
Chapter 8
Compression of Dynamic and Volumetric Medical Sequences
8.1. Introduction
Most of the current medical imaging techniques produce three-dimensional (3D) data distributions. Some of them are intrinsically volumetric and represented as a set of two-dimensional (2D) slices, such as magnetic resonance imaging (MRI), computerized tomography (CT), positron emission tomography (PET) and 3D ultrasound, while others (such as angiography and echography) describe the temporal evolution of a dynamic phenomenon as a time sequence of 2D static images (frames), and thus are more correctly labelled as 2D+t. When displayed in rapid succession, these frames are perceived as continuous motion by the human eye.
The most commonly used digital modalities of medical volumetric data generate multiple slices in a single examination. One slice is normally a cross-section of the body part. Its adjacent slices are cross-sections parallel to the slice under consideration. Multiple slices generated this way are normally anatomically or physiologically correlated to each other (Figure 8.1). In other words, there are some image structural similarities between adjacent slices. Although it is possible to compress an image set slice by slice, more efficient compression can be achieved by exploring the correlation between slices.
Medical 2D+t and 3D images have had a great impact on the diagnosis of diseases and surgical planning. The limitations in storage space and transmission bandwidth on the one hand, and the growing size of medical image data sets on the other, have pushed the design of ad-hoc tools for their manipulation. The increasing demand for efficiently storing and transmitting digital medical image data sets has triggered a vast investigation of volumetric and dynamic image compression. More importantly, compression may help to postpone the acquisition of new storage devices or networks when these reach their maximal capacity.
A common characteristic of digital images is that neighboring pixels have a high degree of correlation. To enhance the coding performance, data compression aims to reduce the spatial or temporal redundancy by first decreasing the amount of correlation in the data and then encoding the resulting data.

Figure 8.1. Example of volumetric medical image data set
The two major types of medical image data set compression are lossless and lossy. Lossless techniques allow an exact reconstruction of the original image. unfortunately, the tight constraints imposed by lossless compression usually limit the compression ratio to about 2 or 4:1. Lossy techniques can reduce images by arbitrarily large ratios but do not perfectly reproduce the original image. However, the reproduction may be good enough that no image degradation is perceptible and diagnostic value is not compromised.
When lossless compression is used, 3D image data can be represented as multiple two-dimensional (2D) slices, it is possible to code these 2D images independently on a slice-by-slice basis. Several methods have been proposed for lossless (medical) 2D image compression, such as predictive coding like Differential Pulse Code Modulation (DPCM), Context-based Adaptive Lossless Image Coding (CALIC), Hierarchical INTerpolation (HINT) or simply a variable length coder, for example arithmetic coding, Huffman and Lempel-Ziv. However, such 2D methods do not exploit the data redundancy in the third dimension, i.e. the property that pixels in the same position in neighboring image frames are usually very similar. As pixels are correlated in all three dimensions, a better approach is to consider the whole set of slices as a single 3D data set. Although dynamic medical sequences differ in nature to volumetric ones, it is difficult to distinguish between lossless compression techniques applied to the two families. This aspect will be considered in detail in section 8.2.
While further research into lossless methods may produce some modest improvements, significantly higher compression ratios, reaching 60:1, can be achieved using lossy approaches. Unfortunately, lossy compression schemes may only achieve modest compression before significant information is lost (see Chapter 5). The choice of the compression rate is consequently adjusted in a way which will reduce the volume of data without discarding visually or diagnostically important information.
The development of a lossy compression algorithm adapted to (2D+t) sequences is a critical problem. For example, the ultrasound images are corrupted by a random granular pattern, called a “speckle” pattern. This noise is generated by physical phenomena related to the acquisition technique and can be considered as a texture representing information about the observed medium. Furthermore, in the case of angiogram sequences, images obtained from projection radiography may reveal lesions by image details that are extremely sensitive to lossy compression since they are small or have poorly defined borders (e.g. the edge of coronary arteries), and are only distinguishable by subtle variations in contrast. The lossy (irreversible) compression approaches to 2D+t medical images will be considered in section 8.3.

Figure 8.2. Example of dynamic medical images, from left to right: angiographic image; echographic (ultrasonic) image
Section 8.4 deals with the irreversible compression methods of the 3D medical data sets. As will be discussed later, the direct use of dynamic data compression approaches is not appropriate for volumetric medical images. These coding techniques are usually based on object motion estimation approaches. When applied to volumetric images, the inter-image correlation is considered as a temporal one. The assumption of object motion is not realistic in 3D image sets, where image frames are not snap shots of moving objects but instead plane slices of 3D objects. It should be noted that fully 3D wavelet-based coding systems are very promising techniques in the field of volumetric medical data compression.
8.2. Reversible compression of (2D+t) and 3D medical data sets
As mentioned earlier, in order to efficiently compress volumetric or dynamic medical sequence, it is important to use spatial and temporal redundancy. Image sequence coding can use redundancies at both intra-frame (within a frame) and interframe (between frames) levels. At the inter-frame level the redundancy between successive images across time or along the third spatial dimension, is used. As 2D+t and 3D data can be represented as sets of 2D images, it is possible to code these 2D images independently on an image-by-image basis. Several excellent 2D lossless compression algorithms are in existence, which are presented in Chapters 2 and 7. Some of these reversible 2D compression techniques, such as the JPEG-LS or CALIC algorithm, are applied independently on each 2D image of a dynamic or volumetric data set. However, as mentioned by Clunie [CLU 00], such 2D methods are still limited in terms of compression ratio since they do not use the dependencies that exist among pixel values across the third scale.
Lossless video coding techniques have been investigated to compress volumetric and dynamic medical image sequences. Those that have been proposed in the literature are often essentially 2D techniques, such as the CALIC algorithm, which have been modified to use some information from the previously encoded frame(s). Other approaches combine the intra-frame prediction and modeling steps that typically occur in 2D techniques with inter-frame context modeling. On the other hand, some techniques adapt predictive 2D image coders by providing several possible predictors and encoding each pixel using the predictor that performed best at the same spatial position in the previous frame. These techniques also use Motion Compensation (MC). The principle of MC is simple: when a video camera shoots a scene, objects that move in front of the camera will be located at slightly different positions in successive frames. Block MC considers a square region in the current frame and looks for the most similar square region in the previous frame (motion estimation). The pixels in that region are then used to predict the pixels in the current frame.
Existing 2D lossless coders [ASS 98] have been extended in order to exploit the inter-image correlation in 3D sequences. These extended coders use an intra-frame predictor, but they incorporate inter-frame information in the context model. A simplified description of this technique is shown in Figure 8.3; for each pixel a fully intra-frame prediction is made. Then, after subtracting this prediction from the original pixel value, a residual is obtained (and stored for later use in the compression of the next frame). In the context modeling step, the context parameter for encoding the current pixel is a quantized version of the intra-frame prediction error in the previous frame at the same position. The underlying idea is that in smooth regions, where intra-frame prediction works well, the context parameter will be low. On the other hand, near moving or static edges, the context parameter will be high. Thus, the context model effectively forces the use of different probability tables in both of these region types. It was experimentally shown that this interframe context modeling leads to an additional 10% increase in compression ratio compared to 2D fully predictive techniques.

Figure 8.3. Combination of intra-frame prediction and inter-frame context modeling
The GRINT (Generalized Recursive Interpolation) coding approach [AIA 96], which is an extension of HINT algorithm [AIA 96], is a progressive inter-frame reversible compression technique of tomographic sections that typically occur in the medical field. An image sequence is decimated by a factor of 2, first along rows only, then along columns only, and possibly along slices only, recursively in a sequel, thus creating a gray level hyper-pyramid whose number of voxels halves at every level. The top of the pyramid (root) is stored and then directionally interpolated by means of a 1D kernel. Interpolation errors with the underlying equally-sized hyper-layer are stored as well. The same procedure is repeated, until the image sequence is completely decomposed. The advantage of the novel scheme with respect to other non-causal DPCM schemes is twofold: firstly, interpolation is performed from all error-free values, thereby reducing the variance of residuals; secondly, different correlation values along rows, columns and sections can be used for a better decorrelation.
8.3. Irreversible compression of (2D+t) medical sequences
Due to the limited performance of lossless compression techniques, in terms of compression ratio, there has been significant interest in developing efficient lossy (irreversible) image compression techniques that achieve much higher compression ratios without affecting clinical decision making. Similar to reversible compression schemes, the developed irreversible compression algorithms are also classified as either intra or inter-frame.
8.3.1. Intra-frame lossy coding
Similar to reversible compression, it is naturally possible to compress each frame of the dynamic sequence using a 2D coding method. For example, three angiographers reviewed the original and the Joint Photographic Experts Group (JPEG) compressed format of 96 coronary angiographic sequences in a blind fashion to assess coronary lesion severity [RIG 96]. The obtained results have shown that at small compression ratios, of about a 10:1 to 20:1, the variability in assessing lesion severity between the original and compressed formats is comparable to the reported variability in visual assessment of lesion severity in sequential analysis of cine film.
The high performance that characterizes wavelet-based 2D compression algorithms, such as SPIHT and JPEG 2000 coders, has triggered their use on dynamic medical sequences. However, when applied to video angiographic sequences the efficiency of wavelet-based encoding schemes is hampered by the comparatively small valued transform coefficients in the high frequency subbands. The high frequency subbands can be broadly subdivided into regions containing diagnostically important information, and regions which do not. Regions which contain diagnostically important information tend to contain far more structure in the high frequency subbands detailing, for example, the precise position of an artery's boundary. In contrast, regions not containing diagnostically important information tend to be noise-like in texture [GIB 01b]. Significant amounts of noise-like texture reduce the effectiveness of the wavelet coding approaches, especially at the relatively high bitrates required for diagnostically lossless images. This higher bitrate results in a much larger number of significant wavelet coefficients in the high frequency subbands which in turn must be encoded in the final bit stream. This is inconvenient as it weakens the key quality of energy compaction, requiring the transmission of significant amounts of information to identify the locations of significant wavelet coefficients. To overcome this problem, region-based approaches have been investigated to distinguish between the two different types of regions.
Despite the improvement in efficacy of object-based frameworks, which integrate ROI-based functionalities [RAB 02], to assign high priority to the semantically relevant object, to be represented with up to lossless quality and lower priority to the background, these frameworks are not adapted to angiographic images. In fact, the ROI is generally assimilated to square blocks of fixed size that do not necessary fit to medical image structures. In order to improve the diagnosis quality of reconstructed angiographic sequences, the method developed in [GIB 01a] proposes making a distinction between the two different types of regions, with the regions containing diagnostically important information encoded using a standard wavelet encoding algorithm, and the remaining area encoded more efficiently using a wavelet parameter texture modeling approach. This procedure is applied to the two highest frequency subbands, with the remaining levels of the wavelet pyramid encoded in their entirety using a modified version of the SPIHT coder (see Figure 8.4). Despite its compression efficiency, as well as the main concern with important diagnostic information, this method has the disadvantage of not exploiting the temporal correlations between successive frames.

Figure 8.4. Alternation between MC and intra-image prediction
Recently, compression systems that support ROI coding using a presegmentation approach have been investigated in many image applications. However, segmentation is one of the most significant and difficult tasks in the area of image processing. If a segmentation algorithm fails to detect the correct ROIs then the result would be disastrous since the important diagnostic data in the original image would risk being lost. To solve the problems associated with the presegmentation approach, a region scalable coding scheme, based on a post-segmentation approach, has been developed [YOO 04] for interactive medical applications such as telemedicine. Its principle can be described as follows: lossless compression is applied to the whole image and stored in the server. By applying special treatment (set partitioning and rearrangement) to the transformed data, small regions of an image are identified and compressed separately. This will allow a client to access a specific region of interest efficiently by specifying the ROI.
8.3.2. Inter-frame lossy coding
8.3.2.1. Conventional video coding techniques
The conventional video coding methods have much in common, usually being centered on a combined motion estimation-compensation strategy and followed by an often frequency-based, residual coding method in order to carry out a good prediction which takes into account the motion present between consecutive images. Several approaches have been suggested in order to take this movement into account:
– block matching MC, which is adopted in MPEG1 [GAL 91], MPEG2, H.261, H.263 and H.264 coding schemes;
– region-based MC [KAT 98], such as MPEG4, which belongs to region-based coding schemes.
To compress the residual images, the quantization process is directly applied to the prediction error in the spatial or frequency domain, after a Discrete Cosine Transform (DCT).
Conventional video coding techniques can give impressive compression ratios (100:1) with relatively small amounts of image quality degradation. Unfortunately, most of them are principally based on a block-based DCT method, in conjunction with block-based motion estimation. As a result, blocking artefacts, often visible when using block-based DCT, could potentially be mistaken as being diagnostically significant or interpreted erroneously as pathological signs. Furthermore, the effectiveness assessment results of MC, applied to dynamic medical sequences have shown that conventional MC strategies are not optimal for this type of data, specifically angiogram video sequences. This is largely due to the particular structure of this type of data, i.e. the unusual motion patterns and large amounts of background texture. Unlike High Definition Television (HDTV), individual frames from an angiogram sequence may be extracted and closely scrutinized. All of these requirements have triggered the development of compression methods, specifically designed for dynamic medical data.
8.3.2.2. Modified video coders
In angiogram video sequences, temporal correlation in the high frequency image bands results partially from the high frequency noise and partially from the layered nature of the data in which multiple overlaid, semi-transparent layers all move differently. For this reason, constructive use of temporal redundancy in angiogram sequences is an absolute necessity. One solution has been suggested in [GIB 01b] by integrating a low-pass spatial filtering process to the MC feedback loop in conventional DCT based video coders. The two key stages in the modified feedback loop are the MC block and the low-pass spatial filter. The low pass filter employs a Gaussian operator which removes the majority of the high frequency spatial texture. This is essential for angiogram images, because in its absence the MC proves completely counter productive. The MC block is selected according to one of the following schemes: block matching, global compensation or no compensation.
To reduce blocking artefacts often visible when DCT is used in conjunction with block-based motion estimation methods, some solutions [TSA 94] [HO 96] propose using a block-matching approach, to estimate image motion, followed by a global wavelet compression method, instead of the more conventional block-based DCT arrangement. Nevertheless, wavelet-based coding functionalities enable, not only the avoidance of blocking effects, but also the support of object-based bit allocation [BRE 01] and progressive decoding, at the cost of a fuzzy or smoothing effect (see section 8.3.2.3).
In their comparative study, Gibson et al. [GIB 01b] have shown that the use of MC is not beneficial in the case of 2D+t medical image compression. This is principally due to the displacement nature of the considered organs; the amount of motion present in dynamic medical sequences is relatively small compared to the motions present in standard video scenes. Furthermore, block-based MC depends on the assumption that objects only move from frame to frame but do not deform or rotate. This assumption is not always satisfied in video applications since, for example, objects may rotate or shrink as they move away from the camera. In the same study, efficiency of 2D DCT and wavelet approaches has been reviewed. Experimental results for these intra-frame compression techniques have shown that wavelet and DCT based algorithms gave very similar results, both numerically and visually. All of these reasons led researchers to define new compression approaches more adapted to 2D+t medical sequences [GIB 04].
8.3.2.3. 2D+t wavelet-based coding systems limits
More recent studies were oriented towards scalable 2D+t wavelet based coding techniques, inspired by 3D wavelet based coding approaches [LOW 95]. To reduce the computational complexity and the huge amount of memory space, needed to calculate the 2D+t wavelet coefficients, dynamic image sequences are divided into groups of images (GOP: Group Of Picture). These groups are compressed independently.
Although they are well adapted to natural video scenes, wavelet-based coding techniques are not suitable for dynamic medical data sets, such as video angiograms [MEN 03]. These images are highly contrasted: very sharp edges are juxtaposed with a smooth background. The edges spread out in the whole subband structure generating a distribution of non-zero coefficients whose spatial arrangement cannot be profitably used for coding. This is principally due to the fact that wavelets are not suitable descriptors of images with sharp edges.
8.4. Irreversible compression of volumetric medical data sets
8.4.1. Wavelet-based intra coding
With the widespread use of the Internet, online medical volume databases have gained popularity. With recent advances in picture archiving communication systems (PACS) and telemedicine, improved techniques for interactive visualization across distributed environments are being explored. Typically, data sets are stored and maintained by a database server, so that one or more remote clients can browse the datasets interactively and render them. In many cases, the client is a low-end workstation with limited memory and processing power. An interactive user may be willing to initially sacrifice some rendering quality or viewing field in exchange for real-time performance. Thus, one of the fundamental needs of a client is breadth in terms of interactivity (such as reduced resolution viewing, ability to view a select subsection of the volume, view select slices, etc.) and a pleasant and real-time viewing experience (immediate and progressive refinement of the view volume, etc.). Such a setup enforces the use of hierarchical coding schemes that allow progressive decoding. out of all the lossless compression methods presented in section 8.2, only HINT and GRINT approaches allow progressive reconstruction. However, since no binary allocation process is made in these two compression schemes, the compression ratios attained are considerably low.
The wavelet transform has many features that make it suitable for progressive transmission (or reconstruction). The implementation via the lifting steps scheme is particularly advantageous in this framework. It provides a very simple way of constructing non-linear wavelet transforms mapping integer-to-integer values. This is very important for medical applications because it enables a lossy-to-lossless coding functionality; i.e. the capability to start from lossy compression at a very high compression ratio and to progressively refine the data by sending detailed information, up until the point where a lossless decompression is obtained. We will not return to the description of 2D compression algorithms, supporting progressive transmission. At present, we only mention 2D wavelet-based embedded image coding algorithms, which have extended our knowledge of 3D coding of the volumetric medical images:
– EZW and SPIHT coders;
– SPECK algorithm;
– QT-L algorithm;
– EBCOT coder.
It is important to note that these techniques support lossless coding, all the required scalability modes, as well as ROI coding.
8.4.2. Extension of 2D transform-based coders to 3D data
8.4.2.1. 3D DCT coding
To take into account the inter-image correlation in volumetric images, DCT-based coding systems have been extended to 3D coding [VLA 95]. A 3D image can then be seen as a volume of correlated content to which 3D DCT transformation is applied for decorrelation purposes. The 3D JPEG-based coder is composed of a discrete cosine transform, followed by a scalar quantizer and finally a combination of run-length coding and adaptive arithmetic encoding. The basic principle is simple: the volume is divided into cubes of 8×8×8 pixels and each cube is separately 3D DCT-transformed, similar to a classical JPEG-coder. Thereafter, the DCT coefficients are quantized using a quantization matrix. In order to derive this matrix, we have to consider two options. One option is to construct quantization tables that produce an optimized visual quality based on psycho-visual experiments. It is worthwhile mentioning that JPEG uses such quantization tables, but this approach would require elaborate experiments in order to come up with reasonable quantization tables for volumetric data. The simplest solution is to create a uniform quantization matrix. This option is motivated by the fact that uniform quantization is optimal or quasi-optimal for most of the distributions. Currently, the uniform quantizer is optimal for Laplacian and exponential input distributions; otherwise the differences with respect to an optimal quantizer are marginal. A second possibility involving quantizers that are optimal in the rate-distortion sense is discussed elsewhere.
The quantized DCT-coefficients are scanned using a 3D space-filling curve, i.e. a 3D instantiation of the Morton-curve, to allow for the grouping of zero-valued coefficients and thus to improve the performance of the run-length coding. This curve was chosen due to its simplicity compared to that of 3D zigzag curves. The non-zero coefficients are encoded using the same classification system as for JPEG. The coefficient values are grouped into 16 main magnitude classes (ranges), which are subsequently encoded with an arithmetic encoder. Finally, the remaining bits to refine the coefficients within one range are added without further entropy coding.
The adopted entropy coding system shown in Figure 8.5 is partially based on the JPEG architecture, except that the Huffman coder is replaced by an adaptive arithmetic encoder which tends to have a higher coding efficiency. The DC coefficients are encoded with a predictive scheme: apart from the first DC coefficient the entropy coding system encodes the difference between the current DC coefficient and the previous one. The AC coefficients are encoded in the form of pairs (RUN, BEEN WORTH), where “RUN” specifies the amount of zeros preceding the encoded symbol, designated by the “BEEN WORTH” term. The range of the encountered significant symbol is encoded, using an arithmetic encoder with a similar (AC) model as in the case of the DC coefficients. Nevertheless, similar to their 2D counterparts, 3D DCT-based compression techniques are not able to satisfy the requirements of progressive transmission and perfect reconstruction.

Figure 8.5. 3D DCT-based coder
8.4.2.2. 3D wavelet-based coding based on scalar or vector quantization
Before describing the 3D wavelet-based coding techniques, it is important to note that these techniques support lossless coding, all the required scalability modes, as well as ROI coding and this is a significant difference with respect to the 3D DCT technique presented above, which is not able to provide these features.
For all 3D wavelet based coders adapted to medical applications, a common wavelet transform module was designed that supports lossless integer lifting filtering, as well as finite-precision floating-point filtering. Different levels of decomposition for each spatial direction (x-, y-, or z- direction) are supported by the wavelet module. In [LOW 95] [WAN 95], a 3D separable wavelet transform is used to remove inter-slice redundancy, while in [WAN 96], different sets of wavelet filters are used in the (x, y) plane and z direction, respectively, to account for the difference between the intra- and inter-slice resolution. In fact, the distance between adjacent pixels in the same 2D image varies from 0.3 to 1 mm, while the distance between two successive images in IRM or CT sequences varies from 1 to 10 mm. This has led to the common consensus that the use of the full 3D data correlation potentially improves compression. The obtained wavelet sub-volumes are independently quantized, either by uniform scalar quantization or vector quantization, and finally entropy coded. It is worth noting that many works have been investigated in order to define a quantization policy which ensures the highest decoding quality, for a given rate, over the entire image volume.
8.4.2.3. Embedded 3D wavelet-based coding
Since contemporary transmission techniques require the use of concepts such as rate scalability, quality and resolution scalability, multiplexing mechanisms need to be introduced to select from each slice the correct layer(s) to support the currently required Quality-of-Service (QoS) level. However, a disadvantage of the slice-by-slice mechanism is that potential 3D correlations are neglected. Evaluation of wavelet volumetric coding systems that meet the above-mentioned requirements has shown that these coder types deliver the best performance for lossy-to-lossless coding.
3D wavelet-based embedded image coding algorithms typically apply successive approximation quantization (SAQ) to provide quality scalability and facilitate the embedded coding. The resolution scalability is a direct consequence of the multiresolution property of the DWT. Both resolution and quality scalability are provided by the multi-layered organization of the code-stream into packets. In what follows, we will restrict ourselves to the description of 3D wavelet-based embedded coding techniques that employ zero tree- or block-based structures. It is worth mentioning that 3D SPIHT (Set Partitioning into Hierarchical Trees) [KIM 00] and 3D SB-SPECK (SuBband-based Set Partitioned Embedded bloCK coding) [WHE 00] are the well-known representatives of the family of inter-band embedded 3D coding approaches.
In the case of 2D images, these strategies use the inter-band dependencies of the wavelet coefficients to provide a progressive improvement of the reconstructed image quality. More recently, other 3D wavelet-based coding algorithms have been developed, taking into account the intra-band dependencies between wavelet coefficients. Among these algorithms, a new coder called the 3D Quadtree Limited (3D QT-L) combines the basic principles of quadtree and block-based coding.
The investigations performed in the context of the new standard for 2D image coding, JPEG 2000 (based on the wavelet transform), like random access to regions of interest and lossy-to-lossless coding, triggered the ISO/IEC JTC1/SC29/WG1 committee to develop the JP2000 3D coder equipped with a 3D wavelet transform. The latter is one of the functionalities provided by the latest Verification Model software (from V7.0 on), which was added to support multi-spectral image coding. More recently, the ISO/IEC JTC1/SC29/WG1 committee decided to develop JP3D (i.e. Part 10 of JPEG 2000 standard), which gives support to 3D encoding mechanisms. The MLZC (Multi Layered Zero Coding) algorithm was proposed recently in [MEN 03] and provides high coding efficiency, fast access to any 2D image of the dataset and quality scalability. Its structural design is based principally on the layered zero coding (LZC) algorithm coder [TAU 94] designated to video coding. The main differences between LZC and the MLZC algorithm concern the underlying subband structure and the definition of the conditioning terms.
8.4.2.3.1. 3D set partitioning in hierarchical trees
The 3D SPIHT [KIM 00] implementation uses balanced 3D spatial orientation trees (Figure 8.6). Therefore, the same number of recursive wavelet decompositions is required for all spatial orientations. If this is not respected, several tree nodes are not linked within the same spatial location, and consequently the dependencies between different tree-nodes are destroyed and thus the compression performance is reduced. The examined 3D SPIHT algorithm follows the same procedure as its 2D homologous algorithm, with the exception that the states of the tree nodes, each embracing eight wavelet coefficients, are encoded with a context-based arithmetic coding system during the significance pass. The selected context models are based on the significance of the individual node members, as well as on the state of their descendants.
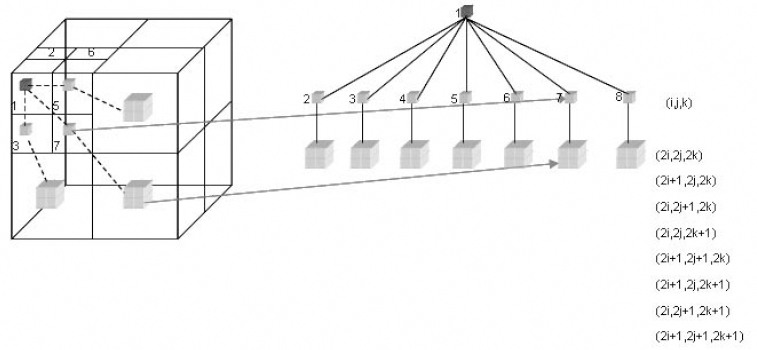
Figure 8.6. Parent descendant inter-band dependency
8.4.2.3.2. Cube splitting
The cube splitting technique is derived from the 2D square partitioning coder (SQP) applied to the angiography sequences [MUN 99]. In the context of volumetric encoding, the SQP technique was extended to a third dimension: from square splitting towards cube splitting. Cube splitting is applied to the wavelet image in order to isolate smaller entities, i.e. sub-cubes, possibly containing significant wavelet coefficients. Figure 8.7 illustrates the cube splitting process.
During the first significance pass S, the significance of the wavelet image (volume) is tested for its highest bit-plane. The wavelet image is spliced into eight sub-cubes (or octants). When a significant wavelet coefficient, in a descendent cube, is encountered, the cube (Figure 8.7a) is spliced into eight sub-cubes (Figure 8.7b), and so on (Figure 8.7c) up until the pixel level. The result is an octree structure (Figure 8.8d), with the SGN symbol indicating the significant node and the NS symbol designating the non-significant node. In the next significance pass, the non-significant nodes that contain significant wavelet coefficients are refined further. As we may observe, all branches are accorded equal importance.
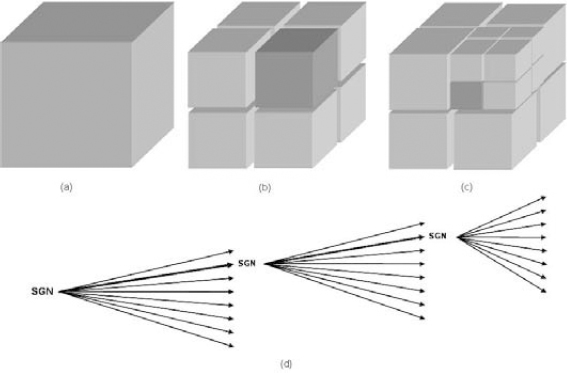
Figure 8.7. Cube splitting according to the wavelet coefficients significance
When the complete bit-plane is encoded with the significance pass, the refinement pass R is initiated for this bit-plane, refining all coefficients marked as significant in the octree. Thereafter, the significance pass is restarted in order to update the octree by identifying the new significant wavelet coefficients for the current bit-plane. During this stage, only the previously non-significant nodes are checked for significance, and the significant ones are ignored since the decoder has already received this information. The described procedure is repeated, until the complete wavelet image is encoded or until the desired bitrate is obtained. To encode the generated symbols efficiently, a context-based arithmetic encoder has been integrated.
8.4.2.3.3. 3D QT-L
The QT-L coder has also been extended towards 3D coding. The octrees corresponding to each bit-plane are constructed following a similar strategy as for the cube splitting coder. However, the partitioning process is limited in such a way that once the volume of a node becomes smaller than a predefined threshold, the splitting process is stopped, and the entropy coding of the coefficients within such a significant leaf node is activated. Similar to the 2D version, the octrees are scanned using depth-first scanning. In addition, for any given node, the eight descendant nodes are scanned using a 3D instantiation of the Morton curve. For each bit-plane, the coding process consists of the non-significance, significance and refinement passes. For the highest bit-plane, the coding process consists of the significance pass only. The context-conditioning scheme and the context-based entropy coding are similar to their 2D counterparts.
8.4.2.3.4. 3D CS-EBCOT
The CS-EBCOT coding [SCH 00] combines the principles utilized in the cube splitting coder with a 3D instantiation of the EBCOT coder. The interfacing of the cube splitting coder with a version of EBCOT adapted to 3D is outlined below:
– firstly, the wavelet coefficients are partitioned EBCOT-wise into separate, equally sized cubes, called codeblocks. Typically, the initial size of the codeblocks is 64×64×64 elements (Figure 8.8);
– the coding module, CS-EBCOT, consists of two main units, the Tier 1 and Tier 2 parts: Tier 1 of the proposed 3D coding architecture is a hybrid module combining two coding techniques: cube splitting and fractional bit-plane coding using context-based arithmetic encoding. Tier 2 part is identical to the one used in the 2D coding system. Its concerns the layer formation in a rate-distortion optimization framework.
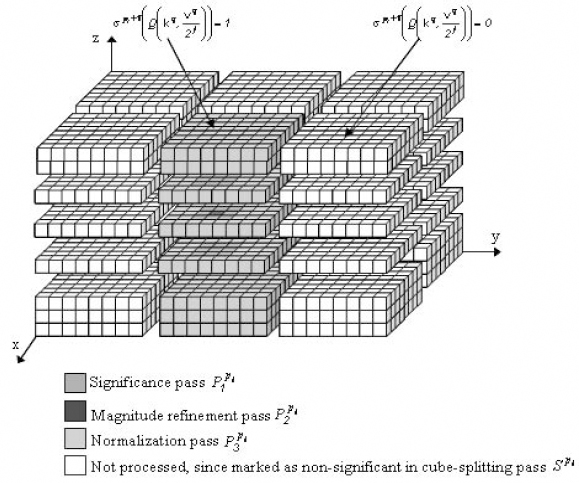
Figure 8.8. Cube-splitting based on wavelet coefficient significance
To use pixel correlation with its neighborhood, according to the three spatial directions, CS-EBCOT uses 3D context models for the adaptive arithmetic coding which is identical to those utilized in the previously mentioned encoders.
8.4.2.3.5. JP3D
Part 10 of JPEG 2000 (JP3D) [BIS 03] is a work item that provides extensions of JPEG-2000 for rectangular 3D hyper-spectral and volumetric medical data sets with no time component. It provides a specification for the coding of 3D data sets that are as isotropic as possible; i.e. identical processing capabilities will be provided in all three dimensions. The proposed volumetric coding mechanism is based on a 3D instantiation of the EBCOT coder. To assure the adoptability of the Part 10 extension of the JPEG 2000 standard, two important requirements are imposed; i.e. the backward compatibility requirement and the isotropic functionality requirement. The backward compatibility requirement demands that any compliant Part 1 or Part 2 code-stream needs to be recognized as a compliant JP3D code-stream, respecting the original semantic interpretation of all markers, parameters and bit-streams. In particular, when given a compliant Part 1 or Part 2 code-stream and legal decoding options, a JP3D decoder will produce the same reconstructed image as a Part 1 or Part 2 reference decoder. Secondly, the new or extended technology, included for JP3D, shall provide the same, i.e. isotropic functionality in all 3 coordinate directions, while remaining compatible with the syntax used in Part 2 that describes volumetric images as enumerated sets of 2D image components. It is evident that typical requirements such as quality and resolution scalability and ROI, apart from additionally improved rate-distortion behaviour, should also be supported by JP3D in an isotropic fashion. The proposed volumetric coding mechanism is based on a 3D instantiation of the EBCOT coder [SCH 05]. All of the mentioned requirements have had a great impact on JP3D coding technology: consisting of rate control and rate-distortion modeling for 3D data, 3D rate/distortion optimization, coding and code-stream formation for 3D data, provision of 3D arithmetic coding contexts and coding passes, enabling the signalling of user-specified anisotropic context models.
8.4.2.4. Object-based 3D embedded coding
Medical images usually consist of a region representing the part of the body under investigation (i.e. the heart in a CT or MRI chest scan, the brain in a head scan) on an often noisy background of no diagnostic interest. It seems very natural therefore to process such data in an object-based framework [BRE 01] assign high priority to the semantically relevant object, to be represented with up to lossless quality, and lower priority to the background. The texture modeling perfectly fits into the framework of object modelling-based coding.
In the context of object-based coding, this means that texture modeling can be applied only to objects for which the constraint of being able to recover the original data without loss can be relaxed. This naturally maps onto the medical imaging field: objects which are diagnostically relevant should be selectively encoded by one of the methods mentioned above with the remaining objects (or even the background) replaced by a suitable synthetic model. Although local structures and regular edges can be effectively coded, it is worth pointing out that similar to other pre-segmentation approaches where ROIs are identified and segmented before encoding, this method does not allow direct access to the regions of interest. To alleviate the pre-segmentation problem, region scalable coding schemes, based on post-segmentation approaches have been developed. The 3D MLZC (Multi Layered Zero Coding) algorithm [MEN 03] proposes a fully 3D wavelet-based coding system allowing random access to any object at the desired bitrate. Continuous wavelet-based segmentation is used to select objects that should be coded independently. Although this approach, also referred to as the spatial approach, has the advantage that the ROI information coincides with the physical perception of the ROI, extra complexity is inserted at the level of the wavelet transform (shape-adaptive transform).
Although it is possible to compress an image set in intra mode, which uses the intra image correlation, a more efficient compression can be achieved by exploring the correlation between slices. However, the experiments carried out in [MEN 00] have shown that the benefit of an inter-image correlation depends on the slice distance of the image set. The smaller the slice distance, the better the correlation in the slice direction, and the better the compression performance. In general, effective results are produced for image sets with slice distances smaller than 1.5 mm. The same experimental results have demonstrated that the use of 3D context models is not profitable if it is integrated into a 3D wavelet compression scheme.
8.4.2.5. Performance assessment of 3D embedded coders
The lossy and lossless compression performances of the embedded wavelet-based coders, described previously, were evaluated according to a set of volumetric data obtained with different imaging modalities [SCH 03a], including: positron emission tomography, PET (128×128×39×15bits), computed tomography, CT1 (512×512×100×12bits), CT2 (512×512×44×12bits), ultrasound, US (256×256×256×8bpp), and MRI data, MRI (256×256×200×12bpp). Lossless coding results are reported for most of the techniques discussed so far: CS, 3D QT-L, 3D SPIHT, 3D SB-SPECK (only for the CT2 and MRI data-based), CS-EBCOT and JPEG 2000. For obvious reasons the 3D DCT coder was not included in the lossless compression test due to the lossy character of its DCT front-end. Additionally, the coding results obtained with the JPEG 2000 coder equipped with a 3D wavelet transform (JPEG2K-3D) are reported. For all the tests performed in lossless coding (as well as for lossy coding later), typically a 5-level wavelet transform (with a lossless 5x3 lifting kernel) was applied to all spatial dimensions, except for the low-resolution PET image (4 levels). The same number of decompositions in all dimensions was used to allow fair comparison with the 3D SPIHT algorithm. Table 8.1 shows the increase in percentage of the bitrate achieved in lossless compression, with the reference technique taken as the algorithm yielding the best coding results for each test volume.

Table 8.1. The increase of the lossless bitrate in terms of percentage, with the reference technique taken as the algorithm yielding the best coding results for each test volume
Based on Table 8.1, we can observe that for the US and PET volumes, the 3D QT-L coder delivers the best coding performance, while for the other three volumetric data, the CS-EBCOT performs best. If we refer to the average increase in percentage taking the CS-EBCOT coder as the reference, then we will observe that the 3D QT-L yields a similar performance, since the average difference between the two is only 0.1%. The CS coder follows it, with a difference of 1.45%. The 3D SPIHT and the JPEG2K-3D coders provide similar results, with an average difference of 3.56% and 3.65% respectively. Finally, the average difference increases up to 7.07% and 12.78% for the 3D SB-SPECK and JPEG 2000 coders. We also observe from Table 8.1 that the relative performance of several techniques is heavily dependant on the data set involved. For example, 3D SPIHT delivers excellent results for the US, CT1 and MRI sets, while for the other ones the performance is relatively poor. JPEG 2000 yields the worst coding results of all, except for the CT2 image, which has a low axial resolution. The results of the 3D SB-SPECK have been reported only for the CT2 and MRI data sets, and the results are situated in between JPEG2K and JPEG2K-3D for the MRI volume.
In summary, these results lead to the following important observations for lossless coding:
– CS-EBCOT and 3D QT-L deliver the best lossless coding results on all images;
– the 3D wavelet transform as such significantly boosts the coding performance;
– as spatial resolution and consequently inter-slice dependency diminishes, the benefit of using a 3D de-correlating transform and implicitly a 3D coding system decreases.
Lossy coding experiments were carried out on the five volumetric data sets for the aforementioned coders, and in addition, the 3D DCT-based coding engine is included [SCH 03b]. The peak signal-to-noise ratio (PSNR) is measured at seven different bitrates: 2, 1, 0.5, 0.25, 0.125, 0.0625 and 0.03125 bits-per-pixel (bpp). Similar to the lossless coding experiments, the performance of the lossy wavelet coders is evaluated. In a first evaluation, we observe that the 3D QT-L coder outperforms all the other wavelet coders in the whole range of bitrates. For example, the 3D QT-L coder yields on the US data set at 1.00 bpp a PSNR of 38.75dB, which is 0.5 dB better than the JPEG 2000 3D, and 1.43 dB better than CS-EBCOT. At higher rates (2bpp) the differences between them increase up to 0.88 dB and 1.45 dB for the JPEG 2000 3D and CS-EBCOT coders respectively. The 3D QT-L and the JPEG 2000 3D algorithms perform equally well at low rates (0.125 bpp) on the US data set, and outperform the CS-EBCOT coder with 0.37 dB and 0.25 dB respectively. A similar ranking according to their performance can be achieved by taking into account the result obtained on the MRI data set. At 0.125bpp the results are in order 52.01 dB, 51.61 dB and 51.17 dB for the 3D QT-L, JPEG 2000 3D, and CS-EBCOT respectively. Note that at lower rates CS-EBCOT gives slightly better results (0.03125bpp – 46.52 dB) than JPEG 2000 3D (0.03125bpp – 46.22 dB) but still less than those provided by 3D QT-L with 46.75 dB at the same rate. Similarly, the 3D QT-L outperforms on the CT1 data set the next rated wavelet coder JPEG 2000 3D, but the differences between them are smaller: from 0.27 dB at 1bpp, to 0.57 dB at 0.03125bpp.
The results obtained on the PET volumetric data indicate that at rates below 0.25 bpp the 3D QT-L coder outperforms all the other coders. However, at higher rates the JPEG 2000 3D outperforms the 3D QT-L coder on this data. If we look at the JPEG 2000 standard, we note that this coder typically delivers poor coding results on the PET, US volumes and MRI data; on CT1 it yields good results at rates higher than 0.25bpp, but the results are modest at lower rates. However, for CT2, JPEG 2000 is the best coder at high bitrates, and is only beaten by JPEG 2000 3D and SB-SPECK at low-bitrates.
8.5. Conclusion
This chapter provides an overview of various state-of-the-art lossy and lossless image compression techniques, which were applied to dynamic and volumetric medical images. Although both of the datasets considered are composed of 2D image sequences, the coding performance of lossy compression has been shown to be heterogenous with the image representation or characteristics. For example, since video angiogram sequences are highly contrasted, very sharp edges are juxtaposed to a smooth background. Wavelet-based coding techniques are not suitable for this kind of data. The edges spread out in the whole subband structure generating a distribution of non-zero coefficients whose spatial arrangement cannot be profitably used for coding.
Conversely, in the case of volumetric medical sequences, the combination of the 3D wavelet transform with an ad-hoc coding strategy provides a high coding efficiency. Another important advantage of 3D wavelet transforms is the ability to produce a scalable data stream which embeds subsets progressing in quality all the way up to a lossless representation which is very important for medical applications. The zero-trees principle, as well as other set partitioning structures such as quadtrees, allow for the grouping of zero-valued wavelet coefficients, taking into account their intra or inter-band dependencies. Therefore, by using such models, we can isolate interesting non-zero details by immediately eliminating large insignificant regions from further consideration. Before passing through the entropy coding process, the significant coefficients are quantized with successive approximation quantization to provide a multiprecision representation of the wavelet coefficients and to facilitate the embedded coding.
It is obvious that diagnostic zone selection according to the “ROI” principle supported by cubic splitting compression systems is not very reliable. This is mainly due to the fact that the particular structures that characterize them are not modeled with sufficient precision. The hybrid compression techniques recently implemented propose hybrid coding systems of embedded object oriented type.
The progressive compression systems highlighted in this chapter can be approved by different strategies developed in [KIM 98], [XIO 03] and [KAS 05]. The latter reference also integrates a novel MC technique that addresses respiratory and cardiac activity movement. Cardiac image compression is a more complex problem than brain image compression, in particular because of the mixed motions of the heart and the thorax structures. Moreover, cardiac images are usually acquired with a lower resolution than brain images. This highlights certain problems induced by the spatio-temporal image acquisition that hamper MC in dynamic medical image compression schemes. The integration of multiple complementary data, generated in “listmode” acquisition mode, into a common reference provides information relevant to compression research. For example, in a cardiac image coding framework, based on MC, additional physiological signals such as ECG-gated film sequences as well as the respiration movement are required to take account of heart motion and deformation; for more details, see [VAN 05].
8.6. Bibliography
[AIA 96] AIAZZI B., ALBA P. S., BARAONTI S., ALPARONE L., “Three dimensional lossless compression based on a separable generalized recursive interpolation”, Proc. ICIP '96, Lausanne, Switzerland, p. 85-88, 1996.
[ASS 98] VAN ASSCHE S., DENECKER K., PHILIPS W., LEMATHIEUI., “Lossless compression of three-dimensional medical images”, PRORISC'98, p. 549-53, 1998.
[BAS 95] BASKURT A., BENOIT-CATTINH., ODET C., “On a 3-D medical image coding method using a separable 3-D wavelet transform”, Proc. SPIE Medical Imaging, vol. 2431, p. 173-183, 1995.
[BRE 01] BRENNECKE R., BURGEL U., RIPPIN G., POST F., RUPPERCHET HJ., MEYER J., “Comparison of image compression viability for lossy and lossless JPEG and Wavelet data reduction in coronary angiography”, Int J. Cardiovasc. Imaging, vol. 17, p. 1-12, 2001.
[BRI 03] BRISLAWN C., SCHELKENS P., “Embedded JPEG 2000 Part 10: Verification model (VM10) users' guide”, ISO/IEC JTC1/SC29/WG1, 2003.
[CLU 00] CLUNIE D.A., “Lossless compression of grayscale medicale images – effectiveness of traditional and state of the art approaches”, Proceedings of SPIE – The International Society for Optical Engineering, vol. 3980, p. 74-84, 2000.
[GAL 91] LE GALL D., “MPEG: A video compression standard for multimedia applications”, IEEEPMRC'95, vol. 1, p. 120-124, 1995.
[GIB 01a] GIBSON D., TSIBIDIS G., SPANN M., WOOLLEY S., “Angiogram video compression using a wavelet-based texture modelling approach”, Human Vision and Electronic Imaging VI, Proc. of SPIE, vol. 4299, 2001.
[GIB 01b] GIBSON D., SPANN M., WOOLEY S., “Comparative study of compression methodologies for digital angiogram video”, ISPACS 2000, Honolulu, Hawaii, 2000.
[GIB 04] GIBSON D., SPANN M., WOOLEY S., “A Wavelet-based region of interest encoder for the compression of angiogram video sequences”, IEEE Trans. on Information Technology in Biomedicine, vol. 8, no. 2, 2004.
[HO 96] HO B., TSAI M., WEI J., MA J., SAIPETCH P., “Video compression of coronary angiograms based on discrete wavelet transform with block classification”, IEEE Trans. on Medical Imaging, vol. 15, p. 814-823, 1996.
[KAS 05] KASSIM AA., YAN P., LEE WS., SENGUPTA K. “Motion compensated lossy-to-lossless compression of 4-D medical images using integer wavelet transforms”, IEEE Trans. on Medical Imaging, vol. 9, p. 132-138, 2005.
[KAT 98] KATSAGGELOS A.K., KONDI L.P., MEIER F.W., OSTERMANN J., SCHUSTER G.M., “MPEG-4 and rate-distortion-based shape-coding techniques”, Proc. of the IEEE, no. 6, p. 1126-1154, 1998.
[KIM 98] KIM Y-S., AND KIM W-Y., “Reversible decorrelation method for progressive transmission of 3-D medical image”, IEEE Trans. on Medical Imaging, vol. 17, p. 383-394, 1998.
[KIM 00] KIM. B-J., PEARLMAN W. A., “Stripe-based SPIHT lossy compression of volumetric medical images for low memory usage and uniform reconstruction quality”, Proc. ICASSP, vol. 4, p. 2031-2034, June 2000.
[MEN 00] MENEGAZ G., “Model-based coding of multi-dimensional data with applications to medical imaging”, PhD dissertation, Signal Processing Lab. (LTS), Ecole Polytechnique Fédérale de Lausanne, Switzerland, 2000.
[MEN 03] MENEGAZ G., THIRAN J. P., “Three-dimensional encoding two-dimensional decoding of medical data”, IEEE Trans on Medical Imaging, vol. 22, no. 3, 2003.
[MUN 99] MUNTENANU A., CORNELIS S.J., CRISTEA P., “Wavelet-based lossless compression of coronary angiographic images”, IEEE Trans. on Medical Imaging, vol. 18, p. 272-281, 1999.
[RAB 02] RABBANI M., JOSHI. R., “An overview of the JPEG2000 still image compression standard”, Signal Processing Image Communication, vol. 17, no. 3, 2002.
[RIG 96] RIGOLIN V.H., ROBIOLIO P.A., SPERO L.A., HARRAWOOD B.P., MORRIS K.G., FORTIN D.F., BAKER W.A., BASHORE T.M., CUSMA J.T., “Compression of digital coronary angiograms does not affect visual or quantitative assessment of coronary artery stenosis severity”, Am J Cardiol, vol. 78, p. 131-136, 1996.
[SCH 00] SCHELKENS P., GIRO X., BARBARIEN J., CORNELIS J., “3-D compression of medical data based on cube-splitting and embedded block coding”, Proc. ProRISC/IEEE Workshop, p. 495-506, December 2000.
[SCH 03a] SCHELKENS P., MUNTEANU A., BARBARIEN J., MIHNEAI G., GIRO-NIETO X., CORNELIS J., “Wavelet coding of volumetric medical datasets”, IEEE Trans. on Medical Imaging, vol. 22, no. 3, March 2003.
[SCH 03b] SCHELKENS P., MUNTEANU A., “An overview of volumetric coding technologies”, ISO/IEC JTC1/SC29/WG1, WG1N2613, 2002.
[SCH 05] SCHELKENS P., MUNTAEANU A., CORNELIS J., “Wavelet coding of volumetric medical data set”, ICIP 2005, Singapore, 2005.
[TAU 94] TAUBMAN D., ZKHOR A., “Multirate 3-D subband coding of video”, IEEE Trans. Image Processing, vol. 3, p. 572-588, September 1994.
[TSA 94] TSAI M., VILLASENOR J., HO B., “Coronary angiogram video compression”, Proc. IEEE Conference on Medical Imaging, 1994.
[VAN 05] VANDERBERGUE S., STAELENS S., VAN DE WALLE R., DIERCKX R., LEMATHIEU I., “Compression and reconstruction of sorted PET listmode data”, Nucl. Med. Commun., vol. 26, p. 819-825, 2005.
[VLA 95] VLAICU A., LUNGU S., CRISAN N., PERSA S., “New compression techniques for storage and transmission of 2-D and 3-D medical images”, Proc. SPIE Advanced Image and Video Communications and Storage Technologies, vol. 2451, p. 370-377, February, 1995.
[WAN 95] WANG J., HUANG H.K., “Medical image compression by using three-dimensional wavelet transformation”, Proc. SPIE Medical Imaging, vol. 2431, p. 162-172, 1995.
[WAN 96] WANG J., HUANG. H.K., “Three-dimensional medical image compression using a wavelet transform with parallel computing”, IEEE Trans. on Medical Imaging, vol. 15, no. 4, p. 547-554, August 1996.
[WHE 00] WHEELER F.W., “Trellis source coding and memory constrained image coding”, PhD thesis, Dept. Elect., Comput. Syst. Eng., Renselaer Polytech. Inst., Troy, New York, 2000.
[XIO 03] XIONG Z., WU X., CHENG S., HUA J., “Lossy-to-lossless compression of medical volumetric data using three-dimensional integer wavelet transforms”, IEEE Trans. on Medical Imaging, vol. 22, p. 459-470, 2003.
[YOO 04] YOON S.H., LEE J.H., KIM J.H., ALEXANDER W., “Medical image compression using post-segmentation approach”, ICASSP 2004, p. 609-612, 2004.