
Chapter 8. Oozie Bundles
Leading up to this chapter, we have covered two important and basic Oozie concepts, namely the workflow and the coordinator, and everything that goes into authoring and implementing them. Workflows are at the core of any Oozie application and coordinators are the next level of abstraction that allows the orchestration of these workflows through time and data triggers, as explained in Chapters 6 and 7. In this chapter, we will cover Oozie bundles, the highest level of abstraction in Oozie that helps users package a bunch of coordinator applications into a single entity, often called a data pipeline.
Bundle Basics
Oozie’s evolutionary path gives us a lot of context on how bundles were born. Oozie version 1.0 was all about workflows and the basic features around it. Version 2.0 introduced coordinators and triggers. Bundle became the next step for Oozie and was introduced in version 3.0. As you can see, there is a nice rhythm to this evolutionary arc and users wanted higher abstractions and more features for a Hadoop-based workflow engine at every stage. Bundle was the direct result of users wanting Oozie to support large data pipelines involving many workflows with complex interdependencies.
Bundle Definition
An Oozie bundle is a collection of Oozie coordinator applications with a directive on when to kick off those coordinators. As with the other parts of Oozie, bundles are also defined via an XML-based language called the Bundle Specification Language. Bundles can be started, stopped, suspended, and managed as a single entity instead of managing each individual coordinator that it’s composed of. This is a very useful level of abstraction in many large enterprises. These data pipelines can get rather large and complicated, and the ability to manage them as a single entity instead of meddling with the individual parts brings a lot of operational benefits. Figure 8-1 shows a pictorial representation of an Oozie bundle.

Figure 8-1. Oozie bundle
As the picture suggests, a bundle is designed to contain one or more coordinators. Bundles don’t support any explicit definition or management of dependencies between the coordinators, but they can wait on each other implicitly through the data dependency mechanism that the coordinator supports. For example, coordinator C can wait on datasets generated by coordinator A and B. This is how data pipelines are implemented in Oozie using coordinators and bundles.
Why Do We Need Bundles?
Some users, when exposed to the concept of an Oozie bundle for the first time, are a little confused about its usefulness and necessity. Users need and want to run workflows. They also understand the coordinator and its features. But the benefits of an Oozie bundle are not readily apparent. So it might be instructive to go through some concrete use cases and the value of using an Oozie bundle in those example scenarios. bundles are basically available for operational convenience more than anything else.
Let’s look at a typical use case of a rather large Internet company that makes its revenue through advertising and ad clicks. Let’s say that Apache web logs are collected in a low-latency batch and delivered to the backend. The data pipeline then picks it up and kicks off a variety of processing on it. The list of applications using this input log data include but is not limited to the following workflows:
There is one workflow that counts ad clicks, calculates the cost to the advertiser account IDs, does some basic comparisons to the same time of the day last week to make sure there are no abnormalities, and publishes a revenue feed. This workflow is called the
Revenue WFand runs every 15 minutes.There is a
Targeting WFthat looks at the user IDs corresponding to the ad clicks and does some processing to segment them for behavioral AD targeting. This workflow also runs every 15 minutes, but it satisfies a completely different business requirement than therevenue WFand is developed and managed by another team.There is an Hourly workflow called the
AD-UI WFthat rolls up the 15 minute revenue feeds generated by therevenue WFand pushes a feed to a operational database that feeds an advertiser user interface. This UI is where advertisers and customers log in and track their AD expenditure at an hourly grain.There is a
Reporting WFthat runs daily in the morning to aggregate a lot of the data from the previous day and generate daily canned reports for the executives of the company.Last but not the least, the advertiser billing logic and the SOX (Sarbanes–Oxley) compliance checks run monthly because that’s when the larger advertisers actually get a bill and are expected to pay. They don’t actually pay daily or hourly. This makes up the
BillingWFand involves monthly aggregations and rollups.
Given the varied use cases detailed here, you can see how the entire, consolidated data pipeline can get rather complex. There are several moving parts and interdependencies, though these individual use cases seem to fit nicely into individual Oozie workflows. There will be corresponding coordinator apps that take care of the necessary time and data triggers for these workflows. The same input dataset (weblogs) drives all of the processing, but different groups within the company actually own specific business use cases. Table 8-1 summarizes these workflows and their time frequency and business owners.
| No. | Workflow name | Workflow frequency | Business unit |
|---|---|---|---|
| 1 | Revenue WF | 15 minutes | AD Operations |
| 2 | Targeting WF | 15 minutes | Behavioral Targeting |
| 3 | AD-UI WF | Hourly | AD Operations |
| 4 | Reporting WF | Daily | Business Intelligence |
| 5 | Billing WF | Monthly | Accounting |
In addition to the time frequency, the workflows also have data
dependencies among them. For instance, the monthly billing WF will be dependent on the entire
month’s worth of revenue feeds from the AD-UI
WF, which itself is dependent on the output of the revenue WF. These dependencies can be
specified via the coordinator app like we saw in Chapter 6. Bear in mind that there is a one-to-one
correspondence between a coordinator app and the workflow it runs. So a
coordinator by definition cannot run two workflows of different
frequencies as part of one job.
Assuming the layout of coordinator and workflow apps as defined in the previous paragraph, let’s look at some failure scenarios that are common in such a complex data pipeline. Let’s say the operations team finds out at 11 p.m. on March 31 that some of the data for that day is missing. Specifically, there was a network hiccup that caused some silent data loss in the previous four hours starting at 7 p.m. It is finally detected and a high-priority alert is issued. Many operations teams across the organization get into an emergency mode to fix the issue. Once the issue is fixed, the old data that’s missing will be delivered to the data pipeline. But the pipeline is long done with hours 7 through 9 and is minutes away from kicking of the hourlies for the 10 p.m. hour. And we are also pretty close to the dailies kicking off and the monthly billing is not too far either, as this is the last day of the month. There is no point kicking off the daily and monthly jobs without completing the reprocessing of the last four hours. The operations team has to stall all those coordinator jobs and reprocess the 15-minute and hourly ones from the last four hours. The coordinator has the right tools and options for suspending, starting, and reprocessing all those jobs, but it’s a lot of manual work for the data pipeline operations team responsible for all these coordinator jobs. As we all know, manual processing is quite error-prone.
This is exactly where the bundle comes in. If they had defined the entire data pipeline as a bundle, the life of the operations team becomes a lot easier. They can stop the bundle, and all processing for all coordinators stops right away with one command. They can then handle what needs to be reprocessed through Oozie tools (refer to “Reprocessing” for more details). Reprocessing will require some diligent analysis, but some of this reprocessing can happen at the bundle level as well. Bundle level reprocessing features are being developed and released in increments at the time of writing this book. So check your specific Oozie version for details. When it’s time to restart the pipeline, they can again do it with one command and Oozie bundle will take care of the rest.
As you can see, bundles are a very powerful abstraction, and for certain high-end use cases, they add a lot of operational flexibility and convenience.
Bundle Specification
Let’s now look at the actual bundle specification. As with the other parts of Oozie, bundle specification is also XML based. It borrows and leverages all the concepts of the pipeline definition language, variable substitution, and parameterization that we have covered thus far in the book. bundle specification is a lot less complicated and has fewer elements than the workflow and the coordinator. Figure 8-2 captures the elements that make up a bundle pretty concisely. The optional elements are represented by boxes enclosed by dotted lines.

Figure 8-2. Bundle Specification
The optional <parameters> section serves the same
purpose as it does for the workflows as explained in “The <parameters> Section”. That’s the section where you can
declare bundle parameters and optionally add default values so Oozie can
check for the variables before running the bundle. The <controls>
section is optional and the <kick-off-time> is when you want the bundle to be started and run. It’s
explained in detail in the next section. A given bundle can have one or
more coordinators as shown in the picture above. Each coordinator has a
name and an application path with an optional <configuration> section. The <configuration> section is similar to what
we have seen throughout this book.
Execution Controls
Kick-off time: The only
real bundle-specific control element that Oozie supports
is the <kick-off-time>. This
determines when a submitted bundle should actually be run. Let’s assume
you are submitting the Oozie jobs via the CLI. Regardless of whether the
job is a workflow, coordinator, or a bundle, the interface is the same.
You can submit a bundle using ""oozie job
–submit" or directly run it using "oozie job -run". If you execute "-run", Oozie will run the bundle regardless
of the <kick-off-time>, which
will basically be ignored. But if you invoke "-submit", the bundle will be submitted, but
Oozie will not run it until the <kick-off-time> is reached. The bundle
will be in PREP state until then. The
figure below from the Oozie’s bundle UI shows you the state of the
bundle when the <kick-off-time>
has not been reached yet. As you can see, the coordinator list in the
bottom half of the figure is empty because the coordinators have not yet
been submitted by the bundle, which is still waiting to kick off.

Figure 8-3. Bundle Kick-off Time
If the <kick-off-time> is
not specified, the bundle submit and
run behave the same and the job will
be run “now” as soon as it is submitted. Do keep in mind that the
coordinators being invoked by this bundle could also be time triggered.
The bundle <kick-off-time> is
different from the coordinator start time and orthogonal to the schedule
of the coordinator(s) included. The bundle does not even submit the
coordinators until the kick-off time. Once submitted, the coordinator
instances could run right away or wait depending on the time
dependencies at the coordinator level.
Example 8-1 shows an example of a real bundle and as you can see, the specification is pretty simple and straightforward.
Example 8-1. Bundle application
<bundle-app name='bundle-example' xmlns:xsi='http://www.w3.org/2001/
XMLSchema-instance'xmlns='uri:oozie:bundle:0.2'>
<parameters>
<property>
<name>start</name>
</property>
<property>
<name>end</name>
<value>2014-12-20T10:45Z</value>
</property>
</parameters>
<controls>
<kick-off-time>2014-12-20T10:30Z</kick-off-time>
</controls>
<coordinator name='coord-1'>
<app-path>${nameNode}/user/apps/coord-1/coordinator.xml</app-path>
<configuration>
<property>
<name>start</name>
<value>${start}</value>
</property>
<property>
<name>end</name>
<value>${end}</value>
</property>
</configuration>
</coordinator>
<coordinator name='coord-2'>
<app-path>${nameNode}/user/apps/coord-2/coordinator.xml</app-path>
<configuration>
<property>
<name>start</name>
<value>${start}</value>
</property>
<property>
<name>end</name>
<value>${end}</value>
</property>
</configuration>
</coordinator>
</bundle-app>Caution
When using bundles, make sure the coordinator definition is
using the Oozie schema version 0.2
(xmlns="uri:oozie:coordinator:0.2")
or higher. Bundle execution will fail if the included coordinators are
still conforming to version 0.1.
As always, the bundle specification has to be copied to HDFS. The configuration to the Oozie command line is passed via a job.properties file. An example properties file for Example 8-1 is shown in Example 8-2.
Example 8-2. The job.properties file for the bundle
nameNode=hdfs://localhost:8020
jobTracker=localhost:8032
oozie.bundle.application.path=${nameNode}/user/apps/bundle/
start=2014-12-20T10:45Z
end=2014-12-30T10:45ZBundles are invoked just like workflows and coordinators, using the
same interfaces. If you are using the Oozie CLI, the commands in Example 8-3 work for bundles, too. The oozie.bundle.application.path
variable in the job.properties tells Oozie that this is a
bundle application.
Example 8-3. CLI commands for bundles
$ oozie job -config job.properties -submit
job: 0000056-141219003455004-oozie-oozi-B
$ oozie job 0000056-141219003455004-oozie-oozi-B -run
$ oozie job 0000056-141219003455004-oozie-oozi-B –suspend
$ oozie job 0000056-141219003455004-oozie-oozi-B -resume
$ oozie job -info 0000046-141219003455004-oozie-oozi-B
Job ID : 0000046-141219003455004-oozie-oozi-B
--------------------------------------------------------------------------------
Job Name : test-bundle
App Path : hdfs://nn.mycompany.com:8020/user/joe/oozie/test_bundle/
Status : SUCCEEDED
Kickoff time : Tue Dec 20 10:30:00 UTC 2014
--------------------------------------------------------------------------------
Job ID Status Freq Unit
Started Next Materialized
--------------------------------------------------------------------------------
0000047-141219003455004-oozie-oozi-C SUCCEEDED 1 DAY
2014-12-20 10:30 GMT 2014-12-20 10:30 GMT
--------------------------------------------------------------------------------Bundle State Transitions
Figure 8-4 captures the state transitions that an Oozie bundle goes
through in detail. START, RUNNING, SUSPENDED, PAUSED, SUCCEEDED, FAILED, and KILLED are the most important and the most
common states you will encounter. Users are rarely exposed to some of the
other states in the picture, though they are all processed internally as part of the state management. The bundle
states are pretty self-explanatory and are very similar to the states for
the workflow and the coordinator that we have already seen.
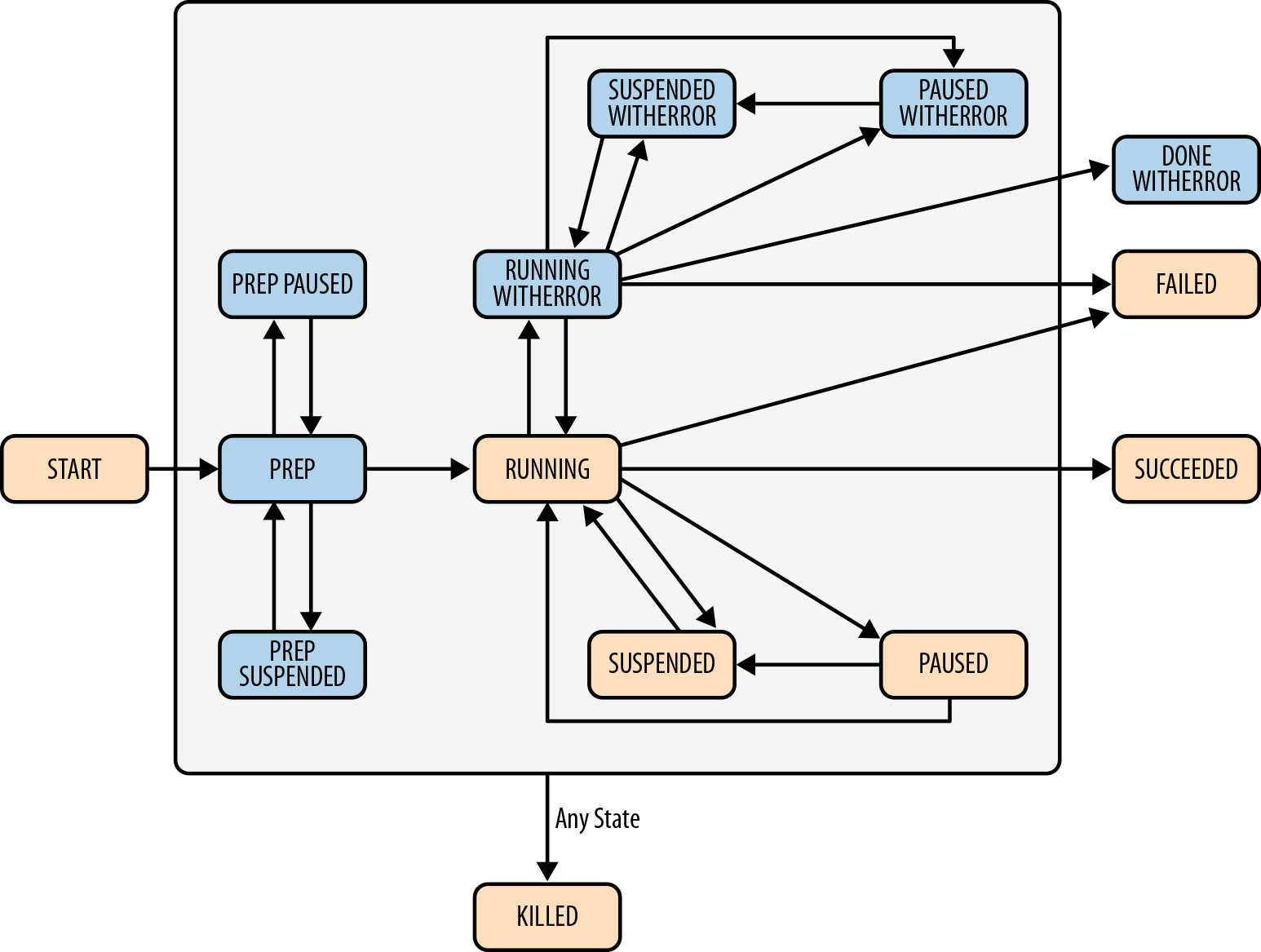
Figure 8-4. Bundle states
Note
Any state management operation you perform on the bundle, like suspending or killing it, will be propagated to the coordinators and workflows that are part of that bundle as well. They will also get killed or suspended or resumed implicitly. This is one of the benefits of using Oozie bundles.
In this chapter, we covered the Oozie bundle in detail. It’s not a complicated topic for application developers, but more of an operational concept. We encourage you to use the bundle construct to better manage your data pipelines. With this chapter, we are done covering all of the fundamental Oozie concepts in the form of workflows, coordinators, and bundles. You should be able to write and operate complete Oozie applications at this point. We will now look at more advanced topics starting with the next chapter and through the rest of this book.