
B
Topics Selected from Linear Algebra and Matrix Theory
Whereas Appendix A deals with general linear spaces and linear operators, the current appendix restricts attention to linear spaces with finite dimension, that is ℝN and ℂN. Therefore, all that has been said in Appendix A also holds true for the topics of this appendix.
B.1 Vectors and Matrices
Vectors in ℝN and ℂN are denoted by bold-faced letters, for example f and g. The elements in a vector are arranged either vertically (a column vector) or horizontally (a row vector). For example:

The superscript T is used to convert column vectors to row vectors. Vector addition and scalar multiplication are defined as in Section A.1.
A matrix H with dimension N × M is an arrangement of NM numbers hn,m (the elements) on an orthogonal grid of N rows and M columns:

The elements are real or complex. Vectors can be regarded as N × 1 matrices (column vectors) or 1 × M matrices (row vectors). A matrix can be regarded as a horizontal arrangement of M column vectors with dimension N, for example:
Of course, a matrix can also be regarded as a vertical arrangement of N row vectors.
The scalar–matrix multiplication αH replaces each element in H with αhn,m. The matrix–addition H = A + B is only defined if the two matrices A and B have equal size N × M. The result H is an N × M matrix with elements hn,m = an,m + bn,m. These two operations satisfy the axioms of a linear space (Section A.1). Therefore, the set of all N × M matrices is another example of a linear space.
The matrix–matrix product H = AB is defined only when the number of columns of A equals the number of rows of B. Suppose that A is an N × P matrix and that B is a P × M matrix; then the product H = AB is an N × M matrix with elements:

Since a vector can be regarded as an N × 1 matrix, this also defines the matrix–vector product g = Hf with f an M-dimensional column vector, H an N = M matrix and g an N-dimensional column vector. In accordance with these definitions, the inner product between two real N-dimensional vectors introduced in Section A.1.2 can be written as

It is easy to show that a matrix–vector product g = Hf defines a linear operator from ℝN into ℝN and ℂM into ℂN. Therefore, all definitions and properties related to linear operators (Section A.4) also apply to matrices.
Some special matrices are:
- The null matrix O. This is a matrix fully filled with zero. It corresponds to the null operator: Of = 0.
- The unit matrix I. This matrix is square (N = M), fully filled with zero, except for the diagonal elements, which are unit:

- This matrix corresponds to the unit operator: If = f.
- A diagonal matrix
 is a square matrix, fully filled with zero, except for its diagonal elements λn,n:
Often, diagonal matrices are denoted by upper case Greek symbols.
is a square matrix, fully filled with zero, except for its diagonal elements λn,n:
Often, diagonal matrices are denoted by upper case Greek symbols.
- The transposed matrix HT of an N × M matrix H is an M × N matrix; its elements are given by hTm, n = hn, m.
- A symmetric matrix is a square matrix for which HT = H.
- The conjugated of a matrix H is a matrix
 the elements of which are the complex conjugated of the one of H.
the elements of which are the complex conjugated of the one of H. - The adjoint of a matrix H is a matrix H* which is the conjugated and the transposed of H, that is:
 . A matrix H is self-adjoint or Hermitian if H* = H. This is the case only if H is square and
. A matrix H is self-adjoint or Hermitian if H* = H. This is the case only if H is square and  .
. - The inverse of a square matrix H is the matrix H–1 that satisfies H–1 H = I. If it exists, it is unique. In that case the matrix H is called regular. If H–1 does not exist, H is called singular.
- A unitary matrix U is a square matrix that satisfies U–1 = U*. A real unitary matrix is called orthonormal. These matrices satisfy U–1 = UT.
- A square matrix H is Toeplitz if its elements satisfy hn,m = g(n–m) in which gn is a sequence of 2N – 1 numbers.
- A square matrix H is circulant if its elements satisfy hn,m = g(n–m)%N. Here, (n – m)%N is the remainder of (n – m)/N.
- A matrix H is separable if it can be written as the product of two vectors: H = fgT.
Some properties with respect to the matrices mentioned above:
The relations hold if the size of the matrices are compatible and the inverses exist. Property (B.10) is known as the matrix inversion lemma.
B.2 Convolution
Defined in a finite interval, the discrete convolution between a sequence fk and gk:

can be written economically as a matrix–vector product g = Hf. The matrix H is a Toeplitz matrix:

If this ‘finite interval’ convolution is replaced with a circulant (wrap-around) discrete convolution, then (B.11) becomes

In that case, the matrix–vector relation g = Hf still holds. However, the matrix H is now a circulant matrix:
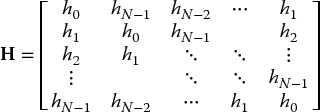
The Fourier matrix W is a unitary N × N matrix with elements given by

The (row) vectors in this matrix are the complex conjugated of the basis vectors given in (A.24). Note that W* = W–1 because W is unitary. It can be shown that the circulant convolution in (B.13) can be transformed into an element-by-element multiplication provided that the vector g is represented by the orthonormal basis of (A.24). In this representation the circulant convolution g = Hf becomes (see Equation (A.36))
Writing W = [w0 w1 ⋅⋅⋅ wN − 1] and carefully examining Hwk reveals that the basis vectors wk are the eigenvectors of the circulant matrix H. Therefore, we may write Hwk = λkwk with k = 0, 1, …, N − 1. The numbers λk are the eigenvalues of H. If these eigenvalues are arranged in a diagonal matrix:

the N equations Hwk = λkwk can be written economically as HW = W![]() . Right-sided multiplication of this equation by W–1 yields H = W
. Right-sided multiplication of this equation by W–1 yields H = W![]() W–1. Substitution in Equation (B.16) gives
W–1. Substitution in Equation (B.16) gives
Note that the multiplication Λ with the vector W–1f is an element-by-element multiplication because the matrix Λ is diagonal. The final result is obtained if we perform a left-sided multiplication in (b.18) by W:
The interpretation of this result is depicted in Figure B.1.

Figure B.1 Discrete circulant convolution accomplished in the Fourier domain.
B.3 Trace and Determinant
The trace trace(H) of a square matrix H is the sum of its diagonal elements:

Properties related to the trace are (A and B are N × N matrices, f and g are N-dimensional vectors)
The determinant |H| of a square matrix H is recursively defined with its co-matrices. The co-matrix Hn,m is an (N – 1) × (N – 1) matrix that is derived from H by exclusion of the nth row and the mth column. The following equations define the determinant:

Some properties related to the determinant:

If λn are the eigenvalues of a square matrix A, then

The rank of a matrix is the maximum number of column vectors (or row vectors) that are linearly independent. The rank of a regular N × N matrix is always N. In that case, the determinant is always non-zero. The reverse also holds true. The rank of a singular N × N matrix is always less than N and the determinant is zero.
B.4 Differentiation of Vector and Matrix Functions
Suppose f(x) is a real or complex function of the real N-dimensional vector x. Then the first derivative of f(x) with respect to x is an N-dimensional vector function (the gradient):
If f (x) = aTx (i.e. the inner product between x and a real vector a), then
Likewise, if f(x) = xTHx (i.e. a quadratic form defined by the matrix H), then
The second derivative of f(x) with respect to x is an N × N matrix called the Hessian matrix:
The determinant of this matrix is called the Hessian.
The Jacobian matrix of an N-dimensional vector function f(): ℝM → ℝN is defined as an N × M matrix:
Its determinant (only defined if the Jacobian matrix is square) is called the Jacobian.
The differentiation of a function of a matrix, for example f(H), with respect to this matrix is defined similar to the differentiation in (B.30). The result is a matrix:
Suppose that we have a square, invertible R × R matrix function F(H) of an N × M matrix H, that is F(): ℝN × ℝM → ℝR × ℝR; then the derivative of F(H) with respect to one of the elements of H is

From this the following rules can be derived:
Suppose that A, B and C are square matrices of equal size. Then some properties related to the derivatives of the trace and the determinant are
In Equation (B.44), [A–1]m,n is the m, nth element of A–1.
B.5 Diagonalization of Self-Adjoint Matrices
Recall from Section B.1 that an N × N matrix H is called self-adjoint or Hermitian if H* = H. From the discussion on self-adjoint operators in Section A.4 it is clear that associated with H there exists an orthonormal basis V = {v0 v1 ⋅⋅⋅ vN − 1} that we now arrange in a unitary matrix V = [v0 v1 ⋅⋅⋅ vN − 1]. Each vector vk is an eigenvector with corresponding (real) eigenvalue λk. These eigenvalues are now arranged as the diagonal elements in a diagonal matrix Λ.
The operation Hf can be written as (see Equations (A.42) and (B.5))

Suppose that the rank of H equals R. Then there are exactly R non-zero eigenvalues. Consequently, the number of terms in Equation (B.45) can be replaced with R. From this, it follows that H is a composition of its eigenvectors according to
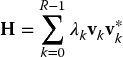
The summation on the right-hand side can be written more economically as VΛV*. Therefore:
The unitary matrix V* transforms the domain of H such that H becomes the diagonal matrix ![]() in this new domain. The matrix V accomplishes the inverse transform. In fact, Equation (B.47) is the matrix version of the decomposition shown in Figure A.2.
in this new domain. The matrix V accomplishes the inverse transform. In fact, Equation (B.47) is the matrix version of the decomposition shown in Figure A.2.
If the rank R equals N, there are exactly N non-zero eigenvalues. In that case, the matrix Λ is invertible and so is H:

It can be seen that the inverse H–1 is also self-adjoint.
A self-adjoint matrix H is positive definite if its eigenvalues are all positive. In that case the expression ![]() satisfies the conditions of a distance measure (Section A.2). To show this it suffices to prove that
satisfies the conditions of a distance measure (Section A.2). To show this it suffices to prove that ![]() satisfies the conditions of a norm (see Section A.2). These conditions are given in Section A.1. We use the diagonal form of H (see Equation (B.47):
satisfies the conditions of a norm (see Section A.2). These conditions are given in Section A.1. We use the diagonal form of H (see Equation (B.47):
Since V is a unitary matrix, the vector V*f can be regarded as the representation of f with respect to the orthonormal basis defined by the vectors in V. Let this representation be denoted by: ϕ = V*f. The expression f*Hf equals

Written in this form, it is easy to show that all conditions of a norm are met.
With the norm ![]() , the sets of points equidistant to the origin, that is the vectors that satisfy f*Hf = constant, are ellipsoids (see Figure B.2). This follows from Equation (B.50):
, the sets of points equidistant to the origin, that is the vectors that satisfy f*Hf = constant, are ellipsoids (see Figure B.2). This follows from Equation (B.50):

Figure B.2 ‘Circles’ in ℝ2 equipped with the Mahalanobis distance.
Hence, if we introduce a new vector u with elements defined as ![]() , we must require that:
, we must require that:

We conclude that in the u domain the ordinary Euclidean norm applies. Therefore, the solution space in this domain is a sphere (Figure B.2(a)). The operation ![]() is merely a scaling of the axes by factors
is merely a scaling of the axes by factors ![]() . This transforms the sphere into an ellipsoid. The principal axes of this ellipsoid line up with the basis vectors u (and
. This transforms the sphere into an ellipsoid. The principal axes of this ellipsoid line up with the basis vectors u (and ![]() ) (see Figure B.2(b)). Finally, the unitary transform f = V
) (see Figure B.2(b)). Finally, the unitary transform f = V![]() rotates the principal axes, but without affecting the shape of the ellipsoid (Figure B.2(c)). Hence, the orientation of these axes in the f domain is along the directions of the eigenvectors vn of H.
rotates the principal axes, but without affecting the shape of the ellipsoid (Figure B.2(c)). Hence, the orientation of these axes in the f domain is along the directions of the eigenvectors vn of H.
The metric expressed by ![]() is called a quadratic distance. In pattern classification theory it is usually called the Mahalanobis distance.
is called a quadratic distance. In pattern classification theory it is usually called the Mahalanobis distance.
B.6 Singular Value Decomposition (SVD)
The singular value decomposition theorem states that an arbitrary N × M matrix H can be decomposed into the product
where U is an orthonormal N × R matrix, Σ is a diagonal R × R matrix and V is an orthonormal M × R matrix. R is the rank of the matrix H. Therefore, R ≤ min (N, M).
The proof of the theorem is beyond the scope of this book. However, its connotation can be clarified as follows. Suppose, for a moment, that R = N = M. We consider all pairs of vectors of the form y = Hx, where x is on the surface of the unit sphere in ℝM, that is ‖x‖ = 1. The corresponding y must be on the surface in ℝN defined by the equation yTy = xTHTHx. The matrix HTH is a symmetric M × M matrix. By virtue of Equation (B.47) there must be an orthonormal matrix V and a diagonal matrix S such that1
The matrix V = [v0 ⋅⋅⋅ vM − 1] contains the (unit) eigenvectors vi of HTH. The corresponding eigenvalues are all on the diagonal of the matrix S. Without loss of generality we may assume that they are sorted in descending order. Thus, Si,i ≥ Si+1,i+1.
With ![]() , the solutions of the equation yTy = xTHTHx with ‖x‖ = 1 is the same set as the solutions of
, the solutions of the equation yTy = xTHTHx with ‖x‖ = 1 is the same set as the solutions of ![]() . Clearly, if x is a unit vector, then so is
. Clearly, if x is a unit vector, then so is ![]() because V is orthonormal. Therefore, the solutions of yTy =
because V is orthonormal. Therefore, the solutions of yTy = ![]() TS
TS![]() is the set
is the set
where
![]() is the matrix that is obtained by taking the square roots of all (diagonal) elements in S. The diagonal elements of
is the matrix that is obtained by taking the square roots of all (diagonal) elements in S. The diagonal elements of ![]() are usually denoted by the singular values
are usually denoted by the singular values
![]() . With that, the solutions become a set:
. With that, the solutions become a set:
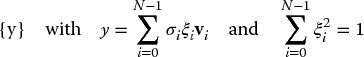
Equation (B.54) reveals that the solutions of yTy = xTHTHx with ‖x‖ = 1 are formed by a scaled version of the sphere ‖x‖ = 1. Scaling takes place with a factor σi in the direction of vi. In other words, the solutions form an ellipsoid.
Each eigenvector vi gives rise to a principal axis of the ellipsoid. The direction of such an axis is the one of the vector Hvi. We form the matrix HV = [Hv0 ⋅⋅⋅ HvM − 1], which contains the vectors that point in the directions of all principal axes. Using Equation (B.52):
Consequently, the column vectors in the matrix U that fulfils
successively points in the directions of the principal axes. Since S is a diagonal matrix, we conclude from Equation (B.47) that U must contain the eigenvectors ui of the matrix HHT, that is U = [u0 ⋅⋅⋅ uM − 1]. The diagonal elements of S are the corresponding eigenvalues and U is an orthonormal matrix.
The operator H maps the vector vi to a vector Hvi whose direction is given by the unit vector ui and whose length is given by σi. Therefore, Hvi = σiui. Representing an arbitrary vector x as a linear combination of vi, that is ξ = VTx, gives us finally the SVD theorem stated in Equation (B.51).
In the general case, N can differ from M and R ≤ min (N, M). However, Equations (B.51), (B.52), (B.54) and (B.55) are still valid, except that the dimensions of the matrices must be adapted. If R < M, then the singular values from σR up to σM–1 are zero. These singular values and the associated eigenvectors are then discarded. The ellipsoid mentioned above becomes an R-dimensional ellipsoid that is embedded in ℝN.
The process is depicted graphically in Figure B.3. The operator ![]() = VTx aligns the operand to the suitable basis {vi} by means of a rotation. This operator also discards all components vR up to vM–1 if R < M. The operator
= VTx aligns the operand to the suitable basis {vi} by means of a rotation. This operator also discards all components vR up to vM–1 if R < M. The operator ![]() stretches the axes formed by the {vi} basis. Finally, the operator y = U
stretches the axes formed by the {vi} basis. Finally, the operator y = U![]() hangs out each vi component in ℝM as a ui component in ℝN.
hangs out each vi component in ℝM as a ui component in ℝN.

Figure B.3 Singular value decomposition of a matrix H.
An important application of the SVD is matrix approximation. For that purpose, Equation (B.51) is written in an equivalent form:

We recall that the sequence σ0, σ1, ... is in descending order. Also, σi > 0. Therefore, if the matrix must be approximated by less then R terms, then the best strategy is to nullify the last terms. For instance, if the matrix H must be approximated by a vector product, that is H = fgT, then the best approximation is obtained by nullifying all singular values except σ0, that is H ≈ σ0u0vT0.
The SVD theorem is useful to find the pseudo inverse of a matrix:

The pseudo inverse gives the least squares solution to the equation y = Hx. In other words, the solution ![]() is the one that minimizes ‖Hx − y‖22. If the system is underdetermined, R < M, it provides a minimum norm solution, that is
is the one that minimizes ‖Hx − y‖22. If the system is underdetermined, R < M, it provides a minimum norm solution, that is ![]() is the smallest solution of y = Hx.
is the smallest solution of y = Hx.
The SVD is also a good departure point for a stability analysis of the pseudo inverse, for instance by studying the ratio between the largest and smallest singular values. This ratio is a measure of the sensitivity of the inverse to noise in the data. If this ratio is too high, we may consider regularizing the pseudo inverse by discarding all terms in Equation (B.57) whose singular values are too small.
Besides matrix approximation and pseudo inverse calculation the SVD finds application in image restoration, image compression and image modelling.
B.7 Selected Bibliography
- Bellman, R.E., Introduction to Matrix Analysis, McGraw-Hill, New York, 1970.
- Strang, G., Linear Algebra and Its Applications, Third Edition, Harcourt Brace Jovanovich, San Diego, CA, 1989.