
The web is a sort of ecosystem and, like other ecosystems, is exposed to risks. Its body, the Internet, inevitably suffers occasional glitches in the physical hardware. The programs that support the communication protocols contain the logic bugs that plague every large-scale software system. There are external threats too: software invasions created with the specific intention of damaging the system.
Like any ecosystem, the web reacts. It differs from other human artifacts, which collapse entirely when trivial faults occur. Its network structure bestows a robustness that is familiar to biologists and shared by many scale-free networks. During the gloomy days of the dot-com boom-and-bust cycle, you might be forgiven for wondering whether the web is just another nine-day wonder, another zany computer project that will enjoy its fifteen minutes of fame and then sink into obscurity over the years ahead. But you would be wrong. With its almost biological structure, the web will surely evolve, but it certainly won’t disappear.
The most serious threats to biological ecosystems are often not external but come from within. In the early 1990s, the killer lobster arrived in the Versilia area of Italy, off the coast of Pisa. With an extraordinarily prolific rate of reproduction, it invaded the ecosystem and overwhelmed everything else. In an emergency of Hitchcock proportions, lobsters arose from the sea and entered people’s gardens—even their houses.36 Soon this was the only species around. Fishermen seeking to fill their nets with a seafood cornucopia were doomed to disappointment. Likewise, those trawling the web for information will meet nothing but disappointment if it becomes infested with low-quality documents that stifle everything else with their overwhelming rate of reproduction.
To neutralize the risk of the web being invaded, we must encourage and preserve a panoply of biological diversity. But we must do more. In The Name of the Rose, Umberto Eco describes an abbey whose library seems to have been inspired by Borges’ Library of Babel. It’s a labyrinth whose twisting paths are known only to the librarian; before he dies, he communicates the secret plan to the assistant who is to succeed him. According to the abbot, there’s a good reason for this: “Not all truths are for all ears, not all falsehoods can be recognized as such by a pious soul”—for as well as truth, the library holds many books that contain lies. The mission of untold generations of abbey librarians is to protect the monks from corruption.
The explosion of low-quality documents on the web is reminiscent of the abbey library, except that the abbot and his trusty librarian have gone missing. To find information, we monks are forced to rely not on inspired human judgment, but on machines, the web dragons, to make the right kind of documents visible. It is they who fight spam, the killer lobsters of the web. And it’s a tough battle. At least Umberto Eco’s abbot, in trying to recognize falsehood, could aspire to perfection by invoking the divine. In our story, web spam might be the devil. But who is the abbot?
PRESERVING THE ECOSYSTEM
WebCrow is a program that is capable of cracking crosswords in any language, using the web as its source of knowledge. It reads the clues, converts them into a search engine query, and fits the answers into the puzzle. Devised in 2004, after a few months of intensive development it entered a competition with 25 university students. Four puzzles were posed, with one hour to solve them all; the students worked individually through a well-crafted interactive web application. Only three of them achieved performances comparable with the program.
For a novice like WebCrow, this was a great achievement. Of course, it was possible only because it inhabits the web, an ecosystem in which the food is information. The students could also use the web during the competition—indeed, they were encouraged to do so. In effect, they acted as cyborgs natural organisms whose human intelligence is enhanced by artificial technology. What the experiment showed was that the constraints posed by crosswords can be more effectively exploited by computer programs than by humans. Although only a game, for both WebCrow and the cyborgs the process of cracking crosswords was an adventurous mix of discovery and dialogue with the web.
The web is a living ecosystem that supplies information. It isn’t just a passive repository. It’s a fertile breeding ground that supports a continual process of dialogue and refinement. As we learned in Chapter 1, this process has been at the very center of knowledge creation since before Plato’s time. Despite its teenage immaturity, this artificial ecosystem has already become so crucial to our work and lives that most of us question how we could possibly operate without it.
As with other ecosystems, sustaining and preserving the web is a noble and important mission. We need to consider how it is being used—what we ask of it—and establish conventions, or perhaps even enact legislation, to help protect its resources. For example, the access demanded by crawlers might have to be restricted. We also need to preserve the network’s ecosystem from natural damage. Broken links are defects that, as we have seen (page 66), are inherently related to basic web design choices. Other damage stems from failure of the underlying Internet communication infrastructure. Still more arises from software bugs, which neither defensive programming practices nor redundant and introspective machines will ever completely eradicate.
More serious problems have begun to emerge from deliberate attacks. If the web is regarded as the natural home for the knowledge repository of the future, we must take care to safeguard it from malign influences—and from collective madness. Alexandria’s library was eventually destroyed by zealots, the seeds of destruction having been sown by Julius Caesar’s rampage. Nearly two millennia later, in May 1933, the same tragic story was echoed in Berlin’s Babelplatz, where a convulsive mass of screaming humanity participated in a gigantic book burning, promoted by the Nazis, and incinerated 20,000 volumes. The burning of the web might arise out of different emotions, in another context, and with flames in bizarre and unconventional form, yet it behooves us not to ignore the possibility.
PROXIES
As in any great city, the movement of information around the web creates heavy traffic that compromises the efficiency of the overall system. A surprisingly large volume of traffic comes when a particular user or group of users repeatedly downloads the same pages. People in the same institution often seek the same information: they have the same interests, track the same trends, and hear rumors through the same grapevine. It turns out that traffic can be greatly reduced if institutions retain on their own computers a cache containing local copies of the pages their members download.
In order for this to work, users’ browsers must first consult the institutional computer to check whether the page they seek is in the cache, before venturing out onto the web to fetch it. In webspeak, the institutional computer acts as a proxy server. The user’s browser delegates to it the task of accessing external web servers on its behalf. The proxy server’s job is to serve pages to all clients in the institution. It manages the cache. Whenever it receives a request, it looks to see whether there is a local copy, checks the remote copy’s date over the web in case it has changed, and if not, serves it up. Otherwise, the system retrieves the content from the web, sends it to the browser, and stashes it in the cache in case it’s requested again in the future. A well-designed caching service decreases traffic significantly, particularly if it makes smart decisions about which pages should be cached and when to ditch them to make room for new entries. Intelligent caching policies yield a dramatic reduction in network traffic.
CRAWLERS
Search engines spawn massive crawling operations that account for a fair proportion of overall web traffic. The load they impose on individual servers depends on the volume of other traffic that the site attracts. For large and popular commercial sites that already process a huge volume of requests, the additional load that crawlers impose is negligible. For small specialist sites, crawlers frequently account for more than 50 percent of the traffic, and for sites that get few requests, they could well consume an even greater proportion of resources. Fortunately, only a few companies download large numbers of pages, and the massive crawling performed by major search engines is an extreme example.
The web ecosystem is inherently protected because of two properties. First, the number of competing search engine companies is necessarily rather small.37 Second, even if these companies decided to make substantial capital investments to increase their crawling rate, the bandwidth of individual servers inherently restricts the overall volume of traffic on the web. This is the same argument that was raised when introducing the uncertainty principle in Chapter 3. Individuals may increase the capacity of their own web connection, only to find that it doesn’t help when trying to download information from a sluggish server. The same holds for search engines, whose crawling efficiency is limited by the bandwidth of web servers internationally.
Things could change quickly. The web ecology could be significantly perturbed by crawling if different retrieval models were adopted. As an extreme example, suppose all users decided to create their own individual copy of the pages that are of interest to them by unleashing a personalized robot to inspect the web and return relevant information. Given the current Internet infrastructure, this would result in a state of global congestion, a deadly embrace. New retrieval models such as this could easily radically disturb the ecology.
Of course, the web may protect itself: the new scheme might soon become so slow that no one used it. Or it may not: the well-known “tragedy of the commons” is that public land can be rendered worthless when subjected to overgrazing, yet it is in each individual’s self-interest to use it as much as possible. The interests of the individual conflict with those of the group as a whole. New web retrieval models may need to conform with ecology restrictions to limit the load imposed by robots to a reasonably small percentage of ordinary page requests.
As we observed in Chapter 3, crawlers incorporate the principle that each web server can take steps to avoid unwanted downloading of its site. Crawling is permitted by default: it’s up to the system administrator to withdraw permission by placing an appropriate specification in a configuration file (called robot.txt). A particular site operator might exclude search engines because, although she wanted to put information on the web for the benefit of a restricted group of people who knew the location, she did not want it to be available to all and sundry. For instance, a spin-off company might choose not to be searchable on the web because of an agreement with investors. An alternative is to protect your data using a password. Note, incidentally, what a different place the world would be if the default were the other way around—if crawlers could only visit sites that had explicitly given permission rather than being denied access to sites that explicitly withdrew permission.
PARASITES
Crawling isn’t the only process that must observe restrictions. The idea of using huge numbers of computers on the Internet to perform intensive computational tasks is exploited by the SETI@home project, a Berkeley-based venture that is analyzing radio signals in a search for extraterrestrial intelligence. Anyone can join the project and donate computer time to help in the search by downloading special software that runs when their computer is otherwise idle. As we playfully observed in Chapter 3, most computers spend most of their time running the screen saver: SETI puts their idle moments to more productive use. However, this is an opt-in system: the resources that are harnessed are ones that have been willingly volunteered. By 2006, 5.5 million computers had been enlisted, and 2.5 million years of processing time had been donated.
A robot that recruited your computer’s resources without explicit permission would be a sinister proposition. Zombies are supernatural powers that, according to voodoo belief, can enter and reanimate a dead body. A “zombie attack” is a nefarious scheme for seeking out an unused, unprotected computer—and there are many forgotten machines on the Internet—and entering it with an alien program. For example, purveyors of junk e-mail manage to commandeer machines in other countries, particularly developing ones where lower levels of technical savvy results in generally weaker security, and use them as servants. If the computer happens to be one that is derelict, it could serve its new master for months without being detected. Eventually the breach is discovered, and the computer’s innocent owner harassed, perhaps disconnected, by the Internet community. Of course, the solution is to take proper security precautions to avoid being hijacked in this way.
Astonishingly, it turns out that computers on the Internet whose operation has not been compromised at all can be unknowingly recruited to undertake computation on behalf of another. This is done by cunningly exploiting the protocols that support Internet communication. Remote computers already perform computation, stimulated by ordinary requests to download pages. At a lower level of operation, such requests are broken into packets of information and delivered to the remote site. Every packet is checked at its destination to ensure that it was delivered without transmission errors. This requires a small computation by the computer that receives the packet. The trick is to formulate a problem in such a way that it is solved when massive numbers of remote computers perform these routine checks.
Such a technique was described in a letter to Nature in 2001. There is a classic set of problems in computer science, the infamous “NP-complete” problems, for which no efficient solution methods are known. However, these problems yield easily to a tedious and inefficient brute-force approach, where candidate solutions are generated and tested one by one. An example is the “traveling salesman” problem, which seeks the shortest route between a given set of cities. You can try out all possible routes—there is an exponentially large number of them—but no more efficient solution methods are known. One computer was used to generate possible solutions, possible routes in this example, each of which was encoded as an Internet packet. The clever part was to formulate the packets in such a way that the check calculation revealed whether or not it was the true solution. Because of the way the Internet protocol works, only valid solutions to the problem were acknowledged by a return message. On all other packets the check failed, so they were discarded.
This ingenious construction illustrates the idea of what was aptly called parasitic computing. Fortunately, it is not effective for practical purposes in its current form. The small amount of computation that the remote server performs for free is far outweighed by the effort required by the host to transmit the packet in the first place. The researchers who developed the scheme remarked that their technique needed refinement but noted that although it was “ethically challenging,” it overcame one of the limitations of the SETI@home approach, which is that only a tiny fraction of computer owners choose to participate in the computation. Whether it could in fact form the basis of a viable scheme for commandeering other people’s resources to do your work is a moot point.
A distributed infrastructure, like the Internet, relies on cooperation among all parties, and trust is essential for successful communication. Parasitic computing exploits trust by getting servers to solve a particular problem without authorization. Only a tiny fraction of each machine on the Internet would amount to colossal overall computational power, the largest computer on earth. Whereas SETI@home exploits the resources of computers that explicitly subscribe to its mission, parasitic computing uses remote resources without asking permission.
In a sense, parasitic computing demonstrates the Internet’s vulnerability. But it isn’t really very different from crawling. Crawling happens behind the scenes, and most people don’t know about it, but when they find out they tolerate it because the result is used for their own good—it allows them to search the web. Crawling exclusively for private or commercial purposes would be a different matter. Similarly, if parasitic computing became practical, it might be tolerated if it were used to attack complex problems of general scientific or public interest that required huge computational resources. But the idea of enslaving the Internet and forcing it to perform private computations is repugnant.
RESTRICTING OVERUSE
In any case, the ecosystem must be protected to limit pollution and avoid abuse, and in the future this may require active steps. It is clear that the privileges of crawling and parasitic computing cannot be extended to everyone. It seems reasonable to ask schemes that use global Internet resources to at least make their results publicly available. Whether further policing will be required to protect the ecology, and what form that should take, are important open questions.
WebCrow is a good example of the issues that are already arising. During the crossword competition, it downloaded as many as 200 pages per minute. Search engines offer a great public service, which in this case is being used to solve crosswords—not for private profit but in a curiosity-driven public research program. Whereas there are natural limits to the load that can be imposed by individual human queries, machines that are programmed to make queries can soak up limitless resources. If the idea of creating automatic systems that make intensive use of the web were scaled up to significant proportions, this would impact human access. In fact, it is already happening.
Individual search engines already place restrictions on the number and rate of queries that are processed from any one site, an example of local administration of the web ecology. However, these limits are imposed individually and arbitrarily by organizations which themselves consume public resources through crawling in an unregulated way. The web community needs to face up to such conundrums with sensitivity and wisdom. Regulating ecologies is not easy!
RESILIENCE TO DAMAGE
Broken links, hardware failure in the Internet communication infrastructure, and software bugs, are examples of natural damage that affect the web ecosystem. Although technologists can take steps to reduce the damage and localize its impact, it will never be possible to rid the web of defects entirely. Overall, the web’s reliability and the extent to which it resists local damage is generally superior to the reliability and dependability of individual computers, considering the hardware and software problems they typically suffer. A fault in a single memory chip prevents you from running your favorite program—indeed, your computer will likely not even be able to bootstrap the operating system.
Bugs have plagued us ever since people began their adventures in the sphere of technology. Almost all artifacts exhibit brittle behavior when reacting to the fault of a single component. On the other hand, natural systems have strong resilience to damage. They don’t crash just because a component fails. The human brain is the most striking example of such admirable behavior. In contrast to faults in the transistors of a microchip, the brain’s response to the death of neurons is a graceful degradation in the ability to perform cognitive tasks.
Similar behavior is found in artificial neural networks, one of the few artifacts that exhibit robust fault-tolerance. Neural networks trained to recognize handwritten characters continue to work even if you break a few connections or remove some neurons. As with the human brain, behavior becomes compromised after much damage, but even then, the system can often relearn the task and recover its original performance, or something like it. Neural networks and the World Wide Web share with natural systems, such as the brain, an inherent resilience to damage. What do they have in common? A network-based structure!
What happens to the overall connectivity of the web when links are broken? And what happens on the Internet when a fault arises in one of the routers that directs the traffic? Such questions are of great practical importance and have been widely studied. If the network were a random graph, created by randomly selecting pairs of nodes and attaching links between them, theoretical analysis shows that removing nodes beyond a certain critical threshold could fragment the network into small clusters. In the web, this would cause serious problems, for if enough links became broken, search engine crawlers wouldn’t be able to explore it properly.
In fact, despite the continual incidence of natural damage, the web does not break into fragments, but retains its overall connectivity. What it shares with many natural systems is the power-law distribution of the number of links that connect the nodes, introduced in Chapter 3 (page 89). And this makes scale-free networks more robust to faults than the classical Gaussian distribution. Intuitively, the reason is that robustness stems from the presence of a number of massively connected hubs. Since there are far more nodes with just a few links than there are hubs, most faults don’t affect hubs. But it is the hubs that are primarily responsible for the network’s overall connectivity.
The innate resistance to damage that scale-free networks exhibit is very strong indeed. You can gradually remove nodes without the network fragmenting into clusters, provided that the exponent of the power law lies below a certain critical threshold.38 This property holds for both the Internet and the web, and their steadfast resilience under adversity has been observed experimentally.
VULNERABILITY TO ATTACK
The fault-tolerance of scale-free networks is predicated on the fact that damage affects links randomly. If critical nodes are purposely targeted, that’s a different matter altogether. Random damage is what tends to occur in nature. But with artificial systems, it would be unwise to neglect the possibility of deliberate attack.
Unfortunately, healthy resistance to damage has a flip side: scale-free networks are particularly vulnerable to deliberate aggression. The reason is quite obvious: they inherit their connectivity principally from the hubs. These are unlikely to suffer much from random damage since, though large, hubs contain a small minority of the overall links. But they are prime targets for deliberate attack. Resilience to random damage comes hand in hand with fragility under assaults that are perpetrated intentionally. If we want to preserve the web’s ecosystem, we have to study the risk of attack.
Targeted network attacks can have consequences that are far more serious than the fragmentation that occurs when hubs are destroyed. If an important Internet node is brought down, the problem is not just the broken connections that ensue. The traffic that it handled previously will be directed to other nodes, creating an overload. The resulting cascade effect resembles the massive power outages that our highly networked world has begun to experience—but worse. On the Internet, difficulties in information delivery are indicated by the lack of a receipt. This eventually causes nodes to resend the information, which increases traffic and escalates the problem. Destroying a single important hub causes serious network congestion—perhaps even a global catastrophe.
Despite their great technical sophistication, computer attacks are reminiscent of medieval sieges, and there are similarities in the strategies for attack and defense. The effective defense of a fort requires weapons and, if the battle lasts for days, adequate stores of food and medical supplies. If any of these resources are destroyed, the consequences are serious. The same is true for computer networks: in addition to the main targets, there are many critical supporting elements. Attacks are directed not only at major hubs, but also at sites that contain anti-virus software and security upgrades. When discussing ecological vulnerability, we need to consider the whole question of security, with emphasis on the overall integrity of the web rather than the local effect of attacks on a single computer or large organization.
VIRUSES
As everyone knows, computers can be attacked by contaminating them with a virus. This idea originated in the 1972 novel When Harlie was One, which described a computer program that telephoned numbers at random until it found another computer into which it could spread.39 A virus is a piece of program code that attaches copies of itself to other programs, incorporating itself into them, so that as well as performing their intended function, they surreptitiously do other things. Programs so corrupted seek others to which to attach the virus, and so the infection spreads. To do so the programs must be executed; viruses cannot spread from one computer to another on their own.
Successful viruses lie low until they have thoroughly infiltrated the system, only then revealing their presence by causing damage. Their effect can be mischievous, ranging from simulated biological decay of your screen to sounds that suggest your computer is being flooded by water. They can equally well inflict serious damage, destroying files or—perhaps even worse—silently corrupting them in subtle and potentially embarrassing ways.
Viruses cannot spread without communication. In the early days, they thrived in personal computer environments where users shared floppy disks or other removable media, by infiltrating the system’s hard disk. Nowadays networks provide a far more effective vehicle for virus infection. Infection can occur when you download any kind of program—computer games are common carriers—or open an e-mail attachment. Even word processor and spreadsheet documents are not immune. Clicking your mouse to open an attachment is just so easy it’s irresistible. Users who are unaware, or only vaguely aware, of the threat often experience the potentially disastrous effects of viral attacks.
It is always necessary to guard against viruses when sharing any kind of computer program. They work by subtly altering files stored on your computer and can be detected by inspecting recent changes to files—particularly unexpected changes. Anti-virus software regularly examines recently changed files and analyzes them for traces of known viral code, moving them to a quarantine area to prevent you from inadvertently executing them.
Viruses may bother individual users, but they do not represent a serious threat to the overall integrity of the web. Today the main source of infection is e-mail, but although such attacks can be devastating for naïve users, they are ineffective on critical targets. Important hubs are run by trained professionals who are wise to the ways of viruses and take care to follow sanitary operating practices. As a result, viral attacks are unlikely to compromise the integrity of the entire network.
WORMS
There are more serious threats than virus infection. On November 3, 1988, a small “worm” program was inserted into the Internet. It exploited security flaws in the Unix operating system to spread itself from computer to computer. Although discovered within hours, it required a concerted effort (estimated at 50,000 hours), over a period of weeks, by programmers at affected sites, to neutralize it and eliminate its effects. It was unmasked by a bug: under some circumstances it replicated itself so quickly that it noticeably slowed down the infected host.
That flaw was quickly fixed. But others continually appear. In January 2003, Sapphire, a program of just 376 bytes, began to flood the Internet. It let itself in through an open communication port in a popular database system, the Microsoft SQL server, masquerading as an ordinary database request. Instead, it gave rise to a cascading failure in the database servers. First, it threw an error whose consequences had not been anticipated by the server designers. The error was not just a local server fault, but affected the entire installation. Having gained entry, the program repeated its malevolent effect, doubling the number of infected servers every few seconds. As a result, about 70,000 servers crashed in just ten minutes, causing widespread devastation. Fortunately, this malicious program neither destroyed files nor did any permanent damage, but it did result in a billion-dollar productivity loss—a so-called denial-of-service attack. This is just one of the worms that has inflicted damage on the Internet. Like most others, it exploited a portal that was insufficiently fortified.
Computer worms, like biological organisms, continually evolve. A crucial step in their evolution is the development of self-defense mechanisms. For instance, one worm (Blaster) caused infected machines to continually reboot themselves sufficiently quickly to make it difficult for the user to remove it and install an immunization patch. It simultaneously launched a denial-of-service attack on Microsoft’s update service, the web’s store of food and medicine.
The Internet is such an attractive target for evil-doers that attack strategies will certainly evolve. There will always be some onslaughts for which defenses have not been properly prepared. But considering the integrity of the web as a whole, the fact that its vulnerability is restricted to a limited number of crucial hubs suggests that effective protective defense mechanisms will be established. There are only a limited number of experts of sufficient technical caliber to pose serious security threats. Ethical, if not economic, arguments suggest that if the web is generally considered to be a worthwhile endeavor for society as a whole, more of these people might be persuaded to wield their intellectual weaponry to defend the fort than to mount attacks on it.
INCREASING VISIBILITY: TRICKS OF THE TRADE
There are countless different reasons that lead one to visit a web page. Regardless of your motivation and interests, the web is a place where speed is highly valued, so for a page to become widely visible, it must reside on a site with a sufficiently fast network connection. Once you reach the page, the quality of its content, and allure of its presentation, are good reasons to bookmark it for future visits. But, for the most part, the extent to which pages and sites are visible is determined by the ranking they receive from major search engines. These are the gateways through which we reach the treasure.
A typical search engine query returns tens or hundreds of thousands of pages. For pragmatic reasons, users can only view those near the beginning of the list. In practice, the visibility of pages is determined by search engines: most users view the web through the lens that the dragons provide. Pages that are not highly ranked are simply buried under a mountain of documents: for most of the world, they might as well not exist. Now that the web is indispensable to almost every aspect of our lives, some of the people who create or own pages are desperate to make them more visible.
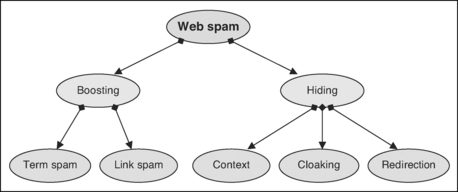
Although the precise way in which search engines work is a closely guarded secret, the criteria they use to rank pages can be surmised by combining information from public documents, experimental evidence, and reverse engineering. A large and growing array of methods have been discovered that aspire to increase the visibility of web pages and web sites. Boosting techniques are directly concerned with elevating the rank of particular target pages. You can boost for specific query terms, or you can boost a site’s overall visibility. In either case, the process involves including artificial text or creating artificial pages whose sole purpose is to fool—persuade, their proponents might say—search engines into increasing the target’s rank. Hiding techniques have been developed to conceal these artifacts from human eyes—that is, to ensure that different information is delivered to search engines and human readers. Figure 5.1 shows the techniques discussed in this section.
TERM BOOSTING
Chapter 4 explained how search engines assess the relevance of documents to a given query. They assign higher weight to documents that contain more of the query terms, particularly terms that appear often in the document but seldom in the collection as a whole. You should bear this in mind if you are working on a web page that you would like to be more visible with respect to a particular query. Deliberately repeat the query term: that will increase its influence. Avoid referring to it by pronouns: that wastes the opportunity for another mention. Increase the term’s density by avoiding articles, function words, and other linguistic distractions. None of these are recipes for compelling prose. The resulting pages will be stilted and, if these hints are taken to extremes, completely unacceptable to human readers.
The contribution of each term to the rank depends on just where in the page it is located. For example, it’s conjectured—but only the dragons really know the truth—that terms occurring early in the document, and particularly in the title, are deemed to be more relevant than others. Metatags also play an important role (perhaps). For instance, the VIP keyword that we attached to Felix in Chapter 3 is simply intended to fool the dragons. Logically, search engines ought to attach great import to metatags which, after all, are supposed to be a way of specifically indicating what the page is about. Inserting misleading terms here has the added advantage that readers will never see them. Terms can also be boosted by putting them into the URL, on the assumption that search engines break this down into components and use them in the ranking—probably with more weight than the ordinary words that occur in the body of the document.
As explained in Chapter 4 (page 113), the text that accompanies links into a web page—the anchor text—gives a clue to its content, ostensibly a more reliable clue than the words in the page itself, because it is apparently written by another person and represents an independent view. Another deceitful way of boosting rank is to create links to the page and insert critical terms into their anchor text. For example, the presence of this link
in some other web page enriches Felix’s own page—see Figure 3.11(b) on page 68—with the term VIP and is likely to be more effective than simply including VIP in a metatag or the text body, as in Figure 3.1(c). Replicating inbound links on a large scale boosts the term’s weight significantly, more significantly than replicating the term in the body of the text. Unlike the previous techniques, the fake terms are added to a page other than the one being boosted. Note, incidentally, that it could be more effective to include A true example of a VIP than the single term VIP because the whole phrase might match a query in its entirety. It’s a good idea to attach popular phrases that stand a chance of matching queries perfectly.
LINK BOOSTING
So far, we have discussed how to boost a page by adjusting the text it contains, or the text associated with links that point to it. As we learned in Chapter 4, inbound links play a crucial role in determining rank. Creating more links to a target page is likely to increase its standing. Like anchor-text boosting but unlike the other term-based methods, this one needs control over the pages from which the links originate. But the rewards are great. Whereas term boosting only increases the rank of a page with respect to a particular query, creating new links increases its rank for all queries. Moreover, if we can somehow create highly ranked pages, the links that emanate from them will be particularly valuable because of how the pagerank calculation works.
The easiest way to implement this boosting strategy is to create your own website. Of course, if you can somehow gain control of someone else’s site—preferably a high-ranking one—so much the better. But you can sometimes accomplish the desired effect by legitimate usage of an existing site. For example, you might visit a high-ranking site like www.whitehouse.gov and sign the guest book there with a message that contains a link to your page. While you’re at it, why not sign it several times? Or program a robot to crawl for sites containing guest books. Better still, simply use a search engine to find high-ranking guest books for you—and sign them in your stead. Why stop at guest books? Wikis are open collaborative environments, and most allow anyone to contribute to them. You might have to set up a user name and password, and then you can write what you like—including links to your own page. Again, you can program a robot to find blogs and wikis and add your graffiti automatically. It’s not hard to hijack the cooperative social mechanisms of the web for your own nefarious purposes.
Now that you know how to create artificial links to your page, let’s see how they can be used to greatest effect with the two link-analysis algorithms described in Chapter 4. Consider, first, PageRank and begin by focusing attention on a particular website that you want to boost. Surprisingly, its overall rank grows with the number of pages it contains. This is a straightforward consequence of the probabilistic interpretation of PageRank: a random walker is likely to stay longer and return more often to sites that are bigger. Given a certain amount of content, it’s advantageous to distribute it among as many pages as possible. This is illustrated in Figure 5.2. The rule is simply that the same content is ranked higher if split into more pages.
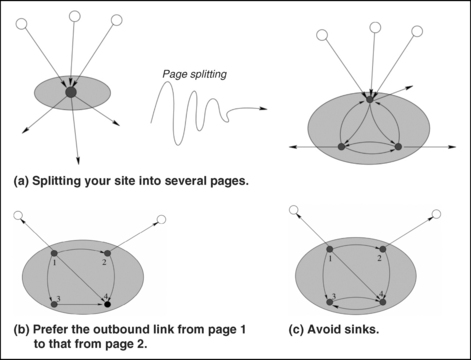
The overall rank of a site can be increased by limiting the number of links to the outside world. Again, the explanation is a simple application of the random walk: the more links there are out of a site, the greater the chance of exit. If you must have external links, it is best to direct them from pages that have many outbound links within the site, because this reduces the probability of choosing the external links. In Figure 5.2(b), the outbound link from page 1 is preferable to that from page 2 because there is only a 25 percent chance of it being taken versus the 33 percent chance of exiting from page 2. Finally, it’s best to avoid trapping states or “sinks” within your site, because then the random surfer will necessarily be forced to teleport away. Thus, you should add a link out of page 4 in Figure 5.2(b), as shown in Figure 5.2(c).
These strategies only affect the structure of your own website, the one you are trying to boost. You can implement them without having control of any external site. Another way of increasing ranking is to attract as many incoming links as possible. Each external link increases the overall rank of your site. This, of course, is the fundamental insight of PageRank: links are a sign that your site is well established, contains relevant information, and is sufficiently valued by others to be worth referring to. Suppose you control a site elsewhere from which you can send links to your own pages, the target community. The best way to manage this, from the point of view of maximizing visibility, is to create a site designed specifically to promote PageRank, often called a “link farm.” This is illustrated in Figure 5.3, where each page in the promoting community sends a link to the target community. Of course, you should design the promotion community with the preceding rules in mind.

Other tricks can be used to boost pages in the eyes of the HITS scheme for hub/authority ranking. You can easily construct a highly ranked hub simply by sending many outbound links to sites that are known to have high authority—for instance, cnn.com or www.sony.com. To create a highly ranked authority, you need to engineer links to it from several good hubs. So, create many artificial good hubs using the previous method, and link these to the target, which in turn becomes a good authority. In principle, the process is only limited by your wallet and the cost of the pages you create.
CONTENT HIDING
Term boosting tends to clutter up the page with unnatural and unwanted text, such as fake terms and hundreds of replications of the same word. Everyone can see that there’s something wrong with the page. Here’s a simple way of hiding all the extraneous text: color it the same as the background. Although the default text color is black, other colors can easily be specified in HTML. Human readers will not see words written in the background color, but the text is plainly visible in the HTML code and so search engines will—or may—be deceived.
The same applies to link boosting. Pages can include hordes of outbound links to improve their HITS hub ranking and the rank of other pages, but if these are visible, readers might smell a rat. It’s the anchor text that makes links visible, and it can easily be concealed. When users mouse over a link anchor, the cursor changes shape to indicate that it can be clicked; so to avoid detection, you should not only have invisible anchors but make them as small as possible. The best choice is a one-pixel image of the background color. For instance, the anchor text Click here in Felix’s page (Figure 3.1a) could be replaced by:
A page can contain many hidden and virtually undetectable links expressed in this way, whose sole purpose is to deceive search ranking mechanisms.
Instead of hiding terms and anchors, here’s a more radical technique known as “cloaking.” Simply present different pages to search engines than those you show to ordinary users. When a web server receives a page request, it can identify where it comes from. If the source is a known crawler, serve up something different—something that contains various boosting tricks as well as the real content for the crawler to index. There is nothing to stop a web server from presenting robots with an entirely fictitious view of the site. Search engine operators today do not seem to disguise their robots as ordinary users, though they could. However, they probably do perform anonymous checks to determine whether what their crawlers are seeing is the same as what ordinary users see.
Another way to deceive search engines—and people—is to exploit HTML’s ability to redirect users automatically from one page to another. You have probably experienced this when surfing the web, typically when a site has moved from one host to another. What you see is a page that invites you to update your bookmark with the new address, to which you are automatically redirected after a few seconds. If the delay time is set to zero, the original page—called the “doorway”—is not displayed at all and can be used to boost visibility through the techniques described earlier. Redirection is just another way of creating pages that are indexed by search engines but unseen by human users.
DISCUSSION
These are some ideas for boosting visibility. They are well known to search engine operators, who take pains to detect tricks and neutralize their effects. Other techniques will arise in the future, and it’s hard to foretell their guise. The boosters and the dragons will continue to wage war. New tricks will emerge from the underworld; dragons will adapt; spammers will reverse-engineer their changes and exploit loopholes. In the middle, of course, are the users, innocently relying on the web for their daily information, ignorant of the battleground heaving beneath their feet. Boosting will continue to develop hand in hand with information hiding. The most effective techniques involve gaining control of a large number of websites, and people in the boosting business will team up with hackers who are expert in network attack and intrusion.
BUSINESS, ETHICS, AND SPAM
Everyone wants to increase their visibility on the web. One way is to pay the dragons for advertising services. A second is to recruit companies that boast expertise in “search engine optimization” and seek their advice about how to reorganize your site to increase its visibility; they will help you use some of the techniques described here. A third is to buy links from highly ranked pages. In the murky world of search engine optimization, some people run link farms and—for a fee—place links to your pages from pages they have artificially boosted. Building an extensive link farm or a set of highly ranked hubs is costly, and selling links is a way of amortizing the investment. A fourth is to buy highly ranked pages on auction sites such as eBay. The web has huge inertia, and pages retain their ranking even if their content changes completely, because sites that link to them take a long time to notice the changes and alter their links. Squatters look for pages whose naming license is about to expire and snap them up within seconds if the owner forgets to renew. The license database is online, and all this can be done by an agent program that operates automatically.
You might find it hard to persuade a search engine to sell you a higher rank. As mentioned in Chapter 4, most take great care to keep paid advertising distinct from their search results. They make it clear to the public that while advertising can be bought, placement in the search results cannot. Otherwise, the answer to any query might be biased by economic issues—and you, the user, would never know. Web search is good business because of its popularity and advertising potential; in reality, it is more concerned with making money than providing library-quality information retrieval services. But to maintain their standing, the dragons must keep a watchful eye on their user base by continually striving to offer an excellent and trustworthy information service. Although users might be hard put to find out whether search results are biased by commercialism, the betrayal of trust if the word got out probably makes it too dangerous for the dragons to contemplate.
Search engine optimization is also good business, and there are many companies that do it. While it is perfectly reasonable to strive to attract links from other sites by making your pages as alluring as possible, web spam is a consequence of extreme interpretations of popularity-seeking. Junk pages used to promote documents and advertisements pollute the ecosystem. While viruses and worms have dramatic effects that can easily be spotted, spam is more insidious. It’s difficult to find neat ways of filtering it out. The free and easy publication style that characterizes the web provides fertile ground for spam. Unlike viruses and worms, its growth and diffusion don’t violate any law. The killer lobster—the spam—has already entered the ecosystem, and it spreads by apparently respecting the spirit of its environment.
What’s really wrong with making strenuous efforts to boost visibility? It opens the door to business, and one might well argue that ethics and business are unnatural bedfellows. Perhaps people cry about ethics only when they are on the defensive, when they are losers in the great world of commerce. Or are ethical considerations of crucial importance in order to preserve the web, encourage a healthy ecosystem, and facilitate its evolution? Surely search engine companies are aware that crawling is a parasitic operation that must be regarded as a privilege rather than a right? By the same token, search engine optimization enthusiasts should bear in mind the damaging effects of spam on the ecosystem as a whole.
Web visibility is becoming the target of stock-market-style speculation. As the fever takes hold, people pay to promote their sites, gaining top-ranked positions for crucial keywords—regardless of the quality of the information—and competing for people’s attention. But there’s only a finite amount of attention in the world. Will the bubble burst?
THE ETHICS OF SPAM
SPAM is ground pork and ham combined with spices, packed in cans. Originally called Hormel Spiced Ham, the name was invented to market this miracle meat, a savior of the allies in the Second World War. Its negative connotations originated when a zany British comedy troupe created a café full of Vikings singing “spam, spam, spam, …” and rendering normal conversation impossible.40 All e-mail users are depressingly familiar with the annoyance of finding meaningless jingles in their mailbox. Just as Monty Python’s Vikings prevent you from communicating with friends at your table, the spam in your e-mail inbox threatens to drown out the real conversations.
The web is the café where the new Vikings sing. Now that you have learned the tricks of the visibility-boosting trade, it’s not hard to imagine the lyrics. You encounter doorways that redirect you to a target page without announcing themselves on the screen; synthetic pages created automatically by software, comprised solely of links to other pages, particularly high-authority ones; pages containing long lists of terms that will match almost any query. What they all have in common is that they are junk. They are the killer lobsters that threaten to drown out real life in the ecosystem and make the lives of fishermen a misery.
Spam on the web denotes pages created for the sole purpose of attracting search engine referrals—either to the page itself or to some other target page. In 2004, 10 to 15 percent of web pages were estimated to be spam. It’s not yet clear whether the growth trend will be reversed. These songs, these killer lobsters, are parasites that waste communication resources all over the planet. Once indexed by search engines, they pollute their results. Although they may increase visibility initially, sooner or later search engine operators react by changing their ranking algorithms to discriminate against spam—spam as they see it, that is. In their efforts to save the web by purifying search results, they might have a hard time distinguishing the real thing—and your innocent website may suffer. For sometimes one person’s spam is another person’s ham.
Web spam goes hand in hand with deceit. Visual tricks hide terms and links. Cloaks disguise pages with unseen surrogates. Doorways conceal surreptitious wormholes. Guest books contain mysterious messages. Wiki pages take forever to load because they are stuffed with invisible hyperlinked one-pixel images. In the extreme, entire sites are infiltrated and perverted to serve their new masters. Apart from intrusion, these deceptions are unlikely to run afoul of the law. But they raise ethical concerns—particularly if we aspire to cultivate the web into the ultimate interactive library, a universal and dynamic repository of our society’s knowledge.
Concerns arise regardless of one’s philosophical stance or school of thought. Whether we strive to obey Kant’s categorical imperative to respect other rational beings or Bentham’s utilitarianism principle to attain the greatest happiness and benefit for the greatest number of people, the deceit that web spam represents is harmful. It’s harmful because, like e-mail spam, it wastes time and resources while producing nothing of value to society as a whole. PageRank—and, ultimately, human attention—is a zero-sum game: one site’s enhanced visibility inevitably detracts from another. More seriously, not only is spam wasteful but, like any other kind of pollution, it compromises beauty and healthy growth—in this case, the beauty and healthy growth of our society’s knowledge as represented in the universal library. Deceit neither respects other rational beings nor brings happiness and benefit to the greatest number of people.
There is nothing wrong with boosting one’s own site by making it sufficiently informative and alluring to attract the genuine attention of others. We should not decry the boosting of visibility in general: the issue is the means that are used to reach the end. And whereas our discussion has singled out just a couple of popular schools of Western philosophy, the web is an international endeavor and other mores will prevail in different parts of the world. (And other problems: we already mentioned the prevalence of zombie attacks in developing countries.) We need a broader discussion of the web as a public good that is to be respected by all. It’s unwise to neglect ethical issues when considering the future of an ecosystem.
ECONOMIC ISSUES
Visibility of knowledge is crucial if the web is to evolve into a universal library that serves society effectively. But in addition to being a repository of knowledge, the web is a shopping center too, and visibility plays a central role in driving commercial transactions. Promotion of websites is big business. Companies that undertake search engine optimization also help you submit your site to search engines and place it in appropriate directories. They advise on the design of your site, its visual impact and logical structure. They provide guidelines for selecting keywords in the title, inserting metatags, creating a site map, avoiding image buttons in links, and structuring internal links. Some also use unethical techniques for boosting visibility, like those just described.
Customers should be skeptical about promises from any company to position their pages “in the top ten” irrespective of content. These companies have no influence over the ranking schemes that search engines use. They cannot fulfill such promises without adopting unethical boosting techniques. Although they may succeed in boosting visibility, the victory will be short-lived. Search engine operators constantly watch for spam and adjust their algorithms to defeat new techniques. They are likely to discriminate heavily against what they see as artificially boosted pages. Your pages may appear briefly in the top ten and then drop out of sight altogether, far below where they were originally. It’s no good complaining. This is war: there are no referees.
SEARCH ENGINE ADVERTISING
Web visibility in general, and search engine optimization in particular, is big business. But the dragons of the business are the search engines themselves. They offer an invaluable service that we use every day for free. Their business model is to make money through advertising, inspired by the phenomenal commercial success of traditional broadcast advertising. Some sell placement within the search results, a straightforward way to offer an advertising service based on keywords in user queries. Others keep their search results pure and ensure that any advertisements are completely separate.
We use Google as an example; similar services are offered by other major search engines. It displays advertisements separately from search results. It gives advertisers access to a program that helps them create their own ads and choose keywords that are likely to attract the targeted audience. Whereas a few years ago advertisers paid Google whenever their ad appeared on a user’s screen, today they pay only when a user actually clicks on the ad. Advertisers bid for keywords and phrases, and Google’s software chooses the winner in an online auction that happens every time a user makes a query whose terms attract advertising.
For each ad, Google’s software calculates the “clickthrough rate”—the proportion of times the ad is actually clicked. Up to a certain maximum number of ads are shown on the query results page. Originally they were sorted by the product of clickthrough rate and bid amount. This was justified not on the basis of maximizing revenue to Google (though that is exactly what it did), but rather by the idea of providing a valuable service to users by showing them ads they are likely to click. These ads are targeted to people with a particular information need. Google promotes ads not as distracters, but as rewarding opportunities in their own right.
At the end of 2005, Google began to take into account the content of the page that an ad pointed to (so-called “landing pages”). It began rewarding advertisers who provided a “good user experience” and penalizing those whose ads were seductive (or misleading) enough to generate many clickthroughs but led to a “disappointing user experience”—polite language for “spammy” pages. Advertisers in the latter category have been forced to bid higher if they wish to be seen. This caused controversy because the evaluation criteria were secret—indeed, it was not even known whether landing pages were assessed by humans or by a computer algorithm.
Advertisers adopt complex strategies to maximize their return on investment. Some change their bid dynamically throughout the day. For example, to gain maximum benefit from a scheduled TV program on a topic related to their product, they may increase their bid while it is airing. A clickthrough for insomnia pills in the middle of the night might be more valuable than one during the day; a clickthrough for raingear might be more valuable during a storm. Advertisers are interested in the cost per action, where an action is purchasing an item or signing up for a new account. The likelihood of a click turning into an action is called the “conversion rate.” Canny advertisers monitor variations in the conversion rate and try to correlate them with the time of day, or external events, in an effort to find good ways of determining how much to bid in the auction.
The pay-per-click advertising model, coupled with sophisticated strategies for tweaking the bid price to make the best use of an advertising budget, has been a resounding success. However, it is susceptible to “click fraud,” where users with no intention of buying a product or service click simply to deplete the advertiser’s budget. This might be done systematically—manually or automatically—by someone in a rival company. You click repeatedly on a competitor’s ad to use up their daily budget and force them out of the auction—and then reduce your bid. No one knows how much of this goes on: media estimates vary from 5 percent of clicks to 50 percent. Click fraud represents yet another threat for search engines. Some make concerted efforts to detect it and refrain from billing for clicks that they judge to be fraudulent.
CONTENT-TARGETED ADVERTISING
Google also places ads on other people’s sites. When you join the service, it performs an automatic analysis of your site to determine what it is about and delivers ads that match the contents of each page, automatically integrating them visually into the page. When others visit your site, they also see the ads—which are matched to the page content. If they click on one, you get some money from the advertiser (so, of course, does Google). The service adapts to changes in your site’s content by periodically reanalyzing it.
This is a bonanza for some websites. You collect revenue with no effort whatsoever! Indeed, you can generate it for yourself by clicking on the ads that Google has put on your page, another form of click fraud. But it’s not the ultimate free lunch that it appears, because overtly commercial activity may put off those who visit your pages. The scheme rewards entrepreneurs who create sites designed for advertising rather than real content and boost their visibility in artificial ways. Another activity of search engine optimization companies is to advise on setting up pay-per-click accounts and to design websites that attract lucrative ads. Like click fraud, this may represent a further threat to search engines.
Does content-targeted advertising pollute the web, or does it provide a useful service, one valued by potential customers? It’s a matter of opinion. But regardless of perspective, any sound and lasting business model must follow ethical principles. Is it ethical for a search engine to sell placement in its search results—that is, web visibility? Obviously not, if users are deceived. But suppose the search engine company declares that its business policy is to sell visibility, just as search optimization companies do. Our view is that the web is a public good, and those who exploit its resources by crawling (or parasitic computing) have an obligation to offer a useful public service, one that benefits a significant proportion of the web population. This is Bentham’s utilitarianism principle of ethics, often expressed as the catchphrase “the greatest good for the greatest number.” Whether selling placement in search results is compatible with that obligation is arguable at best.
THE BUBBLE
In Holland in the late sixteenth century, tulip bulbs exceeded gold in value. Strange as it may seem, ordinary people sold everything they possessed to buy tulips, anticipating that the price, already high, would continue to rise further. Their dream was to become rich. However, prices crashed and a prolonged financial crisis ensued. This is a classic early example of the havoc that irrational expectations can play with valuations. Ever since, speculative crazes have appeared with depressing regularity. Indeed, since the famous—or infamous—1929 financial crash, nine such events have been identified. They are called “bubbles”; they swell up with air under the pressure of a speculative market, and the ultimate burst is as sudden as it is inevitable.
Economic bubbles share a common cause: local, self-reinforcing, imitative behavior among traders. The growing economic importance of the web has given rise to a sort of fever of web visibility, where people artificially promote products and ideas in order to reap economic benefits and wield cultural influence. The currency is not tulips but eyeballs: we crave attention, readers, clickthroughs, inbound links. But the risk of speculation lurks just beneath the surface. There is only a limited amount of attention in the world. If all website owners compete to push their pages higher in the search results, the process may become unstable. The pressure to buy additional visibility is local self-reinforcing imitation—precisely the conditions that accompany economic bubbles. As page promotion becomes more popular, the cost of visibility continues to increase, leading, perhaps, to a bubble of web visibility.
The bubble’s growth is related to the quality of the information present. The lower the quality, the more artificial the promotion and the higher the probability of a burst. A true speculative bubble and its inevitable collapse into depression would have serious consequences for everyone connected with the web business. Search engines, as the information gateways, are in a position to control inflation by guaranteeing high-quality search results. This meets Bentham’s utilitarianism principle of ethics. It also raises new concerns—practical, not ethical—about the strategy of selling placement in search results. Clean separation between commercial and noncommercial information, between ads and search results, seems an effective way to gently deflate the bubble. Even then, however, spam and artificial site promotion methods are powerful inflationary forces. The war against spam is also a war against inflation.
When ethics and economics point in the same direction, we should take heed! In this case, they both converge on the importance of paying particular attention to the quality of the information delivered by web search.
QUALITY
Jean-Paul Sartre, the renowned existential philosopher who won the Nobel Prize for literature in 1964, painted an evocative picture of the relationship between reader and reading material that is both sensuous and eerie:
… but it is always possible for him to enter his library, take down a book from the shelf, and open it. It gives off a slight odor of the cellar, and a strange operation begins which he has decided to call reading. From one point of view it is a possession; he lends his body to the dead in order that they may come back to life. And from another point of view it is a contact with the beyond. Indeed the book is by no means an object; neither is it an act, nor even a thought. Written by a dead man about dead things, it no longer has any place on this earth; it speaks of nothing which interests us directly. Left to itself, it falls back and collapses; there remain only ink spots on musty paper.
– Jean-Paul Sartre (1947)
Transport this into the relationship between the surfer and the web, the prototype universal library. Information, left to itself, is dead—written by dead people about dead things. It’s just ink spots on musty paper; limp pixels on a fictitious screen; neither an act nor even a thought. By downloading a page, we lend it our body and liberate it from the land of the dead. When we honor its link anchor with a click, we bring it temporarily to life: it possesses us. Through it we make fleeting contact with the beyond.
In the gigantic ecosystem of the web, how can we possibly discover information that is worth lending our mind to? Traditional publication is expensive. Books undergo a stringent review process before being published that greatly simplifies the reader’s task of selecting relevant material—though it’s still far from easy. But web publication is cheap, and the human review process can hardly be transposed to this domain. Instead, we rely on computers to rank the stuff for us. As we saw in the previous chapter, the schemes that search engines use are superficial. They count words and links, but they do not weigh meaning.
What are the frontiers of automatic quality assessment? We have been focusing on spam. This is part of the problem—an important part, and one that involves a fascinating duel between dragon and spammer, good and evil—but it’s by no means the whole story. Can intelligent agents replace human reviewers? Is quality assessment a formal technical process, that is, an activity that is susceptible to automation, even though a complex one that has not yet been cracked by artificial intelligence research? Or is it a creative process, on the same level as the production of quality content that is worth taking down from the shelf and breathing life into? More immediately, can we expect to benefit in the near future from filters that are capable of offering high-quality individualized views of the web, thus excluding spam? We return to these questions in the final chapter.
THE ANTI-SPAM WAR
Visibility fever has spawned a global market of customers who vie with one another for the top-ranked listing for queries relevant to their business. Just as the dragons compete among themselves to offer a better service, so do search engine optimization companies. Both are concerned with web visibility, but from opposite directions. In some cases their interests converge: for example, both seek to protect customers who buy advertisements against click fraud.
When search engine optimization borders on spamming, the competition becomes war, and both sides use sophisticated weaponry. Search engines jealously guard the secrecy of their code—especially their ranking policy, the crown jewels of their operation. While lack of transparency is undesirable from the point of view of serving society’s information needs, it seems the only way to protect the web from spam. We are trapped in an irresolvable dilemma—unless we are prepared to consider major changes to the basic model of the web.
Perhaps documents, like the inhabitants of a sophisticated ecosystem, should have to undergo rigorous testing before they are permitted to evolve and reproduce. Individuals who are too simple often have a hard time finding an evolutionary niche. In the web, no document is actually threatened, no matter how atrocious its content. This is a mixed blessing. Universal freedom to publish is a great thing, the force that has driven the web’s explosion. Yet a completely unrestricted environment is precisely what has sown the seeds of war.
Sun-Tzu, a Chinese general from the sixth century B.C., wrote a landmark treatise on military strategy in his seminal book The Art of War, and many of his lessons apply outside the military. For example, long-term strategic planning is often greatly superior to short-term tactical reaction. Instead of the present series of skirmishes, the time may have come to ponder more broadly an overall plan for the web. Perhaps spammers should be thinking of individualizing and improving search services rather than initiating parasitic attacks on the treasure the dragons guard—and society should find ways of rewarding this. The strategy for dragons might be to transcend their fixation on a single ranking policy, which makes them especially vulnerable to attack.
THE WEAPONS
Spammers use software tricks, some dramatically referred to as “bombs,” that arise from the boosting and hiding techniques described earlier. While some can easily be detected, others are lethal. The boosting of PageRank is an insidious example. The promoting community can include any content whatsoever and embed its links within an arbitrary network of connections. However, although it can be concealed, a characteristic interconnection pattern underlies the network, and this gives search engines a chance to discover the bomb lurking within.
Search engines devise shields against the spammers’ weapons. For example, in 2004 Google proposed a simple way to defeat guest-book spam. The idea was to introduce a new kind of link called “nofollow” that anyone can use. These links work in the normal way, except that search engines do not interpret them as endorsing the page they lead to. In an unprecedented cooperative move, MSN and Yahoo, as well as major blogging vendors, agreed to support Google’s proposal. Technically it involves adding a nofollow tag to existing links, rather than defining a completely new link, so existing applications—web servers and browsers—are unaffected. It’s not hard for guest-book software, and wiki and blog systems, to scan user-entered text and place the nofollow tag on all links therein.
Like spammers, search engines employ secrecy and occasionally deceit. As mentioned earlier, they probably crawl the web in disguise to check for cloaking. Spammers fill honey pots with attractive information (for example, copies of useful public documents, or copied hubs) to deceive legitimate websites into linking to them. Search engines, if they spot this happening, simply artificially downgrade the honey pot’s PageRank or HITS score. The code is kept secret and no one will ever know, except that the spammer’s efforts will mysteriously prove ineffectual.
One way in which search engines can purify their results is based on the simple observation that reputable sites don’t link to disreputable ones—unless they have actually been infiltrated, which is rare. Suppose a person manually inspects sample pages and labels them as good or bad, ham or spam, trusted or untrustworthy. Links from trusted pages almost always lead to other trusted ones, and this allows a trust map of the web to be drawn up. However, good sites can occasionally be deceived into linking to bad ones—honey pots are an explicit attempt to engineer this—so it is advantageous to keep inference chains short. Of course, if an error is discovered, it can immediately be corrected by hand-labeling that page.
When propagating trust from a given number of hand-labeled sample pages, the result can be improved by selecting ones that lead directly to a large set of other pages, so that their trust status can be inferred directly. Indeed, we should select pages that point to many pages that in turn point to many other pages, and so on. This leads to a kind of inverse PageRank, where the number of outlinks replaces the number of inlinks, measuring influence rather than prestige.
As time goes by, spammers’ bombs become ever more sophisticated. Effective defenses like the trust mechanism are likely to benefit significantly from human labeling. Machine learning technology should prove a powerful ally. Given a set of examples that have been judged by humans, automated learning methods generalize that judgment to the remaining examples. They make decisions on the basis of a model that is determined during a learning phase and is designed to minimize error on the human-labeled examples. This defense mechanism exhibits a feature that is highly prized by search engines: even if spammers know what learning algorithm is used, the model cannot be predicted because it depends on the training examples. Moreover, if spammers invent new tactics, the dragons can relabel a few critical pages and learn a new defensive model from scratch.
THE DILEMMA OF SECRECY
In 1250 B.C., the city of Troy was finally destroyed after ten years of unsuccessful siege. In one of the first notable examples of the importance of secrecy in military action, the Greeks built a hollow wooden horse, filled it with soldiers, and left it in front of the city gates. The rest, as they say, is history. Well over three millennia later, during World War II, secrecy remained a crucial ingredient in a totally different technological context. German scientists refined an earlier Polish invention into Enigma, an encryption machine whose purpose was to keep radio communications—such as planned U-boat attacks—secret. The code was cracked by British scientists led by Alan Turing, the father of computer science, who invented a computer specifically for that purpose and made a significant contribution to the Allied victory.
Secrecy also plays a central role in the dragons’ war against spammers. Spammers hide their work, of course; otherwise it would be easy for the dragons to discriminate against improperly boosted pages. The software code that implements the dragons’ ranking policies is kept secret, for knowing it would give spammers an easy target on which to drop their bombs. Moreover, the policies can be surreptitiously changed at will—and they are.
Search engines use secrecy to help combat spam, which is necessary to keep our view of the web in good order. But secrecy is a crude weapon. In the realm of computer security, experts speak disparagingly of “security by obscurity.” In the past, computers kept lists of users and their passwords in obscure files. This information had to be heavily guarded because it was an obvious point of weakness: if it got out, the entire system would instantly be compromised. The modern approach is to employ cryptographic devices such as one-way functions—ones that scramble information in a way that cannot be reversed—to store the password file. Then it does not need to be kept secret, for it is no use to an interloper. The passwords that users present are scrambled and checked against the file to determine whether to grant access, but the file cannot be unscrambled to reveal them. Today’s dragons rely on security by obscurity, creating a serious weakness: a huge incentive to bribe a disgruntled or corrupt employee, or otherwise crack the secret.
There is an even more compelling objection to the dragon’s secrecy. Users have a legitimate reason to know the recipe that governs the emergence of certain web pages from underneath a mountain of documents. What are you missing if you inspect the first three, or the first twenty, pages from the ranking? What if the ranking policy changes? The view of the web that the dragons present is arbitrary and changes mysteriously at unpredictable times. We are trapped in a dilemma: users want to know how their information is selected—indeed, they have a right to—but if this information were made public, spam would increase without bound, with disastrous consequences. And, of course, publishing the details of the ranking policy would create far more interest among spammers than among most ordinary users.
TACTICS AND STRATEGY
Spammers and dragons are waging a tactical war by engaging in a succession of minor conflicts. They perform optimizations aimed at preserving and expanding their own businesses, which are both based on web visibility. Spammers seek to control as many pages as possible. They typically create their own websites, though if they can manage to attract links from other sites—preferably ones of high repute—so much the better. But this is not the whole story. As in real war, alliances can be very effective. Spammers interconnect their link farms for mutual benefit or through economic agreements. Such alliances tend to improve the ranking of every member, boosting the visibility of each spammer’s link farm, which in turn is used to boost the visibility of paying customers who suffer from visibility fever. Figure 5.4 shows a simple alliance in which two link farms jointly boost two targets.

Dragons do their best to render spammers ineffective, and particularly to break up alliances. The fact that their code is secret allows them to quietly shift the target. When spammers focus on a particular feature of the ranking algorithm that they believe crucially affects visibility, dragons can simply change that feature. Given the growing public distaste for spam, and the fact that the dragons provide the only means for large-scale web search, they can mount broad public anti-spam campaigns, perhaps even supported by legislation. While this has its merits, it could be a double-edged sword, for ethical concerns can also be raised about the business model adopted by some search engines (e.g., selling placement in search results).
While fighting this tactical war, the dragons should also be hatching an overall strategic plot that reaches much further than individual battles. And for all we know, they are. New ideas might go far beyond the simple keyword-based query model. The web is suffering to an extent that is already beginning to create a dilemma for us users. Parents who ignore cries for help from teenagers often end up learning the hard way.
SO WHAT?
The World Wide Web was created by scientists and quickly became the playground of academic computer researchers. Then commerce took over, introducing a competitive element into what until then had been a fundamentally cooperative environment. The playground became a battleground. As gateways to the web, search engines are the arbiters of visibility. Web visibility is free advertising to the most attractive possible audience—people who are actively seeking information related to your product. Promoting visibility has become an industry. There are perfectly legitimate ways to do this: make your pages attractive and informative and ensure that they are listed in the right places. But some people attempt to discover and exploit loopholes in how the dragons sift information. This has the effect of polluting our information universe, and search engine companies work hard on our behalf to eliminate the deleterious effects of web spam on their search results.
Next we turn to broader questions of the control of information, both on the web and in our society.
WHAT CAN YOU DO ABOUT ALL THIS?
• Donate some computer time to a good cause (SETI@home?).
• List the websites you rely on—ones whose failure you are most vulnerable to—and spend a day without them to see how vulnerable you are.
• Install a spyware prevention program on your PC.
• Hide a message in e-mail spam (try spammimic).
• Learn the market price of PageRank (try eBay).
• Find a web page that contains some hidden content.
• Find web pages of search engine optimization companies and learn what they do.
• Learn about Google’s AdSense.
• Discuss different boosting methods from an ethical point of view.
NOTES AND SOURCES
The WebCrow program was designed by one of the present authors, Marco Gori, along with Marco Ernandes, a Ph.D. student at the University of Siena. It soon attracted the attention of another student, Giovanni Angelini, who began to improve it using techniques from computational linguistics. It was announced in Nature (Castellani, 2004) and is sponsored by Google under their Research Program Awards.
The idea of parasitic computing was developed by Barabási and his colleagues at Notre Dame University, who also announced their results in a seminal paper in Nature (Barabási et al., 2001). The consequences of gradual breakdown in the network of links in the web are analogous to the consequences of faults in the routing computers of the Internet, a topic that has been widely investigated and is addressed in Barabási’s (1999) book, Linked. Shlomo Havlin and colleagues at Bar-Ilan University in Israel discovered the intriguing result that you can remove nodes from power-law networks without fragmenting them into clusters, provided the exponent of the power law is not greater than 3 (Cohen et al., 2000). Intrusion detection was introduced by Dorothy Denning (1987), who initiated the academic study of viruses, worms, and their detection. A systematic treatment with historical references can be found in Bace (2000).
Many studies of how to combat web spam are undertaken by search engine companies but are not made available to the public. Gyongyi and Garcia-Molina (2005a) published a comprehensive survey that includes a taxonomy of boosting and hiding techniques currently used to enhance the visibility of websites. They estimated that in March 2004, spam represented 10 to 15 percent of web pages. The same authors observed that links from trusted pages generally lead to other trusted ones (Gyongyi et al., 2004) and discussed the insidious problem of spam alliances (Gyongyi and Garcia-Molina, 2005b). Google has indicated interest in technologies for the propagation of trust by registering a U.S. trademark for the word TrustRank. Fetterly et al. (2004) give interesting statistical analyses of how to locate websites containing spam. The topic of web visibility and the growth of a speculative bubble has been studied by Gori and Witten (2005). Johansen et al. (1999) discuss significant financial crashes between 1929 and 1998 and point out that almost all of them share common preconditions. Figures 5.2 and 5.3 are from Bianchini et al. (2005).
Finally, some brief notes about the literature cited in this chapter: Umberto Eco’s masterpiece The Name of the Rose (Eco, 1980) was originally published in Italian as Il Nome della Rosa and has been likened to transplanting Sherlock Holmes to a medieval monastery, incorporating elements of the gothic thriller. Harlie in When Harlie was One (Gerrold, 1972) is a more endearing version of HAL 9000 in Stanley Kubrick’s film 2001: A Space Odyssey (1968). The story revolves around his relationship with the psychologist whose job it is to guide him from childhood to adulthood. Sartre’s famous essay “What is Literature?” (Sartre, 1947) presents an Existentialist account of literature, which he argues is an important part of our difficult but essential task of facing up to human freedom. The Art of War (Sun-Tzu, 515–512 B.C.) is a definitive work on military strategy and tactics that has had a vast influence on Western military planning ever since it was first translated into a European language (French) two centuries ago.
Trawling for fish while battling a spam attack.
36Read about it at www.uniurb.it/giornalismo/lavori2002/fedeli (in Italian).
37In the next chapter, we will describe a “rich get richer” tendency which suggests that economic reasons tend to stifle growth in competing search engine companies.
38In fact, it has been shown theoretically that the critical value is 3. For the web, the power-law exponents have been empirically determined to be 2.1 for inbound links and 2.7 for outbound links (Broder et al., 2000).
39The first actual virus program seems to have been created in 1983, at the dawn of the personal computer era.
40In fact, they were echoing a 1937 advertising jingle—possibly the first ever singing commercial—to the chorus of “My Bonny Lies Over the Ocean.” Instead of “Bring back, bring back / Oh, bring back my bonnie to me,” the lyrics were “SPAM SPAM SPAM SPAM / Hormel’s new miracle meat in a can / Tastes fine, saves time / If you want something grand / Ask for SPAM!”