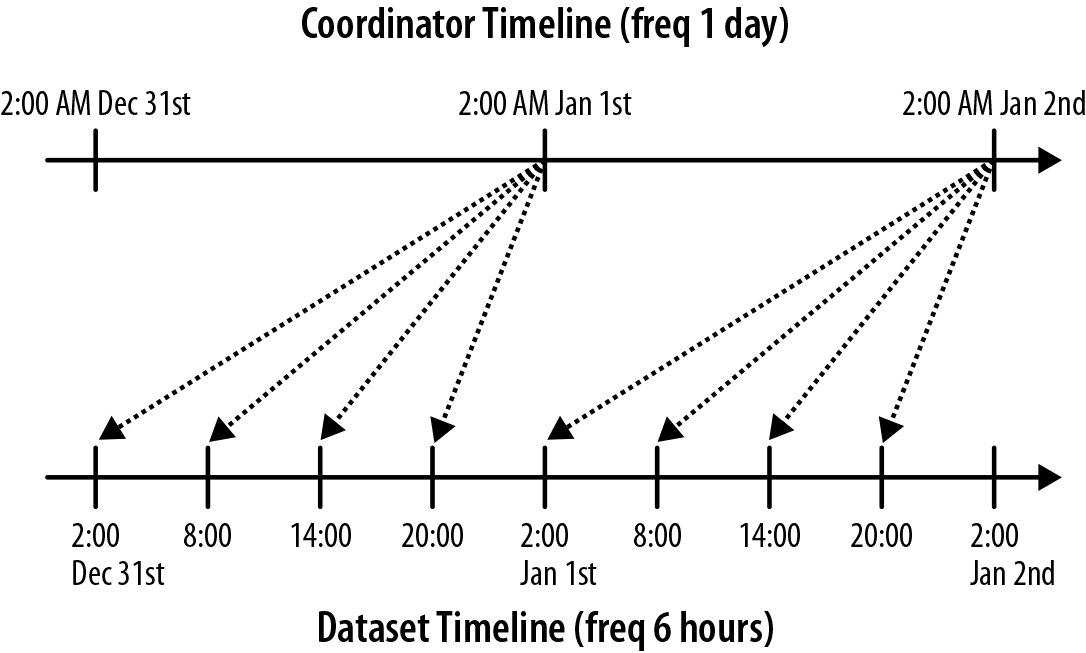
Figure 7-1. Coordinator job rolling up six-hourly data into daily data
Parameterization of Dataset Instances
Each coordinator action waits for data instances defined in <data-in>. Each data instance ultimately
needs the absolute timestamp to evaluate the exact directory provided in
uri-template. Since this timestamp is
usually relative to the nominal and execution times, users often can’t
specify it in absolute values. So Oozie provides several EL functions to
express and parameterize the data instances. These EL functions are used
to support a variety of complex use cases and hence require close
attention.
The instance timestamp primarily depends on two time parameters from
the coordinator action and the dependent datasets. First and foremost,
coordinator action’s nominal time plays a critical role in determining the
data instance. coordinator action’s nominal time, in turn, depends on the
time-related attributes in the coordinator job specifications such
as start time and
frequency. For example, if the start
time of a coordinator job is cS and the
frequency is cF, the nominal time of
the nth
coordinator action is calculated as follows (not considering Daylight
Saving Time):
Nominal Time (caNT) = cS + n * cF
Second, the dataset definition has two time attributes,
initial-instance (dsII) and frequency
(dsF), which also play an important
role in determining the actual data instance.
Apart from the time attributes just discussed, the instance expressed in the data-in section of a coordinator XML plays a
direct role in determining the actual dependent data directories. An
instance is usually defined using EL functions like current(n), latest(n), offset(n,
timeunit), and future(n).
Among them, current(n) is the most
frequently used, followed by latest(n).
The usage of offset(n,
timeunit) and future(n) are
rare. We will discuss the first two functions in detail here with examples
(refer to the Oozie
coordinator specification for the other, less commonly used
functions).
current(n)
This EL function returns the timestamp of the nth instance of a
dataset relative to a specific
coordinator action’s nominal time (caNT). The value of n can be any integer number. Any negative value
for n refers to an instance earlier
than the nominal time. While any positive value for n refers to some instance after the nominal
time. The simplest equation to approximately calculate the timestamp of
the nth
instance is as follows:
current(n) = dsII + dsF * (n + (caNT – dsII) / dsF)
The following example further clarifies the concept with real
values. Assume the coordinator job has the start time of 2014-10-18T06:00Z and a frequency of one day.
This means Oozie will materialize coordinator actions with the following
nominal times (in order): 2014-10-18T06:00Z, 2014-10-19T06:00Z, 2014-10-20T06:00Z, and so on. Let’s also
assume that there are four datasets with the attributes in Table 7-2 to demonstrate the different
scenarios.
| Dataset name | Initial instance | Frequency |
|---|---|---|
| ds1 | 2014-10-06T06:00Z | 1 day |
| ds2 | 2014-10-06T06:00Z | 12 hours |
| ds3 | 2014-10-06T06:00Z | 3 days |
| ds4 | 2014-10-06T07:00Z | 1 day |
We explain below how to calculate some of the time instances of
these datasets. This calculation is in the context of the second
coordinator action with a nominal time of 2014-10-19T06:00Z.
current(0) of ds1: The current(0) of any dataset specifies the
dataset instance/timestamp that is closest to and no later than the
coordinator action’s nominal time. In general, finding current(0) is the first step in understanding
any other data instance. Most instance calculations are based on the
coordinator action’s nominal time. Conceptually, we can start from the
dataset’s initial instance and go forward to the coordinator action’s
nominal time with an increment of dataset frequency. In this example, we
start with dsII=2014-10-06T06:00Z and
go toward caNT= 2014-10-19T06:00Z
with a frequency of one day. The dataset instances will correspond to
10/6, 10/7, 10/8, and so on (in order). In this example, the nominal
time and the dataset (ds1) initial timestamp have the same time
component (6 a.m.) and that makes the calculation a little easier. So
the closest dataset timestamp is the same as the nominal time and is
2014-10-19T06:00Z. Hence this time
represents current(0) as well. We can
also calculate the same using the following equation:
current(n) = dsII + dsF * (n + (caNT – dsII) / dsF)
= 2014-10-06T06:00Z + 1 day x
(0 + (2014-10-19T06:00Z - 2014-10-06T06:00Z))/ 1 day
= 2014-10-06T06:00Z + 13 day = 2014-10-19T06:00ZSimilarly, we can calculate current(-1), which is the immediate previous
instance of current(0), and current(1), which is the immediate next
instance of current(0). We also
describe the same concept in Figure 7-2.
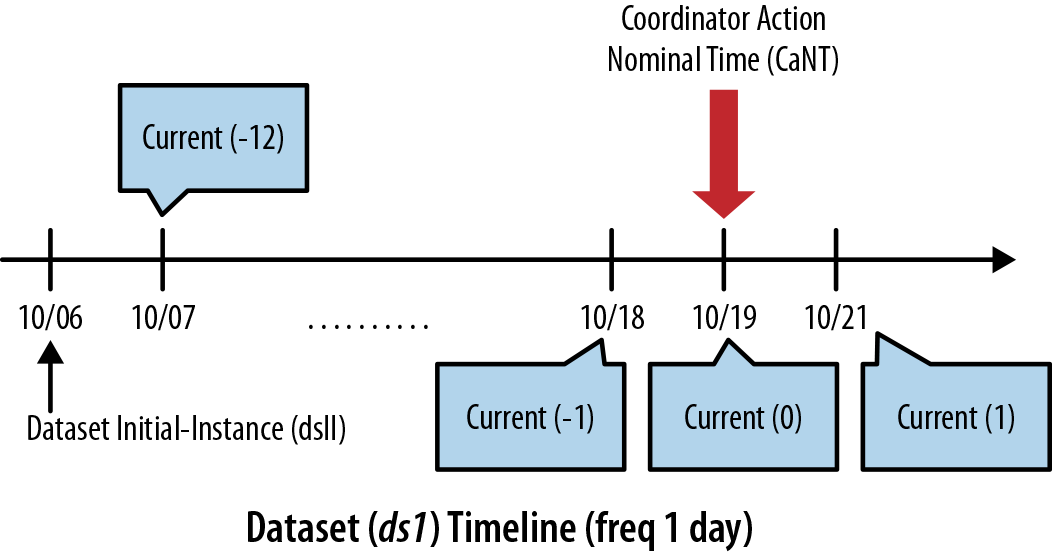
Figure 7-2. Timestamps of current() EL function for dataset ds1
current(0) of ds3: We use dataset
ds3 to explain the same idea in a
slightly different scenario. In this example, the dataset instances
starts with dsII=2014-10-06T06:00Z
and moves toward caNT=
2014-10-19T06:00Z with a frequency of three days. Dataset instances will be 10/6,
10/9, 10/12, 10/15, 10/18, 10/21, and so on (in order). So the closest
instance to nominal time is 10/18, which becomes current(0) for this scenario. Notably, the
nominal time 2014-10-19T06:00Z and
current(0) do not exactly match in
this example. Figure 7-3 displays the
different data instances including current(-1), current(1), and so on.
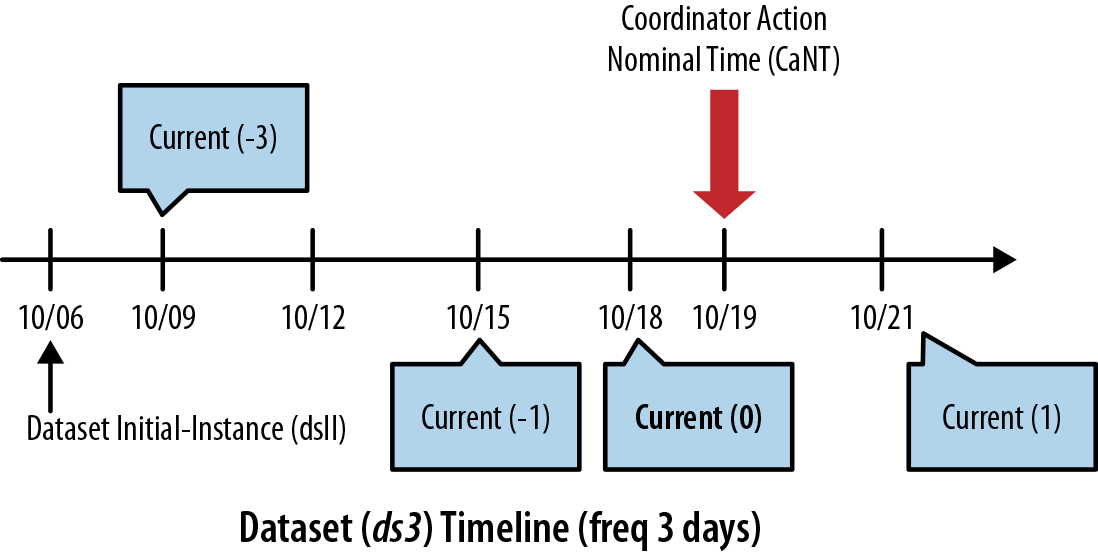
Figure 7-3. Timestamps of current() EL function for dataset ds3
Table 7-3 shows the return value of
current(n) given different values of
n for all of the example datasets in
Table 7-2.
| Instance | ds1 | ds2 | ds3 | ds4 |
|---|---|---|---|---|
| current(0) | 2014-10-19T06:00Z | 2014-10-19T06:00Z | 2014-10-18T06:00Z | 2014-10-18T07:00Z |
| current(-1) | 2014-10-18T06:00Z | 2014-10-18T018:00Z | 2014-10-15T06:00Z | 2014-10-17T07:00Z |
| current(-2) | 2014-10-17T06:00Z | 2014-10-18T06:00Z | 2014-10-12T06:00Z | 2014-10-16T07:00Z |
| current(1) | 2014-10-20T06:00Z | 2014-10-19T18:00Z | 2014-10-21T06:00Z | 2014-10-19T07:00Z |
Instances before the dataset’s
initial-instance: The
data instances before the initial-instance of any dataset doesn’t count.
So if the EL function (e.g., current()) refers to any such dataset instance,
coordinator doesn’t really check the existence of that data. In other
words, there could be some data on HDFS before the dataset’s initial-instance as defined in the dataset
definition, but Oozie disregards those data instances. However, Oozie
returns an empty ("") string for any
such instance. For instance, current(-14)
for dataset ds1 points to
2014-10-05T06:00Z, which is earlier
than the declared initial-instance
(2014-10-06T06:00Z) of ds1. In this case, Oozie returns an empty
string ("") without checking for the
existence of the data.
Caution
During initial testing, users are frequently confused with this
behavior and are often surprised to find that their workflows have
started to run with an empty input path. This usually happens when the
coordinator start time and the dataset initial-instance are the same or close to
each other. This can be solved and the tests can be made more useful
by either moving the dataset’s initial-instance to an earlier time or by
moving the coordinator start time to a later time.
Scope: The current() EL function is valid only within the
<data-in> and <data-out> sections of a coordinator XML.
latest(n)
This EL function returns the timestamp of the nth latest
available dataset. Evaluating this
“latest” available data instance happens with respect to either one of
the two points in time listed here:
present timeThe wall-clock time when Oozie evaluates the
latest()functionactual timeThe time when Oozie actually materializes a coordinator action
Oozie selects this option based on the property oozie.service.ELService.latest-el.use-current-time
defined in the oozie-site.xml file.
The default is to evaluate “latest” based on the action’s actual
time.
Note
The latest(n) function does
not support positive integers (n) and cannot be used to look “forward”
in time. Unlike the curent(n)
function, specifications like latest(1) and latest(2) are not supported.
Nominal versus actual versus present time
Before going further into the explanation of the latest() function, we need to clarify the
newly introduced terms related to time. We are already familiar with the
action nominal time. We just
introduced two new terms, present
time and actual time.
Present time represents the current wall clock time when the latest evaluation logic is executed. In other
words, if the same latest function is
executed multiple times, it will obviously use different present (wall-clock) times for its dataset
evaluations.
On the other hand, the action’s actual time represents the time when the action is materialized by Oozie. Although this sounds very similar to nominal time, there are subtle but important differences. For instance, when a coordinator is delayed and is running in catch-up mode, an action may be actually created at 6 p.m. but it should have been ideally created at 2 p.m. In other words, action’s nominal time is 2 p.m., but the action’s actual time is 6 p.m.
Now let’s also assume this delayed action has a latest() dependency and is checking and
waiting for data availability. For example, at 10 p.m., the coordinator
evaluates the latest() function. At
that moment, the present time on the
wall clock is 10 p.m. whereas the nominal time (2 p.m.) and the actual
time (6 p.m.) remain unchanged. In short, the nominal time of an action
is always fixed, the actual time
becomes fixed once the action is created, and the present time is
always changing and follows the wall
clock.
latest() evaluation
As already mentioned, Oozie evaluates latest(n) based on either the coordinator
action’s actual time or the present wall clock time. Let’s generalize
this time as look-back start time
denoted by Tlbs. At first, Oozie
determines the closest time instance of the dataset to Tlbs. Oozie starts from
the dataset’s initial-instance (dsII) and increments it by the dataset’s
frequency (dsF) until it reaches
Tlbs. Let’s
assume the closest timestamp value to Tlbs is determined to
be Tds. Oozie
first checks if the data directory for time Tds is available. If it
is available, it will consider it as the first available data instance
or latest(0). If the data for
Tds is not
available yet, Oozie will walk back and look for data for time Tds - dsF (dataset
frequency). If that data is available, Oozie will consider this second
time instance as the first available data instance or latest(0). If data is not available for that
instance as well, Oozie will skip it and keep walking back.
Continuing with this example, if all previous data instances are
available, the nth available
instance (latest(n)) will be the data
instance for time Tds -
n x dsF. If any one data instance between time Tds and Tds - n x dsF is not
available for whatever reason, Oozie needs to look back further to find
(latest(n). If it can’t get to the
nth
instance after searching backward all the way to the initial-instance of the dataset (dsII), Oozie will go to sleep and start the
evaluation process again in the next cycle starting with the calculation
of the time Tlbs. Finally, when
Oozie finds the nth available instance, it returns the
corresponding timestamp.
The following detailed example attempts to further clarify the
concept with real values. Assume the coordinator job specifies the
start time as 2014-10-18T06:00Z and the frequency as one
day. Oozie materializes the first coordinator action with a nominal time
of 2014-10-18T06:00Z.
Let’s further assume that the dependent dataset has the following attributes:
Initial-instance=2014-10-06T06:00Zfrequency=1 dayuri-template=hdfs://foo:8020/logs/${YEAR}-${MONTH}-${DAY}
Let’s consider the scenario where Oozie is evaluating latest()for this dataset at two different
times on the wall clock: 2014-10-19T10:00Z and 2014-10-19T11:00Z. At these times, let’s also
assume that the actual data availability is as it appears in Table 7-4.
| Wall Clock Time = 2014-10-19T10:00Z | Wall Clock Time = 2014-10-19T11:00Z |
|---|---|
| hdfs://foo:8020/logs/2014-10-19 | hdfs://foo:8020/logs/2014-10-19 |
| Missing | hdfs://foo:8020/logs/2014-10-18 |
| Missing | Missing |
| hdfs://foo:8020/logs/2014-10-16 | hdfs://foo:8020/logs/2014-10-16 |
| Missing | Missing |
| hdfs://foo:8020/logs/2014-10-14 | hdfs://foo:8020/logs/2014-10-14 |
Table 7-5 shows the return value of the
latest(n) timestamp for various
values of n given the above example
scenario. The example assumes that the property oozie.service.ELService.latest-el.use-current-time
is set to true. In other words, it
utilizes the present wall-clock time (instead of the actual time) in evaluating latest().
| Instance | Wall Clock Time = 2014-10-19T10:00Z | Wall Clock Time = 2014-10-19T11:00Z |
|---|---|---|
| latest(0) | 2014-10-19T06:00Z | 2014-10-19T06:00Z |
| latest(-1) | 2014-10-16T06:00Z | 2014-10-18T06:00Z |
| latest(-2) | 2014-10-14T06:00Z | 2014-10-16T06:00Z |
latest()
at 10 a.m.: At first, Oozie determines the closest timestamp
that could be the candidate for latest(0). It starts from 2014-10-06T06:00Z (dataset initial-instance, dsII) and increments the
timestamp using the frequency (dsF) until it reaches the present time (2014-10-19T10:00Z). In this
example, that instance evaluates to 2014-10-19T06:00Z and that’s where
Oozie starts its data availability checks. Since the data from 10/19 is
available at wall-clock time 10 a.m., that instance is determined to be
the latest(0). But for latest(-1), Oozie looks for the 10/18 data,
which is actually missing at wall-clock time 10 a.m. So Oozie continues
to look backward and finds there is no data for 10/17 either. However,
it finds data for 10/16 and returns that as the latest(-1). Using the same approach, it looks
backwards for latest(-2) and skips 10/15 due to missing data. Oozie
finally finds data in 10/14 and returns that instance as the latest(-2). We demonstrate this pictorially in
Figure 7-4.
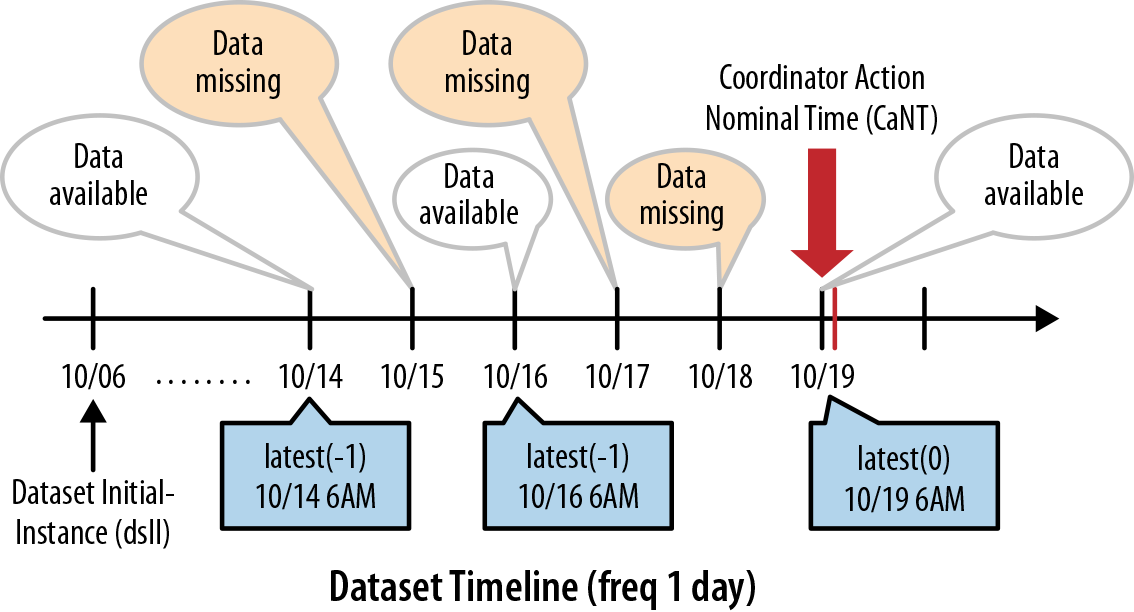
Figure 7-4. Timestamps of latest() EL function at wall-clock time 10 a.m.
latest()
at 11 a.m.: The only context change between wall clock time
10 a.m. and 11 a.m. is the arrival of new data for 10/18. This changes
the timestamp evaluations for latest(-1) and latest(-2). Specifically, if Oozie evaluates
at 11 a.m., it will return 10/18 as latest(-1) and 10/16 as latest(-2).
Scope:
The latest() EL function is valid only within the <data-in> and <data-out> sections of the coordinator
XML.
Comparison of current() and latest()
The latest() and current() functions have subtle but important differences. It’s important
that you have a good understanding of both these concepts so that you
can pick the correct EL function for your application. Broadly, if you
want to process the same dependent datasets irrespective of when the
job executes, you should use current(). In other words, for every run for
a specific nominal time if you want to process the same input
datasets, the right function is current(). For example, if you execute the
February 1, 2014 instance of your job and always want to process the previous 3 days of
data (i.e., 01/29/14. 01/30/2014, and 01/31/2014), you should use the
current() EL function. On the other
hand, if you want to process the latest available data at the time of
execution irrespective of the nominal time, you should use the
latest() function. Note that if you
run the same coordinator action multiple times, your job may end up
processing different datasets with latest(). With the preceding example, if you
run the job on February 14, 2015 and use current(), you will still process the same
three days (01/29/2014, 01/30/2014, and 01/31/2014) of data. On the
other hand, if you use latest(), Oozie will pick more recent
datasets, probably 02-11-2015, 02-12-2015, and 02-13-2015 if they are
available. Table 7-6 compares some of the key
properties of these two functions.
| Topics | current(n) | latest(n) |
|---|---|---|
| Data checking starts from | Action nominal time | Action actual time OR the present wall clock time |
| Fixed versus Variable | Fixed. Returns the same timestamp for the same action irrespective of when it checks. | Variable. Returns different timestamps based on when the check happens. |
| Gaps in data availability | Disregards gaps in data availability. Always returns the same instance(s) of data for a given action and does not skip any data whether it exists or not. | Accounts for the gaps in data availability. Skips missing data instances. Only considers the available instances. |
| Range of ‘n’ | Any integer | Only ‘0’ OR negative integer. |
Parameter Passing to Workflow
An Oozie workflow, launched by a coordinator action, doesn’t directly deal with any time-dependent parameters such as nominal time or actual time. The coordinator primarily deals with these aspects. Nevertheless, workflows frequently need those parameters for its execution. For instance, the dependent data directories checked by a coordinator action is typically directly used by some workflow action as input. Therefore, Oozie provides the following EL functions to easily pass those parameters to the launched workflow. The workflow can refer to the parameters as EL variables in its XML definition.
dataIn(eventName):
This function evaluates all input data directories of a dataset for a
specific time instance and returns the directories as a string. The
dataIn() function doesn’t really
check if the data is available or not. This function takes eventName as a parameter. First, Oozie
identifies data-in from the input-events definition using the eventName. Second, Oozie finds the name of the
dataset from the data-in definition.
Last, Oozie takes the uri-template
from the dataset definition and resolves the paths corresponding to the
particular time instance. Oozie evaluates the time instance based on
nominal time and the instance number defined in the EL function. We
already saw the details of this process in “Parameterization of Dataset Instances”. If there are multiple instances
(e.g., current(0), current(-1), etc.) in data-in, Oozie concatenates them using
, as a separator.
For instance, consider the EL function ${coord:dataIn('event_input1')} in the context
of the example dataset and input-events defined in “Defining a dataset” and “input-events”, respectively. Let’s also assume
the nominal time of the coordinator action is 2015-01-01T02:00Z. Using the event name
event_input1, Oozie initially
determines the corresponding dataset name ds_input1 from the data-in definition. Then using the nominal
time and instance count (such as -1
for current(-1)), Oozie calculates
the exact time instance of the data and ultimately resolves the uri-template defined in the dataset. For
example, current(-1) returns 2014-12-31T20:00Z for this coordinator action.
Finally, Oozie resolves the uri-template with this time instance and
evaluates the final directory as hdfs://localhost:8020/user/joe/revenue_feed/2013-12-31-20.
Oozie follows the same process for each current instance and
concatenates them with a comma (,). The EL function dataIn() finally returns the following
string:
hdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-02,
hdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-08,
hdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-14,
hdfs://localhost:8020/user/joe/revenue_feed/2014-12-31-20
Tip
You could take the input directory and add wildcards to it in the workflow XML. For example, /part*. This will work well for a single directory returned, but for a list like the one shown above, the wildcard will be added only to the last directory in the list, and this probably is not what you want.
Scope: dataIn() is valid within the <workflow>
section of a coordinator XML.
nominalTime()
This function returns the nominal time or the action creation time (explained in section “Our First Coordinator Job”) of a particular coordinator action.
Scope: nominalTime() is valid within the
<workflow> section of a coordinator XML.
actualTime()
This function calculates the actual time of a coordinator action as defined in “Parameterization of Dataset Instances”. In an ideal world, the nominal time and the actual time of an action will be the same. But during catch-up scenarios, where the coordinator action execution is delayed, the actual time of a coordinator action is different and later than its nominal time.
Scope: actualTime() is valid within the <workflow> section of a coordinator XML.
dateOffset(baseTimeStamp, skipInstance, timeUnit)
This utility function returns a date as a string using the base time and offset. Oozie calculates the new date using the following equation (not considering Daylight Saving Time).
New Date = baseTimeStamp + skipInstance *
timeUnit
Scope: dateOffset() is valid within the
<workflow> section of a coordinator XML.
formatTime(timeStamp, formatString)
This utility function formats a standard ISO8601 compliant
timestamp into another timestamp string based on formatString. The formatString should follow the conventions
used in Java’s SimpleDateFormat
.
Scope: formatTime() is valid within the <workflow> and <input-events> sections of a coordinator
XML.
A Complete Coordinator Application
We now extend the rollup window example described in “Example: Rollup”. The additional features of this example include the following:
Extensive parameterization using appropriate EL functions
Demonstration of the EL functions to pass parameters to the launched workflow
The example code is as follows:
<coordinator-app name="my_rollup_job" start="2014-01-01T02:00Z "
end="2014-12-31T02:00Z” frequency="${coord:days(1)}"
xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:hours(6)}"
initial-instance="2013-12-29T02:00Z">
<uri-template>
hdfs://localhost:8020/user/joe/revenue_feed/${YEAR}-${MONTH}-${DAY}-
${HOUR}
</uri-template>
<done-flag>_trigger</done-flag>
</dataset>
<dataset name="daily-feed" frequency="${coord:days(1)}"
initial-instance="2013-12-29T02:00Z">
<uri-template>
hdfs://localhost:8020/user/joe/revenue_daily_feed/${YEAR}-${MONTH}-
${DAY}
</uri-template>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<start-instance>${coord:current(-4)}</start-instance>
<end-instance>${coord:current(-1)}</end-instance>
</data-in>
</input-events>
<output-events>
<data-out name="event_output1" dataset="daily-feed">
<instance>${coord:current(0)}</instance>
</data-out>
</output-events>
<action>
<workflow>
<app-path>${myWFHomeInHDFS}/app</app-path>
<property>
<name>myInputDirs</name>
<value>${coord:dataIn('event_input1')}</value>
</property>
<property>
<name>myOutputDirs</name>
<value>${coord:dataOut('event_output1')}</value>
</property>
<property>
<name>myNominalTime</name>
<value>${coord:nominalTime()}</value>
</property>
<property>
<name>myActualTime</name>
<value>${coord:actualTime()}</value>
</property>
<property>
<name>myPreviousInstance</name>
<value>${coord:dateOffset(coord:nominalTime(), -1, 'DAY')}</value>
</property>
<property>
<name>myFutureInstance</name>
<value>${coord:dateOffset(coord:nominalTime(), 1, 'DAY')}</value>
</property>
<property>
<name>nameNode</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>jobTracker</name>
<value>localhost:8032</value>
</property>
</workflow>
</action>
</coordinator-app>For evaluating the function dataIn(), Oozie uses the event name event_input1 that was passed in to find the
dataset ds_input1 from the data-in definition. After translating the
myInputDirs into an actual list of
directories, Oozie passes it to the launched workflow where the workflow
refers to it using the variable ${myInputDirs}. Workflows generally use this as
input data for its actions.
For the first coordinator action, Oozie returns 2014-01-01T02:00Z as the value of myNominalTime. For the second action, myNominalTime is 2014-01-02T02:00Z.
For the second action with nominal time 2014-01-02T02:00Z, the value of myPreviousInstance is 2014-01-01T02:00Z, and the value of myFutureInstance is 2014-01-03T02:00Z.
The value of property myOutputDir
is resolved as hdfs://localhost:8020/user/joe/revenue_daily_feed/2014-01-01
for the first coordinator action with nominal time 2014-01-01T02:00Z. Again, this variable is
passed to the workflow where it is often used as application
output.
This concludes our explanation of data availability triggers, which
is as important as time-based triggers for the Oozie coordinator. This
chapter, along with the previous chapter, discusses the details of a
coordinator application in a comprehensive fashion. We covered when and
how to launch a workflow based on user-defined time and data triggers. In
the next chapter, we will introduce another abstraction on top of the
coordinator called the bundle, which
helps users easily manage multiple coordinator jobs.