
13
Creating Effective Documentation
Many developers consider documentation as a burden rather than a meaningful activity. This is comprehensible since often enough, the documentation is not updated anymore after it has been written. Soon, it is full of wrong statements and outdated information, which is indeed something that nobody wants.
We are convinced that documentation is too important to abandon it. If done right, it will be a valuable addition and an important building block for writing clean code, especially when Working in a Team.
Therefore, in the last chapter of this book, we want to give you some ideas about how to write documentation that is practical and maintainable.
We are going to cover the following main topics in this chapter:
- Why documentation matters
- Creating documentation
- Inline documentation
Technical requirements
For this chapter, there are no additional technical requirements. All code samples can be found in our GitHub repository: https://github.com/PacktPublishing/Clean-Code-in-PHP.
Why documentation matters
Welcome to the last chapter of this book. You have come a long way, and before you put this book down, for the time being, we want to draw your attention to the often-neglected topic of creating documentation. Let us convince you on the following pages that documentation does not necessarily have to be tiring and annoying, but instead has valuable benefits.
Why documentation is important
Why should we actually create any documentation? Is our code, or our tests, not enough documentation already? There is some truth in these thoughts, and we will discuss this topic further in this section. Yet over the years, countless developers have never stopped creating countless documents, so there must be something about it.
We create documentation because we can make it easier for other people to work with our software. It is about context, which cannot be easily extracted from reading the code of a couple of classes. Documentation is often not only about the what or how, but also about the why.
Knowing the motivation or the external factors that lead to a decision is crucial to understanding and accepting why a project was built in a certain way. For example, you might complain about your former colleague who has implemented a brittle, cronjob-triggered download of comma-separated values (CSV) files from an external File Transfer Protocol (FTP) server, unless you learn from the documentation that the customer was simply unable to provide a REpresentational State Transfer (REST) application programming interface (API) endpoint to deliver the data before the project deadline.
A new colleague who starts on your project will surely be happy to have at least some documentation to read, to not need to ask (and probably disturb) other developers for every little question. And let us not forget our future selves, who have not touched that project for many months and must fix a critical bug now. If only we knew what our past selves did back in the day... and why.
If you create open source software (OSS), then documentation is also important. If you need to evaluate several third-party packages to decide which one to use in a project, it is more likely that a package will be considered if it has good documentation. Wouldn’t it be a shame if you invested countless hours in a tool, but nobody uses it because it has no or no good documentation?
Lastly, if you do software development for a living, you should consider it part of the duty of a professional developer to write documentation. This is what you get paid for.
Developer documentation
When we think of documentation, it is usually user documentation that comes to our minds first: long, hard-to-read, and boring texts about how to use every single feature of a software product, such as—for example—a word processor. Of course, this documentation exists for a good reason, but that should not interest us in the context of this book, as it is usually not written by (and for) developers.
Software documentation is an extensive field, and as such, cannot be covered in total in this chapter. We rather want to focus on documentation that supports you in the development process and enables you to write clean code, as described in the following, non-exhaustive list:
- Administration and configuration guides: Besides the obvious need to describe how to install and configure the software, make sure to include a section about code quality. This should contain information about which tools are used locally, and how they are configured.
- System architecture documentation: As soon as your project becomes big enough that the basic server setup (usually a web server and database on one physical machine) becomes a bottleneck, and you start scaling it, you should think about documenting your infrastructure as well. Eventually, this will save you and others a lot of time searching for the correct Uniform Resource Locators (URLs) or server accesses, especially in critical situations. It might be a good place to add information about the continuous integration (CI) pipeline as well.
- Software architecture documentation: How is your software built internally? Does it use events to communicate between the modules? Are there any queues that should be used? Questions such as these should be answered in the software architecture documentation. This makes it easier for other developers to follow the principles.
- Coding guidelines: In addition to the software architecture documentation, coding guidelines offer advice on how to write the code. We discussed this topic in depth in Chapter 12, Working in a Team.
- API documentation: If your PHP: Hypertext Preprocessor (PHP) application has an API that is used by other developers or even customers, you need to provide a good overview of the API functionality. This makes theirs and your life easier, as you will have fewer interruptions from people who want to know how the API works. You can also give good examples of how to build additional API endpoints.
In the next section, we would like to have a closer look at how writing these types of documentation can be made easier.
Creating documentation
Documentation can be written in many ways. There is no one correct approach, and it is often predetermined by the tools already in use, such as the repository service or the company wiki. Still, there are a few tips and tricks that will help you to write and maintain it, and we want to introduce you to these in this section.
Text documents
Let us first focus on the typical, manually written text documents. The classic approach is to set up a wiki, as these have the great advantage that they can be accessed and used even by less-technical people. This makes them a great choice for companies. Modern wikis, either self-hosted or software-as-a-service (SaaS), offer a lot of reassurance and useful features such as inline comments or versioning. They also can connect with many external tools, such as ticket systems.
Another option is to keep the documentation close to your code by adding it to the repository—for example, within a subfolder. This is a valid approach as well, especially for smaller teams or open source projects. You should not use bloated formats such as Word or Portable Document Format (PDF), though, and rather focus on text-based formats such as Markdown. They are many times smaller, and changes to them are easy to track through the version control history.
The crux with manually written documentation is to keep it up to date. Text files or wikis are patient and do not forget, and over time, many pages of documentation virtually pile up in their storage. It gets problematic when it is unclear which documentation is correct and which is outdated. Once in doubt, it is not trustworthy at all anymore.
The only way to address this problem is to set up a process that makes sure that the documents get updated. In the previous chapter, we already introduced a possible way: code reviews in combination with a Definition of Done (DoD). This makes sure that, whenever we are about to add some new or changed code to our code base, we get reminded by a checklist to update the documentation, if necessary.
In particular, system and software architecture are documented using diagrams. Therefore, in the next section, we want to show you how to effectively create these.
Diagrams
A good diagram is usually much more telling than a long text. There are many free-to-use diagramming tools available, and you can choose to either manually draw the diagrams or generate them from text definitions.
Drawing diagrams manually
The classical way of creating a diagram is by using a diagramming tool that allows you to draw it manually. These tools are specifically designed to assist you in the creation process—for example, by offering templates and icon sets, or by maintaining the connecting arrows between objects if they are moved.
A versatile tool that we want to present to you in this chapter is diagrams.net (https://www.diagrams.net). In fact, we also used it to create illustrations for this book. It offers a library of elements that, for example, can be used to create diagrams such as Unified Modeling Language (UML) diagrams and flow charts. It also offers icons for the most popular cloud providers, such as Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure.
If you intend to use it, we recommend saving your diagrams as Scalable Vector Graphics (SVG). SVG is based on Extensible Markup Language (XML), and although XML is quite verbose, it still consumes less disk space than graphic formats such as Portable Network Graphics (PNG).
More importantly, it can be loaded and amended in the editor repeatedly, so you do not have to start over again every time your system changes. Most integrated development environments (IDEs) and all browsers will display SVG files as graphical images that can even be scaled indefinitely, and if necessary, they can easily be exported into the most popular image formats.
Generating diagrams from definitions
Not everybody likes to use fiddly editors to draw diagrams, though. Luckily, there is a variety of diagramming tools that can generate diagrams from definitions. To demonstrate how they work in general, we chose Mermaid.js (https://mermaid-js.github.io) as an example. It is written in JavaScript and utilizes a Markdown-inspired language to define the diagrams.
Before we check out the advantages of this approach, let us first have a look at a simple example of a flow chart:
graph LR
A{Do you know how to write great PHP code?} --> B[No]
A --> C[Yes]
C --> E(Awesome!)
B --> D{Did you read Clean Code in PHP?} --> F[No]
D --> G[Yes]
G --> H(Please read it again)
F --> I(Please read it)The preceding code would render a diagram, as shown here:
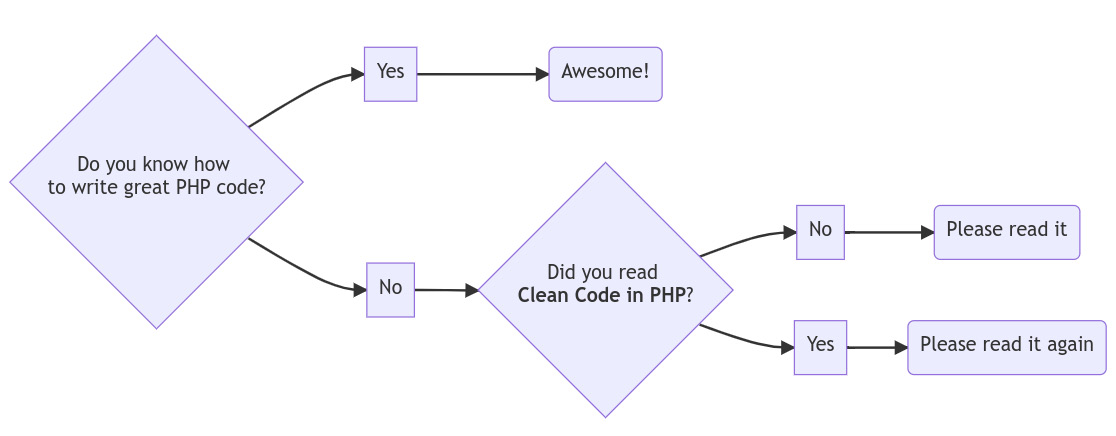
Figure 13.1: Mermaid diagram example
Diagram generation tools help you to create several diagram types, such as sequence diagrams, Gantt charts, or even the well-known pie charts. You do not have to think about how to style them or how they are arranged. The main work is taken over by the diagramming tool. Of course, Mermaid.js offers many ways to affect the appearance of generated diagrams.
Since the diagram definitions are simple text blocks, they can be added to the code repository. Changes to them are comfortably traceable through the version history. Mermaid diagrams integrate especially well in Markdown documents since the most popular IDEs can display these diagrams directly in the document through additional extensions.
Lastly, if you just want to play around with the possibilities of Mermaid, you can use the Mermaid Live Editor (https://mermaid.live) to better understand how it works.
Mermaid alternatives
Other noteworthy diagramming tools are PlantUML (https://plantuml.com), which offers even more practical diagram types to document software architecture, and Diagrams (https://diagrams.mingrammer.com), which is strong in documenting system architecture.
Documentation generators
Probably the best documentation is one we do not need to create ourselves and is still as useful as human written content. Unfortunately, this will continue to be a dream for now, although we do not know where machine learning (ML) will take us in the future.
Right now, we can already use tools to create documentation from our code. At least, we can use them to aggregate information that is spread across the many classes of our projects.
API documentation
In this section, we will show you how to create documentation from code using an example of API documentation. If your application provides an API, it is fundamental to have up-to-date documentation for it. Writing such documentation is a time-consuming and error-prone process, but we can at least make it a bit easier.
There exist many approaches to documenting APIs. In this book, we will introduce you to one format that has become more and more popular: OpenAPI. This format, formerly known as Swagger, describes all aspects of an API in a YAML Ain’t Markup Language (YAML) document, which could look like this:
openapi: 3.0.0 info: title: 'Product API' version: '0.1' paths: /product: get: operationId: getProductsUsingAnnotations parameters: - name: limit in: query description: 'How many products to return' required: false schema: type: integer responses: '200': description: 'Returns the product data'
This might be a bit too much information at first glance. Do not worry, though—it is not that complicated. In a nutshell, the preceding YAML describes the Product API in its version 0.1, which offers one endpoint, /product. This endpoint can be called using the Hypertext Transfer Protocol (HTTP) verb GET and accepts the optional parameter limit, which is of type integer and must be written in the URL query (for example, /product?limit=50). If all goes well, the endpoint will return with the HTTP code 200.
OpenAPI documentation
The OpenAPI format is quite extensive, so we cannot cover it in this book. If you are interested in learning more about it, please look at the official documentation: https://oai.github.io/Documentation.
As a welcome benefit, IDEs such as PhpStorm by default support you in writing these YAML files by checking the validity of the schema. If you, for example, wrote operation instead of operationId, the IDE would highlight the wrong usage.
You can either write a YAML file manually or have it generated. We want to have a closer look at the latter use case. To achieve this, we need the help of a Composer package called swagger-php (https://github.com/zircote/swagger-php). Please refer to the package documentation on how to install it.
Of course, the package cannot magically create documentation out of nothing. Instead, swagger-php parses meta information that is written directly in the PHP code, either as DocBlock annotations or, with PHP 8.1, as attributes. In other words, we need to make sure that the meta information is already there before we can generate the YAML file.
What does this information look like? Let us have a look at the first example, using annotations:
/**
* @OAInfo(
* title="Product API",
* version="0.1"
* )
*/
class ProductController
{
/**
* @OAGet(
* path="/product",
* operationId="getProducts",
* @OAParameter(
* name="limit",
* in="query",
* description="How many products to return",
* required=false,
* @OASchema(
* type="integer"
* )
* ),
* @OAResponse(
* response="200",
* description="Returns the product data"
* )
* )
*/
public function getProducts(): array
{
// ...
}
}Based on the information inside the DocBlocks, swagger-php will return the documentation of our API as a YAML file that will look exactly like the preceding example. But why should we use swagger-php when we could write the YAML directly?
Indeed, not everybody wants to have big blocks of documentation within the code, and depending on the level of detail you want to document, they can become much bigger than in our previous example. If you think of an API with many endpoints that are scattered across various controllers in your code, though, you might already realize the benefits: all required meta information is stored close to the code, so if changes are made on the endpoint, it is much easier for the developer to simply amend the DocBlock annotations than to do these changes in some additional document or wiki. Since the comments are part of the code, the changes are also already under version control. In the end, the decision to use swagger-php is up to you or the team.
In the Inline documentation section of this chapter, we will discuss why DocBlocks are not the best place to store meta information. Since PHP 8.0, we luckily have a better place for them—namely, attributes, which we already talked about in Chapter 6, PHP is Evolving- Deprecations and Revolutions.
Before we discuss why they are the better option, let us have a look here at how our endpoint would be documented by using attributes:
use OpenApiAttributes as OAT;
#[OATInfo(
version: '0.1',
title: 'Product API',
)]
class ProductController
{
#[OATGet(
path: '/v2/product',
operationId: 'getProducts',
parameters: [
new OATParameter(
name: 'limit',
description: 'How many products to return',
in: 'query',
required: false,
schema: new OATSchema(
type: 'integer'
),
),
],
responses: [
new OATResponse(
response: 200,
description: 'Returns the product data',
),
]
)]
public function getProducts(): array
{
// ...
}
}Admittedly, the attribute syntax might look a bit unfamiliar. We recommend using attributes instead of annotations, however, because they come with convenient advantages. Firstly, they are real code; they get parsed by the PHP interpreter, and your IDE will be able to support you in writing them. In the first line of the preceding example, you can see that we need to import the OpenApiAttributes namespace to make this example work.
Within this namespace, you will find actual classes that are referenced here. The files are located inside the vendor folder of your project. This enables you to use features such as autocompletion, and you will get immediate feedback from your IDE if something is not correct, which makes the writing of such documentation much easier.
As the last step, you need to generate a YAML file from the code. This step can, of course, be automated in the CI pipeline, which we introduced in Chapter 11, Continuous Integration. You can find examples of the usage in our Git repository for this book.
You might wonder: what can I do with this API documentation? Surely, it can already function as documentation for other developers, but there is much more to it. You can, for example, import it into HTTP clients such as Insomnia or Postman. That way, you can immediately start to interact with the API without having to look up the exact schema.
Another use case is to help you write functional tests for your API. There are packages such as PHP Swagger Test (https://github.com/byjg/php-swagger-test) or Spectator (https://github.com/hotmeteor/spectator) that can assist you in writing tests against the OpenAPI Specification (OAS), which can also be considered as a contract. You can test, for example, if the returned object for a specific HTTP status code equals what is specified in that contract.
Lastly, and probably the most important use case, is to use the OAS specification with Swagger UI (https://github.com/swagger-api/swagger-ui), which is a visual and interactive documentation of your API.
The following screenshot shows what our example API would look like:

Figure 13.2: Swagger UI
Exploring all possibilities of OpenAPI and Swagger UI would go beyond the scope of our book. We recommend you check out both tools if you want to learn more about them.
OpenAPI alternatives
There are other formats such as RESTful API Modeling Language (RAML) (https://raml.org) or API Blueprint (https://apiblueprint.org) that you could use, and we are not opinionated toward any solution.
Inline documentation
A special case is documentation that many of us have done regularly since we started writing software: comments. These are written directly in the code, where the developers can immediately see them, so that seems to be a good place to put documentation. But should comments really be seen as or used for documentation?
In our opinion, comments should generally be avoided. Let us have a look at some arguments on the next pages.
Annotations are no code
Comments are not part of the code. Although it is possible to parse comments through the Reflection API of PHP, they were originally not meant to store meta information. Ideally, your software should still work the same after stripping out all comments.
Today, though, this is often not the case anymore. Frameworks and packages such as object-relational mappers (ORMs) use DocBlock annotations to store information in them, such as route definitions or relations between database objects. Some code quality tools use annotations to control their behavior on certain parts of the code.
PHP cannot throw error messages if your annotations are wrong. If they serve an important purpose, your tests will hopefully catch the bug before they are deployed to production. A better choice is attributes, which are a real language construct. We discussed these in more detail earlier in this chapter when we talked about API documentation.
Unreadable code
Furthermore, as we already discussed in Chapter 12, Working in a team, comments are often an indicator of code that is too complex. Instead of explaining your code, you should rather aim to write code that does not need to be commented in the first place.
It can be a fun exercise to compress a whole function into a one-liner—for example, by using some quadruple-nested ternary operators or a frighteningly complicated if clause that nobody will understand. You will regret having written it latest at the point when there is a high-priority bug in the production environment, and it is on you to fix it without having the slightest idea anymore what your cryptic masterpiece is supposed to do.
Or, even worse, your new colleague on their first on-call shift has the honor of debugging late at night, when the alerts keep coming in. There are better ways to start a working relationship.
Outdated comments
A comment is quickly written, but also quickly forgotten. Since comments are not parsed by the PHP interpreter, you will not get informed when they are not correct anymore—for example, when the function they are supposed to explain gets rewritten and suddenly serves a different purpose. There is no other way to validate the comments than a developer trying to read and understand their meaning, and comparing it with the actual function code.
At the time of writing, this might not sound like a problem but imagine coming back to a class after a year and finding a comment that you do not understand anymore. Why did you write it in the first place? And if you do not know why, how is anybody else supposed to know?
Outdated comments are wrong information within your code. They are distracting and costly since the developer time does not come for free. Therefore, think twice before you add them.
Useless comments
Try to avoid comments that state the obvious and do not add any further information. The following code snippet is a real-life example of this:
// write the string to the log file file_put_contents($logFileName, $someString)
Although it could be considered a nice gesture that the developer took the time to explain the file_put_contents function, it does not add value to the code. If you do not know a function, you can look it up. Other than that, it is just an unnecessary line of code you need to scan when reading the code.
It is sometimes not easy to draw a line between useful and useless comments. You could use code reviews to cope with this problem; as discussed in Chapter 12, Working in a Team, having somebody else from your team do honest reviews of your code will help to avoid comments such as these.
Wrong or useless DocBlocks
We already discussed DocBlocks and what makes them problematic in Chapter 12, Working in a Team, when we introduced coding guidelines. In short, since DocBlocks are basically comments (yet following a certain structure), they can get outdated or simply go wrong quickly if— for example—the parameters of a function call change and necessary changes were not updated in the DocBlock too. Your IDE might throw warnings, but PHP will not.
With the introduction of better type hinting in PHP, many DocBlocks can simply be removed. The redundancy is of no benefit and can rather confuse the reader if the actual code diverges from the annotations.
TODO comments
Comments are not a suitable place to store tasks. You probably know comments such as this:
// TODO refactor once new version of service XY is released
While some IDEs can assist you in managing your TODO comments, this approach will only work if you are the only one on the project. As soon as you are Working in a Team, using a work management tool such as JIRA, Asana, or even Trello, writing such a comment is simply a way of creating technical debt, or, in other words, you are offloading the task into some uncertain day in the future. Somebody else will hopefully fix it one day—most of the time, this will not happen, though.
Instead of a comment, consider creating a task in your work management tool of choice. This way, it is transparent to your colleagues, and it is much easier to plan this work.
When commenting is useful
After discussing what should not be commented, are there any use cases left where comments are useful? Indeed, not so many, but there are some occasions where comments still make sense, such as in the following cases:
- To avoid confusion: If you can anticipate that other developers might wonder why you chose that implementation, you should add more context by adding a comment.
- When implementing complex algorithms: Even if we try to avoid it, we sometimes have to write code that is hard to understand—for example, if we need to implement a certain algorithm or some unknown business logic. In these cases, a brief comment can be a lifesaver.
- For reference purposes: If your code implements some logic that is already explained elsewhere—for example, in a wiki or a ticket—you can add a link to the corresponding source to make it easier for others to find more information about it. This should only be an exception and not the rule.
Please bear in mind that we do not want to be dogmatic. If you feel a comment is needed at some point, write it. It can still be deleted, probably after discussing the topic with another developer in the code review.
Tests as documentation
Developers who write tests often say that these tests also function as documentation. We, too, made the claim in Chapter 10, Automated Testing when we talked about the benefits of automated tests.
If you do not know what the purpose of a class is, you can at least infer its expected behavior from the tests, because this is precisely what tests do: they make assertions that the code will be tested against. By looking at these assertions, you know what the code is supposed to do.
If the tests fail, you at least know that there is a discrepancy between the assertions and the actual code, and you cannot trust them now. Unless test failures are not generally ignored in your project, you can be sure that someone will fix them soon—or, in other words, the implicit documentation gets updated.
If all the tests pass, you know that you can trust the class implementation—given the tests are well written and do not just test the implementation of a mock object, as discussed in Chapter 10, Automated Testing, when we talked about unit tests.
Surely, reading and understanding tests are not the easiest form of documentation, but they can be a reliable source of truth (SOT) if there is no other documentation. They should, however, not be the only type of documentation in your project.
Summary
Writing clean code is not only knowing how to do it yourself but also about making sure that other developers will follow this path too. To be able to do this, they need to know the rules that apply to the project.
In this chapter, we discussed how to create documentation that can help you to achieve this goal. We discussed best practices for manually writing documentation, as well as creating informative and at the same time maintainable diagrams. Lastly, we introduced ways to generate documentation from the code and elaborated on the pros and cons of inline documentation.
Congratulations! You made it to the end of this book. We hope you enjoyed reading it and are now fully motivated to write clean code.
You will probably not succeed with it right away. Strengthening your coding skills is a process that can be frustrating and sometimes even hard to do when working on a commercial project. Try to be patient, and over time you will get better and better.
Reading just one book about clean code is surely not enough. Over the course of this book, we were often only able to merely scratch topics on the surface, and we encourage you to dive deeper into the topics that interest you—and into those that you might not consider interesting in the first place. It requires more studies, an open mind, and the willingness to accept feedback from others to grow your skills.
Yet we are convinced that with this book, we gave you more than a solid starting point for your future journey as a great PHP developer. We would be glad if you think that too.
Further reading
If you want to learn more about Mermaid.js, we recommend the book The Official Guide to Mermaid.js by Knut Sveidqvist and Ashish Jain, published by Packt in 2021.