
Today the World Wide Web pervades the remotest corners of our planet. Like water and energy, it has become an invaluable public resource. Used for countless purposes, in countless contexts, through countless devices, it’s the land of copies and the universe of knowledge. But like Borges’ library with which we opened this book, the web is a deceiver. It beguiles us into aspiring to understand things by typing in our questions, trusting that someone, somewhere in this galactic universe (which others call the Web) has already provided the answer. But everything links together in an infinite loop. The knowledge we glean from the web may be deep, but it may be illusory. It’s a paradox of the infinite.
In this chapter, we examine the web, our precocious teenager, from different viewpoints. We want to see how it works, recognize its strengths, aptitudes, and skills—and perhaps foretell its future. We normally associate the web with technical constructs such as the Hypertext Transfer Protocol (HTTP), Universal Resource Locators (URLs), and the Hypertext Markup Language (HTML). But it also incorporates stimulating contributions from librarians, psychologists, economists, linguistics, lawyers, social anthropologists, and humanities scholars. Indeed, they propose ideas that never cross the minds of computer experts.
While it’s easy to talk about specific technical issues—you probably already know quite a bit about how the web works—it’s hard to arrive at a full understanding of the shape, size, and capabilities of the web. Yet it’s of major importance! In terms of components, the web is a collection of documents—more properly of “resources,” for it contains much that transcends even the most generous interpretation of “document”—distributed all over the planet. Its resources speak to us in a multitude of expressive forms: text, voice, imagery, animation, movies, and arbitrary interaction styles. All this has been enabled by the convergence of multimedia and network technology, enriched and bound together by hypertext.
Splendid and fascinating as they are, technologies do not by themselves account for the web’s extraordinary success. From the outset, the key was the elegant simplicity underlying its document representation and hypertext protocol. Exponential growth in web pages could only be sustained because the barrier to publishing was set very low indeed. Yet—paradoxically—exactly the same ideas open the door to sophisticated technologies for document production and low-key collaborative environments like wikis and blogs. To empower ordinary people to publish what they want and simultaneously provide a platform for continual creative innovation is the genius of the web.
The web obeys the laws of networks. These yield insights into many interesting questions: how many clicks it takes to get from one randomly chosen page to another, the average number of links out of and into a page, and how these figures are growing. Despite its myriad components, the web is seen as an entity in its own right, a sort of “small world”—though not so small! It has a holistic identity that transcends its detailed structure. But, as we will see, the real structure is more complex: the web fragments into “continents” and is strongly organized into communities that directly reflect human struggles and concerns. Moreover, because pages in many major portals emerge only after an extended sequence of queries, there is a huge hidden web that is largely unexplored.
The web is growing fast, and perhaps (for one is never quite sure with teenagers) maturing. Its personality and physiognomy are changing. In order to be sure that we will recognize its face tomorrow, we need a secure understanding of the basic principles by which it operates. The effort will be worthwhile.
BASIC CONCEPTS
In Chapter 1, we related how Tim Berners-Lee created the program that was to become the World Wide Web, and remarked that it is one of the greatest success stories in the history of technology. What are the ingredients of this incredible success? People attribute such things to a combination of luck and genius: luck in thinking about the right things at the right time; genius in recognizing elegance—the right solution, the right degree of functional simplicity. In this case, as we explained in Chapter 1, there was a third factor: the soil had been tilled by philosophers from Socrates to Wittgenstein and fertilized by visionaries from Wiener and Bush to Engelbart and Nelson.
The genius of the web was not recognized immediately. At the time, hypertext was an established field of research with its own experts and academic conferences, and criticisms were raised of the web’s implementation of many basic concepts. Berners-Lee’s system was too naïve, too simplistic, for hypertext gurus—indeed, it still is. As Steve Jobs, CEO of Apple Computer, put it:
The Web reminds me of early days of the PC industry. No one really knows anything. There are no experts. All the experts have been wrong.
The web was born from a paradigm shift: crucial design choices that violated contemporary assumptions of what hypertext should be. First, it did not incorporate Nelson’s original idea for a collaborative environment because pages can only be modified by their creator. Second, hyperlinks are directed. They can point to any page without seeking the owner’s permission—and the target is not obliged to return the favor by linking back. One-way links are reminiscent of citations in the scientific literature. These two ingredients have been of crucial importance in making the web “world wide.” People find it natural to publish information this way, and make such massive use of the linking mechanism that the web is perceived as a unique entity rather than an extension of existing publication media. Last but not least, the simplicity of the underlying HTML language in which documents are expressed has contributed to the enormous diffusion of the web.
The remainder of this section gives a whirlwind tour of the basic concepts underlying the web: HTTP, HTML, URIs and URLs, and crawling. Skip right over it if you already know about these things.
HTTP: HYPERTEXT TRANSFER PROTOCOL
The information on the web is stored in computers referred to as “web servers” and is processed and promptly transmitted upon request. Any computer with a connection to the Internet can be turned into a web server by installing appropriate software. Users access information on the web through programs called “web browsers,” which make requests behind the scenes to web servers to obtain the desired information.
The conventions that govern this dialogue constitute the hypertext transfer protocol (HTTP). A protocol is a list of rules that define an agreed way of exchanging information. In HTTP, the browser first opens a connection, specifying the address of the desired server. Then it makes its request. After delivering the response, the server closes down the connection. Once the transaction is complete, that is the end of the matter. HTTP is a “stateless” protocol, that is, it does not retain any connection information between transactions. All these operations are expressed in the protocol—indeed, web servers are often referred to as HTTP servers.
Browsers provide the environment that we all use to surf the web and are among the world’s most popular computer programs. (But they are not the ones that occupy computers the most. Like automobiles, which spend most of their time stationary, computers are most often at rest—or running screen savers, which is what usually passes as rest. Screen savers are the all-time most popular program in terms of the amount of time computers spend on them.) Browsers let us navigate by following hyperlinks in web pages. Eventually, if we wish, we can return to whence we came by clicking the Back button (or selecting Back from a menu). The return link is not stored in the web but constructed by the browser, which simply memorizes the path taken as we go. Hyperlinks on the web are not symmetric: a link from page A to page B does not imply a return link, and although return links sometimes exist, they are the exception rather than the rule. Web browsers have a huge variety of capabilities and are among the world’s most complex computer programs.
Web servers, like browsers, also have an elaborate structure; they offer a multitude of different services. Like travelers entering a country through immigration, client programs enter the server through a “port” that is able to restrict their visit. In web servers, different ports are used to support different services. For instance, when you surf the web, your browser contacts the HTTP server on port 80 in order to download pages. Sometimes you play an active role by uploading information—for example, when filling out information on a web form. If the information needs to be kept secure, like a credit card number, you will enter through port 443 instead.
There are billions of documents on the web. And it’s not just documents: there are millions of other kinds of resources. You can download a pre-stored video (a kind of document). Or you can watch a webcam, a camera integrated into a web server that takes ten to fifteen pictures per second—enough for reasonably smooth motion—and sends them to your browser. You can listen to music, fill out a form for a bank loan, look things up in the Library of Congress catalog, query a search engine, read your e-mail, do your shopping, find the weather in Timbuktu, make a phone call, get a date, or book a hotel. Given its vast scope, how do we locate the web’s resources? Well, how do you find that heartthrob you met in the club last week, or a hotel in an unfamiliar city? You need the address!
URI: UNIFORM RESOURCE IDENTIFIER
A web address could be simply the name of the file containing the information. However, different people might choose the same filename. The best way to avoid confusion is to exploit the structure implicit in the way web servers are organized. Each server is given an address, and the information on it is identified by the pathname of the corresponding file. This yields a structured name called a Universal Resource Identifier (URI) because it serves to identify a web resource. For instance, en.wikipedia.org/wiki/Main_Page identifies the main page of the Wikipedia encyclopedia. The server that stores this page has the address en.wikipedia.org and contains the information in the file Main_Page within the folder wiki. Following the same path leads to other information in that folder. For instance, current events are at en.wikipedia.org/wiki/current_events, and the Wikipedia search facility is at en.wikipedia.org/wiki/Special:Search.
All these are static web pages—even the little one-box form that you fill out when you request a Wikipedia search. They are “static” because the pages are pre-stored. However, portals such as Wikipedia give access to a host of pages that are generated on the fly: they come out when particular queries are submitted from the search page. Dynamically generated pages are also identified by a kind of address. For instance, searching Wikipedia for World Wide Web generates a page that can be identified by
If you type this arcane expression into your web browser, you will see exactly the same result as if you entered World Wide Web into the Wikipedia search box. It’s another kind of URI, constructed from the name of the search page
The result of the search is not pre-stored but is generated by the Wikipedia web server. It makes it up as it goes along.
Queries are a powerful way of discovering information located deep within the web. Indeed, there is much that can be obtained only in this way. And the mechanism can be very sophisticated, involving a far more complex formulation than the preceding simple example. Basically, whereas a static address gives a path to the information, a dynamic address invokes a program to find the information. The name of the program—search in the previous example—is signaled by a preceding question mark. And this program belongs to the web server—Wikipedia’s server in this case—not your browser. Wikipedia’s search program constructs the answer to your query at the very time you pose it.
The example URIs just given are incomplete. They should also include the name of the protocol that is used to access the resource—in this case HTTP. The full URI for Wikipedia’s main page is http://en.wikipedia.org/wiki/Main_Page. Other resources use different protocols. When you access your bank account, the bank’s web server uses a different protocol that encrypts all transactions. This is signaled by a URI that starts with https://—the s stands for “secure.” It was a brilliant idea to include the protocol name in the URI because it allows the gamut of protocols to be extended later. As well as HTTP and HTTPS, many other protocols are used when surfing the web: for transferring files, dealing with e-mail, reading news feeds, and so on.
Incidentally, people often wonder about the meaning of the mysterious double slash (//). After a lecture on the evolution of the web in London in 1999, Tim Berners-Lee was asked, “If you could go back and change one thing about the design, what would it be?” His characteristically low-key response was that he would use http: rather than http://. Originally he thought the two slashes looked nice, but now he regrets the countless hours that humanity wastes every year typing them. (And saying them. The BBC used to announce its website over the air as “aitch tee tee pee colon forward slash forward slash double-you double-you double-you dot bee bee cee dot cee oh dot you kay”; recently they dropped the “forward” in favor of simply “slash.”) As a concession to human error browsers now accept both // and \, and http:// may be omitted entirely.
BROKEN LINKS
The ephemeral nature of resources is a critical issue on the web. During a power cut, the documents on affected web servers disappear from sight. When you reorganize a web server’s folders, all the links pointing in are wrong. The same happens when a computer is retired and its files are copied over to a replacement machine. In all these situations, surfers experience an error (perhaps “404 error: page not found,” referring to the HTTP error number) instead of the page they were expecting. The link to the resource is broken: at that moment it points nowhere.
Web hyperlinks are attached without seeking permission from the target. Most authors are completely unaware that others have linked to their pages. This is a mixed blessing: it’s quick and easy to link, but links can break at any time simply because the target page is moved to a different place or a different server. People call this “link rot”: the linkage structure of the web gradually deteriorates over time. But although unidirectional links may cause local breakdowns, they do not compromise the integrity of the web as a whole—which other, more elaborate solutions may risk doing. The system is imperfect but robust. (We return to this issue in Chapter 5.)
Broken links certainly represent a serious problem.16 As its name implies (I stands for “identifier”), the URI is really intended to act as a name rather than an address. The closely related concept URL stands for Universal Resource Locator. In fact, most URIs are also URLs: they show how to locate the file containing the information. However, it is possible to include a “redirect” on the web server that takes you from a URI to a different location, that is, a different URL.
Schemes have been devised for persistent identifiers that are guaranteed to survive server reorganizations. One possibility is to register names (URIs) with ultra-reliable servers that record their actual location (URL). Any reference to the resource goes through the appropriate server in order to find out where it is. When a resource is moved, its URL server must be notified. These mechanisms are not widely used: users just have to put up with the inconvenience of link rot.
Another solution that has been proposed is to use associative links. Pages can be identified not just by a name or a location, but also by their content—the very words they contain. A few well-chosen words or phrases are sufficient to identify almost every web page exactly, with high reliability. These snippets—called the page’s “signature”—could be added to the URI. Browsers would locate pages in the normal way, but when they encountered a broken link error, they would pass the signature to a search engine to find the page’s new location. The same technique identifies all copies of the same page in the web—an important facility for search engines, for they need not bother to index duplicates. The scheme relies on the uniqueness of the signature: there is a trade-off between signature size and reliability.
HTML: HYPERTEXT MARKUP LANGUAGE
Web pages are expressed using the Hypertext Markup Language (HTML), which is designed for visualization of online documents. HTML allows you to lay out text just as typesetters do with paper documents—except that the “page” can be as long as you like. You can include illustrations, and, transcending paper, movie clips, sound bites, and other multimedia objects too. In addition, you can link to other pages on the web.
Figure 3.1 shows HTML in action. The code in Figure 3.1(a) generates the web page in Figure 3.1(b). HTML “tags” such as <html>, <body> and <p> give information that affects the presentation of the document. Plain text (e.g., Felix is looking for inspiration!) is shown on the page, but tags are not. The opening <html> signals the beginning of an HTML document, whose ending is marked by the closing tag </html>. The second tag indicates the beginning of the “body” of the document, while <p> marks the beginning of a paragraph. Most tags have closing versions. The page contains an image that is identified by the tag <img> (with no closing tag). Unlike the others, this tag gives further information to specify the image to be shown—its filename (src) and dimensions (width and height). Beneath the image is a paragraph, delimited by <p> and </p>, with a brief note on Felix. The tag <br> is used to break the line.

You can learn more about Felix by following a hyperlink. This is introduced by the “anchor” tag <a>, which, like <img>, contains additional information. The incantation href=“http://www.everwonder.com/david/felixthecat/“ indicates the destination of the link. In this example, we use the instruction Click here to make it clear how to follow the link. This text is delimited by the <a> and </a> tags, and the browser underlines it and shows it in a different color. If </a> had been placed at the end of the sentence, the entire text Click here to learn more about Felix would have been underlined.
This little piece of HTML generates the page shown in Figure 3.1(b). But there’s more: when you view the actual page, the cat walks back and forth! The image file, called felix3.gif, is not a static picture but contains a sequence of images that give the impression of motion—a so-called animated gif image. Browsers recognize animated gifs and display them appropriately.
Unlike word processors, HTML does not do pagination. You specify a single page by beginning with <html> and ending with </html>. Long pages are viewed using the browser’s scroll bar. This was a crucial design choice that simplifies the development of web pages. Departing from the book metaphor encourages a general notion of “page” that emphasizes content over formatting and reflects the spirit of online resources that reference each other using hyperlinks as opposed to offline ones that use page numbers. It also makes it easier to present the pages in any window, regardless of size.
HTML is one of the prime drivers behind the web’s explosive growth. Yet it is a limiting factor for future development because, although it dictates a document’s presentation, it does not provide any indication of what the document means. Its development can be traced back to research on document representation in the 1960s. But even in those days, researchers already recognized the importance of describing markup in semantic as well as visual terms. Berners-Lee was not unaware of these issues when he designed the web, but he chose to set them aside for the time being. Behind the scenes, ideas for semantic markup continued to develop, and a simple language for formal specification of document content, the Extensible Markup Language (XML), appeared and became a World Wide Web standard in 1999. We describe it later in this chapter (page 78).
CRAWLING
As the web dawned in the spring of 1993, MIT undergraduate Matthew Gray wondered how big it was. He wrote the World Wide Web Wanderer, a program that counted web servers, and later extended it to capture the actual URLs they served. As we will see in Chapter 4, this was rapidly followed by other programs, embryo ancestors of today’s web dragons, that sought to capture the entire web. In keeping with the arachnid metaphor, these systems were called “crawlers” or “spiders,” or, because of their autonomous operation, “robots” or simply “bots.”
Crawlers work by emulating what you yourself would do if faced with the problem of counting all web pages. Start with one, check its content, and systematically explore all links leading from it. Repeat for each of these pages, and so on, until your time, resources, or patience runs out. The hypertext structure allows the web to be systematically explored, starting from any point.
More formally, a robot crawler starts with an initial seed page, downloads it, analyzes it to identify the outgoing links, and puts these links into a queue for future consideration. It then removes the head of the queue, downloads that page, and appends its links to the queue. Of course, it should avoid duplication by first checking whether the link is already in the queue, or whether that page has already been downloaded because it was the target of some other link. (Avoiding duplication is essential, not just for efficiency but to avoid getting into unending cycles.) The process continues until no links remain in the queue. For today’s web, this will take a long time and challenge the resources of even the largest computer system.
The crawling process eventually visits all pages that are reachable from the seed. As we will see later, a substantial fraction of pages on the web are all connected to one another (this property holds for many large-scale linked structures, including the brain). Thus, regardless of the seed, the same group of pages is crawled.
The actual crawling strategies used by today’s web dragons are more elaborate. They reduce effort by checking to see whether pages have changed since the previous crawl. They take care not to hit individual sites too hard, by restricting the rate at which pages are downloaded from any one server. They visit rapidly changing pages more frequently than static ones. They use many processors operating in parallel. They have high bandwidth connections to the Internet. Today’s crawlers can fetch thousands of pages every second, which allows them to visit a good percentage of the web in a few weeks.
Some web crawlers—known as “focused crawlers”—are topic-specific. With a particular topic in mind, they start from a relevant seed page and selectively expand links that appear to be on-topic. To do this, the program must be able to recognize when a particular link refers to an on-topic page, which can only be done by downloading the page and analyzing its content. This is a hard problem! People identify topics by understanding the text, which requires linguistic analysis at syntactic, semantic, and even pragmatic levels—as well as knowledge of the topic itself. Although artificial intelligence techniques have yielded some promising results, automatic text classification, and hence accurate focused crawling, is still a challenging problem.
A critical part of a crawler is how it interacts with web servers when downloading their pages. Pages that are referenced by ordinary URLs are retrieved using the HTTP protocol. But some servers contain dynamic pages that emerge only after specific querying, which is hard to do automatically. These pages belong to what is called the “deep web.” Crawlers cannot formulate sensible queries, and so they cannot explore the deep web as a person can. Fortunately, many dynamic pages also belong to the shallow web. As mentioned earlier (page 65), the page that Wikipedia returns in response to the query World Wide Web arises dynamically from
Yet that very page is indexed by all major search engines as
Crawlers are led to this dynamic page because other web pages, static ones, link to it.
Crawling has its hazards. Web servers can unintentionally contain traps—and if the potential exists, you can be sure that some jokers will try to make life difficult for crawlers by setting traps on purpose. Traps—particularly intentional ones—can be subtle. A dynamic page can refer to itself using an address that is different each time, causing crawlers to fetch it over and over again without limit. Smart crawlers watch out for traps, but they can be concealed, and there is no guaranteed way to detect them automatically. Trap sites typically give themselves away because of the grotesquely large number of documents they appear to contain. The contents of these documents can be analyzed to determine whether they form a natural distribution or are constructed artificially.
Early on it was realized that a mechanism was needed to allow shy websites to opt out of being crawled—for reasons of privacy, computer loading, or bandwidth conservation. Even though the web is public, it is not unreasonable to want to restrict access to certain pages to those who know the URLs. A “robot exclusion protocol” was developed whereby robots look on each site for a particular file (called robot.txt) and use it to determine what parts of the site to crawl. This is not a security mechanism. Compliance with the protocol is voluntary, but most crawlers adhere to it.
WEB PAGES: DOCUMENTS AND BEYOND
Charlemagne, whom both France and Germany regard as a founding father of their countries, was a scholar king, significantly better educated than other kings of the early Middle Ages. He learned to read as an adult, but the legend grew that he couldn’t write. This isn’t surprising, for at the time writing was the province of a trained elite. The tools were difficult to use: parchment, typically goatskin treated with slaked lime, stretched and dried; a goose feather—or, better, a top-quality swan feather, or a crow feather for very fine drawings, preferably, for right-handed writers, from the left wing. The actual process of writing was an art that required small, accurate hand movements and training in calligraphy. In sum, the skills of writing and reading were strongly asymmetric. Publishing was likewise reserved for an elite and had been carefully controlled—and jealously guarded—for centuries.
Computers (jumping quickly over many intermediate technologies) dramatically redress the imbalance between reading and writing in terms of the production of high-quality typeset documents. And the web offers a revolutionary new dissemination method, vastly superior to traditional publishing. Distribution is fast and free. A given URI might yield a static page, the same every time you return, or a form that you can fill out and send back, or a dynamic page that changes with time, or an active page that shows a program-driven visualization. The web supports different methods of publishing, some simple and widely accessible and others requiring hard-won technical skills. It promotes cooperation by allowing people to share documents and contribute articles to electronic journals and weekly or daily—even hourly—newsletters. All this greatly facilitates scholarship and the rapid growth of ideas.
It is now easy to produce and publish information with high standards of presentation quality. But retrieval is still in its infancy. The web explosion has been fueled by documents whose strengths lie more in visual presentation than in natural, human-like retrieval of information. The XML language (see page 78) offers expressive mechanisms to declare the content of the document, and this is crucial when trying to lace queries with a modicum of semantics.
STATIC, DYNAMIC, AND ACTIVE PAGES
Your browser is your web surfboard. You type a URL, and the HTML file at that address is downloaded and rendered on your screen. Unless the page’s owner updates it, you find the same information every time you visit. You might (unusually) see something move, like Felix—but (at least in Felix’s case) all you get is a preprogrammed motion repeated over and over. In short, most web documents show a static electronic publication that remains there until someone updates the content. It’s like writing a newsletter with a word processor and presenting it to the world on electronic paper.
The web also offers something more dynamic. You might find different information at the same address, like the Wikipedia search page (whose operation was explained on page 65). This mechanism ends up executing a program that belongs to the web server in order to come up with the information to display. Dynamic information such as this goes well beyond traditional means of publication. An ordinary HTML description completely defines the content and presentation of the page, the same at every visit. Dynamic pages are defined by a linguistic description as well, but they also specify some processing that the server must undertake before returning the page to the browser as an HTML document description. When you view a static page, what you see is produced entirely by your browser on the basis of stored information sent by the server. But when you view a dynamic one, the server does some processing too.
Consider our well-worn example of entering World Wide Web as a Wikipedia search. The resulting URI contains ?search=World+Wide+Web&go=Go, and this is interpreted by the server at en.wikipedia.org/wiki/Special:Search. The server produces the appropriate information and uses it to construct an HTML page, which it then transmits to your browser, which in turn shows it on your screen. Dynamic pages, plus the possibility of transmitting information from browser to server (in this case, your query is coded as World+Wide+Web), transcend what is possible with static presentations.
Dynamic web pages are capable of many useful things. A particular page can show the number of times that people have visited by keeping a counter on the server and increasing it at every access—like a book that counts its readers. Alternatively, and much more surprisingly, it can show how many times you—yes, just you, not all the others—have visited. This requires a counter just for you, accessible to the server. This can be arranged using a mechanism called “cookies.” A cookie is a packet of information sent to your browser by a web server the first time you visit it. Your browser stores it locally, and later, when you revisit the site, it sends the cookie back unmodified. One thing the server can do with this is keep track of the number of times you have visited, by storing the information in the cookie, updating it, and sending it back at each visit. It’s a sort of user profile.
Cookies are powerful—and dangerous. Earlier we explained that HTTP is a stateless protocol: it does not retain information between transactions. But the cookie does retain information, and web servers often use cookies to store user profiles. For instance, if you leave your name on a web server, don’t be surprised if it greets you personally next time you visit. According to the HTTP protocol, every return to a page is exactly the same as the first visit. This can be annoying: the server might repeatedly ask you to identify yourself and reset preferences that you already specified last time. Cookies solve the problem: the server stores your identity and user profile in a cookie which it leaves on your computer. On the other hand, cookies might compromise your privacy by revealing your profile. Don’t leave your bank account number and password on a machine in an Internet café! We return to this in Chapter 6.
Cookies allow servers to execute programs that know about your previous interactions. But web resources can be interactive in an even more powerful sense. Visiting a given page can cause a program to be downloaded and executed on your own computer rather than the server. Such programs are called “applets” (small applications) and are written in the Java programming language: they are embedded into HTML using an <applet> metatag. Applets are popular for online demos that interact with the user directly, without having to wait for responses from across the Internet.
Web pages go far beyond the paper documents that flood our desk and the books that have lurked in libraries for centuries. They are living entities that evolve. They can contain multimedia. They can cause programs to run on the server, programs that can use data recalled from past interactions. They can even cause programs to run on your own computer, the one running your web browser. Not only is more information published as time goes by, but as technology evolves, existing information can be represented in different ways—like intellectual spirits reincarnated in new bodies.
AVATARS AND CHATBOTS
According to Hindu lore, the Avatara descends from Heaven as a material manifestation of God in a particular form, an incarnation of the Godhead. In computer animation, avatars have a more prosaic interpretation which can be traced back to 1985 when George Lucas of Star Wars fame catapulted animated cartoon figures, humanoid in appearance, into a popular chat system. These figures could move around, manipulate objects, and converse with one another. In the future avatars will be used to facilitate access to websites.
Imagine being guided around a field of knowledge by a wise, omniscient, and infinitely patient teacher, who can speak your language—and everyone else’s. Among the many ways that existing information can be reincarnated in a new body, avatars represent a sort of platonic perfection, a divine teacher who offers an ideal presentation—Socrates on your laptop. (The reality may fall short of the dream, however.) Avatars lend their humanoid appearance to chat robots or chatbots, programs capable of providing guidance by maintaining a conversation with a person. Some chatbots can talk to one other, creating a framework for autonomous interaction.
Research on chatbots has a checkered history, success mingling with failure. The challenge of natural language understanding seems to be inseparable from the whole of human intelligence. Intensive research at the height of the Cold War in the 1950s, when the U.S. government regarded automatic translation from Russian to English as a strategic national problem, bore little fruit apart from a sharper realization of just how difficult it is. Ten years later, a chatbot posing as a psychotherapist called Eliza created a minor sensation in computer circles. Early in the conversation, Eliza could fool even careful observers, but the interchange eventually degenerated into a bizarre charade because she didn’t understand questions at all. Instead, the program detected simple linguistic patterns and produced canned responses that cleverly interpolated words from prior input. Today, after decades of research, chatbots can behave impressively on a few examples but eventually make stupendous blunders. To behave like people, they need to acquire a vast store of knowledge and use it as a basis for reasoning, which is very difficult—particularly for conversation in unrestricted domains.
Nevertheless, chatbots, personalized as avatars, will play a significant role in the evolution of the web. They work well in certain domains and can offer personalized, user-friendly guidance in navigating websites to obtain useful information. They represent a new frontier in human-computer interaction and multimedia information presentation. But true semantic information retrieval is still way beyond reach, and today’s chatbots, like their great-grandmother Eliza, are limited to cooperative conversations on particular, well-defined topics.
COLLABORATIVE ENVIRONMENTS
As we learned in Chapter 1, a quest for congenial and effective environments for collaboration was part of the heady atmosphere that led to the web. However, Berners-Lee’s decision to allow free hyperlinking to other pages, without notification or request, was inimical to the kind of support being envisaged at the time. Of course, the web’s explosion—due in some measure to that very decision—has greatly facilitated information sharing through the Internet. But the thirst for more intimately collaborative environments continues unquenched, and as technology develops, they are emerging in different guises.
Wiki—wiki wiki is Hawaiian for “quick”—is one of today’s most popular collaboration systems. Devised in 1995, it is server software that allows you to use your browser to create and edit web pages. Many people can contribute to a wiki, and the system helps them organize their contributions as well as create and edit the content. Wikis are widely used, particularly by nontechnical people, thereby contributing to democracy on the web. In the last few years, this technology has supported community-based collaboration in countless companies and research institutes. It has also given rise to Wikipedia, an online encyclopedia to which anyone can contribute, which represents a fascinating social experiment in its own right. Wikipedia crosses community boundaries and has become a respected—though controversial—repository of information that some regard as library quality.
In blogging, the emphasis is on individual publication rather than coordinated collaboration. A blog (short for weblog) is an electronic journal that is frequently updated and usually intended for a broad readership. Unlike most websites, blogs are based on templates that govern the presentation of content from a database. New pages can be created very quickly, since content is entered in raw form and the template takes care of the presentation and how the entry links to existing material. Templates include metadata, so content can be filtered by category, date, or author. Blogs can be found on any subject under the sun, but the initial driving spirit was to promote democracy by giving a public soapbox for minority points of view. Blogging has emerged as a cultural process that affects nearly every field.
Typical blogs consist of title, body—which can include text, hyperlinks, and often photos, video, music—and comments added by readers. They’re far easier to create than ordinary web pages. They differ from forums like newsgroups because authors can introduce any subject for discussion; follow-up postings comment on that subject. Blogs are defined by the article’s URL or “permalink”; the date of posting is also commonly used as a search criterion. Some blogs are maintained by software on the user’s own computer; others are supported by tools provided by web hosting companies, who also store the documents.
Blogs, like wikis, have become popular because of their versatility. Their uses range from professional journalism, to teenage diaries intended to keep friends up to date with events and thoughts. The idea of minute-by-minute updating is affecting schools of journalism and having a profound impact on social and political life. Blogs often bring key information to the attention of the mainstream media. They gain popularity through word of mouth and citations (permalinks) that reveal who their readers are. Some people criticize the quality of this kind of journalism with its occasional disregard of proper attribution.
Wikis and blogging exemplify rapid publication par excellence. Charlemagne’s quill and parchment presented a formidable barrier to writing and publication, but software eliminates that barrier almost entirely. Of course, quick-fire production of articles in blogs means that they tend to be opinion pieces and commentary rather than carefully reasoned arguments and in-depth analyses. On the other hand, rapid expression and cross-linking of many different viewpoints provides a sort of cultural mirror. Blogs permit collaborative growth of individual ideas and thoughts in a public space, and are emerging as an important new cultural phenomenon.
ENRICHING WITH METATAGS
Chapter 2 argued that metadata plays a central role in organizing libraries. Though HTML was conceived primarily for presentation, it allows supplementary information to be included with a document. This is done using special tags that are not intended for presentation but for describing the content of the page. These “metatags” are included at the beginning of the page in an area delimited by <head> … </head>. Figure 3.1(c) shows an example where two metatags are used, one to describe Felix’s page, and the other to include suitable keywords (see page 68). This content is not shown on the web page but is available for information retrieval or other automatic processing. While the keywords metatag offers a compact description of Felix’s page, the description metatag enriches the textual description on the page. A <title> tag also appears within the head area; browsers show the title in the top border of the web page.
Metadata can be extremely useful for retrieval. The designer might flag one page as containing “adult content” to facilitate the filtering of pornography, and another as one containing informed medical recommendations. However, self-assessment is obviously suspect—particularly since the information is not displayed but used solely for automatic processing. While almost everyone would disagree with a “VIP” keyword attached to Felix, machines are more gullible. Of course, Felix might pose as a VIP just for fun, but, to be useful, metadata must be taken seriously.
Metadata is essential when it comes to image retrieval. Automatic understanding of both text and images falls far below human levels, but whereas text in some sense describes itself, images give few clues. When someone creates a web page that comprises an image, they can insert metatags that describe it, but this raises the nasty question of duplicity—and while machines can do some sanity checking of textual pages, with images they are completely at the tagger’s mercy.
Here’s an imaginative way to exploit the web to provide accurate image metadata. Two strangers play a collaborative game, just for fun (it’s called the ESP game; you can find it on the web and play it yourself). They don’t know anything about each other: the server pairs each user randomly with an opponent, perhaps in another country, whose identity is completely unknown. The server chooses an image from the web, shows it to both partners simultaneously, and asks them to label it. Each player’s goal is to guess what the other is typing, without any communication. As soon as you both type the same phrase, the system offers a new image and you play again. Meanwhile, behind the scenes, that phrase is recorded as metadata for the image. This is a simple yet effective means of producing reliable metadata. Random pairing and anonymity eliminate any opportunity to spoof the system by colluding with a friend or bribing your partner. All parties win: the players have fun—for the machine displays scores, providing a constant challenge—and the system gathers metadata. This is a creative use of anonymity and real-time communication on the web.
XML: EXTENSIBLE MARKUP LANGUAGE
HTML describes the visual form of web documents, not their content. The M is for markup, which applies to the format—just as copyeditors mark up manuscripts in traditional publishing. This emphasis on visual aspects contrasts with database representations, which are rich in expressing content in terms of well-structured data records but impoverished in expressing presentation.
Database records are interpreted with respect to a schema, which gives a complete definition of the fields that constitute each record. Personal records, for example, contain separate fields (first and last names, birth data, address, and so on), some of which—such as “birth data” and “address”—are themselves structured into further fields. This kind of organization makes it possible to answer complex queries, because meanings are attached to each field of the record. Whereas databases were conceived for automatic processing and born in computers, documents were conceived for human communication. Documents are difficult to process automatically simply because it is hard to interpret natural language automatically. The schema is the key to interpreting database records, but no corresponding semantic description is available for documents.
The Extensible Markup Language, XML, is a systematic way of formulating semantic document descriptions. It’s neither a replacement for HTML nor an evolution of it. Whereas HTML was designed to display information, XML focuses on describing the content. It’s a declarative language: it doesn’t actually do anything. Figure 3.2 shows a note that the CatVIP club sent to Felix begging him to stop pacing back and forth across the screen, expressed in XML.
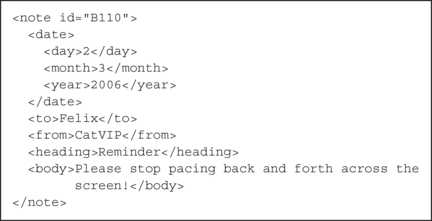
When interpreted by a web browser, the HTML in Figure 3.1(a) produces the web page in Figure 3.1(b). In contrast, the XML in Figure 3.2 produces … nothing. It focuses on content, not presentation. There’s a message header (<heading> … </heading>) and a body (<body> … </body>), preceded by some auxiliary information using other tags (<date>, <day>, etc.). Unlike HTML, XML tags are not predefined—you make them up as you go along. The assumption is that you choose them to provide a useful semantic description.
The whole note is embraced within a <note> tag. Attributes can accompany tags (as with HTML), and this note has the identifier B110 as an attribute, which could be used to refer to it. Another way of specifying the date would be to make it an attribute too, like
The advantage of using separate elements, as Figure 3.2 does, is that it’s more suitable for computer interpretation, just like database records.
In addition to the date, the description in Figure 3.2 also specifies the sender and the receiver. Of course, these could be further decomposed into subfields if appropriate. The body is the truly textual part, which is typically unstructured. As this simple example shows, XML yields semi-structured representations that lie somewhere between database schema and free text.
XML documents have a hierarchical organization. A collection of notes like the one in Figure 3.2 could be framed within an enclosing <messages> … </messages> construct, so that individual notes were identifiable by their id attribute. It is possible to define a formal schema—like a database schema—that precisely expresses constraints on the structure of the document in terms of the elements and their nesting, and the attributes that can occur with each element. Furthermore, elements are extensible. We could later decide to add a new item <weather> … </weather> to the note, indicating whether it was written on a sunny or a cloudy day.
XML offers new opportunities for document processing by exploiting the semantics associated with the tags. Everyone is free to define his or her own tags, and only the page author (or the author of the corresponding XML schema) knows what they are supposed to mean. XML doesn’t help others to understand the meaning of the tags. In Chapter 4, we’ll see that the semantic web, another creation of Tim Berners-Lee’s fertile mind, is moving in the direction of removing this obstacle too.
METROLOGY AND SCALING
William Thomson (1824–1907), better known as Lord Kelvin, was a renowned Scottish mathematician who made many major discoveries, including the formulation and interpretation of the second law of thermodynamics. An infant prodigy, he was renowned for his self-confidence and strongly held views. He was a passionate advocate of the importance of measurement in physics.
I often say that when you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meager and unsatisfactory kind; it may be the beginning of knowledge, but you have scarcely in your thoughts advanced to the state of Science, whatever the matter may be.
For example, he studied the fascinating problem of calculating the age of the earth. Unfortunately, the figure he came up with, 25 million years, is a gross underestimate—for reasons he couldn’t have known (concerned with radioactive elements, which produce heat at the earth’s core and significantly enhance the geothermal flux). That unlucky prediction is a salutary reminder of the fallibility of even the most expert reasoning.
The importance of expressing knowledge with numbers, so dear to Kelvin’s heart, goes well beyond physics. The universe that we know as the web—like the one we actually live in—is huge and expanding. No one can see it all: we can only comprehend it secondhand, through the misty glass of measuring instruments. How big is the web? How fast is it growing? Is the growth sustainable by computer and communication technologies? What does it take to crawl the web and make a copy? How many links separate any two pages? The answers to these questions might help us anticipate the web’s future.
ESTIMATING THE WEB’S SIZE
Counting the pages on the web seems almost as daunting as counting the books in the Library of Babel. Fortunately, hypertext links—something librarians do not have—come to our aid, and we have already learned how they can be used to crawl the web. In June 1993, the pioneer World Wide Web Wanderer estimated its size to be 100 servers and 200,000 documents, an average of 2,000 pages per site.
Today’s search engines, operating in essentially the same way, give an estimate four orders of magnitude larger. They report how many pages they crawl and index, and compete for the greatest coverage. But the web is clearly even bigger than any of these figures. For one thing, pages are added continuously, whereas search engines’ figures are based on their last crawl. More importantly, it is easy to find pages indexed by one search engine that have been overlooked by another.
Different search engines use different crawling strategies. If two turn out to have a high proportion of pages in common, the web is probably not much larger than the greater of the two. On the other hand, a small overlap would suggest that the actual dimension significantly exceeds both numbers. This simple idea can be operationalized by submitting random queries to different search engines, analyzing the overlap, and repeating the procedure many times. From the results, simple probabilistic reasoning leads to a lower bound on the web’s dimension.
Counting how many pages two search engines have in common is not quite as simple as it sounds. Any particular page might have a replica that is indexed with a different URL. This situation occurs frequently, and unless care is taken to detect it, common pages might be excluded from the overlap, leading to an overestimate of the lower bound. It is better to check the pages’ content than simply inspect their URL.
Using these techniques, the number of pages in the indexable web was estimated to be at least 11.5 billion in early 2005. The estimate was made by creating 440,000 one-term test queries in a systematic way and submitting them to four major search engines (Google, MSN, Yahoo, and Ask). Care was taken to ensure that the queries contained words in many different languages (75). The four individual search engines had coverages ranging from 2 billion to 8 billion pages. The estimated intersection of all four was 3 billion pages, and their union was 9 billion. At that time, even the most comprehensive search engine covered only 70 percent of the indexable web. And as we will see, the web contains many pages that cannot be found by crawling and are therefore not indexable.
In practice, different crawlers do not yield independent samples of the web. Though they act independently, they share many design principles. Moreover, the fact that the web has a few huge sites biases the crawling process. This lack of independence is the reason why the estimate is a lower bound. An upper bound would allow us to pin down how big the haystack really is. Unfortunately, there is no credible procedure for bounding the size of the web, for when pages are generated dynamically, there is really no limit to how many there can be. We return to this question when discussing the deep web.
RATE OF GROWTH
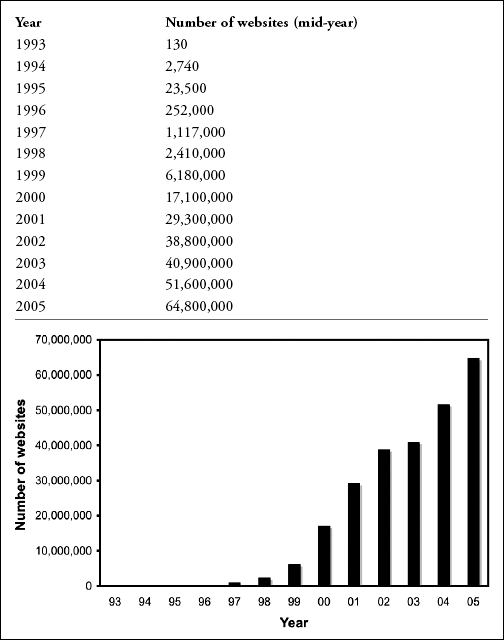
In 1997, Mathew Gray, who had introduced the World Wide Web Wanderer four years earlier, confirmed that the web was growing exponentially, doubling every six months. Growth had slowed since the heady days of 1993, when it doubled in just three months. Other studies have confirmed a relentless exponential trend, though the magnitude of the exponent is tailing off. Table 3.1 shows the growth of the web in terms of sites, in both tabular and chart form.
What are the limits to growth? One relates to the protocol underlying the Internet, called TCP/IP, which provides addresses for only 4 billion web servers. However, a new version, the Next Generation Internet Protocol, overcomes this restriction. In any case, a technique called “virtual hosting” allows you to place an essentially limitless number of unique sites at a single Internet address. Only a small percentage of computer disk space is used for web pages, and anyway disk capacity will grow significantly over the next few years.
The scale of objects in nature is governed by natural laws. The bodily proportions of elephants are not just those of ants scaled up. If they were, it would be hard to explain why ants easily drop from a tree while a far lesser fall will injure an elephant. Imagine scaling an ant up 500 times, bringing it to the dimensions of a large African elephant. Volume grows with the cube of linear dimension and would increase 125 million times. The same goes for weight (if it were still made of ant-stuff, which is not all that different from elephant-stuff). But leg strength depends on cross-sectional area, not volume, and increases with the square of the linear dimension, so the legs could only bear a weight increase of 250,000. The giant ant’s skinny legs couldn’t carry its gargantuan body.
Similar laws govern the growth of artifacts. Laptop designers take no special precautions to dissipate heat from the power supply, whereas transformers in power stations need refrigeration. The heat generated by a transformer is proportional to its volume, but heat dispersion is proportional to area. This imposes limits to growth. Engineers understand this: when more power is required, they employ more units rather than scaling up a single one.
In the field of electronics and communication, huge improvements in processing and transmission technologies have produced a vast increase in the number of intercommunicating devices on our planet. Like ants, elephants, and transformers, these networks must obey laws that govern growth. However, whereas engineers are familiar with the scaling issues that surround physical devices, the effects of scaling in information technology are far less well understood.
In Chapter 2, we met what is commonly called “Moore’s law”: the number of transistors on a chip doubles about every 18 months. The ant-chips of the 1960s, whose bodies contained just a few transistors, have become gigantic. Moore’s is not a natural law like those of physics, but an empirical observation coupled with a strong intuition of how things will evolve in the future—and so far it has turned out to be amazingly accurate. Exponential growth also holds for disk storage, whose capacity is growing even faster than processing power.
To analyze the sustainability of web growth, we must also consider the evolution of communication technology. In 1998, Jacob Nielsen, who the New York Times calls the “guru of web page usability,” predicted that users’ connection speeds would grow by 50 percent per year on average. Though large, this rate is nowhere near as high as for processing and disk technologies. And doubling the capacity of your local connection might not double the speed at which web pages arrive. The Internet is a complex infrastructure, and you don’t necessarily benefit from upgrading the local connection.17
COVERAGE, FRESHNESS, AND COHERENCE
Predictions of developments in Internet bandwidth suggest that even though it is growing exponentially (at perhaps 50 percent per year) it will fall behind the web itself, which is also growing exponentially but with a greater exponent.18 The time taken to download the entire web depends on the capacity of all its individual sites. Regardless of a crawler’s effectiveness, download time increases with the size of the web—which is increasing exponentially.
The coverage of a particular engine can be expressed as the percentage of pages that it indexes. Once a page has been processed, the crawler can keep it in its entirety or discard it (but retain the URL, which is needed to avoid reprocessing the page). If it is kept, the search engine can offer its cached copy to users—which means they can access the page even when the original source is unreachable, either because it has been removed or the server is temporarily down.
Early search engines took several weeks to crawl the entire web. Today, as we shall see, the situation is more complex. In any case, because of the time needed to complete the crawl, search engines’ cached versions aren’t necessarily identical to the actual pages themselves. The coherence of a copy of the web is the overall extent to which it corresponds to the web itself, and the freshness of a particular page can be defined as the reciprocal of the time that elapses between successive visits to it.
Coverage, freshness, and coherence are three key properties of a web crawler. If pages are crawled uniformly—that is, if they all have the same freshness—then doubling coverage implies halving freshness. This is a kind of uncertainty principle. But unlike Heisenberg’s celebrated result in quantum mechanics, it can be ameliorated by tuning the freshness to the nature of the page. A good strategy is to classify pages into categories with different freshness, and crawl the web accordingly. Of course, this isn’t easy because it requires predicting the times at which web pages will be updated.
Search engines don’t crawl the web uniformly, visiting every page equally often. A university web page might be updated a few times a year, whereas most news channels change their information daily—or hourly—and should be captured more frequently. To optimize coherence, crawlers visit volatile pages more often than static ones. Depending on the crawling policy, the freshness of different pages can be very different and might also change with time.
Given a perfectly accurate crystal ball, a crawler should download each page as soon as it is created or updated, ensuring optimum coherence within the constraints of available bandwidth. This would achieve the same effect as automatically notifying search engines of every change. Unfortunately, crystal balls are hard to come by. Instead, one can take into account the page’s usage and the time between its last updates, preferring popular pages that change frequently. It is not easy to find a good recipe for mixing these ingredients.
Even using a crystal ball, the uncertainty principle holds and becomes critical if the web’s exponential growth outpaces the growth in bandwidth. One solution is to increase the overall quality of the index by paying frequent visits only to important pages. Of course, this raises the difficult question of how to judge the quality of a document automatically.
If we regard the web as a repository of human knowledge, once the initial target of collecting everything is accomplished, one would only have to keep up with its rate of increase. Exponential growth in our planet’s population cannot be sustained over the long run, and the same must surely hold for worthwhile web pages. Growth has to saturate eventually. If this is true, in the long run all will be well: computer and communication technologies will ultimately be in good shape to sustain the growth of the web. We will eventually have the technology to create the building of the Library of Babel and house all its books. But there is far more to it than that: we need to sort the wheat from the chaff and provide useful access to the content.
STRUCTURE OF THE WEB
Borges’ library, with its countless floors, labyrinthine galleries, lustrous mirrors, and infinite repetitions of myriad books, seems designed to demoralize and confuse. In contrast, real librarians organize books so as to facilitate the retrieval process. They proceed in careful and measured ways. They design and implement well-defined structures for information seeking. They promote standardization so that they can cooperate effectively with other libraries. They plan their acquisitions according to clearly stated policies.
The web does not grow in accordance with any plan or policy—far from it. Growth arises from a haphazard distributed mechanism which at first glance appears virtually random. Whereas other striking engineering achievements—bridges, airplanes, satellites—are fully documented by the design team in the form of technical drawings, Berners-Lee drew no map of the web. Of course, if you had enough resources, you could make yourself one by crawling it and reconstructing the linkage structure on the way. Simple in principle, this exercise in cartography calls for all the infrastructure of a major search engine. And for reasons explained before, a complete and up-to-date map will always elude you.
Notwithstanding its distributed and chaotic nature, structure does play a central role in the web. Surprising insights can be obtained from the network induced by the hyperlinks, insights that also apply to other large-scale networks, whether natural or artificial. The fact that links are directed implies further structure that many other networks do not share. A good approximation to the web’s gross structure can be obtained from elegant models of random evolution. Structure emerges out of chaos. As for the fine details, they reflect the social behavior of users and their communities. The organization of parts of the web is recorded in manually created hierarchies. Finally, the web that search engines know is just the tip of the iceberg: underneath lurks the deep web.
SMALL WORLDS
Stanley Milgram was one of the most important and influential psychologists of the twentieth century. Notwithstanding his scientific achievements, his professional life was dogged by controversy. To study obedience to authority, he conducted experiments in which people were asked to administer severe electric shocks (up to 450 volts) to victims. In fact—as the subjects were informed later—the victims were actors and the shocks were simulated. Astonishingly, most people deferred to the authority of the experimenter and were prepared to inflict apparently severe pain on another human being. Needless to say, this work raised serious ethical concerns.
In 1967, Milgram published in Psychology Today a completely different but equally striking result which he called the “Small World Problem.” He selected people in the American Midwest and asked them to send packages to a particular person in Massachusetts—the “target.” They knew the target’s name and occupation, but not the address. They were told to mail the package to one of their friends, the one who seemed most likely to know the target. That person was instructed to do the same, and so on, until the package was finally delivered. Though participants expected chains of hundreds of acquaintances before reaching the target, the astonishing result was that the median was only 5.5. Rounded up, this gave rise to the widely quoted notion of “six degrees of separation.”19 It’s a small world after all! In their own specialized milieu, mathematicians boast of their “Erdös number,” which is the number of degrees they are separated from Paul Erdös, a famously prolific mathematician, in the chain defined by joint authorship of published papers.
The idea of six degrees of separation has emerged in different guises in other contexts. And unlike Milgram’s study of blind obedience to authority, it has strong mathematical foundations in an area known as graph theory. Mathematical graphs—which are not the same as the quantitative plots used in empirical science—comprise elements called “nodes,” connected by links. In Milgram’s experiment, nodes are people and links are to their friends. In the web, nodes are web pages and links are hyperlinks to other pages. The amount of connectedness determines how easy it is to reach one page from another, and affects the operation of the crawlers that dragons use to make copies of the web to index.
Computer scientists often employ abstract devices called “trees”—not the same as biological trees—which are nothing more than special graphs with a root node and no cycles in the link structure. A family tree is a familiar example. Factor out the complication of sexual reproduction (if only real life were so easy!) by restricting the tree to, say, females. At the top is the root node, the matriarch—Eve, perhaps. There can be no cycles because biology prevents you from being your own mother or grandmother. Trees occur in all kinds of problems in computer science: they first appeared in 1846 in a paper on electric circuits.
The number of nodes in a tree grows exponentially with its height. This is easy to see. For simplicity, suppose each node has exactly two children. If there is but a single node (the root), the height is 1. If the root has children (height 2), there are two of them, and whenever you pass to the next generation, the number of children doubles: 4, 8, 16,…. This is an exponential sequence, and it means that the number of nodes in the tree grows exponentially. Conversely, height grows logarithmically with the number of nodes. If the number of children is not two—indeed, if different generations have different numbers—growth is still exponential, the exponent depending on the average branching factor. For example, if the number of children ranges randomly from 0 to 2, it can be shown that the average height grows to about 40 percent of the figure for two children. If there are 32 children per node and the tree represents seven generations, the tree will contain 32 billion nodes.
Similar results hold for graphs, except that they lack the concept of height because there is no root. Instead, the height of a tree corresponds to the length of the longest path connecting any two nodes in the graph, which is called the graph’s “diameter.” Sometimes the average path length is used instead of the longest.
Studies of the web reveal a structure that resembles Milgram’s original discovery. In an early experiment, a single domain about 3000 times smaller than the web was crawled and analyzed. Its average degree of separation was found to be 11. To scale the result to the entire web, experiments were carried out on smaller portions to determine the rate of growth, and then the actual value for the entire web was extrapolated. Using a 1999 estimate of the web size, the average degree of separation was predicted to be 19.
This result indicates that, despite its almost incomprehensible vastness, the web is a “small world” in the sense that all its pages are quite close neighbors. However, the value found for the average degree of separation is biased by the special connection structure of the small sample that was used. Full-scale experiments are difficult to conduct because the entire web must be crawled first—and even then the magnitude of the graph challenges ordinary computer systems. Later studies using data from a major search engine painted a more subtle picture. Many pairs of websites are simply not connected at all: with random start and finish pages, more than 75 percent of the time there is no path between. When a path exists, its length is about 16. However, if links could be traversed in either direction, a far larger proportion of random pairs would be connected, and the distance between them would be much smaller—around 7. These figures are all astonishingly small, considering that the web contains many billions of pages.
If you could construct an intelligent agent that traversed the web following only the most relevant links, as Milgram’s subjects did, you could get to any target that was reachable in just a few judicious clicks. The previous section closed with some reassurance about the sustainability of the web by electronic and communication technologies. And now we know that, immense as it is, even the web is a fairly small world! Once again, however, we have fetched up on the same rocky shore: the intransigent problem of finding good ways to access the relevant information.
SCALE-FREE NETWORKS
Organizing things in the form of networks seems to be a principle that nature adopts to support the emergence of complex systems. The idea of connecting basic building blocks applies from the molecular structure of benzene to neural pathways in the brain. The blocks themselves are not the principal actors because, at a finer scale, they can be regarded as networks themselves. What is primarily responsible for both molecular reactions and human behavior? It’s not so much the nodes as the pattern of connections.
Complex human artifacts also adopt the network organization. Roadmaps, airline routes, power grids, VLSI chip layouts, the Internet, and, of course, the web are all characterized by their interconnection patterns. Amazingly, these systems obey laws that are independent of the particular domain, and applying knowledge that is standard in one field to another field can yield valuable new insights. A crucial feature of all networks is the number of links per node and the distribution of this number over all the nodes in the network. For example, a quick glance at an airline routing map shows that the network is characterized by a few important airports—hubs—that are massively connected.
Despite their underlying organization, most large networks, including the web, appear to be largely random. You could model the web as a graph in which links emanate from each page randomly. Given a particular page, first determine the number of outgoing links by rolling dice. Then, for each link, figure out its destination by choosing a random page from the entire web. This strategy distributes the number of links emanating from each page uniformly from 1 to the number of faces on a die (6, in most casinos).
In scientific domains, quantities are commonly distributed in a bell-shaped or Gaussian curve around a particular average value. Indeed, in the preceding experiment, it can be shown that the number of links into a node is distributed in an approximately Gaussian manner.20 However, the number of outbound links is uniform, not Gaussian, because it is determined by throwing a die, which gives an equal probability to 1, 2, 3, 4, 5, and 6 links. An alternative method of construction is to randomly choose start and end pages and connect them, repeating the process over and over again until sufficiently many links have been created. Then the links emanating from each node will have a Gaussian distribution whose average is determined by dividing the total links by the number of nodes—the link density.
How are the numbers of inbound and outbound links distributed in the web itself? The first experiments were performed on the Internet, which is the computer network that supports the World Wide Web (and many other things as well), not just the web, which links documents rather than computers. The results disagreed substantially with both the Gaussian and uniform models. It turns out that most Internet nodes have few connections, while a small minority are densely connected. As we will learn, this is not what the Gaussian model predicts. Subsequent experiments on the number of links to and from websites revealed the same behavior.
Measurements of everyday phenomena usually exhibit the bell-shaped Gaussian distribution sketched in Figure 3.3(a). Values cluster around a particular average value. The average conveys a tangible sense of scale. For example, people’s heights have a distribution that is fairly narrow. Although height differs from one person to the next, there is a negligible probability that an adult’s height is twice or half the average value. The average depends (slightly) on sex and ethnic origin and is quite different for other species (ants and elephants). Values deviate from the average to some extent depending on whether the bell is broad or narrow, but there are no radical departures outside this general variation.

Figure 3.3(b) shows a statistical distribution called the power law, which is a far better fit to the empirical distribution of links in the web (and the Internet too) than the Gaussian distribution. According to it, the most common number of links is the smallest possible number, and pages with more links become rarer as the number of links increases.21 Unlike the Gaussian distribution, the number of links doesn’t cluster around the average. Also, radical departures aren’t so rare. Compared to Gaussian, the power law has a heavy tail: it drops off far less quickly as you move to the right of the graph. If people’s heights followed the power law, most of us would be very short, far shorter than the average, but some would be very tall—and it would not be too surprising to find someone five or ten times taller than the average. Another way of looking at the difference is that in the Gaussian distribution, the mean (average value) is the same as the mode (most popular value), whereas with the power law, the mode is the smallest value and the mean is skewed well above it.
Power-law distributions are unusual in daily phenomena. Because they don’t cluster around a particular value, they convey no sense of scale. If you pick a few samples from a Gaussian distribution, they will all be pretty well the same as the mean, where the interpretation of “pretty well” is determined by the variance. Just a few samples give a good idea of scale—they’ll tell you whether you’re looking at ants or elephants. But if you pick a few samples from the power-law distribution, they do not convey a sense of scale. You can still calculate the mean and variance, but these are abstract mathematical constructs without the same visceral interpretation as their Gaussian counterparts. Regardless of whether a network is large or small, the power-law distribution of links always has the shape of Figure 3.3(b).
Whereas Gaussian distributions do not exhibit radical outliers (10-meter giants), power-law distributions do. In networks, an outlier is a hub, a node with far more links than average. This is an attractive feature for many practical purposes, as travel agents who plan airplane journeys will confirm. Hubs, though rare, are plainly visible because they attract a large number of links.
EVOLUTIONARY MODELS
In the web, the process of attaching links is inherently dynamic. Nodes that turn out to be popular destinations are not defined in advance but emerge as the network evolves. Earlier we described how to generate a web randomly, but unrealistic distributions resulted—Gaussian for the number of inbound links, and uniform or Gaussian distributions for the outbound links. In these scenarios, we began with all pages in place and then made links between them. However, in reality, pages are created dynamically and only link to then-existing pages. If the random-generation model is adjusted to steadily increase the number of pages and only attach links to pages that already exist, the Gaussian peaks disappear. However, the result is not quite a power law, for the probability of a certain number of links decays exponentially with the number.
This generation model favors old nodes, which tend to become more frequently connected. In the web, however, it seems likely that popularity breeds popularity. Regardless of its age, a node with many inbound links is a more likely target for a new link than one with just a few. Destinations are not chosen randomly: strongly connected nodes are preferred. If the model is altered so that new links are attached to nodes in proportion to the number of existing links, it turns out that a power-law distribution is obtained for inbound links, just as occurs in the web. This state of affairs has been metaphorically (though inaccurately) dubbed “winners take all.” A few popular pages with many inbound links tend to attract most of the attention, and, therefore, most of the new links. Meanwhile, most pages suffer from poor visibility and have difficulty attracting attention—and new links.
This elegant evolutionary model provides an excellent explanation of the distribution of inbound links in the web. It turns out that the number of outbound links is distributed in the same way.22 The web is a scale-free network. It can evolve to any size whatsoever and the power-law link distribution still holds. Although you can work out the mean number of links per page, the actual figures do not cluster around the mean.
The model, though quite accurate, is still rather simplistic. First, nodes that have been around for a long time are more likely targets of links—in fact, nodes are favored in proportion to their age. But this aging effect is inconsistent with reality: venerable web pages are not popular purely by virtue of their longevity. The model can be improved by introducing a fitness measure for every node, chosen randomly, so that it is possible for a latecomer to vie in popularity with old nodes. The probability of attaching a new link is the product of the number of already attached links and this fitness measure.
Second, in large networks like the web, generating links independently of nodes does not always yield a satisfactory approximation. In some circumstances, the distribution departs from the power law, especially among pages on the same topic. For example, if you take all university home pages, or all company home pages, the distribution is an amalgamation of the peaked distribution of Figure 3.3(a) and the heavy tail of Figure 3.3(b).23 Most company home pages were observed to have between 100 and 150 inbound links (in 2002), whereas the power-law distribution predicts that the most popular number of links is 1. Yet despite local variations, the overall distribution for all web pages does respect the power law.
BOW TIE ARCHITECTURE
Milgram’s studies of the small world phenomenon remind us that our society is a strongly connected network: that is, one that links everyone to everyone else. Nature has produced many such networks—most notably the human brain. This contains 100 billion neurons with 10,000 connections each, and the growth mechanism clearly favors a strongly connected organization over a fragmented structure. The web is also, in large measure, strongly connected rather than broken up into a multitude of fragments. This is important to its success, since a disconnected structure would not support crawling, and consequently searching.
What accounts for the development of single, large, connected structures as opposed to many fragmented clusters? In the web, it emerges from a bottom-up process of connecting pages all over the world, without any centralized control. In other fields, different reasons apply. In physics, insight into the phenomenon has been gained through the study of percolation—gravity-driven movement of water between soil and rock layers. It turns out that under weak assumptions, a random distribution of connections yields a single, holistic, connected component, which is essentially what happens in the network of human relationships. Randomness helps to create connected components.
In the web, things are more complicated, as the above-mentioned estimates of the average degree of separation showed. It’s clear that the degree of separation in the web is significantly higher than the magic number 6. And, as it happens, at the time these estimates were made, there were fewer web pages than people on earth. One explanation is that real people have more friends than web pages have links. However, this only partially explains the discrepancy.
A more significant difference is that the web’s links are directed. Unlike relationships between people, which by and large (ignoring unrequited love) are symmetric, a page can receive a link from another without returning the favor. It’s the mixed blessing of one-way roads: security, in that you have to make fewer decisions about which way to turn, yet tortuous paths to the target, as everyone who has been lost in a one-way system can testify. The reason that web links are one-way is precisely to simplify the publication of pages. You can attach a link wherever you want without asking the permission of the target page.24 The fact that links are directed makes paths to targets longer than in Milgram’s experiment and gives the network a more complex structure.
Figure 3.4 shows a chart of the web, produced during a systematic study of the overall linkage structure in 1999. Its shape is reminiscent of a bow tie. The central knot is a giant connected subnet that we call “Milgram’s continent,” a large, strongly connected structure in which all pages are linked together. Here you can travel from one page to any other by following the links—just as when surfing with a browser. This continent is Milgram’s “small world.” It’s where most surfing takes place. Crawlers explore it all. It’s the dominant part of the web.
The directed links create other regions, also shown on the chart. There are three, each the same size or slightly smaller than the main continent. The new archipelago is a large group of fragmented islands; Milgram’s continent can be reached from each island by following links. Most pages here are likely to be quite new and haven’t received many links. The archipelago’s youth explains its fragmentation. The fact that it contains no large strongly connected components reflects its recent evolution—it’s like the dawn of the web. It does nevertheless contain some old pages to which no one in Milgram’s continent has thought fit to link.
The corporate continent comprises a large collection of pages that can all be reached from Milgram’s. Some of its members are sinks, pages without any outward links at all (for example, most Word documents and PDF files). However, these are a minority. This continent is highly fragmented and comprises an immense number of connected islands. Although it contains the second largest strongly connected component in the web (not shown on the chart), this component is hundreds of times smaller than Milgram’s continent. The corporate continent includes company websites that do not link out to Milgram’s continent. Though relatively small compared with Milgram’s continent, these islands are significantly larger than those of the new continent.
Terra incognita is the rest of the universe. The distinctive feature of its pages is that surfers who reach them haven’t come from Milgram’s continent and won’t get there in the future—though they may have traveled from the new archipelago, and they may end up in the corporate continent. Linked trails in terra incognita do not cross the main part of the web: the pages here are simply disconnected from it. However, as shown in the chart, pages in terra incognita can be connected to the new or corporate continents, giving rise to tendrils of two different kinds. Some tendrils only receive links from pages in the new continent, whereas others send links to the corporate continent. Like those in the new archipelago, pages in terra incognita are likely to be new.
The web is bigger and more complex than we had imagined. The seemingly innocuous decision to make links directed implies the chart in Figure 3.4. If links were bi-directional, the chart’s complexity would evaporate into one large connected region, leaving only the few small islands shown near the bottom left. As it is, search engines explore Milgram’s and the corporate continent. They encounter the rest of the universe only if someone submits a page directly as a new seed for exploration. Without explicit notification, the other two regions are invisible.
COMMUNITIES
The English word community, which can be traced back to the fourteenth century, derives from Middle French comuneté, from the Latin root comunis. Today the term is used to refer to a state of organized society, the people living in a district, a sense of common identity, and the quality of sharing something in common—like goods, and also interests. A community is
a group of people who share a common sense of identity and interact with one another on a sustained basis. While traditionally communities have existed in geographically defined areas, new telecommunications technology allows for the creation of communities with members spread throughout the world.
The web, with its links from one page to another, is a good place to locate communities that share interests and enjoy a common sense of identity. It not only includes technological counterparts to established communities (people in the same university or the same company), but also encourages the creation of new communities from the ground up. The organization that emerges is not just of interest to sociologists, but can inspire new ways of searching. In the web, communities significantly enrich the general structure inherited from the science of networks described before. In addition to hubs that accumulate links and the fragmented bow tie structure induced by directed links, many features of the interconnection pattern arise out of relationships established by the people who inhabit the web.
The notion of “community” as just a set of members is simplistic: in reality the concept that emerges from social interactions is far more complex. Not all members are equal, and rather than partition the universe into members and non-members, it might be more accurate to talk of degree of membership. However, the degree of membership is not explicitly stated, but must be induced from the interactions between community members.
On the web, an extreme example of a community is a collection of pages that each link to each other (they may also link to pages outside the community). Mathematicians call this a “clique,” the word for a small, exclusive circle of people. In general, communities are characterized by different patterns of links and are not necessarily easily detectable. One definition is a set of pages that link (in either direction) to more pages within the community than to pages outside it. This makes the clique a strong community. For any page, the ratio between the number of links within and outside the community give a measure of its degree of membership.
HIERARCHIES
Hierarchies are a classic way of organizing large amounts of information—or anything else. Beginning in the early days of the web, enthusiasts created hierarchical directories, structures that computer operating systems have used for organizing files since the 1960s. Web directories are intuitive, easy to use, and a natural way to locate resources. But, being hand-crafted, they are expensive. The web is so large that it is hard to achieve good coverage even when the work is distributed among volunteers, and quality control is difficult to enforce as the operation scales up. In fact, today’s directories cover only a small portion of web resources, and their organization reflects the personal view of a new generation of web librarians.
Many individual users produce their own directories using the bookmarking facility that web browsers provide. Related bookmarks are placed in folders, and folders can be nested to reflect subtopics at any level of refinement. Bookmarks identify a microcosm of the web that corresponds to the user’s personal view. Again they are constructed entirely by hand, which greatly restricts their coverage. Manual classification schemes, which are exemplified by the organization of traditional libraries, were ineffective in the Library of Babel, and the web shares the same problem: scaling up to the seemingly infinite.
The web does contain some natural hierarchical structure. Individual sites are organized hierarchically. Top-level descriptions are located at or near the root, while pages dealing with specific topics lie deep within the structure. There is evidence that this hierarchy is to some extent reflected in the structure of the links, although the effect is less apparent when considering links between pages of different domains.
It would be nice to be able to organize pages into a sensible hierarchy automatically, and even to tag nodes in the hierarchy with metadata. Joint analysis of the links and the page content offers a rich source of information for this kind of enterprise, and we return to this topic in Chapter 7. In addition, the social relationships between users, and their browsing behavior, are useful sources of information that can be profitably explored.
THE DEEP WEB
The quasi-random evolution of the web and its links makes it a “small world,” like the sphere of human relationships that Milgram studied. However, as we have seen, directed links give the web a more complex geography by fragmenting it into four continents. Links imply further structure—the presence of communities—which is also reflected to some extent in the content of the pages. All these properties are clear signs that there’s order in the web: in fact, they give it a rich and fascinating aspect. But that’s not the whole story. The web is even richer, because many of its pages are inaccessible to the robots that crawl it and map out its structure. “There are finer fish in the sea that have ever been caught,” declares an Irish proverb. Untold gold is buried in the web, untrawled by today’s search engines.
Somewhere in the deep Atlantic lies a casualty of World War II, a Japanese submarine code-named Momi that is believed to carry tons of gold. The movie Three Miles Down recounts the gripping tale of an attempt to recover the treasure. Never before had anyone risked depths four times greater than the Titanic’s watery grave. A story of courage, it also tells of surprising intuitions and clever discoveries—though not enough to complete the mission by reaching the submarine.25
Like the deep sea, there’s a deep web. It contains treasure that you can’t harvest just by dragging a net across the surface, as crawlers do. Crawlers will never find pages that are dynamically created in response to a direct query issued to a searchable database. Portals for electronic commerce provide examples galore—from booking flights to making domestic purchases. The web servers on these systems deliver the appropriate page to the user only after a dynamic query, that is, an interaction through a web interface that garners specifications for one or more database retrieval operations. Other treasures are hard to reach because you need privileged information to track them down, like the Momi submarine. For instance, all projects sponsored by the Italian Ministry of Research and Education are described on the web, but to access them you need a password. In fact, however, only a small fraction of the deep web (estimated at 5 percent) requires a password to access.
It is difficult to find automatic ways of discovering information in the deep web that are capable of working independently of the portal. As in Three Miles Down, the deeper you delve, the greater the difficulties you face. For the web, depth corresponds to the amount of interaction required to select the page. What’s the problem? Suppose your robot reaches a portal for finding apartments in Boston. First, it must understand the interface the portal offers. Unless you decide to limit crawling to a finite list of portals whose interfaces have previously been mapped, the robot needs to be intelligent enough to understand the intermediate pages and formulate appropriate queries, one by one, until the required depth is reached.
Digital libraries are a prime example of the deep web. A digital library is a focused collection of digital objects, including text, audio, and video, along with methods for access and retrieval, and for selection, organization, and maintenance of the collection. They differ from the web at large because their material is selected and carefully organized. In addition to large collaborative efforts such as the Gutenberg and Million Book projects mentioned in Chapter 2, countless smaller, more focused digital library collections are created and maintained by individual institutions and national or international associations. Some are closed: only accessible from within a particular institution or with the necessary authorization; but most are open. Some are served up to crawlers and become part of the indexable web, but most remain hidden.
The deep web is controlled by organizations that run the underlying databases. As a rule—though there are many exceptions—their owners take care of the content because it affects their corporate image. This means that it is likely to be well checked: quality tends to be higher than on the open web. And it’s huge. In September 2001, based on the same kind of overlap analysis described earlier (page 80), the deep web was estimated to be 400 to 550 times larger than the surface web. Though automatic exploration of the deep web is hard, efforts to mine the treasure will be amply rewarded. Progress in the field of artificial intelligence is likely to provide useful tools for mining.
SO WHAT?
This chapter has equipped you with the technical background to the web and the way it works: the acronym-laden world of HTML, HTTP, HTTPS, XML, URIs and URLs; new meanings for cookies and crawling; mysterious-sounding avatars and chatbots, blogs and wikis. And not just the technical background: there’s a mathematical side too. The web is a huge network that, viewed from afar, shares the properties of scale-free random networks. The pattern of links does not give a sense of scale: it doesn’t make much sense to talk about the “average” number of links into or out of a node. The connectivity imparted by links breaks the web up into distinct regions or continents. Zooming in, the details start to come into focus: the connection pattern is not random at all but reflects the myriad communities that have created the web.
How can you possibly find stuff in this gargantuan information space? Read on.
WHAT CAN YOU DO ABOUT ALL THIS?
• Estimate what proportion of broken links you’ve encountered recently.
• How many cookies are on your computer? Find out the consequences of deleting them (be careful—some may be more important than you think).
• Search the wikiHow to learn how you can safely delete your usage history.
• Play with image search and figure out what’s being searched.
• Donate some metadata—play the ESP game on the web.
• Talk to a chatbot (the chatbot George won the illustrious Loebner Prize for the most convincing conversational program in 2005).
• Surf around the deep web. Why is this hard for search engines?
• Comment on the book using the blog at www.blogger.com/home.
• Watch Felix walk: try out Figure 3.1(a) in a web browser.
• Surf around to find an example of static, dynamic, and active pages.
• What properties do the Internet and web share with biological structures?
NOTES AND SOURCES
The development of the web is regulated by the World Wide Web Consortium,26 of which Berners-Lee is a founding member. It continues to define new specifications and refine existing ones—including HTML, HTTP, and XML. The term hypertext was coined by Ted Nelson long before the web was born. Markup languages such as HTML originated even earlier when Charles Goldfarb, an attorney practicing in Boston, joined IBM in 1967 and began to work on a document markup language with Edward Mosher and Raymond Lorie. They defined a language called GML (their own initials) which many years later, in 1986, became the Standard Generalized Markup Language (SGML), a general concept of which HTML is a particular application. SGML also spawned XML, a far simpler version. The quote from Steve Jobs on page 63 is from a 1996 interview in Wired Magazine (Wolf, 1996).
The idea of countering the brittleness of the web by using associative links to identify pages by a few well-chosen rare words and phrases was suggested by Phelps and Wilensky (2000). Two Carnegie Mellon University graduate students, von Ahn and Dabbish (2004), developed the ESP game for providing accurate image metadata.
The 2005 estimate of the size of the indexable web was obtained by Gulli and Signorini (2005). The continued growth of the web shown in Table 3.1 is documented by Hobbes’s Internet Timeline,27 which confirms a relentless exponential trend. Bharat and Broder (1999) and Lawrence and Giles (1999) worked on quantifying the number of pages that are indexed by inventing random queries and sending them to different search engines.
The estimate of 19 for the degree of separation on the web is due to Albert et al. (1999), who studied the Notre Dame University website. Based on data crawled by the (now-defunct) AltaVista search engine, researchers at IBM and Compaq estimated that the average degree of separation exceeds 500 (Broder et al., 2000).
The classic way of generating a random graph by allocating a given number of links to randomly chosen pairs of nodes is due to Erdös and Reny (1960). This predicts Gaussian distributions for the number of links. In 1999, an analysis of links in the Internet came up with the power-law distribution instead (Faloutsos et al., 1999). Barabási and Albert (1999) devised the elegant explanation of the generation of power laws in the web; Bianconi and Barabási (2001) improved the model by introducing a fitness measure for every node. Pennock et al. (2002) found that the distribution exhibits significant local departures from the power law, especially among competing pages on the same topic.
The bow tie model of the web is due to Broder et al. (2000); Barabási (2002) introduced the continent metaphor. Dorogovtsev et al. (2001) discuss algorithms for calculating the size of the strongly connected components.
The Elmer Social Science Dictionary, the source of our definition of community, is online.28 Flake et al. (2002) came up with the notion of a web community as a set of pages that link (in either direction) to more pages in the community than to pages outside it.
The estimate that the deep web is 400 to 550 times bigger than the surface web is due to BrightPlanet.com, who believe that only a small fraction (say 5 percent) requires a password for access. Digital libraries are discussed by Witten and Bainbridge (2003) and Lesk (2005).
Nodes of the web: everything is here; everything is connected.
16According to Brewster Kahle, who began the Internet Archive in 1997, at that time the average web document lasted only 44 days (Kahle, 1997).
17Slow web content delivery inspires cynical surfers to call the WWW the “World Wide Wait.”
18When two exponential growths compete, the one with the larger exponent wins. In fact, the effect is equivalent to exponential web growth (with exponent equal to the difference between web and bandwidth exponents) under fixed bandwidth.
19The basic idea had been proposed forty years earlier by the Hungarian writer Frigyes Karinthy in a short story called “Chains.” However, Milgram was the first to provide scientific evidence.
20The distribution of the number of links is technically not Gaussian but Poisson. Gaussian distributions are symmetric. The number of links into a particular node could be very large, but cannot be less than 0, which makes the distribution asymmetric. However, the Poisson distribution shares many Gaussian properties. It has an approximate bell shape (though asymmetric) whose peak is close to the mean, and for large mean and relatively small variance, it is indistinguishable from the Gaussian distribution. We loosely refer to it as “Gaussian” throughout.
21With the power law, the probability that a randomly selected page has k links is proportional to k−γ for large k, where γ is a positive constant.
22The exponent γ has been empirically determined as 2.1 for inbound links and 2.7 for outbound links (Broder et al., 2000).
23Technically, the body of the distribution is log-normal while the tail fits a power law.
24Of course, it is always possible to implement a symmetric relationship, if the target page does the source page the favor of returning the link.
25That was finally achieved by Paul Tidwell, shipwreck salvager and decorated Vietnam veteran. He headed an expedition that was less well funded and equipped, but perhaps luckier.