
In This Chapter
The Java 2 Platform, Enterprise Edition (J2EE) is a specification for developing very portable, scalable, and maintainable applications using the Java programming language. The specification is also very large, complex, and detailed in its description of how the J2EE technology components and services can be applied towards developing J2EE applications, which can be quite overwhelming when you just want the information needed to learn J2EE at your fingertips.
To develop J2EE applications, you must understand the application architectures that the J2EE specification promotes. This chapter provides a comprehensive and logical approach to developing a technical grounding on J2EE from two educationally proven perspectives: An understanding of the logical structures of J2EE applications and an exposition of the J2EE Application Programming Model.
The number of logical tiers in an enterprise solution has been an evolutionary process. Originally applications were huge monolithic programming structures, mainframe applications that were accessed through terminals. Because the terminal was essentially free of any logic—just a viewing device—all presentation and business logic as well as all data access mechanisms typically resided as one extremely large application on one application infrastructure—the mainframe. Such an approach had advantages, the principal of these being that only one application infrastructure needed to be maintained and trained upon. However, mainframe systems, which are a classic example of a single-tier system model, posed many challenges in the areas of application modification, maintenance, and scalability because the applications were designed as very large and complex monolithic systems.
Client/server applications later standardized the two-tier system model; the data resided on a server and the presentation and business logic were tightly coupled in the context of a client application, which communicated with the data server via ODBC or native database access mechanisms. This two-tier system model enabled the central sharing and management of data through bespoke applications. However, in addition to the single-tier challenges that still existed, the two-tier system gave rise to some new challenges:
The application was still large and complex.
The residency of the application had shifted from a mainframe system environment to a desktop system environment—the desktop was now the workhorse for the application.
The task of modifying an application was dependent on the complexity of the business and presentation logic and proportional to the number of applications rolled-out.
The monitoring of the applications had shifted from one application infrastructure, the mainframe, to the desktop, for which a distributed (desktop) solution needed to be designed and developed and centrally maintained.
Inter-application communication had now shifted to a distributed desktop environment and was dependent on the capabilities of the technologies used to develop the applications (Visual Basic, C, C++, and PowerBuilder). Only after a long void were capabilities such as DCOM and technology-based proxy objects available to enable inter-application communication.
After a lot of application modification, maintenance, and scalability pains, the next logical step was very clear and simple:
The application interface had to be separated from the business logic.
The business logic needed to exist as self-contained functional units of code (business objects or components).
Scalability needed to be addressed at the business logic level, enabling business objects or components to reside transparently on server machines that were suited to the type and performance of business processing required.
The result was a three-tier system model consisting of a user interface layer, a business logic layer,, and a data layer, respectively. This approach promotes the capability to modify each layer independently without cascading the changes to the other layers.
The evolution of designing applications still continues. For example, in most cases an enterprise application accessed through an intranet or extranet or the Internet is implemented with a minimum of four tiers as follows:
A user’s Web browser, for viewing and interacting with the application.
A Web server, for data entry validation and dynamic Web page creation.
An application server, such as the WebLogic Server, which acts as a secure, scalable, and highly available container for the business and presentation logic associated with an application and a provider of services the logic might require during its execution.
A data tier, which is typically comprised of an enterprise relational database management system from such vendors as Oracle, Sybase, or Microsoft.
Note
The responsibilities of any one tier may not be concrete. For example, some business logic may exist at the Web server or data layer for performance reasons. Though it is to be avoided, you might have to compromise the model to serve the customer.
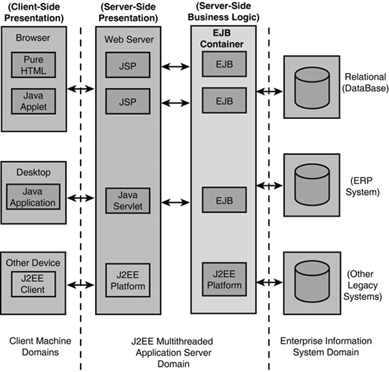
These four tiers mesh well with Sun’s J2EE architecture diagram in version 1.3 of the J2EE specification, as shown in Figure 5.1.

Referencing Figure 5.1:
A J2EE user interface is typically a thin client comprised of a Java-enabled Web browser that can execute applets or a Java application client.
Applets are, by design, small client-oriented Java applications that can run inside the Java virtual machine (JVM) of a Web browser. An online connection to a Web server is initially required to download and load the applet into the Web browser.
The J2EE specification outlines a methodology for hosting applets inside a standardized applet container environment with added support for acting as J2EE-based clients to J2EE-based servers. For more information on applets, please refer to http://java.sun.com/applets/.
Application clients are Java-based clients that typically run in a desktop environment in the context of a JVM. They offer a heavier and richer GUI experience than the thin client approach of a Web browser and are typically developed using the Java Swing or Abstract Window Toolkit (AWT) APIs. Java application clients do not need a Web or J2EE server connection to execute, and can be updated automatically once deployed using the Java Network Launching Protocol and API (JNLP). Also, as long as there are no firewall issues, a Java application can use the Remote Method Invocation (RMI) communication mechanism to interact with an EJB container. When firewalls are a concern, the Java client must use the HTTP and HTTPS protocols to communicate with the Web container.
The Web server can be associated with the J2EE Web container, whose role is to manage all the Web-related interactions of a J2EE application via the HTTP, HTTPS, and Wireless Application Protocol (WAP) communication protocols. The Web container is also an environment that supports the presentation logic associated with the application interface. The Web container delivers both static and dynamic Web content to requesting clients. The static content is HTML, XML, or other MIME types, whereas the dynamic content is served by Java servlets and JavaServer Pages (JSP).
The J2EE application server, such as WebLogic Server, can be associated with the J2EE EJB Container, which provides a runtime environment for distributed Java objects called Enterprise JavaBeans (EJBs). . EJB components represent application-specific business logic components, usually built by a developer or a third-party vendor. According to EJB Specification 2.0 (part of J2EE v1.3), there are three types of EJBs—Session EJB, Entity EJB, and Message Driven Bean (MDB):
Once invoked through its methods, a session bean is dedicated to serving the business processing requests of its calling client (Java application client, Applet client, or JSP/Servlet client). A session bean is not persistent, implying that when its invoking client terminates, it also appears to terminate and is no longer associated with the client. For this reason, a session bean implements business logic similar to an interactive session.
Entity beans model the permanent data in a system that is usually persisted in a database. Entity beans do not contain business process logic; they model the data. Typically, each entity bean has an underlying table in a relational database, and each instance of the bean corresponds to a row in that table. Entity beans are usually called by the session beans to interact with a relational database system.
A Message Driven Bean (MDB), introduced by the EJB 2.0 specification, offers the integration between the Java Messaging Service (JMS) and Enterprise JavaBean (EJB) specification. The main role of an MDB is to act as a JMS message listener, receiving and processing messages asynchronously.
The database represents the data tier. Depending on the data or information source to the J2EE application, the data tier can also be referred to as the Enterprise Information System tier, which can comprise database management systems such as Oracle, mainframe applications, CORBA servers, MQSeries applications, and any other legacy application used to service requests from the J2EE server.
Even though most J2EE applications can conceptually consist of four tiers, as illustrated in Figure 5.1, J2EE applications are considered to be three-tiered applications. This is because in practice, J2EE applications are distributed over three physical domains of machines:
The client machine(s)
A J2EE-compliant multithreaded application server machine(s), which implements the Web and EJB containers
The enterprise information system machine(s) that supports databases, legacy systems, or other informational resources pertaining to the J2EE application
This J2EE three-tier system model is illustrated in Figure 5.2.
The previous section provided you with a contextual overview of the J2EE architecture, which is an excellent jumping-off point for a discussion of the J2EE architecture. However, to understand how to implement a J2EE solution, you do need to understand the J2EE Application Programming Model, which is shown in Figure 5.3.

The objective of the J2EE Application Programming Model is to provide an understanding of the technical scope of the J2EE services and technology components that can constitute a J2EE solution and hence provide guidance on how they can be used. The following sections of this chapter will reference this model and focus on explaining each of its constituent elements.
Note
Because the technical details of a J2EE client have already been explained in the previous section of this chapter, they will not be discussed in the remaining sections of this chapter.
All J2EE solutions are developed, tested, and deployed in the context of application servers that are certified with the J2EE platform, such as WebLogic Server. If you are learning to develop J2EE solutions, inarguably you will need to become familiar with a J2EE server.
As illustrated in Figure 5.3, the J2EE server is effectively the nucleus of all J2EE solutions. Depending on the context in which it is used, it either serves as the operating system for a J2EE application, or, if it is part of an application infrastructure solution, as in the case of WebLogic Platform, it serves as an Internet platform/operating system for Web-based solutions.
Note
▸ For more information on WebLogic Platform 7.0, which includes WebLogic Server 7.0, see “Employing BEA’s Unified, Simplified, and Extensible Formula for Application Infrastructure: WebLogic Platform 7,” p. 268.
The primary role of an application server is to provide an environment, through the employment of the Web and EJB containers, for the execution and management of J2EE components (Servlets, JavaServer Pages, and EJBs). The J2EE server containers are the interface between a J2EE component and the low-level platform-specific functionality that supports that component.
J2EE containers are configurable based on the deployment requirements of a J2EE component or application, which can customize the underlying support services provided by the J2EE server, for example security, transaction management, Java Naming and Directory Interface (JNDI) lookups, and remote database connectivity. The J2EE containers can also provide non-configurable services such as enterprise bean and servlet life cycle management, database connection pooling, data persistence management, and access to the J2EE platform APIs.
The bottom layer of a J2EE server is the native operating system (OS) on which it runs. The OS ultimately controls the memory, I/O, and CPU resources assigned to the J2EE server. Even though all J2EE servers are configurable, they generally consume large amounts of these resources, so the OS may have to be configured to accommodate this.
The objective of the JVM layer is to make the choice of the OS development and deployment environments transparent to the Java developer. To enable this transparency to the developer, JVMs are hardware- and OS-dependent because they must interface with the native OS APIs.
At a high-level, the primary job of the JVM is to load Java class files that contain pre-execution Java byte code and translate them into native machine instructions, which are then executed by the respective operating system. The JVM controls memory management by garbage collecting unreferenced memory and providing heap and stack memory allocation. The JVM also provides classes that the application developer uses to interact with the OS.
Note
All JVMs are configurable to the type of OS and hardware they are running on, as well as the applications they are supporting.
There are many JVMs that are available in the marketplace today providing different techniques in the compilation and execution of Java code and the overall management of the loaded Java class files. The most popular JVM is the Java HotSpot VM provided by Sun, which is installed with most J2EE servers. However, BEA has opted to select the WebLogic jRockit JVM, which is more performance-oriented in its design and architecture to support enterprise applications.
Note
▸ For more information on the WebLogic jRockit JVM, see “An Introduction to the WebLogic Platform 7.0,” p. xxx. (Chapter 9)
The execution environment uses the JVM to control applications running within the J2EE server, which are primarily Web-based EJB applications. These applications require resources and services such as memory, threads, database connections, and network connections, which are controlled by the J2EE server execution environment. The server execution environment is also responsible for bootstrapping the system, handling failover, and the clustering of Web and EJB containers.
The J2EE Application Programming Model shown in Figure 5.3 essentially wraps the application tiers in the context of containers (Application Client, Web, and EJB containers) through the use of interfaces and APIs. This approach implies that you need only communicate with the container through a familiar interface or API rather than attempting to manage the complexities of the enterprise environment.
The J2EE containers have access to this J2EE service layer, which consists of two parts: the API and the service implementation. The APIs are the interfaces or contracts used by the application programmer to use the services. The service implementation is the underlying Java software classes, such as JDBC and JMS, providing the service, which is provided by a J2EE server vendor as long as it adheres to the J2EE service API specification.
In this section only the J2EE APIs in the J2EE Services Layers will be discussed because the service provider classes are only relevant to J2EE software vendors.
Remote Method Interface (RMI) is Java’s native mechanism for object-oriented JVM to JVM synchronous communication. RMI enables an object in one JVM to access an object in another JVM using the same semantics for accessing local Java objects, with the exception that RMI-based objects must catch exceptions associated with network failures (that is, java.rmi.RemoteException).
RMI is the principle mechanism used by clients to access EJBs. Clients are usually servlets, JSPs, or Java applications, but they can also be CORBA applications and Java applets. The EJB container does not support HTTP and cannot be accessed directly over the Web. RMI is also used by Web containers and EJB container components to access CORBA or RMI-based services external to a J2EE server.
Note
EJB services can be deployed as Web Services automatically in WebLogic Server 7.0; therefore they can be accessed over the Web via HTTP.
Because J2EE is a distributed architecture, RMI is critical to its inner workings. However, the use of RMI is concealed by the EJB container, which generates RMI code and makes RMI calls without the explicit involvement of the application developer.
The RMI service is an environment used by Java applications when performing distributed object computing.
According to the RMI specification from Sun, RMI has the following features:
Stubs and skeletons allow transparent communication with a J2EE component outside the local JVM. The stub and skeleton classes handle all data marshalling and network transmission issues. The transport protocol used by RMI is either Internet-Inter-Orb-Protocol (IIOP) or Java Remote Method Protocol (JRMP).
The RMI object registry or RMI naming service maps a name to a remote object. An RMI client program passes the name of the requested RMI object to the Registry. If the name is found, a remote object reference is returned to the client. The client uses the reference to connect to the RMI object.
Dynamic class loading, which allows objects transmitted over RMI to be loaded when they are discovered.
HTTP tunneling, which embeds RMI calls within the body of an HTTP post request, and receives the return information in the body of an HTTP response.
Object activation in RMI allows objects to execute on an as-needed basis. That is, RMI objects that are registered as such can be activated if they are not currently executing. RMI objects can also be set up to be started manually.
Distributed Garbage Collection (DGC) provides a way for an RMI server to remove unused objects from its address space hence providing lifecycle management for RMI objects. DGC maintains reference counts for objects so that when an object is not referenced it is moved into the JVM garbage collection bin. DGC also performs polling and maintains timers to determine whether connections are alive. If a connection times out, reference counts are decremented and the RMI server object may become eligible for garbage collection.
J2EE servers must implement these features to provide a J2EE-compliant RMI service. The following list shows how a J2EE server uses these RMI features:
Stubs and skeletons. The J2EE server generates stubs and skeletons for internal use in various places (EJBs, JNDI, and so on).
RMI object registry. A J2EE server uses JNDI for object reference lookup and persistent storage.
Dynamic class loading. A J2EE server has its own class loaders for dynamically loading classes.
HTTP tunneling. A J2EE server provides HTTP tunneling for RMI.
Object activation. The J2EE server provides object activation for EJB objects by loading them at startup time or by dynamically loading them during live deployment.
Distributed Garbage Collection (DGC). Object life cycle is controlled by the J2EE server. In particular, DGC lifecycle management is not used by the EJB container.
RMI is implemented using a number of underlying data transfer protocols. The most commonly used protocols are IIOP and JRMP, which do have their differences as follows:
Both protocols provide the basic stub/skeleton data marshalling and network communication, but JRMP has a timeout mechanism, used with DGC, which is not present in IIOP.
IIOP cannot use the RMI object registry and instead must use another mechanism, such as JNDI.
JRMP uses Java object serialization for data marshalling.
IIOP uses the Common Data Representation (CDR) standard for data marshalling, which is defined by Object Management Group (OMG).
Because the J2EE server does not explicitly use JRMP features or provides a replacement, it can use IIOP and JRMP interchangeably.
To make an RMI method call, the RMI developer must first define and create an interface on a remote object that extends the java.rmi.Remote interface, which will describe the methods available to remote client programs. The developer must also write the Java code to implement the methods for that remote interface. This code serves as the server-side RMI object.
The RMI interface and server-side files are compiled by the Java compiler. The class files created from the RMI interface compilation are used by the RMI compiler (rmic) to generate the stub and skeleton proxy object class files. RMI clients use these stub or proxy objects to access RMI objects.
Referencing Figure 5.4, the following steps describe a simple RMI method call:

The client program obtains an object reference (proxy object) from the RMI object repository.
The client program calls a method in the proxy object, passing arguments as native types or Java objects.
The proxy object connects to the remote RMI server. Data is marshalled using CDR (for IIOP) or Java object serialization (for JRMP) and the data packet is shipped over the network to the waiting RMI server.
The server proxy object unmarshals the data and issues a call down to the corresponding RMI object.
The RMI object executes the application’s code and returns the result to the server proxy object.
The server’s proxy object marshals the result and transmits it back to the waiting client’s proxy object.
The client’s proxy object unmarshals the packet and returns the result to the client application.
The client application continues processing as if the call were made in its own address space.
The Java Naming and Directory Interface (JNDI) is an API that describes hierarchical structures. The “Naming” part associates names with objects. The “Directory” part associates attributes of those objects with the names. JNDI provides a way to store global information available to Web and EJB containers.
JNDI is primarily used for looking up J2EE resources. JNDI stores important resources, such as JMS connection factories, JDBC data sources, J2EE resource adapters, environment variables, JavaMail drivers, RMI names, and JTA resource managers.
JNDI is also used for storing state information for session beans.
There are three parts to the namespace hierarchy stored in JNDI, as shown in Figure 5.5.
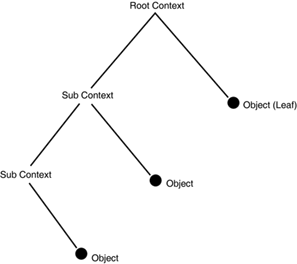
At the top of the tree is the root context. This defines the start of the namespace. The root context contains objects and subcontexts. A subcontext contains objects and other subcontexts. An object represents the leaf in a tree. This is the information that was stored in the tree; everything else is just organizational information.
For a Web or EJB component program to use JNDI it must first establish a connection to the J2EE server’s JNDI service. The JNDI driver and root context are specified in two JVM system variables, java.naming.factory.initial and java.naming.provider.url. The initial factory context specifies the JNDI driver and the provider URL specifies the root context.
To connect to the JNDI service, the Web or EJB component must get the JNDI initial context. The javax.naming.InitialContext object contains the connection information for JNDI. Once connected to JNDI you can use the Context interface of the javax.naming package for looking up, binding, unbinding, and renaming objects as well as creating and destroying subcontexts.
The Java Database Connection (JDBC) is a Java API for accessing table data such as that usually found in relational databases. JDBC is a set of classes and interfaces that allows Java programs to use SQL statements against any data source written to the JDBC specifications.
The primary JDBC interfaces used with J2EE are the following:
javax.sql.DataSourceis a factory for connection objects. The data source manages database resources and provides access to the database.java.sql.Connectionrepresents a connection to the underlying data source.java.sql.Statementcontains information necessary to issue an SQL request to the database.java.sql.PreparedStatementandjava.sql.CallableStatementare subclasses ofjava.sql.Statementused for SQL prepared statements and stored procedures respectively.java.sql.ResultSetcontains the row results from an SQL query.
JDBC is used when coding servlets, JSPs, session beans, and bean-managed persistence (BMP) entity beans that need to access relational databases from vendors such as Oracle or Sybase. JDBC is also used by the EJB container when writing container-managed persistence (CMP) entity beans. However, when CMP is used the developer does not write database code. Instead, the EJB container generates and executes the appropriate JDBC code to access the database.
When using JDBC, several steps are involved. First, a JDBC DataSource object must be registered with JNDI. A DataSource object represents a data repository, such as a file or a DBMS connection. The DataSource object typically supports connection pooling, distributed transactions, and access to the JDBC driver.
After a DataSource object is registered with JNDI, programs can access it, retrieve connections and issue SQL statements. However, to use a DataSource object, Web components and EJB components must define references to the JDBC resources in their deployment descriptors (ejb-jar.xml for EJBs and web.xml for Web components). Listing 5.1 shows JDBC resource references for a servlet and an EJB.
Example 5.1. JDBC Resource References for an EJB and Servlet
ejb-jar.xml
<enterprise-beans>
<entity>
. . .
<resource-ref>
<res-ref-name>jdbc/myPool</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
. . .
</enterprise-beans
web.xml
<web-app>
<servlet>
. . .
</servlet>
<resource-ref>
<res-ref-name>jdbc/myPool</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
. . .
</servlet>
Tip
DataSource objects are administered objects, which means they must be registered with the J2EE server. In WebLogic Server 7.0, this can be performed via the Web-based WebLogic Administration Console.
After the DataSource objects are registered and the Web and EJB components are deployed, they can be used by J2EE clients.
Listing 5.2 describes a simple JDBC example for accessing a table and retrieving a result set.
Example 5.2. A Simple JDBC Example for Accessing a Table and Retrieving a Result Set
Connection con=null;
try
{
InitialContext ic = new InitialContext();
//Look up the DataSource in JNDI
DataSource ds = (DataSource) ic.lookup("myDataPool");
//Obtain a connection to the database
con = ds.getConnection();
//Create and prepare a statement to access the database
PreparedStatement ps = con.prepareStatement(
"select * from MyTable where id=?");
ps.setString(1,"999");
//Execute the query and receive the results
ResultSet rs = ps.executeQuery();
//Read the ID from the MyTable table in the database
int id = rs.getInt("id");
}
catch (Exception ex)
{
. . .
}
Transactions are used to cause a set of related operations to perform like a single isolated operation—Single Unit of Work. A single operation either succeeds (it is committed) or fails (it is rolled back). There are no partial successes or failures. For isolated operations, data used by the operation is not changed by other programs.
Because J2EE is a distributed architecture, transactions can span multiple J2EE servers, databases, or other resources. For local transactions, which do not span resources, J2EE resources can manage their own transactions. For distributed transactions, J2EE requires a transaction manager to control the two-phase commit protocol. The two-phase commit protocol is used to guarantee that all participants in a distributed transaction agree to either commit or rollback an operation. Resources participating in a distributed transaction must be XA-compliant.
Referencing the J2EE Architecture diagram shown in Figure 5.2, transactions are typically requested from the client tier and then executed and managed by the server-side business tier.
Transactions are controlled either programmatically or declaratively using statements in a deployment descriptor. Because multiple components can be part of a transaction, the J2EE container must forward the transactional context to each participant. JDBC and the Java Transactional API (JTA) provide methods for programmatic transactional control. JDBC transactions are controlled using a java.sql.Connection interface, obtained by calling the getConnection method from the JDBC DataSource. JTA transactions are controlled using an object implementing the javax.UserTransaction interface. These objects are either retrieved from JNDI under the name javax.transaction.UserTransaction, or from the session context of a session bean or from the message context of a message bean.
Entity beans cannot use programmatic transaction controls. Declarative or container-managed transactions are used by session, message, or entity beans. An EJB must be identified as using container-managed transactions in its deployment descriptor. For this style of transaction, each method is assigned a transaction attribute. There are six types of transaction attributes, but the most commonly used value is “Required.” Setting a transactional attribute “Required” for a method implies the method will always run in the context of a transaction. If a transaction is already in effect, the method will use it. If a transaction is not in effect, the method’s entry and exit points demarcate a new transaction. Figure 5.6 illustrates the transaction options available to the J2EE components.

These options operate as follows:
Servlets, JSP, and Java application and applet clients must use programmatic transactions.
Session and Message beans can use either programmatic transactions or use declarative transactions.
Transactions can be programmed using JDBC transactions or the Java Transaction API. JTA supports distributed transactions.
Declarative transactions, controlled by the EJB container, and programmatic transactions pass transactional context to EIS systems.
Listing 5.3 describes a simple deployment descriptor declaring an EJB that uses container-managed transactions for all its methods. The transaction attributed is set to “Required.” The EJB first has to have its transaction type set to “Container” or “Bean.”
Example 5.3. Transaction Elements in the ejb-jar.xml
<ejb-jar>
<enterprise-beans>
<entity>
<ejb-name>MyBean</ejb-name>
. . .
<transaction-type>Container</transaction-type>
. . .
</entity>
</enterprise-beans>
<assembly-descriptor>
<container-transaction>
<method>
<ejb-name>MyBean</ejb-name>
<method-name>*</method-name>
</method>
<trans-attribute>Required</trans-attribute>
</container-transaction>
</assembly-descriptor>
In Listing 5.3, the <container-transaction> keyword defines the method level transaction for EJBs described by the deployment descriptor. The <trans-attribute> keyword describes how the container should manage transactions when executing a method.
Listing 5.4 describes a skeleton Servlet class using programmatic transactions. First an object implementing the UserTransaction is retrieved from JNDI. Next the begin method is called on the object, which starts the transaction. At this point, you can add business logic relating to a transaction, such as an SQL statement. If the business transaction is successful, the commit method is called, which causes all changes to be permanent. If an exception occurs the transaction is rolled back.
Example 5.4. Programming Transactions in J2EE
public class MyBusiness extends HTTPServlet
{
public void getPost(HttpServletRequest req,
HttpServletResponse res)
{
UserTransaction ut=null;
try
{
Context c = new InitialContext();
ut = (UserTransaction)c.lookup(
"javax.transaction.UserTransaction");
ut.begin()
/...do business
ut.commit();
}
catch (Exception e)
{
ut.rollback();
}
}
}
Container-managed transactions do not require special coding to start and commit or rollback transactions as this is managed by the EJB. However, if a transaction must be aborted, EJBs must call the setRollbackOnly method of the EJBContext object to notify the EJB container. The container will mark the transaction and it will be rolled back at the earliest opportunity.
The Java Messaging Service (JMS) API provides J2EE programs with loosely coupled, loosely typed distributed communication. There are two types of users of JMS: consumers and producers. Producers send messages to a repository where they can later be retrieved by a consumer. This is in contrast to the synchronous, strongly typed mechanism used in remote procedures calls (RPC), such as with RMI. With JMS, the producer only needs to know the message format and the message destination. With RPC, the caller must know the argument data types and the lifecycle of the caller’s methods is intertwined with the receiver’s methods.
The primary functions provided by JMS are as follows:
Persistent and non-persistent messages: Messages are always delivered unless the provider fails. If persistent messages are sent, messages are written to a reliable data store. If a provider fails, it will retransmit the messages upon restart.
Asynchronous and synchronous transmission and delivery of messages: Messages are transmitted either using synchronous messaging where the producer waits for the message to be consumed or asynchronous messaging where the producer posts the message to a repository and continues processing. Similarly, the consumer can either wait for incoming messages or specify a receiver thread to be notified when messages arrive.
Message filtering: Filtering is done using message selectors. Properties are associated with a message and consumers wait for messages matching those properties. Consumers can also specify fields in the message header and only receive messages matching those values.
Message types: JMS messages consist of a header, optional properties, and an optional body. The header holds the message destination, creation time, priority, and so on. The properties are set by the developer when message filtering is used. The main content of the message is in the body. The consumer receives the message and extracts the header, properties, and body of the message. JMS supports five message types: text, keyword and value pairs, byte streams, mixed primitive data type streams, and Java objects.
Transactions: JMS supports both local and distributed transactions. Local transactions enable a producer or consumer to identify a group of messages that must be processed as a whole. However, the consumer and producer do not share the transaction. The transaction is only on the producer’s or consumer’s end. The developer must call the
commitorrollbackmethods explicitly. With distributed transactions using JTA or container-managed transactions for EJBs, the message consumer can associate message consumption with database updates and communications with other transaction-aware components.
The JMS API has a number of basic components. The starting point is the connection factory. The connection factory allows a J2EE client to connect to a JMS provider. The connection factory is stored in JNDI. Using the connection factory a developer obtains a connection, which is a virtual link to a JMS provider. Using the connection, a session is created that serves as a single-threaded context for producing and consuming messages as well as maintaining transactional and reliability controls. Using a session, message producers and consumers are created to send and receive messages to a particular destination. After this set-up is complete, messages are exchanged.
JMS supports two models for delivering messages, Point-to-Point (PTP) and Publish/Subscribe (pub/sub).
PTP messages are delivered to one consumer. JMS stores PTP messages in a queue that reside there until a consumer removes them. The receiver sends an acknowledgment to the provider after successfully processing the message.
Publish and subscribe messages are delivered to all consumers who have registered to receive messages. JMS stores pub/sub messages in a topic, which is a subject identity in the message queue. A topic consumer can only receive messages after it subscribes to a topic. A topic consumer must also be active to receive messages, unless it is using a durable subscription.
Topics are commonly used in systems with multiple consumers and a single producer. Queues are commonly used when a single or multiple producers send messages to a single consumer. These scenarios are illustrated in Figure 5.7:

Several JMS applications send messages to Queue #1.
Messages for Queue #1 are written to persistent storage so they can be recovered and delivered in case of a system or application failure.
Messages are delivered to single application handling Queue #1 processing.
A single producer sends messages to Topic #1. The producer broadcasts messages to all listeners of the topic.
Messages for Topic #1 are written to persistent storage so they can be recovered and delivered in case of a system or application failure.
A copy of the topic message is delivered to each listening consumer.
JMS is primarily used to deliver messages to message-driven beans (MDB). MDBs reside in EJB containers and receive messages asynchronously. MDBs can use container-managed transactions and interact with other J2EE components, such as entity beans, as part of their transactions. They can also participate in distributed transactions.
JMS is also used to integrate legacy applications with J2EE applications. Many legacy applications use messaging products, such as MQSeries and TIBCO that have JMS interfaces. JMS is also used for event notification, where a J2EE component is a producer and a number of client applications are consumers.
To use JMS in a J2EE, a JMS connection factory and destination (queue or topic) must be registered with the J2EE server. This usually is done using a vendor-specific tool. The connection factory and destination objects are stored in JNDI.
After JMS is configured, producers and consumers can exchange messages. Producers, such as servlets and EJBs, deliver messages to a destination. Listing 5.5 shows the code of a producer that connects to a JMS queue and sends a PTP message.
Example 5.5. PTP JMS Producer
//Use JNDI to look up connection factory and destination
Context context = new InitialContext();
QueueConnectionFactory qcf =
(QueueConnectionFactory)context.
lookup("weblogic.mydomain.jms.QueueConnectionFactory");
Queue q = (Queue)context.lookup(
"weblogic.mydomain.jms.MyQueue");
//Set up the message using the following components
// Connection <== ConnectionFactory
// Session <== Connection
// Producer <== Session
// Message <== Session
// Get connection to JMS service
Connection c = qcf.createQueueConnection();
// Create a session
QueueSession s = c.createQueueSession(false,
Session.AUTO_ACKNOWLEDGE);
// Create a producer. Create a QueueSender for queues and TopicPublisher for topics.
QueueSender qs = s.createSender(q);
// Create a message.
TextMessage tm = s.createTextMessage("This is a message);
// Send the message. For topics, a message is published
qs.send(tm) ;
There are two types of consumers, synchronous and asynchronous. There is no difference in the administrative set up for each consumer type and the programmatic set up is also similar. Listing 5.6 shows the code for a synchronous PTP receiver.
Example 5.6. JMS PTP Receiver
//Use JNDI to look up connection factory and destination
Context context = new InitialContext();
QueueConnectionFactory qcf =
(QueueConnectionFactory)context.
lookup("weblogic.mydomain.jms.QueueConnectionFactory");
Queue q = (Queue)context.lookup(
"weblogic.mydomain.jms.MyQueue");
//Set up the message using the following components
// Connection <== ConnectionFactory
// Session <== Connection
// Consumer <== Session
// Start the session using the Connection
// Get connection to JMS service
Connection c = qcf.createQueueConnection();
// Create a session
QueueSession s = c.createQueueSession(false,
Session.AUTO_ACKNOWLEDGE);
// Create a consumer. Create a QueueReceiver for queues and TopicSubscriber for topics
QueueReceiver qr = s.createReceiver(q);
// Start listening on the connection
c.start();
// Wait for a message by issuing a receive method call
Message m = qr.receive();
When using an asynchronous receiver, the following changes must be made:
Create a class that implements the
javax.jms.MessageListenerinterface.OnMessageis the only method to be implemented.Before calling the start method on the connection, call the
setMessageListenermethod on the consumer object, passing an instance of the class created in step 1.Remove the
receivemethod call from the consumer object because theonMessagemethod will now receive all incoming messages.
Message beans are asynchronous message consumers. Most of the programmatic steps to use JMS are performed by the EJB container. The ejb-jar.xml deployment descriptor describes how the message’s bean is going to use JMS. The message bean must implement the Message Listener interface to receive messages in the onMessage method.
J2EE server security concerns itself with authentication (the users are who they claim to be) and authorization (the users can do what they are trying to do). J2EE Security is enforced at three levels:
Note
The Java Authentication and Authorization Service (JAAS) could be used to provide programmatic security services for client applications and J2EE components.
The Web container enables Web components (such as JSP pages, HTML pages, or servlets) to be protected by authentication and authorization constraints. Identifying a constraint with a Web component causes access to the container to be qualified by an authentication sequence. There are three authentication mechanisms used for the Web container: HTTP basic authentication, form-based authentication, and public key certification.
When HTTP basic authentication is used, the browser client must provide a valid username and password to the J2EE server before any resources can be accessed. Form-based authentication is similar to Web-based authentication, but the application program must supply an HTML form to be filled out by the user and the application developer must write the Java code to authenticate users. With public key certification, a browser client passes a certificate that is validated on the server side. If it is valid, encrypted messages are passed between the client and J2EE server using the Secure Socket Layer (SSL) protocol. Messages that are passed in this manner use the secure HTTPS protocol.
The Web container also supports programmatic authorization security checking using the HttpServletRequest interface. In particular, the methods getRemoteUser, isUserInRole, and getUserPrincipal provide information about who is trying to use a Web component.
The EJB container provides method-level protection for its components. The user of an EJB component is called the principal. The accesses allowed to a principal are determined by the bean’s ejb-jar.xml deployment descriptor. Listing 5.7 shows the <method-permission> keyword for a method in an EJB. In this example, only the users who have been assigned the boss or manager role have access to any of the methods in the BigBean EJB. The <role-name> keyword defines principals who are allowed access to the BigBean EJB.
Example 5.7. Usage of the Method Permission in ejb-jar.xml
<assembly-descriptor>
<method-permission>
<role-name>manager</role-name>
<role-name>boss</role-name>
<method>
<ejb-name>BigBean</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
. . .
Listing 5.8 shows how those roles are defined for EJBs using this deployment descriptor.
Example 5.8. Usage of the Security Role Definitions in ejb-jar.xml
<security-role>
<description>
This role represents everyone who is allowed
to access the big bean
</description>
<role-name>boss</role-name>
<role-name>manager</role-name>
</security-role>
Roles determine who can access a given resource. Principals are assigned roles in a vendor-specific manner. J2EE has adopted the concept of users and groups where a user is a specific principal and a group is a set of specific users. A user-assigned role implies the user can perform the activities related to that specific role. When a group is assigned a role, all users of that group can perform the activities related to that role.
For technical information on J2EE application security in the context of WebLogic Server 7.0, see Chapter 26.
JavaMail is an optional API package included in J2EE. It enables the developer to create, receive, and send electronic mail messages using a vendor-neutral interface. The JavaMail API interacts with an underlying mail system using protocols such as SMTP and POP, which provide the actual delivery of the messages. The specific mail driver is stored in the JNDI tree and is used when creating a mail session. Because JavaMail requires the Java Activation Framework API (JAF), JAF is also included in J2EE.
The capability to access enterprise mail systems, such as Lotus Notes and Microsoft Outlook, is becoming a very popular requirement for Web-based applications. Even though most mail system vendors provide their own Web-based interfaces, the requirement and business emphasis for most J2EE solutions is to provide a consistent Web-based interface to the mail systems, for example, via a portal application that can also provide a seamless and transparent mechanism for workflow type operations. To ease the development effort and provide a cost-effective solution to your J2EE application and mail system integration requirements, it is advisable to first perform a due diligence on the vendor-based software/component solutions that already exist and are proven to demonstrate success with as little customization as possible. For example, Compoze provides an out-of-the-box proven solution for integrating J2EE applications with Microsoft Outlook and Lotus Notes mail systems.
J2EE Connectors allow J2EE application components to integrate with Enterprise Information Systems (EIS). Connectors can be purchased from application server vendors such as BEA, or from the EIS vendors that have developed proprietary connectors for their systems to enable communication with J2EE components and systems. The more difficult route when existing connector solutions do not exist is to develop your own EIS connector using the J2C Adapter Development Kit, which is an integral part of the WebLogic Integration product.
Connectors work by abstracting EIS components into resource adapters that are plugged into the J2EE server. A resource adapter is a system-level software driver that exposes an API. This is similar to how a JDBC driver is used to access a database.
A resource adapter is added to the J2EE server configuration using a descriptor (rar.xml) and a set of classes or other executable files, which are loaded by the J2EE server. Each resource adapter defines a client API. This client API can use any API required to communicate with the EIS. A Common Client Interface (CCI) can also be defined so applications can treat disparate resources using the same API; however, this is not always required because the resource adapter’s client API could be the JDBC API, which can be used to access a non-standard DBMS.
In addition to the client API, there are three system contracts between the J2CA container in the J2EE server and the Resource Adapter: connection management, transaction management, and security management.
Connection management provides connection pooling and lifecycle operations for the application components. The connection pooling allows limited resources to be shared across many users. The lifecycle operations create and destroy connections when necessary and prevent the application developer from having to know the idiosyncrasies of the specific EIS.
Three types of transactions can be supported by a resource adapter:
No Transactions: In this case the resource adapter cannot support transactions. For this reason, it is important not to interact with the EIS in a transactional manner if the completion of a transaction is critical to the application’s integrity and operation.
Local Transactions: For local transactions, the J2EE server starts a transaction dependent on the current transactional context and issues a commit when the connection is closed.
XA Transactions: This type of transaction allows an EIS component to participate with other EIS components or XA-compliant resources using the two-phase commit (2PC) mechanism.
J2EE connectors support both container and application managed sign-on. Security information, usually in the form of a principal’s username and a password is sent to an EIS system. After the principal is authenticated by the EIS, a connection is returned which can be used by the application component for the EIS services.
The EJB container provides a runtime environment for distributed Java objects, which includes the following features:
Declarative security: Method-level authorization for EJBs is based on users and user-groups. Security declarations are part of the EJB deployment descriptors.
Concurrency control: All EJBs are single-threaded. The container creates multiple instances of EJBs to simulate concurrent access.
Lifecycle management: EJBs are created, destroyed, and allocated for use by the container. The container can also maintain the persistent state for an EJB if needed.
Request dispatching: The EJB container receives all EJB requests and dispatches them to the appropriate component. It also forwards results back to the requestor.
Declarative transactional control: Transactional controls are specified in the EJB deployment descriptors.
Container-managed persistence (CMP): With CMP persistence, all data store calls (JDBC) are performed by the EJB container. The mapping of the data in the EJB to the data store is specified in EJB deployment descriptors.
Resource management: The EJB container maintains free object pools and in-memory caches to manage EJB loads. The container can also swap EJBs between disk and memory when memory resources are constrained.
Figure 5.8 illustrates a simple scenario on how EJBs are used inside an EJB container, where:
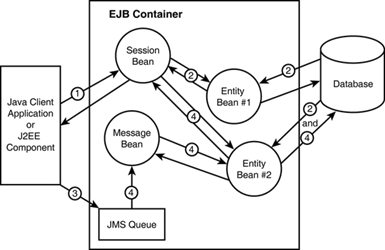
A Java client application or a J2EE component (JSP or Servlet) uses RMI or a local method to call into a session bean (1).
The session bean method performs application-specific steps, including calling methods on two entity beans. The entity beans then update the database in the context (2).
Java programs use JMS to deliver a message to a JMS queue inside the EJB container (3).
A message-driven bean receives messages from the JMS queue and uses an entity bean to update the database.
EJBs are J2EE components that implement the complex business logic for a J2EE application. An EJB component consists of the following parts:
Deployment descriptors describe and declare the resources needed by EJBs and are stored as XML files. The vendor-independent deployment descriptor file is named
ejb-jar.xml. In addition, there may be vendor-specific deployment descriptors.Component and/or Local interfaces, except in the case of message-driven beans. These interfaces describe the business methods available to the client. The EJB container, using these interfaces, creates classes that enable clients to use the EJBs. These stub classes enable clients to transparently use EJBs over the network. The skeleton classes enable the container to intercept calls and provide services to EJBs. All component interfaces extend the
javax.ejb.EJBObjectinterface. Local interfaces extend thejavax.ejb.EJBLocalObjectinterface.Home and/or LocalHome interfaces, except in the case of message-driven beans. These interfaces describe the factory methods for creating, destroying, and obtaining references to EJBs. The container creates factory classes from these interfaces. The stub classes allow the client to acquire and release EJB instances. The skeleton classes allow the container to intercept the client requests to provide services. Home interfaces extend the
javax.ejb.EJBHomeinterface. LocalHome interfaces extend thejavax.ejb.EJBLocalHomeinterface.An EJB class. The EJB class contains the business logic and data specific to the application. This class is provided by the application developer. All EJB implementation classes indirectly implement the javax.ejb.EnterpriseBean interface.
Helper classes. These classes are used by the EJB for application-specific purposes.
JAR file. The EJB is packaged in a JAR file containing the elements listed above.
There are three types of EJBs:
Session beans: These beans are accessed by clients (Servlet, application client, or another EJB). They represent single or groups of related operations for accessing persistent or legacy data. They contain procedural business logic.
Entity beans: These beans represent persistent data. They generally are accessed by session beans.
Message-driven beans: These EJBs process JMS messages, providing an asynchronous entry point to EJBs.
The following sections describe each of the above EJB types in more depth.
Session beans are EJB components used for managing client interactions. Generally, they are not used for updating data stores and usually work best as a transactional facade to entity beans. That is, session bean methods conceal the client application from the complexities of business workflow logic. The interfaces provided by session beans should be simple where the client only needs to call a single method or a group of simple methods to achieve a result that has business value.
There are two kinds of session beans: stateless and stateful.
Stateless session beans are allocated by the container from a free pool of identical objects. The bean is then used for a single method invocation, and then it is released back into the free pool. Stateless session beans provide good performance because they can be multiplexed between clients.
Stateful session beans are dedicated to clients for the lifetime of the bean. These beans retain EJB-specific information (such as its state) across method calls.
The rule of thumb for determining when to use a stateful or a stateless session bean is as follows: If a transaction can be completed with a single method call use a stateless session bean; otherwise, use stateful session beans. Although session beans do not represent the state of a data attribute in the data store, they can use JMS and JDBC to read and write persistent state information.
Session beans are declared in the ejb-jar.xml file using the <session> and <session-type> tags. The <session> tag identifies the bean as a session bean. The session type tag with a value of Stateless causes the EJB container to create a stateless session bean. Alternatively, a value of Stateful causes the container to create a stateful session bean.
The Home interface for session beans must have a create method because session beans are not persistent. This create method maps to the ejbcreate() method implemented by the EJB bean class. The EJB container takes care of creating new beans according to the EJB pool deployment descriptor.
Session beans implement the SessionBean interface. The SessionBean interface has the following methods:
ejbActivate: This method is used for stateful beans when the container decides to allocate it to a client or remote it from a passivated state.ejbPassivate: The container calls this method before the bean is placed into a dormant state. A stateful bean is passivated to conserve memory resources. This usually means writing the bean to disk. The passive state for a stateless bean is usually in a memory-free pool.ejbRemove: The container invokes this method before permanently removing a session bean from its pool.setSessionContext: This method is called by the container after the session bean is created. The session context is used to access container information about the current session bean.ejbCreate: This method is called when a bean is created or re-initialized. The method signature depends on thecreatemethod in the Home interface.
Entity beans represent persistent data maintained in a database. Entity bean data is usually mapped to a row in a database table. Like stateless session beans, a particular instance is allocated to a client for the duration of a method call. Entity beans are allocated from a free pool by the container when they are needed.
Because entity beans represent data, they need a unique primary key and must support relationships with other entity beans. This mirrors the functionality supported by relational databases with primary and foreign keys.
Note
Each entity EJB needs a primary key class. It can be a native Java object, such as a string or a user-defined Java object.
The Home interface for an entity bean must define create and finder methods matching those in the entity bean.
Entity beans use two persistence mechanisms. Data can be saved and read by either making explicit JDBC calls from the EJB class or declaratively using the entity bean’s deployment descriptors, where the container issues the JDBC calls. Explicit persistence is referred to as bean-managed persistence (BMP) and declarative persistence is called container-manager persistence (CMP).
With BMP the bean developer writes the code to retrieve and save persistent data using JDBC. Bean data is stored in instance fields and mapped to a database. Relationships with other entity beans are also stored in instance fields. The database mapping can be done either explicitly by the developer or by using an object-to-relational database mapping tool.
For entity beans using container-managed persistence, the EJB container loads and saves data from/to the data store. There is no JDBC code in the CMP bean.
Because the container performs all data updates and reads, it must have access to the data fields of the entity bean. In fact, the entity bean developer does not define any data field objects in their source code. Instead, the developer defines public abstract get and set methods whose names correspond to entries in the EJB deployment descriptor (ejb-jar.xml). The EJB container creates an entity bean that subclasses the developer’s abstract entity bean, defining non-abstract get and set methods with objects to store the bean’s data.
Entity beans participate in relationships with other entity beans, just as tables maintaining foreign keys from other tables in a relational database. A CMP bean contains two types of fields: data fields and relationship fields. A relationship field does not represent the bean’s state, as the data field does, but instead is a foreign key to another EJB. The EJB deployment descriptor allows 1-1, 1-n, and n-n relationships between EJBs. These relationships are called container-managed relationships (CMR) and are declared between EJBs and relationship fields using the EJB deployment descriptor.
The mapping between fields in a CMP entity bean and a column in a database table is accomplished by using the EJB deployment descriptor file (ejb-jar.xml) and a vendor-specific CMP deployment descriptor file for the EJB container. For example, in the case of the WebLogic Server the CMP deployment descriptor file is named weblogic-cmp-rdbms-jar.xml.
The ejb-jar.xml provides the following tags for CMP beans:
<persistence-type>, which must have a value of “Container” to indicate the bean is using container-managed persistence.<abstract-schema-name>, which provides an identifying name for the memory-schema of the EJB.<field-name>, which, within the context of the<cmp-field>tag, provides persistent fields for the bean. Each persisted field corresponds to the public abstract get/pub methods of the entity bean.<primary-field>, which identifies which one of the field entries under the<cmp-field>tag is the bean’s primary key.
The objective of the vendor-specific deployment descriptor is to provide CMP bean information to the EJB container. For example:
Which JDBC data source to use for the CMP bean.
Which tables in the relational database to use.
The mapping information between the fields declared in the
ejb-jar.xmlfile and the database columns.
Another key element of the ejb-jar.xml file for CMP beans is the <query> tag. Because the entity bean developer does not write JDBC code, the container must create finder methods to look up beans. Using EJB-QL statements, the container can generate finder methods defined in the EJBHome or EJBLocalHome interfaces.
Entity beans implement the EntityBean interface. The business methods of the entity bean do not access the database directly, because database access is managed by the ejbCreate, ejbFindByPrimaryKey, ejbFind< Method >, ejbLoad, ejbRemove, and ejbStore methods.
The EntityBean interface has the following methods:
ejbActivate: This method is used when the container decides to allocate the entity bean instance to a client or load a bean from the passivated state. This method must set the primary key of the entity bean.ejbPassivate: The container calls this method before the bean is placed into a dormant state. An entity bean is passivated to conserve memory resources and this usually means writing it to disk.ejbRemove: The container invokes this method before permanently removing an entity bean and its corresponding entry in the data store.ejbLoad: The container calls this method at the start of a transaction or when the bean is first loaded into memory. This method loads the current value of the data store entry for this bean into memory.ejbStore: The container calls this method at the end of a transaction just before the entity bean’s data is written to disk.ejbFindByPrimaryKey: This method is called by the container and it returns the primary key object for the bean. This method matches thefindByPrimaryKeymethod of the Home interface.setEntityContext: This method is called by the container after the entity bean is created. The entity context is used to access container information specific to the current entity bean, such as who is using the bean.ejbPostCreate: This method is called after the bean and data store elements for the bean have been written to the persistent storage. It sets the container-managed relationships with other beans.ejbCreate: This method is called when a bean is created or re-initialized. The method signature depends on the create method in the Home interface. This method sets the primary key and other container-managed fields. This method also returns an instance of the primary key to the entity bean.ejbFind <Method>: This method corresponds to finder methods in the Home interface. It returns either a collection of primary keys or a single primary key for an entity bean.
Message-driven beans (MDB) are asynchronous JMS message consumers. They provide a loosely coupled mechanism to access services and business logic contained in a J2EE server. MDBs can use entity beans, EIS components, and other J2EE components during their processing. Also, MDBs are ideal for B2B and logging applications where requests are delivered without expecting an immediate response.
MDBs are very similar to stateless session beans. They contain no state, are allocated from a free pool when needed, and are placed back in the free pool after a message is processed. They also support container-managed transactions for the lifetime of the onMessage JMS method call. However, unlike session beans, MDBs have no identity information in their messages; all messages are anonymous. In addition, MDBs do not require a Home or Remote/Local interfaces because they can only receive messages via JMS.
The EJB container performs most of the steps necessary to connect to JMS. At startup, the EJB container creates a pool of free MDBs and connects itself to JMS to receive messages on their behalf. When a MDB is created, the container calls the setMessageContext method. The receipt of a message causes the container to remove an MDB from the free pool and call the onMessage method. When the method call completes, the MDB is placed back in the free pool.
MDBs are declared in the ejb-jar.xml deployment description. The <message-driven> tag identifies the EJB as an MDB. The queue or topic receiving messages is specified in the <message-driven-destination> tag.
MDBs implement the MessageDrivenBean and MessageListener interfaces.
The MessageDrivenBean interface defines the following methods:
ejbRemove: This method is invoked by the container just before the message bean is permanently removed.SetMessageDrivenContext: This method is called just after a message bean is created. The container passes aMessageDrivenContextobject to the message bean. TheMessageDrivenContextcontains methods into the container for information about the current message bean instance.
The MessageListener interface defines only one method, onMessage, which receives messages from JMS via the container. The bean’s business logic is contained in this method.
The Web container provides a runtime environment for primarily supporting Web-based applications that use the JavaServer Pages (JSP) and/or Servlet J2EE components. A Web container typically exists in the context of a J2EE server that provides both the Web and EJB containers, such as the BEA WebLogic Server 7.0. However, J2EE Web servers do exist that only provide the Web container to support Web applications that serve dynamic content through the employment of Servlets and/or JSPs, for example BEA WebLogic Express 7.0. Because Web applications can also make requests to Web containers for HTML files that contain static content, such as GIF image files, PDF files, and video clips, the Web container is also responsible for serving static content when required.
Note
J2EE Web servers should not be confused with HTTP Web servers, which only handle HTTP/HTTPS requests on behalf of a Web application.
The Web container’s runtime environment has the following features:
Authentication security: The Web container provides login security using customized HTML forms, HTTP server-based security, and mutual authentication using X 5.09 certificates (public key certificates, or PKCs).
JSP engine: This part of the container translates JSP files into Java servlet code and then compiles and loads the resultant classes into memory. Once in memory, the JSPs execute as servlets.
Static context server: The Web container serves static content, such as HTML pages, GIF image files, and so on.
Lifecycle management: Servlet classes are loaded into memory, instances are created, and, if necessary, instances are removed by the Web container. The Web container also maintains various levels of state information for servlets and JSP pages.
Dispatching: The Web container receives HTTP requests and dispatches them to the proper components, such as JSPs, and Servlets.
Resource management: The Web container has a timeout mechanism to free the memory resources of inactive servlets. It can also serialize servlet classes to disk in an effort to conserve memory.
A servlet is a Java class that extends the HttpServlet (javax.servlet. http.HttpServlet) class and implements the Servlet (javax.servlet.Servlet) interface.
Servlets execute in the context of a J2EE Web container handling HTTP requests and providing dynamically generated responses. For this reason, servlets are used to provide dynamic Web content and flow control for Web applications. They are also used as front-ends to session beans, as XML processors for B2B applications and as Web server applications for non-EJB environments.
Tip
Servlets, although able to return dynamic HTML pages, are better used in conjunction with JSPs. In this scenario, servlets prepare business data and store information in Java beans. They then forward the request to a JSP, which generates HTML for the client.
Servlets have access to J2EE services such as JDBC, JNDI, JTA, and JMS. However, unlike the EJB container, they do not support declarative features for transactions, security, and persistence.
Servlets have a number of features for managing client requests and serving dynamic Web content. These features and more are discussed in the following sections.
A Web or HTTP session is a series of related requests from a client to a particular Web site within a given time period. Sessions allow clients to traverse multiple Web pages and retain contextual information across these pages.
A session begins when a client first contacts a Web site. During a session, clients use a number of Web pages. A session can end for a number of reasons, for example:
Servlets are created by the Web container and participate in sessions with Web clients. Each session consists of a series of HTTP requests and responses. Servlets can store and access contextual information regarding their session through the following objects and methods:
HTTPSessionobject is used to store information for a session. The methodsgetAttributeandsetAttributeare used to retrieve and store data specific to a session.HttpServletis a base class for servlets and it implements theServletConfiginterface. Servlets define initialization parameters in the vendor-independentweb.xmldeployment descriptor. These values are read using thegetInitParametermethod of this object.ServletContextis stored in theHttpServletobject. This class has thegetAttributeandsetAttributemethods, which are used for retrieving and storing data specific to a servlet object.An object implementing the
HTTPServletRequestinterface is created and passed as an argument to thedoGetordoPostmethods of a servlet by the Web container. ThisHTTPServletRequestobject contains contextual information for the current request; for example, the request URL, HTTP headers, and the query string.HTTPResponseinterface is used to return content to the client. In addition to the content to be rendered, the response can contain persistent information specific to a client; for example, cookies.
Servlets are created by the Web container the first time a request is made for them. Upon the initial servlet request, the Web container loads the servlet class from storage, creates an instance of it, and invokes the init method of the HttpServlet object. The developer can override the init method and perform servlet-specific initialization.
After the servlet is created and initialized, it can handle HTTP requests and responses. An HTTP request generally is a GET or POST operation. A GET operation uses the query-string in the URL to transfer information. The POST operation uses the message body to transfer information and supports larger and more efficient data transfers. An object implementing the HTTServletRequest interface is passed as an argument to the doGet and doPost methods of the servlet. The developer overrides these methods to handle requests.
The HTTPServletRequest object contains cookie information, the query string data, and binary data in the message body. The servlet also uses this information to perform its work. When the request is processed, the servlet using the HTTPServletResponse object (also passed as a parameter to the doGet or doPost methods of a servlet) fills out the response header, setting cookie values if necessary. When this task is complete, the servlet either dynamically builds the content for the response or forwards the request to another servlet or JSP. The response is eventually returned to the requestor by the Web container.
When the servlet is no longer needed, for example if the servlet class changes on disk and must be reloaded, the Web container removes the servlet from memory after calling the destroy method of HttpServlet class.
Servlets support chains of request filters. A filter is an object that transforms the header or body of an HTTP request or response. Hence Servlets, for example, can be used to customize requests and responses, authenticate requests, and transform XML data.
Servlets can dispatch requests to other servlets or to JSPs. The RequestDispatcher object has methods that allow the servlet to forward requests to and include content from other servlets and JSPs. The RequestDispatcher object is obtained from the ServletContext or HTTPServletRequest objects as discussed earlier.
Servlets use the Web container’s authentication mechanism. They can provide authorization by using the getUserPrincipal or isUserInRole methods in the HTTPServletRequest interface. Security roles and constraints are defined the web.xml deployment descriptor. However, the mechanism for mapping users to roles is performed by the Web container provider and hence is vendor-specific.
Cookies provide long-term user-specific information to be maintained on the client side. Cookies are a piece of information that the Web server asks the client browser to save locally on a user’s disk. Each time a browser accesses the same Web server, it sends all the cookies belonging to that site as part of the HTTP request. Cookies are stored as a name, value pair.
The HttpServlet class provides most of the structure needed by a servlet. The application developer primarily has to be concerned with overriding the doGet and doPost methods. These methods handle the incoming HTTP request and prepare an HTTP response.
Servlets are activated by supplying a URL to the Web container using the following URL syntax:
http://host:port/appName/servletPath?query-string
where:
http://host:portidentifies the Web container listening for incoming requests at a specific port.appNameidentifies the Web application name as defined in theweb.xmldeployment descriptor.servletPathdefines the location of the servlet class file relative to where the Web application is stored by the Web container.query-stringis request-specific information passed to the servlet.
All servlet declarations and configurations are performed via the vendor-neutral web.xml and vendor-specific deployment descriptor XML-based files respectively. Through these deployment descriptor files you can
Declare EJBs referenced by the servlet.
Declare resources, such as databases used by the servlet.
Define security roles and security constraints to restrict access to the servlet.
Map HTTP error codes to other Web components for standardizing error reporting.
Use filter mapping to associate a Filter class with a URL pattern or specific servlet.
Initialize servlet-level environment values.
JavaServer Pages are a template-based approach for creating dynamic Web pages where Java code is embedded within an HTML page. The premise behind using JSPs is to enable the Java code within a Web page, which is used for business logic, to be separated from the HTML/XML presentation instructions. This approach permits a Web page designer to focus on designing the Web pages with very little understanding of the Java programming language, and enables the Web developer to focus on the business logic of the page without learning how to design Web pages, which in itself is an art.
Note
JSPs do not require any client-side Java support, such as Java plug-ins or the Java Runtime Environment, as the JSP execution occurs in the Web container, as in the case of applets and Java client applications.
When a Web browser requests a JSP, the Web container checks if the same JSP has been already been processed. If this is the first time the container has seen the JSP, it is translated into Java servlet code and compiled into a Java Servlet class. The JSP then executes as a Java servlet.
Figure 5.9 depicts the steps the Web container takes to process HTTP requests and provide responses to a calling client.

Referencing Figure 5.9:
A client application sends an HTTP request to the Web container/server.
If the request is for a static page, the Web container reads the page off the disk system and posts it back to the requesting client.
If the request is for a JSP file (.jsp), the Web container passes the HTTP request off to the JSP engine. If necessary, the JSP engine compiles the JSP file into a Java Servlet. Control is then passed to the servlet execution engine.
If the request is for a servlet, the Web container passes the request to the Servlet engine. If necessary, the Servlet engine loads the Servlet class. It then executes the servlet.
The servlet then prepares an
HTTPResponseobject, which the Web container uses to post results back to the requesting client.
Because JSPs are transformed into Java servlets, they need language statements to interact with the underlying Java classes. As stated earlier, JSP files are composed of HTML content and JSP-specific XML-like elements. JSPs have three types of elements for controlling the JSP servlet: directives, script control statements, and actions:
Directive elements provide environmental controls, such as referencing Java classes, tag libraries (taglibs), controlling output buffer sizes, and statically including other JSP files such as headers or trailers. A few directive elements are discussed in the following bullets:
Note
Tag libraries (taglibs) are HTML/XML-like special constructs that enable the Web page designer to execute Java code without using Java. The taglib elements map to Java methods that perform operations.
<%@include ... %>are begin and end tags that statically include JSP and HTML files of other Web components.<%@page and ... %>are begin and end tags to control page environment features, such as error pages, output buffer sizes, content type, and thread access controls.<%@taglib and ... %>are begin and end tags used to reference tag libraries.
Scripting elements allow Java code, methods, variable declarations, and expression output to be added to the generated JSP servlet. There are three scripting elements:
<% ... %>are begin and end tags that allow Java code to be inserted between these elements.<%! ... %>are begin and end tags that allow method and data declarations to be made in the JSP file.<%= ... %>are begin and end tags that allow expressions to be evaluated and the results added to the servlet output buffer. The output is converted to a Java String.
Action elements allow the JSP Web developer to access Java beans, include dynamic output from other JSPs, and forward requests to other JSP pages or servlets. A few of the action elements are described in the following list:
The
<jsp:forward ... />tag forwards requests to other Web components.The
<jsp:include ... />tag dynamically includes pages from other Web components in the current page.The
<jsp:useBean ... />tag is used to reference Java beans.The
<jsp:get/setProperty ... />tag is used to access and change business data stored in Java beans.
In addition to the JSP directives there are a number of reserved JSP variables, most of which enable JSP developers to access the servlet environment and control classes. Some of these variables are listed in Table 5.1.
Table 5.1. Reserved JSP Variables
Variable | Servlet class | Description |
|---|---|---|
| Used to extract information to process requests from clients. | |
| Used to send a response back to requesting clients. | |
| Used to write the response to the client. | |
| Used to maintain information across pages within a session. | |
| Used to access the Web container. | |
|