
In 1828, at the age of 19, Mary Novello married the 41-year-old writer and publisher Charles Clarke. He was a Shakespeare scholar, and the next year Mary embarked on a monumental task: to produce a systematic concordance of all Shakespeare’s plays. Today we are so used to machines doing all our clerical work that it’s hard to imagine the scale of her undertaking—and she probably had no idea what she was letting herself in for, either. At the start, she was an enthusiastic amateur, brought up in the company of the Regency literati. It took her twelve years to extract and order the data, then another four to check it against current editions and prepare it for the press. After sixteen years of toil—almost half her young life—the concordance’s 310,000 entries appeared in eighteen monthly parts in 1844–45. This was the first concordance to any body of secular literature in English.
Every word that Shakespeare wrote was arranged alphabetically, along with the play, scene, and line numbers in which it appeared. The preface proudly proclaimed that “to furnish a faithful guide to this rich mine of intellectual treasure … has been the ambition of a life; and it is hoped that the sixteen years’ assiduous labour … may be found to have accomplished that ambition.” It certainly saved users labor: they could now identify half-remembered quotations, make exhaustive surveys of chosen themes, and undertake systematic studies of Shakespeare’s writing. It laid a foundation that today we would call an enabling technology.
Comprehensive indexes to many other books—such as the Bible and the writings of famous authors and classical philosophers—were produced by hand in the nineteenth and early twentieth centuries. The prefaces of these works tell of years of painstaking toil, presumably driven by a belief in the worthiness of the text being indexed. The word concordance originally applied just to biblical indexes. Its root, concord, means “unity,” and the term apparently arose out of the school of thought that the unity of the Bible should be reflected in consistency between the Old and New Testaments, which could be demonstrated by a concordance.
The task of constructing concordances manually is onerous and time consuming. Sometimes it was passed on from father to son. A concordance for the Greek version of the New Testament, published in 1897, has since undergone several revisions, and responsibility for the task has passed down through three generations of the same family. Figure 4.1 shows part of the entry for the word ‘εραυνα’ω, a Greek verb for search. The task is not entirely mechanical, since several inflections of the verb are recorded under the one heading.

Figure 4.1 A concordance entry for the verb to search from the Greek New Testament (Moulton and Geden, 1977).
Reprinted by permission from T & T Clark, Ltd.
Technology improved. In 1911, a concordance of William Wordsworth’s poetry was published. The 1,136-page tome lists all 211,000 nontrivial words in the poet’s works, from Aäaliza to Zutphen’s, yet took less than seven months to construct. The task was completed so quickly because it was undertaken by a highly organized team of 67 people—three of whom had died by the time the concordance was published—using three-by-five-inch cards, scissors, glue, and stamps.
Of course, the biggest technological improvement came when computers were recruited to work on the task. In the beginning, computer resources were scarce: in 1970, an early pioneer blew most of his computer budget for the entire year on a single run to generate a concordance. Early works were printed on a line printer, in uppercase letters, without punctuation. Figure 4.2 shows some entries from a 1959 concordance of Matthew Arnold: note that she’ll is indistinguishable from shell. As computers became cheaper and more powerful, it became easier and more economical to produce concordances, and print quality improved. By the 1980s, personal computers could be used to generate and print concordances whose quality was comparable to that of handmade ones—possibly even better.

Figure 4.2 Entries from an early computer-produced concordance of Matthew Arnold (Parrish, 1959).
Reprinted from A Concordance to the Poems of Matthew Arnold. Copyright © 1959 by Cornell University. All rights reserved.
Technology now makes it trivial. Today you can generate a concordance for any document or corpus of documents on your laptop or home computer in a few seconds or minutes (perhaps hours, for a monumental corpus). You only need an electronic version of the text. They might be your own files. Or a set of web pages. Or a public-domain book somewhere on the web, perhaps in the Gutenberg or Internet Archives corpus. But you probably needn’t bother, for the web dragons have already done the work and will let you use their concordance for free. Just one hundred years after Mary Clarke died, search engines were regularly churning out a concordance of the entire web every few months. A few years later, they brought within their ambit massive portions of our treasury of literature—including, of course, Shakespeare’s plays, over which she had labored so hard. It is hard to imagine what she would have made of this.
Today a concordance is usually called a “full-text index.” With it, not only can you examine all the contexts in which a word appears, but you can also search for any part of a text that contains a particular set of words that interest you. You might include phrases; specify whether all the words must appear or just some of them; or determine how far apart they may be. You might restrict your search to a particular work, or website. You might control the order in which results are presented, sorted by some metadata value like author, or date, or in order of how well they match the query. If you work with information, you probably use full-text retrieval every day.
SEARCHING TEXT
Searching a full text is not quite as simple as having a computer go through it from start to finish looking for the words you want to find. Despite their reputation for speed and blind obedience, an exhaustive search is still a lengthy business for computers. Even a fast system takes several minutes to read an entire CD-ROM, and on the enormous volumes of text managed by web search engines, a full scan would take longer than any user would be prepared to wait.
FULL-TEXT INDEXES
To accomplish searching very rapidly, computers use precisely the same technique that Mary did: they first build a concordance or full-text index. This lists all the words that appear in the text, along with a pointer to every occurrence. If the text were Hamlet’s famous soliloquy “To be or not to be, that is the question …,” the index would start as shown in Figure 4.3(a). Here, pointers are numbers: the 2 and 6 beside be indicate that it is the second and sixth word in the text, as shown in Figure 4.3(b). Words are ordered alphabetically, and in reality the list will contain many more—from aardvark to zygote, perhaps. Alongside each word are several pointers, sometimes just one (for unusual words like these) and sometimes a great many (for a, and, of, to, and the). Each word has as many pointers as it has appearances in the text. And the grand total number of pointers is the number of words in the text. In this example, there are ten words and therefore ten pointers.

Mary Clarke’s Shakespeare concordance recorded pointers in terms of the play, scene, and line number. Our example uses just the word number. In reality, one might use a document number and word within the document, or perhaps a document number, paragraph number, and word within the paragraph. It really depends on what kind of searches you want to do.
How big is the index? Any large corpus of text will contain a host of different words. It is surprisingly hard to estimate the size of the vocabulary. It isn’t useful to simply count the words in a language dictionary, because each inflected variant will have its own entry in the list (we discuss this further soon). For English, around 100,000 to 200,000 words seems a plausible ballpark figure. But bulk text contains far more than this, because of neologisms, proper names, foreign words, and—above all—misspellings. A typical collection of a billion web pages—equivalent to about 2,000 books—will include as many as a million different words (assuming they’re in English). Google’s text base is several orders of magnitude larger and contains many billions of different words—only a tiny fraction of which are bona fide ones that would appear in a language dictionary. Fortunately, computers can quickly locate items in ordered lists, even if the lists are very long.
The size of the list of pointers that accompanies each word depends on how many times that word appears. Unique words, ones that occur only once in a corpus of text, are referred to by the Greek term hapax legomena, and their list contains just one pointer. It turns out that around half of the terms in a typical text are hapax legomena: for example, around 45 percent of the 31,500 different words in The Complete Works of Shakespeare occur just once. At the other extreme, Shakespeare used 850 words more than 100 times each. At the very extreme, today Google says it indexes 21,630,000,000 pages that contain the word the, and it surely appears many times on the average page. There will probably be 100 billion pointers for this one word.
How much space does the index occupy? As we saw earlier, it contains as many entries as there are words in the text, one pointer for every word appearance. In fact, the space needed to store a pointer is not all that different from the amount needed to store the word itself: thus the size of the index is about the same as the size of the text. Both can be compressed, and practical compression techniques reduce the index slightly more than they reduce the text. Search engines keep both a full-text index and a text-only version of all documents on the web, and in broad terms they are about the same size as each other. That’s not surprising, for they store exactly the same amount of information: from the text you can derive the index and vice versa.
USING THE INDEX
Given an index, it’s easy to search the text for a particular word: just locate it in the ordered list and extract its associated list of numbers. Assuming that each appearance position comprises both the document number and the word within the document, a search will find all the documents that contain the word. Although computers cannot scan quickly all the way through large amounts of text, they can rapidly locate a word in an ordered list (or report that it doesn’t appear).
To process a query that contains several terms, first locate them all and extract their lists of document and word numbers. Then scan the lists together to see which document numbers are common to them—in other words, which documents contain all the query terms. Merging the lists is easy because each one is sorted into ascending order of position. Alternatively, to locate those documents that contain any (rather than all) of the words, scan along the lists and output all the document numbers they contain. Any logical combination of words can be dealt with in like manner.
So far we have only used the document numbers, not the word-within-document numbers. Word numbers become important when seeking phrases. To see where the phrase to be occurs in Hamlet’s soliloquy, retrieve the lists for to and be and check whether they contain any adjacent numbers. To is word 1 and be word 2, which indicates an occurrence of the phrase to be. Scanning to the next item on both lists indicates a second occurrence. On the other hand, although the words is and not both appear, the phrase is not does not, since their respective positions, 8 and 4, are not consecutive. Instead of phrase searching, it is sometimes useful to find terms that occur within a certain distance of each other—a proximity search. To do this, instead of seeking consecutive words, look for positions that differ by up to a specified maximum.
These techniques return the documents that match a set of query terms in the order in which the documents appear in the collection. In practice, documents are encountered haphazardly—perhaps by crawling the web—and this ordering is not meaningful. It is better to try to return documents in relevance order, beginning with those that are most closely related to the query.
Computers cannot comprehend the documents and determine which is really most relevant to the query—even human librarians have a hard time doing that. However, a good approximation can be obtained simply by counting words. A document is more relevant
When evaluating these factors, you should give more weight to terms that seldom occur in the document collection than to frequent ones, for rare terms like martini are more important than common ones like the.
These rules lead to a simple method for estimating the relevance of a document to a query. Imagine a very high-dimensional space, with as many dimensions as there are different words in the collection—thousands (for Shakespeare), millions (for a small library), or billions (for the web). Each axis corresponds to a particular word. A document defines a certain point in the space, where the distance along each axis corresponds to the number of times the word appears. But the scale of the axis depends on the word’s overall popularity: to move one inch along the woman axis requires more appearances of that term than to move the same distance along the goddess axis simply by virtue of the relative frequency of these words (for most collections). The intuition is that words that occur frequently in a particular document convey information about it, while words that appear rarely in the collection as a whole convey more information in general.
The position of a document in this high-dimensional space depends greatly on its size. Suppose that from document A we construct a new document B that contains nothing more than two copies of A. The point corresponding to B is twice as far from the origin, in precisely the same direction, as that for A—yet both documents contain exactly the same information. As this illustrates, what really characterizes a document is not its position in the space, but the direction of the line to it from the origin. To judge the similarity of two documents, we use the angle between their vectors. To judge the relevance of a document to a query, we treat the query as a tiny little document and calculate the similarity between it and the document. Technically, the cosine of the angle is used, not the angle itself, and this is called the cosine similarity measure. It ranges from 1 if the documents are identical to 0 if they have no words in common.
The cosine similarity measure treats each document as though its words are completely independent of one another—documents are just a “bag of words.” A scrambled document will match the original with a 100 percent similarity score! This is a gross oversimplification of real language, where John hit Mary differs radically from Mary hit John. Nevertheless, it seems to work quite well, since word order rarely affects what should be returned as the result of a query. You are more likely to be looking for documents about John and Mary’s aggression in general, rather than who was the aggressor—and in that case, you could always use a phrase search.
WHAT’S A WORD?
Where does one word end and the next begin? There are countless little decisions to make. Basically, each alphabetic or alphanumeric string that appears in the text is a potential query term. Numbers should not be ignored: queries often contain them, particularly in the form of dates or years. Punctuation is ignored, but embedded apostrophes (and unmatched trailing apostrophes) should be retained. Ideally, so should periods that indicate abbreviations. Hyphens should sometimes be ignored and sometimes treated like a space: usage is inconsistent. Other punctuation, like white space, is a word separator. Probably a maximum word length should be imposed, in case there is a very long string—like the expansion of φ to a million digits—that could choke the indexing software.
Case “folding” replaces uppercase characters with their lowercase equivalents. For example, the, The, THE, tHe, and four other combinations would all be folded to the representative term the. We assumed case folding in the example of Figure 4.3 by combining the entries for To and to. If all terms in the index are case folded, and the query terms are as well, case will be ignored when matching. This is not always appropriate—when searching for General Motors, you do not want to be swamped with answers about general repairs to all kinds of motors.
“Stemming” gives leeway when comparing words with different endings—like motor, motors, motoring, motorist. It involves stripping off one or more suffixes to reduce the word to root form, converting it to a stem devoid of tense and plurality. In some languages, the process is simple; in others, it is far more complex. If all terms in the index are stemmed, and the query is too, suffixes will be ignored when matching. Again, this is sometimes inappropriate, as when seeking proper names or documents containing particular phrases.
Another common trick is to ignore or “stop” frequently occurring terms and not index them at all. The ignored words are called stop words. In an uncompressed index, this yields a substantial saving in space—billions of pages contain the word the, which translates into a list of tens of billions of numbers in a full-text index. However, such lists compress very well, and it turns out that if the index is compressed, omitting stop words does not save much space—perhaps 10 percent, compared with a 25 percent saving for uncompressed indexes (since roughly every fourth word is a stop word).
If you create an index that ignores words, you are assuming that users will not be interested in those terms. In reality, it is not easy to predict what will attract the attention of future scholars. Mary Clarke omitted common words in her concordance of Shakespeare. But because when, whenever, and until were excluded, the concordance could not be used to investigate Shakespeare’s treatment of time; the exclusion of never and if ignored crucial terms in Lear and Macbeth; and studies of Shakespeare’s use of the verb to do were likewise precluded. A further problem is that many common stop words—notably may, can, and will—are homonyms for rarer nouns: stopping the word may also removes references to the month of May.
These effects combine. After special characters, single-letter words, and the lowercased stop word at have been removed from the term AT&T, there is nothing left to index!
DOING IT FAST
Constructing a full-text index for a large document collection, and using it to answer queries quickly is a daunting undertaking—almost as daunting as Mary Clarke’s production of the Shakespeare concordance. It is accomplished, of course, by breaking the problem down into smaller parts, and these into smaller parts still, until you get right down to individual algorithms that any competent computer science student can implement. The student’s advantage over Mary is that he or she can rerun the procedure over and over again to fix the bugs and get it right, and once the program is complete, it can process any other document collection without additional labor.
Building an index is a large computation that may take minutes for Shakespeare’s complete works, hours for a small library, and days for a vast collection. The problem is to read in the text word by word, and output it dictionary word by dictionary word (aardvark to zygote) in the form of pointers. This is easy in principle—so easy it is often set as an introductory undergraduate student computing assignment. The snag is that for a large collection, all the information—the input text and the output word list—will not fit into the computer’s main memory. Simply putting it on disk won’t work because access is so much slower that the operation would take literally centuries (and the disk drives would wear out).
Making an indexing program work is just a matter of detail. First, you partition the collection—do a slice at a time, where each slice fits into main memory. Then you must solve the problem of putting the bits back together. Second, compress the data, so more fits into main memory at once. In fact, those lists of pointers compress well if you use the right technique. Third, fiddle with the algorithms to make them read information off disk sequentially as much as possible, which is far faster than random access. The result is a complex system whose components are all carefully optimized, involving a great deal of mathematical theory.
The second part is doing the searching. Whereas the index only has to be built once, or perhaps periodically whenever the collection is updated, searching is done continually—and a multiple-user system must respond to different queries simultaneously. The fundamental problem is to look up each query term, read its list of pointers off disk, and process the lists together. Computers consult entries in alphabetical dictionaries by “binary searching,” checking the middle to narrow the search down to one half or the other, and repeating. This is very fast, because doubling the size of the dictionary only adds one more operation. Dealing with the lists of pointers is more challenging because it seems necessary to scan through them in order, which is excessively time-consuming for long lists. However, if there is only one query term, you don’t need to look through the list: just present the first 10 or 20 documents to the user as the search results. If you are looking for documents that contain all the query terms, you can start with the rarest term and, for each occurrence, look it up in the other term lists using binary search.
These operations can be done extremely efficiently. And there is no reason at all why queries should be restricted to the one or two words that are typical when searching the web. Indeed, when documents are required to include all the query terms (rather than just some of them), which is normally the case with a web search, it is far more efficient to seek a complete paragraph—even a full page of text—than a couple of words. The reason is that, when merging, you can start with the rarest word, immediately pruning the list of document numbers down to just a few entries. Search engines have tiny query boxes purely for aesthetic reasons, not for efficiency, and because most users issue only tiny queries.
Returning results in order of relevance, estimated using a similarity measure, is more challenging. If there are many matches, even sorting the documents into order can be a substantial undertaking. However, you don’t need all the results at once, just the top 10 or 20, and there are ways of finding the top few documents without sorting the entire list. But we do need to compute all the similarity values to find the best ones—or do we? Having found a few good ones, there are ways of quickly ruling out most of the others on the basis of a partial computation. These are things you might learn in a graduate computer science course.
Building an efficient, web-scale, robust, industrial-strength full-text indexing system is a substantial undertaking—perhaps on a par with the sixteen person-years it took to produce a concordance of Shakespeare manually. Once done, however, it can be applied again and again to index new bodies of text and answer simultaneous full-text queries by users all over the world.
EVALUATING THE RESULTS
A good indexing system will answer queries quickly and effectively, be able to rebuild the index quickly, and not require excessive resources. The most difficult part to evaluate is the effectiveness of the answers—in particular, the effectiveness of relevance ranking.
The most common way to characterize retrieval performance is to calculate how many of the relevant documents have been retrieved and how early they occur in the ranked list. To do this, people adopt the (admittedly simplistic) view that a document either is or is not relevant to the query—and this judgment is made by the human user. We consider all documents up to a certain cutoff point in the ranking—say, the first 20 of them (typically the number that appears in the first page of search results). Some documents in this set will be relevant, others not. Retrieval performance is expressed in terms of three quantities: the number of documents that are retrieved (20 in this case), the number of those that are relevant, and the total number of relevant documents (which could be far larger). There are two measures that depend on these quantities:

The number on the top is the same in both cases. For example, if 20 documents are retrieved in answer to some query, and 15 of them are relevant, the precision is 75 percent. If, in addition, the collection contained a total of 60 relevant documents, the recall is 25 percent. The two quantities measure different things. Precision assesses the accuracy of the set of search results in terms of what proportion are good ones, while recall indicates the coverage in terms of what proportion of good ones are returned.
There is a tradeoff between precision and recall as the number of documents retrieved is varied. If all documents in the collection were retrieved, recall would be 100 percent—but precision would be miniscule. If just one document were retrieved, hopefully it would be a relevant one—surely, if asked for just one document, the search system could find one that was certainly relevant—in which case precision would be 100 percent but recall would be miniscule.
You can evaluate precision by looking at each document returned and deciding whether it is relevant to the query (which may be a tough decision). You probably can’t evaluate recall, for to do so you would have to examine every single document in the collection and decide which ones were relevant. For large collections, this is completely impossible.
SEARCHING IN A WEB
Given a query and a set of documents, full-text retrieval locates those documents that are most relevant to the query. This now-classic model of information retrieval was studied comprehensively and in great detail from the 1960s onward. The web, when it came along, provided a massive, universally accessible set of documents. For computer scientists, this was a new adventure playground, and many eagerly rushed off to apply information retrieval techniques. The web presented an interesting challenge because it was huge—at the time, it was not easy to get hold of massive quantities of electronic text. There was also the fun of downloading or “crawling” the web so that inverted indexes could be produced, itself an interesting problem.
This kept scientists busy for a couple of years, and soon the first search engines appeared. They were marvelous software achievements that faithfully located all web pages containing the keywords you specified, and presented these pages to you in order of relevance. It was a triumph of software engineering that such huge indexes could be created at all, let alone consulted by a multitude of users simultaneously.
Prior to the inception of search engines, the web was of limited practical interest, though aficionados found it fascinating. Of course, it was great that you could easily read what others had written, and follow their hyperlinks to further interesting material. But if you didn’t already know where it was, seeking out information was like looking for needles in haystacks. You could spend a lot of time getting to know where things were, and early adopters became real experts at ferreting out information on the web. But it was an exhausting business because the haystack kept changing! You had to invest a lot of time, not just in getting to know the web, but also in maintaining your knowledge in the face of continual evolution.
Search engines changed all that. They finally made it worthwhile coming to grips with the baby World Wide Web. When academics and researchers learned about search engines (for this was before the web’s discovery by commerce), they started to learn more about the web.
While most were playing in this new sandbox and marveling at its toys and how easily you could find them, a perspicacious few noticed that something was slightly wrong. Most web queries were—and still are—very short: one or two words.29 Incidentally, by far the most common web query is … nothing, the empty string, generated by users who reach a search engine and hit the Enter key. If a particular word occurs at most once in each document, a one-word query with the cosine ranking algorithm returns documents in order of length, shortest first, because brevity enhances the apparent significance of each word. In an early example from Google’s pioneers, the word University returned a long but haphazard list of pages, sorted in order of occurrence frequency and length, not prestige. (The pioneers were at Stanford and were probably irked that it appeared way down the list, outranked by minor institutions.)
DETERMINING WHAT A PAGE IS ABOUT
There were other problems. One arose when people started to realize how important it was to get noticed and began putting words into their pages specifically for that purpose. Traditional information retrieval takes documents at face value: it assumes that the words they contain are a fair representation of what they are about. But if you want to promote your wares, why not include additional text intended solely to increase its visibility? Unlike paper documents, words can easily be hidden in web pages, visible to programs but not to human readers.
Here’s a simple idea: judge people by what others say about them, not by their own ego. And judge what web pages are about by looking at the “anchor text”—that is, the clickable text—of hyperlinks that point to them. Take the book you’re reading now. If many people link to the publisher’s web page and label their links “great book about the web,” that’s a far more credible testament than any self-congratulatory proclamation in the book itself, or in its web page.
This insight suggests an advantage in including the words on all links into a page in the full-text index entries for that page, as though the anchor text were actually present in the page itself. In fact, these words should be weighted more highly than those in the page because external opinions are usually more accurate. All this is very easy to do, and in a world tainted with deceit, it substantially improves retrieval effectiveness.
MEASURING PRESTIGE
Suppose we want to return results in order of prestige, rather than in order of density of occurrence of the search terms, as the cosine rule does. Dictionaries define prestige as “high standing achieved through success or influence.” A metric called PageRank, introduced by the founders of Google and used in various guises by other search engine developers too, attempts to measure the standing of a web page. The hope is that prestige is a good way to determine authority, defined as “an accepted source of expert information or advice.”
In a networked community, people reward success with links. If you link to my page, it’s probably because you find it useful and informative—it’s a successful web page. If a whole host of people link to it, that indicates prestige: my page is successful and influential. Look at Figure 4.4, which shows a tiny fraction of the web, including links between pages. Which ones do you think are most authoritative? Page F has five incoming links, which indicates that five other people found it worth linking to, so there’s a good chance that this page is more authoritative than the others. B is second best, with four links.
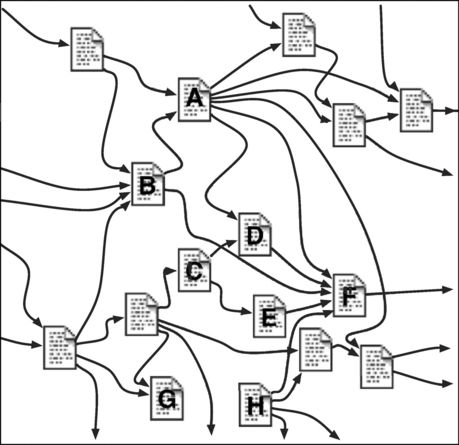
Merely counting links is a crude measure. We learned earlier that when ranking retrieval results, some words should count more than others because they are rarer and therefore more informative. Likewise, some web pages have thousands of outgoing links whereas others have just one or two. Rarer links are more discriminating and should count more than others. A link from your page to mine bestows more prestige if your page has few outlinks; less if it has many. In Figure 4.4, the many links emanating from page A mean that each link carries less weight, simply because A is a prolific linker. From F‘s point of view, the links from D and E may be more valuable than the one from A.
There is another factor: a link is more valuable if it comes from a prestigious page. The link from B to F may be better than the others into F because B is more prestigious. At first sight, this smacks of the English “old school tie” network of political elite, which bestows a phony and incestuous kind of prestige. But here it’s different: prestige is not an accident of breeding, but must be earned by attracting links. Admittedly, this factor involves a certain circularity, and without further analysis it’s not clear that it can be made to work. But indeed it can.
Underlying these ideas is the assumption that all links are bona fide ones. We fretted earlier that deceitful authors could insert misleading words into their pages to attract attention and ensure that they were returned more often as search results. Could they not also establish a fake kind of prestige by establishing phony links to their page? The answer is yes—and we will discuss this issue extensively in the next chapter. But arranging phony links is not as easy as editing the page to include misleading words. What counts are links in to the page, not links from it to others. And placing thousands of links from another page does not help much because inlinks are not just counted—their influence is attenuated by the host of outlinks from the linking page.
To summarize: We define the PageRank of a page to be a number between 0 and 1 that measures its prestige. Each link into the page contributes to its PageRank. The amount it contributes is the PageRank of the linking page divided by the number of outlinks from it. The PageRank of any page is calculated by summing that quantity over all links into it. The value for D in Figure 4.4 is calculated by adding one-fifth of the value for A (because it has five outlinks) to one-half the value for C.
Calculating PageRank
The definition is circular: how can you calculate the PageRank of a page without knowing the PageRanks of all the other pages? In fact, it’s not difficult: we use what mathematicians call an “iterative” method. Start by randomly assigning an initial value to each page. Each value could be chosen to be different, or they could all be the same: it doesn’t matter (provided they’re not all zero). Then recompute each page’s PageRank by summing the appropriate quantities, described earlier, over its inlinks. If the initial values are thought of as an approximation to the true value of PageRank, the new values are a better approximation. Keep going, generating a third approximation, and a fourth, and so on. At each stage, recompute the PageRank for every page in the web. Stop when, for every page, the next iteration turns out to give almost exactly the same PageRank as the previous one.
Will this converge? And how long does it take? These are questions for mathematicians. The answer is yes (subject to a couple of modifications discussed later). And the number of iterations depends on the desired accuracy (and other more technical factors). The relevant branch of mathematics is called linear algebra, and the web presents the largest practical problem in linear algebra that has ever been contemplated.
Mathematicians talk of the “connection matrix,” a huge array of rows and columns with each cell containing either 1 or 0. A row represents the links out of a particular web page, and a column represents the links into another web page. A 1 (one) is placed at the intersection if the row’s page contains a link to the column’s page; otherwise a 0 is written there. The number of rows and columns are both the same as the number of pages in the web. Most entries are 0 since the probability of one randomly chosen web page having a direct link to another randomly chosen page is very small.
Mathematicians have studied matrix computations for 150 years and have come up with clever methods for solving just the kind of problem that PageRank presents. One day, out of nowhere, along came the web, bearing the largest, most practical matrix problem ever encountered. Suddenly mathematicians found themselves in demand, and their expertise is at the very core of companies that trade for billions of dollars on the stock exchange.
The iterative technique described earlier is exactly what search engines use today, but the precise details are only known to insiders. The accuracy used for the final values probably lies between 10−9 and 10−12. An early experiment reported 50 iterations for a much smaller version of the web than today’s, before the details became a trade secret; several times as many iterations are probably needed now. Google is thought to run programs for several days to perform the PageRank calculation for the entire web, and the operation is—or at any rate used to be—performed every few weeks.
As we have seen, a random starting point is used. You might think that the current values of PageRank would be an excellent choice to begin the iteration. Unfortunately, it turns out that this does not reduce the number of iterations significantly over starting from scratch with a purely random assignment. Some pages—for example, those concerning news and current events—need updating far more frequently than once every few weeks. Incrementally updating the PageRank calculation is an important practical problem: you somehow want to use the old values and take into account changes to the web—both new pages (called node updates) and new links on old pages (link updates). There are ways of doing this, but they don’t apply on a sufficiently large scale. Perhaps an approximate updating is good enough? This is an active research area that you can be sure has received a great deal of attention in search engine companies.
The Random Surfer
There are two problems with the PageRank calculation we have described, both relating to the bow tie structure of the web depicted in Figure 3.4. You probably have a mental picture of PageRank flowing through the tangled web of Figure 4.4, coming into a page through its inlinks and leaving it through its outlinks. What if there are no inlinks (page H)? Or no outlinks (page G)?
To operationalize this picture, imagine a web surfer who clicks links at random. If he (or she, but perhaps young males are more likely to exhibit such obsessive behavior) is on a page with a certain number of outlinks, he chooses one at random and goes to that link’s target page. The probability of taking any particular link is smaller if there are many outlinks, which is exactly the behavior we want from PageRank. It turns out that the PageRank of a given page is proportional to the probability that the random surfer lands on that page.
Now the problem raised by a page with no outlinks (G) becomes apparent: it’s a PageRank sink because when the surfer comes in, he cannot get out. More generally, a set of pages might link to each other but not to anywhere else. This incestuous group is also a PageRank sink: the random surfer gets stuck in a trap. He has reached the corporate continent.
And a page with no inlinks (H)? The random surfer never reaches it. In fact, he never reaches any group of pages that has no inlinks from the rest of the web, even though it may have internal links, and outlinks to the web at large. He never visits the new archipelago.
These two problems mean that the iterative calculation described earlier does not converge, as we earlier claimed it would. But the solution is simple: teleportation. With a certain small probability, just make the surfer arrive at a randomly chosen web page instead of following a link from the one he is on. That solves both problems. If he’s stuck in the corporate continent, he will eventually teleport out of it. And if he can’t reach the new archipelago by surfing, he will eventually teleport into it.
The teleport probability has a strong influence on the rate of convergence of the iterative algorithm—and on the accuracy of its results. At the extreme, if it were equal to 1, meaning that the surfer always teleported, the link structure of the web would have no effect on PageRank, and no iteration would be necessary. If it were 0 and the surfer never teleported, the calculation would not converge at all. Early published experiments used a teleportation probability of 0.15; some speculate that search engines increase it a little to hasten convergence.
Instead of teleporting to a randomly chosen page, you could choose a predetermined probability for each page, and—once you had decided to teleport—use that probability to determine where to land. This does not affect the calculation. But it does affect the result. If a page were discriminated against by receiving a smaller probability than the others, it would end up with a smaller PageRank than it deserves. This gives search engine operators an opportunity to influence the results of the calculation—an opportunity that they probably use to discriminate against certain sites (e.g., ones they believe are trying to gain an unfair advantage by exploiting the PageRank system). As we will see in Chapter 6, this is the stuff of which lawsuits are made.
COMBINING PRESTIGE AND RELEVANCE
For a one-word query, we have suggested locating all pages that contain the word and returning them in order of prestige, that is, PageRank. But what about the number of occurrences of the word: shouldn’t that be taken into account? And, more importantly, what about multiword queries? Ordinary ranked retrievals treat multiword queries as OR queries and calculates the cosine measure for each document to determine its relevance. The prestige model suggests sorting retrieved documents by PageRank instead.
Because the web is so vast, popular search engines treat all queries as AND queries, so that every returned page contains all the search terms. However, that does not solve the problem: there is still the question of how many times the search terms appear in each page. Moreover, search engines modulate the influence of terms in the page using a number of heuristics. A word appearance is more important if it
• occurs in the document’s URL
• occurs in a larger font than the rest of the document
Actually, this is all guesswork. No one knows the precise set of factors used by search engines. Some guesses are likely to be wrong, or change over time. For example, in an ideal world, words in HTML metatags ought to be especially important, because they are designed to help characterize the content of the document. But in the web’s early days, tags were widely misused to give an erroneous impression of what the document was about. Today’s search engines may treat them as more influential, or less, or ignore them, or even use them as negative evidence. Who knows? Only insiders.
All these factors are combined with the PageRank of the returned document—which clearly plays a dominant role—into a single measure, and this is used to sort documents for presentation to the user. The recipe is a closely guarded secret—think of it as the crown jewels of the search engine company—and, as we will learn in the next chapter, changes from one month to the next to help fight spam.
HUBS AND AUTHORITIES
The PageRank concept was invented by Google founders Larry Page and Sergey Brin in 1998, and its success was responsible for elevating Google to the position of the world’s preeminent search engine. According to the Google website, “the heart of our software is PageRank … it provides the basis for all of our web search tools.” An alternative, also invented in 1998, was developed by leading computer science academic Jon Kleinberg. Called HITS, for Hypertext-Induced Topic Selection, it has the same self-referential character as PageRank, but the details are intriguingly different. Though their work proceeded independently, Page/Brin’s and Kleinberg’s papers cite each other.
Whereas PageRank is a single measure of the prestige of each page, HITS divides pages into two classes: hubs and authorities. A hub has many outlinks; a good hub contains a list of useful resources on a single topic. An authority has many inlinks and constitutes a useful source document. Good hubs point to good authorities; conversely, good authorities are pointed to by good hubs. In Figure 4.4, page F looks like a good authority, while A may be a good hub.
In this model, each page has two measures, hub score and authority score. The hub score is the sum of the authority scores of all the pages it links to. The authority score is the sum of the hub scores of all the pages that link to it. Although—like PageRank—this sounds circular, the solution can be formulated as a problem in linear algebra based on the web’s connection matrix, that gargantuan array of 1s and 0s mentioned earlier.
FINDING HUBS AND AUTHORITIES FOR A QUERY
The HITS method uses the formulation in a rather different way from PageRank. Instead of applying it once and for all to the whole web, it computes hub and authority scores that are particular to the query at hand. Given a query, a set of related pages is determined as follows. First, all pages that contain the query terms are located and placed in the set. Next, the pages that are linked to by these original set members (that is, have inlinks from them), and the pages that the original set members link to (the ones they have outlinks to), are added to the set. The process could be continued, adding neighbors linked in two steps, three steps, and so on, but in practice the set is probably quite large enough already. Indeed, it may be too large: perhaps, though all query-term pages were included, only the first 100 pages that each one points to should be added, along with the first 100 pages that point to each query-term page.
The result is a subgraph of the web called the neighborhood graph of the query. For each of its pages, hub and authority scores are derived using the same kind of iterative algorithm that we described earlier for PageRank. Mathematical analysis shows that division into hubs and authorities sidesteps some of the PageRank algorithm’s convergence problems—problems that the teleportation option was introduced to solve. However, lesser convergence problems can still arise, and similar solutions apply. Of course, the computational load is far smaller than the PageRank calculation because we are dealing with a tiny subset of the web. On the other hand, the work must be redone for every query, rather than once a month as for PageRank.
A nice feature of HITS is that it helps with synonyms. A classic problem of information retrieval is that many queries do not return pertinent documents, merely because they use slightly different terminology. For example, search engines like Google do not return a page unless it contains all the query terms. HITS includes other pages in the neighborhood graph—pages that are linked to by query-term pages, and pages that link to query-term pages. This greatly increases the chance of pulling in pages containing synonyms of the query terms. It also increases the chance of pulling in other relevant pages. To borrow an example from Kleinberg, there is no reason to expect that Toyota’s or Honda’s home pages should contain the term automobile manufacturers, yet they are very much authoritative pages on the subject.
USING HUBS AND AUTHORITIES
The user will find the list of hubs and authorities for her query very useful. What the algorithm has computed is a hub score and an authority score for every page in the neighborhood graph—which includes every page containing all the query terms. Those with the highest authority scores should be the best authorities on the query, even though they do not necessarily contain all (or indeed any) of the query terms. Those with the highest hub scores will be useful for finding links related to the query. Depending on the application, hubs may be even more useful than authorities. Sometimes there is nothing more valuable than a good reading list.
One obvious drawback of HITS is the computational load. Whereas PageRank is query-independent, HITS is not. It seems far easier to undertake an offline calculation of PageRank every few weeks than to compute hubs and authorities dynamically for every query. And PageRank, a general measure of the prestige of each page, is useful for many other purposes—for example, it’s an obvious yardstick for deciding which sites to crawl more frequently in an incremental update. On the other hand, HITS does not need incremental updates: hubs and authorities are computed afresh for every query. (In practice, though, caching is used for frequent queries.)
HITS is easier to spam than PageRank. Simply adding to your web page outlinks that point to popular pages will increase its hub score. From a web page owner’s point of view, it is far easier to add outlinks than inlinks, which are what PageRank uses. For a more systematic spam attack, first you create a good hub by linking to many popular pages. Then, you populate it with lots of different words to maximize its chance of being selected for a query. Having created a few good hubs, you create a good authority by pointing the hubs at them. To make matters worse (or, depending on your point of view, better), HITS does not offer the search engine operator the opportunity to combat spam by tweaking the teleportation probability vector. However, an advantage of HITS is that it is more transparent than PageRank because it doesn’t involve a secret recipe for combining relevance with prestige.
HITS suffers from a problem called topic drift. If the pages selected for a query happen to contain a strikingly authoritative document on a cognate topic, its rating may rise above that of more relevant documents. Suppose the query is for Sauvignon Blanc (a fine New Zealand wine). A high-quality hub page devoted to New Zealand wine might have links to Chardonnay and Pinot Noir too. If the page is a universally good hub, the pages about Chardonnay and Pinot Noir will be good authorities and will occur high up the list of search results, even though they are not really relevant to the query. In the HITS algorithm, once the neighborhood graph has been built, the query plays no further role in the calculations.
HITS can be extended with heuristics to address this problem. One might insist that returned pages be a good match to the query terms independent of their status as authorities, or identify interesting sections of web pages and use these sections to determine which other pages might be good hubs or authorities.
DISCOVERING WEB COMMUNITIES
Within a fair-sized subset of the web, it seems plausible that you could identify several different communities. Each one would contain many links to the web pages of other community members, along with a few external links. Scientific communities are a good example: biologists will tend to link to web pages of other biologists. Hobbies provide another: the home pages or blog entries of people interested in, say, skateboarding might exhibit similar link targets.
It has long been known that a simple mathematical technique—simple, that is, to mathematicians—can be used to identify clusters of self-referential nodes in a graph like the web. People call this “social network analysis,” but the details involve advanced mathematical concepts that we will not explain here (eigenvalues and eigenvectors). It would be fascinating to apply these techniques to the web graph, but because of its immense size, this is completely impractical.
The fact that HITS works with a far more manageable matrix than the entire web opens the door to new possibilities. The hub and authority scores found by the iterative algorithm we have described represent the structure of just one of the communities—the dominant one. Other techniques can be used to calculate alternative sets of hub/authority scores, many of which represent particular identifiable subcommunities of the original set of web pages. These might give more focused results for the user’s query.
Consider the neighborhood graph for the Sauvignon Blanc query mentioned earlier, and recall that pages containing the query terms have been augmented by adding linking and linked-to pages as well. It might include many pages from a New Zealand wine community, as well as subcommunities for Sauvignon Blanc, Chardonnay, and Pinot Noir—and perhaps for individual wine-growing regions too. Each community has its own hubs and authorities. Rather than simply returning a list of search results, a query gives an entrée into the entire space, created on the fly by the search engine. The original broad topic is distilled—an appropriate metaphor for this example—into subtopics, and high-quality pages are identified for each one.
Is it really feasible for a search engine to do all this work in response to a single user’s query? Are social network algorithms efficient enough to operate on the fly? A 1999 research project reported that it took less than a minute of computation to process each query—fast, but nowhere near fast enough to satisfy impatient users, and far beyond what a mass-market search engine could afford. Of course, just how search engines work is a closely guarded secret. This is why mathematicians expert in matrix computation suddenly became hot property.
The Teoma search engine, at the core of the Ask web search service, organizes websites relevant to a query into naturally occurring communities that relate to the query topic.30 These communities are presented under a Refine heading on the results page, and allow users to further focus their search. According to Teoma’s website, a search for Soprano would present the user with a set of refinement suggestions such as Marie-Adele McArthur (a renowned New Zealand soprano), Three Sopranos (the operatic trio), The Sopranos (a megapopular U.S. television show), and several other choices. In practice, however, many of the subcommunities that Teoma identifies are not so clear-cut.
As with any HITS-based technique, the search results include hubs and authorities for the query. Authorities are listed in the form of conventional search results—documents that satisfy the query. Hubs are portrayed as a set of resources: sites that point to other authoritative sites and give links relating to the search topic. The Teoma website mentions an example of a professor of Middle Eastern history who has created a page devoted to his collection of websites that explain the geography and topography of the Persian Gulf. That page would appear under the heading Resources in response to a Persian Gulf–related query.
There has been a great deal of discussion about how well the method described earlier works. Does it really discover good and useful communities? Examples of anomalous results abound. For instance, at one time a search for jaguar reputedly converged to a collection of sites about the city of Cincinnati, because many online articles in the local newspaper discuss the Jacksonville Jaguars football team, and all link to the same Cincinnati Enquirer service pages. The HITS method ranks authorities based on the structure of the neighborhood graph as a whole, which tends to favor the authorities of tightly knit communities. An alternative is to rank authorities based on their popularity in their immediate neighborhood, which favors authorities from different communities.
BIBLIOMETRICS
Some of the ideas underlying both PageRank and HITS echo techniques used in bibliometrics, a field that analyzes the citation or cross-reference structure of printed literature. Scientists are ranked on the basis of the citations that their papers attract. In general, the more citations your papers receive from highly ranked scientists, the greater your prestige. But citations carry more weight if they come from someone who links to a few select colleagues. Even a mention by a Nobel Prize winner counts for little if that person tends to cite copiously. There’s also a parallel to teleporting: scientists with no citations at all still deserve a nonzero rank.
The impact factor, calculated each year by the Institute for Scientific Information (ISI) for a large set of scientific journals, is a widely used measure of a journal’s importance. Impact factors have a huge, though controversial, influence on the way published research is perceived and evaluated. The impact factor for a journal in a given year is defined as the average number of citations received by papers published in that journal over the previous two years, where citations are counted over all the journals that ISI tracks. In our terms, it is based on a pure counting of inlinks.
More subtle measures have been proposed, based on the observation that not all citations are equally important. Some have argued that a journal is influential if it is heavily cited by other influential journals—a circular definition just like the one we used earlier for “prestige.” The connection strength from one journal to another is the fraction of the first journal’s citations that go to papers in the second. In concrete terms, a journal’s measure of standing, called its influence weight, is the sum of the influence weights of all journals that cite it, each one weighted by the connection strength. This is essentially the same as the recursive definition of PageRank (without the problem of pages with no inlinks or no outlinks). The random surfer model applies to influence weights too: starting with an arbitrary journal, you choose a random reference appearing in it and move to the journal specified in the reference. A journal’s influence weight is the proportion of time spent in that journal.
What about HITS? The scientific literature is governed by quite different principles than the World Wide Web. Scientific journals have a common purpose and a tradition of citation (enforced by the peer review process), which ensures that prestigious journals on a common topic reference one another extensively. This justifies a one-level model in which authorities directly endorse other authorities. The web, on the other hand, is heterogeneous, and its pages serve countless different functions. Moreover, the strongest authorities rarely link directly to one another—either they are in completely different domains, or they are direct competitors. There are no links from Toyota’s website to Honda’s, despite the fact that they have much in common. They are interconnected by an intermediate layer of relatively anonymous hub pages, which link to a thematically related set of authorities. This two-level linkage pattern exposes structure between the hubs, which are likely unaware of one another’s existence, and authorities, which may not wish to acknowledge one another for commercial reasons.
LEARNING TO RANK
Analyzing huge networks containing immense amounts of implicit information will remain a fertile research area for decades to come. Today it is bubbling with activity—which is not surprising, considering that the search engine business is populated by a mixture of mathematicians and multimillionaires. The only thing we can be sure of is that radical new methods will appear, perhaps ousting today’s megadragons. The book is by no means closed on search engine technology.
One way of tackling the problem of how to rank web pages is to use techniques of machine learning. First, create a “training set” with many examples of documents that contain the terms in a query, along with human judgments about how relevant they are to that query. Then, a learning algorithm analyzes this training data and comes up with a way to predict the relevance judgment for any document and query. This is used to rank queries in the future.
There is no magic in machine learning: these are perfectly straightforward algorithms that take a set of training data and produce a way of calculating judgments on new data. This calculation typically uses numeric weights to combine different features of the document—for example, the features listed earlier (page 118) when discussing how prestige and relevance are combined into a single page rank value. It might simply multiply each numeric feature value by its weight and add them all together. The weights reflect the relative importance of each feature, and training data are used to derive suitable values for them, values that produce a good approximation to the relevance judgments assigned to the training examples by human evaluators. Of course, we want the system to work well not just for the training data, but for all other documents and queries too.
We cannot produce a different set of weights for each query—there are an infinite number of them. Instead, for each document, a set of feature values is calculated that depends on the query term—for example, how often it appears in anchor text, whether it occurs in the title tag, whether it occurs in the document’s URL, and how often it occurs in the document itself. And for multiterm queries, values could include how often two different terms appear close together in the document, and so on. The list mirrors that on page 118. There are many possible features: typical algorithms for learning ranks use several hundred of them—let’s say a thousand. Given a query, a thousand feature values are computed for every document that contains the query terms and are combined to yield its ranking. They may just be weighted and added together. Some machine learning techniques combine them in ways that are a bit more complex than this, but the principle remains the same.
The trick is to derive the one thousand weights from the training data in a way that yields a good approximation to actual human judgments. There are many different techniques of machine learning. Microsoft’s MSN search engine uses a technique called RankNet which employs a “neural net” learning scheme. Despite its brainy anthropomorphic name, this need not be any more complex than calculating a weight for each feature and summing them up as described earlier.
Although the actual details of how MSN employs RankNet are a commercial secret, the basic idea was described in a 2005 paper by Microsoft researchers. Given a query, they calculated 600 features for each document. They assembled a training set of 17,000 queries, with almost 1000 documents for each one. Human evaluators judged the relevance of a few of the documents that contained the query terms on a scale of 1 (“poor match”) to 5 (“excellent match”), but for each query an average of only about 10 documents were labeled. The majority of queries and documents were used for training, and the remainder were kept aside for independent testing. Evaluation focused on assessing the quality of ranking on the top 15 documents returned, on the basis that most users rarely examine lower-ranked documents. The authors conclude that, even using the simple weighted linear sum described earlier, the system yields excellent performance on a real-world ranking problem with large amounts of data. If more complex ways were used to combine the features, performance was better still.
The clever part was the way the training data were used. Given a query and a document, values are calculated for all 600 features. The set of 600 numbers is a single training example. The innovative feature of the learning method was to take pairs of training examples with the same query but different documents. Each example has a relevance judgment between 1 and 5, and the essential feature of an example pair is not the particular values—after all, they are on an arbitrary scale—but which of the pair is ranked higher than the other. Pairing up examples had the twin effect of greatly multiplying the number of different inputs, and eliminating the arbitrariness of the rating scale. Although the details are beyond the scope of this book, this ingenious idea allowed the researchers to thoroughly train the neural net on what was, compared with the size of the web, a puny example set.
Learning techniques have the potential to continually improve their performance as new data are gathered from the users of a search engine. Suppose a query is posed, and the user picks some of the documents that are returned and indicates “I like these ones,” perhaps even giving them a score, and picks others and clicks a button to say “These are red herrings.” This provides new training data for the learning algorithm, which can be used offline to improve the ranking method by altering the weights to give better performance.
Judgments of which documents are approved and disapproved gives a rich set of additional information for the search engine to use. In practice, harried users are hardly likely to give explicit feedback about every document in the search results. However, information can be gleaned from the user’s subsequent behavior. Which documents does he click on, how long does he dwell on each one? Are her needs satisfied, or does she return to search again? There is a lot of information here, information that could be used to improve search performance in general. It could also be used to improve results for specific searches. As we will learn shortly, typical queries are not unique but are issued many times—sometimes hundreds of thousands of times—by different users. The subsequent behavior of each user could be integrated to provide an enormous volume of information about which documents best satisfy that particular query.
You might object that once you have made a query, search engines do not get to see your subsequent behavior. However, they could very well intercept the clicks you make on the search results page: it’s not hard to arrange to return information about which link is clicked by redirecting the link back through the search engine’s own site. Still, it seems hard for them to determine information about your subsequent behavior: how long you spend with each document, or what you do next. But that depends. Who wrote the web browser? Have you downloaded the Google toolbar (a browser add-on)? If the outcome improves the results of your searches, you might well be prepared to share this information with the dragons. After all, you’re sharing your queries.
Full-text search, the classic method of retrieval, uses information supplied by authors—the document text. Link analysis, the innovation of Google and company, uses information supplied by other authors—the links. User feedback, perhaps the next wave, uses information supplied by users—readers, not writers. It’s potentially far more powerful because it is these end users, not the authors, who are actually doing the searching.
DISTRIBUTING THE INDEX
How search engines deliver the goods is one of the marvels of our world. Full-text search is an advanced technology, the kind you learn about in computer science graduate school. Although the concepts are simple, making them work in practice is tricky. Leading search engines deal with many thousands of queries per second and aim to respond to each one in half a second or less. That’s fast! Though computers may be quick, this presents great challenges. Leading search engines deal with many terabytes—even petabytes—of text. That’s big! Though disks may be large and cheap, organizing information on this scale is daunting. But the real problem is that with computers, time and space interact. If you keep everything in main memory, things go fast. If you put it on disk, they can be big. But not both together.
Couple full-text searching with link analysis: searching in a web. We have already seen the general idea, but heavy theory lurks behind. This involves a different set of skills, the kind you learn about in math graduate school. Calculating PageRank is hard enough, but building the neighborhood graph’s connection matrix and analyzing it to determine communities require sophisticated techniques. Combining prestige and relevance, and finding good ways to take into account the various types and styles of text, involve tedious experimentation with actual queries and painstaking evaluation of actual search results. All these variables will affect your company’s bottom line tomorrow, in a hotly competitive market.
An even greater technical marvel than fast searching and web analysis is the standard of responsiveness and reliability set by search engines. They involve tens or hundreds of thousands of interlinked computers. In part, speed and reliability are obtained by having separate sites operate independently. If the lights go out in California, the site in Texas is unaffected. Your query is automatically routed to one of these sites in a way that balances the load between them, and if one is down, the others silently share its burden.
At each site, the index and the cached web pages are divided into parts and shared among many different computers—thousands of them. Specially designed supercomputers are uneconomical; it’s cheaper to buy vast arrays of standard machines at discount prices. Each one resembles an ordinary office workstation, loaded with as much memory and disk as it can hold in the standard way without going to special hardware. But the machines are not boxed like office workstations; they are naked and mounted en masse in custom-designed racks.
Creating and operating the network presents great challenges. Most search engine companies (except Microsoft) probably use the Linux operating system—Google certainly does. Wherever possible, they use open source software—for databases, for compressing the text, for processing the images, for the countless routine tasks that must be undertaken to maintain the service to users.
When you have ten thousand computers, you must expect many failures. One calendar day times ten thousand corresponds to 30 years, a human generation. How many times does your computer fail in a generation? With so many machines, you must plan for a hundred failures every day. The system monitors itself, notices wounds, isolates them, and informs headquarters. Its human operators are kept busy swapping out complete units and replacing them with new ones. Since you must plan for failure anyway, why not buy cheaper, less reliable machines, with cheaper, less reliable memory?
DEVELOPMENTS IN WEB SEARCH
There are many developments in the air that could radically affect the search process. Web pages are beginning to be expressed in different ways. The HTML and XML languages described in the last chapter, and the way that servers can process them, have turned out to be extraordinarily flexible and are beginning to be employed in new ways as web usage evolves. We will briefly introduce three trends that are affecting (or will affect) how search works: blogs, a lightweight way of supporting commentary and collaboration introduced in Chapter 3 (page 76); AJAX, a new technical way of making web pages more interactive by breaking them down into small pieces; and—by far the most ambitious—the semantic web, a vision of how automated computer “agents” could be provided with the same kind of web services as human users are today. These are just examples of forthcoming changes in how the World Wide Web will work.
SEARCHING BLOGS
Searching the “blogosphere”—for that’s what bloggers call their information environment—is similar to searching the web, with two exceptions. First, freshness of information plays a crucial role. Most blog retrieval systems allow users to indicate whether to sort results by relevance or by date. In this domain, only recent entries are regarded as important information.
Second, blog authors usually attach metadata tags to their entries to describe the subject under discussion. (Blog entries also include trackbacks, which are links to other sites that refer to that entry, and a blogroll, which is a list of other blogs read by the author.) This metadata can be exploited when searching to make it easier to retrieve relevant blogs on a particular topic.31 However, as blogging spreads, so does the lack of agreement on the meaning of tags. Free and easy tagging is becoming a mixed blessing: on one hand, the simplicity of annotation encourages the assignment of metadata, while on the other, tags become ineffective at retrieval time because there is no standardization of terms. We return to this dilemma when discussing folksonomies in Chapter 7 (page 231).
AJAX TECHNOLOGY
AJAX, an acronym for “asynchronous JavaScript and XML,” is growing ever more popular as we write. While the details are shrouded in technospeak, think of it as a way of updating little bits of web pages without having to re-download the whole page. When you click on links in websites today, whole new pages are downloaded—and web crawlers emulate this in order to find pages to index. However, if the link is an internal one, much of the page content may remain the same and shouldn’t have to be retransmitted—such as all the branding and navigation information. With AJAX, the web server can arrange to download just that little piece of information that does change, and slot it into the right place on the existing page. Web browsers are powerful pieces of software, quite capable of doing this. The result is a far more reactive system, with faster access—it feels as though things are happening locally on your machine instead of remotely over the web.
This idea is likely to be widely adopted: we return to it in Chapter 7, when we talk about future developments, and predict that you will ultimately use the web as a global office. (Google already uses AJAX in its GMail system.) AJAX has immense implications for the search environment. Websites will send information to your browser in little nuggets, not as fully contextualized pages. Should nuggets be indexed individually, or in the context of the page in which they occur? Which would you prefer? These are issues for the search engine gurus to ponder.
THE SEMANTIC WEB
The web was made for people, conceived as a universal library in which we read, write, and organize our thoughts. It is not a congenial environment for machines that aspire to work alongside humans. Again and again in this book, we have come up against the same limitation. The dragons, and other systems that mediate access to knowledge on the web, simply do not understand what you are talking about. More to the point, they don’t understand what the web page you are reading is talking about either.
Remember that delicious dessert you ate when you visited the Tyrol? If you asked your landlady or concierge there—or any person of a certain age—how to make the popular local pastry, they would immediately know you were talking about apple strudel and give you the recipe. Try that on the web! No problem if you remember the name, but otherwise you must rely on luck, perseverance, and considerable skill.
This is a situation that requires you to make an inference to come up with the answer. First, find the name of the most popular Tyrolean dessert; then, seek the recipe. Today’s dragons do not perform reasoning, even at this modest level of sophistication. The first part is the hard bit, but the web’s resources can be brought to bear on this kind of problem. An agent connects to a search engine through a back door, poses a query, downloads the responses, and processes the text to ascertain the necessary information. Just as people access web applications over the Internet to obtain and process information, so can machines, through what are called web services. For this to succeed in general on a large scale, we must clarify how the machines are to exchange knowledge.
The semantic web is an attempt to enrich web pages so that machines can cooperate to perform inferences in the way that people do. Computers find human inference hard to emulate because of the difficulty of processing natural language—anyone who has written a program to extract information from text knows this all too well. On the other hand, there is a compelling motivation to equip machines to perform tasks by exploiting the treasure of information on the web. The idea behind the semantic web is to give information a well-defined meaning specifically in order to enable interaction among machines. Today’s web is for people; tomorrow’s semantic web will be for machines too.
We have explained in Chapter 3 (page 78) how the extensible markup language (XML) can be used to embed structured data in a document, alongside the unstructured text. This is the first step toward incorporating information specifically aimed at facilitating mechanical interpretation. The second is to exploit the flexibility of the web’s mechanism for identifying resources. A Universal Resource Identifier (URI) can be given to anything, not just web pages, and anything with a URI can become the subject of reasoning on the semantic web. A further level of abstraction is achieved by describing relationships between resources in a way that can be processed by machines. Consider this three-part statement:
It’s not difficult to guess its meaning. The first URI is the subject of the statement, namely, the web page on Felix the cat. The second is a predicate that relates the subject to the object, represented by the third. The predicate expresses the meaning, which is that Felix likes fish. This way of describing relations between resources is called the Resource Description Framework, or RDF, and provides a simple way to express statements about web resources.
RDF statements can claim nearly anything—even contradictions. The preceding example was expressed as a triple, in which URIs identify the subject, predicate, and object. Unlike web pages, a collection of statements expressed in this way presents a clear structure. When browsing pages about Felix, people readily learn that the cat likes fishing. Although machines cannot interpret the text, the RDF statement expresses the same information. However, just as the page’s text does not explain the meaning of the terms it employs, neither does the RDF. To make use of the information, we must describe what subject, predicate, and object mean.
The semantic web accomplishes this using ontologies. The word derives from Greek onto and logia, meaning “being” and “written or spoken discourse.” An ontology is a formal description of the concepts and relationships that can exist for a community of agents. Recall from Chapter 1 Wittgenstein’s obsession with the social nature of language, the fact that language is inseparable from community. Now the community includes computers—programmed agents. A formal description is what is needed to allow machines to work with concepts and relationships, and build bridges among related concepts. Machines can then interpret these statements and draw conclusions—perhaps putting the result of their deliberations back on the web.
The semantic web is a huge challenge, conceived by Tim Berners-Lee, the father of the web. If successful, it will open the door to a panoply of new web applications. However, its growth has been throttled by the effort needed to create RDF statements and ontologies. The web’s new form may not share the elegant simplicity that underpins the original design and fuelled its explosion into our lives.
The semantic web envisions a paradigm shift. The emphasis is no longer on documents alone, but on documents backed up with fragments of data arranged to support automated reasoning. The new web will not be for people only, but for machines too, which will join with people in new partnerships. If the dream comes to fruition, its impact will extend far beyond the dragons and into our daily lives. It will bring the web one step closer to real life—or vice versa.
BIRTH OF THE DRAGONS
The Internet opened for business in 1973 when the U.S. Defense Advanced Research Projects Agency (DARPA) began a research program designed to allow computers to communicate transparently across multiple networks. The early Internet was used by computer experts, engineers, and scientists. There were no home or office computers, and the system was arcane and complex to use. You could only access a computer on the network if you had an account on it, in which case you could log in remotely. As a goodwill gesture, many sites provided guest accounts that were open to all, but these had few privileges and there was little you could do.
The first modern file transfer protocol (FTP) was defined in 1980, following early efforts dating back to the beginning of the Internet. At first, you needed an account on the remote computer to transfer files from it, but in another friendly gesture, an “anonymous” variant was developed. Anyone could open up anonymous FTP on a remote computer that supported it and take a look at what files it made available. (For resource reasons, you couldn’t transfer files to sites anonymously.)
There was no way to find anything unless you already knew where it was, and what the file was called. Nevertheless, at last this vast network of computers was able to do something useful for people who were not affiliated with the big projects that provided accounts on remote computers. You could put your files up under anonymous FTP on your computer, tell your friends, and they could download them. But it wasn’t easy: the commands for using the file transfer protocol were (and still are) arcane and nerdy.
THE WOMB IS PREPARED
Now all the structure was in place to support the automatic creation of an index, and there was a growing need for one—for there was no way to find anything in the FTP jungle except by asking people. In 1989, a group at McGill University in Canada wrote a program that automatically connected to FTP sites, which were commonly called “archives,” and built up a directory of what files were there. They supplied it with a set of sites and let it loose. It updated the directory by reconnecting to each site once a month, politely avoiding soaking up excessive resources on other people’s computers. The program was called Archie, an abbreviation for archives—although it did not download or archive the files themselves, but only listed their names. To search the directory for a file of a particular name, or whose name matched a particular pattern of characters, you again had to use arcane commands. But with patience and computer expertise, you could now find things.
Two years later, a more usable substrate was developed for the files that were proliferating on the publicly accessible Internet. Originally designed to give access to information in files on the University of Minnesota’s local network, it was called Gopher, after the University mascot. Built on a simple protocol that allowed distributed access to documents on many servers, Gopher presented users with a menu of items and folders much like a hierarchical file system, Menu items could point to resources on other computers. At last, you could look at the Internet without being a computer expert: you just typed or clicked on a number to indicate the desired menu selection. Selecting a file downloaded it; selecting a folder took you to its files—which could be on another computer.
This software was distributed freely and became very popular. Within a few years, there were more than 10,000 Gophers around the world. But in 1993, the University of Minnesota announced that they would charge licensing fees to companies that used it for commercial purposes, which some believe stifled its development. (They later relented, relicensing it as free, open-source software.)
Archie had to be provided with an explicit list of sites to index. But Gopher links could point to other computers, paving the way for an automatically produced directory of files on different sites. And the ease that Gopher brought to navigation inspired a similar menu-based scheme to access the directory. A radical and whimsically named scheme called Veronica—ostensibly an acronym for “Very Easy Rodent-Oriented Netwide Index to Computerized Archives” but actually the name of Archie’s girlfriend in the well-known comic strip—crawled Gopher menus around the world, collecting links for the directory. It was a constantly updated database of the names of every menu item on thousands of Gopher servers. News of Veronica spread like wildfire from the University of Nevada at Reno, where it was created. The service rapidly became so popular that it was difficult to connect to—the first of many “flash crowds” on the Internet—and sister sites were developed to spread the load. Meanwhile, acronym creativity ran rampant, and Archie’s best friend Jughead entered the arena as Jonzy’s Universal Gopher Hierarchy Excavation And Display, providing a Veronica-like directory for single sites.
Across the Atlantic Ocean, the World Wide Web was in the crucible at CERN, the European Laboratory for Particle Physics. Sir Tim Berners-Lee, knighted in 2004 by Queen Elizabeth for his services to the global development of the Internet, proposed a new protocol for information distribution in 1989, which was refined and announced as the World Wide Web in 1991. This was an alternative to Gopher’s menu-oriented navigation scheme, and it eradicated the distinction between documents and menus. Menus could be enriched with free text and formatting commands, making them into documents. Conversely, links to other documents could be embedded within a document. Hypertext was an active research area at the time, and the web was a simple form of hypertext that exploded onto the scene like a supernova in left field, blinding every player and all but obliterating the hypertext research community.
Uptake was slow at first, because Berners-Lee’s software only worked on the soon-to-be-obsolete NeXT computer, and although browsers for other platforms soon appeared, the early ones did not allow images to be displayed. Its rapid uptake in the mid-1990s is attributed to the emergence of the Mosaic web browser, followed by Netscape Navigator, a commercial version.
THE DRAGONS HATCH
As the World Wide Web became established, a clutch of search engines hatched, built mostly by creative students who were just playing around. The first crawler was the World Wide Web Wanderer in 1993, whose purpose was not to index the web, but to measure its growth. It caused controversy by hogging network bandwidth, downloading pages so rapidly that servers crashed. In response to these problems, Aliweb—whose expansion, “Archie-Like Index of the Web,” betrays its inspiration—was created and still lives today. Instead of automatic crawling, Aliweb invited users to submit web pages along with their own description. By year’s end, these two were joined by JumpStation, which gathered the title and header from web pages and used a simple linear search to retrieve items. (The part-time product of a junior systems administrator at Stirling University in Scotland, JumpStation was abruptly terminated when some prestigious U.S. institutions complained to the university’s Director of Computing Services about mysterious downloads.) The World Wide Web Worm built a proper search index and so became the first scalable search engine. These early systems all listed search results in whatever order they had crawled the sites.
In 1994, full-text indexing began. The first to index entire web pages was WebCrawler. Soon followed Lycos, which provided relevance ranking of search results and other features such as prefix matching and word proximity. An early leader in search technology and web coverage, by late 1996 Lycos had indexed a record 60 million pages. Begun at Carnegie Mellon University, Lycos went commercial in 1995 and public in 1996. Infoseek also began in 1994. The search engine Hotbot was introduced in 1996 using software from Inktomi, written by two Berkeley students. In 1997, Ask Jeeves and Northern Light were launched.
OpenText, another early system, taught search operators a sharp lesson. It quickly sank into obscurity when it introduced a “preferred listings” scheme that allowed you to gain exposure by purchasing the top spot for a query. You chose a term and it guaranteed your website priority listing whenever a user sought that term. Ever since, most search engines have taken great care to distinguish advertisements from search results and to make it clear to the public that placement in the search results cannot be bought. Of course, users have no way of checking this: search engine companies trade on trust. Did you know that publishers pay Amazon to have their books listed first in response to user’s queries?
Unlike most search engines, AltaVista (“a view from above”) did not originate in a university project. It was developed by the computer manufacturer Digital Equipment Corporation and was designed to showcase their new Alpha range of computers. A public advertisement of the product, it was engineered for extreme responsiveness and reliability, a hallmark of the search engine business today. AltaVista was backed up by computing resources of unprecedented size and an exceptionally fast Internet connection. It opened its doors to the public in December 1995 with an index of 16 million web pages. Its astounding speed immediately made it the market leader, a favorite of information professionals and casual users alike—a position it held for years. It started to decline with the advent of Google and with changes in its parent company’s business direction. Eventually spun off as an independent company intending to go public, it was instead acquired by an Internet investment company. Relaunched in 2002, it offered some innovative features—including BabelFish, an automatic translation service for web pages. It was purchased in 2003 for a small fraction of its valuation three years earlier and is now part of the Yahoo empire.
Google led a second generation of search engines that adopted the revolutionary new idea of looking beyond a document’s text to determine where to place it in the search results. Until Google’s appearance in 1998, search engines followed the classic model of information retrieval: to see whether a document is a good match to a query, you need only look inside the document itself. The new insights were that you can help determine what a page is about by examining the links into it, and—even more importantly—you can assess its prestige by analyzing the web matrix.
THE BIG FIVE
Search engines were the brightest stars in the Internet investing frenzy of the late 1990s. Several companies made spectacular market entries with record gains during their initial public offerings. Now, most have dismantled their public search engine and concentrate on behind-the-firewall search products for large companies. From this market shakedown, five major players remained in 2005: Google, Yahoo, MSN Search, AOL, and Ask. This list is in order of their mid-2006 popularity in searches per day in the United States: Google with 49 percent, followed by Yahoo with 23 percent, MSN with 10 percent, AOL with 7 percent, and Ask with 2 percent, leaving 9 percent for others. At the time Google’s dominance was even more apparent in the international market, with more than 60 percent of searches according to some reports.
As we mentioned when discussing PageRank, Google was founded by Stanford graduate students Larry Page and Sergey Brin. The name is a play on the word googol, which refers to the number represented by the digit 1 followed by 100 zeros. Google began in September 1998 in the time-honored manner of a high-tech startup, with two geeks in a garage—literally—and three months later was cited by PC Magazine as one of its Top 100 Web Sites and Search Engines. The news of its revolutionary PageRank technology and trademark spartan web pages spread by word of mouth among academics everywhere. Its clean, cool image was enhanced by funky colors and the cocky I’m feeling lucky button. Google did everything right. Once they discovered Google, people stayed with it—most still use it today. From the outset, it cultivated a trendy, quirky image, with specially designed logos to celebrate public holidays, and April Fool’s jokes about pigeons pecking PageRank and a new office on the moon. During 2000, their index climbed to a billion pages, the first to reach this size, and at that time Google provided the search facility for Yahoo—as it does for AOL today. Google held on until 2004 before going public, and did so in a blaze of publicity.
Yahoo was also founded by two Stanford Ph.D. students, David Filo and Jerry Yang, who, like Larry and Sergey, are still on leave of absence from their Ph.D. program. It started in 1994 as a collection of their favorite web pages, along with a description of each one. Eventually the lists became long and unwieldy, and they broke them into categories and developed a hierarchy of subcategories. The name is a goofy acronym for “Yet Another Hierarchical Officious Oracle.” Yahoo was incorporated in 1995 and went public in 1996. It acquired a team of website reviewers who visited hundreds of Internet sites daily. As the collection grew, Yahoo had to continually reorganize its structure and eventually became a searchable directory. In 2002, it acquired Inktomi and, in 2003, AltaVista. Previously powered by Google, in 2004 Yahoo launched its own search engine based on the combined technologies of its acquisitions, and provided a service that now focuses as much on searching as on the directory.
After years of planning, Microsoft finally launched its own web search service at the beginning of 2005 and stopped using Yahoo’s Inktomi search engine on its main portal pages. MSN Search is a home-grown engine that allows you to search for web pages, news, products, MSN Groups, images, and encyclopaedia articles; it also offers local search with a Near Me button. It sports its own text ads, designed to compete directly with Google and Yahoo. Microsoft offers the 40,000 articles in its own encyclopaedia (Encarta) free with the service, in addition to 1.5 million other facts contained in Encarta. The search method is based on the machine learning approach using neural nets that was described earlier (page 125).
AOL relies on others to provide its searching. Excite, an early search engine company, bought out WebCrawler, the first full search engine, in 1997, and AOL began using Excite to power its NetFind. Since 2002, AOL Search has used Google for searching, with the same advertisements, and today a search on both systems comes up with similar matches. One operational difference is that AOL Search has an internal version that links to content only available within the AOL online service, whereas the external version lacks these links. On the other hand, it does not offer many of Google’s features (such as cached pages).
Ask (which used to be called “Ask Jeeves” after Jeeves the Butler) was launched in 1997 as a natural-language search engine that sought precise answers to users’ questions. After going public in 1999, the company suffered badly in the dot-com bust. However, it survived and has reinvented itself as a keyword-triggered search engine using the Teoma technology mentioned earlier, which it acquired in 2001. In July 2005, Ask Jeeves was bought by Internet media conglomerate InterActiveCorp, who renamed it by dropping Jeeves and rebranding its core search technology to ExpertRank.32
These are the leading search engines as we write. Other systems (such as Dogpile) perform metasearch by combining their results: if you pose a query, a combination of results from various search engines is returned, tagged with where they came from. There is intense interest in comparing performance; pundits speculate who is edging ahead as the dragons constantly tweak their algorithms in an ongoing multibillion-dollar competition.
One way to achieve an unbiased comparison is for a metasearch engine to route queries to a random search engine and display the results without showing their origin. The user is invited to select any of the results and rate their relevance on a scale from (say) 1 to 5. Figure 4.5(a) shows the overall scores for four search engines, displayed by such a system (in early 2006).33 Figure 4.5(b) gives a histogram of the five rating values and shows that people tend to use the extreme ends of the scales. It is unusual to be indifferent about the quality of a search result.

The search engine business is extremely volatile. Some predict that today’s big five will be ousted next week by upstarts with names like Wisenut and Gigablast—or, more likely, by something completely unheard of. Expect seismic shifts in the structure of the whole business as media giants wade in—for today, as much money is spent on web advertising as on TV advertising. Fortunately, the actual players are of minor concern to us in this book: our aim is to tease out the implications of the change in how people access information—whatever search system they use.
INSIDE THE DRAGON’S LAIR
It is hard for mortals to comprehend the scale of usage of search engines. The book you are reading contains 100,000 words. The Complete Works of Shakespeare is nearly 10 times as big, with 885,000 words. Taken together, the 32 volumes of the 2004 Encyclopedia Britannica are 40 times bigger again, with 44 million words. How many queries do large search engines process per day? Although the exact figures are not public, Google was reported to process around 100 million U.S. queries per day by mid-2006.34 The actual number will be far larger when international traffic is taken into account. But even this figure amounts to 150 million words per day, assuming most queries are one or two words. Over three times the complete Encyclopedia Britannica every day, day after day, week after week, month after month. Throughout this section, we continue to use Google as an example, mainly because its website provides the public with some fascinating glimpses into its operation.
In a typical month some years ago, according to its website, Google received 200,000 queries for Britney Spears. The number is staggering—that’s nearly half a million words, enough to fill five full-length novels (not very interesting ones) in a month, one book a week. And these are old figures, from a time when Google was still taking off. Table 4.1 shows a few misspellings of the query, along with the number of users who spelled it this way. Each variation was entered by at least forty (!) different users within a three-month period, and was corrected to britney spears by Google’s spelling correction system. If we had included variations entered by two or more different users, the list would have been eight times as long. Data for the correctly spelled query is shown at the top.
Table 4.1 Misspellings of Britney Spears Typed into Google
| 488941 | britney spears |
|---|---|
| 40134 | brittany spears |
| 36315 | brittney spears |
| 24342 | britany spears |
| 7331 | britny spears |
| 6633 | briteny spears |
| 2696 | britteny spears |
| 1807 | briney spears |
| 1635 | brittny spears |
| 1479 | brintey spears |
| 1479 | britanny spears |
| 1338 | britiny spears |
| 1211 | britnet spears |
| 1096 | britiney spears |
| 991 | britaney spears |
| 991 | britnay spears |
| 811 | brithney spears |
| 811 | brtiney spears |
| 664 | birtney spears |
| 664 | brintney spears |
| 664 | briteney spears |
| 601 | bitney spears |
| 601 | brinty spears |
| 544 | brittaney spears |
| 544 | brittnay spears |
| 364 | britey spears |
| 364 | brittiny spears |
| 329 | brtney spears |
| 269 | bretney spears |
| 269 | britneys spears |
| 244 | britne spears |
| 244 | brytney spears |
| 220 | breatney spears |
| 220 | britiany spears |
| 199 | britnney spears |
| 163 | britnry spears |
| 147 | breatny spears |
| 147 | brittiney spears |
| 147 | britty spears |
| 147 | brotney spears |
| 147 | brutney spears |
| 133 | britteney spears |
| 133 | briyney spears |
| 121 | bittany spears |
| 121 | bridney spears |
| 121 | britainy spears |
| 121 | britmey spears |
| 109 | brietney spears |
| 109 | brithny spears |
| 109 | britni spears |
| 109 | brittant spears |
| 98 | bittney spears |
| 98 | brithey spears |
| 98 | brittiany spears |
| 98 | btitney spears |
| 89 | brietny spears |
| 89 | brinety spears |
| 89 | brintny spears |
| 89 | britnie spears |
| 89 | brittey spears |
| 89 | brittnet spears |
| 89 | brity spears |
| 89 | ritney spears |
| 80 | bretny spears |
| 80 | britnany spears |
| 73 | brinteny spears |
| 73 | brittainy spears |
| 73 | pritney spears |
| 66 | brintany spears |
| 66 | britnery spears |
| 59 | briitney spears |
| 59 | britinay spears |
| 54 | britneay spears |
| 54 | britner spears |
| 54 | britney’s spears |
| 54 | britnye spears |
| 54 | britt spears |
| 54 | brttany spears |
| 48 | bitany spears |
| 48 | briny spears |
| 48 | brirney spears |
| 48 | britant spears |
| 48 | britnety spears |
| 48 | brittanny spears |
| 48 | brttney spears |
| 44 | birttany spears |
| 44 | brittani spears |
| 44 | brityney spears |
| 44 | brtitney spears |
From the cataclysmic to the trivial, from the popular to the arcane, from the sublime to the ridiculous, the web dragons silently observe our requests for information. Nothing could be more valuable than our treasury of literature, the intellectual heritage of the human race, to which web dragons are the gatekeepers. But there is another treasure that is potentially valuable, at least in commercial terms, which the dragons hoard in their lair and guard jealously: their query logs. They certainly do not provide access to these. For one thing, people wouldn’t search the web if they thought their queries were not private. Your record of requests for information reveals what you are thinking about. It would be incredibly valuable to advertisers, private investigators, and nosy governments (we return to this in Chapter 6).
A search engine’s record of all queries reveals what everyone is thinking about. At regular intervals, Google updates its Zeitgeist, a word that combines the German Zeit (time) and Geist (spirit) to denote the general intellectual, moral, and cultural climate of an era. At year’s end, they record the most popular queries (Janet Jackson in 2005), popular men (Brad Pitt), popular women (in 2005 Janet Jackson overtook Britney Spears), popular events (Hurricane Katrina and tsunami), popular tech stuff (xbox 360), popular consumer brand names, television shows, sports topics, news outlets, companies, … the list goes on. And that’s just for text search. They give popular image queries, popular queries to their electronic shopping service, local search, and so on. And not just for the year: for the week and month too.
Google calls its Zeitgeist a “real-time window into the collective consciousness … that showcases the rising and falling stars in the search firmament as names and places flicker from obscurity to center stage and fade back again.” In fact, you can now go to Google Trends and find out search trends for any query you choose.35 On their website, Google thanks its users for their contribution to these fascinating bits of information, which, as they put it, “perhaps reveal a little of the human condition.” They add that “in compiling the Zeitgeist, no individual searcher’s information is available to us.” Though, of course, Google has this information. The point is that it’s not available to anyone else.
The proportion of queries in the English language has steadily dropped over the years; today over half are in other languages. Web dragons don’t know only what America is thinking, they know what the whole world is thinking. Google publishes Zeitgeists for Australia, Brazil, Canada, Denmark, … even little New Zealand. We can tell you that muttertag was up among the top in Germany in May, indicating Mother’s Day there, and that in New Zealand trade me—the name of a popular electronic store there—was the top query.
When dramatic events happen across the world, they are reflected in people’s requests for information. In the days after September 11, 2001, search engines were overwhelmed by queries for World Trade Center, New York skyline, Statue of Liberty, American flag, eagle—the last ones presumably from people seeking images for their web pages. The 2004 Boxing Day tsunami evoked a tsunami of requests for information about tidal waves and the various places struck by the tragedy. Of course, it doesn’t take a search engine to learn about such cataclysmic events.
Smaller events—ones you would never know about—are also noticed by search engine companies. A huge flurry of people posing the four-word query carol brady maiden name was prompted when the million-dollar question on the popular TV show Who Wants to Be a Millionaire? asked, “What was Carol Brady’s maiden name?” The same peak was observed one, two, and three hours later as the show aired in later time zones; another peak occurred when it finally reached Hawaii. In February 2001, Google engineers noticed a plethora of queries for the curious phrase all your base are belong to us. The target was a cult video game, execrably translated from the original Japanese, which swept like wildfire through an Internet subculture.
Web dragons find out what’s going on, and they find it out first. They have a virtual monopoly on this information. Whereas websites and our treasury of literature reflect what the literati, the reporters, the columnists, and the academics are thinking and writing about, search engine query logs show what ordinary people—the readers—want to know. They give an objective, quantitative record of our society’s concerns, day by day, week by week, month by month, year by year. This is immensely valuable information, to which only the dragons are privy.
What do they do with it? Aye, there’s the rub. No one outside knows.
We can make some guesses. One practical application is to save the results of common queries to avoid having to repeat the search when they are asked again. Answering a query from scratch is far more onerous than looking up the answer in a cache. Search engines probably reap enormous benefits from this—and the ones with most to gain are those that do query-specific processing using the HITS algorithm to discover web communities. In 2001, a trivia game called “Google-whacking” appeared in which users playfully sought obscure two-word queries that could only be found in a single, unique web page. It was rumored that Google was dismayed: whereas the vast majority of ordinary queries were answered from its cache, all the obscure ones posed by Google-whackers required a full search, making them inordinately expensive.
Another application of live queries is to improve the performance of spell correction. When the user is presented with a possible alternative, success can immediately be judged by whether or not the user accepts it by clicking it.
Query logs are a veritable mine of information. Gleaning meaningful information from natural-language text is often referred to as text mining; the process of analyzing text to extract information that is useful for particular purposes. For example, one could segment text into sentences and cluster the words in each one to automatically induce associations between words. Mining large query logs is a wide-open area, and the nuggets found will be immensely valuable. But alas, the data are only accessible to the dragons.
SO WHAT?
In the beginning, scientists developed large-scale full-text search techniques that work by counting words, weighing them, and measuring how well each document matches the user’s query. This was an appropriate way of finding information in a set of unrelated documents. However, pages on the web are not unrelated: they are densely hyperlinked. Today’s search engines acknowledge this by counting links as well as words and weighing them too. This is an appropriate way of measuring the objective reality that is the web. However, the dragons do not divulge the recipe they use to weigh and combine links and words. It’s not a science open to public scrutiny and debate. It’s a commercial trade secret.
More fundamentally, as we will learn in the next chapter, secrecy is an unavoidable side effect of the need to maintain the illusion of an objective reality—an illusory reality that the bad guys, the spammers, are trying to distort.
WHAT CAN YOU DO ABOUT ALL THIS?
• Be a random surfer and see where you get.
• Find some hubs for your hobby.
• Investigate spelling correction on a major search engine. Does context matter?
• Play with a metasearch engine.
• What happened last week? Check Google’s Zeitgeist.
• Find out which are the biggest dragons today.
• List the stop words in the quotation that begins Chapter 1.
• Explain why most pages returned for a query such as using Google don’t contain the query term (Hint: Consider anchor text).
• Use the same query in different search engines and compare the results.
NOTES AND SOURCES
The earliest Bible concordance was constructed in the thirteenth century by Frère Hewe of S. Victor (also known as Hugo de St. Caro, or Cardinal Hugo). The Shakespeare concordance with which this chapter opened was finally published in 1875 (Clarke, 1875); coincidentally another Shakespeare concordance, in this case of his poems, was published in the United States in the same year (Furness, 1875). More information about Mary Clarke’s life and times can be found in Bellamy et al. (2001). The Greek concordance edited by three generations of the same family was originally published in 1897 (Moulton and Geden, 1897) and was revised most recently in 1977 (Moulton and Geden 1977); Figure 4.1 is from the latter. The concordance of Wordsworth was published by Cooper (1911). One of the first to use computers for concordancing was Todd Bender, professor of English at the University of Wisconsin, who produced nine concordances single-handedly and contributed to a further 22. The remark about using a year’s computing budget for one run is from one of his later works (Bender and Higdon, 1988). Figure 4.2 is from Parrish (1959).
A technical description of full-text searching from which some of the material in this chapter is distilled can be found in Witten et al. (1999); Berry and Browne (2005) provide another perspective on this subject. The Google founders’ early paper introducing PageRank is Brin and Page (1998); Kleinberg (1998) wrote a paper on the HITS algorithm. At the same time, Gibson et al. (1998) introduced the idea of identifying communities from the topology of the web. Borodin et al. (2002) discuss these ideas further and identify some deficiencies of HITS: they came up with the jaguar example in the text. Davison et al. (1999) applied these ideas to the web, and it was their system that took one minute to process each query. Langville and Meyer (2005, 2006) produced excellent surveys of algorithms for web information retrieval. Microsoft’s RankNet technology is described by Burges et al. (2005); a related algorithm is described by Diligenti et al. (2003). For more information about machine learning techniques, including the neural net method, see Witten and Frank (2005). The impact factor in bibliometrics was introduced by Garfield (1972); a more recent account of citation structures is Egghe and Rousseau (1990).
You can read about AJAX technology in Crane et al. (2005). The semantic web is the brainchild of Tim Berners-Lee, who penned his vision for Scientific American in 2001 (Berners-Lee et al., 2001). Wikipedia is an excellent source of information about the development of indexing. The information about Google comes from its website. A rich mine of information about search engines can be found at http://searchenginewatch.com.
The dragon stands guard over a treasure chest.
29This is just what people do. We have already noted on page 110 that there is no good technical reason to restrict queries to a few words.
30Teoma is Gaelic for “expert.”
31For example, Technorati (www.technorati.com) performs retrieval on author-defined subject tags.
32The butler-as-personal-servant metaphor was totally missed by some users. Children see a picture of this old guy but have no idea that Jeeves is a butler, or what a butler is.
33RustySearch, at www.rustybrick.com/search-engine-challenge.php
34Figures from Nielsen NetRatings search engine ratings.