
1
Security Posture
Over the years, investments in security have moved from nice to have to must have, and now organizations around the globe are realizing how important it is to continually invest in security. This investment will ensure that a company remains competitive in the market. Failure to properly secure their assets could lead to irreparable damage, and in some circumstances could lead to bankruptcy. Due to the current threat landscape, investing in protection alone isn’t enough. Organizations must enhance their overall security posture. This means that the investments in protection, detection, and response must be aligned. In this chapter, we’ll be covering the following topics:
- Why security hygiene should be your number one priority
- The current threat landscape
- The challenges in the cybersecurity space
- How to enhance your security posture
- Understanding the roles of the Blue Team and Red Team in your organization
Let’s start by going into a bit more detail about why security hygiene is so vital in the first place.
Why security hygiene should be your number one priority
On January 23rd, 2020, Wuhan, a city with more than 11 million people, was placed in lockdown due to the novel coronavirus (2019-nCoV). Following this major event, the World Health Organization declared a global health emergency on January 30th. Threat actors actively monitor current world events, and this was an opportunity for them to start crafting their next attack. On January 28th, the threat actors behind Emotet started to exploit the curiosity and lack of information about the novel coronavirus (2019-nCoV) to start a major spam campaign, where emails were sent pretending to be official notifications sent by a disability welfare provider and public health centers. The perceived intent of the email was to warn the recipient about the virus and to entice the user to download a file that contained preventive measures. The success of this campaign led other threat actors to follow in Emotet’s footsteps, and on February 8th, LokiBot also used the novel coronavirus (2019-nCoV) theme as a way to lure users in China and the United States.
On February 11th, the World Health Organization named the new disease COVID-19. Now with an established name, and the mainstream media utilizing this name in its mass coverage, this prompted another wave of malicious activities by the threat actors that were monitoring these events. This time Emotet expanded its campaigns to Italy, Spain, and English-speaking countries. On March 3rd, another group started to use COVID-19 as the main theme for their TrickBot campaign. They were initially targeting Spain, France, and Italy, but rapidly became the most productive malware operation at that point.
What do all these campaigns have in common? They use fear around COVID-19 as a social engineering mechanism to entice the user to do something, and this something is what will start the compromise of the system. Social engineering via phishing emails always has a good return on investment for threat actors, because they know many people will click on the link or download the file, and this is all they need. While security awareness is always a good countermeasure to educate users on these types of attacks and ensure that they are more skeptical before acting upon receiving emails like that, you always need to ensure that you have security controls in place to mitigate the scenarios where even an educated user will fall into this trap and click on the link. These security controls are the proactive measures that you need to have in place to ensure that your security hygiene is flawless and that you’ve done everything you can to elevate the security state of all resources that you are monitoring.
The lack of security hygiene across the industry was highlighted in the Analysis Report (AR21-013A) issued by the Cybersecurity and Infrastructure Security Agency (CISA). The report, called Strengthening Security Configurations to Defend Against Attackers Targeting Cloud Services, emphasized that most threat actors are able to successfully exploit resources due to poor cyber hygiene practices, which includes the overall maintenance of resources as well as a lack of secure configuration.
Without proper security hygiene, you will always be playing catchup. It doesn’t matter if you have great threat detection, because as the name says, it is for detection and not prevention or response. Security hygiene means you need to do your homework to ensure that you are using the right security best practices for the different workloads that you manage, patching your systems, hardening your resources, and repeating all these processes over and over. The bottom line is that there is no finish line for this, it is a continuous improvement process that doesn’t end. However, if you put in the work to continually update and improve your security hygiene, you will ensure that threat actors will have a much harder time accessing your systems.
The current threat landscape
With the prevalence of always-on connectivity and advancements in technology that are available today, threats are evolving rapidly to exploit different aspects of these technologies. Any device is vulnerable to attack, and with the Internet of Things (IoT) this became a reality. In October 2016, a series of distributed denial-of-service (DDoS) attacks were used against a DNS provider used by GitHub, PayPal, etc., which caused those major web services to stop working. Attacks leveraging IoT devices are growing exponentially.
According to SonicWall, 32.7 million IoT attacks were detected during the year 2018. One of these attacks was the VPNFilter malware.
This malware was leveraged during an IoT-related attack to infect routers and capture and exfiltrate data.
This was possible due to the amount of insecure IoT devices around the world. While the use of IoT to launch a massive cyber-attack is something new, the vulnerabilities in those devices are not. As a matter of fact, they’ve been there for quite a while. In 2014, ESET reported 73,000 unprotected security cameras with default passwords. In April 2017, IOActive found 7,000 vulnerable Linksys routers in use, although they said that it could be up to 100,000 additional routers exposed to this vulnerability.
The Chief Executive Officer (CEO) may even ask: what do the vulnerabilities in a home device have to do with our company? That’s when the Chief Information Security Officer (CISO) should be ready to give an answer because the CISO should have a better understanding of the threat landscape and how home user devices may impact the overall security that this company needs to enforce. The answer comes in two simple scenarios, remote access and bring your own device (BYOD).
While remote access is not something new, the number of remote workers is growing exponentially. 43% of employed Americans report spending at least some time working remotely, according to Gallup, which means they are using their own infrastructure to access a company’s resources. Compounding this issue, we have a growth in the number of companies allowing BYOD in the workplace. Keep in mind that there are ways to implement BYOD securely, but most of the failures in the BYOD scenario usually happen because of poor planning and network architecture, which lead to an insecure implementation.
What is the commonality among all the technologies that were previously mentioned? To operate them you need a user, and the user is still the greatest target for attack. Humans are the weakest link in the security chain. For this reason, old threats such as phishing emails are still on the rise. This is because they deal with the psychological aspects of the user by enticing the user to click on something, such as a file attachment or malicious link. Once the user performs one of these actions, their device usually either becomes compromised by malicious software (malware) or is remotely accessed by a hacker. In April 2019 the IT services company Wipro Ltd was initially compromised by a phishing campaign, which was used as a footprint for a major attack that led to a data breach of many customers. This just shows how effective a phishing campaign can still be, even with security controls in place.
The phishing campaign is usually used as the entry point for the attacker, and from there other threats will be leveraged to exploit vulnerabilities in the system.
One example of a growing threat that uses phishing emails as the entry point for the attack is ransomware. In just the first three months of 2016, the FBI reported that $209 million in ransomware payments were made. Trend Micro predicted that ransomware growth would plateau in 2017, but that the attack methods and targets would diversify. This prediction was actually very accurate as we see can now in the latest study from Sophos that found that ransomware attacks dropped from 51% in 2020 to 37% in 2021.
The following diagram highlights the correlation between these attacks and the end user:
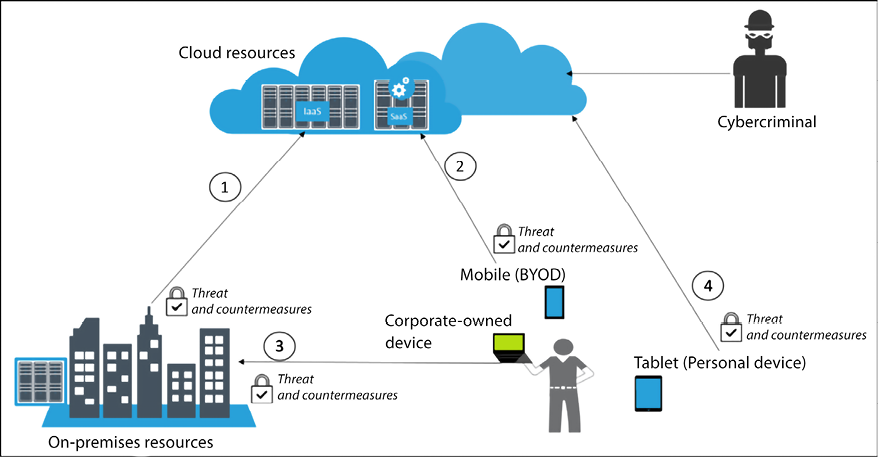
Figure 1.1: Correlation between attacks and the end user
This diagram shows four entry points for the end user. All of these entry points must have their risks identified and treated with proper controls. The scenarios are listed here:
- Connectivity between on-premises and cloud (entry point 1)
- Connectivity between BYOD devices and cloud (entry point 2)
- Connectivity between corporate-owned devices and on-premises (entry point 3)
- Connectivity between personal devices and cloud (entry point 4)
Notice that these are different scenarios, but they are all correlated by one single entity: the end user. This common element in all scenarios is usually the preferred target for cybercriminals, which is shown in the preceding diagram accessing cloud resources.
In all scenarios, there is also another important element that appears constantly, which is cloud computing resources. The reality is that nowadays you can’t ignore the fact that many companies are adopting cloud computing. The vast majority will start in a hybrid scenario, where infrastructure as a service (IaaS) is their main cloud service. Some other companies might opt to use software as a service (SaaS) for some solutions, for example, mobile device management (MDM), as shown in entry point 2. You may argue that highly secure organizations, such as the military, may have zero cloud connectivity. That’s certainly possible but, commercially speaking, cloud adoption is growing and will slowly dominate most deployment scenarios.
On-premises security is also critical, because it is the core of the company, and that’s where the majority of the users will be accessing resources. When an organization decides to extend their on-premises infrastructure with a cloud provider to use IaaS (entry point 1), the company needs to evaluate the threats for this connection and the countermeasure for these threats through a risk assessment.
The last scenario description (entry point 4) might be intriguing for some skeptical analysts, mainly because they might not immediately see how this scenario has any correlation with the company’s resources. Yes, this is a personal device with no direct connectivity with on-premise resources. However, if this device is compromised, the user could potentially compromise the company’s data in the following situations:
- Opening a corporate email from this device
- Accessing corporate SaaS applications from this device
- If the user uses the same password for their personal email and corporate account, this could lead to account compromise through brute force or password guessing
Having technical security controls in place could help mitigate some of these threats against the end user. However, the main protection is the continuous use of education via security awareness training.
Two common attacks that are particularly important to bear in mind during awareness training are supply chain attacks and ransomware, which we will discuss in more detail in just a moment.
Supply chain attacks
According to the Threat Landscape for Supply Chain Attacks, issued by the European Union Agency for Cybersecurity (ENISA) in July 2021, around 62% of the attacks on customers were possible because of their level of trust in their supplier. Keep in mind that this data is based on 24 supply chain attacks that were reported from January 2020 to July 2021. It is also important to add that the trust relationship mentioned above is a reference to MITRE ATT&CK technique T1199, documented at https://attack.mitre.org/techniques/T1199. This technique is used by threat actors that target their victims through a third-party relationship. This relationship could be a non-secure connection between the victim and the vendor. Some of the most common attack techniques leveraged in a supply chain attack include the ones shown in the table below:
|
Attack |
Use Case Scenario |
|
Malware |
Steal credentials from users. |
|
Social engineering |
Entice users to click on a hyperlink or download a compromised file. |
|
Brute force |
Commonly used to exploit VMs running Windows (via RDP) or Linux (via SSH). |
|
Software vulnerability |
SQL injection and buffer overflow are common examples. |
|
Exploiting configuration vulnerability |
Usually happens due to poor security hygiene of workloads. One example would be widely sharing a cloud storage account to the internet without authentication. |
|
Open-source intelligence (OSINT) |
Use of online resources to identify relevant information about the target, which includes systems used, usernames, exposed APIs, etc. |
Table 1.1: Common supply chain attack techniques
To better understand how a supply chain attack usually works, let’s use the diagram shown in Figure 1.2 as a reference:
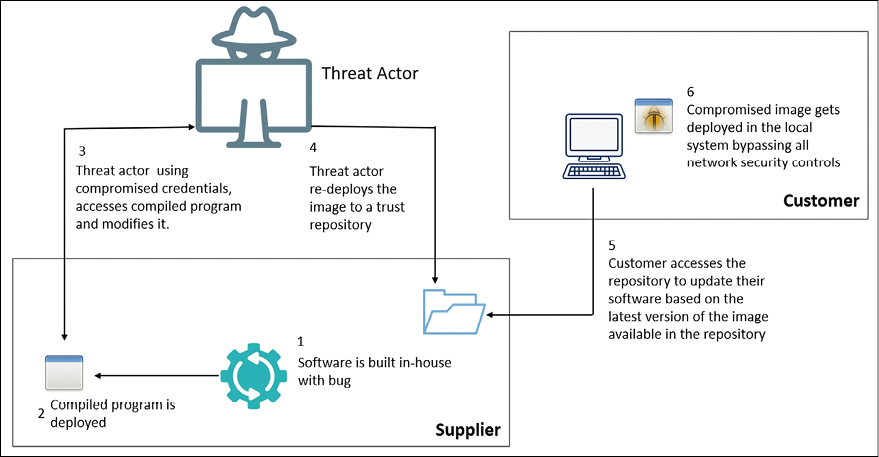
Figure 1.2: Example of a supply chain attack
In the example shown in Figure 1.2 there is already an assumption that the threat actor started its spear-phishing campaign targeting the supplier and it was able to obtain some valid user credentials that will be leveraged in step 3. Many professionals still ask why the threat actor doesn’t go straight to the victim (in this case, the customer) and the answer is because in this type of attack the threat actor identified a supplier that has more potential for a bigger operation and it is easier to compromise because of the supplier’s weaker security defenses. Many times, the true victim has more security controls in place and it is harder to compromise.
Another scenario that attracts threat actors to this type of attack is the ability to compromise one supplier that is utilized by multiple companies. The SolarWinds case is a typical example of this, where the malicious code was deployed as part of a software update from SolarWinds’ own servers, signed with a compromised certificate. The update was targeting the most widely deployed SolarWinds product, Orion, a Network Management System (NMS). Now every single customer that uses this software and receives this version of the update will be compromised too. As you can see, the threat actor doesn’t need to compromise many targets, they just need to focus on one target (the supplier) and let the chain of effects take place.
To minimize the likelihood that your organization will be compromised by a supply chain attack, you should implement at least the following best practices:
- Identify all suppliers that your organization deals with
- Enumerate those suppliers per order of priority
- Define the risk criteria for different suppliers
- Research how the supplier performs supply chain mitigations for their own business
- Monitor supply chain risks and threat
- Minimize access to sensitive data
- Implement security technical controls, such as
Throughout this book you will also learn many other countermeasure controls that can be used for this purpose.
Ransomware
Cognyte’s Cyber Threat Intelligence Research Group released some eye-opening statistics regarding the growth of Ransomware in their Annual Cyber Intelligence Report. One alarming finding was that in the first half of 2021 the number of ransomware victims grew by 100%, but 60% of the attacks came from the same three major ransomware groups, which operate as Ransomware-as-a-Service (RaaS):
Conti: documented in the MITRE ATT&CK at https://attack.mitre.org/software/S0575/
Avaddon: documented in the MITRE ATT&CK at https://attack.mitre.org/software/S0640/
Revil: documented in the MITRE ATT&CK at https://attack.mitre.org/software/S0496/
In the same report it was also revealed that the manufacturing industry accounts for more than 30% of victims, which makes it rank number one in the top five industries hit by ransomware, followed by financial services, transportation, technology, and legal and human resources.
To protect against ransomware, you must understand how it typically works, from the beginning to the end. Using Conti and Revil, mentioned earlier as an example, let’s see how they operate across the kill chain:
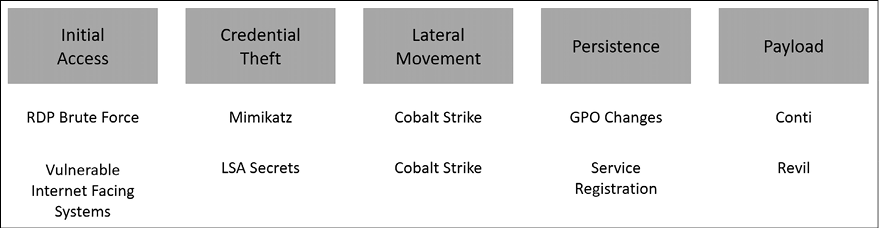
Figure 1.3: Examples of how RaaS compromises a system
As shown in Figure 1.3, different RaaSes will utilize different methods to move across the cyber kill chain; they may have one or more phases that will leverage a common technique, but for the most part they will have their own unique qualities. By understanding how they operate you ensure that you are prioritizing the improvement of your cybersecurity hygiene to address your infrastructure’s weaknesses.
Using Microsoft Defender for Cloud as an example of a security posture management platform, you can review all recommendations according to the MITRE ATT&CK framework. For the example, let’s start by filtering all recommendations that are applicable to the Initial Access phase:
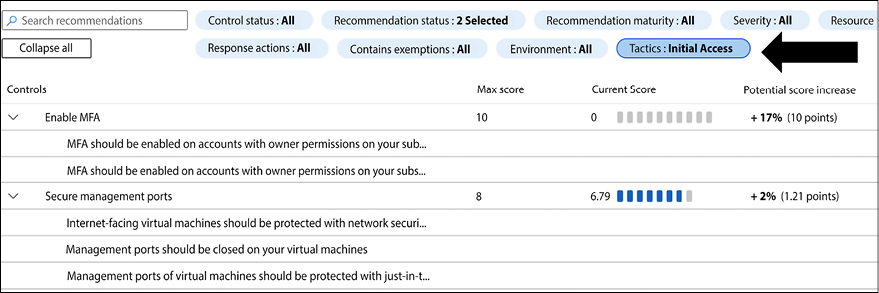
Figure 1.4: Recommendations applicable to the Initial Access phase of MITRE ATT&CK
Notice the arrow in Figure 1.4 that points to the Tactics filter, where you can select the MITRE ATT&CK phase. By utilizing this capability in Microsoft Defender for Cloud, you can start prioritizing the security recommendations that are currently open based on the MITRE ATT&CK tactic, and ensure that you are enhancing your security posture.
The point of this demonstration is to show you that there is no “silver bullet” to protect your organization against ransomware, and if a vendor comes to you to try to sell a black box saying that it is enough to protect against ransomware, run away from it, because that is not how protection works. Just by looking at the diagram shown in Figure 1.3, you can see that each phase targets different areas that will most likely be monitored by different security controls.
Let’s use as an example the initial access of Conti RaaS, which is RDP Brute Force. Management ports shouldn’t be always enabled for internet access anyway, and that’s the reason a security posture management platform such as Microsoft Defender for Cloud has a recommendation specifically for that, as shown in Figure 1.5:
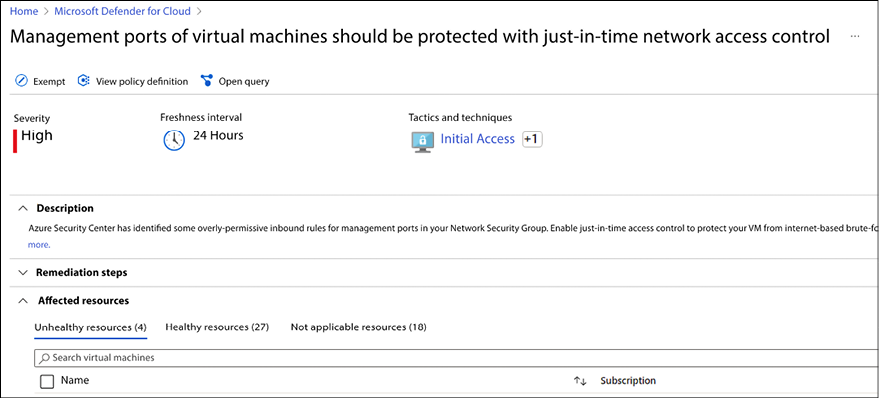
Figure 1.5: Recommendation to close management port
You can see the MITRE ATT&CK tactic and technique mapped for this recommendation, and the workloads that are vulnerable if this recommendation is not remediated. This is the preventive work that needs to be done: the security hygiene. In addition, you should also have threat detection to identify scenarios that were not predicted, now that there is a threat actor trying to exploit a management port that is open. For that, you also need security controls that can identify this type of attack. Microsoft Defender for Servers has threat detection for RDP Brute Force attacks.
Other mitigation controls that you can add in place are shown in the table below:
|
Scenario |
Core Mitigation |
|
Remote access to a company’s resource |
|
|
Endpoints |
|
|
User account |
|
|
Email and collaboration |
|
Table 1.2: Mitigation controls for ransomware attacks
While this list brings some key mitigations, you must also ensure that your infrastructure is secure enough to make it harder for the threat actor to escalate privilege or advance to other attack phases in case they were already able to compromise a system. To decrease the likelihood that the threat actor will be able to continue moving forward on their mission once they are able to compromise a system, you should address the following scenarios:
|
Scenario |
Core Mitigation |
|
Privilege access |
|
|
Detection and response |
|
Table 1.3: Scenarios and mitigations to prevent threat actor escalation
Additional security controls and mitigations may be necessary according to the organization’s needs and industry. As mentioned earlier, some threat actors are actively investing in certain industries, hence the potential need to add more layers of protection.
Using the assume breach mindset, we know that it is important to be ready to react in case your organization gets compromised. In the case of ransomware, what should you do once you learn that a threat actor has already compromised a system and escalated privilege? In this case the intent is always to minimize the financial leverage that the threat actor may have. To accomplish this, you need to ensure that you have:
- A good backup that is in a secure location, ideally isolated from production, and that you trust that backup since you routinely test it, by restoring some of the data to validate the backup.
- Protection in place to access this backup. Not everyone should have access to the backup, and whoever has access to it needs to be using strong authentication mechanisms, which includes Multi-Factor Authentication (MFA)
- A disaster recovery plan in place to know exactly what needs to be done in case of emergency
- Encryption of the data at rest to ensure that even if the threat actor gets access to the data, they will not be able to read it
Having each of these elements in place significantly reduces the financial leverage a threat actor will have should a breach occur.
While there are several different techniques that threat actors can use to stage attacks – such as supply chain attacks and ransomware – it is also important to note that there are multiple different entry points they can attack from. A user is going to use their credentials to interact with applications in order to either consume data or write data to servers located in the cloud or on-premises. Everything in bold has a unique threat landscape that must be identified and treated. We will cover these areas in the sections that follow.
The credentials – authentication and authorization
According to Verizon’s 2020 Data Breach Investigations Report , the association between the threat actor, their motives, and their modus operandi varies according to the industry (to access this report, visit https://www.verizon.com/business/resources/reports/2021/2021-data-breach-investigations-report.pdf?_ga=2.263398479.2121892108.1637767614-1913653505.1637767614). The report states that attacks against credentials still remain one of the most common. This data is very important, because it shows that threat actors are going after users’ credentials, which leads to the conclusion that companies must focus specifically on the authentication and authorization of users and their access rights.
The industry has agreed that a user’s identity is the new perimeter. This requires security controls specifically designed to authenticate and authorize individuals based on their job and need for specific data within the network. Credential theft could be just the first step to enable cybercriminals to have access to your system. Having a valid user account in the network will enable them to move laterally (pivot), and at some point find the right opportunity to escalate privilege to a domain administrator account.
For this reason, applying the old concept of defense in depth is still a good strategy to protect a user’s identity, as shown in the following diagram:
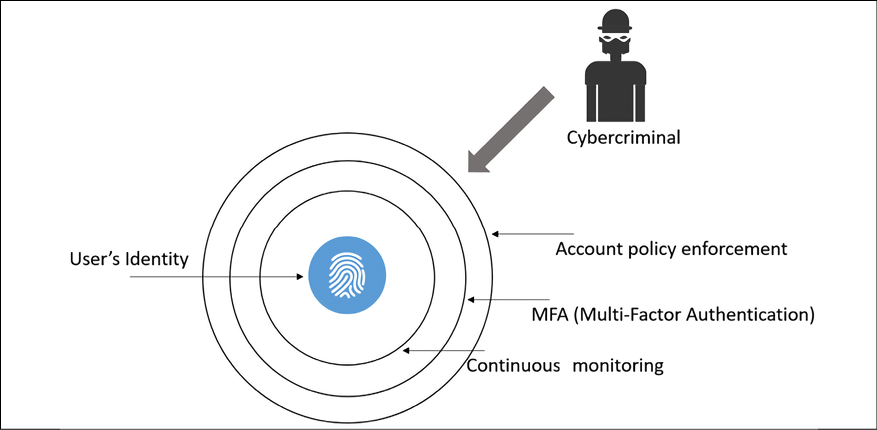
Figure 1.6: Multi-layer protection for identity
In the previous diagram there are multiple layers of protection, starting with the regular security policy enforcement for accounts, which follows industry best practices such as strong password requirements, including frequent password changes and high password strength.
Another growing trend to protect user identities is to enforce MFA. One method that is seeing increased adoption is the callback feature, where the user initially authenticates using their credentials (username and password), and receives a call to enter their PIN. If both authentication factors succeed, they are authorized to access the system or network. We are going to explore this topic in greater detail in Chapter 7, Chasing a User’s Identity. Another important layer is continuous monitoring, because at the end of the day, it doesn’t matter if you have all layers of security controls if you are not actively monitoring your identity to understand normal behavior and identify suspicious activities. We will cover this in more detail in Chapter 12, Active Sensors.
Apps
Applications (we will call them apps from now on) are the entry point for the user to consume data and transmit, process, or store information on the system. Apps are evolving rapidly, and the adoption of SaaS-based apps is on the rise. However, there are inherent problems with this amalgamation of apps. Here are two key examples:
- Security: How secure are the apps that are being developed in-house and the ones that you are paying for as a service?
- Company-owned versus personal apps: Users will have their own set of apps on their own devices (BYOD scenario). How do these apps jeopardize the company’s security posture, and can they lead to a potential data breach?
If you have a team of developers that are building apps in-house, measures should be taken to ensure that they are using a secure framework throughout the software development lifecycle, such as the Microsoft Security Development Lifecycle (SDL) (Microsoft’s full account of SDL can be found at https://www.microsoft.com/sdl ). If you are going to use a SaaS app, such as Office 365, you need to make sure you read the vendor’s security and compliance policy. The intent here is to see if the vendor and the SaaS app are able to meet your company’s security and compliance requirements.
Another security challenge facing apps is how the company’s data is handled among different apps, the ones used and approved by the company and the ones used by the end user (personal apps).
This problem becomes even more critical with SaaS, where users are consuming many apps that may not be secure. The traditional network security approach to support apps is not designed to protect data in SaaS apps, and worse, they don’t give IT the visibility they need to know how employees are using them. This scenario is also called Shadow IT, and according to a survey conducted by the Cloud Security Alliance (CSA), only 8% of companies know the scope of Shadow IT within their organizations. You can’t protect something you don’t know you have, and this is a dangerous place to be.
According to the Kaspersky Global IT Risk Report 2016, 54% of businesses perceive that the main IT security threats are related to inappropriate sharing of data via mobile devices. It is necessary for IT to gain control of the apps and enforce security policies across devices (company-owned and BYOD). One of the key scenarios that you want to mitigate is the one described in the following diagram:
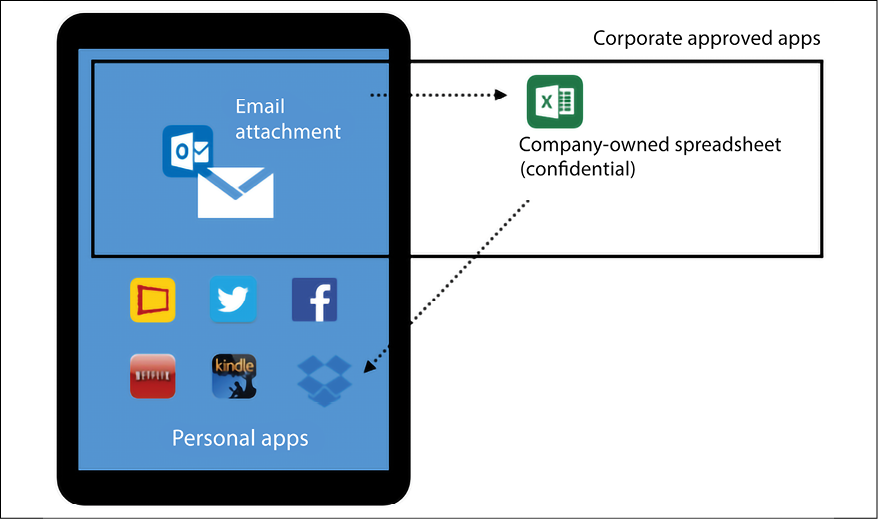
Figure 1.7: BYOD scenario with corporate app approval isolation
In this scenario, we have the user’s personal tablet that has approved applications as well as personal apps. Without a platform that can integrate device management with application management, this company is exposed to a potential data leakage scenario.
In this case, if the user downloads the Excel spreadsheet onto their device, then uploads it to a personal Dropbox cloud storage and the spreadsheet contains confidential information about the company, the user has now created a data leak without the company’s knowledge or the ability to secure it.
Data
It’s always important to ensure that data is protected, regardless of its current state (in transit or at rest). There will be different threats according to the data’s state. The following are some examples of potential threats and countermeasures:
|
State |
Description |
Threats |
Countermeasures |
Security triad affected |
|
Data at rest on the user’s device. |
The data is currently located on the user’s device. |
An unauthorized or malicious process could read or modify the data. |
Data encryption at rest. It could be file-level encryption or disk encryption. |
Confidentiality and integrity. |
|
Data in transit. |
The data is currently being transferred from one host to another. |
A man-in-the-middle attack could read, modify, or hijack the data. |
SSL/TLS could be used to encrypt the data in transit. |
Confidentiality and integrity. |
|
Data at rest on-premise (server) or in the cloud. |
The data is located at rest either on the server’s hard drive located on-premise or in the cloud (storage pool). |
Unauthorized or malicious processes could read or modify the data. |
Data encryption at rest. It could be file-level encryption or disk encryption. |
Confidentiality and integrity. |
Table 1.4: Threats and countermeasures for different data states
These are only some examples of potential threats and suggested countermeasures. A deeper analysis must be performed to fully understand the data path according to the customer’s needs. Each customer will have their own particularities regarding the data path, compliance, rules, and regulations. It is critical to understand these requirements even before the project is started.
As you can see from the topics we have covered so far, there are many different areas to consider within the current landscape of security threats. You must consider the unique issues facing apps, data, credentials, supply chain attacks, and ransomware in order to better prepare for threats.
With this in mind, we will now move on to discussing cybersecurity challenges – more specifically, we will look into how particular attacks have shaped the cybersecurity landscape, and how techniques used by threat actors have evolved over time.
Cybersecurity challenges
To analyze the cybersecurity challenges faced by companies nowadays, it is necessary to obtain tangible data and evidence of what’s currently happening in the market. Not all industries will have the same type of cybersecurity challenges, and for this reason we will enumerate the threats that are still the most prevalent across different industries. This seems to be the most appropriate approach for cybersecurity analysts that are not specialized in certain industries, but at some point in their career they might need to deal with a certain industry that they are not so familiar with.
Old techniques and broader results
According to Verizon’s 2020 Data Breach Investigations Report, 2020 showed an interesting trend with COVID-19 as the main theme for attackers. While some new techniques were utilized, some old ones were still at the top:
- Phishing email
- Ransomware
- Use of stolen credentials
- Misconfiguration
These old techniques are used in conjunction with aspects related to lack of security hygiene. Although the first one in this list is an old suspect, and a very well-known attack in the cybersecurity community, it is still succeeding, and for this reason it is still part of the current cybersecurity challenges. The real problem is that it is usually correlated to human error. As explained before, everything may start with a phishing email that uses social engineering to lead the employee to click on a link that may download a virus, malware, or Trojan. This may lead to credential compromise and most of the time this could be avoided by having a stronger security posture. As mentioned in the Analysis Report (AR21-013A) issued by the US Cyber Security & Infrastructure Security Agency, “threat actors are using phishing and other vectors to exploit poor cyber hygiene practices within a victims’ cloud services configuration.” Poor cyber hygiene basically means that customers are not doing their homework to remediate security recommendations, which includes weak settings or even misconfigurations.
The term targeted attack (or advanced persistent threat) is sometimes unclear to some individuals, but there are some key attributes that can help you identify when this type of attack is taking place. The first and most important attribute is that the attacker has a specific target in mind when he/she/they (sometimes they are sponsored groups) start to create a plan of attack. During this initial phase, the attacker will spend a lot of time and resources to perform public reconnaissance to obtain the necessary information to carry out the attack. The motivation behind this attack is usually data exfiltration, in other words, stealing data. Another attribute for this type of attack is the longevity, or the amount of time that they maintain persistent access to the target’s network. The intent is to continue moving laterally across the network, compromising different systems until the goal is reached.
One of the greatest challenges when facing a targeted attack is to identify the attacker once they are already inside the network. Traditional detection systems such as intrusion detection systems (IDSes) may not be enough to alert on suspicious activity taking place, especially when the traffic is encrypted. Many researchers have already pointed out that it can take up to 229 days between infiltration and detection. Reducing this gap is definitely one of the greatest challenges for cybersecurity professionals.
Crypto and ransomware are emerging and growing threats that are creating a whole new level of challenge for organizations and cybersecurity professionals. In May 2017, the world was shocked by the biggest ransomware attack in history, called WannaCry. This ransomware exploited a known Windows SMBv1 vulnerability that had a patch released in March 2017 (59 days prior to the attack) via the MS17-010 bulletin. The attackers used an exploit called EternalBlue that was released in April 2017, by a hacking group called The Shadow Brokers. According to MalwareTech , this ransomware infected more than 400,000 machines across the globe, which is a gigantic number, never seen before in this type of attack. One lesson learned from this attack was that companies across the world are still failing to implement an effective vulnerability management program, which is something we will cover in more detail in Chapter 16, Vulnerability Management.
It is very important to mention that phishing emails are still the number one delivery vehicle for ransomware, which means that we are going back to the same cycle again; educate the user to reduce the likelihood of successful exploitation of the human factor via social engineering and have tight technical security controls in place to protect and detect. Threat actors are still using old methods but in a more creative way, which causes the threat landscape to shift and expand – this will be explained in more detail in the next section.
The shift in the threat landscape
As mentioned earlier in this chapter, supply chain attacks added a series of new considerations to the overall cybersecurity strategy for organizations, exactly because of the shift in the threat landscape. Having said that, it is important to understand how this shift occurred over the last five to ten years to understand some of the roots and how it has evolved.
In 2016, a new wave of attacks gained mainstream visibility, when CrowdStrike reported that it had identified two separate Russian intelligence-affiliated adversaries present in the United States Democratic National Committee (DNC) network.
According to their report, they found evidence that two Russian hacking groups were in the DNC network: Cozy Bear (also classified as APT29) and Fancy Bear (APT28). Cozy Bear was not a new actor in this type of attack, since evidence has shown that in 2015 they were behind the attack against the Pentagon email system via spear-phishing attacks . This type of scenario is called a government-sponsored or state-sponsored cyber-attack.
The private sector should not ignore these signs. According to a report released by the Carnegie Endowment for International Peace, financial institutions are becoming the main target for state-sponsored attacks. In February 2019 multiple credit unions in the United States were targets of a spear-phishing campaign, where emails were sent to compliance officers in these credit unions with a PDF (which came back clean when ran through VirusTotal at that time), but the body of the email contained a link to a malicious website.
Although the threat actor is still unknown, there are speculations that this was just another state-sponsored attack. It is important to mention that the US is not the only target; the entire global financial sector is at risk. In March 2019 the Ursnif malware hit Japanese banks. Palo Alto released a detailed analysis of the Ursnif infection vector in Japan, which can be summarized in two major phases:
- The victim receives a phishing email with an attachment. Once the user opens up the email, the system gets infected with Shiotob (also known as Bebloh or URLZone).
- Once in the system, Shiotob starts the communication with the Command and Control (C2) using HTTPS. From that point on, it will keep receiving new commands.
We keep emphasizing the importance of security hygiene, and there is a reason for that. In 2021 we saw the Colonial Pipeline attack, where the threat actor was able to take down the largest fuel pipeline in the United States, which lead to shortages across the East Coast. Guess how this all happen? By compromising only one password. The account’s password was actually found on the dark web. While the end result was a ransomware attack, the entire operation was only possible due to this single password compromise.
For this reason, it is so important to ensure that you have strong security hygiene via the enhancement of your security posture and also that you are continuously monitoring your workloads. This security monitoring platform must be able to leverage at least the three methods shown in the following diagram:
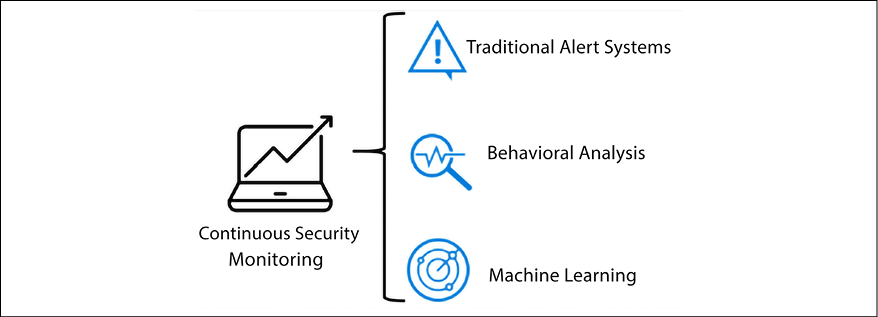
Figure 1.8: Continuous security monitoring, facilitated by traditional alert systems, behavioral analysis, and machine learning
This is just one of the reasons that it is becoming foundational that organizations start to invest more in threat intelligence, machine learning, and analytics to protect their assets. We will cover this in more detail in Chapter 13, Threat Intelligence. Having said that, let’s also realize that detection is only one piece of the puzzle; you need to be diligent and ensure that your organization is secure by default, in other words, that you’ve done your homework and protected your assets, trained your people, and continuously enhance your security posture.
Enhancing your security posture
If you have carefully read this entire chapter, it should be very clear that you can’t use the old approach to security facing today’s challenges and threats. When we say old approach, we are referring to how security used to be handled in the early 2000s, where the only concern was to have a good firewall to protect the perimeter and have antivirus on the endpoints. For this reason, it is important to ensure that your security posture is prepared to deal with these challenges. To accomplish this, you must solidify your current protection system across different devices, regardless of the form factor.
It is also important to enable IT and security operations to quickly identify an attack, by enhancing the detection system. Last but certainly not least, it is necessary to reduce the time between infection and containment by rapidly responding to an attack by enhancing the effectiveness of the response process. Based on this, we can safely say that the security posture is composed of three foundational pillars as shown in the following diagram:
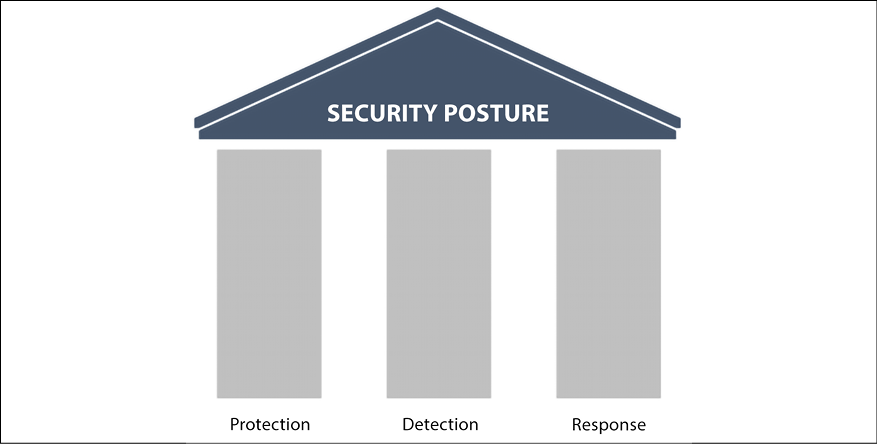
Figure 1.9: The three pillars of an effective security posture: Protection, Detection, and Response
These pillars must be solidified; if in the past the majority of the budget was put into protection, nowadays it’s even more imperative to spread that investment and level of effort across all pillars. These investments are not exclusive to technical security controls; they must also be done in the other spheres of the business, which includes administrative controls. It is recommended to perform a self-assessment to identify the weaknesses within each pillar from the tool perspective. Many companies evolved over time and never really updated their security tools to accommodate the new threat landscape and how attackers are exploiting vulnerabilities.
A company with an enhanced security posture shouldn’t be part of the statistics that were previously mentioned (229 days between the infiltration and detection); the response should be almost immediate. To accomplish this, a better incident response process must be in place, with modern tools that can help security engineers to investigate security-related issues.
Chapter 2, Incident Response Process, will cover incident response in more detail and Chapter 14, Investigating an Incident, will cover some case studies related to actual security investigations.
The sections that follow will cover some important considerations that should be in place when planning to improve your overall security posture – starting with an encompassing approach to security posture (Zero Trust) before focusing on particular areas that need attention within security posture management.
Zero Trust
When it comes to the improvement of the overall security posture, it becomes imperative nowadays to have a Zero Trust Architecture (ZTA) in place. While you may have read many articles about Zero Trust from different vendors, the ultimate agnostic source of ZTA is the NIST 800-207 standard for Zero Trust. It is imperative that you read this publication if you want to have a vendor-neutral approach to implement Zero Trust. Regardless of the vendor’s implementation of ZTA, is important that you understand the core principles below:
- With ZTA there are no trusted networks, even the internal corporate network is not implicitly trusted: This is an important principle, since the idea is that all assets are always assuming that the threat actor is present and actively trying to attack them.
- Many devices will be on the corporate network, and many will not be owned by the corporation: With the growth of BYOD, it becomes critical to assume that users will be using a wide variety of devices and that the corporation will not necessarily own them.
- No resource is inherited trusted: This aligns with the first principle, but expands to any resource, not only network infrastructure. If you are already using the assume breach approach (which will be discussed later in this chapter), you probably are already skeptical about how trustworthy the communication among resources can be. This principle is basically taking it to the next level and already assuming that you can’t inherently trust a resource, you need to verify it.
- Assets moving across corp and non-corp infrastructure should have a consistent security policy and posture: Keeping a consistent security policy and security police for assets is a key principle to ensure ZTA adoption.
Although the NIST 800-207 standard defines six core principles, the other two are basically an expansion of the first and second ones described in the previous list.
To build a ZTA you need to assume that threats exist, regardless of the location, and that users’ credentials can be compromised, which means that attackers might already be inside of your network. As you can see, a ZTA, when applied to a network, is more a concept and approach to network security than a technology per se. Many vendors will advertise their own solution to achieve a Zero Trust network, but at the end of the day, Zero Trust is broader than just a piece of technology sold by a vendor.
From the network perspective, one common way to implement a Zero Trust network is to use the device and the user’s trust claims to gain access to a company’s data. If you think about it, the ZTA approach leverages the concept that “Identity is your new perimeter,” which you will see in more detail in Chapter 7, Chasing a User’s Identity.
Since you can’t trust any network, the perimeter itself becomes less important than it was in the past, and the identity becomes the main boundary to be protected.
To implement a ZTA, you need to have at least the following components:
- An identity provider
- A device directory
- A conditional policy
- An access proxy that leverages those attributes to grant or deny access to resources
The diagram shown below has a representation of the trust attributes that are part of a Zero Trust architecture:
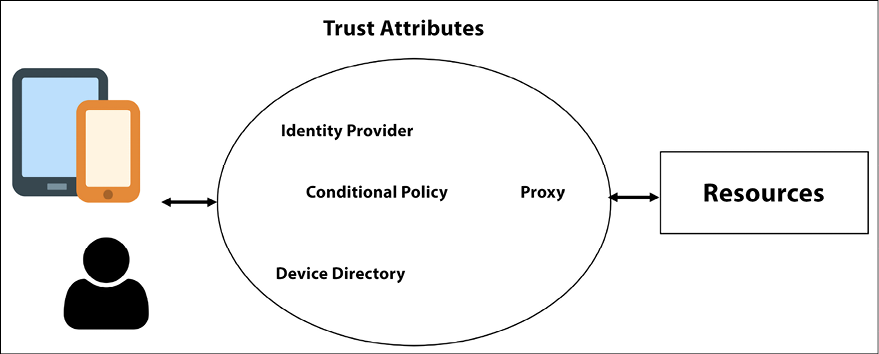
Figure 1.10: Some components of ZTA
The great advantage of this approach is that a user, when logged in from a certain location and from a certain device, may not have access to a specific resource, compared to if the same user was using another device and was logged in from another location in which they could have access. The concept of dynamic trust based on those attributes enhances the security based on the context of access to a particular resource. As a result, this completely changes the fixed layers of security used in a traditional network architecture.
Microsoft Azure Active Directory (Azure AD) is an example of an identity provider that also has a conditional policy built in, the capability to register devices, and can be used as an access proxy to grant or deny access to resources.
The implementation of a Zero Trust network is a journey, and many times this can take months to be fully realized. The first step is to identify your assets, such as data, applications, devices, and services. This step is very important, because it is those assets that will help you to define the transaction flows, in other words, how these assets will communicate. Here, it is imperative to understand the history behind the access across these assets and establish new rules that define the traffic between these assets.
The following are just some examples of questions that will help you to determine the traffic flow, the conditions, and ultimately the boundaries of trust. The next step is to define the policies, the logging level, and the control rules. Now that you have everything in place, you can start working on:
- Who should have access to the set of apps that were defined?
- How will these users access this app?
- How does this app communicate with the backend server?
- Is this a cloud-native app? If so, how does this app authenticate?
- Will the device location influence data access? If so, how?
The last part is to define the systems that are going to actively monitor these assets and communications. The goal of this is not only for auditing purposes, but also for detection purposes. If malicious activity is taking place, you must be aware as fast as possible.
Having an understanding of these phases is critical, because in the implementation phase you will need to deal with a vendor’s terminologies and technologies that adopt the Zero Trust network model. Each vendor may have a different solution, and if you have a heterogeneous environment, you need to make sure the different parts can work together to implement this model.
Cloud Security Posture Management
When companies start to migrate to the cloud, their challenge to keep up with their security posture increases, since the threat landscape changes due to the new workloads that are introduced. According to the 2018 Global Cloud Data Security Study conducted by Ponemon Institute LLC (January 2018), 49% of respondents in the United States were:
”not confident that their organizations have visibility into the use of cloud computing applications, platform or infrastructure services.”
According to the Palo Alto 2018 Cloud Security Report (May 2018), 62% of respondents said that misconfiguration of cloud platforms was the biggest threat to cloud security. From these statistics we can clearly see a lack of visibility and control over different cloud workloads, which not only causes challenges during the adoption, but also slows down the migration to the cloud. In large organizations the problem becomes even more difficult due to the dispersed cloud adoption strategy. This usually occurs because different departments within a company will lead their own way to the cloud, from the billing to infrastructure perspective. By the time the security and operations team becomes aware of those isolated cloud adoptions, these departments are already using applications in production and integrated with the corporate on-premises network.
To obtain the proper level of visibility across your cloud workloads, you can’t rely only on a well-documented set of processes, you must also have the right set of tools. According to the Palo Alto 2018 Cloud Security Report (May 2018), 84% of respondents said that “traditional security solutions either don’t work at all or have limited functionality.”
This leads to a conclusion that, ideally, you should evaluate your cloud provider’s native cloud security tools before even start moving to the cloud. However, many current scenarios are far from the ideal, which means you need to evaluate the cloud provider’s security tools while the workloads are already on it.
When talking about cloud security posture management (CSPM), we are basically referring to three major capabilities: visibility, monitoring, and compliance assurance.
A CSPM tool should be able to look across all these pillars and provide capabilities to discover new and existing workloads (ideally across different cloud providers), identify misconfigurations and provide recommendations to enhance the security posture of cloud workloads, and assess cloud workloads to compare against regulatory standards and benchmarks. The following table has general considerations for a CSPM solution:
|
Capability |
Considerations |
|
Compliance assessment |
Make sure the CSPM meets the regulatory standards used by your company. |
|
Operational monitoring |
Ensure that you have visibility throughout the workloads, and that best practice recommendations are provided. |
|
DevSecOps integration |
Make sure it is possible to integrate this tool into existing workflows and orchestration. If it is not, evaluate the available options to automate and orchestrate the tasks that are critical for DevSecOps. |
|
Risk identification |
How is the CSPM tool identifying risks and driving your workloads to be more secure? This is an important question to answer when evaluating this capability. |
|
Policy enforcement |
Ensure that it is possible to establish central policy management for your cloud workloads and that you can customize it and enforce it. |
|
Threat protection |
How do you know if there are active threats in your cloud workloads? When evaluating the threat protection capability for CSPM, it is imperative that you can not only protect (proactive work) but also detect (reactive work) threats. |
Table 1.5: Considerations for a CSPM solution
These considerations provide a valuable starting point for most CSPM solutions, but you may find more points that also need to be considered based on the unique needs of a particular company.
Multi-cloud
COVID-19 accelerated digital transformation and with that many companies started to rapidly adopt cloud computing technologies to stay in business, or to expand their current capabilities. With this reality, it is also possible to notice that multi-cloud adoption grew over the past two years, where customers were focused on redundancy and disaster recovery, and avoiding vendor lock-in. With that a new challenge arises, which is how to keep visibility and control across multi-cloud from a centralized location.
This new reality pushed vendors to start working on integrations across cloud providers and enhancing their cloud security posture management and workload protection offering to cover multiple clouds. At Ignite 2021, Microsoft announced the change from Azure Security Center and Azure Defender to Microsoft Defender for Cloud. The intent of the renaming was to ensure that the market could identify Microsoft Defender for Cloud as an agnostic solution that can protect workloads not only in Azure but also in a different cloud provider. One of the main capabilities in this new format is seeing CSPM-related recommendations in a single dashboard as shown in the image below:
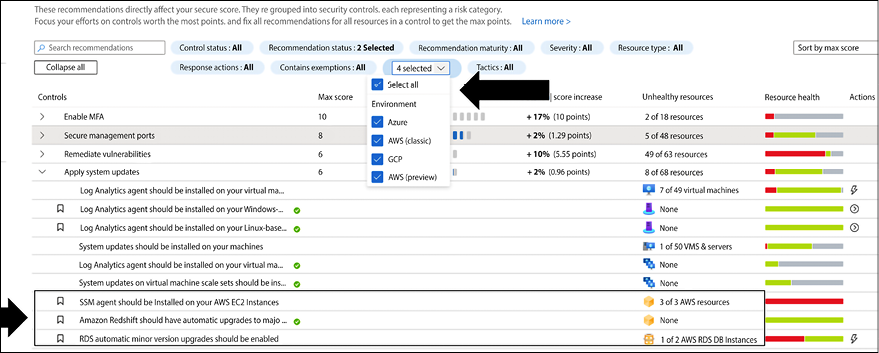
Figure 1.11: CSPM recommendations across Azure, AWS, and GCP
In Figure 1.11 you can see a filter to select the environment (cloud provider) and if you want to see all recommendations for all cloud providers that you configured connectivity with, you can keep all filters selected and observe the difference between resources in Azure, AWS, and GCP based on the icon.
Is also very common that in a multi-cloud adoption, most of your resources will be in one cloud provider, and some others will be in a different cloud provider. This means that when you plan your CSPM/CWPP selection, you need to evaluate the capabilities of the platform based on the criticality of the majority of the workloads that you have. In other words, if you have most of your resources in Azure, you want to ensure that your CSPM/CWPP solution has the full set of functionalities natively integrated in Azure. In addition to that, ensure that the solution you choose has at least the following capabilities:
- Ability to create a custom assessment for each cloud provider and workload
- Visibility of the security posture progress over time and prioritization of security recommendations that will influence the enhancement of the security posture
- Vulnerability assessment across compute-based workloads
- Capability to map security controls with regulatory compliance standards
- Threat detection created for each workload type
- Incident response integration via workflow automation
The solution you choose should have all of the above capabilities, and perhaps even more depending on your particular needs.
The Red and Blue Teams
The Red/Blue Team exercise is not something new. The original concept was introduced a long time ago during World War I and like many terms used in information security, originated in the military. The general idea was to demonstrate the effectiveness of an attack through simulations.
For example, in 1932 Rear Admiral Harry E. Yarnell demonstrated the efficacy of an attack on Pearl Harbor. Nine years later, when the Japanese attacked Pearl Harbor, it was possible to compare and see how similar tactics were used. The effectiveness of simulations based on real tactics that might be used by the adversary is well known in the military. The University of Foreign Military and Cultural Studies has specialized courses just to prepare Red Team participants and leaders.
Although the concept of a “Red Team” in the military is broader, the intelligence support via threat emulation is similar to what a cybersecurity Red Team is trying to accomplish. The Homeland Security Exercise and Evaluation Program (HSEEP) also uses Red Teaming in prevention exercises to track how adversaries move and create countermeasures based on the outcome of these exercises.
In the cybersecurity field, the adoption of the Red Team approach also helps organizations to keep their assets more secure. The Red Team must be composed of highly trained individuals with different skill sets and they must be fully aware of the current threat landscape for the organization’s industry. The Red Team must be aware of trends and understand how current attacks are taking place. In some circumstances and depending on the organization’s requirements, members of the Red Team must have coding skills to create their own exploit and customize it to better exploit relevant vulnerabilities that could affect the organization. The core Red Team workflow takes place using the following approach:
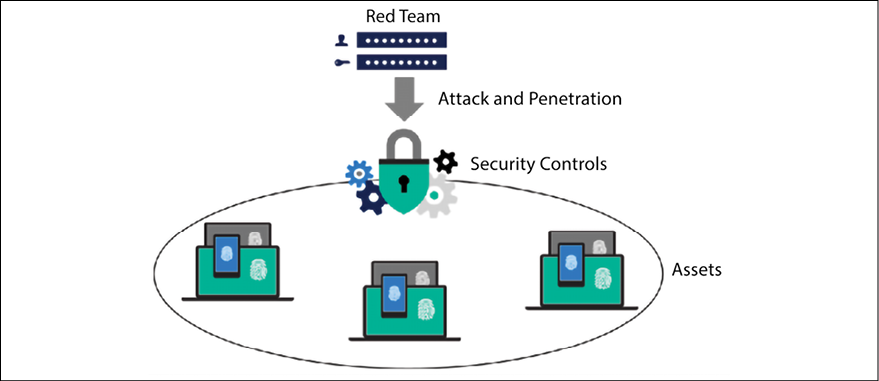
Figure 1.12: Red Team core workflow
The Red Team will perform an attack and penetrate the environment in order to find vulnerabilities. The intent of the mission is to find vulnerabilities and exploit them in order to gain access to the company’s assets. The attack and penetration phase usually follows the Lockheed Martin approach, published in the paper Intelligence-Driven Computer Network Defense Informed by Analysis of Adversary Campaigns and Intrusion Kill Chains (available at https://www.lockheedmartin.com/content/dam/lockheed/data/corporate/documents/LM-White-Paper-Intel-Driven-Defense.pdf). We will discuss the kill chain in more detail in Chapter 4, Understanding the Cybersecurity Kill Chain.
The Red Team is also accountable for registering their core metrics, which are very important for the business. The main metrics are as follows:
- Mean time to compromise (MTTC): This starts counting from the minute that the Red Team initiated the attack to the moment that they were able to successfully compromise the target
- Mean time to privilege escalation (MTTP): This starts at the same point as the previous metric, but goes all the way to full compromise, which is the moment that the Red Team has administrative privilege on the target
So far, we’ve discussed the capacity of the Red Team, but the exercise is not complete without the counter partner, the Blue Team. The Blue Team needs to ensure that the assets are secure and if the Red Team finds a vulnerability and exploits it, they need to rapidly remediate and document it as part of the lessons learned.
The following are some examples of tasks done by the Blue Team when an adversary (in this case the Red Team) is able to breach the system:
- Save evidence: It is imperative to save evidence during these incidents to ensure you have tangible information to analyze, rationalize, and take action to mitigate in the future.
- Validate the evidence: Not every single alert, or in this case piece of evidence, will lead you to a valid attempt to breach the system. But if it does, it needs to be cataloged as an indicator of compromise (IOC).
- Engage whoever it is necessary to engage: At this point, the Blue Team must know what to do with this IOC, and which team should be aware of this compromise. Engage all relevant teams, which may vary according to the organization.
- Triage the incident: Sometimes the Blue Team may need to engage law enforcement, or they may need a warrant in order to perform further investigation; a proper triage to assess the case and identify who should handle it moving forward will help in this process.
- Scope the breach: At this point, the Blue Team has enough information to scope the breach.
- Create a remediation plan: The Blue Team should put together a remediation plan to either isolate or evict the adversary.
- Execute the plan: Once the plan is finished, the Blue Team needs to execute it and recover from the breach.
The Blue Team members should also have a wide variety of skill sets and should be composed of professionals from different departments. Keep in mind that some companies do have a dedicated Red/Blue Team, while others do not. Companies might put these teams together only during exercises.
Just like the Red Team, the Blue Team also has accountability for some security metrics, which in this case are not 100% precise. The reason the metrics are not precise is that the true reality is that the Blue Team might not know precisely what time the Red Team was able to compromise the system. Having said that, the estimation is already good enough for this type of exercise. These estimations are self-explanatory as you can see in the following list:
- Estimated time to detection (ETTD)
- Estimated time to recovery (ETTR)
The Blue Team and the Red Team’s work doesn’t finish when the Red Team is able to compromise the system. There is a lot more to do at this point, which will require full collaboration among these teams. A final report must be created to highlight the details regarding how the breach occurred, provide a documented timeline of the attack, the details of the vulnerabilities that were exploited in order to gain access and to elevate privileges (if applicable), and the business impact to the company.
Assume breach
Due to the emerging threats and cybersecurity challenges, it was necessary to change the methodology from prevent breach to assume breach. The traditional prevent breach approach by itself does not promote ongoing testing, and to deal with modern threats you must always be refining your protection. For this reason, the adoption of this model in the cybersecurity field was a natural move.
The former director of the CIA and the National Security Agency, Retired Gen. Michael Hayden, said in 2012:
”Fundamentally, if somebody wants to get in, they’re getting in. Alright, good. Accept that.”
During the interview, many people didn’t quite understand what he really meant, but this sentence is the core of the assume breach approach. Assume breach validates the protection, detection, and response to ensure they are implemented correctly. But to operationalize this, it becomes vital that you leverage Red/Blue Team exercises to simulate attacks against your own infrastructure and test the company’s security controls, sensors, and incident response process.
In the following diagram, you have an example of the interaction between phases in the Red Team/Blue Team exercise:
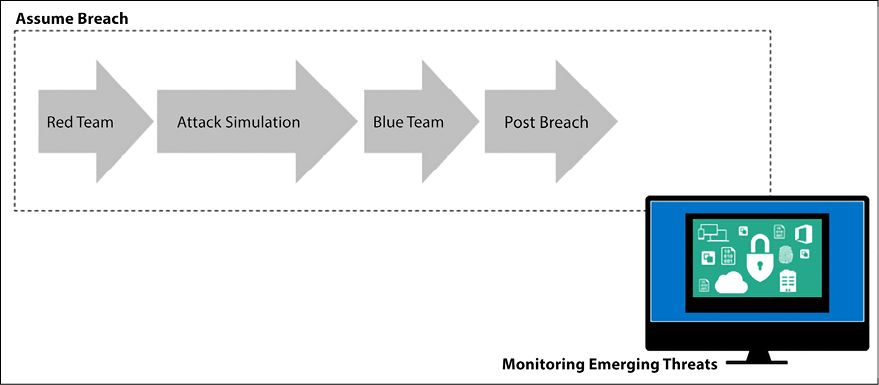
Figure 1.13: Red Team and Blue Team interactions in a Red Team/Blue Team exercise
The preceding diagram shows an example of the Red Team starting the attack simulation, which leads to an outcome that is consumed by the Blue Team to address the vulnerabilities that were found as part of the post-breach assessment.
It will be during the post-breach phase that the Red and Blue Teams will work together to produce the final report. It is important to emphasize that this should not be a one-off exercise, but instead, must be a continuous process that will be refined and improved with best practices over time.
Summary
In this chapter, you learned about the current threat landscape and how these new threats are used to compromise credentials, apps, and data. In many scenarios, old hacking techniques are used, such as phishing emails, but with a more sophisticated approach. You also learned about the current reality regarding the nationwide types of threats and government-targeted attacks. In order to protect your organization against these new threats, you learned about key factors that can help you to enhance your security posture. It is essential that part of this enhancement shifts the attention from protection only to include detection and response. For that, the use of Red and Blue Teams becomes imperative. The same concept applies to the assume breach methodology.
In the next chapter, you will continue to learn about the enhancement of your security posture. However, the chapter will focus on the incident response process. The incident response process is essential for companies that need a better method for the detection of and response to cyber threats.
References
You can refer to the following articles for additional information:
- New IoT Botnet Discovered: http://www.darkreading.com/attacks-breaches/new-iot-botnet-discovered-120k-ip-cameras-at-risk-of-attack/d/d-id/1328839
- ESET reports 73,000 unprotected security cameras with default passwords: https://www.welivesecurity.com/2014/11/11/website-reveals-73000-unprotected-security-cameras-default-passwords/
- IOActive finds 7,000 vulnerable Linksys routers in use, possibility of up to 100,000 additional routers exposed to this vulnerability: https://threatpost.com/20-linksys-router-models-vulnerable-to-attack/125085/
- 43% of employed Americans reported spending some time working from home in 2017: https://www.nytimes.com/2017/02/15/us/remote-workers-work-from-home.html
- The ISSA Journal publishes vendor-agnostic guidelines to adopting BYOD: https://blogs.technet.microsoft.com/yuridiogenes/2014/03/11/byod-article-published-at-issa-journal/
- The FBI reports that in just the first 3 months of 2016, $209 million in ransomware payments were made: http://www.csoonline.com/article/3154714/security/ransomware-took-in-1-billion-in-2016-improved-defenses-may-not-be-enough-to-stem-the-tide.html
- Trend Micro predicted that ransomware growth would plateau in 2017, but that attack methods and targets would diversify: http://blog.trendmicro.com/ransomware-growth-will-plateau-in-2017-but-attack-methods-and-targets-will-diversify/
- Sophos reports that ransomware attacks have dropped from 51% in 2020 to 37% in 2021: https://www.sophos.com/en-us/medialibrary/pdfs/whitepaper/sophos-state-of-ransomware-2021-wp.p
- The Telegraph details the dangers of using the same password for multiple accounts: http://www.telegraph.co.uk/finance/personalfinance/bank-accounts/12149022/Use-the-same-password-for-everything-Youre-fuelling-a-surge-in-current-account-fraud.html
- Verizon’s 2020 Data Breach Investigations Report highlights that a threat-actor’s motives and style of attack vary according to industry, but that attacks utilize COVID-19 as a main theme: https://www.verizon.com/business/resources/reports/2021/2021-data-breach-investigations-report.pdf?_ga=2.263398479.2121892108.1637767614-1913653505.1637767614
- Microsoft explains their Security Development Lifecycle in depth: https://www.microsoft.com/sdl
- Microsoft Office 365 Security and Compliance can be found at: https://support.office.com/en-us/article/Office-365-Security-Compliance-Center-7e696a40-b86b-4a20-afcc-559218b7b1b8
- The Cloud Security Alliance’s adoption practices and priorities survey can be found at: https://downloads.cloudsecurityalliance.org/initiatives/surveys/capp/Cloud_Adoption_Practices_Priorities_Survey_Final.pdf
- Researchers point out the significant delay between infiltration and detection: https://info.microsoft.com/ME-Azure-WBNR-FY16-06Jun-21-22-Microsoft-Security-Briefing-Event-Series-231990.html?ls=Social
- The Microsoft bulletin provides more information on the WannaCry attacks: https://technet.microsoft.com/en-us/library/security/ms17-010.aspx
- This article details the Shadow Brokers’ data dump: https://www.symantec.com/connect/blogs/equation-has-secretive-cyberespionage-group-been-breached
- For an account of WannaCry, refer to https://twitter.com/MalwareTechBlog/status/865761555190775808
- CrowdStrike identifies two separate Russian intelligence-affiliated adversaries present in the United States Democratic National Committee (DNC) network: https://www.crowdstrike.com/blog/bears-midst-intrusion-democratic-national-committee/
- Russian hackers use spear-phishing attacks against the Pentagon’s email system: http://www.cnbc.com/2015/08/06/russia-hacks-pentagon-computers-nbc-citing-sources.html
- The Verge discusses the damage cause by EternalBlue: https://www.theverge.com/2017/5/17/15655484/wannacry-variants-bitcoin-monero-adylkuzz-cryptocurrency-mining
- For a discussion on Red-Teaming tactics, refer to: https://www.quora.com/Could-the-attack-on-Pearl-Harbor-have-been-prevented-What-actions-could-the-US-have-taken-ahead-of-time-to-deter-dissuade-Japan-from-attacking#!n=12
- You can download the University of Foreign Military and Cultural Studies’ Red Team handbook at: http://usacac.army.mil/sites/default/files/documents/ufmcs/The_Applied_Critical_Thinking_Handbook_v7.0.pdf
- FEMA explains how the Homeland Security Exercise and Evaluation Program uses Red Teaming in prevention exercises: https://www.fema.gov/media-library-data/20130726-1914-25045-8890/hseep_apr13_.pdf
- Lockheed Martin describes the attack and penetration phase in their paper Intelligence-Driven Computer Network Defense Informed by Analysis of Adversary Campaigns and Intrusion Kill Chains, available at: https://www.lockheedmartin.com/content/dam/lockheed/data/corporate/documents/LM-White-Paper-Intel-Driven-Defense.pdf
- Former director of the CIA comments on cyber espionage: http://www.cbsnews.com/news/fbi-fighting-two-front-war-on-growing-enemy-cyber-espionage/
- Palo Alto reports on Trojan Ursnif: https://unit42.paloaltonetworks.com/unit42-banking-trojans-ursnif-global-distribution-networks-identified/
- Cognyte’s Cyber Threat Intelligence Research Group’s 2021 Annual Cyber Intelligence Report can be found at: https://www.cognyte.com/blog/ransomware_2021/
- The 2022 Flexera State of the Cloud Report is available at: https://info.flexera.com/CM-REPORT-State-of-the-Cloud#download
Join our community on Discord
Join our community’s Discord space for discussions with the author and other readers:
