
In This Chapter
Scalability and high availability (fault resilience) are two key infrastructure adaptability requirements that organizations must reflect in the architectural (system) design of their mission-critical e-business solutions. As illustrated in Figure 25.1, during the client/server era, scalability and high-availability solutions were primarily implemented in the Database or Server tiers, where

Databases were partitioned to provide scalability to the data architecture.
Data-centric business processing was migrated from the Client tier into the Database tier whenever feasible—for example, through the use of stored procedures, triggers, and packages in an Oracle database.
High availability was implemented in the Database tier through
Hardware and database software clustering solutions, which involved in-memory or file-system replication of data.
Hot-standby databases in conjunction with a robust and efficient backup and recovery solution.
To implement an agile and robust J2EE e-business solution, scalability and high availability solutions for the Database tier still remain applicable as they did for the client/server system, but now they address the Enterprise Information System (EIS) tier. However, as illustrated in Figure 25.2, scalability and high availability must now also be addressed at the distributed middle tiers of the J2EE Application Programming Model—the Presentation (Web servers) and Application (Application servers) tiers—which brings a whole new dimension of challenges. These challenges are as follows:
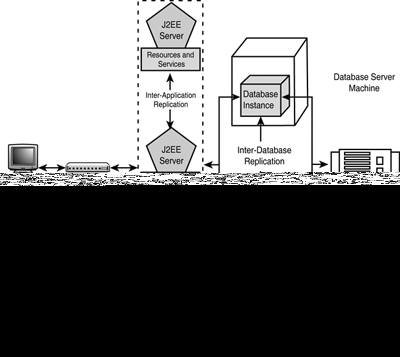
Figure 25.2. Scalability and high-availability requirements within the J2EE Application Programming Model.
Any potential points of failure must be masked from system users through effective Web and J2EE server failover mechanisms, thus eradicating or minimizing an application’s downtime.
Performance should not be compromised for scalability through the dynamic introduction of additional online Web and J2EE servers and hardware.
Scalability and high-availability solutions should not incur complex development or management efforts for realization.
The hardware and operating system portability of J2EE solutions should not be constrained through the mechanics of introducing scalability or high availability.
Scalability and high availability within a J2EE architecture are achieved through the implementation of client-request load-balancing techniques in combination with the clustering capabilities of the J2EE application server that constitutes the middle tier, such as the BEA WebLogic Server cluster. A cluster cannot possess scalability or high availability without the support of an intelligent and robust load-balancing service.
A cluster in a J2EE architecture is generally defined as a group of two or more J2EE-compliant Web or application servers that closely cooperate with each other through transparent object replication mechanisms to ensure each server in the group presents the same content. Each server (node) in the cluster is identical in configuration and networked to act as a single virtual server. Client requests directed to this virtual server can be handled independently by any J2EE server in the cluster, which gives the impression of single entity representation of the hosted J2EE application in the cluster.
The following sections introduce the three highly interrelated core services—scalability, high availability, and load balancing—that any J2EE server clustering solution must provide.
How these services are implemented within WebLogic Server will be discussed later in this chapter.
Scalability refers to the capability to expand the capacity of an application hosted on the middle tier without interruption or degradation of the Quality of Service (QoS) to an increasing number of users. As a rule, an application server must always be available to service requests from a client.
As you may have discovered through experience, however, if a single server becomes over-subscribed, a connecting client can experience a Denial of Service (DoS) or performance degradation. This could be caused by a computer’s network interface, which has a built-in limit to the amount of information the server can distribute regardless of the processor’s capability of higher throughput, or because the J2EE server is too busy servicing existing processing requests.
As client requests continue to increase, the J2EE server environment must be scaled accordingly. There are two approaches to scaling:
Forklift method—. This method involves replacing the old server computer with a new, more robust and powerful server to host the J2EE server. The problem with this approach is that it is a short-term fix. As traffic continues to increase, the new computer will likely become obsolete, like the server it replaced.
Clusters—. Clustering the J2EE servers makes it easy to dynamically increase the capacity of the cluster by just adding another node and updating the configuration of the load balancer to use the additional resource. Load balancers use a variety of algorithms to detect server request flows and monitor server loads to distribute server requests optimally across the cluster’s nodes. Conversely, you can just as easily remove a node to scale down or replace a node during normal maintenance or upgrading.
By applying conventional wisdom, the most logical method for achieving scalability is though the implementation of a clustering solution.
High availability refers to the capability to ensure applications hosted in the middle tier remain consistently accessible and operational to their clients.
High availability is achieved through the redundancy of multiple Web and application servers within the cluster and is implemented by the cluster’s “failover” mechanisms. If an application component (an object) fails processing its task, the cluster’s failover mechanism reroutes the task and any supporting information to a copy of the object on another server to continue the task. If you want to enable failover:
The same application components must be deployed to each server instance in the cluster.
The failover mechanism must be aware of the location and availability of the objects that comprise an application in a cluster.
The failover mechanism must be aware of the progress of all tasks so that the copy of a failed object can continue to complete a task where the processing last stopped without duplicating persistent data.
In the event of a failure to one of the J2EE servers in a cluster, the load-balancing service, in conjunction with the failover mechanism, should seamlessly reroute requests to other servers, thus preventing any interruption to the middle-tier service.
In addition to application server clustering, which provides high availability in the middle tier of an application architecture, organizations must accept that people, processes, and the technology infrastructure are all interdependent facets of any high-availability solution. People and process issues comprise at least 80% of the solution, with the technology infrastructure assuming the remainder.
From a people and process perspective, the objective is to balance the potential business cost of incurring system unavailability with the cost of insuring against planned and unplanned system downtime. Planned downtime encompasses activities in which an administrator is aware beforehand that a resource will be unavailable and plans accordingly—for example, performing backup operations, making configuration changes, adding processing capacity, distributing software, and managing version control. Unplanned downtime, also known as outages or failures, includes a multitude of “What happens if” scenarios, such as
What happens if a disk drive or CPU fails?
What happens if power is lost to one or more servers by someone tripping over the power cord?
What happens if there is a network failure?
What happens if the key system administrator finds a better job?
In practice, organizations should initially focus on developing mature, planned downtime procedures before even considering unplanned downtime. This is supported through extensive studies conducted by research firms, which concluded that 70–90% of downtime may be directly associated with planned downtime activities. However, the organizational reality indicates that more time and effort are applied to preventing unplanned downtime.
From a technology infrastructure perspective, for a system to be truly highly available, redundancy must exist throughout the system. For example, a system must have the following:
Redundant and failover-capable firewalls
Redundant gateway routers
Redundant SAN switching infrastructure
Redundant and failover-capable load balancers/dispatchers
Redundant Enterprise Information System (EIS) layer, for example, content management systems, relational databases, and search engine systems
As stated earlier, the extent of redundancy should be directly related to the business cost of system unavailability versus the realized cost of insuring against system downtime.
For a server cluster to achieve its high-availability, high-scalability, and high-performance potential, load balancing is required. Load balancing refers to the capability to optimally partition inbound client processing requests across all the J2EE servers that constitute a cluster based on factors such as capacity, availability, response time, current load, historical performance, and also administrative weights (priority) placed on the clustered servers.
A load balancer, which can be software or hardware based, sits between the Internet and the physical server cluster, also acting as a virtual server. As each client request arrives, the load balancer makes near-instantaneous intelligent decisions about the J2EE server best able to satisfy each incoming request. Software-based load balancers can come in the form of computers, routers, or switches with integrated load-balancing software or load-balancing capabilities. Hardware load balancers are separate pieces of equipment that provide advanced load-balancing features and additional reliability features such as automatic failover to a redundant unit.
In general terms, a WebLogic cluster is a group (two or more) of WebLogic Server instances (managed servers) that have been configured to share their resources, and through coordinated load balancing and replication mechanisms, the WebLogic cluster provides a very highly available and scalable execution environment for deployed J2EE Web and enterprise applications. An application deployed homogeneously to every server instance in a WebLogic cluster appears as a single instance of the application to a client, regardless whether the client is Web or Java based.
As illustrated in Figure 25.3, the administration server is responsible for configuring, managing, and monitoring all WebLogic Server instances (nonclustered and clustered) and resources in that domain. Because the administration server contains the configuration information for a WebLogic cluster, it must be available for connection to enable the clustered server instances to start up. When the clustered server instances are running, the availability of the administration server has no effect on the load-balancing and failover capabilities of the cluster. In a production environment, the administration server should not be configured as part of a WebLogic cluster because it must always be available for monitoring all other WebLogic instances and hence should not be overloaded with client requests.

From an administration perspective, each WebLogic cluster is managed as a single logical entity in the domain. For this reason, all WebLogic Server instances that constitute a cluster must reside in the same domain. Clusters cannot span across WebLogic domains.
For a clustering solution to be realized for both J2EE Web and enterprise applications, the WebLogic cluster provides scalability (via load balancing) and high-availability (via failover mechanisms) support for the following J2EE objects:
Note
File and Time services can be used within a cluster but cannot take advantage of any load-balancing or failover mechanisms.
The mechanisms the WebLogic cluster implements to ensure failover and load balancing for these objects vary in their implementation and are discussed in their respective sections later in this chapter.
The deployment restrictions differ between WebLogic Server 7 and WebLogic Server 7 SP1 (Service Pack 1) as follows:
WebLogic Server 7 SP1 allows the deployment of an application to a partial cluster, where all the clustered servers may not be reachable during the deployment process. As soon as the unreachable managed servers become available, the deployment process is reinitiated to these servers to complete the deployment process.
WebLogic Server 7 SP1 allows you to deploy a pinned service, such as an application to individual servers in a WebLogic cluster. However, because this type of deployment does not take full advantage of the load-balancing and failover capabilities of a WebLogic cluster, it is recommended you deploy such services to managed servers outside a WebLogic cluster.
Network communication between WebLogic Servers within a cluster is serviced by IP Multicast for all one-to-many broadcast type communications and IP sockets for all peer-to-peer messages and data transfers. The following sections describe how WebLogic Server uses these communication types.
IP Multicast is a network bandwidth-conserving broadcasting technology that reduces network traffic by efficiently delivering a single stream of information to a group of servers, known as a multicast group. In the context of the WebLogic cluster, the cluster itself is the multicast group, and the group’s membership or subscription to receive broadcast information is determined by the IP Multicast address specified for the cluster. For this reason, all WebLogic Server instances that constitute a WebLogic cluster share the same IP Multicast address. The Internet Assigned Numbers Authority (IANA), which controls the assignment of IP Multicast addresses, specifies an IP Multicast address must fall in the range of 224.0.0.0 to 239.255.255.255.
You specify the IP Multicast address when you create or configure a WebLogic cluster, as described later in this chapter.
Clustered WebLogic Servers use the IP Multicast address in conjunction with their TCP listen port to announce and listen for clusterwide communications, such as the following:
The availability of clustered objects that are either deployed or removed locally. This information is updated in the clusterwide JNDI tree, which is created and maintained locally by each WebLogic Server instance in a cluster. A clusterwide JNDI tree is similar to a single server instance JNDI tree, except that it also stores the services offered by clustered objects from other WebLogic Server instances in the cluster. Hence, through the combination of IP Multicast and JNDI, WebLogic Servers in a cluster are aware of the availability and location of all deployed clustered objects.
Cluster heartbeats, which are broadcast by each WebLogic Server instance in the cluster to uniquely advertise their availability to participate in load-balancing and failover operations. Each managed server in a WebLogic cluster broadcasts heartbeat messages approximately every 10 seconds and marks a peer clustered server as “failed” if it has not received a heartbeat from it within 30 seconds or three heartbeats. Upon marking a peer clustered server as “failed,” a managed server will update its local JNDI tree to avoid any failover mechanisms from leveraging that server in any way.
Because IP Multicast communications are critical to the operation of a WebLogic cluster, BEA recommends the following guidelines for avoiding transmission and reception problems with Multicast communication in a cluster:
Avoid spanning a WebLogic cluster over multiple subnets. However, if this is a requirement for your clustering topology, ensure your network meets the following requirements:
The network has complete and reliable support for IP multicast packet propagation.
The network latency allows multicast messages to be received at their destination within 200 to 300 milliseconds.
The value of the Multicast Time to Live (TTL) parameter for the WebLogic cluster is high enough to guarantee network routers do not discard multicast packets before they reach their final destination.
In general, WebLogic Server uses IP sockets for all Remote Method Invocation (RMI) communications. However, in the context of a WebLogic cluster, WebLogic Server also uses IP sockets for the following types of inter-cluster communications:
Replicating HTTP session and session bean states between two clustered servers during a failover operation
Accessing nonclustered and clustered objects that reside on another clustered server
Note
WebLogic Server also uses the unexpected closure of an IP socket during the transmission of data as an indication that a server in the peer-to-peer communication has failed.
Because these activities are critical, the type of IP socket reader you use has to be performance based. WebLogic Server can be configured to use the following IP socket reader implementations:
The pure-Java socket reader implementation, where the socket reader threads continually poll all opened sockets to determine whether they contain data to be read, even if the sockets have no data to read.
The native IP socket reader provided by the host machine’s operating system, where the socket reader threads target only active sockets that contain data to be read. Native socket readers never poll sockets because they are immediately notified when a socket needs to be serviced.
In general, for best performance, you should always use the native socket reader if possible. You should do so because, with the Java socket reader, you will always have to assess the potential socket usage of each managed server in a cluster based on peak usage of your cluster and then set the number of socket reader threads accordingly.
You can configure WebLogic Server easily to use the native socket reader thread implementation by following these steps in the Administration Console:
Select the Servers node in the left pane.
Select the WebLogic Server to configure.
In the right pane, select the Configuration, Tuning tab.
Check the Enable Native IO attribute and click Apply.
Tip
If you do use the pure-Java socket reader implementation, you can still improve the performance of socket communication by configuring the proper number of socket reader threads for each server instance. For best performance, the number of socket reader threads in WebLogic Server should equal the potential maximum number of opened sockets.
If you are using Java clients to access a WebLogic cluster, they will use the Java implementation of socket reader threads. In this case, to ensure high performance, you should configure enough socket reader threads in the Java Virtual Machine (JVM) that runs the client.
To implement a WebLogic cluster that meets the high-availability and scalability requirements of your J2EE application, you must understand the elements that constitute a WebLogic clustering environment as well as the benefits of one type of clustering design over another. The following section addresses these two topics and brings clarity to how you can architecturally design your WebLogic cluster.
If you are new to the concept of clustering, it is imperative for you to understand what constitutes a typical WebLogic clustering environment before you even begin to design an architecture for your WebLogic cluster.
As illustrated in Figure 25.4, a typical WebLogic cluster environment can consist of the following logical software tiers and services, which do not necessarily imply a division in hardware in the overall clustering architecture.

Figure 25.4. The typical software tiers and services that can constitute a WebLogic cluster environment.
A load balancer is a software or hardware mechanism that can distribute client connection requests to the servers in a WebLogic cluster. The objective of a load balancer is to ensure all clustered servers service incoming requests in the most optimal manner, which typically implies they are all operating at near full-processing capacity.
The load balancer serves as the single point of entry for a WebLogic cluster.
The distribution criteria of a load balancer are based on algorithms applied to the inbound network traffic. The following are some examples:
Note
The exact available algorithm depends on the capabilities of your load balancer. For example, the WebLogic Server HttpClusterServlet proxy supports only a round-robin algorithm for distributing requests, whereas dedicated load-balancing appliances offer more sophisticated load-balancing algorithms.
If you have an existing Web tier composed of Netscape, Microsoft, or Apache Web servers, you can leverage this software and hardware layer with a proxy plug-in supplied with WebLogic Server to serve only the static HTTP content of your J2EE application. Dynamic content requests to servlets or JSPs are delegated via the Web Server’s proxy plug-in to the servers in the WebLogic cluster that form the Presentation tier. You can also use WebLogic Server as a Web Proxy server by deploying the HttpClusterServlet.
Using a Web Proxy server does have its advantages because you can leverage the existing infrastructure as well as any firewall policies for the Web tier, which prevents direct connections to the WebLogic cluster. However, having a separate Web tier does involve extra setup and administration activities, and the load-balancing capabilities are constrained to a round-robin type strategy. Also, if clients are primarily accessing dynamic content, having a Web tier will increase the number of network connections required to access the WebLogic cluster, which will affect the latency of a client’s response.
As illustrated in Figure 25.4, WebLogic Server can be divided into two logical tiers, as follows:
Presentation tier—. This tier is, in essence, the Web container of WebLogic Server and is responsible for serving the dynamic content of a J2EE application via servlets and JavaServer Pages.
Object tier—. This tier is, in essence, the EJB container of WebLogic Server, which provides an execution environment for the business logic in a J2EE application via Enterprise JavaBeans.
The DeMilitarized Zone, or DMZ as it is known in the network community, is a perimeter network that is used to protect a specific trusted network environment from direct exposure to an untrusted (external network) environment. To define a DMZ, you first must identify the network environment you need to protect and then identify all the entrance points (front and back doors) to that network. In most cases, the entrance point is a Web server that is connected to the Internet or an untrusted intranet. In such a scenario, the Web server exists in the DMZ.
As you can see in Figure 25.4, you can secure a DMZ by using two firewalls. The one in front of the DMZ should be between the external network (Internet) and your DMZ, which is typically a group of Web servers. The second firewall should be between the DMZ and the internal network.
Generally, whenever an architectural discussion on how to design a WebLogic cluster occurs, the primary topics that influence the design directly relate to the way the cluster can guarantee the hosted application is very scalable and highly available. However, a WebLogic cluster in conjunction with a load-balancing mechanism, by default, provides a very scalable solution; WebLogic Servers can be added and removed from the cluster transparently to the clients.
Even though clustering is synonymous with both high availability and scalability, your architectural thoughts should be primarily aligned with ensuring a performance-oriented, highly available clustering solution. The following sections discuss two such clustering architectures you can consider: the combined-tier and multi-tier architectures, which differ based on the physical location of the presentation and object tiers.
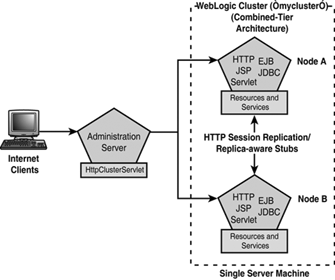
The combined-tier architecture, as illustrated in Figure 25.5, combines the Presentation and Object tiers of a J2EE application into a single WebLogic cluster. If a Web Proxy server is not used, the Web tier is also introduced into the cluster.

This clustering architecture meets the high-availability and scalability requirements for most J2EE applications, with the addition of the following advantages:
Ease of administration of the WebLogic cluster because a J2EE application needs to be deployed/undeployed only to and from the same WebLogic cluster using the Administration Console.
Optimized local method calls between the Presentation and Object tier. WebLogic Server uses a collocation strategy to optimize method calls to clustered objects (EJB or RMI classes), which prioritizes method calls to objects that are hosted on the same WebLogic Server instance as their replica-aware stub and avoids incurring any additional network overhead. Because all application objects are available locally to each WebLogic Server in the same cluster, the combined-tier architecture presents the best performance for J2EE applications where there is a high frequency of method invocations in the Object tier by the Presentation tier.
The limitation of the combined-tier architecture is that it does not provide an opportunity for introducing load balancing between the Presentation and Object tiers, which may be necessary if the method calls to the Object tier become unbalanced between the servers in the cluster. In such a scenario, the appropriate approach would be to split the Presentation and Object tiers of the J2EE application onto separate physical clusters as in the multi-tier architecture.
The primary purpose of the multi-tier architecture is to introduce load balancing between the Presentation and Object tiers of a clustered J2EE application. As illustrated in Figure 25.6, this load balancing is achieved by deploying the Presentation and Objects tiers of a J2EE application onto two different clustered servers.
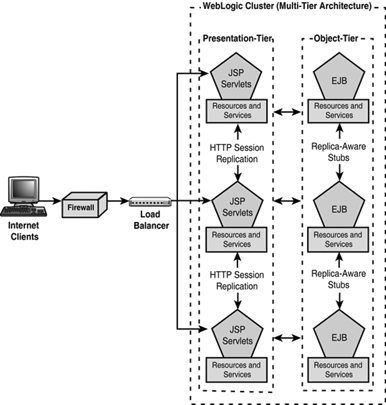
By hosting the Object tier on a dedicated clustered server, WebLogic Servers in the Presentation tier cannot use the collocation optimization strategy for accessing clustered objects.
As depicted in Figure 25.6, however, the Presentation tier does gain the capability to load-balance each method call to a clustered object. In the multi-tier architecture, a servlet acts as the client to the clustered objects. When requests are made to invoke an EJB, the servlet performs a JNDI lookup for the EJB and obtains a replica-aware stub for that bean, which contains the addresses of all servers that host the bean, as well as the load-balancing logic for accessing bean replicas.
Note
EJB replica-aware stubs and EJB home load algorithms are specified using elements of the EJB deployment descriptor.
The following are additional benefits for using the multi-tier architecture:
You have more options for load balancing the entire WebLogic cluster without having to scale the Presentation and Object tiers in tandem. For example, if you have a higher frequency of client access to the Presentation tier than the Object tier, you can increase (scale) the number of WebLogic Servers hosting the Presentation tier to a smaller number of Object tier WebLogic Servers.
Two clusters present a higher availability option for a J2EE application than just one, as in the case of the combined-tier architecture.
Although the multi-tier clustering architecture provides greater scalability and high-availability options, it does impose the following disadvantages when compared to the combined-tier architecture:
Whenever you have to deploy and manage an application over two clusters, it requires twice as much effort as just using one cluster.
There is a network overhead for all method calls to clustered objects. You also utilize more IP sockets in the Presentation tier to replicate sessions and connect to WebLogic Servers that host the clustered objects.
If you create a DMZ for the Presentation tier by placing a firewall between the Presentation and Object tiers, you will need to bind all WebLogic Servers in the Object tier to public DNS names as opposed to IP addresses because IP address translation problems can occur between the two tiers.
Now that you have gained an understanding of the types of clustering architectures you can employ with the WebLogic cluster, the next logical step is to create an actual WebLogic cluster. To methodically assist you in this process, the following sections focus on
How you can create and configure a WebLogic cluster using the tools provided with WebLogic Server
The guidelines you should adhere to when configuring your WebLogic cluster
How to configure a WebLogic cluster from existing managed servers within a domain
How to start your WebLogic cluster after you have configured it
How to monitor server participation in your WebLogic cluster
The primary tools you have available to create or configure a WebLogic cluster are the Domain Configuration Wizard and the Administration Console. Which tool you use depends on the type of clustering architecture you want to employ and the capabilities of these tools to support your efforts.
The Domain Configuration Wizard is an excellent tool if you are creating a WebLogic cluster from scratch. This tool presents you with options on the type of WebLogic domain you want to create. One such option is a domain with an administration server and one or more managed servers that are clustered. However, this option creates the administration server and the clustered WebLogic Server instances on the same single server machine.
The Administration Console is a tool that you can use to configure a WebLogic cluster from existing managed servers in a domain. For example, if your clustering architecture warrants the clustered servers to be on separate server machines, the best approach would be to create the administration server and managed servers independently on each of those machines using the Domain Configuration Wizard. After the managed servers are created and registered with the domain’s administration server, you could use the Administration Console to graphically configure a cluster from the existing managed servers.
You can also use the Administration Console to do the following:
Before you start creating your WebLogic cluster, it is worth reviewing the following guidelines for creating a cluster:
You should try to use DNS names in a production environment to specify the location of the managed servers that will comprise a WebLogic cluster. The use of IP addresses can result in IP address translation errors if you are using a firewall to form a DMZ. However, if you do use IP addresses, they should be permanently assigned to the server machine (static) and not dynamically assigned.
The WebLogic cluster must have a unique IP address and listen port combination for each of its managed server instances. The following are some examples:
If managed server instances in a cluster share an IP address, as in the case of a non-multihomed single server, a unique listen port number is assigned to each server instance in the cluster.
If managed server instances in a cluster have different IP addresses, they may use the same or different listen port numbers. This is applicable if managed servers exist on a multihomed machine or are physically located on separate server machines.
Each WebLogic Server instance in a cluster must run the same version of WebLogic Server software, including service packs.
You should use a dedicated multicast address and port for the sole purpose of enabling cluster communications. Also, each server machine must be able to receive multicast traffic. As you can see in Figure 25.7, you can test the capability of a server machine to receive and respond to multicast traffic by using the
MulticastTestutility and typing the following at the command prompt:
Figure 25.7. Testing the multicast network capabilities of a server machine using the
MulticastTestutility.java utils.MulticastTest -N Test -A <multicast address>Ideally, all managed servers should be located on the same network subnet. Avoid WAN tunneling if you can.
Do not cluster the administration server because the administration objects cannot be clustered and take advantage of any failover mechanisms.
This section provides a step-by-step guide showing how you can configure a WebLogic cluster using the Administration Console. The assumptions for this exercise are that you already have a WebLogic domain set up with two managed servers, and the network configuration for the WebLogic domain adheres to the clustering guidelines discussed in the preceding section. The name of the WebLogic domain, cluster and managed servers, and their network configurations can differ from those used in the example because the steps to configure the WebLogic cluster still remain the same.
Note
▸ To learn how to set up and configure a WebLogic domain, see “Understanding WebLogic Domains,” p. 777, “Creating and Extending WebLogic Domains,” p. 785, and “Configuring the Network Resources for a WebLogic Domain,” p. 798.
As illustrated in Figure 25.8, the WebLogic cluster to be configured (mycluster) will be hosted on a single, non-multihomed server machine, which implies that the same IP address will be used for each managed server, with differing listen port numbers. The attributes of the managed servers that will be used to form the mycluster WebLogic cluster are described in Table 25.1.

Tip
It is good practice to visualize and document the attributes of your cluster before you create it.
Table 25.1. The Attributes of the Managed Servers in the mycluster WebLogic Cluster
Managed Server Name | Listen Address (DNS) | Listen Port |
|---|---|---|
NodeA | EINSTEIN | 7003 |
NodeB | EINSTEIN | 7005 |
Tip
If your server machines are dynamically assigned IP addresses, you should use the server DNS names as the listen addresses.
To configure the mycluster WebLogic cluster using the Administration Console, follow these steps:
Launch the Administration Console in a Web browser using the appropriate URL for your administration server.
From the left pane in the Administration Console, select the Clusters node.
In the right pane of the Administration Console, click Configure a New Cluster.
On the Create a New Cluster screen (the Configuration, General tab), enter the following information, as shown in Figure 25.9:
Name—. Enter a name to identify the WebLogic cluster—for example,
mycluster.Cluster Address—. Define the address to be used by clients to connect to your cluster as a list that contains the DNS name (or IP address) and listen port for each managed server that will comprise the cluster—for example,
DNSName1:port1,DNSName2:port2,DNSName3:port3 DNSName1:port1,DNSName1:port2,DNSName1:port3
Note
The cluster address is used in entity and stateless beans to construct the hostname portion of URLs.
You can also specify just the DNS name that maps to the IP addresses for each WebLogic Server instance in the cluster. However, this assumes that each managed server has a unique IP address and the same port—for example,
DNSName1:port1,DNSName1:port2,DNSName1:port3
From Table 25.1, the cluster address for the mycluster WebLogic cluster is as follows:
EINSTEIN:7003,EINSTEIN:7005
Each WebLogic Server instance in a cluster must have a unique combination of IP address and listen port number.
Default Load Algorithm—. Select the algorithm to be used for load-balancing method calls between replicated EJBs and RMI classes; your choices are Round-Robin, Weight-Based, or Random. (The default is Round-Robin.)
WebLogic Plug-in Enabled—. Select this option if you are using a WebLogic plug-in for a third-party Web server.
Service Age Threshold—. Enter the number of seconds by which the age of two conflicting services must differ before one is considered older than the other. (The default is 180 seconds.)
Client Cert Proxy Enabled—. Select this option if you are using the
HttpClusterServletproxy because it enables the client certificate to be securely proxied using a special header.
Click Create to configure your new cluster.
Select the Configuration, Multicast tab to configure the Multicast parameters for your new WebLogic Server. Enter the following Multicast information for your new WebLogic cluster, as shown in Figure 25.10:
Multicast Address—. Enter the multicast address to be used by cluster members to broadcast messages and communicate between each other. (The default is 237.0.0.1.)
Multicast Port—. Enter the multicast port number to be used in conjunction with the multicast address. The default is 7001, but if it conflicts with your other ports, you should change it to a value between 1 and 65535.
Multicast Send Delay—. Enter the number of milliseconds to delay broadcasting message fragments over multicast to avoid an OS-level buffer overflow. (The default is 12 seconds.)
Multicast TTL—. Enter the number of network hops that a multicast message is allowed to travel. (The default is 1, which restricts the cluster to multicast within the local subnet.)
Multicast Buffer Size—. Enter the multicast socket send/receive buffer size. (The default is 64KB.)
Click Apply to save your multicast settings.
Click the Servers tab and select the managed servers that will be assigned into your WebLogic cluster, as shown in Figure 25.11.
Click Apply to save your clustered server settings.



This completes the tasks related to configuring a WebLogic cluster using the Administration Console. The next section describes how you can now start your WebLogic cluster.
You can start a WebLogic cluster using the following methods:
Using the command shell, where each clustered server is manually started in a separate command shell
Using the Administration Console in conjunction with the Node Manager
To start any clustered managed server, you first need to start the administration server for the domain, which will copy the clustered configuration information to the clustered managed servers upon startup. The general steps for starting an administration server are as follows:
From a command shell, set the environment for your domain by executing the
setEnvcommand.Execute the
startWebLogiccommand.
The following sections describe how to start the mycluster WebLogic cluster created previously using both of these methods.
You start managed servers that participate in a WebLogic cluster in the same manner as you would start them if they were not clustered. The command syntax for starting a managed server is
StartManagedWebLogic server_name address:port
where
server_nameis the name of the managed server you need to startaddressis the IP address or DNS name for the administration server for your domainportis the listen port for the administration server for the domain
For example, to start the clustered managed servers in mycluster, you enter the following commands in separate command shells:
StartManagedWebLogic NodeA EINSTEIN:7001 StartManagedWebLogic NodeB EINSTEIN:7001
As shown in Figure 25.12, during the startup process, a clustered managed server joins its WebLogic cluster and tries to synchronize information with other online managed servers in the cluster.

The primary advantage of using the Administration Console to start a WebLogic cluster is that you can start all constituent clustered managed servers at the same time. Alternatively, you can start the clustered managed servers individually, if required.
The Administration Console can, by default, be used to kill managed servers without the Node Manager. However, the Administration Console can only start managed servers in conjunction with the Node Manager. For this reason, even if the clustered managed servers are located on the same machine as the administration server, you need to perform the following tasks to enable the Administration Console to start a clustered managed server or a cluster of managed servers:
Configure and run the Node Manager on each server machine where a clustered managed server resides. For example, if you have configured a WebLogic cluster on a single non-multihomed machine (such as mycluster), you still need to configure and run the Node Manager on that machine.
Configure machine definitions for each managed server in the WebLogic cluster.
Configure the Node Manager’s listen address and port for each machine definition.
Configure SSL communication for all managed servers in the WebLogic cluster. (Node Manager uses SSL for all communication between the administration server and managed servers.)
Even though these procedures may appear to be very complicated, they are relatively easy to perform and are methodically explained in Chapter 4.
After you configure your administration server to remotely start managed servers using the Node Manager, you can follow these steps to start a WebLogic cluster:
As shown in Figure 25.13, this procedure initiates WebLogic tasks to start all the managed servers assigned to your WebLogic cluster.

After you set up a WebLogic cluster, the next administration task is to adopt a technique that allows you to monitor the number of active servers participating in it. This task is important because in a production environment the capability to provide performance-based high availability and workload load balancing is directly influenced by the number of active managed servers that constitute a WebLogic cluster.
The most immediate technique to accomplish this task is via the Administration Console using the following steps:
Select the WebLogic cluster you want to monitor in the left pane of the Administration Console.
Select the Monitoring tab in the right pane, which will display a high-level view of the servers participating in your cluster.
Click the Monitor Server Participation in This Cluster link to open a detailed view of your clustered managed servers, as shown in Figure 25.14.
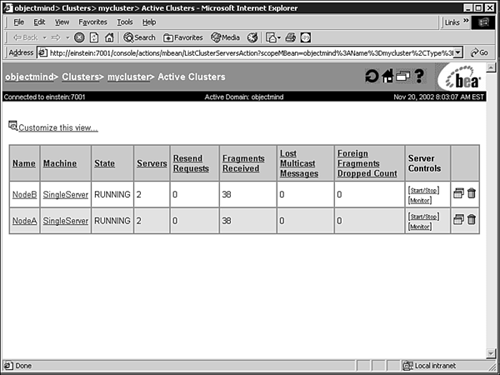
Alternatively, you can create a servlet or JavaServer Page to access WebLogic Server’s Runtime MBeans to display customized and consolidated information about your WebLogic domain and its managed resources, including nonclustered and clustered servers. To programmatically retrieve information about a WebLogic cluster, you must access the APIs of an instance of the ClusterRuntimeMBean, which are hosted only on those managed servers actively participating in a WebLogic cluster.
To assist you in creating such a servlet or JavaServer Page, Listing 25.1 provides the fully commented Java code for the infoCluster servlet, which performs the following tasks:
Retrieves the Administration MBeanHome, which runs on the administration server and provides access to all ClusterRuntimeMBeans in the domain
Retrieves the name of the active domain
Retrieves the name, listen address, and port information of the WebLogic Servers in the domain
Retrieves the name of the managed servers where the instance of the ClusterRuntimeMBean has been accessed
Retrieves the number and names of the active managed servers in a WebLogic cluster
Example 25.1. The infoCluster Servlet for Accessing Runtime Information about Your WebLogic Domain and Cluster
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.Set;
import java.util.Iterator;
import javax.naming.*;
import weblogic.jndi.Environment;
import weblogic.management.MBeanHome;
import weblogic.management.configuration.ServerMBean;
import weblogic.management.runtime.ClusterRuntimeMBean;
import weblogic.management.WebLogicObjectName;
public class infoCluster extends HttpServlet {
public void service(HttpServletRequest req,
HttpServletResponse res)
throws IOException {
// Declare MBean and other variables
MBeanHome home = null;
ServerMBean server = null;
ClusterRuntimeMBean clusterRuntime = null;
String name="";
String[] aliveServerArray = null;
// Initialize
Set mbeanSet = null;
Iterator mbeanIterator = null;
// Set the content type for the response
res.setContentType("text/html");
// Obtain a PrintWriter to insert HTML into
PrintWriter out = res.getWriter();
// Setup the start of the HTML page
out.println("<HTML><HEAD><TITLE>infoCluster Servlet Example</TITLE>");
out.println("<BODY><H1><strong><font size=5>Your WebLogic Cluster" +
"Information:</font></strong></H1>");
// Set the initial context
try {
Environment env = new Environment();
Context ctx = env.getInitialContext();
// Get the Administration MBeanHome
home = (MBeanHome) ctx.lookup("weblogic.management.adminhome");
} catch (Exception e) {
out.println("<br>Exception caught: " + e);
}
try {
out.println("<p><BR><strong><u>Your Active Domain is " +
"<font color=#000000>"+ home.getActiveDomain().getName() +
"</font></u></strong></p>");
} catch (Exception e) {
out.println("<br>Exception: " + e);
}
out.println("<p><strong> <u>The WebLogic Servers in your Domain are:" +
"</u></strong></p>");
try {
mbeanSet = home.getMBeansByType("Server");
mbeanIterator = mbeanSet.iterator();
while(mbeanIterator.hasNext()) {
server = (ServerMBean)mbeanIterator.next();
out.println("<p><strong> <u> Server Name</u>:" +
"<font color=#000000>" + server.getName() +
"</font> <BR>");
out.println("ListenAddress: " + server.getListenAddress() +
"<BR>");
out.println("ListenPort: " + server.getListenPort() + "<BR>");
}
} catch (Exception e) {
out.println("<br>Exception: " + e);
}
// Retrieving a list of ClusterRuntime MBeans in the domain.
out.println("<p><strong><u>Your WebLogic Clustering Information:" +
"</u> <BR>");
try {
mbeanSet = home.getMBeansByType("ClusterRuntime");
mbeanIterator = mbeanSet.iterator();
while(mbeanIterator.hasNext()) {
// Retrieving one ClusterRuntime MBean from the list.
clusterRuntime = (ClusterRuntimeMBean)mbeanIterator.next();
// Get the name of the ClusterRuntime MBean.
name = clusterRuntime.getName();
out.println("Cluster information retrieved from the " +
"ClusterRuntime MBean on server " + name + "<BR>");
// Using the current ClusterRuntimeMBean to retrieve the number
// of servers in the cluster.
out.println("Number of active servers in the cluster: " +
clusterRuntime.getAliveServerCount() + "<BR>");
// Retrieving the names of servers in the cluster.
aliveServerArray = clusterRuntime.getServerNames();
break;
}
} catch (Exception e) {
out.println("<br>Exception: " + e);
}
if(aliveServerArray == null) {
out.println("<br>There are no running servers in the cluster");
}
else {
out.println("The running Managed Servers in the cluster are: ");
for (int i=0; i < aliveServerArray.length; i++) {
out.println("("+ aliveServerArray[i] + ")" +" ");
}
}
out.println("</strong> </p></BODY></HTML>");
}
}
Note
You can find the full list of APIs for the ClusterRuntimeMBean in WebLogic Server’s JavaDoc documentation, which you can download from e-docs.bea.com.
The infoCluster servlet should be deployed to your administration server to ensure you are monitoring your WebLogic cluster from an external server. The output of the infoCluster servlet is shown in Figure 25.15.

As stated earlier in this chapter, you have two options for implementing a load-balancing mechanism for your Presentation tier:
Use a WebLogic proxy plug-in.
Use a separate load-balancing hardware appliance.
Both options are discussed in detail in the following sections.
The WebLogic proxy plug-in is an ideal solution if you want to leverage an existing Web tier composed of Netscape, Microsoft, or Apache Web servers to proxy (forward) connection requests to the WebLogic cluster. Alternatively, you can also use WebLogic Server with the HttpClusterServlet as a proxy server.
In a proxy server load-balancing scenario, when an HTTP client requests a servlet or JSP, the proxy plug-in or HttpClusterServlet proxies the request to a managed server in the WebLogic Server cluster. The accessed servlet or JSP maintains data on behalf of a connecting client by using a dedicated HttpSession object, which is created on a per-session basis. When the HTTP response is sent back to a client via the proxy server, the client’s browser is instructed to write a cookie that lists the primary and secondary locations of the session’s HttpSession object.
Tip
If the client’s browser does not support cookies, the managed server can use URL rewriting instead to embed the primary and secondary locations of the HttpSession object into the URLs passed between the client and proxy servers.
The primary location is the address of the managed server that received and processed the initial HTTP connection request. For subsequent HTTP requests, the proxy plug-in or HttpClusterServlet automatically maintains a “sticky” connection between the client and its primary HttpSession object location. The secondary location is the address of a managed server that maintains a replica of the HttpSession object that is used for in-memory session state failover purposes only; this object is discussed later in this chapter.
Tip
The HttpClusterServlet automatically maintains a list of managed servers in a WebLogic cluster, but you will have to configure this information manually and identically for each third-party Web server using the WebLogic proxy plug-in.
The limitation for using a proxy server load-balancing solution is that you are currently constrained to using a round-robin strategy for distributing client requests to the managed servers in a WebLogic cluster.
To showcase the load-balancing capabilities of the WebLogic proxy plug-in, as well as set up a WebLogic environment for subsequent examples in this chapter, the following section discusses how you can easily configure an HttpClusterServlet load-balancing solution.
By default, the HttpClusterServlet is included with every WebLogic Server installation. However, for it to be able to function, the servlet must be deployed as the default application to WebLogic Server that will serve as the proxy server for a domain. Previously in this chapter, you configured the mycluster WebLogic cluster in your WebLogic domain. To demonstrate the load-balancing capabilities of the WebLogic proxy plug-in, you can deploy the HttpClusterServlet as the proxyApp default Web application on the administration server (AdminServer) of your WebLogic domain, which will serve as the proxy server, as illustrated in Figure 25.16.
Caution
This configuration is used for demonstration purposes only. In a production environment, you should use a dedicated managed server as a proxy server and ensure the administration server is used only for administration tasks.
Follow these steps to create and deploy the proxyApp Web application to the administration server of your WebLogic domain:
Note
If you use different names for your domain, administration server, and WebLogic cluster, substitute those names where appropriate.
Create a directory named
proxyAppin the root of your%BEA_Home%objectminduser_projectsdirectory. Within this directory, create another directory calledWEB-INF.Create a file called
web.xmlin theWEB-INFdirectory and open it with any text editor.Enter the text shown in Listing 25.2, ensuring you modify the names and port numbers of the managed servers you specified when you created your WebLogic cluster.
Example 25.2. The
web.xmlFile for the proxyApp Application<web-app> <servlet> <servlet-name>HttpClusterServlet</servlet-name> <servlet-class>weblogic.servlet.proxy.HttpClusterServlet</servlet-class> <init-param> <param-name>WebLogicCluster</param-name> <param-value>EINSTEIN:7003|EINSTEINt:7005</param-value> </init-param> <init-param> <param-name>DebugConfigInfo</param-name> <param-value>ON</param-value> </init-param> </servlet> <servlet-mapping> <servlet-name>HttpClusterServlet</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>HttpClusterServlet</servlet-name> <url-pattern>*.jsp</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>HttpClusterServlet</servlet-name> <url-pattern>*.htm</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>HttpClusterServlet</servlet-name> <url-pattern>*.html</url-pattern> </servlet-mapping> <web-mapping>You can also include the following useful parameter, which creates a proxy log file under the default temp directory:
<init-param> <param-name>Debug</param-name> <param-value>ALL</param-value> </init-param>Save the file.
Create the proxyApp Web application (WAR file) by executing the following command from within the root of the
proxyAppdirectory:jar cfv proxyApp.war *.*
From the left pane of the Administration Console, select Web Applications under the Deployments node and click the Configure a New Web Application link.
At the bottom of the screen, navigate until you find the
proxyAppdirectory you created earlier. Click the proxyApp link and then click the Select link next toproxyApp.war, as shown in Figure 25.17.On the Configure Application or Component screen, select your target proxy server (AdminServer) and click Configure and Deploy.

After you deploy the proxyApp Web application, the next task is to specify that it is the default Web application on your proxy server. To do this, follow these steps:
As you can see in Figure 25.18, you can test the HttpClusterServlet by using the following URL in a Web browser, substituting the correct IP address or DNS name and port for your proxy server:
http://EINSTEIN:7001/foo.jsp?__WebLogicBridgeConfig

From this point onward, you can access applications deployed on your WebLogic cluster via a single entry point, your proxy server, using the following URL:
http://ip_address_of_proxy_server:port_of_proxy_server/<Application>
If you require a more sophisticated HTTP connection distribution strategy than just purely a round-robin approach, you should opt to use a hardware load-balancing appliance solution.
In a load-balancing appliance scenario, when a client requests a servlet or JSP directly using an IP address, the load balancer routes the client’s connection request to any available managed server in the WebLogic cluster in accordance with a selected load-balancing algorithm supported by the appliance. The managed server that receives the client request serves as the primary location of the client’s HttpSession object. The secondary or replica HttpSession object is immediately created on another managed server. As a client initiates subsequent HTTP requests to the WebLogic cluster, the load-balancing appliance uses an identifier in the client-side cookie to ensure these requests are directed to the primary location of the client’s HttpSession object.
In its default configuration, WebLogic Server uses client-side cookies to keep track of the primary and secondary locations of the HttpSession object. Hence, to ensure a “sticky” connection between the client and its primary HttpSession object location using cookies, the load-balancing appliance must support a passive or active cookie persistence mechanism, as well as SSL persistence. If cookies are not supported by the client, as in the case of WAP-enabled devices, you must do the following:
Enable the managed server’s URL rewriting capabilities by setting the
URLRewritingEnabledattribute in theweblogic.xmlfile, under the<session-descriptor>element. The default value for this attribute istrue.Configure the load-balancing appliance to extract the location of the primary
HttpSessionobject from inbound URLs.
A clustered WebLogic Server provides high availability for servlets and JSPs (in the Presentation tier) by transparently replicating client session data contained in HttpSession objects via in-memory replication or file-based or JDBC-based persistence. The following sections discuss each of these HTTP session state failover mechanisms.
With in-memory replication, a primary HttpSession object is created on the clustered managed server to which the client first connects and accesses a servlet or JSP. To support automatic failover for HTTP session states, a clustered managed server replicates the primary HttpSession object in memory to a secondary managed server in the same WebLogic cluster. The replicated HttpSession object is known as the replica or backup HttpSession object. As session data is modified in the primary HttpSession object, the managed server ensures the replica is kept up to date so that it may be used if the clustered managed server that hosts the primary HttpSession object fails.
If the managed server hosting a primary HttpSession object were to fail, the mechanism that a WebLogic cluster uses to provide transparent session state failover is dependent on the type of load-balancing solution that is being used: a WebLogic proxy plug-in or hardware appliance.
In the case of a load-balancing solution that uses a WebLogic proxy plug-in and client-side WebLogic Server cookies, the proxy plug-in uses the cookie information to automatically redirect subsequent HTTP requests to the clustered server hosting the replica HttpSession object. The replica HttpSession object is then upgraded to the primary HttpSession object, and a replica HttpSession object is created on another managed server in the WebLogic cluster. In the HTTP response, the proxy server updates the client’s cookie to reflect the new primary and secondary servers as a safeguard for subsequent HttpSession object failovers.
Note
If URL rewriting is used, the proxy server extracts the session ID and the primary and secondary HttpSession object servers from the inbound client URL.
In the case of a load-balancing solution that uses a hardware appliance, the primary and replica HttpSession object locations in a cookie or URL serve only as a history for a client’s session state locations. Because the hardware appliance will redirect the failed HTTP request to any available managed server in a WebLogic cluster based on a certain algorithm, the WebLogic cluster uses the replica to create a new primary HttpSession object on the newly targeted managed server. Hence, the replica HttpSession object remains as the replica. The new information about the primary HttpSession object location is updated in the client’s cookie, or via URL rewriting.
The type of session state persistence you are going to implement is specified in the WebLogic Deployment Descriptor (weblogic.xml) file for a deployed Web application via the PersistentStoreType parameter. To specify in-memory replication for a Web application, edit the weblogic.xml file using an XML editor and set the value of this parameter to replicated as follows:
<session-descriptor>
<session-param>
<param-name>PersistentStoreType</param-name>
<param-value>replicated</param-value>
</session-param>
</session-descriptor>
When a primary HttpSession object is created, it is the responsibility of the hosting managed server to rank other managed servers within the same WebLogic cluster to determine which server will host the replica HttpSession object. By default, a managed server will attempt to create the replica HttpSession object on a different machine than the one that hosts the primary HttpSession object.
Through the configuration of replication groups, however, you can influence the location of the replica HttpSession objects. A replication group is a list of clustered managed servers within the same WebLogic cluster that serve as preferred locations for replica HttpSession objects.
You can use the Administration Console, as shown in Figure 25.19, to assign a clustered managed server to

A replication group, which defines a preferred logical group of clustered managed servers for hosting the replica
HttpSessionobjectsA preferred secondary group, which defines a secondary logical group of clustered managed servers that can be considered for hosting the replica
HttpSessionobjects
How a managed server ranks other managed servers in a WebLogic cluster is described in Table 25.2.
Table 25.2. The Ranking Rules for Selecting a Host for a Replica HttpSession Object
Server Rank | Managed Server Resides Physically on Another Machine | Managed Server Is a Member of the Preferred Replication Group |
|---|---|---|
1 | Yes | Yes |
2 | No | Yes |
3 | Yes | No |
4 | No | No |
Using the rules described in Table 25.2, the primary managed server ranks other members of the cluster and selects the highest-ranked server to host the replica HttpSession object.
The quickest way to verify whether your WebLogic cluster is providing session state failover using in-memory replication in conjunction with your load-balancing solution is to build and deploy the inmemrep Web application, which comes bundled with WebLogic Server if you opted to install the WebLogic Server examples during the server’s installation process.
The following steps describe how to build and deploy the inmemrep Web application to the WebLogic cluster (mycluster) you configured earlier in this chapter:
Open a new command shell and set up your WebLogic environment by executing the
setEnvcommand from the root of your domain’s (objectmind) directory.Change directories to the following:
%wl_home%samplesserversrcexamplesclustersessionrepinmemrepUse the build script to compile the Web application by executing the
antcommand. This process builds both the JSP and deployment descriptors and packages them in a WAR file namedInMemRepClient.war.From the Administration Console, click the Application link under the Deployments node in the left pane and click the Configure a New Application link.
Use the links at the bottom of the page to navigate to the location of the
InMemRepClient.warfile and click the Select link next to theInMemRepClient.warfilename.Select the cluster that was previously created (mycluster) as your target for deployment and click Configure and Deploy.
When the InMemRepClient Web application is deployed, you can access it by navigating to the following URL in a Web browser:
http://ip_address_of_proxy:port_of_proxy /InMemRepClient/Session.jsp.
You can add some values to the JSP, as shown in Figure 25.20, and bring down the clustered server from which you just requested the JSP. Now you can refresh the browser to demonstrate in-memory session persistence. You will notice the session is now hosted on another machine.

File-based persistence implies that you will be using a system directory to store all the session information related to your Web application. The requirements for using this type of session persistence mechanism are as follows:
The system directory must be shared and available to each managed server in the WebLogic cluster.
You must have enough disk space to store the session information (the number of valid sessions multiplied by the size of each session).
To specify file-based persistent session storage for a Web application, edit the associated weblogic.xml file using an XML editor and set the value of the PersistentStoreType and PersistentStoreDir parameters as follows:
<session-descriptor>
<session-param>
<param-name>PersistentStoreType</param-name>
<param-value>file</param-value>
<param-name>PersistentStoreDir</param-name>
<param-value>your_shared_folder_name</param-value>
</session-param>
</session-descriptor>
Here, your_shared_folder_name specifies the directory path where the clustered managed servers will write and retrieve their respective session’s data.
Using the file-based persistence approach allows all managed server instances in a WebLogic cluster to have access to all the generated session data. Hence, client HTTP requests can be serviced by any managed server in a WebLogic cluster. The HttpSession object can fail over to any clustered server in a WebLogic cluster and still have access to its session state data.
However, there is a significant reduction in the WebLogic cluster’s performance using this approach because session state is continuously being written to the disk system, and session data needs to be retrieved from the disk upon session failover. Also, an added concern is that if you lose the disk system where the session is persisted, you also lose all your session data.
JDBC-based persistence is similar to file-based persistence because it also allows all managed server instances in a WebLogic cluster to have access to all the generated session data, with the exception that the session data is now persisted to database instead of a file system. The advantage of using a database for storing persistent session storage is that you can leverage the high-availability, scalability, and high-performance features of a database to safeguard as well as provide performance-based writing and retrieval of session data. However, this method of session persistence is still not as fast as in-memory replication.
To specify JDBC-based persistent session storage for a Web application, follow these steps:
Create a table named
wl_servlet_sessionsin the database using the column and data type information described in Table 25.3.Table 25.3. The Column and Data Type Information for the
wl_servlet_sessionsTableColumn Name
Data Type
wl_id(primary key)Variable-width alphanumeric column, up to 100 characters
wl_context_path(primary key)Variable-width alphanumeric column, up to 100 characters
wl_is_newSingle-character column
wl_create_time20-digit numeric column
wl_is_validSingle-character column
wl_session_valuesLarge binary column
wl_access_time20-digit numeric column
wl_max_inactive_intervalInteger column
Assign a connection pool that has read/write permissions to the
wl_servlet_sessionsdatabase table to your WebLogic cluster.Assign the connection pool’s associated data source to the same cluster.
Edit the associated
weblogic.xmlfile using an XML editor and set the value of thePersistentStoreTypeandPersistentStorePoolparameters as follows:<session-descriptor> <session-param> <param-name>PersistentStoreType</param-name> <param-value>jdbc</param-value> <param-name>PersistentStorePool</param-name> <param-value>Connection_Pool_Name</param-value> </session-param> </session-descriptor>
Here, Connection_Pool_Name specifies the JDBC connection pool to be used for persistence storage.
As illustrated in Figure 25.21, in a nonclustered WebLogic Server environment, a client such as a servlet or JSP uses the Home interface of the EJBHome object to locate and create an instance of the bean (EJBObject). After receiving a reference to the bean instance, the client is then able to invoke the methods of the EJBObject via the bean’s Remote interface.
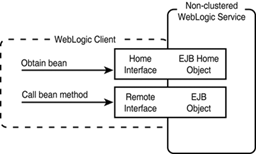
Figure 25.21. The Home and Remote interfaces of an EJB in a nonclustered WebLogic Server environment.
As illustrated in Figure 25.22, in a WebLogic cluster environment, the load-balancing and failover mechanisms for EJBs, as well as RMI objects, are implemented using replica-aware stubs for the Home and Remote interfaces. These replica-aware stubs are generated through the compilation process of a cluster-aware EJB, as defined in the weblogic-ejb-jar.xml file. The weblogic.ejbc utility passes the cluster-aware interfaces through the rmic compiler, which then generates the replica-aware stubs for the respective EJB.

Note
Replica-aware stubs for the RMI object are created explicitly using the command-line options to the rmic utility.
The following section describes the replica-aware stubs for the Home and Remote interfaces in more detail.
When you deploy a clustered EJB to a clustered WebLogic Server, the replica-aware Home stub of the bean is bound to the server’s local JNDI tree. The clustered server then updates the clusterwide JNDI tree by sending a JNDI announcement to other server members of the WebLogic cluster via a multicast broadcast message.
When clients connect to a WebLogic cluster and look up a clustered EJB, they obtain a replica-aware stub for that EJBHome object. However, instead of representing a single EJBHome object, this replica-aware stub contains the following:
The logic required to locate the replicas (
EJBHomeobjects) on any clustered server instance on which the EJB was deployedThe load-balancing logic for distributing the workload among those clustered server instances on which the replicas are located
The failover logic, to transparently retry the call to another replica, if the stub intercepts an exception
Tip
To ensure scalability and high availability for your clustered EJBs, you should deploy them homogeneously to your WebLogic cluster.
When a client invokes the create() method, the replica-aware Home stub routes the call to one of the EJBHome object replicas it is aware of via the replica handler. The replica then creates an instance of the bean and returns a replica-aware Remote (EJBObject) stub, which contains the logic to locate replicas (EJBObject objects) on any clustered server instance on which the EJB is deployed. However, unlike EJBHome objects, which can all use replica-aware Home stubs, only stateful and stateless session EJBs can leverage replica-aware Remote stubs.
Because all Home stubs are replica aware, the replica handler can provide the following load-balancing and failover algorithms for routing calls to the EJBHome object:
Round-robin load balancing—. Is the default load-balancing strategy for replica-aware stubs if no algorithm is specified. This is a simple and predictable load-balancing strategy in which the replica handler cycles through a list of clustered server instances that host the target replicas for a specific stub.
Weight-based load balancing—. Improves the round-robin strategy by allowing you to factor a pre-assigned weight between 1 and 100 to each clustered server. This weight value determines what proportion of the overall workload a server will bear relative to other servers. The higher the weight value, the more likely a server will be chosen by the replica handler. For example, you can assign a higher weight value to those servers that have a greater processing capability.
Random load balancing—. Distributes replica requests randomly among targeted server hosts. This approach should be used only if the other load-balancing strategies do not meet your requirements and you have a homogeneous WebLogic cluster environment.
Parameter-based routing—. Is a Call Router class created by a developer and associated with a replica-aware stub to provide custom parameter-based routing of your replica requests. The Call Router class is called before the replica request is invoked and passed the parameters of the request. The Call Router examines these parameters and returns the name of the server where the replica request should be made based on its programmed routing logic. See the BEA WebLogic Server documentation for more information on how to implement a Call Router class.
You can configure a cluster to use one of the preceding algorithms, with the exception of the parameter-based routing mechanism, using the Administration Console:
From the left pane of the Administration Console, select the Clusters node.
Select your cluster.
On the Configuration, General tab, shown in Figure 25.23, perform the following tasks:
Default Load Algorithm—. Select your load-balancing algorithm from the drop-down list.
Service Age Threshold—. Enter a value that specifies the number of seconds by which the age of two conflicting services must differ before one is considered older than the other.

The algorithm you select is maintained within the replica-aware stubs obtained for the clustered EJB objects.
WebLogic Server does not always perform load balancing for an EJB method call because it is more efficient to use a replica that is collocated with the Remote stub itself. This prevents additional overhead for calling a replica located on a remote server.
By default, a stateless session bean’s Home stub provides load balancing and failover for its method invocations to any clustered server where the bean is deployed. Because stateless session beans hold no state on behalf of their clients, stateless beans of the same type are identical in a WebLogic cluster. For this reason, a replica-aware Remote stub can also load-balance its method invocations to any clustered server where the bean is deployed.
By default, the Remote stub supports automatic failover of only those methods that occur after a method completes or if the method fails to connect to a server. If a method incurs a failure before it completes, the Remote stub does not automatically fail over the method invocation from one replica to another. Preventing automatic failover in this manner ensures a recovered method call is never able to duplicate persistent information, which could have been modified when the method initially failed.
If your stateless session bean contains idempotent methods, however, you can force the replica handler to retry a failed call without knowing whether the method actually completed on the failed server. Idempotent methods are those methods that typically do not persist their results and can be called repeatedly with the same arguments to produce the same result, irrespective of the location of the bean.
You can specify that a stateless session bean contains idempotent methods via the following clustering-descriptors in the bean’s deployment descriptors:
At the bean level, you can set the
stateless-bean-methods-are-idempotentparameter totrue. This ensures automatic failover for all the methods of the bean.At the method level, you can use the
idempotent-methodsdeployment property.
By default, a stateful session bean’s Home stub provides load balancing and failover for its method invocations to any clustered server where the bean is deployed.
When the bean instance is created, however, the bean’s hosting WebLogic Server selects a secondary WebLogic Server instance to host the replicated state of the EJB using the same rules as defined in replication groups for the HTTP Session state. The primary WebLogic Server hosts the actual instance of the bean. To minimize resource overhead, the secondary server stores only the replicated state of the primary bean for failover purposes; the secondary server does not create an instance of the bean. Replication groups were discussed earlier in this chapter.
The client receives a Remote stub that maintains a list of the primary and secondary server locations of the bean’s state. However, all method calls to the bean are “pinned” to the primary state location; there is no load balancing of remote method calls. As a client modifies the primary state, the EJB container replicates the state from the primary to the secondary servers in the WebLogic cluster. This replication scheme is similar to that used by the HTTP session state and occurs immediately after the transaction commits or after each method invocation. To replicate the state of a stateful session EJB, ensure the bean is homogeneously deployed within the WebLogic cluster.
If the primary state location should fail, the secondary WebLogic Server creates a new bean instance using the replicated state, thus forming a new primary server location for the bean’s method calls. The replica handler redirects subsequent requests to the bean to this new primary state. At the same time, a WebLogic Server is selected to hold the bean’s replicated state (secondary), and the client’s replica-aware Remote stub is updated with the new primary and secondary bean locations.
By default, an entity bean’s Home stub provides load balancing and failover for its method invocations to any clustered server where the bean is deployed.
The load balancing and failover capabilities of the Remote stub depend on the read-write and read-only cache strategy employed by the entity bean as follows:
For read-write entity bean caches, the bean’s remote method calls are “pinned” to the instance of the bean and cannot be load-balanced to other servers. Method calls fail over only if the request is made outside a transaction.
For read-only entity bean caches, each remote method call is load-balanced. However, failover does not automatically occur in the event of a recoverable call failure.
Organizations have extremely high expectations for their mission-critical Web-enabled applications. They not only expect them to be up and running 24/7, but they also expect them to be scalable and transparently meet growing end-user demands. Meeting these requirements by leveraging larger, more powerful server machines is not only an expensive proposition, but can also be a short-lived solution that is prone to exhibiting signs of failure in the long term.
This chapter introduced the WebLogic cluster, which in conjunction with a load-balancing solution, is a far more cost-effective, flexible, and reliable solution for meeting the demands of highly available and scalable J2EE applications. You have not only learned how to intelligently discuss high availability and scalability in the context of your J2EE solutions, but also how to implement clustering solutions using the WebLogic cluster.